

Abstract
The appearance and growth of social networking brings an exponential growth of information. One of the main solutions proposed for this information overload problem are recommender systems, which provide personalized results. Most existing social recommendation approaches consider relation information to improve recommendation performance in the static context. However, relations are likely to evolve over time in the dynamic network. Therefore, temporal information is an essential ingredient to making social recommendation. In this paper, we propose a novel social recommendation model based on evolving relation network, named SoERec. The learned evolving relation network is a heterogeneous information network, where the strength of relation between users is a sum of the influence of all historical events. We incorporate temporally evolving relations into the recommendation algorithm. We empirically evaluate the proposed method on two widely-used datasets. Experimental results show that the proposed model outperforms the state-of-the-art social recommendation methods.
Keywords: Social recommendation, Dynamic evolving, Relation network, Network embedding
Introduction
The last decades have witnessed the booming of social networking such as Twitter and Facebook. User-generated content such as text, images, and videos has been posted by users on these platforms. Social users is suffering from information overload. Fortunately, recommender systems provide a useful tool, which not only help users to select the relevant part of online information, but also discovery user preference and promote popular item, etc. Among existing techniques, collaborative filtering (CF) is a representative model, which attempt to utilize the available user-item rating data to make predictions about the users preferences. These approaches can be divided into two groups [1]: memory-based and model-based. Memory-based approaches [2, 8, 16] make predictions based on the similarities between users or items, while model-based approaches [3, 9] design a prediction model from rating data by using machine learning. Both memory-based and model-based CF approaches have two challenges: data sparsity and cold start, which greatly reduce their performance. In particular, matrix factorization based models [13, 19] have gained popularity in recent years due to their relatively high accuracy and personalized advice.
Existing research works have contributed improvements in social recommendation tasks. However, these approaches only consider static social contextual information. In the real world, knowledge is often time-labeled and will change significantly over time. Figure 1 shows the entire social contextual information over time which can be derived from links on social networks. User Jack post message 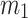 , which mention users Tom and Eric, at time point
, which mention users Tom and Eric, at time point  . Subsequently, user Jack post message
. Subsequently, user Jack post message  , which mention user Eric again, at time point
, which mention user Eric again, at time point 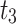 . Meanwhile, message
. Meanwhile, message 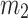 is retweeted by user Ellen at time point
is retweeted by user Ellen at time point 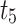 . We observe that new social action is often influenced by historical related behaviors. In addition, historical behaviors have an impact on current action over time, and the impact strength decreases with time. On the other hand, we notice that the evolving relation network is very sparse, which greatly reduce the recommendation performance. In order to deal with data sparsity, we leverage network embedding technology, which has contributed improvements in many applications, such as link prediction, clustering, and visual.
. We observe that new social action is often influenced by historical related behaviors. In addition, historical behaviors have an impact on current action over time, and the impact strength decreases with time. On the other hand, we notice that the evolving relation network is very sparse, which greatly reduce the recommendation performance. In order to deal with data sparsity, we leverage network embedding technology, which has contributed improvements in many applications, such as link prediction, clustering, and visual.
Fig. 1.
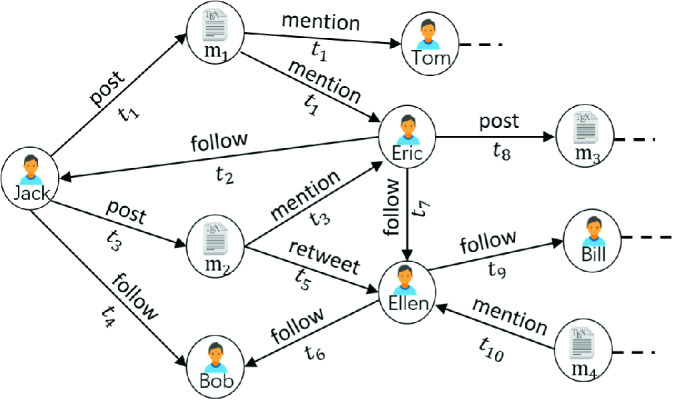
An illustration of social connections that can change and evolve over time.
In this work, we propose a novel social recommendation model based on evolving relation network, named SoERec, which leverages evolving relation network and network embedding technique. The proposed method explicitly models the strength of relations between pair of users learned from an evolving relation network. To efficiently learn heterogeneous relations, network embedding is employed to represent relation into a unified vector space. We conduct experiments on two widely-used datasets and the experimental results show that our proposed model outperforms the state-of-the-art recommendation methods.
The main contributions of this paper are as follows:
We construct a dynamic, directed and weighted heterogeneous evolving network that contains multiple objects and links types from social network. Compared with static relation graph, the evolving graph can precisely measure the strength of relations.
We propose a novel social recommendation model by jointly embedding representations of fine-grained relations from historical events based on heterogeneous evolving network.
We conduct several analysis experiments with two real-world social network datasets, the experimental results demonstrate our proposed model outperforms state-of-the art comparison methods.
The rest of this paper is organized as follows. Section 2 formulates the problem of social recommendation. Section 3 proposes the method of social recommendation based on evolving relation network to recommend the candidate users. Section 4 presents experimental results of recommendation. Finally, Sect. 5 reviews the related work and Sect. 6 concludes.
Related Work
We briefly review the related works from two lines in this section: one on network embedding and the other on social recommendation.
Network Embedding. Network embedding has been extensively studied to learn a low-dimensional vector representation for each node, and implicitly capture the meaningful topological proximity, and reveal semantic relations among nodes in recent years. The early-stage studies only focus on the embedding representation learning of network structure [14, 21, 24, 29]. Subsequently, network node incorporating the external information like the text content and label information can boost the quality of network embedding representation and improve the learning performance [4, 7, 20, 22, 23, 28]. Network embedding indeed can alleviate the data sparsity and improve the performance of node learning successfully. Therefore, this technique has been effectively applied, such as link prediction, personalized recommendation and community discovery.
Social Recommendation. Recommender systems are used as an efficient tool for dealing with the information overload problem. Various methods of social recommendation have been proposed from different perspectives in recent years including user-item rating matrix [15], network structure [11], trust relationship [5, 10, 18, 27], individual and friends’ preferences [6, 12], social information [25] and combinations of different features [19, 26]. The above social recommendation methods are proposed based on collaborative filtering. These methods all focus on fitting the user-item rating matrix using low-rank approximations, and also use all kinds of social contextual information to make further predictions. Most of the studies that use both ratings and structure deal with static snapshots of networks, and they don’t consider the dynamic changes occurring over users’ relations. Incorporating temporally evolving relations into the analysis can offer useful insights about the changes in the recommendation task.
Problem Statement
The intuition behind is that there are two basic accepted observations in a real world: (1) The current behavior of user is influenced by all his/her historical patterns. (2) A behavior with an earlier generation time has a smaller influence on the user’s current behavior, while the one with a later generation time has a greater influence. Therefore, we first formally define the concept of Evolving Relation Network, as follows:
Definition 1
(Heterogeneous Evolving Network). A heterogeneous evolving network can be defined as 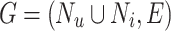 , where
, where  is the set of vertices representing users, and
is the set of vertices representing users, and  is the set of vertices representing items, and E is the set of edges between the vertices. The types of edges can be divided into user-user and user-item relationships with temporal information. Hence, G is a dynamic, directed and weighted heterogeneous evolving network.
is the set of vertices representing items, and E is the set of edges between the vertices. The types of edges can be divided into user-user and user-item relationships with temporal information. Hence, G is a dynamic, directed and weighted heterogeneous evolving network.
From the definition, we can see that each edge not only is an ordered pair from a node to another node, but also has a weight with time-dependent. In order to measure the strength of relations between two nodes objects in the heterogeneous evolving network G, we introduce the concept of evolving strength, which is formally defined as follows:
Definition 2
(Evolving Strength). Given an event  where
where  is an event type (e.g., post, mention, follow, etc.) and t is the timestamp of e. An event sequence
is an event type (e.g., post, mention, follow, etc.) and t is the timestamp of e. An event sequence 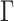 between two nodes is a list of events
between two nodes is a list of events 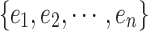 , ordered by their timestamps
, ordered by their timestamps 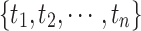 , where
, where  . An event corresponding to an edge. Thus, the strength of evolving relations denoted by F is the sum of individual event influence.
. An event corresponding to an edge. Thus, the strength of evolving relations denoted by F is the sum of individual event influence.
We formulate the problem of social recommendation as a ranking based task in this work, as follows:
Definition 3
(Social Recommendation Problem). Given a heterogeneous evolving network G at time t, and a target user 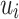 , and a candidate set of items
, and a candidate set of items 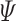 , we aim to generate a top K ranked list of items
, we aim to generate a top K ranked list of items  for
for 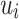 at time
at time 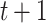 according to the target user’s preference inferred from historical feedbacks.
according to the target user’s preference inferred from historical feedbacks.
The Proposed Social Recommendation Model
Probabilistic Matrix Factorization
Let 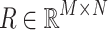 be the rating matrix with M users and N items. The (i, j)-th entry of the matrix is denoted by
be the rating matrix with M users and N items. The (i, j)-th entry of the matrix is denoted by 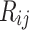 that represent the rating of user i for item j.
that represent the rating of user i for item j. 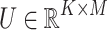 and
and 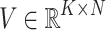 be user and item latent feature matrices respectively, where K is the dimension of latent factors. The preference of i-th user is represented by vector
be user and item latent feature matrices respectively, where K is the dimension of latent factors. The preference of i-th user is represented by vector  and the characteristic of j-th item is represented by vector
and the characteristic of j-th item is represented by vector 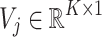 . The dot product of U and V can approximate the rating:
. The dot product of U and V can approximate the rating:  . Recommendation based on Probabilistic Matrix Factorization (PMF) [15] solve the following problem
. Recommendation based on Probabilistic Matrix Factorization (PMF) [15] solve the following problem
 |
1 |
where  is a weight matrix. In this work, we set
is a weight matrix. In this work, we set  if
if  and 0 otherwise.
and 0 otherwise. 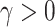 is the regularization parameter.
is the regularization parameter. 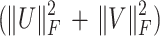 can avoid overfitting,
can avoid overfitting, 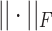 denotes the Frobenius norm of the matrix.
denotes the Frobenius norm of the matrix.
Modeling Relation Strength
Incorporating the knowledge from present and historical behavior data can accurately measure the strength of influence, as shown Fig. 2. In this work, we model the strength of relation between users as a sum of the influence of each event by multiplying a weight. The weight is calculated by a function, called decay function. Since the influence between users can’t be less than zero in social networks, the weight ranges from 0 to 1 and decreases with the event’s existing time. Thus, we formalize the decay function
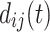 with timestamped information as follows:
with timestamped information as follows:
 |
2 |
where t is the current time,  is the generation time of historical event, and
is the generation time of historical event, and  is a parameter which controls the decay rate. Through the analyses in the following experiments in the paper, we set the parameter
is a parameter which controls the decay rate. Through the analyses in the following experiments in the paper, we set the parameter  as 0.6.
as 0.6.
Fig. 2.

The evolving strength of relation between pair of users over time.
Based on the influence of historical events, we can measure the current strength of social relation between users as follows:
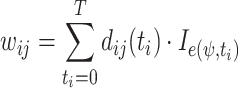 |
3 |
where 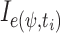 is a parameter which controls the weight of different events. To simplify the model, we assume that the importance of any events is equal.
is a parameter which controls the weight of different events. To simplify the model, we assume that the importance of any events is equal.
Embedding Relation Network
The learned evolving relation network has three characteristics: (1) a weighted and directed graph; (2) a sparsity graph; (3) heterogeneous information network. In order to learn the evolving relation network, we employ large-scale information network embedding (LINE) [17] model to simultaneously retain the local and global structures of the network. In particular, we leverage the LINE model to learn users’ embedded representations of the evolving relation network the first-order proximity and the second-order proximity. As shown Fig. 3, the detailed process is demonstrated as follows.
Fig. 3.

The network embedding representation learning of user relation network.
User Relation with First-Order Proximity. The first-order similarity can represent the relation by the directly connected edge between vertices. We model the joint probability distribution of users  and
and  as the first-order similarity
as the first-order similarity  . The similarity can be defined as follows:
. The similarity can be defined as follows:
 |
4 |
where 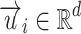 is the low-dimensional vector representations of vertices
is the low-dimensional vector representations of vertices 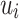 . The empirical distribution between vertices
. The empirical distribution between vertices 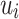 and
and 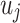 is defined as follows:
is defined as follows:
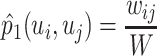 |
5 |
where  , and
, and 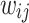 is the relation strength of the edge
is the relation strength of the edge 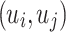 measured by Eq. (3). To preserve the first-order proximity in evolving relation network, we use the KL-divergence to minimize the joint probability distribution and the empirical probability distribution as follows:
measured by Eq. (3). To preserve the first-order proximity in evolving relation network, we use the KL-divergence to minimize the joint probability distribution and the empirical probability distribution as follows:
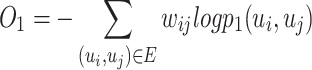 |
6 |
User Relation with Second-Order Proximity. The second-order proximity assumes that vertices sharing many connections to other vertices are similar to each other. In this work, we assume that two users with similar neighbors have high similarity scores between them. Specifically, we consider each user vertex as a specific “ontext”, and users with similar distributions over the “contexts” are assumed to be similar. Thus, each user vertex respectively plays two roles: the user vertex itself and the specific “context” of other user vertices. We introduce two vectors  and
and 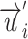 , where
, where  is the representation of
is the representation of 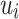 when it is treated as a vertex, and
when it is treated as a vertex, and 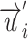 is the representation of
is the representation of  when it is treated as a specific “context”. For each directed user edge
when it is treated as a specific “context”. For each directed user edge  , we firstly define the probability distribution of “context”
, we firstly define the probability distribution of “context” 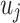 generated by user vertex
generated by user vertex  as follows:
as follows:
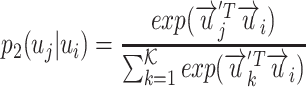 |
7 |
where 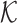 is the number of user vertices or “contexts”. The empirical distribution of “contexts”
is the number of user vertices or “contexts”. The empirical distribution of “contexts” 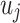 generated by user vertex
generated by user vertex 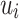 is defined as:
is defined as:
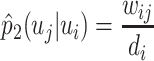 |
8 |
where 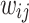 is the weight of the edge (
is the weight of the edge (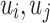 ) as the same, and
) as the same, and 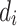 is the out-degree of vertex
is the out-degree of vertex  , i.e.
, i.e. 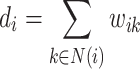 , with N(i) as the set of out-neighbors of
, with N(i) as the set of out-neighbors of  .
.
To preserve the second-order user relation, the following objective function is obtained by utilizing the KL-divergence:
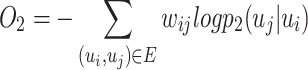 |
9 |
Combining First-Order and Second-Order Proximities. To embed the evolving network by preserving both the first-order and second-order proximities, LINE model can minimize the objective functions 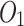 and
and  respectively, and learns two low-dimensional representations for each user vertex. Then, the two low-dimensional representations are concatenated as one low-dimensional feature vector to simultaneously preserve the local and global structures of evolving relation network. Finally, each user vertex
respectively, and learns two low-dimensional representations for each user vertex. Then, the two low-dimensional representations are concatenated as one low-dimensional feature vector to simultaneously preserve the local and global structures of evolving relation network. Finally, each user vertex  is represented as
is represented as 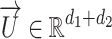 .
.
Evolving Relation Embedding Recommendation Model
Incorporating simultaneously user’s explicit relation and implicit relation can boost the ability of social recommendation. As mentioned above, LINE model can learn users’ embedded representations, where first-order proximity correspond to the strength of explicit relation and second-order proximity correspond to the strength of implicit relation. Hence, the fine-grained relation measure can better predict user ratings by also encoding both the first-order and second-order relationships among users.
After performing the LINE model, we can obtain users’ embedded presentations. We then measure the fine-grained relations among users on the basis of the inner product of the presentations as follows:
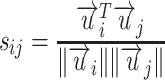 |
10 |
where 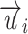 and
and 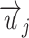 denote the low-dimensional feature representations of users
denote the low-dimensional feature representations of users  and
and 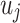 , respectively. In this work, relation strength
, respectively. In this work, relation strength 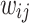 can be viewed as a coarse-grained relation value between users
can be viewed as a coarse-grained relation value between users 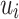 and
and 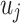 . Compared to coarse-grained measure, the fine-grained measure
. Compared to coarse-grained measure, the fine-grained measure 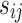 is more informative, and can effectively distinguish the importance of recent and old events among users. In other words, the fine-grained measure can deduce the strength of latent relation based on neighborhood structures while two users have no explicit connections.
is more informative, and can effectively distinguish the importance of recent and old events among users. In other words, the fine-grained measure can deduce the strength of latent relation based on neighborhood structures while two users have no explicit connections.
The fact of matter is that user decision making is influenced by his/her own preferences and close friends in real-world situations. Specifically, on the one hand, users often have different preferences for different items. On the other hand, user are likely to accept their friends’ recommendations. Thus, we assume that the final rating of user 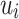 for item
for item  is a linear combination between the user’s own preference and his/her friends’ preferences, where the rating can be defined as follows:
is a linear combination between the user’s own preference and his/her friends’ preferences, where the rating can be defined as follows:
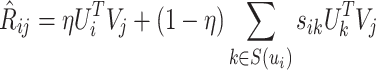 |
11 |
where 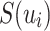 is the set of most intimate friends of user
is the set of most intimate friends of user 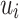 . In the above equation, the first item corresponds to the prediction rating based on their own preferences, while the second item corresponds to the prediction rating based on the preferences of his/her friends, and
. In the above equation, the first item corresponds to the prediction rating based on their own preferences, while the second item corresponds to the prediction rating based on the preferences of his/her friends, and 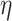 is a parameter that controls the relative weight between user’s own preferences and friends’ preferences.
is a parameter that controls the relative weight between user’s own preferences and friends’ preferences.
The ratings of users to items are generally represented by an ordered set, such as discrete values or continuous numbers within a certain range. In this work, without loss of generality, the differences in the users’ individual rating scales can be considered by normalizing ratings with a function f(x):
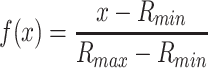 |
12 |
where  and
and 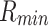 represent the maximum and minimum ratings, respectively. f(x) values can be fell in the [0, 1] interval. Meanwhile, we use the logistic function
represent the maximum and minimum ratings, respectively. f(x) values can be fell in the [0, 1] interval. Meanwhile, we use the logistic function 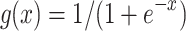 to limit the predicted ratings
to limit the predicted ratings 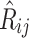 within the range of [0, 1].
within the range of [0, 1].
Based on this, the task of social recommendation is likewise to minimize the predictive error. Hence, the objective function of the evolving relation embedding recommendation algorithm is formalized as:
 |
13 |
where 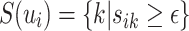 is the set of most intimate friends of user
is the set of most intimate friends of user 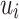 , and the parameter
, and the parameter  is the threshold of the close relation value.
is the threshold of the close relation value.
We adopt stochastic gradient descent (SGD) to solve the local minimum solution of 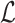 , and learn the latent feature vectors
, and learn the latent feature vectors 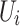 and
and 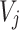 . The partial derivatives of the objective function
. The partial derivatives of the objective function 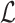 with respect to
with respect to  and
and  are computed as:
are computed as:
 |
14 |
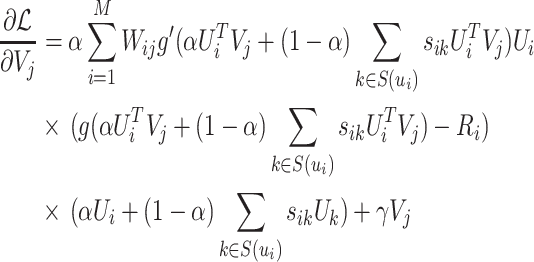 |
15 |
where 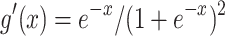 is the derivative of the logistic function g(x).
is the derivative of the logistic function g(x).
Experiments
In this section, we first describe experimental datasets and metrics. We then present the baselines and the experiments settings. Finally, we give the experimental results and analyze them.
Datasets
To evaluate the proposed model, we use two real-world datasets for this task: Weibo and Last.fm.
Weibo Dataset1. The data is collected from Sina Weibo, which is the most popular microblogging platform in China. It includes basic information about messages (time, user ID, message ID etc.), mentions (user IDs appearing in messages), forwarding paths, and whether containing embedded URLs or event keywords. In addition, it also contains a snapshot of the following network of users (based on user IDs).
Last.fm Dataset2. This dataset has been obtained from Last.fm online music system. Its users are interconnected in a social network generated from Last.fm “friend” relations. Each user has a list of most listened music artists, tag assignments, i.e. tuples [user, tag, artist], and friend relations within the dataset social network. Each artist has a Last.fm URL and a picture URL.
For two datasets, the user-user relations are constructed from following or bi-directional friendships between social network users, user-item relations are constructed from the user posting or listening behavior. The statistics of two datasets are summerized in Table 1.
Table 1.
Statistics of the datasets.
| Dataset | Last.fm | |
|---|---|---|
| #User | 840,432 | 1,892 |
| #Item | 30,000 | 17,632 |
| #User-user relations | 154,352,856 | 12,717 |
| #User-item relations | 355,754 | 92,834 |
| Density | 0.014% | 0.71% |
Evaluation Metrics
We use the mean absolute error (MAE), root mean square error (RMSE) and the average precision of top-K recommendation (Average P@K) to evaluate the performance of recommendation algorithms. According to their definition, a smaller MAE/RMSE or bigger Average P@K value means better performance. For each dataset, {40%, 80%} are selected randomly as training set and the rest as the test set. We will repeat the experiments 5 times and report the average performance.
Comparison Algorithms
In order to evaluate the effectiveness of our proposed recommendation algorithm, we select following recommendation algorithms as comparison methods:
PMF [15]: The method adopts a probabilistic linear model with Gaussian distribution, and the recommendations are obtained only by relying on the rating matrix of users to items.
SoRec [11]: The method integrates social network structure and the user-item rating matrix based on probabilistic matrix factorization. However, the algorithm ignore the temporal changes of relations between users.
RSTE [10]: The model fuses the users’ tastes and their trusted friends’ favors together for the final predicted ratings. Similarly, the method doesn’t consider the changes of trust relations over time.
SocialMF [5]: The model integrates a trust propagation mechanism into PMF to improve the recommendation accuracy. However, the algorithm represents the feature vector of each user only by the feature vectors of his direct neighbors in the social network.
TrustMF [27]: The model proposes social collaborative filtering recommendations by integrating sparse rating data and social trust network. The algorithm can map users into low-dimensional truster feature space and trustee feature space, respectively.
SoDimRec [19]: The model adopts simultaneously the heterogeneity of social relations and weak dependency connections in the social network, and employs social dimensions to model social recommendation.
The optimal experimental settings for each method were either determined by our experiments or were taken from the suggestions by previous works. The setting that were taken from previous works include: the learning rate  = 0.001; and the dimension of the latent vectors d = 100. All the regularization parameters for the latent vectors were set to be the same at 0.001.
= 0.001; and the dimension of the latent vectors d = 100. All the regularization parameters for the latent vectors were set to be the same at 0.001.
Experimental Results
Comparisons of Recommendation Model. We use different amounts of training data (40%, 80%) to test the algorithms. Comparison results are demonstrated in Table 2, and we make the following observations: (1) Our proposed approach SoERec always outperforms baseline methods on both MAE and RMSE. The major reason is that the proposed framework exploits heterogeneity of social relations via time dimension and network embedding technique. (2) Recommendation systems by exploiting social relations all perform better than the PMF method only by using user-item rating matrix in terms of both MAE and RMSE. (3) Among these relation-aware recommendation methods, leveraging more indirect relations method generally achieves better performance than only using direct connections methods. In a word, social relations play an important role in context-aware recommendations.
Table 2.
Performance comparisons of different recommender models.
| Dataset | Method | MAE(40%) | MAE(80%) | RMSE(40%) | RMSE(80%) |
|---|---|---|---|---|---|
| PMF | 0.9963 | 0.9110 | 1.0346 | 0.9474 | |
| SoRec | 0.9602 | 0.8957 | 1.0158 | 0.9329 | |
| RSTE | 0.9319 | 0.8515 | 1.0023 | 0.9301 | |
| SocialMF | 0.9044 | 0.8232 | 0.9778 | 0.9168 | |
| TrustMF | 0.8879 | 0.8031 | 0.9465 | 0.8885 | |
| SoDimRec | 0.8528 | 0.7884 | 0.9304 | 0.8757 | |
| SoERec | 0.8249 | 0.7495 | 0.9128 | 0.8655 | |
| Last.fm | PMF | 1.0582 | 1.0292 | 1.2691 | 1.1306 |
| SoRec | 1.0442 | 1.0996 | 1.2009 | 1.0971 | |
| RSTE | 1.0386 | 0.9936 | 1.1716 | 1.0876 | |
| SocialMF | 1.0299 | 0.9869 | 1.1546 | 1.0801 | |
| TrustMF | 1.0076 | 0.9804 | 1.1408 | 1.0718 | |
| SoDimRec | 0.9967 | 0.9768 | 1.1211 | 1.0639 | |
| SoERec | 0.9851 | 0.9617 | 1.1092 | 1.0590 |
Top-K User Recommendation. Figure 4 summarizes the user recommendation performance for the state-of-the-art methods and the proposed model. Generally speaking, it can be shown from the figure that the average P@K value decreases gradually along with the increasing number of K. Besides, we can also observe on both datasets that: Firstly, the proposed method consistently perform better than baseline methods, indicating that the considering cross-time evolving graph embedding by SoERec model can be recommended the more appropriate users than recommendation models without considering time dimension. Secondly, trust-based algorithms (TrustMF, SocialMF and RSTE) consistently perform better than non-trust based benchmarks (SocRec, PMF). It is because trust-based algorithms can fully exploit the network structure, which tackles the incomplete, sparse and noisy problem. Finally, among the different recommendation methods, considering heterogeneous network (SocDimRec and SoERec) significantly performs better than the other methods.
Fig. 4.

The overall average P@K score of each method with different K.
Conclusion
In this paper, we propose a novel social recommendation model by incorporating cross-time heterogeneity network of relations. We construct an evolving heterogeneous relation network with timestamp information based on multiple objects and links types. The evolving graph can learn more accurate user relations. We then use network embedding technique to encode the latent feature spaces of relations into the objective function. To demonstrate the effective of the proposed model, we construct extensive experiments. The experimental results reveal that our proposed method outperforms the state-of-the-art baseline methods.
Acknowledgement
This work is supported by Natural Science Foundation of China (No. 61702508, No. 61802404), and National Social Science Foundation of China (No. 19BSH022), and National Key Research and Development Program of China (No. 2019QY1303). This work is also supported by the Program of Key Laboratory of Network Assessment Technology, the Chinese Academy of Sciences; Program of Beijing Key Laboratory of Network Security and Protection Technology.
Footnotes
Contributor Information
Valeria V. Krzhizhanovskaya, Email: V.Krzhizhanovskaya@uva.nl
Gábor Závodszky, Email: G.Zavodszky@uva.nl.
Michael H. Lees, Email: m.h.lees@uva.nl
Jack J. Dongarra, Email: dongarra@icl.utk.edu
Peter M. A. Sloot, Email: p.m.a.sloot@uva.nl
Sérgio Brissos, Email: sergio.brissos@intellegibilis.com.
João Teixeira, Email: joao.teixeira@intellegibilis.com.
Bo Jiang, Email: jiangbo@iie.ac.cn.
Zhigang Lu, Email: luzhigang@iie.ac.cn.
Yuling Liu, Email: liuyuling@iie.ac.cn.
Ning Li, Email: liujunrong@iie.ac.cn.
References
- 1.Adomavicius G, Tuzhilin A. Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005;6:734–749. doi: 10.1109/TKDE.2005.99. [DOI] [Google Scholar]
- 2.Deshpande M, Karypis G. Item-based top-n recommendation algorithms. ACM Trans. Inf. Syst. (TOIS) 2004;22(1):143–177. doi: 10.1145/963770.963776. [DOI] [Google Scholar]
- 3.Gopalan, P., Hofman, J.M., Blei, D.M.: Scalable recommendation with hierarchical poisson factorization. In: UAI, pp. 326–335 (2015)
- 4.Grover, A., Leskovec, J.: node2vec: scalable feature learning for networks. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 855–864. ACM (2016) [DOI] [PMC free article] [PubMed]
- 5.Jamali, M., Ester, M.: A matrix factorization technique with trust propagation for recommendation in social networks. In: Proceedings of the Fourth ACM Conference on Recommender Systems, pp. 135–142. ACM (2010)
- 6.Jiang, M., et al.: Social contextual recommendation. In: CIKM, pp. 45–54 (2012)
- 7.Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016)
- 8.Linden G, Smith B, York J. Amazon. com recommendations: item-to-item collaborative filtering. IEEE Internet Comput. 2003;7(1):76–80. doi: 10.1109/MIC.2003.1167344. [DOI] [Google Scholar]
- 9.Liu, N.N., Yang, Q.: Eigenrank: a ranking-oriented approach to collaborative filtering. In: Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 83–90. ACM (2008)
- 10.Ma, H., King, I., Lyu, M.R.: Learning to recommend with social trust ensemble. In: Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 203–210. ACM (2009)
- 11.Ma, H., Yang, H., Lyu, M.R., King, I.: SoRec: social recommendation using probabilistic matrix factorization. In: Proceedings of the 17th ACM Conference on Information and Knowledge Management, pp, 931–940. ACM (2008)
- 12.Ma, H., Zhou, D., Liu, C., Lyu, M.R., King, I.: Recommender systems with social regularization. In: WSDM, pp. 287–296. ACM (2011)
- 13.Mnih, A., Salakhutdinov, R.R.: Probabilistic matrix factorization. In: Advances in Neural Information Processing Systems, pp. 1257–1264 (2008)
- 14.Ou, M., Cui, P., Pei, J., Zhang, Z., Zhu, W.: Asymmetric transitivity preserving graph embedding. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1105–1114. ACM (2016)
- 15.Salakhutdinov, R., Mnih, A.: Probabilistic matrix factorization. In: Advances in Neural Information Processing Systems (NIPS), pp. 1257–1264 (2007)
- 16.Sarwar, B.M., Karypis, G., Konstan, J.A., Riedl, J., et al.: Item-based collaborative filtering recommendation algorithms. In: WWW, vol. 1, pp. 285–295 (2001)
- 17.Tang, J., Qu, M., Wang, M., Zhang, M., Yan, J., Mei, Line: large-scale information network embedding. In: Proceedings of the 24th International Conference on World Wide Web, pp. 1067–1077. International World Wide Web Conferences Steering Committee (2015)
- 18.Tang, J., Gao, H., Liu, H.: mTrust: discerning multi-faceted trust in a connected world, pp. 93–102 (2012)
- 19.Tang, J., et al.: Recommendation with social dimensions. In: Thirtieth AAAI Conference on Artificial Intelligence (2016)
- 20.Tu, C., Liu, H., Liu, Z., Sun, M.: Cane: context-aware network embedding for relation modeling. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), vol. 1, pp. 1722–1731 (2017)
- 21.Tu, C., Wang, H., Zeng, X., Liu, Z., Sun, M.: Community-enhanced network representation learning for network analysis. arXiv preprint arXiv:1611.06645 (2016)
- 22.Tu, C., Zhang, W., Liu, Z., Sun, M., et al.: Max-margin deepwalk: discriminative learning of network representation. In: IJCAI, pp. 3889–3895 (2016)
- 23.Tu, C., Zhang, Z., Liu, Z., Sun, M.: Transnet: translation-based network representation learning for social relation extraction. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI) (2017)
- 24.Wang, D., Cui, P., Zhu, W.: Structural deep network embedding. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1225–1234. ACM (2016)
- 25.Wang, M., Zheng, X., Yang, Y., Zhang, K.: Collaborative filtering with social exposure: a modular approach to social recommendation. In: Thirty-Second AAAI Conference on Artificial Intelligence (2018)
- 26.Wang, X., Lu, W., Ester, M., Wang, C., Chen, C.: Social recommendation with strong and weak ties. In: CIKM, pp. 5–14. ACM (2016)
- 27.Bo Yang Y, Lei JL, Li W. Social collaborative filtering by trust. IEEE Trans. Pattern Anal. Mach. Intell. 2016;39(8):1633–1647. doi: 10.1109/TPAMI.2016.2605085. [DOI] [PubMed] [Google Scholar]
- 28.Yang, C., Liu, Z., Zhao, D., Sun, M., Chang, E.Y.: Network representation learning with rich text information. In: Proceedings of the 24th International Joint Conference on Artificial Intelligence (IJCAI), pp. 2111–2117 (2015)
- 29.Yang, J., Leskovec, J.: Overlapping community detection at scale: a nonnegative matrix factorization approach. In: Proceedings of the 6th ACM International Conference on Web Search and Data Mining, pp. 587–596. ACM (2013)