

Abstract
Objectives
Comorbidity network analysis (CNA) is a graph-theoretic approach to systems medicine based on associations revealed from disease co-occurrence data. Researchers have used CNA to explore epidemiological patterns, differentiate populations, characterize disorders, and more; but these techniques have not been comprehensively evaluated. Our objectives were to assess the stability of common CNA techniques.
Materials and Methods
We obtained seven co-occurrence data sets, most from previous CNAs, coded using several ontologies. We constructed comorbidity networks under various modeling procedures and calculated summary statistics and centrality rankings. We used regression, ordination, and rank correlation to assess these properties’ sensitivity to the source of data and construction parameters.
Results
Most summary statistics were robust to variation in link determination but somewhere sensitive to the association measure. Some more effectively than others discriminated among networks constructed from different data sets. Centrality rankings, especially among hubs, were somewhat sensitive to link determination and highly sensitive to ontology. As multivariate models incorporated additional effects, comorbid associations among low-prevalence disorders weakened while those between high-prevalence disorders shifted negative.
Discussion
Pairwise CNA techniques are generally robust, but some analyses are highly sensitive to certain parameters. Multivariate approaches expose additional conceptual and technical limitations to the usual pairwise approach.
Conclusion
We conclude with a set of recommendations we believe will help CNA researchers improve the robustness of results and the potential of follow-up research.
Keywords: systems biology, comorbidity, epidemiologic methods, network analysis, sensitivity analysis
INTRODUCTION
Systems medicine consists in the adoption into medical research of principles and techniques from systems biology, described as global, integrative, and holistic.1–3 Networks have become a staple of systems biology4 and seen extensive use in systems medicine.5 An ongoing focus is the “diseaseome” characterized by comorbid associations among disorders. Clinical comorbidity refers to disease that complicates an index condition for an individual patient. These patterns can reveal clinically relevant differences in prognosis or response to treatment and produce statistical associations in population studies called epidemiological comorbidities.6,7Comorbidity network analysis (CNA) is a systems approach to epidemiology that studies networks aggregated from measures of co-occurrence between pairs or larger subsets of disorders.8,9 CNAs seek to uncover novel clinical associations, to stratify patient populations, and to identify disorders and multimorbidities for further investigation, among other aims.10
Network science11 rests predominantly on the theory of mathematical graphs. The relations that constitute a comorbidity network are usually discretized from incidence data, which makes the analysis of large data sets more computationally tractable but for which no standard procedure exists and which may result in confounding of covariance and loss of sign and magnitude information. Moreover, network tools often rely on theoretical assumptions that do not hold for association data, such as the importance of indirect connections between nodes for the transfer of material, activity, or information, which underpin concepts such as community, brokerage, and centrality.12,13 The graph-theoretic operationalizations of these concepts do not have natural epidemiological interpretations.
OBJECTIVES
We distinguish four concerns with conventional CNA, adapting terminology from14 and:15 (1) Source of incidence data differ in their conventions, completeness, and representativeness, and the consequent differences in network structure have not been explored (results reproducibility). (2) The method of link determination, with respect to statistical signal and association strength, varies across studies, and the effects of adjusting these parameters have not been assessed (stability). (3) Networks aggregated from pairwise associations discard information about higher-order interactions, though these potential effects are important to epidemiological understanding and to the systems paradigm (robustness). (4) The use of network statistics relies on correspondences between theoretical constructs and instrumental definitions, but little theoretical guidance is available for network representations of comorbid associations (interpretability).
Motivated by these concerns, we set out to answer four research questions (Figure 1): (1) How sensitive are the measured strengths of pairwise associations to the choice of network model, in particular whether the model takes additional comorbid associations or patient-level covariates into account? (2) How sensitive are network summary statistics to network model parameters, including the choice of model and model-specific parameters like the choice of association measure and the cutoff for link determination? Does this sensitivity impair the use of these statistics to characterize and distinguish underlying populations? (3) How sensitive is centrality analysis to these parameters? Does this sensitivity problematize the identification of highly comorbid “hub” disorders or the centrality rankings of less central disorders? (4) How does the relational origin of network-analytic tools limit their application or interpretability on co-occurrence data? Do the sensitivity results help inform the answer?
Figure 1.

Motivation and design of this study.
MATERIALS AND METHODS
Data sets
We acquired eight data sets for our analysis (Table 1): Six were provided by the authors of previous CNAs, but only in a form suitable for pairwise analysis.16–20 One (MIMIC-III) is freely available to researchers upon submission of a study design and completion of a short online course.21 For computational feasibility, we crosswalked diagnosis codes to the Clinical Classification Software (CCS) ontology.22 The last, results of the 2011 National Ambulatory Medical Care Survey (NAMCS), was obtained from the website of the Centers for Disease Control and Prevention (https://www.cdc.gov/nchs/ahcd/index.htm). We extracted indicators for 13 chronic disorders for analysis purposes. Coded ontologies included the International Classification of Diseases, 9th and 10th Revisions, Clinical Modifications (ICD9 and ICD10) and the custom ontology of reference 16. The data sets vary widely in the underlying patient population, in the collection of their data by healthcare institutions, and in the researchers’ pre-processing protocols; variation along each of these dimensions contributes to overall variation due to the data source. Disentangling these factors would require a more thorough study using several sources of patient-level data.
Table 1.
Sources of pairwise disorder co-occurrence data used in this study, originally aggregated from patient-level data for previous studies and made available by their authors (except MIMIC-III and NAMCS)
| Source | Time period | Patients | Ontology | Terms |
|---|---|---|---|---|
| Columbia University Medical Center16 | Unreported | 1.5 million | Rzhetsky et al.16 | 161 |
| MedPAR17 | 1990–1993 | 32 million | ICD9 (level 5) | 16 459 |
| ICD9 (level 3) | 657 | |||
| Sct. Hans Hospital18 | 1998–2008 | 5543 | ICD10 (level 3) | 351 |
| University of Michigan Health System19 | Unreported | 1.62 million | ICD9 (level 5) | 14 489 |
| STRIDE (Stanford University)20 | 2008–2013 | 277 290 | Rzhetsky et al. 16 | 161 |
| MIMIC-III (Beth Israel Deaconess)21 | 2001–2012 | 38 645 | CCS | 113–273 |
| NAMCS | 2011 | 10 908 | Chronic disorders | 13 |
SOFTWARE
We performed analyses in R,23 using the tidyverse collection24 and a combination of igraph,25 tidygraph,26 and ggraph.27 English descriptions of ICD9 and ICD10 codes were obtained from icd.28 Full code to reproduce our analyses is available at https://bitbucket.org/corybrunson/comorbidity.
Pairwise constructions
The majority of CNAs construct networks from pairwise co-occurrence data, that is, the values that fill a contingency table. From these data, we calculated both evidential and evaluative thresholds: Evidential thresholds were test-wise error rates (TWERs), optionally adjusting for multiple comparisons using the family-wise error rate (FWER) Bonferroni correction or the false discover rate (FDR) Benjamini–Hochberg correction, both of which have been used in the CNA literature.18,20,29–31 Evaluative thresholds were minimum absolute values of a binary association measure (BAM). We used four BAMs, two risk ratios and two correlation coefficients: the odds ratio 32,33Pearson’s binary correlation coefficient 34Forbes’ coefficient of association 34 and the tetrachoric correlation coefficient calculated using a latent bivariate normal model.35 is recommended as a standard measure of epidemiological comorbidity32 and has been used in several CNA studies.19,36,37 Several other studies have used and together, in part to check the robustness of their results,17,38–41 though these refer to as “relative risk.”42 has not appeared in CNA literature but enables later comparisons between pairwise and multivariate models. We calculated using psych43 and implemented the approximation of reference 44 to calculate standard errors. In the pairwise analysis, only positive associations were included.
Pairwise network construction was thus based on five parameters: the source of data ; the TWER ; the error rate correction , if any; the BAM (possibly none); and the BAM cutoff . We notate specific networks and substitute bullets for values to indicate families of networks taken over all values in the following ranges:
: Columbia, MedPAR(3), MedPAR(5), Sct. Hans, Michigan, Stanford, Columbia*, MIMIC
:
: none (ø), Bonferroni (FWER), Benjamini–Hochberg (FDR)
: (unit), , , ,
: each of four values specific to each measure: (The threshold ranges of for each BAM were chosen so that the corresponding quantiles of pairs in each data set are roughly equal.) , , , .
Multivariate constructions
Conventional measures of comorbidity fail to account for incidence rates of other disorders. Clinically unrelated disorders may co-occur due to common risk factors or complications, and such “transitive correlations”45 are important potential explanations for clustering patterns observed in comorbidity networks.36 Partial correlations account for these confounding effects by generalizing the calculation of regression coefficients: the full partial correlation between response variables and is a standardized effect estimate from the regression model of on all other responses, including (and satisfies ).46 This concept relies on normality assumptions for regression; we use a matrix formulation to obtain partial tetrachoric correlations from the tetrachoric correlations . We computed differently for high-volume, low-dimension data43 and, via shrinkage estimates, for low-volume, high-dimension data.47,48
Another way to account for such confounding is to use an interaction model based on an underlying covariance matrix. An estimator of this matrix can be scaled to obtain an estimated correlation matrix . Epidemiological comorbidities may also arise from patient-level covariates, as when clinically relevant subpopulations (eg, elderly or infirm patients) are at heightened risk of multiple, otherwise etiologically unrelated disorders. We adapted the joint interaction–distribution model (JIDM) of reference 49 to jointly model disorder interactions and patient-level covariates, and by omitting covariates other than intercepts we obtain a comparable interaction model. We denote the models JIDM0 and JIDM1 and their correlation matrices and . We adapted this workflow from reference 49 using JAGS50 via R2jags.51
From the NAMCS data, we generated a correlation matrix for each model, controlling for age, gender, ethnicity, insurance status, region, and metropolitan status in JIDM1. From the MIMIC data, we excluded JIDM1, to reduce computational cost and to limit the scope of the analysis. Each model included every CCS code. We compared all four models on the chronic disorders in NAMCS using correlation biplots. We visualized the relationships among the correlation estimates using scatterplots. Of the two data sources, one (NAMCS) is low-dimensional but high-volume while the other (MIMIC-III) is comparatively high-dimensional and low-volume. This enables us to more confidently take general lessons from the model comparisons.
Global network structure
To assess the effects of the construction parameters on the pairwise models, we calculated several unweighted summary statistics on the networks and fit two regression models to each vector of statistics. The first model (Equation 1) included only the predictors (categorical) and (continuous) and was evaluated on the networks , while the second (Equation 2) was evaluated on the lot and also included an interaction effect of (categorical) with (continuous) in order to allow for the different effects of the evaluative cutoff using different association measures. To simplify computations, we took as the response variable the difference between and the average value on the networks . The coefficient associated with each dataset then indicates the direction in which a statistic deviates, on , from its values on the other .
Equation 1
Equation 2
The statistics included the proportion of disorders in the largest connected component LCP, the graph density , the mean degree , the Gini index 52 the degree assortativity 53 the triad closure , the mean graph distance , the modularity using Walktrap,54,55 and the location and scale parameters and of the log-normal family, which best fit the degree sequence tails.56,57 We complemented these regressions with a principal components analysis (PCA) on the same centered and scaled statistics.
Centrality rankings
CNAs often characterize disorders by their centrality in a comorbidity network:17 and58 used (weighted and unweighted, respectively) degree centrality to measure the connectedness of disorders, or their “total” epidemiological comorbidity;58 also used betweenness centrality to measure the potential influence of an index disorder on a patient’s comorbidities. Several other teams invoked degree, betweenness, and closeness centrality as general indicators of a disorder’s importance.39,59,60 Three studies corroborated the exceptionally high centrality of hypertension in comorbidity networks,39,58,61 while another examined the centralities of disorders comorbid with hypertension.60 An increasingly popular approach is to compare centralities across study populations:61 compared the betweenness centralities of diagnoses between demographic strata such as low- and high-income populations, and62 compared degree centralities of disorders between COPD and non-COPD populations in a case–control design.61 found that the betweenness rankings of disorders were sensitive to their link pruning procedure, and59 noted that the centralities of adverse events in their VAERS networks changed noticeably from month to month.
We calculated degree, betweenness, and closeness centralities in the networks . We compared centrality rankings on entire ontologies using Kendall rank correlations,63,64 which we analyzed geometrically using variance decompositions and biplots. We also identified the several most central disorders from each network and assessed their consistency directly. Finally, we used many-to-one maps between ontologies (level-5 to level-3 ICD9 and level-5 ICD9 to the ontology of reference 16) to compare group centrality measures for concepts in the finer ontology with node centralities for concepts in the coarser ontology.65
Ethical considerations
This study did not involve human or other animal subjects. We conducted secondary analysis on data sets collected and aggregated by other researchers, which are available either publicly or upon request. Of these, patient-level data were only available in MIMIC-III, but our analysis relied exclusively on aggregated data.
RESULTS
Global network structure
Table 2 66 summarizes the linear model of Equation 2 fit to various global statistics. The effect estimates of the interactions can be compared after scaling the ranges of the . Almost all effects are discernible with . The PCA biplot (Figure 267) complements these estimates with information about their relative differences.
Table 2.
LMs of network statistics on data source, test-wise error rate, and binary association measure
| Dependent variable |
|||||||||
|---|---|---|---|---|---|---|---|---|---|
| LCP | |||||||||
| Columbia | 0.24*** | 0.06* | −0.19*** | −51.04*** | −0.001 | −0.34*** | −0.68* | −0.03 | 0.01 |
| (0.03) | (0.03) | (0.02) | (11.46) | (0.18) | (0.05) | (0.27) | (0.03) | (0.02) | |
| MedPAR(3) | 0.31*** | 0.13*** | −0.18*** | −31.79** | 0.31* | −0.08 | 0.30 | 0.12*** | −0.09*** |
| (0.03) | (0.03) | (0.02) | (11.46) | (0.17) | (0.05) | (0.27) | (0.03) | (0.02) | |
| MedPAR(5) | 0.21*** | −0.12*** | 0.03* | −39.54*** | 0.24 | 0.31*** | 1.38*** | 0.18*** | −0.28*** |
| (0.03) | (0.03) | (0.02) | (11.46) | (0.17) | (0.05) | (0.27) | (0.03) | (0.02) | |
| Sct. Hans | 0.13*** | 0.04 | −0.11*** | −59.58*** | −1.16*** | 0.03 | 0.20 | 0.10** | −0.22*** |
| (0.03) | (0.03) | (0.02) | (11.46) | (0.18) | (0.05) | (0.27) | (0.03) | (0.02) | |
| Michigan | 0.51*** | −0.18*** | −0.11*** | 158.43*** | 2.07*** | 0.23*** | 0.31 | 0.12*** | −0.12*** |
| (0.03) | (0.03) | (0.02) | (11.46) | (0.17) | (0.05) | (0.27) | (0.03) | (0.02) | |
| Stanford | −0.21*** | 0.39*** | −0.07*** | −60.66*** | −2.20*** | 0.23*** | −1.50*** | −0.13*** | 0.09*** |
| (0.03) | (0.03) | (0.02) | (11.46) | (0.19) | (0.05) | (0.27) | (0.03) | (0.02) | |
| Columbia* | −0.19*** | 0.07* | −0.14*** | −58.96*** | −0.93*** | −0.45*** | −1.63*** | −0.14*** | 0.01 |
| (0.03) | (0.03) | (0.02) | (11.46) | (0.19) | (0.05) | (0.27) | (0.03) | (0.02) | |
| MIMIC | 0.31*** | 0.02 | −0.07*** | −37.21** | −0.09 | 0.43*** | 1.62*** | 0.15*** | −0.21*** |
| (0.03) | (0.03) | (0.02) | (11.46) | (0.17) | (0.05) | (0.27) | (0.03) | (0.02) | |
| 0.02*** | −0.003 | −0.01*** | 1.95* | 0.06*** | −0.01** | −0.05** | −0.01*** | −0.01*** | |
| (0.002) | (0.002) | (0.001) | (0.80) | (0.01) | (0.003) | (0.02) | (0.002) | (0.001) | |
| −0.01*** | 0.001* | 0.002*** | −1.17*** | −0.04*** | −0.003* | 0.02*** | 0.002*** | −0.003*** | |
| (0.001) | (0.001) | (0.0003) | (0.20) | (0.004) | (0.001) | (0.005) | (0.001) | (0.0003) | |
| −0.01*** | 0.003*** | 0.002*** | −1.14*** | −0.03*** | −0.003** | 0.02*** | 0.003*** | −0.003*** | |
| (0.001) | (0.001) | (0.0003) | (0.20) | (0.004) | (0.001) | (0.005) | (0.001) | (0.0003) | |
| −3.24*** | 2.20*** | 1.46*** | −422.14*** | −19.35*** | 0.47 | 3.70** | 0.57*** | −0.51*** | |
| (0.15) | (0.17) | (0.09) | (59.45) | (1.08) | (0.30) | (1.38) | (0.16) | (0.11) | |
| −0.63*** | 0.19*** | 0.19*** | −125.11*** | −4.50*** | −0.04 | 2.64*** | 0.34*** | −0.22*** | |
| (0.05) | (0.05) | (0.03) | (17.70) | (0.30) | (0.08) | (0.41) | (0.05) | (0.03) | |
| Observations | 576 | 568 | 576 | 576 | 504 | 504 | 576 | 576 | 568 |
| Adjusted | 0.78 | 0.59 | 0.57 | 0.66 | 0.79 | 0.51 | 0.43 | 0.56 | 0.65 |
Note:
P < .1;
P < .01;
P < .001.
Figure 2.
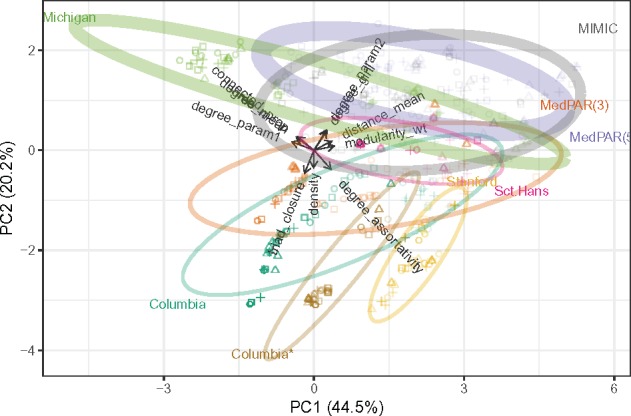
Row-principal PCA biplot for the summary statistics with networks (cases) in principal coordinates and statistics (variables) in standard coordinates. The values for graphs constructed from a common dataset are summarized by 95% confidence ellipses. Symbol corresponds to BAM, color indicates data source, and opacity is proportional to network density. Ellipse thicknesses are proportional to the number of clinical concepts (nodes) in the ontology (graph).
The evidential and evaluative thresholds effect dramatic changes in graph density , which largely explain their effects on connectivity (). Stricter thresholds also led to greater hierarchical structure (). Uniquely, triad closure increased with stricter evidential cutoffs but decreased with stricter evaluative cutoffs. Graph density aligned with the first principal component, which accounted for 40% of the variation among the global statistics.
The second principal component separated more connected and homogeneous networks from those with greater assortativity and triad closure, and more effectively discriminated among the data sources. Each data source produced networks with distinctive properties, and stricter thresholds enhanced these distinctions. Stanford and Columbia* yielded similar networks via identical ontology and processing, though MedPAR(3) and Michigan produced similar networks with no such commonalities; MedPAR(3) and MedPAR(5), like Columbia and Columbia*, differed only in ontology, but the former yielded similar networks while the latter highly dissimilar ones.
Centrality rankings
For each data source and centrality measure, different error rate corrections and BAMs yielded very different rankings of disorders in the underlying ontology. For an example taken at random, rankings of full ICD9 codes based on Michigan data were sensitive to the BAM though robust to the correction (Figure 3). In other cases, rankings were variably more sensitive to the BAM (MedPAR(3), Columbia*) or to the correction (Sct. Hans, MIMIC). Overall, degree centrality was more sensitive to the correction and closeness and betweenness centrality more sensitive to the BAM.
Figure 3.

Eigendecomposition biplots for the Kendall correlations among (left to right) degree, betweenness, and closeness centrality rankings of disorders in networks constructed from the Michigan data, using a 5% TWER with each error rate correction and each BAM. The linetype of each arrow indicates the correction (solid for none, dotted for FWER, dashed for FDR) and its color and label indicate the BAM.
In contrast, the hubs identified using each centrality measure were consistent across constructions for each data source. Hubs identified from regional EHR data included epilepsy, limb pain, respiratory problems, vitamin deficiency, benign neoplasms, and tuberculosis; other data sources produced their own distinctive hubs: non-specific diagnoses of fluid and electrolyte imbalances, urinary tract disorders, and bacterial infections (MedPAR), which may be associated with increased hospital and nursing home care as well as with aging itself; gait and mobility disorders, which are strongly associated with nervous disorders (Sct. Hans); and acute posthemorrhagic anemia (APHA), a common symptom of injury-induced blood loss (MIMIC). Prevalence did not strongly predict centrality, but all hubs were highly prevalent disorders.
Centrality rankings using node versus group centrality on networks constructed using different ontologies were weakly concordant or else discordant, even when constructed using crosswalked data from the same source. Group betweenness centrality was computationally prohibitive, so only degree and closeness centrality were used.
Multivariate constructions
The four correlation matrices yielded both increasingly noisy and progressively less positive association estimates; each set of estimates was roughly linearly related to the others. In and , all 13 disorders loaded positively onto the first eigenvector, which was most aligned with HT, HLD, and IHD; whereas and oriented some disorders, including depression and cancer, in opposition. Several associations changed sign or discernibility as well as magnitude from model to model, though negative associations in were negative throughout and positive associations in were positive in (Figure 4).
Figure 4.

Four comorbidity networks constructed from the NAMCS chronic disease incidence data. From left to right, then top to bottom: conventional comorbidity network with links determined from a 5% TWER and weighted by rt; partial correlation comorbidity network adapted from the conventional network; JDM network controlling only for disease prevalence, with links weighted by ; JDM network also controlling for patient-level demographics. Black (respectively, grey) links indicate positive (negative) associations.
These patterns were reproduced using MIMIC data from each critical care unit. The roughly linear relationships between model estimates held only among more prevalent disorders, while those among less prevalent disorders amounted to noise. In contrast to the robustness in pairwise analyses, and despite the correlation between prevalence and centrality, hub identification was highly inconsistent across network models based on a common care unit.
DISCUSSION
Robustness
We found that data sources are generally more determinative of global network properties and top centrality rankings than network construction parameters, which lends support to the use of CNA to assess differences in network structures between different populations.61,68,69 These differences both sustain and become clearer as links are pruned (up to conventional limits). Global network properties that rely on link weights, including weight distributions and distance-based centrality rankings, are less robust to the relevant parameter choices of error rate correction and of association measure.
Uniquely, triad closure was affected differently by evidential and evaluative link pruning: removing statistically fainter associations increased , while removing lower-magnitude associations decreased . This suggests that many weak but discernible comorbidities are transitive, arising from mutual associations in the incidence data. This further motivates the use of multivariate models to obtain association estimates controlled for such effects.
Among high-prevalence disorders, the primary spectrum from lower to higher incidence observable in the pairwise and partial correlation networks is obscured in the joint interaction–distribution networks. These models also reveal that much observed epidemiological comorbidity can be accounted for by patient-level factors such as age, ethnicity, and insurance status. Whereas these differences nevertheless follow predictable patterns, differences in associations among less prevalent disorders appeared to amount to noise.
Overall, conventional pairwise CNA is robust to the researcher degrees of freedom inherent to network construction, but multivariate models call into question not only global network properties but the signs and magnitudes of the constituent pairwise associations.
Insufficiency of pairwise models
Network analysis is fundamentally dyadic, and comorbidity network construction hinges on the method of link determination, which we have shown to depend profoundly on the network model employed. This raises the prospect that pairwise association mining, while certain to reveal many thitherto unknown comorbidities, may turn up a mixed bag of novel associations, including many that would turn out to be unremarkable or even inverted after controlling for co-related disorders. For example, the unexpected associations between hypothyroidism and shingles () and between Keloids and a history of asthma () uncovered by reference 36 might turn out to be negatively associated once the confounding associations they propose (cancer treatments and racial identity, respectively) are accounted for. Such differences could be epidemiological, but it is also plausible that they are in part administrative, for example, if a limited number of diagnoses are recorded during patient encounters even though others may be present in each patient (see also reference [19]). The authors of reference [39] point out that mined associations do not imply relevance or validity, and that some detected associations may be spurious. However, one lesson of our analysis is that mining for pairwise associations in a system as complex as human health may be little better than chance at selecting comorbidities that survive even statistical scrutiny.
A great deal of statistical machinery exists to facilitate this. In adapting JIDMs in particular, we appeal to the field ecology literature, on the basis of an ecological–epidemiological analogy: Disorders afflicting persons and communities are analytically similar to species occupying geographical sites—in the case of viral, bacterial, and fungal infections, indeed a special case. Association network analysis itself is rooted in ecology, which produced many if not most of the measures commonly used to weight association networks.70,71 More recently, ecologists have honed several other methods to account for the same limitations of pairwise network construction discussed here.72–74 The assumptions underlying an ecological data analytic technique will frequently be met by epidemiological data, in which case the results will be interpretable in a way that translates between the settings.
Interpretability
Though we have focused on the robustness of numerical results, equally important is the validity of interpretations. Association network models are increasingly popular for high-dimensional data sets, and the conclusions drawn about an underlying complex system must be informed by the process that converts the raw data to the network model. Though arising from fundamentally different constructions, these networks are often characterized using concepts grounded in the study of social networks, electrical circuits, and other relational data.
A chronic triad
The triad of hypertension, diabetes, and arthritis help illustrate these problems (Figure 4, Table 3): Each of the three pairs is positively correlated, based on their contingency tables. The HT–DM correlation weakens but remains in the multivariate models; the HT–arthritis correlation weakens more dramatically, to the point that it is not discerned at in the JIDM controlling for demographic covariates; and the DM–arthritis correlation is discernibly negative in each of the multivariate models.
Table 3.
Point estimates and their upper and lower bounds on 95% confidence or credible intervals for the HT–DM–arthritis triad in network models of the NAMCS data
| Disorder 1 | Disorder 2 | Model | Lower | Estimate | Upper |
|---|---|---|---|---|---|
| Arthritis | DM | Pairwise | 0.144 | 0.163 | 0.182 |
| Arthritis | DM | Partial | −0.083 | −0.064 | −0.045 |
| Arthritis | DM | JIDM0 | −0.101 | −0.054 | −0.005 |
| Arthritis | DM | JIDM1 | −0.142 | −0.091 | −0.039 |
| Arthritis | HT | Pairwise | 0.360 | 0.377 | 0.393 |
| Arthritis | HT | Partial | 0.165 | 0.184 | 0.202 |
| Arthritis | HT | JIDM0 | 0.018 | 0.060 | 0.102 |
| Arthritis | HT | JIDM1 | −0.072 | −0.026 | 0.021 |
| DM | HT | Pairwise | 0.563 | 0.576 | 0.588 |
| DM | HT | Partial | 0.334 | 0.351 | 0.368 |
| DM | HT | JIDM0 | 0.299 | 0.341 | 0.382 |
| DM | HT | JIDM1 | 0.201 | 0.245 | 0.291 |
What to make of these differences? The correlation between HT and arthritis may be mediated by gender, the only demographic variable found to have opposite effects on their incidence in JIDM1 (effects on HT and DM all had the same sign); though the correlation was very weak already in JIDM0, suggesting that it was largely attributable to other comorbid associations. The more puzzling relationship is that between HT and DM, which is complicated by the coarseness of the ontology: NAMCS does not distinguish types 1 versus 2 DM, nor osteo- (OA) versus rheumatoid (RA) arthritis. It is not obvious, though, that parsing these subtypes would explain away the association: Systematic reviews75,76 have cemented an epidemiological comorbidity between type 2 DM and OA, and there is emerging agreement on one between DM and RA,77 in both cases likely mediated by BMI.
In any event, the DM–arthritis correlation turns negative upon accounting for the effects of the other chronic disorders; it is less likely due to a protective effect than to diabetic and arthritic populations generally having different multimorbid profiles. The disorders statistically associated with both in the partial correlation and endogenous joint interaction–distribution networks include cancer (negatively), CVD (positively), and depression (differently), in addition to HT, and only cancer remains as a discernible covariate of both after accounting for demographics. The coarseness of these indicators precludes drill-down analysis, but their relative uniqueness and their obviation while controlling for demographics suggest that their effect on the DM–arthritis association may be a proxy for a demographic stratification.
Meanings of centrality
The use of centrality measures is another case in point. The degree of a disorder, calculated as the number of disorders it is comorbid with in a patient population, is sensible enough a measure of its “total comorbidity”17 and a useful concept both epidemiologically and clinically. The weights (using BAMs) associated with these comorbidities are also clearly useful for discriminating between stronger and weaker co-occurrence rates, hence higher or lower risk factors for patients with an index disorder. However, we found that the choice of disease ontology has a significant impact on comorbidity rankings, so much so that the centralities of disorders before crosswalking to a coarser ontology are not predictive of the centralities of their counterparts after crosswalking. For the following discussion, we constructed a typical comorbidity network, using the Rzhetsky data and ontology with a Bonferroni-corrected evidential cutoff and weighting (positive) links by the Forbes coefficient .
First note that none of the weights commonly used to quantify total comorbidity are additive: In our example network, amebiasis, a gastrointestinal infection rare in the United States, and rheumatoid arthritis, a common chronic autoimmune disorder, have 5 and 67 comorbid relations, respectively. Though having very different etiologies and afflicting very different patient populations, these disorders have approximately the same weighted degree (529 and 561). This does not translate to their being similarly severe in any recognized sense, or to their belonging at a similar ranking amidst the other disorders in the ontology.
Betweenness and closeness centrality rely on a different version of additivity that is equally problematic. The graph distance in this network (To calculate graph distances, replace edge weights with .) between type 1 diabetes and breast cancer (in female patients) is the same as that between multiple epiphyseal dysplasia (MED) and hepatitis E (HepE), approximately , though the former two disorders are significantly correlated (ie, directly linked, ) while the latter two can only be reached from each other via three intermediate disorders: multiple epiphyseal dysplasia Albright–Sternberg syndrome cerebral palsy hepatitis C HepE. Yet this indirect sequence of associations leading to HepE is does not have an established clinical interpretation, nor does it imply a natural comparison to the relative risk of MED encoded by the direct link. Furthermore, controlling for covariates and subsetting populations may significantly alter the magnitudes and signs of these links, with unpredictable effects on indirect distances.
These limitations are highlighted by weighting issues, but they arise from the network model itself, which is premised on a principle of “guilt by association” that implicates one node in the effects of another according to their proximity in the network. In the related field of genomics, this principle “does not reflect the dynamic nature of biological networks,”13 and the same may be said of epidemiological networks. As in genomics, comorbidity network centrality analysis is demonstrably effective at prioritization, but without underlying theory it will be difficult to know what critical patterns it may miss, or even what it means for a disorder to be “central” in any specific sense (Such concerns are not specific to CNA. Inconsistency and uncertainty over the interpretations of centrality measures in the study of human communication networks led [12] to propose the concise set of conceptualizations and measures discussed above: degree, based on the idea of communication activity with other nodes; betweenness, based on the control of communication among other actors, and closeness, based on either independence from the control of others or efficiency of dissemination. These interpretations extend to other kinds of resource exchange, but they do not have straightforward interpretations on correlation networks.).
Limitations
Our results come with their own limitations. As discussed above, the data sets best-suited to the investigations undertaken here were only available to us as pairwise contingency tables, rather than as case-level incidence data, so that multivariate comparisons were performed only on open-access sources with important caveats beyond those of all administrative healthcare data. Necessarily, we evaluated only a handful of CNA techniques. Our focus was cross-sectional, whereas many recent CNAs have used longitudinal or case–control designs, often tailoring conventional techniques to these settings. Additional work will be necessary to evaluate these approaches. Additionally, though we have discussed some use cases from our analysis, we have not conducted the kinds of follow-up studies CNA is often used to support. It will be necessary to validate this longer-term workflow as methods are standardized and basic science driven by CNA accumulates. Finally, the companion goal of validating CNA techniques is made difficult by the lack of any ground truth underneath the real-world incidence data used in CNA. Some headway may be gained in future through simulation studies, for instance making use of the generative framework underlying the JIDM, though ultimately this may require network analyses of data generated from artificial complex systems, such as multi-level, whole-system models.
CONCLUSION
To pre-empt and mitigate the concerns raised in the introduction, we urge CNA researchers to include the following steps (according to their objectives):
Make patient-diagnosis incidence data available for secondary use. This will enable ontological crosswalking and multivariate modeling, though it may require additional processing to address privacy concerns.
Provide theoretical justification for the disorder ontology from which networks are constructed. This choice can have dramatic effects on the resulting network structure, including which nodes are identified as hubs.
Provide theoretical justification for weighting networks. Indirect relations are highly sensitive to the association measure; if weighting is important, then results using different measures should be compared.
To summarize global structure, report at least the largest component size, assortativity, and clustering coefficient. These statistics are likely to effectively discriminate between networks constructed from different populations.
Provide theoretical justification for using pairwise versus partial correlations. Controlling for confounding effects can radically change the network structure, and free efficient software exists to calculate partial correlations from pairwise.
Validate associations among common disorders or within specific subsets of disorders using multivariate (eg, joint interaction–distribution) models. These methods do not yet scale but can distinguish primary from secondary or transitive associations among a manageable set of variables.
Funding
JCB was supported in part by an NIDCR T90 training grant (5T90DE021989-07).
AUTHOR CONTRIBUTIONS
JCB, TPA, and RCL conceived the study questions and design. JCB acquired data and performed computational analyses. JCB and TPA interpreted results and examined use cases. JCB, TPA, and RCL contributed to the discussion, wrote and approved the final manuscript, and take responsibility for the integrity of the work.
CONFLICT OF INTEREST STATEMENT
None declared.
Supplementary Material
ACKNOWLEDGMENTS
Beverly Setzer and Lauren Geiser contributed code for processing data and constructing graphs as well as helpful methodological conversations. David Hanauer kindly shared the pre-processed contingency table data from the University of Michigan Health System. Two anonymous reviewers provided suggestions that greatly improved the manuscript.
REFERENCES
- 1. Hood L, Flores MA, Brogaard KR, et al. Systems medicine and the emergence of proactive P4 medicine: predictive, preventive, personalized and participatory In: Walhout AJM, Vidal M, Dekker J, eds. Handbook of Systems Biology. London: Elsevier, 2013445–67. [Google Scholar]
- 2. Ayers D, Day PJ.. Systems medicine: the application of systems biology approaches for modern medical research and drug development. Mol Biol Int 2015; 2015: 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Kirschner M. Systems Medicine: Sketching the Landscape In: Schmitz U, Wolkenhauer O, eds. Systems Medicine. New York, NY: Springer; 2016. 3–15. [DOI] [PubMed] [Google Scholar]
- 4. Pavlopoulos GA, Secrier M, Moschopoulos CN, et al. Using graph theory to analyze biological networks. BioData Mining 2011; 4 (1): 10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Gietzelt M, Löpprich M, Karmen C, et al. Models and data sources used in systems medicine. Methods Inf Med 2016; 55: 107–13. [DOI] [PubMed] [Google Scholar]
- 6. Akker M, van den Buntinx F, Knottnerus JA.. Comorbidity or multimorbidity: what’s in a name? A review of literature. Eur J Gen Pract 1996; 2: 65–70. [Google Scholar]
- 7. Valderas JM, Starfield B, Sibbald B, et al. Defining comorbidity: implications for understanding health and health services. Ann Fam Med 2009; 7 (4): 357–63. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Emmert-Streib F, Tripathi S, Simoes R de M, et al. The human disease network. Syst Biomed 2013; 1 (1): 20–8. [Google Scholar]
- 9. Capobianco E, Liò P.. Comorbidity networks: beyond disease correlations. J Complex Netw 2015; 3 (3): 319–32. [Google Scholar]
- 10. Brunson JC, Laubenbacher RC.. Applications of network analysis to routinely collected health care data: a systematic review. J Am Med Inform Assoc 2017; 25 (2): 210–221. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Brandes U, Robins G, McCranie A, et al. What is network science? Netw Sci 2013; 1 (1): 1–15. [Google Scholar]
- 12. Freeman LC. Centrality in social networks conceptual clarification. Soc Netw 1978; 1 (3): 215–39. [Google Scholar]
- 13. Hou L, Chen M, Zhang CK, et al. Guilt by rewiring: gene prioritization through network rewiring in genome wide association studies. Hum Mol Genet 2014; 23 (10): 2780–90. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Jen E. Stable or robust? What’s the difference? The two concepts lead to different questions; will they give rise to different answers? Complexity 2003; 8: 12–8. [Google Scholar]
- 15. Goodman SN, Fanelli D, Ioannidis JPA.. What does research reproducibility mean? In: Arthur L. Caplan, Barbara K. Redman, eds. Getting to Good: Research Integrity in the Biomedical Sciences. Cham (Switzerland): Springer International Publishing; 2018. 96–102. [Google Scholar]
- 16. Rzhetsky A, Wajngurt D, Park N, et al. Probing genetic overlap among complex human phenotypes. Proc Natl Acad of Sci USA 2007; 104 (28): 11694–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Hidalgo CA, Blumm N, Barabasi A-L, et al. A dynamic network approach for the study of human phenotypes. PLoS Comput Biol 2009; 5 (4): e1000353. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Roque FS, Jensen PB, Schmock H, et al. Using electronic patient records to discover disease correlations and stratify patient cohorts. PLoS Comput Biol 2011; 7 (8): e1002141. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Hanauer DA, Ramakrishnan N.. Modeling temporal relationships in large scale clinical associations. J Am Med Inform Assoc 2013; 20 (2): 332–41. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Bagley SC, Sirota M, Chen R, et al. Constraints on biological mechanism from disease comorbidity using electronic medical records and database of genetic variants. PLoS Comput Biol 2016; 12 (4): e1004885. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Johnson AEW, Pollard TJ, Shen L. et al. MIMIC-III, a freely accessible critical care database. Sci Data 2016; 3: 160035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Agency for Healthcare Research and Quality. Clinical Classification Software (CCS) for ICD-9-CM Fact Sheet. 2012. https://www.hcup-us.ahrq.gov/toolssoftware/ccs/ccsfactsheet.jsp. Accessed December 6, 2019.
- 23.R Core Team. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing; 2016. https://www.r-project.org/. [Google Scholar]
- 24. Grolemund HWG. R for Data Science. O’Reilly Media, Inc; 2016. https://www.oreilly.com/library/view/r-for-data/9781491910382/. Accessed December 6, 2019. [Google Scholar]
- 25. Csardi G, Nepusz T.. The igraph software package for complex network research. Int J Complex Syst 2006; 1695 http://igraph.org. [Google Scholar]
- 26. Pedersen TL. tidygraph: A Tidy API for Graph Manipulation. 2018. https://cran.r-project.org/package=tidygraph. Accessed December 6, 2019.
- 27. Pedersen TL. ggraph: An Implementation of Grammar of Graphics for Graphs and Networks. 2018. https://cran.r-project.org/package=ggraph. Accessed December 6, 2019.
- 28. Wasey JO. icd: Tools for Working with ICD-9 and ICD-10 Codes, and Finding Comorbidities. 2017. https://cran.r-project.org/package=icd. Accessed December 6, 2019.
- 29. Roitmann E, Eriksson R, Brunak S.. Patient stratification and identification of adverse event correlations in the space of 1190 drug related adverse events. Front Physiol 2014; 5: 332. doi: 10.3389/fphys.2014.00332. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Bhavnani SK, Dang B, Visweswaran S, et al. How comorbidities co-occur in readmitted hip fracture patients: from bipartite networks to insights for post-discharge planning. AMIA Jt Summits Transl Sci Proc 2015; 2015: 36–40. [PMC free article] [PubMed] [Google Scholar]
- 31. Kim M-h, Banerjee S, Zhao Y, et al. Association networks in a matched case-control design—co-occurrence patterns of preexisting chronic medical conditions in patients with major depression versus their matched controls. Journal of Biomedical Informatics 2018; 87: 88–95. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Kraemer HC. Statistical issues in assessing comorbidity. Statist Med 1995; 14 (8): 721–33. [DOI] [PubMed] [Google Scholar]
- 33. Parzen M, Lipsitz S, Ibrahim J, et al. An Estimate of the Odds Ratio That Always Exists. Journal of Computational and Graphical Statistics 2002; 11 (2): 420–36. [Google Scholar]
- 34. Hubalek Z. Coefficients of association and similarity, based on binary (presence-absence) data: an evaluation. Biological Reviews 1982; 57: 669–89. [Google Scholar]
- 35. Drasgow F. Polychoric and Polyserial Correlations In: Encyclopedia of Statistical Sciences. Hoboken, NJ, USA: John Wiley & Sons, Inc; 2006. [Google Scholar]
- 36. Hanauer DA, Rhodes DR, Chinnaiyan AM.. Exploring clinical associations using ’-omics’ based enrichment analyses. PLoS One 2009; 4 (4): e5203.. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Kim JH, Son KY, Shin DW, et al. Network analysis of human diseases using Korean nationwide claims data. J Biomed Inform 2016; 61: 276–82. [DOI] [PubMed] [Google Scholar]
- 38. Folino F, Pizzuti C.. Link prediction approaches for disease networks In: Böhm C, Khuri S, Lhotská L, eds., et al. Information Technology in Bio- and Medical Informatics: Third International Conference. Berlin, Heidelberg: Springer; 2012: 99–108. [Google Scholar]
- 39. Chen Y, Xu R.. Mining cancer-specific disease comorbidities from a large observational health database. Cancer Informatics 2014; 37–44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Chmiel A, Klimek P, Thurner S.. Spreading of diseases through comorbidity networks across life and gender. New J Phys 2014; 16 (11): 115013. [Google Scholar]
- 41. Lai Y-H. Network analysis of comorbidities: case study of HIV/AIDS in Taiwan. In: Wang L, Uesugi S, Ting IH, Okuhara K, Wang K, eds. Multidisciplinary Social Networks Research. MISNC 2015. Communications in Computer and Information Science, vol 540. Berlin, Heidelberg: Springer, 2015; 2: 174–86. [Google Scholar]
- 42. Zhang J, Yu KF.. What’s the relative risk? JAMA 1998; 280 (19): 1690. [DOI] [PubMed] [Google Scholar]
- 43. Revelle W. Psych: Procedures for Psychological, Psychometric, and Personality Research. Evanston, IL: Northwestern University; 2017. https://cran.r-project.org/package=psych. [Google Scholar]
- 44. Bonett DG, Price RM.. Inferential methods for the tetrachoric correlation coefficient. Journal of Educational and Behavioral Statistics 2005; 30 (2): 213–25. [Google Scholar]
- 45. Tao T. When is correlation transitive? 2014. https://terrytao.wordpress.com/2014/06/05/when-is-correlation-transitive/.
- 46. Epskamp S, Fried EI.. A Tutorial on Regularized Partial Correlation Networks. arXiv:1607.01367v9 [stat]. 2017; 20pp. [DOI] [PubMed] [Google Scholar]
- 47. Schäfer J, Strimmer K.. A shrinkage approach to large-scale covariance matrix estimation and implications for functional genomics. Statistical Applications in Genetics and Molecular Biology 2005; 4 (1): 32. doi: 10.2202/1544-6115.1175 [DOI] [PubMed] [Google Scholar]
- 48. Schäfer J, Opgen-Rhein R, Zuber V, et al. corpcor: efficient estimation of covariance and (partial) correlation. 2017. http://strimmerlab.org/software/corpcor/. Accessed December 6, 2019.
- 49. Pollock LJ, Tingley R, Morris WK, et al. Understanding co-occurrence by modelling species simultaneously with a Joint Species Distribution Model (JSDM). Methods Ecol Evol 2014; 5 (5): 397–406. [Google Scholar]
- 50. Plummer M. JAGS: a program for analysis of Bayesian graphical models using Gibbs sampling. Distributed Statistical Computing (DSC 2003), Technische Universität Wien; March 20–22, 2003; Vienna, Austria.
- 51. Su Y-S, Yajima M. R2jags: Using R to Run ’JAGS’. 2015. https://cran.r-project.org/package=R2jags.
- 52. Badham JM. Commentary: Measuring the shape of degree distributions. Netw Sci 2013; 1 (2): 213–25. [Google Scholar]
- 53. Newman M. Mixing patterns in networks. Phys Rev E 2003; 67 (2) 026126. [DOI] [PubMed] [Google Scholar]
- 54. Newman MEJ, Girvan M.. Finding and evaluating community structure in networks. Phys Rev E 2004; 69026113. [DOI] [PubMed] [Google Scholar]
- 55. Pons P, Latapy M.. Computing communities in large networks using random walks. JGAA 2006; 10 (2): 191–218. [Google Scholar]
- 56. Clauset A, Shalizi CR, Newman M.. Power-law distributions in empirical data. SIAM Rev 2009; 51 (4): 661–703. [Google Scholar]
- 57. Gillespie CS. Fitting heavy tailed distributions: the poweRlaw package. J Stat Soft 2015; 64 (2): 1–16. [Google Scholar]
- 58. Schafer I, Kaduszkiewicz H, Wagner HO, et al. Reducing complexity: a visualisation of multimorbidity by combining disease clusters and triads. BMC Public Health 2014; 14: 1285.. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59. Ball R, Botsis T.. Can network analysis improve pattern recognition among adverse events following immunization reported to VAERS? Clin Pharmacol Ther 2011; 90: 271–8. [DOI] [PubMed] [Google Scholar]
- 60. Liu J, Ma J, Wang J, et al. Comorbidity analysis according to sex and age in hypertension patients in China. Int J Med Sci 2016; 13 (2): 99–107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61. Feldman K, Stiglic G, Dasgupta D, et al. Insights into population health management through disease diagnoses networks. Sci Rep 2016; 6 (1): 30465. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62. Divo MJ, Celli BR, Poblador-Plou B, et al. Chronic obstructive pulmonary disease (COPD) as a disease of early aging: evidence from the EpiChron cohort. PLoS One 2018; 13 (2): e0193143. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63. Kendall MG. A new measure of rank correlation. Biometrika 1938; 30 (1-2): 81. [Google Scholar]
- 64. Kendall MG. The treatment of ties in ranking problems. Biometrika 1945; 33 (3): 239–51. [DOI] [PubMed] [Google Scholar]
- 65. Everett MG, Borgatti SP.. The centrality of groups and classes. The Journal of Mathematical Sociology 1999; 23 (3): 181–201. [Google Scholar]
- 66. Hlavac M. Stargazer: Well-Formatted Regression and Summary Statistics Tables. Cambridge, USA: Harvard University; 2015. http://cran.r-project.org/package=stargazer. [Google Scholar]
- 67. Brunson JC. ordr: a ‘tidyverse’ extension for ordinations and biplots. 2019. https://github.com/corybrunson/ordr.
- 68. Warner JL, Denny JC, Kreda DA, et al. Seeing the forest through the trees: uncovering phenomic complexity through interactive network visualization. Journal of the American Medical Informatics Association 2015; 22 (2): 324–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69. Glicksberg BS, Li L-2, Badgeley MA, et al. Comparative analyses of population-scale phenomic data in electronic medical records reveal race-specific disease networks. Bioinformatics 2016; 32 (12): i101–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70. Johnston JW. Similarity indices I: what do they measure? 1976. https://inis.iaea.org/search/search.aspx?orig_q=RN:8337829. Accessed December 6, 2019.
- 71. Podani J. Introduction to the Exploration of Multivariate Biological Data Paperbound. Leiden, The Netherlands: Backhuys Publishers; 2000. http://ramet.elte.hu/{∼}podani/subindex.html. [Google Scholar]
- 72. Ulrich W, Gotelli NJ.. Disentangling community patterns of nestedness and species co-occurrence. Oikos 2007; 116 (12): 2053–61. [Google Scholar]
- 73. Ovaskainen O, Hottola J, Siitonen J.. Modeling species co-occurrence by multivariate logistic regression generates new hypotheses on fungal interactions. Ecology 2010; 91 (9): 2514–21. [DOI] [PubMed] [Google Scholar]
- 74. Morueta-Holme N, Blonder B, Sandel B, et al. A network approach for inferring species associations from co-occurrence data. Ecography 2016; 39 (12): 1139. [Google Scholar]
- 75. Louati K, Vidal C, Berenbaum F, et al. Association between diabetes mellitus and osteoarthritis: systematic literature review and meta-analysis. RMD Open 2015; 1 (1): e000077. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76. Williams MF, London DA, Husni EM, et al. Type 2 diabetes and osteoarthritis: a systematic review and meta-analysis. Journal of Diabetes and Its Complications 2016; 30 (5): 944–50. [DOI] [PubMed] [Google Scholar]
- 77. Nicolau J, Lequerré T, Bacquet H, et al. Rheumatoid arthritis, insulin resistance, and diabetes. Joint, Bone, Spine 2017; 84: 411–6. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.