

Abstract
In renal transplantation, polymorphic amino acids on mismatched donor HLA molecules can lead to the induction of de novo donor‐specific antibodies (DSA), which are associated with inferior graft survival. To ultimately prevent de novo DSA formation without unnecessarily precluding transplants it is essential to define which polymorphic amino acid mismatches can actually induce an antibody response. To facilitate this, we developed a user‐friendly software program that establishes HLA class I and class II compatibility between donor and recipient on the amino acid level. HLA epitope mismatch algorithm (HLA‐EMMA) is a software program that compares simultaneously the HLA class I and class II amino acid sequences of the donor with the HLA amino acid sequences of the recipient and determines the polymorphic solvent accessible amino acid mismatches that are likely to be accessible to B cell receptors. Analysis can be performed for a large number of donor‐recipient pairs at once. As proof of principle, a previously described study cohort of 191 lymphocyte immunotherapy recipients was analysed with HLA‐EMMA and showed a higher frequency of DSA formation with higher number of solvent accessible amino acids mismatches. Overall, HLA‐EMMA can be used to analyse compatibility on amino acid level between donor and recipient HLA class I and class II simultaneously for large cohorts to ultimately determine the most immunogenic amino acid mismatches.
Keywords: donor‐specific antibody, immunogenicity, kidney transplantation
1. INTRODUCTION
In renal transplantation, human leukocyte antigen (HLA) antigen matching enhances long‐term graft survival.1, 2 Nonetheless, most recipients receive a graft with one or more HLA antigen mismatches because of high level of polymorphism of the HLA system and scarcity of donor organs. In addition, even grafts that are matched on the antigen level can be mismatched at the allelic level and can therefore induce an alloimmune response.3, 4 The presence of mismatched HLA antigens on the donor graft can lead to the formation of de novo donor‐specific HLA antibodies (DSA), which are associated with graft loss.5, 6 Moreover, sensitisation towards HLA significantly reduces the chance of receiving a repeat transplant. 7
While current matching algorithms are mainly based on HLA‐A, ‐B and ‐DR matching at the antigen level, one should realise that HLA antibodies are not specific for antigens, but recognise B cell epitopes present on HLA molecules. 8 In addition, the immunogenicity of HLA mismatches has been shown to be dependent on configurations of polymorphic amino acids on antibody accessible positions, which have been theoretically defined and are called eplets.9, 10 Indeed, several groups have shown that the chance of developing de novo DSA after transplantation increases with an increasing number of mismatched eplets.11, 12, 13 However, not every eplet mismatch triggers an immune response, indicative of a difference in immunogenicity of individual eplet mismatches. 14 The immunogenicity of a mismatched HLA allele is, amongst others, dependent on the HLA class II phenotype of the recipient as it determines if a specific eplet mismatch will lead to a full‐blown antibody response. B cells require CD4+ T cell help to switch towards IgG antibody producing cells and this help depends on the recognition of T cell epitopes presented by the recipients HLA class II molecules on the B cells.15, 16 Furthermore, the type of amino acid substitution (ie, difference in size, charge) can play a role in immunogenicity as it can affect the structure and physicochemical properties of an HLA molecule. 17 As eplets are theoretically defined, experimental verification is required to determine if an antibody can actually bind to an eplet, which has only been done for a limited number of eplets, mainly present on HLA class I.18, 19, 20
Other approaches based on amino acid mismatches and/or physicochemical scores have shown also to be useful to assess sensitisation risk of HLA allele mismatches on the population level.12, 21, 22, 23 While eplets are predefined entities that are still subject to change, 24 the amino acids that are the underlying basis of the eplets are fixed entities on HLA molecules. Therefore, we aim to define the immunogenicity of specific HLA mismatches based on polymorphic amino acids rather than eplets on HLA class I and class II molecules using large datasets of donor and recipient pairs. Based on these mismatches and the information on de novo DSA formation, polymorphic amino acids crucial for the induction of an antibody response can be defined. For this purpose, we have developed a user‐friendly software program, which analyses HLA class I and class II compatibility between donor and recipient on amino acid level focussing on the solvent accessible amino acid mismatches. For the analyses of large cohorts, a batch analysis option was incorporated into the software program.
2. METHODS
2.1. Development of HLA‐EMMA
The HLA Epitope Mismatch Algorithm (HLA‐EMMA) was developed in Microsoft Visual Studio and uses the. NET framework 4.6. It was written in VB.NET language. The software package is freely available for download (http://www.HLA-EMMA.com).
2.2. HLA amino acid sequences
All available HLA amino acid sequences were extracted from the IPD‐IMGT/HLA database version 3.39 for HLA‐A, ‐B, ‐C, ‐DRB1,3,4,5, −DQA1, ‐DQB1, ‐DPA1 and ‐DPB1 in January 2020, 25 and will be periodically updated in the software program. HLA alleles are included up to the second field typing resolution, 26 since higher resolution typing does not affect the amino acid sequence of the protein. Null alleles, such as DRB4*01:03N, are recognised by the software program and will not be considered for analysis as these HLA alleles are not expressed on cells. HLA‐EMMA contains the amino acid sequences for position 1 to 275 for HLA class I, and position 1 to 226 for HLA class II, the beginning of the mature proteins and regions that are of interest for antibody induction. For some HLA alleles, amino acid data at the beginning and/or end of the sequence are lacking. These HLA alleles, often rare HLA alleles, are marked in the algorithm but not excluded from analysis.
2.3. Solvent accessible polymorphic positions
Solvent accessible polymorphic amino acid positions were determined using publicly available crystal structures and open source relative solvent accessibility prediction tools. HLA crystal structures were obtained from the Research Collaboratory for Structural Bioinformatics Protein Data Bank (PDB, https://www.rcsb.org/ accessed on February 4, 2019). 27 More than 690 PDB HLA structures were available, with the multiple structures of the same HLA allele. Therefore, the initial selection was based on previously described HLA structures used for modelling with accurate structural quality, based on parameters such as atomic resolution, R factor, total number of crystallographically resolved residues and stereochemical quality.17, 28 Only HLA structures that are not in complex with a ligand and without any amino acid mutations were included. The list was extended with other, not yet included, HLA alleles of which structures are available with a correct amino acid sequence, not in complex with other ligands, and with finer atomic resolution (≤2.8 Å). In case of multiple structures for a specific HLA allele the structure with highest atomic resolution was selected. This resulted in a total of 43 HLA class I crystal structures (Table S1) and 20 HLA class II structures (Table S2). Recently, an online database of HLA class I modelled structures of HLA molecules became available at https://www.phla3d.com.br/. 29 Here, HLA class I tertiary structures were predicted by homology modelling using the amino acid sequences and homologous HLA class I structures, and then refined to improve the quality of the structures. From these HLA class I modelled structures only HLA alleles that were missing from the PDB list were selected (database accessed on April 11, 2019), resulting in 72 modelled structures (Table S3).
Open source tools NetSurfP2.0 30 and Porter Pale4.0 31 were used to predict solvent inaccessible amino acid positions. First, for each HLA structure the relative solvent accessibility of each amino acid positions was predicted using both tools. Next, if both tools predicted a relative solvent accessibility of lower than 25% for a specific amino acid position on all HLA structures of an HLA locus than this position was defined as solvent inaccessible. All the remaining positions were defined as solvent accessible. Only positions that are polymorphic within a locus and, in addition, solvent accessible are considered for defining solvent accessible amino acid mismatches.
Due to limited availability of structures for HLA‐DR, the polymorphic solvent accessible positions of HLA‐DR loci were defined by all positions that are not predicted as solvent inaccessible for the available DRB1, DRB3, DRB4 and DRB5 structures and if a position is polymorphic for at least one of the DRB1, DRB3, DRB4 or DRB5 amino acid sequences. In addition, the amino acid sequences of the HLA class II structures are incomplete, and as a result solvent inaccessible prediction was lacking for the positions near the end of the amino acid sequences (HLA‐DR positions 198‐226, ‐DQB1 positions 198‐226, −DQA1 position 199‐226, ‐DPB1 positions 190‐226 and ‐DPA1 positions 183‐226). Those positions are currently defined as solvent accessible if polymorphic.
2.4. Input and output of HLA‐EMMA
The donor and recipient HLA typing input of HLA‐EMMA is preferentially second field HLA typing, since this resolution describes the specific HLA protein. In case an HLA allele is entered that is not present in the IPD‐IMGT/HLA database, HLA‐EMMA will show a warning. However, incomplete HLA typing information can be entered, for example, if DQA1 typing is missing, an output will still be generated.
In case of serological typing or first field DNA typing HLA‐EMMA will convert to the most likely second field typing, based on a panel of high‐resolution typing results of a pre‐defined population. Currently, conversion can be based on most common alleles of the population “the Netherlands, Leiden” (NL n = 1305) (http://www.allelefrequencies.net), or most common HLA alleles of European Caucasians generated from the National Marrow Donor Program (EURCAU n = 81 106).32, 33 If required, upon request the conversion option can be extended to other populations of which high resolution typing data is available and published.
Besides manual entry, a batch analysis option is included for which the input format is a Microsoft Excel file. For comparing donor and recipient HLA, a file containing the HLA typing of an individual is present on each row, and each column represents an allele (Figure S1). The order of recipient and donor in file is irrelevant, provided that each recipient‐donor couple has a unique identification code, for example, R1 and D1, for recipient and donor, respectively.
Upon batch analysis, an export file .xml file is generated as an output file, which can be opened with Microsoft Excel (Figure S2). While the output of the manual entry is generated and presented immediately, it can also be exported as .xml file for downstream application.
2.5. Study cohort for validation
To validate HLA‐EMMA, we used a previously described lymphocyte immunotherapy study cohort (n = 191). 17 Briefly, this cohort consists of women that received their first lymphocyte immunotherapy from their male partner in 2009 and 2010. The HLA type of the women and their partner was determined by genotyping array (Illumina, San Diego, CA) and HLA imputation. In addition, reverse PCR sequence‐specific oligonucleotide was used to type HLA‐A and HLA‐B that were used as quality control. Antibodies against donor antigen were identified by testing sera, obtained 5 weeks (median 33 days, SD 4.5) following lymphocyte immunotherapy, with luminex single antigen bead (SAB) assays (One Lambda, Canoga Park, CA) and DSA were defined as MFI of ≥2000. HLA mismatches of which HLA second field typing could not be determined, towards which DSA were present before treatment, or that were not present in luminex SAB assay were excluded from analysis.
3. RESULTS
3.1. Polymorphic solvent accessible amino acid positions
The main goal of HLA‐EMMA is to analyse HLA class I and class II compatibility on the amino acid level for a large number of donor‐recipient pairs. The software program is based on the hypothesis that any polymorphic amino acid exposed on the surface of an HLA molecule can trigger an antibody response. To this aim, the polymorphic solvent accessible amino acid positions were defined per HLA locus using all known HLA alleles to determine polymorphic positions, and available HLA crystal structures to predict the solvent inaccessible positions, used for deduction of solvent accessible positions. Overall, this led to identification of 174 polymorphic solvent accessible positions for HLA‐A, 169 for HLA‐B, 162 for HLA‐C (Figure 1A), 106 for HLA‐DRB1/3/4/5, 149 for HLA‐DQB1, 48 for HLA‐DQA1, 86 for HLA‐DPB1 and 16 for HLA‐DPA1 (Figure 1B). By analysing the HLA class I modelled structures, additional polymorphic solvent accessible positions were defined; 2 for HLA‐A, 3 for HLA‐B and 10 for HLA‐C (Figure 1C).
FIGURE 1.

Polymorphic solvent accessible amino acid positions. For each locus the defined polymorphic solvent amino acid positions are indicated in grey for HLA class I (A) and HLA class II (B). C, The polymorphic solvent accessible positions defined by the HLA class I modelled structures
3.2. HLA class I and class II solvent accessible amino acid mismatches between donor and recipient
HLA‐EMMA compares the amino acid sequence of each donor HLA allele with the alleles from the same locus of the recipient, known as intralocus comparison, except for HLA‐DRB1/3/4/5 which is interlocus compared. For HLA class I, the default setting is intralocus comparison, but interlocus option can be selected when required. Amino acid mismatches are calculated for: 1) each donor HLA allele by total amino acid mismatches irrespective of location on the molecule, and 2) amino acid mismatches that are solvent accessible. In case of an incomplete HLA allele, indicated by *, only amino acid mismatches are calculated for the known amino acid sequence.
An example of manual entry for defining HLA solvent accessible amino acid mismatches between donor and recipient is shown in Figure 2A. After computation, a table containing the number of amino acid mismatches per donor HLA allele is generated (Figure 2B). In addition, HLA‐EMMA provides detailed information on the position and the type of amino acid that are mismatched for both total amino acid sequence and solvent accessible positions (Figure 2C).
FIGURE 2.
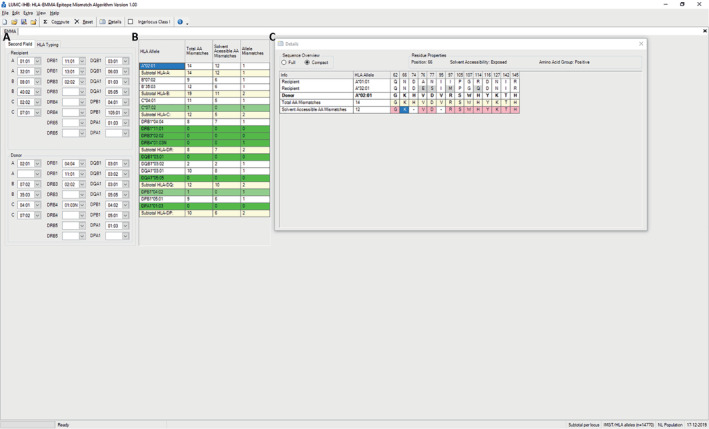
HLA‐EMMA manual entry with an example of a donor‐recipient couple. A, Input field for HLA typing of donor and recipient. B, After selecting compute, the number of amino acid mismatches are generated for each donor HLA allele and shown in the result Table. C, Details of a mismatched donor HLA allele shown after selecting the donor HLA allele in result table. Here, the mismatched amino acids and positions are shown. Residue properties are shown when selecting a specific amino acid
HLA‐EMMA can be used to perform compatibility analysis for large numbers of donor‐recipient pairs simultaneously in the form of a batch analysis. This requires uploading of an input file containing the HLA typing of the respective donor and recipient pairs (Figure S1). HLA‐EMMA generates an output file that consists of both the number of total and solvent accessible amino acid mismatches for each pair, as well as the position and the type of amino acid that are mismatched for each donor HLA allele (Figure S2). In addition, the amino acids of the recipient's HLA on the corresponding positions are provided in a separate column. This output can then be used for further analysis.
Another option available in HLA‐EMMA is an amino acid sequence overview of all HLA alleles (Figure S3). With this overview, multiple HLA alleles can be compared, and it can also be used to consult which HLA alleles share a specific amino acid.
3.3. Proof of principle
For validation of HLA‐EMMA we used a previously described cohort of which the HLA‐specific antibody response was defined for women that received lymphocyte immunotherapy from their male partner. 17 Here, for each HLA‐A, ‐B, ‐DRB1 and ‐DQ mismatch the number of solvent accessible amino acids was determined with HLA‐EMMA using the default settings. For HLA‐DQ the number of solvent accessible amino acids of DQA1 and DQB1 were combined (Figure 3). We determined how often an HLA mismatch with specific solvent accessible amino acid mismatches resulted in DSA formation and observed that the proportion of HLA mismatches that resulted in DSA formation increased with higher number of solvent accessible amino acids. For HLA‐A, ‐B and ‐DQ mismatches, the incidence of DSA was 80% in the group with the highest number of solvent accessible amino acid mismatches.
FIGURE 3.
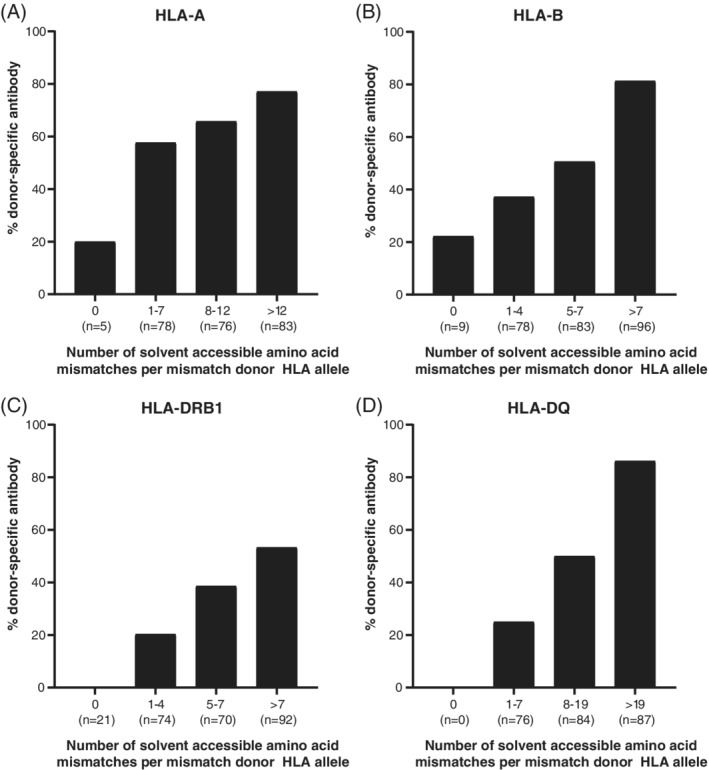
Association between DSA formation and the number of solvent accessible amino acid mismatches. The number of solvent accessible amino acid mismatches was defined and DSA were determined per mismatched donor HLA allele. For HLA‐A (A), HLA‐B (B), HLA‐DRB1 (C) and HLA‐DQ (D) an increased proportion of HLA mismatches formed DSA with higher number of solvent accessible amino acid mismatches
4. DISCUSSION
Here, we present a software program HLA‐EMMA that allows to determine the molecular HLA class I and class II compatibility between donor and recipient. Since amino acids are fixed entities on HLA molecules not dependent on assumptions or preconceptions, as well as the fact that single surface exposed amino acid mismatches can already be sufficient to induce an antibody response, HLA‐EMMA was developed to analyse compatibility on the amino acid level. The software program focuses on solvent accessible amino acids mismatches, since B cell epitopes are known to consist of polymorphic amino acids that are surface exposed.34, 35, 36 Data from recent studies showed no significant differences between eplet and amino acid mismatch scores for the prediction of DSA,12, 21 indicating that both strategies are potentially useful. The benefit of HLA‐EMMA is that large datasets of donor‐recipient pairs from diverse populations can be analysed for both HLA class I and class II simultaneously. Since the position and type of amino acid mismatches are provided these can be used to identify relevant mismatches that are associated with development of de novo DSA.
Currently, HLAMatchmaker is the main tool used to determine HLA compatibility on structural level by analysing eplet mismatches. Eplets are defined as patches of polymorphic amino acids on surface exposed areas of the HLA molecules. The definition of surface exposure in HLAMatchmaker is based on the analysis of polymorphic positions on a select number of HLA crystal structures with Cn3D structure viewer.9, 10 Surface exposure was labelled as prominent, readily visible or somewhat visible. In contrast, in HLA‐EMMA, solvent accessible amino acid positions were defined per HLA locus and by excluding positions that were predicted by two validated tools to be solvent inaccessible for the available HLA structures per locus. These tools are neural network‐based models trained to predict secondary structural features, such as relative solvent accessibility.30, 31 The reason to define accessibility in this way and not by predicted solvent accessibility is the fact that not for every HLA allele a crystal structure is available, which may result in an amino acid position being incorrectly classified as solvent accessible for a specific HLA allele. When more HLA crystal structures or models become available, the solvent accessible amino acid position database in HLA‐EMMA will be updated.
Besides solvent accessible amino acid mismatches, HLA‐EMMA also calculates the total number of amino acid mismatches. This is useful in cases where no solvent accessible amino acid mismatches are defined for a donor HLA antigen mismatch that has resulted in DSA. Such antibody responses may be explained by non‐exposed amino acid mismatches as they could have been induced by surface changes because of buried amino acid polymorphisms.28, 37 A previously described tool, the Cambridge HLA immunogenicity algorithm developed by Kosmoliaptsis and colleagues, also determines the number of total amino acids mismatches as well as hydrophobicity and electrostatic mismatch scores.22, 23
The default setting of HLA‐EMMA is intralocus comparison for HLA class I. This is in contrast with HLAMatchmaker that performs interlocus comparison to determine the eplet mismatches for HLA class I.10, 38 This difference in strategy is because of the fact that eplets are combinations of amino acids, while HLA‐EMMA considers individual amino acids. A possible consequence of interlocus comparison on the individual amino acid level may be that polymorphic amino acids shared by HLA alleles are incorrectly classified as being compatible. With the interlocus comparison option for HLA class I the relevance of inter‐ vs intralocus comparison and antibody induction can be further investigated. In contrast, for HLA‐DR the amino acid sequences are interlocus compared. This is because of the difference in expression of DRB3/4/5 molecules of which an individual can have no more than two of the three possible alleles. Thus, if a donor carries one of the DRB3/4/5 loci that the recipient lacks, all amino acids on this allele would be mismatched by intralocus comparison. This will result in an overestimation of the number of mismatches without any indication of the relevant mismatches.
A previously described clinical cohort was used to validate HLA‐EMMA as a tool to determine the immunogenicity of HLA mismatches on basis of a large data set. As expected, this cohort showed a higher frequency of DSA induction with a higher number of solvent accessible amino acid mismatches, indicating the validity of the software. Strikingly, for two HLA class I mismatches DSA were observed while there were no amino acid mismatches at the solvent accessible level nor at the total amino acid level, when analysed in the default intralocus manner. Interestingly, these cases were analysed with HLAMatchmaker, no eplet mismatches were observed (data not shown). It is important to note that the HLA typing of the individuals of this cohort was not all based on HLA sequencing but was largely done by a genotyping array and HLA imputation, which may have led to false classification of the second field HLA data, potentially resulting in zero amino acid mismatches, while DSA were formed.
By using HLA‐EMMA we aim to establish the ability of specific amino acid mismatches to induce an antibody response by determining the incidence of de novo DSA in case of a mismatch of that specific amino acid. Immunogenicity depends on the HLA phenotype of the recipient but also of the donor, and HLA allele frequencies differ between populations and even within regions.39, 40, 41 This population difference is important to consider as amino acids that are highly immunogenic in one population, might be less immunogenic in another because of difference in HLA allele distribution in the populations. 42 Therefore, HLA‐EMMA is one of the tools that will be used during the 18th International HLA and Immunogenetics Workshop (IHIWS) to identify immunogenic amino acid mismatches for a large group of donor‐recipient pairs from diverse populations with information on de novo DSA development.
Ultimately, defining the immunogenic polymorphic amino acids is just the beginning. Based on this knowledge, we want to define specific polymorphic amino acid configurations similar as what has been done for the definition of the eplets. The immunogenic polymorphic amino acids will serve as a basis for the definition of the relevant amino acid configurations involved in antibody binding. While single amino acid can induce an antibody response, indicating immunogenicity, configurations of amino acids are involved in antibody‐antigen interaction, which is antigenicity. 43
Preventing the induction of de novo DSA formation after transplantation is essential for maximising graft survival and the chance of potential repeat transplantation and therefore of utmost importance in paediatric setting where children will certainly need a repeat transplant. With HLA‐EMMA, we developed a software program to perform HLA class I and class II compatibility analysis on amino acid level for recipient and donor couple individually and for large population studies that will contribute to the identification of these immunogenic polymorphic amino acid mismatches.
CONFLICT OF INTEREST
The authors have declared no conflicting interests.
Supporting information
Figure S1: An example of an HLA typing input file for batch analysis with HLA‐EMMA. For batch analysis, the input format is a Microsoft Excel file according to the template as indicated in the figure. Donor and recipient pairs are indicated by corresponding codes, here indicated by same number, thus compatibility analysis between D1 and R1 will be performed and same applies for D303 and R303, and D20Ser and R20Ser. Both second field typing and serological typing can be entered, as shown for D20Ser and R20ser.
Figure S2: An example of output file of batch analysis with HLA‐EMMA. The output file of HLA‐EMMA batch analysis is a Microsoft Excel file. Here, the output file of input file from Figure S1 is shown. In the output file, the HLA alleles of donor and recipient are presented. The first six columns show the information of the input file, thus code_recipient, Locus_recipient, HLA_allele_recipient, code_donor, Locus_donor, and HLA_allele_donor. Then each column provides information of the analysis. Allele_Mismatches column indicates if the donor allele of that specific row is mismatched with recipient by the number 1 and if the donor allele is matched than a 0 is given. Next, in Total_AA_mismatches the number of total amino acid mismatches is provided for the donor allele, and the number of solvent accessible amino acid mismatches can be found in Solvent_Accessibility column. The Total_AA_Mismatches_Value and Solvent_Accessibility_Value columns list the positions and the type of amino acid that are mismatched. Next column, Profile_Recipients, shows the amino acids of the recipient's HLA allele on the mismatched positions, divided by | to separate each HLA allele within the locus. The HLA‐EMMA version, run date, and other additional information can be found in the last column.
Figure S3: Amino acid sequence overview. HLA‐EMMA also provides all the amino acid sequences in an overview. This can be used to compare different alleles on full amino acid sequence (A) or compact and therefore only showing the positions that are different (B). In addition, filter option is present to filter on HLA alleles or on a specific amino acids (C) to view only the HLA alleles with that specific amino acid.
Table S1 HLA class I crystal structures used to predict solvent accessibility.
Table S2: HLA class II structures used to predict solvent accessibility.
Table S3: HLA class I modelled structures.
ACKNOWLEDGMENT
The authors like to thank Dr Vasilis Kosmoliaptsis from University of Cambridge and Prof. Dieter Kabelitz from Kiel University for kindly sharing the data of the study cohort.
Kramer CSM, Koster J, Haasnoot GW, Roelen DL, Claas FHJ, Heidt S. HLA‐EMMA: A user‐friendly tool to analyse HLA class I and class II compatibility on the amino acid level. HLA. 2020;96:43–51. 10.1111/tan.13883
DATA AVAILABILITY STATEMENT
Data sharing is not applicable to this article as no new data were created or analysed in this study.
REFERENCES
- 1. Opelz G, Dohler B. Effect of human leukocyte antigen compatibility on kidney graft survival: comparative analysis of two decades. Transplantation. 2007;84(2):137‐143. [DOI] [PubMed] [Google Scholar]
- 2. Heidt S, Haasnoot GW, van Rood JJ, Witvliet MD, Claas FHJ. Kidney allocation based on proven acceptable antigens results in superior graft survival in highly sensitized patients. Kidney Int. 2018;93(2):491‐500. [DOI] [PubMed] [Google Scholar]
- 3. Lomago J, Jelenik L, Zern D, et al. How did a patient who types for HLA‐B*4403 develop antibodies that react with HLA‐B*4402? Hum Immunol. 2010;71(2):176‐178. [DOI] [PubMed] [Google Scholar]
- 4. Duquesnoy RJ, Kamoun M, Baxter‐Lowe LA, et al. Should HLA mismatch acceptability for sensitized transplant candidates be determined at the high‐resolution rather than the antigen level? Am J Transplant. 2015;15(4):923‐930. [DOI] [PubMed] [Google Scholar]
- 5. Lachmann N, Terasaki PI, Budde K, et al. Anti‐human leukocyte antigen and donor‐specific antibodies detected by Luminex Posttransplant serve as biomarkers for chronic rejection of renal allografts. Transplantation. 2009;87(10):1505‐1513. [DOI] [PubMed] [Google Scholar]
- 6. Worthington JE, Martin S, Al‐Husseini DM, Dyer PA, Johnson RW. Posttransplantation production of donor HLA‐specific antibodies as a predictor of renal transplant outcome. Transplantation. 2003;75(7):1034‐1040. [DOI] [PubMed] [Google Scholar]
- 7. Kosmoliaptsis V, Gjorgjimajkoska O, Sharples LD, et al. Impact of donor mismatches at individual HLA‐A, ‐B, ‐C, −DR, and ‐DQ loci on the development of HLA‐specific antibodies in patients listed for repeat renal transplantation. Kidney Int. 2014;86(5):1039‐1048. [DOI] [PubMed] [Google Scholar]
- 8. Claas F, Castelli‐Visser R, Schreuder I, van Rood J. Allo‐antibodies to an antigenic determinant shared by HLA‐A2 and B17. Tissue Antigens. 1982;19(5):388‐391. [DOI] [PubMed] [Google Scholar]
- 9. Duquesnoy RJ. A structurally based approach to determine HLA compatibility at the humoral immune level. Hum Immunol. 2006;67(11):847‐862. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Duquesnoy RJ, Askar M. HLAMatchmaker: a molecularly based algorithm for histocompatibility determination. V. Eplet matching for HLA‐DR, HLA‐DQ, and HLA‐DP. Hum Immunol. 2007;68(1):12‐25. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Dankers MK, Witvliet MD, Roelen DL, et al. The number of amino acid triplet differences between patient and donor is predictive for the antibody reactivity against mismatched human leukocyte antigens. Transplantation. 2004;77(8):1236‐1239. [DOI] [PubMed] [Google Scholar]
- 12. Kosmoliaptsis V, Mallon DH, Chen Y, Bolton EM, Bradley JA, Taylor CJ. Alloantibody responses after renal transplant failure can be better predicted by donor‐recipient HLA amino acid sequence and physicochemical disparities than conventional HLA matching. Am J Transplant. 2016;16(7):2139‐2147. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Wiebe C, Pochinco D, Blydt‐Hansen TD, et al. Class II HLA epitope matching‐a strategy to minimize de novo donor‐specific antibody development and improve outcomes. Am J Transplant. 2013;13(12):3114‐3122. [DOI] [PubMed] [Google Scholar]
- 14. McCaughan JA, Battle RK, Singh SKS, et al. Identification of risk epitope mismatches associated with de novo donor‐specific HLA antibody development in cardiothoracic transplantation. Am J Transplant. 2018;18(12):2924‐2933. [DOI] [PubMed] [Google Scholar]
- 15. Dankers MK, Roelen DL, Nagelkerke NJ, et al. The HLA‐DR phenotype of the responder is predictive of humoral response against HLA class I antigens. Hum Immunol. 2004;65(1):13‐19. [DOI] [PubMed] [Google Scholar]
- 16. Fuller TC, Fuller A. The humoral immune response against an HLA class I allodeterminant correlates with the HLA‐DR phenotype of the responder. Transplantation. 1999;68(2):173‐182. [DOI] [PubMed] [Google Scholar]
- 17. Mallon DH, Kling C, Robb M, et al. Predicting Humoral Alloimmunity from differences in donor and recipient HLA surface electrostatic potential. J Immunol. 2018;201(12):3780‐3792. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Duquesnoy RJ, Marrari M, Mulder A, Claas FH, Mostecki J, Balazs I. Structural aspects of human leukocyte antigen class I epitopes detected by human monoclonal antibodies. Hum Immunol. 2012;73(3):267‐277. [DOI] [PubMed] [Google Scholar]
- 19. Duquesnoy RJ, Marrari M, Mulder A, Sousa LCDD, da Silva AS, do Monte SJH. First report on the antibody verification of HLA‐ABC epitopes recorded in the website‐based HLA epitope registry. Tissue Antigens. 2014;83(6):391‐400. [DOI] [PubMed] [Google Scholar]
- 20. Duquesnoy RJ, Marrari M, Tambur AR, et al. First report on the antibody verification of HLA‐DR, HLA‐DQ and HLA‐DP epitopes recorded in the HLA epitope registry. Hum Immunol. 2014;75(11):1097‐1103. [DOI] [PubMed] [Google Scholar]
- 21. Wiebe C, Kosmoliaptsis V, Pochinco D, Taylor CJ, Nickerson P. A comparison of HLA molecular mismatch methods to determine HLA immunogenicity. Transplantation. 2018;102(8):1338‐1343. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Kosmoliaptsis V, Chaudhry AN, Sharples LD, et al. Predicting HLA class I alloantigen immunogenicity from the number and physiochemical properties of amino acid polymorphisms. Transplantation. 2009;88(6):791‐798. [DOI] [PubMed] [Google Scholar]
- 23. Kosmoliaptsis V, Sharples LD, Chaudhry AN, Halsall DJ, Bradley JA, Taylor CJ. Predicting HLA class II alloantigen immunogenicity from the number and physiochemical properties of amino acid polymorphisms. Transplantation. 2011;91(2):183‐190. [DOI] [PubMed] [Google Scholar]
- 24. Duquesnoy RJ, Marrari M, Marroquim MS, et al. Second update of the international registry of HLA epitopes. I. The HLA‐ABC epitope database. Hum Immunol. 2019;80(2):103‐106. [DOI] [PubMed] [Google Scholar]
- 25. Robinson J, Malik A, Parham P, Bodmer JG, Marsh SG. IMGT/HLA database—a sequence database for the human major histocompatibility complex. Tissue Antigens. 2000;55(3):280‐287. [DOI] [PubMed] [Google Scholar]
- 26. Bodmer JG, Marsh SG, Albert ED, et al. Nomenclature for factors of the HLA system, 1990. Tissue Antigens. 1991;37(3):97‐104. [DOI] [PubMed] [Google Scholar]
- 27. Rose PW, Prlic A, Altunkaya A, et al. The RCSB protein data bank: integrative view of protein, gene and 3D structural information. Nucleic Acids Res. 2017;45(D1):D271‐D281. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Kosmoliaptsis V, Dafforn TR, Chaudhry AN, Halsall DJ, Bradley JA, Taylor CJ. High‐resolution, three‐dimensional modeling of human leukocyte antigen class I structure and surface electrostatic potential reveals the molecular basis for alloantibody binding epitopes. Hum Immunol. 2011;72(11):1049‐1059. [DOI] [PubMed] [Google Scholar]
- 29. Menezes Teles EOD, Melo Santos de Serpa Brandao R, Claudio Demes da Mata Sousa L, et al. pHLA3D: an online database of predicted three‐dimensional structures of HLA molecules. Hum Immunol. 2019;80(10):834‐841. [DOI] [PubMed] [Google Scholar]
- 30. Klausen MS, Jespersen MC, Nielsen H, et al. NetSurfP‐2.0: improved prediction of protein structural features by integrated deep learning. Proteins. 2019;87(6):520‐527. [DOI] [PubMed] [Google Scholar]
- 31. Mirabello C, Pollastri G. Porter, PaleAle 4.0: high‐accuracy prediction of protein secondary structure and relative solvent accessibility. Bioinformatics. 2013;29(16):2056‐2058. [DOI] [PubMed] [Google Scholar]
- 32. Gragert L, Madbouly A, Freeman J, Maiers M. Six‐locus high resolution HLA haplotype frequencies derived from mixed‐resolution DNA typing for the entire US donor registry. Hum Immunol. 2013;74(10):1313‐1320. [DOI] [PubMed] [Google Scholar]
- 33. Maiers M, Gragert L, Klitz W. High‐resolution HLA alleles and haplotypes in the United States population. Hum Immunol. 2007;68(9):779‐788. [DOI] [PubMed] [Google Scholar]
- 34. Kringelum JV, Nielsen M, Padkjaer SB, Lund O. Structural analysis of B‐cell epitopes in antibody:protein complexes. Mol Immunol. 2013;53(1–2):24‐34. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35. Novotny J, Handschumacher M, Haber E, et al. Antigenic determinants in proteins coincide with surface regions accessible to large probes (antibody domains). Proc Natl Acad Sci U S A. 1986;83(2):226‐230. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. Ofran Y, Schlessinger A, Rost B. Automated identification of complementarity determining regions (CDRs) reveals peculiar characteristics of CDRs and B cell epitopes. J Immunol. 2008;181(9):6230‐6235. [DOI] [PubMed] [Google Scholar]
- 37. Mallon DH, Bradley JA, Winn PJ, Taylor CJ, Kosmoliaptsis V. Three‐dimensional structural Modelling and calculation of electrostatic potentials of HLA Bw4 and Bw6 epitopes to explain the molecular basis for alloantibody binding: toward predicting HLA antigenicity and immunogenicity. Transplantation. 2015;99(2):385‐390. [DOI] [PubMed] [Google Scholar]
- 38. Duquesnoy RJ, Marrari M. HLAMatchmaker: a molecularly based algorithm for histocompatibility determination. II. Verification of the algorithm and determination of the relative immunogenicity of amino acid triplet‐defined epitopes. Hum Immunol. 2002;63(5):353‐363. [DOI] [PubMed] [Google Scholar]
- 39. Buhler S, Sanchez‐Mazas A. HLA DNA sequence variation among human populations: molecular signatures of demographic and selective events. PLoS One. 2011;6(2):e14643. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Sanchez‐Mazas A, Buhler S, Nunes JM. A new HLA map of Europe: regional genetic variation and its implication for peopling history, disease‐association studies and tissue transplantation. Hum Hered. 2013;76(3–4):162‐177. [DOI] [PubMed] [Google Scholar]
- 41. Solberg OD, Mack SJ, Lancaster AK, et al. Balancing selection and heterogeneity across the classical human leukocyte antigen loci: a meta‐analytic review of 497 population studies. Hum Immunol. 2008;69(7):443‐464. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. Kramer CSM, Israeli M, Mulder A, et al. The long and winding road towards epitope matching in clinical transplantation. Transpl Int. 2019;32(1):16‐24. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43. Kramer CSM, Roelen DL, Heidt S, Claas FHJ. Defining the immunogenicity and antigenicity of HLA epitopes is crucial for optimal epitope matching in clinical renal transplantation. HLA. 2017;90(1):5‐16. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Figure S1: An example of an HLA typing input file for batch analysis with HLA‐EMMA. For batch analysis, the input format is a Microsoft Excel file according to the template as indicated in the figure. Donor and recipient pairs are indicated by corresponding codes, here indicated by same number, thus compatibility analysis between D1 and R1 will be performed and same applies for D303 and R303, and D20Ser and R20Ser. Both second field typing and serological typing can be entered, as shown for D20Ser and R20ser.
Figure S2: An example of output file of batch analysis with HLA‐EMMA. The output file of HLA‐EMMA batch analysis is a Microsoft Excel file. Here, the output file of input file from Figure S1 is shown. In the output file, the HLA alleles of donor and recipient are presented. The first six columns show the information of the input file, thus code_recipient, Locus_recipient, HLA_allele_recipient, code_donor, Locus_donor, and HLA_allele_donor. Then each column provides information of the analysis. Allele_Mismatches column indicates if the donor allele of that specific row is mismatched with recipient by the number 1 and if the donor allele is matched than a 0 is given. Next, in Total_AA_mismatches the number of total amino acid mismatches is provided for the donor allele, and the number of solvent accessible amino acid mismatches can be found in Solvent_Accessibility column. The Total_AA_Mismatches_Value and Solvent_Accessibility_Value columns list the positions and the type of amino acid that are mismatched. Next column, Profile_Recipients, shows the amino acids of the recipient's HLA allele on the mismatched positions, divided by | to separate each HLA allele within the locus. The HLA‐EMMA version, run date, and other additional information can be found in the last column.
Figure S3: Amino acid sequence overview. HLA‐EMMA also provides all the amino acid sequences in an overview. This can be used to compare different alleles on full amino acid sequence (A) or compact and therefore only showing the positions that are different (B). In addition, filter option is present to filter on HLA alleles or on a specific amino acids (C) to view only the HLA alleles with that specific amino acid.
Table S1 HLA class I crystal structures used to predict solvent accessibility.
Table S2: HLA class II structures used to predict solvent accessibility.
Table S3: HLA class I modelled structures.
Data Availability Statement
Data sharing is not applicable to this article as no new data were created or analysed in this study.