

Abstract
Finding graph indices which are unbiased to network size and density is of high importance both within a given field and across fields for enhancing comparability of modern network science studies. The degree variance is an important metric for characterising network degree heterogeneity. Here, we provide an analytically valid normalisation of degree variance to replace previous normalisations which are either invalid or not applicable to all networks. It is shown that this normalisation provides equal values for graphs and their complements; it is maximal in the star graph (and its complement); and its expected value is constant with respect to density for Erdös-Rényi (ER) random graphs of the same size. We strengthen these results with model observations in ER random graphs, random geometric graphs, scale-free networks, random hierarchy networks and resting-state brain networks, showing that the proposed normalisation is generally less affected by both network size and density than previous normalisation attempts. The closed form expression proposed also benefits from high computational efficiency and straightforward mathematical analysis. Analysis of 184 real-world binary networks across different disciplines shows that normalised degree variance is not correlated with average degree and is robust to node and edge subsampling. Comparisons across subdomains of biological networks reveals greater degree heterogeneity among brain connectomes and food webs than in protein interaction networks.
Introduction
The most fundamental parameters of a network are its number of nodes (network size) and number of edges (of which the ratio to total possible number of edges is the network density). The richness of topologies elicited by these simple building blocks has fascinated mathematicians for centuries and science, in general, for decades since the explosion of interest in understanding real-world complex networks. Comparing networks of different sizes and/or densities is difficult because of the dependency of many network features on these fundamental parameters (Dormann et al. 2009), yet the ability to compare between different sizes and densities is necessary to gain an unbiased understanding of the topologies in a given field as well as across fields. Indeed, the fact that differently sized networks explain similar phenomena in a given area is commonplace. For example, social networks depend on the number of participants in the study (Vega-Redondo 2007); infrastructural networks within cities will vary in size according to the size of the city (Batty 2008); and networks constructed from sensors, such as in electrophysiology, depend on the number of sensors used (Smith et al. 2017).
One of the most widespread forms of analyses of real-world networks is that of defining some topological measurement from which one can compare the networks against other networks and null models in order to gain an understanding of the networks’ particular characteristics (Newman 2010). For example, in brain networks, network measures can help inform of brain connectivity differences between patients with some condition and healthy controls (Bullmore and Sporns 2009). The degree distributions of complex networks have been long been an important area of study, where real-world networks generally exhibit heavy tails (Strogatz 2001). The heterogeneity of degrees has been an active area of study in complex networks for some time. The consistent feature of heterogeneity measures is that they are generally maximal in star-like graphs and minimal in regular graphs (where all nodes have same degree). In this way, they measure the inequality of the distribution of the number of connections in the network. The degree variance is the original characteristic (Snijders 1981). Several other measures of heterogeneity have been proposed (Bell 1992; Jacob et al. 2017; Safaei et al. 1011), but the degree variance remains one of the most widespread and easiest to interpret, aiding, for example, in analysing degree distributions of networks from genetics (Horvath and Dong 2008), physics (Cao et al. 2015), chemistry (Randić et al. 2016), sociology (Phillips et al. 2019), neuroscience (Smith et al. 2017), and policy (Mochtak and Diviak 2019; Mäkinen et al. 2019), among others.
However, variance depends on the size of samples used, which varies accordingly for fixed density and varying size– larger size needing more edges to account for the same density. Similarly, the degree distribution is dependent on the number of edges in the network since the maximum possible degree is fixed by network size. Thus, we need to work towards effective and efficient control of the scaling of network size and density in the measurement of degree variance. This is of particular necessity to support increasingly critical interdisciplinary areas using large multi-dimensional datasets.
Here, we propose a mathematically rigorous and computationally efficient normalisation of degree variance, , with a closed form expression. Particularly, we will prove that for all graphs. Not only this, we will show that graph complements achieve equivalent values of ; that only satisfies unity asymptotically for the star graph (and its complement) as n→∞; and that is independent of network density for Erdös-Rényi (ER) random graphs. Furthermore, our normalisation is also well defined for graphs with isolated nodes and thus, we argue, of broader scope than the other relevant normalised measure of heterogeneity (Estrada 2010). Demonstrations are provided that our normalisation is the least variable normalisation with respect to network size and density for a number of network types and that it is also computationally efficient. Finally, we show an application of the new normalisation to 184 real-world networks and its robustness to node and edge subsampling of these networks.
Background
A simple network is defined by a set of nodes, , connected together by a set of edges, . Network size is then . The convention is that including each of the m edges twice ((i,j)& (j,i)). The largest possible size of is obtained in the complete graph with 2m=n(n−1). Thus, network density is d=2m/n(n−1). The degree of a node, ki, is simply the number of edges adjacent to it, and we denote the set of degrees of a graph as . For reference, all repeated notations in the article are in Table 1.
Table 1.
Notation
| Basic network notation | Network heterogeneity notation | ||
|---|---|---|---|
| n | Number of nodes | Gqs | Quasi-star graph |
| m | Number of edges | G∗ | Perfect quasi-star graph |
| d | Network density | v | Degree variance |
| Node set | Normalised degree variance | ||
| Edge set | J | Quasi-star normalisation of | |
| G | Graph | degree variance | |
| ki | Degree of node i | σ2 | Average degree normalisation of |
| k | Degree set | degree variance | |
| Complement of G | ρ | Heterogeneity index | |
| Number of edges in | r | Number of dominant nodes in | |
| Degree of node i in | quasi-star graph | ||
| p | Edge probability in | ||
| random graph | |||
Degree variance is seen as a measure of graph heterogeneity which is essentially conceptually equivalent to graph irregularity. Regular graphs have been of interest to mathematicians for many years, at least since the pioneering work of Petersen (1891). However, it was not until the seminal paper of Collatz and Sinogowitz (1957) that indices to characterise the irregularity of graphs became a topic of interest. In Collatz and Sinogowitz (1957) it was proposed to study the difference between the largest eigenvalue of the graph adjacency matrix and the average degree, , claiming that this measure was only zero in connected graphs for regular graphs. It was conjectured that star graphs attained the highest value of ε(G), but this was disproved by Cvetković and Rowlinson (1988).
With the booming interest in applications of graph theory to real-world networks, the degree variance, v(G)=var(k), was proposed as a measure of graph heterogeneity in 1981 (Snijders 1981). Later, Bell (1992) compared v(G) and ε(G) and found incompatibilities between them, noting that the measures had different relative values for certain pairs of graphs. Using the constructs of quasi-complete and quasi-star graphs introduced by Ahlsewade and Katona (1978), Bell then proved that ε(G) was in fact maximal only for quasi-complete graphs, whereas v(G) was maximal either for a quasi-complete or a quasi-star graph for any given network size and density (although not necessarily uniquely) (Bell 1992).
A quasi-star graph is a graph consisting of r dominant nodes and at most one node of degree s>r+1 connected to other non-dominant nodes, here referred to as a developing node, for a graph with r(n−1)+s edges (Fig. 1, left). If s=1 then the remaining edge connects two non-dominant nodes so that they both have degree r+1. A quasi-complete graph is a graph consisting of a complete subgraph of order s and at least n−s−1 isolated nodes, with the remaining node connected to r nodes of the complete subgraph for a graph with s(s−1)+r edges, see Fig 1, right. We regard here as perfect quasi-complete and quasi-star graphs as such graphs without any remainder, s. These are special in that the perfect quasi-complete graph of order r is the complement of the perfect quasi-star graph of order n−r.
Fig. 1.

Illustration of a quasi-star graph, left, and a quasi-complete graph, right. The golden edges refer to the edges making up the remainders in the graph construction process for a specified density
In a related topic, Ábrego et al. (2009) proved which of either the quasi-star or quasi-complete graphs with n nodes and m edges obtained the maximum sum of squares of degrees. It was then shown by Smith and Escudero (2017) that maximising the sum of squares of degrees for fixed n and m was equivalent to maximising the degree variance by the equation
| 1 |
where ||.||2 is the l2-norm, and thus Abrego et al.’s result was also seen to hold for v(G).
In the work by Snijders (1981), a normalisation of the degree variance was attempted through division by the value achieved for the quasi-star graph with same size and density because it was thought that the quasi-star graph was always maximal. For the quasi-star graph with same size and density as a graph G, Gqs, this can be written
| 2 |
But the previously noted results render such a normalisation invalid. Apart from this, one needs to construct the quasi-star graph to compute it, rendering a general mathematical analysis of this property infeasible and causing computational efficiency problems for very large graphs.
Normalisation of the degree variance has also been proposed through division by the average degree, <k> of the network (Zimmermann et al. 2004),
| 3 |
However the average degree depends on network density and thus network size.
The other notable class of measure of graph irregularity are those based on absolute differences of degrees. This was originated by Alberston (1997) with the measure
| 4 |
Estrada (2010) then provided a normalised measure based instead on inverse square roots of degrees:
| 5 |
by relating it to the Randić index and using its known upper bounds (Li and Shi 2008). Estrada argued that this measure was maximised only by star graphs and not quasi-complete graphs. However, in actuality the measure is not well defined for any graph with isolated nodes, such as quasi-complete graphs, since this leads to division by zero in the terms of for isolated i. On top of this, as we shall see, this measure is biased to network density where graphs with larger densities can be expected to obtain lower values than graphs with small densities.
Thus, a normalised heterogeneity index which is applicable to all graph types and is invariant to network size and density is of interest to help resolve these outstanding issues. Table 2 provides a comparison of traits for normalised measures of heterogeneity, for reference, which is collected on known information from the relevant cited literature and from the observations of our experiments in “Experiments” section.
Table 2.
Traits of degree heterogeneity among proposed normalisations
| Defined for | Computational | Complements | Value for | Value for | Value for | ||
|---|---|---|---|---|---|---|---|
| Metric | Normalised | all networks | efficiency | have equal values | star graph | regular graph | random graph |
| v | No | Yes | High | Yes | →∞ as n→∞ | 0 | (n−1)p(1−p) |
| Yes | Yes | High | Yes | →1 as n→∞ | 0 | ≈2/n | |
| σ2(Zimmermann et al. 2004) | No | Yes | High | No | →∞ as n→∞ | 0 | depends on n and p |
| J(Snijders 1981) | No | Yes | Low | No | 1 | 0 | depends on n and p |
| ρ(Estrada 2010) | Yes | No | Moderate | No | 1 | 0 | depends on n and p |
Normalised degree variance
We will begin with the details of the proposal of our normalisation of degree variance.
Proposition 1
For any graph G with density , the identity
| 6 |
is bounded in the interval [0,1].
Proof
From (1), normalisation for degree variance can be achieved given a known upper bound of for a graph. Fortunately, this exists from a result by de Caen (1998):
| 7 |
Substituting this into (1), we have
| 8 |
| 9 |
| 10 |
| 11 |
| 12 |
| 13 |
| 14 |
where ∗ comes from the fact that 2m≤n(n−1). □
Now, in the special cases that d=0 or 1, we obtain the empty and complete graphs, respectively, and the denominator of (6) would be 0, meaning that the function would be undefined (given that a graph can only be defined for n>0). But empty and complete graphs are regular graphs with (non-normalised) degree variance 0. Indeed, one definitely agreed characteristic of heterogeneity is that regular graphs obtain zero values. Thus, to overcome this we simply define normalised degree variance at d=0 and 1 to be 0. This provides us with the following definition:
Definition 1
For a graph, G, with n nodes, m edges and density d=2m/n(n−1), its normalised degree variance, , is
| 15 |
| 16 |
Note that the matter of complete and empty graphs is a purely technical point. In almost all practical applications networks exhibit non-trivial topologies with d∈(0,1). Now, clearly attains its lower bound, 0, for all regular graphs (where v(G)=0 and given previous discussion of empty and complete graphs). It remains to assess how good is the upper bound of 1. Further, we must check ’s behaviour with respect to network size and density. The following results prove that for a star graph of size n tends to 1 as n→∞, and that perfect quasi-star graphs are a decreasing function of density, thus the star graph is always maximal amongst them. These results validate degree variance as a relevant measure of heterogeneity and, as far as we are aware, the only normalised measure of heterogeneity that is valid for all simple graphs, including those with isolated nodes.
Corollary 1
Let G∗(n,r) be the perfect quasi-star graph with n nodes and r dominant nodes, then the following statements hold:
as n→∞
is a monotonically decreasing function with respect to r for
Proof
-
For a perfect quasi-star graph, m is made up of r dominant nodes of degree n−1 and n−r nodes of degree r. The general degree sequence of a perfect quasi-star graph is thus
17 andso that18 19 20 21 Then22 23 and for a the star graph with r=1, this simplifies to24 25 as required.
-
It is well known that a function is monotonically decreasing if and only if its derivative is always less than or equal to zero. Thus, for , we prove that f′(r)≤0 ∀n≥r≥0.
First we factorise the numerator of (23). It is straightforward to compute for r=n and see that this is a root of this polynomial. Then, by long polynomial division we find that r=n−1 is a double root of this polynomial and the numerator factorises to give26 27 We now differentiate with respect to r using the quotient rule to get28 29 as required.
□
This shows that 1 is indeed a tight upper bound of , that this is approached by the star graph and its complement and that there is a decreasing tendency with respect to increasing density for quasi-star graphs. In Appendix 1, we conduct mathematical analysis to explore lower bounds for a network with a given degree distribution. In fact, we show that a lower bound can be achieved knowing a specific fraction of nodes having a certain degree, and a maximum lower bound from this can be found applying the formula to all degrees of the network and choosing the maximum result. Of note, generally the maximum lower bound is found at either the largest or smallest degree in the network, highlighting the relationship between degree variance and the network’s inequality of degrees.
Now, while the degree variance gives equivalent values for graphs and their complements, it is clear that the heterogeneity index does not, since the value of a star graph is 1 while the value of its complement, the quasi-complete graph of order n−1, is undefined. We will now show that the proposed normalisation of degree variance also provides equivalent values for graphs and their complements.
Proposition 2
For a graph G with complement ,
| 30 |
Proof
For a graph G with 0<m<n(n−1) edges (i.e. non-empty and non-complete) and degrees so that , its complement, , has edges and degrees . Then
| 31 |
and
| 32 |
| 33 |
| 34 |
| 35 |
| 36 |
| 37 |
as required. Finally, the empty graph (m=0) is the complement of the complete graph (m=n(n−1)), both having . □
Normalised degree variance of ER random graphs
The simple and well-known statistical properties of ER random graphs allows us to calculate for ER random graph ensembles directly. Note, there are two versions of ER random graph ensembles. G(n,p) employs p as the uniform probability of the existence of edges. Subsequently, because the calculation of the existence of each of the n(n−1)/2 possible edges is equivalent to a Bernoulli trial with probability p, the number of edges in a realisation of G(n,p) varies and follows a binomial distribution m∼B(n(n−1)/2,p) (Erdös and Rényi 1959). The other prevalent version of the ER random graph ensemble, G(n,m), allows for the control of the number of edges by generating numbers uniformly at random from [0,1] for each possible edge and choosing those possible edges with the m largest values as existent (Gilbert 1959). We shall focus here on G(n,m) since we wish to control for number of edges in our experiments. The equivalent proof for G(n,p) is more involved and is provided in Appendix 1.
Corollary 2
For the ER random graph ensemble G(n,m)
| 38 |
and so does not depend on m.
Proof
From a previous result from Gutman and Paule (2002), we have:
| 39 |
| 40 |
| 41 |
| 42 |
Using our normalisation we obtain
| 43 |
| 44 |
as required. □
Importantly, it is clear from this result that is unbiased to network density for ER random graphs G(n,m). Furthermore, it decays fairly slowly towards 0 at a rate of 1/n.
Experiments
Validity and stability with respect to network size of normalisation approaches
Counter examples for the previously proposed normalisations are not difficult to come by. To demonstrate this we shall consider values for quasi-star graphs, quasi-complete graphs, weighted ER random graphs (Erdös and Rényi 1959), weighted random geometric graphs (Dall and Christensen 2002), scale-free networks (Barabási and Albert 1999), random hierarchy models (Smith and Escudero 2017) and Electroencephalogram (EEG) networks of size n=16,32,64 and 128.
For the ER random graphs and random geometric graphs, 100 realisations were generated for each network size and results averaged. The scale-free networks were chosen at three densities for each network size. Scale-free graphs of density 12.5% were obtained by selecting 12.5% of nodes as the core subgraph and the average degree of additional nodes as 6.25%n. Graphs of density roughly 25% were obtained by selecting 25% of nodes as the core subgraph and the average degree of additional nodes as 12.5%n. Graphs of density roughly 37.5% were obtained by selecting 37.5% of nodes as the core subgraph and the average degree of additional nodes as 25%n. For each, 100 networks were generated and results averaged.
Random hierarchy models generate networks with hierarchical degree structure determined by three parameters: the number of hierarchical levels, the strength of separation of levels and the probability that a node exists in a given level (Smith and Escudero 2017). In our case, the strength parameter was randomly selected between 0.05 and 0.5– in steps of 0.05– and with hierarchical levels randomly selected from 2 to 5, while the level probability distribution was fixed as a geometric distribution with probability 0.6. For each, 1000 networks were generated (due to greater variability of topologies than other models) and results averaged.
The EEG networks are derived from a 129 node EEG eyes open dataset. This is available online under an Open Database License via the Neurophysiological Biomarker Toolbox tutorial (Neurophysiological Biomarker Toolbox 2020). It consists of data for 16 volunteers. We have previously used the data for which full processing details can be found in Smith et al. (2017). Weighted connectivity adjacency matrices were computed using the phase-lag index (PLI) (Stam et al. 2007). To get a network of size n from these EEG networks, n electrodes were chosen at random 100 times and results averaged.
For each n, the perfect quasi-star graphs and perfect quasi complete graphs for each d, and integer percentage binarisation thresholds of ER random graphs, random geometric graphs, random hierarchy models and EEG networks are computed and we take the proposed normalisation, , quasi-star normalisation, J, average degree normalisation, σ2, as well as the heterogeneity index, ρ, of these networks. Figure 2 shows the obtained values plotted against density.
Fig. 2.

Normalisations of degree variance of quasi-star graphs (QS), quasi-complete graphs (QC), ER random graphs (E-R), Random Geometric Graphs (RGG) and EEG PLI networks (EEG) of sizes 16 (dotted lines), 32 (dashed lines), 64 (dash-dotted lines) and 128 (solid lines). The proposed normalisation shows smooth curves which are markedly stable with respect to n for all graphs. Clearly, J and σ2 violate standard normalisation principles and are influenced by network size. On the other hand ρ cannot be computed for graphs with isolated nodes which are particular prominent at lower densities of the weighted models and values are squeezed at high densities
The proposed normalisation works as expected with all values in [0,1]. The maximum value is achieved by the largest (n=128) star graph (perfect quasi-star with r=1) and its complement perfect quasi-complete graph (r=n−1). The normalisation by quasi-star graphs, Fig. 2, centre, shows clear violations of the [0,1] normalisation by the quasi-complete graphs– as is expected in cases where the quasi-complete graph has larger degree variance than the quasi-star graph– as well as low densities of thresholded weighted graph models. The normalisation by average degree increases proportionally with n thus is critically flawed as a normalisation. We shall refrain from using it further and focus on the other indices.
All of the graphs show a remarkable stability with respect to network size of small networks, suggesting that this normalisation is very suitable for comparing networks of different sizes and similar density. Furthermore, for non-extremal values of the EEG networks, there is a marked stability with respect to density also, supporting the claim that this normalisation is unbiased to network density. To quantify these statistically, we compute the coefficient of variance (i.e. the ratio of the standard deviation to the mean) of the normalisations with respect to network size for each density, averaging over densities, and the coefficient of variance of the normalisations with respect to density, averaging over network sizes, respectively.
The resulting average coefficients of variation are reported in Table 3. Smaller values show less variability, with bold indicating best performance for each network. The proposed normalisation has the least variability with respect to network size for quasi-complete graphs, random geometric graphs and EEG networks. For quasi-star graphs, normalisation by quasi-star achieves a variability of 0, redundantly. For ER random graphs, is second only to σ2. The result for σ2 here is quite anomalous, but it is probably achieved actually because it is such a poor normalisation of network size for general networks– for our normalisation, for instance, ER random graph values are inversely proportional to n (43).
Table 3.
Coefficient of variation of network indices with respect to network size, averaged over density
| Network | J | σ2 | ρ | |
|---|---|---|---|---|
| Quasi-star | 0.0249 | 0 | 0.7647 | 0.5831 |
| Quasi-complete | 0.0812 | 0.1600 | 0.8512 | n/a |
| ER Random | 0.7848 | 0.8949 | 0.0585 | 1.0893 |
| Random Geometric | 0.2240 | 0.3432 | 0.6418 | 0.4660 |
| Scale-free model | 0.2251 | 0.2766 | 0.6659 | 0.5211 |
| Random Hierarchy | 0.2454 | 0.3272 | 0.7091 | 0.4642 |
| EEG | 0.0540 | 0.1825 | 0.7724 | 0.5485 |
Boldface indicates the best result among the normalisations
With respect to density, the proposed normalisation has the least variability for quasi-complete graphs, ER random graphs and random geometric graphs. Again, for quasi-star graphs, normalisation by quasi-star achieves a variability of 0, redundantly. For EEG networks, is second only to J. On inspection of Fig. 2, top left and right, however it would appear that this is due to the extremal values. For , values fall steeply towards at lowest and highest densities for all network sizes. For J however, some fall steeply towards 0 and others fall steeply upwards, thus perhaps cancelling each other out in the coefficient of variation.
Indeed, this steep fall towards zero is a notable feature in values of of EEG networks. This means that at low densities, the networks are far from star-like, more similar to quasi-complete graphs, whereas at highest densities, the networks are far from quasi-complete, showing properties more similar to quasi-star networks. This can be interpreted in light of the well known “rich-club” phenomenon of brain networks– nodes with lots of connections are connected particularly strongly together (van den Heuvel and Sporns 2011). This means that at sparse densities the rich-club evolves as an almost complete subnetwork, keeping heterogeneity low. On the other hand, the dominance of connections to hub nodes means that at very high densities, hub nodes and highly connected nodes become saturated (i.e. share edges with all other nodes), leaving, for want of a better term, a ‘poor-club’ of weakly interconnected nodes, similar to quasi-star graphs.
Computational efficiency of the closed-form expression
As the networks grow large, the previously analysed variability becomes negligible for and J, where it appears there is a possible asymptotic convergence to a set limiting curve for each network type in Fig. 2. However, what becomes more important as networks grow large is rather the computational cost. The computational efficiency of compared to J can be garnered by comparing processing times of degree variance normalisations for larger graphs. We also compare with ρ for completeness, which uses the graph Laplacian in its computation (Estrada 2010). We use sparse scale-free graphs (Barabási and Albert 1999) at 1% density to demonstrate this. We will look at graphs of size 5,000, 10,000, 50,000 and 100,000. Scale-free graphs of density 1% can be obtained by selecting 1% of nodes as the core subgraph and the average degree of additional nodes as 0.5%n. The computation time using Matlab algorithms on a single core of a 3.6 GHz Intel Core i7Processor 4274 HE with 32 GB 2400 MHz DDR4 is computed 25 times and the average time is shown in Fig. 3.
Fig. 3.
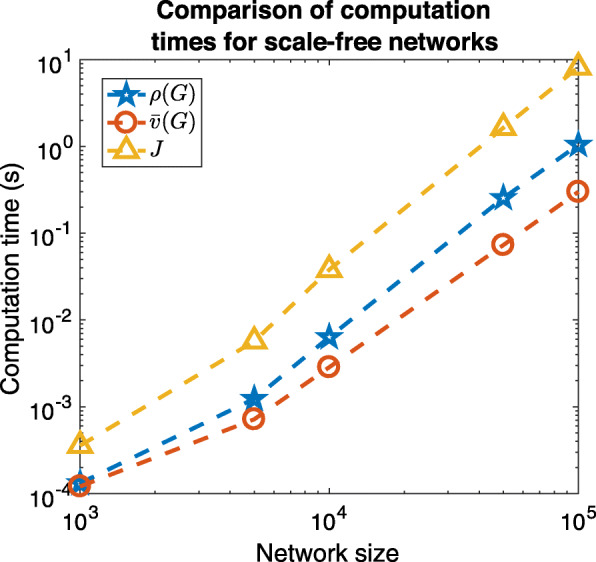
The average computation times of degree variance normalisations , J and ρ of scale-free networks of size 5,000, 10,000, 50,000 and 100,000. Both axes are on log scales. The closed form expression of clearly outperforms J which requires construction of a quasi-star graph in the computation. It also outperforms ρ which employs the construction of the graph Laplacian in its computation
This clearly demonstrates the increased computational efficiency of over J as a normalisation of degree variance. Indeed, was computed an order of 10 times faster at each network size and the trend appears to show that this difference grows with greater network sizes. For example, was computed for 10,000 node networks with an average speed of 0.003s while J was computed with an average speed of 0.038s. Scaling to 100,000 node networks the respective average speeds were 0.300s and 8.163s– a factor of over 27 in difference. Furthermore, has greater computational efficiency than ρ which showed average speeds of 0.006 for 10,000 nodes and 1.043 for 100,000 nodes, the latter being a factor of roughly 3.5 in difference.
Normalised degree variance of real-world binary networks
We analysed the 184 static networks taken from the Colorado Index of Complex Networks (ICON) (Clauset et al. 2016) as used in Ghasemian et al. (2018), covering a variety of biological, social and technological networks. Using the rank-based Spearman correlation coefficient (rs), network size was found to be strongly anti-correlated with density in these networks (rs=−0.840,p=3.910×10−50). For this reason, and since did not have large enough samples at any specific size or density, we assessed Spearman correlations (rs) between normalised heterogeneity indices of these networks and their average degrees, (n−1)d. The values for and ρ are plotted against average degree in Fig. 4. There was a clear trend noted with ρ and average degree, Fig. 4. Normalised degree variance and average degree showed a small positive correlation (rs=0.0210,p=0.1701). However there was a stronger negative correlation between ρ and average degree (rs=−0.2899,p=6.56×10−5). The median and interquartiles (25th and 75th percentiles) of the value of normalised degree variance for real world networks was 0.1203 [0.0245,0.1904], while for the normalised heterogeneity index it was 0.2350 [0.0890,0.3437]. It was observable, however, that the range of values obtained for both metrics was lower at higher average degrees. This is clear from Fig. 4, left, where for average degrees of between 2 and 4 the normalised degree variance values are spread out, taking values between 1 and 0.001. On the other hand, networks with average degree upwards of 4 show a smaller spread, mostly concentrated betewen 0.3 and 0.04. A similar behaviour is seen for network heterogeneity, Fig. 4, right.
Fig. 4.

Normalised degree variance, left, and heterogeneity, right, of 184 real-world networks plotted against their average degrees
From this dataset, we can see how the greater independence of the proposed normalisation aids in understanding general trends of degree variance across domains, Fig. 5, left. It is evident that biological/animal networks such food webs, animal connectomes and protein networks show greater degree distribution heterogeinety than technological and infrastructural networks, such as water distribution networks, road networks and digital circuit networks. Furthermore, four biological network subdomains (animal brain connectomes, food webs, genetic networks and protein interaction networks) have multiple samples (14, 71, 7 and 38, respectively) to allow assessment of group differences. These were tested using Wilcoxon’s rank sum test, and the results are as in Fig. 5, right. Interestingly, animal connectomes and food webs were comparable in terms of degree distribution heterogeneity (bright yellow indicates no difference with p>0.05) while these were statistically larger in general than genetic networks and protein interaction networks. This suggests that food webs and connectomes have a stronger hierarchical structure than genetic and protein interaction networks. Indeed, connectomes are known to have a rich-club of cognitive processing regions which integrate information across lower-order processes such as sensorimotor and heteromodal regions (Smith et al. 2019), while such a rich-club with wide-ranging integrative processes is not seen at the genetic/protein level (Maslov and Sneppen 2002).
Fig. 5.

Normalised degree variance of 184 real-world networks plotted against their average degrees and marked by sub domain, left, and Wilcoxon rank sum tests of normalised degree variance within biological network domains, right
For each real-world network from the ICON corpus, we randomly took out different percentages (5%, 10%, 15%, 20% and 25%) of nodes and edges from the networks and computed and ρ of the resulting subnetworks. This was done 50 times for each percentage and the mean was taken as an approximation of the expected value for that percentage. Nodes were removed uniformly at random in each iteration. Edges were removed in two ways– uniformly at random and randomly with probabilities inversely proportional to the product of the degrees of their adjacent nodes (i.e. probability of removal pr∼((n−1)−ki)((n−1)−kj)), the latter of which better retains the expected topology of the network from an evolutionary perspective. Specifically, this was done by i) computing hij=((n−1)−ki)((n−1)−kj) for all edges ij, ii) computing a vector of the cumulative sum of these values, iii) dividing these values by the sum total, , to normalise the vector in [0,1], iv) sampling the space [0,1] uniformly at random such that wherever the value fell with respect to the normalised cumulative vector corresponded to the edge that was subsequently removed from the network. That is, for m edges, the interval [0,1] was split into m bins whose sizes were proportional to the hij’s such that the probability that a random sample of [0,1] fell in the bin proportional to hij was exactly hij/T.
In each subsampling approach, the resulting subnetworks often contained isolated nodes leading to failure in the computation of ρ. This was the case for an average of 36.3% of the time for a given real world network with nodes removed and 65.1% and 67.1% of the time for edges removed by degree and randomly, respectively. This highlights the intrinsic problem of the ρ metric for broad use in network studies. Still, these were disregarded and the mean value was taken only for those iterations which produced a subnetwork with no isolated nodes. The median absolute difference across the 184 real world networks was then computed for each metric at each percentage of nodes and edges removed. The results are as in Table 4 where and ρsub denote the corresponding metric values of the subnetworks. It is quite clear that, on average, the difference found for is generally less than found for ρ for both node and edge subsampling. Moreover the differences are clearly fairly small, with the worst case scenario presented (25% of edges randomly removed) showing a median change in of just less than 0.01, indicating that the index is indeed robust to subsampling. This robustness was found to be stronger for node subsampling than for edge subsampling as seen by the fact that the median change in was generally smaller in node subsampling than in edge subsampling for the same percentage removed. This is compounded by the fact that for a given number of nodes removed, we found that generally a higher percentage of edges were removed as a consequence, Table 5, row 4. Further, as expected, was more robust in the edge subsampling approach following the evolutionary considerations than it was for the uniformly random subsampling approach, whereas, surprisingly the opposite was found for ρ which may be indicative of the restriction of results for ρ within subsamples which found no isolated nodes.
Table 4.
Coefficient of variation of network indices with respect to density, averaged over network size
| Network | J | σ2 | ρ | |
|---|---|---|---|---|
| Quasi-star | 0.4320 | 0 | 1.1026 | 1.4377 |
| Quasi-complete | 0.4509 | 0.4786 | 0.4877 | n/a |
| ER Random | 0.0378 | 0.6076 | 0.5793 | 1.0417 |
| Random Geometric | 0.3756 | 0.5469 | 0.4606 | 0.6287 |
| Scale-free model | 0.1092 | 0.1733 | 0.1480 | 0.5854 |
| Random Hierarchy | 0.3135 | 0.2972 | 0.6924 | 1.1754 |
| EEG | 0.2610 | 0.2386 | 0.6085 | 0.8387 |
Boldface indicates the best result among the normalisations
Table 5.
Median robustness of normalised degree variance, , and heterogeneity, ρ, to subsampling across 184 real-world networks
| %n removed | 5% | 10% | 15% | 20% | 25% |
| med | 0.0004 | 0.0009 | 0.0013 | 0.0017 | 0.0022 |
| med (|ρ−ρsub|) | 0.0013 | 0.0024 | 0.0034 | 0.0034 | 0.0039 |
| % m lost (mean) | 9.7% | 19.6% | 28.1% | 36.3% | 44.3% |
| %m removed inversely to degree | 5% | 10% | 15% | 20% | 25% |
| med | 0.0012 | 0.0023 | 0.0034 | 0.0043 | 0.0050 |
| med (|ρ−ρsub|) | 0.0027 | 0.0052 | 0.0079 | 0.0107 | 0.0131 |
| %m removed randomly | 5% | 10% | 15% | 20% | 25% |
| med | 0.0018 | 0.0040 | 0.0067 | 0.0078 | 0.0099 |
| med (|ρ−ρsub|) | 0.0022 | 0.0045 | 0.0069 | 0.0101 | 0.0125 |
Conclusion
We introduced and mathematically justified a true normalisation for degree variance in networks, showing a large degree of invariance to network size and network density. The two other previously proposed normalisations were shown to be invalid and another normalised heterogeneity index was shown to be ill-defined for graphs with isolated nodes. Beyond this, our normalisation had generally lower variability with respect to network size in quasi-complete graphs, ER random graphs, random geometric graphs, scale-free networks, random hierarchy models and EEG networks. Using sparse scale-free models, it was also shown to be more computationally efficient than other normalisation approaches. We then demonstrated the normalisation’s applicability and robustness to subsampling in real-world networks. The usefulness of the closed form expression for normalisation was also demonstrated in the production of two mathematical results showing that normalised degree variance of quasi-star graphs decreases with respect to density and that a flexible lower bound for normalised degree variance was possible depending on proportions of given degrees within the network. All things considered, the proposed normalisation is put forward as a standard for measuring heterogeneity in complex networks.
Appendix 1: Normalised degree variance of G(n,p)
Complementary to Corollary 2 for G(n,m), the following is a proof that the normalised degree variance of ER random graph ensemble G(n,p) does not depend on the number of expected edges m, and thus on network density, for fixed n.
Corollary 3
For the ER random graph ensemble G(n,p)
| 45 |
Proof
Recall that, generally, G(n,p) has a binomial degree distribution, B(n,p). The variance of this distribution is then (n−1)p(1−p). This gives
| 46 |
| 47 |
recalling that d=2m/n(n−1). For very large n, it is almost guaranteed that giving d=p and in such case it is evident that the above simplifies to 2(n−1)/n2. However, more precisely, m is determined by n(n−1)/2 Bernoulli trials with probability p and so is distributed binomially as B(n(n−1)/2,p). Therefore, writing M=n(n−1)/2, and C=2(n−1)/n2, we have
| 48 |
| 49 |
| 50 |
| 51 |
where ∗ comes from the law of the unconscious statistician. Now, m=0 and m=M are the special cases of the empty and complete graphs, respectively. These put a 0 on the denominator, but because these are two extremely unlikely cases for any relevant p (having the smallest binomial coefficients), they can be discarded without loss of accuracy in approximation. Now, from the binomial formula, we have
| 52 |
but, again, we can approximate this by discarding negligible terms at the periphery: m=0,1,M,M+1 and M+2, i.e.
| 53 |
By simple algebraic manipulations, we can then rearrange Eq. 51 to get
| 54 |
| 55 |
It then remains to show that the terms
| 56 |
approximate unity. Now M>m and m ranges from 1 to M−1, but also the binomial coefficients are dominated by the middle terms, so we must consider the leading terms of Eq. 56 when m≈M/2. In this case
| 57 |
| 58 |
for large M, as required. So, finally, we have
| 59 |
| 60 |
| 61 |
as required. □
Appendix 2: Network size-independent minimum of normalised degree variance for graphs with a fixed proportion of vertices of a given degree
Here we consider lower bounds for the normalisation’s invariance to network size. Suppose for a graph, G, we guarantee x nodes of degree a, having degrees . Then
| 62 |
| 63 |
| 64 |
| 65 |
| 66 |
where * comes from the fact that and that the minimum value of the sum of squares come from all elements being equal ⇒ kx+i=(2m−x)/(n−x) ∀i.
Now, we fix density so that d=2m/n(n−1), i.e. 2m=dn(n−1) and we get
| 67 |
Then, (67) = 0
| 68 |
| 69 |
| 70 |
which is the average degree of the graph, which makes sense since regular graphs have degree variance 0 where each node has degree 2m/n. Taking a to be small, say 1, the leading terms in (67) are
| 71 |
Noting that x/n is the proportion of nodes which have degree 1, we thus have a constant minimum value of degree variance for such graphs with known density ∀n.
We can also consider a=n−1, i.e. graphs with a known proportion of dominant vertices. Then, (67) becomes
| 72 |
considering the leading terms. Notably, this is precisely (71) if we substitute in d for 1−d, reflecting the equivalence of for graphs and their complements.
Therefore, if the proportions of a given degree of a network is known, then a lower bound of V for such networks can be established. This could help, for example, in questions of hub dominance in real world networks. One can fix the number of dominant nodes in the network and know the range of V possible for such networks with greater accuracy. We applied these results to investigate lower bounds of for the 184 real world networks. To get the maximum lower bound for a single network, Eq. 67 was computed for all degrees and the maximum of these alongside the degree at which the maximum was obtained were recorded. To help comparisons between different networks, the degrees were recorded as relative degrees:
| 73 |
so that the maximum is 1 and minimum is 0. The results are plotted in Fig. 6. Most lower bounds are achieved at either the maximum degree (96 networks) or minimum degree (60 networks) in the network, Fig. 6 top. The achieved value for degree variance was on average (median) 3.33 times the value of the lower bound, with an interquartile range of 2.62. Absolute differences between degree variance and lower bounds are shown in Fig. 6 row 2, on a log scale. Using Wilcoxon rank sum tests, we found that networks whose lower bounds were achieved at degrees larger than the network’s average degree generally had greater normalised degree variance (p=0.0052) and lower bounds (p=0.0014) than those networks whose lower bounds were achieved at degrees lower than the network’s average degree, Fig. 6 bottom. These results all align and support the claim that degree variance provides a measurement of the inequality of the degree distribution.
Fig. 6.

Analysis of the lower bounds for 184 real world networks. The p-values in the box plots come from Wilcoxon rank sum tests. Networks whose lower bound was achieved at a degree larger than the average degree are compared against networks whose lower bounds are at degrees lower than the average. These are recorded for the lower bounds for normalised degree variance (left) and normalised degree variance (right). LB degree is the degree at which the lower bound is achieved in the network and <k> is the average degree of the network
Acknowledgments
Not applicable.
Abbreviations
- ER
Erdös-Rényi
- EEG
Electroencephalogram
- ICON
Colorado index of complex networks
Authors’ contributions
KS and JE conceived the study. KS performed the analyses and wrote the manuscript. JE reviewed the manuscript. All authors read and approved the final manuscript.
Funding
KS was supported by Health Data Research UK (MRC ref Mr/S004122/1), which is funded by the UK Medical Research Council, Engineering and Physical Sciences Research Council, Economic and Social Research Council, National Institute for Health Research (England), Chief Scientist Office of the Scottish Government Health and Social Care Directorates, Health and Social Care Research and Development Division (Welsh Government), Public Health Agency (Northern Ireland), British Heart Foundation and Wellcome.
Competing interests
The authors declare that they have no competing interests.
Footnotes
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- Ábrego BM, Fernãndez-Merchant S, Neubauer MG, Watkins W. Sum of squares of degrees in a graph. J Inequalities Pure Appl Math. 2009;10(3):64. [Google Scholar]
- Ahlsewade R, Katona GOH. Graphs with maximal number of adjacent pairs of edges. Acta Math Acad Sci Hungar. 1978;32:97–120. doi: 10.1007/BF01902206. [DOI] [Google Scholar]
- Alberston MO. The Irregularity of a Graph. Ars Combinatorica. 1997;46:219–225. [Google Scholar]
- Barabási AL, Albert R. Emergence of scaling in random networks. Science. 1999;286(5439):509–512. doi: 10.1126/science.286.5439.509. [DOI] [PubMed] [Google Scholar]
- Batty M. The Size, Scale, and Shape of Cities. Science. 2008;319(5864):769–771. doi: 10.1126/science.1151419. [DOI] [PubMed] [Google Scholar]
- Bell FK. A note on the irregularity of graphs. Lin Alg Appl. 1992;161:45–64. doi: 10.1016/0024-3795(92)90004-T. [DOI] [Google Scholar]
- Bullmore E, Sporns O. Complex brain networks: graph theoretical analysis of structural and functional systems. Nat Rev Neurosci. 2009;10(4):312. doi: 10.1038/nrn2618. [DOI] [PubMed] [Google Scholar]
- Cao X, Wang F, Han Y. Ground-state phase-space structures of two-dimensional j spin glasses: a network approach. Phys Rev E. 2015;91(6):062135. doi: 10.1103/PhysRevE.91.062135. [DOI] [PubMed] [Google Scholar]
- Clauset, A, Tucker E, Sainz M (2016) The Colorado Index of Complex Networks. https://icon.colorado.edu/.
- Collatz L, Sinogowitz U. Spektren endlicher Grafen. Abh Math Sem Univ Hamburg. 1957;21:63–77. doi: 10.1007/BF02941924. [DOI] [Google Scholar]
- Cvetković D, Rowlinson P. On connected graphs with maximal index. Publications de l’Institut Mathématique, Nouvelle Série. 1988;44(58):29–34. [Google Scholar]
- Dall J, Christensen M. Random geometric graphs. Phys. Rev. E. 2002;66:016121. doi: 10.1103/PhysRevE.66.016121. [DOI] [PubMed] [Google Scholar]
- de Caen D. An upper bound on the sum of squares of degrees in a graph. Discrete Math. 1998;185(1-3):245–248. doi: 10.1016/S0012-365X(97)00213-6. [DOI] [Google Scholar]
- Dormann CF, Fründ J, Blüthgen N, Gruber B. Indices, Graphs and Null Models: Analyzing Bipartite Ecological Networks. Open Ecol J. 2009;2:7–24. doi: 10.2174/1874213000902010007. [DOI] [Google Scholar]
- Erdös P, Rényi A. On Random Graphs. Publicationes Mathematicae Debrecen. 1959;6:290–297. [Google Scholar]
- Estrada E. Quantifying network heterogeneity. Phys Rev E. 2010;82:066102. doi: 10.1103/PhysRevE.82.066102. [DOI] [PubMed] [Google Scholar]
- Ghasemian, A, Hosseinmardi H, Clauset A (2018) Evaluating overfit and underfit in models of network community structure. https://arxiv.org/abs/1802.10582.
- Gilbert EN. Random Graphs. Annals Math Stat. 1959;30(4):1141–1144. doi: 10.1214/aoms/1177706098. [DOI] [Google Scholar]
- Gutman I, Paule P. The variance of vertex degrees of randomly generated graphs. Univ Beograd Publ Elektrotehn Fak. 2002;13:30–35. [Google Scholar]
- Horvath S, Dong J. Geometric interpretation of gene coexpression network analysis. PLOS Comp Bio. 2008;4(8):e1000117. doi: 10.1371/journal.pcbi.1000117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jacob R, Harikrishnan KP, Misra R, Ambika G. Measure for degree heterogeneity in complex networks and its application to recurrence network analysis. R Soc Open Sci. 2017;4(1):160757. doi: 10.1098/rsos.160757. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li X, Shi Y. A survey on the Randić index. MATCH Commun Math Comput Chem. 2008;59:127–156. [Google Scholar]
- Mäkinen, J, Lämsä J, Lehtonen K (2019) The analysis of structural changes in Finnish sport policy network from 1989 to 2017. Int J Sport Policy Politics. 10.1080/19406940.2019.1583680.
- Maslov S, Sneppen K. Specificity and stability in topology of protein networks. Science. 2002;296(5569):910–913. doi: 10.1126/science.1065103. [DOI] [PubMed] [Google Scholar]
- Mochtak, M, Diviak T (2019) Looking Eastward: network analysis of Czech deputies and their foreign policy groups. Problems Post-Communism. 10.1080/10758216.2018.1561191.
- Neurophysiological Biomarker Toolbox (2020). available from www.nbtwiki.net.
- Newman MEJ. Networks. Oxford: Oxford University Press; 2010. [Google Scholar]
- Petersen J. Die theorie der regularen graphs. Acta Math. 1891;15:193–220. doi: 10.1007/BF02392606. [DOI] [Google Scholar]
- Phillips, NE, Levy BL, Sampson RJ, Small ML, Wang RQ (2019) The social integration of American cities: network measures of connectedness based on everyday mobility across neighbourhoods. Sociological Methods Res. 10.1177/0049124119852386.
- Randić M, Novič M, Plavšić D. Solved and unsolved problems of structural chemistry. Boca Raton: CRC Press; 2016. [Google Scholar]
- Safaei F, Tabrizchi S, Hadian Rasanan AH, Zare M. An energy-based heterogeneity measure for quantifying structural irregularity in complex networks. J Comput Sci. 1011;36(10):2019. [Google Scholar]
- Smith K, Abasolo D, Escudero J. Accounting for the complex hierarchical topology of EEG phase-based functional connectivity in network binarisation. PLoS ONE. 2017;12(10):e0186164. doi: 10.1371/journal.pone.0186164. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith KM, Bastin ME, Cox SR, Valdes-Hernandez M, Wiseman S, Escudero J, Sudlow C. Hierarchical complexity of the adult human structural connectome. Neuroimage. 2019;191:205–215. doi: 10.1016/j.neuroimage.2019.02.028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith K, Escudero J. The complex hierarchical topology of EEG functional connectivity. J Neurosci Methods. 2017;76:1–12. doi: 10.1016/j.jneumeth.2016.11.003. [DOI] [PubMed] [Google Scholar]
- Snijders TAB. The degree variance: an index of graph heterogeneity. Soc Netw. 1981;3(3):163–174. doi: 10.1016/0378-8733(81)90014-9. [DOI] [Google Scholar]
- Stam CJ, Nolte G, Daffertshofer A. Phase lag index: Assessment of functional connectivity from multi channel EEG and MEG with diminished bias from common sources. Human Brain Mapping. 2007;28(11):1178–1193. doi: 10.1002/hbm.20346. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strogatz SH. Exploring complex networks. Nature. 2001;410:268–276. doi: 10.1038/35065725. [DOI] [PubMed] [Google Scholar]
- van den Heuvel MP, Sporns O. Rich-club organization of the human connectome. J Neurosci. 2011;31(44):15775–15786. doi: 10.1523/JNEUROSCI.3539-11.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vega-Redondo F. Complex Social Networks. Cambridge: Cambridge University Press; 2007. [Google Scholar]
- Zimmermann MG, Eguiluz VM, San Miguel M. Coevolution of dynamical states and interactions in dynamic networks. Phys Rev E. 2004;69:065102. doi: 10.1103/PhysRevE.69.065102. [DOI] [PubMed] [Google Scholar]