

Abstract
Motivation
Approximate Bayesian computation (ABC) is an increasingly popular method for likelihood-free parameter inference in systems biology and other fields of research, as it allows analyzing complex stochastic models. However, the introduced approximation error is often not clear. It has been shown that ABC actually gives exact inference under the implicit assumption of a measurement noise model. Noise being common in biological systems, it is intriguing to exploit this insight. But this is difficult in practice, as ABC is in general highly computationally demanding. Thus, the question we want to answer here is how to efficiently account for measurement noise in ABC.
Results
We illustrate exemplarily how ABC yields erroneous parameter estimates when neglecting measurement noise. Then, we discuss practical ways of correctly including the measurement noise in the analysis. We present an efficient adaptive sequential importance sampling-based algorithm applicable to various model types and noise models. We test and compare it on several models, including ordinary and stochastic differential equations, Markov jump processes and stochastically interacting agents, and noise models including normal, Laplace and Poisson noise. We conclude that the proposed algorithm could improve the accuracy of parameter estimates for a broad spectrum of applications.
Availability and implementation
The developed algorithms are made publicly available as part of the open-source python toolbox pyABC (https://github.com/icb-dcm/pyabc).
Supplementary information
Supplementary data are available at Bioinformatics online.
1 Introduction
Mathematical models have become an essential tool in many research areas to describe and analyze dynamical systems, allowing to unravel and understand underlying mechanisms. To make quantitative predictions and test hypotheses, unknown parameters need to be estimated and parameter and prediction uncertainties need to be assessed.
This is frequently done in a Bayesian framework, where prior information and beliefs about model parameters are updated by the likelihood of observing data under a given model parameterization, yielding by Bayes’ Theorem the posterior distribution of the parameters given the data. Many established parameter estimation methods, including optimization (Banga, 2008), profile calculation (Raue et al., 2009) and standard Monte Carlo sampling (Hines, 2015), require access to at least the non-normalized posterior. However, as models get more complex and stochastic, the likelihood function can become analytically or numerically intractable (Jagiella et al., 2017). Examples of such models include Markov processes, stochastic differential equations (SDE) and stochastically interacting agents. In systems biology, such models are used to realistically describe e.g. gene expression, signal transduction and multicellular systems (e.g. Imle et al., 2019; Lenive et al., 2016; Picchini, 2014).
Likelihood-free inference methods have therefore recently gained interest, including among others approximate Bayesian computation (ABC) (Beaumont et al., 2004; Sisson et al., 2018a), indirect inference (Drovandi, 2018; Gourieroux et al., 1993), synthetic likelihoods (Price et al., 2018; Wood, 2010) and particle Markov Chain Monte Carlo (Andrieu et al., 2010). In particular, ABC has become increasingly popular in various research areas due to its simplicity, scalability and its broad applicability. In a nutshell, in ABC the evaluation of the likelihood function is circumvented by simulating data for given parameters, and then accepting the parameters if the simulated and observed data are sufficiently similar. ABC is frequently combined with a sequential Monte Carlo scheme (ABC-SMC) (Del Moral et al., 2006; Sisson et al., 2007), which allows for an iterative reduction of the acceptance threshold, improves acceptance rates by sequential importance sampling, and can exploit parallel infrastructure well.
Observed data are generally corrupted by noise, resulting from unavoidable inaccuracies in the measurement process. In likelihood-based inference, it has been widely adopted to include noise models in the likelihood function (Raue et al., 2013). Contrarily, in likelihood-free methods, particularly ABC, it is easy to disregard any noise due to the unnecessity of even formulating a likelihood and the various inherent approximation levels, so that error sources can be difficult to pinpoint from the result. In the past, it has repeatedly not been included in ABC analyses (Eriksson et al., 2019; Imle et al., 2019; Jagiella et al., 2017; Lenive et al., 2016; Toni et al., 2009). Asymptotic unbiasedness of ABC is however granted only if the data-generation process is perfectly reproduced. Omitting the measurement noise can lead to substantially wrong parameter estimates, regarding in particular uncertainty (Frazier et al., 2020).
The problem is illustrated in Figure 1 on an ordinary differential equation (ODE) model of a conversion reaction, with one unknown parameter θ1. Synthetic data D were generated by adding normal noise to the model simulation (Fig. 1A). Three different ABC-SMC analyses were performed: Using the noise-free model y together with an (I) or (II) distance, and, to account for noise, randomizing the model output by a corresponding normal random variable (III). Usually, in ABC we would hope to decrease the acceptance threshold ε asymptotically to 0. For (I) and (II), this was however not possible (Fig. 1B). The thresholds converged to some positive values, which in addition differ for the and distance. This mirrors in the inferred posterior distributions (Fig. 1C), where (I) and (II) converge to point estimates, which can be linked to maximum likelihood estimates under the assumption of normal (I) or Laplace (II) noise. This is clearly not the result one would hope for in a Bayesian analysis. In comparison, (III) yields a good approximation of the true posterior. In Supplementary Section S1.5 we discuss the problem of model error in ABC from a theoretical perspective, also explaining what happens in the above analyses. Further, in Supplementary Section S6 we illustrate on some more examples, including stochastic models, how ignoring measurement noise can lead to wrong parameter estimates. In practice, errors in the ABC parameter estimates resulting from model error can be hard to detect, so it is important to correctly account for measurement noise.
Fig. 1.

Illustrative conversion reaction ODE example. (A) The used data. (B) Acceptance thresholds over sequential ABC-SMC iterations for three estimation methods: Using a non-noisy model and an l2 or l1 distance in the ABC acceptance step, and using a noisy model (and an l2 distance). The minimum obtainable values for the respective distances are indicated by dashed lines. (C) Histograms of the corresponding ABC posterior approximations after the last iterations. The true posteriors are indicated by dashed, the true parameter values by dotted lines
In this article, we discuss ways of correctly addressing measurement noise: Either the model output can be randomized, or the ABC acceptance step can be modified in accordance with the noise model. The latter method builds on the insight by Wilkinson (2013) that ABC can be considered as giving exact inference from the original model with an additional error term induced by the acceptance step. Introduced by Wilkinson (2013) for rejection and Markov Chain Monte Carlo (ABC-MCMC) samplers and used by van der Vaart et al. (2018) in the case of replicate measurements, the approach was extended by Daly et al. (2017) to ABC-SMC samplers, presenting two algorithms confined to the situation of additive independent normal noise, and relying on certain tuning parameters. Here, we extend the existing ideas by presenting an ABC-SMC-based algorithm applicable to various model types and noise models. Further, we develop robust approaches tackling several aspects of such an algorithm, like initialization and step size selection, and include ideas from rejection control importance sampling (Liu et al., 1998; Sisson and Fan, 2018), which make our algorithm robust and self-tuned and thus widely applicable. We test and compare it on various models including ordinary and SDE, discrete Markov jump processes (MJP) and agent-based models (ABM), and noise models including normal, Laplace and Poisson noise.
2 Materials and methods
2.1 Basics of ABC-SMC
The goal of Bayesian inference is to infer a posterior distribution over parameters given observed data , where denotes the prior density on the parameters encoding information and beliefs before observing the data, whereas the likelihood is the probability density of data y given model parameters θ. ABC deals with the situation that we have a generative model from which we can simulate data , but evaluating the likelihood is infeasible. Then, classical ABC comprises the following three steps: for some distance function and acceptance threshold ε. This is repeated until sufficiently many, say N, parameters have been accepted. Accepted particles constitute a sample from the approximate posterior distribution
where I denotes the indicator function, also referred to as uniform kernel in this context.
sample parameters ,
simulate data ,
accept θ if ,
Due to the curse of dimensionality, ABC usually works not directly on the data, but employs low dimensional summary statistics (Fearnhead and Prangle, 2012). Here, we abstract from this to simplify the notation. The summary statistics may be assumed to be already incorporated in y.
It can be shown that for under some mild assumptions (e.g. Prangle, 2017, and Supplementary Section S1.4), however there is a trade-off between decreasing the approximation error induced by ε and maintaining high acceptance rates. To tackle both problems, ABC is frequently combined with a Sequential Monte Carlo (SMC) scheme. Here, we present a scheme based on Toni et al. (2009) and Beaumont et al. (2009). In ABC-SMC, a population of parameters is initially sampled from the prior and propagated through a sequence of intermediate distributions , using importance sampling, with the proposal distribution based on the previous iteration’s accepted particles. The tolerances are chosen to yield a gradually better approximation of the posterior distribution, while maintaining high acceptance rates. The steps are summarized in Algorithm 1.
Algorithm 1 ABC-SMC algorithm
fordo
set up gt and
while less than N acceptances do
sample parameter
simulate data
accept θ if
end while
compute weights , with accepted parameters
end for
Here, the proposal distribution in iteration t is
with local perturbation kernels, the accepted parameters in the previous iteration, and importance weights (Klinger and Hasenauer, 2017). The output of ABC-SMC is a population of weighted parameters .
2.2 The problem of measurement noise in ABC
In ABC, the model does often not account for measurement noise. This effectively assumes perfect measurements, which is in practice hardly the case. In the following, we assume that the data D are noisy and thus a realization of a distribution which includes the noise, but that the model does not do so. Further, we can write , so that
The interpretation of is that of a parameterized noise model of observing data under noise-free model output y and parameters θ. Thus, the noise model relates observables that assume perfect measurements to practically obtained noisy data. We call
the noise model,
the model likelihood and
the full likelihood.
The noise model is usually simple, e.g. a normal or a Laplace distribution. Hence, we consider the case that the noise model can be evaluated, while we are only able to sample from, but not evaluate, the model likelihood.
The use of the likelihood p as above would imply that inference for the wrong model is performed. The goal is now to infer the corrected posterior .
2.3 Approaches to account for noise
How can we tackle in ABC the discrepancy between model output y and noisy data D? Principally, three different approaches have been in use, which are visualized in Figure 2.
Fig. 2.

The different conceivable ways of accounting for noise. (A1): Using a uniform kernel with . The posterior is visibly off. (A2): Adding random measurement noise to the model output. The posterior still has a slightly higher variance. (A3): Modifying the acceptance kernel. The posterior matches the true distribution accurately
2.3.1 Using an appropriate uniform kernel
The first approach (A1) is to employ a uniform kernel, with the distance metric d and the acceptance threshold ε chosen such that the resulting acceptance kernel is similar to the underlying noise distribution (e.g. in Daly et al., 2017; Toni et al., 2009). An advantage of this approach is its computational efficiency, as acceptance is deterministic (Sisson et al., 2018b). Further, it is easy to apply in practice as it only uses standard ABC methods available in most software tools. However, a major concern is that this approach effectively assumes a uniform noise distribution (see Theorem 1, Section 2.4), which in practice hardly applies. In addition, the exact choice of ε is ambiguous, e.g. one can fix the kernel variance, or set it to the expected value of the distance function at the true noise-free model value. Doing so requires knowledge of underlying noise parameters, or even of y. This information is in practice not available. Here, we only mention this approach for completeness, and focus on (asymptotically) exact methods.
2.3.2 Randomizing the model output
The second approach (A2) is to modify the forward model simulation to account for measurement noise, i.e. to randomize the model output (e.g. in Toni and Stumpf, 2010), thus replacing p by q. An advantage of this method is that it is again easy to apply, requiring only a basic ABC implementation. Further, if the noise model depends on unknown parameters, these can in theory be included in the overall parameter vector θ and estimated along the way. Also, this approach is in particular applicable to ‘black box’ models where the noise cannot be separated. A major concern with this method is however that the randomness in the simulation of noise can lead to low acceptance rates. Further, the comparison of simulated and observed data still requires a standard acceptance kernel with a non-trivial threshold. A2 is asymptotically exact as , however in practice a small approximation error will remain, which can be hard to quantify.
2.3.3 Modifying the acceptance step
The third approach (A3) is to keep the non-noisy model p, but to modify the acceptance criterion: Based on the insight by Wilkinson (2013) that ‘ABC gives exact inference, but for the wrong model’, we modify the acceptance step from Section 2.1 to
3. accept θ with probability ,
with a normalization constant . This step can be implemented by sampling and accepting if . Theorem 1 (Section 2.4) tells us that this indeed gives exact inference from the true posterior. It is thus the non-degenerate noise model that allows us to perform likelihood-free inference in an exact manner (i.e. up to Monte Carlo errors), still without evaluating the full likelihood. Only for deterministic models do we have the full likelihood, such that this approach is equivalent to likelihood-based sampling techniques. Wilkinson (2013) integrated this idea in an ABC-rejection and an ABC-MCMC algorithm, and Daly et al. (2017) introduced two sequential implementations for Gaussian noise. Building on both works, we present in the following a self-tuned sequential algorithm applicable to a broad class of noise models.
2.4 ABC gives exact inference under the assumption of model error
The algorithms we present in the following are based our extension of the work of Wilkinson (2013) to generic, parameter-dependent noise models:
Theorem 1 (Exact noisy ABC). Consider a prior density , a model likelihood , a noise model and assume . Then ABC with acceptance probability with targets the correct posterior distribution .
Proof. See Supplementary Section S2. □
This facilitates, e.g. multiplicative noise or the estimation of unknown scale terms such as standard deviations for normally distributed measurement noise. This result can also be interpreted in the context of general ABC acceptance kernels, see Supplementary Section S1.3 and Remark 4.
2.5 Toward an efficient exact sequential ABC sampler
To increase efficiency, we want to integrate the exact sampler A3 with an SMC scheme. To do so, we need to replace the gradual decrease of the acceptance threshold ε. The basic idea we employ is motivated by parallel tempering in MCMC (Earl and Deem, 2005), namely to temper the acceptance kernel to mediate from prior to posterior. That is we introduce temperatures , and in iteration t modify the acceptance step to
3. accept θ with probability .
This way, we sample from the distribution
| (1) |
using importance sampling, where yields a sample from the correct posterior. Note that tempering is applicable to any noise model and will yield higher acceptance rates. An exception is the uniform distribution, for which the acceptance rate will remain unchanged, but this noise model can be dealt with by standard ABC already. In the following, we propose approaches to select the normalization constant c, the temperature schedule and the initial temperature.
2.6 Selection of the normalization constant
A problem persistent in the approaches by Wilkinson (2013) and Daly et al. (2017) was the choice of normalization constant c. A trivial choice for this is the highest mode of the noise distribution, which is for common noise models assumed at y = D. Yet, in practice it is often unlikely or impossible for the model to exactly replicate the measured data, yielding unnecessarily small acceptance rates. Thus, of interest is the point such that y is realizable under the model . For deterministic models, this point is the maximum likelihood value and can be computed by optimization. For stochastic models, it is in general unknown. Daly et al. (2017) argue that too small a c leads to a decapitation and uniformization of the noise distribution around the maximum likelihood value. Due to the inability to find good values for c, there the ABC-SMC sampler used here based on Toni et al. (2009) was disregarded in favor of a sampler based on Del Moral et al. (2012), although the former had shown superior accuracy. We can however solve the problems of too low acceptance rates and of the decapitation of the noise model by correcting for that error. Based on ideas from rejection control importance sampling (RCIS, Sisson and Fan, 2018), we derive the following:
Theorem 2 (Importance weighted acceptance). Let arbitrary. If we change the acceptance step to
3. accept with probability
and modify the importance weights to be
(2) the weighted samples target distribution (1).
Proof. See Supplementary Section S3.3. □
This means that we can, for arbitrary c, correct for accepting from the decapitated noise distribution by modifying the acceptance weights. Of course, a smaller c leads to higher acceptance rates, but also to an increase in the Monte Carlo error by weight degeneration. Therefore, it must be chosen carefully. In a sequential approach, it is straightforward to iteratively update c by taking into account previously observed values. In this study, we by default set it to the maximum of the values found in previous iterations. When acceptance rates turn out too low, we set it to , where c is the maximum found value, and increases acceptance rates by up to that factor in the next iteration. Other schemes, e.g. based on quantiles, are possible. Before iteration 1, we draw a calibration sample from the prior.
2.7 Selection of the temperatures
A proper temperature scheme has to balance information gain and acceptance rate. In general, the overall required number of simulations depends both on the number of intermediate populations, and the difficulty of jumping between subsequent distributions. In the following, we propose two schemes based on different criteria.
2.7.1 Acceptance rate scheme
The idea of this scheme is to match a specified target acceptance rate, i.e. to choose such that the expected acceptance rate
| (3) |
matches a specified target rate. Here, in the second line we employ importance sampling from the previous proposal distribution with corresponding Radon–Nikodym derivatives . This is because in the third line, we approximate this integral via a Monte Carlo sample, using all parameters sampled in the previous iteration. This must include rejected particles to avoid a bias. The inner integral is approximated by the corresponding single simulation.
Matching is a one-dimensional bounded optimization problem which can be efficiently solved. Compared to the overall run time of ABC analyses, we found the computation time to be negligible. While this scheme provides only a rough estimate of the expected acceptance rate, it proved sufficient for our purpose.
Assuming convergence and similar in shape to the true posterior distribution, it is to be expected that a such proposed T converges to a value in general. Therefore, the acceptance rate scheme is rather intended as a scheme for the first few iterations and needs to be backed up with an additional scheme, e.g. the one following, that ensures .
2.7.2 Exponential decay scheme
In standard likelihood-based parallel tempering MCMC, empirically a geometric progression, i.e. a scheme with fixed temperature ratios, has shown to yield roughly equal probabilities for swaps between adjacent temperatures (Sugita et al., 2000). This finding can be theoretically justified (Predescu et al., 2004). As a similar approach was recently successfully applied in an ABC-SMC setting by Daly et al. (2017), we used a geometric progression here as well. We specified a fixed ratio such that .
The effective next temperature was then set to the minimum of the temperatures proposed by the acceptance rate scheme and the exponential decay scheme.
2.7.3 Find a good initial temperature
Unanswered has remained the question of how to choose the initial temperature. It should be low enough to avoid simply sampling from the prior without information gain, but have reasonable acceptance rates. Thus it is a crucial tuning parameter. Here, we propose a widely applicable self-tuned mechanism based on the above acceptance rate scheme: The acceptance rate scheme can be applied to find T1 if we set and generate a calibration sample from the prior, the same we use to find the initial normalization c.
For brevity, we denote in the following by ASSA, the exact ABC-SMC sampler proposed here with an adaptive sequential stochastic acceptor, i.e. with c set to the previously observed highest value with weight correction, and the two temperature selection schemes, with target acceptance rate , and in the exponential decay scheme.
2.8 Implementation
We implemented all the algorithms in the open-source python toolbox pyABC (https://github.com/icb-dcm/pyabc, Klinger et al., 2018), which offers a state-of-the-art implementation of ABC-SMC. We put emphasis on an easy-to-use modular implementation, such that it is straightforward to customize the analysis pipeline. To ensure numerical stability, critical operations were performed in log-space. For further details see Supplementary Section S5. Jupyter notebooks illustrating how to use the algorithms have been included in the pyABC online documentation. The complete data and code are available on zenodo (https://doi.org/10.5281/zenodo.3631120).
3 Results
To study the properties of ASSA, and compare it to alternative approaches, we consider six models.
3.1 Model description
The models cover various modeling formalisms, including ODE, SDE, MJP and ABM, as well as various noise models, including normal, Laplace and Poisson noise.
Models M1 and M2 are ODE models of a conversion reaction , a typical building block in many biological systems. We estimated the reaction rate coefficients , assuming only species A to be measured. In model M1, we used independent additive normal noise, a common assumption in systems biology. In model M2, we instead used Laplace noise, which is frequently used when the data are prone to outliers (Maier et al., 2017). Further, M1 was varied in multiple regards to investigate various features of the algorithm.
Model M3 is an SDE model of intrinsic ion channel noise in Hodgkin–Huxley neurons based on Goldwyn et al. (2011). We estimated the parameters describing the input current, and the square root of the membrane area . We assumed measurements to be available for the fraction of open potassium channels K, and used an additive normal noise model to describe inaccuracies in the measurement process.→
Model M4 describes the process of mRNA synthesis and decay, , we estimated the transcription rate constant p1 and the decay rate constant p2. To capture the intrinsic stochasticity of this process at low copy numbers, we sampled from the chemical master equation using the Gillespie algorithm (Gillespie, 1977). We assumed the counts of mRNA molecules from a single cell to be available at discrete time points. Data of this kind can be obtained e.g. by fluorescence microscopy. We used a Poisson noise model, which is frequently used for regression of count data (Coxe et al., 2009).
Model M5 is an ODE model by Boehm et al. (2014) describing the homo- and heterodimerization of the transcription factors STAT5A and STAT5B, for which three types of data with 16 measurements each are available. In the original publication, additive normal measurement noise was assumed, and optimal parameter point estimates obtained using optimization. We estimated 11 logarithmically scaled parameters of this model, including three standard deviations of the normal noise model, one for each data type.
Model M6 is a multiscale ABM model of spheroid tumor growth on a two-dimensional plane, as described in Jagiella et al. (2017). Single cells were modeled as stochastically interacting agents, coupled to the dynamics of extracellular substances modeled via partial differential equations. For the three data types generated by this model, we assumed normal noise models of differing variance. The model has seven unknown parameters. The simulation of this ABM model is computationally relatively demanding, and a single forward simulation on the used hardware took already about 20 s. As often on the order of to forward simulations are required for inference, the overall computation time was on the order of thousands of core hours.
For models M1-4 and M6, we created artificial data by simulating the model and then ‘noisifying’ the simulations by sampling from the respective noise distribution. Model M5 is based on real data without known ground truth but reported literature values. For all models, we used uniform parameter priors over suitable ranges. A summary of the model properties is provided in Table 1, and further details, including a visualization of the used data, can be found in Supplementary Section S7.
Table 1.
Main properties of the considered models
| Id | Description | Type | Noise model | # Parameters | # Data |
|---|---|---|---|---|---|
| M1 | Conversion reaction | ODE | Normal | 2 | 10 |
| M2 | Conversion reaction | ODE | Laplace | 2 | 10 |
| M3 | Hodgkin–Huxley neurons | SDE | Normal | 2 | 100 |
| M4 | Gene expression | MJP | Poisson | 2 | 10 |
| M5 | STAT5 dimerization | ODE | Normal | 11 | 48 |
| M6 | Tumor spheroid growth | ABM | Normal | 7 | 30 |
For parameter estimation, we used pyABC with a multivariate normal kernel with adaptive covariance matrix as proposal distribution between populations, and a median strategy to update the ε threshold under a uniform acceptance kernel (Klinger and Hasenauer, 2017). If not mentioned otherwise, we used a population size of N = 1000. In general, the sufficiency of a population size can be checked by comparing approximations of the posterior distribution obtained for different population size. While this was for computational reasons not explicitly done here, preliminary tests and previous studies for the considered problems suggest that the population sizes used here are sufficient (see e.g. Jagiella et al., 2017).
3.2 Reweighting reliably corrects for bias
As the RCIS reweighting derived in Section 2.6 should allow for exact inference independent of the normalization constant c, we compared the resulting sample distribution with the ground truth. Therefore, we performed sampling for different values of c, for model M1 confined to one estimated parameter (Fig. 3A). The theoretical maximum value of the likelihood of the data D under the model was determined by multistart local optimization, yielding . Here, we used . As already pointed out in Daly et al. (2017), this leads to a decapitation of the posterior distribution, i.e. it flattens out at values of high probability. The difference to the true posterior became smaller the larger c. However, if we corrected for the bias introduced by the too low normalization according to (2), we obtained, even for the lowest c = 20, a posterior that well matched the true distribution.
Fig. 3.

Evaluation of the properties of the components of the proposed sampling scheme. (A) Kernel density estimates (KDE) of four posterior estimates generated for model M1 with one unknown parameter and 10 data points, with different normalization constants c, only once correcting for the acceptance bias by reweighting. (B) Normalization constant c over the iterations for inference for model M1 with 100 data points. (C) Acceptance rate in sampling runs for models M1, M3 and M4 for two population sizes N. Only the acceptance rate criterion was used for temperature scheduling. (D) Total number of simulations in runs for model M1 for different initial temperatures T1. The temperature updates were performed using only the exponential decay scheme. The colors indicate individual iterations, starting at the bottom with the simulations spent in the calibration iteration, and then from t = 1 upwards. (E, F) KDE of simulations obtained for model M1 with one unknown dynamic parameter, and also estimating the normal noise variance. (E) Comparison of a run using the stochastic acceptor, and a run using a noisy model output. (F) Posterior estimates over the sequential iterations using the stochastic acceptor
Employing the proposed strategy to automatically update c after each iteration to the highest value so far, we observed for all test models that the value of c converged over time, larger jumps taking place only in the first few iterations. E.g. for the 2-parametric model M1 with 100 data points (Fig. 3B), c converged to the theoretical minimum upper bound .
3.3 Acceptance rate prediction works reliably
Next, we analyzed the performance of the acceptance rate prediction introduced in Section 2.7 as a means to choose temperatures. We ran six iterations for each of the models M1-3 and found that the deviations to the target value of are acceptable (Fig. 3C). The fit was already good at t = 1, thus allowing to find appropriate initial temperatures. As expected, the fluctuations decreased for a higher population size. This shows that approximation (3) is sufficient for the temperature adaptation.
While the acceptance rate criterion provided a means to adapt the temperature in early iterations, the proposed temperatures T did in most cases not converge to T = 1, at which we have exact inference. This was to be expected, as explained in Section 2.7, and necessitates the presence of a secondary scheme ensuring , for example the exponential decay scheme. We observed that the acceptance rate criterion reliably proposed good initial temperatures and allowed for major temperature jumps in the first iterations (accelerating convergence), while in later iterations the exponential decay scheme took over (e.g. Supplementary Fig. S10).
To illustrate the importance of a proper selection of the initial temperature, we fixed it for model M1 to different values (Fig. 3D), employing only the exponential decay scheme with a fixed number of iterations. Too small values of the initial temperature led to many simulations being necessary in the initial iteration, sometimes even more than for the entire analysis using the self-tuned initial temperature. Too high values of the initial temperature yielded little information gain and resulted in a waste of computation time in the first iterations.
3.4 Approach allows to estimate noise parameters
In Theorem 1, we allowed the noise likelihood to be parameter-dependent for the stochastic acceptor. To test the validity of this, we used model M1 and estimated the standard deviation σ of the normal noise model along with the rate constant θ1 (Fig. 3E). Indeed, the posterior distributions of both parameters obtained using the proposed algorithm match the ground truth. In theory, also employing approach A2, i.e. a noisy model, should approximately allow to estimate noise parameters. However, even after simulations, compared to for the stochastic acceptor, the quality of the estimated posterior distribution for the noise parameter was considerably worse. Meanwhile, parameter θ1 was well estimated.
The sequential improvement of the posterior distribution over the ABC-SMC iterations for the same model (Fig. 3F) indicates that the temperature update scheme suggests steps with an appropriate information gain.
3.5 Applicable to various model types and noise models
To evaluate how our proposed ASSA sampler performs on different types of dynamical models and noise models , we studied models M1-4. Further, we compared ASSA to alternative approaches: Firstly, we used it with only one iteration, nt = 1, giving exact ABC-rejection. Secondly, we set the normalization constant to where it is ignored whether the model is able to simulate such values, as in the initial approach by Wilkinson (2013). In addition, we compared ASSA to the noisy model sampler A2 in a sequential form. We stopped runs when the acceptance rate fell below 1e-3, or exact inference with T = 1 was achieved.
For the deterministic models M1 and M2, we could confirm that the distributions inferred by ASSA closely matched the theoretical ones (Supplementary Fig. S9). Unfortunately, such an analysis is not that easily possible for the stochastic models M3 and M4. Yet, the posterior distributions obtained using ASSA for all four models are centered around the true parameters to a degree that seems reasonable given model and data (Fig. 4A). When other samplers of type A3 reached T = 1, the estimated posteriors were similar in shape. The posterior approximations obtained by the noisy model sampler A2 differed for three models from those obtained by ASSA, indicating that this approach is not able to yield reliable results within a reasonable computational budget.
Fig. 4.

Method comparison for models M1-4. (A) Posterior marginals obtained using the five different samplers. For runs that had to be stopped due to an acceptance rate below 1e-3, the last finished population is shown. True parameters are indicated by dotted lines. The colored check marks indicate the methods reaching T = 1, or for the noisy model an adequate approximation. (B) Total number of simulations over all iterations. For samplers that had to be stopped early, in addition the estimated values are shown hatched. (C) Effective sample sizes for the final posterior estimate obtained by each algorithm in its last iteration
3.6 Substantial speedup compared to established approaches
A commonly used measure for efficiency of a sampler is the total number of required model simulations. This is for dynamical models typically the time-critical part (see e.g. Jagiella et al., 2017). We found that for all models, ASSA required the least simulations (Fig. 4B). For model M4 the advantage was with a factor of two the smallest, which could be explained by the model itself being very stochastic, so that simulating the noisy data was not unlikely. The other models possessed more internal structure, i.e. a higher signal-to-noise ratio, such that model simulations close to the noisy data were rather unlikely. For models M2 and M3, ASSA with , as well as the version with nt = 1, was not even able to reach T = 1 in the computational budget, resulting in a higher posterior variance due to an overestimation of the noise variance (see Fig. 4A).
For our analysis, we provided all samplers with a computational budget which was by far sufficient for ASSA. Unfortunately, for some runs with , this budget was still insufficient. To compare the expected computational budget required for exact sampling, we made use of the roughly inverse proportional dependence of the acceptance rate on the normalization factor c (3). With s the number of simulations required by ASSA in the last iteration, we get the estimate for the required number of simulations for samplers using in the last iteration. The estimates indicate that the sequential samplers with would require 4 and 20 orders of magnitude more simulations than those with self-tuned c, on model M2 and M3, respectively (Fig. 4B). Even with massive parallelization, exact inference would thus not be possible without the proposed self-tuning scheme for c.
On all models M1-4, ASSA required about 22, 11, 6 and 2 times less simulations, respectively, than with nt = 1, indicating that the temperature selection scheme allows to efficiently bridge from prior to posterior.
To assess the influence of the number of data points, we performed the inference for models M1-3 for 10–1000 data points (Supplementary Section S8.3). The value of grew exponentially with the number of data points, while this was not the case for the highest c possible under the model, . Indeed, we found for models M1-3 that for ASSA the number of simulations increased only moderately. The ratio with c the value used by ASSA in the last iteration increased e.g. for model M1 from about 10 for 10 data points to more than 1e200 for 1000 data points. This indicates that ASSA scales well with the number of data points, while approaches with too large c quickly become computationally infeasible.
While the number of required model evaluations provides information about the complexity, it does not account for stability. This is assessed with the effective sample size (Martino et al., 2017), with wi denoting the importance weights. The ESS is a heuristic measure of how many independent samples a population of particles obtained via importance sampling effectively consists of, decreasing for more volatile weights. As we inflate the weights by (2) if the criterion exceeds 1, it is to be expected that ASSA has a lower ESS than the alternative stochastic acceptors, which indeed was the case on the test models (Fig. 4C). However, for all models the ESS was still reasonably high, indicating that the population is not degenerated. E.g. on model M3 an increase of the population size by 25% would presumably yield an ESS of more than 1000. Compared to the orders of magnitude differences between sample numbers, this renders ASSA highly efficient (Supplementary Fig. S13).
3.7 Scales to challenging estimation problems
To assess the performance of the proposed approach in practice, we considered the application problems M5 and M6. As the acceptance rates when updating c always to the highest so far observed value were too low, once acceptance rates fell below 0.1 we used a factor β of 20 and 10, respectively, as defined in Section 2.6.
For model M5, we used a population size of to guarantee stability of the results. The posterior marginals (Fig. 5) indicate that seven parameters can be accurately estimated, two parameters can be constrained, and two parameters are non-identifiable. The posterior distributions recover the reported literature values (Boehm et al., 2014), which had been obtained by optimization, and the parameter samples provide an accurate description of the experimental data (Supplementary Fig. S14). Importantly, in addition to kinetic parameters our approach was able to identify the standard deviations of the normal noise models on all three parameters. In contrast, the application of a sequential version of the noisy model approach A2 performed worse and was in particular unable to fit all noise parameters. The ESS for the stochastic acceptor was 1011 (using in total 8e6 simulations), for the noisy model only 83 (using in total 12e6 simulations).
Fig. 5.
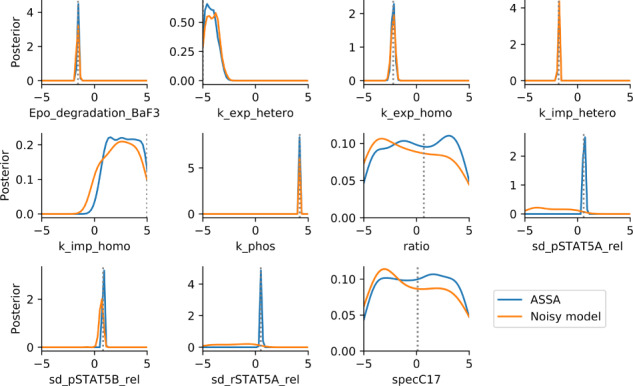
Posterior marginals for model M5, using ASSA and the noisy model sampler. The literature MAP values are indicated by dotted lines
For model M6, we used a population size of due to the high simulation time of the model. Again, the comparison of the posterior marginals with the noisy model, which was given a similar computational budget as required by the stochastic acceptor, reveals that the stochastic acceptor extracted overall more information (Supplementary Fig. S15), and the parameter samples describe the considered data accurately under the assumed noise model (Supplementary Fig. S16). Given the data, the parameters related to initial conditions cannot be inferred well, but for the others the reference values are accurately matched. The numbers of simulations were 4.0e5 and 3.2e5, with an ESS of 222 and 153, respectively for ASSA and the noisy model sampler.
4 Discussion
Modern ABC and ABC-SMC algorithms allow to perform parameter estimation for complex models. However, while easy to apply, these algorithms can lead to wrong results if measurement noise is not correctly accounted for. Here, we discussed ways of dealing with noise and presented an adaptive sequential importance sampling algorithm (ASSA), broadly applicable to various models and noise models. We demonstrated, using several test models, that the proposed algorithm is more accurate and up to orders of magnitude more efficient than existing approaches. We achieved this efficiency gain by learning a required normalization constant in a self-tuned manner, correcting for potential biases by reweighting, and by devising an adaptive tempering scheme which in particular allows to find a good starting temperature. Thence, we were able to perform exact likelihood-free inference on models on which this would have hitherto been impossible. Further, we implemented the algorithm in the freely available toolbox pyABC.
Our approach is self-adaptive to the problem structure by learning good values for several tuning parameters such as the initial temperature and the normalization constant. By learning proper values for these parameters on the fly, our approach is both stable and applicable to diverse problems, and gets rid of the need of manual tuning, which otherwise can be time-intensive. This is a key difference to related approaches (e.g. Daly et al., 2017), in which parameters are manually adapted to the individual problems. Furthermore, the proposed approaches allow to estimate noise levels, facilitating integrated analysis workflows (Hross et al., 2018).
Given that ABC has in the past been frequently applied without a proper noise formulation, the question may be raised whether this may have led to wrong parameter estimates. Unfortunately, this is difficult to answer. However, as we have been able to apply exact likelihood-free inference even to computationally demanding problems, we expect the algorithm to be broadly applicable in the future, thus improving the reliability of parameter estimates for a broad spectrum of applications.
One possible path of future research is to investigate improved tempering schemes. The overall required number of simulations depends both on the number of intermediate populations, and the acceptance rates between steps. The exponential decay scheme we used was rather loosely motivated by analogies to parallel tempering MCMC. There exist approaches to dynamically adjust the temperature steps (Predescu et al., 2004; Vousden et al., 2016), however these are specific to parallel tempering MCMC. For likelihood-based SMC, there exist approaches that try to keep the effective sample size constant (Latz et al., 2018), however it remains to be investigated whether these are applicable in a likelihood-free context. Another interesting use of tempering is for thermodynamic integration, allowing to compute Bayes factors. Thus, the presented algorithm could potentially be extended to allow to perform model selection, as an alternative to e.g. Toni and Stumpf (2010). Furthermore, a comparison with alternative tools and methods would be relevant, e.g. approaches requiring the full likelihood [as e.g. implemented in Stan (Carpenter et al., 2017) and BCM (Thijssen et al., 2016)], or e.g. ABC methods exploiting Gaussian processes (Tankhilevich et al., 2020). In general, alternative methods may be limited in their applicability, e.g. requiring the full likelihood, or may introduce an approximation error.
In conclusion, our results demonstrate the importance and the benefits of using proper noise models. The proposed algorithms can exploit the structure of the noise model to perform exact inference for computationally demanding models. As the implementation in pyABC facilitates massive parallelization, this approach is also applicable to computationally demanding problems.
Author contributions
Both authors derived the theoretical foundation and devised the algorithms. Y.S. wrote the implementation and performed the case study. Both authors discussed the results and conclusions and jointly wrote and approved the final manuscript.
Funding
This work was supported by the German Research Foundation [HA7376/1-1 to Y.S.], and the German Federal Ministry of Education and Research [FitMultiCell; 031L0159A to J.H.].
Conflict of Interest: none declared.
Supplementary Material
References
- Andrieu C. et al. (2010) Particle Markov chain Monte Carlo methods. J. R. Stat. Soc. B, 72, 269–342. [Google Scholar]
- Banga J.R. (2008) Optimization in computational systems biology. BMC Syst. Biol., 2, 47. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Beaumont M.A. et al. (2004) Approximate Bayesian Computation in population genetics. Genetics, 167, 977–2035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Beaumont M.A. et al. (2009) Adaptive approximate Bayesian computation. Biometrika, 96, 983–990. [Google Scholar]
- Boehm M.E. et al. (2014) Identification of isoform-specific dynamics in phosphorylation-dependent stat5 dimerization by quantitative mass spectrometry and mathematical modeling. J. Prot. Res., 13, 5685–5694. [DOI] [PubMed] [Google Scholar]
- Carpenter B. et al. (2017) Stan: a probabilistic programming language. J. Stat. Softw., 76, 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Coxe S. et al. (2009) The analysis of count data: a gentle introduction to Poisson regression and its alternatives. J. Pers. Assess., 91, 121–136. [DOI] [PubMed] [Google Scholar]
- Daly A.C. et al. (2017) Comparing two sequential Monte Carlo samplers for exact and approximate Bayesian inference on biological models. J. R. Soc. Interface, 14, 20170340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Del Moral P. et al. (2006) Sequential Monte Carlo samplers. J. R. Stat. Soc. B, 68, 411–436. [Google Scholar]
- Del Moral P. et al. (2012) An adaptive sequential Monte Carlo method for approximate Bayesian computation. Stat. Comput., 22, 1009–1020. [Google Scholar]
- Drovandi C.C. (2018) ABC and indirect inference In: Sisson,S.A. et al. (eds), Handbook of Approximate Bayesian Computation London/UK: Chapman and Hall/ CRC, pp. 179-209. [Google Scholar]
- Earl D.J., Deem M.W. (2005) Parallel tempering: theory, applications, and new perspectives. Phys. Chem. Chem. Phys., 7, 3910–3916. [DOI] [PubMed] [Google Scholar]
- Eriksson O. et al. (2019) Uncertainty quantification, propagation and characterization by Bayesian analysis combined with global sensitivity analysis applied to dynamical intracellular pathway models. Bioinformatics, 35, 284–292. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fearnhead P., Prangle D. (2012) Constructing summary statistics for approximate Bayesian computation: semi-automatic approximate Bayesian computation. J. R. Stat. Soc. B, 74, 419–474. [Google Scholar]
- Frazier D.T. et al. (2020) Model misspecification in approximate Bayesian computation: consequences and diagnostics. J. R. Stat. Soc. B, 82, 421–444. [Google Scholar]
- Gillespie D.T. (1977) Exact stochastic simulation of coupled chemical reactions. J. Phys. Chem., 81, 2340–2361. [Google Scholar]
- Goldwyn J.H. et al. (2011) Stochastic differential equation models for ion channel noise in Hodgkin–Huxley neurons. Phys. Rev. E, 83, 041908. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gourieroux C. et al. (1993) Indirect inference. J. Appl. Econ., 8, S85–S118. [Google Scholar]
- Hines K.E. (2015) A primer on Bayesian inference for biophysical systems. Biophys. J., 108, 2103–2113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hross S. et al. (2018) Mechanistic description of spatial processes using integrative modelling of noise-corrupted imaging data. J. R. Soc. Interface, 15, 20180600. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Imle A. et al. (2019) Experimental and computational analyses reveal that environmental restrictions shape HIV-1 spread in 3D cultures. Nat. Commun., 10, 2144. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jagiella N. et al. (2017) Parallelization and high-performance computing enables automated statistical inference of multi-scale models. Cell Syst., 4, 194–206. [DOI] [PubMed] [Google Scholar]
- Klinger E., Hasenauer J. (2017) A scheme for adaptive selection of population sizes in Approximate Bayesian computation – sequential Monte Carlo In: Feret J., Koeppl H. (eds.) Computational Methods in Systems Biology. CMSB 2017, volume 10545 of Lecture Notes in Computer Science. Springer, Cham. [Google Scholar]
- Klinger E. et al. (2018) pyABC: distributed, likelihood-free inference. Bioinformatics, 34, 3591–3593. [DOI] [PubMed] [Google Scholar]
- Latz J. et al. (2018) Multilevel sequential2 Monte Carlo for Bayesian inverse problems. J. Comp. Phys., 368, 154–178. [Google Scholar]
- Lenive O. et al. (2016) Inferring extrinsic noise from single-cell gene expression data using approximate Bayesian computation. BMC Syst. Biol., 10, 81. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu J.S. et al. (1998) Rejection control and sequential importance sampling. J. Am. Stat. Assoc., 93, 1022–1031. [Google Scholar]
- Maier C. et al. (2017) Robust parameter estimation for dynamical systems from outlier-corrupted data. Bioinformatics, 33, 718–725. [DOI] [PubMed] [Google Scholar]
- Martino L. et al. (2017) Effective sample size for importance sampling based on discrepancy measures. Signal Process., 131, 386–401. [Google Scholar]
- Picchini U. (2014) Inference for SDE models via approximate Bayesian computation. J. Comp. Graph. Stat., 23, 1080–1100. [Google Scholar]
- Prangle D. (2017) Adapting the ABC distance function. Bayesian Anal., 12, 289–309. [Google Scholar]
- Predescu C. et al. (2004) The incomplete beta function law for parallel tempering sampling of classical canonical systems. J. Chem. Phys., 120, 4119–4128. [DOI] [PubMed] [Google Scholar]
- Price L.F. et al. (2018) Bayesian synthetic likelihood. J. Comp. Graph. Stat., 27, 1–11. [Google Scholar]
- Raue A. et al. (2009) Structural and practical identifiability analysis of partially observed dynamical models by exploiting the profile likelihood. Bioinformatics, 25, 1923–1929. [DOI] [PubMed] [Google Scholar]
- Raue A. et al. (2013) Lessons learned from quantitative dynamical modeling in systems biology. PLoS One, 8, e74335. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sisson S.A., Fan Y. (2018) ABC samplers In: Sisson, S.A. et al. (eds) Handbook of Approximate Bayesian Computation London/UK: Chapman and Hall/CRC, pp. 87–123. [Google Scholar]
- Sisson S.A. et al. (2007) Sequential Monte Carlo without likelihoods. Proc. Natl. Acad. Sci. USA, 104, 1760–1765. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sisson S.A. et al. (2018. a) Handbook of Approximate Bayesian Computation. Chapman and Hall/CRC, London, UK . [Google Scholar]
- Sisson S.A. et al. (2018. b) Overview of ABC In: Sisson,S.A. et al (Eds.), Handbook of Approximate Bayesian Computation. Chapman and Hall/CRC, London, UK, pp. ; 3–54. [Google Scholar]
- Sugita Y. et al. (2000) Multidimensional replica-exchange method for free-energy calculations. J. Chem. Phys., 113, 6042–6051. [Google Scholar]
- Tankhilevich E. et al. (2020) GpABC: a Julia package for approximate Bayesian computation with Gaussian process emulation. Bioinformatics, 36, 3286–3287. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thijssen B. et al. (2016) BCM: toolkit for Bayesian analysis of computational models using samplers. BMC Syst. Biol., 10, 100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Toni T., Stumpf M.P.H. (2010) Simulation-based model selection for dynamical systems in systems and population biology. Bioinformatics, 26, 104–110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Toni T. et al. (2009) Approximate Bayesian computation scheme for parameter inference and model selection in dynamical systems. J. R. Soc. Interface, 6, 187–202. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van der Vaart E. et al. (2018) Taking error into account when fitting models using Approximate Bayesian Computation. Ecol. Appl., 28, 267–274. [DOI] [PubMed] [Google Scholar]
- Vousden W. et al. (2016) Dynamic temperature selection for parallel tempering in Markov chain Monte Carlo simulations. Mon. Not. R. Astron. Soc., 455, 1919–1937. [Google Scholar]
- Wilkinson R.D. (2013) Approximate Bayesian computation (ABC) gives exact results under the assumption of model error. Stat. Appl. Gen. Mol. Biol., 12, 129–141. [DOI] [PubMed] [Google Scholar]
- Wood S.N. (2010) Statistical inference for noisy nonlinear ecological dynamic systems. Nature, 466, 1102–1104. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.