

Abstract
The ongoing COVID‐19 crisis has put the relationship between spatial structure and disease exposure into relief. Here, we propose that mega regions – clusters of metropolitan regions like the Acela Corridor in the United States are more exposed to diseases earlier in pandemics. We review standard accounts for the benefits and costs of locating in such regions before arguing that pandemic risk is higher there on average. We test this mega region exposure theory with a study of the US urban system. Our results indicate that American mega regions have born the early brunt of the disease, and that three mega regions are hotspots. From this standpoint, the extent more than the intensity of New York's urbanization may be implicated in its COVID‐19 experience. We conclude that early pandemic risk is a hitherto unrecognised diseconomy operating in mega regions.
Keywords: COVID‐19, coronavirus, agglomeration, clustering, satellite data, regional economic growth
This paper proposes that large ‘mega‐region’ formations like the Acela Corridor in the US are more vulnerable to pandemics early in their onset. Our analysis of COVID‐19 fatalities in the US supports this. COVID‐19 did not start in mega‐regions, but mega have borne an outsize share of fatalities.

Introduction
COVID‐19 has already killed 260,000 people, infected more than three million (JHU 2020) and disrupted almost every facet of global interaction and exchange. In this context, human geography needs to become a crisis discipline. The ongoing crises demand our interest because we are not insulated from their human and economic toll. They demand our professional attention because they play out differently across geographies, and they have a logic that is familiar to the geographers – they are inescapably spatial.
That the pandemic is global in reach, should not distract from the ways in which it is experienced differently in different places. Most obviously there are hotspots like Wuhan, Lombardy or New York. There are places with more ICU beds than cases, and places where they must be set up in hallways; places that have the infrastructure or economies to shelter in place, and places that do not. If human geographers can contribute to some planetary understanding of the pandemic, then it will be because we are already comfortable with the idea that geography matters in social relations.
Similarly, the profile of this pandemic: its origin, its spread, its politics should not catch human geographers by surprise. There is no shortage of instructive work on past episodes such as H1N1, AIDS, H591 and SARS (Gould 1993; Smallman‐Raynor & Cliff 2008; Ali & Keil 2006; Davis 2006; McLafferty 2010). These events are so closely tied to the human/environment interaction that the field broadly is well‐equipped to investigate COVID‐19's nature and interpret its significance.
This paper brings a human‐geographic approach to the study of COVID‐19's spatial diffusion. We show that we can use an established geographic concept, the mega region, to understand the geography of COVID‐19's spread and its economic toll. We propose that mega regions – clusters of metropolitan regions like the Acela Corridor in the United States– are more exposed to diseases earlier in pandemics. The virus which started in the seafood markets of Wuhan, China (Sheridan 2020), ended up in almost every major region. However, the transmission of the virus along this path seems to have been accelerated by mega regions themselves and the social and trading relationships that define them.
Our primary goal is to determine if mega regions were implicated in the importation and spread of COVID‐19. We ask two basic questions about its spread in the period between early February and early April: first, were mega regions as a class more exposed to COVID‐19? Second, are some mega regions more exposed than others? To get that this, we map the diffusion of disease mortality, at the mega region level, using publicly available data disease data aggregated to the megaregion level. The remainder of the paper is organised as follows. The following section defines mega regions and describes our approach to mapping them. The third section reviews standard explanations for why mega regions would be relatively more or less attractive from the standpoint of human settlement and exchange. The fourth proposes that pandemic risk is an underemphasised diseconomy of megaregions. The fifth section tests this intuition through a short study of how COVID‐19 spread across the US City System. We conclude with thoughts on how policy‐makers can approach pandemics more mega regionally and on how the geography community that conduct mega region studies.
Mega Region Economies and Diseconomies
It is common to describe cities in terms of urban economies and diseconomies – characteristics that make cities more productive or attractive. We argue that the early onset of viral pandemics represents a serious urban diseconomy at the mega region scale. The intensity of social interaction at this spatial scale is most often a source of competitive advantage but can also create the infrastructure for rapid disease transmission. This is true of modern diseases as well as historic cases (Boustan et al. 2013). The long‐term stability of mega regions will depend on their ability to overcome this vulnerability.
Mega regions are of metropolitan areas, that form contiguous agglomerations. They have been discussed in geography since Patrick Geddes coined the term ‘megalopolis’ in 1915. Lewis Mumford (1938) wrote about it in the late 1930s. Jean Gottman (1957) famously defined the term mega region, identifying extended agglomerations of the Bos‐Wash and Chi‐Pitts mega region.
There are at least two dimensions to pandemic vulnerability: earliness of exposure and public health resources. Even if the local health infrastructure is sophisticated, that is if officials are good at detecting a disease and marshalling resources to it, then the areas that are first exposed will still see relatively higher impacts, because early treatment must be conducted under higher uncertainty about what measures will work.
Mega regions are most vulnerable in terms of when they face pandemic events. Pandemics are no more likely to start in mega regions than anywhere else, but they are more likely to be infected earlier, before the disease is properly understood. This was true in 1918, when New York had one of the most complete public responses to H1N1, but also had one of the earliest and highest mortality peaks. Cities like Denver were allowed to be slower with their response because they were not on the frontlines of exposure (Markel et al. 2007). Mega regions can channel their wealth and economies of scale into public health systems, ensuring that they are more productive with these resources on a per dollar basis. However, because pandemics will always tend to be spawned by novel diseases, there will always be a degree of catching up.
In this section, we see that the formation of mega regions is advantageous from an economic standpoint, but for the same reason may open these areas up to earlier exposure to viral pandemics like COVID‐19.
The metro commuting area designates an area over which land and labour costs are somewhat constant, that is the area over which the ‘The Law of One Price’ is supposed to operate (Samuelson 1952; Storper et al. 2015). We can speak of higher housing price level in New York than in Philadelphia, or of different labour costs in Amsterdam versus Brussels. Mega regions, then, are areas with different factor prices but especially high degrees of inter‐regional trade.
It is widely accepted that cities that are closer together will trade more with each other due to lower transactions costs. This is one of the implications of the canonical geographical economics models (Harris 1954; Brakman et al. 2001), and a fact that has been extensively verified (Hanson 2005; Head & Mayer 2006). In the presence of positive trade costs, there will be incentives to agglomerate and as these costs increase to some viability threshold 1 the logic of agglomeration becomes more compelling. The desire to minimise costs can explain why there are mega regions in much the same way that it explains the existence of metro areas to begin with (Krugman 1991; Ottaviano & Thisse 2001). Such advantages can lead to a spatial wage structure, where relatively dense regions pay higher real wages, and an uneven long‐term development pattern.
In addition to trade cost reductions, mega regions should realise so‐called technological externalities, advantages that make workers and firms more productive per unit of input. An obvious source of such externalities for mega regions in particular would be transportation infrastructure. The ‘Bos‐Wash’ and ‘Par‐Am‐Mun’ regions are good examples. Both feature rapid train networks that are faster and more regular than train networks outside of the region. This is most striking in the American case where the Acela train network is currently the country's only high speed train link.
A growing number of studies suggests that such rail links contribute increased agglomeration and trade (Duranton and Turner 2012; Faber 2014). Ahlfeldt and Feddersen (2018) exploit the introduction of a new link between Cologne and Frankfurt to study causal effects, finding that the project increased GDP by an average of 8.5 per cent in nearby communities. In these accounts, agglomeration effects tend to be concentrated within extant urban agglomerations more than they are distributed to previously rural or suburban parts of the rail network. The already urban regions gets more so. In the German study, a large degree of the estimated effect is linked to differential sorting of capital and labour, after the introduction of the infrastructure rather than a direct causal effect.
Educational infrastructure also seems to be organised at something closer to the mega region than the metro level. In the United States, almost 69 per cent of first year students attend university within 100 miles of where they went to secondary school (Wozniak 2018). Of course, not all of these universities are in mega regions but the regional catchment area for post‐secondary education appears to be bigger than the commuting shed.
There may also be human capital benefits for megaregions that are not available outside of them. Educational infrastructure is highly concentrated in the 27 mega regions. Only two of the top 30 universities in The World University Rankings (Times Higher Education 2020) are found outside of mega regions: Cornell and The University of Edinburgh. This is consistent with findings in Florida et al. (2008) that 85 per cent of patents and 88 per cent of author citations accrue to researchers in mega regions, compared to only 18 per cent of the population.
The observation that mega regions are more productive should lead us to wonder why there are not more of them, or perhaps why everyone does not cluster in the same one. Examples of agglomeration diseconomies are easy to find. The most basic of these is the spatial wage structure. Mega regions may have higher real wages (wages adjusted for the local price index) but they also have higher nominal costs. Activities that are most sensitive to the price of labour and land, like manufacturing activities, are channelled away from megaregions. Similarly, workers on budgets who seek standard suburban amenities will tend to migrate away from expensive megaregions (Glaeser 2007). There tends to be a specialisation between mega regions and other areas whereby the former group performs high trade cost work that benefits the most from agglomeration and the latter performs low trade cost work that is most sensitive to high prices.
There are pure or ‘technological’ diseconomies which discourage everyone from cramming into conurbations. A textbook example of this would be traffic congestion. Roads and transit systems are slower and less comfortable in mega regions. Pollution has historically been another one. The great industrial urban regions such as the British Midlands and the Upper Midwest were also quite polluted. In modern times the highest productivity activities (IT, finance, biotech) are low polluting, so any excess pollution in megaregions tends to come from the transport of people and not the production system, which is oriented to these greener activities. However, at a sufficiently high scale, vehicle exhaust emissions can be deleterious (Zhang & Betterman, 2013).
Our focus here is on the relationship between mega regions and pandemic events, which we distinguish from epidemics, endemic diseases and outbreaks. Per WHO guidelines (National Center for Biotechnology 2009), a pandemic describes a disease event that has spread to multiple countries, is continuing to spread, and has achieved community‐level transmission – meaning that it can spread under its own momentum without being imported. An epidemic is a milder event where community‐level transmission is localised to one country or region. Endemic diseases, like measles and chicken pox, are those that are always circulating in a community but are not spreading either in a community or between communities. Prior pandemics include 2009's H1N1 1968's H3N2 1957's H2N2, and 1918's H1N1, known as ‘The Spanish Flu’. Pandemics do not need to be very deadly to be so classified – viruses such as Ebola and AIDS have been deadlier. They are distinguished by their transmissibility. We are most interested in the exposure of mega regions to community‐level transmission early in an epidemic.
The diseases at the centre of each pandemic will have different profiles, owing to the different structures of the virus or bacteria that causes them. COVID‐19 is a disease caused by an underlying virus called SARS‐CoV‐2, which belongs to a family of structures called coronaviruses which attack the respiratory system. Seven such viruses have been discovered to date, including the 2003 SARS outbreaks and the more recent MERS, but only SARS‐CoV‐2 has been implicated in a pandemic, owing to its transmissibility. Our interest, again, is on transmissibility of a virus once it has emerged and not on its initial emergence. The likes of Connolly et al. (2020) and Davis (2006) have speculated that diseases propagate at the urban edge, where animal/human encounters are more common. We are seeking to better understand transmission patterns after the animal‐human boundary has been jumped, that is the post‐zoonosis geography.
Epidemiologists express transmissibility through a metric called R0 which corresponds with the average number of secondary infections that an infected person is expected to cause in a susceptible population (Hethcote 2009). When this number exceeds 1 then disease incidence is expected to increase in a population. A meta study of COVID‐19 finds that its average R0 is 3.79, significantly higher than the number for MERS and ‘SARS 1’ (Liu et al. 2020). This is most likely because people infected with COVID‐19 are most contagious at the onset of their symptoms, while in the other two cases, transmission was highest once symptoms had emerged and patients were admitted to hospitals (Cheng et al. 2020; Wu & McGoogan 2020).
As geographers, our focus is not on any particular kind of viral category but on the relationship between pandemics and spatial structure. For our purposes, it does not really matter that H1N1 is an influenza and SARS‐CoV‐2 is a coronavirus because in each case there is a pandemic with localised incidence, impact and response. On this score, it is useful to consider how epidemiologists approach disease transmissions generally. The most common approach is SER/SEIR (susceptible/exposed/infected/recovered) models which make assumptions about who has, who might get and who has become immune to a disease and then model its spread based in an area based on the number of people in each category. The frontier of epidemiology continues to move forward as scientists develop more sophisticated understandings of who is in each group or how to measure them. There are also simulation models which concoct artificial communities and measure circulation there. The approaches are complementary (Kaiser 2020; Yang et al. 2020).
There are textbook‐level understandings of how diseases spread that directly bear on the current question. Most relevant is the understanding that close human‐to‐human contact is a primary disease vector. Pandemics tend to be seeded across the world via air travel networks (Pastore y Pionitti et al. 2019). In fact, more regular air travel can explain why even older diseases can spread faster and more widely under modern conditions (Grais et al. 2003). This seems to be true of COVID‐19 which is transmitted through saliva droplets and spread rapidly in the first part of 2020 through air networks and was temporarily slowed in places that imposed air restrictions (Chinazzi et al. 2020; Sohrabi et al. 2020).
SARS‐CoV‐2, then, would seem to be comparable to the first SARS (‘Severe Acute Respiratory Syndrome’) outbreak of 2002, which spread rapidly across air transport networks (Shannon & Willoughby 2004; Bowen & LaRoe 2006) and via the global city network (Ali & Keil 2006). Based on this chronicling of the human geography of SARS 1, it is the globalised nature of modern interaction that seeds such events and explains why they seem to be occurring more regularly. If diseases themselves are like forest fires – somewhat unpredictable in where they start – then global transportation networks are like the wind– reliably spreading the fire to more places.
What has been less emphasised in the geographic literature to date is the role of daily interaction patterns in fanning the flames of pandemics. The local pattern is implicated in disease transmission because it involves frequent contact between the exposed and the susceptible. Even with a virus as transmissible as SARS‐CoV‐2, not every interaction will transmit the disease. The probability of transmission increases considerably, with the frequency of exposure. As Pastore y Pionitti et al. (2019, p. 18) put it:
The cyclical nature of our commuting patterns tightly couples neighboring cities within a few hours. In this way, infections that first arrive in a city through airline connections are quickly diffused and spread locally. Such coupling is so evident that, by simply plotting the commuting patterns between neighboring cities, one is able to quickly identify the major metropolitan areas, even in the absence of any other information, as these naturally generate stronger flows.
Current research suggest that train networks have indeed channelled COVID‐19 at the community level. Zhao et al. (2020) find that the spread of COVID‐19 in China was significantly predicted by the train network but not the car or flight network. A Hong Kong study found that the disease was twice as likely to have been brought in by high speed train then by car or bus (Cheng et al. 2020b).
The mega region is relatively more exposed to each of these disease pathways. A disproportionate amount of air traffic in the world is concentrated in mega regions. Seventeen of the 20 busiest airports in the world are found in megaregions (Airports International Council 2019). Only Dallas, Jakarta and Denver have Top 20 airports outside of our mega regions. On the other hand, these areas feature extended trading areas, where high densities firms, workers and students are clustering for the express reason of being able to ‘share, match, and learn’ (Duranton & Puga 2004) with each other. In the language of prominent economic geographers, the mega region is where the physical infrastructure that maintains ‘global pipelines’ is found but also where there is, by virtue of density and industrial structure, there is a high degree of ‘local buzz’ (Bathelt et al. 2004). For these very reasons, the mega region is more susceptible to pandemic events. Our analysis emphasises this localised process.
Guided by this intuition about mega regions and pandemics, we study the early transmission of COVID‐19 in US Mega regions between January and April of 2020. Our primary goal is to determine if mega regions were implicated in the importation and spread of COVID‐19. We ask two basic questions about its spread in the period between early February and Early April:
Were mega regions as a class more exposed to COVID‐19?
Were some mega regions more exposed than others?
Defining and Identifying Mega Regions
Mega regions are clusters of metropolitan areas‐ contiguous urban areas that extend well beyond the daily commuting range. The mega region convenes industries, organisations, and infrastructures. Amsterdam and The Hague are in the same metropolitan region because there is a high degree of regular daily travel between the locations. Amsterdam and Brussels are in the same mega‐region because there is regular interaction: transportation, learning, trading among them.
The commuting area is a useful unit of economic geography because it attempts to capture the organic extent of an area's economy. For the purposes of economic and social analysis, it is usually superior to jurisdictional boundaries like cities or states. However, even when it is drawn with great care, the metro area does not entirely represent the scale of the regional economy. There are other scales at which organic human and economic activity is contained. The smaller area over which the retailer geography studies. We propose that an analysis of how regions are affected by pandemics should consider the mega region: the scale at which commuting areas themselves cluster.
Some metros are urban islands while others are joined to extended urban formations. These clusters of cities are mega regions (Florida et al. 2008; Innes et al. 2010; Marull et al. 2013; Mellander et al. 2015). The ‘Acela Corridor’ which connects the area that runs from Greater Boston to Great New York and south to Greater Washington DC is the most famous American instance of this, but there are 28 such extended agglomerations in the world according to our estimates, and 12 such US regions. The Dutch Randstad region (Amsterdam, Rotterdam, The Hague and Utrecht) is itself part an even larger region (‘Par‐Am‐Mun’) that connects these cities to Paris, Brussels and Munich.
Researchers have used economic and demographic data to more precisely define mega regional clusters. A 2005 study (Lang & Dhavale 2005) identified 10 US mega regions based on their commuting patterns. While such data enable the identification of mega regions in a specific country or economic regions, comparing these data across national contexts has made it virtually impossible to systematically identify and define mega regions globally.
An alternative approach is to use to nighttime satellite data. Here, brightly lit areas that stretch across multiple labour markets are interpreted as megaregions. The advantages of this approach are two‐fold: it defines urbanity through a globally consistent rule, and it uses standardised global data. If there is a consistent relationship between nighttime light levels and economic activity, then this approach should capture it. Using this methodology, Florida and colleagues (2008) identified 40 such contiguous urban areas across the world. A follow‐up study (Mellander et al. 2015) compared these nighttime images to data on settlement and economic activity to determine how predictive satellite images were of actual human activity. That found that luminosity mostly varied with population, especially, population density and was only moderately associated with population level and the density or level of economic activity, confirming that satellite technology can be used to map the extent of human agglomeration. The study also suggested that light tended to be overestimated in the largest cities, and underestimated in rural areas, a finding that points to a more troubling type of measurement areas. The relative under‐detection of rural light may, at its extreme, lead to an overestimation of the extent of relatively urban mega such as the Boston‐Washington corridor.
Advances in technology have brought about much better satellite imagery that can be used to more precisely define urban agglomerations. In 2015, the National Oceanic and Atmospheric Administration began to release data using superior satellite equipment and under a new standard, the Visible Infrared Imaging Radiometer Suite (VIIRS). The new technology is superior to the older, Defense Meteorological Satellite Program (DMSP) standard due to its greater image resolution, its ability to distinguish ‘normal’ nighttime lights from gas flares and fires, and its superior dynamic range (Elvidge et al. 2013), among other things. Although this new data is still being understood, it appears to be a significant improvement (Proville et al. 2017). Crucially, VIIRS data appears to reduce large city bias. Shi et al. (2014) indicate that the error rate is 23 per cent lower for large cities and 27 per cent lower for urban areas.
Adler et al. (2020) use ‘Day/Night Band’ VIIRS images to re‐survey global mega regions, allowing for mega regions to be identified with more precision than in prior mega region studies (Florida et al. 2008; Innes et al. 2010; Marull et al. 2013; Yang et al. 2011). An algorithm is used to detect the level of brightness and proximity of urban regions. Areas where multiple metropolitan areas are joined by bright lights are identified as megaregions. They rely on government metropolitan data assembled by the Brookings Institute (2020) for metropolitan area definitions. Dias (2019) describes the methodology in detail and provides reproducible code. That set of estimates is the basis for the current analysis.
Table 1 lists this new set of global mega regions. Under these boundaries, The Randstad forms the northern part of a mega region that includes nearly all the Netherlands, Belgium and Luxembourg, as well as the larger Rhine‐Ruhr metro area and Frankfurt. For its part, New York is part of a region that extends from Boston, through Philadelphia and past Washington DC.
Table 1.
The 28 global mega‐regions including forming metros, population (millions) and GDP (US$ billions)
| Region | Major cities | Population | Economic output |
|---|---|---|---|
| Bos‐Wash | New York; Washington, D.C.; Boston | 47.6 | 3650 |
| Par‐Am‐Mun | Paris, Amsterdam, Brussels, Munich | 43.5 | 2505 |
| Chi‐Pitts | Chicago, Detroit, Cleveland, Pittsburgh | 32.9 | 2130 |
| Greater Tokyo | Tokyo | 39.1 | 1800 |
| SoCal | Los Angeles, San Diego | 22.0 | 1424 |
| Seoul‐San | Seoul, Busan | 35.5 | 1325 |
| Beijing | Beijing, Tianjin | 37.4 | 1226 |
| Lon‐Leed‐Chester | London, Leeds, Manchester | 22.6 | 1177 |
| Hong‐Shen | Hong Kong, Shenzhen | 19.5 | 1043 |
| NorCal | San Francisco, San Jose | 10.8 | 925 |
| Shanghai | Shanghai, Hangzhou | 24.2 | 892 |
| Taipei | Taipei | 16.7 | 827 |
| Sao Paolo | Sao Paolo | 33.5 | 780 |
| Char‐Lanta | Charlotte, Atlanta | 10.5 | 656 |
| Ista‐Burs | Istanbul, Bursa | 14.8 | 626 |
| Vienna‐Budapest | Vienna, Budapest | 12.8 | 555 |
| Mexico City | Mexico City | 24.5 | 524 |
| Rome‐Mil‐Tur | Rome, Milan, Turin | 13.8 | 513 |
| Singa‐Lumpur | Singapore, Kuala Lumpur | 12.7 | 493 |
| Cairo‐Aviv | Cairo, Tel Aviv | 19.8 | 472 |
| So‐Flo | Miami, Tampa | 9.1 | 470 |
| Abu‐Dubai | Abu Dhabi, Dubai | 5.0 | 431 |
| Osaka‐Nagoya | Osaka, Nagoya | 9.1 | 424 |
| Tor‐Buff‐Chester | Toronto, Buffalo, Rochester | 8.5 | 424 |
| Delhi‐Lahore | New Delhi, Lahore | 27.9 | 417 |
| Barcelona‐Lyon | Barcelona, Lyon | 7.0 | 323 |
| Shandong | Jinan, Zibo, Dongying | 14.2 | 249 |
| Fresno‐Field | Fresno, Bakersfield | 2.3 | 108 |
This article is being made freely available through PubMed Central as part of the COVID-19 public health emergency response. It can be used for unrestricted research re-use and analysis in any form or by any means with acknowledgement of the original source, for the duration of the public health emergency.
All major cities form the center of major metro areas but not all major metro areas are centred on mega regions. Fifteen of the largest 27 areas in the world (Brookings 2020) are part of mega regions (See Table 2). Large regions in more developed countries are generally more likely to be part of mega regions. The largest metros that are not part of larger mega regions are Jakarta, Chongqing, Mumbai, Delhi and Dhaka – each from a middle or low‐income country. The very large metros in developed countries (e.g. Tokyo, Seoul, New York, London) are all themselves part of mega regions. China has three mega regions (Beijing, Shanghai, Hong‐Shen and Shandong) and several other major metros that are not so identified, including Chongqing and Chengdu.
Table 2.
The largest 28 metros in the World Metro Data from Oxford Economics via Brookings (2018)
| Metro | Country | Mega‐region | Population | GDP |
|---|---|---|---|---|
| Tokyo | Japan | Greater Tokyo | 37,738 | $1,739,789 |
| Jakarta | Indonesia | None | 32,111 | $726,205 |
| Chongqing | China | None | 30,656 | $500,690 |
| Seoul | South Korea | Seoul‐Busan | 25,288 | $954,774 |
| Shanghai | China | Shanghai | 24,592 | $891,765 |
| Beijing | China | Beijing | 21,952 | $713,401 |
| Mexico City | Mexico | Mexico City | 21,468 | $490,623 |
| Sao Paulo | Brazil | Sao Paolo | 21,406 | $551,450 |
| New York | United States | Bos‐Wash | 20,227 | $1,663,263 |
| Mumbai | India | None | 20,209 | $340,317 |
| Delhi | India | None | 19,419 | $354,506 |
| Osaka | Japan | Osaka‐Nagoya | 18,711 | $737,027 |
| Dhaka | Bangladesh | None | 18,234 | $140,835 |
| Karachi | Pakistan | None | 16,484 | $114,823 |
| Bangkok | Thailand | None | 16,334 | $549,961 |
| Tianjin | China | Beijing | 16,042 | $512,442 |
| London | United Kingdom | Lon‐Leed‐Chester | 15,150 | $908,103 |
| Istanbul | Turkey | Ista‐Burs | 15,047 | $626,006 |
| Cairo | Egypt | Cairo | 14,814 | $347,609 |
| Kolkata | India | None | 14,758 | $108,897 |
| Chengdu | China | None | 14,664 | $337,901 |
| Buenos Aires | Argentina | None | 14,191 | $311,814 |
| Lagos | Nigeria | None | 14,078 | $163,734 |
| Guangzhou | China | Hong‐Shen | 13,807 | $569,766 |
| Manila | Philippines | None | 13,385 | $308,270 |
| Los Angeles | United States | So‐Cal | 13,377 | $1,009,090 |
| Paris | France | Par‐Am‐Mun | 12,650 | $844,687 |
| Moscow | Russia | None | 12,388 | $811,896 |
This article is being made freely available through PubMed Central as part of the COVID-19 public health emergency response. It can be used for unrestricted research re-use and analysis in any form or by any means with acknowledgement of the original source, for the duration of the public health emergency.
We investigate this question with the help of publicly available data from the COVID Tracking Project (www.covidtracking.com) which aggregates daily state agency data on COVID cases and deaths at the county level. This dataset is the only attempt that we know of to harmonise data from local authorities (i.e. the level at which US public health records are kept). However, as its compilers themselves note the degree of testing and coding decisions will tend to vary somewhat by state. That combined with the novel nature of the underlying virus should suggest that this data is not as reliable as regular government estimates. Data for our study was accessed on 2 May 2020 and should not be considered fully current through that date due to lags in reporting in some states.
In the US, counties are administrative units that are aggregated into metropolitan areas by the federal government, they can be used to aggregate up to metro and mega units. We treat counties in the following 11 mega region areas as the experimental unit of our analysis:
‘Bos‐Wash’ is centred on the Acela‐serving portion of America's mid‐Atlantic region, extending north to Portland Maine and South to Richmond Virginia and as far inland as Harrisburg Pennsylvania.
‘So‐Cal’ radiates west from the city if Los Angeles to the Pacific Ocean, east across the Inland Empire to Riverside and south through Orange County to San Diego and Tijuana. Only the American portion of this region is covered in the empirical estimates.
‘Char‐Lanta’ connects Atlanta and Charlotte, extending west to Knoxville Tennessee and southeast to Charleston South Carolina. It includes the major North Carolina research centres of Raleigh, Durham, and Chapel Hill.
‘Det‐ Pitts’ sits on the eastern edge of the greater Industrial Midwest, bridging the traditional auto manufacturing centres of Detroit and Flint and the traditional steel centre of Pittsburgh. It also includes Cleveland and Columbus, Ohio
‘Nor‐Cal’ is the region surrounding the San Francisco Bay, including San Francisco, San Jose, Sacramento and Stockton.
‘Chi‐Waukee’ connects Chicago and Milwaukee and also includes metro portions surrounding Lake Winnebago (Appleton, Fond du Lac, Oshkosh) and Northern Indiana (Fort Wayne, Elkhart, South Bend).
‘Mid‐Flo’ contains Orlando, Tampa and Deltona, the major metropolitan areas north west of the Everglades. That national park creates a significant barrier between Miami/Palm Beach and this great urban expanse.
‘San‐Austin’ bridges the urban and exurban regions that surround San Antonio and Austin Texas along Interstate 35.
‘Louis‐Apolis’ runs north on Interstate 45 from Louisville to Indianapolis. It, interestingly enough, does not include nearby Cincinnati.
‘The Bayou’ extends east from New Orleans along the Gulf of Mexico into Gulfport, Mobile and Pensacola. We can be more confident that the light detected in this region originates with actual human activity and not oil‐refining processes.
‘Fresno‐Field’ stretches across California's Central Valley, including the farming regions of Fresno, Visalia and Bakersfield.
Figure 1 maps all mega regions in North America, including these.
Figure 1.
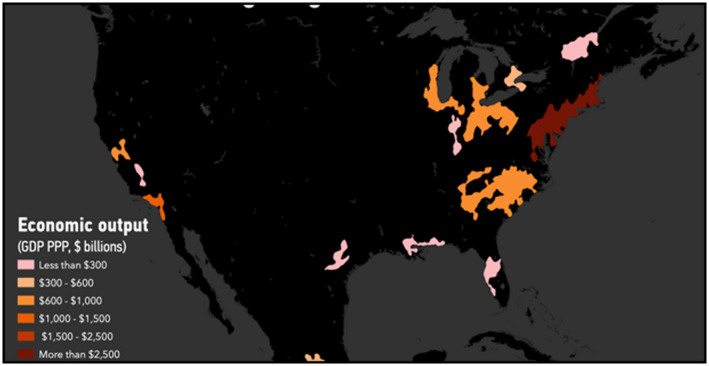
North America's mega regions [Colour figure can be viewed at wileyonlinelibrary.com]. Source: originally from City Lab (https://www.citylab.com/life/2019/02/global-megaregions-economic-powerhouse-megalopolis/583729/).
We compare the 388 counties found in these megaregions to 2,282 counties found outside. The latter category is subdivided into rural counties and metro counties (‘smallest’, ‘small’, ‘medium’, ‘large’, ‘largest’) at each metro size quartile. Of these the ‘largest' category, which includes metro areas like Dallas, Houston, Miami and Seattle is the most relevant benchmark for what is happening inside of mega regions.
When studying COVID‐19 transmission, it is important to choose the appropriate outcome measures Comparing prevalence and incidence of COVID‐19 cases (those who tested positive) is not a good measure of the subnational impact and spread of the virus due to the unevenness of inter‐ and intra‐state COVID‐19 testing. For example, as of 12 April the testing rate in Louisiana was five times higher than that of Texas.1 Instead the analysis will concentrate on a more concrete variable: deaths. Although deaths do not capture the full spread of the disease (as many people recover), the undercount will be less dramatic and can be minimised further using statistical controls.
Were mega regions as a class more exposed to COVID‐19?
COVID‐19 did not start in a megaregion but once it spread to megaregions, it grew faster. The first confirmed case of COVID‐19 in the United States on 21 January 2020 was a 35‐year‐old man in Snohomish County, Washington who had recently returned from Wuhan, China. Snohomish County is in the Seattle‐Tacoma‐Bellevue metro – not a megaregion, according to our definition however part of the ‘Cascadia’ mega region (Florida et al. 2008). The first confirmed COVID‐19 death on 29 February 2020 also occurred in the Seattle‐Tacoma‐Bellevue metro. The first death in a megaregion (Placer County, California in the Sacramento‐Arden‐Arcade‐Roseville metro) occurred four days later on 4 March 2020. From there, the death count continued to grow in both ‘largest’ and megaregions and by 14 March 2020 half of the day's deaths were in megaregions (5 of 10). From that day onward, the proportion of deaths in megaregions continued to grow until 13 April when they plateaued at approximately 82 per cent. The vast majority of the over 60,000 COVID‐19 deaths in the US so far have occurred in megaregions, despite megaregions only having 43 per cent of national population. Figure 2 plots this experience.
Figure 2.
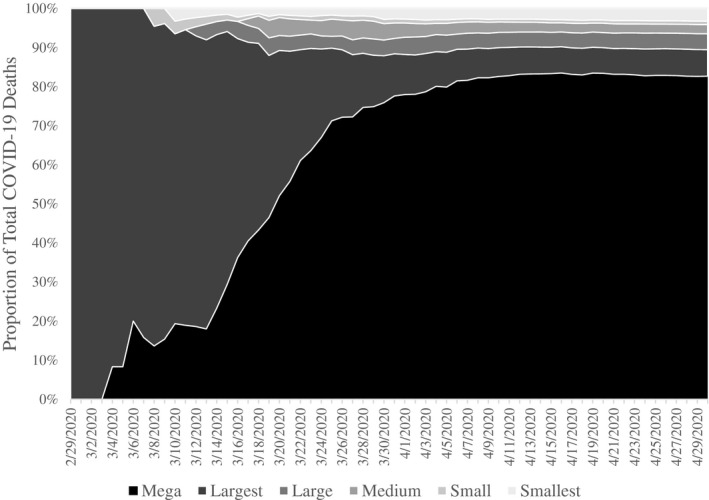
COVID‐19 mortality by regional category.
This experience is consistent with the idea that pandemics filter down the urban hierarchy from mega‐ regions to large metros and then to smaller areas. Here, a disease can start anywhere for completely random reasons that are outside of this model but once it has been introduced to a city system, it will tend to will be transmitted faster and more widely in large commuting sheds with connections to the outside worlds, before eventually making it to elsewhere via regional ‘hub and spoke’ connections.
In this way the US and Chinese experiences seem similar. Like Seattle, Wuhan is a large metro area that is outside of a megaregion. By din of its size and density it was an effective incubator of the disease. Once community transmission was initiated, the disease was spread to small and large regions alike through regular mobility patterns (Fan et al. 2020). However, because the flow from mobility from the initial area to mega regions was stronger, mega regions in both countries began their own community transmission relatively earlier (Figure 3).
Figure 3.
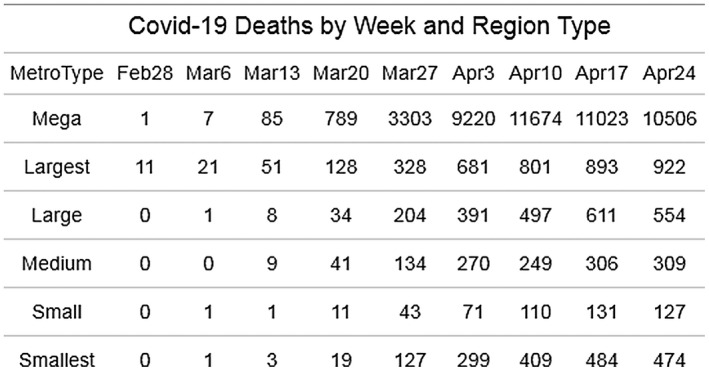
COVID‐19 deaths by week and region type.
To determine if megaregion counties have had a significantly higher amount of COVID‐19 related deaths, we can compare average number of deaths at county level across metro types. To account for dramatic differences in population, we can use a relative rate to measure deaths: log deaths per million population. Age‐specific mortality rates are still not conclusive but we do know that age plays a considerable factor and that older adults are more at risk. Therefore, counties with a younger population may appear to be less impacted by the virus (in terms of deaths) due to the number of younger residents recovering from the virus. As such, we include control variable: proportion adults aged 65‐years‐old and above (US Census Bureau 2018). Pre‐existing health conditions may also augment COVID‐19 related deaths. We include control variable: proportion of adults that report poor or fair health (County Health Rankings and Roadmaps n.d.). As counties in megaregions are, on average, denser than counties in other types of metropolitan areas, population density is included a control variable. Lastly, as air travel played a key part in the spread of COVID‐19 and megaregions are more likely have airports, we have included a dummy control variable that indicates if a county has an airport or not.
Examining average county death rates by metro type, analysis of covariance (ANCOVA) finds a significance difference in mean (log) deaths per million people (F(5, 1155) = 13.35, p < 0.001), while adjusting for poor health, proportion of older adults, population density, and airport connectivity. Figure 4 shows that counties in megaregions had the highest average death rate with and without control variables.
Figure 4.
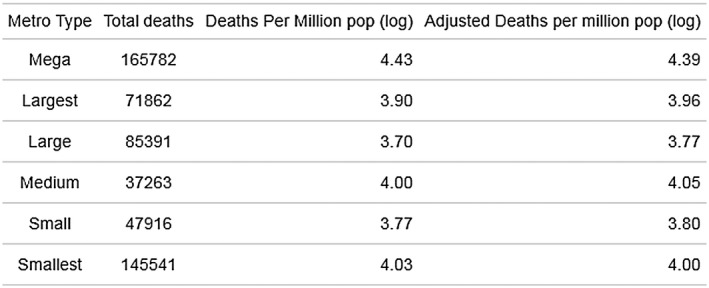
ANCOVA of COVID‐19 deaths by region type. Adjusting for health outcomes, airport size and density.
Follow‐up Bonferroni pairwise comparisons find that counties in megaregions have significantly higher average deaths per million than counties in all other types of metros (at the 0.05 level), controlling for poor health, proportion of older adults, population density and airport connectivity.
The persistence of mega region effects, even after controlling for airport and local density effects points to the possible influence of extended urbanisation, that is being located in a metro region among other metro regions on COVID‐19 transmissibility. Further work will have to use final data and additional controls to measure this conurbanisation effect more thoroughly.
Were some mega regions more exposed to COVID‐19 than others?
We now consider differences above mega regions. There appears to be considerable heterogeneity among this group, as is clear from Figure 5 which shows boxplots for each mega region as well as the distribution of counties within each region. The Bayou – the region centred on New Orleans, Louis‐ Apolis and Bosh‐Wash have higher mortality rates, on average and relatedly they are also home to the most outlier counties. The Central and Southern California regions appear to be relatively low in terms of their average death rates.
Figure 5.
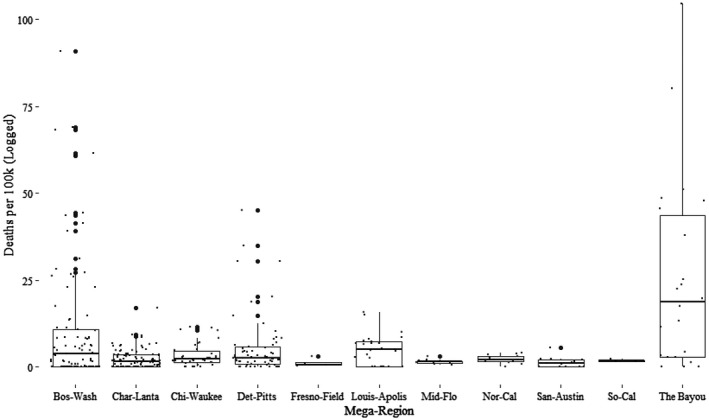
The distribution of county COVID‐19 deaths by megaregion.
That Bos‐Wash, the most extensive and ‘mega‐ey’ mega region would be among the most affected mega‐regions is supportive of our theory. Neither the Bayou nor Louis‐Apolis are especially connected or agglomerated, however, the Bayou's high rate is related to ‘super spreader’ events associated with Mardi Gras festivities, as was the case in Taiwan and China with New Years' activities (Chen et al. 2020).
Looking at expanded metro typology that includes all megaregions as distinct categories, the ANCOVA results again found a significant difference in mean (log) deaths per million people (F(10, 344) = 15.47, p < 0.001), while adjusting for poor health, proportion of older adults, population density and airport connectivity. Looking at the pairwise comparisons, three megas had significantly higher average death rates than the rest: The Bayou, Bos‐Wash and Louis‐Apolis. After controlling for poor health, proportion of older adults, population density and airport connectivity, the average log death rate per million residents in the three megas were 5.55, 5.17 and 4.88, respectively. The megas with the lowest death rates were Fresno‐Field (2.72), Mid‐Flo (3.02) and San‐Austin (3.31).
Together, these results suggest that the differences in morbidity between mega regions and non‐megas are driven by three mega regions: The Bayou/Bos‐Wash/ and Louis‐Apolis. These regions seem to have become early hotspots for the pandemic and, possibly, vectors for the transmission of the disease to elsewhere in the urban system. This said, there are mega regions, even large mega regions like the three California mega regions, that did not become hotspots even though they are dense, globally connected areas. Thus, the apparent relationship between urban structure and early pandemic risk should not be treated as deterministic.
Similarly, we do not find a consistent relationship between urbanisation and pandemic exposure across all categories. Medium size metros outside of metros, are second among all metros in adjusted mortality. Rather than come up with a theory for this ex‐post, we will note that this finding is still consistent with the intuition that the extent of urbanisation (how far the urban range goes), matters more from a transmission standpoint than urban size or density. Mega regions as a class have extensive urbanisation, but not necessarily high degrees of population density or even urban sise.
Differences in morbidity can definitively not be attributed to the timing of social distancing legislation. We calculated the population‐weighted timing of social distancing legislation. Mega regions as a class issued stay‐at‐home orders on 25 March, on average‐ compared to 31 March for other areas. Among mega regionregions, Bos‐Wash (26 March), The Bayou (29 March) and Louis‐Apolis (24 March), did not shutdown especially early or late.
Discussion
Mega regions seem to be at higher risk of importing pandemics at their early stages. In early discussions about how the virus spread in the US, population density has been discussed as a reason why – say – New York's early experience has been so poor. Our results suggest that New York's poor outcomes may be more connected to its location in the country's largest extended agglomeration than to its average population density. This finding implicates local ‘buzz’ type interactions (face to face communication, regularised travel and commuting) in the transmission of disease. While global ‘pipeline’ connections do indeed explain how modern diseases spread so quickly, the degree to which community transmission is established in each place appears to be more a function of the interaction pattern within a given region.
This finding should worry policy‐makers and residents in such places because medical treatment will tend to always be less effective earlier on, as the public health system is still learning about the disease and how to respond to it. As we write this, public health guidance on how to lower the R0 of the virus is still changing; officials in the US and Canada had originally said that masks were not likely to be protective and now they have reversed that. The areas that have had to deal with high levels of infection during this period are likely to have worse outcomes per capita than those that are still waiting for community transmission.
The nature of the pandemic diseconomy is somewhat unusual in that it is probabilistic. There are mega region like Tokyo, Singapore and Taipei, or for that matter So‐Cal and Nor‐Cal that have had relatively mild early experiences even though they are large globally connected centres with extensive agglomeration. Some of this may have to do with unstudied factors but there is also a large stochastic element to epidemiology that makes living in a large city comparable to playing ‘Russian Roulette’. The dynamic we highlight here may still play out in these megaregions in subsequent months. The 1918 pandemic saw several waves in some cities, and in some cities the second or third waves were stronger (Markel et al. 2007). We would expect for mega regions to be relatively more exposed on the second and third waves for the same reasons we outline above.
Pandemics, then, are not like most other negative urban externalities (pollution, crime, noise) which are more certain, or for that matter the more certain advantages (pecuniary cost savings, human capital externalities, infrastructure) to living in mega regions. As economic geographers and urban economists think through the implications of this crisis for cities, they should think more carefully about how standard approaches can be reconciled with pandemic risk. For instance, does the presence of pandemic risk lead to the sorting of more risk‐tolerant workers and firms into mega regions, and risk adverse actors outside? Now that these risks are front of mind, will peripheral areas open that minimise these risks? Cutler and Miller (2004) estimate that the American cities that installed clean water systems in the early twentieth century, lowered total mortality by 13 per cent, will some cities (big and small) develop effective public health responses that overcome the risk posed by COVID‐19 and similar recent events?
Our focus has been on the economic nature of economic regions. We treat them as organic economic units over which there is regularised (if not daily) interaction including: travel, commuting, educational exchange and face‐to‐face interaction. Outside of our analysis and conceptualisation is the understanding of mega regions as political units. It is clear that there are no offical mega region governments in the United States but the degree to which norms, attitudes and actor‐networks can be mapped to mega regions is still unknown. The same can be said of public health responses generally. It is quite clear that none the jurisdictions studied have either the testing or isolation capabilities that seem to have worked in South Korea, Taiwan, Luxembourg and Hong Kong but there may be subtle differences in response that are omitted from our analysis. What is also left for another study is the question of whether there should be more formal governance at the mega region level so that diseases response can be organised at the level of disease transmission.
Future research should also revisit the empirical topic of COVID‐19 transmission across the urban hierarchy, once the pandemic has concluded. Our analysis here is limited because data on case numbers is not reliable and because there was not enough time to conduct a more in‐depth causal study. Once the relevant outcome indicators stabilise, then a follow‐up study can attempt to directly measure mega region connectedness through a direct measure of interaction, as opposed to the present study which infers a degree of interaction from the extent of urbanisation. Although this study is early and focused on the relationship between agglomeration and transmission, it has nonetheless found suggestive evidence and signalled that follow‐up study would be worthwhile.
Note
In these ‘bell‐shaped’ models, there will be a theoretical level of trade costs at which trade itself cannot be justified. However, up to this point agglomeration of some form is justified on the basis of trade cost reduction.
Contributor Information
Patrick Adler, Email: Patrick.Adler@rotman.utoronto.ca.
Richard Florida, Email: florida@rotman.utoronto.ca.
Maxwell Hartt, Email: harttm1@cardiff.ac.uk.
REFERENCES
- Adler, P. , Florida R., & Dias F. (2020), Mega‐Regions, Agglomeration and Economic Structure In: Ratledge E. C. and Iftikhar M. N. eds., Productivity Growth in the US:The Role of Urban and Regional Action. New York: Springer. [Google Scholar]
- Ahlfeldt, G.M. & Feddersen A. (2018), From Periphery to Core: Measuring Agglomeration Effects using High‐speed Rail. Journal of Economic Geography 18, pp. 355–390. [Google Scholar]
- Airports International Council . (2019), Preliminary World Airport Traffic Rankings Released. Available at <https://aci.aero/news/2019/03/13/preliminary‐world‐airport‐traffic‐rankings‐released>. Accessed 7 May 2020. [Google Scholar]
- Ali, S.H. & Keil R. (2006), Global Cities and the Spread of Infectious Disease: The Case of Severe Acute Respiratory Syndrome (SARS) in Toronto, Canada. Urban Studies 43, pp. 491–509. [Google Scholar]
- Bathelt, H. , Malmberg A. & Maskell P. (2004), Clusters and Knowledge: Local Buzz, Global Pipelines and the Process of Knowledge Creation. Progress in Human Geography 28, pp. 31–56. [Google Scholar]
- Brakman, S. , Garretsen H. & van Marrewijk C. (2001), An Introduction to Geographical Economics: Trade, Location and Growth. Cambridge: Cambridge University Press. [Google Scholar]
- Boustan, L., Bunten D. & Hearey O. (2013), Urbanization in the United States, 1800‐2000. NBER Working Paper 19041. [Google Scholar]
- Bowen Jr, J.T. & Laroe C. (2006), Airline Networks and the International Diffusion of Severe Acute Respiratory Syndrome (SARS). Geographical Journal 172, pp. 130–44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brookings Institute (2020), Brookings Metro‐Monitor. Available at <https://www.brookings.edu/wp‐content/uploads/2018/06/Brookings‐Metro_Global‐Metro‐Monitor‐2018.pdf>. Accessed 19 April 2020.
- Chen, S. , Yang J., Yang W., Wang C. & Bärnighausen T. (2020), COVID‐19 Control in China during Mass Population Movements at New Year. The Lancet 395, pp. 764–766. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cheng, H.‐Y. , Jian S.‐W., Liu D.‐P., Ng T.‐C., Huang W.‐T., Taiwan COVID‐19 Outbreak Investigation Team & Lin H.‐H. (2020), High Transmissibility of COVID‐19 near Symptom Onset. MedRxiv. 10.1101/2020.03.18.20034561. [DOI] [Google Scholar]
- Chinazzi, M. , Davis J.T., Ajelli M., Gioannini C., Litvinova M., Merler S., Pastore y Piontti A., Mu K., Rossi L. & Sun K. (2020), The Effect of Travel Restrictions on the Spread of the 2019 Novel Coronavirus (COVID‐19) Outbreak. Science. 10.1126/science.aba9757. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Connolly, C. , Keil R. & Ali S.H. (2020), Extended Urbanisation and the Spatialities of Infectious Disease: Demographic Change, Infrastructure and Governance. Urban Studies. 10.1177/0042098020910873. [DOI] [Google Scholar]
- County Health Rankings (n.d.), How Healthy is your County? Available at <https://www.countyhealthrankings.org/county‐health‐rankings‐roadmaps>. Accessed 7 June 2020. [Google Scholar]
- Cutler, D.M. & Miller G. (2004), The Role of Public Health Improvements in Health Advances: The 20th Century United States. National Bureau of Economic Research Working Paper 10511. [Google Scholar]
- Davis, M. (2006), The Monster at Our Door: The Global Threat of Avian Flu. New York: Macmillan. [Google Scholar]
- Dias, F. (2019), Nightlights. https://github.com/fabioasdias/nightlights [Google Scholar]
- Duranton, G. & Puga D. (2004), Micro‐foundations of Urban Agglomeration Economies. Handbook of Regional and Urban Economics 4, pp. 2063–2117. [Google Scholar]
- Duranton, G. & Turner M.A. (2012), Urban Growth and Transportation. Review of Economic Studies 79, pp. 1407–1440. [Google Scholar]
- Elvidge, C.D. , Baugh K.E., Zhizhin M. & Hsu F.‐C. (2013), Why VIIRS Data are Superior to DMSP for Mapping Nighttime Lights. Proceedings of the Asia‐Pacific Advanced Network 35, pp. 62–69. 10.7125/APAN.35.7. [DOI] [Google Scholar]
- Faber, B. (2014), Trade Integration, Market Size, and Industrialization: Evidence from China's National Trunk Highway System. Review of Economic Studies 81, pp. 1046–1070. [Google Scholar]
- Fan, J. , Liu X., Pan W., Douglas M.W. & Bao S. (2020), Epidemiology of 2019 Novel Coronavirus Disease‐19 in Gansu Province, China 2020. Emerging Infectious Diseases 26 10.3201/eid2606.200251. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Florida, R. , Gulden T. & Mellander C. (2008), The Rise of the Mega region. Cambridge Journal of Regions, Economy and Society 1, pp. 459–476. [Google Scholar]
- Glaeser, E.L. (2007), Do Regional Economies Need Regional Coordination? Harvard Institute of Economic Research Discussion Paper 2131. [Google Scholar]
- Gottmann, J. (1957), Megalopolis or the Urbanisation of the Northeastern Seaboard. Economic Geography 33, pp. 189–200. [Google Scholar]
- Gould, P. (1993), The Slow Plague: A Geography of the AIDS Pandemic. Oxford: Blackwell Publishers. [Google Scholar]
- Grais, R.F. , Ellis J.H. & Glass G.E. (2003), Assessing the Impact of Airline Travel on the Geographic Spread of Pandemic Influenza. European Journal of Epidemiology 18, pp. 1065–72. [DOI] [PubMed] [Google Scholar]
- Hanson, G. (2005), Market Potential, Increasing Returns and Geographic Concentration. Journal of International Economics 67, pp. 1–24. [Google Scholar]
- Harris, C.D. (1954), The Market as a Factor in the Localisation of Industry in the United States. Annals of the Association of American Geographers 44, pp. 315–348. [Google Scholar]
- Head, K. & Mayer T. (2006), Regional Wage and Employment Responses to Market Potential in the EU. Regional Science and Urban Economics 36, pp. 573–594. [Google Scholar]
- Hethcote, H.W. (2008), The Basic Epidemiology Models: Models, Expressions for r0, Parameter Estimation, and Applications In: Ma S. & Xia Y., eds., Mathematical Understanding of Infectious Disease Dynamics, Lecture Notes Series, Institute for Mathematical Sciences, National University of Singapore, pp. 1–61. Singapore: World Scientific. [Google Scholar]
- Innes, J.E. , Booher D.E. & Di Vittorio S. (2010), Strategies for Megaregion Governance. Journal of the American Planning Association 77, pp. 55–67. [Google Scholar]
- JHU (2020), COVID‐19 Map. Johns Hopkins Coronavirus Resource Center; Available at <https://coronavirus.jhu.edu/map.html>. Accessed 7 May 2020. [Google Scholar]
- Kaiser, H.J. (2020), COVID‐19 Models: Can They Tell Us What We Want to Know?’ The Henry J. Kaiser Family Foundation (blog). Available at <https://www.kff.org/coronavirus‐policy‐watch/COVID‐19‐models/>. Accessed on 6 May 2020. [Google Scholar]
- Krugman, P. (1991), Increasing Returns and Economic Geography. Journal of Political Economy 99, pp. 483–499. [Google Scholar]
- Lang, R. & Dhavale D. (2005), Beyond Megalopolis: Exploring America’s New 'Megapolitan' Geography. Washington: Brookings Mountain West Publications, pp. 1–33. [Google Scholar]
- Liu, Y. , Gayle A.A., Wilder‐Smith A. & Rocklöv J. (2020), The Reproductive Number of COVID‐19 Is Higher Compared to SARS Coronavirus. Journal of Travel Medicine 27 10.1093/jtm/taaa021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Markel, H. , Lipman H.B., Navarro J.A., Sloan A., Michalsen J.R., Stern A.M. & Cetron M.S. (2007), Nonpharmaceutical Interventions Implemented by US Cities during the 1918–1919 Influenza Pandemic. JAMA 298, pp. 644–654. [DOI] [PubMed] [Google Scholar]
- Marull, J. , Galletto V., Domene E. & Trullén J. (2013), Emerging Megaregions: A New Spatial Scale to Explore Urban Sustainability. Land Use Policy 34, pp. 353–66. [Google Scholar]
- McLafferty, S. (2010), Placing Pandemics: Geographical Dimensions of Vulnerability and Spread. Eurasian Geography and Economics 51, pp. 143–61. [Google Scholar]
- Mellander, C. , Lobo J., Stolarick K. & Matheson Z. (2015), Night‐time Light Data: A Good Proxy Measure for Economic Activity? PloS One 10, no. 10 10.1371/journal.pone.0139779. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mumford, L. (1938), The Culture of Cities. Science and Society 2, pp. 532–535. [Google Scholar]
- National Center for Biotechnology (2009), U. S. National Library of Medicine 8600 Rockville Pike, Bethesda MD, and 20894 USA. THE WHO PANDEMIC PHASES. Pandemic Influenza Preparedness and Response: A WHO Guidance Document. World Health Organisation; 2009. https://www.ncbi.nlm.nih.gov/books/NBK143061/. [Google Scholar]
- Ottaviano, G.I.P. & Thisse J.‐F.(2001), On Economic Geography in Economic Theory: Increasing Returns and Pecuniary Externalities. Journal of Economic Geography 1, pp. 153–179. [Google Scholar]
- Pastore y Piontti, A. , Perra N., Rossi L., Samay N. & Vespignani A. (2019), Charting the Next Pandemic: Modeling Infectious Disease Spreading in the Data Science Age. Cham: Springer International Publishing. [Google Scholar]
- Proville, J. , Zavala‐Araisa D. & Wagner G. (2017), Night‐time Lights: A Global, Long Term Look at Links to Socio‐Economic Trends. PloS One 12, e0174610. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Samuelson, P.A. (1952), Spatial Price Equilibrium and Linear Programming. The American Economic Review 42, pp. 283–303. [Google Scholar]
- Shannon, G.W. & Willoughby J. (2004), Severe Acute Respiratory Syndrome (SARS) in Asia: A Medical Geographic Perspective. Eurasian Geography and Economics 45, pp. 359–381. [Google Scholar]
- Sheridan, C. (2020), Coronavirus and the Race to Distribute Reliable Diagnostics. Nature Biotechnology 38, pp. 382–384. [DOI] [PubMed] [Google Scholar]
- Shi, K. , Yu B., Huang Y., Hu Y., Yin B., Chen Z., Chen L. & Wu J. (2014), Evaluating the Ability of NPP‐VIIRS Nighttime Light Data to Estimate the Gross Domestic Product and the Electric Power Consumption of China at Multiple Scales: A Comparison with DMSP‐OLS Data. Remote Sensing 6, pp. 1705–1724. [Google Scholar]
- Smallman‐Raynor, M. & Cliff A. D. (2008), The Geographical Spread of Avian Influenza A (H5N1): Panzootic Transmission (December 2003–May 2006), Pandemic Potential, and Implications. Annals of the Association of American Geographers 98, pp. 553–582. [Google Scholar]
- Sohrabi, C. , Alsafi Z., O’Neill N., Khan M., Kerwan A., Al‐Jabir A., Iosifidis C. & Agha R. (2020), World Health Organisation Declares Global Emergency: A Review of the 2019 Novel Coronavirus (COVID‐19). International Journal of Surgery, 76, pp. 71–76. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Storper, M. , Kemeny T., Makarem N.P. & Osman T. (2015), The Rise and Fall of Urban Economies: Lessons from San Francisco and Los Angeles. Stanford, CA: Stanford University Press. [Google Scholar]
- Times Higher Education (2020), World University Rankings. August 20 2019. Available at <https://www.timeshighereducation.com/world‐university‐rankings/2020/world‐ranking>. Accessed on 3 May 2020.
- US Census Bureau (2018), American Community Survey. Available at <https://www.census.gov/programs‐surveys/acs>. Accessed on May 6 2020 [Google Scholar]
- Wozniak, A. (2018), School Distance as a Barrier to Higher Education. Available at <https://econofact.org/going‐away‐to‐college‐school‐distance‐as‐a‐barrier‐to‐higher‐education>. Accessed 7 May 2020. [Google Scholar]
- Wu, Z. & McGoogan J.M. (2020), Characteristics of and Important Lessons From the Coronavirus Disease 2019 (COVID‐19) Outbreak in China: Summary of a Report of 72 314 Cases From the Chinese Center for Disease Control and Prevention. JAMA 323, pp. 1239–42. [DOI] [PubMed] [Google Scholar]
- Yang, J. , Fang C., Ross C. & Song G. (2011), Assessing China's Megaregional Mobility in a Comparative Context. Transportation Research Record., 2244, no 1 pp. 61–68. 10.3141/2244-08. [DOI] [Google Scholar]
- Yang, Z. ,Zeng Z., Wang K., Wong S.‐S., Liang W., Zanin M., Liu P., et al. (2020), Modified SEIR and AI Prediction of the Epidemics Trend of COVID‐19 in China under Public Health Interventions. Journal of Thoracic Disease 12, pp. 165–174. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang K., & Batterman S. (2013), Air pollution and health risks due to vehicle traffic. Science of The Total Environment, 450–451 307 –316. 10.1016/j.scitotenv.2013.01.074. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao, S. , Zhuang Z., Ran J., Lin J., Yang G., Yang L. & He D. (2020), The Association between Domestic Train Transportation and Novel Coronavirus (2019‐NCoV) Outbreak in China from 2019 to 2020: A Data‐driven Correlational Report. Travel Medicine and Infectious Disease 33 10.1016/j.tmaid.2020.101568. [DOI] [PMC free article] [PubMed] [Google Scholar]