

Abstract
Purpose
Infectious agents, such as SARS-CoV-2, can be carried by droplets expelled during breathing. The spatial dissemination of droplets varies according to their initial velocity. After a short literature review, our goal was to determine the velocity of the exhaled air during vocal exercises.
Methods
A propylene glycol cloud produced by 2 e-cigarettes’ users allowed visualization of the exhaled air emitted during vocal exercises. Airflow velocities were measured during the first 200 ms of a long exhalation, a sustained vowel /a/ and varied vocal exercises. For the long exhalation and the sustained vowel /a/, the decrease of airflow velocity was measured until 3 s. Results were compared with a Computational Fluid Dynamics (CFD) study using boundary conditions consistent with our experimental study.
Results
Regarding the production of vowels, higher velocities were found in loud and whispered voices than in normal voice. Voiced consonants like /ʒ/ or /v/ generated higher velocities than vowels. Some voiceless consonants, e.g., /t/ generated high velocities, but long exhalation had the highest velocities. Semi-occluded vocal tract exercises generated faster airflow velocities than loud speech, with a decreased velocity during voicing. The initial velocity quickly decreased as was shown during a long exhalation or a sustained vowel /a/. Velocities were consistent with the CFD data.
Conclusion
Initial velocity of the exhaled air is a key factor influencing droplets trajectory. Our study revealed that vocal exercises produce a slower airflow than long exhalation. Speech therapy should, therefore, not be associated with an increased risk of contamination when implementing standard recommendations.
Electronic supplementary material
The online version of this article (10.1007/s00405-020-06200-7) contains supplementary material, which is available to authorized users.
Keywords: COVID-19, Voice, Pulmonary ventilation, Speech therapy
Introduction
Airborne infectious agents such as SARS-CoV-2, responsible for COVID-19 disease, are transmitted by droplets of different sizes expelled in the exhaled air, especially during violent events such as cough, but also during speech and singing [1, 2]. Health workers, e.g., Otolaryngologist, phoniatricians and speech therapists are, therefore, at high risk of viral exposure during vocal exercises [3]. Associated with ventilated room and physical distancing, masks have shown to reduce the risk of contamination for the wearer [4, 5]. Few data concerning loud voicing, singing and/or vocal exercises are available in literature; moreover, these activities do not always allow the patient to wear a mask. A security issue in the field of vocal speech therapy, singing lessons or in choirs arose during the outbreak. There is a lack of knowledge allowing to resume normal activities.
State of the literature
The risk of contamination during vocal exercises was highlighted in March 2020 within a choir in North America [6].
Current data from the literature establish that the risk of contamination mainly depends on three factors related to the emitted droplets: (1) the intrinsic contagiousness of droplets, (2) the type of vocal exercise, and (3) the spatial dissemination of droplets.
The intrinsic contagiousness of droplets
The droplets emitted by an individual contain all the mucus elements and, potentially, a positive viral load if the emitter is infected. The contagiousness of biological fluids is proportional to their viral load [2]: large droplets contain more viruses and therefore have a higher contagiousness than small droplets [2]. The probabilities that 50-, 10- and 1-micron droplets express (after dehydration) at least one copy of the virus are respectively 37%, 0.37% and < 0.01% [7]. Very small droplets would therefore be less contaminating. However, being able to remain suspended in the air, they were shown to be responsible for SARS-Cov-2 titrations in ambient air for 3 h [8]. Therefore, the time spent with an infected individual could be another key factor. Otherwise, the great number of small droplets expelled probably lead to significant risk of contamination [9].
The type of vocal exercise
It is proven that more bioaerosols are generated during speech than during calm breathing [10, 11]. The number of droplets larger than 50–100 microns expelled during speech is estimated between 1 and 50 particles per second while less than 2 particles per second for normal breathing [12, 13]. Consonants /p/, /t/, /s/ generate more droplets (1.8/cm3) than vowels (1/cm3) and normal breathing (0.1/cm3) [14, 15]. Asadi et al. [14, 15] have shown that droplets emission rates increase with the loudness of the voice, regardless of the language used. Anfinrud et al. [16] also demonstrated that droplets from 20 to 500 microns emitted in loud voices are twice as numerous as in normal voice. Droplets emitted during speech probably partly originate from the vocal folds’ collision during phonation: they could derive from microscopic ruptures of vocal folds lubricating mucus [17]. Indeed, the size distribution of droplets differs between vocalization and whisper [9]. One would think that vocal exercises and singing are considered as violent events leading to a greater number of large droplets than in normal voice, although not demonstrated by scientific evidences. Increased breathing amplitudes, articulatory work and the use of semi occluded vocal tract (SOVT) exercises are supposed to generate more droplets [3].
The spatial dissemination of droplets
The contamination of an individual depends on his physical exposure to the infectious agent and is, therefore, closely related to the spatial dissemination of droplets emitted by an infected individual.
The spatial distribution of droplets emitted depends on their sizes and initial velocities. When speaking, large (> 50–100 microns), intermediated-sized (10–50 microns) and small (< 10 microns) droplets are emitted [18]:
Large droplets have ballistic trajectories, without significant evaporation, which directly depends on their initial velocities [19]. They are quickly slowed down by ambient air and fall to the ground in 1–2 s [12]. They are propelled up to 6 m during sneezing (v = 50 m/s), 2 m during cough (v = 10 m/s) and less than 1 m during normal breathing (v = 1 m/s) [20, 21]. These distances may vary depending on the air distribution in rooms (ventilation systems, patient’s own movement) [5, 22].
Intermediate-sized droplets make the risk of contamination significant because they have trajectories more difficult to predict that strongly depends on their initial velocity but also turbulence and/or shears effects [23]. Their speed of fall depends on their dehydration: a 50-microns droplet reduced to 10 microns decreases its speed of fall from 6.8 to 0.35 cm/s [7].
Small droplets are impacted by air movements and have, therefore, an unpredictable trajectory after the first second. They could be residues of larger dehydrated droplets [5, 23]. But they can also correspond to smaller droplets produced at the free edge of the vocal folds because of aerosolization of secretions lubricating the vocal folds [9, 17].
To date, the velocity of expired air according to the type of vocal exercise performed during speech therapy is unknown. Specifying these velocities would allow to better predict emission distance of droplets during phonation.
The objective of this study was to determine the velocity of the expired air during vocal exercises, and to compare these data with a Computational Fluid Dynamics (CFD) study.
Methods
Experimental study
Two subjects (TR, JR) gave their written consent to participate in this study which was carried out in accordance with the Declaration of Helsinki. It was an observational study that did not substantially change the behavior of subjects who are daily e-cigarette users.
A propylene glycol cloud produced by 2 e-cigarettes’ users allowed visualization of the exhaled air emitted during vocal exercises (Eleaf® TC40W, 29 W, 0 0.58 ohms, 4.15 V). The room was quiet and closed. The ventilation system (ceiling) leads to air movements inferior than 5 cm/s. Exhaled airflow velocities were measured on video records during the first 200 ms during successive vocal exercises and during 3 s for two of them (long exhalation and sustained vowel /a/):
sustained vowel /a/ (comfortable intensity and loud intensity). We were not able to determine the absolute value of intensity.
voiceless fricative consonants /f/ and /ʃ/
voiced fricative consonants /v/ and /ʒ/
during reading of a French sentence: ‘Monsieur Seguin n’avait jamais eu de bonheur avec ses chèvres. Il les perdait toutes de la même façon’ (measures on initial /m/ sounds in’Monsieur’ and /t/ sounds in’toutes’ at comfortable intensity, loud intensity and whispered voice.)
long exhalation after a deep inspiration
use of a SOVT (straw, 5-mm diameter)
Productions were carried out twice most of the times and averaged. Movies were recorded with a Camera (Sony® FDR AX-33) and analyzed using Da Vinci Resolve video editing software (Magic Mirror). Sounds were recorded with the microphone’s camera. A distance marker was used to calculate the size of the cloud.
CFD study
We compared velocities measured experimentally with a two-dimensional CFD simulation. CFD was performed using Star-CCM + ® software (Siemens®). The boundary conditions were as follows: airflow = 200 mm3/s; initial velocity = 1 m/s; humidity = 25%; temperature = 22 °C; and vertical ambient air displacement = 5 cm/s.
Results
Expired air velocities varied according to the vocal exercises and are reported in Table 1. Concerning the production of vowels, we found higher velocities in loud and whispered voice. The production of voiced consonants like /ʒ/ or /v/ generated higher velocities than vowels. For voiceless consonants, some, e.g., /t/, generated very fast airflows, close to normal breathing. SOVT exercises generated airflows faster than loud speech. Velocities decreased when voicing in the device.
Table 1.
Velocity (cm/s) of airflow during the first 200 ms
| Speaker 1 (Female) Average velocity (minimum–maximum) cm/s |
Speaker 2 (Male) Average velocity (minimum–maximum) cm/s |
|
|---|---|---|
| Long exhalation | 180 | 77 (64–88) |
| Exhalation through a 5 mm straw (SOVT) | 102 | 82 (72–90) |
| Voicing through a 5 mm straw (SOVT) | 80 (75–90) | 82 (72–90) |
| /a/ | 38 (25–44) | 28 (14–33) |
| /a/ « louder» | 48 (40–57) | – |
| /m/ | 67 (31–84) | 43 (25–63) |
| /m/ louder | 57 (52–64) | 76 (68–87) |
| /m/ whispered | 90 (80–100) | 78 (57–123) |
| /t/ | 84 (73–87) | 80 (78–100) |
| /t/ louder | 80 (75–82) | 91 (72–118) |
| /t/ whispered | 105 (97–120) | 100 (76–118) |
| /f/ isolated and brief | 132 | 99 (68–144) |
| /f/ sustained | 94 (88–110) | 108 (104–113) |
| /v/ sustained | 79 | 72 |
| /ʃ/ isolated and brief | 154 | 81 (72–90) |
| /ʃ/ sustained | 76 (66–92) | 68 (57–79) |
| /ʒ/ sustained | 44 | 77 |
The evolution of airflow velocities during the first 3 s of a long exhalation and a sustained /a/ are reported in Fig. 1. Evolution of velocities experimentally measured had a profile similar to that of CFD data (Fig. 2). The evolution of the droplets cloud’s length during the production of a sustained /a/ is reported in Figs. 3 and 4 and the corresponding video (Online Resource 1).
Fig. 1.
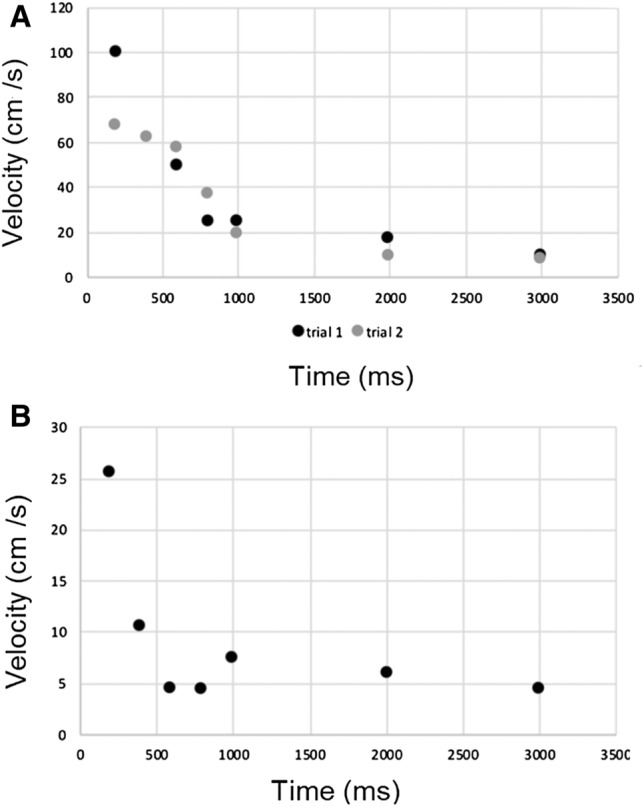
Evolution of airflow velocities (in cm/s) during the first 3 s of two long exhalations for subject n ° 2 (a) and during the first 3 s of a sustained vowel /a/ for subject 1
Fig. 2.

Evolution of expiratory airflow velocity during the digital simulation of a defined expiration at 1 m/s in a calm environment. a Lateral view. The deceleration of speeds during expiration is comparable to the data recorded experimentally; b upper view
Fig. 3.
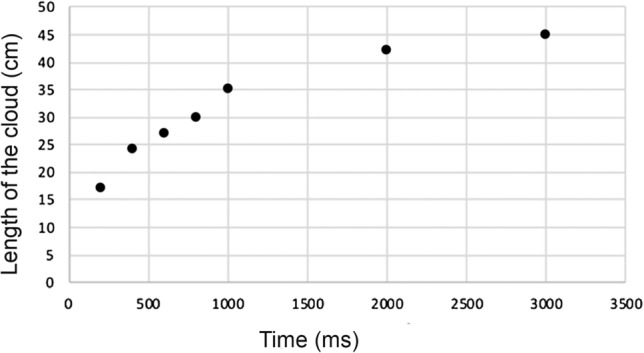
Evolution of the cloud’s length during the first 3 s of a sustained vowel /a/
Fig. 4.
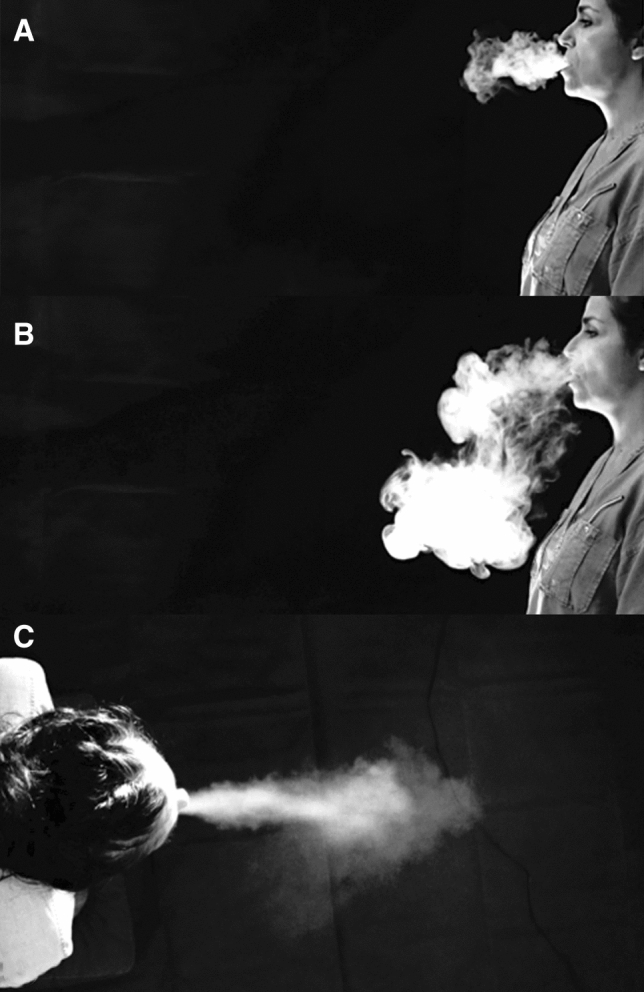
Visualization of the cloud during a sustained vowel /a/. a subject 1, 1 s, lateral view; b subject 1, 5 s, lateral view; c subject 2, 2 s, superior view
Discussion
The objective of this study was to evaluate the initial velocity of the exhaled air during speech and vocal exercises. This study completes our knowledge concerning the dissemination of droplets during speech, which have been reported to be more numerous in loud voice [14]. Our results showed great variability in the expired air velocities, ranging from 0.28 to 1.8 m/s depending on the vocal exercise performed. However, these velocities remained lower than velocities reported for violent events such as coughing and sneezing [20, 21].
The use of propylene glycol for visualization of the exhaled air is a relevant method: e-cigarettes deliver 0.3 microns droplets whose permanence in the air is around 11 s, [24]. However, the future of this cloud after this deadline cannot be accurately evaluated. The deep inspiration required using e-cigarettes was comparable to the deep inspiration required in speech therapy (one of the two subjects is a speech therapist), especially before performing a loud voicing or SOVT exercises. This type of inspiration can also be compared to that used in singing.
The variability of measures reported in Fig. 1 is probably related to the uncertainties of measurements because velocities were calculated on a very short period (200 ms). This is a preliminary study carried out during containment without full access to the technical resources (e.g., velocimeters or lasers) which would have allowed accurate analysis. However, our data agreed with the findings of Anfinrud et al. [16].
In all vocal exercises, the initial velocity remained inferior to 1 m/s for vowels and voiced consonants, even in loud voicing. These data perfectly match with literature: a pressure drop is found at glottic level during voicing and there is no proportionality between the airflow and the acoustic power of the emitted sound [25]. This velocity becomes close to 1 m/s or slightly higher in the production of voiceless consonants, whispered voicing or SOVT, i.e., in productions where airflow is close to normal expiratory airflow.
Our data suggest that the size of the exhaled cloud should remain limited, even in loud voice. As a result, the risk of spatial dissemination of the droplets is not significantly modified compared to long exhalations. Assuming the speaker is COVID-19 positive, high level personal protective equipment are still needed for healthcare workers. However, we do not report an increased risk during loud voicing or vocal exercises compared to standard speech. The usual rules of physical distance, or wearing a mask in cases where this distance cannot be respected or in a closed place, seem valid. More studies should be performed especially regarding choral singing.
Conclusion
The size and velocity of expelled droplets are key factors in transmission of infectious agents. Our study revealed that velocities of the expired air produced during vocal exercises are slower than in long exhalation, suggesting no increased risk compared to standard speech. More studies must be carried out to better understand the infectious risk associated with droplets in speech.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Online Resource 1 Visualization of the cloud according to ample expiration and sustained vowel /a/ (subject 2, lateral view) (MP4 46791 kb)
Author contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were also performed by all authors. The first draft of the manuscript was written by AG and TR and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Funding
The authors declare no funding source.
Availability of data and material
All data and materials support our published claims and comply with field standards.
Compliance with ethical standards
Conflict of interest
The authors declare no conflict of interest.
Ethics approval
Not applicable.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Footnotes
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Antoine Giovanni and Thomas Radulesco equally contributed to the paper and are co-first authors.
References
- 1.World Health Organization (2020) Modes of transmission of virus causing COVID-19: implications for IPC precaution recommendations. https://www.who.int/news-room/modes-of-transmissin-of-virus-causing-covid19
- 2.Wölfel R, Corman VM, Guggemos W, et al. Virological assessment of hospitalized patients with COVID-2019. Nature. 2020;581(7809):465–469. doi: 10.1038/s41586-020-2196-x. [DOI] [PubMed] [Google Scholar]
- 3.Schutte HK, Seidner W. Recommendation by the Union of European Phoniatricians (UEP): standardizing voice area measurement/phonetography. Folia Phoniatr (Basel) 1983;35(6):286–288. doi: 10.1159/000265703. [DOI] [PubMed] [Google Scholar]
- 4.Leung NHL, Chu DKW, Shiu EYC, et al. Respiratory virus shedding in exhaled breath and efficacy of face masks [published correction appears in Nat Med. 2020 May 27] Nat Med. 2020;26(5):676–680. doi: 10.1038/s41591-020-0843-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Thamboo A, Lea J, Sommer DD, et al. Clinical evidence based review and recommendations of aerosol generating medical procedures in otolaryngology—head and neck surgery during the COVID-19 pandemic. J Otolaryngol Head Neck Surg. 2020;49(1):28. doi: 10.1186/s40463-020-00425-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Read R (2020) A choir decided to go ahead with rehearsal. Now dozens of members have COVID-19 and two are dead. Los Angeles Times 2020. https://latimes.com/world-nation/story/2020-03-29/coronavirus-choir-outrbreak
- 7.Stadnytskyi V, Bax CE, Bax A, Anfinrud P. The airborne lifetime of small speech droplets and their potential importance in SARS-CoV-2 transmission. Proc Natl Acad Sci USA. 2020;117(22):11875–11877. doi: 10.1073/pnas.2006874117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Van Doremalen N, Bushmaker T, Morris DH, et al. Aerosol and surface stability of SARS-CoV-2 as compared with SARS-CoV-1. N Engl J Med. 2020;382(16):1564–1567. doi: 10.1056/NEJMc2004973. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Morawska L, Johnson GR, Ristovski ZD, Hargreaves M, Mengersen K, Corbett S, et al. Size distribution and site of origin of droplets expelled from the human respiratory tract during expiratory activities. J Aerosol Sci. 2009;40(3):256–269. doi: 10.1016/j.jaerosci.2008.11.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Gupta JK, Lin CH, Chen Q. Characterizing exhaled airflow from breathing and talking. Indoor Air. 2010;20(1):31–39. doi: 10.1111/j.1600-0668.2009.00623.x. [DOI] [PubMed] [Google Scholar]
- 11.Xie X, Li Y, Sun H, Liu L. Exhaled droplets due to talking and coughing. J R Soc Interface. 2009;6(Suppl 6):S703–S714. doi: 10.1098/rsif.2009.0388.focus. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Wells WF. On air born infection. Study II. Droplet and droplet nuclei. J Hyg. 1934;20:611–618. [Google Scholar]
- 13.Duguid JP. The size and the duration of the air-carriage of respiratory droplets and droplet-nuclei. J Hyg. 1946;44:471–479. doi: 10.1017/s0022172400019288. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Asadi S, Wexler AS, Cappa CD, Barreda S, Bouvier NM, Ristenpart WD. Aerosol emission and superemission during human speech increase with voice loudness. Sci Rep. 2019;9:2348. doi: 10.1038/s41598-019-38808-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Asadi S, Wexler AS, Cappa CD, Barreda S, Bouvier NM, Ristenpart WD. Effect of voicing and articulation manner on aerosol particle emission during human speech. PLoS ONE. 2020;15(1):e0227699. doi: 10.1371/journal.pone.0227699. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Anfinrud P, Stadnytskyi V, Bax CE, Bax A. Visualizing speech-generated oral fluid droplets with laser light scattering. N Engl J Med. 2020;382(21):2061–2063. doi: 10.1056/NEJMc2007800. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Johnson GR, Morawska L. The mechanism of breath aerosol formation. J Aerosol Med Pulm Drug Deliv. 2009;22(3):229–237. doi: 10.1089/jamp.2008.0720. [DOI] [PubMed] [Google Scholar]
- 18.Lindsley W, Reynolds J, Szalajda J, Noti J, Beezhold D. A cough aerosol simulator for the study of disease transmission by human cough-generated aerosols. Aerosol Sci Technol. 2013;47(8):937–944. doi: 10.1080/02786826.2013.803019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Dbouk T, Drikakis D. On coughing and airborne droplet transmission to humans. Phy Fluids. 2020 doi: 10.1063/5.0011960. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Wei J, Li Y. Airborne spread of infectious agents in the indoor environment. Am J Infect Control. 2016;44(9 Suppl):S102–S108. doi: 10.1016/j.ajic.2016.06.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Bourouiba L. Dehandsschoewercker, Bush JWM Violent expiratory events: on coughing and sneezing. J Fluid Mech. 2014;745:537–563. doi: 10.1017/jfm.2014.88. [DOI] [Google Scholar]
- 22.Morawska L, Cao J. Airborne transmission of SARS-CoV-2: the world should face the reality. Environ Int. 2020;139:105730. doi: 10.1016/j.envint.2020.105730. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Bourouiba L. Turbulent gas clouds and respiratory pathogen emissions: potential implications for reducing transmission of COVID-19. JAMA. 2020 doi: 10.1001/jama.2020.4756. [DOI] [PubMed] [Google Scholar]
- 24.Bertholon J-F, Becquemin MH, Roy M, Roy F, Ledur D, Annesi Maesano I, et al. Comparaison de l’aérosol de la cigarette électronique à celui des cigarettes ordinaires et de la chicha. Rev des Maladies Respir. 2013;30(9):752–757. doi: 10.1016/j.rmr.2013.03.003. [DOI] [PubMed] [Google Scholar]
- 25.Traunmüller H, Eriksson A. Acoustic effects of variation in vocal effort by men, women, and children. J Acoust Soc Am. 2000;107(6):3438–3451. doi: 10.1121/1.429414. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Online Resource 1 Visualization of the cloud according to ample expiration and sustained vowel /a/ (subject 2, lateral view) (MP4 46791 kb)
Data Availability Statement
All data and materials support our published claims and comply with field standards.