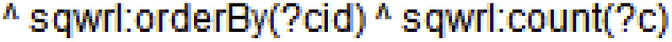An official website of the United States government
Here's how you know
Official websites use .gov
A
.gov website belongs to an official
government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you've safely
connected to the .gov website. Share sensitive
information only on official, secure websites.
As a library, NLM provides access to scientific literature. Inclusion in an NLM database does not imply endorsement of, or agreement with,
the contents by NLM or the National Institutes of Health.
Learn more:
PMC Disclaimer
|
PMC Copyright Notice
aDepartment of Computer Science, Ahmadu Bello University Zaria, Nigeria
bSchool of Computer Science, University of KwaZulu-Natal, King Edward Avenue, Pietermaritzburg Campus, Pietermaritzburg, 3201, KwaZulu-Natal, South Africa
bSchool of Computer Science, University of KwaZulu-Natal, King Edward Avenue, Pietermaritzburg Campus, Pietermaritzburg, 3201, KwaZulu-Natal, South Africa
aDepartment of Computer Science, Ahmadu Bello University Zaria, Nigeria
bSchool of Computer Science, University of KwaZulu-Natal, King Edward Avenue, Pietermaritzburg Campus, Pietermaritzburg, 3201, KwaZulu-Natal, South Africa
∗
Corresponding author.
Received 2020 May 14; Revised 2020 Jul 6; Accepted 2020 Jul 9; Issue date 2020.
Since January 2020 Elsevier has created a COVID-19 resource centre with free information in English and Mandarin on the novel coronavirus COVID-19. The COVID-19 resource centre is hosted on Elsevier Connect, the company's public news and information website. Elsevier hereby grants permission to make all its COVID-19-related research that is available on the COVID-19 resource centre - including this research content - immediately available in PubMed Central and other publicly funded repositories, such as the WHO COVID database with rights for unrestricted research re-use and analyses in any form or by any means with acknowledgement of the original source. These permissions are granted for free by Elsevier for as long as the COVID-19 resource centre remains active.
Coronavirus, also known as COVID-19, has been declared a pandemic by the World Health Organization (WHO). At the time of conducting this study, it had recorded over 11,301,850 confirmed cases while more than 531,806 have died due to it, with these figures rising daily across the globe. The burden of this highly contagious respiratory disease is that it presents itself in both symptomatic and asymptomatic patterns in those already infected, thereby leading to an exponential rise in the number of contractions of the disease and fatalities. It is, therefore, crucial to expedite the process of early detection and diagnosis of the disease across the world. The case-based reasoning (CBR) model is a compelling paradigm that allows for the utilization of case-specific knowledge previously experienced, concrete problem situations or specific patient cases for solving new cases. This study, therefore, aims to leverage the very rich database of cases of COVID-19 to solve new cases. The approach adopted in this study employs the use of an improved CBR model for state-of-the-art reasoning task in the classification of suspected cases of COVID-19. The CBR model leverages on a novel feature selection and the semantic-based mathematical model proposed in this study for case similarity computation. An initial population of the archive was achieved from 71 (67 adults and 4 pediatrics) cases obtained from the Italian Society of Medical and Interventional Radiology (SIRM) repository. Results obtained revealed that the proposed approach in this study successfully classified suspected cases into their categories with an accuracy of 94.54%. The study found that the proposed model can support physicians to easily diagnose suspected cases of COVID-19 based on their medical records without subjecting the specimen to laboratory tests. As a result, there will be a global minimization of contagion rate occasioned by slow testing and in addition, reduced false-positive rates of diagnosed cases as observed in some parts of the globe.
Keywords: COVID-19, Coronavirus, Case-based reasoning, Ontology, Natural language processing
1. Introduction
The novel coronavirus disease, also referred to as COVID-19, was first reported in China in December 2019. The virus has so far affected 213 countries and territories around the world and 2 international conveyances. It is now considered a major global health concern due to its pathogenicity and widespread distribution across the globe. The COVID-19 virus is a highly contagious respiratory disease that has spread rapidly around the world since it first reported in China in late December 2019 [53]. According to the WHO's official reports on COVID-19 [13], by July 6, 2020, it had affected more than 11,301,850 million people and caused more than 531,806 deaths, with a total of 6,586,354 million recovered. Considering the exponential growth in the confirmed and death cases of COVID-19, this has expedited efforts by the scientific and research community in proposing and developing several novel epidemiological model approaches to mitigate the spread of the COVID-19 outbreak.
Some mathematical and statistical models have been developed recently to critically analyze the transmission pattern of the ongoing COVID-19 and other related disease outbreaks [[14], [15], [16], [17], [18], [19]]. It is equally important to recognize all the different epidemiological contributions towards estimating the transmission dynamics of the virus. Still, most of the existing proposed models are parameter-dependent, and they rely mainly on multiple assumptions [20] for them to be effective. Moreover, because during an outbreak of an epidemic, it is often not easy nor reliable to estimate parameters using real data sets, which are not readily available for experimental testing of such proposed models [21,22]. Furthermore, in most of the reported model parameter settings, one can discover that rather than using the actual parameter values that seem close enough to the real-world values derived from the statistical properties of the actual data sets, the authors of those models opted to use hypothesized parameter values. However, the use of hypothesized parameters, in this case, is highly limited because it does not fit the data very well [20]. Therefore, considering the aforementioned challenges associated with the current existing mathematical and statistical epidemiological models, it would be challenging to attribute any high predictive accuracy level for using these models to estimate and forecast the exponential growth of COVID-19 outbreaks correctly. As it stands for now, despite all these measures and attractive modeling proposals, the virus has maintained its capacity to spread exponentially from country to country and continent to continent stretching the functionality and capability of even the most robust healthcare systems of many countries. The exponential spread of the virus has placed an enormous burden on health facilities (testing and laboratory centers, and ICUs) of nations across the globe. Therefore, there is an urgent need for automated systems to speed up the classification of suspected cases rather than manual approaches of diagnoses. Besides, the delayed diagnosis has built up apprehension in cases of common flu and pneumonia which share some characteristics of COVID-19.
Although many related artificial intelligence (AI) based proposed studies in the literature appear to be well-designed for the tasks of handling the current coronavirus pandemic in terms of estimating confirmed cases and forecasting the speed of COVID-19 spread, these models may deteriorate in performance and accuracy due to their heavy reliance on many inaccurate decision variables and imprecise parameter estimations. For instance, the use of deep learning models in the detection of COVID-19 cases is primarily based on digital images [23,[56], [57], [58]] with little efforts being geared towards exploiting the very useful, revealing and abundant knowledge that is domiciled in the patient electronic health record system (EHRs). Consequently, it is assumed that the limitations mentioned above can lead to conflicting forecasting outcomes, which may invariably lead to unsatisfactory and imprecise results. This would have a negative impact on public health planning and policymaking. Therefore, to overcome the abovementioned limitations of the existing epidemiological and AI-based model approaches, the current paper presents a promising alternative diagnostic and forecasting framework with the aim to achieve more accurate results and avoid the previous limitations by combining the strengths of ontology-based natural language processing with case-based reasoning for early detection and diagnosis of the novel coronavirus pandemic. The rich database of cases of confirmed COVID-19 supports the adoption of case-based reasoning (CBR) paradigm as an authentic reasoning structure for improving diagnosis.
The CBR is an artificial intelligence paradigm that has proven to be useful in medical systems and also exploits the similarity of cases in its knowledge base in providing a solution to a new case or problem. Case retrievals that are closely related to the new case are usually computed using different similarity computational models like Euclidean distance which have been adopted by different researches. However, CBR systems all have the challenge of features extraction and formalization. Furthermore, the choice of selecting the best distance measure model for computing similarity of cases is a problem demanding optimal solution considering the sensitivity of medical cases. CBR reasoning means using old experiences to understand and solve new problems. In case-based reasoning, a reasoner remembers a previous situation similar to the current one and uses that to solve the new problem [38]. CBR and expert systems have a long tradition in artificial intelligence. CBR has been formulated since the late 1970s. CBR is an approach for problem solving and learning of humans and computers [39]. Case-based reasoning is useful in problem solving and automation of learning by an agent. Because empirical evidence has shown that reasoning with CBR is more powerful, this has made reasoning by re-using past cases a powerful and frequently applied way to solve problems for humans. An essential feature of case-based reasoning is its coupling to learning and its strong association with machine learning [40]. Ben-Bassat et al. [41] enumerated some features of CBR, and these include: cases that present similar symptoms and findings results from same faults/disease, and “Nearest Neighbor” algorithm is used to identify unknown diagnosis from the known. More so, CBR avoids the knowledge-based acquisition bottleneck of RBR, it compiles past solutions, mimics the diagnostic experience of human experts, avoids past mistakes, interprets rules, supplements weak domain models, facilitates explanation, supports knowledge acquisition and learning, and exploits the database of solved problems so as to learn.
In this paper, we introduce the concept of combining natural language processing, ontology learning and artificial intelligence techniques to the most critical challenges in responding to the novel coronavirus or COVID-19 pandemic. Consequently, the main goal of this study is to apply the concept of natural language processing (NLP) for ontology learning and population task before using an improved CBR technique to the problem of classifying cases of COVID-19 as either positive or negative even when the disease is still in its early stage of manifestation in the presented case. An NLP model for feature extraction of the presented case was designed and implemented. The originality of the current study lies in the robustness and efficiency of the sentence-level extraction of feature-value pair for all a priori declared features. Furthermore, the case retrieval similarity metric applied to the proposed NPL-based CBR framework contributes to the interesting performance of the proposed system. Specifically, the technical contributions of this study are as follows:
i.
Design of an ontology learning algorithm for feature extraction and mapping from suspected cases of COVID-19.
ii.
Proposal of a novel mathematical model for semantic-based and feature based case similarity computation.
iii.
Incorporation of the proposed mathematical model into an improved CBR framework.
iv.
Implementation of CBR framework which allows for the detection or classification of suspected cases of COVID-19 as either positive or negative.
The remainder of the paper is organized into six sections, namely: related works, proposed approach, experimentation, results, discussion, and conclusion. The related works section presents a comprehensive review of related studies on COVID-19. In Section 3, a detail of the approach proposed for the CBR framework is presented, while Section 4 discusses the experimentation and system configuration for the experimentation. In Section 5, we present a comparison of the performance of the proposed approach with some related studies and then conclude the study in Section 6.
2. Related works
In recent times, artificial intelligence (AI) has been considered as a potentially powerful tool in the fight against many evolving pandemics such Ebola hemorrhagic fever (2014–2016), Swine flu (2002–2003), SARS (2002–2003), Middle East respiratory syndrome coronavirus (MERS-CoV) (2012-present), and novel coronavirus (COVID-19) (2019-ongoing). Regarding the ongoing 2019–2020 novel coronavirus pandemic, dozens of research efforts have emerged, and most of the published papers focused on the importance of harnessing artificial intelligence technologies to curb the global COVID-19 Pandemic. This section provides a selective review of recent articles that have discussed the many significant contributions of the application of AI technologies in the fight against COVID-19, as well as the current constraints on these contributions. Specifically, in Ref. [1], six areas where artificial intelligence technologies have emerged as key solutions to combatting coronavirus were identified. These areas include: i) early warnings and alerts, ii) tracking and prediction, iii) data dashboards, iv) diagnosis and prognosis, v) treatments and cures, and vi) social control. Therefore, most of the subsequent discussions presented in this section are focused on investigating to what extent AI has been partly or fully utilized in combatting the spread of the aforementioned pandemic. The selected review discussions presented in this section only cover those articles that have been published in a peer-reviewed journal. Preprinted articles are outside the scope of the current review discussion.
In [2], the analysis of confirmed cases of COVID-19 through a binary classification using artificial intelligence and regression analysis was investigated. In their study, the authors employed the binary classification modeling with group method of data handling type of neural network as one of the artificial intelligence methods of accurately predicting confirmed cases of the COVID-19 epidemic. The study chose the Hubei province in China for their model construction. For the input and output variables, some important factors such as maximum, minimum, and average daily temperature, city density, relative humidity, and wind speed, were considered as the input dataset, while the number of confirmed cases was selected as the output dataset for 30 days. Moreover, the outcome of the investigation revealed that the proposed binary classification model was able to provide a higher performance capacity in predicting the confirmed cases in the province. Also, the analysis of the results showed that certain weather conditions based on the input variables, namely relative humidity with an average of 77.9% had a positive impact on the confirmed cases and maximum daily temperature with an average of 15.4 °C had a negative effect on the confirmed cases.
Mohammed et al. [3] presented the application of two optimization metaheuristic techniques to enhance the predictive performance accuracy of the proposed adaptive neuro-fuzzy inference system that is used for estimating and forecasting the number of confirmed cases of novel coronavirus in the upcoming ten days based on previously confirmed cases that were recorded in China. The developed hybrid metaheuristic based adaptive neuro-fuzzy inference system comprised of Adaptive Neuro-Fuzzy Inference engine and two metaheuristic algorithms, namely, flower pollination algorithm and salp swarm algorithm. The enhanced flower pollination algorithm was utilized by the author to train the neuro-fuzzy inference system by optimizing its parameters, while the salp swarm algorithm was incorporated as a local search method to enhance the quality of the solution obtained by the model. The results of the model implementation show that it has a high capability of predicting the number of confirmed cases within the projected ten days. It was further established that the hybrid system, when compared with other methods, obtained more superior performance accuracy in terms of the following performance metrics: root mean square error, mean absolute error, mean absolute percentage error, root mean squared relative error and coefficient of determination.
Ting et al. [4] explored the potential application of four inter-related digital technologies combating the widespread of the novel coronavirus. These technologies include the Internet of Things, big-data analytics, Artificial Intelligence and blockchain. The authors in their work [4] presented some valid reasons why the four aforementioned digital technologies can be employed to augment the already strained traditional based public-health strategies for tackling COVID-19. Some of the conventional based public healthcare strategies that have been put in place and are continually being used across the globe include (1) monitoring, surveillance, detection and prevention of COVID-19; and (2) mitigation of the impact to healthcare indirectly related to COVID-19. The authors further suggested that digital technologies can be helpful in the following ways. The Internet of Things technology can be used to provide a platform that allows public-health agencies access to data for monitoring the COVID-19 pandemic. The big data technology can be instrumental in providing opportunities for performing modeling studies of viral activity and for guiding an individual country's healthcare policymakers to enhance preparation for the outbreak. The blockchain technology can be vital in the manufacturing and distribution of COVID-19 vaccines once they are available. Similarly, blockchain can be utilized to facilitate the delivery of patients' regular medication to the local pharmacy or patients' doorstep. The AI and deep learning technology can be used to enhance the detection and diagnosis of COVID-19. Further, the utilization of various AI-based triage systems could potentially alleviate the clinical load of physicians.
Vaishya et al. [5] in their study highlighted the significant roles that some of the new technologies such as artificial intelligence, Internet of Things, Big Data and Machine Learning are likely to play in the fight against the new diseases and also the possible forecasting of any pandemics. The authors in Ref. [5] focused on presenting a brief review regarding the utilization of artificial intelligence platforms as a decisive technology to analyze, prepare us for prevention and fight against COVID-19 and any other similar pandemics. In their findings, seven significant application areas of artificial intelligence technology were identified for tackling the spread of COVID-19 disease. These areas as mentioned in Refs. [5] include early detection and diagnosis of the infection, monitoring the treatment, projection of cases and mortality, development of drugs and vaccines, reducing the workload of healthcare workers, and prevention of the disease. Furthermore, the technology was also identified as having the capability to detect clusters of cases and predict the possible location of the virus spread through collecting and analyzing all previous data.
Leung and Leung [6] presented a discussion on the way forward in terms of crowdsourcing data to mitigate epidemics. The authors surveyed different and varied sources of possible line lists for COVID-19. The sources considered by the authors include data clearinghouses or secondary repositories and official websites or social media accounts of various Health Commissions at the provincial and municipal levels in mainland China. Some of the main bottlenecks attributed to the process of crowdsourcing were linked to the rigorous tasks involved in carefully collating as much relevant data as possible, sifting through and verifying the data, extracting intelligence to forecast and inform outbreak strategies, and thereafter repeating this process in iterative cycles to monitor and evaluate progress [6]. However, a possible methodological breakthrough in alleviating these challenges would be to develop and validate algorithms for automated bots to search through cyberspaces of all sorts, by text mining and natural language processing to expedite these processes. Next, we present a brief discussion of some applications of CBR to healthcare with a specific focus on its utilization for analysis, prediction, diagnosis, and recommending treatment for patients.
The CBR is an appropriate methodology to apply in the diagnosis and treatment of a wide range of health issues. Research in CBR has grown to an extent, starting from the early exploration in the medical field by Koton [7], Bareiss [8] in the late 1980s and Gierl et al. [9] in the late 1990s. However, there are still some associated shortcomings with the design and implementation of CBR, especially in the adaptation mechanism. Blanco et al. [10] reported the results of a systematic review of CBR application to the health sector. In their work, the authors proposed some enhancement procedures that could be applied to overcome some of the limitations of CBR, which is focused on preparing the data to create association rules that help to reduce the number of cases and facilitate the learning of adaptation rules.
CBR has equally received noticeable attention in the aspect of disease predictions and diagnosis. In Ref. [11], a hybrid implementation of neural networks and case-based reasoning was proposed for the prediction of chronic renal disease among the Colombian population. The neural network-based classifier, which was trained with the demographic data and medical care information of two population groups, was developed to predict whether a person is at risk of developing chronic kidney disease. The result of the classifier showed that about 3,494,516 people were identified as being at risk of developing the chronic renal disease in Colombia, which in this case is 7% of the total population.
Benamina et al. [12] proposed the integration of fuzzy logic and data mining technique to improve the response time and the accuracy of the retrieval step of case-based reasoning of similar cases. The Fuzzy CBR proposed in Ref. [12] is composed of two complementary parts, namely, the part of classification by fuzzy decision tree realized by Fispro and the part of case-based reasoning realized by the platform JColibri. The main function of fuzzy logic is to reduce the complexity of calculating the degree of similarity that can exist between diabetic patients who require different monitoring plans. The authors compared their results with some existing classification methods using accuracy as performance metrics. The experimental result that was generated by the proposed system revealed that the fuzzy decision tree is very effective in improving the accuracy for diabetes classification and hence improving the retrieval step of CBR reasoning.
Ozturk et al. [23] adopted the deep learning technique for the task of detecting COVID-19 by proposing the use of you only look once (YOLO) in combination with DarkNet. Their approach successfully classified cases of COVID-19 through binary (COVID vs No-Findings) and multi-class (COVID vs No-Findings vs Pneumonia) classifications which yielded an accuracy of 87.02%. Although the deep learning approach is gaining attention among researchers, they have, however, not obtained widespread deployment for practical use compared to CBR systems. Besides, some studies which have combined CBR with deep learning have leveraged the later for the acquisition of domain knowledge or extraction of feature weights, while the former performs the role of detection [24,25]. Although the combined approach yielded good results [52], they are, however, often limited by unavailable datasets, especially in the case of COVID-19 disease [54].
3. Proposed approach
A detail presentation of the methods adopted and adapted in this study is covered in this section: an overview of the entire approach, feature extraction using a natural language processing technique, formalism of cases in the proposed case-based reasoning (CBR) method, and lastly the CBR engine.
3.1. An overview of the approach
The proposed NLP-Ontology-CBR method accepts a text-based patient file as input and then extracts and formalizes the new case using an ontology representation, as shown in Fig. 1
. The extracted case features are further passed to the domain-based feature extraction component which maps each extracted feature at the previous layer to domain-based features. The extracted and mapped features are formalized using description logic (DL) based on a knowledge representation format to allow for efficient computational operations in the CBR engine. Finally, the formalized features are passed on to the CBR-engine as a new case (nc) that support the application of the reasoning paradigm of CBR.
An overview of the proposed framework using case-based reasoning (CBR) model to classify new cases of coronavirus (COVID-19) as either positive or negative.
The pipeline of information flow and processing described in Fig. 1 was therefore adapted to detect the case of positive COVID-19 patient from early stage to the advance stage. A further discussion in the following subsections details the components of the framework.
3.2. The NLP method for feature extraction
The proposal in this study is a text-CBR (TCBR) and whose datasets were derived from patient medical records archived using natural language. And since NLP techniques have archived outstanding performance for textual CBR, we decided to build on the state-of-the-art approach by using NLP to drive a better case representation through feature extraction. The field of natural language processing techniques is an exciting and relevant aspect of artificial intelligence (AI) with a wide range of applications to medicine and even the large number of text-based documents on the internet. Moreover, electronic health record (EHR) systems are now pervasive and are provided as services to other automated healthcare delivery systems. The NLP method for feature extraction described in this section adopts some components and algorithms from Dasgupta et al. [26]. The ontology learning method is widely used for mining information from natural language text to generating an ontology representation of the mined data. Such ontology representation is to provide formal expressivity and a platform for reasoning with an NP-text document. Although this study assumes a similar procedure, we implemented a skeletal outline of the entire procedure.
Fig. 2
shows the modified model of a patient text-based medical record natural language processing (NLP) and the feature extraction pipeline. The model is called a pipeline because of its approach of processing raw file-based text (in the English language) through different procedures which eventually yields the feature (COVID-Fs) for further processing in the CBR-engine.
File Loader and Text Input (FLTI): The FLTI is a very simple component with support for file format and safety authentication, file loading and text-content unloaded into a buffer.
NL Pre-processing (NL-P): The second component consists of other sub-modules named Spelling Checking, Lexical normalizer, and Sentence normalizer, which does a pre-processing of the buffered text in FLTI layer. Generally, the NL-P is aimed at carrying out operations like spell-corrector, tokenization, sentence boundary detector, text singularizer, POS-tagger, co-reference resolver, and named-entity recognizer (NER) by leveraging on Stanford coreNLP toolkit [27]. Our approach of applying NL-P to the buffered text in FLTI was to allow the spell-corrector to scan through the complete buffer and correct wrongly spelt words and to allow for efficient and intelligent mining of features from the buffered text - the improved output of FLTI. This was then converted into a token of sentential forms (SF) in a list format and then sorted according to their appearance in the original document. In each SFs, we attempted to normalize each plural form of its constituents into a singular form through the use of a singularizer. These SFs were extracted from buffered text using sentence boundary detector and annotated with POS-tagging, and the SFs were preserved in an orderly manner to sustain the semantics of health records. Meanwhile, due to the translation task of the raw text to ontology format, we further employed NER models to identify and mark entities and after that their instances which form the elements of taxonomy-box (TBox) and assertion box (Abox) respectively in the resulting ontology. Once the SFs had been pre-processed, we applied them to the next sub-module named lexical normalizer (LN). The use of LN in our study is simply for identification of quantifiers and special symbols (like >, <, = , +, -, and other medical related symbols which may hold meaning in the usage) of subject/objects appearing in the SFs. Our approach in LN allows for such quantifiers/numeric representations and symbols to be normalized into normal forms supportive of the token-to-feature translation in RTCF component of Fig. 2. The role of applying the sentence normalizer (SN) is to ensure that complicated sentences are broken down to simple forms so that an element of SFs, say sfi, is normalized into simpler forms assuming the template of the NSC component to be discussed later. Hence, the resulting simplified sentences of sfi replace it in SFs.
Normalized Sentence Component (NSC): Based on the structural formation of a sentence in the English language, Dasgupta et al. [26] described a particular template or syntax, in their study. We adopted two of the templates, namely the simple and complex sentences as listed in the following:
Q1M1∗ S is-a Q2M2∗ O
Q1M1*S Cl1 IS-A Q2M2*O1 Cl2 IS-A Q3M3*O2
Q: under-lined notation indicates optional component with at most 1 occurrence in the template, e.g. quantification.
M*: under-lined notation with an asterisk (*) indicates 0 or more consecutive occurrences in the template, e.g. adjectives.
Q1: subject quantifier that includes lexical variations of the set: a, an, the, some, all.
Q2: object quantifier that includes lexical variations of the set: the, some, all.
Q3: object quantifier that includes lexical variations of the set: the, some, all.
M: subject/object/verb modifier; value is restricted to the set: Noun, Adjective, Adverb, Numerical, and Gerund
S: subject; value is restricted to the set: common noun (NN), proper noun (NNP), adjective (JJ), adverb (RB), verb gerund and present participles (VBG) as used in part of speech (POS).
O: object; value is restricted to the set: NN, NNP, JJ, RB, VBG as used in part of speech (POS).
IS-A: denotes all possible lexical variations.
Cl1 and Cl2: signify IS-A clausal token and all its variations ‘which’, ‘who’, ‘whose’, ‘whom’, ‘that’.
Finally, we ensured that all the sentences in SFs were adapted to the template described above, and then we applied their Template-Fitting algorithm to all elements of SFs.
Normalized Sentence Component as Token (NSCaT): The CBR-engine to be described in Sub-section 3.4 does not expect input in sentential format but tokenized features which maintain its sentence form syntax and semantics. Therefore, each sfi in SFs are further tokenized into a list of raw (un-normalized features) tokens in the form of tij such that i represents the position of the sentence in SFs and j represents the position of the token in the sfi of SFs that is being processed. The output of NSCaT is, therefore, an irregular 2D array of raw tokens.
Mapping Tokens to Domain Knowledge (MTDK): We assumed that not all the tokens from NSCaT are correctly represented based on the domain knowledge. As a result, we proposed an MTDK layer which was aimed at mapping each token in the NSCaT to its correct recognized name in the domain. We relied strongly on Wordnet (WordNet) and the domain-based lexicon model in this study, as shown in Fig. 3
. The role of the Wordnet lexicon is to generate all likely synonyms of each tij in NSCat. Therefore, this means that each tij indexes into a sub-array of its synonyms. Thereafter, our mapping algorithm aligns each tij to its respective sub-array.
A lexicon of terminologies representing domain knowledge of COVID-19 in addition to symptoms, treatment, epidemiology, disease case status, and other relevant concepts in the domain.
Represent Tokens as COVID-19 Features (RTCF): The output of MTDK is further refined to assume the standard feature categorization and typing as listed in Table 1
. The implication of this is that we attempted to extract known features of COVID-19 from the output of MTDK and assigned their values, as illustrated in Fig. 4
.
Table 1.
A summary of categorization of coronavirus clinical-based features to be extracted by the domain-based feature extractor.
Feature category
Feature Name
Description of feature
Feature calibration
Epidemiological
Sex
Gender of patient
Male/Female
Basic Reproduction
–
range: 1.5–3.5
Mortality rate
–
3%
Incubation time
–
4.8 ± 2.6 days
Age of the deaths
Median age of death was 75
Range: 48 and 89
BMI
Body mass index
23.75 (4.54)
Height
–
167 (11.75)
Weight (kg)
–
65.92 (18.75)
Age
Patient current age
45.11 ± 13.35
Symptom
Cough
Observed in less than half of the mild cases in the largest included study and in two thirds of cases.
Y |N
Fever
The most frequent symptom for mild and moderate cases
<39.1 °C
Anosmia
Stronger predictor of COVID-19 than self-reported fever amongst people in the community
Y |N
Pneumonia
Found in severe cases
Y |N
Acute respiratory distress syndrome (ARDS)
Found in severe cases. Different forms of ARDS are distinguished based on the degree of hypoxia. When PaO2 is not available, a ratio SpO2/FiO2 ≤ 315 is suggestive of ARDS
A formal representation tokens (features) of a new case (nc) of coronavirus (COVID-19).
Raw Features Buffer (RFB): This last component simply buffers the output of raw features collected from previous layers. The RFs buffered in RFB are then translated into ontology formalism described in Section 4.2.
The features described in Table 1 were based on recent studies on COVID-19 that were discussed by Michelen et al. [28] and Yang et al. [55].
3.3. Ontology-based formalization of extracted features
In this stage of our proposed CBR-framework, we processed the raw features buffered in the RBF component of Fig. 2 into ontology formalism. Recall that the proposed framework relies on the CBR paradigm to reasoning over the cases presented to it. Hence, each case was modeled using a formalism supporting computational reasoning operation. Fig. 4 demonstrates an illustration of a case denoted by Case N. We assumed that based on clinical protocols of COVID-19, a case representation must have a relationship to Diagnosis Case (Suspected, Confirmed, Presumed status); Symptoms (as listed in Table 1); Epidemiology (as listed in Table 1); Radiology/Laboratory manifestations (as listed in Table 1); Clinical Diagnosis (Mild, Acute, Severe); and Treatment (as listed in Table 1). Each case of COVID-19 extracted by the NLP pipeline described in Fig. 2 was formalized into this structure, as illustrated in Fig. 4. The Diagnosis Case entity assumes a 1-1 relationship with every case; Symptoms, however, presents with a 1 to many (1-M) relationship for each case; also, the Epidemiology entity allows each case to manifest one-many (1-M) relationship; the Radiology/Laboratory manifestations entity also presents each case in a one-many (1-M) relationship given the number of lab tests and radiological operations that might be exercised for each case; Clinical Diagnosis, however, allows for one-one (1-1) relationship due to the fact that a case can only assume one of the states listed in clinical diagnoses. Finally, the Treatment entity allows for one-many (1-M) because one case may respond to one or more treatment/therapy administered to it.
Moreover, each entity illustrated in Fig. 4 consists of variables/features which are expected to have values. For instance, considering the Symptom entity, it may have variables/features like Cough, Fever, Chest Pain and others. Each of those variables is expected to take values from a particular data type. Hence, potential data types as captured in Fig. 4 are numeric, nominal, ordinals, datetime, and Boolean (which forms the most extensive representation for most values of variables in the representation).
3.4. The CBR model
All previous stages of the proposed CBR-based framework may be classified as data/input pre-processing and formalization operations. However, the main reasoning task is embodied in the CBR engine to be described in this section. Meanwhile, we shall first present a brief description of some status or clinical types of COVID-19 based on clinical presentation [29]:
Mild case: Upper respiratory symptoms such as pharyngeal congestion, sore throat, and fever for a short duration or asymptomatic infection; Positive RT-PCR test for SARS-CoV-2; no abnormal radiographic and septic presentation.
Moderate case: Mild pneumonia; symptoms such as fever, cough, fatigue, headache, and myalgia; and absence of complications and manifestations related to severe conditions.
Severe case: A case presenting with mild or moderate clinical features described above; rapid breath (≥70 breaths per min for infants aged <1 year; ≥50 breaths per min for children aged >1 year); hypoxia; lack of consciousness, depression, coma, convulsions; dehydration, difficulty feeding, gastrointestinal dysfunction; myocardial injury; elevated liver enzymes; coagulation dysfunction, rhabdomyolysis, and any other manifestations suggesting injuries to vital organs.
Critical illness case: Respiratory failure with need for mechanical ventilation, persistent hypoxia that cannot be alleviated by inhalation through nasal catheters or masks; septic shock; organ failure that needs monitoring in the ICU, and acute respiratory distress syndrome (ARDS). Cases presenting with ARDS may show:
i.
Mild ARDS: 200 mmHg < PaO2/FiO2 ≤ 300 mmHg. In not-ventilated patients or in those managed through non-invasive ventilation (NIV) by using positive end-expiratory pressure (PEEP) or a continuous positive airway pressure (CPAP) ≥ 5 cmH2O.
ii.
Moderate ARDS: 100 mmHg < PaO2/FiO2 ≤ 200 mmHg.
iii.
Severe ARDS: PaO2/FiO2 ≤ 100 mmHg.
These clinical types of COVID-19 have been described to allow for their use in the CBR engine, which will be described below.
The CBR method is a reasoning paradigm that depends on a knowledge base of archived cases that have been proven and tested with valid solutions for handling new cases/problems which may share similar features with those archived. As earlier stated, this study builds on this paradigm to carry out the detection and diagnoses of COVID-19 in patients manifesting symptoms of the disease and those presenting with asymptomatic cases. Fig. 5
illustrates our concept of the CBR engine embedded in Fig. 1. The major components of the model are similar to the conventional CBR model, which usually consists of the RETRIEVE, RESUSE, REVISE, and RETAIN steps (4Rs). In addition, the model shows the knowledge base of archived cases which allow for carrying out computational reasoning on the new case presented. The distinctiveness of our proposed CBR model lies in its ability to model its cases using ontology formalism and as well to measure the similarity of cases using features listed in Table 1 and two other important factors: time (temporal) and spatial (location). We shall detail the operations in each level of the 4 R s in the following discussion.
A model of the proposed case-based reasoning (CBR) used in the NLP-Ontology oriented Spatial temporal framework for detecting COVID-19.
3.4.1. Retrieve
Based on the general concept of the CBR paradigm, the RETRIEVE procedure/algorithm simply uses some efficient distance or similarity computation models like the Euclidean distance, Cosine Similarity [30], and Manhattan distance. Our approach for the procedure of the RETRIEVE algorithm is described as follows: Consider new case nc and an archive of stored cases in the CBR knowledge base SC = {sc1, sc2, sc3….scn} such that the CBR model RETRIEVE the most similar sci or some sci from SC. However, the process of retrieval of some sci depends on Eq. (1). The smaller the value of Sim(nc, sci), the more acceptable the case sci becomes for adoption for REUSE. Here is a summary of procedures in the RETRIEVE step:
i.
Query generator and parser are used to construct a query that will fetch all similar cases from the case archive SC. The queries are generated based on the extracted features in the previous stage of the framework described in Fig. 8.
ii.
Semantic Query Web Rule Language (SQWRL) (details later) is employed for modeling the constructed query in the preceding step.
iii.
The output resulting from the SQWRL query is sorted in the order of the most similar to the least similar cases. Cases are assumed to be similar if their measure of look alikeness (based on the corresponding features) is non-negligible. The smaller the value of the similarity, the higher the likelihood of the new case (nc) to share close similarity with a sci or some sci, while the bigger the value of the similarity/distance metric, the lower its tendency to match up with nc.
iv.
Hence, our problem can, therefore, be modeled as a classification problem whereby some sci SC are classified to share some similarity with nc while another class of some sci
SC are categorized as dissimilar cases based on attainment of a threshold. For instance, if some sci
SC results in a meagre similarity value, say k where k < (threshold/4), then such cases are not used. Execution of clinical similarity of cases is done by steadying the computation within the range of [0, 1] using the following equations:
•
Euclidean distance: Describes the length between two points and is the most used distance/similarity metric with most appropriate for cases with continuous or dense data. Eq. (1) models Euclidean distance.
(1)
•
Cosine Similarity: This similarity metric measures the dot product of the two features compared. Based on the cosine computation which yields 1 for 00 and less than 1 for other degrees, it implies that a cosine similarity of 1 signals that features A and B are similar cases while a cosine value of −1 indicates non-similarity. Eq. (2) models Cosine similarity which has strong application in data with sparse vectors. Besides, the Cosine similarity (CS) can perform that Euclidean distance (ED) in cases where ED sees two cases to be distantly similar; CS might observe a closer similarity among the two cases based on their oriented closeness.
(2)
where and are the Euclidean norm of vector and Euclidean norm of vector respectively, and vector defined as ||x||2 = .
•
Manhattan distance: Another similarity or distance metric, also known as Manhattan length measures distance between points along an axis at a right angle. Eq. (3) models Manhattan distance.
(3)
•
Other similarity measures are the Jaccard similarity (use for sets), inverse exponential function and Minkowski distance equations. The inverse exponential function is given by
A visualization of ontology representation of relations of concepts (TBox) in a domain-based knowledge repository of COVID-19 using the is-a relationship.
Now, because our cases in the proposed framework were modeled/formalized in ontology representation, there was a need to be able to carry out quantitative measures of similarity between features of cases, hence the need to use ontology-based semantic similarity between terms. There are six (6) significant techniques for computing such similarities of features in ontology: ontology hierarchy approach, information content, semantic distance, approach based on properties of features, an approach using ontology hierarchy, and hybrid methods [31]. Therefore, to compare two cases, we make the following assumptions:
i.
Two cases are similar if their ontologies demonstrate similarities in both feature values and structure (of their ontological representations).
ii.
That an arbitrary weight wi value is assigned to each property (object and data properties) which may sum up to at most a particular maximum value say M1 in other to represent a case. For example, all properties (denoting object properties) as shown in Fig. 4 from the Case node to the first lower nodes (Diagnoses Case, Symptoms, Epidemiology, Radiology/Laboratory, Clinical Diagnoses, and Treatment) each is assigned a weighted value. Similarly, data properties from the second level lower nodes (Diagnoses Case, Symptoms, Epidemiology, Radiology/Laboratory, Clinical Diagnoses, and Treatment) to the leaf nodes (values) also have weight values summing up to a value which is ≤ a maximum value M2. For instance, the presentsSymptom (object property) may have weight 0.3, hasEpidemiology (object property) may have such that each symptom weight is 0.2, and so on until all second level nodes have weights. However, a case may present n features (with relation to data property on the second lower level) associated with the presentsSymptom object property, i.e a case with symptoms: cough, fever, anosmia and ARDs. So, we compute di.fwi where fwi where f denotes weight of each symptom (cough, fever, anosmia and ARDs) and the weight of the data property denoted by di. This is shown in Eq. (6), which indicates the summation of all (di.fwi). We normalized all level-based weight summations to be 1, so that sum of weights at the three levels evaluates to 1 such that di.fwiimplies 1*1*1 = 1.
Note: all our objects (such as presentsSymptom and hasEpidemiology) and data type properties are detailed and discussed in Section 4.3.
Now that we have established our distance/similarity functions and underlying assumptions for case retrieval, here is the formula for computing similar cases in the archived compared to the new case (nc). This study adopts the approach based on properties and features described in Ref. [32]. The adapted similarity measure is that of Tversky (1977), as shown in Eq. (5):
(5)
The model in Eq. (5) assumes that nc and sci are cases whose features are collected in D1 and D2, respectively. Therefore, the similarity between nc and sci is computed using three components of Eq. (5): distinct features of nc to sci, distinct features of sci to nc, and common features of nc and sci, for 0 ≤ ≤ 1, a function that defines the relative importance of the non-common features. D1 and D2 represent the target and the base respectively while || stands for the cardinality of a set. Although we approve of the similarity model in Eq. (5), we, however, saw its limitation, which is based omission of the effect of weight on selected features. Therefore, we modified Eq. (5) so that we do not use the elements of the set alone, but the weight-value of the elements in each Di which is computed by Eq. (6). Hence, our modification to Eq. (5) is shown in Eq. (7), afterwards, the most similar sci is RETRIEVE and forwarded to REUSE after applying Eq. (8).where D1 or D2 are computed using Eq. (6):
(6)
(7)
According to Eq. (6), the resulting value of is expected to be numeric. Hence, represents the computation of the values of data property (di), object property (wi) and all f after obtaining common features between nc and sci. Similarly, represents the computation of the values of di, wi and all f after a set difference of those features of nc and sci. Hence, in both cases, we compute values resulting from obtainable features from their respective set operations.
Furthermore, since represents our similarity between a new case (nc) and an arbitrary case in the archived, we can compute the similarity score (SS), also known as the degree of similarity between nc and sci using Eq. (8).
(8)
where is pre-computed threshold value representing a maximum summation of all possible features, a case can have, which in our case . The closer is to zero (0) the more similar nc and sci will be. Hence, cases with close to are similar to nc, and as a result, such cases are retrieved. Our approach finds cases with higher similarities to the new case by discarding cases with low similarity values. Then their solutions are utilized to solve the problem. The higher similarity conditioned is measured by Eq. (9) which narrows the number of retrieved cases such that only . In our case, we assumed that since the similarity measures of the best similar cases should be close to 0, acceptable SS () should, therefore, have minimal reduction such that it tends close .
Logically, we can assume that 0.9 is closer to 1.0 than 0.5. Therefore, a retrieved case with close 1.0 is enlisted as an element of while the remaining retrieved cases are classed into .
(9)
where is a function that evaluates close to . Meanwhile, if no case is retrieved by Eqs. (7), (8)), we then conclude that nc might not have any similar case.
We further compute SS for positive cases and apply Eqs. (10), (11)) to determine the following: When the case is classified as a positive case of COVID-19, while if the case is concluded to be negative. However, an evaluation of indicates inconclusive diagnoses, therefore necessitating more similar case(s) to be retrieved.
(10)
(11)
3.4.2. Reuse
The REUSE procedure allows the system to modify the RETRIEVE cases sci in such a manner that we have only one similar case. The similar case is constructed to maintain a similar ontology structure with the nc case. This is achieved by rebuilding an anonymous case (ac) by extracting all similar features of the presented cases in sci until ac assumes the form of nc. As such the modified ac is presented as a temporary solution to nc. The approach proposed here is different from methods used by Gu et al. [33], which relied on clinical protocols guidelines and medical experts, respectively. The ac case is therefore considered a solved case which will be passed on to the REVISE step for processing.
3.4.3. Revise
The evaluation of ac case at this stage is achieved by ensuring that the summation of case features of the proposed solution case is not greater than 1. If they evaluate to more than 1, some non-essential features are dropped and the weights of the features are recomputed until an appropriate value is obtained. The revised and evaluated case now becomes a candidate case for use, and it is called the repaired case (rc). Furthermore, rc is then used to solve the new problem nc presented to the system by presenting it as a candidate solution for adaptation by the physician. The solution to nc is passed to the RETAIN.
3.4.4. Retain
Finally, the RETAIN procedure simply stores the solution to nc as a case that has been learned and is fit to be stored/added to the knowledge base of CBR model for future use. However, it is not all new cases that need to be stored. We propose a retention policy that simply retains solution with tangible difference or improvement from those solutions already archived in the system.
3.5. Algorithm for case retrieval
Algorithm 1 details the complete procedure outlined in proceeding subsections, and describes how a new case of COVID-19 is classified as a positive or negative case using the CBR method. The input to the algorithm is an HER of the new case, and the out is Diagnoses Case (Suspected, Confirm, Presumed status).
Algorithm 1
Pseudocode using NLP-Ontology CBR framework for detecting and diagnosing COVID-19
In addition, Algorithm listing 2 outlines the procedures for ontology learning/population to formalize suspected cases which are presented in natural language representation. The procedures described in Algorithm 2 were defined at a high-level in Algorithm 1. Whereas Algorithm 1 describes a flow of data in the framework in Fig. 1, Algorithm 2, however, details the task of translating raw text in natural language (English) into ontology formalism (ontology learning). The task of ontology learning here is simply to learn terms/concepts and their instances from raw natural language text. The learned concepts are encoded as terminology box (Tbox) whiles their instances, and assertions (class and object) are encoded in the assertion box (Abox). Although Section 4.3 describes the domain ontology (largely the Tbox) engineered in this study, we however note that this does not include the formalization of unknown suspected cases of COVID-19 which the framework needs to translate into a feature-based representation.
Algorithm 2
Pseudocode detailing the ontology learning/population approach for case-to-feature representation
In this section, the clinical data and experimentation environment used in this study are described. In addition, we develop the domain ontology (for COVI19 and other related COVID-based diseases) and also the case-based ontology for new cases. Finally, we demonstrate the implementation of the framework, as shown in Fig. 1.
4.1. Clinical data
The COVID-19 pandemic is currently a global emergency with limited access to health facilities and computerized patient records, which could have allowed access to datasets for computational research. Although there are statistical-based datasets accessible in the forms of structured, semi-structured, and unstructured (e.g. WHO, Johns Hopkins University, mainstream news media, and even social media), however, such datasets are still unfit for tasks, including the one described in this study. After a thorough search for publicly available patient HER-based benchmarked datasets of COVID-19 with none accessible, we decided to adopt the approach of curating new datasets of COVID-19 from some open data on standard domains.
The data curated was obtained from the Italian Society of Medical and Interventional Radiology (SIRM). SIRM is a scientific association which includes the majority of Italian radiologists and is targeted to encourage the progression of diagnostic imaging by promoting studies and research. The data source (https://www.sirm.org/en/italian-society-of-medical-and-interventional-radiology/) listed English-like records (itemizing age, symptoms and signs manifested, and other laboratory details) and CT scans for each of the seventy-one (67 cases of adults and 4 cases of pediatrics which were lumped into one case) COVID-19 patients. We anonymized and cleaned the datasets where necessary, and extracted the essential information, storing them in a format appropriate for this study. Fig. 6
shows the snapshots of a randomly selected case.
Dataset of a sample case of COVID-19 showing some English-like statements extracted and samples of CT scans and X-ray performed on the patient.
The data needed for this study is the EHR-based datasets in natural language (NL) format. Hence, we focused on processing the English-like statements extracted for each patient leaving the image-based for future study using the approach of deep learning for classification of COVID-19 cases.
A careful examination of the curated datasets revealed that only 2 cases (case numbers 51 and 60) were confirmed negative, 19 cases (case numbers 6, 13, 14, 15, 17, 33, 38, 45, 47, 53, 54, 58, 59, 62, 66, 67 and three pediatrics cases) were presented as unconfirmed cases and the remaining 50 cases were confirmed positive cases. We, therefore, modeled the 2 negative and 50 positive cases accordingly in the archive of the CBR-engine. The 19 unconfirmed cases served as input for our framework. Furthermore, we normalized medical records of the positive and negative cases, removing the diagnosis made by physicians and passed each of them as input into the proposed CBR framework. This allows for subjecting our system to a similar examination carried out by the experts.
4.2. Computational environment setup
The implementation was on a personal computer with CPU of Intel (R) Core i5-4210U CPU 1.70 GHz, 2.40 GHz; RAM of 8 Gbytes; Windows 10 OS. Furthermore, we deployed Anaconda shipped with Python 3.7.3, SPIDER 3.3.6, and also installed NetBeans IDE version 8.1. The Python platform allows for the implementation of the NLP feature extraction pipeline shown in Fig. 2. At the same time, the NetBeans IDE provides support for implementing the feature to ontology representation and also the CBR-engine. Modeling of ontologies in this study was achieved using Protégé (Protégé).
4.3. Domain ontology modeling
Ontologies are a formalism for specification of concepts or abstract description of a system in a domain-specific knowledge composition. Ontologies as formalism stem from description logic (DL) and with support for reasoning it has received or has caused it to receive more and more attention in computational biology and bioinformatics. There are different ontology languages like RDF/RDFS, DALM + OIL, and OWL. OWL is a DL-based ontology language with high expressivity and has three variants: OWL-DL, OWL-full and OWL-lite. This study models ontology using OWL2 [34, 23], which is an improved version of OWL (sometimes known as OWL1). We have modeled three different ontologies: the first represents domain knowledge, the second is a formalism of the archived cases, and the third ontology formalizes new cases.
In Fig. 7
, we show a visualization of the ontology representing a new case (nc). The ontology captures concepts/classes like Symptoms, ClinicalDiagnosis, ClinicalManifestation, Epidemiology, RadiologyFeatures, LaboratoryFeatures Case (to denote a new case), DiseaseCase, Cause (to capture the likely causes of the disease in a case), and Treatment (which represents treatments administered to a case). Each of these concepts is related/linked to another concept by a property (object property) with almost all ideas linked to Case. To the right is a list of the object properties. For example, the line connecting Case to Symptoms is the object property presentSymptom. The Case is the domain while Symptoms is the range for the object property presentSymptom. Some concepts have the + symbol at the top-leftmost corner of their bounding boxes. This is an indication that there are other subclasses in that concept/class which can be revealed by clicking on the + symbol.
Ontology representation domain-based mapped tokens (features) of a new case of coronavirus (COVID-19): New Case (nc).
Case formalization is therefore made possible through the Case-Based ontology file shown in Fig. 7. While that illustrates a case of COVID-19, we made a further effort to use an ontology approach to model the archive of stored cases in the CBR engine. To archive this, we represented the structure and the semantic of the information content of such archive using the ontology visualized in Fig. 8. As mentioned earlier, the ontology file was modeled and visualized in Protégé (Protégé). The ontology consisted of 459 axioms, 225 logical axioms, 213 declaration axioms, 196 Class, 11 object property, 8 data type property, 181 subclasses, and 15 instances (except for cases of COVID-19 which forms the archive of cases in the ontology). Fig. 8 captures the is-a relationship existing among classes, and Fig. 9
outlines all the classes (and their hidden subclasses), instances (individuals) of the declared classes, object and datatype properties.
A listing of concepts (classes), individuals (instances of classes), object properties and datatype properties modeled in a domain-based knowledge repository of COVID-19.
Now that we have formalism for archiving all cases in the proposed framework and also a formalism for modeling new cases extracted from electronic records, we shall consider how the proposed approach will implement its query for similar cases as modeled using mathematical models in item A of subsection 3.4. To archive an optimized and effective query of cases from the archive, we decided to construct our query from the mathematical models presented earlier using Semantic Query-Enhanced Web Rule Language (SQWRL), pronounced squirrel. SQWRL is a query language primitive to OWL and also an SWRL-based with the syntax of SQL-like and having operators for extracting information from OWL ontologies [35,36]. We chose SQWRL over SPARQL because of its suitability for use in OWL ontologies since it does not require serializing our OWL ontologies in RDF/RDFS, an operation which often causes a knowledge-base (ontology) to lose some semantics and expressivity as a result of serialization. Moreover, the rule-form of SQWRL and its compatibility with the rule language SWRL allows for improving our framework to use the inference engine, thereby improving the knowledge-base through inference. Protégé also provides a tab for executing our SQWRL queries against the ontology through the SQWRLTab plugging. We may take advantage of this tab to test our generated queries, although the framework proposed in this study has a mechanism for doing the query execution automatically through OWLAPI.
Now for instance, given a new case (nc) presenting with the following features according to their category, we might be interested in translating our mathematical model into an SQWRL query such that similar cases are retrieved: Symptoms (Cough, Temperature, Nausea and vomiting, Shortness of breath, Contact with case(s)); Laboratory Features(Neutrophil, Lymphocyte, Active partial thrombin time);
The following conditions can be assumed from our case: retrieve all cases according to their value of similarity (in descending order), which have values for all or some of the features: Symptom (Cough, Temperature, Nausea and vomiting, Shortness of breath, Contact with case(s)); Laboratory Features (Neutrophil, Lymphocyte, Active partial thrombin time). In Fig. 10
, we present a sample SQWRL-query for extracting similar cases compared to the new case example described here.
A sample SQWRL query constructed to retrieve similar cases corresponding with the new case (nc) accepted as input.
The sample query in Fig. 10 was submitted to the Protégé application for execution and query of the underlying ontology through the SQWRLTab plugins. The syntax of the SQWRL query language aligns itself to the declared classes or entities, properties (both data type and object), and instances/individuals on the ontology. This is why you will observe that the predicates (unary and binary) names in the listed query in Fig. 10 derive their values from the declared classes or entities, properties (both data type and object), and instances in the ontology. This positions the SQWRL query above the use of SPARQL. A detail explanation of the query given in the following lines:
The first line Case(?c) ^ has CaseID(?c, ?cid) extracts all cases and their case IDs from the CBR case archive and stores those two values in the ?c and ?cid variables. Furthermore, the second lines 2–5 of our query select instances of the following symptoms which were keywords/features extracted from the natural language input above: Cough, Temperature, Vomiting, and Shortness of breath, and their weight values. This is summarized in the following lines:
Also, our natural language based query has some laboratory features which we also extracted their values for each of the cases retrieved due to the query on line 1. These laboratory features are queried as follows:
Now that all existing cases in the archive satisfying the above conditions have been retrieved, we further limit the cases to be extracted to the conditions below:
The first and second lines simply ensure the cases retrieved have the time/date when the case manifested and either died or recovered. Line three also allows each case to fetch the result of its clinical diagnosis (Positive or Negative diagnosis). Finally, the respondedTo(?c, ?tr) predicate fetches the treatment (if any) options recorded against each case.
Once all these cases are matched by the rule-like left-hand-side (LHS) of our query (a simulated of semantic web rule langue SWRL), the right-hand-side (RHS) uses the sqwrl:select predicate to fetch all cases (and their attributes/features) satisfied by LHS using the variables. Hence the lines below:
Finally, we are interested in counting the number of cases retrieved after ordering them according to their case IDs. The line of query below does this:
All cases retrieved by the sample query above must have its features represented in the ontology for the query to be able to match them. Case representation is covered in Section 3 of this paper, however, we have captured in Fig. 11
, a formalization of sample patient record shown in Fig. 6. The case representation shown here is a Protégé interface format of the case, although the ontology notational is equally generated.
An illustration of case representation as shown in Protégé for cases a 1, 2, and 3 from the 68 cases extracted from the data source.
4.4. Implementation and experiments
The implementation of the CBR framework proposed in this study adopted JCOLIBRI [37]. JCOLIBRI is a library containing APIs for implementing a CBR framework and is written in Java. As a result, we employed the use of Java programming language to integrate with the JCOLIBRI to achieve the steps in the CBR (shown in the right box or component of Fig. 12
). Python programming to implement the natural language to Normalized Sentence Component (NL-NSC), and finally, the combined use of the two languages made the implementation of the feature extraction and formalization components of Fig. 12 possible.
A graphical user interface (GUI) showing the major components of the proposed CBR-based framework for classifying cases of COVID-19 as either positive or negative case.
The complete implementation of the proposed framework is accessible through a graphical user interface (GUI) designed for this study and shown in Fig. 4. The file loader and raw text extraction component of Fig. 2 are implemented in the rightmost panel with a box and ‘Open Case File’ button in Fig. 12. Furthermore, from Fig. 9, the center panel containing a box and ‘Map Case’ button captures the implementation of the NL-NCS, feature extraction, and feature formalization components identifiable from Fig. 4. To achieve this, standard Python libraries and NL-based libraries (like NLTK and Stanford CoreNLP) were richly employed to carry out the tasks of sentence disambiguation, spelling correction, lexical normalization, and normalization of sentences into their corresponding structures or components, and tokenization of sentences to enhance the process of feature mapping. However, the feature mapping and formalization of cases in ontology format were achieved using OWLAPI, Wordnet API, and Pellet API (an OWL-based knowledge reasoning plugin) which were implemented through skillful use of Python and Java.
The result of the extracted and mapped features presented us with a challenge of accurately extracting values from the processed patient record. For example, we could have extracted features like ‘Fever’, ‘Temperature’ and so many other features which mostly rely on syntax and semantic parsing of domain lexicon. But the challenge we were faced with was detecting the semantics/meaning and context of usage of the features from the patient records. To circumvent this, we took advantage of the named entity resolution technique we applied to the text.
At a sentential-level, an attempt was made to search for values of features within the neighborhood of that feature. For instance, given the sentence:
‘The temperature of the patent was 38oc’, careful parsing of the sentence using NLP technique will reveal that the feature (temperature) has 38° Celsius. But consider the sentence:
‘80-year-old male patient with fever and dyspnea.’
There are two features in the sentence (fever and dyspnea) which do not have an explicit declaration of values assigned to them. In cases like these, we developed a sentiment analysis component which enabled us to detect if such features were stated in the affirmative or negative form. The outcome of our sentiment analysis model outputs was: positive, negative and neutral. These outputs were used accordingly to formalize the feature and its value (true or false, as shown in Fig. 9 and Table 1) in the ontology.
The leftmost panel of Fig. 12 illustrates the implementation of the feature extraction and formalization process. This CBR-engine and the mathematical model presented in Section 3 were implemented with Java using the jcolibri API which models the Retrieve, Retain, Revise, and Reuse (4Rs) of CBR paradigm, allowing for users to adapt it to their frameworks. Meanwhile, we have also added a panel for monitoring the procedures for detection of the status of any presented case of COVID-19; this monitoring begins with file loading component to the CBR-engine processes.
Experimentation using the datasets discussed in Section 4.1 revealed that the implementation of the proposed CBR framework was successful. Fig. 13, Fig. 14
show a demonstration of the File Loader and Feature Mapping components of the CBR framework. Meanwhile, the process of formalizing feature-value relationship was monitored and is shown in the Progress Monitoring panel in Fig. 15
. Lines delimited and prefixed by the <<<Derived>>> symbol represents components of the generated new case ontology learnt by our Algorithm 2. Each line is an assertion resulting from the features extracted from the input raw-text.
A demonstration of the formalization of feature-value extracted in ontology representation.
The progress monitoring panel output shown in Fig. 15 demonstrates how Algorithm 2 successfully extracts features from the first sentence of the patient record shown in Fig. 6. The output is then further translated into an ontology formalism representing the new case (or new problem) the CBR model receives as input for further extraction of similar cases using SQWRL-based query as illustrated in Fig. 10.
The CBR-engine then accepts the ontology representation of the new case for the purpose of reasoning operation. The task of classification of any suspected case of COVID-19 model in Fig. 15 now rests on the CBR-engine, which is detailed in Section 3.5. In Table 2
, the solution to the unconfirmed 19 cases is presented.
Table 2.
Detail of the solution to the 19 unconfirmed cases in the dataset applied to this study.
After a complete testing of the implemented framework using our datasets, we discovered that the classification accuracy of the improved CBR model yielded an interesting result as shown in Fig. 16
.
Result of diagnosis of a case of COVID-19 showing the status (positive or negative), clinical diagnosis (acute, mild or severe), estimated duration (in days), and likely treatment.
5. Result and discussion
In this section, we present the performance of the proposed CBR framework compared to the performances of other similar systems. The following are the metrics and their corresponding formula used in analyzing the performance described in this section.
i.
Accuracy= (TP + TN)/(TP + TN + FP + FN)
ii.
Specificity = TN/(TN + FP)
iii.
Sensitivity = TP/(TP + FN)
iv.
Precision = TP/(TP + FP)
v.
F1=(2*Recall)/((2*Recall)+FP + FN)
vi.
F=(2* Precision * Recall)/(Recall + Precision)
vii.
Recall = TP/(TP + FN)
Note that the following are the derivations for the TN, TP, FN, and FP:
TN = Suspected cases of COVID-19 which both the proposed CBR framework and the curated dataset presented concluded to be negative cases of COVID-19.
TP = Suspected cases of COVID-19 which both the proposed CBR framework and the curated dataset presented as being positive with COVID-19.
FN = Suspected cases of COVID-19 which the proposed CBR framework concluded to be negative cases of COVID-19 while the curated dataset presented as being positive with COVID-19.
FP = Suspected cases of COVID-19 which the proposed CBR framework presented as being positive with COVID-19, while the curated dataset shows negative cases of COVID-19.
5.1. Comparison of the ontology of the systems with others
The ontologies developed in the research are very tangible in enhancing the performance of the proposed CBR framework. However, to measure the performance and importance of the knowledge representation formalism used in this study, we resolved to compare the efficiency of the proposed ontology with other related ontologies used in related studies on CBR by using the following metrics:
i.
Class Complexity: Average number of paths to reach a class from the Thing class
ii.
Property Complexity: Average number of semantic relations for object properties per class
iii.
Abstraction: Average depth of the ontology
iv.
Cohesion: Average number of connected classes
v.
Semantic richness: Ratio of the total number of semantic relations mapped to classes, by all ontology relations consisting of object properties and subsumption relations.
vi.
Inheritance richness: Average number of subclasses in a class. Describes the fan-out of parent classes, in other words, whether the ontology graph is broad or deep
vii.
Attribute richness: Ratio of the total number of data type properties by the number of classes. It also shows the average number of attributes defined per-class within the ontology
viii.
Relationship richness—‘reflects the diversity of relations', by comparing the number of non-subsumption relations to the number of subsumption relations (which stipulate specifically that one class is a sub-class of another)
ix.
Comprehension of properties (object and data type): Percentage of annotation of the features in the ontology
x.
Comprehension of classes: Percentage of annotation of the classes in ontology
Based on these metrics, the performance measurements in the following subsections are presented. Table 3
shows the derivation and description of the metrics used in computation of results in Table 4
.
Table 3.
An outline of metrics and with their respective counts in the COVID-19 ontology modeled in this study.
Metrics
Number of items
Description
Classes
179
sets, collections, concepts, types of objects or things
Class axiom
169
Class-based statements that are asserted to be true in the domain being described: e.g Subclass, Equivalent class, Disjoint class
Individuals
592
An instance of a class
Individuals (Object property assertion)
545
Statements made using object properties and individuals
Individuals (Data property assertion)
1080
Statements made using data properties and individuals
The results of Table 4, Table 5
shows the richness of the axioms, properties (object and data type) and instances of the proposed ontology used in this study.
Table 5.
An evaluation of some related ontologies based on the contents of their terminology box (Tbox).
5.2. Presentation of the accuracy, sensitivity and specificity of the proposed approach
In this section, we present the performance of the proposed CBR model using diagnosis metrics like accuracy, specificity, sensitivity, precision, recall, and F1-score. The choice of these metrics was informed by the peculiarity of the relationship of the values with the disease. For instance, diagnostic accuracy metric was used to evaluate the ability of a diagnostic test to correctly identify a target condition (COVID-19 in this case). This metric mainly is very applicable to cases of diagnoses in medicine since it allows for increased confidence and acceptability of results. In addition, the accuracy of diagnosis could help to determine the difference between life and death, so that a system which outperforms another may be seen from an improved accuracy, which also leads to the reliability of diagnoses results. Other metric considerations for performance measure in this study were sensitivity and specificity, which are also referred to as True Positive Rate (TPR) and True Negative Rate (TNR) respectively. Sensitive and specificity of our system as shown in Table 6
, implies the number of COVID-19 cases with the condition who had a positive result, and the number of COVID-19 cases who did not have the disease and had a negative result respectively. The relationship between these two metrics with respect to the accuracy of diagnosis is that the latter allows for the evaluation of the former.
Table 6.
Performance evaluation of the proposed CBR framework using the accuracy, sensitivity, specificity, precision, recall and F1 score.
Looking at the results of the metrics above as presented in Table 5, we discovered the proposed CBR framework had good accuracy. In addition, the sensitivity and specificity value indicated that our system was able to correctly classify cases of COVID-19 as either positive or negative, respectively. The precision value means that an average of 2 COVID-19 cases can be effectively detected by the proposed CBR framework as negative, while the remaining 8 out of 10 cases are positive. Similarly, the recall value is 99% which means that approximately 10 out of 10 cases of COVID-19 are correctly classified as positive. F1 score presents the ability of our framework to classify the cases of the disease since the metrics represent a harmonious mean of precision and recall. The precision and recall results, therefore, portray the relevance of positive cases and the proportion of correct positive cases are respectively. These are sometimes referred to as Positive Predictive Value (PPV) and True Positive Rate (TPR), respectively.
In the next section, we shall compare the performance recorded by the proposed CBR framework with similar studies.
5.3. Comparing the proposed approach with similar methods
A comparative analysis of the performance of our proposed approach was carried out with other case-based reasoning studies. Although the domain of application of the CBR models reviewed differs (medical and non-medical), we discovered that the most important factor lay in the formalism of cases and condition and similarity measures for retrieval of similar cases. An approach of CBR with dominance in the list of studies reviewed using fuzzy logic and those whose cases used ontology for formalism purpose. Also, we observed that some studies investigated the peculiarity and importance of different similarity metrics like Euclidean distance, cosine similarity and others. The effect of such choice of similarity measure helped them to discover the performance effect of a selected metric. The decision of the selection of distance/similarity measure is sometimes influenced by the formalism in which case features are represented. Considering the wide adoption of the use of ontologies as a tool for formalizing cases and its features, we discovered that the interesting performance of this study must have drawn many benefits from the ontology approach for knowledge modeling. An interesting consideration made in this study which makes it outperform other similar works is the choice of a semantic and ontology-based similarity measure metric. We observed that this allowed for a better comparison of cases during retrieval.
Furthermore, the novelty of the approach proposed in this study lies in the framework, the algorithm proposed, the case similarity function/computation, and the case adaption/application of the CBR approach in handling novel Covid19 cases. In addition, we observed that the comparative work carried out with other similar studies in the last decade added to the impressive efforts of this study. Only our study adopted the use of NLP technique in a unique way (through the NLP model proposed) for the purpose of extraction of features represented in a presenting case. This allowed for non-partial automation of the process of diagnosis/detection/classification of cases. We argue that such an approach allows for an increase in the level of acceptance of the CBR paradigm. This deduction was made based on the popular manual approach for the extraction of cases and their features from documents represented using natural language. Although some fuzzy-CBR frameworks which were reviewed and compared in Table 7
demonstrate good performance, they are, however, surpassed by our model which combines the techniques of NLP and machine learning (sentiment analysis) in the extraction of features in any presenting case. As a result, we presume that an investigation into the hybridization of a CBR model using fuzzy logic, NLP and ontologies may yield a very encouraging performance, and thereby position CBR paradigm as a competitive option for reasoning tasks in artificial intelligence (AI).
Table 7.
A summary of some case-based reasoning (CBR) models and framework, and their domains of application, approaches/techniques used, description of approach and accuracy of the systems.
Studies [Ref]
Year
Approach used for reasoning or diagnoses
Domain of Application
Accuracy (%)
Proposed framework
2020
CBR and NLP, and Semantic Web
Detection and diagnosis of COVID-19 (Novel Coronavirus)
In any medical system, the result of diagnosis is more important because the patient has so much to lose when there is a misdiagnosis. So, both under-diagnosis and over-diagnosis are both errors in medical systems and have been a source of concern to wide acceptance for AI-based diagnostic and detection systems in medicine. While over-diagnoses may have to do with overstating the condition of the diagnosed case, under-diagnosis is a condition where a diagnosed case does not go on to cause any symptoms or ill-health. This can result in the blurring of the borders between health and disease. Therefore, a diagnostic accuracy helps to investigate how well a particular diagnostic test can identify a target condition, in comparison to a reference test. In this study, we carried out our comparison of the proposed CBR framework with other similar studies using diagnostic accuracy. As seen in Table 7, the accuracy of our framework outperforms those of previous studies we compared. Most impressive is the capability of our CBR framework to detect the novel coronavirus (COVID-19) at a higher accuracy. This, therefore, positions this study as a candidate for further improvement of CBR models in future works seeking to diagnose any family of the Coronavirus diseases.
6. Conclusion
This study is largely focused on adapting a CBR concept to the problem of classifying cases of COVID-19 as either positive or negative by using an NLP model for feature extraction. Furthermore, a modified case retrieval similarity metric that was applied to the CBR framework appeared to be an interesting contribution to the performance of the proposed system. Meanwhile, knowledge representation in the proposed framework was achieved using ontology-based knowledge formalization technique. Result obtained shows that our proposed framework demonstrated an interesting performance in comparison with similar state-of-the-art CBR studies using fuzzyCBR. This, therefore, positions our Natural Language Processing and Ontology Oriented Temporal Case-Based Framework for adoption and generalization to the problems of diagnoses associated with other medical purposes and diseases. In future, we intend to investigate the performance of our retrieval algorithm over different similarity and distance measure metrics. This will allow for future studies using ontologies and CBR paradigm to select or even combine similarity metrics effectively. Also, we intend to hybridize the proposed method with machine learning methods which allow for application classification algorithm such as SVM.
Declaration of competing interest
The authors declare that they have no financial nor personal interests that could have influenced the work reported in this paper.
Acknowledgement
We wish to clearly mention that no funding was received for this research and no acknowledgement required for the current manuscript.
References
1.Naudé Wim. Artificial intelligence against covid-19: an early review. IZA discussion paper No. 13110. https://ssrn.com/abstract=3568314 Available at: SSRN:
2.Pirouz B., Shaffiee Haghshenas S., Shaffiee Haghshenas S., Piro P. Investigating a serious challenge in the sustainable development process: analysis of confirmed cases of COVID-19 (new type of coronavirus) through a binary classification using artificial intelligence and regression analysis. Sustainability. 2020;12(6):2427. [Google Scholar]
3.Al-qaness M.A., Ewees A.A., Fan H., Abd El Aziz M. Optimization method for forecasting confirmed cases of COVID-19 in China. J Clin Med. 2020;9(3):674. doi: 10.3390/jcm9030674. [DOI] [PMC free article] [PubMed] [Google Scholar]
4.Ting D.S.W., Carin L., Dzau V., Wong T.Y. Digital technology and COVID-19. Nat Med. 2020:1–3. doi: 10.1038/s41591-020-0824-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
5.Vaishya R., Javaid M., Khan I.H., Haleem A. Artificial intelligence (AI) applications for COVID-19 pandemic. Diabetes & metabolic syndrome. Clin Res Rev. 2020;14(4):337–339. doi: 10.1016/j.dsx.2020.04.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
6.Leung G.M., Leung K. Crowdsourcing data to mitigate epidemics. Lancet Digit Health 2. 2020;4:e156–e157. doi: 10.1016/S2589-7500(20)30055-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
7.oton P.A. MIT Press; 1988. Using experience in learning and problem solving. [Google Scholar]
8.Bareiss E.R. UMI; 300 North Zeeb road, Ann Arbor, MI: 1989. Exemplar-based knowledge acquisition: a unified approach to concept representation, classification and learning. 48106-1346. [Google Scholar]
9.Gierl L., Bull M., Schmidt R. Case-based reasoning technology. Springer; Berlin, Heidelberg: 1998. CBR in medicine; pp. 273–297. [Google Scholar]
10.Blanco X., Rodríguez S., Corchado J.M., Zato C. Distributed computing and artificial intelligence. Springer; Cham: 2013. Case-based reasoning applied to medical diagnosis and treatment; pp. 137–146. [Google Scholar]
11.Vásquez-Morales G.R., Martínez-Monterrubio S.M., Moreno-Ger P., Recio-García J.A. Explainable prediction of chronic renal disease in the Colombian population using neural networks and case-based reasoning. IEEE Access. 2019;7:152900–152910. [Google Scholar]
12.Benamina M., Atmani B., Benbelkacem S. Diabetes diagnosis by case-based reasoning and fuzzy logic. IJIMAI. 2018;5(3):72–80. [Google Scholar]
14.Li Q., Guan X., Wu P., Wang X., Zhou L., Tong Y. Early transmission dynamics in Wuhan, China, of novel coronavirus–infected pneumonia. N Engl J Med. 2020;382(13):1199–1207. doi: 10.1056/NEJMoa2001316. [DOI] [PMC free article] [PubMed] [Google Scholar]
15.Wu J.T., Leung K., Leung G.M. Nowcasting and forecasting the potential domestic and international spread of the 2019-nCoV outbreak originating in Wuhan, China: a modelling study. Lancet. 2020;395(10225):689–697. doi: 10.1016/S0140-6736(20)30260-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
16.Johansson M.A., Apfeldorf K.M., Dobson S., Devita J., Buczak A.L., Baugher B., Moniz L.J., Bagley T., Babin S.M., Guven E., Yamana T.K. An open challenge to advance probabilistic forecasting for dengue epidemics. Proc Natl Acad Sci Unit States Am. 2019;116(48):24268–24274. doi: 10.1073/pnas.1909865116. [DOI] [PMC free article] [PubMed] [Google Scholar]
17.Tuite A.R., Fisman D.N. Reporting, epidemic growth, and reproduction numbers for the 2019 novel coronavirus (2019-nCoV) epidemic. Ann Intern Med. 2020;172(8):567–568. doi: 10.7326/M20-0358. [DOI] [PMC free article] [PubMed] [Google Scholar]
18.Mizumoto K., Kagaya K., Zarebski A., Chowell G. Estimating the asymptomatic proportion of coronavirus disease 2019 (COVID-19) cases on board the Diamond Princess cruise ship, Yokohama, Japan. Euro Surveill. 2020;25(10):2000180. doi: 10.2807/1560-7917.ES.2020.25.10.2000180. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
19.Liu Y., Gayle A.A., Wilder-Smith A., Rocklöv J. The reproductive number of COVID-19 is higher compared to SARS coronavirus. J Trav Med. 2020;27(2) doi: 10.1093/jtm/taaa021. [DOI] [PMC free article] [PubMed] [Google Scholar]
20.Hu Z., Ge Q., Jin L., Xiong M. 2020. Artificial intelligence forecasting of covid-19 in China. arXiv preprint arXiv:2002.07112. [DOI] [PMC free article] [PubMed] [Google Scholar]
21.Funk S., Camacho A., Kucharski A.J., Eggo R.M., Edmunds W.J. Real-time forecasting of infectious disease dynamics with a stochastic semi-mechanistic model. Epidemics. 2018;22:56–61. doi: 10.1016/j.epidem.2016.11.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
22.Johansson M.A., Apfeldorf K.M., Dobson S., Devita J., Buczak A.L., Baugher B., Moniz L.J., Bagley T., Babin S.M., Guven E., Yamana T.K. An open challenge to advance probabilistic forecasting for dengue epidemics. Proc Natl Acad Sci Unit States Am. 2019;116(48):24268–24274. doi: 10.1073/pnas.1909865116. [DOI] [PMC free article] [PubMed] [Google Scholar]
23.Ozturk T., Talo M., Yildirim E.A., Baloglu U.B., Yildirim O., Rajendra Acharya U. Automated detection of COVID-19 cases using deep neural networks with X-ray images. Comput Biol Med. 2020 doi: 10.1016/j.compbiomed.2020.103792. [DOI] [PMC free article] [PubMed] [Google Scholar]
24.Amin Kareem, Kapetanakis Stelios, Althoff Klaus-Dieter, Dengel Andreas, Petridis Miltos. 26th international conference, ICCBR 2018, Stockholm, Sweden, July 9-12, 2018, proceedings. 2018. Answering with cases: a CBR approach to deep learning. [DOI] [Google Scholar]
25.Keane Mark T., Kenny Eoin. Case-Based Reasoning Research and Development; 2019. How case-based reasoning explains neural networks: a theoretical analysis of XAI using post-hoc explanation-by-example from a survey of ANN-CBR twin-systems. In book. [DOI] [Google Scholar]
26.Dasgupta S., Padia A., Maheshwari G., Trivedi P., Lehmann J. 2018. Formal ontology learning from English IS-A sentences. arXiv:1802.03701v1 [cs.AI] [Google Scholar]
27.Christopher M.D., Surdeanu M., Bauer J., Finkel J., Bethard S.J., McClosky D. Proceedings of the 52nd annual meeting of the association for computational linguistics: system demonstrations. 2014. The Stanford CoreNLP natural language processing toolkit; pp. 55–60. [Google Scholar]
29.Cascella M., Rajnik M., Cuomo A., Dulebohn S.C., Napoli R.D. StatPearls Publishing LLC; 2020. Features, evaluation and treatment coronavirus (COVID-19) [PubMed] [Google Scholar]
31.Gan M., Dou X., Jiang R. From ontology to semantic similarity: calculation of ontology-based semantic similarity. Comput Syst Biol. 2013:11. doi: 10.1155/2013/793091. 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
32.Gu D., Liang C., Zhao H. A case-based reasoning system based on weighted heterogeneous value distance metric for breast cancer diagnosis. Artif Intell Med. 2017:1–51. doi: 10.1016/j.artmed.2017.02.003. [DOI] [PubMed] [Google Scholar]
33.Patel-Schneider P.F., Franconi E. International semantic web conference. Springer; Berlin, Heidelberg: 2012, November. Ontology constraints in incomplete and complete data; pp. 444–459. [Google Scholar]
34.Herman I., Horrocks I., Patel-Schneider P.F. second ed. 2012. December 11). OWL 2 web ontology language document overview.https://www.w3.org/TR/owl2-overview Retrieved April 19, 2020, from W3C: [Google Scholar]
35.O'Connor M.J., Das A.K. vol. 529. 2009. October. SQWRL: a query language for OWL. (Owled). 2009. [Google Scholar]
36.O'Connor M.J., Das A. Fifth international workshop. 2009. SQWRL: a query language for OWL, OWL: experiences and directions (OWLED) pp. 1–8. [Google Scholar]
37.Díaz-Agudo B., González-Calero P.A., Recio-García J.A., Sánchez-Ruiz-Granados A.A. Building CBR systems with jCOLIBRI. Sci Comput Program. 2007;69(1–3):68–75. [Google Scholar]
38.Kolodner J.L. An introduction to case-based reasoning. Artif Intell Rev. 1992;6(1):3–34. [Google Scholar]
39.Althoff K. Intelligent Information Systems Lab Institute of Computer Science University of Hildesheim; 2012. Case-based reasoning and expert systems. [Google Scholar]
40.Aamodt A., Plaza E. Case-based reasoning: foundational issues, methodological variations, and system Approaches. AI Commun. 1994;7(1):39–59. [Google Scholar]
41.Ben-Bassat M., Beniaminy I., Joseph D. vol. 13. 1998. Combining model-based and case-based expert systems; pp. 179–205. (Research perspectives and case studies in system test and diagnosis frontiers in electronic testing). (1) [Google Scholar]
42.El-Sappagh S., Elmogy M., Riad A.M. A fuzzy-ontology oriented case based reasoning framework for semantic diabetics diagnosis. Artif Intell Med. 2015:1–30. doi: 10.1016/j.artmed.2015.08.003. [DOI] [PubMed] [Google Scholar]
43.Heras S., Botti V., Juliana V. Agreement Technol. 2013. A knowledge representation formalism for Case-Based-Reasoning; pp. 105–119. [Google Scholar]
44.Rahim R., Purba W., Khairani M., Rosmawati R. November. Online expert system for diagnosis psychological disorders using case-based reasoning method. J Phys Conf. 2019;1381(1) 012044). IOP Publishing. [Google Scholar]
45.Zhong Z., Xu T., Wang F., Tang T. Text case-based reasoning framework for fault diagnosis and predication by cloud computing. Math Probl Eng. 2018;2018 [Google Scholar]
46.Zhang P., Essaid A., Zanni-Merk C., Cavallucci D. Case-based reasoning for knowledge capitalization in inventive design using latent semantic analysis. Procedia Comput Sci. 2017;112:323–332. [Google Scholar]
47.Shen Y., Colloc J., Jacquet-Andrieu A., Lei K. Emerging medical informatics with case-based reasoning for aiding clinical decision in multi-agent system. J Biomed Inf. 2015;56:307–317. doi: 10.1016/j.jbi.2015.06.012. [DOI] [PubMed] [Google Scholar]
48.Li S.T., Ho H.F. Predicting financial activity with evolutionary fuzzy case-based reasoning. Expert Syst Appl. 2009;36(1):411–422. [Google Scholar]
49.Petrovic S., Mishra N., Sundar S. A novel case based reasoning approach to radiotherapy planning. Expert Syst Appl. 2011;38(9):10759–10769. [Google Scholar]
50.Fan C.Y., Chang P.C., Lin J.J., Hsieh J.C. A hybrid model combining case-based reasoning and fuzzy decision tree for medical data classification. Appl Soft Comput. 2011;11(1):632–644. [Google Scholar]
51.Begum S., Ahmed M.U., Funk P., Xiong N., Von Schéele B. A case‐based decision support system for individual stress diagnosis using fuzzy similarity matching. Comput Intell. 2009;25(3):180–195. [Google Scholar]
53.Who . World Health Organization (WHO); Geneva: 2020. Coronavirus disease 2019 (COVID-19)Situation report –55. [Google Scholar]
54.Hashem I.A.T., Ezugwu A.E., Al-Garadi M.A., Abdullahi I.N., Otegbeye O., Ahman Q.O., Mbah G.C., Shukla A.K., Chiroma H. medRxiv; 2020. A machine learning solution framework for combatting COVID-19 in smart cities from multiple dimensions. [Google Scholar]
55.Yang S., Cao P., Du P., Wu Z., Zhuang Z., Yang L., Yu X., Zhou Q., Feng X., Wang X., Li W. Early estimation of the case fatality rate of COVID-19 in mainland China: a data-driven analysis. Ann Transl Med. 2020;8(4) doi: 10.21037/atm.2020.02.66. [DOI] [PMC free article] [PubMed] [Google Scholar]