

Abstract
There is an increasing evidence that smallholder farms contribute substantially to food production globally, yet spatially explicit data on agricultural field sizes are currently lacking. Automated field size delineation using remote sensing or the estimation of average farm size at subnational level using census data are two approaches that have been used. However, both have limitations, for example, automatic field size delineation using remote sensing has not yet been implemented at a global scale while the spatial resolution is very coarse when using census data. This paper demonstrates a unique approach to quantifying and mapping agricultural field size globally using crowdsourcing. A campaign was run in June 2017, where participants were asked to visually interpret very high resolution satellite imagery from Google Maps and Bing using the Geo‐Wiki application. During the campaign, participants collected field size data for 130 K unique locations around the globe. Using this sample, we have produced the most accurate global field size map to date and estimated the percentage of different field sizes, ranging from very small to very large, in agricultural areas at global, continental, and national levels. The results show that smallholder farms occupy up to 40% of agricultural areas globally, which means that, potentially, there are many more smallholder farms in comparison with the two different current global estimates of 12% and 24%. The global field size map and the crowdsourced data set are openly available and can be used for integrated assessment modeling, comparative studies of agricultural dynamics across different contexts, for training and validation of remote sensing field size delineation, and potential contributions to the Sustainable Development Goal of Ending hunger, achieve food security and improved nutrition and promote sustainable agriculture.
Keywords: crowdsourcing, environmental changes, field size, food security, visual interpretation
This paper demonstrates a unique approach to quantifying and mapping agricultural field size globally using crowdsourcing. A campaign was run in June 2017 where participants were asked to visually interpret very high resolution satellite imagery from Google Maps and Bing using the Geo‐Wiki application. The results show that smallholder farms occupy up to 40% of agricultural areas globally, which means that, potentially, there are many more smallholder farms in comparison with the two different current global estimates of 12% and 24%. The global field size map and the crowdsourced data set are openly available.
1. INTRODUCTION
In 2015, Fritz et al. (2015) published the first global field size map at a 1 km2 resolution, which was generated through interpolation of around 13 K field size samples collected using the Geo‐Wiki crowdsourcing tool. Such an approach was possible as a result of the increasing availability of very high resolution satellite imagery from Google Earth from which agricultural field boundaries could be identified in detail, particularly those of smallholder farms. This field size product generated a considerable amount of interest because spatially explicit information on field size at a global scale is currently lacking. As a consequence, this product was used in a number of studies. For example, Samberg, Gerber, Ramankutty, Herrero, and West (2016) mapped mean agricultural area (MAA) by subnational administrative units for Latin America, Sub‐Saharan Africa, and South and East Asia using household census data, where field size was found to be a significant predictor in the MAA model. Herrero et al. (2017) examined the relationship between farm size, agricultural production, and nutritional diversity where the global field size map was used to allocate agricultural production to different farms sizes at the country level. The results showed that small‐ and medium‐sized farms produce up to 77% of all commodities and nutrients considered, particularly in Sub‐Saharan Africa, Southeast Asia, South Asia, and China. The majority of global micronutrients and protein are also produced in more diverse agricultural landscapes, so as farm sizes increase, production diversity must also be maintained to ensure diverse nutrient production.
Both of these studies are part of a larger debate on the role of farm size in global food security (Meyfroidt, 2017), where farm size is related to field size (Graesser & Ramankutty, 2017). For example, an overall farm size may not change due to lack of capacity for expansion but a farmer may increase their existing field sizes. Hence, field size is an important indicator of agricultural intensity, for example, to gain a better understanding of management practices, or to monitor biodiversity and landscape fragmentation. Yet, there is considerable uncertainty concerning estimates of the amount of agricultural land within different field size categories, particularly smallholdings. Using census data from the Food and Agriculture Organization (FAO), Lowder, Skoet, and Raney (2016) estimate that 84% of the 570 million farms globally are <2 ha in size, which represents around 12% of agricultural land. More recently, Ricciardi, Ramankutty, Mehrabi, Jarvis, and Chookolingo (2018) found that farms <2 ha in size occupy 24% of agricultural gross area based on agricultural census data and different surveys from 55 countries. Graeub et al. (2016) estimate that family farms cover 53% of agricultural land but these farms can include field sizes of >2 ha since the definition of family farm is not based on field size. Hence, this number is not directly comparable with Lowder et al. (2016) or Ricciardi et al. (2018). No other estimates exist, and hence, there is a clear need for spatially explicit data on the distribution of field sizes, which can provide an independent estimate to that derived from FAO census data or nationally (or subnationally) representative sample surveys.
Another approach to mapping field size is to use remote sensing. For example, Yan and Roy (2016) developed an automated crop field extraction method which they applied to 30 m Web Enabled Landsat data (WELD) time series to produce a wall‐to‐wall field size map for the contiguous USA (Yan & Roy, 2016). Graesser and Ramankutty (2017) developed a semi‐automated approach involving edge extraction and adaptive thresholding to produce a field size map for five countries in South America. Although the results from both studies were good, that is, accuracies of >84%, both of these studies are limited in geographical coverage and concern areas where field sizes are large with a relatively precise geometry (square or round) in comparison with fields in other parts of the world. Therefore, to map fields globally using remote sensing would require adjustment for the high variability of field geometry in places such as Africa as well as considerable processing power.
An alternative approach to the use of remote sensing or census‐based spatial disaggregation (Samberg et al., 2016) is the crowdsourcing method outlined originally in Fritz et al. (2015). At the time, around 13 K samples were collected using four categories: very small, small, medium, and large, where the definitions were based on simple rules of thumb to aid visual interpretation rather than area‐based estimates. As field size estimation was not the focus of the campaign, the sample collected was limited in size. A simple interpolation method was then applied to produce the global field size map. Although the general patterns of field size were captured globally, there were numerous artifacts from the interpolation method when viewing the map in more detail, and limitations were recognized at a national level, for example, underestimation of small fields in Argentina (Graesser & Ramankutty, 2017). Hence, there was a clear need to improve this map with a much denser sample and apply a more appropriate interpolation algorithm. To achieve this objective, a new Geo‐Wiki campaign was run in June 2017, focused entirely on the collection of field size data, which increased the density of field size samples by an order of magnitude, that is, around 130 K unique samples were collected. Although crowdsourcing and citizen science are becoming popular ways of collecting data, for example, through the eBird project (Sullivan et al., 2014) or Zooniverse (Reed et al., 2013), assuring data quality still remains the most critical issue in this field (Comber, Mooney, Purves, Rocchini, & Walz, 2016; Fonte et al., 2017; Resnik, Elliott, & Miller, 2015; Salk, Sturn, See, Fritz, & Perger, 2016; See et al., 2013). To address this issue, we have improved the quality control mechanism and introduced field measuring tools to improve the accuracy of the data collected. Hence, with these improvements, it is now also possible to estimate the percentage of different field sizes at a global and continental scale as well as nationally. The aim of this paper was to present the improved global field size map and to compare estimates of different field sizes derived from the field size sample with those currently found in the literature. The field size samples are also available from this site, which can be used for training or validation of automatic field size classification algorithms or identifying priority areas for mapping, for example, where there is a high variability in field sizes.
2. MATERIALS AND METHODS
Figure 1 provides an overview of the main steps undertaken in this study, which includes (a) collection of the global field size data via a crowdsourcing campaign; (b) mapping of the dominant field sizes; (c) estimation of the area percentages of the different field size categories; and (d) comparison of the crowdsourced data with other field size data sets. These steps are described in more detail in the sections that follow.
Figure 1.
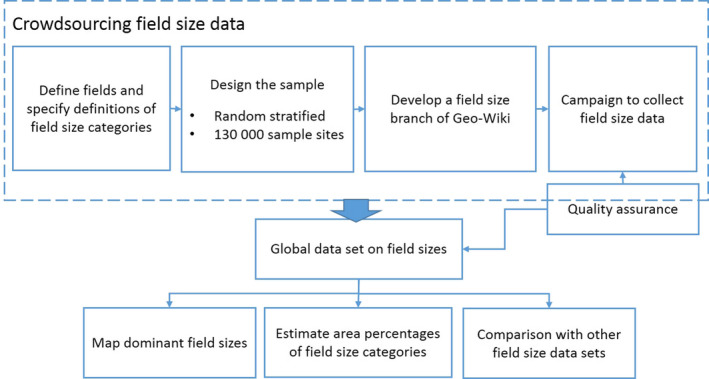
Schematic showing the main steps in the methodology [Colour figure can be viewed at wileyonlinelibrary.com]
2.1. Collecting global field size data via crowdsourcing
To collect information on field size globally, we designed and implemented a crowdsourcing campaign that lasted 4 weeks during June 2017. As outlined in Figure 1, the campaign consisted of a series of steps including the specification of fields and field size categories, the design of a global sample, the development of a new branch of Geo‐Wiki that focused specifically on field sizes, and the actual running of the campaign. The quality assurance process was also a very important part of the campaign. These four steps and the quality assurance process are described below.
2.2. Specification of field and field size definitions
The first definition needed was for a “field”. We defined fields as enclosed agricultural areas, including annual and perennial crops. We also included pastures, hayfields and fallow in the definition to minimize confusion between annual crops and pastures when visually interpreting the images. This definition corresponds to the Food and Agriculture Organization of the United Nations (FAO) definitions of arable land and permanent crops (FAO, World Bank, & United Nations Statistical Commission, 2012), with an exception that we also included permanent pastures.
We then defined rules for determining individual fields, which are usually separated by roads, permanent paths, trees, or shrub shelterbelts. Field boundaries can be further defined by the presence of different crop types or pastures. Temporary paths or signs of machinery are not considered as field boundaries.
Finally, we defined five field size categories. These were based on the crowdsourced results from the 2011 campaign that included field size (Fritz et al., 2015) as well as the field size definitions provided by the Group on Earth Observations Global Agricultural Monitoring Initiative (GEOGLAM ‐ https://ceos.org/document_management/Meetings/SIT/SIT-28/31b_GEOGLAM_Global_Agricultural_Monitoring_User_Requirements_March4.pdf). The field size categories were then adjusted to the Geo‐Wiki grid approach that we describe below. These categories are:
Very large fields with an area of >100 ha;
Large fields with an area between 16 and 100 ha;
Medium fields with an area between 2.56 and 16 ha;
Small fields with an area between 0.64 and 2.56 ha; and
Very small fields with an area <0.64 ha.
2.3. Sampling design
We generated a random stratified sample of 130,000 sites globally. This number was based on how much data were collected during past campaigns, the potential number of participants we could engage, and the optimal duration of the campaign. Each sample site was visited by three different participants, so in total, there were 390,000 classifications to complete.
To stratify and hence better allocate the sample units, we developed a layer of maximum agricultural extent. We selected maps that contain agricultural fields that either fully match the definition of fields used in this study or partly match, that is, they contain a subset of the definition, which include:
A cropland layer derived from Globeland 30 at a 30 m resolution (Chen, Ban, & Li, 2014);
A cropland layer derived from the ESA CCI LC map at a 300 m resolution for 2015 (https://www.esa-landcover-cci.org/);
The unified cropland layer at a 250 m resolution (Waldner et al., 2016);
The IIASA‐IFPRI hybrid cropland layer at a 1 km resolution (Fritz et al., 2015).
Since our definition of fields is very broad, there was no need to harmonize the cropland definitions of these different layers.
The four maps were then aggregated to the same grid as that of the IIASA‐IFPRI hybrid cropland map (Fritz et al., 2015). The rule we followed was that if a pixel contained cropland in at least one of these layers, the pixel was considered as cropland. To avoid oversampling with a change of latitude, we re‐projected the aggregated map from WGS84 to an equal area projection (i.e., the Goode Homolosine projection) and randomly distributed the samples by continent.
2.4. The Geo‐Wiki application for field size data collection
Geo‐Wiki is an online application for crowdsourcing visual interpretations of satellite imagery from Google Maps and Microsoft Bing, for example, land cover, human impact, forest cover, which has been used in a number of data collection campaigns over the last several years (Fritz et al., 2012; See et al., 2015). Google Maps and Microsoft Bing Maps include mosaics of very high resolution satellite and aerial imagery from different time periods and multiple image providers, from Landsat satellites operated by NASA and USGS to commercial providers such as Digital Globe. More information on the spatial and temporal distribution of very high resolution satellite imagery can be found in Lesiv et al. (2018). The maps are used as the underlying layers for visual interpretation, where users could choose between them based on the quality of the imagery.
A new branch of Geo‐Wiki is normally implemented for each new campaign including this recent one devoted to the collection of field size data. Much of the satellite imagery in Google Maps and Bing is very high resolution imagery, ranging from 50 cm to a few meters, which allows field boundaries to be identified with a high precision. Figure 2 is a screenshot of this Geo‐Wiki field size interface, showing additionally the tools (a‐l) that were implemented to facilitate field size estimation and general data collection.
Figure 2.
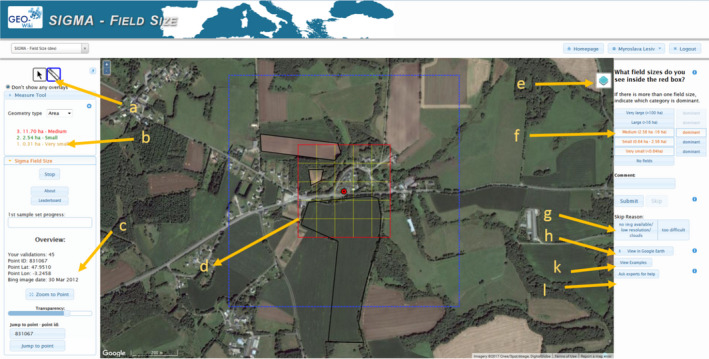
Screenshot of the Geo‐Wiki interface showing: (a) the area measuring tool; (b) the actual field sizes delineated and measured using (a); (c) the cumulative work done by a participant; (d) the main classification area, gridded; (e) the button to switch between different background imagery, that is, Google or Bing; (f) buttons to select the field size categories: very large, large, medium, small, very small, or no fields; (g) possible reasons to skip the current location; (h) a button to display location in Google Earth; (k) examples of field size estimation for training; (l) a button to ask experts for help. Source of imagery: Google Maps [Colour figure can be viewed at wileyonlinelibrary.com]
Before starting the campaign, the participants were shown a series of slides designed to help them gain familiarity with the interface and to train them in how to visually determine and select the most appropriate field sizes for each given location. Once completed, the participants were then shown a random location on the Geo‐Wiki interface and were asked the following two questions: (a) what field size categories do you see in the red box; (b) what is the dominant field size, that is, the field size category corresponding to the fields with the highest total area covered in the red box (Figure 2d). The red box represents an area of 16 ha divided into 25 grid cells. If the user selected more than one field size, they were asked to indicate which of these was dominant. The area measuring tool (Figure 2a,b) allows participants to delineate the fields manually to calculate the sizes. Participants were encouraged to quickly do a visual identification of field sizes, without measuring them, using the grid system (Figure 2d), where yellow cells are 80 × 80 m or 0.64 ha, the red box is 400 × 400 m or 16 ha, and the blue box is 1 × 1 km or 100 ha in size. The field sizes were determined as follows:
Very small: fields smaller than the yellow cells;
Small: fields of a size between one yellow cell and four yellow cells (2.56 ha);
Medium: fields smaller than the red box (16 ha) and bigger than four yellow cells;
Large: fields smaller than the blue box (100 ha) and bigger than the red box; and
Very large: fields larger than the blue box.
When the field size was not clear from visual inspection, for example, when a field was close in size to two categories, participants were encouraged to use the area measuring tool (Figure 2a). Alternatively, if either no imagery was available, or if it was deemed too difficult to determine the field sizes, the participant could skip a location (Figure 2g). If a location was skipped because of being too difficult, such a location would still have been available for other participants, whereas in the case of the absence of imagery in both the underlying layers, that is, Google Maps and Microsoft Bing Maps, this location was taken out of the sample of available locations. In the case of Microsoft Bing Maps, the imagery is not complete, which only becomes apparent when you zoom into the maximum extent. In the case of Google Maps, this occurs when there is a lack of very high resolution imagery and you zoom into the maximum extent. If you zoom out, you will see the Landsat base imagery but it will not be possible to identify the field sizes unless they are very large.
2.5. Quality assurance
Insights from our previous crowdsourcing campaigns (Fritz et al., 2012; Laso Bayas et al., 2016) indicated that we needed to invest in the training of the participants, where there were 130 in total. Summary information about the participants (i.e., their gender, age, level of education, and country of residence) who filled in the survey at the end of the campaign is provided in the Supporting information; Figures S4, S5, S6 and Table S2. In this campaign, we provided initial guidelines for the participants in a form of a video and slides that were shown before the participants could start classifying the field sizes (see Supporting information Figure S1). Additionally, the participants were asked to classify 10 training samples before contributing officially to the campaign. They received text‐based feedback on each of these 10 samples including the measured field size categories, with the possibility of watching an explanatory video for each location showing how these field sizes were selected (Videos and explanations available here: https://www.geo-wiki.org/Application/modules/field_size_sigma/FieldSizeSigma_gallery.html).
During the campaign, the participants were shown a sample site that was part of a “control” or expert data set, which appeared randomly during every 10 classifications. When these sites were incorrectly classified, the participants received text feedback, which is an innovative component that we used for the first time in a crowdsourcing campaign. Our hypothesis behind this approach was that by receiving immediate feedback on a submitted classification, a participant would learn from their mistakes and the quality of their work would increase over time. If the text‐based feedback was insufficient, the participants could ask for more detailed explanation by email (Figure 2‐l).
The control sample set was independent of the main sample of 130,000 sites, and it was created using the same random stratified sampling using maximum agricultural extent as the strata. To determine the size of the control sample, two aspects were considered (a) taking into account the complexity of this task and our past experience with campaigns, the maximum number of sample sites that one person could complete is 40,000 locations; (b) the frequency at which the control sample sites were provided to the participants. Since we decided that a control sample site will appear once every 10 classifications, we needed 4,000 control sample sites (40,000/10 = 4,000) in total. The control sample sites were classified by a small group of experts trained by the lead author at IIASA. Each control sample site was classified twice by two different experts. Where the two experts agreed, these sample sites were added to the final control sample. Where disagreement occurred (approximately 25% of cases), these sample sites were inspected by an IIASA expert and revised accordingly. Only then was it added to the final control sample.
Part of the campaign design was to offer prizes as one incentive for participation. The ranking system for the prize competition was partly linked to the quality of individual contributions (Supporting information Table S1). Whenever a location visited by a participant was a control sample site, the participants received some points that accumulated over the campaign. In the design of the ranking system, we considered both the quality of the classifications and the number of classifications by a participant. These rules indicate how the points (P) were calculated:
Case 1. A sample site with fields present. The following equation was applied:
| (1) |
where D indicates whether the dominant field size is correct (1) or incorrect (0) and E is the total number of mistakes made in identifying the field sizes. Two types of mistakes were considered: (a) if the wrong field size was identified; and (b) if the correct field size was not identified.
Case 2. A sample site with no fields present. The following rule was applied:
| (2) |
Case 3. No imagery or very low resolution images in Google and Bing. In this case, Equation ((2)) was applied.
The maximum amount of points awarded was 20 while the maximum number of points deducted was 15. By awarding 10 points for a correct dominant field size, we emphasized the importance of this question. The relative quality score for each participant was then calculated as the total sum of points gained divided by the maximum sum of points that this participant could have earned.
For any subsequent data analysis, we excluded classifications from those participants whose relative quality score was <71.4%. This threshold corresponds to an average score of 10 points at each location (out of maximum 20 points), that is, these participants were good in defining the dominant field sizes. In total, we removed 10,995 classifications from 32 different participants, or 2.8% of all classifications.
Additionally, since each sample site was visited by three different participants, we calculated the variability of the dominant field size categories as follows: (a) full agreement, or all three participants were in agreement; (b) medium agreement, or only two participants agreed; (c) low agreement, or the three participants identified three different dominant field sizes.
2.6. Creating a global field size map
The first global field size map was produced by interpolation of field sizes (Fritz et al., 2015). Inverse distance weighting (IDW) was chosen as the interpolation method. As with many other interpolation methods in spatial statistics such as kriging or nearest neighbor, IDW assumes that pixels close by to one another have similar values. However, this assumption does not hold for the spatial distribution of fields, for example, large fields may be neighboring smaller fields. Therefore, we adapted the nearest neighbor approach as follows:
A grid of points was created with an interval of circa 1 km, which is also the minimum distance between the sample sites;
At each grid point, k nearest neighbors was applied to the crowdsourced data set where k = 5 was found to yield the best visual representation; more than five neighbors led to a loss in spatial information while <5 neighbors resulted in the overestimation of field sizes that were not dominant.
At each grid point we then summed all the answers from the participants to determine the most frequently selected field size category. If there were field size categories with the same frequency, we removed the values located at the largest distance away from the grid point and repeated this step until we arrived at one dominant field size category. We only applied this procedure to grid points that fell inside cropland areas, where we used a recent cropland map for 2015 to indicate cropland areas (https://www.croplands.org/app/map?lat=0&lng=0&zoom=2), which was originally at a 30 m resolution and then aggregated to our grid size.
The maximum distance from each grid point to the nearest neighbors from the crowdsourced data set varied from 3 to 20 km. This means that the final map of dominant field sizes is a map that shows field sizes that are dominant over a certain area, for example, within a radius of 3 km. To have finer boundaries for fields, users can apply the 30 m meter cropland mask. However, this does not mean that the dominant fields were determined at this spatial resolution.
To evaluate the accuracy of the resulting map, we compared it with the control sample. If any of the fields identified by the experts matched a pixel value on the field size map, this classification was considered to be true; otherwise, there was no match.
2.7. Estimation of the area proportions of different field size categories
The area proportions were calculated from the sample and not the field size map. Therefore, we needed to calculate the dominant field size at each sample site, where each sample site was interpreted by three different participants, each of which had a relative quality score. Hence, to determine the dominant field size at each sample site, we applied a simple weighting approach using the field size answers and the relative quality scores (Foody et al., 2018), and removed sample sites with no fields. Moreover, 2.5% of the sample sites were deemed impossible to classify by the participants due to low resolution imagery, clouds or the absence of imagery. These sample sites were also excluded from the calculations of the area proportions. This 2.5% represents a bias in our later calculations.
We used the resulting data set on dominant field sizes to calculate the agricultural area proportions at the global, continental, and national levels. To calculate the 95% confidence intervals, we followed the methodology described in (Sangeetha, Subbiah, & Srinivasan, 2013). The global administrative unit layers (GAUL) of FAO (https://www.fao.org/geonetwork/srv/en/main.home) were used to determine the country and continent of each sample site. Note that these calculations at global level were made assuming that no changes in field sizes have occurred over the period 2010–2016. Indeed, there are homogenous patterns of imagery dates for a few countries, for example, t Canada, Peru, Ecuador, Columbia, and Ukraine (Supporting information Figure S2).
2.8. Comparison with other field size data sets
We compared the crowdsourced field size data set with a field map for the USA for 2010 produced by Yan and Roy (2016), which was derived from Landsat imagery at a 30 m resolution. This is an openly available wall‐to‐wall map of fields for the United States. To compare this field map with the crowdsourced data set, the following caveats should be noted:
Individual fields in the US field map are those that are separated from each other by roads or shelterbelts with a width of at least 30 m. Hence if fields are separated by a tiny road, for example, 2–3 m wide, they would most likely be classified as one field. An example is shown in Figure 3 where the US field map shows the presence of very large fields (on the left) while the dominant field size from this study would be large. This can be verified from the satellite imagery on Google Maps (shown on the right).
Very small and small fields are not mapped as the resolution is too coarse.
It includes only arable land, no pasture and no hayfields.
The smallest detected fields have an area of 1.53 ha.
Figure 3.
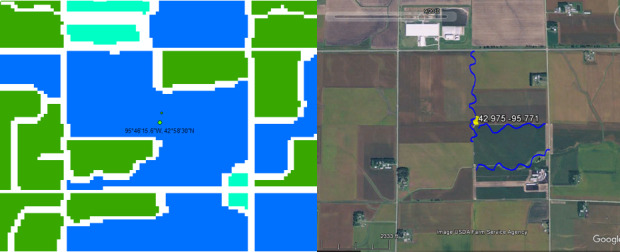
An example taken from the field map of the USA (Yan & Roy, 2016). Left image: blue indicates very large fields, green are large fields, and turquoise are medium‐sized fields. Right image: screenshot of a satellite image from Google Maps from 2010, where the blue lines correspond to tiny field boundaries that are not taken into account on the field map of Yan and Roy (2016). The location of the central point is 95.771°W, 42.975°N [Colour figure can be viewed at wileyonlinelibrary.com]
First, we calculated the area of the mapped fields and converted these values into the field size categories defined in this study. Secondly, we selected sample sites from the crowdsourced data set that fall within the mapped fields and extracted the field sizes. We then calculated a confusion matrix (crowdsourced dominant field size vs. size of the mapped fields). To calculate overall agreement, we assumed that both data sets agreed when fields on the fields map were larger than the crowdsourced field sizes.
2.9. Software
The field size data were collected through the Geo‐Wiki web application as described previously. All the data analyses, including mapping field sizes and estimating the area proportions of the field sizes, were done in the R environment. Bar charts were also produced in R. The following R packages were used: raster 26–7 (https://CRAN.R-project.org/package=raster); RANN 2.5.1 (https://CRAN.R-project.org/package=RANN); and sp 1.2–7 (https://CRAN.R-project.org/package=sp). The figures showing the spatial distribution of the field sizes were prepared in ArcGIS 10.1.
3. RESULTS
3.1. A new global field size data set
The main result of this study is a global field size data set containing all the detected field sizes and the estimated dominant field size. Figure 4 shows the spatial distribution of dominant field size categories. African countries such as Ethiopia, Tanzania, Mali, Nigeria and others, along with India, China, and Indonesia are characterized by very small fields. On the other end are Kazakhstan, Australia, the USA, and Brazil with very large fields. In Europe, the majority of the fields are of a medium size. Figure 4 also highlights areas with high variability in field sizes, for example, Europe, Turkey, central India, northern regions in China (at the border with Russia), Nigeria, Sudan, Zambia, and the northern states of Brazil.
Figure 4.
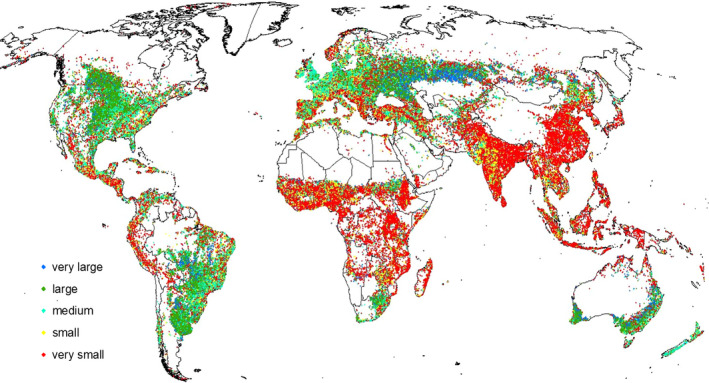
The spatial distribution of dominant field size [Colour figure can be viewed at wileyonlinelibrary.com]
To establish the quality of the data set, we estimated the agreement between the participants in terms of dominant field size category at each sample site (we had three classifications per sample site). Overall there was complete agreement between participants in 56% of sample sites, the majority of participants agreed in 40% of cases while complete disagreement occurred in only 4% of sample sites. Figure 5 shows the spatial distribution of this agreement, which shows no discernible patterns in the distribution of sample sites where complete disagreement occurs. We selected a few sample sites where the participants disagreed and found that these are mostly located where fields have different sizes and it is difficult to identify a dominant one.
Figure 5.
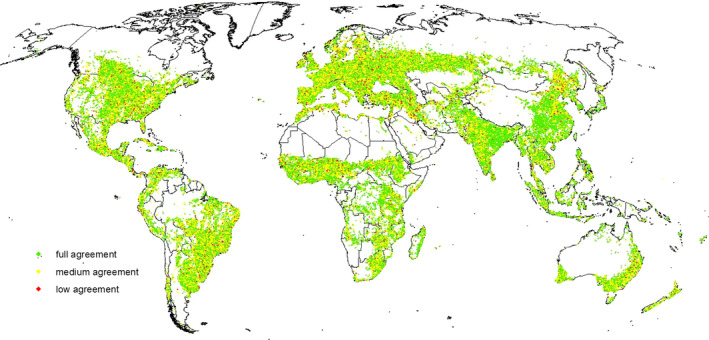
The degree of agreement between the participants at all sample sites [Colour figure can be viewed at wileyonlinelibrary.com]
3.2. Map of dominant field sizes
The map of dominant field sizes is presented in Supporting information Figure S3 since the distribution of dominant field sizes look very similar in overall patter to that of Figure 4. The overall accuracy of the map was estimated to be 93%. More details on how this number was estimated are provided in the methodology section.
3.3. Percentage of agricultural area by field size
For better presentation of the results, we translated area proportions to area percentages. Figure 6 provides the results of the agricultural area estimates by field size at global and continental levels. These results confirm that very small fields sizes have a substantial share in the total agriculture of Asia and Africa while large fields clearly dominate in Australia and North and South America. Medium field sizes have the same percentage as large fields for European countries, which is mainly due to inclusion of post‐Soviet countries such as Ukraine and Russia.
Figure 6.
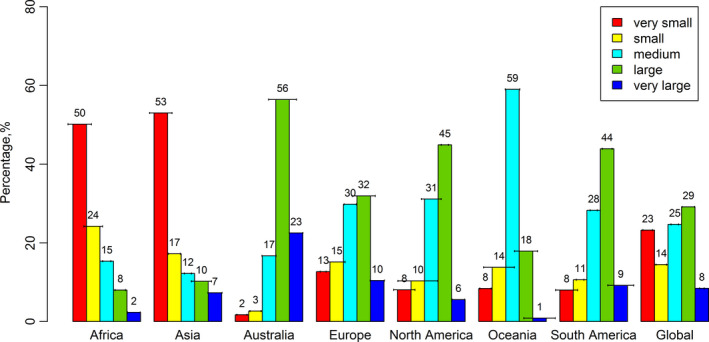
Area percentages of different field sizes by continent and at the global level (confidence interval 95%). Oceania includes New Zealand, Melanesia, Micronesia, and Polynesia [Colour figure can be viewed at wileyonlinelibrary.com]
Figure 7 shows the cropland area percentages for selected countries, sorted by size. Kazakhstan is the only country with a huge share of very large fields. In general, large fields dominate in post‐Soviet Union countries, in the USA, Brazil, Australia, Argentina, Canada, and South Africa. As mentioned already, countries in Central and Western Europe have medium field sizes. Countries such as India, China, Nigeria, Ethiopia, Tanzania, Indonesia, and Pakistan are characterized by dominant smallholder farms or family farms.
Figure 7.
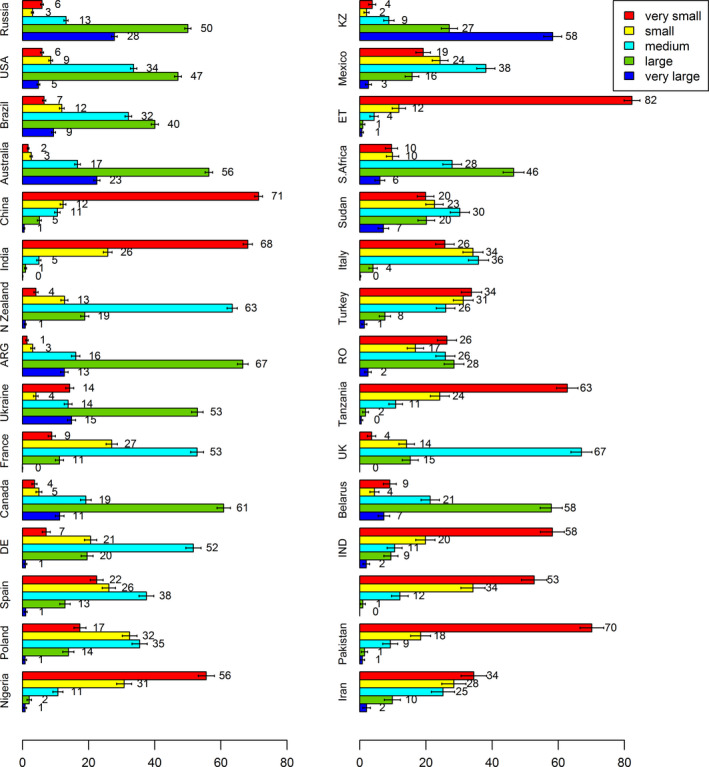
Percentage of area by field size for selected countries (confidence interval 95%). ARG: Argentina; De: Germany; IND, Indonesia; KZ: Kazakhstan; N Zealand: New Zealand; Ro: Romania; S Africa: South Africa; UK: United Kingdom [Colour figure can be viewed at wileyonlinelibrary.com]
The results of all the calculations are provided in the Supporting information (Table S3).
3.4. Comparison with the US field map
We compared the field map for the USA (Yan & Roy, 2016) with the dominant field sizes estimated in this study given the set of caveats outlined in the methodology. The overall agreement between the two data sets is 66.0% and 92.2% if we assume that fields on the US fields map contain smaller fields delineated by tiny paths. Supporting information Table S4 contains a confusion matrix between the US field map and the crowdsourced data. It demonstrates where there is confusion, for example large fields in the US field map contain a few medium fields and very large fields consist of large fields. The highest “wall‐to‐wall” agreement is for large fields.
3.5. Comparison of the results with other estimates
Finally, we compared our results with other estimates in the literature. However, to compare these estimates with our results, we consider that a smallholder farm may include many very small fields with an area of <2 ha and a few small fields. Thus, according to our results, smallholder farms occupy a maximum of 40% of total agricultural area, which is considerably larger than the figure of 12% reported in Lowder et al. (2016). The share of smallholder farms is much higher in Asia (~70%) and Africa (up to ~74%), which is considerably higher that estimates provided in Wu et al. (2018, fig 2C), based on the same data as that used by Lowder et al. (2016). In contrast, our results are smaller than the estimate of 60% reported in Cui et al. (2018) but the latter figure cannot be traced to the original cited source so there is huge uncertainty around the veracity of this figure. Our results are closest to the estimate of 24% provided by Ricciardi et al. (2018), but this figure is only based on data from 55 countries and the definition of agricultural land does not include permanent pastures while our definition does.
4. DISCUSSION
The results from this paper make a significant contribution to the current knowledge on the spatial distribution of different field sizes globally. First, the results are independent from FAO census data and are not related to household surveys. Secondly, the data are more detailed and spatially denser than the previously collected data set on field sizes (Fritz et al., 2015), with additional temporal information. Thirdly, we have considerably improved the quality of the data collected by providing detailed guidelines to the participants, area measuring tools, multiple classifications per sample site, near real‐time feedback, and ranking based on the quality performance of each participant.
The global field size data set presented in this study can be considered as a fundamental benchmark for the distribution of field sizes. It could be used to expand the research study undertaken by Samberg et al. (2016) to the global level as well as enhancing the work on food and nutrient security (Herrero et al., 2017). Since we recorded the dates of the underlying satellite images (Supporting information Figure S2) used in the visual interpretation, this data set may serve as training data for automated classification of field size from remote sensing (although only for field size categories introduced in this study). The temporal reference is crucial in mapping fields as their shape and size change over time due to different socio‐economic factors (Yan & Roy, 2016). Only in the areas with very fragmented or hilly landscapes do field sizes remain small or very small over time, for example, in the mountain region of Italy, the south of China. Additionally, the data set could also guide the choice of which sensor to use for agricultural monitoring and crop type classification, for example, for heterogeneous regions and regions with very small fields, there is a need for a finer resolution sensor such as Sentinel‐2 data at a 10 m resolution.
By interpolating the global field size data set using a method more appropriately suited to the data set, we produced a better global field size map than the previous version (Fritz et al., 2015). This map could be used as an input layer to global land use models or global integrated assessment models, for example, the EPIC (Environmental Policy Integrated Model) or GLOBIOM models (Havlík et al., 2014). To improve the spatial disaggregation of cropland types, this field size layer could also be used as a covariate in the Spatial Production Allocation Model (SPAM) (You et al., 2014).
This study has also addressed the question of what proportion of agricultural area different field sizes occupy at the global, continental, and country level. Our findings confirm that small fields have a substantial percentage at the global level: very small fields with an area <0.64 ha occupy 23.23% while small fields (with an area between 0.64 and 2.56 ha) occupy 14.47% of total agricultural areas (or 40% in total if we count the bias of 2.5%). Although the comparison with the US field map (Yan & Roy, 2016) showed a 92.2% agreement with the crowdsourced data set, there are no other studies that have calculated the percentage of field sizes at the global level. There are a few studies on the distribution and percentage of different farm sizes but field size and farm size are not the same thing as discussed in the introduction. Moreover, farm sizes cannot be defined by taking only the area of land owned into account (Graeub et al., 2016), as this varies between country. Nevertheless, FAO defines smallholder farms as farms with agricultural areas of <2 ha. Reports on the percentage of smallholder farms in total agricultural areas varie considerably, for example, 12% in Lowder et al. (2016) up to 60% in Cui et al. (2018). Moreover, Lowder et al. (2016) include permanent pastures in their estimates, as we do, while Ricciardi et al. (2018) do not, yet report an estimate of 24% smallholder farms. However, we expect that non‐permanent pastures will have a rather small share in our estimates of area proportions. We did not look at this particular aspect in this study because it would have complicated the task undertaken by the crowd and, consequently, would have increased the uncertainties in our results. If there were an accurate global layer of cropland and permanent pastures, separated from each other, we could have excluded non‐permanent pastures from our calculations and could have estimated area proportions for croplands, for permanent pastures, and for croplands together with permanent pastures. Unfortunately, up to now, the spatial distribution of croplands and pastures derived from remote sensing does not yet meet user requirements for cropland monitoring (Pérez‐Hoyos, Rembold, Kerdiles, & Gallego, 2017). If such layers appear in the near future, the potential users of the field size data set could repeat our approach to estimate area proportions of field sizes.
Supporting information
ACKNOWLEDGEMENTS
We would like to thank all the participants of the campaign for their valuable contributions. The work was funded by the following projects: SIGMA (No. 603719) and the ERC CrowdLand project (No. 617754), both funded under the EU's FP7 program.
Lesiv M, Laso Bayas JC, See L, et al. Estimating the global distribution of field size using crowdsourcing. Glob Change Biol. 2019;25:174–186. 10.1111/gcb.14492
DATA ACCESSIBILITY
All the data are of open access. Here is a link: https://pure.iiasa.ac.at/id/eprint/15526/.
REFERENCES
- Chen, J. , Ban, Y. , & Li, S. (2014). China: Open access to Earth land‐cover map. Nature, 514(7523), 434–434. [DOI] [PubMed] [Google Scholar]
- Comber, A. , Mooney, P. , Purves, R. S. , Rocchini, D. , & Walz, A. (2016). Crowdsourcing: It matters who the crowd are. The impacts of between group variations in recording Land Cover.PLoS ONE, 11(7), e0158329 10.1371/journal.pone.0158329. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cui, Z. , Zhang, H. , Chen, X. , Zhang, C. , Ma, W. , Huang, C. , … Dou, Z. (2018). Pursuing sustainable productivity with millions of smallholder farmers. Nature, 555, 363 10.1038/nature25785 [DOI] [PubMed] [Google Scholar]
- FAO, World Bank, & United Nations Statistical Commission (2012). Action plan of the global strategy to improve agricultural and rural statistics. Rome, Italy: FAO UN. [Google Scholar]
- Fonte, C. C. , Antoniou, V. , Bastin, L. , Estima, J. , Arsanjani, J. J. , Laso‐Bayas, J.‐C. , … Vatseva, R. (2017). Assessing VGI data quality In Foody G. M., See L., Fritz S., Fonte C. C., Mooney P., Olteanu‐Raimond A.‐M., & Antoniou V. (Eds.), Mapping and the citizen sensor (pp. 137–164). London, UK: Ubiquity Press. [Google Scholar]
- Foody, G. , See, L. , Fritz, S. , Moorthy, I. , Perger, C. , Schill, D. , … Boyd, D. , (2018). Increasing the accuracy of crowdsourced information on land Cover via a voting procedure weighted by information inferred from the contributed data. ISPRS International Journal of Geo-Information, 7(3), 80 10.3390/ijgi7030080 [DOI] [Google Scholar]
- Fritz, S. , McCallum, I. , Schill, C. , Perger, C. , See, L. , Schepaschenko, D. , … Obersteiner, M. (2012). Geo‐Wiki: An online platform for improving global land cover. Environmental Modelling and Software, 31, 110–123. 10.1016/j.envsoft.2011.11.015. [DOI] [Google Scholar]
- Fritz, S. , See, L. , McCallum, I. , You, L. , Bun, A. , Moltchanova, E. , … Obersteiner, M. (2015). Mapping global cropland and field size. Global Change Biology, 21(5), 1980–1992. 10.1111/gcb.12838. [DOI] [PubMed] [Google Scholar]
- Graesser, J. , & Ramankutty, N. (2017). Detection of cropland field parcels from Landsat imagery. Remote Sensing of Environment, 201, 165–180. 10.1016/j.rse.2017.08.027. [DOI] [Google Scholar]
- Graeub, B. E. , Chappell, M. J. , Wittman, H. , Ledermann, S. , Kerr, R. B. , & Gemmill‐Herren, B. (2016). The state of family farms in the world. World Development, 87, 1–15. 10.1016/j.worlddev.2015.05.012. [DOI] [Google Scholar]
- Havlík, P. , Valin, H. , Herrero, M. , Obersteiner, M. , Schmid, E. , Rufino, M. C. , … Notenbaert, A. (2014). Climate change mitigation through livestock system transitions. Proceedings of the National Academy of Sciences, 111(10), 3709 10.1073/pnas.1308044111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Herrero, M. , Thornton, P. K. , Power, B. , Bogard, J. R. , Remans, R. , Fritz, S. , … Havlík, P. (2017). Farming and the geography of nutrient production for human use: A transdisciplinary analysis. The Lancet Planetary Health, 1(1), e33–e42. 10.1016/S2542-5196(17)30007-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laso Bayas, J. C. , See, L. , Fritz, S. , Sturn, T. , Perger, C. , Dürauer, M. , … McCallum, I. (2016). Crowdsourcing in‐situ data on land cover and land use using gamification and mobile technology. Remote Sensing, 8(11), 905 10.3390/rs8110905. [DOI] [Google Scholar]
- Lesiv, M. , See, L. , Laso Bayas, J. C. , Sturn, T. , Schepaschenko, D. , Karner, M. , … Fritz, S. (2018). Characterizing the spatial and temporal availability of very high resolution satellite imagery in google earth and microsoft bing maps as a source of reference data. Land, 7(4), 118 10.3390/land7040118. [DOI] [Google Scholar]
- Lowder, S. K. , Skoet, J. , & Raney, T. (2016). The number, size, and distribution of farms, smallholder farms, and family farms worldwide. World Development, 87, 16–29. 10.1016/j.worlddev.2015.10.041. [DOI] [Google Scholar]
- Meyfroidt, P. (2017). Mapping farm size globally: Benchmarking the smallholders debate. Environmental Research Letters, 12(3), 031002 10.1088/1748-9326/aa5ef6 [DOI] [Google Scholar]
- Pérez‐Hoyos, A. , Rembold, F. , Kerdiles, H. , & Gallego, J. (2017). Comparison of global land cover datasets for cropland monitoring. Remote Sensing, 9(11), 1118 10.3390/rs9111118. [DOI] [Google Scholar]
- Reed, J., Raddick, M. J., Lardner, A., & Carney,K. (2013). An exploratory factor analysis of motivations for participating in Zooniverse, a collection of virtual citizen science projects. (pp. 610–619) Piscataway, NJ: IEEE; 10.1109/HICSS.2013.85. [DOI] [Google Scholar]
- Resnik, D. B. , Elliott, K. C. , & Miller, A. K. (2015). A framework for addressing ethical issues in citizen science. Environmental Science and Policy, 54, 475–481. 10.1016/j.envsci.2015.05.008. [DOI] [Google Scholar]
- Ricciardi, V. , Ramankutty, N. , Mehrabi, Z. , Jarvis, L. , & Chookolingo, B. (2018). How much of the world’s food do smallholders produce? Global Food Security, 17, 64–72. 10.1016/j.gfs.2018.05.002. [DOI] [Google Scholar]
- Salk, C. F. , Sturn, T. , See, L. , Fritz, S. , & Perger, C. (2016). Assessing quality of volunteer crowdsourcing contributions: Lessons from the Cropland Capture game. International Journal of Digital Earth, 9(4), 410–426. 10.1080/17538947.2015.1039609. [DOI] [Google Scholar]
- Samberg, L. H. , Gerber, J. S. , Ramankutty, N. , Herrero, M. , & West, P. C. (2016). Subnational distribution of average farm size and smallholder contributions to global food production. Environmental Research Letters, 11(12), 124010 10.1088/1748-9326/11/12/124010. [DOI] [Google Scholar]
- Sangeetha, U. , Subbiah, M. , & Srinivasan, M. R. (2013). Estimation of confidence intervals for multinomial proportions of sparse contingency tables using Bayesian, methods. 3(4). [Google Scholar]
- See, L. , Comber, A. , Salk, C. , Fritz, S. , van der Velde, M. , Perger, C. , … Obersteiner, M. (2013). Comparing the quality of crowdsourced data contributed by expert and non‐experts. PLoS ONE, 8(7), e69958 10.1371/journal.pone.0069958. [DOI] [PMC free article] [PubMed] [Google Scholar]
- See, L. , Fritz, S. , Perger, C. , Schill, C. , McCallum, I. , Schepaschenko, D. , … Obersteiner, M. , (2015). Harnessing the power of volunteers, the internet and Google Earth to collect and validate global spatial information using Geo-Wiki. Technological Forecasting and Social Change, 98, 324–335. 10.1016/j.techfore.2015.03.002 [DOI] [Google Scholar]
- Sullivan, B. L. , Aycrigg, J. L. , Barry, J. H. , Bonney, R. E. , Bruns, N. , Cooper, C. B. , … Kelling, S. (2014). The eBird enterprise: An integrated approach to development and application of citizen science. Biological Conservation, 169, 31–40. 10.1016/j.biocon.2013.11.003. [DOI] [Google Scholar]
- Waldner, F. , Fritz, S. , Di Gregorio, A. , Plotnikov, D. , Bartalev, S. , Kussul, N. , … Defourny, P. (2016). A Unified cropland layer at 250 m for global agriculture monitoring. Data, 1(1), 3 10.3390/data1010003. [DOI] [Google Scholar]
- Wu, Y. , Xi, X. , Tang, X. , Luo, D. , Gu, B. , Lam, S. K. , … Chen, D. (2018). Policy distortions, farm size, and the overuse of agricultural chemicals in China. Proceedings of the National Academy of Sciences, 115(27), 7010 10.1073/pnas.1806645115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yan, L. , & Roy, D. P. (2016). Conterminous United States crop field size quantification from multi‐temporal Landsat data. Remote Sensing of Environment, 172, 67–86. 10.1016/j.rse.2015.10.034. [DOI] [Google Scholar]
- You, L. , Wood‐Sichra, U. , Fritz, S. , Guo, Z. , See, L. , & Koo, J. (2014). Spatial Production Allocation Model (SPAM) 2005 Beta Version . [April 2014]. Washington, DC: Retrieved from https://mapspam.info [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
All the data are of open access. Here is a link: https://pure.iiasa.ac.at/id/eprint/15526/.