

Abstract
Meta‐analyses have been increasingly used to synthesize proportions (eg, disease prevalence) from multiple studies in recent years. Arcsine‐based transformations, especially the Freeman–Tukey double‐arcsine transformation, are popular tools for stabilizing the variance of each study's proportion in two‐step meta‐analysis methods. Although they offer some benefits over the conventional logit transformation, they also suffer from several important limitations (eg, lack of interpretability) and may lead to misleading conclusions. Generalized linear mixed models and Bayesian models are intuitive one‐step alternative approaches, and can be readily implemented via many software programs. This article explains various pros and cons of the arcsine‐based transformations, and discusses the alternatives that may be generally superior to the currently popular practice.
Keywords: arcsine‐based transformation, Bayesian model, generalized linear mixed model, meta‐analysis, proportion
1. BACKGROUND
Many research findings in the health sciences are presented in the form of proportions, such as disease prevalence, case fatality rate, a diagnostic test's sensitivity and specificity, among others. 1 , 2 Meta‐analyses have been increasingly used to synthesize proportions that are reported from multiple studies on the same research topic. 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 Many meta‐analyses of proportions are performed using conventional two‐step methods. First, a specific transformation is usually applied to each study's proportion estimate for better approximation to the normal distribution, as required by the assumptions of conventional meta‐analysis models. 11 Second, the meta‐analysis is performed on the transformed scale, and the synthesized result is then back‐transformed to the original proportion scale that ranges from 0% to 100%. Of note, one may also directly synthesize proportions without any transformation; however, this approach is not optimal, because the proportion estimates may not be approximately normally distributed, especially for rare events and small sample sizes. The Wald‐type confidence intervals (CIs) of proportions may be even outside the range of 0% to 100%. 12
Various transformations are available for proportions, including the log, logit, arcsine‐square‐root, and Freeman–Tukey double‐arcsine transformations. 13 , 14 , 15 , 16 , 17 Among them, the Freeman–Tukey double‐arcsine transformation is a popular tool in current practice of synthesizing proportions. 10 We did a search on Google Scholar on June 17, 2020; for each year between 2000 and 2019, we searched for the exact terms “meta‐analysis” and “double‐arcsine” to obtain the number of research items using the double‐arcsine transformation in meta‐analyses. We also searched for the exact term “meta‐analysis,” with restriction to article titles, to obtain the rough number of meta‐analysis publications in each year, and calculated the corresponding proportion of research items using the double‐arcsine transformation. Figure 1 shows that the double‐arcsine transformation has been increasingly used over the past two decades.
Figure 1.
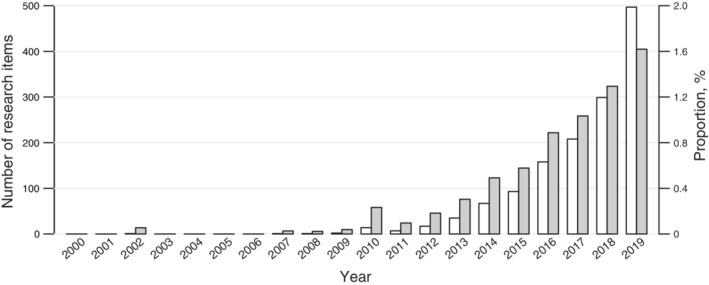
Bar plot of the number of research items using the double‐arcsine transformation in meta‐analyses and the corresponding proportion among meta‐analysis publications over the past two decades based on Google Scholar (https://scholar.google.com/). For each year, the left bar, in white, represents the number of research items, and the right bar, in gray, represents the corresponding proportion (in percentage)
Despite the raising popularity, several authors have previously expressed concerns about arcsine‐based transformations. 18 , 19 In addition, many meta‐analyses do not even specify the transformation used for synthesizing proportions. 10 Even if a transformation is specified, meta‐analysts frequently fail to provide sufficient justification for the selection of the transformation.
This article discusses the purported benefits of the arcsine‐based transformations that potentially explain their popularity in current practice. We also introduce how such transformations may be limited, and recommend alternative methods for meta‐analysis of proportions that may be superior. We focus on meta‐analysis of single proportions, where the arcsine‐based transformations are widely used.
2. METHODS
Suppose a meta‐analysis contains N studies that report single proportions on a common topic. Let pi be the proportion estimate from study i in the meta‐analysis (i = 1, …, N). The proportion is then simply calculated as pi = ei/ni, where ei and ni denote study i's event count and sample size, respectively. The arcsine‐square‐root transformation is , with variance vi = 1/(4ni). The Freeman–Tukey double‐arcsine transformation is
| (1) |
with variance vi = 1/(ni + 0.5). 13 Of note, the formula above of the double‐arcsine transformation is the version originally presented in the article by Freeman and Tukey. 13 While one may also take the average of the two arcsine values (by dividing by 2), leading to the variance vi = 1/(4ni + 2), so that it has the same scale with the arcsine‐square‐root transformation, such a linear transformation does not affect the back‐transformed proportion.
Besides the arcsine‐based transformations, the log and logit transformations are also frequently used for proportions. 10 , 20 , 21 Their formulas are more straightforward: the log transformation is yi = g(pi) = logpi, with variance vi = 1/ei − 1/ni, and the logit transformation is yi = g(pi) = log[pi/(1 − pi)], with variance vi = 1/ei + 1/(ni − ei).
After applying a specific transformation to each study's proportion, conventional meta‐analysis methods 22 are subsequently performed using the transformed data, that is, yi and vi, leading to the synthesized result y with a 95% CI. The synthesized result is finally back‐transformed to the original proportion scale; the overall proportion is usually estimated as p = g−1(y), and its CI limits are also back‐transformed in the same manner.
3. PROS
Because conventional meta‐analysis models assume normally distributed data, 11 the various transformations are applied to the proportion data in an effort to yield better approximations to the normal distribution. As shown in the formulas above, the variances of the arcsine‐based transformations depend only on the sample sizes, which are typically fixed, known values. However, the variances of the log and logit transformations depend additionally on the event counts, which are random variables.
Involving event counts in the variances implies several limitations of the log and logit transformations. First, it does not meet the assumption of conventional meta‐analysis models; that is, the within‐study variances are treated as fixed, known values, while the event counts are not. The violation of this assumption may reduce statistical inference accuracy. 11 Second, because the log‐ or logit‐transformed proportion estimates and their variances both depend on the event counts, they are intrinsically correlated. This intrinsic correlation has been well known to cause substantial biases in meta‐analytic results, especially when the sample sizes are small. 23 , 24 , 25 , 26 , 27 In addition, in the presence of zero event counts, both log‐ and logit‐transformed proportions cannot be calculated, and a continuity correction must be applied to the zero counts, usually by adding 0.5. 28 , 29 , 30 This correction may have considerable impact on the synthesized proportion for rare events. 31
In this sense, the arcsine‐based transformations have the important advantage of stabilizing variances, which is likely the main reason that such transformations are widely used in current practice. As their variances depend only on the sample sizes, they can be validly treated as fixed, known values, and have no correlation with the transformed proportion estimates. These transformations also do not need the continuity correction for zero counts. Moreover, compared with the arcsine‐square‐root transformation, the Freeman–Tukey double‐arcsine transformation may stabilize variances better in general. 13
4. CONS
Despite the advantages of the arcsine‐based transformations listed above, they also suffer from several critical limitations. First, these transformations lack intuitive interpretations from practical perspectives, especially compared with the traditional logit transformation. 18 , 32 The arcsine function is mainly used for technical purposes. More specifically, the variances of transformed proportions are approximated by the so‐called delta method, which uses the derivative of the transformation function. 33 Taking the benefit of the special structure of the arcsine function's derivative, the event counts are canceled out in the approximated variances of the arcsine‐transformed proportions. Unlike the logit proportion that represents the odds on a logarithmic scale, the arcsine‐transformed proportions may not be intuitive for practitioners. 18
Second, as the proportion estimates are usually heterogeneous, the random‐effects meta‐analysis method is frequently used, assuming that each study's underlying true transformed proportion follows the normal distribution across studies. 22 The arcsine‐based transformations might violate this assumption, because the arcsine function has a bounded domain, implying truncations for the assumed normal distribution. On the other hand, the logit‐transformed proportions can take any real value, and thus, may be more suitable for the between‐study normality assumption.
Third, the Freeman–Tukey double‐arcsine transformation has a complicated form of back‐transformation to the original proportion scale. Compared with other transformations, its back‐transformation depends additionally on a sample size that represents the overall synthesized result. 34 This “overall sample size” is not well defined in the meta‐analysis setting; it may be selected as the harmonic, geometric, and arithmetic means of study‐specific sample sizes, 19 , 34 or the inverse of the variance of the synthesized result 15 ; it is generally difficult to justify the value used as the “overall sample size.” More importantly, different values may lead to substantially different proportions in some cases, potentially leading to misleading conclusions. 19
Moreover, numerical problems may occur when using the Freeman–Tukey double‐arcsine transformation. Although this transformation refines the usual arcsine‐square‐root transformation by averaging over the double arcsines for better stabilizing variances, it may have low accuracy at values close to its domain limits, which likely occur in cases of rare events and small sample sizes. 35 Specifically, because the event count ei is between 0 and ni, as indicated in Equation (1), the transformed proportion must be bounded between and . It is possible that the synthesized result is outside this domain based on a certain “overall sample size.” In this case, the result cannot be back‐transformed to the original proportion scale. When such issues occur, one may decide to use the back‐transformation of the arcsine‐square‐root transformation, which is a good approximation of the Freeman–Tukey double‐arcsine transformation for sufficiently large sample sizes; however, this might affect the accuracy of the analysis.
5. ALTERNATIVES
From a statistical perspective, event counts are typically assumed to follow binomial distributions, 36 and all transformations discussed above are applied to the binomial data for approximations to normal distributions within studies. With advances in statistical computing techniques, these approximations in the two‐step methods may be unnecessary, because they can be feasibly replaced with one‐step meta‐analysis methods, including generalized linear mixed models (GLMMs) or Bayesian hierarchical models. 11 , 18 , 19 , 37 , 38 , 39 , 40 , 41 , 42 , 43
GLMMs directly model event counts with binomial likelihoods and fully account for within‐study uncertainties. 37 , 38 , 39 They use a specific link function to transform study‐specific latent true proportion to a linear scale, on which random effects are specified in a manner similar to the conventional two‐step methods. The logit link is the canonical link function for proportions (ie, binomial data), while many other links, such as the log and probit links, may be also used. 36 GLMMs with the log and logit links correspond to the log and logit transformations used in the two‐step methods, but they do not have any of the aforementioned limitations. Specifically, GLMMs do not involve estimating (transformed) proportions and their variances at the within‐study level. Therefore, they do not suffer from the problems caused by the intrinsic correlation between the log‐ or logit‐transformed proportions and their sample variances approximated by the delta method. GLMMs can also effectively model zero event counts without continuity corrections. 44 More importantly, compared with the arcsine‐based transformations, the GLMM with the logit link produces more interpretable results. 18 , 45 , 46 , 47 , 48
Similarly, the multilevel structure of meta‐analyses can be naturally modeled under the Bayesian framework. Bayesian methods assign priors to the unknown parameters, including the overall proportion and the heterogeneity variance on the transformed scale; the conclusions are drawn from the posterior distributions of these parameters. As one of the Bayesian methods' benefits, researchers might use informative priors to improve estimation by incorporating experts' opinion or external evidence. 49
GLMMs and Bayesian models have been seldom used in meta‐analysis applications so far, 10 despite the fact that the current literature offers many software programs to implement these alternative approaches for synthesizing proportions (as well as other measures), including SAS, R, and Stata. 39 , 40 , 45 , 50 , 51 , 52 Bayesian models can be fitted via BUGS, JAGS, Stan, and others that are designed for general purposes of Bayesian analyses.
When the number of studies or the number of events in a meta‐analysis is small (say, <10), GLMMs and Bayesian models may have issues about their algorithm convergence (more specifically, for maximizing likelihood and deriving posterior samples from the Markov chain Monte Carlo, respectively). 53 In such situations, although the conventional two‐step methods might successfully produce results, the synthesized proportion may be subject to large biases and thus should be interpreted with great caution. 39
As stated above, this article has focused on meta‐analysis of single proportions, where the arcsine‐based transformations are widely used. GLMMs and Bayesian methods are also available for jointly modeling multiple proportions, such as sensitivity and specificity of diagnostic tests. 45 , 46 , 47 , 48 , 54
6. DISCUSSION
Compared with the traditional logit transformation, the arcsine‐based transformations for proportions mainly benefit from their stabilized variances that depend only on sample sizes. However, they do not have intuitive interpretations, and the limitations of the logit transformation can be easily overcome by using GLMMs or Bayesian models. These alternatives are straightforward, one‐step methods and are generally superior to the conventional two‐step methods that require transformations of proportions within studies. 55 Importantly, in some cases, the one‐step methods may lead to substantially different results from the two‐step methods. 19 In future studies, it is worthwhile to explore the performance of the different methods with various transformations or link functions based on a large collection of empirical meta‐analysis datasets, and quantitatively investigate the differences between the synthesized proportions produced by these methods.
The limitations of the arcsine‐based transformations in meta‐analysis, however, do not nullify their use in individual studies. We have focused on the synthesis of proportions, and GLMMs or Bayesian models are advantageous for producing such synthesized proportions. When meta‐analysts want to present estimates from individual studies, transformations of proportions are still useful. For example, meta‐analysts frequently use the forest plot to visualize the distributions of study‐specific estimates, 56 and the funnel plot to assess potential publication bias or small‐study effects. 57 , 58 Both plots depend on each study's point estimate of proportion, CI, and SE, which cannot be obtained by GLMMs or Bayesian models. The arcsine‐based transformations can be preferably used at the within‐study level, while they are not recommended at the between‐study level. In fact, many early articles on the arcsine‐based transformations were discussed in the setting of an individual study 13 , 59 , 60 ; these articles did not directly suggest extending the arcsine‐based transformations to the meta‐analysis setting.
In summary, we highly recommend the use of GLMMs or Bayesian models for synthesizing proportions; nowadays, many software programs are readily available for implementing them. Most meta‐analyses of proportions published in recent years continue to use the Freeman–Tukey double‐arcsine transformation, and the rate is increasing (Figure 1); it is a time for change.
FUNDING
This research was supported in part by the U.S. National Institutes of Health/National Library of Medicine grant R01 LM012982 and National Institutes of Health/National Center for Advancing Translational Sciences grant UL1 TR001427. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. The financial support had no involvement in the conceptualization of the report and the decision to submit the report for publication.
CONFLICT OF INTEREST
The authors declare no conflict of interest.
AUTHOR CONTRIBUTIONS
Conceptualization: Lifeng Lin, Chang Xu
Funding Acquisition: Lifeng Lin
Writing‐Original Draft Preparation: Lifeng Lin
Writing‐Review & Editing: Lifeng Lin, Chang Xu
All authors have read and approved the final version of the manuscript. Lifeng Lin had full access to all of the data in this study and takes complete responsibility for the integrity of the data and the accuracy of the data analysis.
TRANSPARENCY STATEMENT
Lifeng Lin affirms that this manuscript is an honest, accurate, and transparent account of the study being reported, and that no important aspects of the study have been omitted.
Lin L, Xu C. Arcsine‐based transformations for meta‐analysis of proportions: Pros, cons, and alternatives. Health Sci Rep. 2020;9999:e178 10.1002/hsr2.178
Funding information National Center for Advancing Translational Sciences, Grant/Award Number: UL1 TR001427; U.S. National Library of Medicine, Grant/Award Number: R01 LM012982
DATA AVAILABILITY STATEMENT
Data sharing is not applicable to this article as no new data were created in this study.
REFERENCES
- 1. Fleiss JL, Levin B, Paik MC. Statistical Methods for Rates and Proportions. 3rd ed. Hoboken, NJ: Wiley; 2003. [Google Scholar]
- 2. Rothman KJ, Greenland S, Lash TL. Modern Epidemiology. 3rd ed. Philadelphia, PA: Lippincott Williams & Wilkins; 2008. [Google Scholar]
- 3. Rotenstein LS, Ramos MA, Torre M, et al. Prevalence of depression, depressive symptoms, and suicidal ideation among medical students: a systematic review and meta‐analysis. JAMA. 2016;316(21):2214‐2236. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Ismail Z, Elbayoumi H, Fischer CE, et al. Prevalence of depression in patients with mild cognitive impairment: a systematic review and meta‐analysis. JAMA Psychiat. 2017;74(1):58‐67. [DOI] [PubMed] [Google Scholar]
- 5. Jenkins HE, Yuen CM, Rodriguez CA, et al. Mortality in children diagnosed with tuberculosis: a systematic review and meta‐analysis. Lancet Infect Dis. 2017;17(3):285‐295. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Lange S, Probst C, Gmel G, Rehm J, Burd L, Popova S. Global prevalence of fetal alcohol spectrum disorder among children and youth: a systematic review and meta‐analysis. JAMA Pediatr. 2017;171(10):948‐956. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Madigan S, Ly A, Rash CL, van Ouytsel J, Temple JR. Prevalence of multiple forms of sexting behavior among youth: a systematic review and meta‐analysis. JAMA Pediatr. 2018;172(4):327‐335. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Ross SB, Jones K, Blanch B, et al. A systematic review and meta‐analysis of the prevalence of left ventricular non‐compaction in adults. Eur Heart J. 2019;41(14):1428‐1436. [DOI] [PubMed] [Google Scholar]
- 9. Sun P, Qie S, Liu Z, Ren J, Li K, Xi J. Clinical characteristics of hospitalized patients with SARS‐CoV‐2 infection: a single arm meta‐analysis. J Med Virol. 2020;92(6):612‐617. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Borges Migliavaca C, Stein C, Colpani V, et al. How are systematic reviews of prevalence conducted? A methodological study. BMC Med Res Methodol. 2020;20(1):96. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Jackson D, White IR. When should meta‐analysis avoid making hidden normality assumptions? Biom J. 2018;60(6):1040‐1058. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Blyth CR, Still HA. Binomial confidence intervals. J Am Stat Assoc. 1983;78(381):108‐116. [Google Scholar]
- 13. Freeman MF, Tukey JW. Transformations related to the angular and the square root. Ann Math Stat. 1950;21(4):607‐611. [Google Scholar]
- 14. Zar JH. Biostatistical Analysis. 5th ed. Essex, UK: Pearson Education; 2014. [Google Scholar]
- 15. Barendregt JJ, Doi SA, Lee YY, Norman RE, Vos T. Meta‐analysis of prevalence. J Epidemiol Community Health. 2013;67(11):974‐978. [DOI] [PubMed] [Google Scholar]
- 16. Negeri ZF, Shaikh M, Beyene J. Bivariate random‐effects meta‐analysis models for diagnostic test accuracy studies using arcsine‐based transformations. Biom J. 2018;60(4):827‐844. [DOI] [PubMed] [Google Scholar]
- 17. Rücker G, Schwarzer G, Carpenter J, Olkin I. Why add anything to nothing? The arcsine difference as a measure of treatment effect in meta‐analysis with zero cells. Stat Med. 2009;28(5):721‐738. [DOI] [PubMed] [Google Scholar]
- 18. Warton DI, Hui FKC. The arcsine is asinine: the analysis of proportions in ecology. Ecology. 2011;92(1):3‐10. [DOI] [PubMed] [Google Scholar]
- 19. Schwarzer G, Chemaitelly H, Abu‐Raddad LJ, Rücker G. Seriously misleading results using inverse of Freeman‐Tukey double arcsine transformation in meta‐analysis of single proportions. Res Synth Methods. 2019;10(3):476‐483. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Simpson S, Blizzard L, Otahal P, van der Mei I, Taylor B. Latitude is significantly associated with the prevalence of multiple sclerosis: a meta‐analysis. J Neurol Neurosurg Psychiatry. 2011;82(10):1132‐1141. [DOI] [PubMed] [Google Scholar]
- 21. Reitsma JB, Glas AS, Rutjes AWS, Scholten RJPM, Bossuyt PM, Zwinderman AH. Bivariate analysis of sensitivity and specificity produces informative summary measures in diagnostic reviews. J Clin Epidemiol. 2005;58(10):982‐990. [DOI] [PubMed] [Google Scholar]
- 22. Borenstein M, Hedges LV, Higgins JPT, Rothstein HR. A basic introduction to fixed‐effect and random‐effects models for meta‐analysis. Res Synth Methods. 2010;1(2):97‐111. [DOI] [PubMed] [Google Scholar]
- 23. Hedges LV. Estimation of effect size from a series of independent experiments. Psychol Bull. 1982;92(2):490‐499. [Google Scholar]
- 24. Berkey CS, Hoaglin DC, Mosteller F, Colditz GA. A random‐effects regression model for meta‐analysis. Stat Med. 1995;14(4):395‐411. [DOI] [PubMed] [Google Scholar]
- 25. Peters JL, Sutton AJ, Jones DR, Abrams KR, Rushton L. Comparison of two methods to detect publication bias in meta‐analysis. JAMA. 2006;295(6):676‐680. [DOI] [PubMed] [Google Scholar]
- 26. Lin L. Bias caused by sampling error in meta‐analysis with small sample sizes. PLOS One. 2018;13(9):e0204056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Doncaster CP, Spake R. Correction for bias in meta‐analysis of little‐replicated studies. Meth Ecol Evol. 2018;9(3):634‐644. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Walter SD. The estimation and interpretation of attributable risk in health research. Biometrics. 1976;32(4):829‐849. [PubMed] [Google Scholar]
- 29. Pettigrew HM, Gart JJ, Thomas DG. The bias and higher cumulants of the logarithm of a binomial variate. Biometrika. 1986;73(2):425‐435. [Google Scholar]
- 30. Higgins JPT, Thomas J, Chandler J, et al. Cochrane Handbook for Systematic Reviews of Interventions. Chichester, UK: Wiley; 2019. [Google Scholar]
- 31. Sweeting MJ, Sutton AJ, Paul LC. What to add to nothing? Use and avoidance of continuity corrections in meta‐analysis of sparse data. Stat Med. 2004;23(9):1351‐1375. [DOI] [PubMed] [Google Scholar]
- 32. Efthimiou O. Practical guide to the meta‐analysis of rare events. Evid Based Mental Health. 2018;21(2):72‐76. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Casella G, Berger RL. Statistical Inference. 2nd ed. Belmont, CA: Duxbury Press; 2001. [Google Scholar]
- 34. Miller JJ. The inverse of the Freeman–Tukey double arcsine transformation. Am Stat. 1978;32(4):138‐138. [Google Scholar]
- 35. Jeong J‐H. Domain of inverse double arcsine transformation. arXiv. 2018;1811:07827. [Google Scholar]
- 36. Agresti A. Categorical Data Analysis. 3rd ed. Hoboken, NJ: Wiley; 2013. [Google Scholar]
- 37. Hamza TH, van Houwelingen HC, Stijnen T. The binomial distribution of meta‐analysis was preferred to model within‐study variability. J Clin Epidemiol. 2008;61(1):41‐51. [DOI] [PubMed] [Google Scholar]
- 38. Stijnen T, Hamza TH, Özdemir P. Random effects meta‐analysis of event outcome in the framework of the generalized linear mixed model with applications in sparse data. Stat Med. 2010;29(29):3046‐3067. [DOI] [PubMed] [Google Scholar]
- 39. Lin L, Chu H. Meta‐analysis of proportions using generalized linear mixed models. Epidemiology. 2020. 10.1097/ede.0000000000001232. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Jackson D, Law M, Stijnen T, Viechtbauer W, White IR. A comparison of seven random‐effects models for meta‐analyses that estimate the summary odds ratio. Stat Med. 2018;37(7):1059‐1085. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41. Smith TC, Spiegelhalter DJ, Thomas A. Bayesian approaches to random‐effects meta‐analysis: a comparative study. Stat Med. 1995;14(24):2685‐2699. [DOI] [PubMed] [Google Scholar]
- 42. Schmid CH. Using Bayesian inference to perform meta‐analysis. Eval Health Prof. 2001;24(2):165‐189. [DOI] [PubMed] [Google Scholar]
- 43. Warn DE, Thompson SG, Spiegelhalter DJ. Bayesian random effects meta‐analysis of trials with binary outcomes: methods for the absolute risk difference and relative risk scales. Stat Med. 2002;21(11):1601‐1623. [DOI] [PubMed] [Google Scholar]
- 44. Xu C, Li L, Lin L, et al. Exclusion of studies with no events in both arms in meta‐analysis impacted the conclusions. J Clin Epidemiol. 2020;123:91‐99. [DOI] [PubMed] [Google Scholar]
- 45. Chu H, Cole SR. Bivariate meta‐analysis of sensitivity and specificity with sparse data: a generalized linear mixed model approach. J Clin Epidemiol. 2006;59(12):1331‐1332. [DOI] [PubMed] [Google Scholar]
- 46. Chu H, Chen S, Louis TA. Random effects models in a meta‐analysis of the accuracy of two diagnostic tests without a gold standard. J Am Stat Assoc. 2009;104(486):512‐523. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47. Dendukuri N, Schiller I, Joseph L, Pai M. Bayesian meta‐analysis of the accuracy of a test for tuberculous pleuritis in the absence of a gold standard reference. Biometrics. 2012;68(4):1285‐1293. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48. Liu Y, Chen Y, Chu H. A unification of models for meta‐analysis of diagnostic accuracy studies without a gold standard. Biometrics. 2015;71(2):538‐547. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49. Turner RM, Davey J, Clarke MJ, Thompson SG, Higgins JPT. Predicting the extent of heterogeneity in meta‐analysis, using empirical data from the Cochrane database of systematic reviews. Int J Epidemiol. 2012;41(3):818‐827. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50. Viechtbauer W. Conducting meta‐analyses in R with the metafor package. J Stat Softw. 2010;36:3. [Google Scholar]
- 51. Bates D, Mächler M, Bolker B, Walker S. Fitting linear mixed‐effects models using lme4. J Stat Softw. 2015;67(1):1‐48. [Google Scholar]
- 52. Schwarzer G. Meta: an R package for meta‐analysis. R News. 2007;7(3):40‐45. [Google Scholar]
- 53. Ju K, Lin L, Chu H, Cheng LL, Xu C. Laplace approximation, penalized quasi‐likelihood, and adaptive Gauss–Hermite quadrature for generalized linear mixed models: towards meta‐analysis of binary outcome with sparse data. BMC Med Res Methodol. 2020;20(1):152. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54. Siegel L, Rudser K, Sutcliffe S, et al. A Bayesian multivariate meta‐analysis of prevalence data. Statistics in Medicine. 2020;1–15. 10.1002/sim.8593. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55. Trikalinos TA, Trow P, Schmid CH. Simulation‐Based Comparison of Methods for Meta‐Analysis of Proportions and Rates. U.S. Agency for Healthcare Research and Quality: Rockville, MD; 2013. [PubMed] [Google Scholar]
- 56. Li G, Zeng J, Tian J, Levine MAH, Thabane L. Multiple uses of forest plots in presenting analysis results in health research. J Clin Epidemiol. 2020;117:89‐98. [DOI] [PubMed] [Google Scholar]
- 57. Sterne JAC, Egger M. Funnel plots for detecting bias in meta‐analysis: guidelines on choice of axis. J Clin Epidemiol. 2001;54(10):1046‐1055. [DOI] [PubMed] [Google Scholar]
- 58. Sterne JAC, Sutton AJ, Ioannidis JPA, et al. Recommendations for examining and interpreting funnel plot asymmetry in meta‐analyses of randomised controlled trials. BMJ. 2011;343:d4002. [DOI] [PubMed] [Google Scholar]
- 59. Anscombe FJ. The transformation of poisson, binomial and negative‐binomial data. Biometrika. 1948;35(3/4):246‐254. [Google Scholar]
- 60. Mosteller F, Tukey JW. The uses and usefulness of binomial probability paper. J Am Stat Assoc. 1949;44(246):174‐212. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Data sharing is not applicable to this article as no new data were created in this study.