

Abstract
Multivariate analysis has been widely used and one of the popular multivariate analysis methods is canonical correlation analysis (CCA). CCA finds the linear combination in each group that maximizes the Pearson correlation. CCA has been extended to a kernel CCA for nonlinear relationships and generalized CCA that can consider more than two groups. We propose an extension of CCA that allows multi-group and nonlinear relationships in an additive fashion for a better interpretation, which we termed as Generalized Additive Kernel Canonical Correlation Analysis (GAKCCA). In addition to exploring multi-group relationship with nonlinear extension, GAKCCA can reveal contribution of variables in each group; which enables in-depth structural analysis. A simulation study shows that GAKCCA can distinguish a relationship between groups and whether they are correlated or not. We applied GAKCCA to real data on neurodevelopmental status, psychosocial factors, clinical problems as well as neurophysiological measures of individuals. As a result, it is shown that the neurophysiological domain has a statistically significant relationship with the neurodevelopmental domain and clinical domain, respectively, which was not revealed in the ordinary CCA.
Subject terms: Mathematics and computing, Statistics
Introduction
Multivariate analysis is a statistical method that considers several variables simultaneously. Compared with univariate analysis, which focus on the influence of one variable only, multivariate analysis takes into account not only the effect of each variable but also interaction between variables. Thus, multivariate analysis gets popular as researchers face to more complex data. A number of statistical methods concerning multivariate analysis have been developed and widely used. For instance, principle component analysis (PCA), first proposed by Pearson1 is a method that compresses the data in the high dimensional space into the low dimensional space by identifying dimensions in which the variability of the data are explained the most. Factor analysis extracts underlying, but unobservable random quantities by assuming variables are expressed with those random quantities2.
One of the popular multivariate analysis is canonical correlation analysis (CCA). CCA, proposed by Hotelling3, explores association between two multivariate groups. CCA finds linear combinations of each group that maximize a Pearson correlation coefficient between them. In this way, CCA can also serve as a dimension reduction method as each multi-dimensional variable is reduced to a linear combination. This advantage makes CCA widely used in many scientific fields that mostly deal with high dimensional data such as psychology, neuroscience, medical science and image recognition4–7, etc.
Despite of its strength, CCA has some limitations. CCA is restricted to linear relationship only so that the result of CCA can be misleading if two variables are linked with a non-linear relation. This limitation is inherited from the characteristics of the Pearson correlation. For example, if two random variables X and Y are related with the equation , then the Pearson correlation of X and Y results in , although two random variables are related. To overcome the linearity constraint of the classical CCA, Bach and Jordan8 proposed Kernel canonical correlation analysis (KCCA), which applies a kernel method to the CCA problem. Unlike CCA, KCCA is a method of finding nonlinear relationship between two groups. Kernelization allows practical nonlinear extension of the CCA method. KCCA has been successful in some scientific fields that need to find nonlinear relationship beyond linear one such as speech communication science, genetics and pattern recognition9–11, etc.
Another limitation of the classical CCA is that it is only applicable to two groups. Often, scientific experiments yield results that can be divided into more than two groups. Pair-wise application of CCA into the groups more than two could ignore the connection and non-connection within the groups. Multi-group version of CCA to overcome such limitation was introduced by Kettenring12, named generalized canonical correlation analysis (GCCA or MCCA). GCCA finds linear combinations of each group that optimize certain criterion, such as the sum of covariances. Tenenhaus et al.13 proposed kernelized version of GCCA termed as kernel generalized canonical correlation analysis (KGCCA). This method is an extension of CCA by combining nonlinearity and multi-group analysis. In spite of fully flexible extension, kernelization of all variables together in each group is not helpful to provide structural analysis of variables. For instance, it is difficult to see the contribution of one variable, say, in a group in relation to the another group using KGCCA. Balakrishnan et al.14 considered an additive model by restricting possible non-linear functions to the class of additive models. This modification enables to analyze the contribution of each variable. However, it is still restricted to two groups.
In this paper, we consider an additivity idea with more than two groups. We call our proposed approach as generalized additive kernel canonical correlation analysis (GAKCCA). We expect the proposed approach has a better interpretability than KCCA or KGCCA and it can be applied to multi-group data. The proposed approach was motivated by a research problem on investigating the relationships among individual measures such as divergent psychological aspects mainly measured psychometric questionnaires and neurophysiological aspects such as brain morphologies. In this study, we analyze four domains of individual variables: neurodevelopmental, psychosocial, clinical characteristics, and structural MRI (Magnetic Resonance Image) measures. The present study was not only to define the link between the above four domains but also to reveal phase of variables of each domain under the hypothesis that a series of associations between domains are assumed to exist. We expect that the proposed method would facilitate identifying the link of neurophysiological basis represented by structural MRI related variables with the psychological variables.
The organization of the paper is as follows. In Materials and Methods section, we review CCA and its variants, then specify the population and empirical versions of the proposed GAKCCA method and introduce how to define the contribution of a variable in a group. As the proposed approach requires a regularization parameter, we discuss selection of a regularization parameter as well. Hypothesis test based on permutation is also performed. In Results section, we show the results of simulation study to confirm that our method is valid and it explains the relationship of groups well. The results of real data analysis are also presented here. Finally, the discussion is given in the “Discussion” section.
Materials and methods
We first briefly review CCA and its variants. Then, we present our GAKCCA method and describe the algorithm for implementation.
Canonical correlation analysis and its variants
For two multi-variate groups, canonical correlation analysis finds linear combination of each group that maximizes correlation between two linear combinations. That is, CCA finds and that satisfy the following: subject to , where has variables and has variables. Here, denotes the transpose of a matrix. Variance constraints are to reduce the freedom of scaling for and .
Instead of linear combination of variables in each group in CCA, Kernel canonical correlation analysis utilizes nonlinear functions to extract the relationship between two groups. KCCA can be formulated as follow: subject to , where for is an unknown function in the reproducing kernel Hilbert space (RKHS)8.
Note that both CCA and KCCA assume two groups of variables. To expand beyond two groups, Kettenring12 introduced multi-group generalization of CCA (GCCA or MCCA). GCCA finds linear combinations of each group that optimize certain criterion to reveal multi-group structure. Given J multi-variate groups , GCCA finds by considering subject to A function g, which is called a scheme function, is related to a criterion for selecting canonical variates12. The examples of g are (Horst scheme15), (Centroid scheme16) or (Factorial scheme17). is an element of design matrix C, where if j and k groups are related and , otherwise.
Tenenhaus and Tenenhaus18 extended GCCA to a regularization version by imposing a constraint on the norm of a coefficient vector in a linear combination as well as the variance of the linear combination (RGCCA). Specifically, the constraint is given by for where is a regularization parameter vector (or shrinkage parameter). Regularization parameters enable an inversion operation by avoiding ill-conditioned variance matrices13,18. All ’s are between 0 and 1.
Also, Tenenhaus et al.13 developed a nonlinear version of GCCA (KGCCA) by considering a function for each group. That is, KGCCA finds that satisfy subject to where each is an unknown function in the RKHS. g and are same as those in RGCCA.
Generalized additive Kernel canonical correlation analysis
In this subsection, we introduce our approach that considers an additive structure in the multi-group setting. As in the previous subsection, we consider J multi-variate random variable groups for . KCCA considers a function on the j-th group variable, , where is a nonlinear function in the RKHS. In our approach, GAKCCA, we assume that is an additive function in RKHS as in Balakrishnan et al.14. That is,
where each is an RKHS with a kernel . Then, GAKCCA finds that satisfies0
| 1 |
where g and are a scheme function and an element of the design matrix C, respectively. Since we assume , we can write so that (1) becomes
| 2 |
subject to for . We denote the expression in the Eq. (2) as .
When we introduce a covariance operator on the RKHS, mathematical treatment can be simpler13,19,20. The mean operator with respect to is defined by
where is an inner product on . The covariance operator with respect to and can be also defined as
Then, the Eq. (2) can be expressed as
| 3 |
subject to for
Note that the Eq. (3) is a theoretical expression. We now explain how to derive an empirical version using samples. Suppose that we have n samples of . The i-th sample of is denoted by . Fukumizu et al.21 suggested an estimated mean operator and an estimated covariance operator which satisfy the following properties:
and
| 4 |
where , and .
Bach and Jordan8 utilized the linear space spanned by denoted by to write , where is a coefficient corresponding to which needs to be estimated and is orthogonal to . With these facts, we can further simplify the Eq. (4) by introducing an symmetric Gram matrix 22 whose -component is . The centered can be represented as , where is the identity matrix and is the matrix whose components are all ones, and its -component is Then, using
| 5 |
the Eq. (4) becomes
where . The third equality in the Eq. (5) is due to the fact that is orthogonal to . is the inner-product linear space generated by with inner product . This leads to for all .
Note that the centered Gram matrix is singular since the sum of rows or columns is zero. Thus, the constraint does not provide a unique solution to our method. So, similar to the regularization approach for the KCCA method8,13, we use instead of and introduce regularization parameters in the constraint conditions such as
| 6 |
where is an identity operator if and a zero operator, otherwise. With the , the Eq. (6) can be rewritten as
In summary, the empirical version of the Eq. (3) with regularization parameters is expressed as
| 7 |
subject to for
To find the solution, to the equation (7), an algorithm similar to the one considered in Tenenhaus et al.13 is developed. The detailed algorithm is described in the Supplementary Appendix A.
In the classical CCA method, the contribution of a variable in a group in relation between the group and the other group is measured by correlation23. To be specific, the contribution of in for the relation between and is measured by , where and are canonical weights in CCA. A high absolute value of implies that plays a significant role in the relation between and . Similarly, we can measure the contribution of a variable in a group in relation between the group and the other group in our approach, GAKCCA. We define the contribution coefficient of , the lth variable in the jth group, in relation between and as
We also define the measure for the relation between and as
The empirical version of and can be formulated as
and
Simulation study shows that empirical contribution coefficient and measure for the relation between two groups describe structural information of variable groups well.
Regularization parameter selection
There can be several approaches for choosing appropriate regularization parameters. We consider a cross validation idea for selecting regularization parameters for GAKCCA. Using the whole data, we approximate and denote as . Using the split data, we approximate and denote as which is obtained by excluding the gth split. Then, we compare these two estimates to select the regularization parameters. This approach is similar to that of Ashad Alam and Fukumizu24.
In detail, we describe the selection procedure as follows. We split the n samples of into G subsets, denoting , where contains samples of and . For each , we estimate such that
where and are calculated from the data excluding while and are obtained from the entire data. Then, we obtain
and selection of is made by minimizing . The main idea of this procedure is that can be expressed as by reproducing property in RKHS and we consider as an approximation of . Then cross validation procedure chooses which minimizes the variability of the estimate of caused by the selection of data. Note that ’s may not be equal, but for the purpose of simplicity in computation, we assume all ’s are equal in the simulation study and real data analysis.
Permutation test
In the classical CCA method, Wilks’ lambda statistic is widely used to test the hypothesis that there is no relationship between two groups25. However, it is difficult to apply the Wilks’ lambda test for GAKCCA due to multivariate normal distribution assumption of the Wilks’ lambda test. Nonlinear extension of GAKCCA makes the model more complex, so formulating test statistics based on the unknown nonlinear function is not feasible. Thus, we consider a permutation test approach to test . That is, we approximate the sampling distribution of test statistics, , by obtaining test statistics from resampling under the null hypothesis.
First, from the original data, we calculate , denoted as . Second, for the j-th group, we sample from with replacement. We do the same procedure for all groups. Note that the resampled set does not necessarily keep the order as it should not matter under the null hypothesis. Third, from the resampled data, we calculate . Fourth, we repeat second and third steps m times and obtain . Lastly, we find an empirical distribution from . We reject the null hypothesis if is less than the pre-specified significant level. In this paper, we set .
Analogous hypothesis test methods can be applied to test whether a certain variable is helpful for relationship within groups or not via the contribution coefficient.
Ethic approval
The data collection was approved by the Seoul National University Research Ethics Committee and all methods to collect the data were performed in accordance with the relevant guidelines and regulations. Informed written consent was obtained from all participants prior to actual participation. Also, all data were anonymized prior to analysis.
Results
Simulation study
To check the effectiveness of our method, we consider two synthesized data; one is an inter-independent case (Case I) and the other is an inter-dependent case (Case II).
For Case I, we consider 3 groups of variables (, , ). The number of members in each group and their distribution assumption are as follows:
: ,
: , , ,
: , ,
Here we assume that all N(0, 1)s are independent so that 3 groups and are mutually independent. From this setting, we generate 100 data points, that is, the number of samples is 100 ().
To apply our method, GAKCCA, we use a Gaussian kernel for each variable. A Gaussian kernel for the lth variable in the jth block is given as , where can be viewed as a bandwidth. We set by median distance between the data points in as in Balakrishnan et al.14 and Tenenhaus et al.13. We use a fully-connected design matrix, that is, if and , otherwise. We adopt a Horst scheme function, . Without further notice, Gaussian kernel with median-based bandwidth, fully-connected design matrix and Horst scheme function are used in all simulation study and real data analysis in this paper.
For the simulated data, we obtain estimates of , , and . By the permutation test described in the previous section, we can calculate a p-value for testing each quantity being zero. We repeat this procedure using three hundreds sets of simulated data.
Table 1 shows that there is no significant relationship between 3 groups (p-value of is 0.517 on average), which correctly captures dependence/independence of the simulation setting for Case I.
Table 1.
Averages of estimated values and the corresponding p-values from the permutation test over 300 simulated data sets for the Case I (Independent case). The number in the parenthesis is standard deviation over 300 simulated data sets.
| Estimate | p-value | |
|---|---|---|
| 0.544 (0.210) | 0.517 (0.268) | |
| 0.303 (0.115) | 0.447 (0.289) | |
| 0.341 (0.077) | 0.465 (0.300) | |
| 0.287 (0.098) | 0.421 (0.286) |
For Case II, we consider 3 groups (, , ) again and the number of members in each group and their distribution assumption are as follows.
: ,
: , , ,
: , , ,
where z follows . Here we assume all N(0, 1)s are independent. Given the structure of the groups, , , and are linked with nonlinear relationship.
From this setting, we generate 100 data points, that is, the number of samples is 100 () and apply our method to estimate , , and . We also obtain the corresponding p-values by the permutation test. We repeat this procedure with 300 simulated data sets. The averages of estimated values and the p-values are provided in Table 2. A small p-value for testing indicates that the groups are related. We can also see from small p-values of , and that all three groups are inter-related, which implies that our approach capture dependence between groups correctly for Case II. Note that the value of can be larger than one as it is a combination of functions of covariances. On the other hand, the relation measure should be less than equal to one as it is a correlation. Also note that 0.000 in the Table 2. indicates the value is zero when it is rounded to the nearest thousandth.
Table 2.
Averages of estimated values and the corresponding p-values from the permutation test over 300 simulated data sets for the Case II (dependent case). The number in parenthesis is standard deviation over 300 simulated data sets.
| Estimate | p-value | |
|---|---|---|
| 1.992 (0.419) | 0.000 (0.001) | |
| 0.779 (0.044) | 0.000 (0.000) | |
| 0.911 (0.022) | 0.000 (0.000) | |
| 0.728 (0.051) | 0.000 (0.000) |
To investigate which variable in the group contributes to the relationship, we calculate contribution coefficients, introduced in the previous section. The results are given in Table 3. Recall that , , and have a common component z in the simulation setting. The bold letters in the first column of Table 3 indicate this true relationship while the bold numbers in the second to fourth columns indicates small p-value cases. in the first group is the one that contributes to the relation between and , and between and . The empirical contribution coefficients and the corresponding p-values show that is contributing to that relationship compared to . Similarly, we can see from Table 3 that the empirical contribution coefficients successfully capture the contribution of , and in relation between their corresponding group and the other groups.
Table 3.
Averages of empirical contribution coefficients and the corresponding p-values from the permutation test over 300 simulated data sets for the Case II (dependent case).
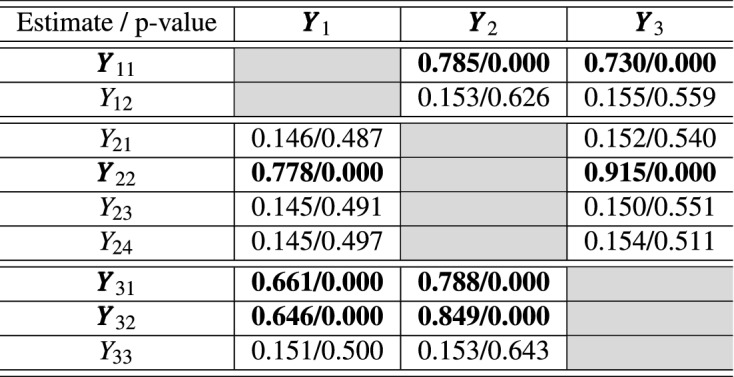
To visualize contribution of each variable in relation with the other group, we utilize a helio plot. Figure 1 shows helio plots between pairs of groups in the second simulation setting (Case II). In the helio plot, variables in two groups are listed in a circular layout. The size of a bar indicates the value of empirical contribution coefficient of that variable to the other group. For example, in the upper left helio plot in Fig. 1, the size of the bar corresponding to represents the value of empirical contribution coefficient of to , i.e. . Also, blue colored bars means the p-value of the corresponding empirical contribution coefficient is below 0.05. Thus, has a significant influence on the relation to and is less relevance in the relation to when we set 0.05 as the significance level. Similarly, from the same helio plot, has a significant influence on the relation to and the other variables in except are less relevance in relation to . From Fig. 1, we can see that GAKCCA reveals nonlinear relation between groups and contribution in Case II, properly.
Figure 1.

Helio plots of contribution coefficients in Case II. The size of a bar indicates the value of empirical contribution coefficient of that variable to the other group. Blue colored bars means the p-value of the corresponding empirical contribution coefficient is below 0.05.
We applied RGCCA to the simulated data of Case II (dependent case) for the comparison with GAKCCA. We utilized RGCCA package in R (www.r-project.org) and implemented the permutation test to extract significant groups. The design matrix, scheme function, the number of resamples for the permutation test and the number of simulated data sets are same as the ones that we considered for GAKCCA. In applying RGCCA, the sign of coefficients changed frequently during the respective simulation and permutation test, so the absolute value of coefficients was considered when we summarized the results. The results are given in Tables 4 and 5. The RGCCA result shows that there is a significant relationship between and (The average of absolute value of empirical correlation between first canonical variate of and that of is 0.875 with p-value 0.000), but weak relationship between and , and between and compared to the results from GAKCCA (The averages of empirical correlations from RGCCA are 0.164, 0.164 with p-value 0.518, 0.579, respectively). The limitation of RGCCA that can only consider linear relationship between groups leads to a failure in identifying clear nonlinear relationship within them.
Table 4.
Averages of estimated absolute values and the corresponding p-values from the permutation test over 300 simulated data for Case II (dependent case) based on RGCCA model. The number in parentheses is standard deviation over 300 simulated data.
| Estimate | p-value | |
|---|---|---|
| 1.299 (0.198) | 0.000 (0.002) | |
| 0.164 (0.073) | 0.518 (0.276) | |
| 0.875 (0.024) | 0.000 (0.000) | |
| 0.164 (0.072) | 0.579 (0.288) |
Table 5.
Averages of empirical absolute contribution coefficients and the corresponding p-values from the permutation test over 300 simulated data for Case II (dependent case) based on RGCCA model.
| Estimate/p-value | |||
|---|---|---|---|
| 0.121/0.500 | 0.117/0.519 | ||
| 0.094/0.588 | 0.094/0.610 | ||
| 0.085/0.532 | 0.083/0.578 | ||
| 0.140/0.308 | 0.890/0.000 | ||
| 0.085/0.529 | 0.083/0.574 | ||
| 0.087/0.517 | 0.080/0.594 | ||
| 0.124/0.411 | 0.774/0.000 | ||
| 0.135/0.385 | 0.790/0.000 | ||
| 0.084/0.568 | 0.088/0.619 |
Real data application
We used the data on individuals’ measures such as demographic information, a number of psychometric questionnaires as well as structural MRI. The data were from 86 undergraduate students in Seoul National University, Seoul, Korea. We analyzed these data using GAKCCA to find out the relationship between four domains (Neurodevelopmental, Psychosocial, Clinical and Neurophysiological domains). A full list of variables in each domain is available in Supplementary Table S6 in the Online Appendix B. Six participants who had high level of Beck Depression Inventory (BDI-II) or Beck Anxiety Inventory (BAI) were excluded so that we use measurements from 80 participants (). To apply GAKCCA method to these data, we chose fully connected design matrix, Gaussian kernel with median-based bandwidth and the Horst scheme function. Also, we set the number of samples for the permutation test to 8,000 ().
When we first applied GAKCCA to this data, we found that the significant association between domains as follows: neurodevelopmental and neurophysiological domains, psychosocial and clinical domains, and clinical and neurophysiological domains. According to this initial finding, the design matrix was modified to maintain the relationships within relevant domains while eliminating those within irrelevant domains in order to clarify the between-group structure. The GAKCCA model was applied with the new design matrix again.
Consistent with previous studies investigating the structural brain correlates of IQ26,27, we defined that there are significant relationships between the neurodevelopmental and the neurophysiological domains (Empirical contribution coefficient is 0.463 with p-value 0.048). Also, a trend toward significance (p = 0.077) is also reported in the clinical and neurophysiological domains (Empirical contribution coefficient is 0.463). In both results, the T1 volume data from structural MRI in the neurophysiological domain appeared to play the most dominant role in association to the neurodevelopmental domain and clinical domain, respectively (Fig. 3).
Figure 3.

Helio plots of significant relationships based on GAKCCA model.
On the other hand, the alcohol use disorder (AUDIT-K) and anxiety (BAI) in the clinical domain shows the most dominant roles for the association to the neurophysiological domain. Also, IQ in the neurodevelopmental domain plays the most dominant role in association to the neurophysiological domain. In terms of this trend-level result, this seems quite plausible in that the current clinical domain was defined through the self-reported questionnaires, not having any diagnoses of psychiatric illnesses. Further research narrowing down the definition of the clinical domain is necessary to exclude individuals with subclinical symptoms.
As expected, there was also a statistically significant relationship with a significance level 0.05 between the psychosocial domain and the clinical domain (Fig. 2). This finding was based on the empirical contribution coefficient of the psychosocial domain to the clinical domain (0.767 with p-value 0.003). With significance level 0.05, major variables contributing to the relationship are KRQ:Emotional regulation, KRQ:Communication, KRQ:Self-expansion, KRQ:Self-positivity, KRQ:Life satisfaction, SSS:Emotional support, SSS:Information support, WHOQOL:Physical, WHOQOL:Social relationship, WHOQOL:Environment, IRI:Personal distress and ULS in the psychosocial group (12 variables), and SCID II:Avoidant, BAI and BDI-II in the clinical group (3 variables) (Fig. 3). Specifically, the psychosocial domain reflecting psychological and environmental resources (KRQ, SSS, etc.) were found to be highly associated with the clinical domain, which was characterized by increased avoidant personality traits, anxiety, and depression. These findings are consistent with previous research28–31.
Figure 2.
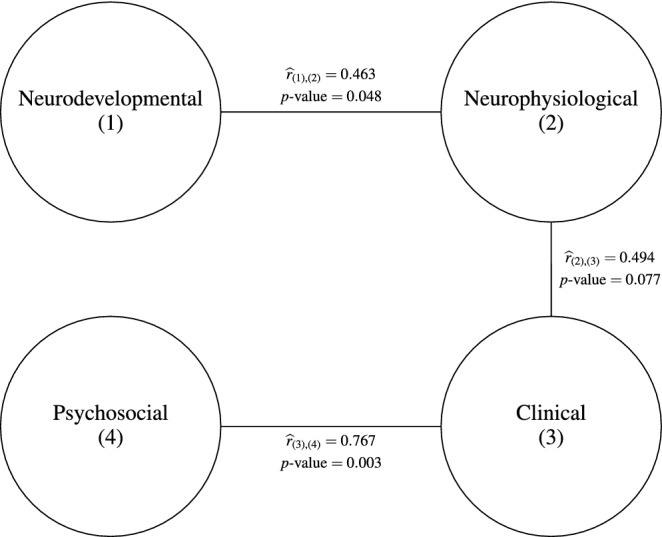
The diagram of the significant relationships between domains based on the GAKCCA model. values are empirical contribution coefficient between (i) and (j) domains, which is provided with p-values.
We also applied RGCCA to the data for comparison with GAKCCA. The design matrix, the scheme function and the number of samples for the permutation test are the same as the ones that we considered for GAKCCA. The RGCCA result shows that there is a significant relationship between psychosocial and clinical domains (The empirical correlation between first canonical variate of psychosocial domain and that of clinical domain is 0.779 with p-value 0.000), but more weak relationship between neurodevelopmental and neurophysiological domains, and clinical and neurophysiological domains than those from GAKCCA (The empirical correlations from RGCCA are 0.305 and 0.389 with p-value 0.320 and 0.124, respectively).
Discussion
In this paper, we have proposed a generalized version of additive kernel CCA. Due to the nature of the objective function, the set of regularization parameters is introduced and we consider the cross validation by comparing estimated additive components for the selection of regularization parameters. A permutation-based test is introduced for checking the relationship between groups. Simulation study shows the proposed method can successfully identify nonlinear relationship between groups and reveals the influence of each variable in the group. Such advantages will be useful in many research areas that deal with multivariate data. However, the proposed approach may not properly handle applications where interactions between different variables in each group exist due to the assumption of additivity.
Compared with the classical CCA, which uses a simple test statistic such as Wilks’ lambda, permutation test requires more computation time. However, the computation burden can be effectively reduced by distributed computing. On the other hand, in selecting regularization parameters in GAKCCA, intensive computation is inevitable. Thus, it is worth investigating on developing an algorithm to make computation faster or finding a computationally more efficient selection method.
The classical CCA can consider the second canonical variates that maximize the correlation among all choices that are uncorrelated with the first canonical variates. This is not straightforward in GAKCCA but it is worth investigating as a future research since it could reveal additional structural information within groups that the current GAKCCA model does not explain
GAKCCA on investigating relation among individuals’ measures that are categorized as one of neurodevelopmental, psychosocial, clinical and neurophysiological domains reveals more relationships than RGCCA and those findings are consistent with previous research.
Supplementary information
Acknowledgements
This work was supported by the Seoul National University Research Grant in 2017. This work was also partially supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. 2019R1A2C1002213).
Author contributions
E.B., C.L. and J.H. wrote the main manuscript text. J.K., J.K., J.L. and S.L. provided the data with domain information of variables and helped with manuscript preparation. E.B. and J.K. pre-processed the data and performed the empirical analysis. All authors reviewed the manuscript.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
The online version of this article (10.1038/s41598-020-69575-x) contains supplementary material, which is available to authorized users.
References
- 1.Pearson K. Liii. on lines and planes of closest fit to systems of points in space. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science. 1901;2:559–572. doi: 10.1080/14786440109462720. [DOI] [Google Scholar]
- 2.Johnson RA, Wichern DW. Applied multivariate statistical analysis. 5. Upper Saddle River: Prentice Hall; 2002. [Google Scholar]
- 3.Hotelling H. Relations between two sets of variates. Biometrika. 1936;28:321–377. doi: 10.1093/biomet/28.3-4.321. [DOI] [Google Scholar]
- 4.Sadoughi F, Afshar HL, Olfatbakhsh A, Mehrdad N. Application of canonical correlation analysis for detecting risk factors leading to recurrence of breast cancer. Iran. Red Crescent Med. J. 2016 doi: 10.5812/ircmj.23131. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Tsvetanov KA, et al. Extrinsic and intrinsic brain network connectivity maintains cognition across the lifespan despite accelerated decay of regional brain activation. Journal of Neuroscience. 2016;36:3115–3126. doi: 10.1523/JNEUROSCI.2733-15.2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Moreira PS, Santos NC, Sousa N, Costa PS. The use of canonical correlation analysis to assess the relationship between executive functioning and verbal memory in older adults. Gerontol. Geriatric Med. 2015 doi: 10.1177/2333721415602820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Yang X, Liu W, Tao D, Cheng J. Canonical correlation analysis networks for two-view image recognition. Information Sciences. 2017;385:338–352. doi: 10.1016/j.ins.2017.01.011. [DOI] [Google Scholar]
- 8.Bach FR, Jordan MI. Kernel independent component analysis. Journal of machine learning research. 2002;3:1–48. [Google Scholar]
- 9.Arora, R. & Livescu, K. Kernel cca for multi-view learning of acoustic features using articulatory measurements. in Symposium on Machine Learning in Speech and Language Processing (2012).
- 10.Larson NB, et al. Kernel canonical correlation analysis for assessing gene-gene interactions and application to ovarian cancer. European Journal of Human Genetics. 2014;22:126–131. doi: 10.1038/ejhg.2013.69. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Yun T, Guan L. Human emotional state recognition using real 3d visual features from gabor library. Pattern Recognition. 2013;46:529–538. doi: 10.1016/j.patcog.2012.08.002. [DOI] [Google Scholar]
- 12.Kettenring JR. Canonical analysis of several sets of variables. Biometrika. 1971;58:433–451. doi: 10.1093/biomet/58.3.433. [DOI] [Google Scholar]
- 13.Tenenhaus A, Philippe C, Frouin V. Kernel generalized canonical correlation analysis. Computational Statistics & Data Analysis. 2015;90:114–131. doi: 10.1016/j.csda.2015.04.004. [DOI] [Google Scholar]
- 14.Balakrishnan, S., Puniyani, K. & Lafferty, J. Sparse additive functional and kernel cca. arXiv preprintarXiv:1206.4669 (2012).
- 15.Krämer, N. Analysis of high dimensional data with partial least squares and boosting. Ph.D. thesis, Technische Universität Berlin, Fakultät IV (2007).
- 16.Wold H. Partial least squares. In: Kotz S, Johnson E, editors. Encyclopedia of statistical sciences. New York: Wiley; 1985. pp. 581–591. [Google Scholar]
- 17.Lohmöller J-B. Latent variable path modeling with partial least squares. New York: Springer; 2013. [Google Scholar]
- 18.Tenenhaus A, Tenenhaus M. Regularized generalized canonical correlation analysis. Psychometrika. 2011;76:257–284. doi: 10.1007/s11336-011-9206-8. [DOI] [PubMed] [Google Scholar]
- 19.Baker CR. Joint measures and cross-covariance operators. Transactions of the American Mathematical Society. 1973;186:273–289. doi: 10.1090/S0002-9947-1973-0336795-3. [DOI] [Google Scholar]
- 20.Fukumizu K, Bach FR, Jordan MI. Dimensionality reduction for supervised learning with reproducing kernel hilbert spaces. Journal of Machine Learning Research. 2004;5:73–99. [Google Scholar]
- 21.Fukumizu K, Bach FR, Gretton A. Statistical consistency of kernel canonical correlation analysis. Journal of Machine Learning Research. 2007;8:361–383. [Google Scholar]
- 22.Schölkopf B, Smola A, Müller K-R. Nonlinear component analysis as a kernel eigenvalue problem. Neural computation. 1998;10:1299–1319. doi: 10.1162/089976698300017467. [DOI] [Google Scholar]
- 23.Sherry A, Henson RK. Conducting and interpreting canonical correlation analysis in personality research: A user-friendly primer. Journal of personality assessment. 2005;84:37–48. doi: 10.1207/s15327752jpa8401_09. [DOI] [PubMed] [Google Scholar]
- 24.Ashad Alam M, Fukumizu K. Higher-order regularized kernel canonical correlation analysis. International Journal of Pattern Recognition and Artificial Intelligence. 2015;29:1551005. doi: 10.1142/S0218001415510052. [DOI] [Google Scholar]
- 25.Anderson TW. An introduction to multivariate statistical analysis. 3. Hoboken: Wiley; 2003. [Google Scholar]
- 26.Mihalik, A. et al. Abcd neurocognitive prediction challenge 2019: Predicting individual fluid intelligence scores from structural mri using probabilistic segmentation and kernel ridge regression. arXiv preprintarXiv:1905.10831 (2019).
- 27.Cox SR, Ritchie SJ, Fawns-Ritchie C, Tucker-Drob EM, Deary IJ. Brain imaging correlates of general intelligence in uk biobank. Intelligence. 2019;76:101376. doi: 10.1016/j.intell.2019.101376. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.McAlinden NM, Oei TPS. Validation of the quality of life inventory for patients with anxiety and depression. Comprehensive Psychiatry. 2006;47:307–314. doi: 10.1016/j.comppsych.2005.09.003. [DOI] [PubMed] [Google Scholar]
- 29.Ehring T, Tuschen-Caffier B, Schnülle J, Fischer S, Gross JJ. Emotion regulation and vulnerability to depression: spontaneous versus instructed use of emotion suppression and reappraisal. Emotion. 2010;10:563–572. doi: 10.1037/a0019010. [DOI] [PubMed] [Google Scholar]
- 30.Beutel ME, et al. Loneliness in the general population: prevalence, determinants and relations to mental health. BMC Psychiatry. 2017;17:97. doi: 10.1186/s12888-017-1262-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Klemanski DH, Curtiss J, McLaughlin KA, Nolen-Hoeksema S. Emotion regulation and the transdiagnostic role of repetitive negative thinking in adolescents with social anxiety and depression. Cognitive therapy and research. 2017;41:206–219. doi: 10.1007/s10608-016-9817-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.