

Highlights
-
•
Non-adaptive pooling strategies can increase testing capacity for COVID-19 without sacrifices in detection time.
-
•
The number of pools needed only grows mildly with pool size and decreasing false positive probability.
-
•
We calculate explicit bounds on the number of pools required and construct such sets of pools.
-
•
This can lead to more efficient use of resources and fast detection in realistic scenarios.
Keywords: Polymerase chain reaction, Pool testing, Non-adaptive testing, COVID-19, SARS-CoV-2
Abstract
Pooling of samples can increase lab capacity when using Polymerase chain reaction (PCR) to detect diseases such as COVID-19. However, pool testing is typically performed via an adaptive testing strategy which requires a feedback loop in the lab and at least two PCR runs to confirm positive results. This can cost precious time. We discuss a non-adaptive testing method where each sample is distributed in a prescribed manner over several pools, and which yields reliable results after one round of testing. More precisely, assuming knowledge about the overall incidence rate, we calculate explicit error bounds on the number of false positives which scale favourably with pool size and sample multiplicity. This allows for hugely streamlined PCR testing and cuts in detection times for a large-scale testing scenario. A viable consequence of this method could be real-time screening of entire communities, frontline healthcare workers and international flight passengers, for example, using the PCR machines currently in operation.
1. Introduction
One key to containing and mitigating the COVID-19 pandemic is suggested to be rapid testing on a massive scale (Huang et al., 2019, Siegenfeld and Bar-Yam, 2003). It would be beneficial to develop the ability to routinely, and in particular rapidly, test groups such as frontline healthcare workers, police officers, and international travellers. Testing for SARS-CoV-2 is currently performed via the polymerase chain reaction (PCR) on nasopharyngeal swabs (Kai-Wang To et al., 2019). Typically, the population size significantly exceeds the capacity for testing, with the number of available PCR machines and reagents an important bottleneck in this process.
There are two basic approaches to PCR testing in populations: 1. individual tests, where every single sample is examined, and 2. pooled tests where larger sets of samples are mixed and tested en bloc. Pooled testing was pioneered by Dorfman in 1943 (Dorfman, 1943) in the context of blood tests and led to a host of research activity, both on the lab side as well as the theoretical side (Aldridge et al., 2019, Du and Hwang, December 1999, Du and Hwang, 2006). If the disease is rare in the population, pooled testing may be advisable. In this case it can assist in optimizing precious testing capacity since most individual results would be negative. Pooling relies on the fact that the PCR is reasonably reliable under the combination of samples: the preprint (Yelin et al., 2020) suggests that a detection of SARS-CoV-2 in pools of size 32 and possibly 64 is feasible.
While a classic pooling strategy has the advantage that less overall PCR tests are required, there are disadvantages in terms of lab organisation and – more crucially – time: pooling only indicates whether a pool contains at least one infected individual. If samples are tested in pools of size n and the incidence is small (more precisely, if is small) then a number of samples will be in pools that are tested positive and hence undergo a second round of testing. In other words, pooled testing with individual verification of positive pools is an adaptive testing strategy, the lab organisation for which is a labour, management, and resource intensive process. It has several drawbacks, since it requires keeping multiple lab samples and re-running of the time-intensive PCR process. The lab feedback loop makes the entire workflow more susceptible to delays (see Fig. 2 ). This may result in delays in individual results – a particular problem when the objective is to rapidly identify infected individuals, who may infect others while waiting for the test outcome. Furthermore, since the number of samples undergoing a second round of testing is an unknown quantity, some reserve capacity is required to prevent further delays. This makes it more challenging for the lab to operate near its maximal capacity.
Fig. 2.

Comparison of the work flow in adaptive testing and non-adaptive testing. In the adaptive setting in Figure (a), two of the time-expensive PCR steps (in red) are required. Furthermore, the interplay of data interpretation after the first PCR and the sample storage management introduces another possible bottleneck. In the non-adaptive case, shown in Figure (b), the work flow is completely linear. (For interpretation of the references to colour in this figure legend, the reader is referred to the web version of this article.)
In the theoretical research on testing strategies the distinction is made between adaptive testing, for example when all samples in a positive pool undergo a second round of testing, and non-adaptive strategies, where all tests can be run simultaneously (Du and Hwang, December 1999). Testing every sample individually can be considered as a trivial non-adaptive strategy, but there exist non-adaptive strategies which combine the benefit of pooling with the advantages of non-adaptive testing.
In this note, we propose a non-adaptive pooling strategy for rapid and large-scale screening for SARS-CoV-2 or other scenarios where detection time is critical. This allows for significant streamlining of the testing process and reductions in detection time. Firstly because only one round of PCR is required, and secondly because it eliminates actions in the lab workflow that require input from results determined in the lab, i.e. the testing infrastructure can be organized completely linearly, cf. Fig. 2 for an illustration. The strategy will systematically overestimate the number of positives, but we can provide error bounds on the number of false positives which scale favourably with large numbers and will be small in realistic scenarios.
2. Definition of the non-adaptive testing strategy: multipools
Our testing strategy is as follows: every individual’s sample is broken up into k samples and distributed over k different pools of size n such that no two individuals share more than one pool. An individual is considered as tested positive if all the pools in which its sample has been given are tested positive or – in our case equivalently – an item is considered as tested negative if it appears in at least one negative pool. This decoding algorithm is also known as COMP (Combinatorial Orthogonal Matching Pursuit), an algorithm easily implementable in practice with low run-time and storage (Johnson et al., February 2019).
Let us make our definition more formal:
Definition 1 Multipools —
Let a population () of size N, a pool size n, and a multiplicity k be given, and assume that is a multiple of n. We call a collection of subsets/pools of an -multipool, or briefly multipool, if all of the following three conditions hold:
(M1) Every pool consists of exactly n elements.
(M2) Every sample is contained in exactly k pools.
(M3) For any two different samples there exists at most one pool which contains both and .
In the context of non-adaptive testing, designs as in Definition 1 are called -disjunct matrices and it is known that such matrices correctly identify up to k infected samples (Mazumdar, 2012). However, we will be interested in scenarios where the number of infected samples can exceed the multiplicity k. If and the construction of an -multipool is quite straightforward, see Fig. 1: arrange the N samples in a rectangular grid and then pool along every row and column, cf. (Sint et al., August 2016, Fargion, 2003, Zuzarte et al., April 2014). However, as we shall see below, is in many realistic scenarios insufficient for the desired precision.
Fig. 1.

Pooling along rows and columns to arrange samples into 16 pools of size 8 to form a -multipool. Different background patterns and colours represent different pools.
Some recent contributions (Fargion, 2003, Mutesa et al., 2020) propose to arrange samples in a (3 or higher dimensional) hypercube and to pool along all hyperplanes. This makes every individual sample appear in three or more pools, but it is not a multipool in the sense of Definition 1 above, since in dimension three and higher, any two hyperplanes will intersect in more than one point, in violation of Property (M3). This creates unnecessary correlations between different pools and impairs performance. If , systems as in Definition 1 are also called Steiner triples and have been recently used in non-adaptive group testing for SARS-CoV-2 (Ghosh et al., 2020). A flexible way to construct multipools of various multiplicities k is given by the Shifted Transversal Design (Thierry-Mieg, 2006, Erlich et al., 0353) which we explain in Section 4.
3. Controlling the number of false positives
We always assume that the incidence of the disease is small compared to the inverse pool size . This is a reasonable requirement, also in classical pooling strategies (a portion of samples will have to undergo second testing, thus a large would attenuate the benefit of pooling).
Assuming perfect performance of the PCR, also under pooling (see Section 6 on how to deal with uncertainty here), multipooling will identify all infected individuals, since all their pools will be positive. However, a sample might falsely be declared positive if all pools in which it is contained happen to contain an infected sample.
The expected portion of false positives in a multipool strategy is
| (3.1) |
| (3.2) |
| (3.3) |
Here, the third identity crucially uses the property (M3) which guarantees independence between the poolmates in the different pools of a sample. By Bayes’ rule, the probability to actually be negative when tested positive by the multipool (i.e. the portion of subjects falsely declared positive among all subjects declared positive) is
| (3.4) |
| (3.5) |
| (3.6) |
Let us calculate for which k the probability of a positive test result being a false positive does not exceed :
| (3.7) |
| (3.8) |
| (3.9) |
| (3.10) |
This provides a lower bound on the necessary multiplicity k in terms of the sample size n, the knowledge on the incidence , and the acceptable portion of false positive results among all positives. Assuming and (which are both reasonable assumptions, recall that is small), the lower bound in (3.10) is monotone increasing in . Hence, if the exact incidence is unknown but we have an upper bound on it, we can work with the largest/worst case . Let us summarize these findings in the following
Theorem 1
Let the incidence be at most , and let . If
(3.11) then in any multipooling strategy with pool size n and multiplicity k, the probability of a positive test being a false positive does not exceed .
The number of tests required in a multipool strategy is , an improvement compared to individual testing by a factor . A key observation is that the lower bound on k in Inequality (3.11) scales favourably with large multiplicities n. Indeed, recall that in an adaptive pooling strategy one wants on the one hand large pool sizes n, but on the other hand should be small. It is therefore reasonable to have n proportional to the inverse of , i.e. . Using that and , the lower bound in (3.11) behaves approximately as
| (3.12) |
that is k grows only logarithmically with the pool size n. An analogous analysis shows that k also grows logarithmically with the inverse of when the error probability is sent to zero. In Fig. 3 , we compare the theoretical ratio of false positives to positives, calculated for Theorem 1, with numerical simulations.
Fig. 3.

Comparison of the ratio of false positives to positive results in simulations on synthetic data for samples with different incidences at pool size and sampling strategies with multiplicities , and the theoretical values calculated in the lead-up to Theorem 1. The code for the simulation can be found in (Täufer, 2020).
4. Generating multipools
The question for which combiniations a multipool exists seems to be in general a non-trivial combinatorial problem. We focus here on the case when and on constructions based on the Shifted Transversal Design (Thierry-Mieg, 2006).
It is useful to imagine all N samples arranged in an -square and label samples by their x and y-coordinate, i.e. denoting the sample at position by , where we define the sample in the lower left (south-west) corner to be . For multiplicity , a -multipool can be constructed by pooling along rows and columns, as in Fig. 1.
Unfortunately, for reasonable parameter choices, a multiplicity of turns out to lead to large false positive rates: For instance, arranging samples from a population with incidence in a rectangular grid and pooling along all rows and columns (in our notation this is an -multipool), Identity (3.6) will imply that on average of positive results will actually be false positives. To improve on this and pass to multiplicity , one can sample along diagonals, where the diagonals are continued periodically, see Fig. 4 . This works for any pool size and leads to.
Theorem 2
Let and . Then there exists an -multipool, obtained by sampling along rows, columns, and all periodically continued south-west-to-north-east diagonals.
Fig. 4.

Pooling along rows, columns, and periodically continued diagonals to arrange samples into 24 pools of size 8 to form a -multipool. Different background patterns and colours represent different pools.
In the situation of and , this allows for the construction of a -multipool in which, by (3.6), the probability of a positive result being erroneous is reduced to . In such a scenario, one would test 64 individuals with 24 tests, a compression by a factor . A higher compression rate would require larger pool sizes n. Since the lower bound (3.11) on k in Theorem 1 is monotonous in n, this will in turn also require to higher multiplicities k in order to achieve comparable false positive error probabilities. To pass to , one might now be tempted to pool along the other (north-west-to-south-east) diagonals, but this is not going to yield a multipool in general, see for instance Fig. 5 where, in the case , two diagonals intersect in more than one point, in violation of Property (M3) in Definition 1.
Fig. 5.
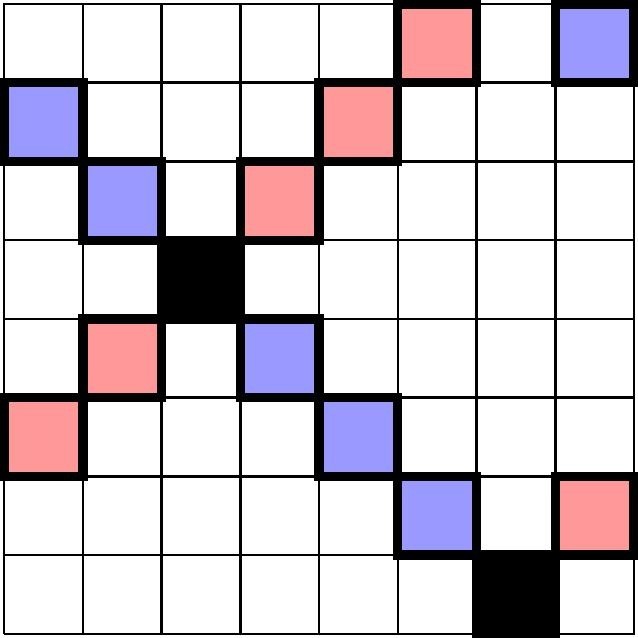
The two diagonals (red and blue) intersect in two points (black). They cannot both be used as pools in a multipool. (For interpretation of the references to colour in this figure legend, the reader is referred to the web version of this article.)
This is due to the fact that has non-trivial divisors, i.e. it is not a prime number. South-west-to-north-east diagonals are of the form
| (4.1) |
and north-west-to-south-east diagonals
| (4.2) |
were, means that we use arithmetic modulo n, that is as soon as we exceed , we start counting from 0 again. These diagonals are lines of slope and , respectively, and the difference of these slopes is 2, which divides 8. Since intersections of two such lines are given by solutions to the equation
| (4.3) |
| (4.4) |
there can be more than one j solving (4.4): Indeed, if some solves (4.4), then is a solution as well, since .
More generally, it is well-known that for and , the equation
| (4.5) |
has a unique solution j if and only if the greatest common divisor of m and n is 1. Since this must hold for all must be a prime number. In this case, the integers modulo n form an algebraic structure called a field, in which every non-zero element has a well-defined multiplicative inverse. For prime n, the unique solution of (4.5) is therefore given by , where denotes the multiplicative inverse of m in arithmetic modulo n.
This suggests to use a prime pool size n and sample along lines of different slopes, that is to use pools of the form
| (4.6) |
We can add one more type of pool by sampling along all vertical lines (their slope can be considered as ”infinity”) which we denote by
| (4.7) |
Such ensembles of pools are sketched in Fig. 6 for the case .
Fig. 6.

Pools of different slopes as in Theorem 3 for .
This construction is also referred to as the Shifted Transversal Design in (Thierry-Mieg, 2006). We summarise our findings in the following.
Theorem 3
Let n be a prime number and let . Then, there exists a -multipool for , and consequently also for every smaller k. This multipool is given by pooling along all sloped lines, that is:
(4.8) and pooling along all columns (or lines of slope infinity), that is
(4.9)
Fig. 6 contains an illustration of elements of such a multipool in the case with multiplicity . Theorem 3 allows for multiplicities up to , but in practice, one will want to work with much lower multiplicities k since a high multiplicity would require many tests and defeat the purpose of pooling. From a practical perspective it seems reasonable to generate large pools by a sequence of unions of two equally diluted pools. This leads to pool sizes which are a power of 2, certainly not a prime number (except for 2 itself). One approach to accomodate for that would be population sizes where n is a prime just below a power of 2, e.g. , which is just below 32 or which is just below 64. Then pools of size n can be mixed by adding a small number of negative dummy samples and proceeding as if n was a power of 2.
5. Examples and scenarios
Let us sketch some concrete examples where the pool sizes are a prime number and where the multipooling strategy might be useful:
Let the population size be . This could for instance be the number of employees in a company or passengers which depart from an international airport within a certain time window. Let the incidence rate be no more than and let us work with a pool size . Since n is prime, Theorem 3 allows to construct -multipools for any and Theorem 1 allows to bound the probability of a positive test being erroneous for different multiplicities k as in Table 1 . Accepting for instance a false positive probability of requires PCR tests, of what would be required in individual testing. Let us emphasize again here that this means that among the results flagged as positive will be false positives, not of the overall test results.
Table 1.
Probability of a positive result being a false positive and the compression compared to individual testing for pool size , incidence and different multiplicities k.
| k | ||
|---|---|---|
| 4 | ||
| 5 | ||
| 6 | ||
| 7 |
The multipool method scales well with larger numbers. Let the population size be and the pool size , which is of the order of pools being used for the PCR today (Yelin et al., 2020). Let furthermore be the incidence rate be no larger than , a realistic upper bound for the prevalence of SARS-CoV-2 in many countries (Office for National Statistics, 2020). Since is prime, Theorem 3 allows to construct -multipools for any and the error bounds in Theorem 1 lead to Table 2 . If we choose and accept as the probability for positive results being false positives, we need tests in order to fast and efficiently test 3721 individuals, that is of what would be needed with individual testing.
Table 2.
Probability of a positive result being a false positive and the compression compared to individual testing for pool size , incidence and different multiplicities k.
| k | ||
|---|---|---|
| 3 | ||
| 4 | ||
| 5 |
6. Discussion and possible extensions
The non-adaptive multi-pooling strategy provides a streamlined and efficient organisation of the testing process and cuts in detection time. This significant benefit comes with potential reductions in accuracy compared with adaptive testing, but this false positive rate can be tightly controlled and tailored to suit the circumstance. The false positive probability deemed an acceptable cost for the increased testing efficiencies may depend on, for example, the infection characteristics, the government policy and resource levels.
A small modification of our strategy might furthermore allow for an improvement of the false negative rate – even compared to usual adaptive pool testing strategies: even though commonly used, pooling samples can potentially dilute samples close to the identification threshold of the PCR and increase the probaility of false negatives. The recent preprint (Yelin et al., 2020) estimates a false negative rate of when detecting SARS-CoV-2 in pools of size 32. One can reduce this type of false negative in our strategy by declaring all samples which are in at least positive pools as tested positive.
This strategy is known as the ”Noisy COMP” (NCOMP) decoding algorithm (Chan et al., 2011, Chan et al., 2014) where an item is declared infected if more than a certain portion of its pools test positive. This will on the one hand lower the probability of false negatives, but more importantly it will only mildly affect the false positive rate. This could be seen by adding a next-order term in the error analysis performed leading up to Theorem 1. For a sound analysis, knowledge on the false positive rate gained through experiments would be required, but the general message that the necessary multiplicity k will grow slowly with large n and small remains.
Let us finally note that the basic idea is close to compressed sensing and sparse recovery (Candes and Tao, 2006, Foucart and Rauhut, 2013). While in our situation the output space consists of -vectors, which make the mathematics we use rather elementary, there also seem to be applications of the PCR where quantitative measurements are taken and where compressive sensing techniques might be applied. A very recent approach in this direction is Tapestry pooling (Ghosh et al., 2020, Ghosh et al., 2020) which takes quantitative data from PCR measurements and uses methods from compressed sensing to decode. In the scenario of testing samples in pools of size discussed in Section 5, this approach suggests reasonable results at multiplicity , a higher compression rate than in our approach. However we emphasise that the (experimental) error analysis performed in the context of Tapestry pooling focuses on fixed numbers of infected samples and is therefore in a slightly different spirit than our approach which is based on the prevalence of the disease in the population.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgement
The author thanks Christoph Schumacher for numerous helpful discussions and comments. Comments by Emma Lawrance, Albrecht Seelmann and Sasha Sodin are also gratefully acknowledged.
References
- Aldridge M., Johnson O., Scarlett J. Group testing: An information theory perspective. Found. Trends® Commun. Inform. Theory. 2019;15(3–4):196–392. [Google Scholar]
- Chan C.L., Che P.H., Jaggi S., Saligrama V. 2011 49th Annual Allerton Conference on Communication, Control, and Computing (Allerton) IEEE; 2011. Non-adaptive probabilistic group testing with noisy measurements: Near-optimal bounds with efficient algorithms. [Google Scholar]
- Chan C.L., Jaggi S., Saligrama V., Agnihotri S. Non-adaptive group testing: Explicit bounds and novel algorithms. IEEE Trans. Inf. Theory. 2014;60(5):3019–3035. [Google Scholar]
- Candes E.J., Tao T. Near-optimal signal recovery from random projections: Universal encoding strategies? IEEE Trans. Inf. Theory. 2006;52(12):5406–5425. [Google Scholar]
- Du D.-Z., Hwang F.K. Combinatorial group testing and its applications. World Sci. 1999 [Google Scholar]
- Du D.-Z., Hwang F.K. Pooling Designs and Nonadaptive Group Testing. World Scientific. 2006 [Google Scholar]
- Dorfman R. The detection of defective members of large populations. Ann. Math. Stat. 1943;14(4):436–440. [Google Scholar]
- Erlich, Y., Gilbert, A., Ngo, H., Rudra, A., Thierry-Mieg, N., Wootters, M., Zielinski, D., Zuk, O., 2015. Biological screens from linear codes: theory and tools. bioRxiv 035352; 2015, doi: 10.1101/035352.
- Fargion, B.I., Fargion, D., De Sanctis Lucentini, P.G., Habib, E., 2003. Purim: a rapid method with reduced cost for massive detection of covid-19. arXiv:2003.11975 [q-bio.PE].
- Office for National Statistics. Coronavirus (COVID-19) infection survey pilot: England, 24 July 2020, 2020.
- Foucart S., Rauhut H. Springer; New York: 2013. A Mathematical Introduction to Compressive Sensing. [Google Scholar]
- S. Ghosh, R. Agarwal, M.A. Rehan, S. Pathak, P. Agrawal, Y. Gupta, S. Consul, N. Gupta, R. Goyal, A. Rajwade, and M. Gopalkrishnan. A compressed sensing approach to group-testing for covid-19 detection. arXiv:2005.07895 [q-bio.QM], 2020. [DOI] [PMC free article] [PubMed]
- S. Ghosh, A. Rajwade, S. Krishna, N. Gopalkrishnan, T.E. Schaus, A. Chakravarthy, S. Varahan, V. Appu, R. Ramakrishnan, S. Ch, M. Jindal, V. Bhupathi, A. Gupta, A. Jain, R. Agarwal, S. Pathak, M.A. Rehan, S. Consul, Y. Gupta, N. Gupta, P. Agarwal, R. Goyal, V. Sagar, U. Ramakrishnan, S. Krishna, P. Yin, D. Palakodeti, and M. Gopalkrishnan. Tapestry: A single-round smart pooling technique for COVID-19 testing. April 2020.
- G. Huang, W. Zeng, W. Wang, Y. Song, X. Mo, J. Li, P. Wu, R. Wang, F. Zhou, J. Wu, B. Yi, Z. Xiong, L. Zhou, F. Wang, Y. Tian, W. Hu, X. Xu, R. Zhai, K. Yuan, X. Li, X. Qiu, J. Qiu, and A. Wang. Triaging patients in the outbreak of the 2019 novel coronavirus. March 2020.
- Johnson O., Aldridge M., Scarlett J. Performance of group testing algorithms with near-constant tests per item. IEEE Trans. Inf. Theory. 2019;65(2):707–723. [Google Scholar]
- Mazumdar A. Algorithms and Computation. Springer; Berlin Heidelberg: 2012. On almost disjunct matrices for group testing; pp. 649–658. [Google Scholar]
- L. Mutesa, P. Ndishimye, Y. Butera, J. Souopgui, A. Uwineza, R. Rutayisire, E. Musoni, N. Rujeni, T. Nyatanyi, E. Ntagwabira, M. Semakula, C. Musanabaganwa, D. Nyamwasa, M. Ndashimye, E. Ujeneza, I.E. Mwikarago, C.M. Muvunyi, J.B. Mazarati, S. Nsanzimana, N. Turok, and W. Ndifon. A strategy for finding people infected with SARS-CoV-2: optimizing pooled testing at low prevalence. May 2020.
- Siegenfeld, A.F., Bar-Yam, Y., 2003. Eliminating covid-19: A community-based analysis. arXiv:2003.10086[q-bio.PE].
- Sint D., Sporleder M., Wallinger C., Zegarra O., Oehm J., Dangi N., Giri Y.P., Kroschel J., Traugott M. A two-dimensional pooling approach towards efficient detection of parasitoid and pathogen DNA at low infestation rates. Methods Ecol. Evol. August 2016;7(12):1548–1557. [Google Scholar]
- M. Täufer. Supplementary material for rapid, large-scale, and effective detection of covid-19 via non-adaptive testing, 2020. doi: 10.5281/zenodo.3964758. [DOI] [PMC free article] [PubMed]
- Thierry-Mieg N. A new pooling strategy for high-throughput screening: the Shifted Transversal Design. BMC Bioinformatics. 2006;7(1):28. doi: 10.1186/1471-2105-7-28. [DOI] [PMC free article] [PubMed] [Google Scholar]
- K. Kai-Wang To, O. Tak-Yin Tsang, C. Chik-Yan Yip, K.H. Chan, T.V. Wu, J. Man-Chun Chan, W.S. Leung, T. Shiu-Hong Chik, C. Yau-Chung Choi, D.H. Kandamby, D.C. Lung, A.R. Tam, R. Wing-Shan Poon, A. Yim-Fong Fung, I. Fan-Ngai Hung, V. Chi-Chung Cheng, J. Fuk-Woo Chan, and K.Y. Yuen. Consistent detection of 2019 novel coronavirus in saliva. Clinical Infectious Diseases, February 2020. [DOI] [PMC free article] [PubMed]
- I. Yelin, N. Aharony, E. Shaer-Tamar, A. Argoetti, E. Messer, D. Berenbaum, E. Shafran, A. Kuzli, N. Gandali, T. Hashimshony, Y. Mandel-Gutfreund, M. Halberthal, Y. Geffen, M. Szwarcwort-Cohen, and R. Kishony. Evaluation of COVID-19 RT-qPCR test in multi-sample pools. March 2020. [DOI] [PMC free article] [PubMed]
- Zuzarte P.C., Denroche R.E., Fehringer G., Katzov-Eckert H., Hung R.J., McPherson J.D. A two-dimensional pooling strategy for rare variant detection on next-generation sequencing platforms. PLoS ONE. April 2014;9(4) doi: 10.1371/journal.pone.0093455. [DOI] [PMC free article] [PubMed] [Google Scholar]