

Abstract
Little is known about the willingness of prospective study participants to share environmental health data. To fill this gap, we conducted a hypothetical vignette survey among 1,575 women who have volunteered to be contacted about breast cancer studies. Eighty-three percent were interested in participating in the environmental studies, with little difference whether data was restricted to the research team, shared with approved researchers, or publicly accessible. However, participants somewhat preferred controlled-access for children’s data. Respondents were more interested in studies with environmental rather than biological samples, and more interested when researchers would return personal results, a practice of increasing importance. They were more reluctant to share location or to participate if studies involved electronic medical records. Many expressed concerns about privacy, particularly security breaches, but re-identification risks were mentioned infrequently, indicating that this topic should be discussed during informed consent.
Introduction
Environmental exposure measurements are often expensive and time-intensive to obtain, and sharing these data—for use in secondary research or pooled analyses—can increase their scientific value and utility for informing policy and promoting health. The ability to share data has become even more critical recently in response to growing interest in the exposome (Stingone et al., 2017). Conceived of as the totality of an individual’s environmental exposures throughout the life-course (Wild, 2005), the exposome encompasses an array of data types, including genetic and biomonitoring data, pollutant measurements, occupation, lifestyle, and community characteristics (Wild, 2012). Exposome research thus requires (1) large sample sizes to support models incorporating a multitude of exposures and, potentially, their interactions and (2) collaboration across fields to combine different types of data (Stingone, et al., 2017). The past few years have seen the launch of two high-profile exposome efforts, the All of Us Research Program (National Institutes of Health, 2018), which is part of the Precision Medicine Initiative (PMI), and the Children’s Health Exposure Analysis Resource (CHEAR), a program to support measurement of environmental exposures in biological samples from NIH-funded children’s health studies that in 2019 expanded to become the Human Health Exposure Analysis Resource (HHEAR) (https://hhearprogram.org/). These projects required substantial investment of time and expertise to navigate complicated logistical barriers, including establishing plans for data sharing (Balshaw, Collman, Gray, & Thompson, 2017; Precision Medicine Initiative Working Group, 2015). Ultimately, however, the success of these ambitious efforts will hinge on how and what study participants are willing to share and how their trust is sustained over time.
Previous research on data sharing has focused on genetic and health data, and studies have shown general support in the US for sharing this type of data for secondary research. As recently reviewed by Garrison et al. (2016), willingness to share genetic and health data has been expressed by patients with different diseases, by participants in genetic research and biobanks, and by the general public in response to hypothetical scenarios. Options for making data available beyond the primary research team include sharing upon request or depositing data in controlled-access repositories. Another option, sharing data publicly online, arguably makes data available to the most people. In several nationally representative surveys, the proportion hypothetically willing to share de-identified data publicly ranged from 43–49% for data from a proposed nationwide gene-environment cohort (Kaufman, Baker, Milner, Devaney, & Hudson, 2016; Kaufman, Murphy-Bollinger, Scott, & Hudson, 2009) to up to 65% for data from medical records and leftover biological samples (Sanderson et al., 2017). Interviews with study participants who have actually agreed to share their genetic and health information in public repositories show that they are aware of potential risks, including privacy issues, discrimination by employers or insurers, and the unknown, possibly objectionable, ways that their data could be used in the future (Oliver et al., 2012; Zarate et al., 2016). For many, these risks are outweighed by altruistic motives – advancing science, helping others with similar health conditions, and improving health for future generations (Oliver, et al., 2012; Zarate, et al., 2016).
Little is known, however, about prospective participants’ views on sharing measurements of environmental chemicals (e.g., pesticides, lead, fragrances and other personal care product chemicals), including samples from their homes (e.g., dust, air, water) or their bodies (e.g., blood, urine, toenails). One possibility is that environmental data are viewed as less personal and/or less unique than genetic and other health data, reducing concerns about privacy and potential discrimination. Yet privacy risks related to environmental datasets are not trivial; it is common for such datasets to be focused on specific geographic areas (e.g., Coombs et al., 2016; Dodson et al., 2017; Polidori, Kwon, Turpin, & Weisel, 2010; Rudel et al., 2010) and to include details about housing characteristics (e.g., age of home, single-family vs. multi-family), consumer product use, and occupation. These variables may be critical for understanding environmental exposures but also create vulnerability for individuals or homes in anonymized datasets to be re-identified, perhaps maliciously, by linking study data with publicly or commercially available datasets (e.g., real estate data, professional licensing registries) (Pool, Rusch, & Roundtable Environ. Health Sci., 2016; Sweeney et al., 2017). Biomonitoring and home environment results could then be used in a manner similar to genetic and health information as a basis for discrimination by employers or insurers. Importantly, such consequences could fall disproportionately on low-income, non-white communities, which often bear higher burdens of polluting facilities (Mikati, Benson, Luben, Sacks, & Richmond-Bryant, 2018) and where housing characteristics (e.g., size, ventilation) can contribute to higher levels of chemicals in homes from both indoor and outdoor sources (Adamkiewicz et al., 2011). Release of such information could also impact the value of a study participant’s home and those of neighbors, and depending on the type of hazard, could impose a legal obligation to disclose the results when selling a property (Goho, 2016). Renters might be subject to retaliation from owners for participating in research that affected the owners.
Equally important, little is known about how participants perceive benefits of sharing environmental health data in public or controlled-access databases. Similar to genetic and clinical health studies, Carrera et al. (2018) showed that participation in environmental health studies is motivated by altruism, but did not explore how people view trade-offs between social benefits of the studies and personal risks if data are shared. As an example of how these questions arise, several years ago, investigators at an environmental health research organization were asked to make data from their “Household Exposure Studies” available in ExpoCast, a publicly accessible database of measurements from personal environmental exposure studies developed by the Environmental Protection Agency (EPA) (Judson et al., 2012). Because of the potential privacy risks and because data sharing was not anticipated in the informed consent form, the research team decided against sharing these data in the public database but did allow their controlled-access use. It is not known, however, what the study participants’ would have preferred. Participants would likely appreciate the concern for their privacy and autonomy (i.e., their ability to consent to data sharing), but they might also wish that their data be used further for the public good, as they intended in volunteering for the original study.
In light of the movement toward one-time, broad consent, recently formalized in the Common Rule as an option for storage and future use of identifiable data (DHHS Federal Policy for the Protection of Human Subjects, 2017), and the creation of large datasets like All of Us with many types of data accessed by many researchers, researchers and institutional review boards (IRBs) need to understand participants’ views on sharing their personal environmental data in order to respectfully request consent to share these data. Earlier research about genetic and health studies indicates that participants’ weighing of risks and benefits incorporates contextual factors, including the study purpose (Trinidad et al., 2012), and that people are more reluctant to share data with government agencies as compared to academic and clinical researchers (Garrison, et al., 2016). Participants also care what type of data are requested. One nationally representative survey found that when considering participation in a hypothetical cohort study with controlled-access data sharing, 83–84% were willing to provide home environmental samples (water, soil) and “lifestyle” information, 73–77% were willing to provide biological samples, Fitbit-type data, genetics, and family medical history, but only 43% of those with a social media account would share that data (Kaufman, et al., 2016). The reasoning behind these choices was not investigated.
To learn more about people’s perspectives on sharing environmental data, we designed a survey to evaluate, in a hypothetical context, whether women who have volunteered to be contacted about breast cancer research – members of the Army of Women – are interested in participating in environmental health studies that involve sharing data. Our goal was to assess (1) whether interest in participating in an environmental health study depends on whether and how data will be shared, (2) how prospective research participants perceive risks and benefits of such studies, and (3) whether views vary with contextual factors, namely the study purpose, type of data, and approach to return of study results.
Method
Study population
We recruited participants from the Dr. Susan Love Research Foundation’s Army of Women (AOW), a network of more than 300,000 women and men who are interested in participating in breast cancer research (Dr. Susan Love Research Foundation, 2019). The majority of the AOW members are Caucasian; at the time of our survey, three percent of registrants were Black or African American, three percent Hispanic or Latina, one percent Asian, two percent Native American, and five percent of “other” ethnicity. Because few AOW members are men, we excluded men from this study. To date, the AOW has recruited for more than 130 studies involving more than 300 researchers and covering a range of topics, including environmental factors (Dr. Susan Love Research Foundation, 2019). Indeed, one of the first studies to recruit from the AOW in 2008 was the National Institutes of Health (NIH) Sister Study, a national prospective cohort of women who had a sister diagnosed with breast cancer. The Sister Study includes environmental assessment using questionnaires, linkage to ambient air pollution data, and collection of blood, urine, toenail and household dust samples (Sandler et al., 2017). We thus considered the AOW to be an appropriate population for this first-look at viewpoints relevant to environmental health studies.
Recruitment for our study began after approval by the AOW Scientific Advisory Committee and the Northeastern University IRB. Using the AOW’s typical procedures, we sent three “Call to Action” emails to all individuals currently subscribed to the mailing list (range across emails: 108,691 – 116,135 people), describing our study and inviting women age 18 or older and able to read and write in English to participate. In the third “Call to Action,” we specifically appealed to women of racial/ethnic minorities to join the study. Those who received the email were encouraged to forward it to friends or family who might be interested in participating. Potential participants could also find out about and sign up for the study on the AOW website.
Survey design
We used a web-based experimental vignette survey (Atzmüller & Steiner, 2010) to evaluate the motivations and beliefs underlying AOW members’ decisions to participate in hypothetical environmental health studies involving different types of data sharing. The focus of this paper is the first section of the survey, in which participants read short descriptions – vignettes – of potential environmental health studies that were structured to resemble the “Call to Action” emails that the AOW sends to its members to recruit them for studies. Before beginning the survey, potential participants reviewed an online Informed Consent document and selected either “Accept” or “Decline.”
Drawing on past studies on sharing genetic and health data (Kaufman, et al., 2016; Kaufman, et al., 2009; Trinidad et al., 2010; Zarate, et al., 2016), we selected four factors to vary across the vignettes: study purpose (4 levels), data type (5 levels), receipt of individual results (yes/no), and type of data sharing (4 levels). Because the number of possible combinations of factors (130) was large, we did not attempt a full factorial design. Instead, we developed three groups of vignettes capturing different types of environmental health studies and compared pairs of scenarios that varied one of the first three factors – study purpose, data type, or receipt of individual results. Combining each of the distinct study descriptions with each data sharing type resulted in 22 vignettes. The three groups of vignettes are shown in Table 1 and described briefly below, and data sharing options are shown in Table 2.
Table 1.
Key Features of Vignettes.
| Scenario | Title | Research Purpose | Data |
|---|---|---|---|
| 1A. | Smallville Breast Cancer Study | Government organization investigating environmental causes of breast cancer cluster.
|
|
| 1B. | Same as 1A | Same as 1A |
|
| 1C. | Smallville Water Study | Government organization monitoring drinking water and health after contamination.
|
|
| 2A. | Children’s Everyday Exposure | University researchers characterizing children’s everyday exposure to chemicals.
|
|
| 2B. | Same as 2A | Same as 2A |
|
| 2C. | Same as 2A | Same as 2A |
|
| 3. | Exposure Reduction | University researchers developing Smartphone app to help people reduce exposure to harmful chemicals.
|
|
Group 1 and 2 scenarios were combined with each of three sharing types (none, controlled-access database, publicly-accessible database) for a total of 18 vignettes. The group 3 scenario was combined with four sharing types (none, controlled-access database, publicly-accessible database, publicly-accessible database with restricted access to zip code) for a total of four vignettes. For groups 1 and 2, italics indicate features that are different in “B” and “C” scenarios compared to the “A” scenario.
Table 2.
Data sharing descriptions.
| Data Sharing Type | Your/your child’s data will be… |
|---|---|
| No sharing | “stored for future research by the research team.” |
| Controlled access | “shared with other researchers in one or more “controlled-access” databases. This means that only researchers who apply for and get permission to use the information for a specific research project will be able to access the information. Your data will not be labeled with [your name/your child’s name] or other information that could be used to easily identify you [or your child].” |
| Public access | “made freely available in a public, unrestricted database that anyone can use. This public information will not be labeled with [your name/your child’s name] or other information that could be used to easily identify you [or your child].” |
| Restricted zip code | “made freely available in a public, unrestricted database that anyone can use. This will include basic information such as your race, ethnic group, and sex; your opinions about causes of breast cancer and your responses to questions about environmental health topics; your product use information; your personalized exposure report; and some variables that we will obtain from the 2010 US Census report to describe your community (such as median household income in your area). Your zip code will be shared with other researchers in a “controlled-access” database. This means that only researchers who apply for and get permission to use the information for a specific research project will be able to access this information. Neither the public information nor the data in the controlled-access database will be labeled with your name or other information that could be used to easily identify you.” |
“Restricted zip code” sharing type was only paired with vignette 3.
In the Smallville vignettes, a government organization is investigating a local environmental health issue, either a breast cancer cluster (1A, 1B) or drinking water contamination (1C). Adult participants contribute household dust, drinking water, and urine samples for chemical analysis, and they receive their personal results. In the breast cancer study, health data are collected either by electronic medical record (EMR)-linkage (1A) or questionnaire (1B). In the drinking water study, health data are from EMR-linkage.
In the Children’s Everyday Exposure vignettes, university researchers are studying children’s chemical exposures and their sources, but no health outcome is specified. Health, neighborhood, and household activities are assessed by questionnaire. In two vignettes (2A, 2B), chemicals and genes are tested in blood from children across the U.S. and parents either receive (2A) or do not receive (2B) results from their child’s blood sample. In the third Children’s Everyday Exposure study (2C), chemicals are tested in household air and dust from three cities and parents receive results from the environmental testing.
Finally, in the Exposure Reduction vignettes (group 3), university researchers are developing an app to help people reduce their exposure to harmful chemicals. The study is collecting opinions about the causes of breast cancer, environmental health knowledge, zip code, and personal care and cleaning product use. Based on their responses, participants will receive personalized feedback about their likely exposure to chemicals in their products and air pollution in their area.
After consenting, participants were randomized to see one of 11 sets of two vignettes (see Table S1). The order of presentation of the two vignettes was randomized. After each vignette, participants responded to the question, “Would you tell these researchers you are interested in participating in their study?” Next, a series of open-ended and fixed choice questions asked about perceived benefits and risks of the proposed study as well as participants’ overall reasons for their interest or lack of interest in participating. Finally, in a later part of the survey, participants were asked generally (i.e. not in the context of a particular hypothetical study) about willingness to share different types of data (e.g., health data, genetic data, chemical testing results from your home). Survey questions included in this analysis are available in the supplemental information.
The online survey was pre-tested in February and March of 2016 among 49 supporters of Massachusetts Breast Cancer Coalition and/or Silent Spring Institute. Survey pre-testers were asked to provide feedback about whether the survey was understandable, meaningful, and user-friendly. Feedback was solicited after each vignette with the question “Do you have any comments about the scenarios and questions you’ve seen so far? If so, please let us know!” After incorporating revisions based on feedback from the pre-test, the final survey was fielded from May 2016 to May 2017.
Data analysis
Among 1,695 participants who answered at least one question in the first part of the survey, we excluded 105 responses from participants who misunderstood the instruction to “Imagine that you would be eligible to participate in this study”; most (89) of these were responses to the vignettes about children’s health (group 2), where respondents mistakenly refused participation because they themselves didn’t have children or didn’t have children in the right age range. We also recoded five responses to the participation question for the group 2 vignettes from “no” to “yes” because responses to the open-ended question about participation clearly indicated that these respondents would have agreed to participate if they had children. Conversely, one response to the participation question and four to the “Do you think there are any risks to the study?” question were recoded from “yes” to “no” because participants stated in response to the opened-ended question that they meant to say “no.” We then restricted our analysis to the 1,613 participants who answered more than one third of the questions in the first section of the survey, which is the focus of this paper. Most (90%) of these participants answered more than 90% of the first section. Finally, after preliminary analysis suggested that responses to the second vignette may have been influenced by carryover from the first vignette (e.g., a participant’s open-ended response included a comment about the type of data sharing viewed in the previous vignette), or by respondent fatigue, as demonstrated by lower proportions interested in participating in the second-viewed vignettes, we focused our analysis on the 1,575 responses to the first vignette. We performed a sensitivity analysis including the second vignette.
Data were first examined descriptively. We computed frequencies of “interest in participating” (IIP) in each hypothetical study by each type of data sharing and frequencies of IIP by demographic characteristics and data sharing type across all studies. We tested for differences in IIP by data sharing type, combining across all hypothetical studies, with Pearson’s Chi-squared test and with two-sample tests for equality of proportions. For individual Likert-type questions about the influence of study features (the researchers, study procedures, receiving results, study purpose, type of data sharing), we computed the percentage reporting that that feature made them “much less,” “somewhat less,” “somewhat more,” or “much more” likely to participate, or that the feature “did not impact my decision.” We also evaluated the percentage who said they were willing to share different types of data (including health history, genetics, zip code, demographics, chemical testing from biological or household samples, product use) in controlled-access or public-access databases in response to a question from later in the survey, outside the vignettes.
We evaluated independent effects of the experimentally manipulated variables (study features and data sharing type) on interest in participating (yes/no) using a modified Poisson regression model with robust error variance to estimate risk ratios (G. Zou, 2004). Each pair of scenarios (1A vs. 1B, 1A vs. 1C, 2A vs. 2B, and 2C vs. 2A) was modeled separately. Initial models included (1) a categorical variable for data sharing type with “controlled-access” as the reference and (2) an indicator for the experimentally manipulated study feature (study purpose, data type or receipt of individual results). For group 3, the initial model just included the variable for data sharing type. In a sensitivity analysis, we examined models that included responses to the second vignette, accounting for potential correlation between responses from the same individual (G. Y. Zou & Donner, 2013).
Next, we evaluated models including demographic variables that have been previously reported to be independently associated with willingness to participate in a hypothetical gene-environment cohort (Kaufman, et al., 2016; Kaufman, et al., 2009): age (18–34, 35–64, and 65+ years old) and education (no college degree, college degree or higher, prefer not to answer). We did not include race/ethnicity because data were too sparse. We also included an indicator (yes/no) of whether respondents had previously participated in a study where they provided biological samples or environmental samples from their homes. Analyses were restricted to respondents with complete data on all predictors. Fifteen percent of participants (N = 248) were missing data for one or more predictor. Because the survey was randomized, we did not expect these variables to be confounders of associations between experimentally manipulated variables and IIP, however we were interested in whether these characteristics were independent predictors of IIP in our population.
Finally, we evaluated (1) whether there was evidence of interaction between data sharing type and the manipulated study feature, by adding a product term for these two variables to the model and (2) whether the influence of sharing type on interest in participating varied with age (< 35 vs. ≥ 35), education, or prior research participation, by including (one at a time) product terms between sharing type and each of these variables. We also considered interaction between data sharing type and the manipulated study feature on the additive scale by computing the relative excess risk of interaction (RERI) with bootstrapped 95% confidence intervals (Assmann, Hosmer, Lemeshow, & Mundt, 1996).
Responses to open-ended questions were coded primarily in Dedoose (SocioCultural Research Consultants, LLC, Los Angeles, CA) with some cleaning and checking of codes using R version 3.6.0 (R Core Team, 2017). An initial set of codes was developed drawing on the risks and benefits cited by prospective (Trinidad, et al., 2012) and actual (Oliver, et al., 2012; Zarate, et al., 2016) participants in genetic studies. One member of the research team (JU) coded all responses and developed additional sub-codes during the analysis, in consultation with JB. Responses from twenty participants were coded by an additional team member (LB) to identify discrepancies and refine code definitions. JB then reviewed coding for 151 participants, achieving very high agreement ranging from 88 to 100% on codes used in this analysis.
All statistical analyses were performed using R version 3.6.0 (R Core Team, 2017).
Results
About 40,000 women opened the Army of Women recruitment email, and 2,204 expressed interest in the study and received a link to the survey. Of the 1,757 individuals who opened the survey, 1,575 (90%) are included in our analysis. Age distribution and race/ethnicity were not significantly different comparing women who did vs. did not open the survey. Participants came from all 50 states and the District of Columbia. Table 3 shows demographic characteristics of these participants; among those who responded to the demographics questions, most (74%) were older than 50 years of age, 94% said they were White, and 81% reported having a bachelor’s or graduate degree. Two percent self-identified as Hispanic.
Table 3.
Characteristics of Army of Women Survey Respondents (N = 1,575).
| Characteristic | N | % |
|---|---|---|
| Age | ||
| 18–35 years | 86 | 5 |
| 36–50 years | 296 | 19 |
| 51–64 years | 619 | 39 |
| 65+ years | 441 | 28 |
| Missing | 133 | 8 |
| Race | ||
| White | 1354 | 86 |
| Non-White | 69 | 4 |
| Prefer not to answer | 20 | 1 |
| Missing | 132 | 8 |
| Ethnicity | ||
| Hispanic/Latina | 27 | 2 |
| Non-Hispanic/Latina | 1408 | 89 |
| Prefer not to answer | 11 | 1 |
| Missing | 129 | 8 |
| Education | ||
| High school diploma or GED | 29 | 2 |
| Some college but no degree | 139 | 9 |
| Associate degree | 95 | 6 |
| Bachelor’s degree (e.g. BA, BS) | 480 | 30 |
| Graduate or professional degree | 696 | 44 |
| Prefer not to answer | 7 | 0.4 |
| Missing | 129 | 8 |
Characteristics for participants included in analysis after applying exclusions described in Data Analysis.
Interest in participating in the environmental health studies
Among our study population of women who had previously volunteered to be contacted about breast cancer research, interest in participating in environmental studies ranged from 62 to 97 percent across all vignettes (Table 4). Interest in participating was 80% or higher for all study scenarios except those involving blood samples from children. Participants were more interested in studies with controlled-access sharing (86%) compared with no (81%) or public access sharing (82%), though the difference between controlled- and public-access sharing was not statistically significant in a two-sample test of equality of proportions (p = 0.07). Army of Women members aged 35 or younger were somewhat less likely to express interest in participating in studies that involved sharing in publicly accessible databases (72% willing to share publicly compared to 78–86% in other age categories), and Hispanic women (N = 27) were less likely to express IIP across all sharing conditions (64%−71% IIP for no sharing, controlled and public sharing conditions vs. 82–87% for non-Hispanic women). In multivariable models examining experimentally manipulated study features, demographic characteristics and prior donation of biological or environmental samples for research were generally not significant predictors of interest in participating (supplemental Table S2), though statistical power to detect potential associations was limited by the lack of diversity in our population. Models for the experimentally manipulated study features presented in Table 5 do not include demographic characteristics or prior research participation.
Table 4.
Percentage Who Expressed Interest in and Number who Viewed Hypothetical Vignette Studies by Data Sharing Type (N = 1,575).
| Data Sharing Type Described in Vignette | ||||||||
|---|---|---|---|---|---|---|---|---|
| None | Controlled | Public | Restricted Zip Code | |||||
| % IIP (N viewed) |
% IIP (N viewed) |
% IIP (N viewed) |
% IIP (N viewed) |
|||||
| Overall | 81 | (503) | 86 | (500) | 82 | (489) | 93 | (83) |
| Age | ||||||||
| 18–35 years | 68 | (31) | 83 | (24) | 72 | (25) | 83 | (6) |
| 36–50 years | 87 | (104) | 88 | (90) | 86 | (93) | 100 | (9) |
| 51–64 years | 78 | (198) | 86 | (208) | 78 | (184) | 93 | (29) |
| 65+ years | 86 | (121) | 87 | (146) | 86 | (141) | 91 | (33) |
| Missing | 76 | (49) | 78 | (32) | 78 | (46) | 100 | (6) |
| Race | ||||||||
| White | 81 | (419) | 87 | (439) | 82 | (421) | 93 | (75) |
| Non-White | 93 | (28) | 89 | (19) | 79 | (19) | 67 | (3) |
| Prefer not to answer | 71 | (7) | 50 | (8) | 80 | (5) | -- | -- |
| Missing | 76 | (49) | 76 | (34) | 80 | (44) | 100 | (5) |
| Ethnicity | ||||||||
| Hispanic/Latina | 64 | (11) | 71 | (7) | 71 | (7) | 100 | (2) |
| Non-Hispanic/Latina | 82 | (441) | 87 | (457) | 82 | (435) | 92 | (75) |
| Prefer not to answer | 100 | (3) | 75 | (4) | 67 | (3) | 100 | (1) |
| Missing | 75 | (48) | 78 | (32) | 80 | (44) | 100 | (5) |
| Education | ||||||||
| High school diploma or GED | 90 | (10) | 86 | (7) | 82 | (11) | 100 | (1) |
| Some college but no degree | 85 | (41) | 92 | (40) | 83 | (47) | 100 | (11) |
| Associate degree | 65 | (26) | 85 | (34) | 81 | (32) | 67 | (3) |
| Bachelor’s degree (e.g. BA, BS) | 82 | (147) | 87 | (157) | 81 | (149) | 93 | (27) |
| Graduate or professional degree | 82 | (229) | 86 | (227) | 83 | (204) | 92 | (36) |
| Prefer not to answer | 100 | (2) | 67 | (3) | 50 | (2) | -- | -- |
| Missing | 75 | (48) | 78 | (32) | 80 | (44) | 100 | (5) |
| Scenario | ||||||||
| 1A: Smallville Breast Cancer Study, EMR data | 84 | (76) | 85 | (89) | 80 | (76) | -- | -- |
| 1B: Smallville Breast Cancer Study, self-reported health data | 91 | (82) | 95 | (80) | 90 | (72) | -- | -- |
| 1C Smallville Water Study, EMR data | 81 | (72) | 81 | (70) | 82 | (68) | -- | -- |
| 2A: Children’s Everyday Exposure Study, blood samples & genetic analyses | 72 | (67) | 84 | (67) | 70 | (54) | -- | -- |
| 2B: Same as 2A but no individual report-back | 62 | (72) | 68 | (69) | 62 | (72) | -- | -- |
| 2C: Children’s Everyday Exposure Study, environmental samples | 83 | (66) | 97 | (61) | 90 | (70) | -- | -- |
| 3: Exposure Reduction Study, opinions, zip code | 91 | (68) | 92 | (64) | 92 | (77) | 93 | (83) |
%IIP = percentage interested in participating. N viewed = total number who viewed the data sharing type. None = data restricted to use for future research by the research team. Controlled = data available to researchers who apply for and get permission to use the data for a specific project. Public = data are freely available in a public, unrestricted database. Restricted zip code = most data shared in a publicly accessible database but zip code is stored in a controlled-access database. The restricted zip code data sharing type only occurred in combination with scenario 3. EMR = electronic medical record.
Table 5.
Modified Poisson Regression Results Showing Associations Between Experimentally Manipulated Study Features and Proportion Interested in Participating.
| Vignette Pair | Factor | Level | RR | 95% CI |
|---|---|---|---|---|
| Model 1 (N = 475) | ||||
| 1A & 1B Smallville Studies |
EMR access | No (health questionnaire) | REF | |
| Yes | 0.9 | (0.84, 0.97) | ||
| Data sharing type | Controlled-access | REF | ||
| None | 0.97 | (0.9, 1.05) | ||
| Public-access | 0.95 | (0.87, 1.03) | ||
| Model 2 (N = 451) | ||||
| 1A & 1C Smallville Studies |
Purpose | Follow-up after municipal water contamination | REF | |
| Investigation of breast cancer cluster | 1.02 | (0.94, 1.12) | ||
| Data sharing type | Controlled-access | REF | ||
| None | 0.99 | (0.89, 1.09) | ||
| Public-access | 0.97 | (0.88, 1.08) | ||
| Model 3 (N = 401) | ||||
| 2A & 2B Children’s Everyday Exposure |
Personal results | Receive overall results only | REF | |
| Receive personal and overall results | 1.17 | (1.03, 1.33) | ||
| Data sharing type | Controlled-access | REF | ||
| None | 0.88 | (0.76, 1.03) | ||
| Public-access | 0.88 | (0.75, 1.03) | ||
| Model 4 (N = 385) | ||||
| 2A & 2C Children’s Everyday Exposure |
Sample type | Biological | REF | |
| Environmental | 1.2 | (1.09, 1.31) | ||
| Data sharing type | Controlled-access | REF | ||
| None | 0.86 | (0.77, 0.96) | ||
| Public-access | 0.89 | (0.81, 0.99) | ||
| Model 5 (N = 292) | ||||
| 3a Exposure Reduction | Data sharing type | Controlled-access | REF | |
| None | 0.99 | (0.89, 1.1) | ||
| Public-access | 1 | (0.91, 1.1) | ||
| Most data public-access, zip code in controlled-access | 1.01 | (0.92, 1.1) | ||
EMR = electronic medical record, RR = risk ratio
In group 3, only the type of data sharing varied, so there was no vignette pair.
Local environmental health – Smallville breast cancer and environmental studies
Depending on the particular vignette, 80 to 95% of participants responded positively to the Smallville studies investigating local environmental health issues, (Table 4).
Data sharing:
IIP was not significantly associated with data sharing type (Table 5, models 1 and 2).
Study purpose:
IIP also did not vary with the particular study purpose – breast cancer cluster (1A) or water contamination (1C) – controlling for data sharing type (Table 5, model 2).
Electronic medical records:
However, the type of health data did influence IIP in the breast cancer studies. Controlling for data sharing type, participants were significantly less likely to express interest in a study with ongoing access to EMRs (1A) compared to a study with health history collected by an in-person survey updated every two years by phone (1B) (Table 5, model 1, RR = 0.9, 95% CI: 0.84–0.97).
Children’s everyday exposure studies
IIP in the Children’s Everyday Exposure studies ranged from 62–97% depending on the particular vignette viewed.
Data sharing:
Participants tended to prefer restricted-access as compared to no sharing or public sharing (Table 5, models 3 and 4).
Biological vs. environmental samples:
Controlling for data sharing type, IIP was higher for the study collecting air and dust from children’s rooms (2C) vs. blood samples from children, including DNA for genetic analyses (2A) (Table 5, model 4, RR = 1.2, 95% CI: 1.09–1.31). IIP for the vignettes with environmental samples were similar to the Smallville studies (Table 4).
Receipt of personal results:
Although participants were less interested in studies involving blood sampling from children, their interest was higher (70–84%) if parents would receive their child’s individual results than if they would not (62–68% IIP) (Table 4). The positive association between receipt of results and IIP was statistically significant in a model controlling for data sharing type (Table 5, model 3, RR = 1.17, 95% CI: 1.03, 1.33).
Exposure reduction study
Depending on the vignette, 91 to 93% of participants expressed interest in the Exposure Reduction study (group 3), which involved collection of opinions, product use, and location (zip code) from adults and return of personalized feedback on how to reduce exposures to chemicals.
Data sharing:
Data sharing type was not significantly associated with interest in participating in this study (Table 5, model 5).
Interactions with data sharing type
We did not observe evidence of interaction on the multiplicative or additive scales between the type of data sharing described and the other experimentally varied vignette factors or any demographic variables (data not shown). Of note, some demographic categories (age < 35, no college degree) were sparse when stratified by data sharing type, limiting the power of these analyses, or causing models to fail (vignette pair 2C vs 2A for age; vignette 3 for age and education).
Sensitivity analysis
Consistent with our findings from preliminary analysis of open-ended questions, our sensitivity analysis showed some differences in responses when a vignette was viewed second rather than first. For example, for the Smallville and Exposure Reduction studies, participants showed less interest in public sharing when they had previously viewed a vignette with no- or controlled-access sharing. Results of the sensitivity analysis along with further discussion are shown in Table S3.
Insight into decision-making process
After each vignette, responses to Likert-type questions about particular study features (study purpose, researchers conducting the study, report-back of individual results, data saved for future research, type of data sharing) and to open-ended questions about perceived risks, benefits, and reasons for participating provided additional insight into how AOW respondents made decisions about the studies.
Likert-type questions
Data sharing:
For all studies, responses to the Likert-type questions suggested that type of data sharing played a role in the decision-making process. While data sharing type was not significantly associated with IIP in most of the regression results reported earlier, this may be because the sharing type contributed to decisions in both directions (i.e., made some people more likely and others less likely to participate). For example, public data sharing was a disincentive for 26 to 53% of participants, while 6 to 22% said it made them more likely to join the study (Figure 1). Further, participants’ views of public sharing were not necessarily reflected in their final decisions; 22–38% who ultimately expressed IIP reported that public sharing negatively influenced their interest in the study.
Figure 1.
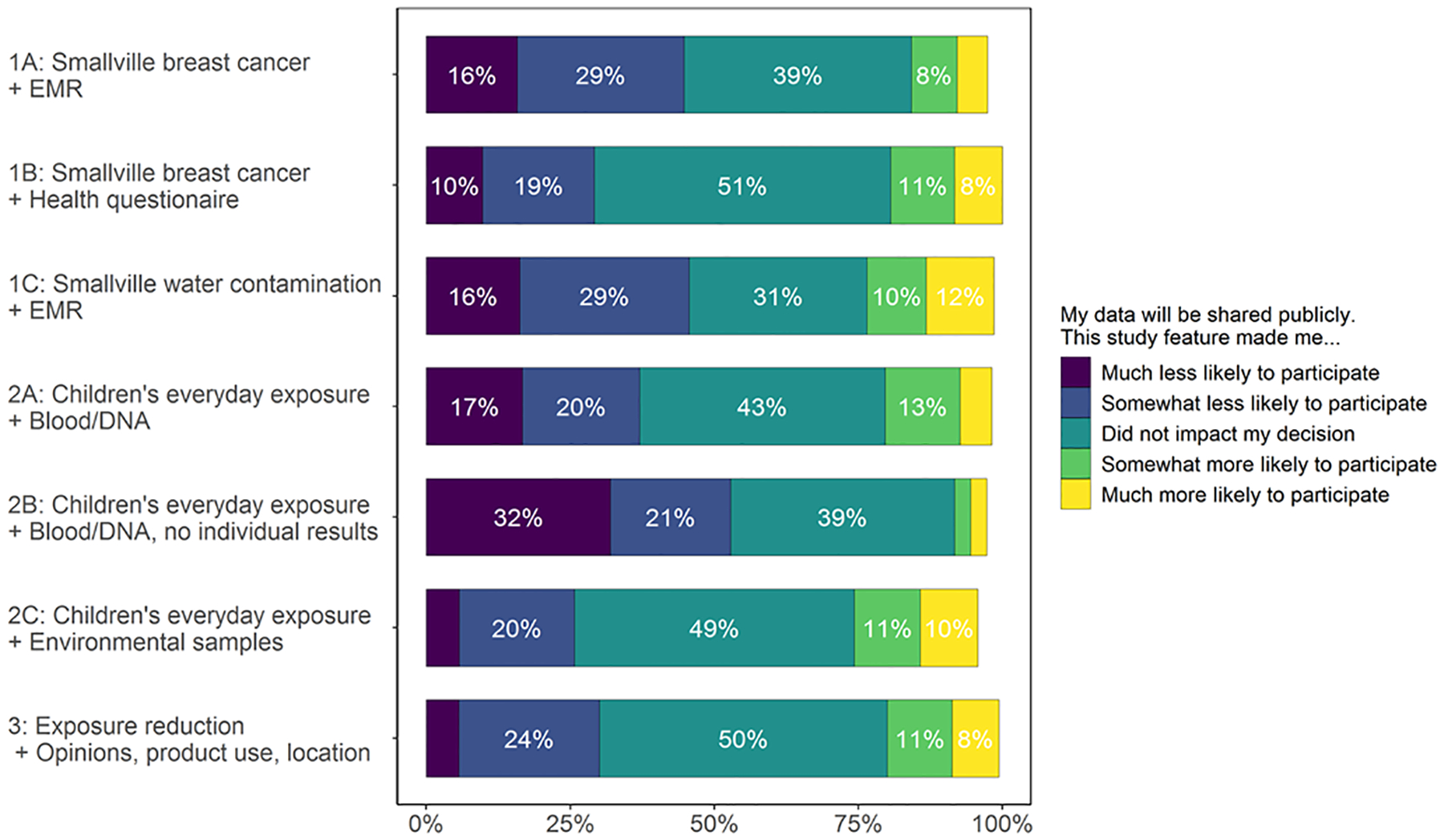
Influence of public data sharing on decision to participate in a hypothetical environmental health study. Public data sharing was a disincentive for 26 to 53% of participants, while 6 to 22% said it made them more likely to join the study. Percentage selecting each response computed based on the total number of participants who could have answered the question (N = 572). Bars that do not sum to 100% reflect participants who did not answer the question.
Study purpose:
The vast majority of AOW respondents cared about the purpose of the vignette they viewed, with 85 to 95% of respondents indicating that the purpose had a positive impact on IIP (Figure S1).
Receipt of personal results:
Consistent with the regression results reported earlier, 60% of participants viewing the Children’s Everyday Exposure vignette 2B said that the “lack of personal results” in this study made them less likely to participate (Figure S2). On the other hand, more than 80% endorsed “I can receive my results” as a positive influence on their decision to participate in every study across all scenarios that offered personal results, regardless of data sharing type.
Storage of data for future research:
Storage of data for future research, a feature of all vignettes, discourage interest for 28–32% of respondents considering the Children’s Everyday Exposure vignettes that involved blood samples and genetic analyses (2A and 2B) compared to 4–15% viewing other vignettes (Figure 2).
Figure 2.
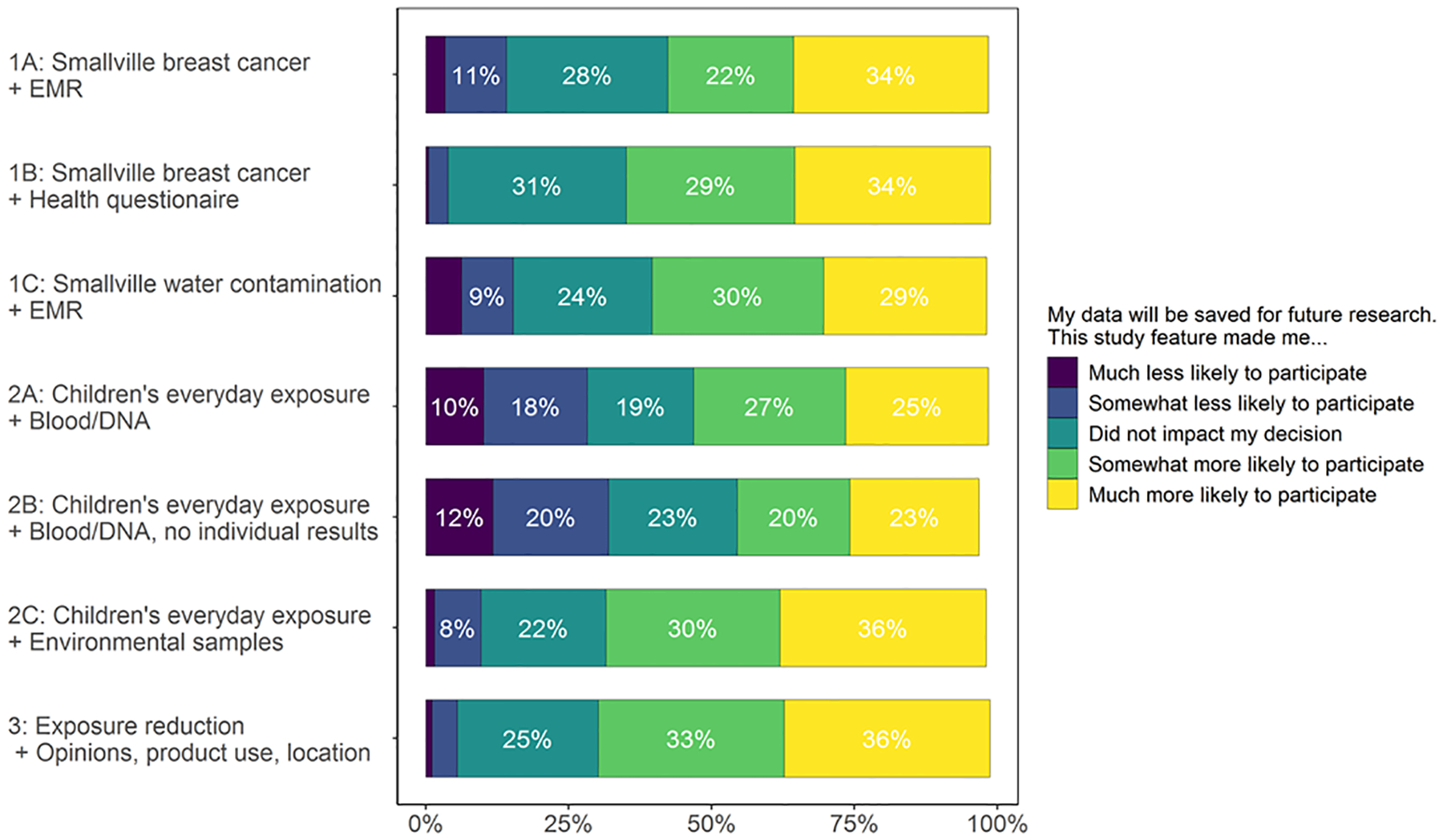
Influence of storing data for future research on decision to participate in a hypothetical environmental health study. Storage of data for future research bothered 28–32% of respondents considering the Children’s Everyday Exposure vignettes that involved blood samples and genetic analyses (2A and 2B) compared to 4–15% viewing other vignettes. Percentage selecting each response computed based on the total number of participants who could have answered the question (N = 1,575). Bars that do not sum to 100% reflect participants who did not answer the question.
Open-ended questions
Participants volunteered comments about their expectations for study benefits and concerns about privacy risks. All but seven participants responded to at least one open-ended question, and 96% of participants answered the question “Please tell us in your own words why you [would/would not] be interested in participating in this study.”
Research altruism:
A large majority (>70%) of those who expressed interest in participating in the hypothetical studies indicated in free-entry text boxes that they were motivated at least in part by research altruism, a sensibility involving participating in research for the greater good rather than for personal gain (Carrera, et al., 2018). These participants expressed a belief that the study would benefit science, that it would add to knowledge, and/or that it would benefit a larger community beyond their family and friends, including future generations. About 20% of those interested in participating volunteered specific ways that they expected the study results could be used in policy or public health actions – such as encouraging clean-up/prevention of environmental contamination locally and in other communities, and informing better chemicals regulation and safer formulation of personal care and cleaning products, for example:
It provides personal benefit (results, updates), as well as community and scientific benefit. If enough people participate and there are correlations between the leaked chemical and negative health outcomes, the published results could be useful in a class- action lawsuit or to secure a grant that would benefit the community.
(ME1–1099, Vignette 1C no sharing).
I value the opportunity to further knowledge, especially where open access is concerned. This research would add to a knowledge database that might be useful in the future, beyond the scope of the study. Also, the knowledge gained by participants might change individual behavior toward better health outcomes for self and community (e.g., fewer chemicals released into the community as a whole). The findings might also help drive advocacy and policy decisions that might be beneficial to health.
(ME1–0483, Vignette 3 public sharing with restricted zip code).
Privacy concerns:
Twenty-three percent of participants mentioned concerns about the privacy, security, and potential misuse of data stored for future research, including when data were not shared. Privacy issues raised for the “no sharing” condition may reflect a limitation of our description for this condition, which stated that information would be stored for future research by the study team, but did not specify that direct identifiers would be kept separately from the data (see Table 2 and supplemental information). Concerns about a “breach,” data “leak,” or “accidental release” were mentioned by nine percent of participants and were expressed most often for the vignettes that involved EMR access (1A and 1C) or that involved data, including genetic analyses, from children’s biological samples (2A and 2B), for example:
Having an outside agency accessing my health information from the state’s medical exchange and sharing it with other studies. I’m really concerned about too many people having access to my data. There have been too many data breaches and I’m concerned about this.
(ME1–0624, Vignette 1C controlled-access sharing).
A few noted that EMR access was not worth the privacy risk when they perceived the information might be unnecessary to achieving the aims of the study. Only three percent explicitly raised concerns about having their de-identified data linked back to them (re-identified) if it was shared in a public or controlled-access database. Re-identification was mentioned in studies that involved environmental or questionnaire data, even if no genetic data or medical records were involved (1B, 2C and 3). Some participants brought up specific concerns about discrimination against individuals by insurance companies or employers in the event of a data breach.
Willingness to share different types of data
When asked about willingness to share different types of data – in questions independent of the vignette descriptions – most were resistant to the idea of sharing their exact locations (GPS coordinate, address) in a public database, while 45% said they would allow inclusion of their zip code and more than 60% were willing to share demographic characteristics – age and race/ethnicity – in publicly-accessible databases. More participants expressed willingness to publicly share home characteristics (46%) and chemical testing results from their homes (49%) than chemical testing results from their bodies (35%) or genetic data (23%) (Figure 3).
Figure 3.
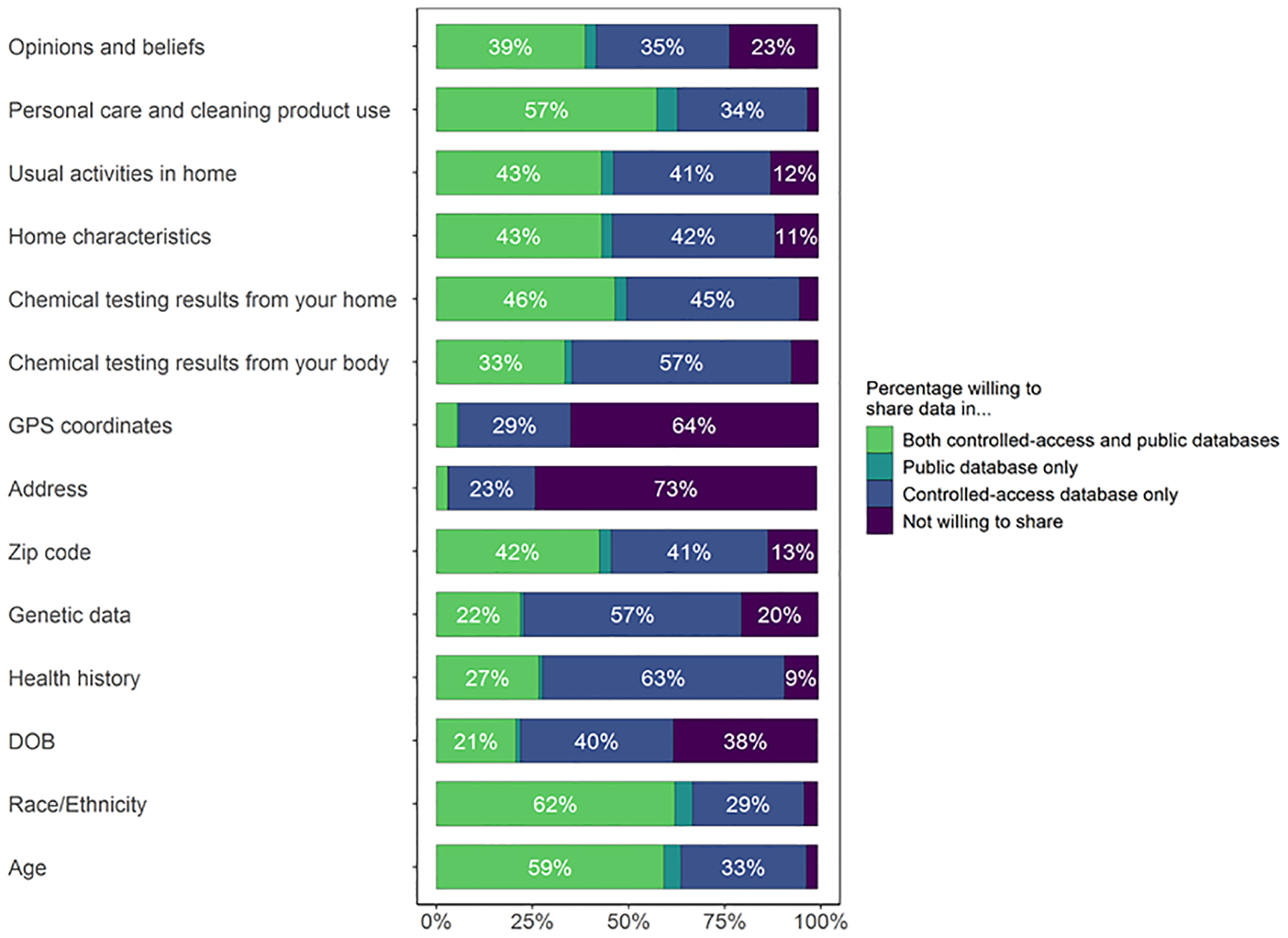
Percentage willing to share each type of data in both restricted and public databases, in a public database only, in a restricted database only, or not willing to share. Denominator is restricted to those who were included in the analysis of Part 1 and who reached the third part of the survey without dropping out (N = 1,453).
Discussion
Vignette survey responses from 1,575 members of the Army of Women demonstrated a high level of interest in participating in a variety of environmental health studies, regardless of the scenarios for data sharing, which ranged from no sharing to controlled-access for approved researchers to public access. Participants expressed altruistic reasons for their interest in participating, similar to findings from hypothetical surveys (Sanderson, et al., 2017), focus groups (Lemke, Wolf, Hebert-Beirne, & Smith, 2010; Trinidad, et al., 2010) and interviews with actual study participants (Jamal et al., 2014; Oliver, et al., 2012; Zarate, et al., 2016) about sharing genetic and/or health data. In addition, some volunteered specific hopes that study results would lead to environmental cleanups and health-protective environmental policies, a distinctive motivation to participate and share data in environmental studies.
Our regression models indicated that public data sharing was not a significant barrier to interest in participating in studies in adult women. This is in line with reports from a recent survey that found no impact of data sharing type (public or controlled) on hypothetical willingness to participate in a local hospital or healthcare organization biobank involving adults (Sanderson, et al., 2017). Still, when asked directly about whether the fact that data would be shared publicly mattered to them, many of our participants indicated that it did, and in response to open-ended questions, some raised concerns about the security of their data in both controlled and public-access databases and the ways that it might be used against them. Perceived risks included security breaches or misuse of confidential information, with less frequent mention of privacy risks related to “de-identified” data. Our findings, like those of Oliver et al. (2012) for genomic study participants, show that AOW members care and have concerns about how their data are shared, even if the data sharing mechanism is not the factor determining participation. One reason that people might accept personal risks of data sharing is that they sense that they don’t actually have control over their data — their information is already “out there.” Another factor could be that people are not aware of concrete stories of harm from data sharing in the research context. Of note, we did find some evidence that public sharing could dampen interest in studies involving children, but this finding differs from results from Antonmaria et al.’s (2018) analysis of hypothetical willingness to participate in a local healthcare organization biobank involving children.
Among the participants who referenced re-identification concerns, very few commented on which types of data they thought were vulnerable. However, participants’ responses to questions later in the survey, outside the context of the specific vignettes, suggest that women study volunteers were more protective of data that are obviously identifying (e.g., address, DOB) or feel more personal to the participant (e.g., genetic analyses and chemical biomonitoring in biological samples) while environmental samples (such as household air and dust) and questionnaire data were generally not considered sensitive. Location has become an important variable in large-scale environmental studies, because of the opportunity to estimate chemical exposures over the life course by linking residential histories to air quality and drinking water monitoring data, so strategies to protect privacy in these studies will be important to encouarage participation. Consequences of sharing genetic information have recently received attention in the news media with the identificiation of individuals from ancestry databases (Kolata & Murphy, 2018, April 27; Shapiro, 2018, Jul 21). Erlich et al. (2018) estimated that searching consumer genomics databases for an indvidual of European descent will lead to a third cousin or closer match 60% of the time. Yet fields that AOW members perceived as less risky—including demographic data, zip codes and home characteristics—can together create substantial re-identification risk. Sweeney et al. (2017) recently demonstrated that 16% of the 50 participants in a small, geographically-based study could be uniquely re-identified using the published study locations and chemical results combined with demographic information and housing characteristics. Given that some of our survey respondents noted concerns about negative consequences—employer or insurance discrimination—if their or their child’s results were “leaked” or identified in a security breach, our results suggest a need to educate prospective participants about the potential for similar consequences in the event that de-identified environmental health data are re-identified.
Other factors driving interest in the studies included receipt of individual study results, a key motivator of participation. Our result is consistent with many earlier findings that participants want to receive personal results and may benefit even when results are not directly relevant to personal health (National Academies of Sciences, 2018). A study of a hypothetical gene-environment cohort with biobanking also noted that receiving personal results can outweigh other concerns about study participation (Kaufman, et al., 2009), and our survey responses are consistent with reports from actual participants in environmental health studies (Brody, Brown, & Morello-Frosch, 2019). The practice of returning results is becoming the norm and is recommended by expert panels (Brody et al., 2014; National Academies of Sciences, 2018). However, our findings caution researchers not to unreasonably use return of personal results to recruit participants for data sharing scenarios they would otherwise reject because of privacy concerns. To guard against this possibility, consent to receive results can be separated from consent to share data.
Knowing that researchers would gain ongoing access to EMRs bothered some participants, regardless of how the data would be shared. Specific concerns raised in open-ended responses included that expanding EMR access to researchers could make the records more vulnerable to hacking, that the health information could potentially be misused by researchers, and that ongoing access to medical records did not seem necessary. Indeed, these concerns are not suprising, in light of the challenges the All of Us cohort encountered obtaining consent to access EMRs (Allen, 2017). One issue raised in previous surveys and focus groups is that potential participants need more information about conditions of access to and use of EMR data (Lemke, et al., 2010; Sanderson, et al., 2017). Sanderson et al. (2017) reported that 86% of respondents to a nationwide survey about participating in a local hospital or healthcare organization’s biobank endorsed the statement that “I would want to know what would happen if a researcher misused the health information in the biobank.” Similarly, Lemke et al. (2010) found that members of the public and participants in an EMR-linked biorepository (NUgene) wanted to know more about specific consequences of a breach and/or misuse of the data, such as what penalities would be imposed on the perpetrators. These types of questions are not typically addressed in informed consent documents (e.g., All of Us Research Program, 2017) or model consent language (Beskow et al., 2009; National Human Genome Research Institute, 2018), but they appear to meet the criteria in the revised Common Rule that informed consent must include “information that a reasonable person would want to know in order to make an informed decision” (DHHS Federal Policy for the Protection of Human Subjects), and addressing them could increase confidence in researchers accessing EMRs or other sensitive data.
Our results may be more relevant than typical vignette studies because the Army of Women is an actual network of people committed to participating in research, perhaps analogous to studies like All of Us. In addition our study scenarios are aligned with NIH initiatives to encourage data sharing for undefined future purposes (National Institutes of Health Office of Strategic Coordination - The Common Fund, 2019; National Library of Medicine, 2018).
Limitations
Limitations of our study include its hypothetical nature, the low rate of participation compared with the number who received the recruitment email, and the lack of diversity among survey respondents, despite efforts to recruit women of racial/ethnic minorities. In order to make choices about study participation more familiar and realistic, we attempted to make our study scenarios resemble, in tone and structure, the recruitment emails that the Army of Women sends to its members. While we cannot compute a response rate based on the data that the AOW is able to provide, we know that the recruitment e-mail was sent to more than 100,000 active subscribers and opened by approximately 40,000 people. It is encouraging that the approximate “open” rate for each of the three recruitment emails was on the upper end of the typical range for the AOW (N. Laurita, personal communication, October 2nd, 2018). Still, it is possible that the views of our survey respondents do not reflect the views of the wider AOW study population. In particular, our study population might capture those who are most interested in protecting privacy or conversely in the topic of wide sharing of environmental exposure and health data. Because Army of Women members are part of a community of people who have already volunteered to be contacted about breast cancer research studies because they have had, or are concerned that they or their loved ones will in the future have breast cancer, they might not be representative of the general population. Indeed, by signing up for the AOW, members have already agreed to share some demographic and contact information. They also may be more experienced and discriminating in evaluating the nuances of different study designs. However, we believe our results are a valuable first-look at viewpoints about data sharing in environmental health studies, because this study represents a large number of participants from a relevant population. Research practices should be responsive to this group, even if additional research is needed to respond to others that were inadequately represented.
Further, the characteristics of the vignettes represented a controlled range of scenarios. We designed our survey to test a variety of study features that we hypothesized could directly influence participation or modify the influence of sharing on participation while at the same time limiting the length of our survey. As a result, we intentionally confounded our study design in a number of ways. For example, we hypothesized that the type of researcher — university researchers vs. researchers from a government agency — might influence willingness to share data, but we did not vary this factor systematically across the vignettes. Instead, we kept the researcher type consistent within each group of vignettes and thus were not able to test whether sharing with government researchers affected interest in participating independently of whether the study involved EMR-linkage. We accepted this limitation because the particular scenario – government researchers requesting EMR access – is highly relevant to the All of Us cohort, CHEAR/HHEAR repositories, and any future national exposome efforts.
Finally, although open-ended questions about perceived risks, benefits, and reasons for participating provided intriguing information about participants’ decision-making processes, we were not able to ask follow-up questions. For example, the fact that most participants did not discuss re-identification risks related to environmental health data might not mean that they are not aware of such risks, but rather that participants do not view these risks as likely or worrisome. Further research with more directed questions about re-identification risks could help to clarify this issue. We also were not able to distinguish whether the reluctance to participate in the Children’s Everyday Exposure studies that involved blood samples was driven by concerns about subjecting children to blood draws or about the type of data – including genetic data – collected for the study.
Best Practices
Overall, our findings highlight an ethical imperative for environmental health studies and exposome efforts to (1) respect and support participants’ altruistic motives and their desire to receive personal results, (2) prioritize the security of researcher access to EMRs and communicate with participants about security measures that have been put in place and procedures in the event of a breach or misuse, and (3) when data will be shared, take steps to protect privacy and discuss with potential participants the re-identification risks associated with their data.
Researchers have a responsibility to disseminate study results in a way that respects participants’ altruistic goals. As noted previously in interviews with participants in the Personal Genome Project, participants expect that sharing their data will speed up research and drive social change (Zarate, et al., 2016), and to meet this expectation, researchers must make data available efficiently and in a way that is accessible and understandable, whether in public or controlled repositories. For example, while some of our survey respondents expressed a general desire to help others and to prevent future disease (especially breast cancer), others envisioned alternative ways that the study data could be used, such as to support legislation restricting harmful chemicals. To facilitate this kind of outcome, researchers should make their overall findings (not necessarily the individual-level data) known to policy-makers. Participants also described how data could be used to target pollution clean-up efforts, raise community awareness about an existing issue, and educate other communities with the hope of preventing similar problems. These efforts can be helped not only by disseminating research findings, but specifically by empowering participants and their communities with data; for example by reporting back personal results and holding community meetings to share study findings (Brown et al., 2012). Further, efforts could be made to link together different communities that have been involved in research where report-back is provided and to develop and share tools to support data literacy among research participants and the general public (D’Ignazio & Bhargava, 2016).
Researchers must also be cognizant of participants’ concerns about the security of EMR-linkage and access to data stored and shared in controlled-access or public repositories. Participants’ confidence in EMR-linkage may be improved with better communication about its benefit, more concrete information about how the records will be kept secure and how security violations will be handled, and mechanisms to support participants in dealing with consequences of a breach. In addition to keeping abreast of and implementing new methods for effectively sharing data while minimizing privacy risks, IRBs and researchers can incorporate into the informed consent process a discussion of re-identification risks related to sharing de-identified environmental data, which our survey suggests are not particularly salient to women enrolled as prospective study participants in the Army of Women. Research teams, including All of Us and HHEAR, should also communicate with each other to further knowledge of the many issues we have raised. People’s concerns about misuse of data are striking, and we hope these concerns can be addressed in future informed consent and recruiting practices.
Research Agenda
Our findings among primarily white non-Hispanic women, most of whom were age 50 or older with a bachelor’s degree or higher, may not be generalizable, so further study is needed in more diverse populations. Previous work suggests that willingness to share data varies with race/ethnicity, education and age and across cultures (Gaskell et al., 2013; Kaufman, et al., 2016; Kaufman, et al., 2009; McGuire et al., 2011). Further study in populations with better representation from these and other groups can identify whether similar variation exists in willingness to share environmental health data and consider ways to enhance participation from groups that would otherwise be under-represented. Research is also needed to understand the role of previous experiences, such as living in an environmentally contaminated community or surviving an environmental disaster, in decisions to share environmental health data. This requires in-depth interviews and focus groups to elicit understandings and desires. Other important topics for future study include views on sharing environmental data internationally, with the private sector and/or for commercial uses. Sharing interview questions across many environmental exposure studies that ask about willingness to participate can help to generate a larger sample that could yield more underrepresented groups.
Educational Implications
Our results suggest that environmental health researchers and their IRBs need to be aware of study participants’ expectations of social benefits, their desire for personal results, and their concerns about security issues related to EMR access and storing data in shared repositories. In addition, researchers and IRBs need to be aware of and communicate with prospective participants about the re-identification risks of environmental data. Open discussion of re-identification risks with participants may become even more critical, depending on the fate of the Environmental Protection Agency’s proposed rule to limit the datasets used to set environmental regulations to those for which individual-level data are made publicly available (Schwartz, 2018), especially since survey respondents cite health-protective legislation as an important way that they hoped data would be used. Some of the most powerful potential societal benefits of participating in environmental health studies – the possibility of effecting change in chemical regulations, raising awareness to prevent future drinking water contamination, supporting safer product formulation – may not be obvious to all prospective participants. Balanced communication of benefits while also explicitly highlighting potential harms of privacy loss will help participants to make informed decisions.
Supplementary Material
Acknowledgments
Recruitment was facilitated by Dr. Susan Love Research Foundation’s Army of Women Program. We thank Bridget Hanna for her valuable input on the study design and Laura Borth for her help with qualitative coding. Silent Spring Institute is a nonprofit scientific research organization dedicated to studying environmental factors in women’s health. This work was supported by NIH 1R01ES021726.
References
- Adamkiewicz G, Zota AR, Fabian MP, Chahine T, Julien R, Spengler JD, & Levy JI (2011). Moving environmental justice indoors: Understanding structural influences on residential exposure patterns in low-income communities. Am J Public Health, 101 Suppl 1, S238–245. doi: 10.2105/AJPH.2011.300119 [DOI] [PMC free article] [PubMed] [Google Scholar]
- All of Us Research Program. (2017). All of Us research program hipaa authorization for research EHR/part 2 supplement Retrieved March 20 2019, from https://allofus.nih.gov/sites/default/files/appendix_informed_consent_hipaa_ehr_part_2_supplement-stamped.pdf
- Allen A (2017). Giant NIH research project finds some reluctance to share ehrs. Politico. Retrieved from October 25 2017 website: https://www.politico.com/story/2017/10/25/giant-nih-research-project-finds-some-reluctance-to-share-ehrs-244160 [Google Scholar]
- Antommaria AHM, Brothers KB, Myers JA, Feygin YB, Aufox SA, Brilliant MH, … Holm IA (2018). Parents’ attitudes toward consent and data sharing in biobanks: A multisite experimental survey. AJOB Empir Bioeth, 1–15. doi: 10.1080/23294515.2018.1505783 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Assmann SF, Hosmer DW, Lemeshow S, & Mundt KA (1996). Confidence intervals for measures of interaction. Epidemiology, 7(3), 286–290. [DOI] [PubMed] [Google Scholar]
- Atzmüller C, & Steiner PM (2010). Experimental vignette studies in survey research. Methodology, 6(3), 128–138. [Google Scholar]
- Balshaw DM, Collman GW, Gray KA, & Thompson CL (2017). The Children’s Health Exposure Analysis Resource: Enabling research into the environmental influences on children’s health outcomes. Curr Opin Pediatr, 29(3), 385–389. doi: 10.1097/MOP.0000000000000491 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Beskow LM, Clayton EW, Eisenberg L, Henriksen-Hellyer J, McCarty C, McGuire AL, … Wolf W (2009). Model consent language Retrieved March 20 2019, from http://www.genome.gov/Pages/PolicyEthics/InformedConsent/eMERGEModelLanguage2009-12-15.pdf
- Brody JG, Brown P, & Morello-Frosch R (2019). Returning chemical exposure results to individuals and communities In Finn S & O’Fallon LR (Eds.), Environmental Health Literacy (pp. 135–163): Springer Nature Switzerland AG. doi: 10.1007/978-3-319-94108-0_6 [DOI] [Google Scholar]
- Brody JG, Dunagan SC, Morello-Frosch R, Brown P, Patton S, & Rudel RA (2014). Reporting individual results for biomonitoring and environmental exposures: Lessons learned from environmental communication case studies. Environ Health, 13, 40. doi: 10.1186/1476-069X-13-40 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brown P, Brody JG, Morello-Frosch R, Tovar J, Zota AR, & Rudel RA (2012). Measuring the success of community science: The northern california household exposure study. Environ Health Perspect, 120(3), 326–331. doi: 10.1289/ehp.1103734 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carrera JS, Brown P, Brody JG, & Morello-Frosch R (2018). Research altruism as motivation for participation in community-centered environmental health research. Soc Sci Med, 196, 175–181. doi: 10.1016/j.socscimed.2017.11.028 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Coombs KC, Chew GL, Schaffer C, Ryan PH, Brokamp C, Grinshpun SA, … Reponen T (2016). Indoor air quality in green-renovated vs. Non-green low-income homes of children living in a temperate region of US (Ohio). Sci Total Environ, 554–555, 178–185. doi: 10.1016/j.scitotenv.2016.02.136 [DOI] [PMC free article] [PubMed] [Google Scholar]
- D’Ignazio C, & Bhargava R (2016). Databasic: Design principles, tools and activities for data literacy learners. The Journal of Community Informatics, 12(3). [Google Scholar]
- DHHS Federal Policy for the Protection of Human Subjects. (2017). 82 Fed. Reg. 12 (January 19, 2017) Retrieved from https://www.gpo.gov/fdsys/pkg/FR-2017-01-19/pdf/2017-01058.pdf. [PubMed]
- Dodson RE, Udesky JO, Colton MD, McCauley M, Camann DE, Yau AY, … Rudel RA (2017). Chemical exposures in recently renovated low-income housing: Influence of building materials and occupant activities. Environ Int, 109, 114–127. doi: 10.1016/j.envint.2017.07.007 [DOI] [PubMed] [Google Scholar]
- Dr. Susan Love Research Foundation. (2019). Army of Women Retrieved March 20 2019, from https://www.armyofwomen.org/
- Erlich Y, Shor T, Pe’er I, & Carmi S (2018). Identity inference of genomic data using long-range familial searches. Science. doi: 10.1126/science.aau4832 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Garrison NA, Sathe NA, Antommaria AH, Holm IA, Sanderson SC, Smith ME, … Clayton EW (2016). A systematic literature review of individuals’ perspectives on broad consent and data sharing in the united states. Genet Med, 18(7), 663–671. doi: 10.1038/gim.2015.138 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gaskell G, Gottweis H, Starkbaum J, Gerber MM, Broerse J, Gottweis U, … Soulier A (2013). Publics and biobanks: Pan-european diversity and the challenge of responsible innovation. Eur J Hum Genet, 21(1), 14–20. doi: 10.1038/ejhg.2012.104 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goho SA (2016). The legal implications of report back in household exposure studies. Environ Health Perspect, 124(11), 1662–1670. doi: 10.1289/EHP187 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jamal L, Sapp JC, Lewis K, Yanes T, Facio FM, Biesecker LG, & Biesecker BB (2014). Research participants’ attitudes towards the confidentiality of genomic sequence information. Eur J Hum Genet, 22(8), 964–968. doi: 10.1038/ejhg.2013.276 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Judson RS, Martin MT, Egeghy P, Gangwal S, Reif DM, Kothiya P, … Richard AM (2012). Aggregating data for computational toxicology applications: The U.S. Environmental protection agency (EPA) aggregated computational toxicology resource (ACToR) system. Int J Mol Sci, 13(2), 1805–1831. doi: 10.3390/ijms13021805 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kaufman DJ, Baker R, Milner LC, Devaney S, & Hudson KL (2016). A survey of U.S adults’ opinions about conduct of a nationwide precision medicine initiative® cohort study of genes and environment. PLoS One, 11(8), e0160461. doi: 10.1371/journal.pone.0160461 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kaufman DJ, Murphy-Bollinger J, Scott J, & Hudson KL (2009). Public opinion about the importance of privacy in biobank research. Am J Hum Genet, 85(5), 643–654. doi: 10.1016/j.ajhg.2009.10.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kolata G, & Murphy H (2018, April 27). The golden state killer is tracked through a thicket of DNA, and experts shudder. The New York Times. Retrieved from https://www.nytimes.com/2018/04/27/health/dna-privacy-golden-state-killer-genealogy.html [Google Scholar]
- Lemke AA, Wolf WA, Hebert-Beirne J, & Smith ME (2010). Public and biobank participant attitudes toward genetic research participation and data sharing. Public Health Genomics, 13(6), 368–377. doi: 10.1159/000276767 [DOI] [PMC free article] [PubMed] [Google Scholar]
- McGuire AL, Oliver JM, Slashinski MJ, Graves JL, Wang T, Kelly PA, … Hilsenbeck SG (2011). To share or not to share: A randomized trial of consent for data sharing in genome research. Genet Med, 13(11), 948–955. doi: 10.1097/GIM.0b013e3182227589 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mikati I, Benson AF, Luben TJ, Sacks JD, & Richmond-Bryant J (2018). Disparities in distribution of particulate matter emission sources by race and poverty status. Am J Public Health, 108(4), 480–485. doi: 10.2105/AJPH.2017.304297 [DOI] [PMC free article] [PubMed] [Google Scholar]
- National Academies of Sciences, E., and Medicine. (2018). Returning individual research results to participants: Guidance for a new research paradigm. Washington, DC: National Academies of Sciences, Engineering, and Medicine. [PubMed] [Google Scholar]
- National Human Genome Research Institute. (2018, January 10 2018). Informed consent for genomics research Retrieved March 26 2019, from https://www.genome.gov/27559024/informed-consent-special-considerations-for-genome-research/
- National Institutes of Health. (2018). All of Us research program Retrieved March 20 2019, from https://allofus.nih.gov/
- National Institutes of Health Office of Strategic Coordination - The Common Fund. (2019). Big data to knowledge Retrieved March 20 2019, from https://commonfund.nih.gov/bd2k
- National Library of Medicine. (2018). NIH data sharing policies Retrieved March 20 2019, from https://www.nlm.nih.gov/NIHbmic/nih_data_sharing_policies.html
- Oliver JM, Slashinski MJ, Wang T, Kelly PA, Hilsenbeck SG, & McGuire AL (2012). Balancing the risks and benefits of genomic data sharing: Genome research participants’ perspectives. Public Health Genomics, 15(2), 106–114. doi: 10.1159/000334718 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Polidori A, Kwon J, Turpin BJ, & Weisel C (2010). Source proximity and residential outdoor concentrations of pm(2.5), OC, EC, and PAHs. J Expo Sci Environ Epidemiol, 20(5), 457–468. doi: 10.1038/jes.2009.39 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pool R, Rusch E, & Roundtable Environ. Health Sci. (2016). Principles and obstacles for sharing data from environmental health research: Workshop summary. Washington DC: Natl. Acad. Press. [PubMed] [Google Scholar]
- Precision Medicine Initiative Working Group. (2015). Precision medicine initiative cohort program - building a research foundation for 21st century medicine Retrieved March 20 2019, from https://www.nih.gov/sites/default/files/research-training/initiatives/pmi/pmi-working-group-report-20150917-2.pdf
- R Core Team. (2017). R: A language and environment for statistical computing. Vienna, Austria: Foundation for Statistical Computing. [Google Scholar]
- Rudel RA, Dodson RE, Perovich LJ, Morello-Frosch R, Camann DE, Zuniga MM, … Brody JG (2010). Semivolatile endocrine-disrupting compounds in paired indoor and outdoor air in two northern california communities. Environ Sci Technol, 44(17), 6583–6590. doi: 10.1021/es100159c [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sanderson SC, Brothers KB, Mercaldo ND, Clayton EW, Antommaria AH, Aufox SA, … Holm IA (2017). Public attitudes toward consent and data sharing in biobank research: A large multi-site experimental survey in the US. Am J Hum Genet, 100(3), 414–427. doi: 10.1016/j.ajhg.2017.01.021 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sandler DP, Hodgson ME, Deming-Halverson SL, Juras PS, D’Aloisio AA, Suarez LM, … Weinberg CR (2017). The sister study cohort: Baseline methods and participant characteristics. Environ Health Perspect, 125(12), 127003. doi: 10.1289/EHP1923 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schwartz J (2018). “Transparency” as mask? The epa’s proposed rule on scientific data. N Engl J Med, 379(16), 1496–1497. doi: 10.1056/NEJMp1807751 [DOI] [PubMed] [Google Scholar]
- Shapiro E (2018, July 21). How DNA and genetic genealogy are becoming ‘major’ game-changers in decades-old cold cases. ABC News. Retrieved from https://abcnews.go.com/US/dna-genetic-genealogy-major-game-changer-heat-decades/story?id=56172244 [Google Scholar]
- Stingone JA, Buck Louis GM, Nakayama SF, Vermeulen RC, Kwok RK, Cui Y, … Teitelbaum SL (2017). Toward greater implementation of the exposome research paradigm within environmental epidemiology. Annu Rev Public Health, 38, 315–327. doi: 10.1146/annurev-publhealth-082516-012750 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sweeney L, Yoo JS, Perovich L, Boronow KE, Brown P, & Brody JG (2017). Re-identification risks in HIPAA Safe Harbor data: A study of data from one environmental health study. Technology Science. [PMC free article] [PubMed] [Google Scholar]
- Trinidad SB, Fullerton SM, Bares JM, Jarvik GP, Larson EB, & Burke W (2010). Genomic research and wide data sharing: Views of prospective participants. Genet Med, 12(8), 486–495. doi: 10.1097/GIM.0b013e3181e38f9e [DOI] [PMC free article] [PubMed] [Google Scholar]
- Trinidad SB, Fullerton SM, Bares JM, Jarvik GP, Larson EB, & Burke W (2012). Informed consent in genome-scale research: What do prospective participants think? AJOB Prim Res, 3(3), 3–11. doi: 10.1080/21507716.2012.662575 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wild CP (2005). Complementing the genome with an “exposome”: The outstanding challenge of environmental exposure measurement in molecular epidemiology. Cancer Epidemiol Biomarkers Prev, 14(8), 1847–1850. doi: 10.1158/1055-9965.EPI-05-0456 [DOI] [PubMed] [Google Scholar]
- Wild CP (2012). The exposome: From concept to utility. Int J Epidemiol, 41(1), 24–32. doi: 10.1093/ije/dyr236 [DOI] [PubMed] [Google Scholar]
- Zarate OA, Brody JG, Brown P, Ramirez-Andreotta MD, Perovich L, & Matz J (2016). Balancing benefits and risks of immortal data: Participants’ views of open consent in the personal genome project. Hastings Cent Rep, 46(1), 36–45. doi: 10.1002/hast.523 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zou G (2004). A modified poisson regression approach to prospective studies with binary data. Am J Epidemiol, 159(7), 702–706. [DOI] [PubMed] [Google Scholar]
- Zou GY, & Donner A (2013). Extension of the modified poisson regression model to prospective studies with correlated binary data. Stat Methods Med Res, 22(6), 661–670. doi: 10.1177/0962280211427759 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.