

Abstract
The present text discusses some basic considerations on the dynamics of the coronavirus pandemic, in particular in France. The goal is not to make accurate predictions, which is probably impossible, but to illustrate some general qualitative behaviors which may be observed. The conclusions of the text only correspond to consequences of the models discussed here, where the parameters are roughly estimated as a function of the evolution of the number of deaths due to COVID-19. They are of course not definitive and are subject to possibly important modifications, due to new information or applications of less simplistic models.
Keywords: COVID-19, Reproduction number R
1. Summary of the main points
This first section serves both as an extended introduction and as a global discussion of our results described in more detail below. The reader may wish to look first at this section briefly to get the main ideas, then consult it again later as a summary.
In this article, we first establish a basic model of the number of infected people as a function of time without involving any policies such as lockdown, social distancing, testing, mask protection, etc. We then modify the basic model to include extra parameters associated with implementing policies. The basic models assume that all infected individuals infect the same number of people on average. We further consider a more sophisticated two-category model, where different categories of individuals infect different numbers of people. We apply various measures, such as age and degree of socialization, to differentiate the two categories, and illustrate them with numerical examples. We also discuss herd immunity for both basic and two-category models.
We use the estimated Chinese fatality rate and the fatality rate aboard the Diamond Princess1 by age to estimate the French fatality rate, taking into account that the age distribution of infected people is not the same as the general age distribution. We then estimate the number of infected individuals by the reported number of deaths and the estimated fatality rate. We use the number of deaths instead of the number of confirmed cases since the majority of cases are expected to remain undetected.
We note that the fatality rate is important for the evaluation of the general public’s acceptance of getting a large proportion of the population infected, which is needed for herd immunity. Some kind of testing sample can be helpful to evaluate the total number of infected people, which implies an evaluation of the fatality rate by dividing the number of deaths by the total number of infected individuals. A large decrease of the fatality rate by effective or at least partially effective treatments may increase the general public’s acceptance of herd immunity.
The well-known reproduction number R in epidemiological models is analyzed and estimated for the models introduced in this article. The general strategy for controlling the spread of the epidemic is to reduce the value of R.
The following observations are drawn from our oversimplified models applied to France which may be modified by additional information:
-
•
The values of R with or without policy implementation. With no action taken to control the epidemic, it grows approximately exponentially until the population quickly reaches herd immunity. The reproduction number in France is likely to be between 2.5 and 4, with an increase in the number of infected people of about 30 percent per day.
The epidemic is globally controlled under lockdown, with a reproduction number estimated to be between 0.4 and 0.7, and an estimated decrease in the number of infected people of about 6 percent per day.
-
•
The fatality rate. We estimate the fatality rate to be less than 0.5 percent among people under 60 years old, around 1 percent for people between 60 and 69 years old, and much higher for people 70 years old or older.
There have been discussions about a partial lockdown for people 70 years old or older. Such a strategy cannot prevent the growth of the epidemic by itself since the lockdown is not perfect, thus a significant proportion of people 70 years old or older may still be infected. However, based on our analysis, this can reduce the proportion of infected people 70 years old or older, which decreases the global fatality rate. The overall fatality rate depends not only on the fatality rate by age, but also on the age distribution of the infected population: it is likely that older people are less infected than younger people because they have less contact with others. In one of the two-category examples presented in this article, we get a possible decrease of the fatality rate by a factor of 2 or 3 in this scenario.
-
•
Herd immunity. The current level of herd immunity is expected to play a minor role in the control of the epidemic, because only a small (but not negligible) minority of the population has been infected. Herd immunity requires a large fraction of the population to be infected. Controlling the growth of the epidemic until herd immunity is reached reduces the proportion of infected people, but not necessarily by very much. The usual formulas giving the proportion of infected people as a function of the reproduction rate are overestimated when the population is not homogeneous in terms of contagion. However, the order of magnitude is not dramatically changed. A possible situation where herd immunity could be reached earlier would be the case where a significant part of the population is, from the beginning, not susceptible to infection (for example, if there is cross immunity with other viruses).
-
•
Simulations. At the end of the article, we present some simulations of the epidemic for the coming months, until the summer of 2021, under twelve different scenarios. The simulations give very different results, depending on the values of the parameters chosen. This illustrates the great uncertainty of the current situation, and suggests that there is an important risk of a second peak around the beginning of summer 2020.
According to our analysis, in order to completely suppress the epidemic in France by itself, a lockdown would need to last more than 6 months. The epidemic will be difficult to control after releasing the lockdown; social distancing, protection like masks, tests and contact tracing are expected to be helpful for that. Social distancing restrictions should be widely respected in order to keep the reproduction number at a low level. A minority of the population not respecting the restrictions may significantly increase the reproduction number. When the reproduction number becomes larger than 1, everyone is affected by the growth of the epidemic, even if those with less contagious contacts remain less infected than those with more contacts.
We should be aware of the uncertainty of the development and investigate carefully the evolution of the epidemic so that we are more prepared to adapt to the new situation. It will be interesting to know if the contagion is slower during spring and summer: this would help to control the pandemic in the coming months, so that we have more time to find effective treatments.
2. The basic model
Here, we consider the following model relative to the number of infected people as a function of time:
-
•
Every day, each infected individual contaminates β new individuals on average.
-
•
Every day, a proportion γ of infected individuals are either recovered, dead, or isolated, and are therefore no longer contagious.
The assumptions implied by this model are the following:
-
•
All infected individuals play the same role in terms of contagion.
-
•
All infected people have the same chance of recovering the next day: we do not distinguish between different stages of the disease.
-
•
There are sufficiently many infected people to neglect random fluctuations and the fact that the number of infected people is an integer.
-
•
The proportion of infected people is small enough to neglect herd immunity.
We choose a date of reference denoted as day 0, and we assume that the number of infected people on this day is X 0. If Xn is the number of infected individuals at day n, we have for this model:
which implies
There are three main cases:
-
•
If β < γ, then the factor is smaller than 1, which indicates that the number of infected people decreases exponentially.
-
•
If then the number of infected people remains constant.
-
•
If β > γ, then the number of infected people increases exponentially.
This model is far too simple to describe reality with any accuracy, but we can still try to find the parameters β and γ which fit observations as well as possible. If we consider the case of the coronavirus in France, the initial rate of growth of the epidemic can be roughly approximated by the rate of evolution of the number of deaths around the date of the lockdown. We look at the number of deaths instead of the number of cases, since the majority of cases are expected to be undetected. During the initial lockdown, we assume that its effect on deaths should be small since the probability of sudden death of newly infected individuals is low. The estimation of the number of deaths in France until March 14 (included), given by Wikipedia, is 91, whereas the number of deaths until March 21, is 562 [1], [4]. The date of the lockdown is March 17. This is a growth by a factor 562/91 ≃ 6 in one week. Hence, values of β and γ fitting the data should satisfy
which gives
Before lockdown in France, the number of infected people appears to have grown by about 30 percent per day! Of course, this is a rough estimate since the total number of infected people is unknown. However, this clearly shows that each day of delay in deciding on lockdown has a huge effect on the evolution of the epidemic. Another remark is that the rate of growth of the number of infected people gives but not β and γ separately. Policies such as lockdown, wearing masks, improving personal hygiene, social distancing, contact tracing, massive testing, vaccines, etc., can decrease the value of β, while treatments, quarantining infected individuals, etc., can increase the value of γ. The overall effects of all scientific policies should be seriously considered to improve the collective values of the two parameters. For example, massive testing can help detect the infected cases earlier so infected individuals can be treated earlier (increasing γ) and isolated earlier (decreasing β as well as increasing γ).
The initial approach implemented by the French government to contain coronavirus was the lockdown policy, therefore, we first focus on analyzing the difference between having or not having lockdown. The goal of the lockdown is to decrease the value of β by decreasing the number of contacts between people. Lockdown has no direct effect on γ a priori. Let us assume that β is replaced by β′ after lockdown, whereas γ remains unchanged. After lockdown, we deduce that the number of infected people is increased by a factor of every day. If day 0 is assumed to be before the lockdown at day ℓ, we have at any day n ≥ ℓ after the lockdown:
where again Xn denotes the number of infected individuals at day n. If β and γ are fixed, with β > γ, we have three possible situations depending on the value of β′:
-
•
If β′ > γ, the epidemic continues to grow exponentially, but at a smaller rate, even after the lockdown.
-
•
If the epidemic stabilizes after the lockdown.
-
•
If β′ < γ, the epidemic grows exponentially until the lockdown, and then decreases exponentially.
Since the daily number of deaths in France is lower at the end of April than at the beginning, we may assume that we are in the third situation β′ < γ. According to the current basic model, the peak of the number of infected people is then at the day of the lockdown. The peak of the number of deaths is later due to the time between infection and death. The rate of decay of the number of infected people after lockdown can be approximated by the rate of decay of the number of deaths if the fatality rate of the disease is assumed to be constant, which appears to be reasonable in a short period of time. However, we have to take observations at sufficiently late periods of the lockdown in order to have (almost) all deaths coming from people infected after the lockdown, and therefore (almost) no influence of the pre-lockdown situation on the evolution of the number of deaths. During the week between April 13 and April 19 (one month after the lockdown), there were (according to Wikipedia) 5325 deaths; during the week between May 4, and May 10, (three weeks later, still during the lockdown), there were 1485 deaths in France [1], [4]. This is a ratio of about 0.28 in three weeks, and thus
which gives
i.e. a decrease of 6 percent per day.
With this rate of decay, we can deduce the time of lockdown which would be needed to suppress the epidemic in France. The order of magnitude of the number of infected people at the lockdown is certainly between 10,000 (not much more than the number of detected cases) and 10,000,000 (more than 1/7 of the total population). In order to suppress the epidemic in France, we have to decrease this number to 0, and this situation is expected to occur when the model provides a value far below 1; hence, a decrease from the peak at the lockdown by a factor, say, between 104 and 108. According to the model, the corresponding day n should be such that
i.e.
which implies
In words, according to the model, the lockdown should have lasted between 5 and 10 months in order to suppress the epidemic in France. Such a time is far longer than what is politically acceptable, and so it is not reasonable to expect that lockdown alone can suppress the epidemic.
3. The parameter R
In basic epidemiological models, the most well-known parameter is R: the average number of new infections arising from each infected individual. In particular, R 0 is a particular value of R, which is valid only at the beginning of the epidemics when most of the population is susceptible, or more precisely, everybody but one infected individual. In the basic model above, each individual infects on average β individuals per day, until (s)he is isolated, recovered, or dead, i.e. no longer contagious. The average time of contagion can be modeled as follows. If some day, an individual is contagious, the probability to no longer be contagious the next day is γ, and so the probability to still be contagious the next day is . The probability to still be contagious after two days is then the probability to still be contagious after three days is and so on. Notice that this reasoning means that the chances to remain contagious from one day to another do not depend on the past, which is of course not very realistic; however, it has the advantage of simplicity. The average time of contagion is then obtained by adding the following numbers:
-
•
1, since all infected individuals are contagious at least the first day.
-
•
since this proportion of infected individuals are contagious at least one extra day.
-
•
since this proportion of infected individuals are contagious at least one further extra day.
-
•
since this proportion of infected individuals are contagious at least one further extra day, and so on.
The average time of infection is then
Multiplying τ by we have,
thus
which implies
and so . An infected individual contaminates on average β individuals per day, for an average time of 1/γ days. The average number of infections arising from an infected individual is then modeled by the number
Since β/γ > 1 is equivalent to β > γ, the discussion above shows that we have:
-
•
An exponential increase of the number of infected individuals if R > 1.
-
•
An exponential decrease of the number of infected individuals if R < 1.
-
•
A constant number of infected individuals if .
Notice that R cannot be recovered directly from the rate of increase of infected people. Indeed, whereas the rate of increase is and β/γ is not uniquely determined by . More concretely, the rate of increase of the epidemic depends not only on the number of new infections per infected individual, but also on the time between generations of infected individuals. That is why the AIDS pandemic has a much slower evolution than most other infectious pandemics, because the average time between generations of infected individuals is some number of months or years, whereas the order of magnitude for the coronavirus is days or weeks. In order to know R, we need not only to have but also β and γ separately. A way to estimate γ is to evaluate the average time τ for which an individual is contagious. Such evaluation is difficult, in particular for asymptomatic infected people. As we have seen before, in the model, and so . It is reasonable to assume that the duration of the contagion is at least 5 days. In the minimal case where we get and in the pre-lockdown situation where we have estimated that we deduce that and then . On the other hand, under lockdown, we have seen that the new value β′ of the rate of infection is expected to approximately satisfy and since β′ ≥ 0, we have γ ≥ 0.06, which means τ ≤ 1/0.06, i.e. τ ≤ 16.7 days. In the case where the average infection time is days, we have and so β ≃ 0.37, which gives approximately . It is then reasonable to assume 2.5 < R < 5.3.
Another way to estimate β and γ separately is to evaluate the decrease of β due to the lockdown. We can, for example, assume the following scenario:
-
•
A proportion of 5 percent of individuals do not respect the lockdown, and therefore their number of contacts remains the same (multiplied by 1).
-
•
A proportion of 30 percent of individuals have to go out, for example for work, and their number of contacts is reduced by a factor of 2 (multiplied by 0.5).
-
•
A proportion of 65 percent of individuals can stay home almost all the time and their number of contacts is reduced by a factor of 10 (multiplied by 0.1).
In this situation, the average number of contacts between individuals is multiplied by
i.e approximately divided by 4. If we assume that the number of contacts transmitting infections is divided by 4, it means that the number of individuals infected by a given person is divided by 4, i.e. . In this scenario, we have the two equations:
Then subtracting the second equation from the first, we get:
hence and R ≃ 2.67. For a division by 3 of the number of infectious contacts, we get for a division by 6, we get R ≃ 3.27, for a division by 10, we get for a perfect lockdown (no new infections), we get . Since it does not seem plausible for the number of contacts to be divided by more than 10, it seems reasonable to assume that
taking into account the lower bound of 2.5 estimated previously (from the fact that the infection time should be more than 5 days).
It is also interesting to investigate the value of R after the lockdown, which will be denoted by R′. We have
Hence,
We then get
For 2.5 < R < 4, we get
Notice that for these estimates, the largest value of R corresponds to the smallest value of R′. A more precise study by the Institut Pasteur gave the confidence intervals 3.18 < R < 3.43 and 0.5 < R′ < 0.54, which were later revised as 2.8 < R < 2.99 and 0.65 < R′ < 0.68 [5]. These intervals are inside the intervals computed here.
4. The fatality rate
The fatality rate by age among confirmed cases of coronavirus in China has been estimated as follows: 0.2 percent under 40 years of age, 0.4 percent between 40 and 49 years, 1.3 percent between 50 and 59 years, 3.6 percent between 60 and 69 years, 8 percent between 70 and 79 years, 15 percent above 80 years [2]. However, it is likely that these fatality rates are overestimates of the true fatality rate, because many infected people are not tested since they have no or few symptoms. An interesting example is the Diamond Princess, where wide testing has been done. The population in the Diamond Princess on February 5 was approximately distributed as follows: 22 percent under 40 years of age, 9 percent between 40 and 49 years, 11 percent between 50 and 59 years, 25 percent between 60 and 69 years, 27 percent between 70 and 79 years, 6 percent above 80 years [3]. Among infected people as of February 20, the distribution was the following: 11 percent under 40 years of age, 4 percent between 40 and 49 years, 9 percent between 50 and 59 years, 29 percent between 60 and 69 years, 38 percent between 70 and 79 years, 9 percent above 80 years. If we apply the estimated Chinese fatality rates to the Diamond Princess infected distribution by age, then the overall fatality rate we get is
i.e. 0.05589, approximately 5.6 percent. The number of deaths from the Diamond Princess is 14, out of 712 infected people, so a true fatality rate of approximately 2 percent. A plausible way to estimate the true fatality rate by age is then to multiply the Chinese rates given above by 2/5.6, i.e. approximately 0.36. We get approximately: 0.07 percent under 40 years of age, 0.14 percent between 40 and 49 years, 0.47 percent between 50 and 59 years, 1.3 percent between 60 and 69 years, 2.88 percent between 70 and 79 years, 5.4 percent above 80 years.
The global French population is distributed approximately as follows: 47 percent under 40 years of age, 13 percent between 40 and 49 years, 13 percent between 50 and 59 years, 12 percent between 60 and 69 years, 8 percent between 70 and 79 years, 7 percent above 80 years. The age distribution of infected people is not the same as the general age distribution. Indeed, for example, people under 40 years old are 22 percent of the population of the Diamond Princess, but only 11 percent of the infected population [3]. Hence, one can estimate that when a person is under 40 years old, his or her probability of being infected is half the corresponding probability for the general population. Similarly, people over 80 years old are 6 percent of the population of the Diamond Princess, but 9 percent of the infected population [3]. Hence, one can estimate that when a person is over 80 years old, his or her probability to be infected is 1.5 times the corresponding probability for the general population. If we apply these ratios to the age distribution of the general French population, we get numbers proportional to
If we rescale this last sequence of numbers in order to get a total of 100 percent, we get the following estimate of the age distribution of infected people in France: 31 percent under 40 years of age, 8 percent between 40 and 49 years, 14 percent between 50 and 59 years, 18 percent between 60 and 69 years, 15 percent between 70 and 79 years, 14 percent over 80 years. Applying the fatality rates by age computed above (by multiplying the Chinese numbers by 0.36), we get an estimation of the overall French fatality rate:
i.e. 0.015207, approximately 1.5 percent.
This computation assumed that the age distribution of infected people is biased with respect to the age distribution of the general population, in the same way for the Diamond Princess and for the general French population. This assumption is questionable because the amount of contact between people of different ages is not distributed in the same way in the boat and in France. If we assume instead that in France, the rate of infection does not depend on age, then the age distribution of infected people is the same as the age distribution of the general population. In this case, we estimate a global French fatality rate of
i.e. 0.008766, approximately 0.9 percent.
The study by the Institut Pasteur mentioned above gives the following confidence intervals for the fatality rates, as functions of age: less than 0.02 percent under 40 years of age, between 0.03 and 0.09 percent between 40 and 49 years, between 0.1 and 0.36 percent between 50 and 59 years, between 0.5 and 1.4 percent between 60 and 69 years, between 1.4 and 3.7 percent between 70 and 79 years, between 6 and 15.6 percent above 80 years [5]. Our estimate is above the confidence interval under 60 years old, inside the confidence interval between 60 and 79 years old, and slightly under the confidence interval over 80 years old.
The overall fatality rate found by Institut Pasteur has a confidence interval between 0.4 and 1 percent [5]; our rate is above this interval in our first computation and at the top of the interval in our second computation. This suggests that in the study by Institut Pasteur, the older people are less likely to be infected than in our estimates.
Notice that all these estimates are subject to very large uncertainty. In particular, they use the fact that there were 14 deaths on the Diamond Princess, which is a small number. The most simple probabilistic model for small random integer numbers is given by a Poisson random variable. Any Poisson random variable with mean between 8 and 22 has more than one percent chance to be exactly equal to 14, whereas the probability is around 10 percent for a Poisson variable of mean 14. Hence, it is plausible that the fatality rate for a large population with the same age distribution as the Diamond Process is anything between 8/14 ≃ 0.57 and 22/14 ≃ 1.57 times the rate effectively observed in the Diamond Princess due to the random fluctuations of the Poisson distribution. These possible multiplicative factors may then be applied to our previous estimate of the French fatality rate. If we combine this uncertainty with the two computations we have done, respectively giving 1.5 and 0.9 percent, we get a range between 0.5 percent and 2.4 percent.
5. The number of infected individuals
The number of infected people is equal to the number of deaths divided by the fatality rate. We can now estimate the number of individuals already infected, or who will be infected until the end of the current lockdown on May 11. Since the peak of infections is on the day of the lockdown (March 17) in the basic model described above, the peak of deaths is at the beginning of April (the typical time between infection and death should be around 2–3 weeks). In the computation of the number of infected people on May 11, we should then roughly take into account the number of deaths until the end of May. This number is approximately 29,000 (28,596 by May 27), then the number of infected people is about 29,000 divided by the fatality rate. All the estimates of the fatality rate discussed above are between 0.4 and 2.5 percent.
For a fatality rate of 2.5 percent, we get 29, 000/0.025, i.e. around 1.2 million infected individuals in France until May 11, i.e. 1.8 percent of the population.
For a fatality rate of 1 percent, we get 29, 000/0.01, i.e. 2.9 million infected people, i.e. 4.3 percent of the population.
For a fatality rate of 0.5 percent, we get 5.8 million infected people, i.e. 8.7 percent of the population.
For a fatality rate of 0.4 percent, we get 7.25 million infected people, i.e. 10.9 percent of the population.
The confidence interval given by the Institut Pasteur was between 2.3 and 6.7 million people, i.e between 3.4 and 10 percent of the population, and has been revised to 1.8 to 4.7 million people, i.e. between 2.7 to 7.1 percent of the population [5].
This estimate of the number of cases gives a slightly refined estimate of the lockdown time we would need in order to suppress the epidemic. We need to go from 1 to 10 million infections to below 1 infection, i.e. a decrease by a factor between 106 to 108. Since the estimated rate of decay under lockdown is 6 percent, we would need between 223 and 298 days, i.e. 7 to 10 months. On the other hand, the infected people are still a small minority of the population. Hence, France is in the most uncertain situation where there is neither hope for a direct suppression of the epidemic by a lockdown, nor significant herd immunity.
6. Reducing R
We recall that the parameter R, representing the average number of persons infected by a given individual, is equal to β/γ where β is the average number of persons contaminated each day by a given infected individual, and γ is the proportion of infected individuals who become non-contagious after one day. In the basic model introduced above, the number of infected individuals is multiplied by every day. The general strategy, in order to reduce the contagion, is to reduce R, which can be done by reducing β and/or increasing γ. In order to reduce β, we have seen that lockdown is effective: other possibilities are social distancing, protection by masks, hygiene improvement, cancellation of events with a large number of participants, and closure of bars and restaurants. In order to increase γ, one needs to isolate infected individuals, and also increase the number of tests. People with higher probability of being infected, and people with a lot of contacts should be prioritized for testing. In the estimates obtained above, if we assume (recall that R has been estimated to be between 2.5 and 4), we have β ≃ 0.43, γ ≃ 0.13 before lockdown, and β′ ≃ 0.07 after lockdown, which gives R′ ≃ 0.54. A crucial question concerns the value of R after lockdown, in particular, whether it can be maintained below 1 or not. With the values just above, a scenario for maintaining R at 1 might be the following:
-
•
Masks, hygiene and social distancing decrease β from 0.43 to 0.2.
-
•
Massive testing manages to detect and isolate 7 more percent of the current infected population every day, increasing γ from 0.13 to 0.2.
An important question concerns the seasonality of the disease, which might reduce R during spring and summer.
Here is a scenario where we do not manage to maintain R below 1: γ increases to 0.18, β decreases to 0.27, and the new value of R is 1.5. In this case, the number of infected people increases by percent per day, i.e. a multiplication by 14 every month. This is a guarantee to reach herd immunity (see below) during the summer, unless more restrictions are introduced again.
7. Herd immunity
Until now, we have neglected herd immunity in the model, which can be justified by the fact that a small proportion of the population has been infected. The most basic model taking herd immunity into account, called SIR, can be described as follows. At day n, a proportion Sn of the population is susceptible, i.e. is not currently infected but may be infected later by other individuals, and a proportion In of the population is currently infected. An infected individual contaminates on average βSn susceptible individuals in one day, and a proportion γ of infected individuals are not contagious anymore the next day and cannot be re-infected later (we assume that being infected provides immunity, which is natural to expect but still not yet proven). The replacement of β by βSn here is due to the fact that among the β infectious contacts of a given infected individual, a proportion of them are already infected, or have already been infected before, so they are supposed to be immune. We get the following equation:
which is similar to the equation satisfied by Xn defined previously, with β replaced by βSn. The model here is close to the basic model above if Sn is close to 1, i.e. most individuals have still not been infected. Moreover, we have
the term meaning that the newly infected people are not susceptible anymore at day . Notice that in general, this model is presented in continuous time, which gives a system of differential equations.
Recall that β ≤ γ corresponds to R ≤ 1 in the previous model. The number of infected individuals is decreasing exponentially if R < 1. Hence, the epidemic is under control. If β > γ, the number of infected people is exponentially increasing at the beginning, until the point where the multiplicative factor becomes smaller than or equal to 1, i.e. βSn ≤ γ, Sn ≤ γ/β, or Sn ≤ 1/R. This means that the number of infected people is maximal (we reach the peak of the epidemic) when the proportion of susceptible individuals is 1/R, i.e. the proportion of individuals already infected is . If 2.5 < R < 4, we get i.e. we need to have 60 to 75 percent of people already infected in order to control the epidemic. Notice that after the point when the number of infected individuals decreases but does not instantly fall to zero, so there are newly infected people. It is not very difficult to approximate the proportion of individuals who are infected some time during the epidemic. Indeed, we observe that the relative variation of I with respect to the variation of S is given by:
Hence,
Now, we can add these equations over all integers n, from (far in the past), to ∞ (far in the future). We get
Let us now suppose that the relative variation of S is small from one day to the next one, i.e. a small proportion of the population is infected on a given day. This approximation may be discussed, and can be made automatically true by replacing a discrete time model by a model in continuous time (which is generally done). If the relative variation of S is small, we can approximate by . In this case, we get
therefore,
Now, and I ∞ are equal to zero, because these numbers correspond to the number of infected individuals before the epidemic and when the epidemic is over. Moreover, : before the epidemic, everybody is susceptible, since nobody is immune. The value of S ∞ is the proportion of people who are never infected during the epidemic, and thus are always susceptible. We get
which gives approximately
where is the proportion of individuals who are infected some time during the epidemic. The solution of this equation does not have a convenient closed form, but it can easily be solved numerically. We can also write the equation as
This equality confirms that we are in the situation R > 1. For we get J ≃ 0.89; and for we get J ≃ 0.98. In other words, without any policy to control the epidemic, most of the population is expected to be infected sometime, according to the SIR model. Notice that the value of J found here is larger than the value of usually given for herd immunity. In fact, these numbers correspond to two different situations:
-
•
If we let the epidemic grow naturally, we get a proportion J of infected people.
-
•
If we control the growth of the epidemic until a proportion larger than of the population is infected, then recovers or dies, we can release the restrictions and the epidemic is stopped by herd immunity.
Hence, temporary control of the epidemic until we reach herd immunity can potentially reduce the proportion of infected people from J to . For and for : we need 60 to 75 percent of infected people for ”controlled herd immunity,” instead of 89 to 98 percent of infected people for ”uncontrolled herd immunity.”
Notice that these numbers are probably an overestimate. Indeed, the model does not distinguish between individuals, and so implicitly assumes that an infected individual contaminates random people in the French population. In reality, contamination is more local (family, friends, colleagues), so ”local herd immunity” (e.g. if all family members are infected) can prevent the epidemic from reaching levels as high as what is predicted by the SIR model. We will later study how the proportion of infected people is reduced when we consider two categories of people, with different rates of infectious contacts. In any case, it is very likely that a large proportion of the population should be infected in order to reach herd immunity, even controlled.
We can also notice that in the current French situation, it is likely that herd immunity plays a minor role. Since less than 10 percent of the population is likely to be immune, the proportion of susceptible people is more than 0.9. We have estimated that and ; if we assume that then in this case, we have βS 0 ≃ 0.39 if . In other words, the daily rate of increase of the number of infected people is reduced by at most 4 percent by herd immunity; and without political decisions to control the epidemic, the ”effective R, ” after taking into account herd immunity, is 0.39/0.13, i.e. 3 instead of 3.3.
8. A model with two categories of individuals
In the models discussed earlier, all infected individuals were assumed to infect the same number of individuals on average. It is possible to consider slightly more sophisticated models, where different categories of individuals are infecting different number of people. We can consider two categories of people, where an individual of category 1 infects β 1,1 people per day in category 1 and β 2,1 people per day in category 2, whereas an individual of category 2 infects β 1,2 people per day in category 1 and β 2,2 people per day in category 2. We assume that these four parameters are strictly positive and we neglect herd immunity for the moment. If at day n, Xn denotes the number of infected individuals in category 1 and Yn is the number of infected individuals in category 2, we have, after taking into account that a proportion γ ∈ (0, 1) of infected individuals is not contagious anymore the next day:
If we denote
we have
where
The eigenvalues λ of the matrix M satisfying the equation:
The discriminant of this equation is given by
Since for all we have
since we have assumed that β 1,2 and β 2,1 are strictly positive. Hence, we have two distinct real eigenvalues,
Since we have
and
The eigenvalues have the same mean as the diagonal entries of M, and a larger mutual difference. If x and y are the coordinates of an eigenvector corresponding to the eigenvalue λ, we need
For we get
and
Since Δ is strictly larger than all these numbers are strictly positive for and strictly negative for . Since β 1,2 and β 2,1 are non-zero, we deduce that the eigenvector should satisfy:
It is not difficult to check that the two last quotients are equal. Moreover, x and y should have the same sign for and opposite signs for . Let us fix two eigenvectors and corresponding to the eigenvalues and . We know that has coordinates with the same sign, by possibly changing to its opposite, we can assume that this vector has positive coordinates. Since has coordinates of opposite signs, and are independent, which implies that they span . We can then write
for some . For all integers n ≥ 0, we have and so
which implies
Since Zn has positive coordinates and has coordinates of opposite signs, we necessarily have . Moreover, we can write
Recall that
and
where
Recall that γ < 1 (the proportion of infected individuals who recover or are isolated the next day), β 1,1, β 2,2 > 0 and hence μ > 0, which implies that . The quantity exponentially decays to zero, which implies that
when n tends to infinity. In more concrete words:
-
•
If we are sufficiently advanced in the epidemic, the number of infected individuals grows approximately exponentially, with a daily growth factor .
-
•
The proportion of infected individuals in each category is proportional to the corresponding coordinates of the eigenvector .
-
•
However, the rate of growth may be different at the beginning of the epidemic.
In the case where Z 0 is proportional to then the number of infected individuals evolves exactly exponentially with rate . If β denotes, in this situation, the average number of individuals contaminated in one day by a given infected individual, then the number of infected individuals grows by a factor every day (the term comes from people who are not contagious anymore the next day). Hence, we should have which gives
The average number of people contaminated by an infected individual during all the contagion is then R ≔ β/γ, i.e.
As in the basic model, the epidemic grows if and only if is larger than 1, i.e. β > γ, or R > 1. The situation is similar to the case of the previous model, but with a more complicated expression for R.
We can now look at a few examples. The first one is when the separation into two categories is irrelevant for the contagion. Let π 1 and π 2 be the proportions of individuals in categories 1 and 2 in the population, respectively, and . If there is no particular preference between the two categories for contamination, then any individual will contaminate β individuals in one day for some value of β: βπ 1 individuals in category 1 and βπ 2 in category 2. We then have:
Recall that β 1,2 represents the contaminations from category 2 to category 1. We get
which gives
The asymptotic rate of growth of epidemic is then the same as in the basic model, namely . In fact, a direct computation of the sum of the coordinates of MV for a given vector V shows that the number of infected individuals is exactly multiplied by each day. Hence, the predictions of the model are the same as the predictions of the basic model, which is not surprising since we have assumed that the separation into two categories is irrelevant for the contagion.
Another example is when we have two categories of the same size (half the population), one more sociable than the other. We might assume that the mutual contamination of the two categories is proportional to the product of their ”degrees of socialization.” If σj denotes the ”degree of socialization” of the category j, we may assume then
One can compute the eigenvalues, and one gets:
One can take for eigenvectors:
The rate of increase of the epidemics is and we can check that
The eigenvector shows that in the long run, people are infected proportionally to their degree of socialization. However, if one of the categories is very sociable, is large even if the other category has a very low sociability. If category 1 has sufficient sociability to make R > 1 even when category 2 has very low sociability, then category 2 will be infected with exponential growth even though it is less infected than category 1. It is then essential that decisions of social distancing are widely respected by the population.
Let us illustrate this fact by another example. We assume that after an exponentially growing epidemic, social distancing restrictions are implemented, but with 15 percent of the population not respecting them when they are together. We assume that and that before social restriction, (this corresponds to the coronavirus before lockdown, in the case where ). Let us divide the population into two categories: category 1 with of the population respecting social distancing, category 2 with of the population not respecting social distancing. Before the decision to social distance, we may assume that the two categories are irrelevant:
The largest eigenvalue is 1.3, which gives a growth of 30 percent per day of the epidemic. The corresponding eigenvector has coordinates 0.85 and 0.15, i.e. 85 percent of the infected population is in category 1 and 15 percent is in category 2. Let us now assume that social distancing divides the contacts by 3.5. If everybody respects social distancing, the rate of contamination is divided by 3.5 and thus β goes from 0.43 down to 0.1229 (which is smaller than ), and so the epidemic is under control (R ≃ 0.94). If people in category 2 do not respect social distancing at all when they are together, we get
and after social distancing, the matrix M becomes:
In this case, the largest eigenvalue is 1.0026, R′ ≃ 1.02, and the epidemic grows. Looking at the coordinates of we see that in the long run, about 79 percent of infected individuals are in category 1, and 21 percent in category 2. Hence, even if people in category 1 are less infected than people in category 2 (79 percent of infections for 85 percent of the population), they are still widely infected, and are impacted by the consequences of the growing epidemic. Notice that in this example, people in category 2 still respect social distancing when they meet people in category 1. We can look at what happens when people in category 2 only partially respect social distancing when they meet people in category 1, say, dividing the contacts by 2 instead of 3.5. In this case, the matrix becomes:
We get a largest eigenvalue of 1.03379, R′ ≃ 1.26, i.e. a rather fast growth of the epidemic (3.4 percent per day). In the long run, 75 percent of infections are in category 1 and 25 percent in category 2.
Another numerical example can be computed in order to model an almost full lockdown of people aged 70 or more, who are approximately 15 percent of the French population. Let us say that people under 70 are in category 1 and people over 70 are in category 2. In the situation before lockdown, if we assume that the categories are irrelevant for contagion (not necessarily very realistic, since people over 70 have in general fewer contacts than people under 70), we get the same matrix
as before. Let us assume that the contacts involving category 2 are divided by 10 after selective lockdown. We then get
This gives a new matrix
In this case, R ≃ 2.8, i.e. a very quick growth of the epidemic (by 23.6 percent per day), not dramatically different from the situation before selective lockdown. In the long run, about 1.8 percent of infected people are in category 2, instead of 15 percent in the situation before lockdown. In other words, in this model, lockdown of people over 70 is inefficient to globally control the epidemic, but it reduces the portion of older people in the infected population by a factor of 8 to 9. If we refer to the previous estimates of the fatality rates by age, we get that the global fatality rate is reduced by a factor of 2 to 3.
Notice that it is likely that people over 70 years old have fewer contacts than people under 70. Then, even without social distancing restrictions, it is natural to expect that they are less infected than younger people. The estimates we have found on the fatality rate by age are not very far from the estimates given in the study by the Institut Pasteur. However, our estimates of the overall fatality rate (0.8 and 1.3 percent) are significantly larger than the estimates of Institut Pasteur (confidence interval between 0.3 and 0.9 percent). This is probably partially due to the fact that our previous estimates do not take into account that older people are likely to be less infected than younger people.
Another remark can be made when we look at the evolution of the total number of infected people just after the selective lockdown. At the time of the lockdown, for each infected individual, we have on average 0.85 individuals in category 1 and 0.15 in category 2. The day after, we get
i.e. 1.0556575 infected individuals in category 1 and 0.13695 in category 2. In one day, the number of infected individuals is then multiplied by 1.1926075, i.e. increased by about 19.3 percent. This is less than the rate of increase of 23.6 percent which occurs in the long run. To summarize, the daily rate of increase of the number of infected people is 30 percent before selective lockdown, goes down to 19.3 percent the day just after the lockdown, and then increases again to 23.6 percent in the long run. Let us now assume that besides the selective lockdown, we do some massive testing which increases the value of γ from 0.13 to 0.33. In this case, everything remains similar, except that the two eigenvalues are shifted by . The rate of increase is now percent just after the lockdown, then grows to 3.6 percent: the number of infected people is decreasing for some time and then increases again.
Here, we have discussed models with two categories, it is of course possible to generalize the study to models with more than two categories by using larger matrices.
9. Herd immunity with two categories of individuals
In the previous section, we considered two kinds of individuals, but we neglected immunity, as in the basic model. We will now present a model where we take immunity into account. We take the same basic parameters β 1,1, β 1,2, β 2,1, β 2,2 corresponding to the rates of contagion in the case where the proportion of immune individuals is negligible.
We have two categories of individuals, a proportion π 1 of them being in category 1 and a proportion π 2 being in category 2, with . We assume that at day n, a proportion S 1,n of the total population is in category 1 and susceptible, a proportion I 1,n of the population is in category 1 and infected, a proportion S 2,n of the population is in category 2 and susceptible, and a proportion I 2,n of the population is in category 2 and infected. The proportion of susceptible individuals in category 1 is S 1,n/π 1 and the proportion of susceptible individuals in category 2 is S 2,n/π 2. Hence, between day n and day with the notation above, an infected individual in category 1 contaminates β 1,1 S 1,n/π 1 individuals in category 1 and β 2,1 S 2,n/π 2 individuals in category 2. Similarly, an infected individual in category 2 contaminates β 1,2 S 1,n/π 1 individuals in category 1 and β 2,2 S 2,n/π 2 individuals in category 2. We then get
If we denote
we get
and
Hence,
We have
If we assume that the relative variation of S 1,n and S 2,n is small in one day, we can approximate by for j equal to 1 or 2. This approximation becomes rigorously true in a continuous time model. Letting
we get
Summing for all n ≥ 1, we get
As in the one-dimensional model, the number of infected people is zero far in the past and the future. Moreover, everybody is susceptible at the beginning, and then, taking into account the proportion of the population in categories 1 and 2,
where Jj is the proportion of individuals in category j who become infected some time during the epidemic. We deduce
which implies
and then
where
In the previous section, we computed a reproduction rate R, and we saw that
In fact, R is the largest eigenvalue of the matrix .
Let us now discuss the examples considered in the previous section.
In the case of irrelevant categories, we have
Notice that in the previous section, we had an extra term on the diagonal entries which is not in the matrices B or . In this case,
Since this vector has two equal coordinates, we need to have then for some J ∈ (0, 1), i.e. the proportion of people who get infected some time is the same in the two categories. Now,
since we have computed in this example. Hence, J should satisfy i.e. the same equation as in the model with a single category. This confirms that the categories are irrelevant in the present example.
In the example with two categories of the same size () and different degrees of socialization σ 1 and σ 2, we have
The equations we need to solve are
The right-hand sides of the equations should be proportional to σ 1 and σ 2, and it should be the same for the left-hand sides. We then have, for some α > 0,
and
i.e.
for and . Notice that we have previously computed and so . Let us assume that so . In this example, category 2 is twice as sociable as category 1. We numerically find α ≃ 1.784, and then
The global proportion of infected people is then about 81.5 percent. This is less than the proportion of 88.6 percent which we obtain for the model with a single category for the same value . As in the example in the previous section for social distancing, if not being respected by 15 percent of the individuals when they are together, we have for and :
which gives approximately:
and R ≃ 1.0205. We now need to solve
We find numerically
The global proportion of infected individuals is
which is slightly less than what we obtain for the model with one category for the same value of R. In the same example with the contacts between 1 and 2 divided by 2 instead of 3.5, we get
and R ≃ 1.26. We solve numerically
We get
and then a global proportion of
This is again smaller than what we get for a single category with i.e. 0.3821.
The partial lockdown of people over 70 years old gives
and R ≃ 2.8166. We solve numerically
and we get
and a global proportion of infected people of 0.8238, instead of 0.9264 for a single category. Notice that the older people are much less infected than the others, but not by a factor of 10.
In all of the examples above, the fact that the contacts are not uniform in the population reduces the total number of infected individuals for a given value of R > 1, but not in a dramatic way.
The proportion of infected individuals we have computed is not the same as the minimum needed in order to get herd immunity. In order to compute this proportion, we assume that we have controlled the epidemic in such a way that there are very few currently infected people, but sufficiently many immune individuals. Since there should be few new infections, we can assume that the proportion of susceptible individuals in each category stabilizes at levels S 1 and S 2. In this situation, the evolution of the number of infected individuals can be written as follows:
where
i.e. the same equation as before, but with a fixed number of susceptible individuals. We get herd immunity, i.e. the epidemic is under control, if the largest eigenvalue of is strictly smaller than 1. If we want to minimize the number of previously infected individuals, we need to maximize the global proportion of individuals who are still susceptible, i.e. . In order for the eigenvalues of to be smaller than 1, we need the eigenvalues of ΣB to be smaller than γ, i.e. the eigenvalues of to be smaller than 1. We have
If we assume that a proportion 1/R of the individuals in each category is immune, we get and
This matrix is conjugated to and so its largest eigenvalue is 1. Hence, we can have herd immunity if the proportion of already infected people is larger than as in the case with one category. However, this situation is not optimal since herd immunity can be obtained with less infected individuals in general. In general, we need to maximize conditioned on the fact that
is smaller than 1.
In the case of irrelevant categories, we get
and then we need
to be smaller than 1. This condition gives i.e. . This gives a proportion of infected individuals equal to and there is no improvement with respect to the model with one category.
In the case with two different degrees of socialization σ 1 and σ 2, and for we have
Since the determinant of the matrix is zero, i.e we deduce that the quantity inside the square root is equal to
and then we need
since in this model. Let us assume that category 2 is more sociable than category 1, i.e. σ 2 > σ 1. In this case, is maximal for fixed values of when S 2 is as small as possible, i.e. the most sociable category is infected first. Since S 1 and S 2 are between 0 and 1/2, the optimal solution is either and S 2 ∈ (0, 1/2), or S 1 ∈ (0, 1/2) and (all category 2 is immune). In the first situation, we need
which gives
where and then . This solution is available when S 2 remains positive, i.e. s 1 < 1. In this case the overall proportion of infected individuals is
If s 1 ≥ 1, we need all category 2 to be infected in order to have optimal herd immunity. In this case, we get the condition
i.e.
which is smaller than 1/2 as needed. The proportion of infected individuals is
In the case where we are in the first situation and we get a proportion of infected individuals given by
74 percent of category 2 and 0 percent of category 1. With a single category, the rate of contamination is about 59 percent. The global improvement is not negligible.
In the case of 15 percent of individuals not respecting social distancing when they are together, we have
and R ≃ 1.0205. We need to maximize for
smaller than 1. The optimum occurs when nobody is infected in category 1, which implies and S 2 ≃ 0.1395. The proportion of infected individuals is then 1.05 percent. With one category, we need 2 percent of infected individuals. In the case where the individuals of category 2 do not fully respect social distancing even if they meet people in category 1, we have computed
and R ≃ 1.26. We need to maximize for
smaller than 1. The optimum again gives nobody infected in category 1, with and S 2 ≃ 0.0661. In this case, 8.39 percent of the population is infected. The usual formula gives 20.6 percent of the population being infected. With lockdown of people over 70 years old, we get
and R ≃ 2.8166. In this case, the optimum is when nobody is infected over 70 years old. We get S 1 ≃ 0.3007 and giving 54.93 percent of infected individuals, all under 70 years old. The usual formula gives 65.5 percent.
The examples above show that the minimal proportion of infected individuals needed for herd immunity can be significantly lower than if the distribution of the infectious contacts is inhomogeneous. However, it remains a large proportion of the population if R is significantly larger than 1. Moreover, reaching the minimum implies that we control how much each category of the population is infected, which cannot be precisely done in practice. Notice that the numerical examples discussed here are not necessarily very relevant, since they assume that social distancing decisions are applied in the long run, whereas the main interest of herd immunity is that one can release social restrictions. It would be more relevant to consider matrices of infection rates corresponding to the situation where there are no particular social restrictions when we reach herd immunity.
10. Some simulations for the coming months
In this section, we present a few simulations of the rate of saturation of the hospitals, for twelve different scenarios. This is based on the SIR model. The parameters are the following:
-
•
The parameter β under lockdown, and without lockdown, after May 11.
-
•
The parameter γ before, and after improvement of the testing capacity.
-
•
The minimum rate of saturation of the healthcare system for which a further lockdown is decided.
-
•
The rate of decay of the hospitalizations due to the improvement of treatments.
-
•
The seasonality of the disease.
-
•
The true proportion of infected people at the beginning of the lockdown, on March 17.
-
•
The time needed to improve testing capacity.
-
•
The rate of saturation of hospitals at the first peak at the beginning of April, arbitrarily taken to be 80 percent.
-
•
The duration of future lockdowns.
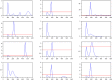
For each of the parameters, different values are considered for each of the twelve scenarios. These values are detailed in the joint scilab program. Each scenario gives a curve representing the evolution of the rate of saturation of hospitals (saturation above the red line), as a function of the date, represented here by the number of days after January 1, 2020. The duration of the simulation is 600 days, i.e. until summer 2021. Summer 2020 is around day 200, and winter 2020–2021 is around day 400. The twelve curves are very different from each other. Seven of them have an important second peak, which can be very big, at the beginning of the summer 2020, one of them (corresponding to a strong seasonality) has a second peak during winter 2020–2021. These curves are not predictions but illustrate the very large uncertainty of the present situation.



CRediT authorship contribution statement
Joseph Najnudel: Conceptualization, Methodology, Validation, Formal analysis, Investigation, Writing - original draft, Software. Ju-Yi Yen: Conceptualization, Methodology, Validation, Formal analysis, Investigation, Writing - original draft, Writing - review & editing.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgments
The authors would like to thank James A. Yorke (University of Maryland) and Roberto De Leo (Howard University) for insightful discussions. We are indebted to H. Scott Dumas (University of New Mexico) for improving our writing. We also thank Pierre Goulange (Bureau Français de Taipei) for his encouragement. J.-Y. Yen is grateful to Academia Sinica, Institute of Mathematics (Taipei, Taiwan) for their hospitality and support during some extended visits.
Footnotes
The Diamond Princess is a British-registered cruise ship on which a widespread COVID-19 outbreak occurred in February 2020.
References
- 1.Covid-19 pandemic in France. https://en.wikipedia.org/wiki/COVID-19_pandemic_in_France?fbclid=IwAR24NQknJutgKpDNTj2l1sI8YuiwQwc0PVT4D8anfRpo2Yu3OCxL5OVMB6A;
- 2.Fatality rate of novel coronavirus COVID-19 in China as of February 11, 2020, by age group. https://www.statista.com/statistics/1099662/china-wuhan-coronavirus-covid-19-fatality-rate-by-age-group/?fbclid=IwAR3BmOtETYr5lJFb2RJISNKKfxhazZPE3uCVIasJ-m1bHTl_Zf_mPWS9gCQ#statisticContainer.
- 3.Field Briefing: Diamond Princess COVID-19 cases, 20 Feb update (2020). https://www.niid.go.jp/niid/en/2019-ncov-e/9407-covid-dp-fe-01.html.
- 4.Infection au nouveau Coronavirus (SARS-CoV-2), COVID-19, France et Monde. https://www.santepubliquefrance.fr/maladies-et-traumatismes/maladies-et-infections-respiratoires/infection-a-coronavirus/articles/infection-au-nouveau-coronavirus-sars-cov-2-covid-19-france-et-monde?fbclid=IwAR2ov7HZMwIGJdHtNqp8E7oPagF_1pksWrMyMe4mRRqvEKGqelI7-_LFrAw.
- 5.Salje H., Kiem C.T., Lefrancq N., Courtejoie N., Bosetti P., Paireau J., et al. Estimating the burden of SARS-CoV-2 in France. hal-pasteur.archives-ouvertes.fr/pasteur-02548181. [DOI] [PMC free article] [PubMed]