

At birth, the auditory system is able to encode speech in fine acoustic details on the basis of its slowest amplitude modulations.
Abstract
Speech perception is constrained by auditory processing. Although at birth infants have an immature auditory system and limited language experience, they show remarkable speech perception skills. To assess neonates’ ability to process the complex acoustic cues of speech, we combined near-infrared spectroscopy (NIRS) and electroencephalography (EEG) to measure brain responses to syllables differing in consonants. The syllables were presented in three conditions preserving (i) original temporal modulations of speech [both amplitude modulation (AM) and frequency modulation (FM)], (ii) both fast and slow AM, but not FM, or (iii) only the slowest AM (<8 Hz). EEG responses indicate that neonates can encode consonants in all conditions, even without the fast temporal modulations, similarly to adults. Yet, the fast and slow AM activate different neural areas, as shown by NIRS. Thus, the immature human brain is already able to decompose the acoustic components of speech, laying the foundations of language learning.
INTRODUCTION
Speech perception requires efficient auditory mechanisms to track subtle differences in the complex combination of spectral and temporal information differentiating linguistic contrasts. Although infants have an immature peripheral and central auditory system (1, 2), they show exquisite speech perception abilities from birth (3–6). How they can achieve this and whether they rely on the same acoustic information as adults remain unknown. The present study investigates whether, and if yes, how newborn infants use the temporal information in the speech signal to discriminate phonemes.
Temporal information plays an essential role in speech perception in adults. Speech is mainly conveyed to the brain by the basilar membrane in the cochlea, the inner ear, which encodes the temporal modulations of the speech signal in different frequency regions, or bands (7). Within each frequency band, the temporal properties are extracted at two time scales: the amplitude modulation (AM) cues, also called temporal envelope, corresponding to the relatively slow variations in amplitude over time and the frequency modulation (FM) cues, also called temporal fine structure, corresponding to the variations in instantaneous frequency close to the center frequency (CF) of the frequency band.
This temporal decomposition is observed at the cortical level in adults. Previous studies measuring brain activation for non-speech sounds modulated in amplitude at different rates showed predominant cortical responses to the lowest AM frequencies (4 to 8 Hz) and hemispheric specialization in temporal envelope coding, as well as a difference in the time course of activations between slow (<16 Hz) and fast (<128 Hz) AM rates (8, 9). For speech sounds, the debate about the hemispheric specialization to different acoustic properties of the speech signal is ongoing (10), but it is usually assumed that fast temporal modulation is preferentially processed by the left auditory cortex, while slow temporal modulation and/or spectral modulation is processed by the right temporal cortex (11, 12).
These temporal modulations also play different roles for speech perception, as different rates of modulations convey different linguistic information. A wealth of studies in psychoacoustics showed that the slowest envelope cues (under 16 Hz) play a primary role in the identification of consonants, vowels, and words in speech presented in quiet (13, 14). Faster envelope cues (closer to the fundamental frequency rate of the voice) and the temporal fine structure play a more important role in perceiving pitch, which, in turn, contributes to the comprehension of speech in noise as well as of linguistic units heavily dependent on pitch information, such as lexical tone (7, 15, 16).
These neuroimaging and behavioral studies only focused on adult listeners who have mature auditory and linguistic systems. However, the auditory system takes years to mature. It is thus possible that the immature auditory system of infants decodes sound differently than that of adults. If so, this has important consequences for language development, which also unfolds during the first years of life, as its auditory input would thus differ from what adults perceive when processing speech. Currently, we have very little knowledge about how the youngest learners perceive the acoustic details of speech. The current study aims to fill this gap.
The few existing behavioral studies with infants (17–21) suggest that 6 month olds might weigh modulation cues differently than adults. Although 6-month-old French infants, like adults, are able to use the speech envelope to discriminate consonants based on voicing such as in /aba/-/apa/ and place of articulation such as in /aba/-/ada/ in quiet, they require more time to habituate to speech sounds containing only envelope cues below 16 Hz than to speech sounds preserving faster modulations. Moreover, 3-month-old infants and adults do not rely similarly on the fast and slow AM cues in quiet and in noise (21). Infants require the fast AM cues (>8 Hz) in both quiet and noise when discriminating plosive consonants, while the slowest AM cues (<8 Hz) are sufficient for adults in quiet but they also need the faster modulations in noise. These results suggest that fast envelope cues may be important for consonant perception in infants even in quiet.
The neural basis of the auditory processing of temporal modulations is still not well understood in infancy and has never been investigated using complex acoustic signals such as speech. One study exploring newborns’ neural responses to non-speech sounds with different temporal structures suggested that, as adults, newborns show different neural responses to slow (~3 to 8 Hz) and fast modulated signals (~40 Hz), with greater bilateral temporal activations for the latter (22), as measured by near-infrared spectroscopy (NIRS), although the auditory evoked potentials recorded using electroencephalography (EEG) were not different. No study has directly compared newborns’ perception of the slow versus fast temporal modulations of speech. The interaction between auditory mechanisms and speech perception at early stages of human development, therefore, remains to a large extent unexplored.
To determine how newborn infants, who have little experience with their native language and an immature auditory system, process the temporal acoustic cues of speech to perceive consonants, we used two hitherto rarely combined approaches. We combined a vocoder manipulation of speech with brain imaging to test how newborns process and perceive the temporal modulations in speech essential for speech intelligibility in adulthood. Vocoders are powerful speech analysis and synthesis tools that can selectively manipulate the spectro-temporal properties of sound (14). We used a vocoder to selectively manipulate simple C(onsonant)-V(owel) syllables in three conditions: (i) The “intact” condition preserved both the temporal envelope and the temporal fine structure, closely matching the original signal and serving as a control for the vocoding manipulations; (ii) the “fast” condition preserved both the fast and the slow envelope components, thus retaining some voice-pitch and formant transition information (<500 Hz) but suppressed the temporal fine structure; and (iii) the “slow” condition only preserved the slowest temporal envelope (<8 Hz), retaining mainly the modulations related to syllables (23). A group of 2-day-old, healthy, full-term French neonates heard syllables differing in their consonants (/pa/-/ta/) in these three conditions (Fig. 1). We recorded newborns’ brain responses to these speech sounds combining EEG and NIRS (Fig. 2) to assess the electrophysiological brain response and its metabolic correlates, respectively. Coupling these two techniques, which has rarely been done before in young infants (22, 24), has the unique advantage of providing both accurate spatial localization and high temporal resolution.
Fig. 1. Waveforms and spectrograms of one syllable exemplar.

Waveforms (upper lines) and spectrograms (lower lines) of /pa/ filtered in the condition Intact (AM + FM) on the left, Fast AM (AM < ERBN/2) in the middle, and the condition Slow AM (AM < 8 Hz) on the right.
Fig. 2. Placement of the NIRS optodes and EEG electrodes.
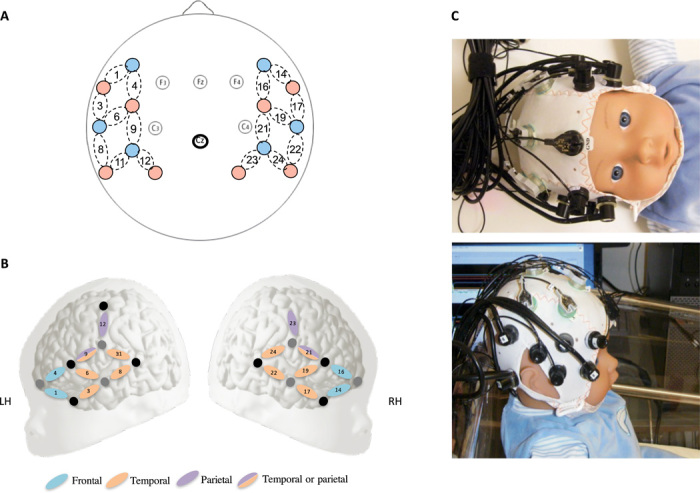
(A) Schematic representation of the sources of NIR lights (red circles) and detectors (blue circles). The dotted ovals represent the NIRS channels (i.e., coupled sources and detectors). The EEG electrodes are represented by solid circles. (B) Configuration of probe sets overlaid on a schematic newborn brain. For each functional NIRS (fNIRS) channel located within this probe set, the identity of the underlying brain area (using the LPBA40 atlas) is illustrated according to their localization. The blue channels indicate the position of the probe over the frontal area, the orange channels over the parietal area, and the purple over the temporal area on the infant head. Gray circles indicate sources, while black circles indicate detectors. (C) Pictures of the cap on a newborn model doll (photo credit: Judit Gervain, Integrative Neuroscience and Cognition Center).
While newborns were lying quietly in their hospital cribs, the syllables were presented to them through loudspeakers in long stimulation blocks (30 s) with six blocks per condition (Fig. 3), satisfying the temporal requirements of the slow hemodynamic response measured by NIRS. The intact sound condition was always played last to avoid priming, while the order of the slow and fast conditions was counterbalanced across babies. Each block contained 25 syllables, of which 20 were standard syllables (e.g., /pa/) and 5 were deviants (e.g., /ta/), allowing an event-related assessment of the responses to individual syllables within blocks similarly to the classical oddball or mismatch design in EEG studies (25). Thus, each block of stimulation comprised a ratio of 80%:20% of standard and deviant sounds. The only difference between standard and deviant sounds is the consonant at the onset of the syllable. The first five sounds were always standards to allow expectations about the standard to build up. The standard and deviant syllables were counterbalanced across babies. This design allowed us to address two research questions: first, whether overall the newborn brain processes the slow, fast, and intact conditions similarly or differently, as indexed by the comparison of the hemodynamic responses to the three conditions; and second, whether newborns can successfully discriminate consonants on the basis of the temporal acoustic cues present in each of the conditions, as indexed by the event-related EEG response to the standard versus deviant syllable.
Fig. 3. Schematic of the experimental design.
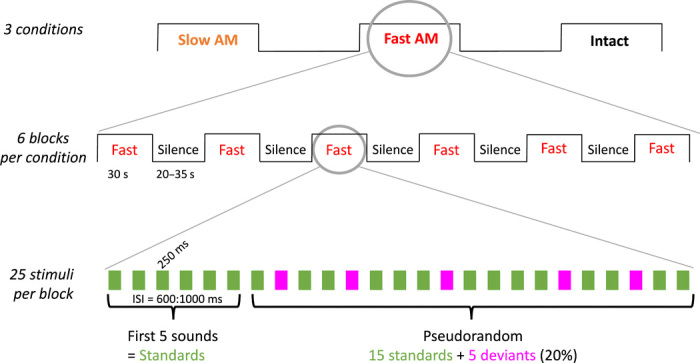
Each infant listened to the three sound conditions within 18 consecutive blocks for about 22 min (six blocks per condition). The Intact condition was always played last, and the order of the Slow and Fast conditions was counterbalanced between babies. In each block, 25 syllables were played following an odd-ball paradigm with 20% deviant syllables.
Changes in the hemodynamic responses were recorded using NIRS optical probes located on the left and right fronto-temporal regions of the newborns’ head (Fig. 2). This localization was based on previous NIRS studies testing speech perception in newborns (5, 26). Two types of analysis were conducted on the recorded hemodynamic activity measured as changes in the concentration of oxygenated (oxyHb) and deoxygenated (deoxyHb) hemoglobin as a function of auditory stimulation. First, cluster-based permutation analyses using paired-sample t tests were conducted to compare concentration changes against a zero baseline in each sound condition. A cluster-based permutation test using a one-way analysis of variance (ANOVA) was carried out to directly compare the three conditions. The results were followed up with permutation tests using paired-sample t tests to identify which pairwise comparisons drove the effects in the permutation test containing the ANOVA. This series of analyses helped to identify the time windows and brain regions of interest (ROI) showing significant activation to auditory stimuli in a data-driven way. Moreover, permutation tests have the advantage of controlling for the multiple comparisons without loss of statistical power, which typically occurs when Bonferroni or other corrections are applied to infant NIRS data (27). Linear mixed effect models were then used to assess the effect of sound conditions (Intact/Fast/Slow), block of stimulation (1 to 6), and ROI derived from the permutation tests on the recorded oxyHb concentration changes. The electrophysiological responses were recorded from EEG electrodes fronto-centrally located on the newborns’ head (F3, F4, Cz, C3, and C4 according to the 10-20 system; Fig. 2). This localization was based on previous EEG and EEG-NIRS co-recording studies testing speech perception in newborns (28). The amplitude of the EEG responses was averaged in each vocoder condition independently for standard sounds and deviant sounds. A linear mixed effects model was then used in each vocoder condition to assess whether the two types of syllables evoked different EEG responses, known as the mismatch response, reflecting an auditory change detection.
We predicted that newborns’ hemodynamic activity should be similar between the intact and fast conditions, if infants can rely on the fast temporal envelope for phoneme discrimination, as previous studies with 3-to-6 month olds suggest (20, 21). By contrast, the slow condition may not convey enough fine-grained acoustic details for the newborn brain to process it similarly to the original signal. For phoneme discrimination more specifically, as a measure of the validity of our design, we expected a significant difference between the standard and deviant syllables in the intact condition, as young infants are known to be able to differentiate syllables differing in a consonant (29). A mismatch response in the other two conditions would indicate that infants can also detect the consonant change using the degraded speech signals.
RESULTS
How temporal information in speech is processed by the newborn brain: Functional NIRS results
The grand average oxyHb NIRS results of the 23 newborns tested are shown in Fig. 4A (for ease of exposition, deoxyHb results are shown separately; fig. S1). Cluster-based permutation tests (26, 28) comparing each condition to the baseline showed significant changes in oxyHb concentrations in a time window between 5 and 25 s after the onset of stimulation. As shown in Fig. 4A, activation was significantly different from the baseline in channels 8 (LH) and 21 (RH) for the Intact condition, in channels 1, 3, 4, 6, and 12 (LH) and 14 and 17 (RH) for the Fast condition, and in channels 3 (LH) and 16 and 17 (RH) for the Slow condition (for all permutation tests, P < 0.0001). For the Fast condition, these significant results indicated a deactivation (negative oxyHb response), whereas for the Intact and the Slow conditions activation was greater than the baseline. Similar analyses over deoxyHb concentrations showed significant changes in the Intact condition versus the baseline (in channel 9 between 13 and 25 s after stimulation onset and in channel 21 between 10 and 16 s) and significant changes in the Fast condition versus the baseline (in channel 11 between 28 and 32 s). No significant activation compared to the baseline was observed for the Slow condition.
Fig. 4. Variations in oxyHb.

(A) OxyHb concentration changes over stimulation blocks in each channel and in each hemisphere. The x axis represents time in seconds, and the y axis represents concentration in millimole-millimeter. The rectangle along the x axis indicates time of stimulation. The black lines represent the concentration for the Intact condition, the red for the Fast condition, and the orange for the Slow condition. Color-coded * represents the channels differing from baseline for each condition (P < 0.05). (B) Condition-by-condition comparisons of the significantly activated channels according to permutation test (P < 0.05).
Cluster-based permutation tests were also used to compare changes in oxyHb concentration between conditions. As shown in Fig. 4B, the permutation test comparing all three conditions in a one-way ANOVA yielded significant differences between the conditions in channels 1, 3, 4, 6, and 24 (P < 0.01). Of these, channels 3, 4, and 6 formed a spatial cluster in the LH and channel 24 in the RH (P < 0.01). To follow up on the ANOVA, we conducted permutation tests with paired-sample t tests comparing the conditions pairwise. The Intact condition evoked significantly greater activation than the Fast condition in LH channels 1, 3, and 4 and in RH channels 14, 22, 23, and 24. Of these, channels 1 and 3 formed a spatial cluster in the RH (P = 0.027) and channels 22 and 24 in the RH (P = 0.046). Responses in the Slow condition were significantly greater than in the Intact condition in LH channel 1 (P = 0.039) and RH channel 22 (P = 0.035). The Slow condition evoked significantly greater activation than the Fast condition in LH channels 1, 3, 4, and 6 and in RH channels 14 and 17 (P < 0.01). Of these, channels 1, 3, and 4 in the LH formed a statistically significant spatial cluster (P = 0.016), while channels 14 and 17 formed a marginally significant cluster in RH (P = 0.065). Furthermore, no significant differences in changes in deoxyHb were found between the three conditions (fig. S1). Consequently, no grand ANOVA was conducted over deoxyHb data.
On the basis of the results of the ANOVA-based permutation test on oxyHb concentration, we selected the fronto-temporal channels 1, 3, 4, and 6 in the LH and 14, 16, 17, and 19 in the RH as ROIs for the linear mixed effects model. Channels 1, 3, 4, and 6 in the LH were identified as the ROI by the cluster-based permutation test comparing the three conditions, and to have a balanced statistical test, we used the analogous channels in the RH as the ROI for that hemisphere. Linear mixed effects models were then run over average oxyHb concentration changes between 5 and 25 s after the onset of stimulation, i.e., the time window identified by the cluster-based permutation tests to assess the effects of Condition (Intact versus Fast versus Slow), Hemisphere (Left versus Right), Channel (4 per hemisphere), and Stimulation Block (1 to 6). Of all the possible models built, the best-fitting one included the fixed factors Condition and Block, with Participants as a random factor. This model revealed a main effect of Condition (F2,2474 = 10.62, P < 0.001; Intact versus Fast, P < 0.001; Fast versus Slow, P < 0.001; Intact versus Slow, P = 0.62), Block (F5,2472 = 4.13, P < 0.001), and a Condition × Block interaction (F10,2473 = 3.69, P < 0.001). The main effect of Condition was due to greater responses in the Intact and Slow conditions than in the Fast condition. The main effect of Block reflected a gradual decrease in neural activity in the later blocks as a result of neural habituation often observed in infants’ NIRS responses (30). The interaction between Block and Condition revealed that oxyHb concentrations in the Intact and Slow conditions differed in Block 1 and that the activation in Fast and Slow conditions was different in Block 3 as shown in Fig. 5.
Fig. 5. Variations in oxyHb over blocks of stimulation.
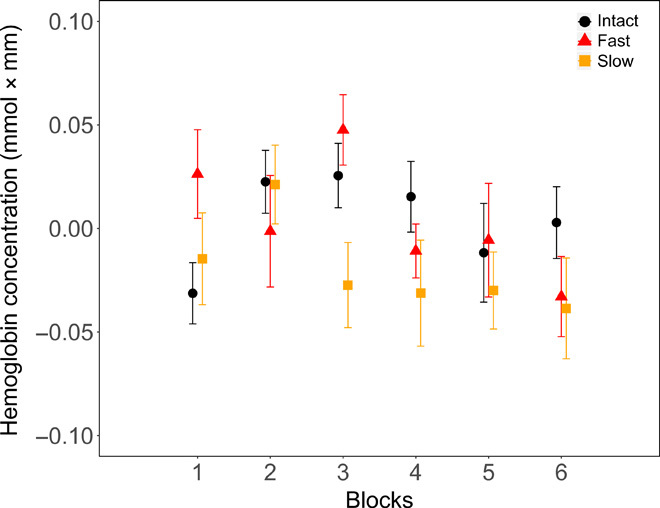
Averaged oxyHb concentration as a function of stimulation blocks in each vocoder condition in the ROI (average of channels 1, 3, 4, 6, 14, 16, 17, and 19). Error bars represent 1 SE.
In sum, different responses were observed in the three vocoder conditions, with the Slow and Intact conditions evoking positive activation mainly in the left fronto-temporal areas, and the Fast condition yielding a gradual deactivation over time bilaterally.
Phoneme discrimination on the basis of degraded speech signals: EEG results
Figure 6 shows the grand average of the EEG responses recorded at F3 for standard and deviant consonants in each condition. We ran linear mixed effects models with fixed factors Trial Type (Standard/Deviant) and Window (eight bins) to assess whether the amplitude of the EEG response recorded for Standard and Deviant sounds was different between 300 and 700 ms after stimulus onset, the usual time window for phoneme discrimination mismatch effects (31). This time window was divided into eight bins of 50 ms to evaluate the latency of the neural responses. In each condition, the best-fitting model included the fixed factors Trial Type and Window with Participants as a random factor. In all three conditions, a significant main effect of Trial Type was observed, indicating that deviant and standard consonants elicited different activations in each sound condition (Intact: F1,270 = 5.22, P = 0.023, η2 = 0.019; Fast: F1,270 = 16.69, P < 0.001, η2 = 0.058; Slow: F1,270 = 8.37, P = 0.004, η2 = 0.03). The mismatch response was positive in the Intact condition but negative in the Fast and Slow conditions. A main effect of Window was also observed in the Intact and Slow conditions (F7,270 = 2.238, P = 0.032, η2 = 0.055; F7,270 = 2.483, P = 0.017, η2 = 0.06, respectively) due to more positive responses in the latter time windows (500 to 700 ms) compared to the first ones (300 to 450 ms). This effect was marginal in the Fast condition (F7,270 = 2.004, P = 0.055, η2 = 0.049). No Trial Type × Window interaction was observed in any condition (Intact: F7,270 = 0.313, P = 0.948; Fast: F7,270 = 0.811, P = 0.578; Slow: F7,270 = 0.079, P = 0.99). Thus, in each condition, responses to the Deviant differed from the Standard starting from 300 to 700 ms after stimulus onset.
Fig. 6. Grand average of EEG responses.

Group mean amplitude variations (μV) of EEG responses recorded at F3 for the Standard (green lines) and the Deviant (magenta lines) in each condition for the group of newborns exposed to a consonant change. Responses to Standard and Deviant differ from each other in each condition in the time window 300 to 700 ms represented by the gray rectangle.
DISCUSSION
The present NIRS-EEG co-registration study indicates that, like adults, neonates do not require the temporal fine structure and fast envelope information to distinguish consonant features in quiet. However, the fast and slow components of the speech envelope are processed differently at birth.
First, the electrophysiological results demonstrate that the neonate brain is able to detect a change in place of articulation between two French stop consonants as shown by the mismatch EEG response in the Intact condition. Consistently with some previous studies with young infants, we observed a positive mismatch response (32). Newborns were also able to detect the consonant change on the basis of the envelope cues without the temporal fine structure as well as on the basis of the slow temporal variations alone (AM < 8 Hz). These results are consistent with behavioral data obtained with older infants and adults (13, 14, 20, 21), for whom the slowest envelope cues are also sufficient to detect consonant changes in silence. However, the direction of the mismatch response differed between the Intact and the degraded conditions. Different polarities for deviant sounds have been observed in previous studies according to difference in the design, interstimulus interval, or reference electrode (33). These methodological factors cannot explain our results, as the polarity difference occurred within the same study. Polarity reversals were also observed in infants as a function of task difficulty, e.g., for more challenging acoustic discriminations, for instance, for small pitch differences (34). This implies that the difficulty of change detection may have been different in the Intact as compared to the two degraded conditions. This hypothesis needs to be further investigated at different ages to track the role of temporal modulations in speech perception during early development.
However, note that, while discrimination was possible in all three conditions, as indicated by brain potentials, the full and slow envelope cues were not processed in the same way. The hemodynamic responses differed in their magnitude, time course, and localization according to the vocoder condition, that is, as a function of the temporal information available in the speech signal. More precisely, the NIRS recordings revealed bilateral activations for the Slow condition and a more left-lateralized one for the Fast condition. This different pattern of activation may reflect adult-like brain specialization for the slow and fast modulation cues already at birth. Previous studies in adults suggest that slow modulations preferentially activate the right hemisphere, while the faster temporal modulations preferentially activate the left hemisphere (8, 9, 35, 36), although some recent models have called this simple division of labor view into question (10). In adults, the fast and slow rates of the temporal envelope are processed by both distinct and shared neural substrates. One neuroimaging study using vocoded-speech sounds showed similar activation for original speech and noise-vocoded speech preserving slow and fast AM (<320 Hz, extracted in six channels) in the superior temporal gyrus, but dissimilar activations in the superior temporal sulcus (37), demonstrating that the processing of the full speech signal and of fast AM cues does not involve the same neural processing in adults. Slow and fast modulations have not been directly compared in adults using speech sounds. For non-speech sounds, e.g., white noise, functional magnetic resonance imaging studies found different brain responses between AM rates below 16 Hz and above 128 Hz (8). More specifically, slow and fast envelope rates in non-speech sounds activated the same cortical regions (superior temporal gyrus and sulcus), but the time courses of the activation differed according to the AM rate. Responses recorded bilaterally in Heschl’s gyrus were tuned to the slowest AM rates, 8 Hz, and the faster modulations of non-speech sounds have been shown to activate preferentially the LH (9). The present findings provide unique insight showing that the newborn brain also exhibits differential processing for different AM rates in speech and suggest that a differential hemispheric specialization for the processing of slow and fast envelope information is already present at birth. The human brain is thus already tuned to fast and slow AM information in speech from the get-go, laying the foundations of later language learning and speech comprehension.
Note that the time course of the hemodynamic responses was more similar between the Intact and Slow conditions than between the Intact and Fast conditions. This is surprising given that the slow condition is more acoustically degraded, i.e., less similar to the Intact condition, than the Fast one. Deactivation (negative oxyHb response) is often observed in newborn studies (30) and may be related to neural habituation due to stimulus repetition. In the present study, it is possible that the sharply decreasing hemodynamic response over time in the Fast condition may reflect faster neural habituation in this condition than in the other two conditions. This deactivation cannot be due to systemic variations in blood flow because the fast and slow conditions were presented in a counterbalanced order. This result is consistent with previous studies using non-speech sounds (22) showing a specific neural response for relatively fast temporal modulations (change every 25 ms that is equivalent to ~40-Hz fluctuations), but not for slower modulations in neonates. Moreover, a recent magnetoencephalography study showed that fetuses are able to detect slow and fast AM rates (from 2 to 91 Hz) modulating non-speech sounds and that they show the highest response to 27-Hz modulations, assumed to be better transmitted by bone conduction than slower AM rates (38). Responses to 4 Hz were progressively maturing over the 31st and 39th gestational week. The development of these specific auditory responses has not been clearly related to the development of speech perception yet. One may hypothesize that the present responses for relatively fast temporal modulations of speech observed at birth might reflect that infants depend more heavily on fast envelope cues than any other modulation cues. Because fast envelope cues carry more information about fundamental frequency and formant transitions that slow envelope cues, this specific response may be consistent with infants’ early ability to detect phonetic difference and their preference for exaggerated prosodic cues (39). While we cannot be certain that the present vocoded syllables were processed as speech, there are two pieces of evidence pointing in this direction. First, there is an overlap in the localization of the activated channels in the three conditions, including the intact condition, which is undeniably speech. Second, these activated channels are in the temporal and inferior frontal areas, i.e., in the auditory and language network. The fact that activation was bilateral does not argue against the sounds being processed as speech, because bilateral activation in response to speech is commonly observed in newborns (40, 41).
Future studies with young infants are needed to fully characterize the maturation of the auditory pathway to better understand the interplay between auditory development and language development. During the first year of life, infants become better at discriminating the speech contrasts of their native language but do not show the same improvement for nonnative contrasts (42). This phenomenon is called perceptual attunement or speech specialization. It is possible that with a given auditory experience, listeners learn to ignore specific acoustic cues of speech irrelevant to develop native language categories (20). Thus, the reliance on fast speech AM cues may change with greater exposure to the native speech sounds. More studies comparing the reliance upon the acoustic cues of the speech signal during early development are needed to explore this hypothesis. The advantage of the psychoacoustic approach for psycholinguistic studies is to describe the role of fine spectral and temporal modulations, which have neuro-correlates in the auditory system, for speech perception. Thus, this approach offers a great opportunity to characterize precisely the auditory sensory mechanisms involved in speech processing during early development that is during a critical period for language development.
In sum, our study demonstrates that the human auditory system is able to encode speech in fine details on the basis of highly reduced acoustic information, specifically the slowest AM cues, already from birth. Furthermore, the newborn brain already shows considerable specialization to different temporal cues in the speech signal, laying the foundations of infants’ astonishingly sophisticated speech perception and language learning abilities.
MATERIALS AND METHODS
Participants
Newborn infants born at a gestational age between 37 and 42 weeks, with Apgar scores ≥8 in the first and fifth minutes following birth, a head circumference greater than 32 cm, and having no known neurological or hearing abnormalities, were recruited for the study at the maternity ward of the Robert Debré Hospital, Paris, France. Newborns’ hearing was assessed by a measurement of auditory brainstem responses during their stay at the hospital. The study was approved by the research ethics committee of University Paris Descartes (CERES approval no. 2011-13), and all parents provided written informed consent before participation.
A group of 74 healthy full-term neonates (mean age, 1.8 days; range, 1 to 4 days) were tested. Thirteen newborns did not complete the study due to crying (n = 10) and parental/external interference (n = 3). Of the 61 infants who completed the study, 7 were excluded from the NIRS analysis because of technical problems during the recording and 31 because of poor data quality (large motion artifacts or noise). A total of 23 newborns were included in the functional NIRS (fNIRS) analyses (16 females). Of the 61 completers, 3 were excluded from the EEG analysis due to technical problems and 38 because of poor data quality (artifacts). A total of 20 newborns were thus included in the EEG analyses (11 females). The mothers of all infants spoke French during the pregnancy, but 10 also spoke a second language around 50% of the time (Arabic, Bambara, Italian, Kabyle, Mandarin, Portuguese, Soninke, or Swahili).
Stimuli
Eight natural occurrences of the syllables /pa/ and /ta/ were recorded by a native French speaker, who was instructed to speak clearly. All tokens were comparable in duration (mean = 194 ms, SD = 14 ms) and F0 (213 Hz, SD = 4 Hz). All stimuli were equated in global root mean square (RMS) level. Each stimulus was processed in three vocoder conditions. Specifically, three different tone-excited vocoders were designed. In each condition, the original speech signal was passed through a bank of 32 second-order gammatone filters (43), each 1-equivalent rectangular bandwidth (ERB) wide, with CFs uniformly spaced along an ERB scale ranging from 80 to 8020 Hz. A Hilbert transform was then applied to each band-pass–filtered speech signal to extract the envelope component and temporal fine structure carrier. The envelope component was low-pass–filtered using a zero-phase Butterworth filter (36 dB/octave roll-off) with a cutoff frequency set to either ERBN/2 (Intact and Fast condition) or 8 Hz (Slow condition). In the Fast and Slow conditions, the temporal fine structure carrier in each frequency band was replaced by a sine wave carrier with a frequency corresponding to the CF of the gammatone filter and a random starting phase. Each tone carrier was then multiplied by the corresponding filtered envelope function. In the Intact condition, the original temporal fine structure was multiplied by the filtered envelope function in each band. The narrow-band speech signals were then added up, and the level of the wideband speech signal was adjusted to have the same RMS value as the input signal in each condition. Thus, in the Intact condition, the resulting speech signal contained the original envelope and original temporal fine structure in 32 bands. In the Fast condition, the vocoder manipulation discarded the original (within channel) temporal fine structure cues but retained the fast envelope cues (cutoff frequency set to ERBN/2). In the Slow condition, the manipulation discarded both the original temporal fine structure and the fast envelope cues to preserve only the slowest envelope information in each band (<8 Hz). Syllabic information was thus preserved in both degraded conditions, but voice-pitch and formant transition information was preserved only in the Fast condition and drastically reduced in the Slow condition.
Equipment and procedure
Optical imaging was performed with a NIRScout 816 machine (NIRx Medizintechnik GmbH, Berlin, Germany), using pulsated light-emitting diode (LED) sequential illumination with two wavelengths of 760 and 850 nm to record the NIRS signal at a 15.625-Hz sampling rate. Three LED sources were placed on each side of the head in analogous positions and were illuminated sequentially. They were coupled with four detectors on each side of the head. The configuration of the 16 channels (8 per hemisphere) created with the three sources and four detectors per hemisphere is shown in Fig. 2. We embedded the optodes in an elastic cap (EasyCap). The source-detector separation was 3 cm. For each infant, we selected a cap size according to their head circumference. We also adjusted the cap according to Cz measurement and ear location. Localization analysis for our newborn headgear was performed as in (26). The electrophysiological recording was performed with a Brain Products actiCHamp EEG amplifier (Brain Products GmbH, Munich, Germany) and active electrodes. Five active electrodes (F3, Fz, F4, C3, and C4, 10-20 system), embedded in the same cap as the NIRS optodes, were used to record the EEG signal at a 2000-Hz sampling rate, referenced to the vertex (Cz). The stimuli were played through two speakers elevated to the height of the crib, approximately 30 cm from the infants’ head on each side and at around 70-dB sound pressure level (SPL).
While newborns were lying quietly in their hospital cribs, the syllables were presented to them in long stimulation blocks (30 s) with six blocks per vocoder condition. The interstimulus interval between syllables within a block was varied randomly between 600 and 1000 ms and the interblock interval between 20 and 35 s. The Intact sound condition was always played last, while the order of the Slow and Fast conditions was counterbalanced across babies. Each block contained 25 syllables, of which 20 were standard syllables (e.g., /pa/) and 5 were deviants (e.g., /ta/), allowing an event-related assessment of the responses to individual syllables within blocks similarly to the classical oddball or mismatch design in EEG studies. Thus, each block of stimulation comprised a ratio of 80:20% of standard and deviant sounds. The first five sounds were always standards to allow expectations about the standard to build up. The standard and deviant syllables were counterbalanced across babies. The whole experiment lasted around 22 min.
Data analysis: fNIRS
Analyses were conducted on oxyHb and deoxyHb. Data were band-pass–filtered between 0.01 and 0.7 Hz to remove low-frequency noise (i.e., slow drifts in Hb concentrations) as well as high-frequency noise (i.e., heartbeat). Movement artifacts were removed by identifying block-channel pairs, in which a change in concentration greater than 0.1 mmol × mm over a period of 0.2 s occurred, and rejecting the block for that channel. Channels with valid data for less than three of six blocks per condition were discarded. A baseline was established by using a linear fit over the 5-s time window preceding the onset of the block and the 5-s window beginning 15 s after the end of the block. The 15-s resting period after stimulus offset was used to allow the hemodynamic response function to return to baseline. Analyses were conducted in MATLAB (version R2015b) with custom analysis scripts.
ROIs were defined according to the permutation analyses. For the cluster-based permutation test, we used paired-sample t tests to compare each vocoder condition to a zero baseline in each channel. Then, all temporally and spatially adjacent pairs with a t value greater than a standard threshold (we used t = 2) were grouped together into cluster candidates. We calculated cluster-level statistics for each cluster candidate by summing the t values from the t tests for every data point included in the cluster candidate. We then identified the cluster candidate with the largest t value for each hemisphere. Then, a permutation analysis evaluated whether this cluster-level statistic was significantly different from chance. This was done by randomly labeling the data as belonging to one or the other experimental condition. The same t test statistic as before was computed for each random assignment, which allowed us to obtain its empirical distribution under the null hypothesis of no difference between the baseline and each condition. Clusters were then formed as before. The proportion of random partitions that produce a cluster-level statistic greater than the actually observed one provides the P value of the test. In all, 100 permutations under the null hypothesis were conducted for this robust comparison.
Similar permutation tests were run to directly compare the three conditions, except that the t test was replaced with a one-way ANOVA with factor Condition (Intact versus Fast versus Slow) and 1000 permutations were conducted.
The channels identified by the permutation tests as spatial clusters were included in linear mixed effect models comparing the effects of the fixed factors Condition (Intact versus Fast versus Slow), Block of stimulation (1 to 6), Channel and Hemisphere (LH versus RH), and the random effect of Participant on the variations in oxyHb concentration. The best-fitting model is reported and interpreted.
Electroencephalography
The EEG signal was resampled at 200 Hz and band-pass–filtered at 0.5 to 20 Hz (31, 32). The continuous EEG data were segmented into epochs of 1000 ms including a 200-ms baseline (−200 to 0 ms) and time-locked to stimulus onset. Epochs including the first standard sound of each vocoder condition and standards directly following deviant sounds were excluded to avoid large dishabituation/novelty detection responses. Epochs with abnormal values (<−120 μV and >+120 μV) were then excluded automatically. Infants were retained for data analysis if the number of deviant trials was at least 10 in each condition. For the group of infants included in the final analysis, the average number of deviant epochs retained for analysis was 28 in the Intact condition and 27 in both the Fast and Slow conditions.
For statistical purposes, we averaged together all good deviant epochs and all good standard epochs in each condition for each infant in each channel. On the basis of visual inspection (see fig. S2), the EEG amplitude recorded at F3 was averaged between 300 and 700 ms after stimulus onset to assess the mismatch response in each condition.
Supplementary Material
Acknowledgments
We wish to thank all the parents and infants who participated in the study and all the personnel of Hôpital Robert-Debré, Paris, France. Funding: This work was supported by an Emergence(s) Programme Grant from the City of Paris, a Human Frontiers Science Program Young Investigator Grant (RGY-0073-2014), as well as the ERC Consolidator Grant “BabyRhythm” (no. 773202) to J.G. L.C. is currently supported by ANR grant 17-CE28-008. Author contributions: L.C. and J.G. designed the experiment. L.C. performed the research. L.C. and J.G. analyzed the data. L.C. and J.G. wrote the paper. Competing interests: The authors declare that they have no competing interests. Data and materials availability: All data needed to evaluate the conclusions in the paper are present in the paper and/or the Supplementary Materials. Additional data related to this paper may be requested from the authors.
SUPPLEMENTARY MATERIALS
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/6/30/eaba7830/DC1
REFERENCES AND NOTES
- 1.Moore J. K., Maturation of human auditory cortex: Implications for speech perception. Ann Otol. Rhinol. Laryngol. 111, 7–10 (2002). [DOI] [PubMed] [Google Scholar]
- 2.Abdala C., A longitudinal study of distortion product otoacoustic emission ipsilateral suppression and input/output characteristics in human neonates. J. Acoust. Soc. Am. 114, 3239–3250 (2003). [DOI] [PubMed] [Google Scholar]
- 3.Kuhl P. K., Early language acquisition: Cracking the speech code. Nat. Rev. Neurosci. 5, 831–843 (2004). [DOI] [PubMed] [Google Scholar]
- 4.Bertoncini J., Bijeljac-Babic R., Blumstein S. E., Mehler J., Discrimination in neonates of very short CVs. J. Acoust. Soc. Am. 82, 31–37 (1987). [DOI] [PubMed] [Google Scholar]
- 5.Gervain J., Macagno F., Cogoi S., Peña M., Mehler J., The neonate brain detects speech structure. Proc. Natl. Acad. Sci. U.S.A. 105, 14222–14227 (2008). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Moon C., Cooper R. P., Fifer W. P., Two-day-olds prefer their native language. Infant Behav. Dev. 16, 495–500 (1993). [Google Scholar]
- 7.Rosen S., Temporal information in speech: Acoustic, auditory and linguistic aspects. Philos. Trans. R. Soc. Lond. B Biol. Sci. 336, 367–373 (1992). [DOI] [PubMed] [Google Scholar]
- 8.Giraud A. L., Lorenzi C., Ashburner J., Wable J., Johnsrude I., Frackowiak R., Kleinschmidt A., Representation of the temporal envelope of sounds in the human brain. J. Neurophysiol. 84, 1588–1598 (2000). [DOI] [PubMed] [Google Scholar]
- 9.Liégeois-Chauvel C., Lorenzi C., Trébuchon A., Régis J., Chauvel P., Temporal envelope processing in the human left and right auditory cortices. Cereb. Cortex 14, 731–740 (2004). [DOI] [PubMed] [Google Scholar]
- 10.Poeppel D., The neuroanatomic and neurophysiological infrastructure for speech and language. Curr. Opin. Neurobiol. 28, 142–149 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Hickok G., Poeppel D., The cortical organization of speech processing. Nat. Rev. Neurosci. 8, 393–402 (2007). [DOI] [PubMed] [Google Scholar]
- 12.Zatorre R. J., Belin P., Spectral and temporal processing in human auditory cortex. Cereb. Cortex 11, 946–953 (2001). [DOI] [PubMed] [Google Scholar]
- 13.Drullman R., Temporal envelope and fine structure cues for speech intelligibility. J. Acoust. Soc. Am. 97, 585–592 (1995). [DOI] [PubMed] [Google Scholar]
- 14.Shannon R. V., Zeng F.-G., Kamath V., Wygonski J., Ekelid M., Speech recognition with primarily temporal cues. Science 270, 303–304 (1995). [DOI] [PubMed] [Google Scholar]
- 15.Xu L., Pfingst B. E., Relative importance of temporal envelope and fine structure in lexical-tone perception (L). J. Acoust. Soc. Am. 114, 3024–3027 (2003). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Zeng F.-G., Nie K., Stickney G. S., Kong Y.-Y., Vongphoe M., Bhargave A., Wei C., Cao K., Speech recognition with amplitude and frequency modulations. Proc. Natl. Acad. Sci. U.S.A. 102, 2293–2298 (2005). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Bertoncini J., Nazzi T., Cabrera L., Lorenzi C., Six-month-old infants discriminate voicing on the basis of temporal envelope cues (L). J. Acoust. Soc. Am. 129, 2761–2764 (2011). [DOI] [PubMed] [Google Scholar]
- 18.Cabrera L., Bertoncini J., Lorenzi C., Perception of speech modulation cues by 6-month-old infants. J. Speech Lang. Hear. Res. 56, 1733–1744 (2013). [DOI] [PubMed] [Google Scholar]
- 19.Warner-Czyz A. D., Houston D. M., Hynan L. S., Vowel discrimination by hearing infants as a function of number of spectral channels. J. Acoust. Soc. Am. 135, 3017–3024 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Cabrera L., Lorenzi C., Bertoncini J., Infants discriminate voicing and place of articulation with reduced spectral and temporal modulation cues. J. Speech Lang. Hear. Res. 58, 1033–1042 (2015). [DOI] [PubMed] [Google Scholar]
- 21.Cabrera L., Werner L., Infants’ and adults’ use of temporal cues in consonant discrimination. Ear Hear. 38, 497–506 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Telkemeyer S., Rossi S., Koch S. P., Nierhaus T., Steinbrink J., Poeppel D., Obrig H., Wartenburger I., Sensitivity of newborn auditory cortex to the temporal structure of sounds. J. Neurosci. 29, 14726–14733 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Varnet L., Ortiz-Barajas M. C., Erra R. G., Gervain J., Lorenzi C., A cross-linguistic study of speech modulation spectra. J. Acoust. Soc. Am. 142, 1976 (2017). [DOI] [PubMed] [Google Scholar]
- 24.Mahmoudzadeh M., Dehaene-Lambertz G., Fournier M., Kongolo G., Goudjil S., Dubois J., Grebe R., Wallois F., Syllabic discrimination in premature human infants prior to complete formation of cortical layers. Proc. Natl. Acad. Sci. U.S.A. 110, 4846–4851 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Mueller J. L., Friederici A. D., Männel C., Auditory perception at the root of language learning. Proc. Natl. Acad. Sci. U.S.A. 109, 15953–15958 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Abboub N., Nazzi T., Gervain J., Prosodic grouping at birth. Brain Lang. 162, 46–59 (2016). [DOI] [PubMed] [Google Scholar]
- 27.Nichols T. E., Holmes A. P., Nonparametric permutation tests for functional neuroimaging: A primer with examples. Hum. Brain Mapp. 15, 1–25 (2002). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Benavides-Varela S., Gervain J., Learning word order at birth: A NIRS study. Dev. Cogn. Neurosci. 25, 198–208 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Dehaene-Lambertz G., Baillet S., A phonological representation in the infant brain. Neuroreport 9, 1885–1888 (1998). [DOI] [PubMed] [Google Scholar]
- 30.Bouchon C., Nazzi T., Gervain J., Hemispheric asymmetries in repetition enhancement and suppression effects in the newborn brain. PLOS ONE 10, e0140160 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Dehaene-Lambertz G., Cerebral specialization for speech and non-speech stimuli in infants. J. Cogn. Neurosci. 12, 449–460 (2000). [DOI] [PubMed] [Google Scholar]
- 32.Dehaene-Lambertz G., Pena M., Electrophysiological evidence for automatic phonetic processing in neonates. Neuroreport 12, 3155–3158 (2001). [DOI] [PubMed] [Google Scholar]
- 33.Martynova O., Kirjavainen J., Cheour M., Mismatch negativity and late discriminative negativity in sleeping human newborns. Neurosci. Lett. 340, 75–78 (2003). [DOI] [PubMed] [Google Scholar]
- 34.Morr M. L., Shafer V. L., Kreuzer J. A., Kurtzberg D., Maturation of mismatch negativity in typically developing infants and preschool children. Ear Hear. 23, 118–136 (2002). [DOI] [PubMed] [Google Scholar]
- 35.Zatorre R. J., Belin P., Penhune V. B., Structure and function of auditory cortex: Music and speech. Trends Cogn. Sci. 6, 37–46 (2002). [DOI] [PubMed] [Google Scholar]
- 36.Poeppel D., Pure word deafness and the bilateral processing of the speech code. Cognit. Sci. 25, 679–693 (2001). [Google Scholar]
- 37.Scott S. K., Rosen S., Lang H., Wise R. J. S., Neural correlates of intelligibility in speech investigated with noise vocoded speech—A positron emission tomography study. J. Acoust. Soc. Am. 120, 1075–1083 (2006). [DOI] [PubMed] [Google Scholar]
- 38.Draganova R., Schollbach A., Schleger F., Braendle J., Brucker S., Abele H., Kagan K. O., Wallwiener D., Fritsche A., Eswaran H., Preissl H., Fetal auditory evoked responses to onset of amplitude modulated sounds. A fetal magnetoencephalography (fMEG) study. Hear. Res. 363, 70–77 (2018). [DOI] [PubMed] [Google Scholar]
- 39.Mehler J., Jusczyk P., Lambertz G., Halsted N., Bertoncini J., Amiel-Tison C., A precursor of language acquisition in young infants. Cognition 29, 143–178 (1988). [DOI] [PubMed] [Google Scholar]
- 40.Sato H., Hirabayashi Y., Tsubokura H., Kanai M., Ashida T., Konishi I., Uchida-Ota M., Konishi Y., Maki A., Cerebral hemodynamics in newborn infants exposed to speech sounds: A whole-head optical topography study. Hum. Brain Mapp. 33, 2092–2103 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.May L., Byers-Heinlein K., Gervain J., Werker J. F., Language and the newborn brain: Does prenatal language experience shape the neonate neural response to speech? Front. Psychol. 2, 222 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Werker J. F., Tees R. C., Cross-language speech perception: Evidence for perceptual reorganization during the first year of life. Infant Behav. Dev. 7, 49–63 (1984). [Google Scholar]
- 43.Gnansia D., Péan V., Meyer B., Lorenzi C., Effects of spectral smearing and temporal fine structure degradation on speech masking release. J. Acoust. Soc. Am. 125, 4023–4033 (2009). [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/6/30/eaba7830/DC1