

Abstract
Little is known about the spatial clustering of neighborhood deprivation across the United States (U.S.). Using data from the 2010 U.S. Census Bureau, we created a neighborhood deprivation index (NDI: higher NDI indicates higher deprivation/ lower neighborhood socioeconomic status) for each county within the U.S. County level scores were loaded into ArcGIS 10.5.1 where they were mapped and analyzed using Moran’s I and Anselin Local Moran’s I. Ultimately, NDI varies spatially across the US. The highest NDI scores were found in the Southeastern and Southwestern U.S. states, and inland regions of Southern California. This information is critical for public health initiative development as planners may need to tailor the scale of their efforts based on the higher NDI neighborhoods of the county or geographic region with potentially greater chronic disease burden.
Keywords: neighborhood deprivation index, socioeconomic status, health disparities, health policy, applied spatial statistics
1. Introduction
Living in an area with lower socioeconomic status (SES) has been linked to poor physical and mental health outcomes as SES indicators (e.g., income, poverty, education) are major predictors of health and health disparities not just in the United States (US), but across the world.1–3 A recent study illuminated the link between neighborhood SES and 18 mental and physical health conditions using a nationally representative cohort, the longitudinal Midlife in the United States (MIDUS) study.1 Results indicated that even after adjusting for individual-level factors, the odds of developing two or more health conditions (mental and/or physical illness) was lower for every $10,000 increase in neighborhood income regardless of length of time spent in the neighborhood.1 These relationships may be due to neighborhood socioeconomic level influencing the number of grocery stores, recreation centers, and other available health-promoting community assets.4–8
In recent years, Geographic Information Systems (GIS) have been beneficial in community assessments, particularly in representing the distribution of resources within specific geographic areas.9 For instance, GIS has been used to examine the socioeconomic distribution across particular states such as through the South Carolina Commission for Minority Affairs which identified South Carolina’s most socioeconomically affluent and deprived counties.10 Using z-standardized scores from variables on poverty, unemployment, per capita income, and median household income, these values were used to create ordinal categories (below average, average, and above average).10Their maps illustrated that the most deprived counties appear to cluster in rural parts of South Carolina, where the more affluent counties appear to cluster in the more urban parts of the state.10 On a broader scheme, the distribution of zip code-level neighborhood disadvantage throughout the U.S has recently been examined.11 The area deprivation index was created using 17 variables taken from the 2013 American Community Survey data, where higher deprivation represents lower SES. The most deprived zip codes appear to be geographically clustered (i.e., unusually concentrated) in the Southeastern and Southwestern regions of the U.S.; however, there was no statistical analysis to examine the extent of the spatial clustering of deprivation in the U.S.11 In examining these studies that have developed deprivation indices in the U.S., in fact, very few have examined the spatial distribution and spatial clustering of neighborhood deprivation using GIS across the U.S. and within geographic regions.10,11
Using publicly available data from the U.S. Census Bureau, we sought to create a neighborhood deprivation index (NDI) to visually represent county level deprivation across the U.S. We investigated the spatial distribution of NDI scores on the county level across the United States. Thus, the objectives of this study were to plot NDI across the U.S. and to test whether NDI varies spatially. Ultimately, identifying where NDI clusters geographically in the U.S. may be important in helping to inform community-based research, aid in targeting public health resources, and inform policy makers about potential deleterious characteristics within their jurisdictions.
2. Methods
2.1. Data and measures
The NDI was created using publicly available data from the 2010 5-year estimates of the American Community Survey from the U.S. Census Bureau,12 and the methods for creating this NDI were adapted from those published previously.13,14 We gathered 13 sociodemographic variables on employment/occupation, education, housing conditions, wealth, and income from the 2010 American Community Survey (additional information on the variables within these constructs can be found in Table 1).15 Each variable was then loaded into SPSS, where they were z-standardized. Using Promax rotation, having a minimum loading score of 0.40, and a minimum eigenvalue of 1, factor analysis was conducted. Ultimately, those factors with a Cronbach’s alpha greater than 0.70 were used to create the final NDI measures. The variables from the factors that fit the criteria were: 1) Household Income, 2) Home Value, 3) % Public Assistance, 4) % Family Poverty, 5) % Employed in Management, 6) % Housing Units Receiving Rental Income, 7) % Female-Headed Household, 8) % Households Without Telephone, 9) % Owner Occupied Housing Units, 10) % High School Graduates, and 11) % Bachelor’s Degree or Higher. The sum of these variables was used to create the final NDI measure at the county level. Higher scores are associated with higher deprivation, indicating that these areas have lower SES.
Table 1.
Neighborhood Deprivation Index construct variables and descriptions.
| Construct | Variables | Description | Reverse-Coded | Log-Transformed | Variable loaded for NDI* |
|---|---|---|---|---|---|
| Employment/Occupation | |||||
| % Employed in Management | % of employed people (age 16 and older) working in management, business, science, and arts | Yes | No | Yes | |
| % Unemployment | % of people age 16 and older that are unemployed | No | No | No | |
| Education | |||||
| % High School Graduates | Population 25 years and older: % with a high school diploma or higher | Yes | No | Yes | |
| % Bachelor’s Degree or Higher | Population 25 years and older: % with a bachelor’s degree or higher | Yes | No | Yes | |
| Housing Conditions | |||||
| % Households Without Telephone | % of households without a telephone | No | No | Yes | |
| % Households Without plumbing | % of households without plumbing | No | No | No | |
| Income and Wealth | |||||
| Household Income | Median household income in the last 12 months | No | Yes | Yes | |
| Home Value | Median home value | No | Yes | Yes | |
| % Family Poverty | % of families in poverty | No | No | Yes | |
| % Public Assistance | % of families receiving public assistance income in the past 12 months | No | No | Yes | |
| % Female-Headed Household | % of female-headed households with children under 18 | No | No | Yes | |
| % Owner Occupied Housing Units | % of housing units that are owner occupied | Yes | No | Yes | |
| % Housing Units Receiving Interest/Dividends/Rental Income | % of housing units that are receiving interest, dividends, or net rental income in the past 12 months for households | Yes | No | Yes |
Variables included in the final NDI calculation had to have a minimum loading score of 0.40, a minimum eigenvalue of 1, and had a Cronbach’s alpha greater than 0.70.
Additional data on the racial/ethnic and age composition of these counties were downloaded from the 2010 Census Summary File. Data on health outcomes and behaviors were downloaded from the 2014 Robert Wood Johnson Foundation County Health Indicator Data as this report contains data from the 2010 study period. These data came from the National Center for Health Statistics, Behavioral Risk Factor Surveillance System, National Center for Chronic Disease Prevention and Health Promotion, Dartmouth Atlas of Health Care, and OneSource Global Business Browser. 2010 Rural Urban Classification Codes were downloaded from the U.S. Census Bureau. These data were used to further contextualize the results of our Anselin Local Moran’s I analyses.
2.2. GIS Process
County cartographic boundary shapefiles were downloaded from the U.S. Census Bureau and then uploaded into ArcGIS 10.5.1 (ESRI, Redlands, CA). NDI scores for each county were converted from Microsoft Excel into a comma separated value (CSV) file. The NDI CSV file was uploaded to ArcGIS 10.5.1 and spatially joined with the county shapefile data. Using choropleth maps in ArcGIS 10.5.1, NDI scores were divided into quintiles and subsequently mapped across the U.S. and stratified by the four U.S. regions (South, Northeast, Midwest, West), presented based on quintiles of NDI scores.
2.3. Analysis
The analysis was completed in a two-step process. In the first step, we used the Global Moran’s I to investigate if NDI scores at the county level were spatially autocorrelated (i.e. similar scores are located near each other) based on the location of counties and the associated NDI values.16 Moran’s I values range between – 1 and +1. If Moran’s I is positive, it represents a clustering of NDI values across the geographic area. If Moran’s I is negative, it means that the NDI values are dispersed across the geographic area. Inverse distance was applied to conceptualize these spatial relationships whereby neighboring features have a larger influence on the computations for a target feature than those further away.17 Using this method, we expected to identify evidence of areas of statistically significant NDI score clustering across the U.S.
In the second step, we used the Anselin Local Moran’s I to identify specific regions within the United States with high and low NDIs in addition to attributes that are significantly different than those near it.18 The resulting output provides a map of the spatial distribution of significant clustering to identify hot spots (areas of higher neighborhood deprivation), cold spots (areas of low neighborhood deprivation), and spatial outliers (e.g., a county with a low neighborhood deprivation index that is surrounded by high deprivation counties). Given that both of these analytical tools rely on the attributes of neighboring counties, we used data only for counties in the contiguous U.S.19
3. Results
3.1. Overall and regional distributions of NDI
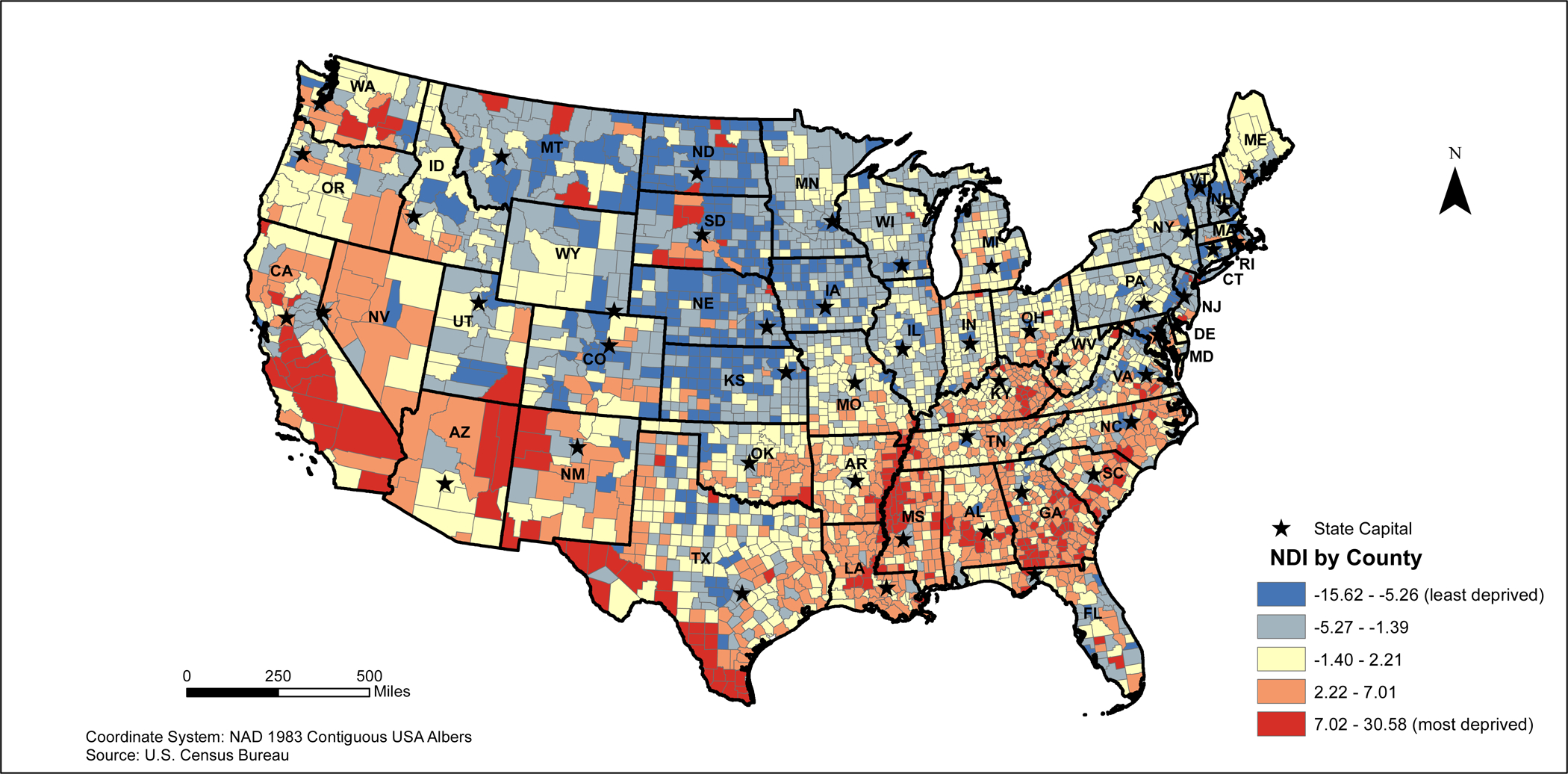
The NDI ranged from −15.62 (least deprived) to 30.58 (most deprived) across the 3,109 counties in the contiguous United States (Main Map). Based on the distribution of NDI scores, higher NDI scores can be found along the Mississippi River and Southeastern U.S. (Main Map, Figure 1). Lower NDI scores tend to be found in Northeast and Midwest regions of the country (Figures 2 and 3), in addition to coastal areas of California (Figure 4).
Figure 1.
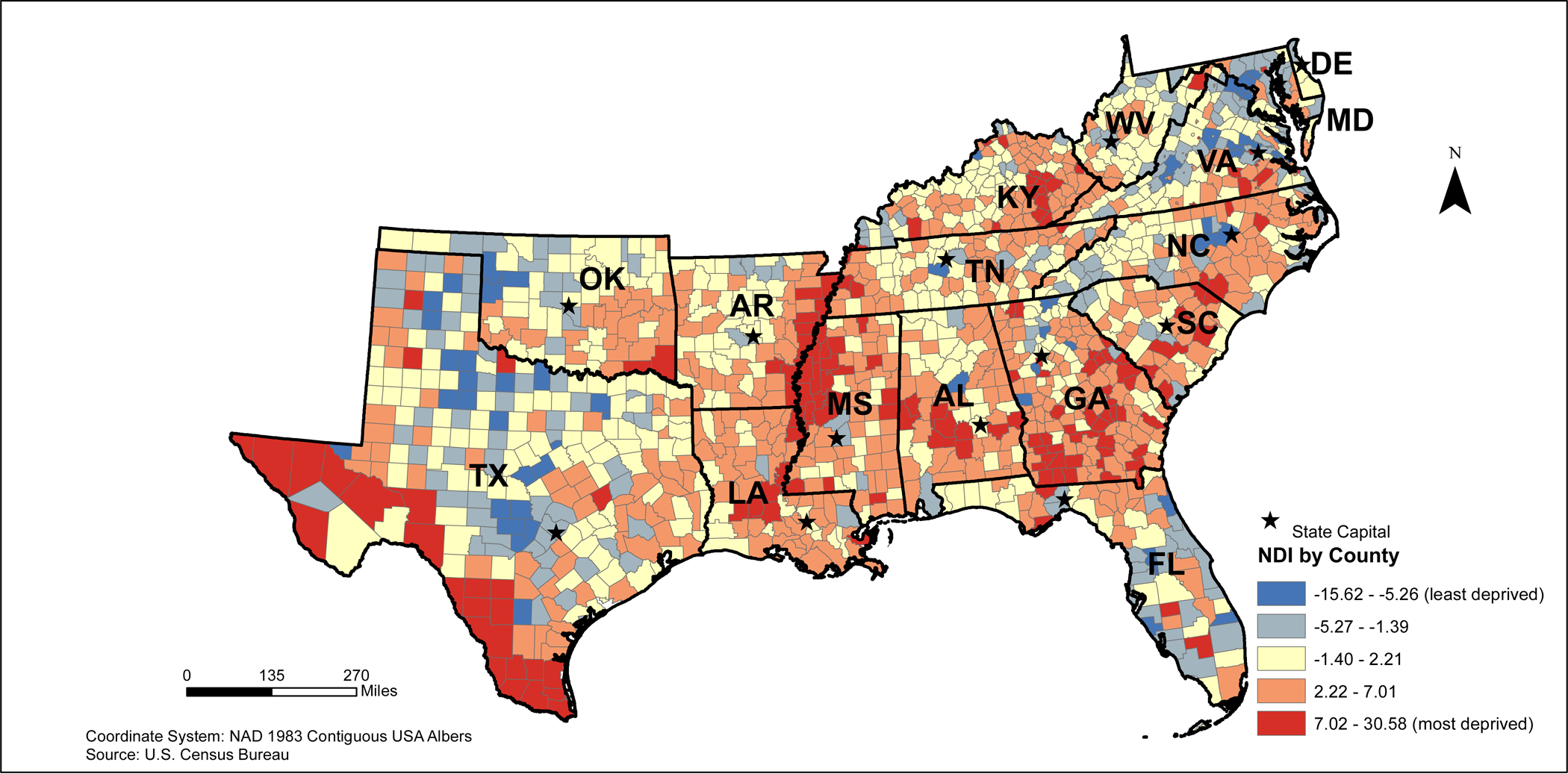
2010 Southeastern States Neighborhood Deprivation Index (NDI)
Figure 2.
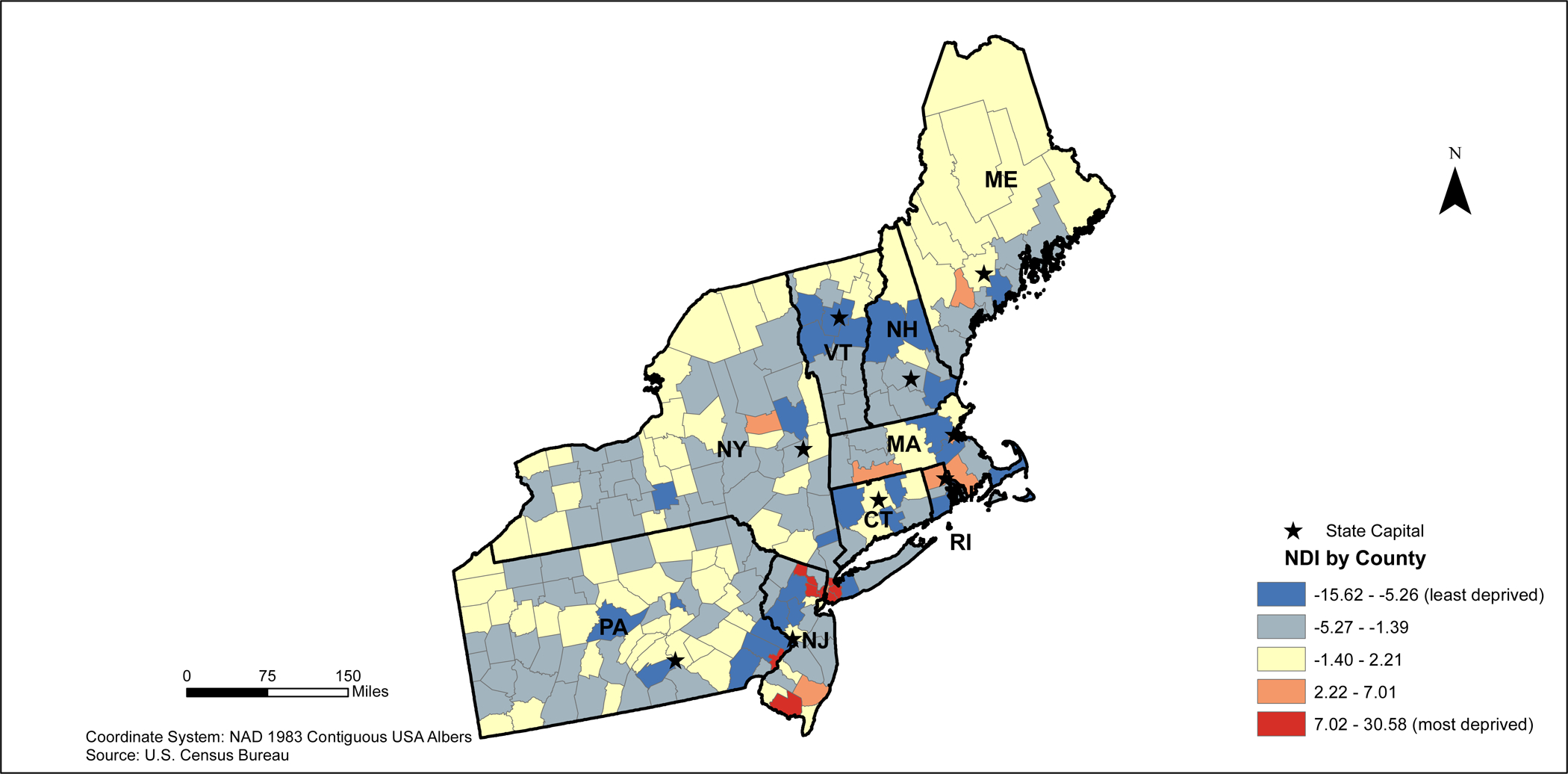
2010 Northeastern States Neighborhood Deprivation Index (NDI)
Figure 3.
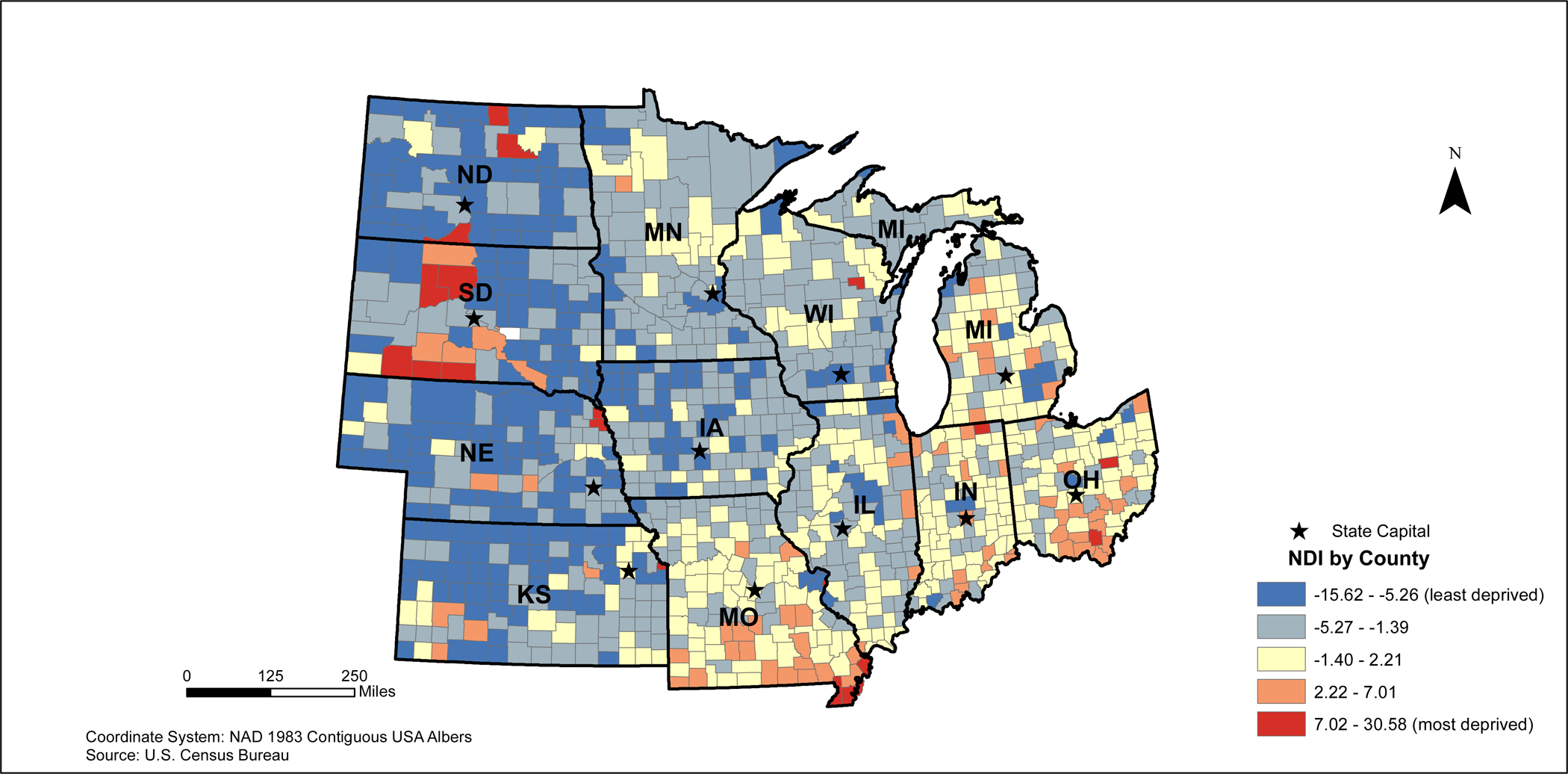
2010 Midwestern States Neighborhood Deprivation Index (NDI)
Figure 4.
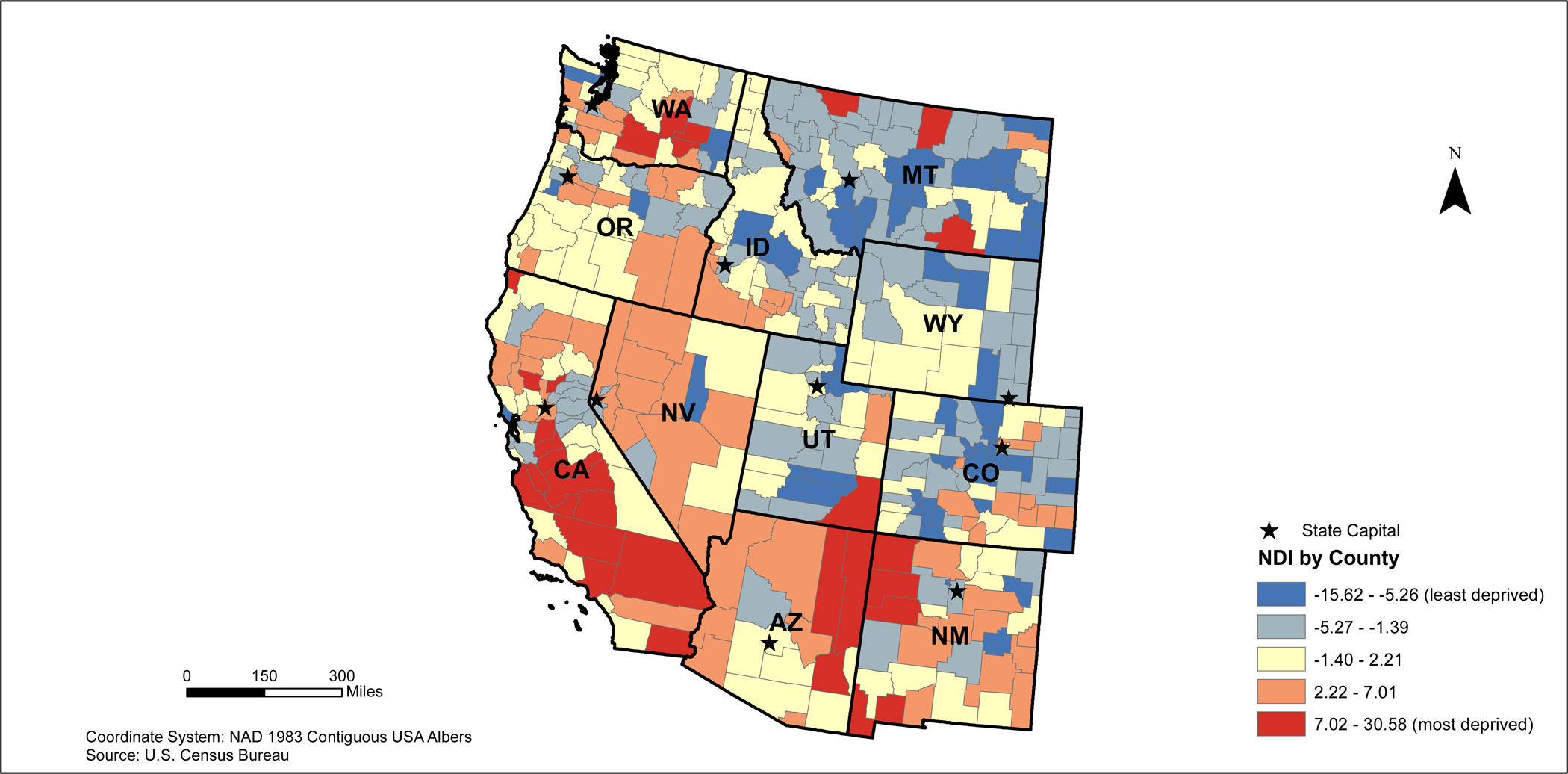
2010 Western States Neighborhood Deprivation Index (NDI)
3.2. Moran’s I Values
The value of Moran’s I for the contiguous areas of the U.S. was 0.41, indicating an overall spatial clustering of NDI by county (Table 2). Since the z-score was 80.57, there was a less than 1% chance that this pattern could have happened by chance. On a regional level, these relationships still existed. Southern states had a Moran’s I value of 0.37 and a z-score of 34.46, Northeast states had a Moran’s I value of 0.21 with a corresponding z-score of 8.55, Midwestern states had a Moran’s I of 0.29 and a z-score of 21.81, and Western states had a Moran’s I of 0.30 and a subsequent z-score of 13.01. Based on the z-scores for each of these variables, there was spatial clustering for NDIs at the county level. For each of these regions, there is a less than 1% chance that these clustering patterns could have happened by chance.
Table 2.
Moran’s Ia Results for United States and Region-Specific Neighborhood Deprivation Index
| Region | Moran’s I | Z-score | P-value |
|---|---|---|---|
| Overall | 0.41 | 80.57 | <0.001 |
| Regional | |||
| South | 0.37 | 34.46 | <0.001 |
| Northeast | 0.21 | 8.55 | <0.001 |
| Midwest | 0.29 | 21.81 | <0.001 |
| West | 0.30 | 13.01 | <0.001 |
Note:
Moran’s I lies between – 1 and +1. If Moran’s I is positive, it represents a clustering of values. If Moran’s I is negative, it represents that the values are dispersed.
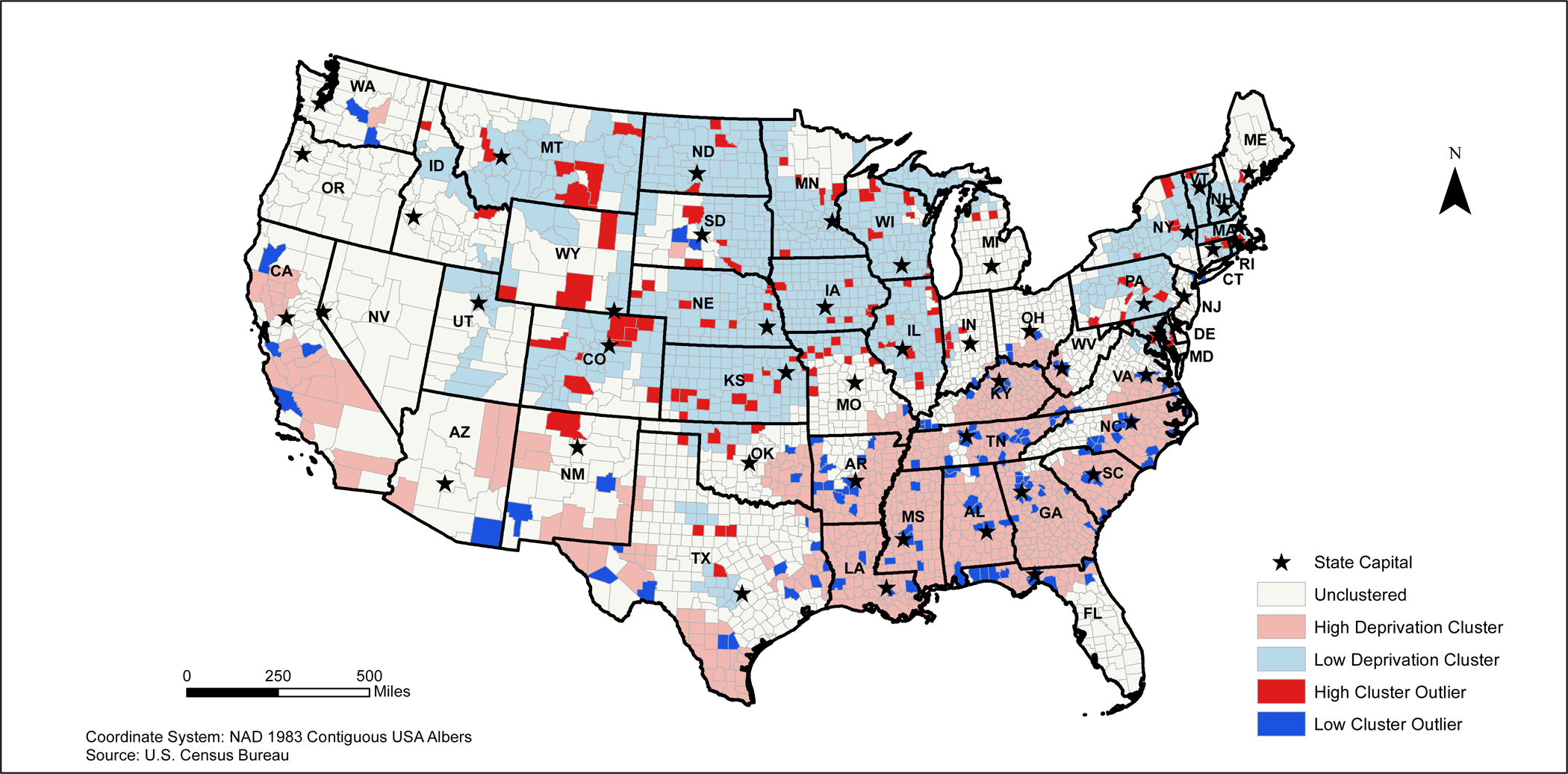
3.3. Anselin’s local Moran’s I - Overall
The Anselin Local Moran’s I identified five different groups of counties based on their similarity or difference to the adjacent counties’ NDI (Table 3). However, there were distinct differences in these relationships based on region. For example, 33% of counties in the South, 35% of counties in the Northeast, 32% of counties in the Mid-West, and 60% of counties in the West were classified as unclustered.
Table 3.
Localized Clusters of Neighborhood Deprivation Index (NDI) based on Anselin Moran’s I Statistics*
| Cluster Type | Overall number of countries | South | Northeast | Mid-West | West |
|---|---|---|---|---|---|
| Unclustered | 1129 (36%) | 464 (33%) | 76 (35%) | 342 (32%) | 247 (60%) |
| High Deprivation | 830 (27%) | 757 (53%) | 5 (2%) | 34 (3%) | 34 (8%) |
| Low Deprivation | 873 (28%) | 50 (4%) | 116 (53%) | 602 (57%) | 105 (25%) |
| High Cluster Outlier | 125 (4%) | 16 (1%) | 18 (8%) | 71 (7%) | 20 (5%) |
| Low Cluster Outlier | 152 (5%) | 136 (10%) | 2 (1%) | 6 (1%) | 8 (2%) |
| Total | 3109 (100%) | 1423 (100%) | 217 (100%) | 1055 (100%) | 414 (100%) |
Note:
Anselin Moran’s I Statistic identifies statistically significant clusters of values
In the U.S., there were statistically significant clusters of both high and low NDIs (Table 3). For example, 27% of all U.S. counties were considered to be within statistically significant clusters of high NDI values. These relationships differed by region with 53% of Southern counties, 2% of Northeastern counties, 3% of Mid-Western counties, and 8% of Western counties being within statistically significant clustering of high NDI values. Similarly, 28% of all U.S. counties were classified as being within a clustering of low NDI values. There are regional differences in the clustering of low NDI scores with 4% of Southern counties, 53% of Northeastern counties, 57% of Mid-Western counties, and 25% of Western counties being classified within a statistically significant cluster of low NDI scores.
3.4. The Anselin Local Moran’s I – Regional
The results of the Anselin Local Moran’s I indicated that high deprivation clusters are located in counties in Northern Arizona, California, and southern Texas in addition to the majority of the Southeastern U.S. (Main Map). Clustering of low NDI scores are primarily located in the Northeastern and Midwestern states (Main Map).
In the Southeastern states, the highest deprived areas appear to be widespread among all of the states, except for Texas. In Texas, high deprivation clusters appear to be in areas bordering Louisiana, Oklahoma, and Arkansas in addition to southern and western Texas. (Figure 5). Large clusters of low deprivation areas appear to be clustered in Maryland and northern Virginia, northern Oklahoma, and central Texas. Several low deprivation cluster outliers can be found around several major cities including Frankfort and Lexington, Kentucky; Nashville and Knoxville, Tennessee; Birmingham, Huntsville, and Montgomery, Alabama; Jackson, Mississippi; Little Rock, Arkansas;; Atlanta, Georgia; Columbia, South Carolina; and Raleigh-Durham, North Carolina (Figure 5).
Figure 5.
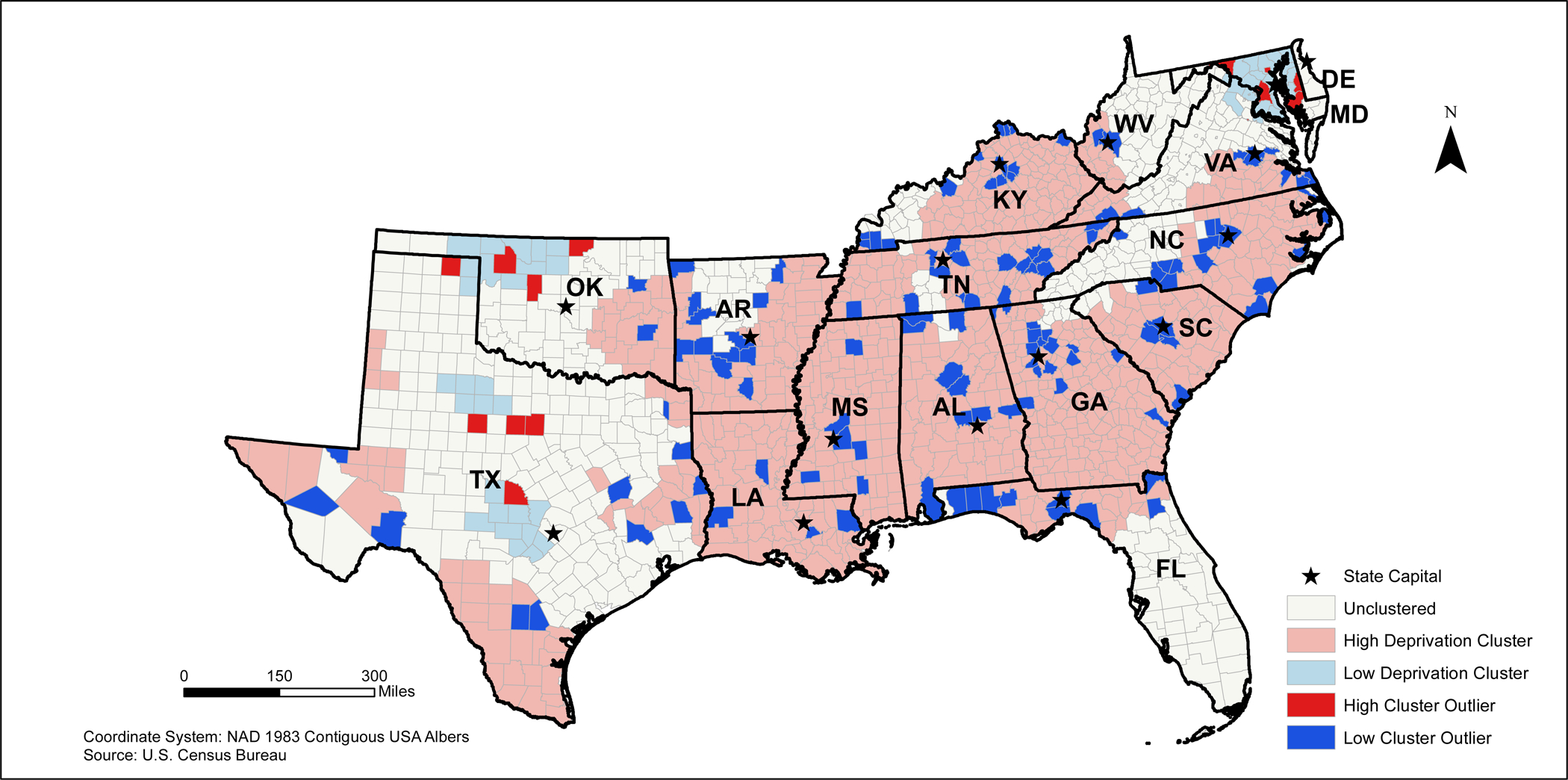
2010 Southeastern States Neighborhood Deprivation Anselin Moran’s I Results
In the Northeastern U.S., the high deprivation clusters are found in the New York City metropolitan area and near Concord, New Hampshire. Large clusters of low deprivation areas are found throughout the majority of these states. However, there are high deprivation outliers located throughout central and south Pennsylvania, east New York, counties in southern Massachusetts, counties in northeastern Connecticut, and counties in northern Rhode Island (Figure 6). Low deprivation outliers were located in the counties outside of the New York City metropolitan area.
Figure 6.
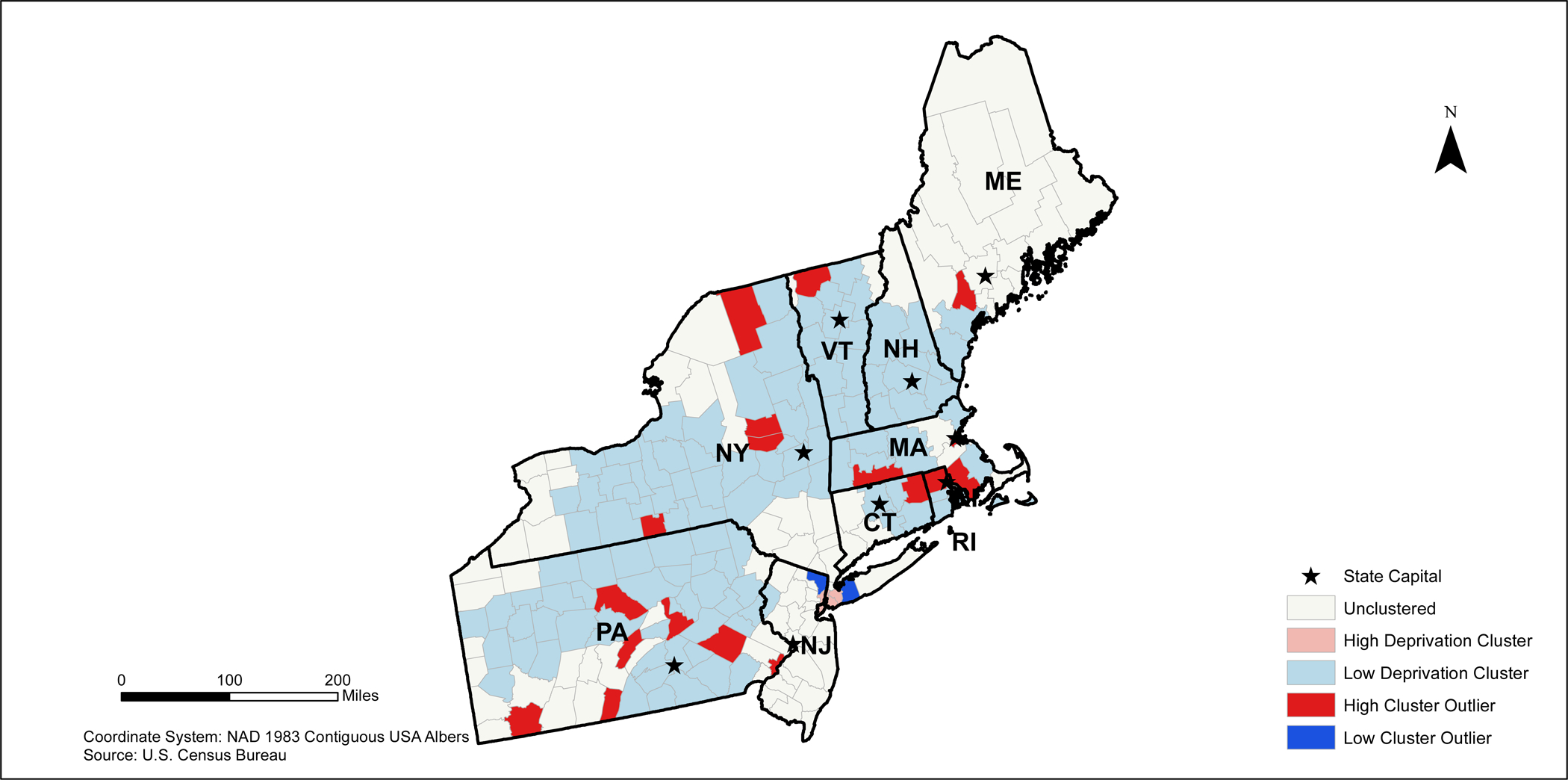
2010 Northeastern States Neighborhood Deprivation Anselin Moran’s I Results
In the Midwestern states, the highest deprived areas appear to be concentrated in southern Missouri and southern Ohio (Figure 7). Low deprivation clusters are found primarily in most states except Ohio; however, high deprivation outliers appear to be concentrated around several midwestern cities including Chicago and Springfield, Illinois (Figure 4b). Low deprivation outliers are relatively sparse in this region except for several counties in central South Dakota, southern Indiana, and southern Ohio.
Figure 7.
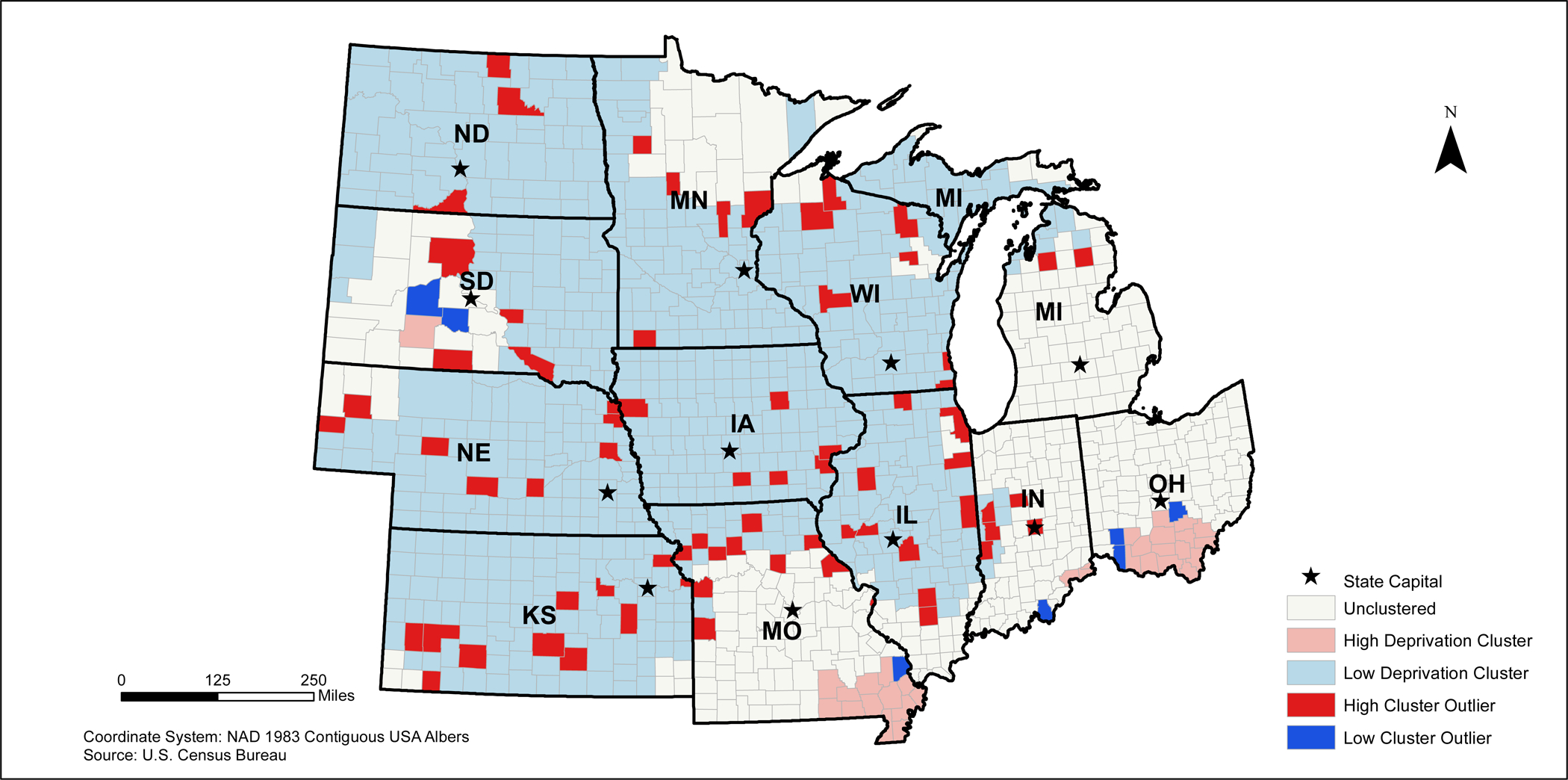
2010 Midwestern States Neighborhood Deprivation Anselin Moran’s I Results
In the western states, areas with a high NDI clusters appear to be located throughout California, northeastern Arizona and northwestern and southeastern New Mexico (Figure 8). Low deprivation clusters are located primarily in Colorado, Wyoming, Utah, and Montana. High deprivation outliers are found primarily in northeastern Colorado, southern Wyoming, and southeastern Montana. Low deprivation outliers are located in several counties near coastal California, southeastern Arizona, western New Mexico, and inland Washington.
Figure 8.
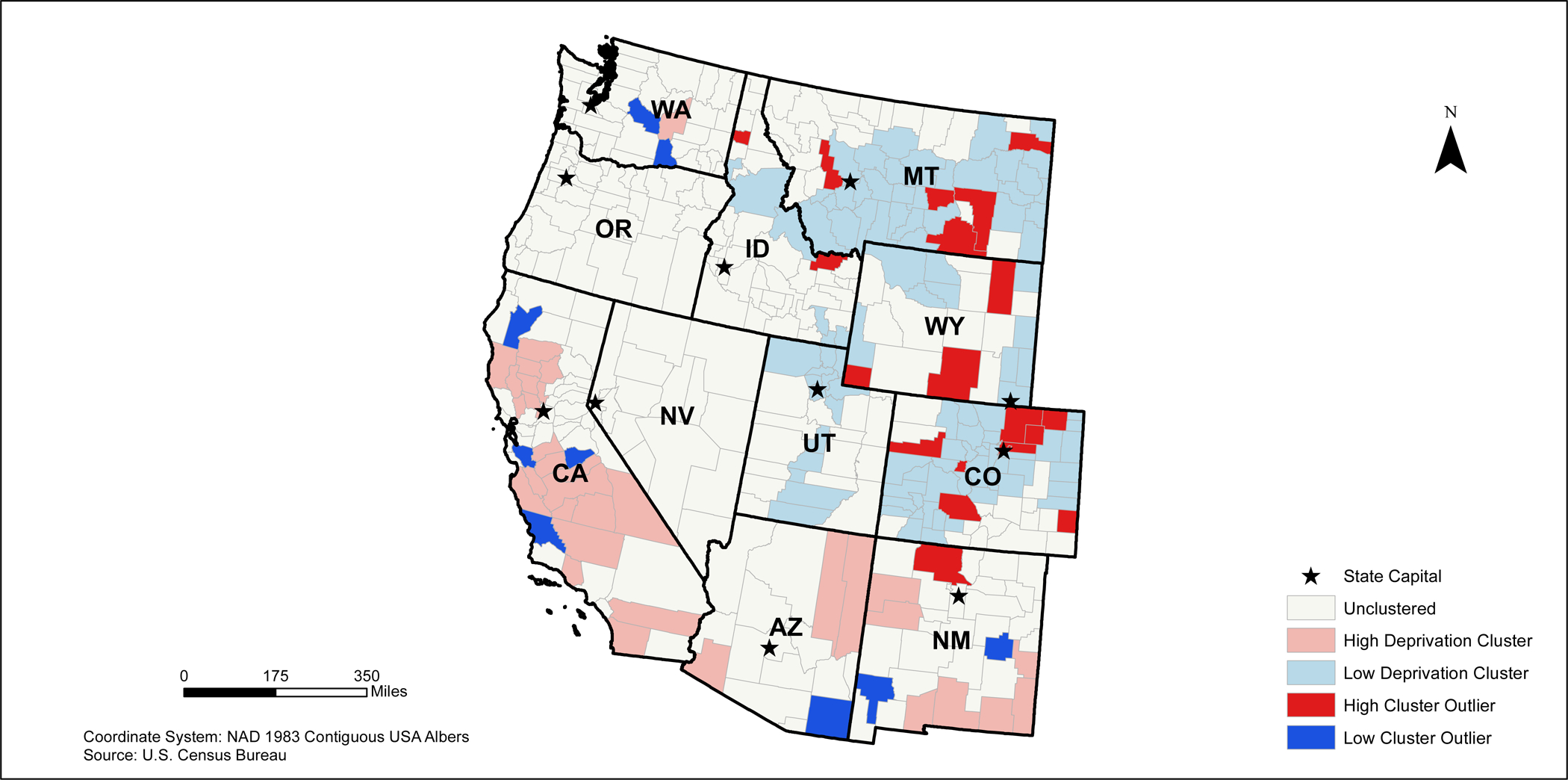
2010 Western States Neighborhood Deprivation Anselin Moran’s I Results
3.5. County Characteristics based on Anselin Local Moran’s I Results
When examining characteristics of counties based on deprivation categories, we found that high deprivation counties were more likely to be mostly rural (n=406) where low deprivation counties were more likely to be mostly urban (n=310) (Table 4). Additionally, high deprivation counties had a higher percentage of people who are under 45 (58.38%), whereas low deprivation counties had a higher percentage of people 45 and older (46.59%). Out of those who live in low deprivation areas, 90.04% of them were White, 1.54% were Black, 4.50% were Hispanic, 0.89% were Native American, 0.93% were Asian, 0.04% were Pacific Islander, 0.07% were Other, and 0.07% were two or more races. Out of those who live in high deprivation areas, 65.74% were White, 21.57% were Black, 8.06% were Hispanic, 1.30% were Native American, 0.74% were Asian, 0.04% were Pacific Islander, 0.08% were Other, and 1.27% were two or more races. In the high deprivation areas, there were 9,922 years of potential life lost, 23% of people reporting fair or poor health, 24% of adults who smoke, 34% of adults who were obese, and 32% of adults who were physically inactive; all of these health outcomes were more prevalent in the high deprivation areas compared to the other types of geographic areas. However, 42% of adults in high deprivation clusters had access to exercise facilities, which was the lowest prevalence across the geographic regions. Low deprivation clusters had the highest percentage of adults with Medicare who received diabetes screening (84.35%) as compared to the other regions.
Table 4.
County Characteristics based on Anselin Moran’s I Results
| Unclustered | High Deprivation | Low Deprivation | High Cluster Outlier | Low Cluster Outlier | |
|---|---|---|---|---|---|
| Characteristics | |||||
| Mostly Urban* | 513 | 261 | 310 | 76 | 83 |
| Mostly Rural* | 419 | 406 | 279 | 29 | 45 |
| Completely Rural* | 195 | 163 | 284 | 20 | 24 |
| % of Age Group (SD) | |||||
| % Under 18 | 23.13 (3.62) | 24.08 (2.83) | 22.88 (2.95) | 25.07 (4.37) | 23.28 (3.14) |
| % 18 to 24 | 8.72 (3.93) | 9.34 (2.82) | 8.15 (3.86) | 9.48 (2.52) | 9.09 (4.04) |
| % 25 to 44 | 23.47 (3.13) | 24.96 (2.46) | 22.39 (3.23) | 25.09 (3.13) | 24.91 (3.18) |
| % 45 to 64 | 28.35 (3.41) | 27.20 (2.58) | 29.07 (3.18) | 26.45 (2.98) | 28.14 (3.11) |
| % 65 and older | 16.25 (4.36) | 14.44 (2.73) | 17.52 (4.39) | 13.91 (3.21) | 14.59 (4.08) |
| Race/Ethnicity (SD) | |||||
| % White | 77.77 (21.13) | 65.74 (23.57) | 90.04 (11.31) | 69.17 (25.32) | 76.28 (18.20) |
| % Black | 4.37 (6.47) | 21.57 (20.44) | 1.54 (2.96) | 5.44 (9.73) | 10.18 (9.89) |
| % Hispanic | 14.33 (10.78) | 8.06 (16.23) | 4.50 (5.58) | 11.72 (13.71) | 6.90 (9.35) |
| % Native American | 1.76 (6.27) | 1.30 (5.58) | 0.89 (2.41) | 7.78 (20.04) | 0.64 (1.83) |
| % Asian | 1.16 (2.37) | 0.74 (1.47) | 0.93 (1.58) | 0.96 (1.22) | 1.70 (3.12) |
| % Pacific Islander | 0.07 (0.13) | 0.04 (0.09) | 0.04 (0.10) | 0.04 (0.08) | 0.05 (0.06) |
| % Other | 0.09 (0.09) | 0.08 (0.08) | 0.07 (0.17) | 0.10 (0.17) | 0.11 (0.08) |
| % Two or More Races | 1.59 (1.06) | 1.27 (1.06) | 0.07 (0.17) | 1.59 (1.02) | 1.51 (0.90) |
| Health Related Outcomes (SD) | |||||
| Premature Death (Years of Potential Life Lost)1 | 1845.70 (7734.02) | 9922.00 (2184.17) | 5747.27 (2523.96) | 8438.8 (3725.69) | 7386.26 (2287.42) |
| % Fair or Poor Health2 | 17.02 (5.02) | 23.00 (5.53) | 10.34 (5.56) | 14.8 (6.62) | 15.26 (6.90) |
| % Adult Smokers3 | 21.50 (5.90) | 24.00 (6.13) | 15.20 (7.90) | 21.37 (8.87) | 18.55 (8.00) |
| % Adult Obese4 | 29.71 (3.93) | 34.00 (3.74) | 29.11 (3.80) | 30.95 (4.44) | 29.91 (3.59) |
| % Diabetes Screening5 | 83.44 (6.10) | 83.00 (6.25) | 84.35 (13.78) | 80.62 (15.08_ | 83.76 (10.52) |
| % of Adults Physical Inactive6 | 26.73 (4.97) | 32.00 (4.60) | 26.20 (4.78) | 27.4 (4.23) | 27.38 (4.99) |
| % Access to Exercise7 | 55.21 (24.05) | 42.00 (23.55) | 55.61 (23.29) | 60.31 (23.82) | 55.73 (22.88) |
These numbers represent the number of counties in the contiguous U.S.
Years of potential life lost before age 75 per 100,000 population (age-adjusted) National Center for Health Statistics
Percent of adults reporting fair or poor health (age-adjusted) Behavioral Risk Factor Surveillance System
Percent of adults reporting smoking >=100 cigarettes and currently smoking; Behavioral Risk Factor Surveillance System
Percent of adults that report a BMI >=30; National Center for Chronic Disease Prevention and Health Promotion, Division of Diabetes Translation
Percent of diabetic Medicare enrollees that receive HbA1c screening; Dartmouth Atlas of Health Care
Percent of adults aged 20 and over reporting no leisure-time physical activity; National Center for Chronic Disease Prevention and Health Promotion, Division of Diabetes Translation
Percent of the population with adequate access to locations for physical activity; OneSource Global Business Browser, Delorme map data, ESRI, & US census Tigerline Files
4. Discussion
Despite being one of the highest income countries around the world, the U.S. has significant disparities in overall NDI. These geospatial analyses demonstrate that NDI scores are significantly clustered across the U.S. Based on the maps, NDI varies spatially within the U.S. For example, the highest deprivation areas are found in the Southeastern and Southwestern U.S. and inland regions of Southern California, while the lowest deprivation areas are located in both the Northeastern and Midwestern regions of the U.S. Moreover, lower NDI scores are found in many metropolitan areas across the United States, especially in the Southern states, which may be related to these areas being centralized locations for post-secondary education, company headquarters, and military bases, thus drawing in a large population that allows these areas to be economically stable and wealthier. The Anselin Local Moran’s I illustrated a significant clustering of counties with high NDI found along the Mississippi River in northeastern Louisiana, western Alabama, and eastern Arkansas and extending through southern regions of Alabama, Georgia, and South Carolina. These findings tend to overlap with regions that are considered to be part of the “Stroke Belt/Alley” suggesting that neighborhood deprivation is likely be related to cardiovascular disease (CVD) burden and CVD events in these regions.20
Our findings contribute to the literature regarding the spatial distribution of neighborhood deprivation index scores across the U.S counties. Given the link between NDI and cardiovascular disease, it is important to examine the regionality of cardiometabolic outcomes.21 For example, research has found that Type II diabetes appears to be clustered in the “Stroke Belt” region of the Southeastern U.S.22,23 Using data from the Reasons for Geographic and Racial Difference in Stroke (REGARDS) Study, counties within the highest tertile of coronary heart disease mortality formed a band stretching from the Northeast through Texas through Southern California.24 Data from the Robert Wood Johnson Foundation indicated a similar pattern based on Anselin’s Morans I results. For example, high deprivation areas had higher premature deaths and a higher percentage of people reporting fair or poor health, adult smokers, adults who are obese, and adults who are physically inactive when compared to the other deprivation groups. Leonard et al., found that poor health and high clusters of food insecurity were common in the Mississippi Delta, Black Belt, Appalachia, and Alaska.25 Our findings are supported by this paper and illuminate how social determinants of health are key to understanding the spatial distribution between material deprivation and adverse health outcomes.
Our Anselin Local Moran’s I results take the existing knowledge around neighborhood deprivation and present it visually using GIS technology. Our study illustrated stark differences in the spatial distribution of both low and high areas of NDI based on region. Our results suggest that more urban areas are considered to be low deprivation areas, whereas rural areas are considered to be high deprivation areas. Additionally, 2010 Census data suggest that those who are in these high deprivation areas are younger and more likely to be Black, Hispanic, or Native American. Most of the largest visual differences can be identified in the Southeast as compared to counties in the Northeast. For example, in the Southeast, clusters of counties with low NDI scores are found in the capital cities including Austin (Texas), Tallahassee (Florida), Atlanta (Georgia), Columbia (South Carolina), Frankfort (Kentucky), Charleston (West Virginia), Annapolis (Maryland), and Raleigh (North Carolina). Richmond, Virginia is located in an area without any significant clustering and Dover, Delaware is located in a high deprivation cluster. While the counties immediately surrounding these cities have low NDI values, the counties that are located further away from these regions have clusters of high NDI values. However, the inverse of this phenomenon can be found in the Northeastern counties. With the exception of Providence (Rhode Island), Newark (New Jersey), Bronx (New York), and Boston (Massachusetts), the remaining major cities in the north are located in areas that are classified as a low deprivation area. Overall, these differences suggest to rurality may serve as a catalyst for deprivation in the South, whereby deprivation is concentrated in urban areas within the North.
4.1. Strengths and Limitations
This investigation has several strengths and limitations. Strengths of this study include objective and publicly available measures of county level characteristics. Additionally, we tested for spatial autocorrelations using Moran’s I and Anselin Local Moran’s I, which have not been used in relation to NDI across the U.S. Limitations include the geographic scale as NDI may be better illustrated on the census tract or census block level to draw more specific conclusions regarding a specific population’s neighborhood-level exposure. Additionally, since we are using the county as our unit of analysis, there may be evidence of the modifiable areal unit problem as geopolitical boundaries may change over time, which may ultimately influence our results and the subsequent comparison of these results across multiple years.26 Drawing attention to disparities in neighborhood deprivation can aid in developing health-related interventions for disadvantaged populations.
4.2. Future Directions
These maps can be used in a variety of ways by public health professionals, local government, city planners/developers, and the public. For example, the Kirwan Institute for the Study of Race and Ethnicity from The Ohio State University was commissioned by the Massachusetts Law Reform Institute to examine the geography of opportunity within Massachusetts.27 Specifically, GIS was used to examine the concentration of subsidized housing, housing foreclosures, and subprime lending.27 By using maps highlighting socioeconomic disadvantage, policy makers could yield insight into the contextual factors faced by their constituents. This information is critical when considering public health or public policy initiatives on a regional scale. Based on the NDI, neighborhood initiatives implemented in the Midwest region may not be as successful or applicable to the Southeast region due to differences in overall deprivation, rurality, and racial composition. In addition, it may be important for public health organizations in the Southeast region to place an emphasis on the neighborhood socioeconomic environment and community assets when planning public initiatives given the widespread clustering of high NDI in the Southeast. For example, The Georgia Smoke and Heart Attack Prevention Program provides monitoring, health assessments, and lifestyle coaching to low-income state residents with hypertension.28 North Carolina’s Medicaid managed care program, North Carolina Area Health Education Centers, the University of North Carolina School of Medicine and primary care groups have collaborated to improve chronic disease self-management efforts which led to an increase in the overall number of patients meeting goals for diabetes and cholesterol control.28
In the Texas border areas, Northeastern, Midwestern, and Western states, specifically counties in Southern California, efforts to improve neighborhood deprivation, and subsequent health disparities, should consider focusing on individual counties and regions. For example, The Steps Program in Broome County, New York enrolled rural families in the area in a walking program to increase the number of adults that were walking for more than 30 minutes per day at least 5 days per week. Their efforts led to a nearly 7% increase in the number of adults meeting the activity recommendations of 150 minutes of physical activity per week.28,29 Additionally, many of the highest deprivation areas found in Arizona, New Mexico, Colorado, Utah, North Dakota, South Dakota, Minnesota, and Wisconsin are located on Native American/Indigenous reservations. These maps can be used to target resources for community-based interventions, healthcare facilities, improvements in the built environment, and other funding allocations that will improve health for individuals living on reservations. For example, The Racial and Ethnic Approaches to Community Health (REACH) project and The Albuquerque Area Indian Health Board, Inc., worked with the Ramah Band of Navajo Indians to provide mammograms for indigenous populations in addition to providing public health training and cancer screening techniques to tribal leaders.28 The development of future, targeted public health initiatives, similar to the examples provided above, may benefit from the visual representation of the spatial distribution of county-level NDI. However, this study highlights the future need for more granular geographic investigations of neighborhood deprivation. The maps developed in the study can provide policy makers, medical and lay health professionals alike, with insight into socioeconomic factors that are likely to influence adverse health outcomes for their patients.11
We recognize the barriers to changing the health status of disadvantaged communities, such as financial limitations of the tax base in high NDI areas with subsequent limited investment and available resources for healthy living.25,30 Our maps also demonstrate the clustering of limited-resource communities, which exacerbates these barriers. However, ongoing partnerships between public health departments in high NDI communities and academia may help in addressing these barriers. Ultimately, these maps can not only aid policy makers, but can help academic researchers when partnering with disadvantaged communities to empower advocacy work by these communities’ leaders, particularly through community-based participatory research efforts to improve population health. Engagement efforts, including community-based participatory research, can also facilitate improved neighborhood social cohesion as increased neighborhood social cohesion has been shown to be protective against adverse health outcomes.31 Recent research has also highlighted the impact of community and research partnerships. The Academic Community Engagement Core of the Mid-South Transdisciplinary Collaborative Center for Health Disparities Research partnered with a disadvantaged community in Birmingham, Alabama to engage in coalition building and a community survey.32 By engaging the community, the research team was able to establish a community coalition to better address the needs of their community. An additional approach for community-academic partnerships could include asset mapping.33 By identifying community assets, researchers can work to help community leaders link residents in these disadvantaged communities to existing resources and identify additional resource needs for which programming can be developed.
Additionally, disadvantaged communities have a variety of structural disadvantages including an increased density of fast food establishments, less conducive environments for physical activity, increased violence, and lack of adequate housing34. A potential policy recommendation could include increasing the number of affordable housing developments in disadvantaged neighborhoods. A recent Stanford University study examined the impact of multifamily housing developments funded by the Low Income Housing Tax Credit on surrounding neighborhoods. Their results indicated that building more affordable housing units in low income areas would lead to a reduction in violent and property crime, an increase in the income of home buyers, and an increase in income diverse populations.35 These increases could potentially lead to more investment and community assets within these materially deprived areas.
Software
NDI data were collected from the United States Census Bureau and downloaded as Microsoft Excel files. NDI data were then loaded into ArcGIS 10.5.1 as a CSV file and spatially joined with United States County Cartographic Shapefiles based on County FIPS Codes. Final map production was conducted using ArcGIS 10.5.1.
Map Design
The choice to omit water systems within the United States was done to ensure that the maps were accurate and legible.
Figure 9.
Main Map. Neighborhood Deprivation Index (NDI) for the United States by County (2010)
Main Map. 2010 Contiguous United States Neighborhood Deprivation Anselin Moran’s I Clusters (2010)
Acknowledgements
The Powell-Wiley laboratory is funded by the Division of Intramural Research of the National Heart, Lung, and Blood Institute and the Intramural Research Program of the National Institute on Minority Health and Health Disparities (National Institutes of Health). This research was also made possible by the National Institutes of Health (NIH) Medical Research Scholars Program, a public-private partnership supported jointly by the NIH and generous contributions to the Foundation for the NIH from the Doris Duke Charitable Foundation, Genentech, the American Association for Dental Research, the Colgate-Palmolive Company, Elsevier, alumni of the student research programs, and other supporters via contributions to the Foundation for the National Institutes of Health. The views expressed in this manuscript are those of the authors and do not necessarily represent the views of the National Heart, Lung, and Blood Institute; the National Institute on Minority Health and Health and Health Disparities; the National Institutes of Health; or the U.S. Department of Health and Human Services.
Footnotes
Conflict of Interest: none.
Financial Disclosure: none.
References
- 1.Robinette JW; Charles ST., Gruenewald T. Neighborhood Socioeconomic Status and Health: A Longitudinal Analysis. J Community Health. 2017;42:865–871. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Diez Roux AV, Mair C, Roux AVD, Mair C, Diez Roux AV, Mair C. Neighborhoods and health. Ann N Y Acad Sci [Internet]. 2010;1186:125–145. Available from: http://search.ebscohost.com/login.aspx?direct=true&db=a9h&AN=48116272&site=ehost-live [DOI] [PubMed] [Google Scholar]
- 3.Commission on the Social Determinants of Health. Closing the gap in a generation: Health equity through action on the social determinants of health. Final Rep Comm Soc … [Internet]. 2008;246 Available from: https://scholar.google.co.in/scholar?q=closing+the+gap+in+a+generation&btnG=&hl=en&as_sdt=0%2C5#2 [Google Scholar]
- 4.Schootman M, Andresen EM, Wolinsky FD, Malmstrom TK, Miller JP, Yan Y, Miller DK. The effect of adverse housing and neighborhood conditions on the development of diabetes mellitus among middle-aged African Americans. Am J Epidemiol. 2007;166:379–387. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Diez-Roux AV, Nieto FJ, Caulfield L, Tyroler HA, Watson RL, Szklo M. Neighbourhood differences in diet: the Atherosclerosis Risk in Communities (ARIC) Study. J Epidemiol Community Heal [Internet]. 1999;53:55–63. Available from: http://www.ncbi.nlm.nih.gov/pubmed/10326055 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Moore LV, Diez Roux AV, Evenson KR, McGinn AP, Brines SJ. Availability of Recreational Resources in Minority and Low Socioeconomic Status Areas. Am J Prev Med. 2008;34:16–22. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Yen IH, Kaplan GA. Poverty area residence and changes in physical activity level: evidence from the Alameda County Study. Am J Public Health [Internet]. 1998;88:1709–1712. Available from: http://ajph.aphapublications.org/doi/10.2105/AJPH.88.11.1709 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Morland K, Wing S, Roux AD. The contextual effect of the local food environment on residents’ diets: The atherosclerosis risk in communities study. Am J Public Health. 2002;92:1761–1767. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Graham SR, Carlton C, Gaede D, Jamison B. The Benefits of Using Geographic Information Systems As a Community Assessment Tool. Public Health Rep. 2011;126:298–303. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Carter C Identifying South Carolina’s Affluent and Deprived Counties: Computing with Standard Scores and Visualizing with Tableau Choropleth Maps. 2018.
- 11.Kind AJH, Buckingham WR. Making Neighborhood-Disadvantage Metrics Accessible — The Neighborhood Atlas. N Engl J Med. 2018; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Bureau USC. American Community Survey [Internet]. 2010;Available from: https://factfinder.census.gov/faces/nav/jsf/pages/searchresults.xhtml?refresh=t
- 13.Lian M, Struthers J, Liu Y. Statistical Assessment of Neighborhood Socioeconomic Deprivation Environment in Spatial Epidemiologic Studies. Open J Stat [Internet]. 2016;6:436–442. Available from: http://www.ncbi.nlm.nih.gov/pubmed/27413589%5Cnhttp://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=PMC4940131 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Diez Roux AV, Borrell LN, Haan M, Jackson SA, Schultz R. Neighbourhood environments and mortality in an elderly cohort: Results from the cardiovascular health study. J Epidemiol Community Health. 2004; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Feng C, Wang H, Lu N, Chen T, He H, Lu Y, Tu XM. Log-transformation and its implications for data analysis. Shanghai Arch psychiatry. 2014; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.MORAN PA. Notes on continuous stochastic phenomena. Biometrika. 1950;37:17–23. [PubMed] [Google Scholar]
- 17.Esri. Spatial Autocrrelation (Global Moran’s I).
- 18.Anselin L Local Indicators of Spatial Association—LISA. Geogr Anal. 1995;27:93–115. [Google Scholar]
- 19.ArcGIS. How Spatial Autocorrelation (Global Moran’s I) works [Internet]. 2018;Available from: http://pro.arcgis.com/en/pro-app/tool-reference/spatial-statistics/h-how-spatial-autocorrelation-moran-s-i-spatial-st.htm
- 20.Prevention C-D for HD and S. Stroke Death Rates, Total Population 35+ [Internet]. 2018. [cited 2018 Sep 8];Available from: https://www.cdc.gov/dhdsp/maps/national_maps/stroke_all.htm
- 21.Stimpson JP, Ju H, Raji MA, Eschbach K. Neighborhood deprivation and health risk behaviors in NHANES III. Am J Health Behav. 2007;31:215–222. [DOI] [PubMed] [Google Scholar]
- 22.Lee LT, Alexandrov AW, Howard VJ, Kabagambe EK, Hess MA, McLain RM, Safford MM, Howard G. Race, regionality and pre-diabetes in the Reasons for Geographic and Racial Differences in Stroke (REGARDS) study. Prev Med (Baltim). 2014; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Cushman M, Cantrell RA, McClure LA, Howard G, Prineas RJ, Moy CS, Temple EM, Howard VJ. Estimated 10-year stroke risk by region and race in the United States: Geographic and racial differences in stroke risk. Ann Neurol. 2008; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Shuaib FM, Durant RW, Parmar G, Brown TM, Roth DL, Hovater M, Halanych JH, Shikany JM, Howard G, Safford MM. Awareness, Treatment and Control of Hypertension, Diabetes and Hyperlipidemia and Area-Level Mortality Regions in the Reasons for Geographic and Racial Differences in Stroke (REGARDS) Study. J Health Care Poor Underserved. 2012; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Leonard T, Hughes AE, Donegan C, Santillan A, Pruitt SL. Overlapping geographic clusters of food security and health: Where do social determinants and health outcomes converge in the U.S? SSM - Popul Heal. 2018; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Waller L a, Gotway C a. Applied Spatial Statistics for Public Health Data [Internet]. 2004. Available from: http://pubs.amstat.org/doi/abs/10.1198/jasa.2005.s15
- 27.Reece Jason; Gambhir S. The Geography of Opportunity: Building Communities of Opportunity in Massachusetts [Internet]. 2009. Available from: http://kirwaninstitute.osu.edu/reports/2009/01_2009_GeographyofOpportunityMassachusetts.pdf
- 28.Health T for A. Examples of Successful Community-Based Public Health Interventions (State-by-State) [Internet]. 2009. Available from: https://www.tfah.org/wp-content/uploads/2018/09/Examplesbystate1009.pdf
- 29.US Department of Health and Human Services. 2008 Physical activity guidelines for Americans. 2008.
- 30.Center FR& A. Why Low-Income and Food-Insecure People are Vulnerable to Poor Nutrition and Obesity.
- 31.Brisson D, Lechuga Peña S, Plassmeyer M. Prioritizing Choice: Perceptions of Neighborhood Social Cohesion for Residents in Subsidized Housing. J Soc Serv Res. 2018; [Google Scholar]
- 32.Bateman LB, Fouad MN, Hawk B, Osborne T, Bae S, Eady S, Thompson J, Brantley W, Crawford L, Heider L, Schoenberger YMM. Examining neighborhood social cohesion in the context of community-based participatory research: Descriptive findings from an academic-community partnership. Ethn Dis. 2017; [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Kretzmann JP, McKnight JL. Introduction. Build Communities from Insid Out A Path Towar Find Mobilizing a Community’s Assets. 1993;1–11. [Google Scholar]
- 34.Khullar D, Chokshi DA. Health, Income, & Poverty: Where We Are & What Could Help. Health Aff. 2018; [Google Scholar]
- 35.Diamond R, McQuade T. Who Wants Affordable Housing in Their Backyard? An Equilibrium Analysis of Low-Income Property Development. J Polit Econ. 2018; [Google Scholar]