

Abstract
In the olfactory system, odor percepts retain their identity despite substantial variations in concentration, timing, and background. We study a novel strategy for encoding intensity-invariant stimulus identity that is based on representing relative rather than absolute values of stimulus features. For example, in what is known as the primacy coding model, odorant identities are represented by the conditions that some odorant receptors are activated stronger than others. Because, in this scheme, the odorant identity depends only on the relative amplitudes of olfactory receptor responses, identity is invariant to both changes in intensity and monotonic non-linear transformations of its neuronal responses. Here we show that sparse vectors representing odorant mixtures can be recovered in a compressed sensing framework via elastic net loss minimization. In primacy model, this minimization is to be performed under the constraint that some receptors respond to a given odorant stronger than others. Using duality transformation, we show that such a constrained optimization problem can be solved by a neural network whose Lyapunov function represents the dual Lagrangian and whose neural responses represent the Lagrange coefficients of primacy and other constraints. The structure of connectivity in such a dual network resembles known features of connectivity in the olfactory circuits. We thus propose that networks in the piriform cortex implement dual computations to compute odorant identity with the sparse activities of individual neurons representing Lagrange coefficients. More generally, we propose that sparse neuronal firing rates may represent Lagrange multipliers, which we call the dual brain hypothesis. We show such a formulation is well-suited to solve problems with multiple interacting relative constraints.
1. INTRODUCTION
Sensory systems face the problem of identifying stimulus features that are invariant to various transformations. The olfactory system, for example, has to identify stimuli despite substantial variations in odorant concentration. Computing concentration invariant odor identity is necessary to enable a stable perception in chemical gradients and turbulent odorant plumes. How can the olfactory system robustly represent odorant identity despite variable stimulus intensity? The first step of olfactory processing involves odorants binding to and activating a set of molecular sensors known as olfactory receptors (ORs). ORs are proteins expressed by olfactory sensory neurons (OSNs) located in the nose. Most mammalian olfactory systems contain ~1000 types ORs, while humans rely on the responses of only 350 (Firestein, 2001; Koulakov et al., 2007; Zhang and Firestein, 2002). Importantly, every OSN expresses only a single type of OR chosen randomly out of the large ensemble. Odorant identity is then interpreted from the patterns of activation of OR and, by extension, OSNs. Here we examine the hypothesis that stimulus identity is inferred by the relative amplitudes of OSN responses. In particular, we propose that odorant identity can be determined using only the information that a subset of receptors individually respond more strongly than all other receptors. We call this type of representation the primacy model. The primacy model is inspired by a recent experimental observation that odorant identity is recognized on the basis of inputs present within the first 100 milliseconds of the animal’s sniff cycle (Wilson et al., 2017). We will show that the coding scheme based on the primacy model yields odorant representations that are independent of absolute odorant concentration. We will formulate this identity decoding scheme using a dual Lagrange-Karush-Kuhn-Tucker problem and argue that this dual problem can be solved by a neural network that we call a dual network. Dual networks that implement the primacy model share many features with real olfactory networks. Our goal is therefore to derive the structure of olfactory circuits from first principles, based on the primacy model.
2. RESULTS
2.1. Representing odorants by sparse vectors.
Ethologically important odorant stimuli are mixtures of monomolecular components. Such stimuli can be represented by a vector of concentrations . Each component of this vector xj is equal to the concentration of an individual monomolecular component numbered by index j. The number of potential monomolecular components, which is equal to the dimensionality of vector , will be denoted here by M. This number can be estimated to be around several million, M ~ 106, based on the count of potentially volatile molecules with molecular weight less than 300 Dalton in the popular database PubChem (Kim et al., 2016). However, ethological odorant mixtures do not contain all of these molecules at the same time, and are therefore represented by sparse vectors . For the purposes of olfactory system, sparseness of the concentration vector is further increased by inability of the system to detect or recognize individual components. Indeed, psychophysical studies suggest that the number of monomolecular components of the vector detectable by a human observer K is close to 12 (Jinks and Laing, 1999). Overall, we suggest that ethologically relevant odorants can be defined by highly dimensional (M ~ 106), sparse concentration vectors with very few non-zero elements (K ~ 10).
Odorant mixtures then enter the olfactory system through the responses of ORs . These responses, to the first approximation, can be represented by a linear nonlinear function of the concentration vector . In the simplest model, using receptors with only one binding site and no cooperativity, the law of mass action yields:
| (2.1) |
| (2.2) |
Here index i = 1…N enumerates OR types. The total number of functional OR types, N, varies between 350 in humans and 1100 in rodents. Matrix element Aij can be interpreted as the affinity of molecule type j to receptors of type i. F(y) = y/(1+y) is the nonlinear function describing activation of a receptor (Appendix A).
The problem solved by the olfactory system can then be formulated as follows: find the identity of the odorant stimulus xj given the set of responses of olfactory sensory neurons ri.
2.2. Sparse olfactory stimulus recovery.
In many concentration regimes, it is reasonable to approximate the receptor response ri using only its linear input yi. In this case, the problem solved by olfactory system (how to find given ) can be reduced to solving the system of linear equations (2.2). This problem is not entirely trivial, because the number of unknowns (components of , M ~ 106) is substantially larger than the number of equations (components of , N ~ 103). Some help comes from the fact that the vector of unknowns is sparse. The problem of recovering a sparse vector from a system of linear equations has been addressed in compressed sensing (Baraniuk, 2007; Donoho and Tanner, 2005, 2006). In this framework, vector can be found exactly, despite the fact that it contains more components than equations. This is because the vector is sparse and the number of non-zero components is small. To be able to find exactly, a certain condition has to be met relating parameters M, N, and K. This condition can be understood by comparing the amounts of information contained in the input and output space. One can accurately determine the unknowns, if the information capacity of exceeds that of . These two amounts can be estimated by using the statistical physics definition of the amount of information:
| (2.3) |
Here H and Γ are the amount of information and the number of states a variable can take, respectively. For example, a string of N binary numbers contains H = N bits of information, which follows from equation (2.3) if the number of possible values of the binary string is Γ = 2N. The number of values taken by the receptor response vector can then be estimated as Γy ~ 2N (for the purposes of our order-of-magnitude estimate, we assume here that the elements of are binary). The number of possible combinations contained in the concentration vector can be estimated as the number of ways to place K non-zero elements into M bins, i.e. . Similar to the estimate for receptor responses, we assume here that concentrations are binary. This assumption is reasonable if the number of distinguishable concentrations for an element of is much less than the total number of elements in , M. Thus, equation (2.2) can be solved exactly if the number of combinations contained in vector is larger than the number of possible states of the concentration vector , i.e. Γy > Γx, which, given our estimates, yields the following condition:
| (2.4) |
This condition can be recognized as the necessary condition for sparse signal recovery using l1 norm minimization obtained by Donoho and Tanner (Donoho and Tanner, 2005, 2006). For K ~ 10 and M ~ 106 we obtain the following constraint for the number of OR types necessary for the recovery of the sparse stimulus: N > 200, which is satisfied for both humans (N ≈ 350) and mice (N ≈ 1100). Thus, equation (2.2) can in principle be solved with the existing machinery in the olfactory system. This means that, with linear responses, the olfactory system can reconstruct K ~ 10 monomolecular components given the responses of N ≈ 1100 ORs.
To determine given within compressed sensing, one can use sparse signal recovery via minimization of the l1 norm (Baraniuk, 2007; Donoho and Tanner, 2005, 2006):
| (2.5) |
Here, because molecular concentrations are constrained to be non-negative, minimization of l1 norm is equivalent to minimization of the sum of the components of . Because the system is overcomplete, there are many vectors for which is satisfied exactly. Minimization of l1 norm ensures that the solution is sparse.
Solving the decoding problem using equation (2.5) is somewhat unrealistic because receptor responses are non-linear. Furthermore, the solution of equation (2.5) is not concentration invariant. That is, doubling the mixture concentration results in doubling of each component of the concentration vector , and, as a result, the doubling of the vector of receptor responses . Solving equation (2.5) under the constraint of doubled vector results in a doubled reconstructed vector of concentrations . Our goal, however, is to build a representation that is concentration invariant, and not to be limited to regimes where receptor response is linear. More specifically, we want a representation of an odor which is invariant to multiplication of the concentration vector of that odor by a scalar. This means that we would like to obtain a framework in which doubling receptor responses or the presence of non-linearities, such as given by equation (2.1), does not impact the reconstructed stimulus. Such a model would yield a concentration invariant odorant identity. Next, we show how a primacy-based decoding model can implement such a computation.
2.3. Concentration invariant decoding algorithm via primacy.
To achieve an odorant representation which is invariant to both concentration fluctuations and monotonic nonlinearities of receptor responses, we reformulate the sparse recovery problem to use only relative constraints. Conceptually, the relative constraints we introduce isolate a set of receptor types, each of which respond more strongly than all other receptor types. We call this strongly-responding set of receptors the primacy set P, while all other receptors are denoted by . The primacy set is expected to include p ≪ 1000 receptor types. For these two sets we can state:
| (2.6) |
Here, rP is the set of components of vector that belong to the primacy group P of the given odorant. The expanded version of equation (2.6) is therefore ri ≥ rj for any i ∈ P and . Because the non-linearity relating ri and yi is monotonic, equation (2.6) results in the same constraint on components of vector :
| (2.7) |
Importantly, the inequality (2.7) is invariant to changes in concentration, because concentration changes () multiply both sides of equation (2.7) by the same factor. Also, the identities of the ORs forming the primacy set, P, are unaffected by the non-linearity relating r to y, so long as this non-linearity is monotonically increasing. Thus, reconstructions of using these inequalities inherently have the desired invariances. We therefore reformulate the sparse recovery problem (2.5) as follows:
| (2.8) |
We implement this minimization and show that it converges to reconstruct the stimulus vector in Figure 1. For this simulation and all subsequent simulations in this paper, we use N=400 receptors and M=1000 molecules. We generate affinities Aij from a zero-mean Gaussian distribution truncated at zero such that all affinities are non-negative. In Supplemental Figure 2 we show that this assumption on the distribution of Aij is unnecessary and that our algorithm works for uniform or lognormally distributed Aij matrices for a wide range of the number of receptors N and molecules M.
Figure 1.
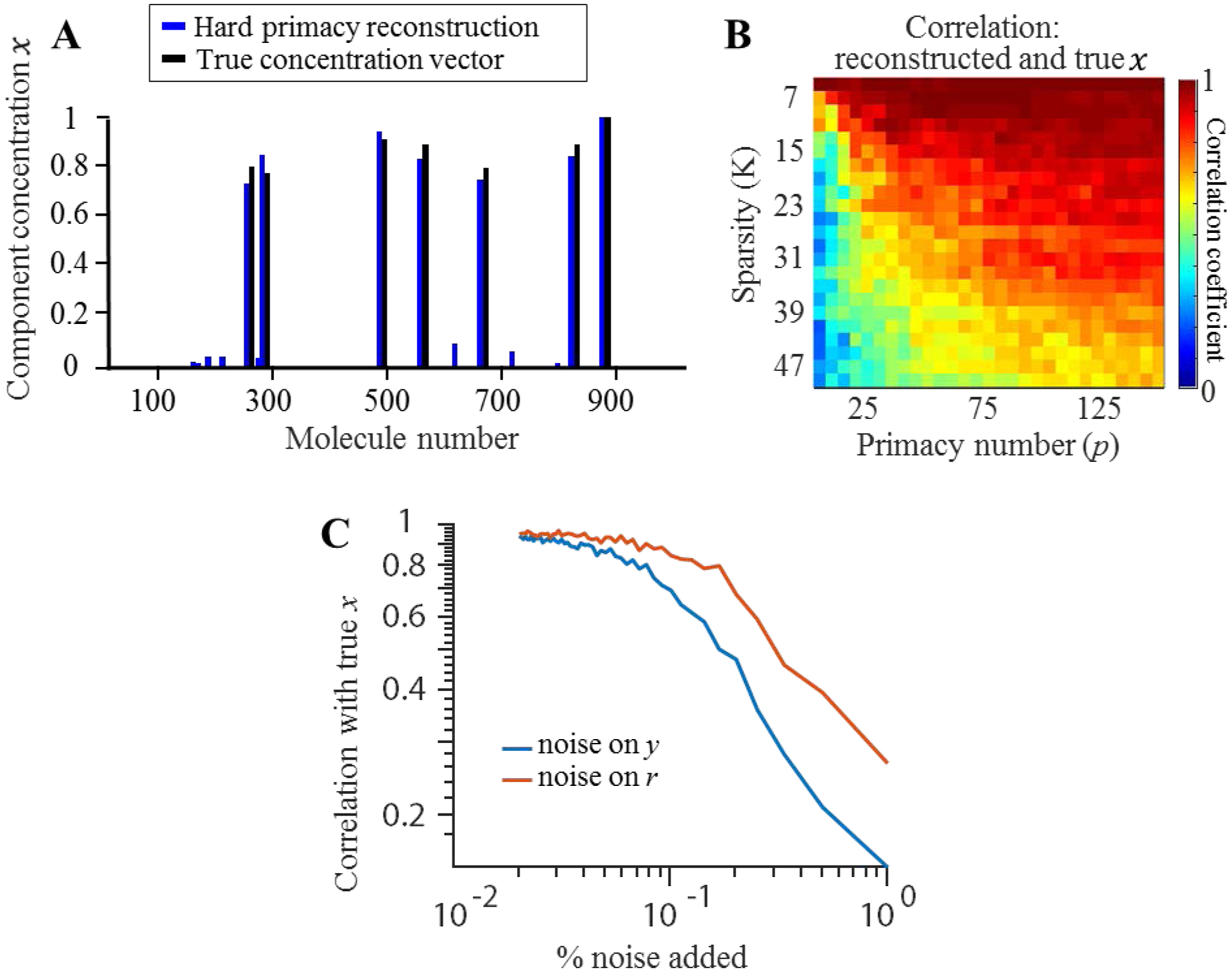
Using relative values of receptor responses can solve the problem of recovering sparse concentration vector . (A) An example concentration vector x alongside its reconstruction (blue) using only relative information that a group of receptors P respond more strongly than the rest. (B) Correlation between the reconstructed and true concentration vectors for different sparsity (K) values and number of primary receptors (p). (C) Correlation between reconstruction and stimulus with various levels of noise injected on input signal(blue) and input neuron response(red).
The nonlinearity on each receptor (2.1) is likely to be similar but not identical. The primacy model would not yield invariant odorant representations when nonlinearities are highly variant for each component of . In this case, large changes in concentration for certain odorants would illicit a different perception as sometimes seen in human perception (Arctander, 1969).
Overall, using the relative rather than the absolute values of sensor responses to recover odorant identity results in invariance with respect stimulus intensity. Using relative responses of sensors has a long history in neuroscience, and includes color constancy (Foster, 2011), responses of differentiating (ON/OFF-center) cells in retina, edge detection in the visual cortex (Rodieck, 1998), and relying on the relative responses of OSNs in the olfactory bulb implemented by normalization (Cleland et al., 2011; Cleland et al., 2007). Although we demonstrated this idea for the particular example of primacy coding, we propose that this neural relativity rule is used to produce perceptual invariance and invariant signal recovery with respect to other stimulus transformations.
In addition to invariance to changes in concentration and monotonic transformations of receptor signals, primacy codes are inherently robust to noise. Not only are the strongest responding receptors the most reliable, but many neighboring concentration vectors share the same primacy set. Furthermore, neighboring primacy sets can produce similar reconstructions. The result is a code unaltered by even high levels of noise, as shown in Figure 1.
Instead of minimizing the pure l1 norm to find sparse solutions, one can minimize the elastic net functional:
| (2.9) |
The equation (2.9) is the same as the l1 norm minimization (2.8) when the parameter ε → 0. For small parameter ε, equation (2.9) yields sparse solutions similar to equation (2.8). Problem (2.9), however allows for an easier dual space formulation. We will therefore use the elastic net minimization [equation (2.9)] to recover olfactory stimuli in the rest of the paper with a sufficiently small parameter ε such that the elastic net and l1 solutions are close.
2.4. Number of receptors needed to implement primacy coding.
Since we are using relative response information to decode the sensory input, we have to amend our estimate (2.4) of the number of receptors necessary to fully recover a sparse stimulus. In the primacy model, the amount of information in is reduced as we are only concerned with the p strongest responding receptors. Therefore, the number of combinations in is given by the binomial coefficient . By keeping the estimate for the number of combinations in the same, i.e. Γx ~ MK, and assuming that, for reconstructing , the number of combinations of has to exceed the number of combinations in , we easily arrive at the following condition:
| (2.10) |
For a typical mammal, such as mouse, in which the number of ORs is approximately N ≈ 1000, we obtain p > 2K. For humans, in which the number of functional ORs is N ≈ 350, the primacy number (the size of the primacy receptor set) required is somewhat higher, p > 2.4K. In both of these estimates we assumed that the number of molecule types available in the environment is close to M ~ 106. If one assumes that the number of discernable molecular components in each mixture is K ~ 12, as follows from human psychophysics (Jinks and Laing, 1999), we obtain the primacy number p > 30 which is substantially less than the total number of receptors in humans N ≈ 350.
2.5. Hard primacy conditions.
Problem (2.9) includes various inequality constraints, including the primacy constraints (2.6) . These conditions can be reformulated in a more convenient form. Indeed, conditions (2.6) have no scale in them. Therefore, minimization of the l1 norm or elastic net functional of connected to via a set of positive coefficients A () results in the trivial solution . To obtain a non-zero solution, one has to introduce a finite scale into the conditions (2.6). A set of conditions with the constrained magnitude is
| (2.11) |
where γ ≥ 0 is the scale parameter. The value of this parameter is arbitrary and so we use γ = 1 in all simulations. In addition to providing a nonzero solution, introduction of a scale parameter also reduces the number of constraints in equation (2.6) from p(N − p) to N. By introducing a sign variable ui = +1 for i ∈ P and ui = −1 for , equation (2.11) can be rewritten as a single set of conditions
| (2.12) |
Here where the affinity of receptor i to odorants j are given by a set of non-negative numbers Aij. Problem (2.9) combined with constraints (2.12) represents our primal optimization problem. Constraints defined by equation (2.12) will be called the ‘hard primacy conditions’.
2.6. Soft primacy conditions.
As an alternative to (2.12), we propose a simpler set of conditions:
| (2.13) |
These conditions operate differently for primary versus non-primary receptors. For the primary set, i ∈ P, they are equivalent to conditions (2.12), i.e. yi ≥ γ. Therefore, these inequalities ensure that the responses of primary receptors are larger than parameter γ. For non-primary receptors, these inequalities become yi ≥ −γ. Since , and both A and x are non-negative, this inequality is always satisfied. Therefore, conditions (2.13) define the lower limit for the primary set of receptors, but not for the non-primary receptors. We therefore call inequalities (2.13) the ‘soft primacy conditions’.
Interestingly, however, the soft primacy conditions implicitly constrain the non-primary receptors as well. Although conditions (2.13) for non-primary receptors become trivial, i.e. yi ≥ −γ, minimization of vector minimizes the unconstrained elements of vector , or non-primary elements. In practice, we find that, after minimizing the norm of , non-primary receptors obey , as required by the hard primacy conditions. Thus, for practical purposes, the soft primacy conditions are equivalent to the hard ones. As we showed before (Kepple, 2016), the hard primacy conditions result in dual networks with an interaction matrix dependent on odor stimuli, i.e. vector ui, which is difficult to implement biologically. Below, we show that the soft primacy conditions can be implemented by a network with weights independent on the odorants presented. Thus, the network implementation based on the soft primacy conditions is more biologically plausible. We will therefore adopt the soft primacy conditions for the remainder of this paper. The approximate equivalence between soft and hard primacy conditions is illustrated in Figure 2. We therefore formulate the following primal problem that can potentially be solved by the olfactory system:
| (2.14) |
Figure 2.
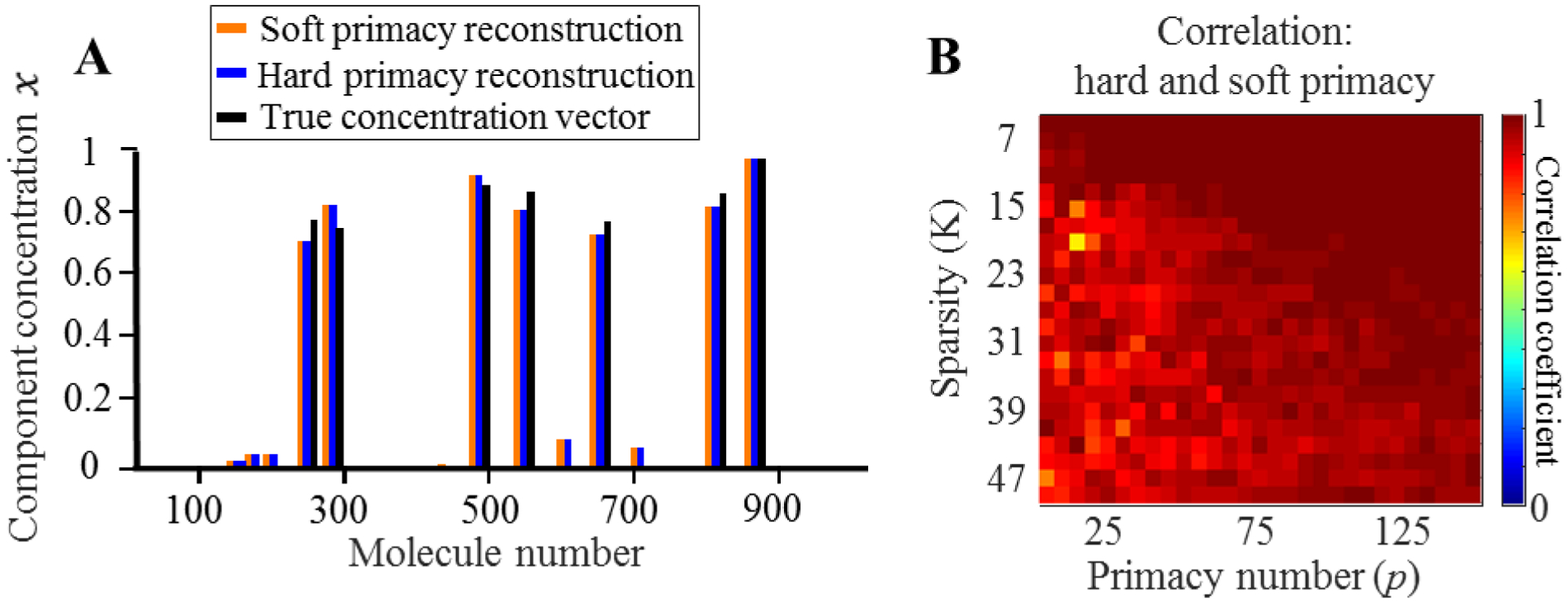
The solutions provided by soft and hard primacy conditions are similar. (A) An example concentration vector alongside its hard primacy reconstruction (blue) and the soft primacy reconstruction (orange). (B) The correlation between the hard and soft primacy solutions for various sparsity K and primacy number p.
2.7. Formulation of the dual problem.
The primal problem (2.14) cannot be easily solved by a neural network. To implement a neural network solution, we use its dual formulation. To transform the primal minimization problem (2.14) into its dual problem, we introduce a cost function (Lagrangian) with two sets of Lagrange multipliers, αi and βj. Each multiplier αi, with i = 1..N, enforces an individual soft primacy constraint (2.13), yi − uiγ ≥ 0. Each βj enforces a constraint xj ≥ 0 for j = 1..M. The full Lagrangian for the elastic net minimization problem (2.14) is as follows
| (2.15) |
In this equation, the Lagrange multipliers αi and βj represent the importance of different constraints. Because the cost function (2.15) will be minimized with respect to , Lagrange multipliers are constrained to have non-negative values, i.e. αi,βj ≥ 0 (Boyd and Vandenberghe, 2004). This ensures that at the minimum of the cost function, the target conditions, yi − uiγ ≥ 0 and xj ≥ 0, are satisfied. If, for example, one of the coefficients βj were negative in equation (2.15), decreasing the corresponding xj below zero may be found to be advantageous from the point of view of minimizing the cost function.
To derive the dual formulation of the primal optimization problem (2.14), we minimize Lagrangian (2.15) with respect to as if no constraints were present. We therefore find the optimal value of denoted here as . We then rewrite the Lagrangian with this optimal value of which depends only on and . The resulting function is called the dual Lagrangian :
| (2.16) |
| (2.17) |
Here is the Gramm matrix (the matrix of pairwise scalar products) for rows of affinity matrix .
According to optimization theory (Boyd and Vandenberghe, 2004; Dantzig, 1963) the dual Lagrangian is to be maximized to find the optimal values of and . These values can then be used to find the solution of the primal problem using equation (2.16). One can think of dual Lagrangian, a function of the constraint multipliers and , as a lower bound for the primal problem. Thus we maximize the dual Lagrangian because we want to find the greatest lower bound for our minimization problem. The dual problem can therefore be formulated as follows
| (2.18) |
The dual problem is formulated in terms of Lagrange multipliers and . This makes it different from the primal optimization problem (2.14), which is formulated in terms of . The solution to the dual problem, however, is also the solution to the primal problem, since they are connected via equation (2.16).
The reason why the dual problem (2.18) is sometimes preferred to the primal problem (2.14) is in the simplicity of its constraints. In many cases, the constraints αi,βj ≥ 0 are easier to implement than the primal problems inequalities. The important observation that we make here is that neural systems are well suited for implementing dual optimizations. For example, it is especially easy to impose non-negativity constraints, because neural responses are described by firing rates that cannot fall below zero. Motivated by this observation, we argue that the Lagrange multipliers and could be represented by responses of different types of olfactory neurons that solve the dual rather than the primal representation problem.
Another motivation for linking neural activity with Lagrange multipliers can be derived from the Karush-Kuhn-Tucker theorem (KKTT) (Boyd and Vandenberghe, 2004; Kuhn and Tucker, 1951). According to KKTT, at the maximum of a dual Lagrangian, such as (2.17), the Lagrangian contributions in equation (2.15) vanish, i.e.
| (2.19) |
| (2.20) |
These equations are valid for all values of i and j. The former equation implies that either αi = 0, in which case can assume any non-negative value (inactive constraint), or , which allows αi to be non-zero (active constraint). The Lagrange coefficients αi = 0 describe constraints that have no impact on the solution of the optimization problem, explaining why they are called inactive. This observation implies that many αi are expected to be zero, making the vector of responses sparse. This observation could provide rationale to the observed sparsity of neural activities in the olfactory system (Kay and Laurent, 1999; Koulakov and Rinberg, 2011; Rinberg et al., 2006; Stettler and Axel, 2009) and beyond (DeWeese and Zador, 2006; Hromadka et al., 2008; Lehky et al., 2005; Vinje and Gallant, 2000). A mapping between the dual problem and neural responses could thus explain sparsity of neural responses as a corollary of KKTT.
2.8. Dual networks.
We will now describe neural networks that can solve the dual problem (2.18). We associate vectors and with the firing rates of two groups of neurons (cell types). The conditions αi ≥ 0 and βj ≥ 0 are then satisfied automatically as the firing rates of neurons cannot be negative. We assume that the neurons are connected into a network and the Lyapunov function of that network is proportional to the negative of the dual Lagrangian. We use the negative dual Lagrangian in order to follow the convention of constructing networks which minimize a Lyapunov function (whereas the dual Lagrangian is to be maximized). For simplicity, we will assume that the Lyapunov function of the network is . For the Lyapunov function, from equation (2.17), we obtain
| (2.21) |
To be able to interpret equation (2.21) as a Lyapunov function, we have to propose a network whose dynamics minimizes it. To generate network equations for each neuron in the network, we define internal variables that can be viewed as the total synaptic input current for each neuron. For αi and βj neurons, these currents will be denoted ai and bj respectively. Consider the following equations for ai and bj
| (2.22) |
| (2.23) |
| (2.24) |
| (2.25) |
Here and throughout this paper we use . The first equation describes inputs into neurons with firing rates αi connected to each other by weights −Wik. Connectivity between α-neurons is symmetric. These cells are also connected to βj neurons with synaptic weights −Aij, i.e. the affinity matrix. α-neurons receive an external excitatory drive equal to . Equation (2.23) describes βj neurons that are connected symmetrically to α-neurons. For both cell types, their firing rates (αi and βj) are related to their inputs (ai and bj) by rectifying threshold-linear relationships (ReLU) (2.25) ([x]+ = x for x ≥ 0 and [x]+ = 0 for x < 0). The circuit diagram for the network described here is presented in Figure 3.
Figure 3.
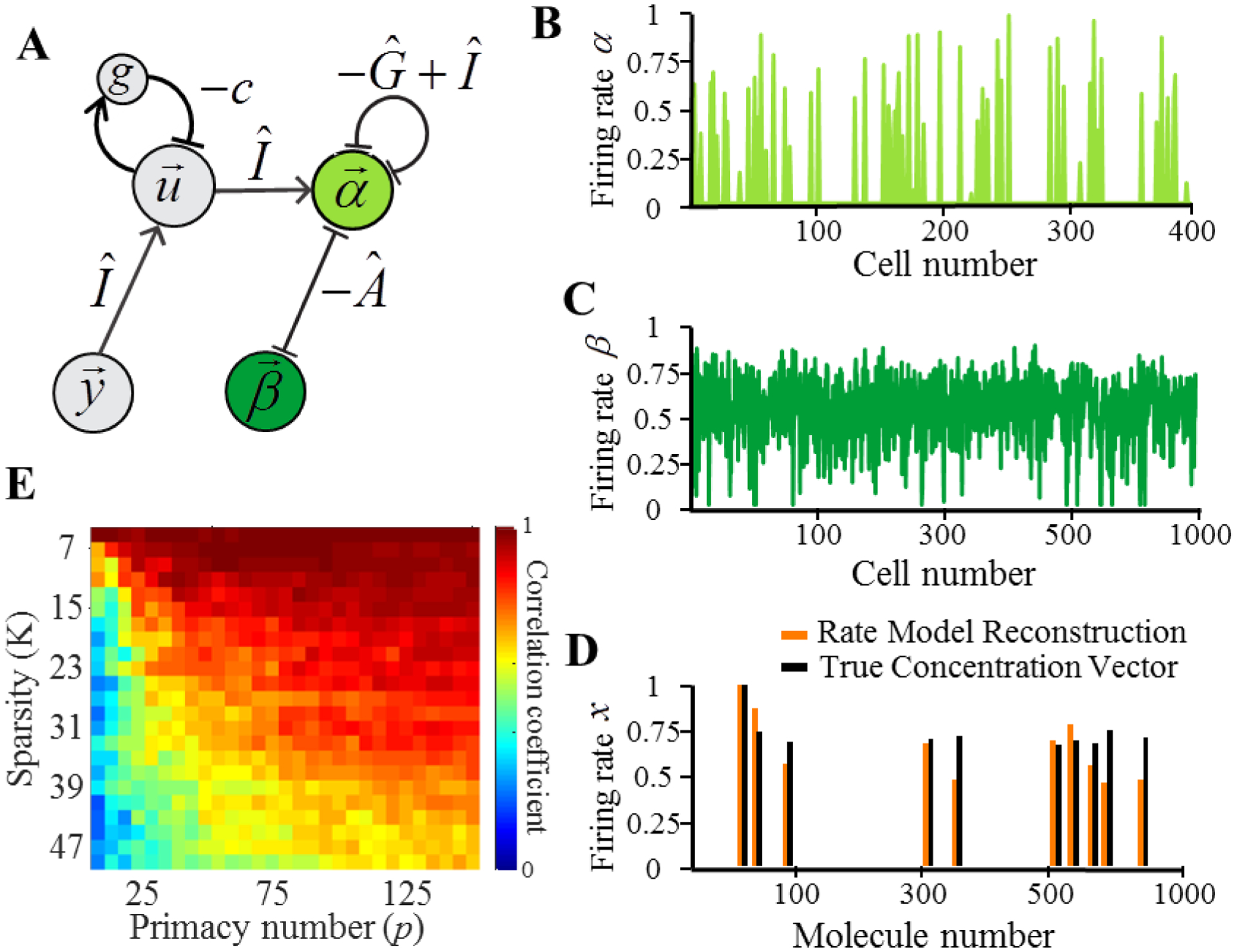
The dual network model described by equations (2.22) through (2.25). (A) The structure of the network. α cells (light green) implement the dual representation of the concentration vector. β cells (dark green) implement the non-negativity constraints on the concentration vector. (B) Example firing rates of alpha cells. (C) Example firing rates of beta cells. (D) Example of the firing rate model’s reconstruction (orange) of the concentration vector compared with the original concentration vector (black). (E) Correlation between the firing rate reconstruction of the concentration vector and the true concentration vector for a range of stimulus and network parameters, K and p.
It is straightforward to verify that these equations can be rewritten as a gradient descent.
| (2.26) |
| (2.27) |
Here is the Lyapunov function given by equation (2.21). To show that is indeed a Lyapunov function, i.e. a function that is not increasing and bounded, we follow conventional methods. To prove monotonicity of time evolution, we observe that
| (2.28) |
Here f(x) = [x]+, f′(x) ≥ 0. Because, according to equation (2.28), , and because equation (2.21) is bounded from below, our network will minimize the Lyapunov function (2.21). Due to the physically imposed non-negativity of firing rates, the variables in (2.25) will stay non-negative throughout course of this optimization-- automatically satisfying the inequalities needed to solve the dual problem. We conclude therefore that our two cell type network can solve the dual optimization problem (2.17) and thereby compute accurately molecular composition of a mixture in dual space.
2.9. Implementing the primacy variables ui.
The purpose of the variables ui is to identify the set of primary variables yi, i.e. the set of p components of vector that are larger than all others. For primary/non-primary yi, variables ui are expected to be equal to +1/−1 respectively. To compute these variables, we introduce a p-winners-take-it-all network that identifies p strongest inputs and suppresses the representations of the remainder of inputs. This network contains a population of inhibitory neurons, g, which are activated by the firing of p of the primacy neurons u. The equations specifying the dynamics of such a network are:
| (2.29) |
| (2.30) |
Here h(x) is the Heaviside function, while s(x) is a hysteretic sign function. The latter function is activated (changes activity from −1 to +1) when x > 0 and is deactivated at very low levels of input. Other parameters include c, the strength of inhibition from neurons of type g, and T, a detection threshold of the u neurons. Odorants that do not activate receptors above T will not be perceived. Because the activities of each ui is controlled by its input from receptor ri, u- cells with the strongest inputs (primary) win over the cells with weaker inputs (non-primary). This dynamic will select a certain number of cells that have the strongest receptor input (Supplementary Figure 1).
We found that this network finds robust solutions if s(x) function, the activation function for the u- cells in equation (2.30), is hysteretic, similarly to previous studies (Sanders et al., 2013; Sanders et al., 2014; Wilson, 2017). This is because activities of receptors are often transient, and therefore the sustained activity of hysteretic neurons following an initial activation makes representations stable until the end of the sniff cycle. Such behavior ensures that primary cells identified early in a sniff cycle remain primary even though receptor responses undergo adaptation or are affected by other network dynamics. This behavior is consistent with presence of non-linear voltage-dependent synaptic currents in the piriform cortex (Poo and Isaacson, 2011).
2.10. Networks implementing primacy.
Figure 3 displays the network implementing the dual problem (2.17). It contains five cell types, each designated by a letter. Receptor neurons (y- cells) are connected to u- cells via feedforward excitatory connections. u- cells then connect to g cells and α neurons. g cells enforce the primacy conditions and α neurons compute the dual representations of the stimulus. α- neurons interact with each other by structured inhibitory connections as indicated. They also form inhibitory connections to β- neurons described by the affinity matrix . In turn, β- neurons inhibit α- cells with the same strength. α- cells enforce the soft primacy constraints (2.13). β- cells represent Lagrange-KKT coefficients that enforce non-negativity of concentrations of individual monomolecular components of the stimulus vector .
Overall, we propose a network that can solve dual constrained optimization problems with time-dependent firing rates. These networks capitalize on the ease with which neural firing rates can implement the dual problem’s non-negativity conditions compared to much more complex conditions in the primal problem. We therefore call these circuits dual networks.
2.11. Simplicial dual networks.
In the previous network architecture (Figure 3), the dual variables ui receive inputs from the receptor neurons yi via an identity weight matrix. This implies that the number of dual variables ui = ±1 is equal to the number of ORs. This assumption is not biologically justified and is unnecessary. Instead, we could amend our soft primacy conditions (2.13) to include weighted combinations of activities of ORs, i.e. . In this case, the soft primacy conditions read:
| (2.31) |
The number of soft primacy conditions, indexed by i, is then arbitrary and is not limited by the number of receptors. Matrix Sij determines the weights with which each receptor contributes to a given condition. For example, if , the identity matrix, the previous primacy conditions (2.13) are recovered. If is a sparse matrix of zeros and ones, each primacy condition will constrain the sum of various receptor responses as opposed to individual receptor responses.
In the simplest case, each row of the matrix contains exactly s non-zero values that are all equal to one. Condition (2.31) then enforces, for each ui = +1, that a sum of s receptor responses is larger than γ. Thus, matrix generalizes primacy from relating the responses of individual receptors to relating the responses of groups of receptors. We will now explore the consequences of such a generalization on the architecture of our dual network. Because the subsets of s receptors form simplexes in the -space, we call this network simplicial.
Since we changed the structure of our soft primacy conditions (2.31), we must also update the information-theoretic argument for mixture recovery (2.10). Assume that matrix contains q rows, i.e. the total number of simplexes is q. In this case, the primacy conditions imply that p sums of receptor responses are larger than the q −p remaining sums. The number of distinct configurations of receptor activities can therefore be described by Γy ∝ qp. Since Γx ∝ MK, as before, we conclude that stimulus recovery in the simplicial model is possible if
| (2.32) |
This condition is less restrictive than in the case of individual receptor-based primacy [equation (2.10)]. This is because the number of primacy conditions q can substantially exceed the number of receptors N.
Including the generalized soft primacy conditions (2.31) into our approach is straightforward. Before, and equation (2.13) lead to . Equation (2.31) states instead that . To include the generalized condition into our approach, one should replace the affinity matrix Aik with the new matrix throughout. We thus obtain, instead of equation (2.21) the following equation for the dual Lyapunov function of the network:
| (2.33) |
Here is the interaction matrix between the coefficients α, which is also a Gramm matrix for the rows of matrix . The network that minimizes function (2.33) can also be derived as before [equation (2.22)–(2.25)]. For completeness, we will list these equations here.
| (2.34) |
| (2.35) |
| (2.36) |
| (2.37) |
These equations can be obtained from equations (2.22)–(2.25) by replacing and .
Equations for the primacy variables ui can be obtained from equation (2.30) by replacing ri with .
2.12. Sparse incomplete representations (SIR) in simplicial dual networks.
The Lyapunov function [equation (2.33)] is a relatively simple function on the activities of β -cells. This function could be explicitly optimized with respect to β cell activity, resulting in a substantial simplification of the network’s dynamics. Indeed, the optimal value of βj in equation (2.33) is
| (2.38) |
Instead of integrating the time-dependent equations (2.35), we can evaluate the instantaneous optimal β-cell membrane voltage and equation (2.38) to obtain β-cell firing rates. Variables given by equation (2.38) are not sparse. Indeed, when the values of α-cell responses are small, i.e. during the early stages of network dynamics, β-cell firing rates would be close to 1. It would only be after some time that values of approach zero. The dense β-cell representation comes as a consequence of the KKT theorem. Because the concentration vector is sparse, , which enforces non-negativity on the zero components of , is dense. To obtain a more biologically plausible network, we introduce a variable which provides a sparse representation of the non-negativity constraints. The optimal values of this variable are
| (2.39) |
By comparing this equation with equation (2.16), we observe that each represents a component of the reconstructed concentration vector :
| (2.40) |
As such, are expected to inherit the sparsity of the concentration vector. In previous work, we suggested by independent logic that granule cells could function directly as the components of the concentration vector (Kepple et al., 2018; Koulakov and Rinberg, 2011). There, we proposed that granule cells in the olfactory bulb form a sparse representation of components in odor mixtures. In that work, we assumed that representations were either temporarily or spatially incomplete. Therefore, we called it the sparse incomplete representation (SIR) model. Here, we associate the variables which represent the concentration vector with responses of the olfactory bulb’s granule cells which are also found to be sparse (Cazakoff et al., 2014). The dual network relying on responses can therefore implement the previously proposed SIR model (Kepple et al., 2018; Koulakov and Rinberg, 2011).
That represent components of the reconstructed concentration vector also has implications for later olfactory processing. In particular, as seen in equations (2.39) and (2.40), the stimulus can be reconstructed by a relatively simple operation on α cells. That is, α cells alone form a full dual representation of the stimulus, no information about the responses of β cells is required. α cell representation contains a unique identifier for each odorant which is concentration invariant and can be used by other brain regions.
Network equations describing the dual SIR network are obtained by expressing the values of βj from equation (2.39) and plugging these values in equations (2.34) through (2.37)
| (2.41) |
| (2.42) |
| (2.43) |
These equations describe a much simpler network than previously [(2.34)-(2.37)]. Indeed, as follows from equation (2.41), this new network lacks structured recurrent connectivity between α-cells (Figure 5). Interestingly, connectivity between α and -cells is antisymmetric: the connectivity is described by the same matrix in both directions, but has an opposite sign.
Figure 5.
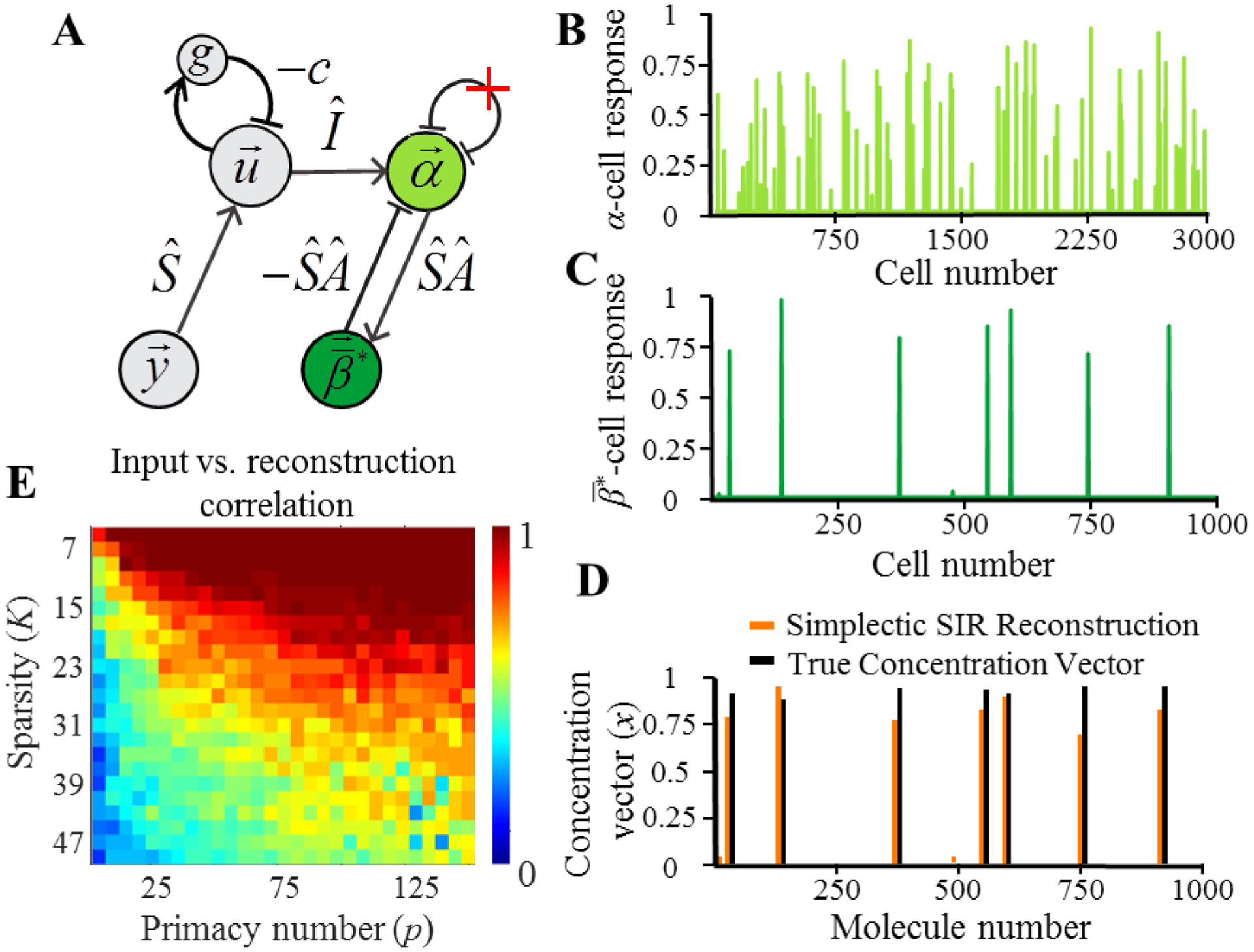
(A) The structure of the dual network implementing SIR model. α cells (light green) implement the dual representation of the concentration vector. cells (dark green) represent the reconstruction of the concentration vector. (B) Example firing rates of α cells. (C) Example of the sparse firing rates of cells. (D) Comparison of the simplicial SIR model’s reconstruction (orange) and the concentration vector. (E) Correlation between simplicial SIR model’s reconstruction of the concentration vector and the true concentration vector for a range of stimulus and network parameters, K and p.
Equation (2.40) suggests that -cells build representations of olfactory mixtures, with activities of individual neurons encoding the concentrations of individual mixture components. As we mentioned, a similar suggestion was made for the activities of granule cell neurons of the olfactory bulb, within the SIR model. We thus can identify -cells in our present model with granule cells of the olfactory bulb. In agreement with this suggestion, the number of granule cells (a few million) matches our estimate of the number of monomolecular chemical compounds.
3. DISCUSSION
Herein we propose a novel model for intensity-invariant encoding of olfactory stimuli. According to the primacy model, an odor can be identified from the identities of the p strongest responding ORs. Importantly, this does not mean that our model uses only p receptors to identify the stimulus. Instead, weakly responding receptors are still informative of which odors are not present. Because the primacy model relies only on the relative rather than absolute strengths of receptor responses, the recovered stimulus is independent of the absolute molecular concentrations of the stimulus. Although we demonstrated this idea for the particular example of primacy coding in olfaction, we suggest that this principle could be used to produce intensity invariant signal recovery for more complex conditions and in other modalities.
We formulated a solution of the olfactory decoding problem from first principles, using optimization theory with inspiration from compressed sensing. Since, within the primacy model, the constraints for inferring a stimulus use relative relationships between the responses of sensors (ORs), we attempted to formulate the problem using a Lagrangian approach to optimize under inequality constraints. Our solution thus involves minimizing a Lagrangian cost function containing two sets of Lagrange coefficients, and . Lagrange coefficients represent weights on different constraints in the optimization problem. They describe the importance of individual constraints, i.e. which constraints were actually used in a particular inference problem. The first set of Lagrange coefficients, , described the importance of individual primacy conditions, while the second set, , described non-negativity constraints imposed on individual molecular concentrations. Solving the sparse optimization problem under inequality constraints is often performed in the dual representation, via optimizing the dual Lagrangian. Dual optimization is performed in the dual space, i.e. using only the Lagrange coefficients and not the primal variables, i.e. values of molecular concentrations.
The driving observation that we make in this study is that neural systems are well suited for implementing dual optimizations. The nonnegativity of Lagrange coefficients is especially easy to enforce in neural responses described by firing rates that cannot physically fall below zero. Furthermore, a well-known theorem in optimization theory states that the Lagrange coefficient acting on an unused constraints is zero. For a dual neural network, we showed that this can result in sparse neural activity. These observations led us to propose the dual brain theory – that firing rates of individual neurons represent the Lagrange coefficients for a set of conditions of varying complexity.
It has been known for a while that recurrent neural nets can minimize cost functions of firing rates, known as Lyapunov functions (Hertz et al., 1991). Mapping a dual Lagrangian onto a Lyapunov function of a recurrent neural network shows that this network solves the dual problem. Using this approach, we found the structure of the neural network whose Lyapunov function matches the dual Lagrangian for the problem of olfactory stimulus recovery.
Although we presented a conceptual model in which our initial approach was to implement a mathematical concept rather than to describe the biology of the olfactory system, we found that some features of our network bear resemblance to the real olfactory networks. In the dual network, the sets of Lagrange multipliers and are represented by the firing rates of two cell types, α and β cells. The firing rates of β cells represent individual molecular components of the olfactory stimulus mixture. In our previous work, we proposed that granule cells form a representation of odorant components (Kepple et al., 2018; Koulakov and Rinberg, 2011). Since, in our present study, β cells perform a similar function, we argued that the β cells of our network [more precisely, neurons, equation (2.39)] are analogous to the granule cells in the real olfactory bulb. The number of β cells in our network is equal to the number of potential molecular components in the environment. Encouragingly, the number of granule cells (several million) (Shepherd, 1972) is also similar to the number of potential volatile monomolecular compounds present in PubChem (Kim et al., 2016).
Because of the downstream position of α neurons from receptor input and their excitatory effect on putative granule cells β, we suggest that α cells could reside in the piriform cortex which is known to feedback to the olfactory bulb. The inhibition from putative granule cells β to putative cortical cells α is then possible through an indirect pathway, via inhibition of mitral cells projecting to the piriform cortex. For this reason, we suggest that receptor input instead travels through the distinct tufted cell channel. As a result, we place u cells in the anterior olfactory nucleus (AON) which receives most projections from tufted cells (Haberly and Price, 1977). Due to the ab initio nature of our approach, the mapping of our dual network onto the real biological network needs further refinement. Overall, we suggest that, within the dual network approach, each neuronal cell type can be associated with a set of Lagrange coefficients implementing individual constraints.
In our study, we presented networks that are capable of inferring concentration-invariant odorant representations by performing a sparse norm minimization (l1 norm or elastic net). We proposed therefore that ORs implement compression of the odorant concentration vector and relied on elements of compressed sensing in olfactory decoding. Several recent studies have argued that decoding algorithm in the olfactory system may use compressed sensing (Grabska-Barwinska et al., 2017; Krishnamurthy et al., 2017; Tootoonian and Lengyel, 2014; Zhang and Sharpee, 2016). These studies usually assume a linear encoding scheme similar to equation (2.2) and a decoding mechanism based on a sparse norm minimization. Some of these studies place the representation of individual component concentrations into the piriform cortex or, equivalently, insect mushroom body (Tootoonian and Lengyel, 2014; Zhang and Sharpee, 2016). Similarly, a study of (Grabska-Barwinska et al., 2017) suggests a Bayesian inference-based approach that relies on representing odors in the activity of cortical cells.
A significant distinction of our study from the previous approaches is that we assume that the activity of cortical neurons (α cells) is representative of, but distinct from, the vector of molecular concentrations. Thus, the vector of molecular concentrations can be decoded uniquely from the activities of α cells but activities of individual neurons cannot be interpreted as molecular concentrations. In this regard our model is similar to the recent study by (Krishnamurthy et al., 2017). We place the vector of molecular concentrations into the olfactory bulb (β cells, Figure 6). In doing so, we propose that the information of molecular composition of the odorant mixture is retained within olfactory bulb, while cortical neurons contain a dual representation of the mixture that is synthetic, i.e. constructed rather than reconstructed. Thus, in our model, the activity of cortical cells displays similar statistics in case of both mixtures and monomolecular stimuli. The reconstruction of the stimulus into monomolecular components performed by the granule cells in the olfactory bulb (β cells) that receive inputs from the cortex (α cells, Figure 6). The purpose of this reconstruction is to check whether the synthetic cortical representation is consistent with any possible mixture of monomolecular compounds. In a separate work, we suggest that this reconstruction could be useful during olfactory learning (Kepple et al., 2018).
Figure 6.
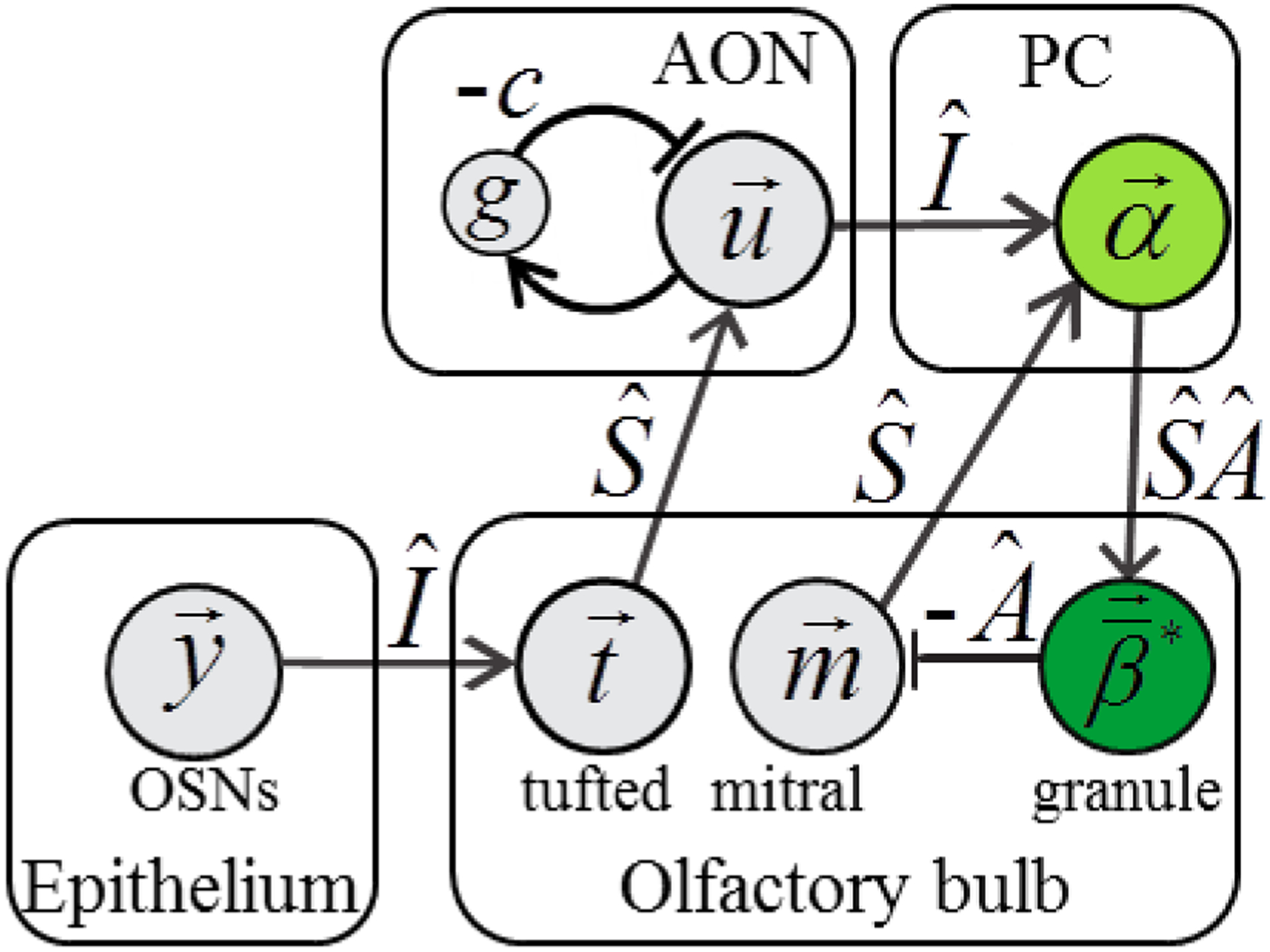
Possible mapping of our simplicial dual network implementing the primacy model to the known olfactory circuitry. The neurons of our network are depicted with circles and the corresponding brain region we suggest for those neurons are shown in the surrounding box. The suggested analogy with specific cell types are given outside each circle. AON, PC, and OSNs stand for anterior olfactory nucleus, piriform cortex, and olfactory sensory neurons respectively.
In formally linking the neurons of our dual network to biological neuronal cell types, we are able to make specific predictions about connectivity in the olfactory system. In particular, our theory suggests that feedback and feedforward connections between the bulb and cortex are dependent. Thus, the feedback connection matrix from cortex (, Figure 6) is a product of feedforward connectivity () and granule-to-mitral cell connectivity (). We also suggest that granule cells represent the olfactory system’s reconstruction of the stimulus, consequently predicting that more complex stimuli (mixtures) should evoke more complex activity in granule cells than monomolecular odorants. More generally, using our dual brain theory to connect the activity of a specific cell types to a class of Lagrange coefficients enables one to determine connectivity on both mesoscopic and single-neuron scales.
Biologically it is known that OSN responses to an odor are roughly exponential distributed. This fact has been used to motivate maximum entropy models of olfactory coding (Stevens, 2016). For these models, the exponential distribution of OSN firing rates is important as it provides a maximal entropy code under certain assumptions. For our primacy-based model, however, there is very little constraint on the distribution of firing rates. Indeed, we show that we can construct the affinity matrix A with elements that have Gaussian, lognormal, or even uniform distributions [Supplementary Figure 2]. This finding results from the primacy model’s invariance to any uniform, monotonic nonlinearity relating r to y.
Our model uses relative rather than absolute responses of ORs to solve the decoding problem. This allowed us to encode the stimulus in a concertation invariant manner, even if the responses of receptors are non-linear. One mechanism for concentration invariance that has been proposed previously is based on normalization of bulbar output (Banerjee et al., 2015; Cleland et al., 2011; Cleland et al., 2007; Kato et al., 2013; Miyamichi et al., 2013; Olsen et al., 2010). This mechanism uses global inhibition to change the gain of receptor responses. The primacy model proposed here is distinct from the normalization model, although they share similar circuit features, such as broadly projecting inhibitory elements. Although we also implement inhibition to achieve concentration invariance, we place the inhibitory circuits in cortex with the goal of identifying the strongest responding receptors. Our mechanism may therefore account for fast odor guided decisions that are dependent on receptors with high-affinity to odorants. We thus propose that normalization and primacy models may operate in series on different levels of olfactory processing.
Tootoonian and Lengyel (Tootoonian and Lengyel, 2014) have proposed that the maximum a posteriori (MAP) solution to the inference problem of recovering a sparse N-dimensional odor vector can be achieved in a low-dimensional measurement space, reflecting the known biology of olfactory processing (Tootoonian and Lengyel, 2014). In their study, the compressed sensing problem was formulated as an l1 norm minimization of the odor concentration vector subject to the linear equality encoding constraint and solved by considering the problem in dual space. The resulting generalized energy function for their network reflects the equality constraints and, as such, their proposed network implementation differs significantly from our solution. Our networks rely on Karush-Kuhn-Tucker-type inequality conditions that implement primacy. Our formulation of the decoding problem is therefore distinct from the work of Tootoonian et al. In particular, our formulation allows to decode an odorant composition even if the encoding problem is non-linear [equation (2.6) and the following discussion]. In addition, due to our inclusion of inequality constraints and the Karush-Kuhn-Tucker theorem, the responses of neurons in our dual network are expected to be sparse.
Two features of dual networks are worth mentioning. First, according to the Karush-Kuhn-Tucker theorem (KKTT), dual Lagrangians are optimized under the constraint of the non-negativity of Lagrange coefficients. Neuronal responses can naturally enforce these constraints, because they are described by firing rates that cannot fall below zero. Thus, dual neural networks could be viewed as analog computers that convert complex conditions, such as those imposed by primacy theory, into non-negativity constraints. The latter constraints can be relatively easily implemented by neuronal firing rates. Second, due to KKTT (Boyd and Vandenberghe, 2004), a large number of the Lagrange coefficients are likely to be zero. This observation is consistent with the observed sparsity of neuronal responses, both in olfaction (Kay and Laurent, 1999; Koulakov and Rinberg, 2011; Rinberg et al., 2006; Stettler and Axel, 2009) and beyond (DeWeese and Zador, 2006; Hromadka et al., 2008; Lehky et al., 2005; Vinje and Gallant, 2000), further strengthening the possible association between neuronal responses and Lagrange coefficients. We therefore propose that neural networks may implement optimization of dual Lagrangians with the responses of individual neurons representing Lagrange multipliers corresponding to a set of individual constraints.
Supplementary Material
Figure 4.
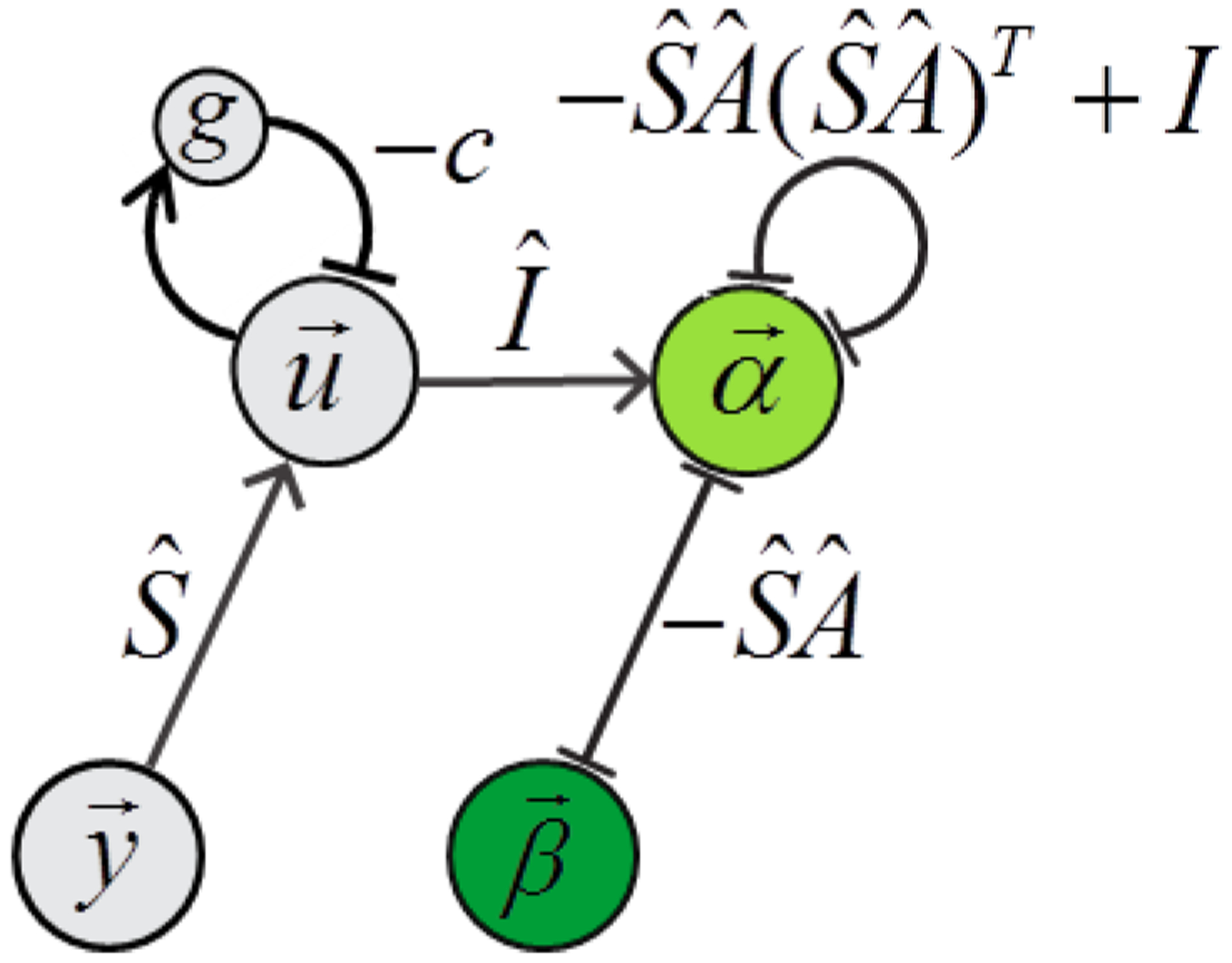
Network diagram of the simplicial dual network.
ACKNOWLEDGEMENTS
We are grateful for discussions with Petr Sulc, Venkatesh Murthy, and Dmitry Chklovskii. This work was made possible by the Swartz Foundation and NIH R01DC014366. We are sincerely grateful to the Kavli Institute for Theoretical Physics at UC Santa Barbara (Grants NSF PHY-1748958, NSF PHY-1748958, NIH Grant No. R25GM067110, and the Gordon and Betty Moore Foundation Grant No. 2919.01) for support during the development of this project. This work was also supported by Aspen Center for Physics (NSF PHY-1066293).
APPENDIX A
Derivation of equation (2.1) and (2.2):
Consider the mass-action law for an OR number i binding odorant number j. For the number of receptor molecules bound by the odorant, Rij, we have
| (A.1) |
Here αij and γij are binding and unbinding rates, and the number of available (unbound) available receptors, , is given by
| (A.2) |
Here Ri0 is the total number of OR molecules of type i exposed to odorant binding. Because in the equilibrium dRij/dt = 0 and , the total number of unbound receptors can be found from equation
We thus obtain and the number of active receptors
Assuming that activity of the cell reflects its relative OR activation we obtain
| (A.3) |
With .
REFERENCES
- Arctander S (1969). Perfume and flavor chemicals (aroma chemicals) (Montclair, N.J.,). [Google Scholar]
- Banerjee A, Marbach F, Anselmi F, Koh MS, Davis MB, Garcia da Silva P, Delevich K, Oyibo HK, Gupta P, Li B, et al. (2015). An Interglomerular Circuit Gates Glomerular Output and Implements Gain Control in the Mouse Olfactory Bulb. Neuron 87, 193–207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baraniuk RG (2007). Compressive sensing. Ieee Signal Proc Mag 24, 118.-+. [Google Scholar]
- Boyd SP, and Vandenberghe L (2004). Convex optimization (Cambridge, UK; New York: Cambridge University Press; ). [Google Scholar]
- Cazakoff BN, Lau BYB, Crump KL, Demmer HS, and Shea SD (2014). Broadly tuned and respiration-independent inhibition in the olfactory bulb of awake mice. Nature Neuroscience 17, 569–U125. [DOI] [PubMed] [Google Scholar]
- Cleland TA, Chen SY, Hozer KW, Ukatu HN, Wong KJ, and Zheng F (2011). Sequential mechanisms underlying concentration invariance in biological olfaction. Front Neuroeng 4, 21. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cleland TA, Johnson BA, Leon M, and Linster C (2007). Relational representation in the olfactory system. Proc Natl Acad Sci U S A 104, 1953–1958. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dantzig GB (1963). Orgins of Linear-Programming. Oper Res 11, B115–B115. [Google Scholar]
- DeWeese MR, and Zador AM (2006). Non-Gaussian membrane potential dynamics imply sparse, synchronous activity in auditory cortex. J Neurosci 26, 12206–12218. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Donoho DL, and Tanner J (2005). Sparse nonnegative solution of underdetermined linear equations by linear programming. P Natl Acad Sci USA 102, 9446–9451. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Donoho DL, and Tanner J (2006). Thresholds for the recovery of sparse solutions via L1 minimization. 2006 40th Annual Conference on Information Sciences and Systems, Vols 1–4, 202–206. [Google Scholar]
- Firestein S (2001). How the olfactory system makes sense of scents. Nature 413, 211–218. [DOI] [PubMed] [Google Scholar]
- Foster DH (2011). Color constancy. Vision Res 51, 674–700. [DOI] [PubMed] [Google Scholar]
- Grabska-Barwinska A, Barthelme S, Beck J, Mainen ZF, Pouget A, and Latham PE (2017). A probabilistic approach to demixing odors. Nat Neurosci 20, 98–106. [DOI] [PubMed] [Google Scholar]
- Haberly LB, and Price JL (1977). Axonal Projection Patterns of Mitral and Tufted Cells of Olfactory-Bulb in Rat. Brain Res 129, 152–157. [DOI] [PubMed] [Google Scholar]
- Hertz J, Krogh A, and Palmer RG (1991). Introduction to the theory of neural computation (Redwood City, Calif.: Addison-Wesley Pub. Co.). [Google Scholar]
- Hromadka T, Deweese MR, and Zador AM (2008). Sparse representation of sounds in the unanesthetized auditory cortex. PLoS biology 6, e16. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jinks A, and Laing DG (1999). A limit in the processing of components in odour mixtures. Perception 28, 395–404. [DOI] [PubMed] [Google Scholar]
- Kato HK, Gillet SN, Peters AJ, Isaacson JS, and Komiyama T (2013). Parvalbumin-expressing interneurons linearly control olfactory bulb output. Neuron 80, 1218–1231. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kay LM, and Laurent G (1999). Odor- and context-dependent modulation of mitral cell activity in behaving rats. Nat Neurosci 2, 1003–1009. [DOI] [PubMed] [Google Scholar]
- Kepple DG,H; Rinberg D; Koulakov A (2016). Deconstructing Odorant Identity via Primacy in Dual Networks. arXiv. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kepple DR, Cazakoff BN, Demmer HS, Eckmeier D, Shea SD, and Koulakov AA (2018). Computational algorithms and neural circuitry for compressed sensing in the mammalian main olfactory bulb. bioarXiv. [Google Scholar]
- Kim S, Thiessen PA, Bolton EE, Chen J, Fu G, Gindulyte A, Han L, He J, He S, Shoemaker BA, et al. (2016). PubChem Substance and Compound databases. Nucleic Acids Res 44, D1202–1213. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Koulakov A, Gelperin A, and Rinberg D (2007). Olfactory coding with all-or-nothing glomeruli. J Neurophysiol 98, 3134–3142. [DOI] [PubMed] [Google Scholar]
- Koulakov AA, and Rinberg D (2011). Sparse incomplete representations: a potential role of olfactory granule cells. Neuron 72, 124–136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krishnamurthy K, Hermundstad AM, Mora T, Walczak AM, and Balasubramanian V (2017). Disorder and the neural representation of complex odors: smelling in the real world. arXiv. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kuhn HW, and Tucker AW (1951). Nonlinear Programming Paper presented at: Proceedings of the Second Berkeley Symposium on Mathematical Statistics and Probability (Berkeley, Calif.: University of California Press; ). [Google Scholar]
- Lehky SR, Sejnowski TJ, and Desimone R (2005). Selectivity and sparseness in the responses of striate complex cells. Vision Res 45, 57–73. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miyamichi K, Shlomai-Fuchs Y, Shu M, Weissbourd BC, Luo L, and Mizrahi A (2013). Dissecting local circuits: parvalbumin interneurons underlie broad feedback control of olfactory bulb output. Neuron 80, 1232–1245. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Olsen SR, Bhandawat V, and Wilson RI (2010). Divisive normalization in olfactory population codes. Neuron 66, 287–299. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Poo C, and Isaacson JS (2011). A major role for intracortical circuits in the strength and tuning of odor-evoked excitation in olfactory cortex. Neuron 72, 41–48. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rinberg D, Koulakov A, and Gelperin A (2006). Sparse odor coding in awake behaving mice. J Neurosci 26, 8857–8865. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rodieck RW (1998). The first steps in seeing (Sunderland, Mass.: Sinauer Associates; ). [Google Scholar]
- Sanders H, Berends M, Major G, Goldman MS, and Lisman JE (2013). NMDA and GABAB (KIR) conductances: the “perfect couple” for bistability. J Neurosci 33, 424–429. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sanders H, Kolterman BE, Shusterman R, Rinberg D, Koulakov A, and Lisman J (2014). A network that performs brute-force conversion of a temporal sequence to a spatial pattern: relevance to odor recognition. Front Comput Neurosci 8, 108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shepherd GM (1972). Synaptic Organization of Mammalian Olfactory Bulb. Physiol Rev 52, 864.-&. [DOI] [PubMed] [Google Scholar]
- Stettler DD, and Axel R (2009). Representations of odor in the piriform cortex. Neuron 63, 854–864. [DOI] [PubMed] [Google Scholar]
- Stevens CF (2016). A statistical property of fly odor responses is conserved across odors. Proc Natl Acad Sci U S A 113, 6737–6742. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tootoonian S, and Lengyel M (2014). A Dual Algorithm for Olfactory Computation in the Locust Brain. Advances in Neural Information Processing Systems 27 (NIPS 2014). [Google Scholar]
- Vinje WE, and Gallant JL (2000). Sparse coding and decorrelation in primary visual cortex during natural vision. Science 287, 1273–1276. [DOI] [PubMed] [Google Scholar]
- Wilson CD, Serrano GO, Koulakov AA, and Rinberg D (2017). Concentration invariant odor coding. Nature Communications (in press). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilson CD, Serrano GO, Koulakov AA, and Rinberg D (2017). A primacy code for odor identity. Nat Commun 8, 1477. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang X, and Firestein S (2002). The olfactory receptor gene superfamily of the mouse. Nat Neurosci 5, 124–133. [DOI] [PubMed] [Google Scholar]
- Zhang Y, and Sharpee TO (2016). A Robust Feedforward Model of the Olfactory System. PLoS Comput Biol 12, e1004850. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.