

Abstract
The human body generates a diverse set of high affinity antibodies, the soluble form of B cell receptors (BCRs), that bind to and neutralize invading pathogens. The natural development of BCRs must be understood in order to design vaccines for highly mutable pathogens such as influenza and HIV. BCR diversity is induced by naturally occurring combinatorial “V(D)J” rearrangement, mutation, and selection processes. Most current methods for BCR sequence analysis focus on separately modeling the above processes. Statistical phylogenetic methods are often used to model the mutational dynamics of BCR sequence data, but these techniques do not consider all the complexities associated with B cell diversification such as the V(D)J rearrangement process. In particular, standard phylogenetic approaches assume the DNA bases of the progenitor (or “naive”) sequence arise independently and according to the same distribution, ignoring the complexities of V(D)J rearrangement. In this paper, we introduce a novel approach to Bayesian phylogenetic inference for BCR sequences that is based on a phylogenetic hidden Markov model (phylo-HMM). This technique not only integrates a naive rearrangement model with a phylogenetic model for BCR sequence evolution but also naturally accounts for uncertainty in all unobserved variables, including the phylogenetic tree, via posterior distribution sampling.
Author summary
Rational vaccine design efforts depend on accurate inference of full evolutionary paths from a given naive sequence to the corresponding mature B cell receptor sequences in a germinal center. Before one can perform ancestral sequence inference for clonal sequences that result from the same naive rearrangement event, one must first obtain an estimate of the clonal phylogenetic tree. Currently, standard phylogenetic inference techniques are used to model the process of sequence evolution along the tree; however, these methods do not account for all the complexities associated with this evolutionary process. In this paper, we propose a Bayesian approach to phylogenetic inference for clonal sequences that is based on a phylogenetic hidden Markov model. Our phylo-HMM models both the naive rearrangement and somatic hypermutation processes and this Bayesian framework allows us to naturally account for uncertainty in all unobserved variables, including a phylogenetic tree, via posterior distribution sampling. We perform simulation-based experiments to show that naive sequence and phylogenetic inference performed jointly provides higher-quality estimates than those obtained by considering these inferences separately. Our application to real data reveals significant uncertainty in naive and ancestral sequences, confirming the importance of a Bayesian approach.
Introduction
One of the most important features of the adaptive immune system is its ability to create a wide variety of high affinity antibodies, the soluble form of B cell receptors (BCRs), that bind to and neutralize pathogens in the body. The initial BCR diversity is generated by randomly joining together various gene segments in a process called V(D)J rearrangement; after an initial testing process B cells reach the “naive” state. When stimulated by binding to foreign material called “antigen,” B cells diversify further by entering germinal centers (GCs) in the secondary lymphoid organs and going through the process of affinity maturation. During the GC reaction, B cells mutate rapidly in a process called somatic hypermutation (SHM), and the high affinity clones are positively selected for via clonal expansion. We would like to better understand the GC mutation and selection processes, because insight into mutational pathways from naive to mature BCR sequences could aid in the development of vaccines for highly mutable pathogens such as influenza and HIV [1]. We have developed a new statistical inference framework that better estimates these mutational pathways and quantifies uncertainty in these estimates.
Rational vaccine design efforts depend on accurate inference of full evolutionary paths from a given naive sequence to the corresponding mature BCR sequences in a GC. By understanding the mutational pathways that lead to broadly neutralizing antibodies (bNAbs), vaccines could then be constructed that induce the production of these bNAbs in the body [2]. For instance, in the case of HIV, most bNAbs are generally not observed until after a long period of chronic infection, requiring prospective studies to characterize them [3]. While there have been many such studies that experimentally test longitudinal B cell samples spanning from an initial HIV infection to the development of mature bNAbs [3–5], obtaining early prospective samples is difficult. One way to avoid the process described above is to infer intermediate lineage sequences computationally, synthesize them in the laboratory, and test their binding and neutralization abilities [4, 6]. Consequently, we will focus on inferring mutational pathways through ancestral sequence reconstruction, a commonly used technique in computational phylogenetics.
Much of the existing BCR sequence analysis literature focuses on modeling either the V(D)J recombination process, or the phylogenetic diversification process, but not both. Elhanati et al. [7] develop a likelihood-based model that encompasses the V(D)J rearrangement, SHM, and clonal selection processes; however, they implicitly assume clonal sequences arise independently and do not consider the phylogenetic structure of SHM. Hoehn et al. [8, 9] introduce novel codon substitution models for ancestral lineage inference that encodes SHM context-dependent mutational effects but does not account for V(D)J rearrangement dynamics in the naive sequence within their maximum likelihood phylogenetic inference framework. Yaari et al. [10] provide estimates of context-dependent SHM substitution probabilities and motif mutability scores based on an aggregated dataset consisting of the synonymous codon positions of productive antibody sequences. Ralph and Matsen [11] are able to infer naive BCR sequences using an HMM-based approach that models the V(D)J rearrangement process but assumes independent evolution across the different lineages. While these efforts have contributed greatly to our understanding of GC dynamics, we believe that the performance of clonal lineage and ancestral sequence inference procedures can be enhanced by using an evolutionary model for SHM that also accounts for uncertainty in the naive rearrangement process.
Kepler [12] has developed a likelihood-based SHM modeling framework that jointly estimates the naive sequence and the associated clonal tree and incorporates information about the V(D)J rearrangement process. However, this work does not consider phylogenetic or ancestral sequence uncertainty in the naive sequence estimation procedure. While there is evidence to suggest that ancestral sequence estimation is robust to phylogenetic uncertainty in other settings [13], the parameter regime of BCR diversification is quite different from that of this previous work, leaving open the question of whether incorporating phylogenetic uncertainty would aid in BCR ancestral sequence inference. Therefore, we would like to construct a phylogenetic inference procedure that not only allows for easy quantification of phylogenetic and ancestral sequence uncertainty but also models the V(D)J recombination as an informative prior for the naive sequence at the root of a phylogenetic tree describing the evolution of one clonal lineage.
In this paper, we propose a Bayesian approach to phylogenetic inference for clonal sequences that is based on a phylogenetic hidden Markov model (phylo-HMM) [14]. Our phylo-HMM models both the naive rearrangement and SHM processes. The Bayesian framework allows us to naturally account for uncertainty in all unobserved variables, including a phylogenetic tree, via posterior distribution sampling. We perform simulation-based experiments to show that naive sequence and phylogenetic inference performed jointly provides higher-quality estimates than those obtained by considering these inferences separately. Our application to real data reveals significant uncertainty in naive and ancestral sequences, confirming the importance of a Bayesian approach.
Results
Simulation experiments
In our simulation experiments, we focus on validating the accuracy of the naive sequence and ancestral sequence estimates produced by linearham. For naive sequence validations, we compare and contrast the performance between linearham, partis, and the ARPP program [12]. The partis package provides maximum likelihood naive sequence estimates [11], but its model assumes a star-tree configuration, which is unrealistic for many CFs going through long periods of SHM and affinity maturation [3–5]. The ARPP program is also a likelihood-based framework that jointly infers a CF tree and the associated naive sequence using information about the V(D)J rearrangement process, but does not quantify phylogenetic or ancestral sequence uncertainty; we use this program in our validations because it is one of the only other programs that estimates CF phylogenies and naive sequences at the same time. We did attempt to use the newer version of ARPP (called Cloanalyst), but ran into difficulties with the program crashing and were unable to successfully resolve this issue when we contacted the program author.
Similarly, for our ancestral sequence validations, we restrict our comparisons to the linearham, RevBayes, and dnaml [38] packages. As discussed before, the RevBayes program performs Bayesian phylogenetic inference on a given MSA, but in this case, we sample CF trees and ASRs from RevBayes using an augmented CF sequence alignment that contains the partis-inferred naive sequence (i.e. D* from above). This approach to ASR was used in [6] and is similar to that of linearham with the main difference being that RevBayes ASR sampling is conditional on the partis-inferred naive sequence whereas linearham ASR inference conditions on naive sequences drawn from a posterior distribution. For all the experiments conducted in this section, we run RevBayes using 50,000 MCMC iterations, sampling every 10 iterations, discard the first 500 RevBayes samples as burn-in, and sample without replacement 225 times from the 4,500 effective RevBayes samples in the case of linearham inference. The dnaml package performs maximum likelihood phylogenetic inference and generates an ASR conditional on this likelihood-based tree estimate. While it is possible to sample ASRs on a maximum likelihood tree [34], dnaml only reports the most probable ancestral sequences. We run dnaml on an augmented CF sequence alignment that contains the ARPP maximum likelihood estimate of the naive sequence. Our simulation input and output data has been made publicly available on Zenodo (https://doi.org/10.5281/zenodo.3746832). In the following subsections, we describe our simulation experiments in more detail from the data-generating mechanism to the validation results.
Simulation setup
To simulate tree topologies with a fixed number of tips in our experiments, we used the single-parameter beta-splitting generative process [39]. The beta-splitting process is able to generate a wide variety of tree topologies ranging from balanced topologies (i.e. trees with approximately equal root-to-tip distances) to imbalanced topologies (i.e. trees with highly variable root-to-tip distances) by varying the associated “balance” parameter β. Intuitively, this process can be seen as a recursive partitioning procedure that, at each tree split, partitions the Uniform(0, 1) random numbers corresponding to the “tips” on the current sub-interval according to a Beta(β + 1, β + 1) distribution. As β → ∞, the generated trees get closer and closer to balanced binary trees and, as β → −2, the simulated topologies look more and more “comb-like” (i.e. imbalanced) [39].
We are motivated to use this topology-generating process because the level of balance of the tree determines the extent to which a phylogenetic approach to naive sequence estimation improves over a star-tree model. Informally speaking, a phylogenetic approach weights the information coming from tips close to the root (in the imbalanced case) more strongly than tips more distant from the root. Thus we expect a phylogenetic approach to be superior in the imbalanced case. On the other hand, partis assumes evolution occurs according to a star tree, which implies the expected number of substitutions from the root to each of the tip sequences should be approximately equal. Thus, for imbalanced trees, that have a large variance in the root-to-tip branch length distances, we would expect partis to provide poor naive sequence estimates for sequence datasets generated on those trees compared to a phylogenetic approach. Throughout the rest of this section, we define “tree imbalance” to be the standard deviation of a tree’s root-to-tip distances.
To generate branch lengths for our simulated trees that preserve the shapes induced by the beta-splitting topology prior, we independently draw values from a Uniform(0, 2M) distribution, where M is a constant derived from HIV bnAb lineage trees. Specifically, we ran the PC64 [40] and VRC01 [41] datasets through partis to obtain augmented CF sequence alignments with the partis-inferred naive sequence, inferred approximate maximum likelihood CF trees using FastTree [42, 43], and set M to be the average across all estimated branch lengths in the two trees (≈ 0.0179). Although the two lineages that we use as a template for our simulated data sets are unusually long, a mean branch length of less than 0.02 will result in intermediate-length simulated trees for the number of leaves simulated here (80 or fewer tips). We describe these two datasets in more detail in the next section when we discuss our real-world dataset applications. In the subsequent parts of this section, we refer to the inferred FastTree trees described above as the PC64 and VRC01 phylogenies, respectively. We emphasize that these trees are only used as the basis for a simulation study and their level of accuracy is not especially important.
Each simulated phylogeny also receives a root branch length, which is not accounted for by the above generative processes. We use the mean of the PC64 and VRC01 root branch lengths (≈0.01759) as the default root branch length for simulation and also assign simulated trees root branch lengths of 0.1 to validate inference in settings with long periods of shared mutational history. For each simulated tree, we draw a naive sequence at the root according to the partis prior distribution that, as mentioned previously, models the V(D)J rearrangement process. We use the default settings in partis for human heavy chain data, since this represents the regime of most common interest.
To simulate DNA sequence data on the selected trees given the partis-generated naive sequences, we use the simulator in the samm package [44]. A complex collection of enzymes introduces mutations to affinity-maturing sequences in a random pattern that is known to be highly sensitive to the sequence motif (i.e. the subsequence of DNA bases surrounding the mutating position) [45–48]. The samm program estimates these motif mutabilities (i.e. the probability a position will mutate given the motif at that position) and substitution probabilities (i.e. the probability a position will mutate to a new base given the motif at that position) using a penalized Cox proportional hazards model and simulates sequence mutations given these inferred parameters. In our work, we use the S5F parameters inferred for human heavy chain sequences [10].
In our simulation experiments, we set the beta-splitting “balance” parameter β to −1.5, −1.25, and −1; the CF sequence count NCF to 40 and 80; and the root branch length t0 to 0.01759 and 0.1. There are thus 12 different parameter combinations, and for each of these, we simulate 15 trees for a grand total of 180 simulated trees (S1 Table). While 180 simulated trees does not seem like a large number of Monte Carlo replicates, we are forced to constrain the number of trees on which we perform inference because the ARPP program has to be run by hand via a GUI. Using these parameter settings allows for the simulation of both balanced and imbalanced trees.
Naive sequence validations
For each of the 180 simulated trees, we validate the accuracy of the naive sequence estimates generated from the linearham, partis, and ARPP programs by computing the hamming distances (i.e. the number of mismatched characters between two equal-length strings) between the estimates and the true naive sequence. We did this for the inferred DNA sequences directly and also for those same sequences translated to amino acids after inference was complete. The partis and ARPP packages provide naive sequence point estimates, but linearham samples naive sequences from a posterior distribution so we take the naive sequence with the highest posterior probability as the linearham “point estimate”.
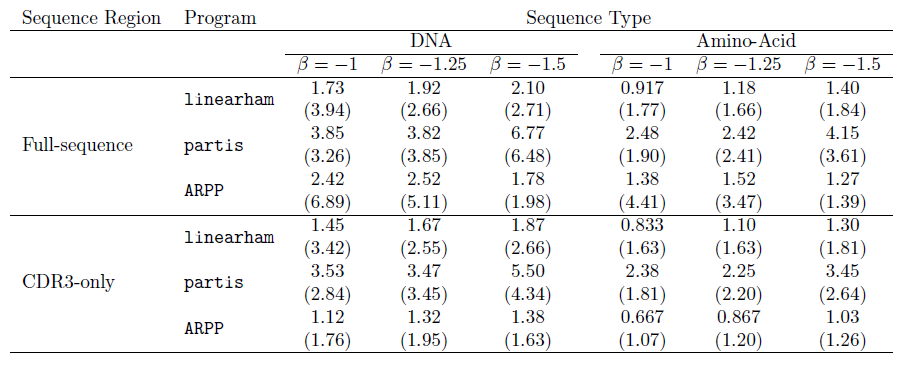
We summarize the hamming distance results for all 180 simulated trees described above and plot this performance metric against the corresponding values of tree imbalance (Fig 1); for reference, we plot the tree imbalance values for the PC64 and VRC01 trees as well. The performance of partis worsens as trees become more imbalanced, which makes sense given that partis assumes a star-tree configuration for clonal family evolution. The linearham and ARPP programs provide accurate naive sequence estimates and perform similarly across the observed tree imbalance spectrum, which is not too surprising because they both incorporate phylogenetic information into their estimates. We also show a summary of these results, split into values for the full-sequence and CDR3 regions, as well as the DNA/amino-acid sequence types (Table 1). Table 1 suggests that linearham and ARPP both perform better than partis does by approximately 2-3 nucleotides (1.6-1.8 amino acids) in the whole sequence and in the CDR3 region. Furthermore, it seems linearham and ARPP perform similarly across all the different settings in Table 1.
Fig 1. Naive sequence validation plot.

The hamming distances between the simulated naive DNA sequences and their corresponding linearham, partis, and ARPP estimates versus the tree imbalance values of the simulated trees. Linear regression lines are superimposed for each method to indicate how the results vary as trees get more imbalanced. For reference, we plot the tree imbalance values for the PC64 and VRC01 trees.
Table 1. Naive sequence validation table.
| Sequence Region | Program | Sequence Type | |
|---|---|---|---|
| DNA | Amino-Acid | ||
| Full-sequence | linearham | 1.92 | 1.17 |
| (3.14) | (1.76) | ||
| partis | 4.81 | 3.02 | |
| (4.91) | (2.84) | ||
| ARPP | 2.24 | 1.39 | |
| (5.06) | (3.32) | ||
| CDR3-only | linearham | 1.66 | 1.08 |
| (2.89) | (1.69) | ||
| partis | 4.17 | 2.69 | |
| (3.70) | (2.29) | ||
| ARPP | 1.27 | 0.856 | |
| (1.78) | (1.18) | ||
Mean hamming distances between the simulated naive sequences and their corresponding estimates, where the hamming distances are averaged over all 180 simulated trees. Results are provided for the linearham, partis, and ARPP programs; the full-sequence and CDR3 regions; and the DNA/amino-acid sequence types. Standard errors are also presented in parentheses.
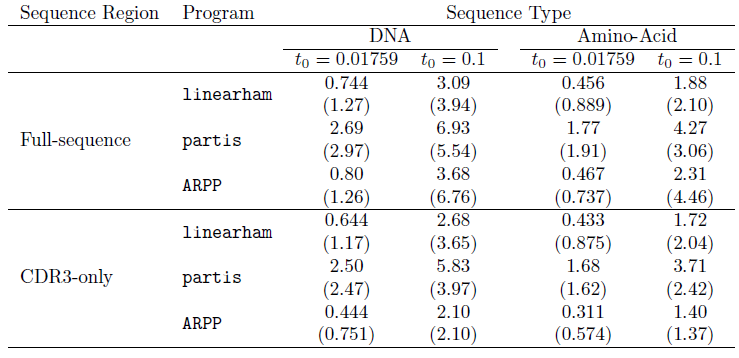
We now present the mean hamming distance results, averaging over all trees generated under the different simulation parameter settings. Specifically, we average over the trees that were simulated using beta-splitting “balance” parameter values β = −1, −1.25, −1.5, CF sequence counts NCF = 40, 80, and root branch lengths t0 = 0.01759, 0.1. The mean hamming distance values seem to increase slightly for linearham and ARPP and considerably for partis as we go from β = −1, −1.25 to β = −1.5 (S2 Table), which is also suggested in Fig 1. The performance of partis appears to deteriorate somewhat as NCF goes from 40 to 80 (S3 Table). The performance of linearham may worsen slightly and ARPP may improve slightly as NCF goes from 40 to 80 but these differences are small compared to the standard errors. With the same caveats, linearham may be slightly better than ARPP at predicting the whole naive sequence. As the root branch length t0 increases from 0.01759 to 0.1, the mean hamming distances increase substantially for all three programs (S4 Table), which is intuitive because we are essentially introducing a higher number of mutations that are shared across all clonal sequences. While these linearham naive sequence validations did not take advantage of the full naive sequence posterior distribution, we demonstrate the usefulness of accounting for phylogenetic uncertainty in our ancestral sequence validations described below.
Intermediate ancestral sequence validations
Our ancestral sequence validation experiments are centered around accurate inference of particular root-to-tip ancestral sequence lineages of interest because immunologists frequently use ASR to estimate the mutational pathways associated with antibody development [4, 6]. For each of our simulated trees, we determine the root-to-tip ancestral lineage of interest by identifying the tip sequence that is farthest from the naive sequence in terms of branch length distance.
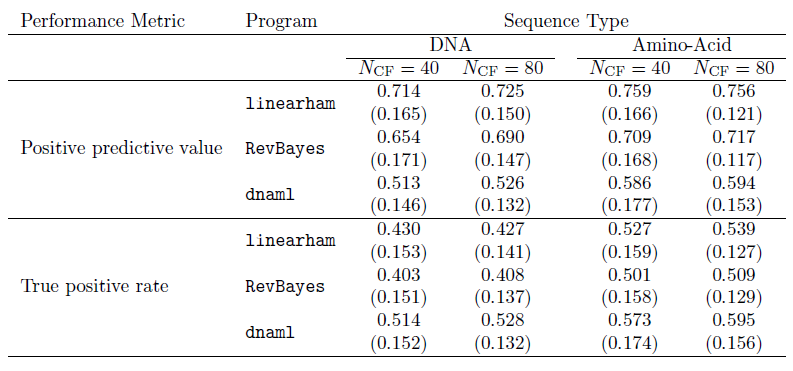
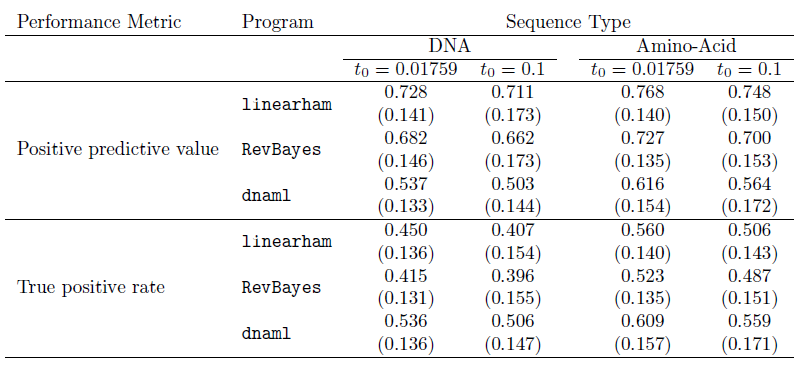
We quantify the results of our ancestral sequence validation by treating it as a machine learning classification problem: do the posterior probabilities aid us in deciding if the ancestral lineage sequences are correct? In all our experiments, we measure classification performance by recording the positive predictive value (i.e. the fraction of sequences in the ancestral lineage prediction set that are on the true ancestral lineage) and the true positive rate (i.e. the fraction of sequences on the true ancestral lineage that are in the ancestral lineage prediction set). The “predicted classification” of these sequences is obtained by applying a decision boundary ρ ∈ {0.25, 0.5, 0.75} to the posterior probability. Thus, for example, if ρ = 0.75 and a given ancestral sequence is on the true ancestral lineage and has posterior probability 0.8, it is considered to be a “true positive” prediction. This analysis is straightforward for the linearham and RevBayes programs, that do estimate posterior probabilities. We define dnaml “posterior probabilities” to be either 0 or 1 depending on whether a lineage sequence is either outside or inside of the dnaml-inferred set of most probable reconstructed lineage sequences.
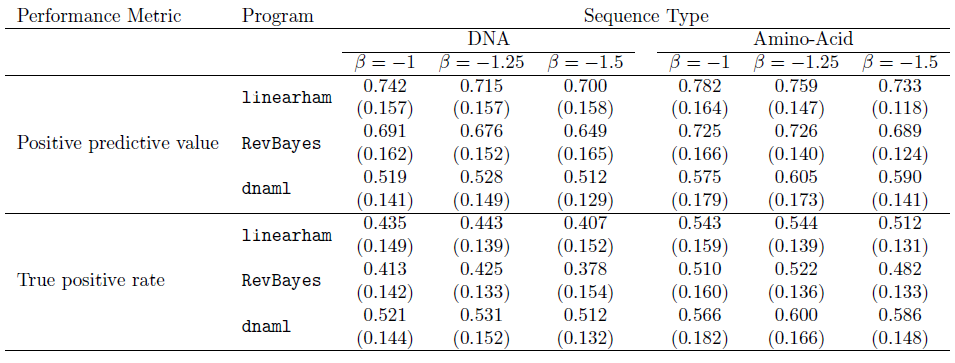
We report the positive predictive values and the true positive rates for all 180 simulated trees and plot these performance metrics against the corresponding values of tree imbalance (Fig 2); for reference, we plot the tree imbalance values for the PC64 and VRC01 trees as well. Notice that the superimposed linear regression lines have negative slopes close to 0, which suggests that ancestral lineage inference is not sensitive to the “balance” of the tree. We also display the mean positive predictive values and mean true positive rates aggregated over all 180 trees for the same three programs, the different decision boundaries ρ ∈ {0.25, 0.5, 0.75}, and the DNA/amino-acid sequence types (Table 2). Table 2 indicates that linearham performs better than RevBayes in every setting, indicating that accounting for naive rearrangement uncertainty in our posterior distribution rather than conditioning on the partis-inferred naive sequence leads to more accurate ancestral lineage sequence estimates. At the lowest decision boundary ρ = 0.25, linearham obtains slightly better positive predictive values and true positive rates than either RevBayes or dnaml does (Table 2). As the decision boundary ρ increases to 0.5 and 0.75, linearham and RevBayes achieve higher positive predictive values at the expense of lower true positive rates, which makes sense because high values of ρ imply that only lineage sequences with high posterior probabilities are predicted to be on the true lineage. In addition, note that the increases in positive predictive values are greater than the decreases in true positive rates for linearham as ρ increases. dnaml obtains the same positive predictive values and true positive rates regardless of ρ because its “posterior probabilities” are either 0 or 1.
Fig 2. Intermediate ancestral sequence validation plot.

The positive predictive values and the true positive rates versus the tree imbalance values of the simulated trees, stratified by decision boundary ρ. Positive predictive values and true positive rates are computed on the DNA sequences and for the linearham, RevBayes, and dnaml programs. Linear regression lines are superimposed for each package to indicate how the results vary as trees get more imbalanced. For reference, we plot the tree imbalance values for the PC64 and VRC01 trees (vertical dashed lines).
Table 2. Intermediate ancestral sequence validation table.
| Performance Metric | Program | Sequence Type | |||||
|---|---|---|---|---|---|---|---|
| DNA | Amino-Acid | ||||||
| ρ = 0.25 | ρ = 0.5 | ρ = 0.75 | ρ = 0.25 | ρ = 0.5 | ρ = 0.75 | ||
| Positive predictive value | linearham | 0.561 | 0.719 | 0.856 | 0.613 | 0.758 | 0.858 |
| (0.139) | (0.157) | (0.176) | (0.131) | (0.145) | (0.146) | ||
| RevBayes | 0.544 | 0.672 | 0.734 | 0.590 | 0.713 | 0.774 | |
| (0.141) | (0.160) | (0.166) | (0.134) | (0.145) | (0.139) | ||
| dnaml | 0.520 | 0.520 | 0.520 | 0.590 | 0.590 | 0.590 | |
| (0.139) | (0.139) | (0.139) | (0.165) | (0.165) | (0.165) | ||
| True positive rate | linearham | 0.545 | 0.428 | 0.304 | 0.640 | 0.533 | 0.398 |
| (0.146) | (0.147) | (0.125) | (0.139) | (0.144) | (0.138) | ||
| RevBayes | 0.517 | 0.406 | 0.276 | 0.606 | 0.505 | 0.370 | |
| (0.147) | (0.144) | (0.116) | (0.140) | (0.144) | (0.134) | ||
| dnaml | 0.521 | 0.521 | 0.521 | 0.584 | 0.584 | 0.584 | |
| (0.142) | (0.142) | (0.142) | (0.166) | (0.166) | (0.166) | ||
Mean positive predictive values and mean true positive rates, averaged over all 180 simulated trees. Results are provided for the linearham, RevBayes, and dnaml programs; the different decision boundaries ρ ∈ {0.25, 0.5, 0.75}; and the DNA/amino-acid sequence types. Standard errors are also presented in parentheses.
We next discuss the mean positive predictive values and mean true positive rates for decision boundary ρ = 0.5, averaging over all trees generated under the different simulation parameter settings. The validation performance of all the programs seems to decline, albeit slightly, from β = −1 to β = −1.5 (S5 Table), which makes sense given the trends in Fig 2. For the most part, mean positive predictive values and mean true positive rates increase for linearham, RevBayes, and dnaml as NCF goes from 40 to 80 (S6 Table), which seems surprising but for larger CFs, the root-to-tip lineage becomes larger and may explain this observed pattern. As the root branch length t0 increases from 0.01759 to 0.1, the ancestral lineage validation results worsen considerably for all three programs (S7 Table), which is logical because, as we stated above, we are essentially introducing a higher number of mutations shared across all clonal sequences when we utilize longer root branch lengths in our simulations.
These results help demonstrate why Bayesian ancestral lineage inference should be favored over likelihood-based approaches to intermediate lineage inference as the Bayesian posterior probabilities quantify the uncertainty in our sequence estimates. In a real-life experimental setting, the decision boundary ρ should be chosen based on the desired level of positive predictive values or true positive rates, and our analysis provides some insight into the mapping between ρ and these classification metrics. In practice, immunologists are probably more interested in controlling positive predictive values than true positive rates because synthesizing computationally-inferred lineage sequences and testing their binding and neutralization abilities is a laborious and expensive endeavor. Thus, knowing the approximate fraction of inferred intermediate lineage sequences that are on the true lineage is of the utmost importance to an immunologist.
PC64/VRC01 ancestral lineage analysis
We illustrate the capabilities of linearham and ARPP/dnaml on real-world datasets by applying the three methods to subsets of the PC64 and VRC01 datasets. The PC64 dataset contains a set of clonal sequences with multiple HIV-binding bNAbs that results from a longitudinal study over 46 months on an African donor (i.e. donor PC64) within the International AIDS Vaccine Initiative Protocol C cohort [49]. Our VRC01 clonal family dataset also originates from an HIV-infected donor and contains many bNAb sequences that are part of a well-known class of HIV-binding antibodies (i.e. the VRC01 class) [41, 50–52]. The tip sequences of interest for the PC64 and VRC01 datasets are chosen to be PCT64-35M and NIH45-46, respectively, which are both monoclonal antibody sequences that have accumulated a large amount of SHM. We use 100 sequences from the PC64 CF dataset using a pruning strategy discussed in [6] and trim the VRC01 CF dataset to 268 sequences using the cd-hit sequence clustering program [53] with a 95% sequence identity cutoff. We perform inference on these subsetted datasets using the same settings as described for our simulation experiments and have uploaded the PC64 and VRC01 input and output data on Zenodo (https://doi.org/10.5281/zenodo.3746832). For reference, the linearham inference pipeline spent approximately 6.6 and 38.5 hours on the PC64 and VRC01 datasets, respectively. In general, the linearham inference pipeline running time is dominated by the RevBayes MCMC step, which scales approximately exponentially in the clonal family size.
The PC64 amino acid naive sequence posterior probability logos suggest that there is little uncertainty in the naive sequence reconstruction (Fig 3a) and, in fact, the most probable linearham amino acid naive sequence has a probability of approximately 0.92. However, the VRC01 naive sequence seems to have considerable uncertainty in the CDR3 region (Fig 3b), which shows that properly modeling ancestral sequence and phylogenetic uncertainty is important for real-world datasets with highly-mutated sequences. The most probable linearham VRC01 naive sequence estimate has a posterior probability approximately equal to 0.036. It is important to note that the VRC01 CF sequences were first collected 5 years after the diagnosis of the associated HIV-1 infection, whereas the PC64 CF sequences contain samples drawn from the corresponding donor as early as 4 months post infection. This indicates that the VRC01 naive sequence reconstruction inherently has more uncertainty because there are not any early time-point samples in the corresponding dataset. Furthermore, the most probable linearham VRC01 naive sequence amino acids do not perfectly match the corresponding ARPP-inferred residues (Fig 3b). In total, these results suggest that in the absence of uncertainty, linearham and ARPP produce similar naive sequence reconstructions. However, when there is a significant amount of naive sequence uncertainty, linearham, unlike ARPP, provides alternate hypotheses that should be considered along with corresponding uncertainty estimates.
Fig 3. Naive sequence posterior probability logos.

The linearham-inferred (top) and ARPP-inferred (middle) amino acid naive sequence posterior probability logos for (a) the pruned PC64 dataset of 100 sequences and (b) the trimmed VRC01 alignment of 268 sequences. We also display the empirical sequence logo (bottom) for each dataset and highlight the inferred CDR3 regions (black lines).
Our linearham analysis demonstrates that there are many probable naive-to-tip sequence paths (Fig 4, S1 Fig), suggesting that intermediate ancestral sequences have high levels of uncertainty; we use 0.04 probability cutoffs in each linearham-inferred lineage graphic. In particular, the linearham lineage diagram for the PC64 dataset (Fig 4) shows many possible routes of evolution from the different naive sequences to the PCT64-35M mature sequence and displays confidence values via posterior probabilities. The VRC01 lineage graphic in Fig 4 does not display connections between any naive sequences and intermediate ancestral sequences, which reflects the fact that naive sequence inference is extremely challenging on this dataset. In summary, there is considerable uncertainty in naive-to-tip mutational trajectory inference in real-world BCR datasets. This finding contradicts the assertions of [12], which states that ancestral sequence and phylogenetic uncertainty is unimportant, and proceeds with a single point estimate.
Fig 4. Naive-to-tip sequence trajectory graphics.

The linearham-inferred naive-to-tip amino acid sequence trajectories for the pruned PC64 dataset of 100 sequences and the trimmed VRC01 alignment of 268 sequences, displaying only the edges that satisfy the given posterior probability threshold, and only the nodes that contact edges above the threshold. The tip sequences of interest for the PC64 and VRC01 datasets are chosen to be PCT64-35M and NIH45-46, respectively, and we use 0.04 probability cutoffs for these lineage graphics (such that any edge with probability less than this threshold is discarded). The nodes correspond to unique ancestral sequences filled with red color, where the opacity is proportional to the posterior probability of the associated sequence. The directed edges connecting nodes represent ancestral sequence transitions and are shaded blue with an opacity proportional to the posterior probability of the associated sequence transition. Nodes without any probable edges connecting them are not displayed in these graphics. The absence of many nodes for VRC01 indicates that these naive-to-tip sequence trajectories are highly uncertain. A more detailed version of this graphic, including predicted lineage mutations, is included as S1 Fig.
Discussion
In this paper, we introduce a novel Bayesian approach to CF phylogenetic inference that is based on a phylo-HMM. Our phylo-HMM posterior sampling methodology not only allows for easy quantification of phylogenetic and ancestral sequence uncertainty but also models the V(D)J recombination process as an informative prior on the root sequence. Specifically, our phylo-HMM models both the naive rearrangement and SHM processes by using a hidden state discrete-time Markov model on naive sequences that explicitly incorporates V(D)J rearrangement information and an emission distribution generating the clonal sequences conditional on the naive sequence that is based on phylogenetic likelihoods. We show that our inference procedure, implemented in the software package linearham, provides state-of-the-art naive sequence and ancestral sequence estimates and augments these estimates with relative confidence values by reporting the associated posterior probabilities.
From our simulation experiments, we see that the partis naive sequence estimates get substantially worse as trees get more imbalanced. This is in contrast to those of linearham and ARPP, which is intuitive because partis assumes a star-tree configuration whereas linearham and ARPP leverage phylogenetic models. The linearham and ARPP programs perform similarly in our naive sequence validations regarding their most highly supported inferences, but only linearham is capable of characterizing naive sequence uncertainty. This is important because, as we see in our VRC01 analysis (and in contrast to the findings of [12]), real datasets of significant practical importance can have substantial uncertainties associated with their naive sequence estimates. In addition, we demonstrate that linearham ancestral lineage inference performs better, via mean positive predictive values and mean true positive rates, than either RevBayes or dnaml does at the lowest decision boundary ρ = 0.25, which suggests that accounting for naive sequence, phylogenetic, and ancestral sequence uncertainty does lead to slightly improved ASR performance. Furthermore, our Bayesian ASR results indicate that ρ can be chosen according to a prespecified trade-off between positive predictive values and true positive rates, which is an important consideration for immunologists looking to synthesize computationally-inferred lineage sequences. Finally, we note that we did not provide a comparison with a phylogenetic inference method in the absence of any V(D)J rearrangement inferences. This was not necessary because such a method, using a standard reversible substitution model, would have no information on where to place the root. Thus if one was to infer the naive ancestor, marginalized over the possible root positions, one would get a highly uninformative result. Indeed, integration of germline information is essential in this case to root the tree.
Based on all the evidence in this manuscript, we recommend using linearham to infer and visualize naive-to-mature mutational pathways in CFs harboring antibodies of particular interest. Bayesian phylogenetic inference has already been shown to be useful for identifying different possible routes of evolution from a fixed naive sequence to a bNAb with relative confidence values [6] and we believe our Bayesian phylo-HMM analysis pipeline in linearham can be used to not only infer similarly-styled maturation pathways but also visualize the uncertainties inherent in the naive sequence and ancestral sequence estimates. Our biological applications in this manuscript are derived from two highly-mutated BCR lineages and so the conclusions may not hold true for other human BCR sequence datasets. On the other hand, in our research we have found that ancestral sequence uncertainty is the rule and not the exception, and levels of uncertainty shown here (Fig 4) are quite typical [6]. If we are to trust binding experiments on predicted ancestral sequences, we must know the level of certainty in those predictions, which can be assessed using the approach described in this paper.
Our Bayesian phylo-HMM inference procedure admits a number of possible future extensions to enhance the effectiveness of our technique. One drawback of our method is that it does not sample the parameters of p(Ynaive) and uses partis (and its star-tree assumption) to estimate them. Ideally, our Bayesian inference procedure would jointly sample all the model parameters, but currently this is not practically feasible. In addition, our method implicitly assumes the CFs have been obtained from partis, which uses the star-tree assumption to cluster repertoire sequences. It may be possible to, as [16] state, incorporate the phylo-HMM in the CF clustering procedure within partis to obtain higher-quality CFs, but in our current Bayesian implementation that would be computationally costly. Finally we would like to provide more efficient alternatives than the current approach of MCMC sampling and resampling.
Methods
Overview
The immune system is able to generate a diverse set of naive BCR sequences due to the V(D)J rearrangement process (Fig 5a). In this process, the B cell first randomly selects V, D, and J gene segments (i.e. DNA sequences) from the respective gene pools in the body. Before joining the gene segments together, the B cell randomly deletes nucleotides at both ends of the V-D and D-J junction regions and randomly inserts nucleotides in the same junction regions (i.e. non-templated insertions). BCRs comprise both heavy chain and light chain sequences, where the former goes through the VDJ rearrangement process described above while the latter undergoes VJ recombination, a process similar to VDJ recombination without D germline genes; in this paper, we focus solely on heavy chain inference, but our methods and implementation extend to light chain inference too. Although the V(D)J rearrangement process samples germline genes from the same gene pools for all the naive BCRs in a given individual, different people may have different collections of germline genes [15]. BCR sequences can be partitioned into framework (FWK) and complementarity-determining (CDR) regions. The BCR binding affinity is largely determined by the sequence segments in the CDR regions, and among all the CDR regions the CDR3 region contributes the most to antigen-binding specificity and has the highest amount of sequence variability. The partis software program [11, 16] treats the naive sequence generative process as a discrete-time Markov chain (DTMC) going from left to right across the sequence bases and also permits maximum likelihood inference of the associated model parameters, which are defined according to the V(D)J rearrangement dynamics. We emphasize that the “time” of this DTMC represents position along the sequence, in contrast to the continuous time Markov chain described below modeling the substitution process through chronological time.
Fig 5. Model overview.

(A) A schematic representation of the naive rearrangement process from [11]. First, V (green), D (orange), and J (purple) genes are randomly selected from the respective gene pools in the body. Then, nucleotides are randomly deleted (red X’s) from both ends of the V-D and D-J junction regions and random bases (blue) are added to the same junction regions before the V, D, and J germline genes can be joined together. The BCR sequences can be partitioned into framework (FWK) and complementarity-determining (CDR) regions. (B) Our Bayesian phylo-HMM jointly models V(D)J recombination at the root of the tree (using an HMM) and then subsequent diversification (via a phylogenetic tree). We do posterior inference conditioning on the observed sequence alignment in a clonal family, but not on a fixed inferred naive sequence.
As we attempt to characterize the affinity maturation process in GCs, we use the concept of a clonal family (CF) to help analyze BCR repertoire datasets that result from high-throughput sequencing experiments. A clonal family consists of a set of BCR sequences that originate from the same naive rearrangement event; in practice, it is simpler to define these families as groups of BCR sequences that share the same naive sequence [16]. In this work, we use the latter definition of a CF. The CF definition used here relies on the basic assumption that the unmutated common ancestor of a collection of clonally related sequences can only be identified by the corresponding DNA sequence. There is a chance that two different naive B cells with identical BCR sequences could seed multiple GCs and form their own lineages, but the observed clones from the two GCs would be collapsed into a single CF because both lineages share the same naive sequence. Thus, a correctly inferred CF under this definition will be a cluster of sequences that derive from naive B cells with the same BCR sequence; because GC mutation and selection occur at the sequence level, all sequences in a CF go through the same mutation and selection processes. Using this CF definition, [16] describe how to cluster BCR sequences from large-scale repertoire datasets into CFs with high accuracy using partis. We want to emphasize that repertoire datasets can be clustered and pre-processed in many different ways, but partis provides one way to cluster repertoire sequences and produce CF-specific multiple sequence alignments (MSAs) which also provides us with estimates for a probabilistic recombination model for BCRs.
As mentioned in the opening section, naive sequences accumulate mutations via SHM and the corresponding B cells undergo cellular replication. Phylogenetic tree models provide a realistic and mathematically convenient way to represent the aforementioned B cell evolutionary dynamics of a CF. In particular, these models define a likelihood at each MSA position/site as a function of unknown parameters. These parameters consist of a tree topology, branch lengths, and continuous-time Markov chain (CTMC) substitution model parameters. While B cell evolution in a CF is not independent across the different site positions, site-specific phylogenetic likelihoods provide a convenient first approximation in modeling this phenomenon. To help us illustrate how these phylogenetic models work, we provide an example tree visualization for 4 sequences (S2 Fig).
Given a tree topology with branch lengths, we use a CTMC substitution model to calculate the probabilities of state changes along the branches of the tree. Specifically if t denotes a branch length on a tree, CTMC substitution models allow one to calculate pij(t), which denotes the probability of going from state i to state j on a branch of length t, where i, j ∈ {A, G, C, T}. It is common to use a reversible CTMC substitution model on a tree [17]; a reversible substitution model is a Markov substitution model that, if started at stationarity, can be run backwards in time, with the resulting backward Markov model following the same probability law as the original forward model. The standard phylogenetic generative process can be described at each alignment site as follows: 1) a DNA state at the root node is drawn independently according to the same 4-state discrete distribution and 2) the states at the other nodes are sampled in a pre-order traversal using the computed CTMC probabilities at each branch pij(t); this model is a special case of a directed graphical model [18] that probabilistically generates sequence alignments.
Standard phylogenetic models do not account for naive rearrangement dynamics at the root because, as we discussed above, the root state at each sequence position is sampled independently according to an identical distribution. Instead, if we draw root sequence states from the DTMC mentioned earlier, we would obtain a phylogenetic model that more accurately describes B cell evolutionary dynamics. Thus, we formulate our phylo-HMM to consist of a hidden state DTMC model for naive sequences that explicitly incorporates V(D)J rearrangement information, and an emission distribution that generates sequence alignments conditional on the naive sequence that is based on phylogenetic likelihoods. This phylo-HMM hopefully leads to more accurate naive sequence estimates and, as a result of that, higher-quality intermediate ancestral sequence estimates. We introduce a pictorial representation of our Bayesian phylo-HMM to make clear our target of inference (Fig 5b).
Notation and assumptions
We now introduce some notation and assumptions that will be used throughout this paper. Let denote the MSA of m clonal DNA sequences of length n. We define and to be the corresponding length-n naive sequence random variable and point estimate, respectively. We let τ represent a tree topology with m tips and a root branch length; in total, this topology has m internal nodes and 2m − 1 branch lengths. We assume that the ancestral sequence at the root of τ is Ynaive. Furthermore, we define t = {ti}i=1:(2m−1) to be the branch lengths associated with τ. Let denote the internal nodes of τ excluding the naive sequence Ynaive. For convenience, we let and symbolize the observed sequence data and unobserved ancestral sequence data, respectively, at MSA site j ∈ {1, …, n}. Conditioned on the root sequence Ynaive, we assume that the ancestral states at each site in the MSA evolve independently along the phylogeny τ according to a general time-reversible (GTR) substitution model [19]. Let e = {eAC, eAG, eAT, eCG, eCT, eGT} and π = {πA, πC, πG, πT} represent the GTR exchangeability rates and equilibrium base frequencies, respectively. We also account for phylogenetic rate variation among sites by employing a discrete gamma distribution with a fixed number of rate classes K [20, 21] and define α to be the associated gamma shape parameter, denote r = {r1(α), …, rK(α)} as the set of discrete rates deterministically induced by α, and let represent the discrete rates chosen at each site in the MSA. In theory, we would like to compute phylogenetic likelihoods with branch lengths scaled by and mix over for j ∈ {1, …, n}. However, these integrals are generally intractable so [20] suggested dividing the Gamma(α, α) distribution into K equal-probability rate classes, with the mean rate in each class used to represent all rates in that class. In practice, we use the Categorical(r, p) distribution to define the models on for j ∈ {1, …, n}, where p is a, possibly unnormalized, probability vector; in addition, this model is used to represent more general discrete distributions.
From a statistical point of view, it is common to assume the naive sequence root node is a leaf node holding naive sequence bases connected to a “virtual root node” (i.e. what we call “root” node for our phylogenetic model described in the previous subsection) via a branch length of 0. Even though it may seem like we have described a rooted tree model above, it turns out that under the assumptions of a reversible substitution model and a nucleotide distribution at the virtual root starting at stationarity, the Pulley Principle, first discussed in [22], states that the virtual root may be placed anywhere on the tree without affecting the likelihood. This implies that the model described above does not correspond to a single rooted tree, but an equivalence class of rooted trees that maps to a unique unrooted tree. This is an important distinction as our phylo-HMM will in fact use an unrooted tree model, which will be justified when we describe our posterior sampling approach.
Phylo-HMM description
Phylo-HMMs are special cases of directed graphical models [18] and treat evolution as a combination of two Markov processes: one across the sites in the MSA and one down the phylogeny. They are commonly used for sequence-level segmentation problems such as gene prediction and detection of highly-conserved regions [14]. In fact, a phylo-HMM is similar in structure to a standard HMM; the main difference between the two model classes is that a phylo-HMM uses a phylogenetic likelihood as its emission probability distribution, while standard HMMs usually specify simpler emission distributions. Our BCR-specific phylo-HMM specifies a Markov process along Ynaive and, conditional on Ynaive, a phylogenetic evolutionary process down the given tree. Phylo-HMMs have not been applied to BCR sequence analysis before and we believe this biologically realistic probabilistic model is uniquely suited to provide higher-quality naive sequence and ancestral sequence estimates compared to those obtained under current state-of-the-art methods.
To help us describe the phylo-HMM generative process, we provide an illustration of the associated graphical model diagram for an example alignment with m = 3 sequences and n = 3 sites (Fig 6). The naive sequence “hidden state” prior distribution p(Ynaive) decomposes to and the bases are generated sequentially; these prior probabilities depend on hyperparameters that can be set using the partis software package [11, 16]. For the tree topology τ, we assume that a tree is drawn from the Uniform distribution over (m + 1)-tip unrooted trees; this seems like a strange choice given that we described τ as a rooted topology above, but this decision will be justified when we discuss how to perform Bayesian inference under the phylo-HMM. The branch lengths t and the gamma shape parameter α are assumed to be a priori independent and to follow Exponential(λ) distributions, where λ is some prespecified rate. The GTR exchangeability rates e and equilibrium base frequencies π are usually assumed to come from six-dimensional and four-dimensional Dirichlet distributions, respectively.
Fig 6. A graphical model representation of our phylo-HMM for an example alignment with m = 3 sequences and n = 3 sites.

The τ, t, π, and e nodes represent the 4-tip unrooted tree topology, the associated 5 branch lengths, the GTR exchangeability rates, and GTR equilibrium base frequencies, respectively. The parameter α denotes the gamma shape parameter associated with the K-class discrete gamma distribution, which is used to model phylogenetic rate variation among sites; r symbolizes the vector of K discrete rates that is deterministically induced by α. The set of nodes defines the rates that are drawn from r at each particular site. The “hidden state” node collection represents the Markov process that stochastically generates the naive sequence in our phylo-HMM. The node sets and denote the internal nodes of τ excluding the naive sequence Ynaive and the observed MSA, respectively. We draw plates around the and D(j) node sets for j ∈ {1, 2, 3} to indicate that any directed edges touching a plate apply to all nodes in the plate (except for edges that originate from t, which apply element-wise to the nodes in the plate).
For each MSA site j ∈ {1, …, n}, a priori follows the distribution. Then, at each site j ∈ {1, …, n}, we assume that and D(j) are generated by drawing DNA states from CTMC transition probability matrices based on augmented branch lengths . For example, in Fig 6, we first sample from , which is a row vector distribution in the CTMC transition probability matrix for the “branch length” , where j ∈ {1, …, n}. Once we have sampled for j = 1, …, n, we can draw and using similar row vector distributions from CTMC transition probability matrices for the “branch lengths” and , respectively. We can recursively continue this process until we generate states at and for j ∈ {1, …, n}.
Posterior distribution inference
We are interested in sampling from the posterior distribution p(τ, t, π, e, α, r, r*, Ynaive, Yint|D):
where this model decomposition results from the definition of a directed graphical model. We also factorize the posterior distribution in the following way:
This formulation is useful because it suggests that we can generate draws from the posterior distribution by sampling sequentially from three conditional probability distributions. Conceptually, to sample from the posterior, we have to draw in-order: 1) the phylogeny-related parameters, 2) the naive sequence, and 3) the ancestral sequences. We describe how to perform these three sampling steps in the following subsections and provide a complete summary of the sampling process in Algorithm 1.
Algorithm 1: Posterior Sampling of p(τ, t, π, e, α, r, r*, Ynaive, Yint|D)
Input: CF multiple sequence alignment D, number of discrete rates K
Npool, Nfinal (Npool/Nfinal ≈ 20)
Output: Nfinal samples of
(τ, t, π, e, α, r, r*, Ynaive, Yint)∼ p(τ, t, π, e, α, r, r*, Ynaive, Yint|D)
Tree Sampling—p(τ, t, π, e, α, r|D)
1. Run partis on input data D.
⇒
2. Run RevBayes MCMC on the augmented MSA D*.
⇒ Npool samples of (τ, t, π, e, α, r) ∼ q(τ, t, π, e, α, r|D*)
3. Run the SIR algorithm without replacement on the Npool (τ, t, π, e, α, r) proposal samples with weights .
⇒ Nfinal samples of (τ, t, π, e, α, r) ∼ p(τ, t, π, e, α, r|D)
Naive Sequence Sampling—p(Ynaive|τ, t, π, e, α, r, D)
For each sample (τ, t, π, e, α, r)∼p(τ, t, π, e, α, r|D):
For each site j ∈ {n, …, 1}:
1. Draw using our phylo-HMM-based backward sampling procedure.
⇒Nfinal samples of (τ, t, π, e, α, r, Ynaive)∼p(τ, t, π, e, α, r, Ynaive|D)
Intermediate Ancestral Sequence Sampling—p(r*, Yint|τ, t, π, e, α, r, Ynaive, D)
For each sample (τ, t, π, e, α, r, Ynaive) ∼ p(τ, t, π, e, α, r, Ynaive|D):
For each site j ∈ {1, …, n}:
1. Sample according to probabilities proportional to .
2. Sample in a pre-order fashion using the standard ASR distribution at internal nodes on a -scaled tree.
⇒ Nfinal samples of (τ, t, π, e, α, r, r*, Ynaive, Yint) ∼ p(τ, t, π, e, α, r, r*, Ynaive, Yint|D)
Tree sampling
Our strategy for sampling from p(τ, t, π, e, α, r|D) is to first draw a large pool of observations from an easy-to-sample proposal distribution q and then perform weighted bootstrap with weights on those samples to obtain approximate draws from the correct distribution. This “sampling-importance-resampling” (SIR) algorithm is a sample filtering method that finds use in a wide variety of statistical applications [23–25]. The original SIR algorithm resampled observations with replacement, but there are theoretical and practical considerations that make resampling without replacement more attractive [26, 27]. A thorough review of SIR sampling can be found in [28, Chapter 24]. We use the SIR algorithm to sample from p(τ, t, π, e, α, r|D) because we want to take advantage of already-existing software programs for Bayesian phylogenetic inference while incorporating biologically-realistic details into our phylo-HMM.
Our phylogeny proposal distribution q comes from the RevBayes software package [46] because this is a proposal that is close to the target distribution p while also being easy to sample from. In short, this q is traditional Bayesian phylogenetic analysis with a point estimate of the naive sequence. In more detail, we first input the MSA D into the partis package, obtain a naive sequence point estimate , and create an augmented MSA . This allows us to generate Markov chain Monte Carlo (MCMC) samples from q(τ, t, π, e, α, r|D*) and provides a convenient way to sample trees that have m tips and an informative root branch length emanating from the naive sequence. In our RevBayes analysis, we require that the prior components of q(τ, t, π, e, α, r|D*) be defined as we discussed in the previous subsection for p(τ, t, π, e, α, r|D) and as we will see, this assumption is critical to the validity of our technique.
For the purposes of this discussion, let us assume that we sample a large number (say Npool) of parameter values from q(τ, t, π, e, α, r|D*) in RevBayes. As we briefly mentioned above, we resample Nfinal times without replacement from the set of Npool q(τ, t, π, e, α, r|D*) draws. Each q(τ, t, π, e, α, r|D*) sample is assigned a sampling weight w = p(τ, t, π, e, α, r|D)/q(τ, t, π, e, α, r|D*). While it seems odd to use the ratio of posterior probabilities that are conditional on different datasets as bootstrap weights, the only technical requirement on p and q is that the parameters of interest (i.e. τ, t, π, e, α, and r) have the same support, which is indeed the case in our situation. Smith and Gelfand [23] suggest picking Npool and Nfinal so while Rubin [30] proposed a safe rule-of-thumb to be ; we use in all the applied experiments conducted in this paper. It may not be immediately clear how one would efficiently compute the numerator in w so we express w in the following form:
where the transition from the second line to the third line is due to the priors on τ, t, π, e, α, and r for both p and q being equal and the decomposition between the fourth and sixth lines is a result of d-separation conditional independencies [18] as follows. Specifically, Ynaive ⊥ {τ, t, π, e, α, r} (here ⊥ denotes independence) because every undirected path in the graphical model between Ynaive and {τ, t, π, e, α, r} does not contain any “conditioned” child nodes and D ⊥ α|{τ, t, π, e, r, Ynaive} as all paths between D and α are “blocked” by the intermediate node r. The final denominator term above q(D*|τ, t, π, e, α, r) is the usual phylogenetic likelihood, here calculated by RevBayes. Note that the marginal likelihood ratio does not affect the bootstrap sampling because the sampling probabilities are proportional to w and the likelihood ratio is a constant with respect to τ, t, π, e, α, and r in the Npool sampling weights. The numerator term in the final equation for w looks complicated, but is actually the phylo-HMM likelihood with the “hidden state” probabilities and for j ∈ {2, …, n} and the “emission probabilities” that marginalize over the site-wise rates for k ∈ {1, …, n}. We can efficiently calculate the phylo-HMM likelihood using the forward algorithm [31], but this approach requires us to be able to compute the phylo-HMM emission probabilities in a straightforward manner. The computation of the emission probabilities is of interest because the hidden state probabilities in p(Ynaive) can be easily inferred using partis, which we now call .
It turns out that we can, again, leverage existing software tools to help us efficiently compute the emission probabilities for k ∈ {1, …, n}. The key point is to recognize that is an entry in the Felsenstein likelihood vector at the node, which denotes the probability of the observed data at only the tips that descend from node , given the conditioned state of node . These vectors are commonly used within a post-order tree traversal algorithm to compute standard phylogenetic likelihoods [22]. Let Fu = (Fu1, …, Fum)T be the vector of partial likelihoods at node u, where Fui denotes the probability of the observed data at only the tips that descend from node u, given that the state of node u is i. Because we utilize an unrooted tree model in our phylo-HMM, we can use a Pulley Principle argument [22] to show that a standard phylogenetic likelihood on our tree can be represented as . Thus, we can compute the phylo-HMM emission probabilities by first calculating the standard site-wise phylogenetic likelihoods on the same tree and then dividing out the stationary probabilities. To compute these standard site-specific phylogenetic likelihoods, we make use of the libpll C library [32], which is a versatile high-performance software library for phylogenetic analysis. We could have instead used a rooted tree with a non-reversible substitution model in our phylo-HMM, performed our own post-order tree traversal algorithm for likelihood computations, and extracted out the appropriate entries in the site-wise Felsenstein likelihood vectors. However, using libpll allowed us to focus on the novel core of our work: combining phylogenetic and HMM likelihood calculations in a Bayesian inference. In the next subsection, we describe how to generate naive sequence draws given the approximate phylogenetic tree samples from p(τ, t, π, e, α, r|D).
Naive sequence sampling
To sample naive sequences, we exploit the fact that our phylo-HMM is essentially a standard HMM with a naive-conditional phylogenetic likelihood as its emission distribution. We draw the “hidden state” naive sequence Ynaive from p(Ynaive|τ, t, π, e, α, r, D) by adapting the hidden state posterior sampling technique for standard HMMs to be used for our specialized phylo-HMM [33]. Just as we perform the forward algorithm by recursively computing and caching intermediate phylo-HMM likelihoods (i.e. forward probabilities) going left to right across the MSA, we can sample Ynaive by doing a backward pass through the phylo-HMM and drawing the states starting at site n and ending at the first alignment site. In fact, the maximum a posteriori probability (MAP) estimate of the hidden state sequence Ynaive is obtained using a similar procedure called the Viterbi algorithm [31, 33]. This backward sampling procedure can actually use the previously cached forward probabilities in the calculation of the sampling probabilities at each site, which is convenient because we already had to run the forward algorithm to sample the phylogeny-related parameters from p(τ, t, π, e, α, r|D). Once Ynaive has been sampled, we can proceed to draw the intermediate ancestral states Yint from the conditional distribution p(r*, Yint|τ, t, π, e, α, r, Ynaive, D).
Intermediate ancestral sequence sampling
Just as we did for our naive sequence sampling, we sample the intermediate ancestral states Yint by utilizing a modified version of the standard ancestral sequence reconstruction (ASR) technique used in phylogenetics [34]. It is important to note that sampling from p(r*, Yint|τ, t, π, e, α, r, Ynaive, D) can be reduced to drawing pairs from for each MSA site j ∈ {1, …, n}, which is justified by d-separation conditional independencies [18]. At each site j ∈ {1, …, n}, we first sample and then according to the previously-described distribution:
where the above decomposition is based on the definition of conditional probability. We draw the site-specific rates before the site-wise intermediate ancestral states because conditioning on the rates allows for simpler and more efficient ancestral state sampling using an already-existing software package.
It turns out that we can draw values from r with probabilities proportional to , which makes intuitive sense because it implies rates should be sampled according to the site-specific likelihoods with branch lengths scaled by the corresponding rates. To understand why the above statement holds true, we express as follows:
where the transition from the second line to the third line stems from the definition of conditional probability, the transition from the third to fourth line is a result of d-separation [18], and the fourth-to-fifth line transition is due to the fact that by assumption. These site-specific likelihoods are in fact almost identical to the naive-conditional phylogenetic likelihoods discussed in the previous two subsections with the only difference being that we now condition on the site-wise rates instead of marginalizing over them.
To illustrate why sampling from is similar to drawing ASRs according to the procedure outlined by [34], we derive the sampling distribution of , the most recent common ancestor of D(j). The distribution can be decomposed in the following manner:
where, as before, the transition between the second and third lines are due to the definition of conditional probability and the transition from the third line to the fourth line is a result of d-separation [18]. The first term in the resulting expression above, , is the CTMC transition probability between and on a scaled branch length and the second term, , is an entry in the Felsenstein likelihood vector at the node on the given tree with -scaled branch lengths. This expression for the sampling distribution of corresponds with the standard ASR distribution at internal nodes described in [34]. Thus, by conceptually treating as a sampled root node and scaling the branch lengths by , we can draw using equation (10) presented by [34]. By recursively using d-separation arguments [18], we can use similar logic to that described above to sample states at the other internal nodes in a pre-order fashion as well. Once we have drawn at each alignment site j ∈ {1, …, n}, our three-stage sampling process of p(τ, t, π, e, α, r, r*, Ynaive, Yint|D) is completed.
Implementation
The entire Bayesian phylo-HMM sampling process is implemented in a pipeline called linearham, which is available at https://github.com/matsengrp/linearham. We developed our phylo-HMM data structure in C++ and, as mentioned before, used the tree structures from the libpll C library [32] to ensure our phylogenetic likelihood computations were as fast as possible. We have provided a Docker container (https://quay.io/repository/matsengrp/linearham) so users can try out the software without installation, as well have an authenticated record of the installation dependencies and an example command in a Dockerfile.
Our linearham program also provides an interface to partis to obtain . It accepts a repertoire FASTA file as input and can infer the hidden state transition probabilities assuming either the repertoire needs to be partitioned into individual CFs before phylogenetic inference or the “repertoire” is a single CF already, which is useful for researchers that want to run linearham inference on a hand-curated CF. It is also possible to specify an external set of p(Ynaive) parameters.
In addition, linearham summarizes its phylogenetic inference output in a user-friendly format. It provides an output FASTA file that contains each sampled amino acid naive sequence and its associated posterior probability, creates a FASTA-like file that maps each sampled amino acid naive sequence to its corresponding set of DNA naive sequences and posterior probabilities, and generates an amino acid naive sequence posterior probability logo using WebLogo [35] to visualize the per-site uncertainties. Furthermore, we provide visualizations for particular naive-to-tip tree lineages of interest by tabulating the posterior probabilities of sampled naive sequences and intermediate ancestral sequences on the lineage. For naive-to-tip lineage analysis, we also create a posterior probability lineage graphic using Graphviz [36] that summarizes the different inferred naive-to-tip sequence trajectories and their relative confidences [37].
Supporting information
The linearham-inferred (left) and dnaml-inferred (right) naive-to-tip amino acid sequence trajectories for the pruned PC64 dataset of 100 sequences and the trimmed VRC01 alignment of 268 sequences, displaying only the edges that satisfy the given posterior probability threshold, and only the nodes that contact edges above the threshold. The tip sequences of interest for the PC64 and VRC01 datasets are chosen to be PCT64-35M and NIH45-46, respectively, and we use 0.04 probability cutoffs for these lineage graphics (such that any edge with probability less than this threshold is discarded). The nodes correspond to unique ancestral sequences filled with red color, where the opacity is proportional to the posterior probability of the associated sequence. Each node has a label that denotes whether the associated sequence is a naive or intermediate ancestral sequence, the posterior probability rank of the sequence among all sampled naive or intermediate ancestral sequences, and the sequence-specific posterior probability itself. The directed edges connecting nodes represent ancestral sequence transitions, are shaded blue with an opacity proportional to the posterior probability of the associated sequence transition, and are annotated with the site-specific mutations between the two sequences. The absence of many nodes for VRC01 indicates that these naive-to-tip sequence trajectories are highly uncertain.
(PDF)
Letters x, y, z, w represent the unobserved internal node states where w is associated with the root node, t0 defines the root branch length, and (t0, t1, t2, …, t6) denotes the entire vector of branch lengths. Given this tree topology and set of branch lengths, we can calculate the likelihood of observing the nucleotide vector (A, T, C, T) by marginalizing probabilities over the unobserved states x, y, z, w.
(PNG)
{kind=link}
A table summarizing the various parameter settings used in our simulation experiments. The beta-splitting “balance” parameter β controls how “comb-like” (i.e. imbalanced) our simulated trees look, NCF represents the number of sequences simulated in each clonal family, and t0 denotes the root branch length. We simulate 15 trees for each combination of parameter values, which results in 180 simulated trees.
(PNG)
{kind=link}
Mean hamming distances between the simulated naive sequences and their corresponding estimates, where the hamming distances are averaged over all trees generated under the different beta-splitting “balance” parameter value settings. Results are provided for the linearham, partis, and ARPP programs; the full-sequence and CDR3 regions; and the DNA/amino-acid sequence types. Standard errors are also presented in parentheses.
(PNG)
{kind=link}
Table analogous to S2 Table, but varying the CF sequence count NCF.
(PNG)
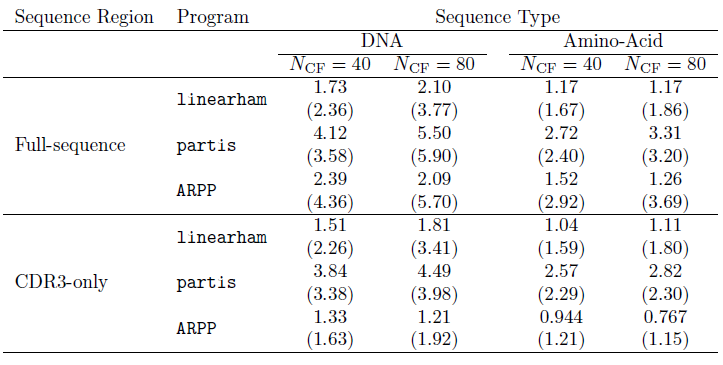{kind=link}
Table analogous to S2 Table, but varying the root branch length t0.
(PNG)
{kind=link}
Mean positive predictive values and mean true positive rates for decision boundary ρ = 0.5, where we average over all trees generated under the different beta-splitting “balance” parameter value settings. Results are provided for the linearham, RevBayes, and dnaml programs and the DNA/amino-acid sequence types. Standard errors are also presented in parentheses.
(PNG)
{kind=link}
Table analogous to S5 Table, but varying the CF sequence count NCF.
(PNG)
{kind=link}
Table analogous to S5 Table, but varying the root branch length t0.
(PNG)
{kind=link}
Acknowledgments
We thank Arman Bilge for many stimulating conversations about our phylo-HMM emission likelihood calculation, Andy Magee for answering all our questions about RevBayes, and Jean Feng for adapting the sequence simulator in samm to be used in our simulations. We also want to thank Chaim Schramm for providing us with the VRC01 sequence dataset used in [41], Bryan Briney for sending us the PC64 multiple sequence alignment used in [40], Tyler Starr for creating the trimmed 268-sequence VRC01 dataset described above, and Laura Doepker for providing us with other experimental datasets to test linearham on.
Data Availability
Data are available at https://zenodo.org/record/3746832.
Funding Statement
The research of FAM was supported in part by NIH grants GM113246, AI146028, AI120961, AI138709, and AI128914; National Science Foundation grant CISE-1564137; and a Faculty Scholar grant from the Howard Hughes Medical Institute and the Simons Foundation. Research of VNM was in part supported by National Science Foundation grant CISE-1561334. AD was supported by an NSF IGERT DGE-1258485 fellowship. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Mascola JR, Haynes BF. HIV-1 neutralizing antibodies: understanding nature’s pathways. Immunological Reviews. 2013;254(1):225–244. 10.1111/imr.12075 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Stamatatos L, Pancera M, McGuire AT. Germline-targeting immunogens. Immunological Reviews. 2017;275(1):203–216. 10.1111/imr.12483 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Liao HX, Lynch R, Zhou T, Gao F, Alam SM, Boyd SD, et al. Co-evolution of a broadly neutralizing HIV-1 antibody and founder virus. Nature. 2013;496(7446):469 10.1038/nature12053 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Doria-Rose NA, Schramm CA, Gorman J, Moore PL, Bhiman JN, DeKosky BJ, et al. Developmental pathway for potent V1V2-directed HIV-neutralizing antibodies. Nature. 2014;509(7498):55 10.1038/nature13036 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Doria-Rose NA, Bhiman JN, Roark RS, Schramm CA, Gorman J, Chuang GY, et al. New Member of the V1V2-Directed CAP256-VRC26 Lineage That Shows Increased Breadth and Exceptional Potency. Journal of Virology. 2016;90(1):76 10.1128/JVI.01791-15 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Simonich CA, Doepker L, Ralph D, Williams JA, Dhar A, Yaffe Z, et al. Kappa chain maturation helps drive rapid development of an infant HIV-1 broadly neutralizing antibody lineage. Nature Communications. 2019;10(1):2190 10.1038/s41467-019-09481-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Elhanati Y, Sethna Z, Marcou Q, Callan CG Jr, Mora T, Walczak AM. Inferring processes underlying B-cell repertoire diversity. Philosophical Transactions of the Royal Society B: Biological Sciences. 2015;370 (1676). 10.1098/rstb.2014.0243 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Hoehn KB, Lunter G, Pybus OG. A Phylogenetic Codon Substitution Model for Antibody Lineages. Genetics. 2017;206(1):417–427. 10.1534/genetics.116.196303 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Hoehn KB, Vander Heiden JA, Zhou JQ, Lunter G, Pybus OG, Kleinstein S. Repertoire-wide phylogenetic models of B cell molecular evolution reveal evolutionary signatures of aging and vaccination. bioRxiv. 2019; p. 558825. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Yaari G, Vander Heiden J, Uduman M, Gadala-Maria D, Gupta N, Stern J, et al. Models of Somatic Hypermutation Targeting and Substitution Based on Synonymous Mutations from High-Throughput Immunoglobulin Sequencing Data. Frontiers in Immunology. 2013;4:358 10.3389/fimmu.2013.00358 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Ralph DK, Matsen FA IV. Consistency of VDJ rearrangement and substitution parameters enables accurate B cell receptor sequence annotation. PLoS Computational Biology. 2016;12(1):e1004409 10.1371/journal.pcbi.1004409 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Kepler TB. Reconstructing a B-cell clonal lineage. I. Statistical inference of unobserved ancestors. F1000Research. 2013;2(103). 10.12688/f1000research.2-103.v1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Hanson-Smith V, Kolaczkowski B, Thornton JW. Robustness of Ancestral Sequence Reconstruction to Phylogenetic Uncertainty. Molecular Biology and Evolution. 2010;27(9):1988–1999. 10.1093/molbev/msq081 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Siepel A, Haussler D. Phylogenetic hidden Markov models In: Statistical Methods in Molecular Evolution. Springer; 2005. p. 325–351. [Google Scholar]
- 15. Watson CT, Glanville J, Marasco WA. The Individual and Population Genetics of Antibody Immunity. Trends Immunol. 2017;38(7):459–470. 10.1016/j.it.2017.04.003 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Ralph DK, Matsen FA IV. Likelihood-Based Inference of B Cell Clonal Families. PLoS Computational Biology. 2016;12(10):e1005086 10.1371/journal.pcbi.1005086 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Felsenstein J. Inferring Phylogenies. Sunderland, Massachusetts: Sinauer Associates; 2004. Available from: https://books.google.com/books?id=GI6PQgAACAAJ. [Google Scholar]
- 18. Lauritzen SL. Graphical Models. vol. 17 Clarendon Press; 1996. [Google Scholar]
- 19. Tavaré S. Some Probabilistic and Statistical Problems in the Analysis of DNA Sequences. Lectures on Mathematics in the Life Sciences. 1986;17:57–86. [Google Scholar]
- 20. Yang Z. Maximum Likelihood Phylogenetic Estimation from DNA Sequences with Variable Rates over Sites: Approximate Methods. Journal of Molecular Evolution. 1994;39(3):306–314. 10.1007/BF00160154 [DOI] [PubMed] [Google Scholar]
- 21. Yang Z. Among-Site Rate Variation and Its Impact on Phylogenetic Analyses. Trends in Ecology & Evolution. 1996;11(9):367–372. 10.1016/0169-5347(96)10041-0 [DOI] [PubMed] [Google Scholar]
- 22. Felsenstein J. Evolutionary trees from DNA sequences: a maximum likelihood approach. Journal of Molecular Evolution. 1981;17(6):368–376. 10.1007/BF01734359 [DOI] [PubMed] [Google Scholar]
- 23. Smith AF, Gelfand AE. Bayesian statistics without tears: a sampling–resampling perspective. The American Statistician. 1992;46(2):84–88. 10.2307/2684170 [DOI] [Google Scholar]
- 24.Gordon NJ, Salmond DJ, Smith AF. Novel approach to nonlinear/non-Gaussian Bayesian state estimation. In: IEE Proceedings F (Radar and Signal Processing). vol. 140. IET; 1993. p. 107–113.
- 25. Andrieu C, Doucet A, Holenstein R. Particle Markov chain Monte Carlo methods. Journal of the Royal Statistical Society: Series B (Statistical Methodology). 2010;72(3):269–342. 10.1111/j.1467-9868.2009.00736.x [DOI] [Google Scholar]
- 26. Skare Ø, Bølviken E, Holden L. Improved sampling-importance resampling and reduced bias importance sampling. Scandinavian Journal of Statistics. 2003;30(4):719–737. 10.1111/1467-9469.00360 [DOI] [Google Scholar]
- 27. Gelman A, Stern HS, Carlin JB, Dunson DB, Vehtari A, Rubin DB. Bayesian Data Analysis. Chapman and Hall/CRC; 2013. [Google Scholar]
- 28. Gelman A, Meng XL. Applied Bayesian Modeling and Causal Inference from Incomplete-Data Perspectives. John Wiley & Sons; 2004. [Google Scholar]
- 29. Höhna S, Landis MJ, Heath TA, Boussau B, Lartillot N, Moore BR, et al. RevBayes: Bayesian phylogenetic inference using graphical models and an interactive model-specification language. Systematic Biology. 2016;65(4):726–736. 10.1093/sysbio/syw021 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Rubin DB. The calculation of posterior distributions by data augmentation: Comment: A noniterative sampling/importance resampling alternative to the data augmentation algorithm for creating a few imputations when fractions of missing information are modest: The SIR algorithm. Journal of the American Statistical Association. 1987;82(398):543–546. [Google Scholar]
- 31. Rabiner LR. An introduction to hidden Markov models. IEEE ASSP Magazine. 1986;3(1):4–16. 10.1109/MASSP.1986.1165342 [DOI] [Google Scholar]
- 32. Flouri T, Izquierdo-Carrasco F, Darriba D, Aberer A, Nguyen L, Minh B, et al. The phylogenetic likelihood library. Systematic Biology. 2014;64(2):356–362. 10.1093/sysbio/syu084 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Scott SL. Bayesian methods for hidden Markov models: Recursive computing in the 21st century. Journal of the American Statistical Association. 2002;97(457):337–351. 10.1198/016214502753479464 [DOI] [Google Scholar]
- 34. Nielsen R. Mapping mutations on phylogenies. Systematic Biology. 2002;51(5):729–739. 10.1080/10635150290102393 [DOI] [PubMed] [Google Scholar]
- 35. Crooks GE, Hon G, Chandonia JM, Brenner SE. WebLogo: a sequence logo generator. Genome Research. 2004;14(6):1188–1190. 10.1101/gr.849004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. Gansner ER, North SC. An open graph visualization system and its applications to software engineering. Software: Practice and Experience. 2000;30(11):1203–1233. [Google Scholar]
- 37. Gong LI, Suchard MA, Bloom JD. Stability-mediated epistasis constrains the evolution of an influenza protein. eLife. 2013;2:e00631 10.7554/eLife.00631 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Felsenstein J. PHYLIP (Phylogeny Inference Package) version 3.6; 2005. Distributed by the author.
- 39. Aldous D. Probability distributions on cladograms In: Random Discrete Structures. Springer; 1996. p. 1–18. [Google Scholar]
- 40. Landais E, Murrell B, Briney B, Murrell S, Rantalainen K, Berndsen ZT, et al. HIV envelope glycoform heterogeneity and localized diversity govern the initiation and maturation of a V2 apex broadly neutralizing antibody lineage. Immunity. 2017;47(5):990–1003. 10.1016/j.immuni.2017.11.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41. Wu X, Zhang Z, Schramm CA, Joyce MG, Do Kwon Y, Zhou T, et al. Maturation and Diversity of the VRC01-Antibody Lineage over 15 Years of Chronic HIV-1 Infection. Cell. 2015;161(3):470–485. 10.1016/j.cell.2015.03.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. Price MN, Dehal PS, Arkin AP. FastTree: computing large minimum evolution trees with profiles instead of a distance matrix. Molecular Biology and Evolution. 2009;26(7):1641–1650. 10.1093/molbev/msp077 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43. Price MN, Dehal PS, Arkin AP. FastTree 2–approximately maximum-likelihood trees for large alignments. PLoS One. 2010;5(3):e9490 10.1371/journal.pone.0009490 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44. Feng J, Shaw DA, Minin VN, Simon N, Matsen FA IV. Survival analysis of DNA mutation motifs with penalized proportional hazards. Annals of Applied Statistics. 2019;13(2):1268–1294. 10.1214/18-AOAS1233 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45. Rogozin IB, Kolchanov NA. Somatic hypermutagenesis in immunoglobulin genes: II. Influence of neighbouring base sequences on mutagenesis. Biochimica et Biophysica Acta (BBA)-Gene Structure and Expression. 1992;1171(1):11–18. 10.1016/0167-4781(92)90134-L [DOI] [PubMed] [Google Scholar]
- 46. Dunn-Walters DK, Dogan A, Boursier L, MacDonald CM, Spencer J. Base-specific sequences that bias somatic hypermutation deduced by analysis of out-of-frame human IgVH genes. The Journal of Immunology. 1998;160(5):2360–2364. [PubMed] [Google Scholar]
- 47. Chahwan R, Edelmann W, Scharff MD, Roa S. AIDing antibody diversity by error-prone mismatch repair In: Seminars in Immunology. vol. 24 Elsevier; 2012. p. 293–300. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48. Methot S, Di Noia J. Molecular mechanisms of somatic hypermutation and class switch recombination In: Advances in Immunology. vol. 133 Elsevier; 2017. p. 37–87. [DOI] [PubMed] [Google Scholar]
- 49. Landais E, Huang X, Havenar-Daughton C, Murrell B, Price MA, Wickramasinghe L, et al. Broadly neutralizing antibody responses in a large longitudinal sub-Saharan HIV primary infection cohort. PLoS Pathogens. 2016;12(1):e1005369 10.1371/journal.ppat.1005369 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50. Wu X, Zhou T, Zhu J, Zhang B, Georgiev I, Wang C, et al. Focused evolution of HIV-1 neutralizing antibodies revealed by structures and deep sequencing. Science. 2011;333(6049):1593–1602. 10.1126/science.1207532 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51. West AP, Diskin R, Nussenzweig MC, Bjorkman PJ. Structural basis for germ-line gene usage of a potent class of antibodies targeting the CD4-binding site of HIV-1 gp120. Proceedings of the National Academy of Sciences. 2012;109(30):E2083–E2090. 10.1073/pnas.1208984109 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52. Zhou T, Zhu J, Wu X, Moquin S, Zhang B, Acharya P, et al. Multidonor analysis reveals structural elements, genetic determinants, and maturation pathway for HIV-1 neutralization by VRC01-class antibodies. Immunity. 2013;39(2):245–258. 10.1016/j.immuni.2013.04.012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53. Li W, Godzik A. Cd-hit: a fast program for clustering and comparing large sets of protein or nucleotide sequences. Bioinformatics. 2006;22(13):1658–1659. 10.1093/bioinformatics/btl158 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
The linearham-inferred (left) and dnaml-inferred (right) naive-to-tip amino acid sequence trajectories for the pruned PC64 dataset of 100 sequences and the trimmed VRC01 alignment of 268 sequences, displaying only the edges that satisfy the given posterior probability threshold, and only the nodes that contact edges above the threshold. The tip sequences of interest for the PC64 and VRC01 datasets are chosen to be PCT64-35M and NIH45-46, respectively, and we use 0.04 probability cutoffs for these lineage graphics (such that any edge with probability less than this threshold is discarded). The nodes correspond to unique ancestral sequences filled with red color, where the opacity is proportional to the posterior probability of the associated sequence. Each node has a label that denotes whether the associated sequence is a naive or intermediate ancestral sequence, the posterior probability rank of the sequence among all sampled naive or intermediate ancestral sequences, and the sequence-specific posterior probability itself. The directed edges connecting nodes represent ancestral sequence transitions, are shaded blue with an opacity proportional to the posterior probability of the associated sequence transition, and are annotated with the site-specific mutations between the two sequences. The absence of many nodes for VRC01 indicates that these naive-to-tip sequence trajectories are highly uncertain.
(PDF)
Letters x, y, z, w represent the unobserved internal node states where w is associated with the root node, t0 defines the root branch length, and (t0, t1, t2, …, t6) denotes the entire vector of branch lengths. Given this tree topology and set of branch lengths, we can calculate the likelihood of observing the nucleotide vector (A, T, C, T) by marginalizing probabilities over the unobserved states x, y, z, w.
(PNG)
A table summarizing the various parameter settings used in our simulation experiments. The beta-splitting “balance” parameter β controls how “comb-like” (i.e. imbalanced) our simulated trees look, NCF represents the number of sequences simulated in each clonal family, and t0 denotes the root branch length. We simulate 15 trees for each combination of parameter values, which results in 180 simulated trees.
(PNG)
Mean hamming distances between the simulated naive sequences and their corresponding estimates, where the hamming distances are averaged over all trees generated under the different beta-splitting “balance” parameter value settings. Results are provided for the linearham, partis, and ARPP programs; the full-sequence and CDR3 regions; and the DNA/amino-acid sequence types. Standard errors are also presented in parentheses.
(PNG)
Table analogous to S2 Table, but varying the CF sequence count NCF.
(PNG)
Table analogous to S2 Table, but varying the root branch length t0.
(PNG)
Mean positive predictive values and mean true positive rates for decision boundary ρ = 0.5, where we average over all trees generated under the different beta-splitting “balance” parameter value settings. Results are provided for the linearham, RevBayes, and dnaml programs and the DNA/amino-acid sequence types. Standard errors are also presented in parentheses.
(PNG)
Table analogous to S5 Table, but varying the CF sequence count NCF.
(PNG)
Table analogous to S5 Table, but varying the root branch length t0.
(PNG)
Data Availability Statement
Data are available at https://zenodo.org/record/3746832.