

A simple method was developed for evaluating the efficacy of face masks to reduce respiratory droplet emission during speaking.
Abstract
Mandates for mask use in public during the recent coronavirus disease 2019 (COVID-19) pandemic, worsened by global shortage of commercial supplies, have led to widespread use of homemade masks and mask alternatives. It is assumed that wearing such masks reduces the likelihood for an infected person to spread the disease, but many of these mask designs have not been tested in practice. We have demonstrated a simple optical measurement method to evaluate the efficacy of masks to reduce the transmission of respiratory droplets during regular speech. In proof-of-principle studies, we compared a variety of commonly available mask types and observed that some mask types approach the performance of standard surgical masks, while some mask alternatives, such as neck gaiters or bandanas, offer very little protection. Our measurement setup is inexpensive and can be built and operated by nonexperts, allowing for rapid evaluation of mask performance during speech, sneezing, or coughing.
INTRODUCTION
The global spread of coronavirus disease 2019 (COVID-19) in early 2020 has substantially increased the demand for face masks around the world while stimulating research about their efficacy. Here, we adapt a recently demonstrated optical imaging approach (1, 2) and highlight stark differences in the effectiveness of different masks and mask alternatives to suppress the spread of respiratory droplets during regular speech.
In general, the term “face mask” governs a wide range of protective equipment with the primary function of reducing the transmission of particles or droplets. The most common application in modern medicine is to provide protection to the wearer (e.g., first responders), but surgical face masks were originally introduced to protect surrounding persons from the wearer, such as protecting patients with open wounds against infectious agents from the surgical team (3) or the persons surrounding a tuberculosis patient from contracting the disease via airborne droplets (4). This latter role has been embraced by multiple governments and regulatory agencies (5), since patients with COVID-19 can be asymptomatic but contagious for many days (6). The premise of protection from infected persons wearing a mask is simple: Wearing a face mask will reduce the spread of respiratory droplets containing viruses. Recent studies suggest that wearing face masks reduces the spread of COVID-19 on a population level and consequently blunts the growth of the epidemic curve (7, 8). Still, determining mask efficacy is a complex topic that is still an active field of research [see, for example, (9)], made even more complicated because the infection pathways for COVID-19 are not yet fully understood and are complicated by many factors such as the route of transmission, correct fit and usage of masks, and environmental variables. From a public policy perspective, shortages in supply for surgical face masks and N95 respirators, as well as concerns about their side effects and the discomfort of prolonged use (10), have led to public use of a variety of solutions that are generally less restrictive (such as homemade cotton masks or bandanas) but usually of unknown efficacy. While some textiles used for mask fabrication have been characterized (11), the performance of actual masks in a practical setting needs to be considered. The work we report here describes a measurement method that can be used to improve evaluation to guide mask selection and purchase decisions.
A schematic and demonstration image are shown in Fig. 1. In brief, an operator wears a face mask and speaks into the direction of an expanded laser beam inside a dark enclosure. Droplets that propagate through the laser beam scatter light, which is recorded with a cell phone camera. A simple computer algorithm is used to count the droplets in the video. The required hardware for these measurements is commonly available; suitable lasers and optical components are accessible in hundreds of research laboratories or can be purchased for less than $200, and a standard cell phone camera can serve as a recording device. The experimental setup is simple and can easily be built and operated by nonexperts.
Fig. 1. Schematic of the experimental setup.

A laser beam is expanded vertically by a cylindrical lens and shined through slits in the enclosure. The camera is located at the back of the box, with a hole for the speaker in the front. The inset shows scattering for water particles from a spray bottle with the front of the box removed. Photo credit: Martin Fischer, Duke University.
Below, we describe the measurement method and demonstrate its capabilities for mask testing. In this application, we do not attempt a comprehensive survey of all possible mask designs or a systematic study of all use cases. We merely demonstrated our method on a variety of commonly available masks and mask alternatives with one speaker, and a subset of these masks were tested with four speakers. Even from these limited demonstration studies, important general characteristics can be extracted by performing a relative comparison between different face masks and their transmission of droplets.
RESULTS
We tested 14 commonly available masks or mask alternatives, one patch of mask material, and a professionally fit-tested N95 mask (see Fig. 2 and Table 1 for details). For reference, we recorded control trials where the speaker wore no protective mask or covering. Each test was performed with the same protocol. The camera was used to record a video of approximately 40 s length to record droplets emitted while speaking. The first 10 s of the video serve as baseline. In the next 10 s, the mask wearer repeated the sentence “Stay healthy, people” five times (speech), after which the camera continued to record for an additional 20 s (observation). For each mask and for the control trial, this protocol was repeated 10 times. We used a computer algorithm (see Materials and Methods) to count the number of particles within each video.
Fig. 2. Pictures of face masks under investigation.

We tested 14 different face masks or mask alternatives and one mask material. Photo credit: Emma Fischer, Duke University. For photos showing the masks as actually worn, see fig. S8 (Supplementary Materials).
Table 1. Face masks under investigation.
This table lists the investigated face masks, mask alternatives, and mask material (masks are depicted in Fig. 2). Masks marked with an asterisk (*) were tested by four speakers; all others were tested by one speaker.
| Mask, name | Description |
| 1, “Surgical”* | Surgical mask, three layers |
| 2, “Valved N95” | N95 mask with exhalation valve |
| 3, “Knitted” | Knitted mask |
| 4, “PolyProp” | Two-layer polypropylene apron mask |
| 5, “Poly/cotton” | Cotton-polypropylene-cotton mask |
| 6, “MaxAT” | One-layer Maxima AT mask |
| 7, “Cotton2” | Two-layer cotton, pleated style mask |
| 8, “Cotton4” | Two-layer cotton, Olson style mask |
| 9, “Cotton3” | Two-layer cotton, pleated style mask |
| 10, “Cotton1” | One-layer cotton, pleated style mask |
| 11, “Neck Gaiter” | One-layer polyester/spandex, 0.022 g/cm2 |
| 12, “Bandana”* | Double-layer bandana, 0.014 g/cm2 |
| 13, “Cotton5”* | Two-layer cotton, pleated style mask |
| 14, “Fitted N95” | N95 mask, no exhalation valve, fitted |
| “Swath” | Swath of mask material, polypropylene |
| “None”* | Control experiment, no mask |
The results of our mask study is depicted in Fig. 3A, where we show the relative droplet count for each tested mask. Data displayed with solid dots represent the outcome of the same speaker testing all masks; the points and error bars represent the mean value and distribution SD, respectively, of the total droplet count normalized to the control trial (no mask). For this speaker’s control trial, the absolute droplet count was about 960. A graph with a corresponding logarithmic scale can be found in fig. S1. Data in Fig. 3A shown with a hollow circle represent an average over four different speakers wearing the same type of masks (surgical, cotton5, and bandana); the values and error bars represent the mean value and SD of the average relative droplet count from all four speakers. The additional speakers’ reference counts for the control trial (no mask) were about 200, with similar fractional variance to the main speaker (see fig. S2 for details).
Fig. 3. Droplet transmission through face masks.
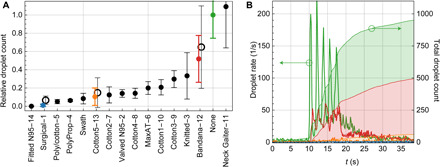
(A) Relative droplet transmission through the corresponding mask. Each solid data point represents the mean and SD over 10 trials for the same mask, normalized to the control trial (no mask), and tested by one speaker. Hollow data points are the mean and SDs of the relative counts over four speakers. A plot with a logarithmic scale is shown in fig. S1. The numbers on the x-axis labels correspond to the mask numbers in Fig. 2 and Table 1. (B) The time evolution of the droplet count (left axis) is shown for representative examples, marked with the corresponding color in (A): no mask (green), bandana (red), cotton mask (orange), and surgical (blue, not visible on this scale). The cumulative droplet count for these cases is also shown (right axis). t, time.
We measured a droplet transmission fraction ranging from below 0.1% (fitted N95 mask) to 110% (neck gaiter, see discussion below) relative to the control trials. In Fig. 3B, the time evolution of detected droplets is shown for four representative examples (surgical, cotton5, bandana, and the control trial) tested by the first speaker—the data for all tested masks are shown in fig. S3. Solid curves indicate the droplet transmission rate over time. For the control trial (green curve), the five distinct peaks correspond to the five repetitions of the operator speaking. In the case of speaking through a mask, there is a physical barrier, which results in a reduction of transmitted droplets and a significant delay between speaking and detecting particles. In effect, the mask acts as a temporal low-pass filter, smoothens the droplet rate over time, and reduces the overall transmission. For the bandana (red curve), the droplet rate is merely reduced by a factor of 2, and the repetitions of the speech are still noticeable. The effect of the cotton mask (orange curve) is much stronger. The speech pattern is no longer recognizable, and most of the droplets, compared to the control trial, are removed. The curve for the surgical mask is not visible on this scale. The shaded areas for all curves display the cumulative particle count over time: The lower the curve, the more droplets are blocked by the mask. Figure 3B shows the droplet count for the four masks measured by one speaker; fig. S4 shows the data for all four speakers using identical masks.
We noticed that speaking through some masks (particularly the neck gaiter) seemed to disperse the largest droplets into a multitude of smaller droplets (see fig. S5), which explains the apparent increase in droplet count relative to no mask in that case. Considering that smaller particles are airborne longer than large droplets (larger droplets sink faster), the use of such a mask might be counterproductive. Furthermore, the performance of the valved N95 mask is likely affected by the exhalation valve, which opens for strong outwards airflow. While the valve does not compromise the protection of the wearer, it can decrease the protection of persons surrounding the wearer. In comparison, the performance of the fitted, non-valved N95 mask was far superior.
DISCUSSION
The experimental setup is very straightforward to implement, and the required hardware and software are ubiquitous or easily acquired. However, this simplicity does go along with some limitations that are discussed here, along with routes for possible improvements and future studies. Again, we want to note that the mask tests performed here (one speaker for all masks and four speakers for selected masks) should serve only as a demonstration. Intersubject variations are to be expected, for example, because of differences in physiology, mask fit, head position, speech pattern, and such.
A first limitation is that our experimental implementation samples only a small part of the enclosure, and hence, some droplets that are transmitted through the masks might not be registered in the laser beam. Similarly, the face of the speaker is positioned with respect to the speaker hole by aligning the forehead and chin to the box. The physiology of each speaker is different, resulting in variations of the position of the mouth relative to the light sheet. Hence, the droplet count reflects only a portion of all droplets, but as we perform the experiment with the same initial conditions for all masks, the relative performance of the masks can be compared. A speaker hole that is sealed around the face would prevent the undetected escape of particles and ease comparison between different speakers.
Second, the use of a cell phone camera poses certain limitations on detection sensitivity, i.e., the smallest recognizable droplet size. To estimate the sensitivity, we consider the light that is scattered by droplets passing through the laser beam. The amount of light scattered into the camera direction depends on the wavelength of light, the refractive index of the droplet, and its size (and shape). To estimate the light scattering of droplets into the camera as a function of their diameter, we used the Python package PyMieScatt (12), which is an implementation of the Lorenz-Mie theory [see (13) for a review]. The result is visualized in Fig. 4. Figure 4A shows an example of the scattering distribution for a 532-nm light scattered from a droplet of 5 μm diameter and a refractive index of water (n = 1.33). In this example, the particle size is substantially bigger than the wavelength of the light (the so-called Mie regime). Almost all the light is scattered into the forward direction (0°) and very little into the direction of the camera (indicated by the shaded green cone around 90°). For the given camera acceptance angle, we display in Fig. 4B the estimated number of photons per frame scattered into the cell phone camera aperture as a function of particle diameter. By illuminating the camera directly with an attenuated laser beam of known power, we determine the detection sensitivity. A minimum of about 75 photons (on a single camera pixel) or about 960 photons (spread over several pixels) per frame were required for the camera to detect a droplet (for details on the detection characterization, see the Supplementary Materials). Both detection thresholds are indicated by horizontal black lines and the red shaded area in Fig. 4B. The more conservative detection threshold corresponds to a minimum detectable droplet size of 0.5 μm. The main limitation is the low collection efficiency of our small camera aperture—we currently capture only 0.01% of the full solid angle. An increased collection efficiency is possible with a larger relay lens in front of the camera, but this would come at the cost of a reduced field of view.
Fig. 4. Light scattering properties.
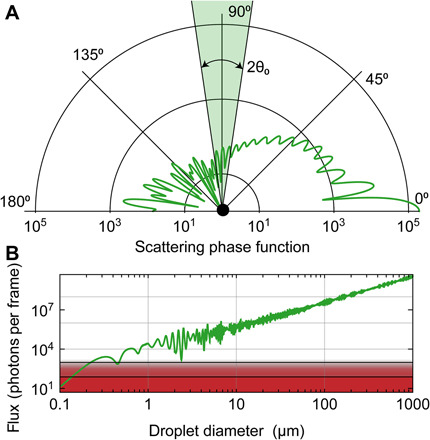
(A) Angle distribution (scattering phase function) for light scattered by a water droplet of 5 μm diameter for illumination with green laser light. Note the logarithmic radial scale. 0° is the forward direction, and 180° is the backward direction. The camera records at around 90°, indicated by the green segment (not to scale). (B) Calculated number of photons recorded by the camera in one frame as a function of the droplet diameter. The red shaded area and the two solid lines indicate the detection thresholds of the camera. For ideal conditions (all photons impinge on a single pixel), the camera requires at least about 75 photons per frame corresponding to a droplet diameter of 0.1 μm; for photons distributed over multiple pixels, the threshold is around 960 photons and corresponds to a diameter of 0.5 μm.
Third, the use of a single cell phone camera also limits the achievable size resolution (currently 120 μm per pixel), given the large field of view that is required to image as many droplets as possible. This makes it unfeasible to directly measure the size of small (aerosol) droplets in our setup. However, while we cannot measure the size of droplets at or below the pixel resolution, we can still detect and count the smaller droplets, down to the sensitivity limit described above. For very large particles, the limited dynamic range of the camera also poses a challenge for determining the size, since pixels easily saturate and hence distort the shape of the recorded droplet. We want to point out that neither the limited pixel resolution nor the saturation affect the particle counts presented in Fig. 3. Choosing a higher quality camera and a smaller field of view, combined with a funnel setup to guide droplets toward the imaging area, would reduce the minimum observable size, so would approaches that use camera arrays to improve resolution without sacrificing sensitivity or field of view (14). Keeping in mind these sizing limitations, we can still estimate the size distribution for the larger droplets (see fig. S5 for a qualitative size plot), which presents some interesting observations such as the neck gaiter performance mentioned earlier.
We should point out that our experiments differ in several ways from the traditional methods for mask validation, such as filtration efficiency of latex particles. As is apparent from the neck gaiter study, liquid filtration (and subsequent particle size reduction) is more relevant than solid filtration. In addition, our method could inform attempts to improve training on proper mask use and help validate approaches to make existing masks reusable.
In summary, our measurements provide a quick and cost-effective way to estimate the efficacy of masks for retaining droplets emitted during speech for droplet sizes larger than 0.5 μm. Our proof-of-principle experiments only involved a small number of speakers, but our setup can serve as a base for future studies with a larger cohort of speakers and checks of mask performance under a variety of conditions that affect the droplet emission rate, like different speakers, volume of speech (15), speech patterns (16), and other effects. This method can also test masks under other conditions, like coughing or sneezing. Improvements to the setup can increase sensitivity, yet testing efficiency during regular breathing will likely require complementing measurements with a conventional particle sizer. A further area of interest is the comparison of mask performance between solid particles and droplets, motivated by the observed liquid droplet breakup in the neck gaiter and mask saturation by droplets, necessitating exchange in regular clinical practice.
MATERIALS AND METHODS
The optical setup we used was recently used to demonstrate expulsion of liquid droplets during speech and for characterization of droplet residence times in air (1, 2). A schematic of the setup is shown in Fig. 1. In short, a light sheet was shined through an enclosure, where light scattering from particles traversing the light sheet was detected with the camera. To form the light sheet, a cylindrical lens transformed a green laser beam into an elliptical profile, which was directed through the enclosure. The laser source was a scientific pump laser (Millennia, Spectra-Physics; power, 2 W; wavelength, 532 nm), but suitable green lasers of similar powers are available for less than U.S. $100; the scientific lasers have better specifications (higher beam pointing and intensity stability, better beam profile), but these advantages are irrelevant in this application. The light sheet at the center of the enclosure had a thickness of 4.4 mm and a vertical size of 78 mm (Gaussian 1/e2 intensity beam widths). The enclosure (length by width by height: 30 cm by 30 cm by 35 cm) was constructed out of (or lined with) black material to minimize stray light. The sides of the box had slits for entry and exit of the light sheet. The front of the box had an 18-cm-diameter hole for the speaker, large enough for a person wearing a mask to speak into the box but small enough to prevent the face (or mask) from reaching the light sheet. To clear droplets from the box between experiments, laminar air from a high efficiency particulate air (HEPA) filter was continuously fed into the box from above through a duct with a cross section of 25 cm by 25 cm. The supplied air was being expelled through the light sheet slits and the speaker hole. A slight positive pressure in the box cleared droplets and prevented dust from entering into the box from outside. On the back of the box, a cell phone (Samsung Galaxy S9) was mounted at a distance of 20 cm from the light sheet. Using the Android application “open camera,” the frame size was set to 1920 × 1080 pixels, the focal distance was set to 20 cm, the exposure time was set to 1/50 s, and the frame rate was set to 30/s. At this focal distance, each camera pixel recorded an area of 120 μm by 120 μm at the position of the light sheet.
For each trial, the camera recorded scattered light from particles in the laser beam before the speech (~10 s), during speech (~10 s), and for a period of droplet clearing (~20 s). The speech consisted of five repetitions of the phrase “Stay healthy, people,” spoken by a male test person with a strong voice but without shouting. Each trial was repeated 10 times, and the speaker drank a sip of water in between to avoid dehydration. Furthermore, for the masks that showed substantial amounts of detected particles (knitted, cotton, neck gaiter, and bandana), we conducted additional tests by repeatedly puffing air from a bulb through the masks, rather than speech from an experimenter. These control trials with air puffs confirmed that we recorded droplets emitted by the speaker, not dust from the masks.
The goal of the analysis is to compare the efficacy of different masks by estimating the total transmitted droplet count. Toward this end, we need to identify droplets in the video and discriminate between droplets and background or noise. For convenience, analysis of the videos was performed with “Mathematica” (Wolfram Research), but use of a commercial package does not pose any general restriction, since almost every high-level programming language (e.g., Python) offers the same functionality. From all videos, we removed a weak background that originated from the light sheet itself and from stray light and diffuse reflections from the experimenter’s face. We then binarized all frames with a common threshold that discriminates between scattered light from droplets and background signal and/or noise. Then, a feature detection algorithm is applied to each frame, which returns the center-of-mass positions and major axis and minor axis length of the best-fit ellipse for every droplet. Note that the major and minor axes returned by the algorithm are not a direct measure of the droplet size but a measurement of the amount of light scattered by the particle into the camera aperture (binary diameter). Furthermore, the major axis length is increased owing to particle motion during the camera exposure time. Because of the small dynamic range of the camera (8-bit), most droplets saturate the camera. However, the axis lengths returned by the algorithm can still be used for a qualitative droplet size estimation: A bigger droplet scatters more light than a smaller droplet. This insight is important to interpret the result of the neck gaiter. The neck gaiter has a larger transmission (110%; see Fig. 3A) than the control trial. We attribute this increase to the neck gaiter dispersing larger droplets into several smaller droplets, therefore increasing the droplet count. The histogram of the binary diameter for the neck gaiter supports this theory (see fig. S5).
If a droplet passes through the light sheet in a time shorter than the inverse frame rate, it will appear only in a single video frame. However, if the droplet spends more time in the light sheet, the droplet will appear in multiple frames. To avoid double counting droplets in consecutive frames, we use a basic algorithm to distinguish between single-frame particles and multiframe trajectories. The algorithm compares the distance between droplets in consecutive frames and assigns two droplets to a trajectory if their distance is smaller than a threshold value or counts them as individual droplets if their distance is larger than the threshold. The threshold value was empirically chosen to be 40 pixels. An example result of the algorithm is shown in fig. S6, which shows a projection of 10 consecutive frames. Every droplet recognized by the algorithm is highlighted by an ellipsoid, labeled with the frame number. Droplets that belong to the same trajectory are highlighted in the same color.
Supplementary Material
Acknowledgments
We thank Mathias Fischer for providing the sketch in Fig. 1 and S. Eriksson and J. Lindale for valuable discussions. Funding: This project has been made possible in part by grant number 2019-198099 from the Chan Zuckerberg Initiative DAF, an advised fund of the Silicon Valley Community Foundation, and internal funding from Duke University through the Advanced Light Imaging and Spectroscopy (ALIS) facility. Author contributions: M.C.F. and E.P.F. performed the experiments, D.G. performed the data analysis, I.H. and E.W. procured the masks, and W.S.W. provided expertise. M.C.F supervised the project. All authors were involved in data interpretation and manuscript preparation. Competing interests: A U.S. provisional patent application has been filed by Duke University on 12 June 2020. The authors of the current manuscript are identical to the inventors on the patent application. The patent information is as follows: Title: “Optical Method to Test Efficacy of Face Masks”; inventors: M.C.F., E.P.F., D.G., W.S.W., I.H., and E.W.; application number: 63/038331. The authors declare that they have no other competing interests. Data and materials availability: All data needed to evaluate the conclusions in the paper are present in the paper and/or the Supplementary Materials. Additional data related to this paper may be requested from the authors. All raw movie files are freely available at the Duke Research Data Repository at https://doi.org/10.7924/r4ww7dx6q.
SUPPLEMENTARY MATERIALS
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/sciadv.abd3083/DC1
REFERENCES AND NOTES
- 1.Stadnytskyi V., Bax C. E., Bax A., Anfinrud P., The airborne lifetime of small speech droplets and their potential importance in SARS-CoV-2 transmission. Proc. Natl. Acad. Sci. U.S.A. 117, 11875–11877 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Anfinrud P., Stadnytskyi V., Bax C. E., Bax A., Visualizing speech-generated oral fluid droplets with laser light scattering. N. Engl. J. Med. 382, 2061–2063 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Belkin N. L., The evolution of the surgical mask: Filtering efficiency versus effectiveness. Infect. Control Hosp. Epidemiol. 18, 49–57 (1997). [DOI] [PubMed] [Google Scholar]
- 4.Dharmadhikari A. S., Mphahlele M., Stoltz A., Venter K., Mathebula R., Masotla T., Lubbe W., Pagano M., First M., Jensen P. A., van der Walt M., Nardell E. A., Surgical face masks worn by patients with multidrug-resistant tuberculosis: Impact on infectivity of air on a hospital ward. Am. J. Respir. Crit. Care Med. 185, 1104–1109 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Advice on the use of masks in the context of COVID-19, WHO Reference Number: WHO/2019-nCov/IPC_Masks/2020.4 (World Health Organization, 2020).
- 6.Klompas M., Morris C. A., Sinclair J., Pearson M., Shenoy E. S., Universal masking in hospitals in the Covid-19 era. N. Engl. J. Med. 382, e63 (2020). [DOI] [PubMed] [Google Scholar]
- 7.Chu D. K., Akl E. A., Duda S., Solo K., Yaacoub S., Schünemann H. J.; COVID-19 Systematic Urgent Review Group Effort (SURGE) study authors , Physical distancing, face masks, and eye protection to prevent person-to-person transmission of SARS-CoV-2 and COVID-19: A systematic review and meta-analysis. Lancet 395, 1973–1987 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Leung N. H. L., Chu D. K. W., Shiu E. Y. C., Chan K.-H., Mc Devitt J. J., Hau B. J. P., Yen H.-L., Li Y., Ip D. K. M., Peiris J. S. M., Seto W.-H., Leung G. M., Milton D. K., Cowling B. J., Respiratory virus shedding in exhaled breath and efficacy of face masks. Nat. Med. 26, 676–680 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Bunyan D., Ritchie L., Jenkins D., Coia J. E., Respiratory and facial protection: A critical review of recent literature. J. Hosp. Infect. 85, 165–169 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Ong J. J. Y., Bharatendu C., Goh Y., Tang J. Z. Y., Sooi K. W. X., Tan Y. L., Tan B. Y. Q., Teoh H.-L., Ong S. T., Allen D. M., Sharma V. K., Headaches associated with personal protective equipment—A cross-sectional study among frontline healthcare workers during COVID-19. Headache 60, 864–877 (2020). [DOI] [PubMed] [Google Scholar]
- 11.Konda A., Prakash A., Moss G. A., Schmoldt M., Grant G. D., Guha S., Aerosol filtration efficiency of common fabrics used in respiratory cloth masks. ACS Nano 14, 6339–6347 (2020). [DOI] [PubMed] [Google Scholar]
- 12.Sumlin B. J., Heinson W. R., Chakrabarty R. K., Retrieving the aerosol complex refractive index using PyMieScatt: A Mie computational package with visualization capabilities. J. Quant. Spectrosc. Radiat. Transfer 205, 127–134 (2018). [Google Scholar]
- 13.G. Gouesbet, G. Gréhan, Generalized Lorenz-Mie Theories (Springer International Publishing, ed. 2, 2017). [Google Scholar]
- 14.L. Zhong, P. Konda, M. Harfouche, R. Horstmeyer, Imaging and Applied Optics (Optical Society of America, 2019). [Google Scholar]
- 15.Asadi S., Wexler A. S., Cappa C. D., Barreda S., Bouvier N. M., Ristenpart W. D., Aerosol emission and superemission during human speech increase with voice loudness. Sci. Rep. 9, 2348 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Asadi S., Wexler A. S., Cappa C. D., Barreda S., Bouvier N. M., Ristenpart W. D., Effect of voicing and articulation manner on aerosol particle emission during human speech. PLOS ONE 15, e0227699 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/sciadv.abd3083/DC1