

Abstract
Recent work within the language sciences, particularly bilingualism, has sought new methods to evaluate and characterize how people differentially use language across different communicative contexts. These differences have thus far been linked to changes in cognitive control strategy, reading behavior, and brain organization. Here, we approach this issue using a novel application of Network Science to map the conversational topics that Montréal bilinguals discuss across communicative contexts (e.g., work, home, family, school, social), in their dominant vs. non-dominant language. Our results demonstrate that all communicative contexts display a unique pattern in which conversational topics are discussed, but only a few communicative contexts (work and social) display a unique pattern of how many languages are used to discuss particular topics. We also demonstrate that the dominant language has greater network size, strength, and density than the non-dominant language, suggesting that more topics are used in a wider variety of contexts in this language. Lastly, using community detection to thematically group the topics in each language, we find evidence of greater specificity in the non-dominant language than the dominant language. We contend that Network Science is a valuable tool for representing complex information, such as individual differences in bilingual language use, in a rich and granular manner, that may be used to better understand brain and behavior.
Keywords: bilingualism, network science, network analysis, individual differences, conversational topics, cognitive control
Graphical Abstract
Each individual uses language in a unique way. This idea, often referred to as a “linguistic fingerprint” or an “idiolect,” lies at the core of fields such as forensic linguistics, where a writing or speech sample may be used to identify a specific person (Svartvik, 1968). For example, maternal linguistic fingerprints have been observed during infant-directed speech across a variety of languages and cultures (Piazza, Iordan, & Lew-Williams, 2017). Less well understood is how linguistic fingerprints change when people regularly use more than one language (i.e., bilingualism). Indeed, bilingualism may open additional space for individual variation and expand the range of linguistic diversity than what is typically seen for monolingualism. Consistent with this conjecture, bilinguals vary in meaningful ways regarding the social use of language that have been related to changes in brain and behavior (e.g., Gullifer, Chai, Whitford, Pivneva, Baum, Klein, & Titone, 2018). Here, we advance these efforts by presenting a novel methodological approach to assess fine grained individual differences in bilingual language experience. Specifically, we use network science to map what conversational topics bilingual adults living in Montréal talk about across communicative contexts and dominant vs. non-dominant languages.
The traditional convention in neurolinguistics, psycholinguistics, and cognitive science has been to compare bilinguals and monolinguals as monolithic groups, or to assume monolingualism as a default and bilingualism as an extension of this experience (i.e., two monolinguals in one; Grosjean, 2010). Inherent to this practice is a broad-stroked presupposition that all individuals, whether monolingual or bilingual, have similar experiences using language in highly homogeneous environments. However, in other fields of linguistic inquiry, such as sociolinguistics and linguistic anthropology, the importance of assessing how social context and varying functional demands shape language use has long been known (e.g., see Wei, 2017 for a discussion on translanguaging). For example, early sociolinguistic work from Hoffman (1971) demonstrated that young Spanish-English bilinguals living in a predominantly Puerto Rican neighborhood in New York City not only use Spanish and English differentially with different people (e.g., Spanish with parents, English with siblings), but that the content of their conversation also constrains their language choice (e.g., they sometimes used English with parents to discuss work and school). Drawing from this work, Grosjean (1985; 1997; 2016) introduced the Complementarity Principle, which states that bilinguals use their various languages for various purposes, across various domains of life, with various people. Over the years, topic and activity-based questionnaire data from several bilingual communities (e.g., English-German, English-French, English-Spanish) corroborated the initial hypotheses of the Complementarity Principle (Carroll & Luna, 2011; Chiaro, 2009; Gasser, 2000; Jaccard & Cividin, 2001). These questionnaires probed which language (or languages) bilinguals used when doing or speaking about a variety of activities and topics. Among all these studies, language use was found to vary across people, contexts, and topics.
The present work explores a similar perspective to characterize the unique ways bilinguals use their languages in daily life in the linguistically diverse setting of Montréal, which has long been the site of ethnographic linguistic research. For example, in examining the relationship between language and identity among gay Montréalers in the 1970s (a critical era of linguistic policy development in Quebec when tensions between Anglophones and Francophones began to escalate), Higgins describes the critical role of gay spaces as both “separate from and joined to the dominant [linguistic] culture,” where a superordinate identity of LGBTQIA+ drove language choice and tempered otherwise palpable linguistic tensions (2004). Similarly, Heller discusses the unique experience of bilingual hospital staffers in Montréal who used codeswitching to balance the convention of everyday English use with the majority Francophone population who visited the hospital (1992). Both of these cases exemplify the importance of socially contextualizing language -- of appraising the specific environment the language is used. Most language users (including monolinguals) use this flexibility to tailor their language use to the context at hand; however, this particular experience is amplified for bilinguals who not only need to resolve intra-linguistic switches (e.g., register, volume, prosody) but also make specific inter-linguistic switches that fit the context.
Under a traditional lens within the language sciences, differences between individuals and environments is typically viewed as noise. However, an increasing number of studies assess bilingualism as a confluence of continuous factors including static experiences (such as age of acquisition), fluid but one- dimensional measures of current language exposure, such as global percentage of L2 use (discussed in Tiv, Kutlu, & Titone, under review). These variables have become the cornerstone of capturing individual differences in bilingual experience within the psycholinguistic community, as they relate to differences in cognitive control strategy (e.g., Kousaie, Chai, Sander, & Klein, 2017; Luk, De Sa, & Bialystok, 2011; Pelham & Abrams, 2014; Tao, Marzecová, Taft, Asanowicz, & Wodniecka, 2011), reading behavior (e.g., Gullifer & Titone, 2019; Palma, Whitford, & Titone, 2019; Pivneva, Mercier, & Titone, 2014; Titone, Libben, Mercier, Whitford, & Pivneva, 2011), and brain organization (e.g., Gullifer et al., 2018; Klein, Mok, Chen & Watkins, 2014; Kousaie et al., 2017). Interestingly, a tradition of measuring and assessing the impact of individual differences in bilingual language experience on brain organization was present in some of the earliest investigations of the topic (e.g., Kim, Relkin, Lee, & Hirsch, 1997, Mechelli et al., 2004, Perani et al., 1998; reviewed in Indefrey, 2006). Increasingly, highly dynamic aspects of bilingual experience have been identified and linked to structural and functional organization of the brain, such as language diversity (e.g., Gullifer et al., 2018; Sulpizio, Del Maschio, Del Mauro, Fedeli & Abutalebi, 2020), language usage in various communicative contexts (Anderson, Hawrylewicz, & Bialystok, 2018; Anderson, Mak, Chahi, & Bialystok, 2018; DeLuca, Rothman, Bialystok, & Pliatsikas, 2019; Gullifer et al., 2018), and language immersion (DeLuca et al., 2019; Pliatsikas, DeLuca, Moschopoulou, & Saddy, 2016). Advances in statistical techniques and computing power, such as network representations of complex systems, make it possible to consider finer grained individual differences, potentially leading to deeper insights about language, brain, and mind.
Neurocognitive theories of bilingual language have begun to incorporate details pertaining to the environment or context. An early example of this comes from Grosjean’s language mode hypothesis, where he theorized that bilinguals differentially activate the two languages in a manner tailored to the language demands required by the linguistic environment (2010). This idea has been expanded by Abutalebi and Green’s adaptive control hypothesis in shaping how the languages are represented, accessed, and controlled (Abutalebi & Green, 2016; Green & Abutalebi, 2013). According to the Adaptive Control Hypothesis, operating in a single (where one language is bound to each context) vs. dual (where more than one language is viable in each context) language context exerts different control demands on the central executive system (Abutalebi & Green, 2016; Green & Abutalebi, 2013). Despite the weighty theoretical implications of this idea, there are still only a limited number of ways the research community has devised to quantify individual differences in context-related language use.
Inspired by the adaptive control hypothesis, recent work has begun to assess the extent to which bilinguals are immersed in single vs. dual language interactional contexts at a surface level through a variety of methods (Yu & Schwieter, 2018). One way to assess single vs. dual language context is to sample participants from locales which are thought to differ in that regard (Beatty-Martínez & Dussias, 2017; Beatty-Martínez, Navarro-Torres, Dussias, Bajo, Guzzardo-Tamargo, & Kroll, 2019). For example, bilinguals attending universities in English dominant environments vs. bilinguals attending universities where code-switching is prevalent.
At the same time, individuals within a locale may engage with many communicative contexts throughout their day (e.g., home, work, social, school, media, etc.), and these contexts may differ with regard to language usage (Anderson et al., 2018a; Anderson et al., 2018b; DeLuca et al., 2019, Gullifer & Titone, 2019). Thus, another approach is to assess the extent to which individuals experience diversity in language usage throughout their daily lives. Inspired by information theory, our group recently proposed language entropy, a multipurpose measure of diversity in language usage that can be computed from questionnaire data (Gullifer & Titone, 2018; Gullifer & Titone, 2019), has now been adapted for use within a leading bilingualism questionnaire (Li, Zhang, Yu, & Zhao, 2019), and been used in two neuroimaging studies of bilingual language control (Gullifer et al., 2018; Supizio et al., 2020). Individuals with high language entropy report balanced, language usage, while individuals with low language entropy report the usage of a single language. Our group assessed individuals’ language entropy across several communicative contexts as measured by a language history questionnaire, and we found that there were differences in language entropy across contexts for our sample of bilingualism living in Montréal. In particular, work and social contexts tended to have higher entropy than other contexts. Moreover, we found that individual differences in language entropy mapped on to language-related self-report outcomes (controlling for overall L2 usage), differentially depending on the context (Gullifer & Titone, 2019). Thus, these findings highlight the importance of quantifying individual differences in language usage beyond the surface level.
Thus far, successful efforts of contextually situating language and cognition have been reared out of integrating observations from multiple fields of study (e.g., information theory, physics, and sociolinguistics). In this spirit, we continue looking beyond the traditional bounds of cognitive science and psychology to develop creative, yet effective, measurements.
Recently, cognitive scientists have started to use methods and theories from Network Science to answer these difficult questions, as illustrated in a new edited volume (Vitevitch, Network Science in Cognitive Psychology, 2019). Network Science is an interdisciplinary field that reaches across mathematics, sociology, physics, computer science, and others (Newman, 2010). The most familiar examples of Network Science methods and theories for cognitive scientists may be neural networks (the application of Network Science to understand the diffusion of information across multiple brain regions), social networks (an assessment of the people one interacts with on a regular or semi-regular basis), semantic networks for language (e.g., Collins & Quillian, 1969), and spreading activation networks for memory (e.g., Collins & Loftus, 1975). However, work from the past decade has applied Network Science to more diverse domains of cognition, such as dreaming, creativity, and word learning (see Network Science in Cognitive Psychology for a recent overview). The underlying goal common to each of these distinct subfields of cognitive science is to represent a complex system or process, such as language or social interaction, as a web-like network.
Network Science 101
All networks have similar core building blocks, which bolsters the idea that they can be used to represent various complex forms of information (reviewed in Vitevitch, 2019). As depicted in Table 1, nodes (or vertices) represent individual entities (e.g., people in social networks, words in semantic networks, brain regions in neural networks). Relationships between nodes are referred to as edges (or ties if the nodes represent people). These edges may be directed (i.e., conveying directional information) or undirected (i.e., no direction flow of information). Moreover, edges may be weighted, which describes the strength of some aspect of the relationship between the nodes. Toy networks and examples of these structures are illustrated in Table 1. As can be seen in these examples, when nodes represent words, the edges can be used to convey some relational information between them, such as co-occurrence. If this relational information has a specific orientation (e.g., word position in a sentence), a directed edge may be drawn to illustrate a directional flow of information. If the relational information does not have an inherent orientation (e.g., co-occurrence), an undirected edge may be drawn. Moreover, the weight of the edge can communicate additional relational information between the nodes, such as co-occurrence strength. Weights are often graphically represented through line thickness or color.
Table 1.
Introduction of network terms and some examples
| Term name | Definition | Image | Example |
|---|---|---|---|
| Node (vertex) | Elements or entities of a network. |  |
e.g., person, word, topic |
| Edge (tie) | Connection or relationship between two nodes. | 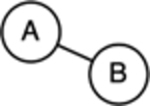 |
e.g., friendship, semantic co-occurrence |
| Directed edge | Edge with an orientation representing a one-way relationship. | 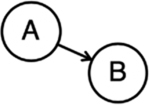 |
e.g., word A precedes word B, but word B doesn’t precede word A |
| Weighted edge | Edge with a numerical weight indicating the strength of a relationship | 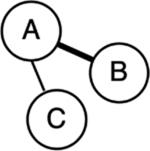 |
e.g., words A and B have high co-occurrence, words A and C have low co-occurrence |
Network scientists have identified a litany of properties or measures that can be extracted from networks (see Table 2, also reviewed in Vitevitch, 2019). These properties may describe the overall network, such as network size (the total number of nodes), network density (the interconnectedness of the nodes), or community size (the number of intermediate communities that can be detected from the network, based on modularity). Other properties may be calculated for each node, and potentially averaged or summed to reflect aspects of the overall network itself. For example, edge strength (the sum of adjacent edge weight) or mean edge weight for the network both reflect differences in the magnitude of connectivity across nodes. Importantly, the list of possible network measures one can calculate is long and can be mathematically complex (e.g., small worldness). Given that a primary aim of this paper is to introduce Network Analysis to the study of language and bilingualism (where readers may be less familiar with graph theory), we settled on a parsimonious set of basic measures to describe our networks.
Table 2.
Some basic network measures
| Term name | Definition |
|---|---|
| Size | The total number of nodes in a network. |
| Density | The interconnectedness of all nodes measured by dividing number of edges by total number of possible edges. Density ranges from 0 (fully unconnected) to 1 (fully interconnected). |
| Strength | The sum of adjacent edge weights for one node, averaged across all nodes. |
| Community Size | The number of intermediate communities detected from the whole network |
| Community | A group of nodes that more connected to each other than with the rest of the network. Often based on modularity calculation. |
| Modularity | The probability that a node belongs to a community minus such probability if the edges were distributed at random. |
The Present Work
As we have just reviewed, Network Science is both a methodological approach and a theoretical framework for understanding complex systems (e.g., Neal, 2013). As such, it can flexibly represent different information through network nodes and their connections. As mentioned above, social network analysis (one of the more common applied forms of Network Science) represents people through nodes, and depicts acquaintance, communication, and other forms of social information through the edges. Similarly, semantic and lexical networks represent words as nodes, and depict co-occurrences or lexical distance through the edges. Indeed, it becomes clear that many complex questions can be examined with a network-based framework.
Despite the prevalent applications of Network Science in cognitive science and related fields, few have used network analysis to assess aspects of bilingual language experience. Those who have typically assess bilingual social networks, or the people that a bilingual may interact with. This work finds that bilinguals serve as critical bridges between otherwise disconnected monolingual communities (Kim, Weber, Wei, & Oh, 2014). Similarly, bilinguals’ second language social network sizes have been found to predict communication-related acculturation stress (Doucerain, Vernaamkhaasti, Segalowitz, & Ryder, 2015). To our knowledge, network science has not been used to assess other aspects of bilingual language experience.
Consequently, we offer a novel methodological application of Network Science to gain a more granular understanding of bilingual language use across varying communicative contexts. In particular, we examine the conversational topics that bilinguals talk about in their dominant vs. non-dominant languages across several communicative contexts (e.g., work, family, home, school, and social). In doing so, we capitalize on the computational power of Network Science to evaluate complex relationships, which allows us to bridge a gap between psycholinguistics and sociolinguistics. Together, this will allow for more nuanced theoretical understanding of language use within psycholinguistics, and potentially additional measures that may contribute to the advancement of sociolinguistic theory.
We propose that basic self-report measures of what conversational topics bilinguals talk about across their communicative contexts and languages can provide additional insight into the social usage of language. To begin, we will review the analytic pipeline that transforms raw questionnaire data into the appropriate adjacency matrices that will then be used to craft networks for each individual. From there, we will visualize subject aggregated networks to answer the following three questions related to group-level behavior: (1) how are conversational topics distributed across five major communicative contexts? (2) how are conversational topics distributed across the dominant and non-dominant languages? (3) are there salient conversational topic themes that we can elucidate from the dominant and non-dominant languages? We predict that some contexts, such as work, will demonstrate starkly different network profiles than the others, based on past work from language entropy (Gullifer & Titone, 2019). Moreover, we expect to find quantitative and qualitative differences in what bilinguals talk about in their dominant and non-dominant language, such that the non-dominant language will be more constrained or focused in the variety of topics that are discussed.
Methods
Participants
One hundred and fifteen bilingual adults (Mean age = 21.44, SD age = 3.41) were recruited from Montréal, Canada. Montréal is located in the legally French monolingual province of Quebec, which is part of the federally bilingual country of Canada. Thus, many Montréalers have high working knowledge of French (the majority language of education and overall exposure) and English (the dominant language of North American culture). The study was conducted at McGill University, where English is predominantly used across educational and administrative spaces.
Participants self-ranked their languages based on fluency (i.e., “please indicate the language you are most fluent in”, “please indicate the second language you are most fluent in”, etc.), which served as the basis for our classification of dominant vs. non-dominant language. All participants reported French as their most fluent (i.e., dominant) language and English as their second most fluent (i.e., non-dominant) language (n = 66, 57.39%) or English as their dominant language and French as their second dominant language (n = 49, 42.61%). We then examined what percent of daily conversations each participant reported using English and French. Only six participants reported using English and French equally in conversations overall (50% in English and 50% in French), but we retained their self-reported order of dominance. This decision was based on the observation that although their usage patterns across some contexts was similar (i.e., 50%−50% at home, work, school and social), all of them used their self-reported dominant language more in the family context (85% dominant, 15% non-dominant).
Many participants reported knowledge of more than two languages (n = 81, 70.43%), but in these cases only the first and second dominant languages were analyzed for the language networks (all languages were considered for the context networks). Among those multilinguals, the most common third dominant languages were Spanish (n = 39, 48.15%) and German (n = 17, 20.99%). In total, twenty-seven different languages were reported, which reflects the rich and diverse multicultural environment of Montreal. Indeed, the majority (n = 63, 62.38%) reported feeling bicultural or multicultural.
Despite this diverse language background, our sample was also similar in many ways. Most participants grew up within a highly educated household, with 83.02% (n = 88) of fathers and 76.64% (n = 82) of mothers having attended university (no same-sex parents reported). The majority were born in Canada (n = 68, 64.76%), and many others were born in France (n = 21, 20.00%). The remaining 16.19% (n = 17) were born in one of the following countries: Bulgaria (1), China (4), Gabon (1), India (1), Ivory Coast (1), Lebanon (1), South Africa (1), Switzerland (1), United Arab Emirates (1), United Kingdom (1), and United States (3). On average, those born outside of Canada reported spending between one month to twenty-two years in Canada (Mean = 6.31 years; Median = 3.25 years). Among the Canadiens, 51.47% (n = 35) were born in Quebec. This might explain why more participants overall reported attending primary and secondary school in French than in English (58.33% (n = 63) French vs. 16.67% (n = 18) English in primary school and 56.48% (n = 61) French vs 25.93% (n = 28) English in secondary school), as the Charter of the French Language (Loi 101) in Quebec enforces French as the primary language of instruction from kindergarten to secondary school (discussed in Leimgruber, Vingron, & Titone, 2020). Participants who did not report attending primary and secondary school in neither French nor English reported attending them in both languages. As for the language of instruction in university, 76.42% (n = 81) of all participants reported attending university in English while only 11.32% (n = 12) reported attending university in French (the remaining 12.26% (n = 13) reported attending university in both languages and/or in other languages). This is likely explained by our sample consisting mainly of students recruited from or around McGill University, which uses English as the language of instruction.
Figure 1 illustrates the relationship between age of language acquisition (AoA) and average self-report proficiency across a variety of domains (reading, writing, speaking, listening) for the dominant vs. non-dominant language. As can be seen in this figure, dominant vs. non-dominant language history and use are quite varied. The dominant language displays close to maximal proficiency, whereas the non-dominant language has a wider distribution. Age of acquisition for both languages varies but is mainly constrained between 0–15 years of life. This method of classifying languages as dominant vs. non-dominant (rather than first vs. second language based on AoA) takes into account individuals who may be heritage language speakers, language attriters, or flipped dominance language users, but for the present sample it was still gathered using self-report information.
Figure 1.

Distribution of participant demographics on language age of acquisition and mean self-rated proficiency (across reading, writing, speaking, and listening) for the dominant and non-dominant language.
Materials
All procedures were approved by the McGill University Research Ethics Board (REB). Participants completed a language history questionnaire that probed various aspects of their language experience. First, we assessed which of their languages was the most dominant by asking participants to indicate the language they felt most fluent in - as described above. Next, we asked which language they used to speak about twenty-one conversational topics (cultural, chit chat, community/civic, daily activities, emotional, family, family activities, gossip, health, hobbies, intellectual, intimate, news, personal history, religious/moral, school, social-political, sports, vacation, weekend activities, and work) in each of six communicative contexts (work, family, home, school, social, and other). For example, at home, one may discuss emotional topics only in their dominant language but then discuss chit chat in both the dominant and non-dominant language. This exercise was repeated for each communicative context (a sample of the question structure may be found at https://osf.io/6z79s/). The conversational topics thus formed the nodes of the network, and the communicative contexts/languages formed the edges.
Before data analysis, we decided to restrict our analysis to only five meaningful contexts (i.e., we discarded the “other” context because there was no way to know what respondents had in mind for this section). Not all respondents provided answers to all the contexts. For example, if a respondent did not have a job they were instructed to leave the work context blank. Given that our sample consisted mostly of university students, less than half of respondents (N=42) completed the work context section. Lastly, the family and home contexts were distinguished in the following way: participants first completed the home section of the questionnaire based on where they currently live. Following this, participants completed the family section of the questionnaire based on immediate family members with whom they do not currently live.
Transformations
Our analytic pipeline, shown in Figure 2 (full code available at https://osf.io/6z79s/), transformed the raw survey responses into an adjacency matrix that was used to compute the network measures in R (R Core Team, 2016). An adjacency matrix marks exactly which nodes have an edge between them (e.g., when two topics are discussed in the same context or language). All possible nodes (conversational topics) are listed as rows and columns. Two nodes that have an edge get a value of 1, and two nodes that do not have an edge get a value of 0. We created two types of adjacency matrices: the first for our context networks and the second for our language networks. In both of these networks, we did not remove any topics or apply any thresholding prior to calculating the three network measures. Moreover, for both networks, our aim was to describe - at a global group level - patterns of the sample as a whole (i.e., we opted for the aggregate final step in Figure 2).
Figure 2.
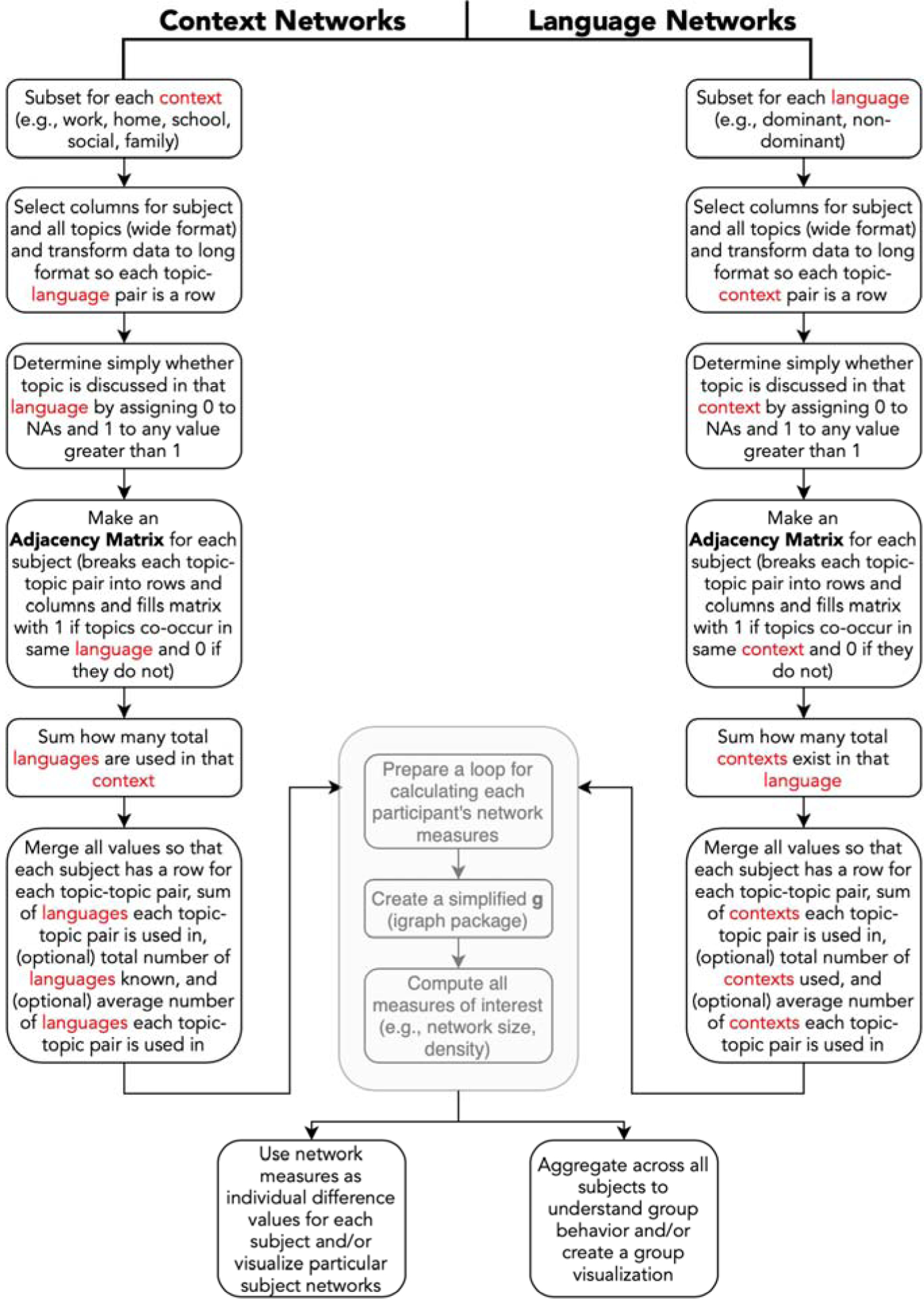
Analytic pipeline for network analysis (prior to community detection)
Context Networks.
As can be seen in the left stream of Figure 2, the first adjacency matrix was used to make five context networks for each participant (i.e., one network per communicative context). Here, we assessed the conversational topics bilinguals discussed in each context (collapsed across languages). To do this, each conversational topic served as a node. If two conversational topics were discussed in the same context, we created an edge between those nodes (e.g., if emotional and chit chat were both discussed at home, we gave the pairing a value of 1). Next, we weighted each edge to reflect the total number of languages in which these two topics were discussed in the same context (e.g., if emotional and chit chat were both discussed at home using multiple languages, the edge weight would be high. The edge weight would be low if this pattern was only discussed in one language). This process was replicated for each of the five communicative contexts, thus ultimately resulting in five unique networks for each participant (work, home, school, family, social).
Language Networks.
As can be seen in the right stream of Figure 2, the second adjacency matrix was used to make two language networks for each participant (a dominant language network and a non-dominant language network). Here, we assessed the conversational topics bilinguals discussed in their dominant language (collapsed across contexts) vs. in their non-dominant language. To do this, each conversational topic served as a node. If two conversational topics were discussed in the same language, we created an edge between those nodes (e.g., if emotional and chit chat were both discussed in the dominant language, we gave that pairing a value of 1). Next, we weighted each edge to reflect the total number of contexts in which those two topics were discussed in the same language (e.g., if emotional and chit chat were both discussed in the dominant language across all five contexts, the edge weight would be high. The edge weight would be low if this pattern was only discussed in one context). This process was replicated twice, thus ultimately resulting in two unique networks for each participant - one for the dominant language and another for the non-dominant language.
Network Measures
For each of the context and language networks, we used the igraph package in R (Csárdi & Nepusz, 2006) to calculate three basic network measures: network size, mean network strength, and network density (this process is demonstrated within the shaded central portion of Figure 2). Network size indicates the total number of conversational topics that are discussed within one context or language. A larger network size reflects greater variability in conversational topics within one context or language, whereas a smaller network size reflects content specificity within one context or language. Mean network strength summarizes the magnitude of each edge weight. A high mean strength value indicates that conversational topics are used in more contexts/languages together, whereas a low mean strength value indicates that conversational topics are used in fewer contexts/languages together. Network density captures the number of edges in a network. Density of 1 means that every possible edge is present in the network, whereas a density of 0.5 indicates that half of the possible edges are present in the network. Thus, values closer to 1 reflect greater interconnectedness, as opposed to values closer to 0. For the two network measures that are related to the edges (density and strength), we removed all self-loops (e.g., chit chat and chit chat).
Community Detection.
We were also interested in identifying how the various conversational topics clustered together in each language. This interest was motivated by past psycholinguistic findings that some topics, such as discussing emotions, are typically reserved for the first, or more dominant language (Ardila, Benettieri, Church, Orozco, & Saucedo, 2019; Dewaele, 2015). Thus, we next identify the steps taken to perform community detection on our two language networks (not depicted in Figure 2).
In network structures, edges are not only connected at a global level, but also at an intermediate level. Interconnected nodes that are more densely connected to each other than with the rest of the network are called communities. Detecting and analyzing such communities have increasingly become one of the most fundamental and relevant in network science (Yang, Algesheimer, & Tessone, 2016; Zhao, 2017). Community detection has many important applications. Notably, it allows the inference of internal relationships between nodes that may not be explicitly accessible with global level analysis (Yang et al., 2016). Accordingly, we applied this data-driven method to our aggregate dominant and non-dominant language networks (i.e., averaged across all participants) to explore the novel ways in which different subgroups of conversational topics may relate to each other and to the overall network structure at a high level.
Weight thresholding.
The intensity of the connection between two nodes is characterized by their weight. However, when most nodes in a network are highly connected to one another (i.e., densely connected networks), community detection algorithms are difficult to apply. The most popular technique for pre-processing densely connected networks is weight thresholding (Yan, Jeub, Flammini, Radicchi, & Fortunato, 2018). Used in many fields (e.g., computational linguistics, neuroscience, finance, and biology (Dugué & Connes, 2019; Garrison, Scheinost, Finn, Shen, & Constable, 2015; Namaki, Shirazi, Raei, & Jafari, 2011), this method consists of removing all edges that fall below a given weight threshold. Although there has been some concern regarding the integrity of network properties after the removal of those edges, some research has shown that only local and global features are altered, but that community structures remain intact (Yan et al., 2018). For this reason, we first computed our regular language networks and then secondarily went through the weight thresholding process for community detection. In other words, the three network measures (network size, mean strength, density) were calculated on the full dataset without any thresholding decisions. Thresholding was later applied for community detection.
A second thresholding method is the density-based/proportional threshold, which considers a subgraph with a given percentage of the strongest connections (Garrison et al., 2015). As opposed to weight thresholding, which can affect the number of nodes in a network (i.e., network size), proportional thresholding ensures that networks match in size. Therefore, using both thresholding methods can ensure a more balanced pre-processing of dense networks and are both commonly used in network analysis (e.g., brain network analysis).
Thus, after we computed the original language networks, we applied a two-step thresholding approach to create the community detection language networks. First, we used a subject-level weight-based threshold, removing all edges with a weight lower than three (i.e., for each subject, we removed all edges which represented talking about the particular conversational topic in two or fewer contexts). We found that our networks were still too dense for generating meaningful results. As such, we applied a second network-level density/proportional threshold. Most applications of density or proportional thresholding do not provide details as to why the specific threshold was selected. Thus, we tried threshold values ranging from 0.5 to 0.9 and ran them through the subsequent community detection algorithms. Ultimately, after taking into consideration resulting communities, as well as the balance of sensitivity (i.e., be able to detect more than one community) and specificity (i.e., remain as close to the original data as possible), we decided on a threshold of 0.75 (i.e., kept the top 75% of edges). This allowed us to retain as much of the data intact as possible while allowing enough variance for at least two communities to be detected. Importantly, the 0.75 threshold was first determined for the dominant language network (any higher thresholds resulted in smaller modularity scores), and then consistently applied to the non-dominant language network so the two could be directly compared.
Community detection algorithms.
Due to the increasing interest in detecting communities in networks, many algorithms have been proposed across different research areas. Although these algorithms aim to optimize accuracy and minimize computational running time, the slightly ambiguous definition of a community leads to a lack of a consensus on which algorithm to use and of a ground truth in most real-world applications (Yang et al., 2016). Many researchers have extensively compared these different community detection algorithms (e.g., Fortunato, 2010; Yang et al., 2016; Zhao, 2017), but for our purposes, we relied on relatively simple algorithms that could be found within the igraph package in R (Csárdi & Nepusz, 2006). Within these, we applied the Multilevel or Louvain algorithm (Blondel, Guillaume, Lambiotte, & Lefebvre, 2008), which has been found to outperform other simple algorithms in terms of both accuracy and computing time (Aynaud & Guillaume, 2010; Yang et al., 2016). This approach is based on modularity, or the probability that a node belongs to a community minus such probability if the edges were distributed at random. The pseudocode for this algorithm can be found in Figure 3, and for an alternative and more in-depth discussion of the Louvain method see Siew (2013).
Figure 3.

Pseudocode of the Louvain Method taken from Aynaud & Guillaume (2010)
Results
Context Networks
The average network structure for each communicative context is illustrated in Figure 4 (i.e., we aggregated network measures across all subjects to understand group-level behavior - the bottom right option from Figure 2). As can be seen from these figures (and Table 3), some contexts seem to share size and weight similarities (e.g., home and family) whereas others visibly vary (e.g., work and social). Notably, the work context displays low network size (suggesting that fewer topics are discussed at work) and low weight and strength distributions (suggesting that fewer languages are used in this context). Conversely, the social context benefits from high network size (on average, people discuss many topics in social interactions) and high weight or strength distributions (more languages are used in this context). The other three, school, home, and family, are distributed somewhere in between these endpoints.
Figure 4.
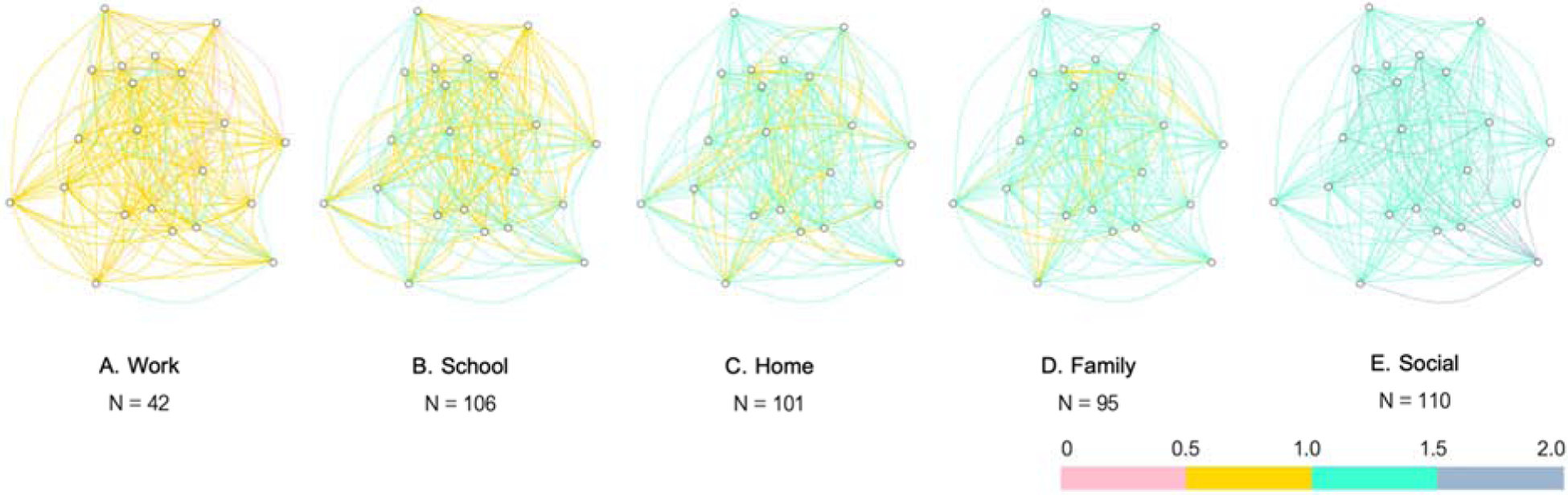
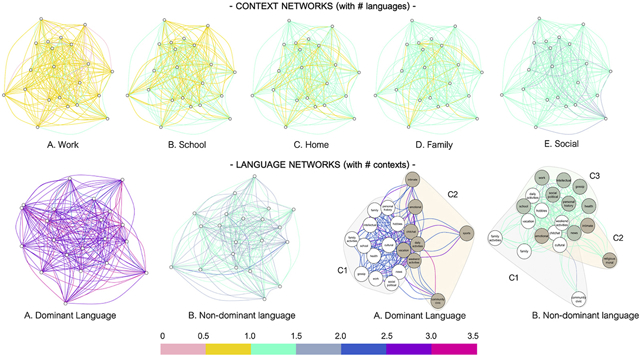
Average network for each context. Nodes represent topics of conversation, and edges indicate whether two topics co-occurred in each context. Edges are weighted by the total number of languages used to discuss two topics in a given context, as demonstrated by color. Green and blue hues indicate more languages and pink and yellow hues indicate fewer languages. The total number of respondents for each context are indicated below the network.
Table 3.
Three dependent network measures for each of the five contexts. SEM indicates one standard error of the mean.
| Network Size | Mean Strength | Density | ||
|---|---|---|---|---|
| Work Context | Mean | 16.024 | 35.659 | 0.986 |
| SEM | 0.837 | 2.372 | 0.010 | |
| School Context | Mean | 17.717 | 44.519 | 0.994 |
| SEM | 0.450 | 1.832 | 0.002 | |
| Home Context | Mean | 20.030 | 43.077 | 0.971 |
| SEM | 0.230 | 1.298 | 0.009 | |
| Family Context | Mean | 19.916 | 45.620 | 0.974 |
| SEM | 0.283 | 1.620 | 0.010 | |
| Social Context | Mean | 19.673 | 56.221 | 0.995 |
| SEM | 0.273 | 2.248 | 0.002 | |
| Df | 4 | 4 | 4 | |
| F-value | 15.680 | 12.880 | 3.072 | |
| p-value | <0.001 | <0.001 | 0.016 |
For each network measure (network size, mean strength, and density), we fit a simple linear regression with context as the independent variable. Context was a significant predictor for all three measures (see Table 3 - Size: (F(4) = 15.68, p < 0.001; Strength: (F(4) = 12.88, p < 0.001; Density: (F(4) = 3.06, p = 0.016)); however, this did not tell us the at which levels of contexts these effects were manifesting (though see Figure 5 for a graphical representation of each network measure for each context). Thus, we computed Tukey Honest Significant Differences between each pair-wise comparison of context. The results of these tests can be seen in Appendix A, and they reveal several interesting patterns.
Figure 5.

Mean values for weight and three network measures on each context. Error bars indicate plus or minus one standard error of the mean.
First, work and social contexts significantly differed from each other on all measures except for network density (Size: HSD = −3.649, p < 0.001; Strength: HSD = −20.562, p < 0.001; Density: HSD = −0.009, p = 0.949). In fact, none of the pair-wise comparisons for density reached significance adjusted for multiple comparisons. Henceforth, we will omit network density from the discussion of results. Second, school and home contexts only varied in network size (HSD = −2.313, p < 0.001), and not weight or strength, such that more topics are discussed at home than school. School and family contexts (HSD = −2.199, p < 0.001) demonstrate this same pattern for network size (more topics with family than at school). Third, the only differences detected for weight and strength distributions (i.e., the number of languages used to talk about two topics within a context), involved comparisons with at least one of the two endpoint contexts (work and social). In other words, context was a significant predictor of social vs. school (HSD = 11.701, p < 0.001), home (HSD = 13.144, p < 0.001), or family contexts (HSD = 10.601, p < 0.001), of work vs. family contexts (HSD = −9.961, p = 0.027), and of work vs. social contexts (HSD = −20.562, p < 0.001). Together, these findings suggest that whereas each context may have a unique set of conversational topics (i.e., network size), the balance of languages used to discuss those topics (i.e., weight, strength) only vary among noticeably different types of contexts, such as work vs. social.
Language Networks
The average network structure for the dominant and non-dominant languages is illustrated in Figure 6. As can be gathered from this figure and the results reported in Table 4, there are clear differences between the dominant and non-dominant languages. Again, we fit a simple linear regression that was summarized with an ANOVA. The dominant language displays greater network size (F(1) = 48.33, p < 0.001), greater strength (F(1) = 78.62, p < 0.001), and greater density (F(1) = 12.99, p < 0.001) than the non-dominant language. Indeed, the density value of the dominant language network (0.993) indicates that the network is nearly full connected. In other words, almost all conversational topics co-occur with each other in this language, compared to the non-dominant language which has significantly lower density.
Figure 6.

Average network for each language. Nodes represent topics of conversation, and edges indicate whether two topics discussed in that language co-occurred in the same context. Edges are weighted by the total number of contexts that two topics are discussed in, as demonstrated by color. Purple hues indicate more contexts and teal hues indicate fewer contexts. The total number of respondents for each language is indicated below the network.
Table 4.
Three dependent network measures for each of the two languages. SEM indicates one standard error of the mean
| Network Size | Mean Strength | Density | ||
|---|---|---|---|---|
| Dominant Language | Mean | 20.539 | 112.820 | 0.993 |
| SEM | 0.125 | 3.835 | 0.003 | |
| Non-Dominant Language | Mean | 16.773 | 62.930 | 0.948 |
| SEM | 0.538 | 4.126 | 0.012 | |
| Df | 1 | 1 | 1 | |
| F-value | 48.33 | 78.62 | 12.99 | |
| p-value | < 0.001 | <0.001 | <0.001 |
Community Detection
Lastly, we re-computed the language networks in accordance with a two-step weight thresholding procedure (discussed in methods) to detect communities within each of the language networks. This is a data-driven way of thematically grouping conversational topics as they play out in real world contexts across the two languages. In applying the Louvain algorithm for community detection, we detected two communities in the dominant language (Modularity, Q= 0.029) and three communities in the non-dominant language (Modularity, Q = 0.020). The particular conversational topics that emerged from each community are outlined in Table 5.
Table 5.
Conversational topics in each language community
| Potential Theme Component conversational topics | ||
|---|---|---|
| Dominant Language (Q=0.029) | ||
| Community 1 | Social- Intellectual | Cultural, Family, Family Activities, Gossip, Health, Hobbies, Intellectual, News, Personal History, School, Social-Political, Work |
| Community 2 | Social-Personal | Chit chat, Community/Civic, Daily Activities, Emotional, Intimate, Sports, Vacation, Weekend Activities |
| Non-Dominant Language (Q=0.020) | ||
| Community 1 | Social | Chit chat, Community/Civic, Cultural, Daily Activities, Family, Family Activities, Hobbies, Vacation, Weekend Activities |
| Community 2 | Personal | Emotional, Intimate, Religious/Moral |
| Community 3 | Intellectual | Gossip, Health, Intellectual, News, Personal History, School, Social-Political, Work |
Community detection allows us to infer why certain nodes are more likely to be connected to each other than at random. If this computation selects a low number of communities (such as the two identified for the dominant language), it may be more difficult to find common ground across the node types. Conversely, if this computation selects a higher number of communities (i.e., three for non-dominant language), then we as human observers may notice more salient patterns within each grouping. For this reason, we qualitatively reviewed the three communities that emerged from the non-dominant language first. Here, the second community (emotional, intimate, religious/moral) stood out as conversational topics that are deeply personal. In contrast, the first community seemed descriptive of social activities that are non-threatening and uncontroversial. Topics such as daily activities, hobbies, and vacation are things that could be discussed in most contexts to socially bond with others, without much risk. Lastly, the third community seemed bound to topics of intellectuality (e.g., news, social-political, work). These topics may be used to socially bond with others as well but may be slightly more divisive or identity-revealing than topics from the first community.
The two communities in the dominant language did not fall into such clean categories. In the first community, we found hobbies, but also news and social-political topics. In the second community, we found highly personal topics (e.g., emotional, intimate) but also non-personal topics that may facilitate social bonding (e.g., daily activities, vacation). Thus, these two communities seemed to diverge along the intersections of two communities from the non-dominant language: the first involved social topics that were more intellectual in nature, and the second involved social topics that were more personal in nature.
Taken together, the fewer, non-specific communities in the dominant language (i.e., two communities that combined themes) compared to the specific non-dominant language communities (i.e., three that clearly distinguished into categories) corroborates the idea that the dominant language is far more general than the non-dominant language. Conversely, in the non-dominant language, intermediate conversational topic grouping patterns, as a function of context, become noticeable.
Discussion
The present work advances a growing body of research demonstrating that people display a unique fingerprint of language usage. Specifically, in applying the dynamic flexibility of Network Science, we find evidence that what bilinguals talk about (i.e., conversational topics) systematically varies across communicative contexts and languages. Here, we summarize three key findings related to this characterization of bilingual individual differences.
First, much like past findings for language entropy (e.g., Gullifer & Titone, 2019), work and social contexts emerged as being significantly distinct from other contexts (school, home, family) in both network size and network strength. In contrast, school, family, and home only varied between each other in network size. This suggests that what bilinguals report talking about (network size) across communicative contexts is broadly distinguishable over all contexts, but how they report talking about these topics (network strength) is only distinguishable over a few contexts that sit at the extremes (work and social). Bilinguals discuss the most topics and do so with the greatest number of languages during social interactions, suggesting that social contexts are highly open and permeable to a variety of topics and languages, which corroborates past findings for language entropy (Gullifer & Titone, 2019). However, unlike language entropy, bilinguals discuss the fewest topics in the fewest number of languages at work. As such, the work environment seems to be a highly focused environment.
These conclusions align well with recent analyses of available data from the 2016 Canadian census showing that work contexts, within Montréal, typically display less diversity than language usage in the home and as a mother tongue (Gullifer & Titone, 2019; Statistics Canada, 2017). One potential reason why our pattern of results diverges from past findings with language entropy could be the granularity with which each questionnaire probed usage. Questions from Gullifer and Titone (2019) relied on recall of language amount of usage (e.g., “Please rate the amount of time you use each language at home”) whereas our conversational topic networks rely on yes or no questions related to most major topics of conversation. Another potential reason is that the sample in the present study generally consists of university students who are more representative of the broader Montréal context. Indeed, in this dataset we made a concerted effort to collect data from the various francophone and anglophone universities. In contrast, the sample of Gullifer and Titone (2019) may have been more likely sampled from the McGill community where English is the predominant language of the environment. Thus, future work should better consider issues of questionnaire design and participant sampling, here and across the field of bilingualism. Importantly, methodological tools such as language entropy and network analysis are only as good as the representative nature of the samples they describe.
A second key finding is that the dominant and non-dominant languages clearly differ in what topics are discussed (network size) and how they are discussed (network strength and density). As expected, network size, strength, and density are greater in the dominant than non-dominant networks. This means that more conversational topics are discussed in the dominant language, and they are discussed across more contexts than the non-dominant language, thus confirming that usage of the dominant language is indeed dominant.
Although usage of the dominant vs. non-dominant languages are visually and statistically distinguishable, it is important to note that the non-dominant language is still critically contributing to the overall language usage of our bilingual sample. For example, in visually reviewing Figure 6, it is clear that there are no pink or yellow edges connecting nodes in either language network. This means that no two topics (on average) are discussed in solely one specialized context. The average weight of the non-dominant network is close to 1.5 (as can be seen by the overwhelming majority of the aquamarine and light blue edges in the network) indicating that bilinguals still talk about two topics, within the non-dominant language, across more than one communicative context. This is an important characteristic of the typical linguistic sample that is tested in Montréal (highly proficient bilinguals), and it highlights one of the strengths of a network-based approach in granularly quantifying language usage patterns. Moreover, the network representations of dominant vs. non-dominant language usage provide a rich, at-a-glance snapshot of how the particular sample uses their various languages.
The third key finding comes from our use of community detection to elucidate what types of conversational topics were being discussed in the dominant vs. non-dominant languages. The Louvain algorithm for community detection returned two, general communities for the dominant language, and three, specialized communities for the non-dominant language. We qualitatively termed the three communities of the non-dominant language social, personal, and intellectual based on our observations of the grouping pattern of the topics, and we noticed that the two communities of the dominant language sat at the intersections of these three communities (social-personal and social-intellectual). However, the modularity of both networks was low (0.029 for the dominant language network and 0.020 for the non-dominant language network), which likely arose from the dense interconnectedness of our networks, despite thresholding efforts. While we encourage cautious interpretation of this exploratory finding, we observe that the community patterns are consistent with past work demonstrating that a second language is often acquired and used for specific purposes. This is often found among language brokers, who are typically children of non-English speaking immigrants to the United States who translate in high-stake situations for the well-being of the family (e.g., López, Lezama, & Heredia Jr., 2019).
Relatedly, Kim and colleagues (2014) assessed tweets from users living in three highly multilingual regions (Quebec, Qatar, and Switzerland) and found that different languages were used to tweet about different topics. Using machine learning, they first classified tweets as either monolingual or multilingual, and then analyzed the contents of all multilingual tweets. Among tweets that utilized the hashtag of the region (e.g., #Qatar) they compared hashtags that appeared in the local language (e.g., Arabic) vs. English to determine what types of topics were discussed in the local language vs. the global language of social media. Across all three regions, the results indicate that the local language was used to discuss informative, political, or debatable topics, whereas English was used to discuss topics related to activities and leisure.
The results outlined here align with these findings from Kim and colleagues in a few meaningful ways. First, our appraisal of the community detection process showed evidence for distinct uses of conversational topics pertaining to social vs. intellectual discussions in the non-dominant language. Second, and more generally, both studies used an analysis of conversational topics among multilingual samples to reveal the thematic structure of what each language is used for. One of the potential themes discovered through our granular analysis of conversational topics in the non-dominant language is using language to discuss personal, or emotional, topics (see Table 5). This finding challenges the idea that a first language (as determined by age of acquisition) is the primary language used to express emotions (e.g., Caldwell-Harris & Ayçiçeği-Dinn, 2009). The detection of this niched theme underlines a valuable strength of a network-based approach: quantifying linguistic phenomena with specificity.
Recently, there has been a surge in psycholinguistics to evaluate and characterize the social context of bilingual language use on brain and behavior. Each of these efforts have their strengths and weaknesses, and in this study, we propose one more tool with this collective goal in mind. Through a network-based approach analysis of conversational topics, we intersect domains of research within bilingualism (e.g., emotional word processing, mode of acquisition, sociolinguistics) to better understand individual differences in usage. Past work has linked such individual differences to meaningful changes in resting state functional connectivity (e.g., Gullifer et al. 2018), and we predict that the specificity and granularity with which our methods assess bilingual language usage may also have implications for neuroscience and neurolinguistics. These fields have recently conceptualized the brain as a connectome (i.e., a network) where the contributions of clusters of interconnected regions working together eclipse the contributions of individual regions (Avena-Koenigsberger, Misic, & Sporns, 2018; Betzel, Avena-Koenigsberger, Goñi, He, De Reus, Griffa et al., 2016). Indeed, language experience and culture likely play a role in shaping these networks (Chen, Xue, Mei, Chen, & Dong, 2009; Grady, Luk, Craik, & Bialystok, 2015).
We acknowledge limitations of the present design in answering some of our questions. Most egregiously, we caution that the communicative contexts must be clearly defined. For example, our results indicated that the work context clearly stood out from the other communicative contexts. However, this context also had the fewest respondents (42 out of full sample of 117, see Figure 4). It is possible that some respondents considered work and school to be the same (especially among our sample of mostly university students), whereas others may have brought to mind very different contexts when answering for work and school. However, this is unlikely the case for family vs. home where participants were instructed to differentiate between where they currently live (home) and language use with family that they do not live with (family). Nevertheless, given the large sample size, we expect that much of the residue of this limitation likely washed out.
It may also be important to consider the particular languages that a bilingual engages with, and whether these languages represent the majority or minority of a given setting. Montreal (and Quebec more broadly) are interesting examples to consider this idea because, despite the global reach of English (including most other provinces in Canada), French serves as the official language of the province, thus rendering English as the minority language (Boberg, 2012). We find it interesting how this relationship plays out across communicative contexts in our data. For example, all workplaces in Quebec are mandated to adopt a “Francization” program - to ensure that French is used for business activities (Kircher, 2004; Leimgruber et al., 2020). Here, French clearly stands out as the majority language (as decreed by the law), and English as the minority, and indeed our network measure calculations reveal that the work context network has the lowest mean strength (i.e., fewer languages are used in this context). However, English would never be considered the minority language in many other parts of the world, and so it would be reasonable that the pattern of results reported here may vary in other linguistic and cultural milieus.
This brings us to the important question of why: Why use Network Science to represent these individual differences in bilingual language usage? There is a longstanding debate among network scientists (much like corpus linguists) as to whether Network Science is merely a methodology to quantify complex systems, or more of a theoretical framework to understand complex systems (Neal, 2013). The present work draws on both capacities to characterize and quantify the complex relationship between bilingualism and social language use. In doing so we gain rich, network visualizations of bilingual language use across communicative contexts, which we can observe for a single individual, or as shown in this paper, aggregated to understand group-level behavioral patterns. These rich visualizations, such as the dramatically different hues portrayed in the dominant vs. non-dominant language networks, can heuristically reveal important differences in usage and prompt us to dig deeper to understand the underlying mechanisms of these differences.
Moreover, over the past several decades, network scientists have identified and validated many network properties to mathematically quantify critical aspects of the network space, most of which boil down to a single numerical value. This is a real strength for language scientists who often have to grapple with hundreds of responses on a language history questionnaire and ultimately end up plucking out the same, basic variables (e.g., age of acquisition, usage) to feed their models. Using a single value, such as network size, to statistically represent the range of topics that are discussed in a given language may bring us one step closer to modelling language use as it occurs in the wild.
Lastly, if we envision Network Science as a theoretical framework, we may begin to formalize many aspects of language that thus far have only been discussed from a theoretical perspective. For example, many aspects of pragmatics (e.g., Gricean principles, Speech Acts Theory) are challenging to represent, in part because they draw from so many different fields. Similarly, networks can represent the complexities of word acquisition to the lexicon (e.g., Hills, Maouene, Maouene, Sheya & Smith, 2009) and may easily be extended to the study of bilingual language learning. Other areas of research within bilingualism, such as emotional word processing, may also benefit from a formal network representation, as some are beginning to do with concept development (e.g., Castro & Siew, 2019; Siew, Wulff, Beckage, & Kennett, 2019). Lastly, recent advances in network psychometrics allow researchers to quantify and examine the robustness of expressing behavioral data through network representation (Epskamp, Borsboom, & Fried, 2018). For all these reasons, we assert that using a Network Science framework to creatively represent and characterize complex aspects of bilingual language experience is a strength that can be wielded to better understand the role of individual differences on bilingualism and cognition.
Figure 7.
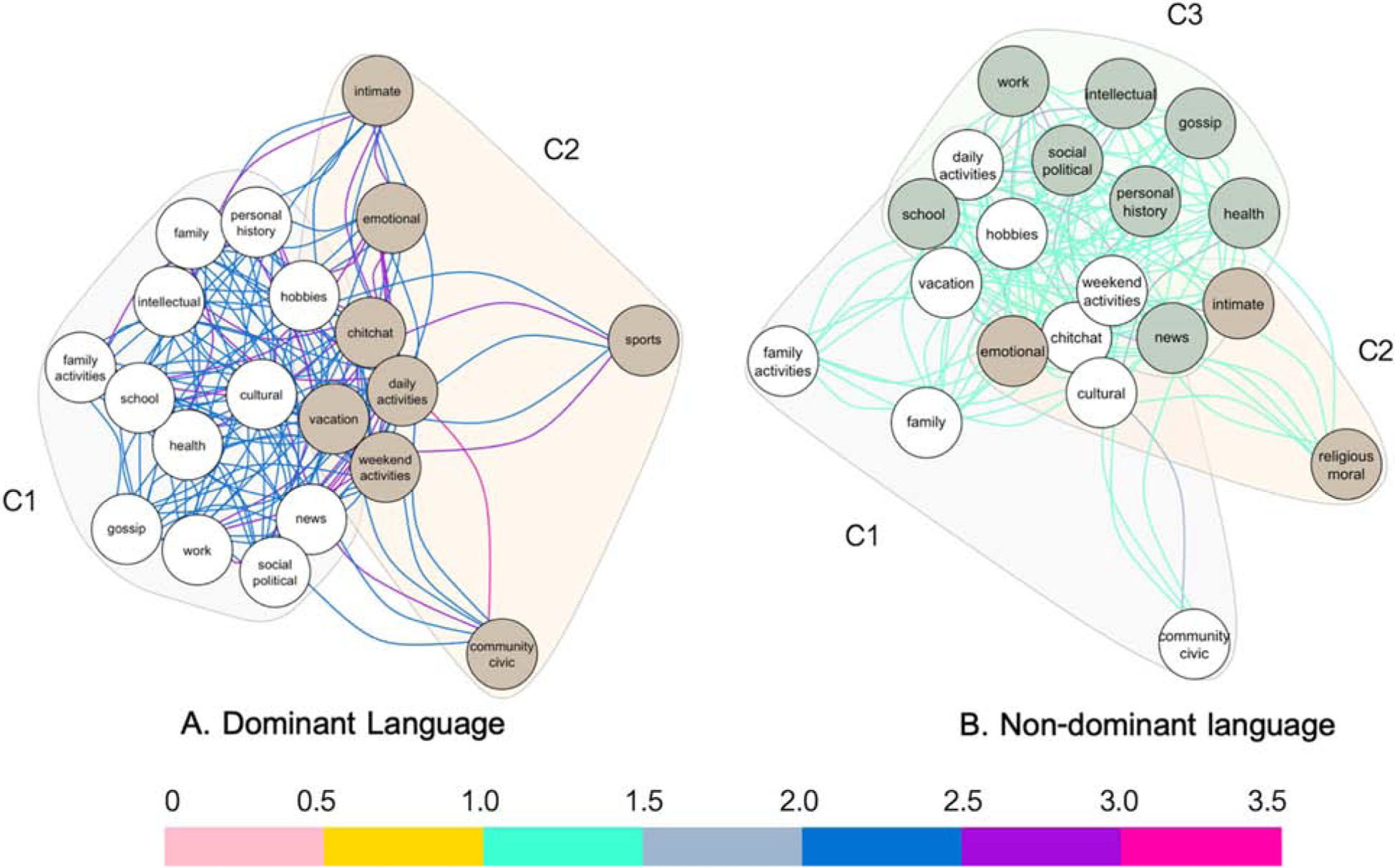
Louvain Community Detection algorithm applied to each of the language networks. This tool groups nodes through modularity, or the probability that a node belongs to a community minus such probability if the edges were distributed at random. Two communities (C1, C2) are detected for the dominant language, and three communities (C1, C2, C3) are detected for the non-dominant language.
Quantifying individual differences in bilingual social language use is important
We propose a novel application of Network Science to map what bilinguals talk about
We find that bilinguals talk about different topics in each of their daily contexts
Bilinguals talk about more topics across more contexts in their dominant language
There is greater topic specificity in the non-dominant language
Appendix A
Table 6.
Tukey HSD pair-wise comparisons
| Network Size | Mean Strength | Density | ||||
|---|---|---|---|---|---|---|
| Tukey HSD | Adjusted p- value | Tukey HSD | Adjusted p- value | Tukey HSD | Adjusted p- value | |
| Home-Family | 0.113 | 0.999 | −2.254 | 0.864 | −0.004 | 0.994 |
| School-Family | −2.199 | 0.000 | −1.100 | 0.993 | 0.020 | 0.185 |
| Social-Family | −0.243 | 0.988 | 10.601 | 0.000 | 0.020 | 0.165 |
| Work-Family | −3.892 | 0.000 | −9.961 | 0.027 | 0.012 | 0.864 |
| School-Home | −2.313 | 0.000 | 1.442 | 0.978 | 0.024 | 0.063 |
| Social-Home | −0.357 | 0.949 | 13.144 | 0.000 | 0.024 | 0.054 |
| Work-Home | −4.000 | 0.000 | −7.418 | 0.173 | 0.015 | 0.683 |
| Social-School | 1.956 | 0.000 | 11.701 | 0.000 | 0.000 | 1.000 |
| Work-School | −1.693 | 0.067 | −8.860 | 0.059 | −0.008 | 0.956 |
| Work-Social | −3.649 | 0.000 | −20.562 | 0.000 | −0.009 | 0.949 |
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Abutalebi J, & Green DW (2016). Neuroimaging of language control in bilinguals: neural adaptation and reserve. Bilingualism: Language and Cognition, 19(4), 689–698. 10.1017/S1366728916000225 [DOI] [Google Scholar]
- Anderson JA, Hawrylewicz K, & Bialystok E (2018a). Who is bilingual? Snapshots across the lifespan. Bilingualism: Language and Cognition, 1–12. [Google Scholar]
- Anderson JA, Mak L, Chahi AK, & Bialystok E (2018b). The language and social background questionnaire: Assessing degree of bilingualism in a diverse population. Behavior research methods, 50(1), 250–263. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ardila A, Benettieri K, Church Y, Orozco A, & Saucedo C (2019). Private speech in simultaneous and early Spanish/English bilinguals. Applied Neuropsychology: Adult, 26(2), 139–143. 10.1080/23279095.2017.1370422 [DOI] [PubMed] [Google Scholar]
- Avena-Koenigsberger A, Misic B, & Sporns O (2018). Communication dynamics in complex brain networks. Nature Reviews Neuroscience, 19(1), 17 DOI: 10.1038/nrn.2017.149 [DOI] [PubMed] [Google Scholar]
- Aynaud T, & Guillaume JL (2010). Static community detection algorithms for evolving networks In 8th International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (pp. 513–519). IEEE. [Google Scholar]
- Beatty-Martínez AL, & Dussias PE (2017). Bilingual experience shapes language processing: Evidence from codeswitching. Journal of Memory and Language, 95, 173–189. 10.1016/j.jml.2017.04.002 [DOI] [Google Scholar]
- Beatty-Martínez AL, Navarro-Torres CA, Dussias PE, Bajo MT, Guzzardo Tamargo RE, & Kroll JF (2019). Interactional context mediates the consequences of bilingualism for language and cognition. Journal of Experimental Psychology Learning, Memory, and Cognition. Advance online publication. 10.1037/xlm0000770 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Betzel RF, Avena-Koenigsberger A, Goñi J, He Y, De Reus MA, Griffa A, … & Van Den Heuvel M (2016). Generative models of the human connectome. Neuroimage, 124, 1054–1064. DOI: 10.1016/j.neuroimage.2015.09.041 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blondel VD, Guillaume JL, Lambiotte R, & Lefebvre E (2008). Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment, 2008(10), P10008 10.1088/1742-5468/2008/10/P10008 [DOI] [Google Scholar]
- Boberg C (2012). English as a minority language in Quebec. World Englishes, 31(4), 493–502. DOI: 10.1111/j.1467-971X.2012.01776.x [DOI] [Google Scholar]
- Caldwell-Harris CL, & Ayçiçeği-Dinn A (2009). Emotion and lying in a non-native language. International Journal of Psychophysiology, 71(3), 193–204. 10.1016/j.ijpsycho.2008.09.006 [DOI] [PubMed] [Google Scholar]
- Carroll R & Luna D (2011). The other meaning of fluency: Content accessibility and language in advertising to bilinguals. Journal of Advertising, 40 (3), 73–84. DOI: 10.2753/JOA0091-3367400306 [DOI] [Google Scholar]
- Castro N & Siew CSQ (2019). Contributions of Modern Network Science to the Cognitive Sciences: Revisiting research spirals of representation and process. Advance online publication; Retrieved from https://psyarxiv.com/gkmb8/. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen C, Xue G, Mei L, Chen C, & Dong Q (2009). Cultural neurolinguistics. Progress in brain research, 178, 159–171. DOI: 10.1016/S0079-6123(09)17811-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chiaro D (2009). Cultural divide or unifying factor? Humorous talk in the interaction of bilingual, cross-cultural couples In Norrick N & Chiaro D (Eds.), Humor in interaction (pp. 211–231). Amsterdam/Philadelphia: John Benjamins. [Google Scholar]
- Collins AM & Loftus EF (1975). A spreading-activation theory of semantic processing. Psychological Review, 82, 407–428. 10.1037/0033-295X.82.6.407 [DOI] [Google Scholar]
- Collins AM & Quillian MR (1969). Retrieval time from semantic memory. Journal of Verbal Learning and Verbal Behavior, 8, 240–247. 10.1016/S0022-5371(69)80069-1 [DOI] [Google Scholar]
- Csárdi G, & Nepusz T (2006). The igraph software package for complex network research. [Google Scholar]
- DeLuca V, Rothman J, Bialystok E, & Pliatsikas C (2019). Redefining bilingualism as a spectrum of experiences that differentially affects brain structure and function. Proceedings of the National Academy of Sciences of the United States of America, 116(15), 7565–7574. 10.1073/pnas.1811513116 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dewaele JM (2015). From obscure echo to language of the heart: Multilinguals’ language choices for (emotional) inner speech. Journal of Pragmatics, 87, 1–17. 10.1016/j.pragma.2015.06.014 [DOI] [Google Scholar]
- Doucerain MM, Varnaamkhaasti RS, Segalowitz N & Ryder AG (2015) Second language social networks and communication-related acculturative stress: the role of interconnectedness. Frontiers in Psychology. 6:1111 10.3389/fpsyg.2015.01111 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dugué N, & Connes V (2019). Complex networks based word embeddings. ArXiv:1910.[Cs] Retrieved from http://arxiv.org/abs/1910.01489 [Google Scholar]
- Epskamp S, Borsboom D & Fried EI (2018). Estimating psychological networks and their accuracy: A tutorial paper. Behavioral Research Methods, 50, 195–212. DOI: 10.3758/s13428-017-0862-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fortunato S (2010). Community detection in graphs. Physics Reports, 486(3–5), 75–174. 10.1016/j.physrep.2009.11.002 [DOI] [Google Scholar]
- Gasser C (2000). Exploring the Complementarity Principle: The case of first generation English-German bilinguals in the Basle area. Master’s Thesis, English Linguistics, University of Basle, Switzerland. [Google Scholar]
- Garrison KA, Scheinost D, Finn ES, Shen X, & Constable RT (2015). The (in)stability of functional brain network measures across thresholds. NeuroImage, 118, 651–661. 10.1016/j.neuroimage.2015.05.046 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grady CL, Luk G, Craik FI, & Bialystok E (2015). Brain network activity in monolingual and bilingual older adults. Neuropsychologia, 66, 170–181. DOI: 10.1016/j.neuropsychologia.2014.10.042 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Green DW, & Abutalebi J (2013). Language control in bilinguals: The adaptive control hypothesis. Journal of Cognitive Psychology, 25(5), 515–530. 10.1080/20445911.2013.796377 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grosjean F (1985). The bilingual as a competent but specific speaker-hearer. Journal of Multilingual and Multicultural Development, 6, 467–477. DOI: 10.1080/01434632.1985.9994221 [DOI] [Google Scholar]
- Grosjean F (1997). The bilingual individual. Interpreting, 2(1–2), 163–187. DOI: 10.1075/intp.2.1-2.07gro [DOI] [Google Scholar]
- Grosjean F (2010). Bilingual. Harvard university press. [Google Scholar]
- Grosjean F (2016). The Complementarity Principle and its impact on processing, acquisition, and dominance In Silva-Corvalán C and Treffers-Daller J (Eds.), Language Dominance in Bilinguals: Issues of Measurement and Operationalization (pp. 66–84). Cambridge: Cambridge University Press. [Google Scholar]
- Gullifer JW, Chai XJ, Whitford V, Pivneva I, Baum S, Klein D, & Titone D (2018). Bilingual experience and resting-state brain connectivity: Impacts of L2 age of acquisition and social diversity of language use on control networks. Neuropsychologia, 117, 123–134. 10.1016/j.neuropsychologia.2018.04.037 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gullifer JW, & Titone D (2018). Compute language entropy with {languageEntropy}. Retrieved from https://github.com/jasongullifer/languageEntropy
- Gullifer JW, & Titone D (2019). The impact of a momentary language switch on bilingual reading: Intense at the switch but merciful downstream for L2 but not L1 readers. Journal of Experimental Psychology, Learning, Memory, and Cognition. 10.1037/xlm0000695 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hartanto A, & Yang H (2016). Disparate bilingual experiences modulate task-switching advantages: A diffusion-model analysis of the effects of interactional context on switch costs. Cognition, 150, 10–19. doi: 10.1016/j.cognition.2016.01.016 [DOI] [PubMed] [Google Scholar]
- Heller M (1992) The politics of codeswitching and language choice, Journal of Multilingual & Multicultural Development, 13:1–2, 123–142, 10.1080/01434632.1992.9994487 [DOI] [Google Scholar]
- Higgins R (2004). French, English, and the idea of gay language in Montréal Speaking in queer tongues: Globalization and gay language, 72–104. Leap W & Boellstorff T (Eds.). University of Illinois Press. [Google Scholar]
- Hills TT, Maouene M, Maouene J, Sheya A, & Smith L (2009). Longitudinal analysis of early semantic networks: Preferential attachment or preferential acquisition?. Psychological science, 20(6), 729–739. DOI: 10.1111/j.1467-9280.2009.02365.x [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hoffman G (1971). Puerto Ricans in New York: A language-related ethnographic summary In Fishman J, Cooper R, & Ma R (Eds.), Bilingualism in the Barrio. (pp. 13–42). Bloomington, Indiana: Indiana University Press. [Google Scholar]
- Indefrey P (2006). A Meta-analysis of Hemodynamic Studies on First and Second Language Processing: Which Suggested Differences Can We Trust and What Do They Mean? Language Learning, 56(1), 279–304. DOI: 10.1111/j.1467-9922.2006.00365.x [DOI] [Google Scholar]
- Jaccard R & Cividin V (2001). Le principe de complémentarité chez la personne bilingue: Le cas du bilinguisme français-italien en Suisse Romande. Master’s Thesis, Language Pathology Program, University of Neuchâtel, Switzerland. [Google Scholar]
- Kapa LL, & Colombo J (2013). Attentional control in early and later bilingual children. Cognitive development, 28(3), 233–246. 10.1016/j.cogdev.2013.01.011 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kim KH, Relkin NR, Lee KM, & Hirsch J (1997). Distinct cortical areas associated with native and second languages. Nature, 388, 171–174. DOI: 10.1038/40623 [DOI] [PubMed] [Google Scholar]
- Kim S, Weber I, Wei L, & Oh A (2014, September). Sociolinguistic analysis of Twitter in multilingual societies In Proceedings of the 25th ACM conference on Hypertext and social media (pp. 243–248). ACM. [Google Scholar]
- Kircher R (2014). Thirty Years after Bill 101: A Contemporary Perspective on Attitudes Towards English and French in Montreal. Canadian Journal of Applied Linguistics/Revue canadienne de linguistique appliquee, 17(1), 20–50. [Google Scholar]
- Klein D, Mok K, Chen JK, & Watkins KE (2014). Age of language learning shapes brain structure: a cortical thickness study of bilingual and monolingual individuals. Brain and language, 131, 20–24. 10.1016/j.bandl.2013.05.014 [DOI] [PubMed] [Google Scholar]
- Kousaie S, Chai XJ, Sander KM, & Klein D (2017). Simultaneous learning of two languages from birth positively impacts intrinsic functional connectivity and cognitive control. Brain and cognition, 117, 49–56. 10.1016/j.bandc.2017.06.003 [DOI] [PubMed] [Google Scholar]
- Leimgruber JR, Vingron N, & Titone D (2020). What Do People Notice from Real-World Linguistic Landscapes?. Reterritorializing Linguistic Landscapes: Questioning Boundaries and Opening Spaces, 16. [Google Scholar]
- Li P, Zhang F, Yu A, & Zhao X (2019). Language History Questionnaire (LHQ3): An enhanced tool for assessing multilingual experience. Bilingualism: Language and Cognition, 1–7. 10.1017/S1366728918001153 [DOI] [Google Scholar]
- López BG, Lezama E, & Heredia D (2019). Language Brokering Experience Affects Feelings Toward Bilingualism, Language Knowledge, Use, and Practices: A Qualitative Approach. Hispanic Journal of Behavioral Sciences, 41(4), 481–503. 10.1177/0739986319879641 [DOI] [Google Scholar]
- Luk G, De Sa ERIC, & Bialystok E (2011). Is there a relation between onset age of bilingualism and enhancement of cognitive control?. Bilingualism: Language and cognition, 14(4), 588–595. 10.1017/S1366728911000010 [DOI] [Google Scholar]
- Mechelli A, Crinion JT, Noppeney U, O'Doherty J, Ashburner J, Frackowiak RS, & Price CJ (2004). Neurolinguistics: Structural plasticity in the bilingual brain. Nature, 431, 757–757. DOI: 10.1038/431757a [DOI] [PubMed] [Google Scholar]
- Namaki A, Shirazi AH, Raei R, & Jafari GR (2011). Network analysis of a financial market based on genuine correlation and threshold method. Physica A: Statistical Mechanics and Its Applications, 390(21), 3835–3841. 10.1016/j.physa.2011.06.033 [DOI] [Google Scholar]
- Neal ZP (2013). The connected city: How networks are shaping the modern metropolis. New York: Routledge. [Google Scholar]
- Newman MEJ (2010). Networks: An introduction. Cambridge, MA: Oxford University Press. [Google Scholar]
- Open Science Framework (2019). Tiv M, Gullifer J, Feng R, & Titone D, Network Science for Mapping Bilingual Conversational Topics.[protocol, data]. Retrieved from https://osf.io/6z79s/
- Palma P, Whitford V, & Titone D (2020). Cross-language activation and executive control modulate within-language ambiguity resolution: Evidence from eye movements. Journal of Experimental Psychology: Learning, Memory, and Cognition, 46(3), 507–528. DOI: 10.1037/xlm0000742 [DOI] [PubMed] [Google Scholar]
- Pelham SD, & Abrams L (2014). Cognitive advantages and disadvantages in early and late bilinguals. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(2), 313 10.1037/a0035224 [DOI] [PubMed] [Google Scholar]
- Perani D, Paulesu E, Galles NS, Dupoux E, Dehaene S, Bettinardi V, Cappa SF, Fazio F, & Mehler J (1998). The bilingual brain. Proficiency and age of acquisition of the second language. Brain : A Journal of Neurology, 121 (10), 1841–1852. DOI: 10.1093/brain/121.10.1841 [DOI] [PubMed] [Google Scholar]
- Piazza EA, Iordan MC, & Lew-Williams C (2017). Mothers consistently alter their unique vocal fingerprints when communicating with infants. Current Biology, 27(20), 3162–3167. 10.1016/j.cub.2017.08.074 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pivneva I, Mercier J, & Titone D (2014). Executive control modulates cross-language lexical activation during L2 reading: Evidence from eye movements. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(3), 787–796. DOI: 10.1037/a0035583 [DOI] [PubMed] [Google Scholar]
- Pliatsikas C, DeLuca V, Moschopoulou E, & Saddy JD (2016). Immersive bilingualism reshapes the core of the brain. Brain Structure and Function, 222, 1785–1795. DOI: 10.1007/s00429-016-1307-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- R Core Team. (2016). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing; Retrieved from www.r-project.org/ [Google Scholar]
- Siew CS (2013). Community structure in the phonological network. Frontiers in psychology, 4, 553 DOI: 10.3389/fpsyg.2013.00553 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Siew CSQ, Wulff DU, Beckage NM & Kenett YN (2019). Cognitive network science: A review of research on cognition through the lens of network representations, processes, and dynamics. Complexity. 10.1155/2019/2108423. [DOI] [Google Scholar]
- Statistics Canada. (2017). Montréal, V [Census subdivision], Quebec and Canada [Country] (table). Census Profile. 2016 Census. Statistics Canada Catalogue no. 98–316-X2016001 Retrieved from https://www12.statcan.gc.ca/census-recensement/2016/dppd/prof/index.cfm?Lang=E
- Sulpizio S, Del Maschio N, Del Mauro G, Fedeli D, & Abutalebi J (2020). Bilingualism as a gradient measure modulates functional connectivity of language and control networks. NeuroImage, 205, 116306 10.1016/j.neuroimage.2019.116306 [DOI] [PubMed] [Google Scholar]
- Svartvik J (1968). The Evans Statements: A Case for Forensic Linguistics. University of Gothenburg Press. [Google Scholar]
- Tao L, Marzecová A, Taft M, Asanowicz D, & Wodniecka Z (2011). The efficiency of attentional networks in early and late bilinguals: the role of age of acquisition. Frontiers in psychology, 2, 123 10.3389/fpsyg.2011.00123 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Titone D, Libben M, Mercier J, Whitford V, & Pivneva I (2011). Bilingual lexical access during L1 sentence reading: The effects of L2 knowledge, semantic constraint, and L1-L2 intermixing. Journal of Experimental Psychology: Learning, Memory, and Cognition, 37(6), 1412 10.1037/a0024492 [DOI] [PubMed] [Google Scholar]
- Tiv M, Kutlu E & Titone D (under review). Bilingualism Moves us Beyond the Ideal Speaker Narrative in Cognitive Psychology. [Google Scholar]
- Vitevich M (2019) Network Science in Cognitive Psychology. New York, NY: Routledge. [Google Scholar]
- Wei L (2017). Translanguaging as a practical theory of language. Applied linguistics, 39(1), 9–30. [Google Scholar]
- Yan X, Jeub LGS, Flammini A, Radicchi F, & Fortunato S (2018). Weight Thresholding on Complex Networks. Physical Review E, 98(4), 042304 10.1103/PhysRevE.98.042304 [DOI] [Google Scholar]
- Yang Z, Algesheimer R, & Tessone CJ (2016). A Comparative Analysis of Community Detection Algorithms on Artificial Networks. Scientific Reports, 6, 30750 10.1038/srep30750 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yu ZY, & Schwieter JW (2018). Recognizing the effects of language mode on the cognitive advantages of bilingualism. Frontiers in Psychology, 9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao Y (2017). A Survey on Theoretical Advances of Community Detection in Networks. (, 9(5), e1403 10.1002/wics.140328852600 [DOI] [Google Scholar]