

Abstract
Information theory provides a mathematical foundation to measure uncertainty in belief. Belief is represented by a probability distribution that captures our understanding of an outcome’s plausibility. Information measures based on Shannon’s concept of entropy include realization information, Kullback–Leibler divergence, Lindley’s information in experiment, cross entropy, and mutual information. We derive a general theory of information from first principles that accounts for evolving belief and recovers all of these measures. Rather than simply gauging uncertainty, information is understood in this theory to measure change in belief. We may then regard entropy as the information we expect to gain upon realization of a discrete latent random variable. This theory of information is compatible with the Bayesian paradigm in which rational belief is updated as evidence becomes available. Furthermore, this theory admits novel measures of information with well-defined properties, which we explored in both analysis and experiment. This view of information illuminates the study of machine learning by allowing us to quantify information captured by a predictive model and distinguish it from residual information contained in training data. We gain related insights regarding feature selection, anomaly detection, and novel Bayesian approaches.
Keywords: information, Bayesian inference, entropy, self information, mutual information, Kullback–Leibler divergence, Lindley information, maximal uncertainty, proper utility
1. Introduction
This work integrates essential properties of information embedded within Shannon’s derivation of entropy [1] and the Bayesian perspective [2,3,4], which identifies probability with plausibility. We pursued this investigation in order to understand how to rigorously apply information-theoretic concepts to the theory of inference and machine learning. Specifically, we wanted to understand how to quantify the evolution of predictions given by machine learning models. Our findings are general, however, and bear implications for any situation in which states of belief are updated. We begin in Section 1.1 with an experiment that illustrates shortcomings with the way standard information measures would partition prediction information and residual information during machine learning training.
1.1. Shortcomings with Standard Approaches
Let us examine a typical MNIST [5] classifier. This dataset comprises a set of images of handwritten digits paired with labels. Let both x and y denote random variables corresponding, respectively, to an image and a label in a pair. In this situation, the training dataset contains independent realizations of such pairs from an unknown joint probability distribution. We would like to obtain a measurement of prediction information that quantifies a shift in belief from an uninformed initial state to model predictions . The symmetric uninformed choice for is uniform probability over all outcomes. Note that both and are simply hypothetical states of belief. Some architectures may approximate Bayesian inference, but we cannot always interpret these as the Bayesian prior and posterior.
Two measurements that are closely related to Shannon’s entropy are the Kullback–Leibler (KL) divergence [6,7] and Lindley’s information in experiment [8], which are computed respectively as
Whatever we choose, we would like to use a consistent construction to understand how much information remains unpredicted. After viewing a label outcome , we let represent our new understanding of the actual state of affairs, which is a realization assigning full probability to the specified outcome. This distribution captures our most updated knowledge about y, and therefore constitutes rational belief. A consistent information measurement should then quantify residual information as the shift in belief from to . For example, the KL version would be .
In order to demonstrate shortcomings with each approach, some cases are deliberately mislabeled during model testing. We first compute information measurements while assuming the incorrect labels hold. Mislabeled cases are then corrected to with corrected belief given by . This allows us to compare our first information measurements with corrected versions. An example of each belief state is shown in Figure 1 where the incorrect label 3 is changed to 0.
Figure 1.

Example of the evolution of plausible labels for an image. Without evidence, the probability distribution assigns equal plausibility to all outcomes. A machine learning model processes the image and produces predictions . The incorrect label 3 is represented by . After observing the image, shown on the right, the label is corrected to 0 in .
Ideally, the sum of prediction information and residual information would be a conserved quantity, which would allow us to understand training as simply shifting information from a residual partition to the predicted partition. More importantly, however, prediction information should clearly capture prediction quality. Figure 2 shows information measurements corresponding to the example given.
Figure 2.

Information measurements before and after label correction. Neither construction of prediction information allows the computation to account for claimed labels. Residual information, however, decreases in the KL construction when the label is corrected. The Lindley forms are totally unaffected by relabeling.
Mislabeling and relabeling shows us that neither formulation of prediction information captures prediction quality. This is because these constructions simply have no affordance to account for our understanding of what is actually correct. Large KL residual information offers some indication of mislabeling and decreases when we correct the label, but total information is not conserved. As such, there is no intuitive notion for what appropriate prediction and residual information should be for a given problem. The Lindley formulation is substantially less satisfying. Although total information is conserved, neither metric changes and we have no indication of mislabeling.
The problem with these constructions is they do not recognize the gravity of the role of expectation. That is, reasonable expectation must be consistent with rational belief. We hold that our most justified understanding of what may be true provides a sound basis to measure changes in belief. Figure 3 gives a preview of information measurements in the framework of this theory. Total information, bits in this case, is conserved, and both prediction information and residual information react intuitively to mislabeling. Determining whether the predictive information is positive or negative provides a clear indication of whether the prediction was informative.
Figure 3.

Information measurements using our proposed framework. Total information is a conserved quantity, and when our belief changes, so do the information measurements. Negative prediction information forewarns either potential mislabeling or a poor prediction.
1.2. Our Contributions
In the course of pursuing a consistent framework in which information measurements may be understood, we have derived a theory of information from first principles that places all entropic information measures in a unified, interpretable context. By axiomatizing the properties of information we desire, we show that a unique formulation follows that subsumes critical properties of Shannon’s construction of entropy.
This theory fundamentally understands entropic information as a form of reasonable expectation that measures the change between hypothetical belief states. Expectation is not necessarily taken with respect to the distributions that represent the shift in belief, but rather with respect to a third distribution representing our understanding of what may actually be true. We found compelling foundations for this perspective within the Bayesian philosophy of probability as an extended logic for expressing and updating uncertainty [4,9]. Our understanding of what may be true, and therefore the basis for measuring information, should be rational belief. Rational belief [10,11,12,13,14] begins with probabilistically coherent prior knowledge, and is subsequently updated to account for observations using Bayes’ theorem. As a consequence, information associated with a change in belief is not a fixed quantity. Just as rational belief must evolve as new evidence becomes available, so also does the information we would reasonably assign to previous shifts in belief. By emphasizing the role of rational belief, this theory recognizes that the degree of validity we assign to past states of belief is both dynamic and potentially subjective as our state of knowledge matures.
As a consequence of enforcing consistency with rational belief, a second additivity property emerges; just as entropy can be summed over independent distributions, information gained over a sequence of observations can be summed over intermediate belief updates. Total information over such a sequence is independent of how results are grouped or ordered. This provides a compelling solution to the thought experiment above. Label information in training data is a conserved quantity and we motivate a formulation of prediction information that is directly tied to prediction quality.
Soofi, Ebrahimi, and others [15,16,17,18] identified key contributions to information theory in the decade following Shannon’s paper that are intrinsically tied to entropy. These are the Kullback–Leibler divergence, Lindley’s information in experiment, and Jaynes’ construction of entropy-maximizing distributions that are consistent with specified expectations. We show how this theory recovers these measures of information and admits new forms that may not have been previously associated with entropic information, such as the log pointwise posterior predictive measure of model accuracy [19]. We also show how this theory admits novel information-optimal probability distributions analogous to that of Jaynes’ maximum uncertainty. Having a consistent interpretation of information illuminates how it may be applied and what properties will hold in a given context. Moreover, this theoretical framework enables us to solve multiple challenges in Bayesian learning. For example, one such challenge is understanding how efficiently a given model incorporates new data. This theory provides bounds on the information gained by a model resulting from inference and allows us to characterize the information provided by individual observations.
The rest of this paper is organized as follows. Section 2 discusses notation and background regarding entropic information, Bayesian inference, and reasonable expectation. Section 3 contains postulates that express properties of information we desire, the formulation of information that follows, and other related measures of information. Section 4 analyzes general consequences and properties of this formulation. Section 5 discusses further implications with respect to Bayesian inference and machine learning. Section 6 explores negative information with computational experiments that illustrate when it occurs, how it may be understood, and why it is useful. Section 7 summarizes these results and offers a brief discussion of future work. Appendix A proves our principal result. Appendix B contains all corollary proofs. Appendix C provides key computations used in experiments.
2. Background and Notation
Shannon’s construction of entropy [1] shares a fundamental connection with thermodynamics. The motivation is to facilitate analysis of complex systems which can be decomposed into independent subsystems. The essential idea is simple—when probabilities multiply, entropy adds. This abstraction allows us to compose uncertainties across independent sources by simply adding results. Shannon applied this perspective to streams of symbols called channels. The number of possible outcomes grows exponentially with the length of a symbol sequence, whereas entropy grows linearly. This facilitates a rigorous formulation of the rate of information conveyed by a channel and analysis of what is possible in the presence of noise.
The property of independent additivity is used in standard training practices for machine learning. Just as thermodynamic systems and streams of symbols break apart, so does an ensemble of predictions over independent observations. This allows us to partition training sets into batches and compute cross-entropy [20] averages. MacKay [21] gives a comprehensive discussion of information in the context of learning algorithms. Tishby [22] examines information trends during neural network training.
A second critical property of entropy, which is implied by Shannon and further articulated by both Barnard [23] and Rényi [24], is that entropy is an expectation. Given a latent random variable z, we denote the probability distribution over outcomes as . Stated as an expectation, entropy is defined as
Following Shannon, investigators developed a progression of divergence measures between general probability distributions, and . Notable cases include the Kullback–Leibler divergence, Rényi’s information of order- [24], and Csiszár’s f-divergence [25]. Ebrahimi, Soofi, and Soyer [18] offered an examination of these axiomatic foundations and generalizations with a primary focus on entropy and the KL divergence. Recent work on axiomatic foundations for generalized entropies [26] includes constructions that are suitable for strongly-interacting systems [27] and axiomatic derivations of other forms of entropy, including Sharma–-Mittal and Frank-–Daffertshofer entropies [28]. Further work uses group theory to relate properties of systems to corresponding notions of entropy and correlation laws [29].
2.1. Bayesian Reasoning
The Bayesian view of probability, going back to Laplace [2] and championed by Jeffreys [3] and Jaynes [4], focuses on capturing our beliefs. This perspective considers a probability distribution as an abstraction that attempts to model these beliefs. This view subsumes all potential sources of uncertainty and provides a comprehensive scope that facilitates analysis in diverse contexts.
In the Bayesian framework, the prior distribution expresses initial beliefs about some latent variable z. Statisticians, scientists, and engineers often have well-founded views about real-world systems that form the basis for priors. Examples include physically realistic ranges of model parameters or plausible responses of a dynamical system. In the case of total ignorance, one applies the principle of insufficient reason [30]—we should not break symmetries of belief without justification. Jaynes’ construction of maximally uncertainty distributions [31] generalizes this principle, which we discuss further in Section 4.6.
As observations x become available, we update belief from the prior distribution to obtain the posterior distribution , which incorporates this new knowledge. This update is achieved by applying Bayes’ theorem
The likelihood distribution expresses the probability of observations given any specified value of z. The normalization constant is also the probability of x given the prior belief that has been specified. Within Bayesian inference, this is also called model evidence and it is used to evaluate a model structure’s plausibility for generating the observations.
Shore and Johnson [32,33] provide an axiomatic foundation for updating belief that recovers the principles of maximum entropy and minimum cross-entropy when prior evidence consists of known expectations. For reference, we summarize these axioms as
Uniqueness. When belief is updated with new observations, the result should be unique.
Coordinate invariance. Belief updates should be invariant to arbitrary choices of coordinates.
System independence. The theory should yield consistent results when independent random variables are treated either separately or jointly.
Subset independence. When we partion potential outcomes into disjoint subsets, the belief update corresponding to conditioning on subset membership first should yield the same result as updating first and conditioning on the subset second.
Jizba and Korbel [34] investigated generalizations of entropy for which the maximum entropy principle satisfies these axioms.
Integrating the maturing notion of belief found within the Bayesian framework with information theory recognizes that our perception of how informative observations are depends on how our beliefs develop, which is dynamic as our state of knowledge grows.
2.2. Probability Notation
Random variables are denoted in boldface; for example, x. Typically, x and y will imply observable measurements and z will indicate either a latent explanatory variable or unknown observable. Each random variable is implicitly associated with a corresponding probability space, including the set of all possible outcomes , a -algebra of measurable subsets, and a probability measure which maps subsets of events to probabilities. We then express the probability measure as a distribution function .
A realization, or specific outcome, will be denoted with either a check , or, for discrete distributions only, a subscript , where and . If it is necessary to emphasize the value of a distribution at a specific point or realization, we will use the notation . Conditional dependence is denoted in the usual fashion as . The joint distribution is then , and marginalization is obtained by . When two distributions are equivalent over all subsets of nonzero measure, we use notation or .
The probability measure allows us to compute expectations over functions which are denoted
The support of integration or summation is implied to be the same as the support of ; that is, the set of outcomes for which . For example, in both the discrete case above and continuous cases, such as a distribution on the unit interval , the integral notation should be interpreted respectively as
2.3. Reasonable Expectation and Rational Belief
The postulates and theory in this work concern the measurement of a shift in belief from an initial state to an updated state . In principle, these are any hypothetical states of belief. For example, they could be predictions given by the computational model in Section 1.1, previous beliefs held before observing additional data, or convenient approximations of a more informed state of belief. A third state , rational belief, serves a distinct role as the distribution over which expectation is taken. When we wish to emphasize this role, we also refer to as the view of expectation.
To understand the significance of rational belief, we briefly review work by Cox [9] regarding reasonable expectation from two perspectives on the meaning of probability. The first perspective understands probability as a description of relative frequencies in an ensemble. If we prepare a large ensemble of independent random variables, , and each is realized from a proper (normalized) probability distribution , then the relative frequency of outcomes within each subset will approach the probability measure for large n. It follows that the ensemble mean of any transformation will approach the expectation
The difficulty arises when we distinguish what is true from what may be known, given limited evidence. This falls within the purview of the second perspective, the Bayesian view, regarding probability as an extended logic. To illustrate, suppose z is the value of an unknown real mathematical constant. The true probability distribution would be a Dirac delta assigning unit probability to the unknown value . Accordingly, each element in the ensemble above would take the same unknown value. If we have incomplete knowledge regarding the distribution of plausible values, then we can still compute an expectation , but we must bear in mind that the result only approximates the unknown true expectation. Since the expectation is limited by the credibility of , we seek to drive belief towards the truth as efficiently as possible from available evidence to fulfill this role.
Within Bayesian Epistemology, rational belief is defined as a belief that is unsusceptible to a Dutch Book. When an agent’s beliefs correspond to their willingness to places bets, a Dutch Book [11,12,13,14,35] means that it is possible for a bookie to construct a table of bets that the agent finds acceptable but also guarantees that the agent will lose money. Therefore the existence of such a table corresponds to the agent holding an irrational state of belief. When multiple bets are allowed to be conditioned on a sequence of outcomes, it has been shown that the agent must use Bayes’ Theorem to account for previous outcomes in the sequence to update beliefs regarding subsequent outcomes to avoid irrationality [14].
For our purposes, it is sufficient to say that if we have a coherent prior belief in a latent variable and a likelihood function that implies beliefs about observations, Bayes’ theorem incorporates observational evidence to from the posterior distribution representing rational belief. For example, we could measure inference information from prior belief to the first posterior conditioned on an observation x. When we have additional evidence y that complements x, then rational belief must corresponds to a second inference , because retaining the belief would not account for y. Likewise, if z is an observable realization, then rational belief must assign full probability to the observed outcome . This case is specifically denoted as , and in continuous settings it is equivalent to the Dirac delta function .
2.4. Remarks on Bayesian Objectivism and Subjectivism
Within the Bayesian philosophy, we may disagree about whether or not rational belief is unique. This disagreement corresponds to objectivist versus subjectivist views of Bayesian epistemology; see [4,36] for a discussion. Note that this is not the same as the more general view of objective versus subjective probabilities.
In the objectivist’s view, one’s beliefs must be consistent with the entirety of evidence and prior knowledge must be justified by sound principles of reason. Therefore, anyone with the same body of evidence must hold the same rational belief. In contrast, the subjectivist holds that one’s prior beliefs do not need justification. Provided evidence is taken into account using Bayes’ theorem, the resulting posterior is rational for any prior as long as the prior is coherent. Note that the subjectivist view does not imply that all beliefs are equally valid. It simply allows validity in the construction of prior belief to be derived from other notions of utility, such as computational feasibility.
While the following postulates in Section 3 and derivation of Theorem 1 do not require adoption of either perspective, these philosophies influence how we understand reasonable expectation. The objective philosophy implies that an information measurement is justified to the same degree as the view of expectation that defines it, whereas the subjective philosophy entertains information analysis with any view of expectation.
3. Information and Evolution of Belief
In order to provide context for comparison, we begin by presenting the properties of entropic information originally put forward by Shannon using our notation.
3.1. Shannon’s Properties of Entropy
Given a discrete probability distribution for which , the entropy is continuous in the probability of each outcome .
If all outcomes are equally probable, namely, , then is monotonically increasing in n.
- The entropy of a joint random variable can be decomposed using a chain rule expressing conditional dependence
The first point is aimed at extending Shannon’s derivation, which employs rational probabilities, to real-valued probabilities. The second point drives at understanding entropy as a measure of uncertainty; as the number of possible outcomes increases, each realization becomes less predictable. This results in entropy taking positive values. The third point is critical, as—not only does it encode independent additivity, it implies that entropic information is computed as an expectation.
We note that Fadeeve [37] gives a simplified set of postulates. Rènyi [24] generalizes information by replacing the last point with a weaker version, which simply requires independent additivity, but not conditional expectation. This results in -divergences. Csiszàr [25] generalizes this further using convex functions f to obtain f-divergences.
3.2. Postulates
Rather than repeating direct analogs of Shannon’s properties in the context of evolving belief, it is both simpler and more illuminating to be immediately forthcoming regarding the key requirement of information in the perspective of this theory.
Postulate 1.
Entropic information associated with the change in belief from to is quantified as an expectation over belief , which we call the view of expectation. As an expectation, it must have the functional form
Postulate 2.
Entropic information is additive over independent belief processes. Taking joint distributions associated with two independent random variables z and w to be , , and gives
Postulate 3.
If belief does not change then no information is gained, regardless of the view of expectation,
Postulate 4.
The information gained from any normalized prior state of belief to an updated state of belief in the view of must be nonnegative
The first postulate requires information to be reassessed as belief changes. The most justified state of belief, based on the entirety of observations, will correspond to the most justified view of information. The second postulate is the additive form of Shore and Johnson’s Axiom 3, system independence. That is, we need some law of composition, addition in this case, that allows independent random variables to be treated separately and arrive at the same result as treating them jointly.
By combining the first two postulates, it is possible to show that for constants . See Appendix A for details. The third postulate constrains these exponential constants and the fourth simply sets the sign of information.
3.3. Principal Result
Theorem 1.
Information as a Measure of Change in Belief. Information measurements that satisfy these postulates must take the form
Proof is given in Appendix A. As Shannon notes regarding entropy, corresponds to a choice of units. Typical choices are natural units and bits . We employ natural units in analysis and bits in experiments.
Although it would be possible to combine Postulate 1 and Postulate 2 into an analog of Shannon’s chain rule as a single postulate, doing so would obscure the reasoning behind the construction. We leave the analogous chain rule as a consequence in Corollary 1. Regarding Shannon’s proof that entropy is the only construction that satisfies properties he provides, we observe that he has restricted attention to functionals acting upon a single distribution. The interpretation of entropy is discussed in Section 4.1.
Normalization of is a key property of rational belief and reasonable expectation. As for and , however, nothing postulated prevents analysis respecting improper or non-normalizable probability distributions. In the Bayesian context, such distributions merely represent relative plausibility among subsets of outcomes. We caution that such analysis is a further abstraction, which requires additional care for consistent interpretation.
We remark that although Rènyi and Csiszàr were able to generalize divergence measures by weakening Shannon’s chain rule to independent additivity, inclusion of the first postulate prevents such generalizations. We suspect, however, that if we replace Postulate 1 with an alternative functional that incorporates rational belief into information measurements, or we replace Postulate 2 with an alternative formulation of system independence, then other compelling information theories would follow.
3.4. Regarding the Support of Expectation
The proof given assumes and take positive values over the support of the integral, which is also the support of . In the Bayesian context, we also have
Accordingly, if for some we have , it follows that . Likewise, would imply both and . This forbids information contributions that fall beyond the scope of the proof. Even so, the resulting form is analytic and admits analytic continuation.
Since both and , limits of information of the form
are consistent with restricting the domain of integration (or summation) to the support of . We gain further insight by considering limits of the form
Information diverges to in the first case and in the second. This is consistent with the fact that no finite amount of data will recover belief over a subset that has been strictly forbidden from consideration, which bears ramifications for how we understand rational belief.
If belief is not subject to influence from evidence, it is difficult to credibly construe an inferred outcome as having rationally accounted for that evidence. Lindley calls this Cromwell’s rule [38]; we should not eliminate a potential outcome from consideration unless it is logically false. The principle of insufficient reason goes further by avoiding unjustified creation of information that is not influenced by evidence.
3.5. Information Density
The Radon–Nikodym theorem [39] formalizes the notion of density that relates two measures. If we assign both probability and a second measure to any subset within a probability space, then there exists a density function, unique up to subsets of measure zero, such that the second measure is equivalent to the integral of said density over any subset.
Definition 1.
Information Density. We take the Radon–Nikodym derivative to obtain information density of the change in belief from to .
The key property we find in this construction is independence from the view of expectation. As such, information density encodes all potential information outcomes one could obtain from this theory. Furthermore, this formulation is amenable to analysis of improper distributions. For example, it proves useful to consider information density corresponding to constant unit probability density , which is discussed further in Section 4.1.
3.6. Information Pseudometrics
The following pseudometrics admit interpretations as notions of distance between belief states that remain compatible with Postulate 1. This is achieved by simply taking the view of expectation to be the weight function in weighted- norms of information density. These constructions then satisfy useful properties of pseudometrics:
Positivity, ;
Symmetry, ;
- Triangle inequality,
Definition 2.
Information Pseudometrics. We may construct pseudometrics that measure distance between states of belief and with the view of expectation , by taking weighted- norms of information density where the view of expectation serves as the weight function
Note that taking results in a pseudometric that is also a pure expectation. The homogeneity property of seminorms, for , implies that these constructions retain the units of measure of information density; if information density is measured in bits, these distances have units of bits as well. Symmetry is obvious from inspection, and the other properties follow by construction as seminorms. Specifically, positivity follows from the fact that is a convex function for . The lower bound immediately follows from Jensen’s inequality:
A short proof of the triangle inequality is given in Appendix B.
We observe that if and are measurably distinct over the support of , then the measured distance must be greater than zero. We may regard states of belief and as weakly equivalent in the view of if their difference is immeasurable over the support of . That is, if and only differ over subsets of outcomes that are deemed by to be beyond plausible consideration, then in the view of , they are equivalent. As such, these pseudometrics could be regarded as subjective metrics in the view of . The natural definition of information variance also satisfies the properties of a pseudometric and is easily interpreted as a standard statistical construct.
Definition 3.
Information Variance. Information variance between belief states and in the view of expectation is simply the variance of information density
where .
4. Corollaries and Interpretations
The following corollaries examine primary consequences of Theorem 1. Note that multiple random variables may be expressed as a single joint variable such as . The following corollaries explore one or two components at a time, such as variables and or observations x and y. Extensions to multiple random variables easily follow.
Note that the standard formulation of conditional dependence holds for all probability distributions in Corollary 1. That is, given an arbitrary joint distribution , we can compute the marginalization as and conditional dependence follows by the Radon–Nikodym derivative to obtain . All proofs are contained in Appendix B.
Corollary 1.
Chain Rule of Conditional Dependence. Information associated with joint variables decomposes as
Corollary 2.
Additivity Over Belief Sequences. Information gained over a sequence of belief updates is additive within the same view. Given initial belief , intermediate states and , and the view , we have
Corollary 3.
Antisymmetry. Information from to is the negative of information from to
4.1. Entropy
Shannon’s formalization of entropy as uncertainty may be consistently understood as the expectation of information gained by realization. We first reconstruct information contained in realization. We then define the general form of entropy in the discrete case, which is cross entropy, and finally, the standard form of entropy follows.
Corollary 4.
Realization Information (Discrete). Let z be a discrete random variable . Information gained by realization from in the view of realization is
Corollary 5.
Cross Entropy (Discrete). Let z be a discrete random variable and be a hypothetical realization. Expectation over the view of information gained by realization from belief recovers cross entropy
Corollary 6.
Entropy (Discrete). Let z be a discrete random variable and be a hypothetical realization. Expectation over plausible realizations of information gained by realization from belief recovers entropy
Shannon proved that this is the only construction as a functional acting on a single distribution that satisfies his properties. As mentioned earlier, the information notation requires some subtlety of interpretation. Probability density 1 over all discrete outcomes is not generally normalized. Although these formulas are convenient abstractions that result from formal derivations as expectations in the discrete case, nothing prevents us from applying them in continuous settings, which recovers the typical definitions in such cases.
In the continuous setting, we must emphasize that this definition of entropy is not consistent with taking the limit of a sequence of discrete distributions that converges in probability density to a continuous limiting distribution. The entropy of such a sequence diverges to infinity, which matches our intuition; the number of bits required to specify a continuous (real) random variable also diverges.
4.2. Information in an Observation
As discussed in Section 2.3, we may regard as prior belief and as the posterior conditioned on the observation of x. Without any additional evidence, we must hold to be rational belief and we recover the Kullback–Liebler divergence as the rational measure of information gained by the observation of x, but with a caveat: once we obtain additional evidence y, then information in the observation of x must be recomputed as . In contrast, this theory holds that Lindley’s corresponding measure,
is not the information gained by the observation of x; it is simply the difference in uncertainty before and after the observation.
4.3. Potential Information
We now consider expectations over hypothetical future observations w that would influence belief in z as a latent variable. Given belief , the probability of an observation w is as usual.
Corollary 7.
Consistent Future Expectation. Let the view express present belief in the latent variable z and w represent a future observation. The expectation over plausible w of information in the belief-shift from to in the view of rational future belief is equal to information in the present view
Corollary 8.
Mutual Information. Let the view express present belief in the latent variable z and w represent a future observation. Expectation of information gained by a future observation w is mutual information
Corollary 9.
Realization Limit. Let z be a latent variable and be the limit of increasing observations to obtain arbitrary precision over plausible values of z. Information gained from to in the realization limit is pointwise information density
4.4. Consistent Optimization Analysis
Bernardo [40] shows that integrating entropy-like information measures with Bayesian inference provides a logical foundation for rational experimental design. He considers potential utility functions, or objectives for optimization, which are formulated as kernels of expectation over posterior belief updated by the outcome of an experiment. Bernardo then distinguishes the belief a scientist reports from belief that is justified by inference.
For a utility function to be proper, the Bayesian posterior must be the unique optimizer of expected utility over all potentially reported beliefs. In other words, a proper utility function must not provide an incentive to lie. His analysis shows that Lindley information is a proper utility function. Corollary 10 holds that information in this theory also provides proper utility. Thus, information measures are not simply ad hoc objectives; they facilitate consistent optimization-based analysis that recovers rational belief.
Corollary 10.
Information Is a Proper Utility Function. Taking the rational view over the latent variable z conditioned upon an experimental outcome x, the information from prior belief to reported belief is a proper utility function. That is, the unique optimizer recovers rational belief
We would like to go a step further and show that when information from to is positive in the view of , we may claim that is closer to than . For this claim to be consistent, we must show that any perturbation that unambiguously drives belief toward the view must also increase information. The complementary perturbation response with respect to immediately follows by Corollary 3.
Corollary 11.
Proper Perturbation Response. Let be measurably distinct from the view and be finite. Let the perturbation preserve normalization and drive belief toward on all measurable subsets. It follows that
It bears repeating, by Corollary 8, that mutual information captures expected proper utility, which provides a basis for rational experimental design and feature selection.
4.5. Discrepancy Functions
Ebrahimi, Soofi, and Soyer [18] discuss information discrepancy functions, which have two key properties. First, a discrepancy function is nonnegative with equality if and only if . Second, if we hold fixed, then is convex in . One of the reasons information discrepancy functions are useful is that they serve to identify independence. Random variables x and z are independent if and only if . Therefore, we have with equality if and only if x and z are independent, noting that . This has implications regarding sensible generalizations of mutual information.
Theorem 1 does not satisfy information discrepancy properties unless the view of expectation is taken to be , which is the KL divergence. We note, however, that information pseudometrics and information variance given in Section 3.6 satisfy a weakened formulation. Specifically, with equality if and only if and are weakly equivalent in the view of . Likewise, these formulations are convex in information density .
4.6. Jaynes Maximal Uncertainty
Jaynes uses entropy to analytically construct a unique probability distribution for which uncertainty is maximal while maintaining consistency with a specified set of expectations. This construction avoids unjustified creation of information and places the principle of insufficient reason into an analytic framework within which the notion of symmetry generalizes to informational symmetries conditioned upon observed expectations.
We review how Jaynes constructs the resulting distribution . Let such kernels of expectation be denoted for and the observed expectations be . The objective of optimization is
The Lagrangian, which captures both the uncertainty objective and expectation constraints, is
where is the vector of Lagrange multipliers. This Lagrangian formulation satisfies the variational principle in both and . Variational analysis yields the optimizer
Information-Critical Distributions
Rather than maximizing entropy, we may minimize while maintaining consistency with specified expectations. Since the following corollary holds for general distributions , including the improper case , this includes Jaynes’ maximal uncertainty as a minimization of negative entropy.
Corollary 12.
Minimal Information. Given kernels of expectation and specified expectations for , the distribution that satisfies these constraints while minimizing information is given by
4.7. Remarks on Fisher Information
Fisher provides an analytic framework to assess the suitability of a pointwise latent description of a probability distribution [41]. As Kullback and Leibler note, the functional properties of information in Fisher’s construction are quite different from Shannon’s, and thus, we do not regard Fisher information as a form of entropic information. Fisher’s construction, however, can be rederived and understood within this theory. He begins with the assumption that there is some latent realization for which is an exact description of the true distribution of x. We can then define the Fisher score as the gradient of information from any independent prior belief to a pointwise latent description , in the view
Note that is fixed by assumption, despite remaining unknown. By the variational principle, the score must vanish at the optimizer . By Corollary 10, the optimizer must be . We can then assess the sensitivity of information to the parameter z at the optimizer by computing the Hessian. This recovers an equivalent construction of the Fisher matrix within this theory:
The primary idea behind this construction is that high-curvature in z implies that a pointwise description is both suitable and a well-conditioned optimization problem.
Generalized Fisher Matrix
We may eliminate the assumption of an exact pointwise description and generalize analogous formulations to arbitrary views of expectation.
Definition 4.
Generalized Fisher Score. Let be the view of expectation regarding an observable x. The gradient with respect to z of information from independent prior belief to a pointwise description gives the score
Definition 5.
Generalized Fisher Matrix. Let be the view of expectation regarding an observable x. The Hessian matrix with respect to components of z of information from independent prior belief to the pointwise description gives the generalized Fisher matrix
Again, a local optimizer must satisfy the variational principle and yield a score of zero. The generalized Fisher matrix would typically be evaluated at such an optimizer .
5. Information in Inference and Machine Learning
We now examine model information and predictive information provided by inference. Once we have defined these information measurements, we derive upper and lower bounds between them that we anticipate being useful for future work. Finally, we show how inference information may be constrained, which addresses some challenges in Bayesian inference.
5.1. Machine Learning Information
Akaike [42] first introduced information-based complexity criteria as a strategy for model selection. These ideas were further developed by Schwarz, Burnham, and Gelman [19,43,44]. We anticipate these notions will prove useful in future work to both understand and control the problem of memorization in machine learning training. Accordingly, we discuss how this theory views model complexity and distinguishes formulations of predictive information and residual information.
In machine learning, observations correspond to matched pairs of inputs and labels . For each sample j of T training examples, we would like to map the input to an output label . Latent variables are unknown model parameters from a specified model family or computational structure. A model refers to a specific parameter state and the predictions that the model computes are . Since the definitions and derivations that follow hold with respect to either single cases or the entire training ensemble, we will use shorthand notation to refer to both scenarios.
We denote the initial state of belief in model parameters as and update belief during training as for . We can then compute predictions from any state of model belief by marginalization .
Definition 6.
Model Information. Model information from initial belief to updated belief in the view of is given by
When we compute information contained in training labels, the label data obviously provide the rational view. This is represented succinctly by , which assigns full probability to specified outcomes. Again, if we need to be explicit, then this could be written as for each case in the training set.
Definition 7.
Predictive Label Information. The realization of training labels is the rational view of label plausibility. We compute information from prior predictive belief to predictive belief in this view as
In the continuous setting, this formulation is closely related to log pointwise predictive density [19]. We can also define complementary label information that is not contained in the predictive model.
Definition 8.
Residual Label Information (Discrete). Residual information in the label realization view is computed as
Residual information is equivalent to cross-entropy if the labels are full realizations. We note, however, that if training labels are probabilistic and leave some uncertainty, then replacing both occurrences of above with a general distribution would correctly calibrate residual information, so that if predictions were to match label distributions, then residual information would be zero.
As a consequence of Corollary 2, the sum of predictive label information and residual label information is always constant. This allows us to rigorously frame predictive label information as a fraction of the total information contained in training labels. Moreover, Corollary 11 assures us that model perturbations that drive predictive belief toward the label view must increase predictive information. In the continuous setting, just as the limiting form of entropy discussed in Section 4.1 diverges, so too does residual information diverge. Predictive label information, however, remains a finite alternative. This satisfies our initial incentive for this investigation.
There is a second type of predictive information we may rationally construct, however. Rather than considering predictive information with respect to specified label outcomes, we might be interested in the information we expect to obtain about new samples from the generative process. If we regard marginalized predictions as our best approximation of this process, then we would simply measure change in predictive belief in this view.
Definition 9.
Predictive Generative Approximation. We may approximate the distribution of new outcomes from model belief using the predictive marginalization . If we hold this to be the rational view of new outcomes from the generative process, predictive information is
5.2. Inference Information Bounds
In Bayesian inference, we have prior belief in model parameters and the posterior inferred from training data . The predictive marginalizations are called the prior predictive and posterior predictive distributions respectively:
We can derive inference information bounds for Bayesian networks [45]. Let y, , and represent a directed graph of latent variables. In general, the joint distribution can always be written as . The property of local conditionality [46] means . That is, belief dependence in is totally determined by that of just as belief in is computed from .
Corollary 13.
Joint Local Inference Information. Inference information in gained by having observed is equivalent to the inference information in both and .
Corollary 14.
Monotonically Decreasing Local Inference Information. Inference information in gained by having observed is bound above by inference information in .
This shows that an inference yields nonincreasing information as we compound the inference with locally conditioned latent variables, which is relevant for sequential predictive computational models, such as neural networks. We observe that the inference sequence from training data to model parameters , to new predictions y, is also a locally conditioned sequence. If belief in a given latent variable is represented as a probability distribution, this places bounds on what transformations are compatible with the progression of information. For example, accuracy measures which snap the maximum probability outcome of a neural network to unit probability impose an unjustified creation of information.
Corollary 15.
Inferred Information Upper Bound. Model information in the posterior view is less than or equal to predictive label information resulting from inference
This is noteworthy because it tells us that inference always yields a favorable tradeoff between increased model complexity and predictive information. Combining Corollary 14 and Corollary 15, we have upper and lower bounds on model information due to inference
5.3. Inference Information Constraints
Practitioners of Bayesian inference often struggle when faced with inference problems for models structures that are not well suited to the data. An under-expressive model family is not capable of representing the process being modeled. As a consequence, the posterior collapses to a small set of outcomes that are least inconsistent with the evidence. In contrast, an over-expressive model admits multiple sufficient explanations of the process.
Both model and predictive information measures offer means to understand and address these challenges. By constraining the information gained by inference, we may solve problems associated with model complexity. In this section, we discuss explicit and implicit approaches to enforcing such constraints.
5.3.1. Explicit Information Constraints
Our first approach to encode information constraints is to explicitly solve a distribution that satisfies expected information gained from the prior to the posterior. We examine how information-critical distributions can be constructed from arbitrary states of belief for . Again, we may obtain critical distributions with respect to uncertainty by simply setting . By applying this to an inference, so that and , we recover likelihood annealling as a means to control model information.
Corollary 16.
Constrained Information. Given states of belief and information constraints for , the distribution that satisfies these constraints while minimizing has the form
Corollary 17.
Information-Annealed Inference. Annealed belief for which information gained from prior to posterior belief is fixed and information is minimal must take the form
Note that the bounds in Section 5.2 still apply if we simply include as a fixed model parameter in the definition of the likelihood function so that . This prevents the model from learning too much, which may be useful for under-expressive models or for smoothing out the posterior distribution to aid exploration during learning.
5.3.2. Implicit Information Constraints
Our second approach introduces hyper-parameters, and , into the Bayesian inference problem, which allows us to define a prior on those hyper-parameters that implicitly encodes information constraints. This approach gives us a way to express how much we believe we can learn from the data and model that we have in hand. Doing so may prevent overconfidence when there are known modeling inadequacies or underconfidence from overly broad priors.
As above, parameters influence the likelihood and can be though of as controlling annealing or an embedded stochastic error model. The parameters control the prior on the model parameter . For example, these parameters could be the prior mean and co-variance if we assume a Gaussian prior distribution. Therefore, the inference problem takes the form
In order to encode the information constraints, we must construct the hyper-prior distribution where
control model information and predictive information, respectively. The function is the likelihood of and given the specified model and prediction complexities. For example, this could be an indicator function as to whether the information gains are within some range. Note that we may also consider other forms of predictive information, such as the predictive generative approximation.
The posterior distribution on model parameters and posterior predictive distribution can be formed by marginalizing over hyper-parameters
6. Negative Information
The possibility of negative information is a unique property of this theory in contrast to divergence measures such as Kullback–Leibler divergence, -divergences, and f-divergences. It provides an easily interpreted notion of whether a belief update is consistent with our best understanding. Negative information can be consistently associated with misinformation in the view of rational belief. That is, if is negative, then is a better approximation of rational belief than . The consistency of this interpretation would be violated if we could construct that is unambigously better than at approximating . Corollary 11 shows, however, that this is not possible. If we construct by integrating perturbations from that drive belief towards on all measurable subsets, then information must be positive. The following experiments illustrate examples of negative information and motivate its utility.
6.1. Negative Information in Continuous Inference
In the following set of experiments we have a latent variable , which is distributed as . Each sample corresponds to realization of an independent latent variable so that . Each is distributed as where . Both prior belief in plausible values of and prior predictive belief in plausible values of y are visualized in Figure 4. Deciles separate annuli of probability . The model information we expect to gain by observing 10 samples of y, which is also mutual information from Corollary 8, is bits. See Appendix C for details.
Figure 4.
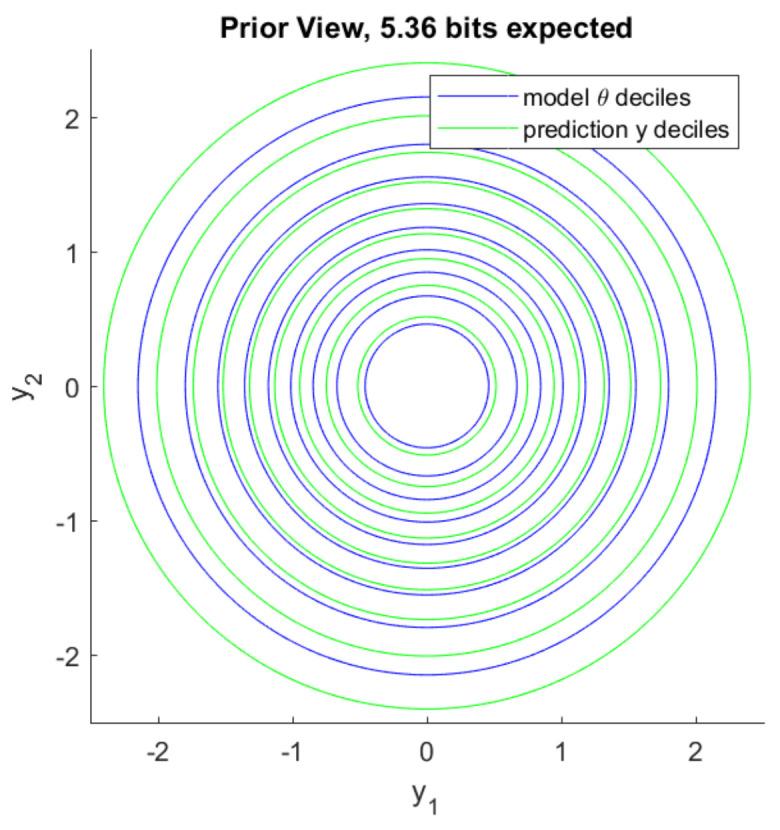
Prior distribution of and prior predictive distribution of individual y samples. The domain of plausible values is large before any observations are made.
The first observation consists of 10 samples of y followed by inference of . Subsequent observations each add another 10, 20, and 40 samples respectively. A typical inference sequence is shown in Figure 5. Model information gained by inference from the first observation in the same view is bits. As additional observations become available the model information provided by first inference is eventually refined to bits. Typically, the region of plausible models resulting from each inference is consistent with what was previously considered plausible.
Figure 5.

Typical inference of from observation of 10 samples of y (left) followed by 10, 20, and 40 additional samples, respectively. Both prior belief and first inference deciles of are shown in gray. As observations accumulate, the domain of plausible values tightens.
By running one million independent experiments, we constructed a histogram of the model information provided by first inference in subsequent views. That is shown in Figure 6. As a consequence of Postulate 4, the model information provided by first inference must always be positive before any additional observations are made. The change in model covariance in this experiment provides a stronger lower bound of bits after first inference, which can be seen in the first view on the left. This bound is saturated in the limit when the inferred mean is unchanged. Additional observations may indicate that the first inference was less informative than initially believed. We may regard the rare cases showing negative information as being misinformed after first inference. The true value of the model may be known to arbitrary precision if we collect enough observations. Said value is the realization limit on the right. Under this experimental design, this limit converges to the Laplace distribution centered at mutual information computed in the prior view.
Figure 6.

Histogram of the earliest inference information in the observation sequence. The vertical line at 5.36 bits is mutual information. Information is positive after first inference, but may drop with additional observations. The limiting view of infinite samples (realization) is shown on the right.
From these million experiments, we can select the most unusual cases for which the information provided by first inference is later found to an extreme. Figure 7 visualizes the experiment for which the information provided by first inference is found to be the minimum after observing 160 total samples from the generative process. Although model information assessed following the first observation is a fairly typical value, additional samples quickly show that the first samples were unusual. This becomes highly apparent in the fourth view, which includes 80 samples in total.
Figure 7.

Minimum first inference information out of one million independent experiments. This particularly rare case shows how first samples can mislead inference, which is later corrected by additional observations. The fourth inference (right) bears remarkably little overlap with the first.
Figure 8 visualizes the complementary case in which we select the experiment for which the information provided by first inference is later found to be the maximum. The explantory characteristic of this experiment is the rare value that the true model has taken. High information in inference shows a high degree of unexpected content, given what the prior distribution deemed plausible. Each inference indicates a range of plausible values of that is quite distant from the plausible region indicated by prior belief. The change in belief due to first inference is confirmed by additional data in fourth inference.
Figure 8.

Maximum first inference information out of one million independent experiments. The true value of has taken an extremely rare value. As evidence accumulates, plausible ranges of confirm the first inference.
Finally, we examine a scenario in which the first 10 samples are generated from a different process than subsequent samples. We proceed with inference as before and assume a single generative process, despite the fact that this assumption is actually false. Figure 9 shows the resulting inference sequence. After first inference, nothing appears unusual because there is no data that would contradict inferred belief. As soon as additional data become available, however, information in first inference becomes conspicuously negative. Note that the one-in-a-million genuine experiment exhibiting minimum information, Figure 7, gives bits after 70 additional samples. In contrast, this experiment yields bits after only 10 additional samples.
Figure 9.

Inconsistent inference. The first 10 samples are drawn from a different ground truth than subsequent samples, but inference proceeds as usual. As additional data become available, first inference information becomes markedly negative.
By comparing this result to the information distribution in the realization limit, we see that the probability of a genuine experiment exhibiting information this negative would be less than . This shows how highly negative information may flag anomalous data. We explore this further in the next section.
6.2. Negative Information in MNIST Model with Mislabeled Data
We also explored predictive label information in machine learning models by constructing a small neural network to predict MNIST digits [5]. This model was trained with 50,000 images with genuine labels. Training was halted using cross-validation from 10,000 images that also had genuine labels. To investigate how predictive label information serves as an indicator of prediction accuracy, we randomly mislabeled a fraction of unseen cases. Prediction information was observed on 10,000 images for which had been randomly relabeled, which resulted in 5521 original labels and 4479 mismatched labels.
The resulting distribution of information outcomes is plotted in Figure 10, which shows a dramatic difference between genuine labels and mislabeled cases. In all cases, prediction information is quantified from the uninformed probabilities for all outcomes to model predictions, which are conditioned on the image input , in the view of the label . Total label information—the sum of predictive label information and residual label information:
or roughly bits for each case. Both Figure 11 and Figure 12 show different forms of anomaly detection using negative information.
Figure 10.

Histogram of information outcomes for mismatched and original labels. Correct label information is highly concentrated at 3.2 bits, which is of the total information contained in labels. Mislabeled cases have mean information at –18 bits, and information is negative for of mislabeled cases.
Figure 11.

Original MNIST labels. The top row shows lowest predictive label information among original labels. Notably, the two leading images appear to be genuinely mislabeled in the original dataset. Subsequent predictions are poor. The bottom row shows the highest information among original labels. Labels and predictions are consistent in these cases.
Figure 12.

Mislabeled digits. The top row shows the lowest predictive label information among mislabeled cases. In each case, the claimed label is implausible and the prediction is correct. The bottom row shows the highest prediction information among mislabeled cases. Although claimed labels are incorrect, most images share identifiable features with the claim.
Figure 11 shows that genuine labels may exhibit negative information when predictions are poor. Only of correct cases exhibit negative predictive label information. The distribution mean is bits for this set. Notably, the first two images appear to be genuinely mislabeled in the original dataset, which underscores the ability of this technique to detect anomalies.
In contrast, over of mislabeled cases exhibit negative information with the distribution mean at bits. The top row of Figure 12 shows that information is most negative when the claimed label is not plausible and model predictions clearly match the image. Similarly to Section 6.1, strongly negative information indicates anomalous data. When incorrect predictions match incorrect labels, however, information can be positive, as shown in the bottom row. The cases appear to share identifiable features with the claim.
7. Conclusions
Just as belief matures with accumulation of evidence, we hold that the information associated with a shift in belief must also mature. By formulating principles that articulate how we may regard information as a reasonable expectation that measures change in belief, we derived a theory of information that places existing measures of entropic information in a coherent unified framework. These measures include Shannon’s original description of entropy, cross-entropy, realization information, Kullback–Leibler divergence, and Lindley information (uncertainty difference) due to an experiment.
Moreover, we found other explainable information measures that may be adapted to specific scenarios from first principles, including the log pointwise predictive measure of model accuracy. We derived useful properties of information, including the chain rule of conditional dependence, additivity over belief updates, consistency with respect expected future observations, and expected information in future experiments as mutual information. We also showed how this theory generalizes information-critical probability distributions that are consistent with observed expectations analogous to those of Jaynes. In the context of Bayesian inference, we showed how information constraints recover and illuminate useful annealed inference practices.
We also examined the phenomenon of negative information, which occurs when a more justified point of view, based on a broader body of evidence, indicates that a previous change of belief was misleading. Experiments demonstrated that negative information reveals anomalous cases of inference or anomalous predictions in the context of machine learning.
The primary value of this theoretical framework is the consistent interpretation and corresponding properties of information that guide how it may be assessed in a given context. The property of additivity over belief updates within the present view allows us to partition information in a logically consistent manner. For machine learning algorithms, we see that total information from the uninformed state to a label-informed state is a constant that may be partitioned into the predicted component and the residual component. This insight suggests new approaches to model training, which will be the subject of continuing research.
Future Work
The challenges we seek to address with this theory relate to real-world applications of inference and machine learning. Although Bayesian inference provides a rigorous foundation for learning, poor choices of prior or likelihood can lead to results that elude or contradict human intuition when analyzed after the fact. This only becomes worse as the scale of learning problems increases, as in deep neural networks, where human intuition cannot catch inconsistencies. Information provides a metric to quantify how well a model is learning that may be useful when structuring learning problems. Some related challenges include:
Controlling model complexity in machine learning to avoid memorization;
Evaluating the influences of different experiments and data points to identify outliers or poorly supported inferences;
Understanding the impact of both the model-structure and fidelity of variational approximations on learnability.
Acknowledgments
We would like to extend our earnest appreciation to Michael Bierma, Christopher Harrison, Steven Holtzen, Philip Kegelmeyer, Jaideep Ray, and Jean-Paul Watson for helpful discussions on this topic. We also sincerely thank referees for providing expert feedback to improve this paper. Sandia National Laboratories is a multimission laboratory managed and operated by National Technology and Engineering Solutions of Sandia, LLC., a wholly owned subsidiary of Honeywell International, Inc., for the U.S. Department of Energy’s National Nuclear Security Administration under contract DE-NA-0003525. This paper describes objective technical results and analysis. Any subjective views or opinions that might be expressed in the paper do not necessarily represent the views of the U.S. Department of Energy or the United States Government.
Appendix A. Proof of Principal Result
Lemma A1.
Let be a function such that for all . It follows that where a is a constant.
Proofs of Lemma A1 given by Erdös [47], Fadeev [37], Rényi [24].
Lemma A2.
Let be a function such that for all . It follows that .
Proof of Lemma A2.
We begin by defining , , and . It follows that . From Lemma A1, we have for some constant a. Similarly, and for constants b and c. We may now construct positive quantities , , and , and observe . The desired result follows by identifying constants , , and . □
Proof of Theorem 1.
We proceed by combining Postulate 1 with Postulate 2, which gives
The last line follows by multiplying each term in the previous line by and , respectively. Since this must hold for arbitrary , this implies
By Lemma A2, we have . From Postulate 3, we require
Since this must hold for arbitrary and , this implies and . Thus we see that , which is a constant times the Kullback–Leibler divergence [6]. Jensen’s inequality easily shows nonnegativity of the form
It follows from Postulate 4 that . As Shannon notes, the scale is arbitrary and simply defines the unit of measure. □
Appendix B. Corollary Proofs
Proof of triangle inequality for Definition 2.
To simplify notation, we use the following definitions
Applying homogeneity followed by Jensen’s inequality, we have
□
Proof of Corollary 1.
We unpack Theorem 1 and write joint distributions as the marginalization times of the corresponding conditional distributions, such as . This gives
□
Proof of Corollary 2.
Again, we simply unpack Theorem 1 and apply the product property of the logarithm as
□
Proof of Corollary 3.
Swapping and reciprocates the argument of the logarithm in Theorem 1, which gives the negative of the original ordering. □
Proof of Corollary 4.
After realization , probability is distributed as . Restricting support to gives
□
Proof of Corollary 5.
Computing the expectation value as given, easily reconstructs the standard formulation of cross entropy
□
Proof of Corollary 6.
This follows by simply replacing with in cross entropy. □
Proof of Corollary 7.
Plausible joint values of z and w are Marginalizing over w recovers present belief . It follows
□
Proof of Corollary 8.
We compute the expectation value stated and simply rewrite the product of the marginalization and conditional distribution as the joint distribution . This gives
□
Proof of Corollary 9.
The limit of increasing precision yields the Dirac delta function . It follows
□
Proof of Corollary 10.
We consider differential variations at the optimizer where variations must maintain normalization and are otherwise arbitrary. Taking the Gâteaux derivative (with respect to the differential element ) and applying the variational principle gives
To satisfy the normalization constraint for otherwise arbitrary , the term in brackets must be constant. The stated result immediately follows. □
Proof of Corollary 11.
Let measurable disjoint subsets of outcomes be and . If drives belief toward on all measurable subsets, then for z almost everywhere in . Likewise, almost everywhere in . Finally, almost everywhere on the complement . In order to retain normalization, we note that . If information is finite, then we may express almost everywhere (except an immeasurable subset that is not contained in for which we could have and ) and observe that for just as for . Since has the same sign as almost everywhere, it follows
□
Proof of Corollary 12.
We proceed by constructing the Lagrangian
We consider differential variations at the optimizer where variations must maintain normalization and are otherwise arbitrary. Taking the Gâteaux derivative and applying the variational principle gives
To satisfy the normalization constraint for otherwise arbitrary , the variational principle requires the term in brackets to be constant. The stated result immediately follows. □
Proof of Corollary 13.
We unpack Theorem 1 and apply the local conditionality property to write . This gives
□
Proof of Corollary 14.
As a consequence of local conditional dependence, we observe that . Then, we apply Jensen’s inequality followed by Bayes’ Theorem to obtain
The first term provides the upper bound we seek. It remains to show that the second term is bound from above by zero, which follows from a second application of Jensen’s inequality
□
Proof of Corollary 15.
The denominator of the first log argument is model evidence, and we apply Bayes’ Theorem to the second log argument. Denominators of log arguments cancel and Jensen’s inequality implies that the first term must be greater than the second.
□
Proof of Corollary 16.
The stated result immediately follows by taking and applying Corollary 12. □
Proof of Corollary 17.
We take , , and and apply Corollary 16 with Bayes’ theorem to obtain
□
Appendix C. Computation of Information in the Experiments
Appendix C.1. Inference
Prior belief is and . Since , we have . If we let n samples have an average , it easily follows that . Bayes’ rule gives or
where and . Normalization yields .
Appendix C.2. Mutual Information
We marginalize over plausible to obtain the corresponding probability of observing as . This gives . Mutual information, which is the expected information gained by observing according to present belief, is computed this way:
Appendix C.3. First Inference Information in a Subsequent View
Let the state of belief before an experiment be . After observing , inference gives . Additional observations yield . Information gained in the first observation in the view of inference following the second observation is computed as
Author Contributions
Conceptualization, J.A.D.; Formal Analysis, J.A.D.; Investigation, J.A.D. and T.A.C.; Software, J.A.D.; Validation, J.A.D. and T.A.C.; Visualization, J.A.D.; Writing–Original Draft, J.A.D.; Writing–Review & Editing, J.A.D. and T.A.C. All authors have read and agreed to the published version of the manuscript.
Funding
The Department of Homeland Security sponsored the production of this material under DOE Contract Number DE-NA0003525 for the management and operation of Sandia National Laboratories. This work was also funded in part by the Department of Energy Office of Advanced Scientific Computing Research.
Conflicts of Interest
The authors declare no conflict of interest.
References
- 1.Shannon C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948;27:379–423. doi: 10.1002/j.1538-7305.1948.tb01338.x. [DOI] [Google Scholar]
- 2.LaPlace P.S. Mémoire sur la probabilité des causes par les événements. Mémoires de l’Academie Royale des Sciences Presentés par Divers Savan. 1774;6:621–656. [Google Scholar]
- 3.Jeffreys H. The Theory of Probability. OUP Oxford; Oxford, UK: 1998. [Google Scholar]
- 4.Jaynes E.T. Probability Theory: The Logic of Science. Cambridge University Press; Cambridge, UK: 2003. [Google Scholar]
- 5.LeCun Y., Bottou L., Bengio Y., Haffner P. Gradient-based learning applied to document recognition. Proc. IEEE. 1998;86:2278–2324. doi: 10.1109/5.726791. [DOI] [Google Scholar]
- 6.Kullback S., Leibler R.A. On Information and Sufficiency. Ann. Math. Stat. 1951;22:79–86. doi: 10.1214/aoms/1177729694. [DOI] [Google Scholar]
- 7.Kullback S. Information Theory and Statistics. Courier Corporation; North Chelmsford, MA, USA: 1997. [Google Scholar]
- 8.Lindley D.V. On a measure of the information provided by an experiment. Ann. Math. Stat. 1956;27:986–1005. doi: 10.1214/aoms/1177728069. [DOI] [Google Scholar]
- 9.Cox R.T. Probability, frequency and reasonable expectation. Am. J. Phys. 1946;14:1–13. doi: 10.1119/1.1990764. [DOI] [Google Scholar]
- 10.Ramsey F.P. Readings in Formal Epistemology. Springer; Berlin, Germany: 2016. Truth and probability; pp. 21–45. [Google Scholar]
- 11.Lehman R.S. On confirmation and rational betting. J. Symbol. Logic. 1955;20:251–262. doi: 10.2307/2268221. [DOI] [Google Scholar]
- 12.Adams E.W. On rational betting systems. Arch. Math. Logic. 1962;6:7–29. doi: 10.1007/BF02025803. [DOI] [Google Scholar]
- 13.Freedman D.A., Purves R.A. Bayes’ method for bookies. Ann. Math. Stat. 1969;40:1177–1186. doi: 10.1214/aoms/1177697494. [DOI] [Google Scholar]
- 14.Skyrms B. Dynamic Coherence and Probability Kinematics. Philos. Sci. 1987;54:1–20. doi: 10.1086/289350. [DOI] [Google Scholar]
- 15.Soofi E.S. Capturing the intangible concept of information. J. Am. Stat. Assoc. 1994;89:1243–1254. doi: 10.1080/01621459.1994.10476865. [DOI] [Google Scholar]
- 16.Soofi E.S. Principal information theoretic approaches. J. Am. Stat. Assoc. 2000;95:1349–1353. doi: 10.1080/01621459.2000.10474346. [DOI] [Google Scholar]
- 17.Ebrahimi N., Soofi E.S., Zahedi H. Information properties of order statistics and spacings. IEEE Trans. Inf. Theory. 2004;50:177–183. doi: 10.1109/TIT.2003.821973. [DOI] [Google Scholar]
- 18.Ebrahimi N., Soofi E.S., Soyer R. Information measures in perspective. Int. Stat. Rev. 2010;78:383–412. doi: 10.1111/j.1751-5823.2010.00105.x. [DOI] [Google Scholar]
- 19.Gelman A., Hwang J., Vehtari A. Understanding predictive information criteria for Bayesian models. Stat. Comput. 2013;24:997–1016. doi: 10.1007/s11222-013-9416-2. [DOI] [Google Scholar]
- 20.Good I.J. Maximum entropy for hypothesis formulation, especially for multidimensional contingency tables. Ann. Math. Stat. 1963;34:911–934. doi: 10.1214/aoms/1177704014. [DOI] [Google Scholar]
- 21.MacKay D.J.C. Information Theory, Inference and Learning Algorithms. Cambridge University Press; Cambridge, UK: 2003. [Google Scholar]
- 22.Tishby N., Zaslavsky N. Deep learning and the information bottleneck principle; Proceedings of the 2015 IEEE Information Theory Workshop (ITW); Jerusalem, Israel. 26 April–1 May 2015. [Google Scholar]
- 23.Barnard G. The theory of information. J. R. Stat. Soc. Methodol. 1951;13:46–64. doi: 10.1111/j.2517-6161.1951.tb00069.x. [DOI] [Google Scholar]
- 24.Rényi A. Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics. University of California Press; Berkeley, CA, USA: 1961. On Measures of Entropy and Information; pp. 547–561. [Google Scholar]
- 25.Csiszár I. Information-type measures of difference of probability distributions and indirect observation. Stud. Sci. Math. Hung. 1967;2:229–318. [Google Scholar]
- 26.Jizba P., Arimitsu T. Generalized statistics: Yet another generalization. Physica A. 2004;340:110–116. doi: 10.1016/j.physa.2004.03.085. [DOI] [Google Scholar]
- 27.Hanel R., Thurner S. A comprehensive classification of complex statistical systems and an axiomatic derivation of their entropy and distribution functions. EPL Europhysic. Lett. 2011;93:20006. doi: 10.1209/0295-5075/93/20006. [DOI] [Google Scholar]
- 28.Ilić V.M., Stanković M.S. Generalized Shannon–Khinchin axioms and uniqueness theorem for pseudo-additive entropies. Physica A. 2014;411:138–145. doi: 10.1016/j.physa.2014.05.009. [DOI] [Google Scholar]
- 29.Tempesta P. Group entropies, correlation laws, and zeta functions. Phys. Rev. E. 2011;84:021121. doi: 10.1103/PhysRevE.84.021121. [DOI] [PubMed] [Google Scholar]
- 30.Bernoulli J. Ars Conjectandi. Basileae Impensis Thurnisiorum Fratrum; Basel, Switzerland: 1713. [(accessed on 15 January 2020)]. Available online: https://books.google.com.hk/books?hl=en&lr=&id=XPOf7STJ3y4C&oi=fnd&pg=PA1&dq=Ars+conjectandi%3B+Impensis+Thurnisiorum,+fratrum,+1713.&ots=Lj-EfRRgbu&sig=KCYr2_EIoMa1ui-2fIbrhQAV5aE&redir_esc=y&hl=zh-CN&sourceid=cndr#v=onepage&q=Ars%20conjectandi%3B%20Impensis%20Thurnisiorum%2C%20fratrum%2C%201713.&f=false. [Google Scholar]
- 31.Jaynes E.T. Information theory and statistical mechanics. Phys. Rev. 1957;106:620. doi: 10.1103/PhysRev.106.620. [DOI] [Google Scholar]
- 32.Shore J., Johnson R. Axiomatic derivation of the principle of maximum entropy and the principle of minimum cross-entropy. IEEE Trans. Inf. Theory. 1980;26:26–37. doi: 10.1109/TIT.1980.1056144. [DOI] [Google Scholar]
- 33.Shore J., Johnson R. Properties of cross-entropy minimization. IEEE Trans. Inf. Theory. 1981;27:472–482. doi: 10.1109/TIT.1981.1056373. [DOI] [Google Scholar]
- 34.Jizba P., Korbel J. Maximum Entropy Principle in statistical inference: Case for non-Shannonian entropies. Phys. Rev. Lett. 2019;122:120601. doi: 10.1103/PhysRevLett.122.120601. [DOI] [PubMed] [Google Scholar]
- 35.Hájek A. The Handbook of Rational and Social Choice. Oxford University Press; Oxford, UK: 2008. Dutch book arguments; pp. 173–196. [Google Scholar]
- 36.Weisberg J. Varieties of Bayesianism. In: Gabbay D.M., Hartmann S., Woods J., editors. Inductive Logic. Volume 10. Elsevier; Amsterdam, The Netherlands: 2011. pp. 477–551. [Google Scholar]
- 37.Fadeev D. Arbeiten zur Informationstheorie I. Deutscher Verlag der Wissenschaften; Berlin, Germany: 1957. Zum Begriff der Entropie einer endlichen Wahrscheinlichkeitsschemas; pp. 85–90. [Google Scholar]
- 38.Lindley D.V. The Bayesian Approach to Statistics. University of California, Berkeley, Operations Research Center; Berkeley, CA, USA: 1980. Technical Report. [Google Scholar]
- 39.Nikodym O. Sur une généralisation des intégrales de MJ Radon. Fundamenta Mathematicae. 1930;15:131–179. doi: 10.4064/fm-15-1-131-179. [DOI] [Google Scholar]
- 40.Bernardo J.M. Expected information as expected utility. Ann. Stat. 1979;7:686–690. doi: 10.1214/aos/1176344689. [DOI] [Google Scholar]
- 41.Fisher R.A. Mathematical Proceedings of the Cambridge Philosophical Society. Volume 22. Cambridge University Press; Cambridge, UK: 1925. Theory of statistical estimation; pp. 700–725. [Google Scholar]
- 42.Akaike H. A new look at the statistical model identification. IEEE Trans. Autom. Control. 1974;19:716–723. doi: 10.1109/TAC.1974.1100705. [DOI] [Google Scholar]
- 43.Schwarz G. Estimating the Dimension of a Model. Ann. Stat. 1978;6:461–464. doi: 10.1214/aos/1176344136. [DOI] [Google Scholar]
- 44.Burnham K.P., Anderson D.R. Kullback-Leibler information as a basis for strong inference in ecological studies. Wildl. Res. 2001;28:111. doi: 10.1071/WR99107. [DOI] [Google Scholar]
- 45.Pearl J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. Elsevier; Amsterdam, The Netherlands: 2014. [Google Scholar]
- 46.Goodfellow I., Bengio Y., Courville A. Deep Learning. MIT Press; Cambridge, MA, USA: 2016. [Google Scholar]
- 47.Erdös P. On the Distribution Function of Additive Functions. Ann. Math. 1946;47:1. doi: 10.2307/1969031. [DOI] [Google Scholar]