

Abstract
There is not much literature on objective Bayesian analysis for binary classification problems, especially for intrinsic prior related methods. On the other hand, variational inference methods have been employed to solve classification problems using probit regression and logistic regression with normal priors. In this article, we propose to apply the variational approximation on probit regression models with intrinsic prior. We review the mean-field variational method and the procedure of developing intrinsic prior for the probit regression model. We then present our work on implementing the variational Bayesian probit regression model using intrinsic prior. Publicly available data from the world’s largest peer-to-peer lending platform, LendingClub, will be used to illustrate how model output uncertainties are addressed through the framework we proposed. With LendingClub data, the target variable is the final status of a loan, either charged-off or fully paid. Investors may very well be interested in how predictive features like FICO, amount financed, income, etc. may affect the final loan status.
Keywords: objective Bayesian inference, intrinsic prior, variational inference, binary probit regression, mean-field approximation
1. Introduction
There is not much literature on objective Bayesian analysis for binary classification problems, especially for intrinsic prior related methods. By far, only two articles have explored intrinsic prior related methods on classification problems. Reference [1] implements integral priors into the generalized linear models with various link functions. In addition, reference [2] considers intrinsic priors for probit models. On the other hand, variational inference methods have been employed to solve classification problem with logistic regression ([3]) and probit regression ([4,5]) with normal priors. Variational approximation methods have been reviewed in [6,7], and more recently [8].
In this article, we propose to apply variational approximations on probit regression models with intrinsic priors. In Section 4, we review the mean-field variational method that will be used in this article. In Section 3, procedures for developing intrinsic priors for probit models will be introduced following [2]. Our work is presented in Section 5. Our motivations for combining intrinsic prior methodology and variational inference is as following
Avoiding manually set ad hoc plugin priors by automatically generating a family of non-informative priors that are less sensible.
Reference [1,2] do not consider inference of posterior distributions of parameters. Their focus is on model comparison. Although the development of intrinsic priors itself comes from a model selection background, we thought it would be interesting to apply intrinsic priors on inference problems. In fact, some recently developed priors that proposed to solve inference or estimation problems turned out to be also intrinsic priors. For example, the Scaled Beta2 prior [9] and the Matrix-F prior [10].
Intrinsic priors concentrate probability near the null hypothesis, a condition that is widely accepted and should be required of a prior for testing a hypothesis.
Also, intrinsic priors have flat tails that prevents finite sample inconsistency [11].
For inference problems with large data set, variational approximation methods are much faster than MCMC-based methods.
As for model comparison, due to the fact that the output of variational inference methods cannot be employed directly to compare models, we propose in Section 5.3 to simply make use of the variational approximation of the posterior distribution as an importance function and get the Monte Carlo estimated marginal likelihood by importance sampling for model comparison.
2. Background and Development of Intrinsic Prior Methodology
2.1. Bayes Factor
The Bayesian framework of model selection coherently involves the use of probability to express all uncertainty in the choice of model, including uncertainty about the unknown parameters of a model. Suppose that models are under consideration. We shall assume that the observed data is generated from one of these models but we do not know which one it is. We express our uncertainty through prior probability . Under model , has density , where are unknown model parameters, and the prior distribution for is . Given observed data and prior probabilities, we can then evaluate the posterior probability of using Bayes’ rule
| (1) |
where
| (2) |
is the marginal likelihood of under , also called the evidence for [12]. A common choice of prior model probabilities is , so that each model has the same initial probability. However, there are other alternatives of assigning probabilities to correct for multiple comparison (See [13]). From (1), the posterior odds are therefore the prior odds multiplied by the Bayes factor
| (3) |
where the Bayes factor of to is defined by
| (4) |
Here we omit the dependence on models to keep the notation simple. The marginal likelihood, expresses the preference shown by the observed data for different models. When , the data favor over , and when the data favor over . A scale for interpretation of is given by [14].
2.2. Motivation and Development of Intrinsic Prior
Computing requires specification of and . Often in Bayesian analysis, when prior information is weak, one can use non-informative (or default) priors . Common choices for non-informative priors are the uniform prior, ; the Jeffreys prior, where is the expected Fisher information matrix corresponding to .
Using any of the in (4) would yield
| (5) |
The difficulty with (5) is that are typically improper and hence are defined only up to an unspecified constant . So is defined only up to the ratio of two unspecified constants.
An attempt to circumvent the ill definition of the Bayes factors for improper non-informative priors is the intrinsic Bayes factor introduced by [15], which is a modification of a partial Bayes factor [16]. To define the intrinsic Bayes factor we consider the set of subsamples of the data of minimal size l such that . These subsamples are called training samples (not to be confused with training sample in machine learning). In addition, there is a total number of L such subsamples.
The main idea here is that training sample will be used to convert the improper to proper posterior
| (6) |
where . Then, the Bayes factor for the remaining of the data , where , using as prior is called a “partial” Bayes factor,
| (7) |
This partial Bayes factor is a well-defined Bayes factor, and can be written as , where and . Clearly, will depend on the choice of the training samples . To eliminate this arbitrariness and increase stability, reference [15] suggests averaging over all training samples and obtained the arithmetic intrinsic Bayes factor (AIBF)
| (8) |
The strongest justification of the arithmetic IBF is its asymptotic equivalence with a proper Bayes factor arising from Intrinsic priors. These intrinsic priors were identified through an asymptotic analysis (see [15]). For the case where is nested in , it can be shown that the intrinsic priors are given by
| (9) |
3. Objective Bayesian Probit Regression Models
3.1. Bayesian Probit Model and the Use of Auxiliary Variables
Consider a sample , where , is a random variable such that under model , it follows a probit regression model with a -dimensional vector of covariates , where . Here, p is the total number of covariate variables under our consideration. In addition, this probit model has the form
| (10) |
where denotes the standard normal cumulative distribution function and is a vector of dimension . The first component of the vector is set equal to 1 so that when considering models of the form (10), the intercept is in any submodel. The maximum length of the vector of covariates is . Let , proper or improper, summarize our prior information about . Then the posterior density of is given by
which is largely intractable.
As shown by [17], the Bayesian probit regression model becomes tractable when a particular set of auxiliary variables is introduced. Based on the data augmentation approach [18], introducing n latent variables , where
The probit model (10) can be thought of as a regression model with incomplete sampling information by considering that only the sign of is observed. More specifically, define if and otherwise. This allows us to write the probability density of given
Expansion of the parameter set from to is the key to achieving a tractable solution for variational approximation.
3.2. Development of Intrinsic Prior for Probit Models
For the sample , the null normal model is
For a generic model with regressors, the alternative model is
where the design matrix has dimensions . Intrinsic prior methodology for the linear model was first developed by [19], and was further developed in [20] by using the methods of [21]. This intrinsic methodology gives us an automatic specification of the priors and , starting with the non-informative priors and for and , which are both improper and proportional to 1.
The marginal distributions for the sample under the null model, and under the alternative model with intrinsic prior, are formally written as
| (11) |
However, these are marginals of the sample , but our selection procedure requires us to compute the Bayes factor of model versus the reference model for the sample . To solve this problem, reference [2] proposed to transform the marginal into the marginal by using the probit transformations . These latter marginals are given by
| (12) |
where
| (13) |
4. Variational Inference
4.1. Overview of Variational Methods
Variational methods have their origins in the 18th century with the work of Euler, Lagrange, and others on the calculus of variations (The derivation in this section is standard in the literature on variational approximation and will at times follow the arguments in [22,23]). Variational inference is a body of deterministic techniques for making approximate inference for parameters in complex statistical models. Variational approximations are a much faster alternative to Markov Chain Monte Carlo (MCMC), especially for large models, and are a richer class of methods than the Laplace approximation [6].
Suppose we have a Bayesian model and a prior distribution for the parameters. The model may also have latent variables, here we shall denote the set of all latent variables and parameters by . In addition, we denote the set of all observed variables by . Given a set of n independent, identically distributed data, for which and , our probabilistic model (e.g., probit regression model) specifies the joint distribution , and our goal is to find an approximation for the posterior distribution as well as for the marginal likelihood . For any probability distribution , we have the following decomposition of the log marginal likelihood
where we have defined
| (14) |
| (15) |
We refer to (14) as the lower bound of the log marginal likelihood with respect to the density q, and (15) is by definition the Kullback–Leibler divergence of the posterior from the density q. Based on this decomposition, we can maximize the lower bound by optimization with respect to the distribution , which is equivalent to minimizing the KL divergence. In addition, the lower bound is attained when the KL divergence is zero, which happens when equals the posterior distribution . It would be hard to find such a density since the true posterior distribution is intractable.
4.2. Factorized Distributions
The essence of the variational inference approach is approximation to the posterior distribution by for which the q dependent lower bound is more tractable than the original model evidence. In addition, tractability is achieved by restricting q to a more manageable class of distributions, and then maximizing over that class.
Suppose we partition elements of into disjoint groups where . We then assume that the q density factorizes with respect to this partition, i.e.,
| (16) |
The product form is the only assumption we made about the distribution. Restriction (16) is also known as mean-field approximation and has its root in Physics [24].
For all distributions with the form (16), we need to find the distribution for which the lower bound is largest. Restriction of q to a subclass of product densities like (16) gives rise to explicit solutions for each product component in terms of the others. This fact, in turn, leads to an iterative scheme for obtaining the solutions. To achieve this, we first substitute (16) into (14) and then separate out the dependence on one of the factors . Denoting by to keep the notation clear, we obtain
| (17) |
where is given by
| (18) |
The notation denotes an expectation with respect to the q distributions over all variables for , so that
Now suppose we keep the fixed and maximize in (17) with respect to all possible forms for the density . By recognizing that (17) is the negative KL divergence between and , we notice that maximizing (17) is equivalent to minimize the KL divergence, and the minimum occurs when . The optimal is then
| (19) |
The above solution says that the log of the optimal is obtained simply by considering the log of the joint distribution of all parameter, latent and observable variables and then taking the expectation with respect to all the other factors for . Normalizing the exponential of (19), we have
The set of equations in (19) for are not an explicit solution because the expression on the right hand side of (19) for the optimal depends on expectations taken with respect to the other factors for . We will need to first initialize all of the factors and then cycle through the factors one by one and replace each in turn with an updated estimate given by the right hand side of (19) evaluated using the current estimates for all of the other factors. Convexity properties can be used to show that convergence to at least local optima is guaranteed [25]. The iterative procedure is described in Algorithm 1.
5. Incorporate Intrinsic Prior with Variational Approximation to Bayesian Probit Models
5.1. Derivation of Intrinsic Prior to Be Used in Variational Inference
Let be the design matrix of a minimal training sample (mTS) of a normal regression model for the variable . We have, for the -dimensional parameter ,
Therefore, it follows that the mTS size is [2]. Given that priors for and are proportional to 1, the intrinsic prior for conditional on could be derived. Let denote the vector with the first component equal to and the others equal to zero. Based on Formula (9), we have
Therefore,
Notice that is unknown because it is a theoretical design matrix corresponding to the training sample . It can be estimated by averaging over all submatrices containing rows of the design matrix . This average is (See [26] and Appendix A in [2]), and therefore
Next, based on , the intrinsic prior for can be obtained by
| (20) |
Since we assume that is proportional to one, set where c is an arbitrary positive constant. Denote by , we obtain
| (21) |
where is component of at position row 1 column 1 and is the first column of . Denote by and by , we then obtain
| (22) |
Therefore, we have derived that
| (23) |
For model comparison, the specific form of the intrinsic prior may be needed, including the constant factor. Therefore, by following (21) and (22) we have
| (24) |
5.2. Variational Inference for Probit Model with Intrinsic Prior
5.2.1. Iterative Updates for Factorized Distributions
We have that
in Section 3.1. We have shown in Section 5.1 that
where and . Since is independent of given , we have
| (25) |
To apply the variational approximation to probit regression model, unobservable variables are considered in two separate groups, coefficient parameter and auxiliary variable . To approximate the posterior distribution of , consider the product form
We proceed by first describing the distribution for each factor of the approximation, and . Then variational approximation is accomplished by iteratively updating the parameters of each factor distribution.
Start with , when , we have
Now, according to (19) and Algorithm 1, the optimal is proportional to
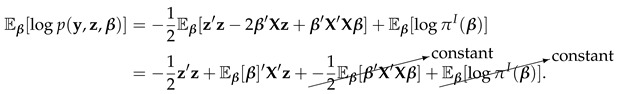 |
So, we have the optimal ,
Similar procedure could be used to develop cases when . Therefore, we have that the optimal approximation for is a truncated normal distribution, where
| (26) |
Denote by , the location of distribution . The expectation is taken with respect to the density form of for which we shall derive now.
For , given the joint form in (25), we have
Taking expectation with respect to , we have
 |
Again, based on (19) and Algorithm 1, the optimal is proportional to ,
First notice that any constant terms, including constant factor in the intrinsic prior, were canceled out due to the ratio form of (19). Then by noticing the quadratic form in the above formula we have
| (27) |
where
Notice that , i.e., , depends on . In addition, from our previous derivation, we found that the update for depends on . Given that the density form of is truncated normal, we have
where is the standard normal density and is the standard normal cumulative density. Denote by . See properties of truncated normal distribution in Appendix A. Updating procedures for parameters and of each factor distribution are summarized in Algorithm 2.
5.2.2. Evaluation of the Lower Bound
During the process of optimization of variational approximation densities, the lower bound for the log marginal likelihood need to be evaluated and monitored to determine when the iterative updating process converges. Based on derivations from previous section, we now have the exact form for the variational inference density,
According to (14), we can write down the lower bound with respect to .
| (28) |
As we can see in (28), has been divided into four different parts with expectation taken over the variational approximation density . We now find the expression of these expectations one by one.
Part 1:
| (29) |
Deal with the inner integral first, we have
| (30) |
where
| (31) |
Substitute (31) into (30), we got
| (32) |
Substituting (32) back into (29) gives
| (33) |
We applied properties of truncated normal distribution in Appendix B to find the expression of the second moment .
Part 2:
| (34) |
Again, see Appendix B for well-known properties of truncated normal distribution. Now subtracting (34) from (33) we got
| (35) |
Based on the exact expression of the intrinsic prior , denoting all constant terms by C, we have
Part 3:
| (36) |
To find the expression for the integral, we have
| (37) |
Substituting (37) back into (36), we obtained
| (38) |
Part 4:
| (39) |
Combining all four parts together, we get
| (40) |
5.3. Model Comparison Based on Variational Approximation
Suppose we want to compare two models, and , where is the simpler model. An intuitive thought on comparing two models by variational approximation methods is just to compare the lower bounds and . However, we should note that by comparing the lower bounds, we are assuming that the KL divergences in the two approximations are the same, so that we can use just these lower bounds as guide. Unfortunately, it is not easy to measure how tight in theory any particular bound can be, if this can be accomplished we could then more accurately estimate the log marginal likelihood from the beginning. As clarified in [27], when comparing two exact log marginal likelihood, we have
| (41) |
| (42) |
| (43) |
The difference in log marginal likelihood, , is the quantity we wish to estimate. However, if we base this on the lower bounds difference, we are basing our model comparison on () rather than (41). Therefore, there exists a systematic bias towards simpler model when comparing models if is not zero.
Realizing that we have a variational approximation for the posterior distribution of , we propose the following method to estimate based on our variational approximation (27). First, writing the marginal likelihood as
we can interpret it as the conditional expectation
with respect to . Next, draw samples from and obtain the estimated marginal likelihood
Please note that this method proposed is equivalent to importance sampling with importance function being , for which we know the exact form and the generation of the random is easy and inexpensive.
6. Modeling Probability of Default Using Lending Club Data
6.1. Introduction
LendingClub (https://www.lendingclub.com/) is the world’s largest peer-to-peer lending platform. LendingClub enables borrowers to create unsecured personal loans between $1000 and $40,000. The standard loan period is three or five years. Investors can search and browse the loan listings on LendingClub website and select loans that they want to invest in based on the information supplied about the borrower, amount of loan, loan grade, and loan purpose. Investors make money from interest. LendingClub makes money by charging borrowers an origination fee and investors a service fee. To attract lenders, LendingClub publishes most of the information available in borrowers’ credit reports as well as information reported by borrowers for almost every loan issued through its website.
6.2. Modeling Probability of Default—Target Variable and Predictive Features
Publicly available LendingClub data, from 2007 June to 2018 Q4, has a total of 2,260,668 issued loans. Each loan has a status, either Paid-off, Charged-off, or Ongoing. We only adopted loans with an end status, i.e., either paid-off or charged-off. In addition, that loan status is the target variable. We then selected following loan features as our predictive covariates.
Loan term in months (either 36 or 60)
FICO
Issued loan amount
DTI (Debt to income ratio, i.e., customer’s total debt divided by income)
Number of credit lines opened in past 24 months
Employment length in years
Annual income
Home ownership type (own, mortgage, of rent)
We took a sample from the original data set that has customer yearly income between $15,000 and $60,000 and end up with a data set of 520,947 rows.
6.3. Addressing Uncertainty of Estimated Probit Model Using Variational Inference with Intrinsic Prior
Using the process developed in Section 5, we can update the intrinsic prior for parameters (see Figure 1) of the probit model using variational inference, and get the posterior distribution for the estimated parameters. Based on the derived parameter distributions, questions of interest may be explored with model uncertainty being considered.
Figure 1.

Intrinsic Prior.
Investors will be interested in understanding how each loan feature affect the probability of default, given a certain loan term, either 36 or 60. To answer this question, we samples 6000 cases from the original data set and draw from derived posterior distribution 100 times. We end up with calculated probability of default, where each one of the 6000 samples yield 100 different probit estimates based on 100 different posterior draws. We summarize some of our findings in Figure 2, where color red representing 36 months loans and green representing 60 months loans.
Figure 2.

Effect of term months and other covariates on probability of default
In general, 60 months loans have higher risk of default.
Given loan term months, there is a clear trend showing that high FICO means lower risk.
Given loan term months, there is a trend showing that high DTI indicating higher risk.
Given loan term months, there is a trend showing that more credit lines opened in past 24 months indicating higher risk.
There is no clear pattern regarding income. This is probably because we only included customers with income between $15,000 and $60,000 in our training data, which may not representing the true income level of the whole population.
Model uncertainty could also be measured through credible intervals. Again, with the derived posterior distribution, the credible interval is just the range containing a particular percentage of estimated effect/parameter values. For instance, the credible interval of the estimated parameter value of FICO is simply the central portion of the posterior distribution that contains of the estimated values. Contrary to the frequentist confidence intervals, Bayesian credible interval is much more straightforward to interpret. Using the Bayesian framework created in this article, from Figure 3, we can simply state that given the observed data, the estimated effect of DTI on default has probability of falling within . Instead of the conventional , we used following suggestions in [28,29], which is just as arbitrary as any of the conventions.
Figure 3.

Credible intervals for estimated coefficients
One of the main advantages of using variational inference over MCMC is that variational inference is much faster. Comparisons were made between the two approximation frameworks on a 64-bit Windows 10 laptop, with 32.0 GB RAM. Using the data set introduced in Section 6.2, we have that
with a conjugate prior and following the Gibbs sampling scheme proposed by [17], it took 89.86 s to finish 100 simulations for the Gibbs sampler;
following our method proposed in Section 5.2, it took 58.38 s to get the approximated posterior distribution and sampling 10,000 times from that posterior.
6.4. Model Comparison
Following the procedure proposed in Section 5.3, we compare the following series of nested models. From the data set introduced in Section 6.2, 2000 records were sampled to estimate the likelihood . Where is one of the 2500 draws sampled directly from the approximated posterior distribution , which serves as the importance function used to estimate the marginal likelihood .
: FICO + Term 36 Indicator
: FICO + Term 36 Indicator + Loan Amount
: FICO + Term 36 Indicator + Loan Amount + Annual Income
: FICO + Term 36 Indicator + Loan Amount + Annual Income + Mortgage Indicator
Estimated log marginal likelihood for each model is plotted in Figure 4. We can see that the model evidence has increased by adding predictive features Loan Amount and Annual Income sequentially. However, if we further adding home ownership information, i.e., Mortgage Indicator as a predictive feature, the model evidence decreased. We have the Bayes factor
which suggests a substantial evidence for model , indicating home ownership information may be irrelevant in predicting probability of default given that all the other predictive features are relevant.
Figure 4.

Log marginal likelihood comparison
7. Further Work
The authors thank the reviewers for pointing out that mean-field variational Bayes underestimates the posterior variance. This could be an interesting topic for our future research. We plan to study the (LRVB) method proposed in [30] to see if it can be applied on the framework we proposed in this article. To see if we can get the approximated posterior variance close enough to the true variance using our proposed method, comparisons should be made between normal conjugate prior with the MCMC procedure, normal conjugate prior with LRVB, and intrinsic prior with LRVB.
Appendix A. Density Function
Suppose has a normal distribution and lies within the interval . Then X conditional on has a truncated normal distribution. Its probability density function, f, for , is given by
and by otherwise. Here
is the probability density function of the standard normal distribution and is its cumulative distribution function. If , then and similarly, if , then And the cumulative density for the truncated normal distribution is
where and .
Appendix B. Moments and Entropy
Let and . For two-sided truncation:
For one sided truncation (upper tail):
where and .
For one sided truncation (lower tail):
More generally, the moment generating function for truncated normal distribution is
For a density defined over a continuous variable, the entropy is given by
And the entropy for a truncated normal density is
Author Contributions
Methodology, A.L., L.P. and K.W.; software, A.L.; writing–original draft preparation, A.L., L.P. and K.W.; writing–review and editing, A.L. and L.P.; visualization, A.L. All authors have read and agreed to the published version of the manuscript.
Funding
The work of L.R.Pericchi was partially funded by NIH grants U54CA096300, P20GM103475 and R25MD010399.
Conflicts of Interest
The authors declare no conflict of interest.
References
- 1.Salmeron D., Cano J.A., Robert C.P. Objective Bayesian hypothesis testing in binomial regression models with integral prior distributions. Stat. Sin. 2015;25:1009–1023. doi: 10.5705/ss.2013.338. [DOI] [Google Scholar]
- 2.Leon-Novelo L., Moreno E., Casella G. Objective Bayes model selection in probit models. Stat. Med. 2012;31:353–365. doi: 10.1002/sim.4406. [DOI] [PubMed] [Google Scholar]
- 3.Jaakkola T.S., Jordan M.I. Bayesian parameter estimation via variational methods. Stat. Comput. 2000;10:25–37. doi: 10.1023/A:1008932416310. [DOI] [Google Scholar]
- 4.Girolami M., Rogers S. Variational Bayesian multinomial probit regression with Gaussian process priors. Neural Comput. 2006;18:1790–1817. doi: 10.1162/neco.2006.18.8.1790. [DOI] [Google Scholar]
- 5.Consonni G., Marin J.M. Mean-field variational approximate Bayesian inference for latent variable models. Comput. Stat. Data Anal. 2007;52:790–798. doi: 10.1016/j.csda.2006.10.028. [DOI] [Google Scholar]
- 6.Ormerod J.T., Wand M.P. Explaining variational approximations. Am. Stat. 2010;64:140–153. doi: 10.1198/tast.2010.09058. [DOI] [Google Scholar]
- 7.Grimmer J. An introduction to Bayesian inference via variational approximations. Political Anal. 2010;19:32–47. doi: 10.1093/pan/mpq027. [DOI] [Google Scholar]
- 8.Blei D.M., Kucukelbir A., McAuliffe J.D. Variational inference: A review for statisticians. J. Am. Stat. Assoc. 2017;112:859–877. doi: 10.1080/01621459.2017.1285773. [DOI] [Google Scholar]
- 9.Pérez M.E., Pericchi L.R., Ramírez I.C. The Scaled Beta2 distribution as a robust prior for scales. Bayesian Anal. 2017;12:615–637. doi: 10.1214/16-BA1015. [DOI] [Google Scholar]
- 10.Mulder J., Pericchi L.R. The matrix-F prior for estimating and testing covariance matrices. Bayesian Anal. 2018;13:1193–1214. doi: 10.1214/17-BA1092. [DOI] [Google Scholar]
- 11.Berger J.O., Pericchi L.R. Model Selection. Institute of Mathematical Statistics; Beachwood, OH, USA: 2001. Objective Bayesian Methods for Model Selection: Introduction and Comparison; pp. 135–207. [Google Scholar]
- 12.Pericchi L.R. Model selection and hypothesis testing based on objective probabilities and Bayes factors. Handb. Stat. 2005;25:115–149. [Google Scholar]
- 13.Scott J.G., Berger J.O. Bayes and empirical-Bayes multiplicity adjustment in the variable-selection problem. Ann. Stat. 2010;38:2587–2619. doi: 10.1214/10-AOS792. [DOI] [Google Scholar]
- 14.Jeffreys H. The Theory of Probability. OUP; Oxford, UK: 1961. [Google Scholar]
- 15.Berger J.O., Pericchi L.R. The intrinsic Bayes factor for model selection and prediction. J. Am. Stat. Assoc. 1996;91:109–122. doi: 10.1080/01621459.1996.10476668. [DOI] [Google Scholar]
- 16.Leamer E.E. Specification Searches: Ad Hoc Inference with Nonexperimental Data. Volume 53 Wiley; New York, NY, USA: 1978. [Google Scholar]
- 17.Albert J.H., Chib S. Bayesian analysis of binary and polychotomous response data. J. Am. Stat. Assoc. 1993;88:669–679. doi: 10.1080/01621459.1993.10476321. [DOI] [Google Scholar]
- 18.Tanner M.A., Wong W.H. The calculation of posterior distributions by data augmentation. J. Am. Stat. Assoc. 1987;82:528–540. doi: 10.1080/01621459.1987.10478458. [DOI] [Google Scholar]
- 19.Berger J.O., Pericchi L.R. The intrinsic Bayes factor for linear models. Bayesian Stat. 1996;5:25–44. [Google Scholar]
- 20.Casella G., Moreno E. Objective Bayesian variable selection. J. Am. Stat. Assoc. 2006;101:157–167. doi: 10.1198/016214505000000646. [DOI] [Google Scholar]
- 21.Moreno E., Bertolino F., Racugno W. An intrinsic limiting procedure for model selection and hypotheses testing. J. Am. Stat. Assoc. 1998;93:1451–1460. doi: 10.1080/01621459.1998.10473805. [DOI] [Google Scholar]
- 22.Bishop C.M. Pattern Recognition and Machine Learning. Springer; Berlin/Heidelberg, Germany: 2006. [Google Scholar]
- 23.Jordan M.I., Ghahramani Z., Jaakkola T.S., Saul L.K. An introduction to variational methods for graphical models. Mach. Learn. 1999;37:183–233. doi: 10.1023/A:1007665907178. [DOI] [Google Scholar]
- 24.Parisi G., Shankar R. Statistical field theory. Phys. Today. 1988;41:110. doi: 10.1063/1.2811677. [DOI] [Google Scholar]
- 25.Boyd S., Vandenberghe L. Convex Optimization. Cambridge University Press; Cambridge, UK: 2004. [Google Scholar]
- 26.Berger J., Pericchi L. Training samples in objective Bayesian model selection. Ann. Stat. 2004;32:841–869. doi: 10.1214/009053604000000229. [DOI] [Google Scholar]
- 27.Beal M.J. Variational Algorithms for Approximate Bayesian Inference. University College London; London, UK: 2003. [Google Scholar]
- 28.Kruschke J. Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan. Academic Press; Cambridge, MA, USA: 2014. [Google Scholar]
- 29.McElreath R. Statistical Rethinking: A Bayesian Course with Examples in R and Stan. Chapman and Hall/CRC; Boca Raton, FL, USA: 2018. [Google Scholar]
- 30.Giordano R.J., Broderick T., Jordan M.I. Linear response methods for accurate covariance estimates from mean field variational Bayes; Proceedings of the Advances in Neural Information Processing Systems; Montreal, QC, USA. 7–12 December 2015; pp. 1441–1449. [Google Scholar]