

Abstract
Recurrent event data occur in many areas such as medical studies and social sciences and a great deal of literature has been established for their analysis. On the other hand, only limited research exists on the variable selection for recurrent event data, and the existing methods can be seen as direct generalizations of the available penalized procedures for linear models and may not perform as well as expected. This article discusses simultaneous parameter estimation and variable selection and presents a new method with a new penalty function, which will be referred to as the broken adaptive ridge regression approach. In addition to the establishment of the oracle property, we also show that the proposed method has the clustering or grouping effect when covariates are highly correlated. Furthermore, a numerical study is performed and indicates that the method works well for practical situations and can outperform existing methods. An application is provided.
Keywords: Additive rate model, event history study, recurrent event data, variable selection, MSC 2010: Primary 62N99, secondary 62P10
Résumé:
Une riche littérature traite de l’analyse des événements récurrents, un type de données observé notamment dans les études médicales et dans les projets de recherche en sciences sociales. Par contre, peu de résultats de recherche portent sur la sélection de variables pour ces modèles. Les méthodes existantes peuvent être vues comme une généralisation directe de procédures pénalisées disponibles pour les modèles linéaires et peuvent offrir des performances inférieures aux attentes. Les auteurs proposent l’approche de régression ridge brisée adaptative où ils procèdent simultanément à l’estimation de paramètres et à la sélection de variables en exploitant une nouvelle fonction de pénalité. Ils prouvent la propriété d’oracle de leur méthode et montrent qu’elle possède une propriété de regroupement lorsque les covariables sont hautement corrélées. Ils présentent une étude numérique qui indique que leur méthode fonctionne bien dans des situations pratiques et peut même s’avérer plus performante que les approches existantes. Ils fournissent également un exemple d’application.
1. INTRODUCTION
This article discusses regression analysis of recurrent event data with the focus on simultaneous parameter estimation and variable selection. By recurrent event data, we mean that in an event history study concerning the occurrence rate of a recurrent event, the observed data on each subject include all occurrence times of the event during the follow up (Andersen etal., 1993;Cook & Lawless, 2007). An example is the study of the hospitalization rate for certain patient groups. Another example is given by investigating the occurrence rate of some disease symptoms or infections, as discussed in Section 5. For recurrent event data, it is assumed that each study subject is observed over a continuous time interval or window. In contrast, sometimes study subjects may be observed only at discrete time points, and thus only incomplete data, often referred to as panel count data, are available (Sun & Zhao, 2013).
Recurrent event data occur in many areas such as medical studies and social sciences and a great deal of literature has been established for their analysis (Andersen etal., 1993; Lawless & Nadeau, 1995; Lin etal., 2000; Cai & Schaubel, 2004; Schaubel, Zeng, & Cai, 2006; Cook & Lawless, 2007). In particular, Cook & Lawless (2007) gave a comprehensive review of the literature on the analysis of such data. However, there exists little research on the variable selection in the context of recurrent event data except Tong, Zhu, & Sun (2009) and Chen & Wang (2013). Tong, Zhu, & Sun (2009) considered the data arising from a multiplicative rate model and proposed a penalized estimating equation-based procedure with the focus on the smoothly clipped absolute derivation (SCAD) penalty function (Fan & Li, 2001). In contrast, Chen & Wang (2013) considered the additive rate model and developed a penalized least square loss function-based method with the use of the SCAD penalty function and the adaptive least absolute shrinkage and selection operator (ALASSO) proposed by Zou (2006). As seen in this article, the two methods may perform poorly sometimes and do not have the grouping effect, which is especially important when variables are highly correlated.
Variable selection is an important topic and has been discussed in many areas such as regression analysis. For this analysis, it is well known that a natural approach is the L0-penalized regression that directly penalizes the cardinality of the variables in the model and seeks the most parsimonious model explaining the data. However, solving an exact L0-penalized nonconvex optimization problem involves an exhaustive combinatorial best subset search, which is NP-hard and computationally infeasible, especially for high-dimensional data. To overcome this, a popular approach is to replace the nonconvex L0-norm by the L1-norm, which is known as the closest convex relaxation of the L0-norm. In addition, the L1-penalized optimization problem can be solved exactly with efficient algorithms and the method became popular since the introduction of the least LASSO method (Tibshirani, 1996). However, it is known that LASSO does not have the oracle property as it tends to select too many small noise features and is biased for large parameters. In addition, it cannot accommodate the grouping effect when covariates are highly correlated. To address these, several approaches have been proposed including the ALASSO and SCAD. In this article, we propose a broken adaptive ridge (BAR) regression approach that approximates the L0-penalized regression using an iteratively reweighted L2-penalized algorithm for variable selection for recurrent event data.
To describe the BAR regression approach, we will first introduce some notation and the model to be used throughout the article and also briefly describe the existing estimation procedure in Section 2. The proposed method is presented in Section 3 and as mentioned above, it approximates the L0-penalized regression using an iteratively reweighted L2-penalized algorithm and takes the limit of the algorithm as the BAR estimator. The approach has the advantages of performing simultaneous variable selection and parameter estimation and accommodating clustering effects, and the BAR iterative algorithm is fast and converges to a unique global optimal solution. Also in Section 3, the asymptotic properties of the proposed BAR estimator including the oracle property are established. Section 4 presents the results of extensive simulation studies to assess the performance of the proposed methodology, and they suggest that the proposed method works well and can outperform the existing method for practical situations. An application is provided in Section 5, and Section 6 contains some discussion and concluding remarks.
2. MODEL AND THE EXISTING ESTIMATION PROCEDURE
Consider an event history study consisting of n independent subjects which concerns the occurrence of a recurrent event of interest. For subject i, let denote the underlying recurrent event process indicating the total number of the occurrences of the event over the time interval [0, t]. Let Ci denote the follow-up time on subject i and let be the observed recurrent event process. Suppose that there exists a p-dimensional vector of external covariate process, denoted by (Kalbfleisch & Prentice, 2002), the main objective is to perform regression analysis with the focus on parameter estimation and covariate selection.
To describe the covariate effect, we assume that given satisfies the model
| (1) |
where denotes an unspecified increasing function and is a p-dimensional vector of regression parameters. Model (1) is usually referred to as the additive rate model and has been studied by many authors for analyzing recurrent event data. Lin et al. (2000), and Schaubel, Zeng, & Cai (2006), and Cook & Lawless (2007) discussed the validity and usefulness of the model and Schaubel, Zeng, & Cai (2006) provided an approach to measure the validity of the model given the observed recurrent event data. But there does not seem to exist an established method that can be used for covariate selection except that of Chen & Wang (2013). As opposed to its commonly used alternative, the proportional rate model, where the regression coefficient reflects relative effects, model (1) characterizes the absolute covariate effects which are often of direct interest in epidemiological and clinical studies.
In the following, we will use boldface to denote vectors or matrices. For the time being, we are only interested in estimation of the regression parameter β. For this, define
One can easily show that Mi(t; β) is a zero-mean stochastic process at the true value, say β0, of the regression parameter, and this motivates the estimating equations
| (2) |
and
| (3) |
for estimation of β0 and μ0(t), where τ is a prespecified constant such that 0 for i = 1,..., n. Solving Equation (2) for μ0(t) with β fixed and plugging the solution into Equation (3), we obtain the estimating equation
| (4) |
Here and with for a vector a, k = 0, 1, 2. Such equations were also given by Schaubel, Zeng, & Cai (2006). Solving Equation (4) gives an explicit estimator of β as
Schaubel, Zeng, & Cai (2006) showed that under some regularity conditions, is a consistent estimator of β and has an asymptotic normal distribution.
3. BAR REGRESSION ESTIMATION PROCEDURE
Now we discuss the covariate selection problem and for this, let
and
and define the loss function
One can easily show that is the minimizer of l(β). Also let X denote the p × p upper triangular matrix given by the Cholesky decomposition of in and Then we can see that the minimization of l(β) is equivalent to minimizing the least squares loss function up to a constant. This suggests that by borrowing the idea behind the penalized least squares, we define the L0-penalized least squares estimator of β as
| (5) |
where is a tuning parameter.
Although with some good properties, the determination of is very difficult or computationally infeasible. To deal with this, we propose to approximate Equation (5) by
which can be rewritten as
where denoting a reasonable or consistent estimator of β0 such that there are no zero components in More discussion on this follows.
To see why the proposed idea works, we note that the quadratic function is an approximation to the L0 penalized regression defined in (5) and that the L0 penalty is a good tool for variable selection except for its difficult computation feature. Also note that the approximation idea of iteratively reweighted quadratic penalization actually has its roots in the well-known Lawsons algorithm in the classical approximation theory and sparse signal reconstruction theory (Lawson, 1961; Gorodnitsky & Rao, 1997). In the approximation above, the weighted penalty for a zero component will iteratively become large and as the consequence, a zero-coefficient estimate is expected to decrease and converge to zero. In contrast, the weighted penalty for a non-zero component is expected to converge to a constant.
We define the BAR estimator of β as
based on the iterative formula For the selection of the initial values for the iteration procedure above, we suggest where When is the ridge estimator; if then reduces to the unpenalized estimator The idea discussed above has been considered under different contexts by Frommlet & Nuel (2016) and Liu & Li (2016), who demonstrated empirically that as an automatic variable selection and parameter estimation procedure, the BAR method can provide substantial improvements over some existing methods. However, no theoretical justification was provided.
To establish the asymptotic properties of we write with β01 and β02 being the first q and remaining p − q components of β0, respectively, and without loss of generality assume that denote the corresponding decomposition of respectively. and and let be the leading q × q submatrix of and respectively.
Theorem 1.
Assume that the regularity conditions (C1)–(C7) given in the Appendix hold. Suppose that the initial estimator satisfies Then with probability tending to 1, the BAR estimator has the following properties:
exists and is the unique fixed point of the equation where
For a variable selection procedure, in addition to the oracle property, another property that is often desired is the grouping effect, meaning that the highly correlated covariates should have similar regression coefficients and be selected or deleted simultaneously. For the proposed BAR approach, it follows from that the (j, k) elements of the two matrices are equal, giving
where xj denotes the jth p-dimensional column vector of This implies that the correlation between the original covariates Zj and Zk can be described by that between xj and xk and leads to the following grouping effect property.
Theorem 2.
Assume that X is standardized in the sense that Then with probability tending to unity, the BAR estimator satisfies
for those non-zero components where ρij denotes the sample correlation coefficient of xi and xj.
The proofs of Theorems 1 and 2 are sketched in the Supporting Information Materials. To implement the procedure, one needs to choose the tuning parameter λn as well as ξn. To reduce the computational burden, we suggest employing the K-fold cross-validation, where K is a positive integer.
4. A SIMULATION STUDY
An extensive simulation study was conducted to investigate the performance of the proposed BAR regression estimation procedure. In the study, recurrent event data were generated from the mixed Poisson processes with the rate function given in (1) multiplied by gamma random variables with mean 1 and variance σ2. The follow-up times Ci were generated from the uniform distribution over [0,4.5]. For the covariate Z, we considered several settings with different P-values, different locations for non-zero components, and different types of distributions, continuous or discrete, with the components being independent or correlated. For each scenario, we considered the sample size n = 100, 300, or 500 with 500 replications.
As comparisons, we also considered the approach of Chen & Wang (2013) with LASSO, ALASSO, and SCAD penalty functions. The LASSO and ALASSO were implemented by using the R package glmnet and the SCAD was realized by the R package ncvreg. For the selection of the tuning parameter, both packages use similar methods to select 50 candidates, and the largest candidates are max for the LASSO, ALASSO, and SCAD, respectively. For the ALASSO, the weights and γ = 1 were used as suggested by Zou (2006), where βols denotes the ordinary least squares estimator of β For the selection of the tuning parameter λn as well as ξn, we used the fivefold cross-validation and considered five candidate values for ξn chosen to be the equally spaced points over [0.01,10] in a logarithmic scale. For each ξn, 50 candidate values were considered for λn that are equally spaced over [ελmax, λmax] also in a logarithmic scale, where ε was set to be 0.001 and λmax = with xl being the lth column of X.
Table 1 presents the covariate selection results with p = 9, where the true value of β0 is (1,0,−1,0,0,0,0,0,0)′, μ0(t) = 0.45t, and σ2 = 0.5 or 1. Here the covariates were generated from the normal distribution and the correlation between Zi and Zj was set as with ρ = 0.1, 0.5, or 0.95. The table includes the average of the empirical values of the mean squared error (MSE) defined as the average of the numbers of correctly selected zero coefficients (Corr), and the average of the numbers of incorrectly selected zero coefficients (Inco). It is seen that with respect to the correctly selected zero coefficients, the BAR always gave the best performance and the BAR and SCAD seemed to significantly outperform LASSO and ALASSO. On the incorrectly selected zero coefficients, no method gave overall better performance than the others. With respect to the MSE, the BAR yielded the least MSE and as expected, all methods gave better performance as the sample size increased.
TABLE 1:
Result on the selection of the normal covariates with p=9.
|
n = 100 |
n = 300 |
n = 500 |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| σ2 | ρ | Method | MSE | Corr | Inco | MSE | Corr. | Inco. | MSE | Corr. | Inco. |
| 0.5 | 0.1 | BAR | 0.586 | 0.829 | 0.084 | 0.136 | 0.922 | 0.000 | 0.082 | 0.919 | 0.000 |
| LASSO | 0.722 | 0.545 | 0.071 | 0.230 | 0.518 | 0.000 | 0.149 | 0.531 | 0.000 | ||
| ALASSO | 0.557 | 0.771 | 0.040 | 0.157 | 0.819 | 0.000 | 0.096 | 0.826 | 0.000 | ||
| SCAD | 0.723 | 0.563 | 0.072 | 0.124 | 0.667 | 0.000 | 0.072 | 0.789 | 0.000 | ||
| 0.5 | BAR | 0.493 | 0.823 | 0.098 | 0.125 | 0.913 | 0.001 | 0.070 | 0.909 | 0.000 | |
| LASSO | 0.594 | 0.557 | 0.104 | 0.195 | 0.525 | 0.000 | 0.117 | 0.539 | 0.000 | ||
| ALASSO | 0.464 | 0.734 | 0.060 | 0.140 | 0.827 | 0.000 | 0.079 | 0.827 | 0.000 | ||
| SCAD | 0.600 | 0.617 | 0.117 | 0.111 | 0.750 | 0.000 | 0.060 | 0.830 | 0.000 | ||
| 0.9 | BAR | 0.196 | 0.759 | 0.179 | 0.051 | 0.869 | 0.012 | 0.030 | 0.881 | 0.000 | |
| LASSO | 0.202 | 0.615 | 0.176 | 0.071 | 0.535 | 0.000 | 0.047 | 0.561 | 0.000 | ||
| ALASSO | 0.187 | 0.701 | 0.136 | 0.059 | 0.743 | 0.003 | 0.035 | 0.789 | 0.000 | ||
| SCAD | 0.225 | 0.722 | 0.236 | 0.049 | 0.804 | 0.010 | 0.027 | 0.870 | 0.001 | ||
| 1 | 0.1 | BAR | 0.564 | 0.797 | 0.078 | 0.147 | 0.908 | 0.000 | 0.088 | 0.923 | 0.000 |
| LASSO | 0.704 | 0.523 | 0.070 | 0.241 | 0.482 | 0.000 | 0.152 | 0.504 | 0.000 | ||
| ALASSO | 0.547 | 0.758 | 0.041 | 0.167 | 0.797 | 0.000 | 0.100 | 0.836 | 0.000 | ||
| SCAD | 0.715 | 0.550 | 0.075 | 0.136 | 0.651 | 0.000 | 0.076 | 0.787 | 0.000 | ||
| 0.5 | BAR | 0.443 | 0.803 | 0.069 | 0.125 | 0.895 | 0.000 | 0.071 | 0.900 | 0.000 | |
| LASSO | 0.539 | 0.524 | 0.072 | 0.201 | 0.501 | 0.000 | 0.125 | 0.503 | 0.000 | ||
| ALASSO | 0.430 | 0.736 | 0.042 | 0.144 | 0.790 | 0.001 | 0.085 | 0.791 | 0.000 | ||
| SCAD | 0.558 | 0.602 | 0.085 | 0.113 | 0.739 | 0.001 | 0.064 | 0.812 | 0.000 | ||
| 0.9 | BAR | 0.207 | 0.771 | 0.209 | 0.053 | 0.843 | 0.016 | 0.027 | 0.893 | 0.002 | |
| LASSO | 0.209 | 0.610 | 0.188 | 0.072 | 0.566 | 0.004 | 0.045 | 0.568 | 0.000 | ||
| ALASSO | 0.190 | 0.697 | 0.144 | 0.059 | 0.749 | 0.005 | 0.033 | 0.796 | 0.000 | ||
| SCAD | 0.234 | 0.718 | 0.241 | 0.050 | 0.797 | 0.020 | 0.023 | 0.886 | 0.000 | ||
Tables 2 and 3 give the results for the same setup as Table 1 but with different values for p and β0. In Table 2, p = 50 and the first six components of β0 were (1,0, −1,1,0, −1)′ with the other components being zero, while in Table 3, p = 100 and the first 30 components of β0 were replicators of (1,0, −1)′ with the other components being zero. The results in Table 4 were obtained for the covariates whose first 3 components of Z followed the Bernoulli distribution with the probability of success being 0.5 and the other components were generated from the standard normal distribution with n = 100 and β0 = (1,1,1,0,0,0,0,0,0)′. Also all components were assumed to be independent of each other and the other setup is the same as Table 1 except that the recurrent event processes followed either the homogeneous Poisson process (σ2 = 0) or the mixed Poisson process with the variance of the gamma random variables being 1(σ2 = 1). It is apparent that all tables gave similar conclusions to those given by Table 1 and again suggest that the proposed BAR procedure seems to give better performance than the other procedures on the covariate selection in general.
TABLE 2:
Result on the selection of the normal covariates with p=50.
| 0.5 | 0.1 | BAR | 3.199 | 0.947 | 0.540 | 0.559 | 0.966 | 0.020 | 0.279 | 0.981 | 0.001 |
| LASSO | 3.299 | 0.843 | 0.516 | 1.132 | 0.693 | 0.014 | 0.701 | 0.679 | 0.000 | ||
| ALASSO | 3.309 | 0.747 | 0.219 | 0.680 | 0.817 | 0.003 | 0.384 | 0.834 | 0.000 | ||
| SCAD | 3.347 | 0.857 | 0.519 | 0.652 | 0.685 | 0.013 | 0.240 | 0.752 | 0.000 | ||
| 0.5 | BAR | 2.059 | 0.949 | 0.576 | 0.403 | 0.965 | 0.031 | 0.184 | 0.982 | 0.001 | |
| LASSO | 2.135 | 0.858 | 0.597 | 0.863 | 0.660 | 0.046 | 0.481 | 0.636 | 0.001 | ||
| ALASSO | 2.198 | 0.759 | 0.281 | 0.500 | 0.804 | 0.005 | 0.265 | 0.829 | 0.000 | ||
| SCAD | 2.146 | 0.874 | 0.607 | 0.441 | 0.728 | 0.037 | 0.141 | 0.813 | 0.000 | ||
| 0.9 | BAR | 0.682 | 0.950 | 0.660 | 0.212 | 0.965 | 0.253 | 0.098 | 0.970 | 0.060 | |
| LASSO | 0.638 | 0.883 | 0.691 | 0.316 | 0.763 | 0.262 | 0.193 | 0.679 | 0.070 | ||
| ALASSO | 0.908 | 0.758 | 0.462 | 0.251 | 0.771 | 0.093 | 0.138 | 0.779 | 0.014 | ||
| SCAD | 0.658 | 0.918 | 0.737 | 0.262 | 0.865 | 0.295 | 0.127 | 0.853 | 0.113 | ||
| 1 | 0.1 | BAR | 3.119 | 0.945 | 0.501 | 0.575 | 0.967 | 0.017 | 0.285 | 0.980 | 0.001 |
| LASSO | 3.294 | 0.839 | 0.492 | 1.152 | 0.675 | 0.009 | 0.714 | 0.690 | 0.000 | ||
| ALASSO | 3.226 | 0.739 | 0.197 | 0.715 | 0.802 | 0.001 | 0.385 | 0.837 | 0.000 | ||
| SCAD | 3.305 | 0.850 | 0.493 | 0.653 | 0.677 | 0.010 | 0.250 | 0.758 | 0.000 | ||
| 0.5 | BAR | 2.025 | 0.942 | 0.522 | 0.379 | 0.964 | 0.017 | 0.201 | 0.981 | 0.002 | |
| LASSO | 2.130 | 0.838 | 0.565 | 0.819 | 0.648 | 0.033 | 0.502 | 0.638 | 0.001 | ||
| ALASSO | 2.206 | 0.744 | 0.262 | 0.490 | 0.799 | 0.001 | 0.272 | 0.831 | 0.000 | ||
| SCAD | 2.134 | 0.860 | 0.572 | 0.390 | 0.719 | 0.020 | 0.153 | 0.806 | 0.000 | ||
| 0.9 | BAR | 0.691 | 0.950 | 0.687 | 0.216 | 0.961 | 0.253 | 0.100 | 0.965 | 0.056 | |
| LASSO | 0.645 | 0.891 | 0.711 | 0.311 | 0.751 | 0.240 | 0.191 | 0.679 | 0.079 | ||
| ALASSO | 0.883 | 0.759 | 0.474 | 0.249 | 0.766 | 0.092 | 0.135 | 0.770 | 0.013 | ||
| SCAD | 0.664 | 0.926 | 0.766 | 0.270 | 0.864 | 0.300 | 0.126 | 0.851 | 0.118 |
TABLE 3:
Result on the selection of the normal covariates with p=100.
|
n = 100 |
n = 300 |
n = 500 |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| σ2 | ρ | Method | MSE | Corr | Inco | MSE | Corr. | Inco. | MSE | Corr. | Inco. |
| 0.5 | 0.1 | BAR | 22.903 | 0.970 | 0.931 | 16.480 | 0.954 | 0.713 | 7.110 | 0.889 | 0.182 |
| LASSO | 20.336 | 0.917 | 0.867 | 16.222 | 0.813 | 0.584 | 8.877 | 0.541 | 0.124 | ||
| ALASSO | 63.584 | 0.569 | 0.493 | 11.013 | 0.704 | 0.172 | 5.469 | 0.691 | 0.022 | ||
| SCAD | 19.821 | 0.936 | 0.887 | 16.626 | 0.847 | 0.610 | 7.493 | 0.606 | 0.131 | ||
| 0.5 | BAR | 10.771 | 0.979 | 0.957 | 8.305 | 0.960 | 0.755 | 3.307 | 0.900 | 0.153 | |
| LASSO | 9.660 | 0.941 | 0.917 | 8.678 | 0.877 | 0.765 | 5.325 | 0.567 | 0.261 | ||
| ALASSO | 27.797 | 0.620 | 0.556 | 5.748 | 0.704 | 0.180 | 2.804 | 0.686 | 0.017 | ||
| SCAD | 9.518 | 0.947 | 0.922 | 8.609 | 0.893 | 0.754 | 3.509 | 0.666 | 0.175 | ||
| 0.9 | BAR | 2.566 | 0.973 | 0.946 | 1.848 | 0.971 | 0.850 | 1.307 | 0.934 | 0.551 | |
| LASSO | 2.282 | 0.940 | 0.912 | 1.899 | 0.896 | 0.800 | 1.492 | 0.739 | 0.513 | ||
| ALASSO | 5.791 | 0.679 | 0.611 | 1.703 | 0.722 | 0.378 | 1.003 | 0.665 | 0.121 | ||
| SCAD | 2.205 | 0.957 | 0.934 | 1.929 | 0.935 | 0.851 | 1.616 | 0.876 | 0.652 | ||
| 1 | 0.1 | BAR | 23.857 | 0.969 | 0.935 | 16.213 | 0.953 | 0.699 | 7.618 | 0.899 | 0.214 |
| LASSO | 20.412 | 0.928 | 0.880 | 16.051 | 0.810 | 0.580 | 9.441 | 0.567 | 0.156 | ||
| ALASSO | 63.446 | 0.578 | 0.500 | 10.684 | 0.705 | 0.160 | 5.585 | 0.698 | 0.025 | ||
| SCAD | 19.897 | 0.939 | 0.891 | 16.395 | 0.848 | 0.606 | 8.117 | 0.625 | 0.159 | ||
| 0.5 | BAR | 10.768 | 0.976 | 0.955 | 8.225 | 0.943 | 0.719 | 3.489 | 0.902 | 0.172 | |
| LASSO | 9.611 | 0.942 | 0.918 | 8.667 | 0.864 | 0.753 | 5.536 | 0.575 | 0.280 | ||
| ALASSO | 26.281 | 0.651 | 0.581 | 5.724 | 0.680 | 0.164 | 2.919 | 0.681 | 0.019 | ||
| SCAD | 9.470 | 0.951 | 0.928 | 8.614 | 0.894 | 0.762 | 3.611 | 0.666 | 0.180 | ||
| 0.9 | BAR | 2.571 | 0.973 | 0.951 | 1.846 | 0.974 | 0.859 | 1.324 | 0.936 | 0.571 | |
| LASSO | 2.262 | 0.944 | 0.918 | 1.895 | 0.900 | 0.802 | 1.505 | 0.743 | 0.519 | ||
| ALASSO | 5.757 | 0.692 | 0.640 | 1.695 | 0.736 | 0.394 | 0.993 | 0.663 | 0.121 | ||
| SCAD | 2.232 | 0.958 | 0.933 | 1.938 | 0.939 | 0.859 | 1.643 | 0.884 | 0.681 | ||
TABLE 4:
Results on the selection of the Bernoulli covariates with p=9.
| σ2 |
n = 100 |
n = 200 |
n = 300 |
|||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MSE | Corr | Inco | MSE | Corr | Inco | MSE | Corr | Inco | ||
| 0 | BAR | 0.081 | 5.510 | 0.004 | 0.037 | 5.674 | 0.000 | 0.023 | 5.738 | 0.000 |
| LASSO | 0.152 | 3.166 | 0.002 | 0.072 | 3.306 | 0.000 | 0.050 | 3.238 | 0.000 | |
| ALASSO | 0.143 | 4.252 | 0.002 | 0.059 | 4.700 | 0.000 | 0.040 | 4.724 | 0.000 | |
| SCAD | 0.101 | 5.330 | 0.004 | 0.041 | 5.546 | 0.000 | 0.031 | 5.488 | 0.000 | |
| 1 | BAR | 0.786 | 5.108 | 0.974 | 0.427 | 5.054 | 0.372 | 0.264 | 5.104 | 0.158 |
| LASSO | 0.780 | 4.186 | 0.916 | 0.515 | 3.392 | 0.256 | 0.353 | 3.050 | 0.060 | |
| ALASSO | 1.042 | 4.096 | 1.048 | 0.606 | 3.764 | 0.358 | 0.380 | 3.892 | 0.140 | |
| SCAD | 0.955 | 5.078 | 0.770 | 0.500 | 5.228 | 0.362 | 0.268 | 5.460 | 0.172 | |
To assess the grouping ability of the methods discussed above, we performed a simulation study with p = 12, β0 = (1,1,1,0.5,0.5,0.5,0,0,0,0,0,0), and n = 10,000; other settings are the same as before. A large sample size was used in order to reveal the grouping effect. For the covariate generation, we assumed that
where the εj are i.i.d. N(0, 0.0252). That is, the 12 covariates were from three different groups with the within-group correlations being nearly 1 and the between-group correlations being close to 0. Figure 1 shows the solution paths of the estimates given by the four methods. One can see the obvious grouping effect of the proposed BAR estimator when the tuning parameters are in the proper range. The method clearly selected the six relevant covariates and organized them into their two separate groups with almost the same coefficients within each group when log(λn) is roughly between 0.7 and 5.6. Although the estimate paths were unstable when λ is small, the cross-validation criterion can successfully find the tuning parameters inducing the grouping effect. In contrast, all three other methods showed little grouping effects as they selected only β1 and β4.
FIGURE 1:
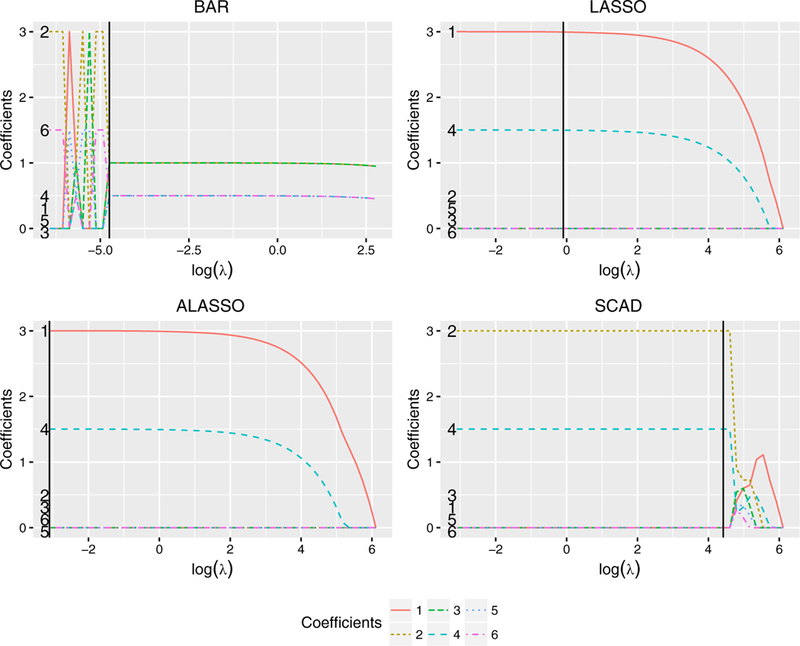
Path plots of the four estimates with the black solid vertical lines corresponding to the optimal tuning parameters based on the 5-fold cross-validation.
5. AN APPLICATION
We apply the proposed BAR regression estimation procedure to the recurrent event data arising from the chronic granulomatous disease (CGD) study discussed by Fleming & Harrington (1991), and Tong, Zhu, & Sun (2009), and Chen & Wang (2013) among others. This disease is a group of inherited rare disorders of the immune function characterized by recurrent pyogenic infections which are usually present in early life and may lead to death in childhood. The CGD study consists of 128 patients with CGD between October 1988 and March 1989. For each subject, the collected information includes the occurrence times of all recurrent serious infections during the study period. The study involves two treatments, a placebo (65) and gamma interferon (63). During the study period, 20 placebo patients and 7 treated patients had experienced at least one serious infection. A goal of the study is to investigate the ability of gamma interferon to reduce the occurrence rate of serious infections.
We use Z1 to denote the treatment with Z1 = 0 for the patients on gamma interferon and Z1 = 1 otherwise. In addition to the treatment, the data set includes information on eight other covariates. Other variables considered include the pattern of inheritance (Z2 = 0 for X-linked patients and Z2 = 1 for autosomal recessive patients), the age, height, and weight of the patient (Z3, Z4, Z5), the use of corticosteroids at time of study entry (Z6 = 0 if yes and Z6 = 1 if no), the use of prophylactics at time of study entry (Z7 = 0 if yes and Z7 = 1 if no), the patient’s gender (Z8 = 1 if female and Z8 = 0 if male), and the hospital category (US-NIH, US-other, Europe-Amsterdam, and Europe-other). For the last covariate, following Tong, Zhu, & Sun (2009) and Chen & Wang (2013), we describe it using three dummy variables as Z9 = 1 for US-NIH and Z9 = 0 otherwise, Z10 = 1 for US-other and Z10 = 0 otherwise, Z11 = 1 for Europe-Amsterdam and Z11 = 0 otherwise.
For the analysis, we consider both the selection of covariates or predictive factors and the estimation of their effects simultaneously. The results are given in Table 5 and here for comparison, we also included the results given by LASSO, ALASSO, SCAD, and the ordinary least squares procedure. Table 5 includes the selected covariates with their estimated effects and the estimated standard errors (in parentheses) for each method. It is seen that all procedures selected the treatment indicator, indicating that gamma interferon had significant effect on reducing the rate of serious infections. In addition, the BAR procedure suggested that the pattern of inheritance and the use of prophylactics at time of study entry seem to have some effects on the rate of serious infections, and also the infection rate appears to be different between the patients in the hospitals in the US-other group and other types of hospitals. Based on the ALASSO procedure, the patient’s age and the use of corticosteroids at the time of study entry could affect the infection rate. It is interesting to note that as LASSO and SCAD, the method given by Chen & Wang (2013) selected only the treatment indicator Z1, while the results obtained here are similar to those given by Tong, Zhu, & Sun (2009) under the proportional rate model.
TABLE 5:
Results on covariate selection and their estimated effects for the CGD study.
| BAR | LASSO | ALASSO | SCAD | OLS | |
|---|---|---|---|---|---|
| Z1 | 0.127 (0.043) | 0.080 (0.038) | 0.104 (0.016) | 0.088 (0.036) | 0.170 (0.050) |
| Z2 | 0.018 (0.004) | 0 | 0 | 0 | 0.152(0.113) |
| Z3 | 0 | 0 | −0.138 (0.020) | 0 | −0.409 (0.152) |
| Z4 | 0 | 0 | 0 | 0 | 0.081 (0.397) |
| Z5 | 0 | 0 | 0 | 0 | 0.105 (0.266) |
| Z6 | 0 | 0 | −0.105 (0.016) | 0 | −0.343 (0.269) |
| Z7 | 0.027 (0.007) | 0 | 0 | 0 | 0.140 (0.087) |
| Z8 | 0 | 0 | 0 | 0 | −0.134 (0.111) |
| Z9 | 0 | 0 | 0 | 0 | 0.059 (0.065) |
| Z10 | 0.018 (0.004) | 0 | 0 | 0 | 0.094 (0.069) |
| Z11 | 0 | 0 | 0 | 0 | −0.051 (0.076) |
To assess the appropriateness of the selected models by each of the four methods given above, as suggested by a reviewer, we performed model checking by using the statistic
based on the sum of the mean squared residuals. Here is defined as with the unknowns replaced by their estimates and the values denote all time points where the Nt(t) have jumps. Lin, Wei, & Ying (2001) employed a similar statistic for checking transformation models with the focus on estimation. The application of this statistic to the data yielded D = 0.4598, 0.4670, 0.4588, and 0.4662 for the models selected by the four methods in Table 5, respectively, and indicates that the four models are not significantly different.
6. DISCUSSION AND CONCLUDING REMARKS
This article discussed simultaneous covariate selection and estimation of covariate effects for the event history study that yields recurrent event data. As mentioned above, only limited research exists for covariate selection in Tong, Zhu, & Sun (2009) and Chen & Wang (2013) due to the special data structures and the difficulties involved. We presented a BAR regression estimation procedure that can not only allow for estimation and variable selection simultaneously but also accommodate the clustering effect when covariates are highly correlated. The oracle property of the proposed approach was established, and the simulation study indicated that the proposed method can have better performance than the existing procedures.
There exist several directions for future research. Here we have focused on the underlying recurrent event process that follows the additive rate model (1). It would be useful to generalize the proposed method to the situation where the event process may follow other models such as the proportional rate model or the semiparametric transformation model. Another extension is to consider a terminal event, which corresponds to the situation where the follow-up time Ci may be related to In this case, it is clear that the proposed method may not be valid and could give biased results (Cook & Lawless, 2007).
Our discussion assumes that the dimension of covariates p is fixed. It would be interesting to consider the case where p is larger than the sample size n. Although the idea described here may still apply, the implementation procedure would not work due to the irregularity of some needed matrices.
Supplementary Material
ACKNOWLEDGEMENTS
The authors wish to thank the Editor, Dr. Yi, the Associate Editor, and two referees for their many helpful comments and suggestions. This work was partly supported by the US National Institutes of Health grants (R03 CA219450, R21 CA198641), the National Nature Science Foundation of China (Nos. 11471135, 11571133), and the self-determined research funds of CCNU from the college’s basic research of MOE (CCNU15ZD011, CCNU18ZDPY08).
APPENDIX: Regularity conditions
The following are the regularity conditions needed for the asymptotic properties of .
(C1) are independent and identically distributed.
(C2) , for i = 1,..., n.
(C3) is bounded by a constant.
(C4) The matrix Ώ is positive definite.
(C5) The Zi(·)’s have bounded total variations, that is, is bounded for all i, where ||Zi(·)|| is the Euclidean metric of the vector Zi(·).
(C6) , for all n > 0 and some large constant c > 1, where λ(Q) stands for the eigenvalues of the matrix Q.
(C7)
Footnotes
Additional Supporting Information may be found in the online version of this article at the publisher’s website.
BIBLIOGRAPHY
- Andersen PK, Borgan O, Gill RD, & Keiding N (1993). Statistical Models Based on Counting Processes. Springer-Verlag, New York. [Google Scholar]
- Cai J & Schaubel DE (2004). Marginal means/rates models for multiple type recurrent event data. Lifetime Data Analysis, 10, 121–138. [DOI] [PubMed] [Google Scholar]
- Chen X & Wang Q (2013). Variable selection in the additive rate model for recurrent event data. Computational Statistics and Data Analysis, 57, 491–503. [Google Scholar]
- Cook RJ & Lawless JF (2007). The Statistical Analysis of Recurrent Event Data. Springer-Verlag, New York. [Google Scholar]
- Fan J & Li R (2001). Variable selection via nonconcave penalized likelihood and its oracle property. Journal of the American Statistical Association, 96, 1348–1360. [Google Scholar]
- Fleming TR & Harrington DP (1991). Counting Processes and Survival Analysis. Wiley, New York. [Google Scholar]
- Frommlet F & Nuel G (2016). An adaptive ridge procedure for L0 regularization. PLoS One, 11(2), e0148620. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gorodnitsky IF & Rao BD (1997). Sparse signal reconstruction from limited data using focus: A re-weighted minimum norm algorithm. IEEE Transactions on Signal Processing, 45, 600–616. [Google Scholar]
- Kalbfleisch JD & Prentice RL (2002). The Statistical Analysis of Failure Time Data. Wiley, New York. [Google Scholar]
- Lawless JF & Nadeau C (1995). Some simple robust methods for the analysis of recurrent events. Technometrics, 37, 158–168. [Google Scholar]
- Lawson CL (1961). Contributions to the Theory of Linear Least Maximum Approximation, Ph.D. Thesis, University of California, Los Angeles, USA. [Google Scholar]
- Lin DY, Wei LJ, Yang I, & Ying Z (2000). Semiparametric regression for the mean and rate function of recurrent events. Journal of Royal Statistical Society, Series B, 69, 711–730. [Google Scholar]
- Lin DY, Wei LJ, & Ying Z (2001). Semiparametric transformation models for point processes. Journal of the American Statistical Association, 96, 620–628. [Google Scholar]
- Liu Z & Li G (2016). Efficient regularized regression with penalty for variable selection and network construction. Computational and Mathematical Methods in Medicine. 2016, 3456153. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schaubel DE, Zeng DL, & Cai JW (2006). A semiparametric additive rates model for recurrent event data. Lifetime Data Analysis, 12, 389–406. [DOI] [PubMed] [Google Scholar]
- Sun J & Zhao X (2013). The Statistical Analysis of Panel Count Data. Springer Science + Business Inc, New York. [Google Scholar]
- Tibshirani R (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society, Series B, 58, 267–288. [Google Scholar]
- Tong X, Zhu L, & Sun J (2009). Variable selection for recurrent event data via nonconcave penalized estimating function. Lifetime Data Analysis, 15, 197–215. [DOI] [PubMed] [Google Scholar]
- Zou H (2006). The adaptive lasso and its oracle properties. Journal of the American Statistical Association, 101, 1418–1429. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.