

Abstract
Background
Parkinson disease (PD) is one of the most common neurological diseases. At present, because the exact cause is still unclear, accurate diagnosis and progression monitoring remain challenging. In recent years, exploring the relationship between PD and speech impairment has attracted widespread attention in the academic world. Most of the studies successfully validated the effectiveness of some vocal features. Moreover, the noninvasive nature of speech signal–based testing has pioneered a new way for telediagnosis and telemonitoring. In particular, there is an increasing demand for artificial intelligence–powered tools in the digital health era.
Objective
This study aimed to build a real-time speech signal analysis tool for PD diagnosis and severity assessment. Further, the underlying system should be flexible enough to integrate any machine learning or deep learning algorithm.
Methods
At its core, the system we built consists of two parts: (1) speech signal processing: both traditional and novel speech signal processing technologies have been employed for feature engineering, which can automatically extract a few linear and nonlinear dysphonia features, and (2) application of machine learning algorithms: some classical regression and classification algorithms from the machine learning field have been tested; we then chose the most efficient algorithms and relevant features.
Results
Experimental results showed that our system had an outstanding ability to both diagnose and assess severity of PD. By using both linear and nonlinear dysphonia features, the accuracy reached 88.74% and recall reached 97.03% in the diagnosis task. Meanwhile, mean absolute error was 3.7699 in the assessment task. The system has already been deployed within a mobile app called No Pa.
Conclusions
This study performed diagnosis and severity assessment of PD from the perspective of speech order detection. The efficiency and effectiveness of the algorithms indirectly validated the practicality of the system. In particular, the system reflects the necessity of a publicly accessible PD diagnosis and assessment system that can perform telediagnosis and telemonitoring of PD. This system can also optimize doctors’ decision-making processes regarding treatments.
Keywords: Parkinson disease, speech disorder, remote diagnosis, artificial intelligence, mobile phone app, mobile health
Introduction
Parkinson disease (PD) is a long-term degenerative disorder of the central nervous system that mainly affects the motor system. In the early stages, the symptoms include tremor; rigidity; slowness of movement; and difficulty with walking, talking, thinking, or completing other simple tasks. Dementia becomes common in the later stages of the disease. More than a third of patients have experienced depression and anxiety [1]. Other symptoms include sensory and sleep problems. In 2017, PD affected more than 10 million people worldwide, making it the second-most common neurological condition after Alzheimer disease. Currently, there is no cure for PD [2]. Accurate diagnosis, prognosis, and progression monitoring remain nontrivial.
As reported in previous work [3,4], approximately 90% of patients with PD develop voice and speech disorders during the course of the disease, which can have a negative impact on functional communication, thus leading to a decline in the quality of life [5]. Reduced volume (ie, hypophonia), reduced pitch range (ie, monotone), and difficulty with the articulation of sounds or syllables (ie, dysarthria) are the most common speech problems [6]. At the same time, many patients gradually dislike communication because of their own language barriers, which will cause more serious speech disorders and then form a vicious circle. Note that the speech signal–based test is noninvasive and can be self-administered. Hence, it has been regarded as a promising approach in PD diagnosis, evaluation, and progression monitoring, especially in the telediagnosis and telemonitoring medical fields.
In this work, we built a publicly accessible real-time system to efficiently diagnose and assess the severity of PD via speech signal analysis. The most relevant works can be found in Lahmiri et al [7] and Wroge et al [8]. They utilize similar machine learning algorithms as those based on previously proposed audio features [9-13]; however, their work neither considered severity assessment of PD nor made a publicly accessible app that allows for real-time mobile-aided PD diagnosis or evaluation, which is actually a trend and even a necessity in the current 4G and future 5G era for telediagnosis and telemonitoring. For instance, the outbreak of coronavirus disease 2019 (COVID-19) highlights the importance of intelligent and accurate telehealth during disease epidemics.
More specifically, our system first collects the speech signals of the subjects and then utilizes speech signal processing techniques to extract a variety of speech impairment features; it further utilizes advanced machine learning algorithms to diagnose PD and analyze the disease severity. In our work, in the speech signal feature-extraction stage, we utilized many traditional and novel methods to obtain clinically meaningful voice signal features, such as jitter, fine-tuning, recurrence period density entropy, pitch period entropy, signal-to-noise ratio, harmonics-to-noise ratio (HNR), and the mel frequency cepstral coefficient [9-11]. We regarded the PD diagnosis task as a classification problem and then utilized classical algorithms (eg, support vector machine [SVM] and artificial neural network [ANN]) to perform diagnosis. We formed the PD severity assessment task into a regression problem, with the Unified Parkinson Disease Rating Scale (UPDRS) score as the dependent variable; the UPDRS is the most widely employed scale for tracking PD symptom progression. Various regression algorithms (eg, support vector regression [SVR] and least absolute shrinkage and selection operator [LASSO] regression) were tested. We then obtained the most suitable model by comparing and blending different algorithms. In the end, we developed a mobile phone app for our system to realize remote diagnosis, severity evaluation, and progression monitoring of PD, which will significantly reduce detection and prevention costs.
The main structure of this paper is divided into four parts: (1) description of the methods used in our system: data collection, data preprocessing, feature extraction of speech signals, classification, and regression problem formulation, (2) analysis of our experimental results, (3) system description of our mobile app, and (4) final discussion.
Methods
Data Collection
The speech signal data used in the experiment came from two sources:
One part of the dataset came from the open data platform from the University of California Irvine (UCI) Machine Learning Repository, where three sets of parkinsonian speech data with different characteristics were obtained.
The other part of the dataset was collected in collaboration with the Department of Neurology, the First Affiliated Hospital of Dalian Medical University, China. The data recorded the voice signals of patients with PD.
In practice, the collected pronunciation content needs to be short and reflect the patient's speech disorder to a certain extent. On one hand, considering the need for different languages, dialects, and accents as well as unclear pronunciations, we adopted the continuous pronunciation method. Meanwhile, the control of the vocal cords and airflow is also weakened due to the weakening control of the pronunciation system of the nervous system. On the other hand, since the relationship between the vibration of the vocal cords and the speech disorder is relatively strong, the vowels can better reflect the degree of speech impairment [6,11,14]. Another fact is that the basic vowels in different regions of the world are very similar, so it is more reasonable to use vowels. The vowels used here are the five long vowels with the following English phonetic symbols: [ɑ:], [ɜ:], [i:], [ɔ:], and [u:]; the subjects are required to pronounce them repeatedly. The collected syllables are shown in Table 1.
Table 1.
Collected syllables.
| International phonetic symbol | Duration (seconds) |
| [ɑ:] | 3 |
| [З:] | 3 |
| [i:] | 3 |
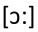
|
3 |
| [u:] | 3 |
The UPDRS [15] is the most commonly used severity indicator in clinical studies of PD. It is evaluated via filling out a form, which requires considerable medical expertise, so it is difficult for patients to perform self-testing using this scale. That explains why we need automatic and artificial intelligence–powered prediction tools. We collected the UPDRS score as the dependent variable in our regression task. At present, UPDRS version 3.0 is the most widely used version, and it can be divided into four parts:
Mentation, behavior, and mood, including a total of four questions (16 points).
Activities of daily living, including a total of 13 questions (52 points).
Motor examination, including a total of 14 questions (108 points).
Treatment complications, including a total of 11 questions (23 points).
In summary, UPDRS version 3.0 has a total of 42 questions and the highest score is 199 points. The higher the UPDRS score, the more serious the PD is. The third item, motor examination, can reflect the severity of speech disorder. In practice, when collecting the data, the doctor is required to evaluate the total UPDRS score as well as the value of the motor examination score.
Note that the first part of the data is open source, and we can easily download this data from UCI's official website. Therefore, the datasets were mainly used to train the machine learning models and verify the validity of the dysphonia features, all of which have been integrated in our app system. This part of the data will be introduced in detail in the Results section. The second part of the data requires us to work closely with local hospitals—we collected PD patients’ vocal data in a local hospital; the data collection table is shown in Multimedia Appendix 1. The Data Preprocessing section that follows describes how we processed the second part of the data, which has been implemented as a function in our app. We then extracted the dysphonia features, which have also been integrated as a function in our app system. Moreover, we tested them with machine learning models, which have been trained based on the first part of data, and achieved good results in the PD diagnosis task. Until now, the number of collected Chinese speech signals is still not big enough to train an effective model. Therefore, our model within our app system was trained by the first part of the data: the first and third datasets were used in the diagnosis task and severity assessment task, respectively. However, this app is continuously collecting new data, including positive and negative samples. As the amount of data increases in the future, we will utilize advanced technology, such as transfer learning, to realize PD diagnosis and severity evaluation for people in various regions.
Data Preprocessing
The initially collected voice signals cannot be directly used; some preprocessing was required. This operation removed some of the interference factors and paved the way for subsequent feature extraction. The formats of different audio files were unified into the WAV file format, with 44,100 Hz sampling frequency and two channels. These audio files were then uploaded into the back-end server for storage.
The first step of data preprocessing is sampling frequency conversion, that is, resampling, which can uniformly record the speech frequency and reduce the amount of calculation by down-clocking. In our work, only one channel of the speech signal (ie, the left channel) is reserved, and then the sampling frequency is converted to 10 kHz.
The second step is pre-emphasis. Since the low-frequency part of speech signals tends to contain noise, we performed pre-emphasis to filter out the low frequencies and improve the resolution of the high-frequency part of speech signals. In our work, a first-order, finite impulse response, high-pass digital filter was used to achieve pre-emphasis [16]. The transfer function is defined in equation 1 of Figure 1. In equation 1, a is the pre-emphasis coefficient; generally, 0.9 < a < 1.0. Let x(n) denote the voice sample value at time n. After the pre-emphasis processing, the result is y(n) = x(n) – ax(n–1), where a=0.9375.
Figure 1.
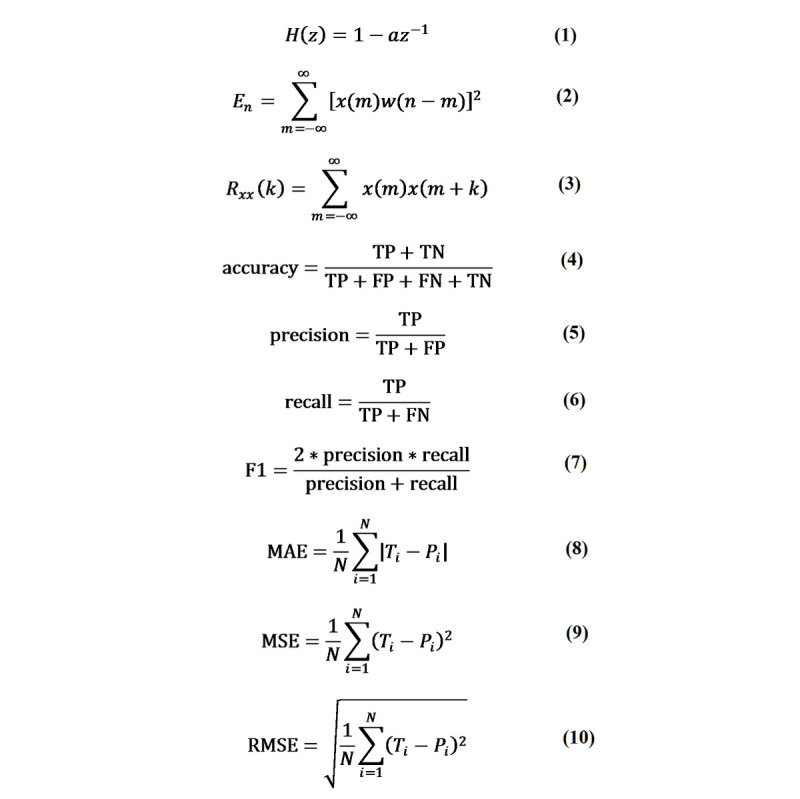
Equations 1-10. FN: false negative; FP: false positive; MAE: mean absolute error; MSE: mean square error; RMSE: root mean square error; TN: true negative; TP: true positive.
The third step is windowing and framing. The speech signal was divided into some shorter signal segments (ie, frames) for processing, which is the framing process, such that the signal can be treated as stationary in the short-time window. In practice, to reduce the impact of segmenting on the statistical properties of the signal, we applied windowing to the temporal segments. The frame width in our work was set as 25 milliseconds long, the frame shift was 10 milliseconds long, and the Hamming window was leveraged as the window function.
The fourth step is silent discrimination. Because there is no guarantee that the collected audio files will always have sound, it is necessary to filter out the blank periods of those sounds. Therefore, silent discrimination, also known as voice endpoint detection, was required. A common solution is to use double-threshold methods [17], which are based on the principles of short-time energy, short-term average amplitude, and short-time zero-crossing rate. In our work, for the sake of simplicity and algorithm efficiency, we utilized only short-term energy as the principle for the double-threshold method. The definition of short-term average energy is shown Figure 1, equation 2.
For illustration, as is shown in Figure 2, we let Th and Tl denote the upper and lower thresholds, respectively. The voiced part must have a section above Th. The endpoint energy of the voiced part is equal to Tl. N1 is the starting point, N2 is the ending point, and w is the Hamming window. The fifth step is fundamental frequency extraction. The fundamental frequency refers to the lowest and theoretically strongest frequency in the sound, which reflects the vibration frequency of the sound source. In our work, we adopted the most widely used autocorrelation method to extract the fundamental frequency.
Figure 2.
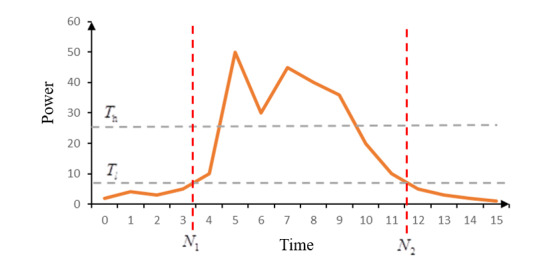
Principle of the double-threshold method. N1: starting point; N2: ending point; Th: upper threshold; Tl: lower threshold.
The short-term autocorrelation function is defined in Figure 1, equation 3. We need to obtain the first positive peak point, Rxx(kf), after crossing the zero point in sequence Rxx(k), and 1/kf is the extracted fundamental frequency.
Note that the audio files may be mixed with unknown noise, which can cause a sudden jump at some points. These points are called wild points or outliers. Therefore, it is necessary to initially remove the wild points. We first calculated the average value of the fundamental frequency of the audio and then deleted the point that was too far from the average value.
Dysphonia Features
In 2012, Tsanas et al summarized 132 features of speech impairments [11]. Considering the speed requirement of the real-time system, the selected model cannot use all of the features. The final selected features [18-23] are illustrated in Table 2.
Table 2.
Dysphonia features.
| Classification and dysphonia features | Description | |
| Pitch [18] (fundamental frequency) |
|
|
|
|
F0_mean | Mean of pitch |
|
|
F0_max | Max of pitch |
|
|
F0_min | Min of pitch |
|
|
F0_median | Median of pitch |
|
|
F0_std | SD of pitch |
| Jitter [18] (pitch period perturbation) |
|
|
|
|
Jitter | Jitter |
|
|
Jitter_abs | Absolute jitter |
|
|
Jitter_PPQ5 | 5 adjacent points’ jitter |
|
|
Jitter_rap | 3 adjacent points’ jitter |
|
|
Jitter_ddp | Difference of 3 adjacent points’ jitter |
| Shimmer [18] (amplitude perturbation) |
|
|
|
|
Shimmer | Shimmer: percentage |
|
|
Shimmer_dB | Shimmer: decibels (dB) |
|
|
Shimmer_APQ5 | 5 adjacent points’ shimmer |
|
|
Shimmer_APQ3 | 3 adjacent points’ shimmer |
|
|
Shimmer_dda | Difference of 3 adjacent points’ shimmer |
|
|
Shimmer_APQ11 | 11 adjacent points’ shimmer |
| Harmonics-to-noise ratio (HNR) and noise-to-harmonics ratio (NHR) [19] |
|
|
|
|
HNR_mean | Mean of HNR |
|
|
HNR_std | SD of HNR |
|
|
NHR_mean | Mean of NHR |
|
|
NHR_std | SD of NHR |
| Nonlinear feature |
|
|
|
|
DFA | Detrended fluctuation analysis [20] |
|
|
RPDE | Recurrence period density entropy [21] |
|
|
D2 | Correlation dimension [22] |
|
|
PPE | Pitch period entropy [23] |
Problem Formulation
Diagnosis
Because the predicted value in PD diagnosis is discrete and binary, it can be regarded as a two-category classification problem. This paper chose the following classical classification algorithms: (1) SVM, (2) ANN, (3) Naive Bayes, and (4) logistic regression.
Severity Assessment
Because the predicted value (ie, the UPDRS score) is continuous in the assessment of the severity of speech impairment in PD, it can be seen as a regression problem. This paper chose the following classical regression algorithms: (1) SVR, (2) linear regression, and (3) LASSO regression.
Results
Overview
We should initially introduce some indicators to evaluate the quality of the algorithms. First, for a two-category classification problem, there are usually the following classification results, as seen in Table 3.
Table 3.
Classification confusion matrix.
| Class | Predictive class | Predictive negative class |
| Actual positive class | True positive (TP) | False negative (FN) |
| Actual negative class | False positive (FP) | True negative (TN) |
Then, the indicators are generally employed to evaluate the classification effect (see Figure 1, equations 4-7). The accuracy represents the proportion of subjects who are classified correctly out of the total number of subjects; precision indicates the proportion of real patients who are predicted to be sick; recall indicates the proportion of patients who are predicted to be sick; and the F1 value is the harmonic mean of the accuracy rate and the recall rate. In our PD diagnosis task, if a normal user is detected to be sick, the impact is usually not large, since we can continue to check the result using various clinical methods. However, if a model fails to detect PD, the impact is relatively large. Hence, the most important indicator is the recall rate.
Second, for a regression problem, if the total number of samples is N, the true value of the i-th sample is Ti, and the predicted value is Pi, then the indicators in equations 8-10 (see Figure 1) are available. Among the indicators, mean absolute error (MAE) measures the average magnitude of the errors in a set of predictions, without considering their direction; mean square error (MSE) and root mean square error (RMSE) are quadratic scoring rules that also measure the average magnitude of the error. However, both MSE and RMSE give a relatively higher weight to large errors. As a result, they are more useful when large errors are particularly undesirable.
According to the characteristics of the dataset, different experiments were performed on the three kinds of datasets downloaded from UCI. The characteristics of these datasets are shown in Table 4.
Table 4.
Characteristics of three datasets from the University of California Irvine.
| Data characteristics | Dataset 1 | Dataset 2 | Dataset 3 | |
| Creation date (year/month/day) | 2008/06/26 | 2014/06/12 | 2009/10/29 | |
| Number of subjects |
|
|
|
|
|
|
Parkinson disease | 23 | 48 | 42 |
|
|
Non-Parkinson disease | 8 | 20 | 0 |
| Number of records (ie, samples) | 195 | 1208 | 5875 | |
| Number of features | 22 | 26 | 18 | |
| Task | Classification | Classification and regression | Regression | |
All results are based on experiments with 5-fold cross validation. To evaluate our models’ efficiency and effectiveness, for the PD diagnosis (ie, classification task), the ratio of the training set to the validation set was 4:1 in the first two datasets. We then used a dataset collected from a local hospital as the test dataset. The data collection table is shown in Multimedia Appendix 1. We collected a dataset that included 14 PD patients and 30 non-PD patients in total. For the PD severity evaluation (ie, regression task), the ratio of training set to the validation set to the testing set was 4:1:1 in the third dataset. The testing results are shown in the following paragraphs.
For the first set of data [9], we conducted classification experiments according to a combination of linear and nonlinear features; the final result is shown in Table 5.
Table 5.
Classification results for the first set of data.
| Algorithm | Accuracy (%) | Precision (%) | Recall (%) | F1 score (%) |
| Support vector machine | 88.74 a | 88.89 | 97.03 | 92.55 |
| Logistic regression | 85.71 | 89.97 | 91.32 | 90.18 |
| Neural network (single layer) | 88.68 | 91.16 | 94.26 | 92.45 |
| Neural network (double layer) | 88.63 | 92.55 | 93.38 | 92.71 |
| Naive Bayes | 69.24 | 96.02 | 62.37 | 75.21 |
aItalics represent the highest values.
We can see that the combination of linear and nonlinear features for the diagnosis of PD patients is feasible and effective. The SVM algorithm achieved higher accuracy and recall rate, and the Naive Bayes algorithm had the worst effect. According to the previous discussion, the recall rate is the most important indicator. At the same time, considering the speed requirement of the mobile app, our system finally leveraged the SVM algorithm to perform the PD patient diagnosis. From Multimedia Appendix 2, we can see that these features have small P values, especially for the nonlinear features, which statistically show the effectiveness of these features.
For the second set of data [24], we conducted classification experiments using only linear features, and the final result is demonstrated in Table 6.
Table 6.
Classification results for the second set of data.
| Algorithm | Accuracy, % | Precision, % | Recall, % | F1 score, % |
| Support vector machine | 66.71 | 66.37 | 83.71 a | 73.98 |
| Logistic regression | 66.56 | 67.68 | 79.08 | 72.84 |
| Neural network (single layer) | 70.78 | 71.13 | 81.54 | 75.89 |
| Neural network (double layer) | 70.29 | 71.45 | 80.81 | 75.40 |
| Naive Bayes | 59.36 | 61.80 | 73.78 | 67.19 |
aItalics represent the highest values.
It can be clearly seen that using only linear features for PD diagnosis brings about a poor model performance, which is consistent with the conclusion from Tsanas et al [11] that feeding linear features into speech models is not very satisfactory. Meanwhile, some researchers claimed that nonlinear features are more effective [23], and another PD speech dataset analysis study [24] also obtained similar results. In particular, our experimental results showed that the SVM algorithm achieved a relatively high recall rate.
For the third set of data (ie, regression) [25], we tested multiple regression algorithms on the third dataset. The final result is illustrated in Table 7.
Table 7.
Regression results on the third dataset.
| Algorithm | Mean absolute error | Mean square error | Root mean square error |
| Linear regression | 8.0786 | 95.1344 | 9.7494 |
| Support vector machine | 3.7699 a | 34.1202 | 5.8357 |
| Least absolute shrinkage and selection operator | 8.0687 | 91.1600 | 9.7452 |
aItalics represent the best values.
Experimental results showed that both linear and nonlinear features contribute to the severity assessment of PD patients. Among regression algorithms, the SVR algorithm achieved the best performance on each indicator, and the prediction results of LASSO and linear regressions were not much different; the reason for this is that LASSO regression is actually a variant of linear regression. Hence, the system finally adopted SVR as the severity evaluation method.
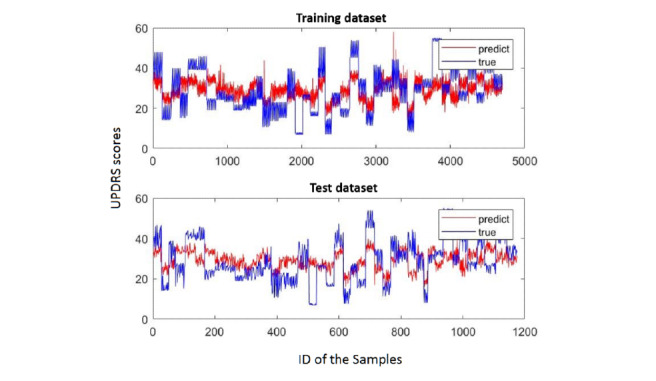
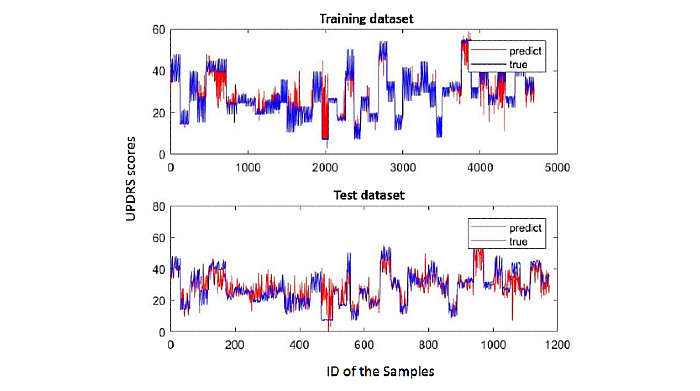
In particular, we selected the best results from each algorithm and observed the degree of fit. Figures 3-5 show the fitting results of the aforementioned three methods. In each figure, the upper graph is the degree of fitting of the training set and the lower graph is the degree of fitting of the test set; the red line is the predicted value and the blue line is the true value. It can be seen from these three figures that SVR fits the best.
Figure 3.
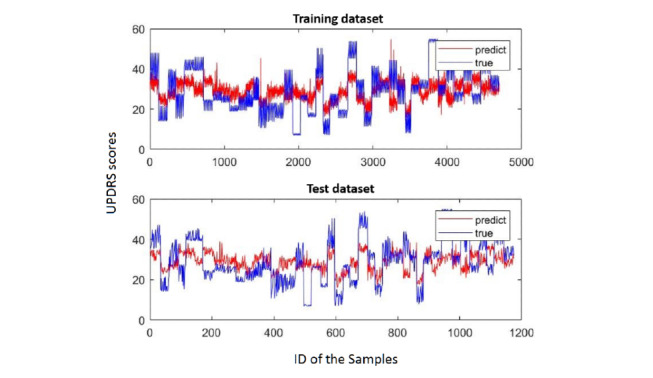
Linear regression fitting. The red line is the predicted value and the blue line is the true value. UPDRS: Unified Parkinson's Disease Rating Scale.
Figure 5.
Least absolute shrinkage and selection operator (LASSO) fitting. The red line is the predicted value and the blue line is the true value. UPDRS: Unified Parkinson's Disease Rating Scale.
As we know, LASSO can perform feature selection [26] by setting the feature weights to zero. The five characteristics most relevant to the value are shown in Table 8.
Table 8.
Top five principal characteristics.
| Feature | Corresponding weighted value |
| Age | 2.84 |
| Harmonics-to-noise ratio mean | –2.66 |
| Absolute jitter | –2.18 |
| Detrended fluctuation analysis | 2.14 |
| Pitch period entropy | 1.51 |
Figure 4.
Support vector regression (SVR) fitting. The red line is the predicted value and the blue line is the true value. UPDRS: Unified Parkinson's Disease Rating Scale.
It can be considered that these five characteristics are highly correlated with the UPDRS score. Age itself is highly related to PD, and the rest of the characteristics have three nonlinear features—HNR mean is also a nonlinear feature—indicating the importance of nonlinear features. Gender also explains why the regression result of the second set of data was relatively poor.
From Multimedia Appendix 2, we see that these features all have small P values—the features of the Jitter series may be a bit higher than others—which proves that we need these features for our system.
In summary, the PD speech detection system uses SVM and SVR for PD speech diagnosis and severity assessment, respectively.
System
System Overview
Figure 6 shows the architecture of our app system—called the No Pa app—including voice signal collection, data preprocessing, data storage and access, and signal modeling. At its core, the PD diagnosis model is SVM trained by the first set of data and the PD severity assessment model is SVR trained by the third set of data. Meanwhile, Figure 6 displays the four key functions and the operating environment in the application layer.
Figure 6.
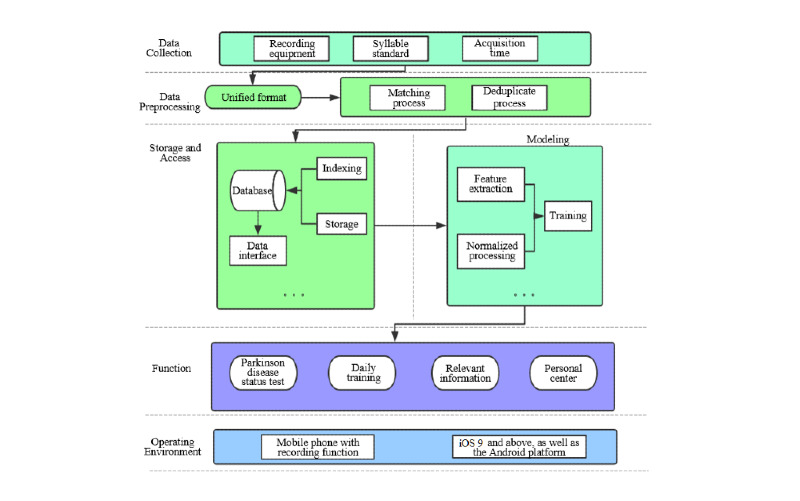
Architecture overview of the No Pa app system.
The Main Function
Android and iOS versions of the No Pa mobile app are currently available online. The app includes four functions—state test, daily training, related information, and personal center—which are shown as follows (see Figure 7 for a few screen captures):
Figure 7.
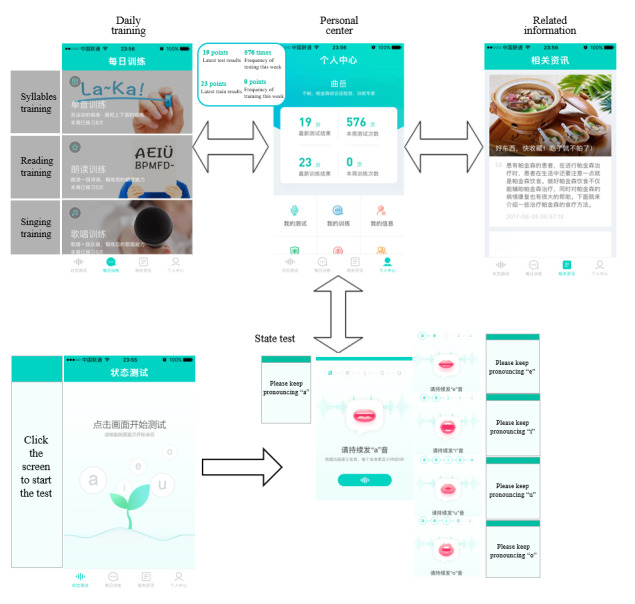
Screen captures from the No Pa app showing four functional modules.
State test: the subject pronounces five long vowels according to the voice guidance, and each long vowel sound lasts for 5 seconds. Then, our system will calculate the current speech impairment severity status.
Daily training: the daily training function aims to improve subjects’ speech impairment status by encouraging them to speak. It includes monophonic training, reading training, and singing training. Monophonic training includes the user's pronunciation training according to some specific single syllables; during reading training, the user reads ancient poetry; and singing training improves the user's daily training interest via singing songs. Note that each training function will give a corresponding feedback score according to our speech signals model. However, since the calculation is not based on the five long vowels, the scores may not be accurate, but it is acceptable since our aim is to attract subjects’ attention to daily training in speaking.
Related information: this function provides users with some advice about PD and physical health.
Personal center: this function helps the user view their testing history and some personal information.
Back-End Configuration
The back-end server of the No Pa app is the Alibaba Cloud Server. Its configuration is as follows: 4-core central processing unit (CPU), 8 GB RAM, 64-bit Ubuntu system, and 200 GB disk space.
Algorithm Acceleration
The original system’s computational cost can range from 20 to 30 seconds without any acceleration techniques. Experimental results showed that autocorrelation calculation is the most time-consuming unit, so the C++ programming language was used to accelerate the autocorrelation calculation. To speed up the system, we adopted MEX (MATLAB executable) technology [27] as the acceleration scheme. In the end, the computational cost for predicting UPDRS scores was compressed from 20 seconds to only about 1 second. This response time is acceptable for an app.
Guide and Interaction
For better a user experience, we provided voice-guided navigation that can offer step-by-step instructions. Meanwhile, considering that PD patients may suffer from hand tremors, we designed big buttons in this app. Moreover, if they do not click the recording function button or the system fails to record an effective sound, the system will give them a reminder.
Discussion
Principal Findings
Traditionally, PD patients need to be diagnosed by physical examination. We can now use a mobile app to help conduct straightforward and rapid detection. For PD patients or healthy people, instant detection and consistent monitoring of disease conditions are extremely important. For doctors, the app can be used as a decision-support tool to provide assistance in treatment and diagnosis.
We have built this mobile app by embedding a voice-oriented system. At the core of the system are machine learning algorithms. Experimental results showed that SVM and SVR achieved the best performance for the diagnosis (ie, classification task) and severity evaluation (ie, regression task) of PD, respectively. The recall rate of the classification task can reach 97.03% (ie, the patient's recognition ability), and the absolute average error of the regression task can reach 3.7699, which is acceptable since the value of UPDRS scores range from 0 to 199.
Finally, we will summarize the contributions of our work. We have built a voice-oriented system that can remotely and conveniently diagnose PD. The system first collects a user’s five long vowels and then efficiently extracts dysphonia features, such that machine learning algorithms can be applied to the classification or regression of PD-related tasks. First, the system has been integrated into an app for public use. Second, our experiments have validated the effectiveness of voice signal–related features proposed by mainstream studies. Third, our system incorporates voice signal collection, feature extraction, and an algorithm interface, which can be regarded as a standard open-source platform for new algorithm development in voice signal–oriented disease identification tasks.
Comparison With Prior Work
There have been various studies utilizing vocal features for PD diagnosis or severity evaluation. More specifically, Lahmiri et al [7] proposed a study about diagnosing PD based on dysphonia measures. They chose the same dataset as our first dataset and their results are similar to ours. However, our method achieved a higher recall value on this dataset. Wroge et al [8] also focused on PD diagnosis by speech signal analysis. After some speech signal processing, they extracted two groups of features—Audio-Visual Emotion recognition Challenge (AVEC) [12] and Geneva Minimalistic Acoustic Parameter Set (GeMAPS) features [13]—which were then fed into some machine learning models. However, their feature extraction process relied on some existing tools, which are not easily integrated into an app. In particular, their work needs to extract 1262 features while our work only extracts 24 features. Moreover, the accuracy of their results based on SVM and ANN were both lower than ours. Similar work that is based on the above features can be found in Tracy et al [28]. Deep learning methods have also been leveraged to learn patterns from vocal feature sets [29]. However, their model lacks explanations due to the inherent nature of deep learning models and achieves an inferior performance compared with our model. Moreover, besides PD diagnosis, our system realizes PD severity evaluation, which may be more helpful for patients and doctors.
Limitations
Our data were collected from healthy people and patients with PD from Dalian, China; the quantity of data is still not big enough. In the future, we plan to collect more disease-related data from different regions worldwide to improve the generalization of the model. At the same time, we will use deep learning methods to study the speech signals of patients with PD to avoid cumbersome manual extraction of speech signals.
Acknowledgments
We are deeply indebted to people from the Department of Neurology, the First Affiliated Hospital of Dalian Medical University, China, who supported us with data collection and offered us a lot of professional advice. In addition, we owe our thanks to all volunteers, who allowed us to collect their voice data with patience, and all users of the No Pa app. This study was supported by the National Key R&D Program of China (2018YFC0116800), the National Natural Science Foundation of China (No. 61772110), the China Education and Research Network (CERNET) Innovation Project (NGII20170711), the Program of Introducing Talents of Discipline to Universities (Plan 111) (No. B20070), and the Liaoning Provincial Hospital Reform Focus on Diagnosis and Treatment in Clinical Departments: Parkinson's Disease and Related Movement Disorders in Individualized Diagnosis and Neural Control Platform Construction Project (LNCCC-C06-2015).
Abbreviations
- ANN
artificial neural network
- AVEC
Audio-Visual Emotion recognition Challenge
- CERNET
China Education and Research Network
- COVID-19
coronavirus disease 2019
- CPU
central processing unit
- GeMAPS
Geneva Minimalistic Acoustic Parameter Set
- HNR
harmonics-to-noise ratio
- LASSO
least absolute shrinkage and selection operator
- MAE
mean absolute error
- MEX
MATLAB executable
- MSE
mean square error
- PD
Parkinson disease
- RMSE
root mean square error
- SVM
support vector machine
- SVR
support vector regression
- UCI
University of California Irvine
- UPDRS
Unified Parkinson Disease Rating Scale
Data collection table.
P values for linear and nonlinear features.
Footnotes
Conflicts of Interest: None declared.
References
- 1.Kano O, Ikeda K, Cridebring D, Takazawa T, Yoshii Y, Iwasaki Y. Neurobiology of depression and anxiety in Parkinson's disease. Parkinsons Dis. 2011;2011:143547. doi: 10.4061/2011/143547. doi: 10.4061/2011/143547. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Davie CA. A review of Parkinson's disease. Br Med Bull. 2008;86:109–127. doi: 10.1093/bmb/ldn013. doi: 10.1093/bmb/ldn013.ldn013 [DOI] [PubMed] [Google Scholar]
- 3.Ho AK, Iansek R, Marigliani C, Bradshaw JL, Gates S. Speech impairment in a large sample of patients with Parkinson’s disease. Behav Neurol. 1999;11(3):131–137. doi: 10.1155/1999/327643. http://downloads.hindawi.com/journals/bn/1999/327643.pdf . [DOI] [PubMed] [Google Scholar]
- 4.Mahler LA, Ramig LO, Fox C. Evidence-based treatment of voice and speech disorders in Parkinson disease. Curr Opin Otolaryngol Head Neck Surg. 2015;23(3):209–215. doi: 10.1097/MOO.0000000000000151. doi: 10.1097/MOO.0000000000000151. [DOI] [PubMed] [Google Scholar]
- 5.Miller N, Noble E, Jones D, Burn D. Life with communication changes in Parkinson's disease. Age Ageing. 2006 May;35(3):235–239. doi: 10.1093/ageing/afj053.afj053 [DOI] [PubMed] [Google Scholar]
- 6.Fox CM, Morrison CE, Ramig LO, Sapir S. Current perspectives on the Lee Silverman Voice Treatment (LSVT) for individuals with idiopathic Parkinson disease. Am J Speech Lang Pathol. 2002 May;11(2):111–123. doi: 10.1044/1058-0360(2002/012). https://pubs.asha.org/doi/10.1044/1058-0360%282002/012%29 . [DOI] [Google Scholar]
- 7.Lahmiri S, Dawson DA, Shmuel A. Performance of machine learning methods in diagnosing Parkinson's disease based on dysphonia measures. Biomed Eng Lett. 2018 Feb;8(1):29–39. doi: 10.1007/s13534-017-0051-2. http://europepmc.org/abstract/MED/30603188 .51 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Wroge TJ, Özkanca Y, Demiroglu C, Si D, Atkins DC, Ghomi RH. Parkinson’s disease diagnosis using machine learning and voice. Proceedings of the IEEE Signal Processing in Medicine and Biology Symposium (SPMB); IEEE Signal Processing in Medicine and Biology Symposium (SPMB); December 1, 2018; Philadelphia, PA. 2018. pp. 1–7. [DOI] [Google Scholar]
- 9.Little M, McSharry P, Hunter E, Spielman J, Ramig L. Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. Nat Precedings. 2008 Sep 12;:1–27. doi: 10.1038/npre.2008.2298.1. https://www.nature.com/articles/npre.2008.2298.1.pdf . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Guo PF, Bhattacharya P, Kharma N. Advances in detecting Parkinson’s disease. Proceedings of the 2nd International Conference on Medical Biometrics; 2nd International Conference on Medical Biometrics; June 28-30, 2010; Hong Kong, China. 2010. Jun, pp. 306–314. [DOI] [Google Scholar]
- 11.Tsanas A, Little MA, McSharry PE, Spielman J, Ramig LO. Novel speech signal processing algorithms for high-accuracy classification of Parkinson's disease. IEEE Trans Biomed Eng. 2012 May;59(5):1264–1271. doi: 10.1109/TBME.2012.2183367. doi: 10.1109/TBME.2012.2183367. [DOI] [PubMed] [Google Scholar]
- 12.Valstar M, Schuller B, Smith K, Eyben F, Jiang B, Bilakhia S, Pantic M. AVEC 2013: The continuous audio/visual emotion and depression recognition challenge. Proceedings of the 3rd ACM International Workshop on Audio/Visual Emotion Challenge (AVEC '13); 3rd ACM International Workshop on Audio/Visual Emotion Challenge (AVEC '13); October 21-25, 2013; Barcelona, Spain. 2013. pp. 3–10. https://dl.acm.org/doi/10.1145/2512530.2512533 . [DOI] [Google Scholar]
- 13.Eyben F, Scherer KR, Schuller BW, Sundberg J, Andre E, Busso C, Devillers LY, Epps J, Laukka P, Narayanan SS, Truong KP. The Geneva Minimalistic Acoustic Parameter Set (GeMAPS) for voice research and affective computing. IEEE Trans Affect Comput. 2016 Apr 1;7(2):190–202. doi: 10.1109/taffc.2015.2457417. [DOI] [Google Scholar]
- 14.Tsanas A. Accurate Telemonitoring of Parkinson’s Disease Symptom Severity Using Nonlinear Speech Signal Processing and Statistical Machine Learning [doctoral thesis] Oxford, UK: University of Oxford; 2012. Jun, [2012-12-30]. https://ora.ox.ac.uk/objects/uuid:2a43b92a-9cd5-4646-8f0f-81dbe2ba9d74/download_file?file_format=pdf&safe_filename=DPhil%2Bthesis_post_viva_v8.pdf&type_of_work=Thesis . [Google Scholar]
- 15.Movement Disorder Society Task Force on Rating Scales for Parkinson's Disease The Unified Parkinson's Disease Rating Scale (UPDRS): Status and recommendations. Mov Disord. 2003 Jul;18(7):738–750. doi: 10.1002/mds.10473. [DOI] [PubMed] [Google Scholar]
- 16.Cohen I, Benesty J, Gannot S, editors. Speech Processing in Modern Communication: Challenges and Perspectives. Berlin, Germany: Springer-Verlag; 2010. [Google Scholar]
- 17.Sakhnov K, Verteletskaya E, Simak B. Dynamical energy-based speech/silence detector for speech enhancement applications. Proceedings of the World Congress on Engineering (WCE 2009). Volume I; World Congress on Engineering (WCE 2009); July 1-3, 2009; London, UK. 2009. Jul, p. 801. http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=6AACCA0D6A768D38D72BF9E501C027C8?doi=10.1.1.149.3572&rep=rep1&type=pdf . [Google Scholar]
- 18.Boersma P, Weenink D. Praat: Doing phonetics by computer. Phonetic Sciences, University of Amsterdam. 2002. [2020-09-02]. http://webcache.googleusercontent.com/search?q=cache:EwTtYfw9KBAJ:fon.hum.uva.nl/praat/+&cd=1&hl=en&ct=clnk&gl=ca .
- 19.Ferrer CA, González E, Hernández-Díaz ME. Evaluation of time and frequency domain-based methods for the estimation of harmonics-to-noise-ratios in voice signals. Proceedings of the Iberoamerican Congress on Pattern Recognition (CIARP 2006); Iberoamerican Congress on Pattern Recognition (CIARP 2006); November 14-17, 2006; Cancun, Mexico. 2006. Nov, pp. 406–415. [DOI] [Google Scholar]
- 20.Peng CK, Buldyrev SV, Havlin S, Simons M, Stanley HE, Goldberger AL. Mosaic organization of DNA nucleotides. Phys Rev E Stat Phys Plasmas Fluids Relat Interdiscip Topics. 1994 Feb;49(2):1685–1689. doi: 10.1103/physreve.49.1685. [DOI] [PubMed] [Google Scholar]
- 21.Kim H, Eykholt R, Salas JD. Nonlinear dynamics, delay times, and embedding windows. Physica D. 1999 Mar;127(1-2):48–60. doi: 10.1016/S0167-2789(98)00240-1. doi: 10.1016/S0167-2789(98)00240-1. [DOI] [Google Scholar]
- 22.Janjarasjitt S, Scher MS, Loparo KA. Nonlinear dynamical analysis of the neonatal EEG time series: The relationship between sleep state and complexity. Clin Neurophysiol. 2008 Aug;119(8):1812–1823. doi: 10.1016/j.clinph.2008.03.024.S1388-2457(08)00211-3 [DOI] [PubMed] [Google Scholar]
- 23.Little MA, McSharry PE, Roberts SJ, Costello DA, Moroz IM. Exploiting nonlinear recurrence and fractal scaling properties for voice disorder detection. Biomed Eng Online. 2007;6(1):23. doi: 10.1186/1475-925X-6-23. doi: 10.1186/1475-925X-6-23. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Sakar BE, Isenkul ME, Sakar CO, Sertbas A, Gurgen F, Delil S, Apaydin H, Kursun O. Collection and analysis of a Parkinson speech dataset with multiple types of sound recordings. IEEE J Biomed Health Inform. 2013 Jul;17(4):828–834. doi: 10.1109/JBHI.2013.2245674. doi: 10.1109/JBHI.2013.2245674. [DOI] [PubMed] [Google Scholar]
- 25.Tsanas A, Little MA, McSharry PE, Ramig LO. Accurate telemonitoring of Parkinson's disease progression by noninvasive speech tests. IEEE Trans Biomed Eng. 2010 Apr;57(4):884–893. doi: 10.1109/TBME.2009.2036000. doi: 10.1109/TBME.2009.2036000. [DOI] [PubMed] [Google Scholar]
- 26.Tibshirani R. Regression shrinkage and selection via the lasso. J R Stat Soc Series B Stat Methodol. 2018 Dec 05;58(1):267–288. doi: 10.1111/j.2517-6161.1996.tb02080.x. doi: 10.1111/j.2517-6161.1996.tb02080.x. [DOI] [Google Scholar]
- 27.Eshkabilov S. Beginning MATLAB and Simulink: From Novice to Professional. New York, NY: Apress; 2019. MEX files, C/C++, and standalone applications; pp. 259–273. [Google Scholar]
- 28.Tracy JM, Özkanca Y, Atkins DC, Hosseini Ghomi R. Investigating voice as a biomarker: Deep phenotyping methods for early detection of Parkinson's disease. J Biomed Inform. 2020 Apr;104:103362. doi: 10.1016/j.jbi.2019.103362.S1532-0464(19)30282-5 [DOI] [PubMed] [Google Scholar]
- 29.Gunduz H. Deep learning-based Parkinson’s disease classification using vocal feature sets. IEEE Access. 2019;7:115540–115551. doi: 10.1109/ACCESS.2019.2936564. doi: 10.1109/ACCESS.2019.2936564. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data collection table.
P values for linear and nonlinear features.