

Abstract
This paper presents a preconditioned Krasnoselskii-Mann (KM) algorithm with an improved EM preconditioner (IEM-PKMA) for higher-order total variation (HOTV) regularized positron emission tomography (PET) image reconstruction. The PET reconstruction problem can be formulated as a three-term convex optimization model consisting of the Kullback–Leibler (KL) fidelity term, a nonsmooth penalty term, and a nonnegative constraint term which is also nonsmooth. We develop an efficient KM algorithm for solving this optimization problem based on a fixed-point characterization of its solution, with a preconditioner and a momentum technique for accelerating convergence. By combining the EM precondtioner, a thresholding, and a good inexpensive estimate of the solution, we propose an improved EM preconditioner that can not only accelerate convergence but also avoid the reconstructed image being “stuck at zero.” Numerical results in this paper show that the proposed IEM-PKMA outperforms existing state-of-the-art algorithms including, the optimization transfer descent algorithm and the preconditioned L-BFGS-B algorithm for the differentiable smoothed anisotropic total variation regularized model, the preconditioned alternating projection algorithm, and the alternating direction method of multipliers for the nondifferentiable HOTV regularized model. Encouraging initial experiments using clinical data are presented.
Keywords: Krasnoselskii-Mann algorithm, image reconstruction, maximum likelihood estimation, positron emission tomography, total variation
I. Introduction
POSITRON emission tomography (PET) is a well-established technique for molecular imaging, where it can produce spatial (and temporal) estimates of a particular tracer’s bio-distribution (images). These images have been instrumental in diagnosis, staging, and are rapidly extending into therapy and response assessment. As a result, improved estimates of the tracer distribution may allow physicians and scientists to more accurately interpret the implications of these bio-distributions and improve patient outcomes. However, because of important health consideration, basic physical processes and work-flow issues, the data is inherently count and resolution limited and must be reconstructed within a few minutes of acquisition. As a result, a great deal of effort has gone into improving both the speed and accuracy of the estimation of the PET tracer distributions.
At present, these efforts have evolved in a penalized likelihood (PL) model where a data fidelity term (KL-divergence for PET, e.g., Poisson data noise models) plus one or more penalty terms to regularize the estimated images are optimized to produce the most likely image given the data and penalty. Despite the introduction of penalty terms can improve the quality of reconstructed images, these penalty terms may be nondifferentiable or even nonconvex, which makes it difficult to develop efficient algorithms for solving the PL model. To address this issue, many algorithms and penalties have been proposed, but without guidance, it is difficult to know if a particular algorithm or penalty is suitable for routine imaging.
The total variation (TV) penalty (regularization) introduced by [1] has had a great deal of success in image denoising by removing unwanted noise while preserving important details such as edges, and has been used successfully in medical imaging modalities, such as CT or MR. Unfortunately, TV can introduce piecewise constant (staircase) artifacts in the smoothly varying regions of the images, which make it unsuitable for PET. However, the addition of a second-order term, which we refer to throughout this paper as a higher-order TV (HOTV) penalty [2], [3], allows the preservation of edges at known tracer boundaries (e.g. liver, bladder, heart, brain, and, in the case of dynamic imaging, at the boundaries of blood vessels), while suppressing the undesired staircase artifacts.
Classical gradient-type algorithms are unable to solve TV or HOTV regularized models due to the nondifferentiability of their objective functions. To address this while maintaining their edge-preserving properties, [4]-[7] have used smooth approximations of the absolute value function to replace the ℓ1 regularized model with a differentiable one. Efficient algorithms, including the preconditioned conjugate-gradient algorithm (PCG) [4], the optimization transfer descent algorithm (OTDA) [6], [8] and the preconditioned limited-memory Broyden-Fletcher-Goldfarb-Shanno with boundary constraints algorithm (L-BFGS-B-PC) [7], have been proposed for solving these smooth edge-preserving regularized models. Though the smooth approximation method used here can avoid the problem of nondifferentiability, it requires a tuning parameter, which is not part of the penalty weight. If this parameter is set too large, the smooth penalty will lose its edge-preserving property, and if it is set too small, as mentioned in [8], convergence of classical gradient-type algorithms may be slow. Therefore, it is necessary to develop new efficient algorithms to directly solve nondifferentiable models.
Recently, many algorithms have been proposed for nondifferentiable regularized models, including EM-based methods [9]-[11], projected quasi-Newton methods [12]-[14], forward-backward approach [15], primal-dual methods [16]-[18], augmented Lagrangian methods [19], [20], and fixed-point proximity methods [3], [21], [22]. Among these algorithms, the alternating direction method of multipliers (ADMM) [19], [20] and preconditioned alternating projection algorithm (PAPA) [3], [21] have shown good performance for regularized emission computed tomography (ECT) image reconstruction. In particular, [21] and [3] have shown that PAPA outperforms the nested EM-TV algorithm [11], the one-step-late method with TV regularization [9], and the preconditioned primal-dual algorithm [17], [23].
The fast proximity-gradient algorithm (FPGA) [24], derived from the multi-step fixed-point proximity framework [25], was developed for general three-term optimization problems. This algorithm has some desirable properties. For example, its development was guided by constructing an averaged nonexpansive operator for fixed-point iteration that guarantees monotone convergence. That is, as the fixed-point iteration proceeds, the distance between the iterative result and the true solution is monotone decreasing. Moreover, the inner iteration, required for ADMM, is unnecessary, which results in more stable convergence. To improve the convergence speed, FPGA introduced the Nesterov momentum technique [26], [27]. However, FPGA does not provide a strategy for choosing efficient preconditioners for three-term optimization problems.
An alternative fixed-point algorithm, PAPA, introduces the EM preconditioner instead of a step-size parameter, which greatly improves its convergence. Although the use of the EM preconditioner in PAPA makes it an efficient algorithm for solving the HOTV regularized PET reconstruction model, both PAPA and the preconditioner introduce problems. In PAPA, the use of extra-gradient step (via reuse of the forward and backward projections), makes it difficult to prove the convergence of PAPA with a momentum technique. This arises because such a method may not be reformulated as a fixed-point iteration of an averaged nonexpansive operator. Another problem is that the classical EM preconditioning matrix may not be strictly positive definite. If a component of the reconstructed image becomes zero or very close to zero at an iteration step, then this component will be stuck at zero in all the remaining iterations.
Based on the construction of averaged nonexpansive operator in FPGA and the EM preconditioner, we propose an efficient preconditioned KM algorithm (PKMA) with an improved EM (IEM) preconditioner that can be easily proven convergent with a momentum technique as well as a preconditioner, and can at the same time avoid the reconstructed images being “stuck at zero.” In PKMA, we propose a simpler but more general form of momentum parameters compared to those used in the Nesterov momentum scheme. The generality of our proposed momentum parameters is demonstrated by two properties. First, our proposed momentum parameters includes the absence of momentum as a special case. Second, we prove that the Nesterov momentum parameters are asymptotically equivalent to a special case of our proposed momentum parameters. The use of the KM based momentum scheme obtains a better approximation of the solution by adding the current fixed-point update to the difference between the current fixed-point update and the update from prior iteration. We will show that, with proper selection of a factor of the difference term (momentum term), this KM based momentum scheme can ensure faster convergence toward the solution. The KM approach is a generalization of fixed-point approach, which leads to a simple convergence proof and provides insight toward choosing the algorithmic parameters.
This paper is organized in four sections and two appendices. In section II, we first describe the HOTV regularized PET image reconstruction model, then develop a preconditioned KM algorithm with an improved EM preconditioner for solving this model. A proof for convergence of PKMA is included. Section III presents simulation results for comparison of our proposed IEM-PKMA with OTDA and L-BFGS-B-PC for the differentiable smoothed anisotropic TV (SATV) regularized model, and that with PAPA and ADMM for the nondifferentiable HOTV regularized model. Initial experiments using clinical data are also presented. Section IV offers a conclusion. In the appendices, we provide technical details for development of PKMA and analysis of its convergence.
II. PET Image Reconstruction
We develop in this section a preconditioned KM algorithm with an improved EM preconditioner for solving the HOTV regularized PET reconstruction model. Here we limit the discussion to only the case of the first-order plus the second-order TV penalty.
A. HOTV Regularized PET Image Reconstruction Model
We begin with describing the HOTV regularized PET reconstruction model. We denote by the set of all nonnegative real numbers. For two positive integers m and d, denotes the PET system matrix whose (i, j)th entry equals to the probability of detection of the photon pairs emitted from the jth voxel of the radiotracer distribution within a patient (or a phantom) by the ith detector bin pair. The vector represents the mean value of the background noise from random and scatter coincidences. The relation of projection data of a PET system with the radiotracer distribution f can be described by the Poisson model
| (1) |
where Poisson(x) denotes a Poisson-distributed random vector with mean x. System (1) may be solved by minimizing the following fidelity term
| (2) |
where is the vector whose components are all 1, the logarithmic function at is defined by ln x := [ln x1, ln x2, … , ln xn]⊤, and is the inner product of x, .
Minimization of the fidelity term is well-known to be ill-posed [5], which results in severe over-fitting in the reconstructed image. To avoid this over-fitting problem, regularization terms were introduced as part of the reconstruction model. In this study, using both the first-order and the second-order TV penalties, we get the following HOTV regularized PET image reconstruction model
| (3) |
where φ1 ∘ B1 and φ2 ∘ B2 represent the first-order and second-order TV, respectively. The two functions φ1, φ2 are defined by the ℓ1-norm for the anisotropic TV or the ℓ2-norm for the isotropic TV, and thus they are convex. Here , are the first-order and second-order difference matrices, respectively, and λ1, are the corresponding regularization parameters. For the detailed definitions of φ1, φ2 and B1, B2, see Appendix A. The indicator function ı on is defined by
To simplify notation, we define m0 := m1 + m2, for with , ,
| (4) |
Then model (3) can be written in a compact form
| (5) |
This is the model on which the proposed reconstruction algorithm is based.
B. Preconditioned Krasnoselskii-Mann Algorithm
We next characterize a solution of model (5) as a fixed-point of a mapping defined via the proximity operator of functions φ and ı. To this end, we let denote the set of n × n symmetric positive definite matrices. For , the H-weighted inner product is defined by ⟨x, y⟩H := ⟨x, Hy⟩ for x, and the corresponding H-weighted ℓ2-norm is defined by . According to [28], for a convex function , the proximity operator of ψ with respect to at is defined by
In particular, we use proxψ for proxψ,I. We let denote the class of all proper lower semicontinuous convex functions defined on and recall that the conjugate ψ* of ψ is defined by . Now we have the following fixed-point characterization of a solution of model (5).
Theorem 1: If is a solution of model (5), then for any and , there exists a vector such that
| (6) |
| (7) |
Conversely, if there exist , , and such that satisfies equations (6) and (7), then f is a solution of model (5).
Proof: It can be verified that in (5), is convex and differentiable with a Lipschitz continuous gradient, and . Using [21, Th. 3.1], we conclude that this theorem holds true. ■
Note that the gradient of the fidelity term F is given by
| (8) |
We shall develop a convergent efficient algorithm for solving model (5) from the fixed-point equations (6) and (7). To this end, we write equations (6) and (7) in a compact form. Define
| (9) |
where In denotes the n × n identity matrix, , are two introduced preconditioning matrices, and define
| (10) |
For the matrix and the operator , we define E – R∇r by (E – R∇r)(v) := E(v)–R∇r(v) for . Then (6) and (7) can be written as the fixed-point equation of T composed with E – R∇r,
This means that if v := [v1, v2, …, vd+m0]⊤ is a fixed-point of T ∘ (E – R∇r), then f = [v1, v2, … , vd]⊤, the subvector of the first d components of v, is a solution of model (5). It was shown in [25] that E is expansive. The fixed-point iteration of T ∘ (E – R∇r) may fail to yield a convergent sequence. To develop a convergent fixed-point algorithm, we choose matrix by
| (11) |
and proceed the fixed-point iteration
| (12) |
where . The iteration (12) is in fact explicit since E – G is strictly block lower triangular (in the block partition as E). We define by
| (13) |
W := R−1G, and let
| (14) |
where denotes the identity operator.
It is important to verify that TG is well-defined. To show this, we let be a given vector, where and . The implicit fixed-point equation (13) then can be written by
| (15) |
| (16) |
Here , . Since and in equation (15) are given, from the definition of proximity operator, we know that the solution of (15) exists and is unique, which implies the existence and uniqueness of the solution of equation (16). This shows that for any given in the equation contained in (13), there exists a unique solution v.
Using the definition of , iteration (12) can be rewritten as the fixed-point iteration
| (17) |
We now comment on convergence of iteration (17). According to [21], ∇F is Lipschitz continuous if all components of γ are positive. Let L denote the Lipschitz constant of ∇F and λW the smallest eigenvalue of W. We will recall the definition of nonexpansive, firmly nonexpansive and averaged nonexpansive operators in Appendix B, and show in Lemma 7 that if , then is ζ-averaged nonexpansive with respect to W, where . The KM theorem (Theorem 4 in Appendix B) implies that iteration (17) converges to a fixed-point of .
To accelerate the convergence speed of iteration (17), for α > 0, we define . Since is αζ-averaged nonexpansive with respect to W, by the KM theorem, we know that the fixed-point iteration
| (18) |
converges to a fixed-point of if . We observe numerically that corresponding to a larger , the fixed-point iteration (18) converges faster. This observation inspires us to choose α ∈ (1, 2) for (18). Iteration scheme (18) may be interpreted as an application of the momentum technique. To see this, we write
Clearly, is an extension of by using a momentum technique. However, we found that iteration (18) is not robust for large α ∈ (1, 2). If the components of the initial vector v0 are too large, to guarantee convergence, the entries of the preconditioning matrix P should be set small, which leads to slow convergence. To overcome this obstacle and obtain a robust fixed-point iteration with momentum acceleration, we use the KM iteration by allowing the momentum parameter α to vary in each iteration. That is, we introduce a sequence of parameters, for given ϱ ∈ (−1, 1) and δ ≥ 0, by
| (19) |
and construct a sequence of operators
| (20) |
Given an initialization , we then proceed the KM based momentum scheme by
| (21) |
We next show that the Nesterov momentum parameters are asymptotically equivalent to a special case of our proposed momentum parameters, defined by (19), by appropriately setting the sub-parameters ϱ and δ. Recall that the Nesterov momentum parameters are given by
| (22) |
When k is sufficient large, in (22) then corresponds to in (19) with the sub-parameter choice ϱ = 1 and δ = 3, in the sense given by Proposition 2. Moreover, the absence of momentum (αk = 1 for all ) is a special case of our proposed momentum scheme with ϱ = 0, which is not the case for the Nesterov momentum since for k ≥ 1. The generality of our proposed momentum scheme provides us a variety of different parameter choices for different scenarios. We now state Proposition 2, whose proof is provided in the supplementary materials. The supplementary materials are available in the supplementary files tab.
Proposition 2: Let be given by (19) with ρ = 1 and δ = 3, and be given by (22). Then and converge to the same value with the same convergence rate.
We now provide specific choice of preconditioning matrices P and Q for iteration (21). We let P := βS and Q := diag (ρ11m1, ρ21m2), where β, ρ1 and ρ2 are positive numbers, S is a d × d diagonal matrix with positive diagonal entries. In this case, it follows from the definition of proximity operator that for ,
| (23) |
The maxima in the above equation is taken component-wise. By using the well-known Moreau decomposition [29]
and the equation
for with , , we have
Now the preconditioned KM algorithm (PKMA) for solving model (3) is given as follows.
One can find the explicit form of proxωφ1 (x) for and proxωφ2 (x) for , where ω > 0, in Appendix A.
In the following theorem, we consider the convergence of PKMA. We let Smax denote the largest diagonal entry of the diagonal matrix S, and .
Theorem 3: Let , and be given vectors, be the sequence generated by PKMA, where ϱ ∈ (−1, 1), δ ≥ 0 and β, ρ1, ρ2 are positive in PKMA. For a given diagonal matrix with positive diagonal entries, if , and , then converges to a solution of model (3).
Proof: By Theorem 8, to prove the theorem, it suffices to verify that λW > ξ. This is done in Lemma 9. ■
Note that in our proof, the preconditioner should be fixed in each iteration. However, we can update it during early iterations and fix it in later iterations to guarantee the convergence.
C. Improved EM Preconditioner
In this subsection, we propose an improved EM (IEM) preconditioner for PKMA to accelerate convergence. We begin by recalling the classical EM preconditioner. To avoid zero components in A⊤1m, we define as a vector such that
| (24) |
for j = 1, 2, …, d. As shown in [21], the EM preconditioner
| (25) |
performs better than the identity preconditioner Id and the diagonal normalization (DN) preconditioner
| (26) |
However, when using the EM preconditioner, once some components of fk are equal to zero, these components will be stuck at zero thereafter, which results in holes in the reconstructed images. Low count data and ordered subsets type algorithms, are particularly susceptible to this problem. From Theorem 3, we know that to guarantee convergence of PKMA, the entries of the diagonal preconditioning matrix S should be positive. However, this may not be the case with the EM preconditioner since some components of fk may be zero. To guarantee the positivity of the preconditioner as well as accelerate convergence, we propose the following IEM preconditioner by including a true mean count (TMC) based thresholding and a good estimate of the true solution f* in the EM preconditioner,
| (27) |
where the positive constant η is set to 0.1 · TMC and
| (28) |
Here ACTc, NPFOV, and NPA represent the total attenuation corrected true counts, the number of pixels within the field of view, and the number of projection angles, respectively.
In the definition of IEM preconditioner given by (27), our choice of the threshold constant 0.1 · TMC was based on TMC being the mean of the components of f*. In addition, as shown in Fig. 2, we empirically found that the inclusion of a good estimate of f* used in the preconditioner leads to faster convergence. This can be exploited by using a good inexpensive estimate of f* for in (27). For example, we can use an image reconstructed by filtered backprojection fFBP as . Alternatively, if we set in (27), then the IEM preconditioner reduces to the case considered in [30].
Fig. 2.

NOFV (left) and NRMSE (right) versus CPU time by PKMA with preconditioners SEM, SIEM(0), , and .
III. Numerical Results
In this section, we present several numerical results. First, we show the performance of different choices of in the IEM preconditioner (27). Then, we compare the performance of different preconditioners and different momentum parameters for PKMA. To see the performance of PKMA with the IEM preconditioner (IEM-PKMA) for differentiable regularized PET image reconstruction model, we compare it with the existing OTDA and L-BFGS-B-PC for the SATV regularized reconstruction model. Following this, we present comparison of PKMA with two existing algorithms, PAPA and ADMM, suitable for nonsmooth penalties. Finally, we provide some initial 3D clinical results of a relaxed ordered subsets version of PKMA (ROS-PKMA).
A. Simulation Setup
We implemented the algorithms via Matlab through a 2D PET simulation model as described in [31]. The number of counts used in these 2D simulations were set to be equivalent to those from a 3D PET brain patient acquisition (administered 370 MBq FDG and imaged 1-hour post injection) collected from the central axial slice via GE D690/710 PET/CT. The resulting reference count distribution was used as the Poisson parameters for the noise realizations. An area integral projection method was used to build the projection matrix based on a cylindrical detector ring consisting of 576 detectors whose width are 4 mm. We set the FOV as 300 mm and use 288 projection angles to reconstruct a 256×256 image.
To simulate the physical factors that will affect the resolution of the reconstructed image, such as positron range, detector width, penetration, residual momentum of the positron and imperfect decoding, the phantom was convolved with an idealized (space-invariant, Gaussian) point spread function (PSF), which was set as a constant over the whole FOV. The full width half maximum (FWHM) of this PSF was set to 6.59 mm based on physical measurements from acceptance testing and [32]. The true count projection data was produced by forward-projecting the phantom convolved by the PSF. Uniform water attenuation (with the attenuation coefficient 0.096 cm−1) was simulated using the PET image support. The background noise was implemented as describe in [33] and was based on 25% scatter fraction and 25% random fraction, given by SF := Sc/(Tc + Sc) and RF:=Rc/(Tc+Sc+Rc), respectively, where Tc, Sc and Rc represent true, random, and scatter counts respectively. Scatter was added by forward-projecting a highly smoothed version of the images, which was added to the attenuated image sinogram scaled by the scatter fraction. Random counts were simulated by adding a uniform distribution to the true and scatter count distributions scaled by the random fraction. We call the summation of Tc, Sc, and Rc the total counts and denote it by TC. In our simulations, we set TC = 6.8 × 106 for the high-count data, and TC = 6.8 × 105 for the low-count data.
We next provide the figure-of-merits used for the comparisons. They include the normalized objective function value (NOFV), normalized root mean square error (NRMSE), normalized relative contrast (NRC) and central line profile (CLP). The NOFV is defined by
where Φ denotes the objective function, Φ0 is the objective function value of the initial image, and Φref denotes the reference objective function value. For simulation results, we set Φref to the objective function value of the image reconstructed by 1000 iterations of IEM-PKMA. The NRMSE is defined by
where is the ground truth, and ∥ · ∥2 is the ℓ2-norm defined by for . For the definition of NRC, we let ROIH be a region within a specific hot sphere, ROIB be a background region that is not close to any hot sphere and its size is the same as ROIH. Define the relative contrast (RC) by , where EROIH and EROIB represent the average activities of ROIH and ROIB, respectively. Then the normalized relative contrast is defined by
where RCfk and RCtrue are the relative contrast of fk and the ground truth respectively.
Two 256 × 256 numerical phantoms shown in Fig. 1 were used for our simulations. The brain phantom was obtained from a high quality clinical PET brain image. The uniform phantom consists of the uniform background with six uniform hot spheres with distinct radii 4, 6, 8, 10, 12, 14 pixels. The activity ratio of the uniform hot spheres to the uniform background is 4:1. In the simulation experiments, we show comparison of NOFV, NRMSE by reconstructing the brain phantom, and NRC, CLP by reconstructing the uniform phantom. All simulations were performed in a 64-bit windows 10 laptop with Intel Core i7-7500U Processor at 2.70 GHz, 8 GB of DDR4 memory and 256GB SATA SSD.
Fig. 1.

(a) Brain phantom: high quality clinical PET brain image. (b) Uniform phantom: uniform background with six uniform hot spheres of distinct radii.
We show the setting of the regularization parameters and the algorithmic parameters of PKMA in Table 1. For the reconstruction of the brain phantom, to suppress the staircase artifacts and avoid over-smoothed images, we empirically found that setting λ2 = λ1 was reasonable and simplified the search for optimal regularization parameters based on the minimum NRMSE. For the uniform phantom, the second-order TV regularization parameters λ2 was set to 0, due to its piecewise constant nature. The setting of ρ1 and ρ2 in PKMA were based on the convergence conditions and the fact that , for the 2D case [34]. The parameters ϱ and δ in the momentum step were set to satisfy that ϱ ∈ (−1, 1) and δ ≥ 0. In addition, we denote by fUD the uniform disk TMC · 1disk with the same size as the FOV, where TMC is defined by (28) and 1disk is the image whose values are 1 within the disk and are 0 outside the disk.
TABLE I.
Regularization Parameters and Algorithmic Parameters for 2D Simulation
| Regularization parameters |
Brain phantom |
High-count: λ1 = λ2 = 0.04 Low-count: λ1 = λ2 = 0.34 |
| Uniform phantom |
High-count: λ1 = 0.4, λ2 = 0 | |
| Algoritdmic parameters |
PKMA | β = 1, , ϱ = 0.9, δ = 0.1 |
| PAPA | β = 1, , | |
| ADMM | σ = τ = 0.1, μ = 1.2 |
B. Simulation Results for IEM-PKMA
1). Comparison of Preconditioners and Momentum Techniques:
In this subsection, we use high-count data to reconstruct the brain phantom for comparison of PKMA with different preconditioners and momentum techniques. The initial image for PKMA was set to fUD. We show in Fig. 2 the plots of NOFV and NRMSE versus CPU time for PKMA with the EM preconditioner and with four different IEM preconditioners: SIEM(0), , and , where , and represent the images reconstructed by EM-PKMA with 2, 20 and 200 iterations respectively. From these figures, we can see that as in the IEM preconditioner (27) is made closer to the solution f*, the convergence of PKMA with the preconditioner improves. For all the experiments of Fig. 3-12, in the IEM preconditioner was always set to fFBP.
Fig. 3.

NOFV (left) and NRMSE (right) versus CPU time by PKMA with IEM, EM and DN preconditioners, FPGA and IEM-PKMA with the Nesterov momentum parameters.
Fig. 12.

Reconstructed images of the uniform phantom by IEM-PKMA, EM-PKMA, PAPA and ADMM with uniform disk initialization using high-count data: top to bottom rows are reconstructed by 5, 10 and 100 iterations respectively.
In Fig. 3, we compare the results for three different preconditioners: IEM, EM and DN preconditioners, which are defined by (27), (25) and (26) respectively. FPGA and IEM-PKMA with the Nesterov momentum parameters (IEM-PKMA-NM) were also presented. There are two differences between FPGA [24] and IEM-PKMA for model (3), which are the choices of preconditioner and momentum parameters. Specifically, FPGA uses Id as the preconditioner, while IEM-PKMA uses the IEM preconditioner, and FPGA selects momentum parameters from Nesterov’s update, while we provide a more general form of momentum parameters given by (19) for IEM-PKMA. To compare the performance of our proposed KM based momentum scheme with Nesterov’s, we replace the momentum parameters of IEM-PKMA by (22), yielding a new method we refer to as IEM-PKMA-NM. Optimal step-size β was tuned for each of DN-PKMA (β = 0.3) and FPGA (β = 0.003) based on the performance of objective function value.
In Fig. 4, we present the normalized root mean square difference (NRMSD) between the images reconstructed by IEM-PKMA and DN-PKMA, as well as the reconstructed images with 5000 iterations. This figure shows that the use of two different positive definite preconditioners SIEM and SDN give the same converged images.
Fig. 4.

(a) NRMSD between the images reconstructed by IEM-PKMA and DN-PKMA versus iteration number. (b) Reconstructed brain images by IEM-PKMA (left) and DN-PKMA (right) with 5000 iterations.
2). Comparison of Algorithms for SATV Regularization:
In this subsection, we show how IEM-PKMA performs using a smoothed approximation of a first-order edge-preserving regularized model (smoothed anisotropic TV penalty) and compare it to two other state-of-the-art algorithms suitable for smooth penalties. The SATV regularized reconstruction model is given by
| (29) |
where F is defined by (2), consists of the indices of both left and up neighbor pixels of the jth pixel of image f, and ϕθ is the Lange function [35] defined by
If we let ϕθ be the absolute value function, then model (29) becomes the anisotropic TV regularized model. By defining , IEM-PKMA for solving (29) can be given by
where is given by (19). Two state-of-the-art algorithms including OTDA and L-BFGS-B-PC for the SATV regularized model (29) were used for comparison. OTDA is based on the surrogate function method and uses the conjugate direction to accelerate convergence, which has been shown to outperform PCG [8]. L-BFGS-B-PC is based on the quasi-Newton method and uses the diagonal of inverse Hessian matrix for preconditioning. These two algorithms perform well for a differentiable regularization model. However, they both need an additional forward- and back-projection for the line search step, which makes each iteration more time consuming.
Fig. 5 shows the performance of IEM-PKMA, OTDA and L-BFGS-PC for solving model (29) with θ = 0.001 (to ensure edge preservation). High-count data was used and the regularization parameter λ was set to 0.06. For both initialization and the preconditioners in IEM-PKMA and L-BFGS-PC, fFBP was used.
Fig. 5.

NOFV (left) and NRMSE (right) versus CPU time by IEM-PKMA, OTDA and L-BFGS-B-PC with fFBP initialization.
3). Comparison of Algorithms for HOTV Regularization:
In this subsection, we compare the performance of PKMA, PAPA and ADMM for the HOTV regularized model. For this purpose, we recall the iteration schemes of PAPA and ADMM. It follows from [3] that PAPA for solving model (3) can be written by
According to [20], ADMM for solving model (3) consists of the following three steps:
| (30) |
Unlike in [20], the term φ in our model is not differentiable and the proximity operator of φ ∘ B has no explicit form, requiring the first sub-problem of (30) to be solved via the first-order primal-dual algorithm (FOPDA) [36]. Here we perform five FOPDA sub-iterations in each complete ADMM iteration to guarantee the convergence. For the second sub-problem, we use the surrogate function strategy as described in [20].
Then we get the following ADMM iteration scheme:
The choice of parameters in PAPA and ADMM for 2D simulation are shown in table 1. For PAPA, the parameters were chosen according to [3]. For ADMM, the parameters σ and τ were set by the convergence condition of FOPDA [36], optimal μ was chosen empirically based on the performance of objective function value.
We first show the performance of these algorithms for the reconstruction of the brain phantom using high-count data. Two different initial images, including the uniform disk fUD and , were used for comparison. Here we set Φ0 = Φ(fUD) in the definition of NOFV for both uniform disk and initialization. In Fig. 6, we show the NOFV and NRMSE versus CPU time by IEM-PKMA, EM-PKMA, PAPA and ADMM with uniform disk and initialization. It shows that IEM-PKMA converges more rapidly than both PAPA and ADMM. The reconstructed brain images with 5, 10 and 100 iterations in Fig. 7 show that IEM-PKMA is able to obtain a reasonably good image very rapidly. We comment here that the results from the use of IEM preconditioner are more pronounced if a uniform image is used for initialization, and less so when initialized by in the IEM preconditioner, though still show improvement.
Fig. 6.

NOFV (left) and NRMSE (right) versus CPU time by IEM-PKMA, EM-PKMA, PAPA and ADMM with uniform disk (top row) and (bottom row) initialization using high-count data.
Fig. 7.
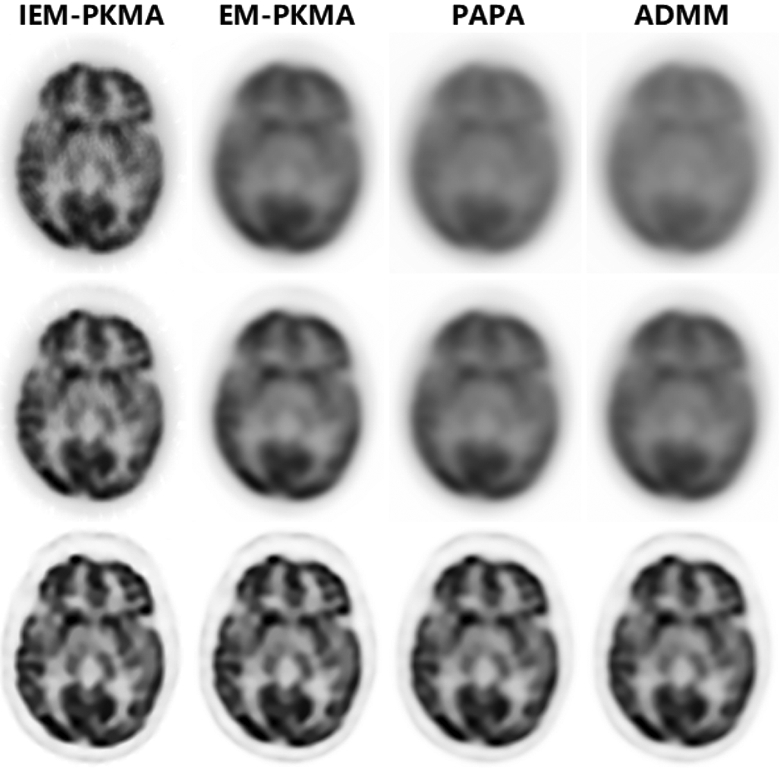
Reconstructed brain images by IEM-PKMA, EM-PKMA, PAPA and ADMM with uniform disk initialization using high-count data: top to bottom rows are reconstructed by 5, 10, and 100 iterations respectively.
To demonstrate the performance of IEM-PKMA for low-count data, we show in Fig. 8 comparisons of NOFV and NRMSE versus CPU time for these algorithms with uniform disk and initialization. The reconstructed brain images using low-count data are shown in Fig. 9.
Fig. 8.

NOFV (left) and NRMSE (right) versus CPU time by IEM-PKMA, EM-PKMA, PAPA and ADMM with uniform disk (top row) and (bottom row) initialization using low-count data.
Fig. 9.
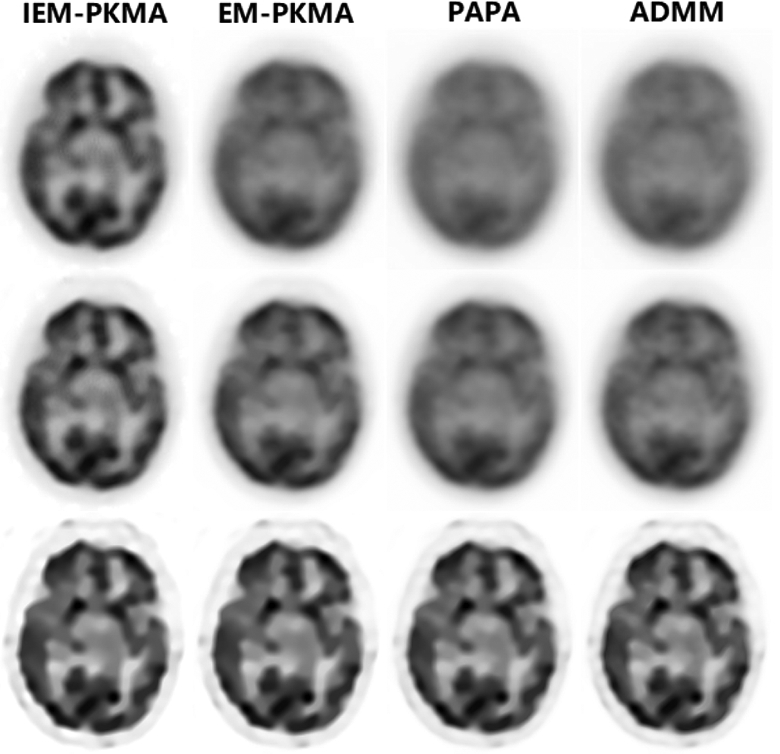
Reconstructed brain images by IEM-PKMA, EM-PKMA, PAPA and ADMM with uniform disk initialization using low-count data: top to bottom rows are reconstructed by 5, 10 and 100 iterations respectively.
We next examine the performance of these algorithms for reconstructing the uniform phantom with uniform disk initialization and high-count data. Fig. 10 shows NRC versus CPU time for the largest and the smallest hot spheres of the uniform phantom. Comparisons of central line profiles of the images reconstructed by 5 and 10 iterations are shown in Fig. 11. The reconstructed images of the uniform phantom are shown in Fig. 12. These figures show that for the uniform phantom, IEM-PKMA outperforms the other algorithms.
Fig. 10.

NRC of the largest hot sphere (left) and the smallest hot sphere (right) versus CPU time by IEM-PKMA, EM-PKMA, PAPA and ADMM with uniform disk initialization using high-count data.
Fig. 11.

CLP of the images reconstructed by 5 iterations (left) and 10 iterations (right) of IEM-PKMA, EM-PKMA, PAPA and ADMM with uniform disk initialization using high-count data.
C. Initial Clinical Results
In this subsection, we present some promising initial 3D clinical results that are based on a relaxed ordered subsets version, ROS-PKMA, according to [31] and [37]. The details of this algorithm and the parameters used are provided in the supplementary materials which are available in the supplementary files tab. We implemented ROS-PKMA, ROS-PAPA [31] and ROS-EM algorithms on a GE D690 PET/CT using a modified version of the GE PET Toolbox release 2.0. A brain scan of 52-year-old male with brain metastases was acquired 1 hour post-injection (370 MBq nominal) for 10 minutes. The images were reconstructed using time-of-flight (TOF) information with a 300 mm FOV using 256 × 256 matrix and an accurate model of the detector PSF (“sharpIR”).
Initial results shown in Fig. 13 appear to indicate that ROS-PKMA with 12 subsets can obtain even better images than both ROS-PAPA and ROS-EM (also with 12 subsets) using only half the iterations.
Fig. 13.
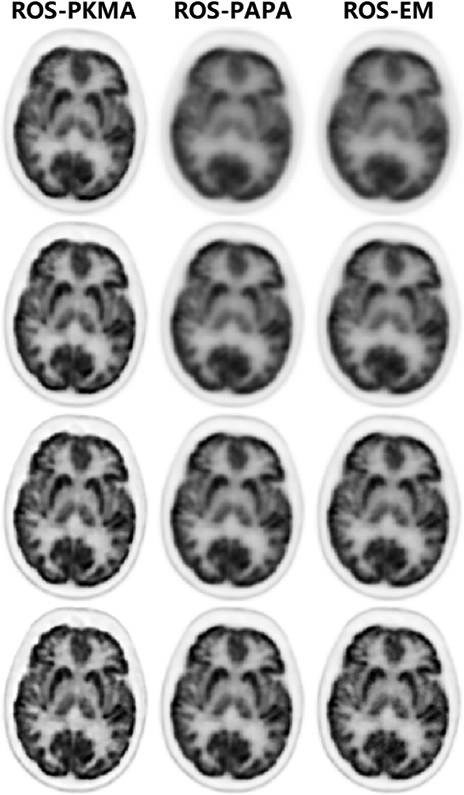
Reconstructed clinical brain images by ROS-PKMA, ROS-PAPA and ROS-EM with 12 subsets: top to bottom rows are reconstructed by 1, 2, 4 and 8 iterations respectively.
IV. Conclusion
This study presents an efficient, easily implemented and mathematically sound preconditioned Krasnoselskii-Mann algorithm for HOTV regularized PET image reconstruction. We prove that PKMA enjoys nice theoretical convergence in the case that the preconditioner is fixed after finite number of iterations. In addition, we show that our proposed generating function for the momentum parameters is more general than the one proposed by Nesterov, able to include both the momentum-free case and an asymptotically equivalent form of the Nesterov momentum parameters as special cases. An improved EM preconditioner that can avoid the reconstructed images being “stuck at zero,” was proposed for accelerating convergence. Numerical experiments demonstrate that the IEM preconditioner improves convergence speed more than the classical EM preconditioner, IEM-PKMA outperforms OTDA, L-BFGS-B-PC for the SATV regularized model, and PAPA, ADMM for the HOTV regularized model. Moreover, for clinical data, promising initial results indicate that ROS-PKMA may be able to obtain sufficiently converged images more rapidly than both ROS-PAPA and ROS-EM, but more research is necessary to properly evaluate these results.
Supplementary Material
Acknowledgement
The authors are grateful to Dr. Guobao Wang and Dr. Jinyi Qi for providing their codes for OTDA, to Dr. Charles W. Stearns, Dr. Sangtae Ahn, Dr. Kris Thielemans and Yu-Jung Tsai for helpful discussions on implementation of L-BFGS-B-PC, and to an anonymous referee for bringing reference [30] to our attention. They are grateful to GE for providing C. R. Schmidtlein, through a research agreement with MSKCC, the PET toolbox for the clinical experiments.
This work was supported in part by the Special Project on High-performance Computing through the National Key R&D Program under Grant 2016YFB0200602, in part by the Natural Science Foundation of China under Grant 11771464, Grant 11601537, Grant 11471013, and Grant 11501584, in part by the Fundamental Research Funds for the Central Universities of China, and in part by the Imaging and Radiation Sciences subaward of the MSK Cancer Center Support Grant/Core Grant under Grant P30 CA008748.
Appendix A
We provide the definition of 2D first-order and second-order isotropic TV (ITV) and the explicit form of the corresponding functions’ proximity operator. For the 3D case, please refer to [3]. The first-order and second-order ITV can be written as φ1 ∘ B1 and φ2 ∘ B2 respectively. For the definition of B1 and B2, we let , IN denote the N × N identity matrix, D denote the N × N backward difference matrix such that Dj,j = 1 and Dj,j–1 = −1 for j = 2, 3, … , N, and all other entries of D are zero. Through the matrix Kronecker product ⊗, and are defined, respectively, by
For , define , where
| (31) |
For , define , where
| (32) |
Next, we provide explicit forms of the proximity operator of φ1 and φ2. Let ω be a positive number. As shown in [3], for , by denoting u := proxωφ1 (x), we have
for j = 0, 1, i = 1, 2,…, d, where is defined by (31). For , we denote v := proxωφ2(x). Then
for j = 0, 1, 2, 3, i = 1, 2, … , d, where is defined by (32).
Appendix B
In this appendix, we prove the convergence of PKMA by employing the KM theorem.
To recall the KM theorem, we first recall the definition of nonexpansive operator. Let . We say that is nonexpansive with respect to H if for any , , .
Theorem 4 (Krasnoselskii-Mann [38]-[40]): Let be a nonexpansive operator such that the set of its fixed points is non-empty. For and , define
| (33) |
If , then converges to a fixed-point of .
We shall employ Theorem 4 to prove the convergence of PKMA. For this purpose, we rewrite iteration (21) in the form of (33). To this end, we first prove that is averaged nonexpansive with respect to R−1 G. We recall the definition of firmly nonexpansive and averaged nonexpansive operators, and two related lemmas.
An operator is called firmly nonexpansive with respect to if for any , . If there exists a nonexpansive operator with respect to H such that , we say that is α-averaged nonexpansive with respect to H. Firmly nonexpansiveness of an operator corresponds to its -averaged nonexpansiveness by [41, Remark 4.24].
Lemma 5 (Baillon-Haddad [41]): Let be differentiable and convex, L be a positive real number. Then ∇ψ is L-Lipschitz continuous if and only if for all x, , , .
Lemma 6 (Combettes-Yamada [42]): Let , 0 < α1 < 1 and 0 < α2 < 1. If is α1-averaged nonexpansive with respect to H, and is α2-averaged nonexpansive with respect to H, then T1 ∘ T2 is -averaged nonexpansive with respect to H.
Notice that is symmetric since P, Q are both symmetric. Therefore, if and only if its smallest eigenvalue λW > 0. Next we prove that is averaged nonexpansive with respect to W.
Lemma 7: Let TG, , r, R and G be defined by (13), (14), (9), (10) and (11) respectively, and . If , then is ζ-averaged nonexpansive with respect to W.
Proof: gives that and
| (34) |
where λmax(W) denotes the largest eigenvalue of W. [24, Lemma 3.2] shows that TG is firmly nonexpansive with respect to W. Hence it is -averaged nonexpansive with respect to W. According to Lemma 6 and the definition of , to prove that is averaged nonexpansive with respect to W, it suffices to show that is averaged nonexpansive with respect to W.
Define and . Then 0 < α < 1 and . It is easy to verify that r is convex and differentiable with an L-Lipschitz continuous gradient. For w, , let z := ∇r (w) – ∇r (v). By (34), Lemma 5 and by , we have that
Hence
which implies that is nonexpansive with respect to W. Thus is α-averaged nonexpansive with respect to W. Therefore, is ζ-averaged nonexpansive with respect to W by Lemma 6. ■
Now we prove the convergence of iteration (21).
Theorem 8: Let , αk, be defined by (14), (19) and (20) respectively, where ϱ ∈ (−1, 1) and δ ≥ 0. For given , let be a sequence generated by iteration (21), and , . If , then converges to a solution of model (5).
Proof: We shall employ Theorem 4 to prove this theorem. To this end, we define , and show below that there exists a nonexpansive operator with respect to W such that
| (35) |
and
| (36) |
It follows from Lemma 7 that is ζ-averaged nonexpansive with respect to W. By the definition of averaged nonexpansiveness, there exists a nonexpansive operator with respect to W such that . Substituting this equation into the definition (20) of , we obtain (35).
It remains to verify that αkζ satisfies (36) for . If −1 < ϱ < 0, then and 1 + ϱ ≤ αk ≤ 1, . Hence and , . In this case, . If 0 ≤ ϱ < 1, then and 1 ≤ αk ≤ 1 + ϱ, . Hence and , . Given ζ, 0 ≤ ϱ < 1 implies that there exists ϱ′ such that ϱ < ϱ′ < 1 and . Thus , and then .
Therefore, by Theorem 4, converges to a fixed-point of . By Theorem 1, we conclude that converges to a solution of model (5). ■
For specific choice of the preconditioning matrices P and Q, we have the following lemma for proving the convergence of PKMA.
Lemma 9: Let β, ρ1, ρ2 and ξ be positive numbers, be a diagonal matrix with positive diagonal entries, P := βS, Q := diag(ρ11m1, ρ21m2), , , and . If , and , then λW > ξ.
Proof: Clearly, W is symmetric. To prove that λW > ξ, it suffices to show that
is positive definite. Let , . If β, ρ1 and ρ2 satisfy the conditions in this lemma, then p – ξ > 0, , , and moreover, P−1–ξId and Q−1–ξIm0 are both positive definite. Define
Then
by the definitions of Q and B. It follows from [25, Lemma 6.2] that W – ξId+m0 is positive definite if and only if , which we verify below. For any and , by the definition of matrix ℓ2 norm, we have
Thus
which completes the proof.
Footnotes
This article has supplementary downloadable material available at http://ieeexplore.ieee.org, provided by the author.
Contributor Information
Yizun Lin, School of Mathematics, Sun Yat-sen University, Guangzhou 510275, China.
C. Ross Schmidtlein, Department of Medical Physics, Memorial Sloan Kettering Cancer Center, New York, NY 10065 USA.
Qia Li, School of Data and Computer Science, Sun Yat-sen University, Guangzhou 510275, China.
Si Li, School of Computer Science and Technology, Guangdong University of Technology, Guangzhou 510006, China.
Yuesheng Xu, Department of Mathematics and Statistics, Old Dominion University, Norfolk, VA 23529 USA, and also with the Guangdong Key Laboratory of Computational Science, Sun Yat-sen University, Guangzhou 510275, China.
References
- [1].Rudin LI, Osher S, and Fatemi E, “Nonlinear total variation based noise removal algorithms,” Phys. D, Nonlinear Phenomena, vol. 60, nos. 1–4, pp. 259–268, 1992. [Google Scholar]
- [2].Bredies K, Kunisch K, and Pock T, “Total generalized variation,” SIAM J. Imag. Sci, vol. 3, no. 3, pp. 492–526, 2010. [Google Scholar]
- [3].Li S et al. , “Effective noise-suppressed and artifact-reduced reconstruction of SPECT data using a preconditioned alternating projection algorithm,” Med. Phys, vol. 42, no. 8, pp. 4872–4887, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Fessler JA and Booth SD, “Conjugate-gradient preconditioning methods for shift-variant PET image reconstruction,” IEEE Trans. Image Process, vol. 8, no. 5, pp. 688–699, May 1999. [DOI] [PubMed] [Google Scholar]
- [5].Yu DF and Fessler JA, “Edge-preserving tomographic reconstruction with nonlocal regularization,” IEEE Trans. Med. Imag, vol. 21, no. 2, pp. 159–173, February 2002. [DOI] [PubMed] [Google Scholar]
- [6].Wang G and Qi J, “Penalized likelihood PET image reconstruction using patch-based edge-preserving regularization,” IEEE Trans. Med. Imag, vol. 31, no. 12, pp. 2194–2204, December 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Tsai Y-J et al. , “Fast quasi-Newton algorithms for penalized reconstruction in emission tomography and further improvements via preconditioning,” IEEE Trans. Med. Imag, vol. 37, no. 4, pp. 1000–1010, April 2018. [DOI] [PubMed] [Google Scholar]
- [8].Wang G and Qi J, “Edge-preserving PET image reconstruction using trust optimization transfer,” IEEE Trans. Med. Imag, vol. 34, no. 4, pp. 930–939, April 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Panin VY, Zeng GL, and Gullberg GT, “Total variation regulated EM algorithm,” IEEE Trans. Nucl. Sci, vol. 46, no. 6, pp. 2202–2210, December 1999. [Google Scholar]
- [10].Jonsson E, Huang S-C, and Chan T, “Total variation regularization in positron emission tomography,” Univ. California, Los Angeles, Los Angeles, CA, USA, CAM-Rep. 98-48, 1998, pp. 1–25. [Google Scholar]
- [11].Sawatzky A, Brune C, Wubbeling F, Kosters T, Schafers K, and Burger M, “Accurate EM-TV algorithm in PET with low SNR,” in Proc. IEEE Nucl. Sci. Symp. Conf. Rec., October 2008, pp. 5133–5137. [Google Scholar]
- [12].Bardsley JM, “An efficient computational method for total variation-penalized Poisson likelihood estimation,” Inverse Problems Imag, vol. 2, no. 2, pp. 167–185, 2008. [Google Scholar]
- [13].Bardsley JM and Luttman A, “Total variation-penalized Poisson likelihood estimation for ill-posed problems,” Adv. Comput. Math, vol. 31, nos. 1–3, p. 35, 2009. [Google Scholar]
- [14].Bardsley JM and Goldes J, “Regularization parameter selection and an efficient algorithm for total variation-regularized positron emission tomography,” Numer. Algorithms, vol. 57, no. 2, pp. 255–271, 2011. [Google Scholar]
- [15].Chaux C, Pesquet J-C, and Pustelnik N, “Nested iterative algorithms for convex constrained image recovery problems,” SIAM J. Imag. Sci, vol. 2, no. 2, pp. 730–762, 2009. [Google Scholar]
- [16].Bonettini S and Ruggiero V, “An alternating extragradient method for total variation-based image restoration from Poisson data,” Inverse Problems, vol. 27, no. 9, 2011, Art. no. 095001. [Google Scholar]
- [17].Sidky EY, Jørgensen JH, and Pan X, “Convex optimization problem prototyping for image reconstruction in computed tomography with the Chambolle–Pock algorithm,” Phys. Med. Biol, vol. 57, no. 10, p. 3065, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Komodakis N and Pesquet J-C, “Playing with Duality: An overview of recent primal–dual approaches for solving large-scale optimization problems,” IEEE Signal Process. Mag, vol. 32, no. 6, pp. 31–54, November 2015. [Google Scholar]
- [19].Boyd S, Parikh N, Chu E, Peleato B, and Eckstein J, “Distributed optimization and statistical learning via the alternating direction method of multipliers,” Found. Trends Mach. Learn, vol. 3, no. 1, pp. 1–122, January 2011. [Google Scholar]
- [20].Chun SY, Dewaraja YK, and Fessler JA, “Alternating direction method of multiplier for tomography with nonlocal regularizers,” IEEE Trans. Med. Imag, vol. 33, no. 10, pp. 1960–1968, October 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Krol A, Li S, Shen L, and Xu Y, “Preconditioned alternating projection algorithms for maximum a posteriori ECT reconstruction,” Inverse Problems, vol. 28, no. 11, 2012, Art. no. 115005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Wu Z, Li S, Zeng X, Xu Y, and Krol A, “Reducing staircasing artifacts in SPECT reconstruction by an infimal convolution regularization,” J. Comput. Math, vol. 34, no. 6, pp. 626–647, 2016. [Google Scholar]
- [23].Pock T and Chambolle A, “Diagonal preconditioning for first order primal-dual algorithms in convex optimization,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), November 2011, pp. 1762–1769. [Google Scholar]
- [24].Li Q and Zhang N, “Fast proximity-gradient algorithms for structured convex optimization problems,” Appl. Comput. Harmon. Anal, vol. 41, no. 2, pp. 491–517, 2016. [Google Scholar]
- [25].Li Q, Shen L, Xu Y, and Zhang N, “Multi-step fixed-point proximity algorithms for solving a class of optimization problems arising from image processing,” Adv. Comput. Math, vol. 41, no. 2, pp. 387–422, 2015. [Google Scholar]
- [26].Nesterov YE, “A method of solving a convex programming problem with convergence rate O(1/k2),” Sov. Math. Dokl, vol. 27, no. 2, pp. 372–376, 1983. [Google Scholar]
- [27].Beck A and Teboulle M, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,” SIAM J. Imag. Sci, vol. 2, no. 1, pp. 183–202, 2009. [Google Scholar]
- [28].Moreau JJ, “Proximité et dualité dans un espace Hilbertien,” Bull. Soc. Math. France, vol. 93, no. 2, pp. 273–299, 1965. [Google Scholar]
- [29].Moreau JJ, “Fonctions convexes duales et points proximaux dans un espace Hilbertien,” C. R. Acad. Sci. Paris A, Math, vol. 255, pp. 2897–2899, December 1962. [Google Scholar]
- [30].Mumcuoglu EU, Leahy R, Cherry SR, and Zhou Z, “Fast gradient-based methods for Bayesian reconstruction of transmission and emission PET images,” IEEE Trans. Med. Imag, vol. 13, no. 4, pp. 687–701, December 1994. [DOI] [PubMed] [Google Scholar]
- [31].Schmidtlein CR et al. , “Relaxed ordered subset preconditioned alternating projection algorithm for PET reconstruction with automated penalty weight selection,” Med. Phys, vol. 44, no. 8, pp. 4083–4097, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Moses WW, “Fundamental limits of spatial resolution in PET,” Nucl. Instrum. Methods Phys. Res. A, Accel. Spectrom. Detect. Assoc. Equip, vol. 648, pp. S236–S240, August 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [33].Berthon B et al. , “PETSTEP: Generation of synthetic PET lesions for fast evaluation of segmentation methods,” Phys. Med, vol. 31, no. 8, pp. 969–980, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [34].Micchelli CA, Shen L, and Xu Y, “Proximity algorithms for image models: Denoising,” Inverse Problems, vol. 27, no. 4, 2011, Art. no. 045009. [Google Scholar]
- [35].Lange K, “Convergence of EM image reconstruction algorithms with Gibbs smoothing,” IEEE Trans. Med. Imag, vol. 9, no. 4, pp. 439–446, December 1990. [DOI] [PubMed] [Google Scholar]
- [36].Chambolle A and Pock T, “A first-order primal-dual algorithm for convex problems with applications to imaging,” J. Math. Imag. Vis, vol. 40, no. 1, pp. 120–145, 2011. [Google Scholar]
- [37].Kim D, Ramani S, and Fessler JA, “Combining ordered subsets and momentum for accelerated X-ray CT image reconstruction,” IEEE Trans. Med. Imag, vol. 34, no. 1, pp. 167–178, January 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Krasnosel’skii MA, “Two remarks on the method of successive approximations,” Uspekhi Matematicheskikh Nauk, vol. 10, no. 1, pp. 123–127, 1955. [Google Scholar]
- [39].Mann WR, “Mean value methods in iteration,” Proc. Amer. Math. Soc, vol. 4, no. 3, pp. 506–510, 1953. [Google Scholar]
- [40].Bauschke HH and Combettes PL, Convex Analysis and Monotone Operator Theory in Hilbert Spaces. New York, NY, USA: Springer, 2011. [Google Scholar]
- [41].Baillon J-B and Haddad G, “Quelques propriétés des opérateurs anglebornés etn-cycliquement monotones,” Isr. J. Math, vol. 26, no. 2, pp. 137–150, 1977. [Google Scholar]
- [42].Combettes PL and Yamada I, “Compositions and convex combinations of averaged nonexpansive operators,” J. Math. Anal. Appl, vol. 425, no. 1, pp. 55–70, 2015. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.