

Abstract
The hazard function plays a central role in survival analysis. In a homogeneous population, the distribution of the time to event, described by the hazard, is the same for each individual. Heterogeneity in the distributions can be accounted for by including covariates in a model for the hazard, for instance a proportional hazards model. In this model, individuals with the same value of the covariates will have the same distribution. It is natural to think that not all covariates that are thought to influence the distribution of the survival outcome are included in the model. This implies that there is unobserved heterogeneity; individuals with the same value of the covariates may have different distributions. One way of accounting for this unobserved heterogeneity is to include random effects in the model. In the context of hazard models for time to event outcomes, such random effects are called frailties, and the resulting models are called frailty models. In this tutorial, we study frailty models for survival outcomes. We illustrate how frailties induce selection of healthier individuals among survivors, and show how shared frailties can be used to model positively dependent survival outcomes in clustered data. The Laplace transform of the frailty distribution plays a central role in relating the hazards, conditional on the frailty, to hazards and survival functions observed in a population. Available software, mainly in R, will be discussed, and the use of frailty models is illustrated in two different applications, one on center effects and the other on recurrent events.
Keywords: Correlated failure times, frailty models, random effects models, survival analysis, unobserved heterogeneity
1 Introduction
The central concept in survival analysis is the hazard function. It describes the instantaneous risk of the event of interest for an individual, given that the individual has not experienced the event previously. The hazard function indirectly also describes the distribution of the time to event; there is a one-to-one relation between the probability of being alive over time, the survival function, and the hazard function. Individuals may differ with respect to their survival probabilities, or, equivalently, with respect to their hazards. Females tend to live longer than males, or in terms of hazards, the mortality rate of males is higher than that of females; patients with more severe disease tend to die earlier and have a higher hazard than less severely diseased patients. Such characteristics can be accounted for in survival models by including them in models for the hazards. The most influential of such models is Cox’s proportional hazards model.1 The proportional hazards assumption specifies that the ratio of the hazards between any two individuals is constant over time, and the shape of the hazard is given by a non-parametric “baseline hazard”. If a model is perfectly specified, so that all possible relevant covariates are accounted for, then the baseline hazard reflects the randomness of the event time, given the value of covariates.
In practice, however, it is rarely possible to account for all relevant covariates. Then the explanatory variables account for observed heterogeneity, and the unaccounted part is termed unobserved heterogeneity. If this is the case, then the estimated hazard for a specific set of covariates does not have an individual interpretation.2 Rather, it represents an average hazard function, where the average is taken at each time point over the individuals still alive at that time point. The effects of unobserved heterogeneity on life times are collectively referred to as frailty in demographic research.3 The frailty is an unobserved individual random effect that acts multiplicatively on the hazard. The estimated spread of this random effect (e.g. variance) is an indication of the amount of unobserved heterogeneity. The frailty model quickly gained popularity in econometrics,4 demographics5 and biostatistics.6
Frailty models are useful for two purposes. First, univariate frailty models can be used to explain effects of selection of healthier subjects over time, and also to explain lack of fit, such as deviations from the proportional hazards model. Frailty models can be used in this context to offer alternative explanations for the behavior of the hazard and of hazard ratios over time. These alternative explanations are hypothetical to a large degree, because of identifiability issues, but useful nonetheless. Second, in shared frailty models, frailties can also be used to model dependence of survival times in clustered data or recurrent events. Here the frailty term is shared among individuals in the same cluster, or, in the case of recurrent events, among subsequent events of the same individual.
The aim of this tutorial is to provide an overview of theory and practice in the field of frailty models, while offering insight into the problems that are addressed by such models. We concentrate on the use of frailty models in survival analysis. Frailties have also been used in, for instance, infectious disease modeling,7,8 but this is outside the scope of the present tutorial. For more detailed information, we recommend the books.9–11 In section 2 we study the effects of unobserved heterogeneity in survival data, univariate frailty models, and we discuss different frailty distributions. In section 3, we analyze the effect of unobserved heterogeneity in shared frailty models, covering clustered survival data, recurrent events, and an overview of estimation methods. In section 4, we compare available software packages for frailty models and the representation of event history data in the R statistical software. In section 5 we examine different extensions to the frailty models. Finally, in section 6, we illustrate the application of frailty models in two common situations, the modeling of center effects and the analysis of recurrent events.
2 Univariate frailty models
2.1 Heterogeneity in the Cox model
Before we introduce the frailty model and start discussing the effects of unobserved heterogeneity, we illustrate here some of these effects in the more familiar setting of the Cox proportional hazards model.
2.1.1 Heterogeneity over time
The Cox model specifies the hazard of a time to event T as
| (1) |
where β is a vector of regression coefficients, x is a vector of covariates and is an unspecified baseline hazard function. The hazard functions of two individuals with covariate vectors and are equal only when . The exponent is the hazard ratio between an individual with xj = 1 and an individual with xj = 0 (the other covariates being the same for the two individuals). Time-dependent covariates are easily accommodated in equation (1) and are discussed in section 4. For the time being, we assume that x is time-constant.
The risk set at time t is composed of individuals that have not yet experienced the event of interest and have not yet been removed for other reasons, such as censoring. The distribution of the covariates among the individuals in the risk set changes over time. We illustrate this by considering model (1) and a single covariate following a standard normal distribution and , so that individuals with larger values of x have a higher hazard. At time t = 0, the mean and variance of x are 0 and 1, respectively. Because individuals with higher hazards tend to be the first to die, as time passes, the risk set progressively comprises individuals with lower values of x. For this reason, the average value and the sample variance of x among the individuals at risk decreases over time.
This is illustrated by simulating a single sample of life times of size n = 100, according to equation (1), with a covariate , β = 1, and uniform censoring on (20, 50). In this simulated sample, at time 0, x had mean 0.007 and standard deviation 1.068. The estimated β was 0.943, with a standard error of 0.127. The mean and standard deviation of x among the individuals in the risk set are shown in Figure 1, as a function of time. The message is that, over time, the population of “survivors” (those still at risk) becomes more homogeneous and of lower risk than the original risk set at time 0.
Figure 1.

Changes in the mean and variance of a covariate x over time among survivors in a proportional hazards model.
2.1.2 Heterogeneity due to missing covariates
The proportional hazards assumption in the Cox model (1) specifies that the ratio divided by equals , which does not depend on time. When this assumption is violated, the covariate effect β is time-dependent. The true model is then
with not constant.
Assume that the model (1) is correct and . Then, if important covariates are omitted from the model, the proportional hazards assumption does not usually hold for the remaining covariates. This is illustrated by simulating a single large data set with sample size n = 10,000. Two independent covariates x1 and x2 are considered, both , with and uniform censoring on (20, 50). The following output is shown from Cox models fitted with the standard survival package in R.12 When both covariates are included into the model, the results are close to the simulation scenario, with both estimated regression coefficients close to 1:
## Call:
## c12 <- coxph(formula = Surv(time, status) ∼ x1 + x2, data = d)
##
## coef exp(coef) se(coef) z p
## x1 1.0016 2.7225 0.0138 72.7 <2e-16
## x2 1.0240 2.7843 0.0140 73.2 <2e-16
##
## Likelihood ratio test = 9014 on 2 df, p = 0
## n= 10000, number of events= 8240
No evidence of violation of the proportional hazards assumption is found, when a test based on Schoenfeld residuals is used13
## Call: cox.zph(c12, transform = “identity”)
## rho chisq p
## x1 0.00101 0.0081 0.928
## x2 -0.00357 0.1050 0.746
## GLOBAL NA 0.1510 0.927
However, when x2 is omitted, the resulting estimate of the effect of x1 is visibly smaller than 1:
## Call:
## c1 <- coxph(formula = Surv(time, status) ∼ x1, data = d)
##
## coef exp(coef) se(coef) z p
## x1 0.7028 2.0195 0.0124 56.6 <2e-16
##
## Likelihood ratio test = 3271 on 1 df, p = 0
## n= 10000, number of events= 8240
Moreover, there is clear evidence against the proportional hazards assumption.
## Call: cox.zph(c1, transform = “identity”)
## rho chisq p
## x1 -0.0852 55.3 1.06e-13
This is also illustrated by the plot of scaled Schoenfeld residuals of in Figure 2. It appears that the effect of x starts close to the true value 1, and then decreases over time. The result given by the Cox model only with x1 is an “average” effect in this case. The attenuation of the estimated effect of x1 when a covariate is omitted has been studied in detail in the literature.14–16
Figure 2.
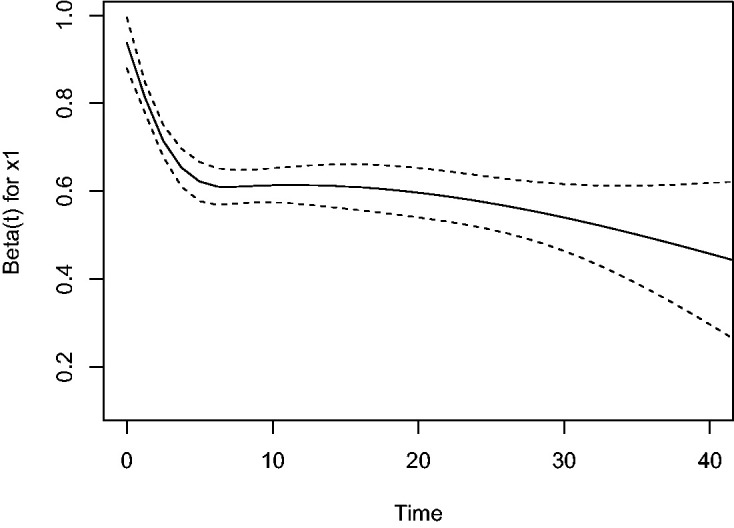
Plot of scaled Schoenfeld residuals-based induced by omitting a covariate from a proportional hazards model.
The explanation for the phenomenon illustrated in the simulated example is that the individual hazard is determined by the combined effect of x1 and x2. Since β1 and β2 are both positive, the “high risk” individuals (high x1, high x2) are the first to experience the event, on average, followed by the “moderate risk” ones (high x1 and low x2, or low x1 and high x2), and eventually the “low risk” ones (low x1 and low x2). This causes the correlation between x1 and x2, which is initially around 0, to become negative, as can be seen in Figure 3, where the sample correlation between x1 and x2 over time, among the survivors at the time, is shown in the large simulated data set. This phenomenon is also known in epidemiology as the obesity paradox.17 The result of this negative correlation is that if x2 is not accounted for, the individuals with high x1 in the population of survivors artificially appear at lower risk than before, since they are likely to have a low value of x2, if they are still alive. This induced loss of independence has profound consequences. Suppose that x1 stands for a treatment in a randomized clinical trial. Since the treatment has been randomized, at randomization x1 may be expected to be independent of any measured or unmeasured characteristics influencing the time to the event of interest. Putting it differently, the distribution of these characteristics is expected to be the same for the randomized treatment arms at baseline. The above shows that this independence between x1 and the unmeasured characteristics can no longer be expected to hold at later points in time, ultimately implying that the hazard ratio is unsuited as a causal effect measure for survival data in the presence of unobserved heterogeneity.18,19
Figure 3.
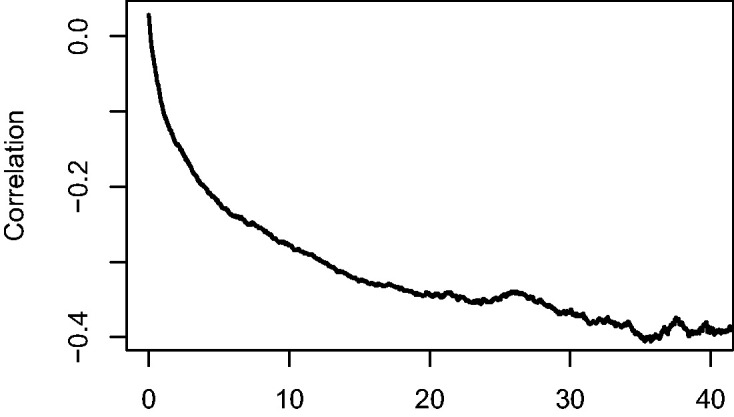
Correlation between x1 and x2 among survivors over time.
2.1.3 Conditional and marginal hazards
More generally, suppose that the proportional hazards model (1) holds for a covariate vector with covariate effects , so that the true model is
| (2) |
Imagine that a Cox model is fitted only including . If we are aiming for , then this will result in an estimated effect that is attenuated towards 0 and, usually, a violation of the proportional hazards assumption. Thus, the proportional hazards model lacks an internal consistency, in the sense that, if equation (2) is the true proportional hazards model, then the model with only does not obey a proportional hazards structure.20 In reality, it is possible that some relevant covariates are not measured (here represented by ). In this case, these omitted covariates are said to induce unobserved heterogeneity. The differences between individuals that are explained by are referred to as observed heterogeneity.
The , as defined in model (2), is referred to as the conditional hazard, with summarizing the conditional effect of . When unobserved heterogeneity is present, the resulting is referred to as the marginal hazard (although it is only marginal with respect to but still conditional on ). The estimated effect from the marginal model does not have an individual interpretation. Namely, represents a weighted average of the individual hazards corresponding to those individuals in the risk set at time t, where the weighting is determined by the distribution of in this risk set.
Since the effect of cannot be directly observed, one can define the random variable , and write equation (2) as . Z is referred to as a “frailty” term that acts multiplicatively on the hazard.
2.2 The frailty model
A frailty model is a model for the hazards in which this unobserved heterogeneity is explicitly included as a multiplicative random effect, the frailty. In the univariate frailty model, the hazard of an individual with frailty Z is specified as
| (3) |
The frailty Z is a latent random term, assumed to have a certain non-negative distribution. Individuals with a higher frailty can be thought of as being more frail, and therefore expected to die sooner than other individuals with the same measured covariates. If the event of interest is a positive outcome, like pregnancy or recovery, subjects with a higher “frailty” are expected to experience the positive outcome sooner than others with the same covariates. For identifiability, Z is assumed to be scaled so that . The term in equation (3) is the conditional hazard for an individual with Z = 1. We refer to simply as the conditional hazard. This conditional hazard may include covariates, but for simplicity this is not expressed in the notation. The conditional cumulative hazard is defined as . The conditional survival function for an individual with frailty Z is then given by
| (4) |
The survival function corresponds to the survival of an individual with average frailty value 1. The survival of the heterogenous population, consisting of individuals with different frailty values, is called the marginal survival curve associated with , and is obtained by taking the expectation of with respect to Z
| (5) |
Unlike S(t), has a population averaged interpretation. If there are no covariates, may be seen as a weighted average of individual survival curves, where the weighing depends on the distribution of Z. The marginal hazard may be derived from the survival function as . Therefore, the marginal hazard may be calculated as
| (6) |
A population averaged interpretation may also be given here: may be seen as a weighted average of individual hazards of individuals alive at time t, where the weighting depends on the distribution of Z among the individuals alive at time t.
The conditional and marginal hazards are equal only if for all t, in other words if all frailties Z are equal to 1. Otherwise, the frailty distribution among the survivors at time t behaves in a similar fashion as the distribution of an observed covariate among survivors, as shown in section 2.1.1.
If observed covariates are also present, then it is usually assumed that the proportional hazards assumption holds conditional on the frailty, with
| (7) |
Then, the population averaged interpretations of and hold conditional on x. In other words, for a hypothetical population of individuals with given covariate values x. This is the same as the interpretation that is given to the marginal hazard in section 2.1.2.
Regardless of whether the differences between individuals come from observed covariates x or from the frailty, individuals with higher hazards die earlier. Therefore, the population of survivors is more homogeneous and at a lower risk for events than the general population at time 0. Before we further study the relation between marginal and conditional hazards in section 2.4, we first discuss different frailty distributions.
2.3 Frailty distributions
2.3.1 The Laplace transform
The Laplace transform turns out to be a very useful concept in describing relations between the conditional hazards and the marginal hazards and survival functions. The distribution of a non-negative random variable Z can be uniquely specified by its Laplace transform
It is immediate that . The expectation of Z may be obtained as minus the derivative of evaluated at 0, . Furthermore, , and, denoting as the k-th derivative of the Laplace transform, in general we have . The squared coefficient of variation, defined as , may be expressed as
Let us return to the frailty model of the previous section, where we wrote the hazard as , with the conditional hazard, and the conditional survival function. In terms of the Laplace transform, the marginal survival function from equation (5) may be written as
and the marginal hazard as
The Laplace transform of the frailty distribution of survivors can be easily expressed in terms of the Laplace transform of Z. First, denote the density of Z as f(z) and the density of as . From Bayes’ theorem and the definition of the conditional survival function (4), it follows that
The Laplace transform of can then be written as
| (8) |
The expectation, variance and squared coefficient of variation of follow as
2.3.2 Infinitely divisible distributions
A rich family of frailty distributions with tractable Laplace transform are formed by the infinitely divisible distributions with Laplace transform specified as with and . They are called infinitely divisible because their distributions can be expressed as the probability distribution of a sum of an arbitrary number of independent and identically distributed random variables from that same family. For to be a proper Laplace transform, we require . The expectation, variance and coefficient of variation of Z, conditional on survival until time t, can be expressed in terms of derivatives of ψ as
| (9) |
The unconditional expectation, variance and coefficient of variation of Z follow by replacing by 0.
The gamma distribution is a prominent member of the infinitely divisible family. The density of the gamma distribution with parameters and is given by , where is the gamma function. Its Laplace transform is given by
which, in terms of equation (9), can be expressed as , and . By convention, the expectation of the frailty is fixed to 1, so the restriction is applied. In this parametrization, Z follows a distribution, with and . The expectation and variance of the frailty distribution of the survivors is given through equation (9), resulting in
Both functions reach their maximum over at t = 0, with expectation 1 and variance , and decrease over time. For the gamma frailty, it is immediate that . In words, the marginal hazard is always smaller than the hazard of an individual with frailty 1.
A more general family of infinitely divisible distributions is the power-variance-function (PVF) family, with the Laplace transform described by
where is the sign of m, and . It was proposed in a series of papers21–23 and is studied in detail in Hougaard.9 To obtain and , one can set and . Particular cases of the distributions in the PVF family include:
The gamma frailty, obtained as a limiting case when and in such a way that ;
The inverse Gaussian distribution, when ;
The so-called Hougaard distributions, when m < 0;
The compound Poisson distribution, when m > 0, which has probability mass at 0. This is consistent with a scenario where a part of the population is not susceptible for the event of interest;
The positive stable distribution, obtained as a limiting case when , and in such a way that , for some positive constant . The resulting Laplace transform takes the simple form , with . This distribution cannot be scaled to have , so usually the restriction is imposed. Its expectation is infinite and the variance is not defined (but they are finite for the conditional distribution , if ).
2.3.3 Other frailty distributions
The log-normal distribution has often been used for frailty models, although it is not part of the PVF family. The normal distribution is infinitely divisible, but the log-normal distribution is not, and its Laplace transform and expressions for the distribution of survivors are not easily obtained in closed form. Its popularity stems from the normal random effects in linear models. The log-normal frailty is usually standardized with and , corresponding to a normally distributed random effect on the scale of the covariates. If matched by mean and variance, it is virtually indistinguishable from the inverse Gaussian distribution. Other families of distributions, such as the Addams and Kummer families of distributions were also introduced in the context of frailty models.24,25
2.4 Frailty effects
The different frailty distributions discussed in section 2.3 represent different ways of expressing unobserved heterogeneity. Different frailty distributions lead to different selection effects, such as the one illustrated in section 2.1.1. Moreover, they impact the marginal effect of the observed covariates in different ways, generalizing the phenomenon illustrated in section 2.1.2. An advantage of the PVF family of distributions and their closed form Laplace transforms is that it facilitates the study of these phenomenons.5,6,26 An overview may be found in Aalen et al.,24 Chapter 6.
2.4.1 The selection effect
In section 2.3, it was shown that, for the gamma frailty model, the expectation and variance of the frailty distribution of the survivors decrease over time, in a similar way as illustrated in section 2.1.1. In Figure 4, we show the expectation and the variance of , when the conditional hazard is given by , for frailty variances 0.2, 0.5, 1 and 2. It follows that the marginal hazard appears as a “dragged down” version of the conditional hazard, similar to Figure 1. This selection effect is stronger if the frailty variance is larger. In particular, depending on the variance of the frailty, the marginal hazard may appear to grow, reach a peak and then decrease beyond a time point, even if the conditional hazard is increasing. As in section 2.1.1, the explanation is that individuals with a higher hazard die earlier, on average, than individuals with a lower hazard. In particular, this is true for all frailty distributions discussed in section 2.3. For example, for the compound Poisson distribution, when individuals with frailty 0 never experience the event of interest, the marginal hazard will eventually decrease towards 0 after some time.
Figure 4.

Frailty distribution of survivors, gamma frailty, .
2.4.2 The marginal hazard ratio
In section 2.1.2, we illustrated that, when important covariates are omitted from a Cox model, the marginal effect of the remaining covariates is time-dependent. The same phenomenon happens with the marginal covariate effect in the case of frailty models. Suppose that only one observed covariate is present, , and that the frailty model (7) is true. Then, is the hazard ratio between two individuals with the same frailty, one with x = 1, the other with x = 0. The marginal hazards for the two subgroups defined by x are given by
The marginal effect of x can be quantified by the ratio of these two marginal hazards. This results in
It follows that the original hazard ratio is distorted over time by differential selection effects over time in the two subgroups, caused by the frailty. As a result, will generally not be constant over time. If Z is a gamma frailty with variance , for example, this is
If is an increasing function with a minimum of β and an asymptotic maximum of 0, if . Conversely, if , then is a decreasing function with a maximum of β and asymptotic minimum of 0. The conclusion is that, at the population level, the covariate effect appears to vanish over time. Therefore, the gamma frailty shows a similar behavior with the unobserved covariates scenario to that in the simulation in section 2.1.2.
Similar considerations apply for other frailty distributions. For example, for the inverse Gaussian distribution, the marginal hazard ratio is
In this case, we see that if , as . A peculiar case is that of the positive stable distribution, for which
which does not depend on time, so we have . Since is an “attenuated” version of β.
The effect of different frailty distributions on the hazard ratio is illustrated in Figure 5. For the gamma frailty distribution, the marginal hazard ratio approaches 1 with time, while for the inverse Gaussian it approaches . For the positive stable distribution, the attenuated marginal effect is observed. For the compound Poisson distribution, a “crossover” is present, where the marginal hazard ratio actually crosses 1. This is the effect of having non-susceptible individuals, represented by the mass at 0 of the distribution. As a result, in the risk set at sufficiently large time points, the proportion of non-susceptible individuals is higher in the high risk group than in the low risk group.
Figure 5.

Marginal hazard ratio between two groups of individuals: a low risk one with , and a high risk one with . For comparability, the distributions are matched by the squared coefficient of variation of the distribution of survivors at time t = 1, with .
2.5 Identifiability
In the frailty model, the marginal hazard equals . If there are no covariates, then only is observed. Without strong parametric assumptions on , it is impossible to decide whether frailty is present or not. In other words, the frailty model is not identifiable in this case. The presence of covariates, together with the assumption of proportional hazards conditional on the frailty, makes the frailty model identifiable, as long as the frailty distribution has finite expectation. This is due to the marginal non-proportional effect of the observed covariates, as exemplified in Figure 5. This identifiability result has been studied in Elbers and Ridder.27
Without further assumptions, observing a time-dependent covariate effect of the type shown in Figure 5 is equally compatible with (at least) two explanations. One is that the proportional hazards assumption holds in the conditional model, and this effect appears distorted at the marginal level as a result of unobserved heterogeneity. The second is that there is no unobserved heterogeneity, and the observed covariate has a time-dependent effect. In the first case, the frailty model is the natural choice. The frailty then explains heterogeneity due to unobserved covariates or other sources of natural variation. Even with an exhaustive set of covariates, the remaining natural between-subject variation can be explained by the frailty. In the second case, the modeling strategy would include a stratified analysis or an extended Cox model with interactions of covariates with time [Therneau and Grambsch,12 Chapter 6.5]. Further explanations of violation of the proportional hazards assumption are discussed in Van Houwelingen and Putter,28 Chapter 5.
In this context, the result of Elbers and Ridder,27 while theoretically interesting, is of little practical use. Only a firm – and probably naïve – belief in the conditional proportional hazards assumption can substantiate a claim towards the presence of frailty. In principle, this situation changes in the case of clustered survival data, because positive correlation between the event times is induced by the frailty. This is discussed in section 3. The more information on the correlation structure, the easier it is to distinguish the presence of frailty from non-proportional hazards. However, when the cluster sizes are small, identifying the appropriate model remains a difficult problem because presence of frailty and violations of proportional hazards are confounded.29
The positive stable distribution does not have finite expectation, and therefore it does not fall under the result of Elbers and Ridder.27 As shown in Figure 5, it preserves the proportional hazards assumption at the marginal level. It is not identifiable with univariate survival data, even with covariates in a proportional hazards model. In some sense, this may be seen as an advantage, since it illustrates that the identifiability of univariate frailty models is based on a strong assumption about the mechanism that generated the data. The positive stable distribution does prove useful in the context of clustered failures or recurrent events in section 3.
Since the presence of frailty in a conditional proportional hazards model with univariate frailties is only identifiable through the distortion of the proportional hazards assumption in the marginal model, it follows that the frailty distribution is extremely hard to determine from such univariate data. Basically, it can be identified, assuming proportional hazards for the conditional model, only through the way in which the non-constant behaves in the marginal model. As a result, quite different estimates of the conditional regression coefficients can result when (univariate) frailty models with different frailty distributions are fitted on the same data. This is illustrated in Keiding et al.,30 where the authors argue for the use of the accelerated failure time model in this context.
3 Shared frailty models
In the previous section we used the familiar setting of the Cox model to illustrate some of the “odd effects of frailty”.24 Also here, before introducing shared frailty models in clustered and recurrent events data, we will illustrate, again in the Cox model setting with shared covariates, some of the issues that turn out to play a role in shared frailty models.
3.1 Missing covariates in paired data
Consider the situation of paired event times, where covariate values are shared between individuals from the same pair. Assume that individuals from a given pair have the same distribution of the event time, denoted as T, with the hazard function . Conditional on x, all the life times are assumed to be independent. Further, assume that x is a realization of a random variable X with density . We denote and as the density and survival function of T, given X = x. The marginal survival function of T (where the covariate x is integrated out) is given by .
Consider one pair, with event times T1 and T2. The marginal survival function of either T1 or T2 is given by . If T1 = t1 is observed, the shared covariate will cause the conditional survival function of T2 to change. Heuristically, if a large life time t1 is observed, then it is likely that the pair has a low hazard, which in turn makes it more likely that the value of x in that pair is low if (or high if ). Since x is shared by both individuals, a low hazard for T1 means that the hazard for T2 is also low, and that in turn makes it more likely that the corresponding life time t2 is large as well.
All this leads to a positive marginal correlation of the two life times. More specifically, it is straightforward to show that the marginal survival function of T2, given T1 = t1, is given by
with , the conditional density of X, given T1 = t1. Figure 6 shows for and , for the case where the conditional distribution of T1 and T2, given x = 0, is exponential with mean 1, and β = 1, and X has a normal distribution with mean 0 and standard deviation σ, for different values of σ.
Figure 6.

Conditional survival function of T2, given and given ; the conditional distribution of T1 and T2 given X = x is exponential with rate , λ = 1 and β = 1, and X has a normal distribution with mean 0 and standard deviation , with different values of σ.
It can be seen that for , the conditional survival curves are higher than the marginal survival curve, while for this is the other way around. For higher standard deviation of the distribution of X, the conditional survival curves are more distinct from the marginal survival function. That means that for higher standard deviation of X, the influence of knowing the value of T1 is higher, and the correlation between T1 and T2 is higher. In fact, one can derive an explicit expression of the correlation between T1 and T2, when the baseline distribution of T1 is exponential with rate λ. It is given by
A plot of the correlation as a function of , for β = 1, is shown in Figure 7. The form of this correlation depends on several factors, such as the baseline distribution, the distribution of X and the effect of X on T1 and T2. However, the phenomenon may be observed by simulation in general scenarios: larger unexplained between-subject variation leads to larger marginal correlation between the two event times.
Figure 7.
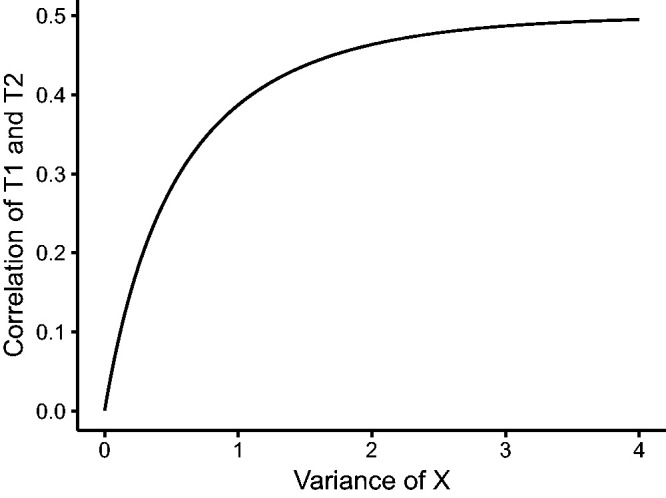
Correlation between T1 and T2 as a function of ; the conditional distribution of T1 and T2 given X = x is exponential with rate and β = 1, and X has a normal distribution with mean 0 and variance .
If the correlation of life times cannot be explained by observed covariates (for example, because x is omitted), then there are two practical approaches. One is marginal modeling, which is in the spirit of general estimating equation (GEE) models. For the Cox model, this involves adjusting the standard errors of the observed covariates.31 The second is to model the conditional hazard by introducing a “shared” frailty Z, that would take the place of in the previous example. The resulting “shared” frailty model is discussed in section 3.1. The advantage of this approach is that differences between clusters can be quantified, and that the covariate effects have an individual interpretation, as in the case of univariate frailty models.
3.2 Clustered failures
3.2.1 The shared frailty model
Assume that there are N clusters and ni individuals are part of cluster i. The hazard of the jth individual from cluster i is specified as
| (10) |
The individuals in cluster i share the frailty Zi, and conditional on Zi their lifetimes are assumed to be independent. While in the univariate case individuals are thought to be a random sample from a larger population of individuals, in the clustered failures case the clusters are thought to be an independent random sample from a population of clusters, and the individuals within a cluster are considered to be an independent random sample from a distribution specific to the cluster and further modified by covariates.
In the univariate case, the marginal survival function was derived, and also the marginal hazard. In the clustered failure case, we can derive the marginal joint survival function of a pair of individuals (or more), and it is useful to derive the posterior distribution of the frailty, given all information about the cluster, including observed events and censorings. This is studied in the next section.
3.2.2 Frailty distributions and clustered failures
Consider two individuals j = 1, 2 in the same cluster, with conditional hazards λ1 and λ2. The conditional cumulative hazards for these individuals are given by . Conditional on Z, the joint survival function of (T1, T2) is defined as
The last equation follows from the assumed conditional independence of T1 and T2, given the frailty. The marginal joint survival probability is obtained by taking the expectation with respect to Z, which results in
| (11) |
There is a close connection with copulas, see for instance.10 The Laplace transform of Z, given that individual 1 and 2 are alive at t1 and t2, is obtained, with the same arguments as in equation (8), as
The only difference from the univariate case is that is now replaced by .
Assume now that the event time T1 of the first subject is observed at t1, and subject 2 is still seen to be alive at t2. Recall that the density of Tj is given by . We obtain
The Laplace transform of Z, given , defined as
can be calculated from Bayes’ theorem
For a more detailed derivation, see equation (8). If both events are observed, the Laplace transform of Z given can be calculated similarly as
where is the second derivative of the Laplace transform of Z. A general pattern can be observed, where for each event observed in the cluster a further derivative of the Laplace transform is involved.
So far the Laplace transforms of the conditional distribution of Z, given T1 and T2, have been expressed in terms of generic hazard rates. Let us now turn to the situation where we have observed data from a cluster of arbitrary size, in which all subjects share the same frailty. Some of these observations include right-censored observations, for others the event of interest has been observed. Suppose we have a model that, conditional on observed covariates x, specifies the hazard rate λj of each individual j in the cluster. We can use the relations derived above to derive the posterior distribution of the frailty, given the observed data in the cluster (rather its Laplace transform). We denote the observed data of the cluster (the event history of all its individuals up to some horizon τ) as . Assume that the data comprises observed events, and let
| (12) |
where is the at risk indicator of subject j in the cluster, equal to 1 if subject j is at risk at time s, and 0 otherwise. Recall as the k-th derivative of the Laplace transform. The Laplace transform of Z, given the event history of the cluster, is given by
| (13) |
The expectation of this distribution follows as minus the derivative of its Laplace transform at c = 0
| (14) |
For the gamma frailty, we obtain that
The class of infinitely divisible distributions, discussed in section 2.3.2, allows similar expressions to be derived.
3.2.3 Dependence and the cross-ratio
The estimated frailty variance offers an indication of unobserved heterogeneity between clusters, but it offers little information on the resulting marginal correlation of the event times. Even for paired data, the formulas for the bivariate survival function in equation (11) are difficult to interpret.
One measure of bivariate dependence is Kendall’s coefficient of concordance (Kendall’s tau). Denote two pairs of individuals as and , where (ij) refers to individual j of cluster (pair) i. Denote Tij as the event time of subject (ij). Kendall’s tau is defined as
where is the sign function. This is proportional to the probability that the order of events is concordant between the two clusters. The median concordance is a similar measure that only involves one pair
This is proportional to the probability that the events within the same cluster are concordant, in the sense that they occur both before the median survival time or after. In frailty models, both τK and κ are positive quantities, since the specification (10) only allows for positive dependence. Under independence, both measures would be 0. However, the reverse statement is not usually true. Estimation of these coefficients in censored data is detailed in Hougaard,9 Chapter 4.
A more natural way of exploring the within-cluster dependence structure is via the cross-ratio,32 defined for pairs of subjects from the same cluster. It compares how the hazard of one subject in the pair would behave if an event would happen to the other subject, as opposed to an event not happening. Unlike τK and κ, it is a local measure of dependence. To illustrate this, we consider one cluster with individuals 1 and 2. Conditional on the frailty, their event times T1 and T2 are independent. Denote the hazard of individual 2 if individual 1 is alive at t1 as
and the hazard of individual 2 if individual 1 had an event at time t1 as
These two hazards concern different hypothetical event histories of the other individual in the cluster. They are equal only if there is no dependence between the two individuals. The cross-ratio can be expressed as
which is a function of . Intuitively, if there is positive dependence between the two event times, we have . It was suggested in Hougaard9 that a more interpretable comparison would be to replace the denominator by , to compare the hazard given that “individual 1 died at time t1” with “individual 1 is alive now”. This “adjusted cross ratio” is defined as
can be interpreted as the ratio between the hazard of individual 1 when individual 2 is dead and the hazard of individual 1 when individual 2 is alive.
In Figure 8, we illustrate the unadjusted and adjusted cross-ratio functions for the gamma, inverse Gaussian and positive stable distributions. For comparison purposes, the distributions are matched by Kendall’s tau rather than variance. Both unadjusted and adjusted cross-ratio functions show that the hazard of individual 2 is larger if individual 1 has an event. The unadjusted cross-ratio for the gamma frailty is constant, showing that the event of individual 1 affects the hazard in the same way over time. The shape of the unadjusted cross-ratio for the inverse Gaussian and positive stable frailties shows that there is a strong immediate dependence that vanishes over time.
Figure 8.

Cross-ratio (top row) and adjusted cross-ratio (bottom row, at ) for the gamma, inverse Gaussian and positive stable distributions, for different values of Kendall’s tau. The individual hazard, conditional on Z = 1, is taken as .
The adjusted cross-ratio paints a slightly different picture. For the gamma, it implies that, if one member of the pair dies, the hazard for the survivor would appear increasingly larger as compared to the scenario where the partner would still be alive. For the positive stable distribution, the surviving individual is at a perceived high risk right after the partner died, but the differences quickly decreases. This can be interpreted as a large correlation between the life times on the short term. As before, the inverse Gaussian is somewhere in the middle.
The unadjusted cross-ratio may be interpreted as an “instantaneous odds ratio”,33 and for bivariate survival data it may be used for selecting the frailty distribution (Duchateau and Janssen,10 Chapter 4). One disadvantage is that it depends on the conditional cumulative hazard; a scaled cross-ratio that overcomes this has been proposed by Paddy Farrington et al.25
The gamma frailty is said to induce “late dependence” (a high probability of events occurring close by at later time points), the positive stable frailty induces “early dependence” (a high probability of event occurring close by early in the follow-up) and the inverse Gaussian is somewhere in the middle. The timing of the dependence can be studied by analyzing the joint distribution of T1 and T2.9 A disadvantage of this approach is that the marginal distributions of T1 and T2 must be known separately, which is usually not possible.
3.2.4 Frailty model for recurrent events
Recurrent events are most commonly defined in the framework of counting processes. Each individual is described by a process N(t) that “counts” the number of events experienced by the individual until time t.
The two common frameworks for modeling N are the Poisson process and the renewal process.34 If unobserved individual heterogeneity is present, then there are two approaches that may be used in practice. One is the marginal approach, where the unobserved heterogeneity is treated as a nuisance.35 In that case, the focus of analysis is the marginal rate of N, which is defined as the probability of observing an increase in N in the small interval .
The second approach is to model the intensity of N. While the hazard is defined as the instantaneous probability of an event given that the individual is alive, the intensity is defined as the instantaneous probability of an event given the whole previous event history of the individual. One way of incorporating the previous event history of the individual is to assume that the intensity at time t depends in some way on the number of events observed prior to time t. When the Poisson and renewal processes depend explicitly on the past, they result in so-called modulated Poisson and renewal processes. Another way is to implicitly model the dependence on the event history through a frailty Z. The conditional intensity of N, given Z, is then specified as
| (15) |
where Y(t) is an indicator function that is 1 if the individual is under observation at time t and 0 otherwise. Similarly to the univariate frailty, the variance of Z describes between-individual unobserved heterogeneity.
The marginal intensity is obtained by replacing Z by , with now representing the event history of the individual until just before time t. As in the case of univariate frailty in section 2.4, the effect of the covariates in the marginal intensity is usually time-dependent. Similar to the clustered failures scenario, includes information on previous event times.
The intensity in equation (15), with t referring to “time since origin of the recurrent event process”, is referred to as the calendar time or Andersen-Gill formulation. In the Andersen-Gill formulation, N is assumed to be a Poisson process, conditional on Z, meaning that its intensity conditional on Z does not depend on the history . Alternatively, in the gap-time scale, t refers to “time since the previous event”. The intensity may then be expressed as , where B(t) is the time of the event before time t. From a practical point of view, the gap time scale has a very similar representation to (10), where is interpreted as the hazard of the j-th event, on the time scale since the last observed event. Conditional on Z, N is then a renewal process.
In the case of recurrent events, the frailty mainly expresses that, if two individuals with identical covariates were observed over the same period of time, the expected number of events is larger for the one with the higher frailty. The number of events carries the most information on the frailty9 (Chapter 9). Therefore, the measures of dependence discussed in subsection 3.2.3 are of little interest in this context.
Modeling recurrent events is a complex task and several types of models may be accommodated with counting processes (Therneau and Grambsch,12 Section 8.5). Furthermore, time-dependent covariates representing, for example, the number of previous events, may also be added in the model (Aalen et al.,24 Chapter 8). A comprehensive reference on recurrent event modeling may be found in Cook and Lawless.34
3.3 Estimation and inference for frailty models
Depending on the nature of the baseline hazard or intensity λ0, the frailty models may be classified as semi-parametric or parametric. In semi-parametric models, no assumptions are made on the baseline hazard or intensity λ0 and the maximum likelihood estimate of λ0 has mass only at the event times, as is the case for the Breslow estimator.36 In parametric models, λ0 is determined by a small number of parameters, such as the exponential, Weibull or Gompertz models, or flexible parametric approaches employing spline-based estimators.
3.3.1 Likelihood and EM-based approaches
The likelihood construction for counting processes is detailed in most survival analysis textbooks.24,37 To cover all the scenarios described previously, assume that i denotes the cluster, (i, j) the j-th individual within the cluster i and tijk denotes the k-th event or censoring time observed on individual (i, j). We define the event indicator δijk as 1 if tijk is an event time and 0 otherwise. Suppose that the conditional hazard of subject (i, j), conditional on the frailty Zi is given by with . Denote the at risk indicator of subject j in cluster i by and let , with τ the horizon, be the sum of conditional cumulative hazards of cluster i, as defined in equation (12).
Assuming that the frailties Zi are observed, the conditional likelihood contribution of cluster i is given by
and the likelihood for all the individuals is a product of all Lis. The clustered failure data is represented by having only one time point per individual (), while the recurrent events case is represented by having only one individual per cluster (). An implicit assumption here is that censoring is independent. In terms of counting processes, the at-risk process Y(t) is assumed to be independent of N(t), given the covariates and event history up to time t.
In the first part of this expression, Zi appears to the power Ni•, the total number of events from the cluster i. The marginal likelihood contribution of cluster i is obtained by taking the expectation over Zi
| (16) |
The parameters to be optimized are β, the vector of regression coefficients, λ0, the baseline hazard, and θ, the parameters of the frailty distribution, usually the frailty variance. For valid inference based on , the censoring or at-risk process must also not involve the frailty, for reasons outlined in Nielsen et al.38 This assumption is similar to that of regular Cox models, where dependent censoring arises, for example, if the censoring process depends on unobserved covariates. In models where the baseline hazard λ0 is parametric, direct optimization of the likelihood is feasible. When the baseline hazard is non-parametric, as in a (conditional) Cox model, the dimension of λ0 is usually equal to the number of total distinct event time points in the data. This prevents a direct maximization of the likelihood.
For semi-parametric gamma frailty models, the Expectation-Maximization (EM) algorithm39 has been proposed.38,40 It can be extended in a straightforward way to the class of infinitely divisible distributions described in section 2.3.2.9,41 This involves iterating between two steps:
- The “E” step, which involves calculating the expected log-likelihood
In practice, this involves calculating and possibly .
2. The “M” step, where and θ are updated, by maximizing .
The advantage of this approach is that the M step may be calculated via Cox’s partial likelihood,42 effectively eliminating the problem of the high-dimensional λ0. For the E step, the “posterior” distribution of Zi, given the event history of cluster i, needs to be evaluated. It has the density kernel
This is available in closed form only for the gamma frailty, and is typically difficult to calculate for other frailty distributions. The expectation of this distribution, , is also known as the empirical Bayes frailty estimate. It can be calculated via the Laplace transform, as discussed in section 3.2.2, see equation (14). This may involve having to take many derivatives of the Laplace transform, if is large. In principle, for the “E” step, also is needed. Calculation of can be avoided via a “profile EM” algorithm, which involves performing the EM algorithm described here for fixed values of θ, and maximizing over θ in an outer loop.38 As an alternative for the EM algorithm, a Monte Carlo EM algorithm may be employed, which involves a stochastic approximation of the E step.43
3.3.2 Alternative approaches
The penalized likelihood method44,45 is a very popular way of estimating gamma and log-normal semi-parametric frailty models. The basic idea behind it is that, for fixed θ, the 's may be treated as regular parameters (on the same scale with the regression coefficients β). Afterwards, a penalization of a specific form is imposed upon them. Depending on the penalization, the results are equivalent to those of a gamma or a log-normal distributional assumption. This approach is typically the fastest for semi-parametric models, and is implemented in coxph in the survival package. A downside is that it is not immediately possible to extend the estimation to other frailty distributions.
Other approaches include a pseudo-likelihood method,46 which leads to consistent estimators and may be employed for a larger number of frailty distributions, and the h-likelihood method.47,48 This approach relies on maximizing the joint likelihood of the observed and unobserved data. It has been developed for the gamma and log-normal distributions.
3.3.3 Inference
For parametric models, the variance–covariance matrix is typically obtained directly, as the inverse of the numeric Hessian matrix. This is usually provided directly by optimization software. For models estimated with the EM algorithm, Louis’ formula may be used49 to obtain standard errors of the estimates. It has been shown that the baseline hazard may be regarded, for practical purposes, as an ordinary finite dimensional parameter and the information matrix may be constructed from the matrix of second derivatives.50
For the profile EM algorithm, the variance covariance matrix for is obtained under the assumption of fixed θ. Similarly to the penalized likelihood methods, the variance–covariance matrix for β, based on the partial likelihood, is also obtained under fixed θ. The complete variance–covariance matrix for or for β should then be adjusted for the variability of θ (Hougaard9 Chapter B3),51 although this is usually ignored in practice.
Inference regarding the frailty variance is more challenging. The limiting case, when the variance is 0, is a proportional hazards model without frailty. A likelihood ratio test based on a 50:50 mixture of distributions with 0 and 1 degree of freedom can be employed to test the difference between these two models.52,53 Another issue is that, since the variance must be positive, symmetric confidence intervals are not very meaningful. An alternative is to calculate likelihood-based confidence intervals, as is illustrated in Therneau and Grambsch,12 Chapter 9.
4 Frailty models in practice
4.1 Software
Support for frailty models exists in major statistical packages such as R,54 SAS55 and Stata.56 The PHREG command in SAS implements the penalized likelihood method for the gamma and log-normal frailty models. The streg procedure in Stata implements parametric gamma and inverse Gaussian frailty models. In what follows, we will focus on packages for R.
Semi-parametric gamma and log-normal frailty models may be estimated via the penalized likelihood method in the survival package.12,57 Semi-parametric frailty models with the infinitely divisible class of frailty distributions discussed in section 2.3.2 may be estimated via the profile EM algorithm with the frailtyEM package.58 Log-normal frailty models (including correlated frailties, discussed in section 5) may be estimated with the coxme package.59 Similar models may be fitted with the Monte Carlo EM algorithm with the phmm R package.60 Log-normal and gamma frailty models can also be estimated via likelihood with the frailtyHL package.61 The pseudo-likelihood approach is implemented in the frailtySurv package,62 supporting some of the infinitely divisible distributions from the PVF family.
Parametric and flexible parametric frailty models for the gamma and log-normal distributions are supported by the frailtypack package63,64 (including correlated random effects, nested random effects and numerous other scenarios). Parametric frailty models with support for some of the PVF family distributions are implemented in the parfm package.65
4.2 Data representation
In R,54 the canonical resources for survival analysis are found in the survival package.57 Event histories corresponding to survival times or to recurrent events have a very similar representation, as described in detail in Therneau and Grambsch.12
An event history is represented by a collection of observations, which are vectors where (tL, tR) are two time points that define an “at-risk” interval, δ is equal to 1 if the interval ended with an event and 0 otherwise, and x is a vector of covariate values that are constant on this interval. In R, the tuple is referred to as (tstart, tstop, status). Univariate survival times and clustered failures are usually represented by having tL = 0 and a simplified (tstop, status) notation. Furthermore, the notation may also be used to express:
Recurrent events in calendar time (or “Andersen-Gill” representation). In this case, for an individual, tR are event times and tL is usually 0 or the time of the previous event. Usually, the last observation is censored with the last tR being the end of follow-up.
Recurrent events in gap time. In this case, tL = 0 and tR are observed gap times. The last observation may be censored, indicating an incomplete gap time at the end of follow-up.
Left truncated survival times, where tL is the time point after which the individual enters the study.
Time-dependent covariates. In this case, if the value x changes at time , this results in two observations corresponding to time intervals and , with the first one being artificially censored.
In the presence of frailty, an observation is interpreted as a contribution to the conditional likelihood of the form
For a collection of observations sharing the same frailty Z, the software maximizes
which is the contribution of one cluster to the marginal likelihood (16). This is appropriate in the case of recurrent events and time-dependent covariates, or for clustered survival times without left truncation.
For left truncated survival times, however, this is generally incorrect. In the univariate case, the frailty distribution of a left truncated individual is that of , referred to as the distribution of survivors (until time tL) in section 2.4.
In the case of clustered survival times, the event of observing the whole cluster must be taken into account.66–68 If the individuals from the same cluster have truncation times that are independent given Z, then the frailty distribution of the cluster is that of .
More complicated selection schemes arise when the left truncation times are not independent, even conditional on the frailty.69 In the case of recurrent events, such selection schemes may arise when individuals are included into the study only if they experience a certain number of events.70 Such scenarios usually require ad-hoc estimation procedures and are not generally supported by the main software packages.
In R, one of the reasons why the same notation is used to denote both recurrent events and left truncation is because they lead to the same likelihood in frailty-less models. In the case of frailty models, the treatment depends on the package used. For example, the survival package calculates the correct likelihood for the recurrent events case, parfm calculates the correct likelihood for the left truncation case. In frailtypack and frailtyEM, both scenarios are supported.
5 Extensions
The standard shared frailty model assumes that the frailty is shared among all individuals in the same cluster. This assumption can be relaxed by assuming that the frailty terms of individuals in the same cluster are not shared, but correlated.7,11,71,72 Correlated frailty models address the limitation that shared frailty models may only be employed for positively correlated event times.
Furthermore, so far the random effect Z has been assumed to be time-constant. This is consistent with the interpretation that Z accounts for individual specific or cluster specific characteristics that are fixed from the time origin, and have an effect that is constant over time. However, the unobserved heterogeneity might be time-dependent, thus better explained by an unobserved random process that unfolds over time. Several approaches based on this idea have been proposed. The frailty may be modeled with diffusion processes73,74 or Levy processes.75 More recently, an approach on birth-death Poisson processes has been proposed.51 Simpler, piecewise constant, frailty models have also been considered.76,77 A limited implementation combining the birth-death processes and the piecewise constant frailty is implemented in the R package dynfrail.78 Related approaches include the constructions of auto-regressive frailty processes based on log-normal frailties79,80 or gamma frailties.81
Since the models presented in sections 2 and 3 are intended for the analysis of one stochastic event process, it has been assumed that the censoring does not depend on the frailty included in the time to event model. This assumption may be tested,82 and in case a violation of this independence assumption is detected, the event and censoring processes can be modeled jointly. An example is when the observation recurrent event process may be stopped by death83 or when the frailty is also associated with the censoring.84
Moreover, we assumed that in case of time-dependent covariates, the vector is “external” to the event process, in the sense of Kalbfleisch and Prentice.37 If x contains internal time-dependent covariates, such as repeated individual measurements, the processes should be modeled jointly (Rizopoulos,85 Chapter 2). In this case, the frailty is shared by the model for the time-dependent covariate (or biomarker) and the model for the event process. Software for estimating joint models is also available in R.86
More advanced random effect structures may be, in theory, considered. For example, if individuals experience recurrent events and are nested within clusters, a hierarchical random effects model may be considered. This is, however, not easily done in practice, and there is no standard software that currently supports such models.
6 Illustration
We end by discussing two illustrations of the use of frailty models. The first is a study on center effects in a breast cancer study, the second on recurrent events in patients with chronic granulomatous disease. The R code for the analyses performed is available as Supplementary Material.
6.1 Frailty models for center comparisons
The data originate from a clinical trial in breast cancer patients, conducted by the European Organization for Research and Treatment of Cancer (EORTC-trial 10854). The objective of the trial was to study whether a short intensive course of perioperative chemotherapy yields better therapeutic results than surgery alone. The trial included patients with early breast cancer, who underwent either radical mastectomy or breast conserving therapy before being randomized. The trial consisted of 2795 patients, randomized to either perioperative chemotherapy or no perioperative chemotherapy. Results of the trial were reported in literature.87,88 The data have been studied in a multi-state model in Putter et al.89 and Van Houwelingen and Putter.28 This data is based on a subset of all 2687 patients with complete information on all covariates used below. For descriptives on these covariates, see Van Houwelingen and Putter,28 Appendix A.2.
In the trial, patients have been included in 15 participating centers. The size of the centers varies between 6 patients (the smallest one) and 880 (the largest), as illustrated in Figure 9.
Figure 9.

Histogram of center sizes.
Figure 10.

Kaplan–Meier survival estimates, overall and by center.
For this illustration, the endpoint of interest is overall survival. In Figure 10, we show the Kaplan–Meier estimates corresponding to each center (gray) and the overall estimate (black). These survival curves do not make it easy to compare centers. One of the reasons is that the survival curves are not controlled for possible differences between the distribution of covariates across centers (so-called case-mix), another is that it is difficult to disentangle randomness from systematic differences between centers.
For the inclusion of covariates, we start with a proportional hazards model, where the hazard of subject j from center i, given its covariates , is given by
This model does not yet include any differences between centers. Estimating it is straightforward in principle, but for the standard maximum likelihood approach, the event times of the individuals are assumed to be independent. This assumption might not hold when observations come from the same center. Generalized estimating equations (GEE), with independent working covariance, may be used to obtain valid (sandwich) standard errors in this case. The results, with unadjusted and adjusted (robust) standard errors, are shown in Table 1, under “Cox model”. The hazard ratios have a marginal interpretation, in the sense that they are averaged over all unmeasured covariates (such as, for example, center effects). Therefore, the estimated regression coefficients apply to an individual selected at random from the population.
Table 1.
Estimates from the Cox model, the fixed effects model, the gamma and log-normal frailty models.
| Cox model |
Fixed Effects |
Gamma frailty |
Log-normal frailty |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coef | SE | Robust SE | Coef | SE | Coef | SE | Coef | SE | |||||
| Type of surgery | Mastectomy with RT | ||||||||||||
| Mastectomy without RT | 0.25 | 0.11 | 0.17 | 0.16 | 0.13 | 0.16 | 0.12 | 0.16 | 0.12 | ||||
| Breast conserving | −0.07 | 0.10 | 0.10 | −0.09 | 0.10 | −0.08 | 0.10 | −0.08 | 0.10 | ||||
| Tumor size | <2 cm | ||||||||||||
| 2–5 cm | 0.35 | 0.10 | 0.10 | 0.35 | 0.10 | 0.35 | 0.10 | 0.35 | 0.10 | ||||
| >5 cm | 0.89 | 0.15 | 0.16 | 0.83 | 0.16 | 0.84 | 0.16 | 0.84 | 0.16 | ||||
| Nodal status | Node negative | ||||||||||||
| Node positive | 0.97 | 0.11 | 0.26 | 0.77 | 0.11 | 0.79 | 0.11 | 0.78 | 0.11 | ||||
| Age | 50 | ||||||||||||
| >50 | 0.01 | 0.10 | 0.12 | 0.10 | 0.10 | 0.09 | 0.10 | 0.09 | 0.10 | ||||
| Adjuvant chemo | No | ||||||||||||
| Yes | −0.38 | 0.13 | 0.35 | −0.15 | 0.14 | −0.17 | 0.13 | −0.17 | 0.14 | ||||
| Tamoxifen | No | ||||||||||||
| Yes | −0.17 | 0.12 | 0.31 | 0.12 | 0.13 | 0.08 | 0.12 | 0.08 | 0.12 | ||||
| Perioperative chemo | No | ||||||||||||
| Yes | −0.12 | 0.07 | 0.06 | −0.13 | 0.07 | −0.13 | 0.07 | −0.13 | 0.07 | ||||
| Frailty variance | 0.122 | 0.132 | |||||||||||
Note: Estimated center effects of the fixed effects model have been omitted from the table.
To explain more of the underlying heterogeneity, we account for center effects. The centers are included in a fixed effects model. The underlying model would be given by
Such a model can be fitted using center as a factor variable, taking one of the centers, usually the first, as reference center. The resulting estimates of the regression coefficients are shown in Table 1, under Fixed Effects. We can visually assess the differences between centers via a caterpillar plot, shown in Figure 11. The error bars denoted with “fixed effects” correspond to the estimates and 95% confidence intervals of the fixed effects estimates. In the Cox model estimated above, the first center is taken as reference, with an implicit . Denote γ as the vector of regression coefficients of the remaining centers, and as their average. For this visual representation, we center the γ’s at 0, i.e. we set , and , with the average of the original estimates of the γ’s. The standard errors are then also calculated accordingly. The confidence intervals suggest that there is a lot of variability in estimated center effects in this way. Most of the confidence intervals include 0, with the exception of center E, which shows a lower mortality, and centers M, N, and O, which show a higher mortality.
Figure 11.

Center effects from the fixed effects and frailty models, expressed in hazard ratios.
More naturally, we would think about the centers as being randomly drawn from a population of centers, and their effects as being realizations from a frailty distribution. The underlying model would be
where Zi is the (random) center effect corresponding to center i. The frailty variance can then be used to quantify the degree of between center variability. The result of fitting a gamma frailty model is shown in Table 1, under frailty model. The frailty variance is estimated as 0.122. The 95% confidence interval for the frailty variance, given by (0.048, 0.324), is based on the profile likelihood function (see section 3.3.1). This means that there is a one-to-one correspondence between the confidence interval for the frailty variance and the profile likelihood ratio test. Although the frailty variance is not really large, the likelihood ratio test deems the differences in mortality rates between centers, after adjustment for covariates, as statistically significant. Figure 11 shows a caterpillar plot of the center effects from the fixed effects model and from the frailty model. For the frailty model, for each center, the estimate shown is the empirical Bayes estimate, and the 95% interval is given by the 2.5% and 97.5% percentiles of the posterior frailty distribution, given the data in the center, as detailed in equation (13) in section 3.2.2.
It may be observed that, particularly for the extreme centers, the frailty estimates are shrunken towards the mean (1). In terms of interpretation of the frailty estimates, it is helpful to study the form of the empirical Bayes estimates. For the gamma frailty model, it may be shown that the empirical Bayes estimate for center i is given by
where is the estimate of the inverse variance parameter, Ni the number of events in center i and the sum of the cumulative hazards of all individuals from center i, evaluated at the end of follow-up of each individual, cf. equation (12). While Ni is the “observed” number of events, may be interpreted as the expected number of events in center i, based on the case-mix and the length of follow-up of the patients in the center. We can re-write as
with
Therefore, is a weighted average of the ratio between observed and expected number of events and the overall average (1). In particular, smaller centers (with smaller ) will show more shrinking.
The proportional hazards assumption may be checked with, for example, with a test based on residuals.13 In the case of the Cox model, this tests shows evidence against non-proportionality for tumor size and nodal status. For the frailty model, the same test can be carried out on the same Cox model, but with the logarithm of the log-frailties as offset. In this case, the conclusions are unchanged and indicate that further modeling of these variables may be required. Note that this may not be the case if the clusters would be smaller in size; we discuss this in section 7.
For comparison, we also estimated the same model with log-normal instead of gamma frailty. The maximized likelihood of this model was −5449.4 versus −5450.9 for the gamma frailty, suggesting a better fit to the data. The estimates of the regression coefficients are also shown in Table 1. The results from the two models are virtually identical, except for the estimated frailty variance which is slightly larger than the one from the gamma frailty.
6.2 Frailty models for recurrent events
The data are from a placebo controlled trial of gamma interferon in chronic granulomatous disease (CGD) and are available in the survival package. It contains the time to recurrence of serious infections, observed from randomization until end of study for each patient. The follow-up and event history of each individual are visualized in Figure 12. Most individuals, in fact, have no events during their follow-up; see Figure 13 for a histogram of the number of recurrences per individual.
Figure 12.

Event history of the CGD data. The length of the line indicates the length of follow-up, and the dots indicate the infections.
Figure 13.

Histogram of number of events per individual.
A preliminary Cox model fit reveals that the treatment is highly significant, and that age, inherit and steroid usage are also significant. For the purpose of illustration, we will include these variables, plus sex, from now on. The results from the Cox model with these selected covariates are shown in Table 2. The covariates explain part of the differences between intensities in the occurrence of infections between the individuals. To quantify the unobserved heterogeneity in the intensities, we fit a shared gamma frailty model to the data. The frailties reflect the increase or decrease in infection rates of different individuals. The result is shown in Table 2. The frailty variance is estimated as 0.555, with (profile) likelihood ratio test-based 95% confidence interval . A histogram of the empirical Bayes frailty estimates is shown in Figure 14.
Table 2.
Estimates of the regression coefficients and fit summary from the Cox model and shared frailty models, with gamma, inverse Gaussian, positive stable and compound Poisson (with parameters 0.5 and 1.1) distributions, fitted on the CGD data.
| Inverse | Positive | Compound Poisson | |||||
|---|---|---|---|---|---|---|---|
| Cox model | Gamma | Gaussian | Stable | (m = 0.5) | (m = 1.1) | ||
| Treatment | Placebo | ||||||
| IFN-g | −1.10 (0.26) | −1.01 (0.30) | −1.03 (0.30) | −1.10 (0.30) | −1.00 (0.30) | −1.00 (0.31) | |
| Sex | Male | ||||||
| Female | −0.68 (0.39) | −0.70 (0.48) | −0.67 (0.47) | −0.63 (0.45) | −0.71 (0.48) | −0.72 (0.48) | |
| Age (years) | −0.04 (0.01) | −0.04 (0.02) | −0.04 (0.02) | −0.04 (0.02) | −0.04 (0.02) | −0.04 (0.02) | |
| Pattern of | X-linked | ||||||
| inheritance | Autosomal | 0.64 (0.28) | 0.60 (0.33) | 0.59 (0.34) | 0.61 (0.34) | 0.60 (0.33) | 0.61 (0.33) |
| Use of | No | ||||||
| corticosteroids | Yes | 1.40 (0.56) | 1.56 (0.78) | 1.49 (0.73) | 1.41 (0.62) | 1.59 (0.80) | 1.60 (0.82) |
| Log-likelihood | −324.939 | −322.206 | −322.431 | −324.837 | −322.160 | −322.149 | |
| Frailty variance | 0.555 | 0.557 | 0. 544 | 0.529 | |||
| 95% CI | (0.067, 1.449) | (0.049, 1.865) | (0.071, 1.328) | (0.072, 1.234) | |||
| LRT p-value | 0.0085 | 0.0110 | 0.2568 | 0.0081 | 0.0080 |
Figure 14.

Histogram of the estimated frailties.
It is possible to question our choice for the gamma frailty. Partially due to software limitations, other distributions are rarely considered in practice. Table 2 also shows estimated frailty variances with 95% confidence intervals, as well as marginal log-likelihoods of fitted frailty models with other frailty distributions, including the inverse Gaussian, compound Poisson (m = 0.5), and positive stable distributions. Recall that the inverse Gaussian is a particular case of the PVF distributions. So is the compound Poisson distribution, where the parameter m, initially chosen as 0.5, determines the actual distribution. A grid search among possible values of the m parameter of the compound Poisson distribution (from 0.2 to 2.0 in steps of 0.1) identified m = 1.1 as optimal value, in terms of maximizing the log-likelihood. The small differences between the log-likelihoods for different values of m, however, indicate that no clear difference can be seen between any of the compound Poisson distributions. It is notoriously difficult to choose between frailty distributions; in practice this choice is usually made by convenience.
The positive stable distribution is interesting to note. As mentioned before it does not have finite mean or variance; in contrast to the other frailty models, the fit of the positive stable frailty model is not deemed significantly better than that of the Cox model without frailty, by the likelihood ratio test.
In a sense, a frailty model implies that the marginal intensity of the counting process, given the past, depends on the previous number of events, through , with representing the event history of the individual until just before time t. The past can also be incorporated directly, by including the number of previous events, or a pre-specified function of it, as a covariate in a proportional hazards model. Including the number of previous events leads to a regression coefficient of 0.182 (SE = 0.101), p = 0.069, with a log-likelihood of −323.396. Including the logarithm of the number of previous events leads to a regression coefficient of 0.615 (SE = 0.252), p = 0.015, with a log-likelihood of −322.086, which is, interestingly, higher than the log-likelihoods of all frailty models considered here.
7 Practical modeling advice
In practice, one would fit the frailty model for clustered survival data or recurrent event modeling. For univariate survival data, estimating frailty models involves a large degree of speculation, and their practical value is therefore limited. Nevertheless, they are useful tools in situations where there is a strong a priori evidence for heterogeneity, as for example in modeling time to pregnancy,90 or when the objective is to understand or provide alternative explanations of the shape of the hazard.91
In the context of clustered survival data, one would fit a frailty model for estimating covariate effects while adjusting for, and with the objective of quantifying the between-cluster heterogeneity. In the context of recurrent event data, one would fit a frailty model for estimating covariate effects without assuming that the recurrent event process is Poisson and quantifying the between-subject heterogeneity. The usage of random effects is particularly sensible when the clusters (or individuals, in the case of recurrent events) are considered to be a random sample from a larger population.
The starting point for modeling is typically a marginal model, using the GEE approach. The point estimates for covariate effects are obtained from a proportional hazards model, and the standard errors are calculated using a sandwich estimator. With coxph, for example, this may be obtained with the +cluster() option. In some cases, this explanation may suffice. The hazard ratios in such a marginal model quantify the effect of the covariates at the population level.
When the clusters are large in size, or when individuals have numerous recurrent events, one may consider including cluster-specific (or individual-specific, in the case of recurrent events) fixed effects. The variability of these fixed effects may be assessed informally, as illustrated in section 6.1. A meaningful variability would indicate the presence of unobserved heterogeneity. One issue with this is that the fixed effects estimates of the clusters with few subjects will have a large variability, and shrinkage towards the mean would be desirable. This was also illustrated in the same section. All frailty distributions will provide some degree of shrinkage, but only for the gamma and a limited set of other frailty distributions closed-form results are easily available. One way to formally evaluate the presence of unobserved heterogeneity is with the Commenges-Andersen score test. In practice, a frailty model may be useful to be estimated anyway, to be able to quantify the heterogeneity and formally evaluate the improvement in model fit via the likelihood ratio test.
In terms of choosing which frailty distribution is most appropriate, we start with the practical considerations. The gamma frailty model is the simplest and most well understood frailty model, and may be estimated by the base R survival package. Furthermore, theoretical results indicate that the gamma distribution is the limiting distribution of the frailty of long-time survivors,92 irrespective of the frailty distribution at baseline. The log-normal frailty model is conceptually simple as well, since it involves considering an additive random effect on the same scale as the other covariates. This can also be estimated by the survival and coxme packages. In both cases, a likelihood ratio test can be carried out to formally explore whether the frailty models provide significantly better fits to the data. This aspect is illustrated in section 6.2.
In principle, different frailty models may be compared via their log-likelihoods. Such a procedure might be useful for selecting a well-fitting frailty distribution from a larger class of frailty distributions, such as the power variance family, but since the frailties are latent, there typically is not a lot of information in the data to make a well informed choice, as could also be seen in section 6.2. Since the gamma frailty distribution is the most popular frailty distribution, a number of procedures for testing goodness-of-fit of the frailty distribution in the shared gamma frailty model have been proposed. Shih and Louis93 suggest to visually assess the fit of the gamma frailty distribution by plotting the empirical Bayes estimators of the frailties given the observable data so far over time. For the gamma frailty model, these should be constant over time. This test was later extended by Glidden.94 Geerdens et al.95 developed a goodness-of-fit test by constructing a class of frailty model that extend the gamma frailty model using polynomial expansions that are orthogonal to the gamma density. The aforementioned tests focus on the goodness-of-fit of the gamma frailty distribution in the gamma frailty model. When evaluating the fit of a proportional hazards frailty model, another aspect is the validity of the (conditional) proportional hazards assumption. This assumption may be assessed in a similar way as in a regular survival model, by including the logarithm of the empirical Bayes frailty estimates as an offset in the proportional hazards model, and studying the Schoenfeld residuals.12 This is most sensible when cluster sizes are relatively large (e.g. above 10 subjects). When this is not the case, the presence of frailty and the proportional hazards assumption may still be, to some extent, confounded.29
Acknowledgement
The European Organisation for Research and Treatment of Cancer (EORTC) is gratefully acknowledged for making available anonimized data of the EORTC-10854 trial.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
ORCID iD
Hein Putter https://orcid.org/0000-0001-5395-1422
References
- 1.Cox DR. Regression models and life-tables. J Royal Stat Soc, Ser B (Methodological) 1972; 34: 187–220. [Google Scholar]
- 2.Woodbury MA, Manton KG. A random-walk model of human mortality and aging. Theoretical Population Biol 1977; 52: 37–48. [DOI] [PubMed] [Google Scholar]
- 3.Vaupel JW, Manton KG, Stallard E. The impact of heterogeneity in individual frailty on the dynamics of mortality. Demography 1979; 16: 439–454. DOI:10.2307/2061224. [PubMed] [Google Scholar]
- 4.Heckman J, Singer B. A method for minimizing the impact of distributional assumptions in econometric models for duration data. Econometrica: J Econometric Soc 1984; 52: 271–320. [Google Scholar]
- 5.Vaupel JW, Yashin AI. Heterogeneity’s ruses: some surprising effects of selection on population dynamics. Am Stat 1985; 39: 176–185. [PubMed] [Google Scholar]
- 6.Aalen OO. Heterogeneity in survival analysis. Stat Med 1988; 7: 1121–1137. [DOI] [PubMed] [Google Scholar]
- 7.Hens N, Wienke A, Aerts M, et al. The correlated and shared gamma frailty model for bivariate current status data: an illustration for cross-sectional serological data. Stat Med 2009; 28: 2785–2800. [DOI] [PubMed] [Google Scholar]
- 8.Unkel S, Farrington CP, Whitaker HJ, et al. Time varying frailty models and the estimation of heterogeneities in transmission of infectious diseases. J Royal Stat Soc: Ser C (Appl Stat) 2014; 63: 141–158. [Google Scholar]
- 9.Hougaard P. Analysis of multivariate survival data. New York, NY: Springer-Verlag, 2000. [Google Scholar]
- 10.Duchateau L, Janssen P. The frailty model. New York, NY: Springer, 2007. [Google Scholar]
- 11.Wienke A. Frailty models in survival analysis. Amsterdam, The Netherland: CRC Press, 2010. [Google Scholar]
- 12.Therneau TM, Grambsch PM. Modeling survival data: extending the Cox model. New York: Springer-Verlag, 2000. [Google Scholar]
- 13.Grambsch PM, Therneau TM. Proportional hazards tests and diagnostics based on weighted residuals. Biometrika 1994; 81: 515–526. [Google Scholar]
- 14.Struthers CA, Kalbfleisch JD. Misspecified proportional hazards models. Biometrika 1986; 73: 363–369. [Google Scholar]
- 15.Schumacher M, Olschewski M, Schmoor C. The impact of heterogeneity on the comparison of survival times. Stat Med 1987; 6: 773–784. [DOI] [PubMed] [Google Scholar]
- 16.Bretagnolle J, Huber-Carol C. Effects of omitting covariates in Cox’s model for survival data. Scand J Stat 1988; 15: 125–138. [Google Scholar]
- 17.Schmidt DS, Salahudeen AK. Cardiovascular and survival paradoxes in dialysis patients: obesity-survival paradox – still a controversy? Seminars Dialysis 2007; 20: 486–492. [DOI] [PubMed] [Google Scholar]
- 18.Hernán MA. The hazards of hazard ratios. Epidemiology 2010; 21: 13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Aalen OO, Cook RJ, Røysland K. Does cox analysis of a randomized survival study yield a causal treatment effect? Lifetime Data Analysis 2015; 21: 579–593. [DOI] [PubMed] [Google Scholar]
- 20.Aalen OO. A linear regression model for the analysis of life times. Stat Med 1989; 8: 907–925. [DOI] [PubMed] [Google Scholar]
- 21.Hougaard P. Life table methods for heterogeneous populations: distributions describing the heterogeneity. Biometrika 1984; 71: 75–83. [Google Scholar]
- 22.Hougaard P. A class of multivanate failure time distributions. Biometrika 1986; 73: 671–678. [Google Scholar]
- 23.Hougaard P. Survival models for heterogeneous populations derived from stable distributions. Biometrika 1986; 73: 387–396. [Google Scholar]
- 24.Aalen O, Borgan O, Gjessing H. Survival and event history analysis: a process point of view. New York, NY: Springer-Verlag, 2008. [Google Scholar]
- 25.Paddy Farrington C, Unkel S, Anaya-Izquierdo K. The relative frailty variance and shared frailty models. J Royal Stat Soc, Ser B (Stat Methodol) 2012; 74: 673–696. [Google Scholar]
- 26.Aalen OO. Effects of frailty in survival analysis. Stat Meth Med Res 1994; 3: 227–243. [DOI] [PubMed] [Google Scholar]
- 27.Elbers C, Ridder G. True and spurious duration dependence: the identifiability of the proportional hazard model. Rev Economic Studies 1982; 49: 403–409. [Google Scholar]
- 28.Van Houwelingen HC, Putter H. Dynamic prediction in clinical survival analysis. Boca Raton, FL: CRC Press, 2011. [Google Scholar]
- 29.Balan TA, Putter H. Non-proportional hazards and unobserved heterogeneity in clustered survival data: When can we tell the difference? Stat Med 2019; 38: 3405–3420. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Keiding N, Andersen PK, Klein JP. The role of frailty models and accelerated failure time models in describing heterogeneity due to omitted covariates. Stat Med 1997; 16: 215–224. [DOI] [PubMed] [Google Scholar]
- 31.Lin DY, Wei LJ. The robust inference for the Cox proportional hazards model. J Am Stat Assoc 1989; 84: 1074–1078. [Google Scholar]
- 32.Oakes D. Bivariate survival models induced by frailties. J Am Stat Assoc 1989; 84: 487–493. [Google Scholar]
- 33.Anderson JE, Louis TA, Holm NV, et al. Time-dependent association measures for bivariate survival distributions. J Am Stat Assoc 1992; 87: 641–650. [Google Scholar]
- 34.Cook RJ, Lawless J. The statistical analysis of recurrent events. New York, NY: Springer Science & Business Media, 2007. [Google Scholar]
- 35.Cook RJ, Lawless JF. Marginal analysis of recurrent events and a terminating event. Stat Med 1997; 16: 911–924. [DOI] [PubMed] [Google Scholar]
- 36.Breslow NE. Contribution to discussion of paper by DR Cox. J Royal Stat Soc Ser B (Methodol) 1972; 34: 216–217. [Google Scholar]
- 37.Kalbfleisch JD, Prentice RL. The statistical analysis of failure time data. 2nd ed Hoboken, NJ: Wiley, 2002. [Google Scholar]
- 38.Nielsen GG, Gill RD, Andersen PK, et al. A counting process approach to maximum likelihood estimation in frailty models. Scand J Stat 1992; 19: 25–43. [Google Scholar]
- 39.Dempster AP, Laird NM, Rubin DB. Maximum likelihood from incomplete data via the EM algorithm. J Royal Stat Soc, Ser B (Methodol) 1977; 39: 1–38. [Google Scholar]
- 40.Klein JP. Semiparametric estimation of random effects using the Cox model based on the EM algorithm. Biometrics 1992; 48: 795–806. [PubMed] [Google Scholar]
- 41.Balan TA, Putter H. frailtyEM: An R package for estimating semiparametric shared frailty models. J Stat Software 2019; 90: 7. [Google Scholar]
- 42.Cox DR. Partial likelihood. Biometrika 1975; 62: 269–276. [Google Scholar]
- 43.Vaida F, Xu R. Proportional hazards model with random effects. Stat Med 2000; (19): 3309–3324. [DOI] [PubMed] [Google Scholar]
- 44.Ripatti S, Palmgren J. Estimation of multivariate frailty models using penalized partial likelihood. Biometrics 2000; 56: 1016–1022. [DOI] [PubMed] [Google Scholar]
- 45.Therneau TM, Grambsch PM, Pankratz VS. Penalized survival models and frailty. J Computat Graph Stat 2003; 12: 156–175, http://www.jstor.org/stable/1391074 [Google Scholar]
- 46.Gorfine M, Zucker DM, Hsu L. Prospective survival analysis with a general semiparametric shared frailty model: a pseudo full likelihood approach. Biometrika 2006; 93: 735–741. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Ha ID, Lee Y, Song JK. Hierarchical likelihood approach for frailty models. Biometrika 2001; 88: 233–233. [Google Scholar]
- 48.Ha ID, Jeong JH, Lee Y. Statistical modelling of survival data with random effects. New York, NY: Springer, 2017. [Google Scholar]
- 49.Louis TA. Finding the observed information matrix when using the EM algorithm. J Royal Stat Soc Ser B (Methodol) 1982; 44: 226–233. [Google Scholar]
- 50.Andersen PK, Klein JP, Knudsen KM, et al. Estimation of variance in Cox’s regression model with shared gamma frailties. Biometrics 1997; 53: 1475–1484. [PubMed] [Google Scholar]
- 51.Putter H, Van Houwelingen HC. Dynamic frailty models based on compound birth–death processes. Biostatistics 2015; 16: 550–564. [DOI] [PubMed] [Google Scholar]
- 52.Self SG, Liang KY. Asymptotic properties of maximum likelihood estimators and likelihood ratio tests under nonstandard conditions. J Am Stat Assoc 1987; 82: 605–610. [Google Scholar]
- 53.Claeskens G, Nguti R, Janssen P. One-sided tests in shared frailty models. Test 2008; 17: 69–82. [Google Scholar]
- 54.R Core Team. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing, 2017, https://www.R-project.org/ [Google Scholar]
- 55.SAS Institute Inc. SAS/STAT software, Version 9.4. Cary, NC, 2003, http://www.sas.com/
- 56.StataCorp. Stata statistical software: Release 15. College Station, TX: StataCorp LLC, 2017, http://www.stata.com
- 57.Therneau TM. A package for survival analysis in S, 2015, https://CRAN.R-project.org/package=survival. Version 2.38.
- 58.Balan TA, Putter H. frailtyEM: Fitting frailty models with the EM algorithm, 2017, https://CRAN.R-project.org/package=frailtyEM. R package version 0.8.2.
- 59.Therneau TM. coxme: Mixed effects cox models, 2015, https://CRAN.R-project.org/package=coxme. R package version 2.2-5.
- 60.Donohue MC, Xu R. phmm: Proportional hazards mixed-effects models, 2013. R package version 0.7-5.
- 61.Ha ID, Noh M, Lee Y. frailtyHL: A package for fitting frailty models with h-likelihood. R J 2012; 4: 28–36. [Google Scholar]
- 62.Monaco JV, Gorfine M, Hsu L. frailtySurv: general semiparametric shared frailty model, 2017, https://CRAN.R-project.org/package=frailtySurv. R package version 1.3.2. [DOI] [PMC free article] [PubMed]
- 63.Rondeau V, Gonzalez JR. frailtypack: A computer program for the analysis of correlated failure time data using penalized likelihood estimation. Comput Meth Programs Biomed 2005; 80: 154–164. [DOI] [PubMed] [Google Scholar]
- 64.Rondeau V, Mazroui Y, Gonzalez JR. frailtypack: An R package for the analysis of correlated survival data with frailty models using penalized likelihood estimation or parametrical estimation. J Stat Software 2012; 47: 1–28, http://www.jstatsoft.org/v47/i04/ [Google Scholar]
- 65.Munda M, Rotolo F, Legrand C. parfm: Parametric frailty models in R. J Stat Software 2012; 51: 1–20. DOI: 10. 18637/jss.v051.i11. [Google Scholar]
- 66.Erikson F, Martinussen T, Scheike TH. Clustered survival data with left-truncation. Scand J Stat 2015; 42: 1149--1166. DOI:10.1111/sjos.12157. [Google Scholar]
- 67.Van den Berg GJ, Drepper B. Inference for shared-frailty survival models with left-truncated data. Econometric Rev 2016; 35: 1075–1098. [Google Scholar]
- 68.Jensen H, Brookmeyer R, Aaby P, et al. Shared frailty model for left-truncated multivariate survival data. University of Copenhagen, Copenhagen, 2004. [Google Scholar]
- 69.Rodrguez-Girondo M, Deelen J, Slagboom EP, et al. Survival analysis with delayed entry in selected families with application to human longevity. Stat Meth Med Res 2018; 27: 933–954., 10.1177/0962280216648356. [DOI] [PubMed] [Google Scholar]
- 70.Balan TA, Jonker MA, Johannesma PC, et al. Ascertainment correction in frailty models for recurrent events data. Stat Med 2016; 35: 4183–4201. [DOI] [PubMed] [Google Scholar]
- 71.Yashin AI, Vaupel JW, Iachine IA. Correlated individual frailty: an advantageous approach to survival analysis of bivariate data. Math Popul Studies 1995; 5: 145–159. [DOI] [PubMed] [Google Scholar]
- 72.Yashin AI, Iachine IA, Begun AZ, et al. Hidden frailty: myths and reality. Document de Travail 2001; 34: 1--48. [Google Scholar]
- 73.Yashin AI, Manton KG. Effects of unobserved and partially observed covariate processes on system failure: a review of models and estimation strategies. Stat Sci 1997; 12: 20–34. [Google Scholar]
- 74.Aalen OO, Gjessing HK. Survival models based on the Ornstein-Uhlenbeck process. Lifetime Data Analysis 2004; 10: 407–423. [DOI] [PubMed] [Google Scholar]
- 75.Gjessing HK, Aalen OO, Hjort NL. Frailty models based on Lévy processes. Adv Appl Probabil 2003; 35: 532–550. [Google Scholar]
- 76.Paik MC, Tsai WY, Ottman R. Multivariate survival analysis using piecewise gamma frailty. Biometrics 1994; 975–988. [PubMed] [Google Scholar]
- 77.Wintrebert C, Putter H, Zwinderman AH, et al. Centre-effect on survival after bone marrow transplantation: application of time-dependent frailty models. Biometric J 2004; 46: 512–525. [Google Scholar]
- 78.Balan TA. dynfrail: Fitting dynamic frailty models with the EM algorithm, 2017, https://CRAN.R-project.org/package=dynfrail. R package version 0.5.2.
- 79.Yau K, McGilchrist C. ML and REML estimation in survival analysis with time dependent correlated frailty. Stat Med 1998; 17: 1201–1213. [DOI] [PubMed] [Google Scholar]
- 80.Munda M, Legrand C, Duchateau L, et al. Testing for decreasing heterogeneity in a new time-varying frailty model. Test 2016; 25: 591–606. [Google Scholar]
- 81.Fiocco M, Putter H, Van Houwelingen JC. A new serially correlated gamma-frailty process for longitudinal count data. Biostatistics 2008; 10: 245–257. [DOI] [PubMed] [Google Scholar]
- 82.Balan TA, Boonk SE, Vermeer MH, et al. Score test for association between recurrent events and a terminal event. Statistics in Medicine 2016; 35: 3037–3048. [DOI] [PubMed] [Google Scholar]
- 83.Liu L, Wolfe RA, Huang X. Shared frailty models for recurrent events and a terminal event. Biometrics 2004; 60: 747–756. [DOI] [PubMed] [Google Scholar]
- 84.Huang X, Wolfe RA. A frailty model for informative censoring. Biometrics 2002; 58: 510–520. [DOI] [PubMed] [Google Scholar]
- 85.Rizopoulos D. Joint models for longitudinal and time-to-event data with applications in R. London: Chapman and Hall, 2012. [Google Scholar]
- 86.Rizopoulos D. The R package JMbayes for fitting joint models for longitudinal and time-to-event data using MCMC. J Stat Software 2016; 72: 1–46, https://www.jstatsoft.org/v072/i07 [Google Scholar]
- 87.Clahsen PC, van de Velde CJH, Julien JP, et al. Improved local control and disease-free survival after perioperative chemotherapy for early-stage breast cancer. J Clin Oncol 1996; 14: 745–753. [DOI] [PubMed] [Google Scholar]
- 88.van der Hage JA, van de Velde CJH, Julien JP, et al. Improved survival after one course of perioperative chemotherapy in early breast cancer patients: long-term results from the European Organization for Research and Treatment of Cancer (EORTC) trial 10854. Eur J Cancer 2001; 37: 2184–2193. [DOI] [PubMed] [Google Scholar]
- 89.Putter H, van der Hage J, de Bock GH, et al. Estimation and prediction in a multi-state model for breast cancer. Biometric J 2006; 48: 366–380. [DOI] [PubMed] [Google Scholar]
- 90.van Geloven N, Balan TA, Putter H, et al. The effect of treatment delay on time-to-recovery in the presence of unobserved heterogeneity. Biometric J 2020; 1–13 (in press). DOI:10.1002/bimj.201900131. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 91.Aalen OO, Gjessing HK, et al. Understanding the shape of the hazard rate: a process point of view (with comments and a rejoinder by the authors). Stat Sci 2001; 16: 1–22. [Google Scholar]
- 92.Abbring JH, Van Den Berg GJ. The unobserved heterogeneity distribution in duration analysis. Biometrika 2007; 94: 87–99. [Google Scholar]
- 93.Shih JH, Louis TA. Assessing gamma frailty models for clustered failure time data. Lifetime Data Analys 1995; 1: 205–220. [DOI] [PubMed] [Google Scholar]
- 94.Glidden DV. Checking the adequacy of the gamma frailty model for multivariate failure times. Biometrika 1999; 86: 381–393. [Google Scholar]
- 95.Geerdens C, Claeskens G, Janssen P. Goodness-of-fit tests for the frailty distribution in proportional hazards models with shared frailty. Biostatistics 2013; 14: 433–446. [DOI] [PubMed] [Google Scholar]