

Abstract
The relationship between a screening tests’ positive predictive value, ρ, and its target prevalence, ϕ, is proportional—though not linear in all but a special case. In consequence, there is a point of local extrema of curvature defined only as a function of the sensitivity a and specificity b beyond which the rate of change of a test’s ρ drops precipitously relative to ϕ. Herein, we show the mathematical model exploring this phenomenon and define the prevalence threshold (ϕe) point where this change occurs as:
where ε = a + b. From the prevalence threshold we deduce a more generalized relationship between prevalence and positive predictive value as a function of ε, which represents a fundamental theorem of screening, herein defined as:
Understanding the concepts described in this work can help contextualize the validity of screening tests in real time, and help guide the interpretation of different clinical scenarios in which screening is undertaken.
1 Introduction
Screening is defined as the presumptive identification of unrecognised disease in asymptomatic individuals by means of tests, examinations or procedures [1]. The ultimate purpose of a screening test is two-fold: 1) to allow for the early detection of a disease, and thus establish a surveillance plan to assess progression, and/or 2) to detect a condition early in order to treat it most effectively. Screening tests are not considered diagnostic, but are used to identify a subset of the population that should undergo additional testing in order to accurately establish the presence or absence of disease [2].
In 1968, the World Health Organization (WHO) published guidelines on the principles and practice of screening for disease, which are often referred to as the Wilson–Jungner criteria [3]. These principles are still broadly applicable today and include the following: 1) The condition should be an important health problem. 2) There should be a treatment for the condition. 3) Facilities for diagnosis and treatment should be available. 4) There should be a latent stage of the disease. 5) There should be a screening test or examination for the condition. 6) The test should be acceptable to the population. 7) The natural history of the disease should be adequately understood. 8) There should be an agreed policy on whom and when to treat. 9) The total cost of finding a case should be economically balanced in relation to medical expenditure as a whole. Finally, 10) Case-finding should be a continuous process.
In keeping with these ideas, it is important to contextualize them into the natural disease process (Fig 1). The biological onset of disease is followed by clinical symptoms, then diagnosis and therapy until there is an outcome, including survival or death [4]. The time from the onset of disease until clinical symptoms occur is known as the pre-clinical phase. The individual has the disease but doesn’t know it. The clinical phase is the latter part of the process, from the occurrence of clinical symptoms through therapy and outcome [4]. Within the preclinical phase, there may be an interval between the onset of the disease and the occurrence of clinical symptoms during which disease can be detected with certain screening tests. This is called a detectable pre-clinical, or latent, phase. If treatment is more effective during the preclinical stage of disease, as is the case for most conditions, screening for disease during the detectable pre-clinical phase offers an advantage [4].
Fig 1. Natural progression of disease.

When conducting a screening test, 4 different parameters help to determine its overall ability to correctly identify individuals with the disease in question [5]. These include the sensitivity a, specificity b, positive predictive value ρ and negative predictive value σ. Sensitivity refers to the proportion of affected individuals that have a positive test (true positive rate), and specificity refers to the proportion of unaffected individuals that have a negative test (true negative rate). On the other hand, the positive predictive value (ρ) is defined as the percentage of patients with a positive test that do in fact have the disease, and conversely, the negative predictive value (ϕ) refers to the percentage of patients with a negative test that do not have the disease. To further explore these properties in detail, we draw a 2 x 2 table (Table 1) as follows:
Table 1. 2x2 Table.
| Condition | ||
|---|---|---|
| Present | Absent | |
| Positive Test | True Positive (α) | False Positive (β) |
| Negative Test | False Negative (γ) | True Negative (δ) |
Where the following variables are thus defined:
prevalence = ϕ = (α + γ)/(α + β + γ + δ),
sensitivity = a = α/(α + γ),
specificity = b = δ/(δ + β),
PPV = ρ = α/(α + β),
NPV = σ = δ/(γ + δ).
2 Bayes’ theorem
Bayes’ Theorem describes the probability of an event based on prior knowledge of conditions related to that specific event [6]. Mathematically speaking, the equation translates to the conditional probability of an event A given the presence of an event or state B. As per Bayes’ Theorem, the above relationship is equal to the probability of event B given event A, multiplied by the ratio of independent probabilities of event A to event B. Simply stated, the equation is written as follows:
| (1) |
Where A, B = events, P(A|B) = probability of A given B is true, P(B|A) = probability of B given A is true, and P(A) and P(B) are the independent probabilities of A and B. If we use T +/- as either a positive or negative test, and denote D +/- as the presence or absence or disease then we can use Bayes’ theorem to calculate the positive predictive value by asking the following question: given a positive screening test, what is the probability that an individual does in fact have the disease in question?
| (2) |
Since the probability of not having the disease is equal to the complement of the prevalence and the false positive rate is equal to the complement of the specificity, Bayes’ theorem yields the PPV as follows:
| (3) |
where ρ(ϕ) = PPV, a = sensitivity, b = specificity and ϕ = prevalence.
We have thus shown that the PPV, ρ, is a function of prevalence, ϕ. As the prevalence increases, the ρ(ϕ) also increases but the NPV, σ(ϕ), decreases and vice-versa.
By the above equation, we obtain:
| (4) |
and,
| (5) |
Inversely, we can isolate the prevalence as a function of sensitivity, specificity and the PPV as follows:
| (6) |
It is important to bear in mind that screening curves come in two forms: one prevalence-independent relating the sensitivity to the specificity, also known as the receiver operating characteristc (ROC) curve, and one prevalence-dependent relating a tests’ positive predictive value to its target disease’s prevalence—as depicted in this work [7]. The latter screening curves are continuous, positive functions in the real plane, whose domain spans 0 < ϕ < 1 and cross the spectrum boundaries at coordinates [0, 0] and [1,1]. The relationship between ϕ and ρ is proportional and as such, these curves retain their concavity or convexity throughout the domain.
3 The screening paradox
If a disease process is recognized and treated early, and a diagnosis is therefore prevented, the prevalence of such disease would drop in the population, which as per Bayes’ theorem, would make the tests’ predictive value drop in return [8]. Put another way, assuming as per Wilson–Jungner criteria that a curative/preventative treatment following an abnormal screening test exists, a very powerful screening test would, by performing and succeeding at the very task it was developed to do, paradoxically reduce its ability to correctly identify individuals with the disease it screens for in the future. Now, this paradoxical effect tends to be well tolerated by the system up to a well defined prevalence point beyond which the geometry of the screening curve changes most drastically. Technically speaking, there is a prevalence level below which the rate of change of a test’s ρ drops precipitously relative to ϕ. In order to explore this notion further, we define a new entity henceforth known as the screening coefficient, ε, defined as the sum of the sensitivity and specificity, a + b.
4 The screening coefficient (ε)
To preface this section, we hereby define a new entity, the screening coefficient (ε), as the sum of sensitivity a and specificity b.
| (7) |
We know from Eq (3) that an increase in prevalence will bring about an increase in the PPV (and vice-versa) at different velocities depending on the prevalence/pre-test probability level. We can calculate this velocity by taking the first order derivative of Eq (3) as follows:
| (8) |
Since both ϕ and ρ are positive real numbers between 0 and 1, dρ/dϕ is a positive real number as well as per Eq (8). This implies that the relationship between ϕ and ρ is directly proportional throughout the interval . However, in order to determine whether the rate at which the PPV is changing with respect to prevalence is accelerating or decelerating, we take the second order derivative of Eq (3) as follows:
| (9) |
From Eq (9) it follows that when:
| (10) |
| (11) |
| (12) |
In order to illustrate the above concepts, let us define a hypothetical condition. Condition X is a disease present in a population. It has a preclinical phase and is amenable to screening. Test X is the screening test developed to detect the latent phase of Condition X. Test X therefore has all of the pertinent screening parameters—sensitivity, specificity, and negative and positive predictive values. If condition X has a high prevalence in the population (e.g. hyperlipidemia, hypertension, diabetes, endemic infections, amongst others) or a high pre-test probability in a given individual and ε > 1, then significant drops in prevalence will not bring about significant drops in PPV until prevalence drops below a certain threshold, which for cases of ε > 1, occurs at low prevalence levels. It thus follows that in cases like this, the screening tests detection ability remains relatively stable until it has significantly helped drop the prevalence. On the other hand, if condition X has a high prevalence in the population and ε < 1, then small drops in prevalence will bring about significant drops in PPV until prevalence drops below a certain threshold at a higher prevalence (Fig 2).
Fig 2. The first graph represents scenarios where ε > 1.

We denote the line tangent to the point of maximum curvature κ from which we derive the radius of curvature R, perpendicular to it. The second graph represents the more rare scenarios where ε < 1. The sensitivity and specificity are constant and were randomly chosen to satisfy the ε condition.
5 Derivation of the radius of curvature of ρ(ϕ)
In order to determine the radius of curvature of the ρ(ϕ) graph at any given point M, we consider a circle with radius R, which is perpendicular to the tangent line of the function at that point. We consider an adjacent point increment by dϕ and draw another tangent line to this point N, which we join to the center of the circle with radius R. As such, an arc of length dS is formed, which in turn creates an angle φ between M and N. These variables see the following properties:
| (13) |
| (14) |
From equalities (13) and (14), the differential equation follows:
| (15) |
From the trigonometric identity 1 + tan2(φ) = sec2(φ), it follows that:
| (16) |
Therefore,
| (17) |
Since tan(φ) = dρ/dϕ, Eq (17) becomes:
| (18) |
Isolating dφ/dϕ, we obtain:
| (19) |
Using Eq (14) this relationship then becomes:
| (20) |
Finally, isolating the radius of curvature R:
| (21) |
The radius of curvature R is inversely proportional to κ such that:
| (22) |
Now that we know what the curvature function κ is, we can determine where the curvature of ϕ(ρ) falls at a maximum. Practically speaking, this represents the point of sharpest change in , known as the extrema. In order to do so, we find the derivative of the κ function and determine its roots:
| (23) |
The above equation yields the value of ϕ where the maximum curvature κ and thus a minimum radius of curvature R exist. We define this point as the point of local extrema [ϕe, ρe] of the ρ(ϕ) function. On the other hand, the inflection point [ϕi, ρi] is a point on a curve at which the sign of the curvature (i.e., the concavity) changes. The points of local extrema are distinguishable from the inflection point only in that the curvature function’s second order-derivative equals 0:
| (24) |
However, as we described previously, given the proportionality between ϕ and ρ all screening curves retain their concavity/convexity throughout the domain [0, 1] as a function of a and b, and thus no inflection points are observed in these curves. Conversely, the point of local extrema ϕe, ρe tells us where the sharpest turn, or change, in PPV as a function of prevalence occurs. In cases of when ε > 1 the sharp increase occurs at lower prevalence levels with higher PPV levels, and vice-versa for ε < 1.
By equating Eq (22) to 0 and looking for its roots, we re-arrange the terms and the above expression simplifies to:
| (25) |
| (26) |
Taking the fourth root of both sides, we obtain:
| (27) |
Expanding and isolating ϕ while taking the positive value of the root so that the value obtained may fall inside the domain of the function, we obtain:
| (28) |
This is the value of prevalence where the point of local extrema ϕe of ρ(ϕ) is found. We denote this value of ϕ as the prevalence threshold. By plugging ϕe into Eq (3) we obtain its corresponding ρe value. Note the inverse relationship between ϕe and ε.
| (29) |
It is critical to understand that an identical value of ε can provide significantly different prevalence thresholds as sensitivities and specificities do not respect commutative laws in this context. Since the specificity is a measure of the true negative rate, slight changes in specificity provide greater changes in the positive predictive value. In keeping with this idea, the equation for the prevalence threshold contains the specificity parameter b thrice whereas the sensitivity parameter a appears only twice, indeed implying the prevalence threshold is more sensitive to changes in specificity, even for a fixed ε. For a given ε, the higher the specificity, the lower the prevalence threshold and the sharpest the curvature of the local extrema.
Using the prevalence threshold as a prevalence value, we can calculate the corresponding positive predictive value by plotting ϕe into the positive predictive value equation to retrieve [ρ(ϕe),ϕe]. In so doing we obtain:
| (30) |
Interestingly, the above expression leads to the well known formulation for the positive predictive value as a function of prevalence and the positive likelihood ratio (LR+), defined as the sensitivity over the compliment of the specificity.
| (31) |
5.1 The fundamental theorem of screening
While the curvature κ and the point of local extrema ϕe, ρe provide a quantitative determination of the prevalence threshold, we can establish a qualitative determination of this statistic as well, which is far more intuitive. We can calculate the area under the curve (AUC) of ρ(ϕ) by integrating through the function’s domain between [0, 0] and [1, 1]. Intuitively, the greater the area, the greater ε must be and vice-versa. From the indefinite integral:
| (32) |
It thus follows that:
| (33) |
We deduce that as ε approaches its maximum possible value of 2, the AUC of ϕ(ρ) goes to 1. As Eq (33) describes the relationship between all of the pertinent parameters of a positive screening test as a function of prevalence, we define the latter as a fundamental theorem of screening. Since we know from Eq (29) that the ϕe is inversely proportional to ε, we infer that the greater the AUC, the lower the prevalence threshold and vice-versa.
5.2 Clinical corollaries
All screening parameters are fundamental to the understanding of the value of screening tests, their limitations, and the concepts thus far described in this work. That said, we can consider the predictive values ρ(ϕ) to be most consequential to the individual clinician over the other parameters. Why is ρ(ϕ) a more critical parameter for the clinician than sensitivity and specificity? This is simply because the interpretation of predictive values is done at the level of a single test result, among individuals in whom a diagnosis has not yet been made, and whose ultimate diagnostic status is therefore unknown. In the case of sensitivity and specificity, the ultimate diagnostic status in the patient must be known a priori in order to determine whether a particular screening test is sensitive and/or specific. As such, chronologically speaking, since screening tests lead to eventual diagnoses, the interpretation of a test must occur before a diagnosis is made.
Fig 3 depicts a random sample of combinations of ε values calculated from random sensitivities and specificities, and their corresponding prevalence threshold (ϕe) values. To obtain the prevalence at which the threshold is crossed, multiply the values in red by 10. ϕe is undefined in the special case where the geometry of the screening curve becomes linear as a consequence of ε equalling 1. Though there is indeed little clinical applicability for tests whose ε value is < 1, the point of demonstrating the aforementioned cases is to complete the theory for all possible values of prevalence and sensitivity/specificity even if they’re not commonly encountered in clinical practice. The reason is simple—sometimes those tests are all that exist for certain conditions. One can contemplate a test whose specificity is poor but whose sensitivity to rule out disease is good so that ε ∼ 1.
Fig 3. Sample screening curves as a function of ε.

5.3 Example of SARS-CoV-2 pandemic
The current COVID-19 pandemic provides an excellent opportunity to apply the methods herein described. The nasal swab PCR screening test for COVID-19 has been shown to have a high analytical sensitivity of 95 percent limit of detection (LOD) for the RNA-dependent RNA polymerase (RdRP) gene. Likewise, the test is 99 percent specific for SARS-CoV-2 when tested against 31 common respiratory pathogens [9]. We thus draw the screening curve for this test ρ(ϕ) (Fig 4):
Fig 4. The screening curve for the SARS-CoV-2 nasal PCR test (blue) and the prevalence threshold level (red) below which the positive predictive value drops.
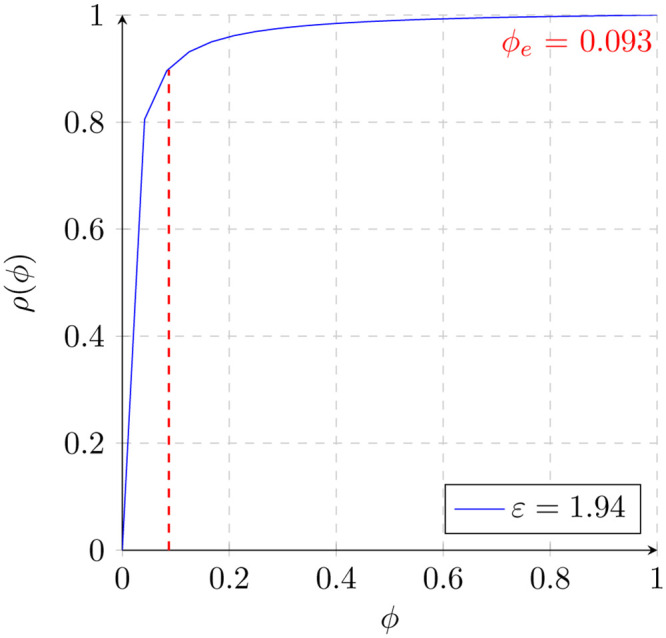
We calculate the prevalence threshold ϕe by using Eq (28), with values for a = 0.95, b = 0.99 and therefore ε = 1.94. We thus obtain:
| (34) |
As noted in the figure above, significant drops in prevalence only marginally impact the PPV until the prevalence threshold is reached. In other words, when the prevalence of active COVID-19 cases drops below 9.3 percent, the nasal RT-PCR test’s PPV drops significantly faster. Since 9.3 percent of the population has thankfully not been infected at any given time, we deduce that a significant proportion of the current positive nasal RT-PCR tests are false positives. The benefits of contextualizing the validity of a screening test in real time cannot be understated This is indeed a critical exercise since a large number of public health decisions rely on the validity of these screening tests. With a reliable test, we can better inform the individual on his or her risk of contracting and transmitting the disease in question. Likewise, it can guide quarantine guidelines so as to best integrate that individual back into the economy and society at large. Furthermore, reliable estimates of incidence and prevalence with good tests can guide the proper distribution of resources to contain the spread of the virus. All in all, understanding where this prevalence point lies in the curve has important implications for the administration of healthcare systems, the implementation of public health measures, the development of epidemiologic models, and in cases of pandemics like SARS-CoV-2, the functioning of society at large. When the prevalence drops below the prevalence threshold, the censoring of patients never affected needs to be contrasted with the Bayesian limitations imposed by the screening paradox.
6 Conclusion
The curvilinear relationship between a screening test’s positive predictive value and its target disease prevalence is proportional. In consequence, there is an inflection point of maximum curvature in the screening curve defined as a function of the sensitivity and specificity beyond which the rate of change of a test’s PPV declines sharply relative to disease prevalence. Herein, we demonstrate a mathematical model exploring this phenomenon and define the prevalence threshold point where this change occurs. To the best of our knowledge, while this concept is a simple consequence of Bayes’ theorem and the natural shape of screening curves, it has never been properly formalized mathematically as showcased in this work. The prevalence threshold can help contextualize the validity of a screening test in real time, thereby enhancing our understanding of the dynamics and epidemiology of specific conditions. Finally, this simple equation can be applied to any and all screening test whose sensitivity, specificity and target prevalence are known—so its clinical utility is widespread.
Data Availability
All relevant data are in the manuscript.
Funding Statement
The author(s) received no specific funding for this work.
References
- 1. James Maxwell Glover Wilson, Gunnar Jungner, World Health Organization, et al. Principles and practice of screening for disease. 1968. [Google Scholar]
- 2.David L Sackett. Screening for early detection of disease: to what purpose? Bulletin of the New York Academy of Medicine, 51(1):39, 1975. [PMC free article] [PubMed]
- 3.Anne Andermann, Ingeborg Blancquaert, Sylvie Beauchampb, and Véronique Déryc. Public health classics. Bulletin of the World Health Organization, 86(4), 2008. [DOI] [PMC free article] [PubMed]
- 4. Cheryl Herman. What makes a screening exam” good”? AMA Journal of Ethics, 8(1):34–37, 2006. 10.1001/virtualmentor.2006.8.1.cprl1-0601 [DOI] [PubMed] [Google Scholar]
- 5. Brenner Hermann and Gefeller OLAF. Variation of sensitivity, specificity, likelihood ratios and predictive values with disease prevalence. Statistics in medicine, 16(9):981–991, 1997. [DOI] [PubMed] [Google Scholar]
- 6. Moons Karel GM, van Es Gerrit-Anne, Deckers Jaap W, Habbema J Dik F, and Grobbee Diederick E. Limitations of sensitivity, specificity, likelihood ratio, and bayes’ theorem in assessing diagnostic probabilities: a clinical example. Epidemiology, pages 12–17, 1997. 10.1097/00001648-199701000-00002 [DOI] [PubMed] [Google Scholar]
- 7.Tom Fawcett. An introduction to roc analysis. Pattern recognition letters, 27(8):861–874, 2006.
- 8. Smith James E, Winkler Robert L, and Fryback Dennis G. The first positive: computing positive predictive value at the extremes. Annals of internal medicine, 132(10):804–809, 2000. 10.7326/0003-4819-132-10-200005160-00008 [DOI] [PubMed] [Google Scholar]
- 9. Cheng Matthew P, Papenburg Jesse, Desjardins Michaël, Kanjilal Sanjat, Quach Caroline, Libman Michael, et al. Diagnostic testing for severe acute respiratory syndrome–related coronavirus-2: A narrative review. Annals of internal medicine, 2020. 10.7326/M20-1301 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
All relevant data are in the manuscript.