

Abstract
We performed RNA-seq and high-resolution mass spectrometry on 128 blood samples from COVID-19-positive and COVID-19-negative patients with diverse disease severities and outcomes. Quantified transcripts, proteins, metabolites, and lipids were associated with clinical outcomes in a curated relational database, uniquely enabling systems analysis and cross-ome correlations to molecules and patient prognoses. We mapped 219 molecular features with high significance to COVID-19 status and severity, many of which were involved in complement activation, dysregulated lipid transport, and neutrophil activation. We identified sets of covarying molecules, e.g., protein gelsolin and metabolite citrate or plasmalogens and apolipoproteins, offering pathophysiological insights and therapeutic suggestions. The observed dysregulation of platelet function, blood coagulation, acute phase response, and endotheliopathy further illuminated the unique COVID-19 phenotype. We present a web-based tool (covid-omics.app) enabling interactive exploration of our compendium and illustrate its utility through a machine learning approach for prediction of COVID-19 severity.
Keywords: COVID-19, ICU, ARDS, multi-omics, severity, outcomes, RNA sequencing, mass spectrometry, machine learning
Graphical Abstract
Highlights
-
•
We surveyed biomolecules in 102 COVID-19 and 26 non-COVID-19 patient blood samples
-
•
We found 219 biomolecules strongly associated with COVID-19 status and severity
-
•
We observed pronounced dysregulation of lipid transport and neutrophil degranulation
-
•
Our resource of measurements and patient data is located at https://covid-omics.app
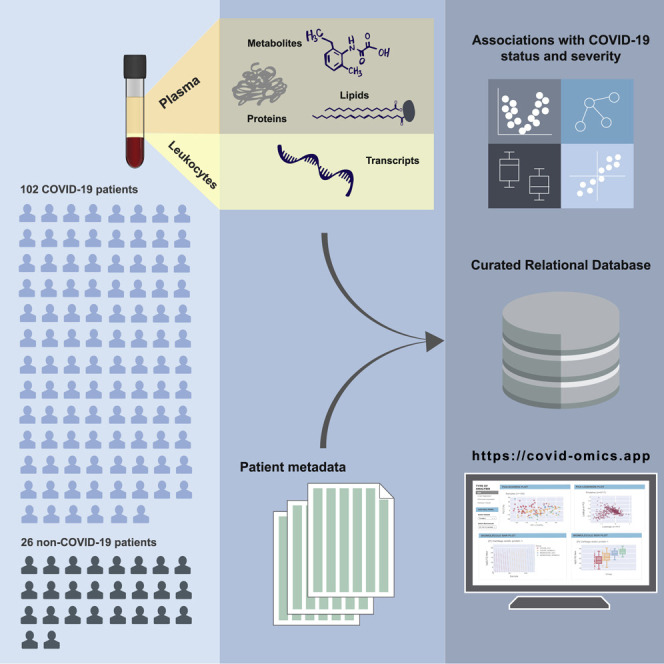
Leukocyte mRNA expression and plasma protein, metabolite, and lipid levels were measured in 102 COVID-19 and 26 non-COVID-19 patient samples. 219 diverse biomolecules were strongly associated with COVID-19 status and severity and pointed to dysregulation of processes related to lipid transport, blood coagulation, acute phase response, endotheliopathy, and neutrophil degranulation in this disease.
Introduction
As of September 2020, the COVID-19 pandemic has caused over a million deaths worldwide, primarily due to complications from SARS-CoV-2-associated acute respiratory distress syndrome (ARDS) (Guan et al., 2020). The clinical course of COVID-19 infection is highly variable, ranging from an asymptomatic state to a life-threatening infection. Recent evidence indicates that, in addition to viral factors, disease severity depends substantially on host factors (Zhang et al., 2020a, 2020b, 2020c), supporting the need to better understand the individuals’ responses at a molecular level. While rapidly accumulating evidence indicates that distinct genetic (Ellinghaus et al., 2020), physiological (Gattinoni et al., 2020), pathological (Fox et al., 2020), and clinical (Richardson et al., 2020) signatures differentiate patients with and without COVID-19-driven ARDS, more clarity on the molecular basis explaining the observed differences is needed.
It is widely accepted that clinical syndromes of non-COVID-19 ARDS and sepsis result from an aggregation of different patient subgroups with distinct molecular signatures and responses to standardized treatments (Reddy et al., 2020). For example, in non-COVID-19 ARDS patients, a relatively hyper-inflammatory phenotype is associated with higher mortality than a hypo-inflammatory state (Calfee et al., 2014). Information on the association of the inflammatory landscape with COVID-19 patients’ outcomes is less clear (Sinha et al., 2020). Even though leukocytes from patients with severe infections demonstrate an association between a relatively hyper-inflammatory transcriptome and better prognosis (Davenport et al., 2016), further insight into these processes could facilitate identification of potential therapeutic targets of immunomodulation, leading to better outcomes. Beyond the typical inflammatory response, COVID-19 patients demonstrate profound coagulation dysregulation (Zhang et al., 2020a, 2020b, 2020c). A sensitive marker of fibrinogen degradation, D-dimer, is found consistently elevated in severe cases of COVID-19 (Guan et al., 2020; Richardson et al., 2020). In addition, data from autopsies demonstrate microvascular clotting (Fox et al., 2020), and clinical observations suggest that anticoagulation therapies may lower mortality of COVID-19-associated ARDS (Paranjpe et al., 2020).
Despite the rapid global scientific response to this new disease, relatively few studies have investigated the broad molecular-level reorganization that drives the host COVID-19 viral response. Technologies for deep sequence analysis of nucleic acids (i.e., transcriptomics) are broadly available. High-resolution mass spectrometry (MS) can provide similar quantitative data for large-scale protein, metabolite, and lipid measurements. With the supposition that broad profiling across these various planes of biomolecular regulation could allow for a holistic view of disease pathophysiology, we sought to leverage these technologies on a large number of patients.
Accordingly, we conducted a cohort study involving 128 patients with and without COVID-19 diagnosis. To ensure that we generated molecular profiles that could illuminate the COVID-19 pathological signature, protein, metabolite, and lipid profiles were measured from blood plasma. Additionally, leukocytes derived from patient blood samples were isolated for RNA sequencing. Using state-of-the-art sequencing and mass spectrometric technologies, we identified and quantified over 17,000 transcripts, proteins, metabolites, and lipids across these 128 patient samples. The abundances of these biomolecules were then correlated with a range of clinical data and patient outcomes to create a rich molecular resource for COVID-19 host response to be made available to the biomedical research community.
Here, we leverage this resource to examine the pathophysiology of COVID-19, identify potential therapeutic opportunities, and facilitate accurate predictions of patient outcome. Briefly, we found 219 biomolecules, which were highly correlated with COVID-19 status and severity. Tapping into the ability of our multi-omic method to uncover associations between different biomolecule classes, we discovered sets of covarying molecules that shed light on disease mechanisms and provide therapeutic opportunities. Although some of the disease mechanisms described here are not novel, our study provides critical, confirming evidence that key biological processes are indeed modulated under COVID-19, including complement system activation, lipid transport, vessel damage, platelet activation and degranulation, blood coagulation, and acute phase response. Given the focus of our study on plasma, our data constitute unique insights into the COVID-19 hypercoagulation phenotype. This rich molecular compendium has been made available through a freely accessible web resource (https://covid-omics.app) to aid the current global efforts to study this disease. We also present an application example that leverages this resource for the development of a disease severity predictive model based on all omics data. While patients’ comorbidities are powerfully associated with COVID-19 outcomes, our multi-omics-based predictive model significantly improved COVID-19-severity predictions over the standardized clinical Charlson comorbidity score (Richardson et al., 2020).
Results
Sample Cohort and Experimental Design
From 6 April 2020 through 1 May 2020, we collected blood samples from 128 adult patients admitted to Albany Medical Center in Albany, NY, for moderate to severe respiratory issues presumably related to SARS-CoV-2 infection. In addition to collection of various clinical data (Table 1 ), a blood sample was obtained at the time of enrollment. Patients who tested positive (n = 102) and negative (n = 26) for the virus were assigned to COVID-19 and non-COVID-19 groups, respectively (see STAR Methods for enrollment details). Females comprised 37.3% and 50.0% of the COVID-19 and non-COVID-19 groups, respectively. The average age of patients was similar—61.3 and 63.1 years in the COVID-19 group (females and males, respectively; p value = 0.56)—with some statistically insignificant differences between females and males in the non-COVID-19 group (59.5 and 67.0 years, respectively; p value = 0.25) (Figure 1 A). The average number of days hospitalized before study enrollment was 3 and 1 for the COVID-19 and non-COVID-19 groups, respectively (Table 1). The COVID-19 group was more racially diverse than the non-COVID-19 group, with white individuals comprising only 46% of the total (versus 80% of the non-COVID-19 control group); these demographics are consistent with the reported racial and ethnic health disparities of COVID-19 (Webb Hooper et al., 2020).
Table 1.
Demographics and Baseline Characteristics of COVID-19 and Non-COVID-19 in Intensive Care Unit (ICU) and Non-ICU Settings
| COVID-19 |
Non-COVID-19 |
|||||
|---|---|---|---|---|---|---|
| Variables | Total n = 102 | Non-ICU n = 51 | ICU n = 51 | Total n = 26 | Non-ICU n = 10 | ICU n = 16 |
| Days admitted pre-enrollment (IQR) | 3.37 (1–5) | 2.78 (1–3) | 3.96 (1–6) | 0.97 (1–1) | 0.9 (0.8–1) | 0.94 (1–1) |
| Sex −n (%) | ||||||
| Male | 64 (62.7%) | 30 (58.8%) | 34 (66.7%) | 13 (50%) | 4 (40%) | 9 (56%) |
| Female | 38 (37.3%) | 21 (41.2%) | 17 (33.3%) | 13 (50%) | 6 (60%) | 7 (44%) |
| Age-year | ||||||
| Mean (IQR) | 61.3 (50.0–74.3) | 59.7 (49.0–80.0) | 62.9 (55.0–73.0) | 63.8 (52.3–76.8) | 60.4 (47.3–74.0) | 66 (55.3–80.3) |
| Ethnicity − n (%) | ||||||
| White | 46 (45.1%) | 28 (54.9%) | 18 (35.3%) | 21 (80.8%) | 8 (80%) | 13 (81.2%) |
| Black | 11 (10.8%) | 5 (9.8%) | 6 (11.8%) | 4 (15.4%) | 2 (20%) | 2 (12.5%) |
| Asian | 2 (1.9%) | 0 (0%) | 2 (3.9%) | 0 (0%) | 0 (0%) | 0 (0%) |
| Hispanic | 21 (20.6%) | 7 (13.7%) | 14 (27.5%) | 1 (3.8%) | 0 (0%) | 1 (6.3%) |
| Other | 22 (21.6%) | 11 (21.6%) | 11 (21.6%) | 0 (0%) | 0 (0%) | 0 (0%) |
| BMI, kg/m2 mean (IQR) | 30.39 (25.30–32.24) | 29.84 (26.09–32.37) | 30.92 (24.50–32.05) | 30.36 (26.53–33.10) | 27.20 (23.68–30.38) | 32.34 (26.98–37.67) |
| Severity Indexes (IQR) | ||||||
| Charlson comorbidity index | 3.3 (1–5) | 3.16 (1–5) | 3.49 (2–5) | 4.35 (2–6) | 3.3 (1–5) | 5 (3–7) |
| APACHEII | N/A | N/A | 21.6 (15–27) | N/A | N/A | 20.6 (12–26) |
| SOFA | N/A | N/A | 8.2 (6–11) | N/A | N/A | 8.6 (3–11) |
| SAPSII | N/A | N/A | 51.8 (45–62) | N/A | N/A | 47.6 (33–65) |
| Biomarkers (IQR) | ||||||
| Ferritin (ng/mL) | 938.9 (301.8–1,203.8) | 782.6 (206.0–934.5) | 1,076.9 (378.0–1,294.0) | 250.5 (80.5–382.5) | 205.3 (58.0–411.0) | 285.7 (92.0–438.5) |
| C-reactive protein (mg/L) | 140.9 (52.0–204.3) | 120.6 (44.7–155.0) | 158.9 (61.7–248.3) | 73.8 (20.0–110.2) | 34.7 (8.9–56.8) | 99.8 (37.8–175.2) |
| D-dimer (mg/L FEU) | 11.7 (1.0–12.8) | 2.3 (0.6–1.73) | 18.6 (1.7–21.6) | 5.3 (0.5–4.6) | 5.2 (0.4–1.9) | 5.5 (0.6–10.2) |
| Procalcitonin (ng/mL) | 3.2 (0.2–1.8) | 1.7 (0.2–1.0) | 4.4 (0.3–2.3) | 2.1 (0.2–0.7) | 2.2 (0.1–3.4) | 2.1 (0.3–1.21) |
| Lactate (mmol/ L) | 1.2 (0.9–1.5) | 1.2 (0.9–1.4) | 1.3 (0.9–1.5) | 2.1 (0.9–2.5) | 1.2 (0.8–1.5) | 2.53 (0.9–3.4) |
| Fibrinogen (mg/dL) | 543.6 (413.0–667.0) | 559.3 (420.0–703.0) | 531.7 (391.5–663.0) | 362.3 (257.3–550.0) | 348.0 (256.75–441.5) | 373 (257.3–572.0) |
| Albumin (mg/L) | 2.9 (2.6–3.3) | 3.2 (2.9–3.5) | 2.7 (2.4–2.9) | 3.4 (2.9–3.8) | 3.8 (3.4–4.1) | 3.19 (2.6–3.8) |
| Hemogram (IQR) | ||||||
| White blood cells (K/μL) | 10.8 (6.1–12.5) | 7.1 (4.9–8.5) | 14.4 (8.4–15.4) | 12.7 (7.2–17.3) | 8.3 (6.7–9.7) | 15.4 (8.2–20.9) |
| Hemoglobin (g/dL) | 11.2 (9.7–12.6) | 11.6 (10.2–13.0) | 10.7 (9.4–12.1) | 12.4 (9.9–14.7) | 12.8 (10.45–14.85) | 12.3 (9.6–14.5) |
| Mean corpuscular volume (fL) | 87.1 (84.5–93.7) | 88.0 (85.6–94.2) | 86.2 (82.5–93.0) | 92.3 (88.6–95.4) | 91.2 (87.2–94.6) | 93.0 (89.4–97.8) |
| Platelet (K/μL) | 266.0 (192.5–320.5) | 269.2 (209.0–334) | 262.8 (187.0–317.0) | 203.5 (151.8–247.8) | 228.1 (163.5–278.0) | 188.2 (127.5–229.5) |
| Neutrophils (%) | 76.2 (68.5–86.0) | 69.7 (61.0–82.0) | 82.8 (80.0–90.0) | 77.7 (74.0–87.0) | 73.1 (58.8–82.5) | 80.5 (79.25–89.25) |
| Lymphocytes (%) | 13.8 (5.0–18.5) | 19.4 (9.0–26.0) | 8.3 (4.0–11.0) | 12.7 (6.0–18.0) | 16.9 (7.0–26.0) | 10.1 (4.3–10.8) |
| Monocytes (%) | 7.1 (4.0–9.0) | 8.8 (6.0–11.0) | 5.5 (3.0–8.0) | 8.0 (4.0–9.3) | 7.7 (4.0–10.3) | 8.2 (4.0–9.0) |
| Eosinophils (%) | 0.8 (0.0–1.0) | 1.1 (0.0–1.0) | 0.5 (0.0–1.0) | 1.0 (0.0–1.25) | 1.8 (0.0–3.3) | 0.44 (0.0–1.0) |
| Respiratory Parameters | ||||||
| PaO2/FiO2 ratio | N/A | N/A | 161.6 (98–211) | N/A | N/A | 149.4 (73–184) |
| Positive-end expiratory pressure (CmH2O) | N/A | N/A | 10.8 (10–12) | N/A | N/A | 6.6 (73–184) |
| Inspiratory plateau (CmH2O) | N/A | N/A | 22.8 (19.7–25.3) | N/A | N/A | 23.9 (19.8–28.8) |
| Treatment −n (%) | ||||||
| Replacement therapy (pre-enrollment) | 12 (11.8%) | 3 (5.9%) | 9 (17.6%) | 3 (11.5%) | 0 (0%) | 3 (18.8%) |
| Hydroxychloroquine | 87 (85.3%) | 43 (84.3%) | 44 (86.3%) | 0 (0%) | 0 (0%) | 0 (0%) |
| Antibiotics | 98 (96.1%) | 47 (92.2%) | 51 (100%) | 16 (61.5%) | 3 (30.0%) | 13 (81.3%) |
| Antiviral | 1 (0.98%) | 0 (0%) | 1 (1.9%) | 0 (0%) | 0 (0%) | 0 (0%) |
| IL6− antagoinist | 4 (3.9%) | 1 (1.9%) | 2 (3.9%) | 0 (0%) | 0 (0%) | 0 (0%) |
| Convalescent plasma | 26 (25.5%) | 8 (15.7%) | 18 (35.3%) | 0 (0%) | 0 (0%) | 0 (0%) |
| Steroid | 46 (45.1%) | 12 (23.5%) | 34 (66.7%) | 4 (15.4%) | 1 (10.0%) | 3 (18.8%) |
| Therapeutic anticoagulation | 37 (36.3%) | 2 (3.9%) | 35 (68.6%) | 8 (30.8%) | 1 (10.0%) | 7 (43.8%) |
Figure 1.

Overview of Sample Cohort and Experimental Design
(A) Age and sex distributions of COVID-19 (n = 102) and non-COVID-19 (n = 26) groups; for each box, the middle horizontal line is at the median, and box margins are first and third quartiles, with vertical lines extending ± 1.5-times the interquartile range.
(B) Distributions of hospital-free days over a continuous 45-day period aggregated with survival (HFD-45, see “Outcomes Selection” section in the STAR Methods) among COVID-19 and non-COVID-19 groups.
(C) The proportion (%) of female and male patients that were admitted to the intensive care unit (ICU) and that required the support of a mechanical ventilator.
Severe COVID-19 infections require hospitalization and can lead to death due to respiratory deterioration. Thus, patients with the most severe cases requiring ventilatory support in the ICU entail longer admissions, while those with the most extreme cases die during hospitalization. In order to integrate length of hospital stay with mortality in one single outcome measure reflecting disease burden, we scored hospital-free days at day 45 (HFD-45). This composite outcome variable assigns a zero value (0-free days) to patients who remain admitted longer than 45 days or die while admitted and higher values of HFD-45 to patients with shorter hospitalizations and milder disease severity. Similar composite outcome variables are frequently used in the ICU setting (Young et al., 2015; Jaitovich et al., 2019). The World Health Organization (WHO) has also designated a COVID-19-specific outcome measure for clinical improvement (World Health Organization, 2020); this WHO ordinal score from 0–8 captures disease-specific severity metrics and also mortality (8 denotes death). The WHO ordinal score at 28 days is provided as an alternative outcome metric for the study and to facilitate future comparative studies. We found that the WHO ordinal score at 28 days and HFD-45 provided comparable outcome scores, yet HFD-45 was more granular and enabled a severity assessment for our control, non-COVID-19 patients (Figure S1). Other clinically relevant information was obtained, including: acute physiologic assessment and chronic health evaluation (APACHE II) score, sequential organ failure assessment (SOFA) score, Charlson comorbidity index score, the number of days spent on mechanical ventilators, need for admission into the intensive care unit (ICU), and laboratory measurements of C-reactive protein (CRP), D-dimer, ferritin, lactate, procalcitonin, fibrinogen, and others (Table 1). Members of the non-COVID-19 group had, on average, considerably more HFD-45 than those of the COVID-19 group (32.3 versus 22.0, respectively, p value = 0.004; Figure 1B). APACHE II and SOFA severity scores, used to stratify the severity of critical illness, were assigned to ICU-requiring patients, and both metrics exhibited similar distributions between the groups (Table 1). Consistent with previous reports, we observed male sex predominance in the ICU-requiring COVID-19 group (53.1% versus 44.7%) and the group requiring mechanical ventilatory support (46.9% versus 34.2%) (Figure 1C).
This comprehensive clinical characterization of the cohort provided substantial data to be integrated with multi-omic measurements. Following collection, blood samples were centrifuged to separate their components for various omic analyses. We performed four individual MS-based assays— shotgun proteomics, discovery lipidomics, discovery metabolomics, and targeted metabolomics—on the plasma components using high- resolution, high-mass-accuracy MS coupled with either gas or liquid chromatography. RNA-seq was used to characterize the transcriptomes of leukocytes extracted from patient samples.
Collectively, these data, containing abundance measurements of over 17,000 diverse biomolecules (517 proteins, 13,263 transcripts, 646 lipids, 110 metabolites, and 2,786 unidentified small molecule features), enabled a comprehensive systems analysis of COVID-19 blood samples. The clinical measurements correlated well with the multi-omics measurements of the same molecules (i.e., clinically measured albumin and ALB measured by MS), and blood cell counts/percentages were correlated with the expected proteins and transcripts and enriched for matching gene ontology (GO) terms; for example, the percentage neutrophils correlated with molecules involved in neutrophil degranulation (Figure S2). We compiled all biomolecule abundance measurements and de-identified patient information with clinical data into a highly curated relational (SQLite) database, which is publicly available for exploration and further analysis (see Data and Code Availability; Figure S3). The database includes additional metadata for each molecular measurement, such as GO terms, alternative identifiers, and analytical metrics used to filter data, among others (see STAR Methods). To facilitate exploration of this dataset by the broader scientific community, we also created a companion webtool (https://covid-omics.app) that accesses data and various analyses and performs on-demand data visualization. Detailed description of this tool is presented in a later section.
Systems Analysis Reveals Strong Biomolecule Associations with COVID-19 Status and Severity
We hypothesized that measurement of a large number of biomolecules across different molecular classes (i.e., nucleic acids, proteins, lipids, and metabolites) would provide insight into the COVID-19 molecular landscape and facilitate understanding of factors associated with higher severity. To test this hypothesis in an unsupervised manner, we initially performed a principal component analysis (PCA) (Figure 2 A). Here, we note grouping of patient samples based on severity (HFD-45) with samples of high and low severity diverging along the diagonal axis of principal components 1 and 2. This, together with a subtler grouping based on status (COVID-19 versus non-COVID-19), merited further supervised exploration.
Figure 2.

Multi-omics Analysis Reveals Strong Molecular Signatures Associated with COVID-19 Status and Severity
(A) PCA using quantitative values from all omics data (leukocyte transcripts, and plasma proteins, lipids, and small molecules, log2 transformed and centered around 0, for n = 125 patient samples, also see STAR Methods) shows that principal components 1 and 2 capture 16% and 10%, respectively, of the variance between patient samples. Plotting samples by these two components show a linear trend with hospital-free days at 45 days (HFD-45).
(B) Associations of biomolecules with COVID-19 status were determined using differential expression analysis (EB-seq) for transcripts and linear regression log-likelihood tests for plasma biomolecules (see Table S1). The adjusted p values (1 - posterior probability or Benjamini Hochberg-adjusted p values, respectively) are plotted relative to the log2 fold-change of mean values between COVID and non-COVID samples. In total, 2,537 leukocyte transcripts, 146 plasma proteins, 168 plasma lipids, and 13 plasma metabolites had adjusted p values < 0.05.
(C) Associations between biomolecules and HFD-45 was estimated using a univariate linear regression (HFD-45 ~ biomolecule abundance + age + sex) resulting in 7,408 biomolecules significantly associated with HFD-45, see Table S1. A multivariate linear regression with elastic net penalty was applied to each omics dataset separately to further refine features of interest, and resulted in 946 features that were retained as coefficients predictive for HFD-45, also see Table S1. In total, 219 features were determined as most important for distinguishing COVID status and severity.
(D) Abundance of the 219 features were visualized via a heatmap (Z scored by row) and clustered with hierarchical clustering.
(E and F) Features that were elevated (E) or reduced (F) with COVID-19 status and severity were used for GO term and molecular class enrichment analysis (see Table S2).
To gain biological insight into the host’s response to SARS-CoV-2 and pathways influencing its severity, we integrated our biomolecule measurements with clinical outcome variables. For this supervised analysis, we used univariate and multivariate regression to identify features that associate with (1) COVID-19 status and (2) HFD-45. Significant changes in plasma proteins, lipids, and metabolites associated with COVID-19 were determined by ANOVA and log-likelihood ratio tests, which incorporated potentially confounding variables, such as sex, age, and ICU status. Significant changes in leukocyte transcripts associated with COVID-19 diagnosis were analyzed separately by EB-seq. Figure 2B presents the statistical significance relative to the log2 of the fold changes of means for COVID-19 versus non-COVID-19 groups for each biomolecule. In total, 2,537 leukocyte transcripts, 146 plasma proteins, 168 plasma lipids, and 13 plasma metabolites were significantly associated with COVID-19 status (Table S1). Next, we applied GO and molecular class enrichment analysis to these features (Tables S2A and S2B). Among the biological processes that were enriched in biomolecules whose abundance was altered with COVID-19 (combined proteins and transcripts), many support recent findings (Messner et al., 2020) (Shen et al., 2020). These GO terms include mitotic cell cycle, phagocytosis recognition, positive recognition of B cell activation, complement activation (classical pathway), and innate immune response. Some of these enriched GO terms were driven by transcripts, for example, mitotic cell cycle (38 transcripts versus 0 proteins up with COVID-19), while other GO terms, like phagocytosis recognition or positive regulation of B cell activation, were driven by both transcripts and proteins (11 transcripts/18 proteins and 10 transcripts/18 proteins, respectively; Tables S2C–S2F). Triacylglycerides (TGs) were also enriched and more abundant in COVID-19 samples, while plasmenyl–phosphatidylcholines (PCs) were less abundant in COVID-19 samples compared to non-COVID-19 samples. These results are in line with prior reports of significant changes in lipid composition in COVID-19 sera (Shen et al., 2020).
In addition to the annotated features, 511 unidentified metabolites and lipids were also significantly associated with COVID-19 diagnosis. We performed additional spectral database searching and manually confirmed the identity of several of these features (Table S3). Initially, we explored the features with the largest fold change between COVID-19 and non-COVID-19 (Figure 2B). The tandem mass spectrum from the unidentified feature with a mass-to-charge ratio (m/z) of 350.1625, and the largest fold-change in COVID-19 versus non-COVID-19, contained a fragment ion diagnostic of chloroquine/hydroxychloroquine (m/z 247.10, C14H16ClN2) suggesting this top feature is a metabolite of the experimental therapeutic hydroxychloroquine (Figure S4). The feature with the second largest increase in abundance in COVID-19-positive plasma (Figure 2B) having a m/z value of 749.5155 was matched to the antibiotic azithromycin (Figure S4). By referencing patient medical records (Table 1), we determined that 85% of COVID-19 patients received hydroxychloroquine and 80% of COVID-19 patients received azithromycin treatment prior to sample collection (versus 0% and 8% of non-COVID-19 patients, respectively), thus explaining the strong association with COVID-19 status. This ability to detect drug metabolites highlights both the power of this discovery approach and the complexity of these samples, as these biomolecular data provide an archival-quality detailed snapshot of both the patients’ physiological response and exposures to therapies.
One ongoing challenge with COVID-19 disease is the broad and unpredictable range of patient outcomes, i.e., disease severity. To find biomolecules associated with severity, we regressed HFD-45 against abundance of each biomolecule. Using this univariate approach that accounted for confounders sex and age, we found 6,202 transcripts, 189 plasma proteins, 218 plasma lipids, and 35 plasma small molecules that were associated with disease severity (Table S1). To further refine features of interest, for each molecule-type we performed multivariate linear regression on HFD-45 using the elastic net penalty (Zou and Hastie, 2005) (STAR Methods). The elastic net simultaneously performs regression and feature selection; the elastic net penalty induces sparsity in the fit coefficients, which leads to selection of key features that best predict the response variable. In contrast to other approaches that also incorporate sparsity, such as LASSO, elastic net is known to have a “grouping effect” where it selects groups of correlated, predictive features enabling more informative results in downstream enrichment analyses. With the elastic net approach, 497 transcripts, 382 proteins, 140 lipids, and 60 metabolites were retained as predictive features for the outcome HFD-45 (Table S1). In total, we used the following criteria: (1) significance with COVID-19 status, (2) significance with HFD-45, and (3) elastic net feature selection, and generated a list of 219 features that were most significantly associated with COVID-19 status and severity (Figure 2C; Table S1). Levels of these biomolecules in each sample are visualized in a heatmap in Figure 2D. Hierarchical clustering in the heatmap shows clear grouping by COVID-19 status and severity and reveals clusters of molecules (across omes) with similar trends across patient samples.
Applying GO term and molecular class enrichment analysis to these 219 most differentially abundant features (Figures 2E and 2F), we found that biomolecules in GO terms for complement activation (classical pathway), antimicrobial humoral response, and neutrophil degranulation were enriched with COVID-19 severity (Tables S2G and S2H). The “complement activation” term encompassed many variable segments of immunoglobulins encoded by genes that undergo recombination to allow expression of light or heavy chains; twelve of them (8 IGHVs, 2 IGHVs, and 2 IGLVs) correlated with and predicted lower HFD-45 (Table S1). In general, the complement system is involved in immune response to virus infection (Stoermer and Morrison, 2011) and has been postulated as a target for therapeutics (Risitano et al., 2020). Our observations about immunoglobulins offer a glimpse into the early humoral response to SARS-CoV-2 and the relationship between preferential variable segment use and individual response trajectories. To better understand production of protective, or possibly injurious antibodies, serial studies and characterization of the properties of individual antibodies are required (Ju et al., 2020; Seydoux et al., 2020). Another top feature was pulmonary surfactant-associated protein B (SFTPB), notable because circulating SFTPB correlates with decreased lung function in smokers (Leung et al., 2015), and may be a surrogate marker of lung deterioration in COVID-19 individuals.
Features that were reduced in COVID-19 samples and whose abundance was lowest in the most severe cases were enriched in the following categories: response to folic acid, PCs, plasmenyl-PCs, and high density lipoprotein particle remodeling. These features suggest a significant change in plasma lipid regulation. Similar to previous reports, we observed lower levels of APOA1, APOA2, and APOM in COVID-19 patients relative to non-COVID-19 patients (Messner et al., 2020); (Shen et al., 2020).
Cross-ome Correlation Analysis
Correlating Plasma Proteins, Metabolites, and Lipids
A major strength of multi-omic approaches is the ability to uncover functional connections or co-regulation between different classes of biomolecules. This effort is particularly informative for small molecules, especially lipids, whose biological roles are often less well annotated. Strongly perturbed biological systems, as found with COVID-19, are instrumental for finding these meaningful connections because of enhanced phenotypic variation (Stefely et al., 2016). For this analysis, we integrated all omic measurements acquired by performing cross-ome correlation analysis (Table S4); this was conducted in an unsupervised manner and all sample data were included regardless of COVID-19 status. We calculated Kendall’s Tau coefficients in the pairwise fashion for all features. The heatmap in Figure 3 A focuses on measurements from plasma; these associations reveal significant hierarchical clustering of Kendall Tau coefficients between proteins (rows) and small molecules (lipids and metabolites; columns) with statistical significance for their correlation with each other. Significance for COVID-19 status and HFD-45 is also annotated along the top to indicate biomolecules that also had disease associations (colored as a binary metric where the q value < 0.05). The approach identified many dense clusters with strong associations across biomolecule classes.
Figure 3.

Leveraging the Value of Multi-omic Data through Cross-ome Correlation Analysis
(A) Hierarchical clustering of Kendall’s Tau coefficients calculated for correlations between abundances of proteins (rows) and small molecules (lipids and metabolites; columns) in the pairwise fashion, using data from n = 127 samples (also see Table S4). Significance of their association with HFD-45 and COVID-19 status is indicated above the biomolecule clusters, and significance of the correlation is denoted by ∗, corresponding to adjusted p values < 0.05.
(B) Re-clustering of biomolecules found in the clusters highlighted in panel-a with molecule annotations.
(C) Enrichment analyses of protein GO terms (purple) and small molecule classes (green) present in the cluster in (B).
(D) A schematic of a high-density lipoprotein (HDL) particle containing APOA1 and APOA2 proteins surrounded by various lipids, specifically plasmalogens. SAA2, also detected in the cluster in (B), can replace APOA1 within the particle.
(E) Relative abundance measurements of plasma gelsolin (pGSN), cellular gelsolin (cGSN), and total gelsolin obtained using parallel reaction monitoring (PRM) on representative peptide sequences (see Table S5); p values based on linear regression are presented. For each box, the middle horizontal line is at the median, and box margins are first and third quartiles, with vertical lines extending ± 1.5-times the interquartile range.
(F) Regression analysis of plasma gelsolin levels and SOFA scores (R2 = 0.267, p = 4.53 × 10−5).
One cluster with a diverse mix of biomolecules and multiple associations between each other and with COVID-19 status and severity is highlighted in Figure 3B. This cluster captured the lipids, PC and plasmenyl-PCs, and high-density lipoproteins (Figure 3C). These categories were found to be significantly associated with COVID-19 status and severity (vide supra), and the cross-ome analysis links these molecules as possible molecular interactors. Plasmenyl-PCs are among lipids known as plasmalogens, and these lipids act as potent antioxidants due the ether linkage at the sn1 position (Messias et al., 2018). We recently reported that plasma plasmenyl-PCs (containing 16:0) had strong genetic associations to the APOA2 locus in mice (Linke et al., in. press, http://LipidGenie.com), and this cross-ome correlation analysis provides further evidence that these plasmalogen species are associated with APOA2 and APOA1 in humans. APOA1 and APOA2 are among the most abundant proteins in HDL particles (Figure 3D) (Davidson et al., 2009). During a proinflammatory response, SAA2 can displace APOA1 within HDL particles and change HDL particles’ functions and lead to increased clearance of HDL (Feingold and Grunfeld, 2019; Khovidhunkit et al., 2004). In our correlation analysis, we found SAA, S100A8/A9, SERPINA3, and LCP1 to be negatively correlated with plasmenly-PCs, opposite to that of APOA1 and APOA2 proteins (Figure 3B). Relevant to COVID-19, reduced levels of HDL-cholesterol are associated with an increased risk of hospitalization for infections (Trinder et al., 2020) and poorer outcomes during infections (Feingold and Grunfeld, 2019). Consistent with this, more severe COVID-19 patients have significantly lower blood HDL cholesterol and ApoA1 (Nie et al., 2020; Wei et al., 2020). These multi-omic data provide further evidence that HDL is lower with increased COVID-19 severity and implicate other biomolecules, such as plasmenyl-PCs, as components of this process. These data point to the potential of mitigating COVID-19 severity by using therapeutic strategies aimed at restoring HDL particles, for example, through statins (Feingold and Grunfeld, 2019).
The notable cluster in Figure 3C also includes the protein gelsolin (GSN) and the metabolite citrate. Citrate is a calcium chelator that is used to prevent coagulation, while GSN is a Ca2+-activated, actin-severing protein. Both features were among the 219 most significant features relating to COVID-19 infection and severity, and their reduced abundances were associated with worse outcomes. A possible confounding variable is that some patients received citrate as part of renal replacement therapy prior to sample collection; however, we found that this confounder had no significant effect on the overall observation that citrate was lower in COVID-19 versus non-COVID-19 (Figure S5). The decrease in abundance of circulating GSN in sera was recently reported by Messner et al. (2020) and Shen et al. (2020); however, confirming the reduced GSN levels in plasma samples (versus sera) can help mitigate the confounding issue of variable loss of GSN into the fibrin clot (Piktel et al., 2018).
Two proteoforms of GSN arise from the use of alternative transcriptional start sites: the cytoplasmic form, involved in remodeling of intracellular actin (cGSN) (Feldt et al., 2019), and the plasma form, secreted by multiple cell types, including skeletal muscle (pGSN). Pools of circulating GSN, the aggregation of the two proteoforms, scavenge circulating filamentous actin and possess anti-inflammatory activities (Piktel et al., 2018). As cGSN may enter plasma upon cellular injury, we used parallel reaction monitoring to independently quantify levels of pGSN and cGSN via targeting five distinguishing peptides (Table S5) (Peterson et al., 2012). Abundance of pGSN correlated strongly with COVID-19 and ICU status, while cGSN levels were not reduced and did not correlate with COVID-19 severity (Figure 3E). These results indicate that cGSN from damaged cells is a relatively small contributor to the pool of circulating GSN and suggest that reduction of pGSN in COVID-19 may result from decreased biosynthesis and/or increased clearance from plasma.
Furthermore, in the sub-group of ICU patients, decreased pGSN significantly correlated with SOFA scores (R2 = 0.27, p value = 4.5 × 10−5; Figure 3F), demonstrating its potential utility as a prognostic biomarker of COVID-19 severity. These data also indicate that pGSN supplementation has excellent potential as a COVID-19 therapeutic, as recently suggested by Messner et al (2020). Indeed, pGSN is known to decrease in acute lung injury, and in animal models of lung injury repletion of pGSN has favorable effects (Piktel et al., 2018). Recombinant pGSN has been given safely in phase I/II trials to patients with community-acquired pneumonia (NCT03466073, ClinicalTrials.gov). As of this writing, a trial of the recombinant pGSN in COVID-19 is in the recruiting stage (NCT04358406).
Biological Processes Dysregulated in COVID-19 Patients
Based on recent literature reports on COVID-19 pathophysiology and our systems analyses, we subsequently focused on specific biological processes evidently dysregulated in COVID-19 patients: neutrophil degranulation, vessel damage, platelet activation and degranulation, blood coagulation, and acute phase response.
Neutrophil Degranulation
Our list of 219 features strongly correlated to COVID-19 status and severity contained multiple transcripts and proteins involved in neutrophil degranulation (GO term 0043312; Table S2g); enrichment of this term has been previously reported by Shen et al based on protein abundance measurements alone. The volcano plot in Figure 4 A illustrates the mean fold-change in abundance of GO-associated proteins (pink) and transcripts (purple), plotted against adjusted p values of significance with COVID-19. We noticed an increased expression of multiple genes related to neutrophil function, including PRTN3, LCN2, CD24, BPI, CTSG, DEFA1, DEFA4, MMP8, and MPO (Table S1). The latter encodes neutrophil myeloperoxidase, a protein instrumental in complexing extracellular DNA for the development of neutrophil extracellular traps (NETs) (Jiao et al., 2020). NETs are extracellular aggregates of DNA, histones, toxic proteins, and oxidative enzymes released by neutrophils to control infections, and their overdrive can amplify tissue injury by inflammation and thrombosis (Twaddell et al., 2019). NETs have been associated with the pathogenesis of ARDS (Narasaraju et al., 2011; Middleton et al., 2020; Lefrançais et al., 2018) and thrombosis (Ali et al., 2019), both phenotypes observed in severe COVID-19 patients, and elevated neutrophil counts predict worse outcomes in COVID-19 patients (Wang et al., 2020a, 2020b). Several NETs proteins that are also linked to thrombosis (Wang et al., 2017; Healy et al., 2006), including calprotectin (S100A8/9), ferritin, CRP, and histone H3, were also increased in our cohort (Table 1; Table S1). Thus, our data strengthen earlier suggestions (Barnes et al; Shen et al, 2020; Zuo et al, 2020) that combating dysregulated NETs may present an avenue toward mitigation of disease severity in COVID-19. For example, dipyridamole, an FDA-approved drug that can inhibit NET formation by activation of adenosine A2A receptors (Ali et al., 2019), has recently been shown to improve outcomes of COVID-19 patients with respiratory failure (Liu et al., 2020). Similarly, the platelet P2Y12 receptor antagonist, ticagrelor, has been proposed to attenuate NET formation in COVID-19 (Omarjee et al., 2020) and may simultaneously inhibit platelet activation, a process also involved in COVID-19 pathophysiology (Manne et al., 2020). Drugs that antagonize the NET–IL1β loop, such as anakinra, are currently being tested (NCT04324021), and colchicine, a potent neutrophil recruiter and IL1β-secretion inhibitor, is also under evaluation (NCT04326790).
Figure 4.

Biological Processes Dysregulated in COVID-19
(A) Volcano plots highlighting proteins (pink) and transcripts (purple) assigned with the GO term 0043312 “Neutrophil Degranulation,” where an increased point size signifies the inclusion of the biomolecule in the list of 219 features most significantly associated with COVID-19 status and severity (see Figure 2E; Tables S1 and S2).
(B) Linear regressions of protein abundance versus HFD-45 for the indicated proteins as measured in COVID-19 (left) and non-COVID-19 patients (right). Resulting R2 values and their associated ± slope indicate the goodness of fit and change in abundance of a given protein with severity (HFD-45). Proteins that are more decreased in severe cases appear blue, while proteins that are increased in severe cases appear red. Significance of the protein versus HFD-45 correlation is denoted by a dot (p value < 0.01).
(C) Relative abundance measurements of peptides attributed to plasma fibronectin (pFN) and cellular fibronectin (cFN).
(D) Relative abundance measurements of VWF multimers and VWF antigen-2 (VWF Ag2), as estimated based on relative abundances of their unique peptides. Peptide- and protein-level data are log2-transformed and grouped into two categories, according to patient status: COVID-19 (red), non-COVID-19 (blue), where × and ∗∗ indicate p values < 0.05 and 0.001, respectively, calculated with ANOVA; for each box, the middle horizontal line is at the median, and box margins are first and third quartiles, with vertical lines extending ± 1.5-times the interquartile range.
Vessel Damage
Numerous proteins involved in the body’s response to blood vessel damage, including AGT, FBLN5, NID1, and SERPINB1, increased in the COVID-19 samples relative to the non-COVID-19 group and were especially higher in abundance in more severe patients (Figures 4B and S6, Category #1). Neuropilin-1 (NRP1) is a regulator of vascular endothelial growth factor (VEGF)-induced angiogenesis, and an increase in its abundance with COVID-19 severity is of particular relevance given the recent report describing excessive pulmonary intussusceptive angiogenesis at autopsy in COVID-19 (Ackermann et al., 2020). In contrast, other vessel damage-associated proteins, such as SERPINA4, were significantly decreased in abundance in COVID-19 patients (p value = 2.715 × 10−4), highlighting the regulatory intricacies of this biological process.
Platelet Degranulation
In accord with earlier reports, we observed severe dysregulation of proteins associated with platelet activation and degranulation (Figure 4B, Category #2) (Manne et al., 2020). For example, abundance of histidine-rich glycoprotein (HRG), which binds heme, heparin, thrombospondin, and plasminogen (Priebatsch et al., 2017), was significantly reduced in patients with COVID-19, with the mean level 1.8-fold lower than in non-COVID-19 patients (Figure S5; p value = 8.138 × 10−12). Similarly, abundances of GPLD1 and CLEC3B significantly decreased in COVID-19 and correlated with disease severity (Figure 4B, Category #2; Figure S6). In contrast, the abundances of other platelet-associated proteins were increased in COVID-19 samples versus non-COVID-19 samples (Figure S5), for example, serglycin (SRGN) and the von Willebrand Factor (VWF); through the use of an FDA-approved antibody test, VWF has recently been implicated in COVID-19-associated endotheliopathy (Goshua et al., 2020).
VWF is synthesized by endothelial cells as a 2,813 amino acid-long protein that is processed intracellularly to form VWF antigen 2 (VWFAg2) and VWF multimers (Haberichter, 2015). VWFAg2 is released constitutively into circulation, whereas VWF multimers are stored for later release upon stimulation of endothelial cells (Nightingale and Cutler, 2013). To distinguish between these two products, we quantified 19 peptides unique to VWFAg2 and 107 peptides unique to VWF (Figure 4C). Abundances of both VWFAg2 and VWF multimer were increased and correlated with COVID-19 severity (p values = 4.860 × 10−2 and 1.715 × 10−2, respectively). We propose that endothelial cells increase synthesis of, package, and release both VWFAg2 and VWF multimers, particularly in severe COVID-19 cases.
Fibronectin (FN1) works alongside VWF and fibrinogen to mediate the interaction of platelets with endothelial surfaces of injured vessels (Wang et al., 2014). Previous studies have reported increased FN1 levels in COVID-19 patients, relative to non-COVID-19 patients (Stukalov et al., 2020), but did not distinguish cellular (cFN) and plasma (pFN) proteoforms. By monitoring unique peptides (IAWESPQGQVSR for cFN and ESVPISDTIIPAVPPPTDLR for pFN), we specifically determined the abundance of each and revealed that cFN was significantly increased (p value = 2.8 × 10−6) in COVID-19 patients, relative to non-COVID-19 patients, whereas pFN was not (Figure 4D). Such a finding is of considerable interest given that forced over-expression of cFN in plasma of mice is associated with increased thrombo-inflammation (Dhanesha et al., 2019).
Coagulation Cascade
Consistent with the widely reported hypercoagulative phenotype of COVID-19 patients (Becker, 2020; Lax et al., 2020; Goshua et al., 2020), all our patients exhibited evidence of excessive clotting in vivo, as demonstrated by the increased levels of circulating fibrin D-dimer (Table 1). To further examine the coagulative dysregulation in COVID-19 patients at a molecular level, we deliberately conducted our proteomic analyses using plasma, which retains clotting factors otherwise depleted in serum. These plasma proteins, working alongside proteins of the vessel wall and platelets, undergo a cascade of regulated proteolytic reactions to generate thrombin, which converts fibrinogen to fibrin (Kattula et al., 2017). We detected significant increases in abundance of fibrinogen alpha (FGA) and beta (FGB) in COVID-19 versus non-COVID-19 patient plasma, which was consistent with the clinically measured fibrinogen (Figure S6; Table 1); however, gamma (FGG) chains showed less significant trends in COVID-19 patients. We also observed decreases in abundance of prothrombin (F2) and thrombin-activation factor XIII (F13A1 and F13B) in COVID-19 samples compared with non-COVID-19, and these proteins were further decreased in the most severe COVID-19 patients (Figures 4B and S5, Category #3). Significant reductions and correlations with HFD-45 were found for plasminogen (PLG), the zymogen precursor of plasmin (Urano et al., 2018); kallikrein (KLKB1) and kininogen (KNG1), which function in the intrinsic coagulation cascade leading to generation of thrombin (Schmaier, 2016); heparin cofactor 2 (SERPIND1), which forms an inhibitory complex with thrombin (Huntington, 2013); protein C (PROC), which is activated by thrombin to activated protein C (APC) (Griffin et al., 2018); and protein C inhibitor (SERPINA5) (Figures 4B and S6). The decreases of abundance of PROC and SERPINA5 with severity assume greater significance when considered alongside the finding that soluble plasma thrombomodulin (THBD) rivals elevated VWF as a predictor of mortality in COVID-19 (Goshua et al., 2020). THBD is normally tethered to the surface of endothelial cells, where it forms a complex with thrombin that efficiently activates PROC to APC (Ikezoe, 2015). APC also serves to modulate inflammatory response, and administration of recombinant APC mutant has been proposed as a therapy to mitigate thrombo-inflammation, which occurs with ARDS and in severe COVID-19 patients (Griffin and Lyden, 2020).
Our data are pertinent to current discourse on prevention and treatment of the thrombotic diathesis in COVID-19. Several serpin-protease interactions, modified by heparin and heparin-like compounds, are being investigated as anticoagulant therapeutics for COVID-19 patients (Cattaneo et al., 2020). Our data suggest such compounds and alternative antithrombotic therapies (e.g., anti-platelets) may also be useful in the subset of most severely affected COVID-19 patients.
Acute Phase Response
Next, we evaluated acute phase proteins, i.e., proteins— including S100A8, S100A9, SAA1, and SAA2—whose plasma concentration changes by at least 25% during inflammatory disorders as a result of reprogramming by cytokines, and these are often secreted from the liver (Gabay and Kushner, 1999). Our findings both support previous reports of significant increase in abundance of these four proteins in COVID-19 patient samples (p values = 1.673 × 10−3, 1.966 × 10−4, 2.830 × 10−2, and 9.71 × 10−3, respectively) and reveal their correlation with severity as estimated by HFD-45 (p values = 1.408 × 10−8, 1.996 × 10−7, 1.808 × 10−4, and 1.420 × 10−5, respectively) (Figures S6 and 4B, Category #4). We also found that attractin (ATRN), a protein involved in chemotactic activity (Duke-Cohan et al., 1998), decreased in abundance in COVID-19 samples versus non-COVID-19 samples and was significantly associated with severity (p value = 1.124 × 10−3). Four of these proteins were also found in the cross-ome correlation analysis (Figure 3B), where S100A8, S100A9, and SAA2 were negatively correlated with plasmalogens, while ATRN was positively correlated with these lipids.
Our data also revealed the increase in abundance of a liver-derived protein transketolase (TKT). One of the top 219 significant features (Figure 2), TKT was significantly elevated in COVID-19 patient plasma (p value = 5.592 × 10−4, Table S1). Other acute-phase proteins detected include GSN (vide supra) and SERPINA3, both of which decreased in abundance in COVID-19 patients and correlated with HFD-45 (p value = 7.823 × 10−4 for SERPINA3). In general, abundances of most identified plasma proteins associated with the acute phase response were significantly altered with COVID-19 status and indicative of severity.
An Interactive Webtool for Accessible Data Visualization
A primary goal of this study was to create a multi-omic compendium of biomolecules and their abundances in COVID-19 that could aid in the elucidation of disease pathophysiology and therapeutic development. To make our dataset accessible, we have developed a web-based tool with interactive visualizations that allows for simple and quick navigation of our resource and performs on-demand PCA, linear regression, differential expression, and hierarchical clustering analysis via a clustered heatmap (https://covid-omics.app; Figure 5 ). The webtool provides interactive visualizations with supervised and unsupervised, and univariate and multivariate, analysis of the omic datasets in the context of highly curated clinical data. While the web resource will enable accessibility of our dataset, the underlying relational database and unprocessed data are also made freely available (STAR Methods) to support reproducibility and further analysis as desired.
Figure 5.

Overview of the COVID-19 Multi-omics Webtool
(A) The homepage provides PCA scores and loadings plots (also see STAR Methods). Selected biomolecules are presented in a barplot and a boxplot. Boxplots have a horizontal line at the median and the box extends to the first and third quartile with whiskers extending to 1.5-times the interquartile range. Each page provides buttons to navigate to the other web tools.
(B) The differential expression page displays a multi-omics volcano plot with the y axis representing −log10 (p values) where the p values are derived from the analysis in Figure 2 and the x axis is the log2 fold-change between the means of COVID-19 samples versus non-COVID-19 samples.
(C) The linear regression page allows users to select any combination of biomolecule and clinical measurement to analyze via univariate linear regression. R2 and p values for the F-statistic are displayed on the plot.
(D) The Clustergrammer page offers an interactive clustered heatmap (see STAR Methods).
To illustrate how these interactive visualizations may facilitate biological insights, we focus on a standout in the proteomics dataset, cartilage acidic protein 1 (CRTAC1), which appears on the diagonal axis of the PCA loadings plot separated in both principal components 1 and 2 (Figure 5A). The biomolecule bar plots and boxplots, found just below the PCA plot on the homepage, show the per-sample abundance and distribution across sample groups of this protein, respectively (Figure 5A). Collectively, these data visualizations identify CRTAC1 as an important feature in the innate structure of the proteomics data with a distinct abundance distribution for each patient subgroup. CRTAC1 is a secreted matrix-associated protein involved in chondrocyte development and also belongs to the GO process “Olfactory Bulb Development” (GO:0021772), which is notable given previous reports of anosmia in COVID-19 patients (Marinosci et al., 2020).
To learn how CRTAC1 relates to our clinical measurements, such as HFD-45, the user can redirect to the linear regression page, which provides scatter plots and calculations of R2 values and (coefficient) p values between any biomolecule and clinical covariate pair (Figure 5B). For the levels of CRTAC1 and HFD-45, the linear regression tool reports the R2 value as 0.14 and a p value of 1.704e-05 (n = 125). Checkboxes on the control panel of the page allow users to select various patient subgroups and independently calculate the metrics for them. For example, for the COVID-19 subset, the R2 is 0.079 and p value is 4.490e-03 (n = 100) (Figure S7A), whereas for the non-COVID-19 subset of patient samples, the R2 is 0.099 and p value is 1.254 e-01 (n = 25) (Figure S7B).
The third analysis enabled by the web tool is differential expression. The page depicts a volcano plot, where effect size represents the log2 of the fold-change of biomolecule abundance in COVID-19 versus non-COVID-19 patient samples, and significance is −log10 (p value). Here, the p value is calculated using a likelihood ratio that compares linear models with and without possible confounders, including age, sex, and ICU status. For any given biomolecule, an accompanying table (data not shown) lists the effect size, p value, q value (adjusted by false discovery rate [FDR]), type of statistical test, and associated formula used to calculate the p values. This information provides users with a convenient means of examining the implications of potential confounding variables. According to the differential expression analysis, abundance of CRTAC1 is the second-most reduced in the comparison of COVID-19 versus non-COVID-19 patients (Figure 5C). Even after accounting for age, sex, and ICU status, the adjusted p value of the reduction in abundance of CRTAC1 in COVID-19 versus non-COVID-19 samples is 2.236e-08.
The final data visualization tool is an interactive heatmap, powered by Clustergrammer (Fernandez et al., 2017) and provided to aid in investigation of how a biomolecule of interest may fit into larger patterns across samples (Figure 5D). Here, CRTAC1 groups with a series of apolipoproteins (vide supra). Thus, as exemplified by our examination of CRTAC1, the covid-omics.app website provides a convenient interface to visualize and analyze our multi-omics dataset.
A Resource Application: Machine Learning Approach
To demonstrate how the scientific community could leverage our resource, we present a complementary analysis by utilizing our multi-omic data to train machine-learning models that accurately predict COVID-19 outcome. The data provided in this resource can be leveraged for training clinically relevant models for predicting COVID-19 severity. The ability to predict COVID-19 severity early on in admission would help clinicians prioritize patients for treatments. Thus, we tested whether a machine-learning model trained with the multi-omic data in our resource could accurately predict COVID-19 severity. The 100 COVID-19 patients with complete multi-omic profiles were assigned to “severe” and “less severe” groups based on HFD-45 using the median day 26 as the threshold. They were then randomly split into two groups: 80 were used for training and the remaining 20 were held out as a test set (Figure 6 A). We optimized hyperparameters of ExtraTrees classification models using both the combined data and each of the four omic datasets separately via 5-fold cross-validation on the training set. This comparison shows that each omic dataset possessed a different predictive utility (combined model AUROC = 0.93, average precision = 0.96; Figure 6B). Examination of the individual predictions from the combined model show that 2/4 incorrect predictions were for the patients with HFD-45 values near the median (Figure 6C), all of whom were also misclassified by the omic subset models (Figure S8). Although preexisting comorbidities are associated with poor COVID-19 outcomes (Guan et al., 2020), the model based on the combined multi-omic data was a substantially better predictor of disease severity than a model based on Charlson scores—the clinical estimate of 10-year survival (Richardson et al., 2020). Adding Charlson scores to the multi-omic data did not improve model performance (Figure 6D).
Figure 6.

Results from Analyses Demonstrating a Use-Case of this Multi-omic Resource
(A) Data splitting scheme for training and test sets from the 100 COVID-19 patients with all four omics datasets. A random 20% was held out to be used for model evaluation, and the remaining 80% was used to determine the best hyperparameters with 5-fold cross validation.
(B) ExtraTrees classifier performance metrics on the test set after hyperparameter optimization using each of the four omic datasets separately for training or all omics data combined.
(C) Macro-averaged receiver-operator characteristic curves for the models trained with multi-omic data, Charlson score, or both multi-omic data and Charlson score.
(D) Test set predictions of the extra trees model trained on the combined multi-omic dataset showing correct predictions as a function of the disease severity defined by hospital-free days.
(E) Top 5 most important predictive features for each of the models trained on the four omic subsets (see Table S6). Feature importance for each set was normalized to the most important feature.
The use of the tree-based model also enabled determination of the most predictive features (Figure 6E; Table S6). Some of them overlap with other analyses presented above, such as plasmalogen lipids and proteins S100A8 and S100A9. However, this model-based prioritization also highlighted potentially disease-relevant features not yet discussed. For example, for the metabolomic model, the most important features were the tryptophan metabolites, kyneurinin and quinolinic acid, which are known mediators of immune function and inflammation in various contexts (Heyes et al., 1992; Sofia et al., 2018) and have recently been implicated in COVID-19 severity (Migaud et al., 2020). Comparison of the top 25 predictive features from our proteomic and metabolomic models to those from another COVID-19 severity prediction model (Shen et al., 2020) revealed several overlapping features, including metabolite L-kynurenine and proteins SAA2, SERPINA3, and LCP1. All in all, these results indicate that our multi-omic data can be utilized to accurately predict COVID-19 severity, and the significant features highlighted by these models might further aid in understanding disease pathophysiology.
Discussion
In this cohort study, we used cutting-edge technologies to monitor—in relation to the disease severity and outcomes—thousands of diverse biomolecules from patients with and without COVID-19. The overarching aim of this work was to capture the molecular signatures of COVID-19, correlate them with disease severity and clinical metadata, and generate both testable hypotheses and opportunities for therapeutic intervention. Altogether, we have made these data broadly available through a free web resource—covid-omics.app—in the hope that experts worldwide will continue to mine these data.
This resource has revealed several exciting findings that merit further exploration. First, our discovery that citrate, plasmenyl-PCs containing 16:0, and pGSN are covarying and reduced with COVID-19 severity is notable, especially because several studies have found lower circulating gelsolin in COVID-19 patients (Messner et al., 2020; Shen et al., 2020). In contrast, other studies have measured circulating citrate and have reported it to be unchanged (Thomas et al., 2020; Shen et al., 2020) or mildly reduced (Song et al., 2020). Similarly, conflicting results have been reported with plasmenyl-PCs; Shen et al. found no significant change in abundance with COVID-19 (Shen et al., 2020), while Song et al. found that reductions in plasmenyl-PCs species significantly negatively correlated with upregulated inflammatory markers, CRP and IL-6 (Song et al., 2020). Loss of citrate, plasmenyl-PCs, and pGSN would likely promote a poorer disease outcome, and as previously suggested for GSN (Messner et al., 2020), these molecules have the potential to be supplemented in patients to mitigate the dysregulated response. pGSN, a circulating protein that regulates innate immunity by inhibiting proinflammatory mediators, inactivating bacterial endotoxins, and boosting endogenous antimicrobial peptides (Piktel et al., 2018), is already being investigated as a therapy for treatment of community-acquired pneumonia and is being investigated for repurposing in COVID-19 treatment (NCT04358406). Citrate has been tested as a regional anticoagulant in dialysis procedures and has also been noted to reduce the negative effects of neutrophil degranulation (Gritters et al., 2006). Monitoring and supplementing citrate levels could offer beneficial effects in severe COVID-19 patients. Lastly, treatment with statins or polyunsaturated lipid supplements could counteract the reductions in HDL in severe COVID-19 patients; statin use has already been associated with improved survival in COVID-19 patients (Zhang et al., 2020a, 2020b, 2020c).
Our data not only confirm the pronounced hypercoagulative signature of COVID-19 but also expand on our current understanding of its pathophysiology. Anticoagulation strategies in non-COVID-19 critical illness have been extensively discussed, but no treatment has yet been identified. Note that activated protein C has been tested but has not shown benefits in large trials (Ranieri et al., 2012), and recent evidence suggests that heparin use in COVID-19 patients may be beneficial. Our data strengthen the motivation for additional candidate therapeutics (Messner et al., 2020; Shen et al., 2020; Goshua et al., 2020; Connors and Levy, 2020). For example, we observed significant reduction in abundance of prothrombin and its correlation with disease severity. Levels of another coagulation-related protein, cellular fibronectin (cFN), not pFN, were highly increased in COVID-19 patients. Finally, we confirmed previously reported dysregulation of VWF and circulating coagulation factors (Goshua et al., 2020), using an orthogonal technique. These data provide a rationale for more tailored antithrombotic treatments, including the addition of several drugs that work synergistically at different levels, e.g., coagulation and upstream endotheliopathy events.
Currently, the potential benefits of systemic corticosteroids in COVID-19 patients are under intense debate (Wu et al., 2020; Huang et al., 2020). While patients with severe non-COVID-19 infections and ARDS represent an aggregation of different transcriptomic sub-phenotypes (Calfee et al., 2014; Davenport et al., 2016; Bos et al., 2017), corticosteroids appear to be beneficial only to specific patient subgroups (Antcliffe et al., 2019). Our RNA-seq analysis will allow further characterization of immunomodulation targets that could either be focused on globally captured pathways or on subpopulations associated with specific outcomes demonstrating enriched features. Moreover, the identification of a leukocyte and proteomic signature confirms earlier observations on the critical role of neutrophil extracellular trap formation (NETosis) in COVID-19 and strengthens the search for drugs that target specific steps in neutrophil activation and function for COVID-19 repurposing (Zuo et al., 2020; Barnes et al., 2020).
The use of machine learning revealed additional features relevant to COVID-19 severity and underlined the utility of the multi-omics based model for predictions, as this model performed better than the well-established Charlson comorbidity index. Moreover, adding the Charlson score as a variable to our proposed model did not result in better predictive power. This finding could indicate that the clinical score is highly collinear with the multi-omic variables used by the model and that the clinical observation cannot fully capture the features leading to patient outcomes. Furthermore, the combination of leukocyte transcripts with plasma biomolecules for predictive modeling provides a valuable resource for future investigations.
All large-scale omics studies have limitations but, ideally, still stimulate the generation of numerous testable hypotheses. This work is no exception, and, in a very real sense, it represents a starting point in the response to the urgent need to wholly define this devastating disease. Future work should include a larger and broader patient population. The samples derived here came from a single center, and although our population is racially diverse, it does not necessarily replicate factors related to, among others, geography or population socioeconomic status. Another limitation was that the control group was generated by blindly enrolling patients presenting with COVID-19-compatible symptoms. While this approach provided an important reference, not all of these non-COVID-19 patients that were admitted to the ICU presented with the same criteria of ARDS. We recognize this approach is not ideal and expect that future studies with prospective enrollment of patients fully matching the present COVID-19 clinical features will provide a better reference to the current cohort.
The practicalities associated with study design and implementation during a pandemic presented another possible limitation. For example, while we enrolled the patients near the time of hospital admission, we could not control the period that elapsed between the disease development and the blood sampling. Typically, most observational clinical ICU research is based on inception cohort studies, in which the timeline is arbitrarily defined by the moment of patient enrollment (Sakr et al., 2016). Relevant to this study, previous research on the genomic landscape of patients with sepsis indicates the timing of blood sampling in relation to ICU admission was not predictive of the patients transcriptomic profiling (Davenport et al., 2016). Relatedly, we had no control of the various drugs administered to the patients based on recommendations including azithromycin, hydroxychloroquine, and others, which could have impacted the overall COVID-19 data generated. We note, however, that our detection of these therapeutics and their strong correlation with COVID-19 adds credibility to the quality of our analytical platform.
Disease burden was difficult to assess, and we relied upon the metric of HFD-45. Ultimately, the data presented here conveys that this metric is a good outcome measure; however, our study was not powered to demonstrate the association of omic data with survival, which is the most impactful patient-centered outcome measure. Finally, our study relies on a single sample per patient, which, despite reflecting the patient’s status to some extent, is limited compared with trajectory analyses that could be contributed by serial blood sample determinations. Future studies will ideally have multiple temporal sampling time points per patient to allow for better controlled longitudinal severity correlations.
STAR★Methods
Key Resources Table
| REAGENT or RESOURCE | SOURCE | IDENTIFIER |
|---|---|---|
| Biological Samples | ||
| Human plasma, NaHep, pooled gender | BioIVT | Cat# HMN378062 |
| Chemicals, Peptides, and Recombinant Proteins | ||
| Lysyl Endopeptidase (Lys-C) | Wako Chemicals | Cat# NC9242798 |
| Sequencing Grade Modified Trypsin | Promega | Cat# V5111 |
| MSTFA (N-Methyl-N-trimethylsilyltrifluoroacetamide) | Thermo Fisher Scientific | Cat# TS-48911 |
| MTBE (tert-Butyl methyl ether), ACS reagent, ≥99.0% | Sigma Aldrich | Cat# 443808-1L |
| Pyridine for HPLC, ≥99.9% | Sigma Aldrich | Cat# 270407 |
| 2-Propanol (Optima™ LC/MS) | Fisher Scientific | Cat# A461-4 |
| Acetonitrile (Optima™ LC/MS) | Fisher Scientific | Cat# A9554 (CS) |
| Methanol (Optima™ LC/MS) | Fisher Scientific | Cat# A454SK-4 |
| Water (Optima™ LC/MS) | Fisher Scientific | Cat# W6-4 |
| Pierce™ Formic Acid, LC-MS Grade | Thermo Scientific | Cat# PI28905 |
| TCEP HCl (tris(2-carboxyethyl)phosphine hydrochloride) for biotechnology | VWR | Cat# VWRVK831-10G |
| Critical Commercial Assays | ||
| LeukoLOCK™ Total RNA Isolation System | Thermo Fisher Scientific | Cat# AM1923 |
| Quantitative Colorimetric Peptide Assay | Pierce | Cat# 23275 |
| Deposited Data | ||
| Mass spectrometry raw and analyzed data | This study | MassIVE: MSV000085703 https://doi.org/10.25345/C5F74G |
| Raw fastq data and RSEM expression estimates | This study | GEO: GSE157103https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE157103 |
| Software and Algorithms | ||
| Xcalibur Qual Browser | Thermo Scientific | V 4.0.27.10 |
| Y3K-GC-Quantitation-Software | Stefely et al 2016 | https://github.com/coongroup/Y3K-GC-Quantitation-Software |
| LipiDex v1.1.0 | Hutchins et al 2018 | https://github.com/coongroup/LipiDex; |
| Compound Discoverer | Thermo Scientific | V 2.1 and 3.1 |
| MaxQuant Quantitative Software v1.6.10.43 | Cox et al 2014 | https://www.maxquant.org/ |
| Skyline Open Access Software v20.1 | MacLean et al 2010 | https://skyline.ms/wiki/home/software/Skyline/page.view?name=default |
| R Statistical Software v3.3.3 and 3.6.2 | R Core Team, 2017 | https://www.r-project.org/ |
| Python Programming Language v3.7.4 | van Rossum and Drake, 1995 | https://www.python.org/ |
| Plotly Dash v1.12.0 | Sievert, 2020 | https://plotly-r.com |
| RSEM v1.3.0 | Li and Dewey 2011 | https://deweylab.github.io/RSEM/ |
| EBSeq v1.26.0 | Leng et al. 2013 | https://www.bioconductor.org/packages/release/bioc/html/EBSeq.html |
| Bowtie-2 v2.3.4.1 | Langmead and Salzberg, 2012 | http://bowtie-bio.sourceforge.net/bowtie2/index.shtml |
| MASS v7.3-53 | Venables and Ripley 2002 | https://cran.r-project.org/web/packages/MASS/index.html |
| SQLite | https://www.sqlite.org | V 3.32.0 |
| Webtool covid-omics.app | This study | https://github.com/ijmiller2/COVID-19_Multi-Omics/ |
| Scikit-learn v0.23.0 |
Zou and Hastie 2005; Pedregosa et al., 2011 |
https://scikit-learn.org/stable/ |
| Other | ||
| ACQUITY UPLC CSH C18 Column, 130Å, 1.7 μm, 1 mm X 150 mm | Waters | Cat# 186005294 |
| TraceGOLD TG-5SilMS GC Columns; 0.25um film thickness; 0.25mm ID; 30m length | Thermo Scientific | Cat# 26096-1420 |
| IonPac AS-11 HC strong anion-exchange analytical column, 2 mm x 250 mm, 4 μm particle diameter | Thermo Scientific | Cat# 082313 |
| Strata™-X 33 μm Polymeric Reversed Phase, 10 mg / well, 96-Well Plates | Phenomenex | Part# 8E-S100-AGB |
| Self-Pack PicoFrit Columns 360x75x10 | New Objective | Part# PF-360-75-10-N-5 |
| 1.7 μm, 130 Å pore size, Bridged Ethylene Hybrid (BEH) C18 particles | Waters | Cat# 186004690 |
Resource Availability
Lead Contact
Further information and requests for resources should be directed to and will be fulfilled by the Lead Contact, Ariel Jaitovich (jaitova@amc.edu).
Materials Availability
This study did not generate any new reagents.
Data and Code Availability
-
-
Mass spectrometry raw files and the SQLite database file have been deposited to the MassIVE database (accession number MSV000085703; https://doi.org/10.25345/C5F74G). Raw fastq data and RSEM expression estimates are available at GEO (accession GSE157103; https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE157103).
-
-
Original code for the data analysis and webtool creation is accessible via GitHub (https://github.com/ijmiller2/COVID-19_Multi-Omics/).
-
-
Scripts for reproducing figures in the manuscript can be found in the GitHub repository: https://github.com/ijmiller2/COVID-19_Multi-Omics/
-
-
Any additional information required to reproduce this work is available from the Lead Contact.
Experimental Model and Subject Details
Human Subject Enrollment
We conducted a single-center observational study of adult subjects admitted to either the medical floor or the medical intensive care unit (MICU) of Albany Medical Center. Ethical approval was obtained from the Albany Medical College Committee on Research Involving Human Subjects (IRB# 5670-20). Enrollment took place between April 6th, 2020 and May 1st, 2020 and follow-up continued until June 15, 2020. Patients were considered for enrollment if they were older than 18 years and were admitted to the hospital due to symptoms compatible with COVID-19 infection. Exclusion criteria were imminent death or inability to provide consent, which was obtained from the patient or a legally authorized representative. Patients who tested positive for COVID-19 were later assigned to that specific group and analyzed accordingly, and the COVID-19 negative group was composed of the remaining individuals. Prehospital comorbidities were determined by clinical history and with hospital documentation, and aggregated through the validated Charlson comorbidity index (Charlson et al., 1987). Severity of critical illness at ICU admission was collected with the validated APACHE II and SOFA scores (Ferreira et al., 2001). Sex and age of the subjects is summarized in Table 1 and available for each subject in the SQLite database table ‘deidentified_patient_metadata’ found in the MassIVE repository (https://massive.ucsd.edu/ProteoSAFe/dataset.jsp?accession=MSV000085703).
Selection of Outcome Measure
We intended to analyze the data with one encompassing outcome measure that fulfills the following criteria: 1) be able to combine severity of disease with mortality in one single metric; 2) be amenable to both ICU and medical floor populations; 3) use a timeframe that accounts for the fact that COVID-19 patients with respiratory failure require longer hospitalizations compared with non-COVID-19 individuals (Wang et al., 2020a, 2020b); 4) consider that COVID-19 causes a linear disease’s deterioration pattern that transition from mild respiratory compromise to respiratory failure, followed by respiratory distress requiring mechanical ventilatory support and eventually death. Thus, we selected the composite outcome variable “hospital-free days at day 45” (HFD-45), which assigns zero value to patients requiring admission longer than 45 days or who die during the admission, and progressively more free days depending on the hospitalization length.
Method Details
Sample Collection, Storage, and Aliquoting
At enrollment, blood samples were collected in two plasma preparation tubes (PPT) tubes. One tube, used for Leukocyte RNA sequencing, was processed through LeukoLOCK® filters, and the remaining blood was centrifuged for plasma separation and aliquoted for further analysis. RNA was then eluted from LeukoLOCK filters following manufacturer recommendation, and samples were stored at -80°C degrees for later analyses.
Samples were shipped on dry ice and kept in the -80°C freezer until analysis was performed. For MS acquisition, samples were randomly assigned into seven analytical batches. Samples for each batch were thawed on ice and mixed gently by tapping on a hard surface prior to aliquoting. In addition to patient plasma samples, an aliquot of pooled, mixed-gender plasma sample (BioIVT, Human Plasma NaHep Lot# HMN378062) was used as a batch control in mass spectrometry based assays. An aliquot of pooled plasma was extracted with each batch.
Metabolomics MS Analyses
Sample Preparation
100 μL of plasma was aliquoted into 750 μL of Methyl Tert-Butyl Ether in a 1.5 mL Eppendorf tubes labelled with the sample name. This formed a biphasic separation, which was then vortexed for 1-2 s and shaken on an orbital mixer for 15 minutes. Then, 350 μL of a 1:1 chilled water:methanol mixture was added to each tube and then vortexed for 20 seconds and then centrifuged at 4°C for 2 minutes at a speed of 14,000 x g to separate the fractions completely. 250 μL of the bottom layer of this biphasic extraction was pipetted into a 1.5 mL Eppendorf tube containing 250 μL acetonitrile to precipitate proteins. This mixture was centrifuged at 4°C for 2 minutes at a speed of 14000 x g to pellet the protein completely. GC-MS: 100 μL of the extract was removed from the tube and collected into a low volume borosilicate glass autosampler vial with tapered insert. The volume of extract was dried in a vacuum concentrator until completely dry. The sample was resuspended in 50 μL methoxyamine hydrochloride solution (20mg/mL, pyridine solution), vortexed for 15 s and incubated at 37°C for 90 minutes. Then, 100 μL of N-methyl-N-trimethylsilyltrifluoroacetamide (MSTFA) was added, vortexed for 15 s and heated at 60°C for an additional 30 minutes. The sample was cooled at room temperature and then quickly centrifuged to ensure no sample remained near the vial’s cap. Samples were placed in the instrument autosampler at room temperature to await injection with no more than 24 hours between final centrifugation and analysis.
GC-MS
Samples were analyzed using a GC-MS instrument comprising a Trace 1310 GC coupled to a Q Exactive Orbitrap mass spectrometer (Thermo Scientific). A temperature gradient ranging from 50°C to 320°C was employed spanning a total runtime of 30 min. Analytes were injected onto a 30 m TraceGOLD TG-5SILMS column (Thermo Scientific) using a 1:25 split at a temperature of 275°C and ionized using electron ionization (EI). The mass spectrometer was operated in full scan mode using a resolution of 30,000.
AEX-LC-MS/MS
100 μL of protein precipitated solution (as for GC-MS analysis) was aliquoted into a low volume borosilicate glass autosampler vial with tapered insert. This volume was dried in a vacuum concentrator until completely dry. Then 100 μL of water was added to each tube to resuspend the contents and the sample was vortexed for 10 s to resuspend and then quickly centrifuged to ensure no sample remained near the vial’s cap. Samples were placed in the instrument’s autosampler at 4°C to await injection with no more than 30 hours between final centrifugation and analysis. LC-MS/MS analyses were performed using a randomized sample order with a 10 μL injection volume. An Ultimate HPG-3400RS pump and WPS-3000RS autosampler cooled to 4°C (Thermo Fisher) were mated to an IonPac AS-11 HC strong anion-exchange analytical column (2 mm x 250 mm, 4 μm particle diameter, Thermo Scientific) with AG-11 HC guard column (2 mm x 50 mm) heated to 40°C. Mobile phase A (Waters) and mobile phase B (100 mM NaOH) were degassed and used in a gradient to elute analytes of interest. Column eluent passed through a 2 mm AERS 500e suppressor operated via a reagent-free controller (RFC-10, Dionex) set to 50 mA. The suppressor was operated in external water regeneration mode with water delivered at 0.5 mL/min by an Agilent 1100 binary pump. The multi-step gradient method was performed at 0.350 mL/min and performed as follows: 0.0 to 5.0 min (hold at 12.5% B), 5.0 to 10.0 min (12.5 - 20% B), 10.0 to 17.5 min (20 - 27.5% B), 17.5 to 22.5 min (27.5 - 42.5% B), 22.5 to 33.5 min(42.5 - 95% B), 33.5 to 34.0 min (hold at 95 % B, increase to 0.400 mL/min), 34.0 to 43.0 (hold at 95% B, 0.400 mL/min), 43.0 to 43.5 min (95 - 12.5% B, hold at 0.400 mL/min). The LC system was coupled to a TSQ Quantiva Triple Quadrupole mass spectrometer (Thermo Scientific) by a heated ESI source. The Ion Transfer Tube and Vaporizer Temp were kept at 350°C. Sheath gas was set to 18 units, Auxiliary Gas to 4 units, and Sweep Gas to 1 unit. Both positive and negative spray voltage was static and set to 3,800 V. For targeted analysis the MS was operated in single reaction monitoring (SRM) mode acquiring scheduled, targeted scans to quantify selected metabolite transitions. All transitions and collision energies were previously optimized by infusion of each metabolite. The retention time window ranged from 3.5 min - 10 min and the “Use Calibrated RF Lens” option was selected. MS acquisition parameters were 0.7 FWHM resolution for Q1 and 1.2 FWHM for Q3, 0.8 s cycle time, 1.5 mTorr CID gas, and 30 s Chrom Filter.
Shotgun Proteomics
Sample Preparation
5μl plasma from each sample were aliquoted into 1.5 ml Eppendorf tubes, containing 50 μl Lysis Buffer A (5.4 M guanidinium hydrochloride, 50 mM Tris, 10 mM TCEP, 40 mM chloroacetamide, pH ~ 8). After brief, gentle mixing by inversion, tubes were placed into a sand bath and boiled at 100-110°C for 10 min. Samples were then allowed to cool down to room temperature, and 450 μl methanol (up to ~90% vol/vol) were added. Proteins were precipitated by spinning at 13,000 g for 6 min, and supernatants were discarded. The tubes were briefly air dried, and protein pellets were resuspended in 100 μl Lysis Buffer B (8 M urea, 100 mM Tris, 10 mM TCEP, 40 mM chloroacetamide, pH ~ 8). Samples were vortexed for ~10 min to ensure the pellets dissolved completely. 7 μl LysC (1:50 enzyme: protein ratio; Wako Chemicals, Richmond, VA) was added to each sample; tubes were inverted to mix and incubated at 37°C for 1 hour. Then samples were diluted with 450 μl 100 mM Tris (pH=8.0), and 15 μl trypsin (1:50 enzyme: protein ratio; Promega, Madison, WI) was added. After 1 hr incubation at 37°C samples were acidified with 10% trifluoroacetic acid to final concentration of 1%. Digested peptides were extracted using Strata X SPE cartridges in a 96-well plate format. Samples were dried in a SpeedVac (Thermo Fisher, Waltham, MA) and resuspended in 0.2% formic acid. Peptide concentrations were determined using Quantitative Colorimetric Peptide Assay (Pierce, Rockford, IL), and 1 μg peptides were used in each analysis. NanoLC-MS/MS. A capillary column was fabricated in-house by filling self-pack PicoFrit 75–360 μm inner-outer diameter bare-fused silica shells with integrated 10 μm electrospray emitter tips (New Objective, Woburn, MA) with 1.7 μm, 130 Å pore size, Bridged Ethylene Hybrid (BEH) C18 particles (Waters, Milford, MA) to a final length of ~40 cm using in-house built ultra-high-pressure column packing station (Shishkova et al. Analytical Chem 2018). The column was installed on a Dionex Ultimate 3000 nano HPLC system (Thermo Fisher, Sunnyvale, CA) and kept at 53°C inside an in-house made heater. The gradient was delivered using mobile phase A (0.2% formic acid in water) and mobile phase B (0.2% formic acid in 70% HPLC-MS grade acetonitrile) at a flow rate of 300 nl/min over a 90-minute gradient, including column wash and re-equilibration time. Electrosprayed peptide ions were analyzed on a quadrupole-ion trap-Orbitrap hybrid Eclipse® mass spectrometer (Thermo Scientific, San Jose, CA). Orbitrap survey scans were performed at a resolving power of 240,000 at 200 m/z with normalized AGC target of 250% ions and maximum injection time of 50 ms. The instrument was operated in the Top Speed mode with 1 s cycle time using an advanced precursor determination algorithm(Hebert et al., 2018) for monoisotopic precursor selection. Precursors were isolated in the quadrupole with an isolation window of 0.5 Th. Tandem MS scans were performed in the ion trap using turbo scan rate on precursors with 2-5 charge states using HCD fragmentation with normalized collision energy of 25 and dynamic exclusion of 10 s. Normalized ion trap MS/MS ion count target was set to 300% with the maximum injection time of 14 ms and the fixed m/z range of 150–1,350.
Parallel Reaction Monitoring (PRM)
Tryptic plasma peptides, generated for shotgun proteomics, were separated over 35-min gradients using the Dionex Ultimate 3000 nano HPLC system. Five peptide ions, whose sequences were representative of cellular gelsolin (cGSN), plasma GSN (pGSN) or shared between the two isoforms, were sequentially targeted for MS2 analysis using Orbitrap Eclipse for the length of five minute windows centered around their expected retention times (Table S5). Precursor ions were isolated using a quadrupole with 1.3 Da isolation window and fragmented using HCD with an NCE of 25. Orbitrap MS2 scans of all fragments were performed over a 150-2,000 m/z scan range at a resolving power of 60,000 at m/z of 200 with an AGC target of 2x105 ions and maximum injection time of 350 ms.
Lipidomics
Sample Preparation
20 μL of plasma was extracted with 500 μL of ice-cold extraction solvent containing 3:1:1 n-Butanol:water:acetonitrile. Samples were vortexed for 10 s, incubated on ice for 5 min, vortexed for another 10 s, and then centrifuged at 14,000 x g for 2 min to precipitate protein. 200 μL of the supernatant was dried by vacuum concentration in amber glass autosampler vials and resuspended in 100 μL of 9:1 Methanol:Toluene. Instrumental Analysis: for LC-MS analysis, 10 μL of extract was injected by a Vanquish Split Sampler HT autosampler (Thermo Scientific) onto an Acquity CSH C18 column held at 50°C (100 mm x 2.1 mm x 1.7 μm particle size; Waters) using a Vanquish Binary Pump (200 μL/min flow rate; Thermo Scientific). Mobile phase A was 0.2% formic acid in water, and mobile phase B was 0.2% formic acid in IPA:ACN (90:10, v/v) with 10 mM ammonium formate. Mobile phase B was initially held at 5% for 1 min and then increased to 40% over 3 min. Mobile phase B was further increased to 70% over 11 min, then raised to 80.5% over 4 min, raised to 85% over next 2 min, raised to 89.5% over next 5 min, raised to 91% over next 3 min, and finally raised to 100% over 5 min and held at 100 % for 5 min. The column was re-equilibrated with mobile phase B at 5% for 9 min before the next injection. The LC system was coupled to a Q Exactive HF Orbitrap mass spectrometer through a heated electrospray ionization (HESI II) source (Thermo Scientific). Source conditions were as follows: HESI II and capillary temperature at 275°C, sheath gas flow rate at 30 units, aux gas flow rate at 6 units, sweep gas flow rate at 0 units, spray voltage at |4.5 kV| for both positive and negative modes, and S-lens RF at 60.0 units. The MS was operated in a polarity switching mode acquiring positive and negative full MS and MS2 spectra (Top2) within the same injection. Acquisition parameters for full MS scans in both modes were 30,000 resolution, 1 × 106 automatic gain control (AGC) target, 100 ms ion accumulation time (max IT), and 200 to 1600 m/z scan range. MS2 scans in both modes were then performed at 30,000 resolution, 1 × 105 AGC target, 50 ms max IT, 1.0 m/z isolation window, stepped normalized collision energy (NCE) at 20, 30, 40, and a 30.0 s dynamic exclusion.
RNA-Seq
Libraries were standardized to 2nM. Paired-end 2x50bp sequencing was performed using standard SBS chemistry (v3) on an Illumina NovaSeq6000 sequencer. Images were analyzed using the standard Illumina Pipeline (version 1.8.2). Two samples did not pass quality control criteria and were excluded from further analysis.
Quantification and Statistical Analysis
Metabolomics Data Processing
GC-MS
GC-MS raw files were processed using a software suite developed in-house that is available at https://github.com/coongroup. Following data acquisition, raw EI-GC/MS spectral data was deconvolved into chromatographic features and then grouped into features based on co-elution. Only features with at least 10 fragment ions and present in 33% of samples were kept. Feature groups from samples and background were compared, and only feature groups greater than 3-fold higher than background were retained. Compound identifications for the metabolites analyzed were assigned by comparing deconvolved high-resolution spectra against unit-resolution reference spectra present in the NIST 12 MS/EI library as well as to authentic standards run in-house. To calculate spectral similarity between experimental and reference spectra, a weighted dot product calculation was used. Metabolites lacking a confident identification were classified as “Unknown metabolites” and appended a unique identifier based on retention time. Peak heights of specified quant m/z were used to represent feature (metabolite) abundance. The data set was also processed through, where we applied a robust linear regression approach, rlm() function (Marazzi et al., 1993), non- log2 transformed intensity values versus run order, to normalize for run order effects on signal. AEX-LC-MS/MS: raw files were processed using Xcalibur Qual Browser (v4.0.27.10, Thermo Scientific) with results exported and further processed using Microsoft Excel 2010. The prepared standard solution was used to locate appropriate peaks for peak area analysis.
Proteomics Data Processing
Shotgun Proteomics
raw files were searched using MaxQuant quantitative software package (Cox et al., 2014) (version 1.6.10.43) against UniProt Homo Sapiens database (downloaded on 6.18.2019), containing protein isoforms and computationally predicted proteins. If not specified, default MaxQuant settings were used. LFQ quantification was performed using LFQ minimum ratio count of 1 and no MS/MS requirement for LFQ comparisons. iBAQ quantitation and “match between runs” were enabled with default settings. ITMS MS/MS tolerance was set to 0.35 Da. Lists of quantified protein groups were filtered to remove reverse identifications, potential contaminants, and proteins identified only by a modification site. LFQ abundance values were log2 transformed. Missing quantitative values were imputed by randomly drawing values from the left tail of the normal distribution of all measured protein abundance values (Tyanova et al., 2016). Protein groups that contained more than 50% missing values were removed from final analyses. Relative standard deviations (RSDs) for each protein group quantified across all seven technical replicates of healthy plasma controls were calculated, and proteins with RSD greater than 30% were removed from final analyses. PRM: identification and quantification of targeted peptides for PRM analysis were performed using Skyline open access software package (version 20.1). 4-5 most intense and specific transitions were used to quantify peptide abundances, and area-under-the-curve measurements for each peptide were exported for further analysis.
Lipidomics Data Processing
The LC–MS data were processed using Compound Discoverer 2.1 (Thermo Scientific) and LipiDex (Hutchins et al., 2018) (v. 1.1.0). All peaks between 1 min and 45 min retention time and 100 Da to 5000 Da MS1 precursor mass were grouped into distinct chromatographic profiles (i.e., compound groups) and aligned using a 10-ppm mass and 0.3 min retention time tolerance. Profiles not reaching a minimum peak intensity of 5x10ˆ5, a maximum peak-width of 0.75, a signal-to-noise (S/N) ratio of 3, and a 3-fold intensity increase over blanks were excluded from further processing. MS/MS spectra were searched against an in-silico generated lipid spectral library containing 35,000 unique molecular compositions representing 48 distinct lipid classes (LipiDex library “LipiDex_HCD_Formic”, with a full range of acyl-chains included). Spectral matches with a dot product score greater than 500 and a reverse dot product score greater than 700 were retained for further analysis, with a minimum 75% spectral purity for designating fatty acid composition. Removed from the data set were adducts, class IDs greater than 3.5 median absolute retention time deviation (M.A.D. RT) of each other, and features found in less than 3 files. Data were additionally searched with Compound Discoverer 3.1 with the discovery metabolomics nodes for additional spectral matching to mzCloud and mzVault libraries but retaining the feature group and peak picking settings as detailed for the Compound Discoverer 2.1 analysis.
RNA-Seq Data Processing
All RNA transcripts were downloaded from the NCBI refseq ftp site (wget ftp://ftp.ncbi.nlm.nih.gov/refseq/H_sapiens/mRNA_Prot/∗.rna.fna.gz ). Only mRNA (accessions NM_xxxx and XM_xxxx) and rRNA (excluding 5.8S) was then extracted, and immunoglobulin transcripts were downloaded from ENSEMBL (IG_C, IG_D, IG_J and IG_V ). We created a file mapping accession numbers to gene symbols, and then used rsem-prepare-reference to build a bowtie-2 reference database. Fastq files were trimmed and filtered using a custom algorithm tailored to improve quality scores and maximize retained reads in paired-end data. RNA-Seq expression estimation was performed by RSEM v 1.3.0 (parameters: seed-length=20, no-qualities, bowtie2-k=200, bowtie2-sensitivity-level=sensitive) (Li and Dewey, 2011), with bowtie-2 (v 2.3.4.1) for the alignment step (Langmead and Salzberg, 2012), using the custom hg38 reference described above. After the collation of expression estimates, hemoglobin transcripts were removed from further analysis, and TPM values were rescaled to total 1,000,000 in each sample. Differential Expression analysis was performed using the EBSeq package (v 1.26.0) (Leng et al., 2013) in R (v 3.6.2).
Principal Component Analysis
With log2() transformed abundance measurements from patient samples that had transcript, protein, lipids, and small molecule measurements (complete cases, n=125), we performed principal component analysis (PCA) using the R statistical and graphing environment (R version 3.3.3) and the function prcomp(). With this method, log2() transformed data were scaled to a mean equal to zero prior to PCA analysis.
Determining Significance with COVID-19 Status
Log2 normalized abundance values were used as a response variable and the following models were fit against the data using the R statistical and graphing environment and lm() function (R version 3.3.3) (R Core, Team, 2017).
-
(1)
Normalized_abundance ~ COVID status + Age + Sex + ICU status
-
(2)
Normalized_abudnace ~ Age + Sex + ICU status
Models (1) and (2) were compared using the anova() function in R, which returns the log-likelihood ratio and significance. The p.adjust() function was applied to resulting p-value tables using the ‘fdr’ method to return adjusted p-values. Included in the database ‘pvalues’ table are p-values calculated with robust methods: linear regression using the rlm() function from the MASS package (Venables and Ripley, 2002) and likelihood ratio comparisons using the lrtest() function in the lmtest package in R.
Determining Significance with HFD-45
HFD-45 were used as the response variable and the following models were fit against the data using the lm() function in R.
-
(3)
HFD-45 ~ normalized_abundance + Age + Sex
-
(4)
HFD-45 ~ Age + Sex
Models (3) and (4) were compared using the anova() function in R which returns the log-likelihood ratio and significance. The p.adjust() function was applied to resulting p-value tables using the ‘fdr’ method to return adjusted p-values. As above, we have also included in the database p-values calculated with robust methods: linear regression using the rlm() function from the MASS package (Venables and Ripley, 2002) and likelihood ratio comparisons using the lrtest() function in the lmtest package in R.
Elastic Net Regression Analysis on HFD-45
We fit a least-squares, linear regression model with an elastic net penalty (Zou and Hastie, 2005) using each molecule’s value for all COVID-19 patients as covariates and HFD-45 as the response variable. For the transcriptomic data, we first transform the transcripts per million (TPM) output from RSEM using log(TPM+1). We also include age and gender as covariates. Specifically, elastic net solves the following optimization problem:
where is the number of training samples, is the matrix of covariates, are the response variables, are the model coefficients, is a parameter that sets the strength of regularization, and is a parameter that balances the strength of the L1 and L2 penalty-terms.
To determine the parameters for the elastic net model (i.e. and ), we performed a grid search over a set of pairs of values for these two parameters where for each set of parameters, we perform five-fold cross-validation and evaluate each trained model according to the mean squared error on the held-out test set. We selected the best parameters according to this grid search and then used these parameters to fit the full dataset.
GO and Molecular Class Enrichment Analysis
GO biological processes were obtained from UniProt for transcripts and proteins. These terms were used, in addition to terms based on compound class (e.g., triglyceride), to perform a Fisher's exact test for biomolecules within a subset relative to all measured biomolecules (phyper() function in R).
Correlation Analysis
Cor.test() function in R was used to perform cross-ome correlation analysis using method = Kendall. The Kendall correlation method is a rank-based approach and was chosen because it performs well with non-parametric data and, in contrast to Spearman, can perform better when values of the same rank occur (Arndt et al., 1999).
Creation of Covid-omics.app
The webtool was developed in Python (3.7.4) using the Plotly Dash package (1.12.0), and the source code is accessible via GitHub (https://github.com/ijmiller2/COVID-19_Multi-Omics/), under the src/dash directory. All package versions are described in the requirements.txt file. The R2 and p-value metrics displayed on the linear regression page are calculated using the statsmodels (0.11.1) library in Python. Note that, because the transcriptomics and lipidomics datasets have thousands of features, scatter plots in the webtool (including the volcano plot on the differential expression page and the loadings plot on the PCA page), only the top 1,000 features (ranked by variance across samples) are displayed to ensure reasonable speed and performance from the web server. However, all biomolecules that passed QC cutoffs are queryable using their respective drop down tools and available in the curated SQLite database (see Data and Code Availability).
ExtraTrees Classification of Cases
Molecular measurements of metabolites, lipids, proteins, and transcripts were read into Python from the SQLite database. Note unknown features detected in the metabolomic and lipidomic analyses were excluded from machine learning models. Patients were filtered to include only those with all four omic datasets, resulting in a total of 100 COVID-19 patients. 20% of the data was randomly held aside to be the true test set, and the other 80% of the data was used for 5-fold cross validation to determine the best model hyperparameters. Multiple classification models were compared with scikit-learn (Pedregosa et al., 2011), and Extratrees Classification was found to perform best and used for further modeling. The median HFD-45 of the 100 patients was chosen to split the patients into severe and less severe (26 days). ExtraTrees classifier hyperparameters were optimized separately for each omic data subset or the combined multi-omic data. Five folds were fitted for each of 5,940 candidates, totalling 29,700 model fits per dataset. A grid of the following parameters were tested: 'n_estimators': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000], 'max_features': ['auto', 'sqrt', 'log2'], 'max_depth': [10, 31, 52, 73, 94, 115, 136, 157, 178, 200, None], 'min_samples_split': [2, 5, 10], 'min_samples_leaf': [1, 2, 4], 'bootstrap': [True, False]. All metrics were computed with the standard functions in scikit-learn, and the reported feature importances are the Gini type. All code is available on github as a jupyter notebook along with the python environment.yml for building the unique python environment with anaconda.
Acknowledgments
We thank Christina Kendziorski, Robert Campbell, and Alicia Williams for helpful discussions. We also thank the Biotech Center core for the expedited RNA-seq processing. This work was supported in part by the National Institutes of Health and, specifically, by the National Human Genome Research Institution through a training grant to the Genomic Sciences Training Program Grant 5T32HG002760 (T.M.P.), the National Heart Lung and Blood Institute (NHLBI) through awards K01-HL-130704 (A.J.) and 5R01HL-049426 (H.A.S.), the National Institute of General Medical Sciences through 1R01GM124133 (A.P.A.), and the National Center for Quantitative Biology of Complex Systems (5P41GM108538, J.J.C.). Further support was provided by the Collins Family Foundation Endowment (A.J.) and the Morgridge Institute through a postdoctoral fellowship (M.N.B.).
Author Contributions
Conceptualization: K.A.O., E.S., I.M., J.B., M.J., A.A., B.S., H.S., R.S., J.J.C., and A.J.; Methodology: K.A.O., E.S., J.B., B.P., and A.J.; Validation: K.A.O., E.S., T.P.C., Q.Q., L.M., E.A.T., Y.H., B.P., Y.Z., L.S., V.L., and D.M.; Software: I.M. and D.R.B.; Formal analysis: K.A.O., E.S., I.M., J.B., M.N.B., T.P.C., J.M., E.A.T., Y.H., S.S., and R.S.; Investigation: K.A.O., E.S., J.B., A.C., H.C., A.T., B.P., L.D., A.A., and A.J.; Resources: B.S., H.S., R.S., J.J.C., and A.J.; Data curation: K.A.O., I.M., J.B., D.R.B., and S.S.; Writing - original draft: K.A.O., E.S., I.M., M.N.B., T.P.C., J.M., B.P., J.J.C., and A.J.; Writing—review/editing: K.A.O., E.S., I.M., J.B., M.N.B., T.P.C., J.M., Q.Q., E.A.T., D.R.B., L.S., A.A., B.S., H.S., S.S., D.M., R.S., J.J.C., and A.J.; Visualization: K.A.O., E.S., I.M., J.B., M.N.B., T.P.C., J.M., L.M., D.R.B., and Y.Z.; Supervision: K.A.O., E.S., I.M., J.B., R.S., J.J.C., and A.J.
Declaration of Interests
The authors declare no competing interests.
Published: October 7, 2020
Footnotes
Supplemental Information can be found online at https://doi.org/10.1016/j.cels.2020.10.003.
Supplemental Information
References
- Ackermann M., Verleden S.E., Kuehnel M., Haverich A., Welte T., Laenger F., Vanstapel A., Werlein C., Stark H., Tzankov A. Pulmonary vascular endothelialitis, thrombosis, and angiogenesis in Covid-19. N. Engl. J. Med. 2020;383:120–128. doi: 10.1056/NEJMoa2015432. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ali R.A., Gandhi A.A., Meng H., Yalavarthi S., Vreede A.P., Estes S.K., Palmer O.R., Bockenstedt P.L., Pinsky D.J., Greve J.M. Adenosine receptor agonism protects against NETosis and thrombosis in antiphospholipid syndrome. Nat. Commun. 2019;10:1916. doi: 10.1038/s41467-019-09801-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Antcliffe D.B., Burnham K.L., Al-Beidh F., Santhakumaran S., Brett S.J., Hinds C.J., Ashby D., Knight J.C., Gordon A.C. Transcriptomic signatures in sepsis and a differential response to steroids. From the VANISH randomized trial. Am. J. Respir. Crit. Care Med. 2019;199:980–986. doi: 10.1164/rccm.201807-1419OC. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Arndt S., Turvey C., Andreasen N.C. Correlating and predicting psychiatric symptom ratings: Spearman’s R versus Kendall's Tau correlation. J. Psychiatr. Res. 1999;33:97–104. doi: 10.1016/s0022-3956(98)90046-2. [DOI] [PubMed] [Google Scholar]
- Barnes B.J., Adrover J.M., Baxter-Stoltzfus A., Borczuk A., Cools-Lartigue J., Crawford J.M., Daßler-Plenker J., Guerci P., Huynh C., Knight J.S. Targeting potential drivers of COVID-19: neutrophil extracellular traps. J. Exp. Med. 2020;217:e20200652. doi: 10.1084/jem.20200652. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Becker R.C. COVID-19 update: Covid-19-associated coagulopathy. J. Thromb. Thrombolysis. 2020;50:54–67. doi: 10.1007/s11239-020-02134-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bos L.D., Schouten L.R., van Vught L.A., Wiewel M.A., Ong D.S.Y., Cremer O., Artigas A., Martin-Loeches I., Hoogendijk A.J., van der Poll T. Identification and validation of distinct biological phenotypes in patients with acute respiratory distress syndrome by cluster analysis. Thorax. 2017;72:876–883. doi: 10.1136/thoraxjnl-2016-209719. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Calfee C.S., Delucchi K., Parsons P.E., Thompson B.T., Ware L.B., Matthay M.A., NHLBI ARDS Network Subphenotypes in acute respiratory distress syndrome: latent class analysis of data from two randomised controlled trials. Lancet Respir. Med. 2014;2:611–620. doi: 10.1016/S2213-2600(14)70097-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cattaneo M., Bertinato E.M., Birocchi S., Brizio C., Malavolta D., Manzoni M., Muscarella G., Orlandi M. Pulmonary embolism or pulmonary thrombosis in COVID-19? Is the recommendation to use high-dose heparin for thromboprophylaxis justified? Thromb. Haemost. 2020;120:1230–1232. doi: 10.1055/s-0040-1712097. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Charlson M.E., Pompei P., Ales K.L., MacKenzie C.R. A new method of classifying prognostic comorbidity in longitudinal studies: development and validation. J. Chronic Dis. 1987;40:373–383. doi: 10.1016/0021-9681(87)90171-8. [DOI] [PubMed] [Google Scholar]
- Connors J.M., Levy J.H. COVID-19 and its implications for thrombosis and anticoagulation. Blood. 2020;135:2033–2040. doi: 10.1182/blood.2020006000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cox J., Hein M.Y., Luber C.A., Paron I., Nagaraj N., Mann M. Accurate proteome-wide label-free quantification by delayed normalization and maximal peptide ratio extraction, termed MaxLFQ. Mol. Cell. Proteomics. 2014;13:2513–2526. doi: 10.1074/mcp.M113.031591. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Davenport E.E., Burnham K.L., Radhakrishnan J., Humburg P., Hutton P., Mills T.C., Rautanen A., Gordon A.C., Garrard C., Hill A.V.S. Genomic landscape of the individual host response and outcomes in sepsis: a prospective cohort study. Lancet Respir. Med. 2016;4:259–271. doi: 10.1016/S2213-2600(16)00046-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Davidson W.S., Silva R.A., Chantepie S., Lagor W.R., Chapman M.J., Kontush A. Proteomic analysis of defined HDL subpopulations reveals particle-specific protein clusters: relevance to antioxidative function. Arterioscler. Thromb. Vasc. Biol. 2009;29:870–876. doi: 10.1161/ATVBAHA.109.186031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dhanesha N., Chorawala M.R., Jain M., Bhalla A., Thedens D., Nayak M., Doddapattar P., Chauhan A.K. Fn-EDA (fibronectin containing extra domain A) in the plasma, but not endothelial cells, exacerbates stroke outcome by promoting thrombo-inflammation. Stroke. 2019;50:1201–1209. doi: 10.1161/STROKEAHA.118.023697. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Duke-Cohan J.S., Gu J., McLaughlin D.F., Xu Y., Freeman G.J., Schlossman S.F. Attractin (DPPT-L), a member of the CUB family of cell adhesion and guidance proteins, is secreted by activated human T lymphocytes and modulates immune cell interactions. Proc. Natl. Acad. Sci. USA. 1998;95:11336–11341. doi: 10.1073/pnas.95.19.11336. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ellinghaus D., Degenhardt F., Bujanda L., Buti M., Albillos A., Invernizzi P., Fernández J., Prati D., Baselli G., Asselta R. Genomewide association study of severe Covid-19 with respiratory failure. N. Engl. J. Med. 2020 doi: 10.1056/NEJMoa2020283. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Feingold K.R., Grunfeld C. The effect of inflammation and infection on lipids and lipoproteins. In: Feingold K.R., Anawalt B., Boyce A., Chrousos G., Dungan K., Grossman A., Hershman J.M., editors. Endotext. 2019. https://www.endotext.org/ [Google Scholar]
- Feldt J., Schicht M., Garreis F., Welss J., Schneider U.W., Paulsen F. Structure, regulation and related diseases of the actin-binding protein gelsolin. Expert Rev. Mol. Med. 2019;20:e7. doi: 10.1017/erm.2018.7. [DOI] [PubMed] [Google Scholar]
- Fernandez N.F., Gundersen G.W., Rahman A., Grimes M.L., Rikova K., Hornbeck P., Ma’ayan A. Clustergrammer, a web-based heatmap visualization and analysis tool for high-dimensional biological data. Sci. Data. 2017;4:170151. doi: 10.1038/sdata.2017.151. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferreira F.L., Bota D.P., Bross A., Mélot C., Vincent J.L. Serial evaluation of the SOFA score to predict outcome in critically ill patients. JAMA. 2001;286:1754–1758. doi: 10.1001/jama.286.14.1754. [DOI] [PubMed] [Google Scholar]
- Fox S.E., Akmatbekov A., Harbert J.L., Li G., Quincy Brown J.Q., Vander Heide R.S. Pulmonary and cardiac pathology in African American patients with COVID-19: an autopsy series from New Orleans. Lancet Respir. Med. 2020;8:681–686. doi: 10.1016/S2213-2600(20)30243-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gabay C., Kushner I. Acute-phase proteins and other systemic responses to inflammation. N. Engl. J. Med. 1999;340:448–454. doi: 10.1056/NEJM199902113400607. [DOI] [PubMed] [Google Scholar]
- Gattinoni L., Coppola S., Cressoni M., Busana M., Rossi S., Chiumello D. COVID-19 does not lead to a ‘typical’ acute respiratory distress syndrome. Am. J. Respir. Crit. Care Med. 2020;201:1299–1300. doi: 10.1164/rccm.202003-0817LE. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goshua G., Pine A.B., Meizlish M.L., Chang C.-H., Zhang H., Bahel P., Baluha A. Endotheliopathy in COVID-19-associated coagulopathy: evidence from a single-centre, cross-sectional study. Lancet Haematol. 2020;7:e575–e582. doi: 10.1016/S2352-3026(20)30216-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Griffin J.H., Zlokovic B.V., Mosnier L.O. Activated protein C, protease activated receptor 1, and neuroprotection. Blood. 2018;132:159–169. doi: 10.1182/blood-2018-02-769026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Griffin J.H., Lyden P. COVID-19 hypothesis: activated protein C for therapy of virus-induced pathologic thromboinflammation. Res. Pract. Thromb. Haemost. 2020;4:506–509. doi: 10.1002/rth2.12362. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gritters M., Grooteman M.P.C., Schoorl M., Schoorl M., Bartels P.C.M., Scheffer P.G., Teerlink T., Schalkwijk C.G., Spreeuwenberg M., Nubé M.J. Citrate anticoagulation abolishes degranulation of polymorphonuclear cells and platelets and reduces oxidative stress during haemodialysis. Nephrol. Dial. Transplant. 2006;21:153–159. doi: 10.1093/ndt/gfi069. [DOI] [PubMed] [Google Scholar]
- Guan W.J., Ni Z.-Y., Hu Y., Liang W.-H., Ou C.-Q., He J.-X., Liu L., Shan H., Lei C.-L., Hui D.S.C. Clinical characteristics of coronavirus disease 2019 in China. N. Engl. J. Med. 2020;382:1708–1720. doi: 10.1056/NEJMoa2002032. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haberichter S.L. Von Willebrand factor propeptide: biology and clinical utility. Blood. 2015;126:1753–1761. doi: 10.1182/blood-2015-04-512731. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Healy A.M., Pickard M.D., Pradhan A.D., Wang Y., Chen Z., Croce K., Sakuma M., Shi C., Zago A.C., Garasic J. Platelet expression profiling and clinical validation of myeloid-related protein-14 as a novel determinant of cardiovascular events. Circulation. 2006;113:2278–2284. doi: 10.1161/CIRCULATIONAHA.105.607333. [DOI] [PubMed] [Google Scholar]
- Hebert A.S., Thöing C., Riley N.M., Kwiecien N.W., Shiskova E., Huguet R., Cardasis H.L., Kuehn A., Eliuk S., Zabrouskov V. Improved precursor characterization for data-dependent mass spectrometry. Anal. Chem. 2018;90:2333–2340. doi: 10.1021/acs.analchem.7b04808. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heyes M.P., Saito K., Crowley J.S., Davis L.E., Demitrack M.A., Der M., Dilling L.A., Elia J., Kruesi M.J., Lackner A. Quinolinic acid and kynurenine pathway metabolism in inflammatory and non-inflammatory neurological disease. Brain. 1992;115:1249–1273. doi: 10.1093/brain/115.5.1249. [DOI] [PubMed] [Google Scholar]
- Huang C., Wang Y., Li X., Ren L., Zhao J., Hu Y., Zhang L., Fan G., Xu J., Gu X. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet. 2020;395:497–506. doi: 10.1016/S0140-6736(20)30183-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huntington J.A. Thrombin inhibition by the serpins. J. Thromb. Haemost. 2013;11:254–264. doi: 10.1111/jth.12252. [DOI] [PubMed] [Google Scholar]
- Hutchins P.D., Russell J.D., Coon J.J. Lipidex: an integrated software package for high-confidence lipid identification. Cell Syst. 2018;6:621–625.e5. doi: 10.1016/j.cels.2018.03.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ikezoe T. Thrombomodulin/activated protein C system in septic disseminated intravascular coagulation. J. Intensive Care. 2015;3:1. doi: 10.1186/s40560-014-0050-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jaitovich A., Khan M.M.H.S., Itty R., Chieng H.C., Dumas C.L., Nadendla P., Fantauzzi J.P., Yucel R.M., Feustel P.J., Judson M.A. ICU admission muscle and fat mass, survival, and disability at discharge: a prospective cohort study. Chest. 2019;155:322–330. doi: 10.1016/j.chest.2018.10.023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jiao Y., Li W., Wang W., Tong X., Xia R., Fan J., Du Jianer, Zhang Chengmi, Shi X. Platelet-derived exosomes promote neutrophil extracellular trap formation during septic Shock. Crit. Care. 2020;24:380. doi: 10.1186/s13054-020-03082-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ju B., Zhang Q., Ge Jiwan, Wang R., Sun J., Ge X., Yu J., Shan S., Zhou B., Song S. Human neutralizing antibodies elicited by SARS-CoV-2 infection. Nature. 2020;584:115–119. doi: 10.1038/s41586-020-2380-z. [DOI] [PubMed] [Google Scholar]
- Kattula S., Byrnes J.R., Wolberg A.S. Fibrinogen and fibrin in hemostasis and thrombosis. Arterioscler. Thromb. Vasc. Biol. 2017;37:e13–e21. doi: 10.1161/ATVBAHA.117.308564. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Khovidhunkit W., Kim M.S., Memon R.A., Shigenaga J.K., Moser A.H., Feingold K.R., Grunfeld C. Effects of infection and inflammation on lipid and lipoprotein metabolism: mechanisms and consequences to the host. J. Lipid Res. 2004;45:1169–1196. doi: 10.1194/jlr.R300019-JLR200. [DOI] [PubMed] [Google Scholar]
- Langmead B., Salzberg S.L. Fast gapped-read alignment with bowtie 2. Nat. Methods. 2012;9:357–359. doi: 10.1038/nmeth.1923. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lax S.F., Skok K., Zechner P., Kessler H.H., Kaufmann N., Koelblinger C., Vander K., Bargfrieder U., Trauner M. Pulmonary arterial thrombosis in COVID-19 With fatal outcome: results from a prospective, single-center, clinicopathologic case series. Ann. Intern. Med. 2020;173:350–361. doi: 10.7326/M20-2566. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lefrançais E., Mallavia B., Zhuo H., Calfee C.S., Looney M.R. Maladaptive role of neutrophil extracellular traps in pathogen-induced lung injury. JCI Insight. 2018;3:e98178. doi: 10.1172/jci.insight.98178. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Leng N., Dawson J.A., Thomson J.A., Ruotti V., Rissman A.I., Smits B.M.G., Haag J.D., Gould M.N., Stewart R.M., Kendziorski C. EBSeq: an empirical Bayes hierarchical model for inference in RNA-seq experiments. Bioinformatics. 2013;29:1035–1043. doi: 10.1093/bioinformatics/btt087. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Leung J.M., Mayo J., Tan W., Tammemagi C.M., Liu G., Peacock S., Shepherd F.A., Goffin J., Goss G., Nicholas G. Plasma pro-surfactant protein B and lung function decline in smokers. Eur. Respir. J. 2015;45:1037–1045. doi: 10.1183/09031936.00184214. [DOI] [PubMed] [Google Scholar]
- Li B., Dewey C.N. RSEM: accurate transcript quantification from RNA-Seq data with or without a reference genome. BMC Bioinformatics. 2011;12:323. doi: 10.1186/1471-2105-12-323. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu X., Li Z., Liu S., Sun J., Chen Z., Jiang M., Zhang Q., Wei Y., Wang X., Huang Y.-Y. Potential therapeutic effects of dipyridamole in the severely ill patients with COVID-19. Acta Pharm. Sin. B. 2020;10:1205–1215. doi: 10.1016/j.apsb.2020.04.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- MacLean B., Tomazela D.M., Shulman N., Chambers M., Finney G.L., Frewen B., Kern R., Tabb D.L., Liebler D.C., MacCoss M.J. Skyline: an open source document editor for creating and analyzing targeted proteomics experiments. Bioinformatics. 2010;26:966–968. doi: 10.1093/bioinformatics/btq054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Manne B.K., Denorme F., Middleton E.A., Portier I., Rowley J.W., Stubben C., Petrey A.C. Platelet gene expression and function in COVID-19 patients. Blood. 2020;136:1317–1329. doi: 10.1182/blood.2020007214. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marazzi A., Joss J., Randriamiharisoa A. Wadsworth & Brooks/Cole Advanced Books & Software; 1993. Algorithms, Routines, and S Functions for Robust Statistics: The FORTRAN Library ROBETH with an Interface to S-PLUS. [Google Scholar]
- Marinosci A., Landis B.N., Calmy A. Possible link between anosmia and COVID-19: sniffing out the truth. Eur. Arch. Otorhinolaryngol. 2020;277:2149–2150. doi: 10.1007/s00405-020-05966-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Messias M.C.F., Mecatti G.C., Priolli D.G., de Oliveira Carvalho P. Plasmalogen lipids: functional mechanism and their involvement in gastrointestinal cancer. Lipids Health Dis. 2018;17:41. doi: 10.1186/s12944-018-0685-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Messner C.B., Demichev V., Wendisch D., Michalick L., White M., Freiwald A., Textoris-Taube K., Vernardis S.I., Egger A.S., Kreidl M. Ultra-high-throughput clinical proteomics reveals classifiers of COVID-19 infection. Cell Syst. 2020;11:11–24.e4. doi: 10.1016/j.cels.2020.05.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Middleton E.A., He X.Y., Denorme F., Campbell R.A., Ng D., Salvatore S.P., Mostyka M., Baxter-Stoltzfus A., Borczuk A.C., Loda M. Neutrophil extracellular traps contribute to immunothrombosis in COVID-19 acute respiratory distress syndrome. Blood. 2020;136:1169–1179. doi: 10.1182/blood.2020007008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Migaud M., Gandotra S., Chand H.S., Gillespie M.N., Thannickal V.J., Langley R.J. Metabolomics to predict antiviral drug efficacy in COVID-19. Am. J. Respir. Cell Mol. Biol. 2020;63:396–398. doi: 10.1165/rcmb.2020-0206LE. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Narasaraju T., Yang E., Perumal Samy R., Ng H.H., Poh W.P., Liew A.-A., Phoon M.C., van Rooijen N., Chow V.T. Excessive neutrophils and neutrophil extracellular traps contribute to acute lung injury of influenza pneumonitis. Am. J. Pathol. 2011;179:199–210. doi: 10.1016/j.ajpath.2011.03.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nie Shuke, Zhao X., Zhao K., Zhang Z., Zhang Z., Zhang Z. Metabolic disturbances and inflammatory dysfunction predict severity of coronavirus Disease 2019 (COVID-19): a retrospective study. medRxiv. 2020 https://www.medrxiv.org/content/10.1101/2020.03.24.20042283v1.abstract [Google Scholar]
- Nightingale T., Cutler D. The secretion of von Willebrand factor from endothelial cells; an increasingly complicated story. J. Thromb. Haemost. 2013;11:192–201. doi: 10.1111/jth.12225. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Omarjee L., Meilhac O., Perrot F., Janin A., Mahe G. Can ticagrelor be used to prevent sepsis-induced coagulopathy in COVID-19? Clin. Immunol. 2020;216:108468. doi: 10.1016/j.clim.2020.108468. [DOI] [PMC free article] [PubMed] [Google Scholar]
- World Health Organization COVID-19 therapeutic trial synopsis. 2020. https://www.who.int/publications/i/item/covid-19-therapeutic-trial-synopsis
- Paranjpe I., Fuster V., Lala A., Russak A.J., Glicksberg B.S., Levin M.A., Charney A.W., Narula J., Fayad Z.A., Bagiella E. Association of treatment dose anticoagulation with in-hospital survival among hospitalized patients with COVID-19. J. Am. Coll. Cardiol. 2020;76:122–124. doi: 10.1016/j.jacc.2020.05.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pedregosa F., Varoquaux G., Gramfort A., Michel V., Thirion B., Grisel O., Blondel M., Prettenhofer P., Weiss R., Dubourg V. Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 2011;12:2825–2830. [Google Scholar]
- Peterson A.C., Russell J.D., Bailey D.J., Westphall M.S., Coon J.J. Parallel reaction monitoring for high resolution and high mass accuracy quantitative, targeted proteomics. Mol. Cell. Proteomics. 2012;11:1475–1488. doi: 10.1074/mcp.O112.020131. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Piktel E., Levental I., Durnaś B., Janmey P.A., Bucki R. Plasma gelsolin: indicator of inflammation and its potential as a diagnostic tool and therapeutic target. Int. J. Mol. Sci. 2018;19:2516. doi: 10.3390/ijms19092516. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Priebatsch K.M., Kvansakul M., Poon I.K.H., Hulett M.D. Functional regulation of the plasma protein histidine-rich glycoprotein by Zn2+ in settings of tissue injury. Biomolecules. 2017;7:22. doi: 10.3390/biom7010022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ranieri V.M., Thompson B.T., Barie P.S., Dhainaut J.-F., Douglas I.S., Finfer S., Gårdlund B., Marshall J.C., Rhodes A., Artigas A. Drotrecogin alfa (activated) in adults with septic shock. N. Engl. J. Med. 2012;366:2055–2064. doi: 10.1056/NEJMoa1202290. [DOI] [PubMed] [Google Scholar]
- Reddy K., Sinha P., O’Kane C.M., Gordon A.C., Calfee C.S., McAuley D.F. Subphenotypes in critical care: translation into clinical practice. Lancet Respir. Med. 2020;8:631–643. doi: 10.1016/S2213-2600(20)30124-7. [DOI] [PubMed] [Google Scholar]
- Richardson S., Hirsch J.S., Narasimhan M., Crawford J.M., McGinn T., Davidson K.W., the Northwell COVID-19 Research Consortium, Barnaby D.P., Becker L.B., Chelico J.D. Presenting characteristics, comorbidities, and outcomes Among 5700 patients hospitalized with COVID-19 in the New York City area. JAMA. 2020;323:2052–2059. doi: 10.1001/jama.2020.6775. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Risitano A.M., Mastellos D.C., Huber-Lang M., Yancopoulou D., Garlanda C., Ciceri F., Lambris J.D. Complement as a target in COVID-19? Nat. Rev. Immunol. 2020;20:343–344. doi: 10.1038/s41577-020-0320-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sakr Y., Ferrer R., Reinhart K., Beale R., Rhodes A., Moreno R., Timsit J.F., Brochard L., Thompson B.T., Rezende E. The intensive care global study on severe acute respiratory infection (IC-GLOSSARI): a multicenter, multinational, 14-day inception cohort study. Intensive Care Med. 2016;42:817–828. doi: 10.1007/s00134-015-4206-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schmaier A.H. The contact activation and kallikrein/kinin systems: pathophysiologic and physiologic activities. J. Thromb. Haemost. 2016;14:28–39. doi: 10.1111/jth.13194. [DOI] [PubMed] [Google Scholar]
- Seydoux E., Homad L.J., MacCamy A.J., Parks K.R., Hurlburt N.K., Jennewein M.F., Akins N.R., Stuart A.B., Wan Y.H., Feng J. Analysis of a SARS-CoV-2-infected individual reveals development of potent neutralizing antibodies with limited somatic mutation. Immunity. 2020;53:98–105.e5. doi: 10.1016/j.immuni.2020.06.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shen B., Yi X., Sun Y., Bi X., Du J., Zhang C., Quan S., Zhang F., Sun R., Qian L. Proteomic and metabolomic characterization of COVID-19 patient sera. Cell. 2020;182:59–72.e15. doi: 10.1016/j.cell.2020.05.032. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sievert C. CRC Press; 2020. Interactive Web-Based Data Visualization with R, Plotly, and Shiny. [Google Scholar]
- Sinha P., Matthay M.A., Calfee C.S. Is a ‘cytokine storm’ relevant to COVID-19? JAMA Intern. Med. 2020;180:1152–1154. doi: 10.1001/jamainternmed.2020.3313. [DOI] [PubMed] [Google Scholar]
- Sofia M.A., Ciorba M.A., Meckel K., Lim C.K., Guillemin G.J., Weber C.R., Bissonnette M., Pekow J.R. Tryptophan metabolism through the kynurenine pathway is associated with endoscopic inflammation in ulcerative colitis. Inflamm. Bowel Dis. 2018;24:1471–1480. doi: 10.1093/ibd/izy103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Song J.-W., Lam S.M., Fan X., Cao W.-J., Wang S.-Y., Tian H., Chua G.H. Omics-driven systems interrogation of metabolic dysregulation in covid-19 pathogenesis. Cell Metab. 2020;32:188–202.e5. doi: 10.1016/j.cmet.2020.06.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stefely J.A., Kwiecien N.W., Freiberger E.C., Richards A.L., Jochem A., Rush M.J.P., Ulbrich A., Robinson K.P., Hutchins P.D., Veling M.T. Mitochondrial protein functions elucidated by multi-Omic mass spectrometry profiling. Nat. Biotechnol. 2016;34:1191–1197. doi: 10.1038/nbt.3683. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stoermer K.A., Morrison T.E. Complement and viral pathogenesis. Virology. 2011;411:362–373. doi: 10.1016/j.virol.2010.12.045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stukalov A., Girault V., Grass V., Bergant V., Karayel O., Urban C., Haas D.A., Huang Y., Oubraham L., Wang A. Multi-level proteomics reveals host-perturbation strategies of SARS-CoV-2 and SARS-CoV. bioRxiv. 2020 doi: 10.1101/2020.06.17.156455. [DOI] [PubMed] [Google Scholar]
- R Core, Team R: a language and environment for statistical computing (Vienna) 2017. http://finzi.psych.upenn.edu/R/library/dplR/doc/intro-dplR.pdf
- Thomas T., Stefanoni D., Reisz J.A., Nemkov T., Bertolone L., Francis R.O., Hudson K.E., Zimring J.C., Hansen K.C., Hod E.A. COVID-19 infection alters kynurenine and fatty acid metabolism, correlating with IL-6 levels and renal status. JCI Insight. 2020;5:e140327. doi: 10.1172/jci.insight.140327. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Trinder M., Walley K.R., Boyd J.H., Brunham L.R. Causal inference for genetically determined levels of high-density lipoprotein cholesterol and risk of infectious disease. Arterioscler. Thromb. Vasc. Biol. 2020;40:267–278. doi: 10.1161/ATVBAHA.119.313381. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Twaddell S.H., Baines K.J., Grainge C., Gibson P.G. The emerging role of neutrophil extracellular traps in respiratory disease. Chest. 2019;156:774–782. doi: 10.1016/j.chest.2019.06.012. [DOI] [PubMed] [Google Scholar]
- Tyanova S., Temu T., Sinitcyn P., Carlson A., Hein M.Y., Geiger T., Mann M., Cox J. The perseus computational platform for comprehensive analysis of (prote)omics data. Nat. Methods. 2016;13:731–740. doi: 10.1038/nmeth.3901. [DOI] [PubMed] [Google Scholar]
- Urano T., Castellino F.J., Suzuki Y. Regulation of plasminogen activation on cell surfaces and fibrin. J. Thromb. Haemost. 2018;16:1487–1497. doi: 10.1111/jth.14157. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van Rossum G., Drake F.L., Jr. Python reference manual. 1995. https://ir.cwi.nl/pub/5008 Department of Computer Science [CS]. CWI.
- Venables W.N., Ripley B.D. Springer; 2002. Modern Applied Statistics with S. [DOI] [Google Scholar]
- Wang Y., Reheman Adili, Spring C.M., Kalantari J., Marshall A.H., Wolberg A.S., Gross P.L., Weitz J.I., Rand M.L., Mosher D.F. Plasma fibronectin supports hemostasis and regulates thrombosis. J. Clin. Invest. 2014;124:4281–4293. doi: 10.1172/JCI74630. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang Y., Gao H., Kessinger C.W., Schmaier A., Jaffer F.A., Simon D.I. Myeloid-related Protein-14 regulates deep vein thrombosis. JCI Insight. 2017;2:e91356. doi: 10.1172/jci.insight.91356. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang D., Hu B., Hu C., Zhu F., Liu X., Zhang J., Wang B., Xiang H., Cheng Z., Xiong Y., Yhao Y. Clinical characteristics of 138 hospitalized patients With 2019 novel coronavirus-infected pneumonia in Wuhan, China. JAMA. 2020;323:1061–1069. doi: 10.1001/jama.2020.1585. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang Y., Lu X., Li Y., Chen H., Chen T., Su N., Huang F., Zhou J., Zhang B., Yan F. Clinical Course and Outcomes of 344 intensive care patients with COVID-19. Am. J. Respir. Crit. Care Med. 2020;201:1430–1434. doi: 10.1164/rccm.202003-0736LE. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Webb Hooper M., Nápoles A.M., Pérez-Stable E.J. COVID-19 and racial/ethnic disparities. JAMA. 2020;323:2466–2467. doi: 10.1001/jama.2020.8598. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wei X., Zeng W., Su J., Wan H., Yu X., Cao X., Tan W., Wang H. Hypolipidemia is associated with the severity of COVID-19. J. Clin. Lipidol. 2020;14:297–304. doi: 10.1016/j.jacl.2020.04.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wu C., Chen X., Cai Y., Xia J., Zhou X., Xu S., Huang H., Zhang L., Zhou X., Du C. Risk factors associated with acute respiratory distress syndrome and death in patients with Coronavirus Disease 2019 pneumonia in Wuhan, China. JAMA Intern. Med. 2020;180:934–943. doi: 10.1001/jamainternmed.2020.0994. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Young P., Saxena M., Bellomo R., Freebairn R., Hammond N., van Haren F., Holliday M., Henderson S., Mackle D., McArthur C. Acetaminophen for fever in critically ill patients with suspected infection. N. Engl. J. Med. 2015;373:2215–2224. doi: 10.1056/NEJMoa1508375. [DOI] [PubMed] [Google Scholar]
- Zhang X., Tan Y., Ling Y., Lu G., Liu F., Yi Z., Jia X., Wu M., Shi B., Xu S. Viral and host factors related to the clinical outcome of COVID-19. Nature. 2020;583:437–440. doi: 10.1038/s41586-020-2355-0. [DOI] [PubMed] [Google Scholar]
- Zhang X.J., Qin J.J., Cheng X., Shen L., Zhao Y.C., Yuan Y., Lei F., Chen M.M., Yang H., Bai L. In-hospital use of statins is associated with a reduced risk of mortality among individuals with COVID-19. Cell Metab. 2020;32:176–187.e4. doi: 10.1016/j.cmet.2020.06.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang Y., Xiao M., Zhang S., Xia P., Cao W., Jiang W., Chen H., Ding X., Zhao H., Zhang H. Coagulopathy and antiphospholipid antibodies in patients with Covid-19. N. Engl. J. Med. 2020;382:e38. doi: 10.1056/NEJMc2007575. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zou H., Hastie T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. B. 2005;67:301–320. [Google Scholar]
- Zuo Y., Yalavarthi S., Shi H., Gockman K., Zuo M., Madison J.A., Blair C., Weber A., Barnes B.J., Egeblad M. Neutrophil extracellular traps (NETs) as markers of disease severity in COVID-19. medRxiv. 2020 doi: 10.1101/2020.04.09.20059626. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
-
-
Mass spectrometry raw files and the SQLite database file have been deposited to the MassIVE database (accession number MSV000085703; https://doi.org/10.25345/C5F74G). Raw fastq data and RSEM expression estimates are available at GEO (accession GSE157103; https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE157103).
-
-
Original code for the data analysis and webtool creation is accessible via GitHub (https://github.com/ijmiller2/COVID-19_Multi-Omics/).
-
-
Scripts for reproducing figures in the manuscript can be found in the GitHub repository: https://github.com/ijmiller2/COVID-19_Multi-Omics/
-
-
Any additional information required to reproduce this work is available from the Lead Contact.