

Abstract
Glutamic acid is an alpha-amino acid used by all living beings in protein biosynthesis. One of the important glutamic acid modifications is post-translationally modified 4-carboxyglutamate. It has a significant role in blood coagulation. 4-carboxyglumates are required for the binding of calcium ions. On the contrary, this modification can also cause different diseases such as bone resorption, osteoporosis, papilloma, and plaque atherosclerosis. Considering its importance, it is necessary to predict the occurrence of glutamic acid carboxylation in amino acid stretches. As there is no computational based prediction model available to identify 4-carboxyglutamate modification, this study is, therefore, designed to predict 4-carboxyglutamate sites with a less computational cost. A machine learning model is devised with a Multilayered Perceptron (MLP) classifier using Chou’s 5-step rule. It may help in learning statistical moments and based on this learning, the prediction is to be made accurately either it is 4-carboxyglutamate residue site or detected residue site having no 4-carboxyglutamate. Prediction accuracy of the proposed model is 94% using an independent set test, while obtained prediction accuracy is 99% by self-consistency tests.
Subject terms: Biotechnology, Computational biology and bioinformatics, Computer science
Introduction
Proteins are a key element of every cell necessary to build and repair tissues. They are macromolecules constructed using a chain of amino acid residues. Proteins exhibit numerous properties, they may work as hormones, enzymes or may be a part of structural cellular component. Among 20 common proteins, glutamic acid is an important protein with a wide range of functions. Specifically, it has role in proper functioning of central and the peripheral nervous system1.
Vitamin K-dependent carboxylase is a bifunctional enzyme. It catalyzes the oxygenation of vitamin K hydroquinone, helps in formation of vitamin K epoxide, resulting the formation of carboxyglutamate. 4-carboxyglutamate is a modification of glutamic acid formed due to post-translational modification (PTM). The structure of glutamic acid and 4-carboxyglutamate is explained in Figs. 1 and 2. These modified residues are then further exploited to bind calcium ions. These calcium ions provide positive charges to glutamic acids which further interact with the negatively charged phospholipid membrane2,3. Carboxylation has role in blood clotting and other biological processes4,5. The deficiency of vitamin K also results in deficiency of protein S and C which also formulate a Moyamoya disease. Carboxylation of glutamic acid causes disorders including bone resorption, osteoporosis, papilloma and plaque atherosclerotic6–8.
Figure 1.
Structure of glutamic acid9.
Figure 2.
Structure of 4-carboxyglutamate10.
Experimenting and identification of 4-carboxyglutamate residue sites at laboratory is costly and time-consuming. Therefore, it is necessary to formulate a computational model to identify 4-carboxyglutamate residue sites.
This study focuses on the post translational modification of glutamic acid into 4-carboxyglutamic acid within the glutamic acid domain modification. An accurate and efficient prediction model is devised to serve the purpose. The methodology is based on a Chou’s 5-step rule11. These rules serve as a benchmark for dataset collection, mathematical formulation of samples, prediction-algorithm, and cross-validation of results and the development of web server. This methodology is further carried out one by one in the above said sequential order.
Materials and methods
Chou’s peptide formulation11,12 is widely used in many studies13–19. In this study, Chou’s formulation is also adopted to reach the solution. The operational flow chart of the chosen methodology is depicted in Fig. 3.
Figure 3.
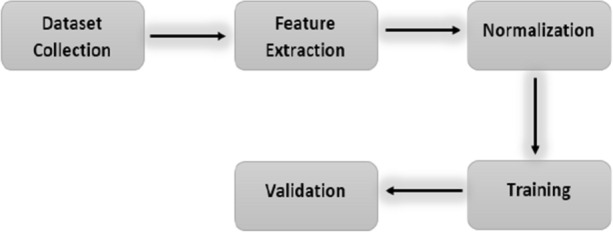
Flow chart of methodology.
Benchmark dataset
4-Carboxyglutamate sequences are extracted from a universal resource of protein (www.UniProt.org) through an advanced search query. The data is bifurcated as one with 4-carboxyglutamate modification and the other without 4-carboxyglutamate residues (also termed as positive and negative respectively). The redundancy and homology biases were excluded through CD-HIT web server (https://weizhongli-lab.org/cd-hit/) and the similarity threshold is 90%. Finally, a refined benchmark dataset of 261 proteins are constructed containing 560 positive and 600 negative samples. The total observations of obtained dataset are 560 + 600 = 1160. The dataset is represented by O. The positive observations are represented by O+, and negative observations within the data set are depicted by O−. U represents union according to the set theory.
| 1 |
Sequence logo
The PTM sequencing of the obtained dataset is graphically and visually represented in Figs. 4 and 5. Sequence conservation at a specific position is represented by the overall height of the stack.
Figure 4.

Sequence logo of positive 4-carboxyglutamate.
Figure 5.

Sequence logo of negative 4-carboxyglutamate.
Sample formulation
The formulation of biological sequencing is one of the most critical problems in computational biology. Vector quantification is a key to formulate the sequence by maintaining their sequence patterns and features that are required for targeted analysis. As vector quantification paves a way for addressing the formulated sequencing using machine learning algorithms20. In this work, a pseudo amino acid composition (PseAAC)21 is chosen. According to the chosen composition, samples in the dataset can be described as34. Equation (2) depicts that each sample is a subsequence of fixed size while Eq. (3) depicts that 20 residues upstream and 20 residues downstream were extracted while R21 is the 4-carboxyglutamate site.
| 2 |
where u = 1, 2, 3 …Ω. It elaborates how useful features can be extracted from relevant peptide sequencing and T denotes transpose operator. Each sample peptide sequence is 41 in length due to which Eq. (2) can be formulated as.
| 3 |
Statistical moment calculation
The composition of each sequence of proteins follows some specific pattern. Due to such distinction, each sequence is to be described with different statistical parameters. In previous work, statistical moments are used for feature extraction22,23. In order to have feature extraction, raw, central and Hahn moments are used. The composition of amino acids has a very important role in the functionality and nature of the proteins. The extraction of the feature can be location and scale variant. To address location variant features, raw moments are used to calculate mean, variance and asymmetry of sample distribution in the dataset. Central moments are also used for feature extraction by estimating mean, variance and asymmetry but it is location invariant as the estimations are made using centroid but central moments are actually scaled variant24,25. Hahn moments are used to estimate statistical parameters but these moments are both location and scale variant26,27. Therefore Hahn moments are computed using Hahn polynomials to estimate the mean in dataset and variance in dataset and asymmetry of the probability distribution. For the said method, moments are computed in a two-dimensional n × n matrix denoted by B′28.
| 4 |
A function ω29 is a mapping function used for matrix transformation of B as B′. It uses the element from this matrix B′. Moments were computed up to order three such as M01, M10, M11, M12, M21, M30 and M03. The raw moments are computed as given below.
| 5 |
The sum of i and j represents the order of the moments that is i + j and it can be less than or equal to three. The Central moments can be computed as given below.
| 6 |
Hahn moments can be easily computed for even dimensional data organization. Reversible property of Hahn moments is evident due to their orthogonality28. Hahn moments of order n are computed as following,
| 7 |
Normalized orthogonal Hahn moments of two dimensional discrete are computed as
| 8 |
Determination of PRIM and RPRIM
The primary sequence and relative position of residues are key factors to predict the characteristics of proteins. Quantitative characterization of the relative position of amino acid is also necessary. In order to serve the said purpose, 20 × 20 matrix is constructed as representative of Position relative Incidence Matrix (PRIM) to extract information about the relative position of each amino acid residue in the protein as given in Eq. (9).
| 9 |
Information is extracted as 400 coefficients for PRIM. In order to reduce PRIM dimensionality, statistical moments are computed for PRIM which produces a set of 24 elements.
To make it more effective and better, identifying hidden features, Reverse Position Relative Incidence Matrix (RPRIM) is also computed as:
| 10 |
By adapting the procedure explained in PRIM, 400 coefficients are also obtained from RPRIM. Similarly, with the help of computing statistical parameters, a set of 24 elements is obtained by reducing the dimensionality of RPRIM.
Feature scaling
Feature scaling is actually used to provide all features an opportunity to give an equal contribution to detect and predict the 4-carboxyglutamate sequencing. In this work, a standard scaler function is used within the Python environment to scale all features30. The standard scaler is used to scale the given data such that each feature should have mean around zero and unit variance. The standard scaling formulation is given in Eq. (11).
| 11 |
Prediction algorithm
In this work, Multilayered Perceptron (MLP), Logistic Regression and Random Forest classifiers are applied for the prediction of 4-carboxyglutamate residue sites. MLP classifier provides better prediction which is 94% in comparison to other methods. So MLP is discussed further in detail.
The dataset has consisted of a total of 1160 sequences including 560 positive samples and 600 negative samples including 194 features. A supervised learning approach is used in this work to predict 4-carboxyglutamate residue sites. The prediction algorithm has to predict between residue sites having 4-carboxyglutamate or not.
MLP is a feed-forward artificial neural network that is used to map input data against the most appropriate output. It is actually a directed graph consisting input and an output layer and multiple hidden layers in between them. All nodes are connected to all other nodes in the adjacent layer and therefore, it is called a fully connected network31. The graphical representation of the MLP classifier is given in Fig. 6.
Figure 6.

Graphical representation of MLP classifier32.
MLP classifier consists of N neurons in the hidden layer and each neuron has R weights, which is described in the N × R matrix33. The input weight matrix has N elements and is denoted by I as described in Eq. (12). The functional processing of the hidden layer is explained with the help of Eqs. (12) – (14).
| 12 |
| 13 |
| 14 |
The sequential processing of output layer form hidden layer is explained with the help of Eqs. (15)–(17).
| 15 |
| 16 |
| 17 |
Results
This study is first to predict 4-carboxyglutamate residue sites. Data samples are collected and formulated as described in “Materials and methods” section. The obtained data sets had non-numeric values having a series of alphabetic values. A featured set of numeric values is obtained as explained in “Sequence logo” section. As there were a lot of variations in obtained data so feature scaling technique is used so that each feature should have equal contribution in the prediction and detection of 4-carboxyglutamate residue sites. A neural network named MLP Classifier is used to train the obtained data sets and then based on training 4-carboxyglutamate residue sites are then predicted efficiently. The process of MLP classifier is well explained using graphical representation as shown in Fig. 6 and mathematically described in Eqs. (12) – (17) respectively.
The confusion matrix obtained from the MLP classifier is described in detail in Table 1. True positive, true negative, false positive, false negative is represented as TP, TN, FP and FN respectively.
Table 1.
Confusion matrix of the proposed model.
| n = 232 | Predicted | Predicted | |
|---|---|---|---|
| No | Yes | ||
| Actual | |||
| No | T N = 106 | F P = 8 | 114 |
| Actual | |||
| Yes | F N = 6 | T P = 112 | 118 |
| 112 | 120 | ||
The test set consists of 232 samples where 106 negative samples out of 114 negative samples are correctly predicted and 112 positive samples out of 118 are correctly identified, as shown in Table 1.
There is a number of metrics used to validate prediction accuracy. Correct and actual prediction can be validated by Sensitivity, Specificity, Accuracy and Mathew’s Correlation Coefficient. Accuracy, Sensitivity Specificity and Mathew’s Correlation Coefficient are represented at many places in this study by Acc, Sn, Sp and Mcc respectively. Their formulation is also given below34–36 where Sensitivity is applied to measure the probability of the model to predict target values. Mathew’s Correlation Coefficient is used to evaluate the quality of the classification framework37.
| 18 |
| 19 |
| 20 |
| 21 |
The obtained sensitivity, specificity, accuracy and Mathew’s Correlation Coefficient are 95%, 93%, 94% and 0.88 respectively. The obtained results validate the accuracy of the prediction model. Test methods are also applied for further validation which will be elaborated in “Test methods” section.
Test methods
There are many popular test methods in data mining and machine learning to evaluate the validity of the devised model. In this work, the independent set test, K-fold cross-validation test, and jackknife test are used to validate the devised model38. The independent test has 94% accuracy. K-fold cross-validation is performed with K = 10. The tenfold cross-validation test has 85% accuracy. Jackknife testing always gives you a unique value for the same dataset8. Jackknife testing is mostly used by an investigator to examine the quality of various predictors38–50. This study also uses a Jackknife test to check the quality of the predictor. The jackknife testing produced 94% accuracy. The result of all these test cases is given in Table 2. These test methods are also further explained in the coming subsections.
Table 2.
Combined results of Multilayered Perceptron (MLP), Logistic Regression (LR) and Random Forest (RF).
| Independent set test | Self-consistency test | Tenfold cross validation test | Jack Knife test | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc (%) | Sn (%) | Sp (%) | MCC | Acc (%) | Sn (%) | Sp (%) | Mc | Acc (%) | Sn (%) | Sp (%) | MCC | Acc (%) | Sn (%) | Sp (%) | MCC | |
| MLP | 94 | 95 | 93 | 0.88 | 99 | 99 | 99 | 0.99 | 85 | 92 | 79 | 0.71 | 94 | 93 | 96 | 0.88 |
| LR | 93 | 92 | 93 | 0.85 | 97 | 97 | 96 | 0.93 | 88 | 91 | 82 | 0.74 | 93 | 92 | 94 | 0.86 |
| RF | 91 | 90 | 91 | 0.81 | 89 | 90 | 88 | 0.78 | 81 | 86 | 77 | 0.62 | 88 | 88 | 89 | 0.76 |
Independent set test
It is the basic performance metric of the proposed model in which obtained values from a confusion matrix are used to evaluate the accuracy of the model. The dataset is split into 80% training set and 20% test set and also shown in Fig. 7.
Figure 7.
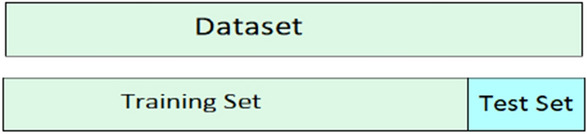
Sample dataset for independent set test.
In this study, an independent set test has 94% Acc, 95% Sn, 93% Sp and is having 0.88 Mcc achieved by Multilayered Perceptron. The results of Logistic Regression and Random Forest results can also be seen in Table 2. Acc, Sn, Sp, and Mcc is mathematically described in Eqs. (18) – (21) respectively.
The area under the curve (AUC), obtained by Multilayered Perceptron, Logistic Regression and Random Forest are 97%, 97% and 95% respectively. The F1—score obtained by Multilayered Perceptron, Logistic Regression and Random Forest are 94%, 93% and 91% respectively. It also shows correctness of classifier. ROC-Curve is given in Fig. 8.
Figure 8.
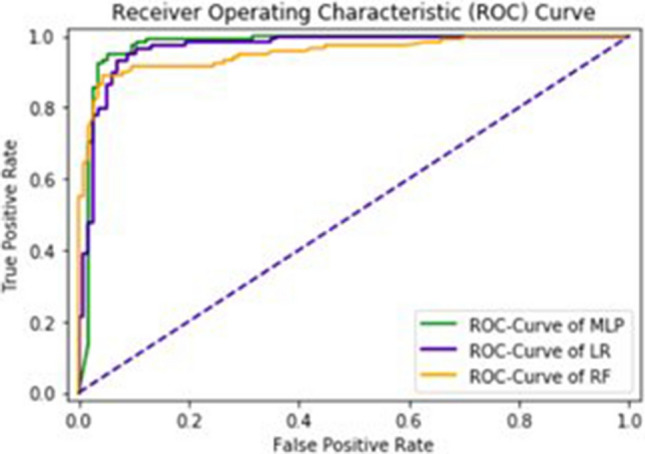
ROC-Curve of an independent set test.
Self-consistency testing
This technique is used to have same data for both training and testing. The results are written in Table 2 and the ROC—Curve for Multilayered Perceptron, Logistic Regression and Random Forest is shown in Fig. 9.
Figure 9.
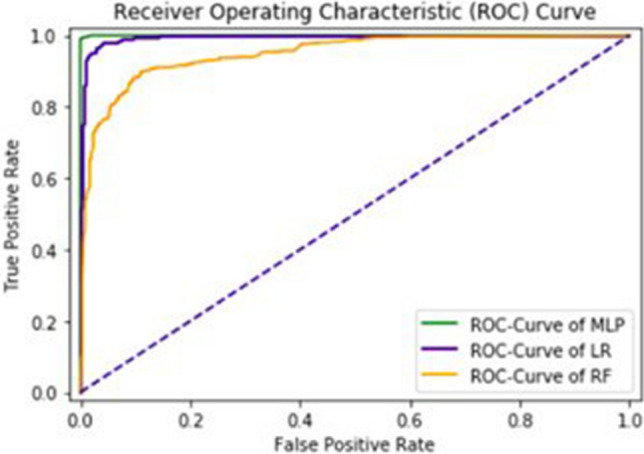
ROC-curve of self consistency test.
K-fold cross-validation testing
It is a sampling technique used to validate the proposed models by using a limited number of data samples. It has a single parameter k which indicates the number of groups into which the data samples should be divided51–53. It is mostly used to evaluate the performance of the machine learning model to invisible data54.
K can have any numeric value such as 5 or 10. In this work, tenfold cross validation sampling test is applied to evaluate the performance of the proposed model. The process of tenfold cross validation is also explained in Fig. 10. The data are divided into 10 equal observation sets (10 data samples). All the values such as Acc, An, Sp and Mcc are obtained for each observation set. The average of obtained accuracy for all observation sets is 85%, average sensitivity is 92%, average specificity is 79% and average Mathew’s correlation coefficient is 0.71 as given in Table 2.
Figure 10.

Tenfold cross validation process.
The detailed of ROC-Curve of MLP, LR and RF is given in Fig. 11. The AUC of MLP, LR and RF are 0.96, 0.96 and 0.93 respectively.
Figure 11.
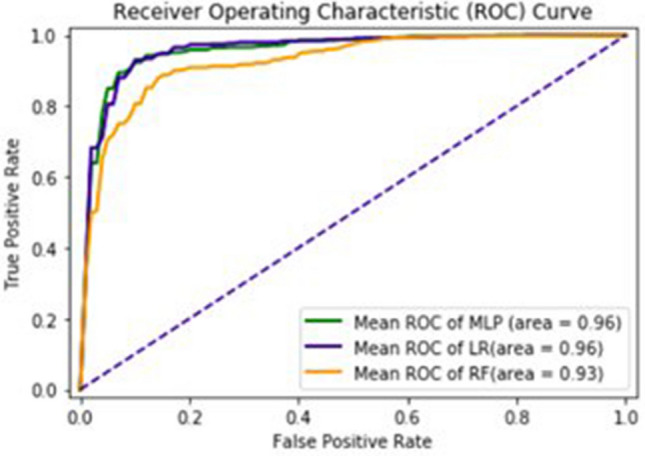
ROC-curve of tenfold cross validation test.
Jackknife testing
It is considered a resample technique that is mostly used to compute the bias, mean and variance55–57.
It evaluates the classification model sample by sample. The proposed classification model is validated on each sample using Jackknife testing and an average is computed of all the obtained results based on each sample. The process is also explained in Fig. 12. Overall observation samples are 1160 and therefore classification model is run 1160 times with obtained accuracy 94% along with sensitivity 93%, specificity 96% and Mathew’s Correlation Coefficient 0.88.
Figure 12.

Jackknife sample test.
The sequences are taken from a universal resource of protein (www.UniProt.org) through an advanced search. The chosen sequencings are streams of alphabets. It is difficult to process these sequences directly through the machine learning algorithm as they are unable to provide quantification measures. In order to address this issue, the feature vector is extracted from chosen sequences in a way that it has a strong correlation among features. In order to scale the obtained features, a standard normalization technique is used. A multilayered perceptron classifier is then applied to learn hidden patterns within observed features. Based on the said intelligent learning, observed features are going to be trained first which will then be a groundbreaking step for prediction. The validation of the proposed algorithm is carried out using a confusion matrix which is given in Table 1. Acc, Sn, Sp, and Mcc are estimated using FP, FN, TP, and TN within the confusion matrix which are 94%, 95%, 93% and 0.88 respectively as given in Table 2 and area under the curve is 0.97. Three different Machine learning algorithms are applied such as Multilayer Perceptron (MLP), Logistic Regression (LR) and Random Forest (RF). Four different types of tests are applied such as an independent set test, self-consistency test, cross validation test, and jackknife test. In this study it is clear from ROC curves that MLP is a better approach. The obtained results using different test cases validates the authenticity of our proposed model that it performs well even if the data set has large variations. Along with independent set test, self-consistency test, tenfold cross-validation test and jackknife test also obtained very good results as given in Table 2.
Conclusion
Glutamate is an important type of common alpha-amino acid. 4-Carboxyglutamic acid is produced by a post-translational carboxylation of glutamic acid residues. This study is conducted to predict 4-carboxyglutamate following Chou’s 5 steps rule. An MLP, RF and LR classification frameworks are adopted for the prediction of 4-carboxyglutamate residue sites. The accuracy of the independent set test, self-consistency test, tenfold cross-validation test, and Jackknife testing were determined to be 94%, 99%, 85% and 94%, respectively. A properly devised model will help in accurate detection of 4-carboxyglutamate which may be useful in evaluation of blood clotting, bone proteins, bone resorption, osteoporosis, papilloma and plaque atherosclerotic statuses.
Author contributions
A.A.S.: Manuscript write up; Machine learning algorithm implementation; Obtaining results; Applying all types of test cases. Y.D.K.: Bench mark dataset; Sample formulation; Statistical Moment Calculation; Guidance in the whole process.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Danbolt NC. Glutamate uptake. Prog. Neurobiol. 2001;65:1–105. doi: 10.1016/S0301-0082(00)00067-8. [DOI] [PubMed] [Google Scholar]
- 2.Lee CA. Textbook of Hemophilia. Hoboken: Wiley; 2014. [Google Scholar]
- 3.Horava SD, Peppas NA. Recent advances in hemophilia B therapy. Drug Deliv. Transl. Res. 2017;7:359–371. doi: 10.1007/s13346-017-0365-8. [DOI] [PubMed] [Google Scholar]
- 4.Suttie JW. Vitamin K-dependent carboxylase. Annu. Rev. Biochem. 1985;54:459–477. doi: 10.1146/annurev.bi.54.070185.002331. [DOI] [PubMed] [Google Scholar]
- 5.Burnier JP, Borowski M, Furie BC, Furie B. Gamma-carboxyglutamic acid. Mol. Cell. Biochem. 1981;39:91–207. doi: 10.1007/BF00232574. [DOI] [PubMed] [Google Scholar]
- 6.Pacifici R, et al. Spontaneous release of interleukin 1 from human blood monocytes reflects bone formation in idiopathic osteoporosis. Proc. Natl. Acad. Sci. 1987;84:4616–4620. doi: 10.1073/pnas.84.13.4616. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Malm J, Cohen E, Dackowski W, Dahlback B, Wydro R. Expression of completely gamma-carboxylated and beta-hydroxylated recombinant human vitamin-K-dependent protein S with full biological activity. Eur. J. Biochem. 1990;187:737–743. doi: 10.1111/j.1432-1033.1990.tb15361.x. [DOI] [PubMed] [Google Scholar]
- 8.Gijsbers BL, Haarlem LJV, Soute BA, Ebberink RH, Vermeer C. Characterization of a Gla-containing protein from calcified human atherosclerotic plaques. Arteriosclerosis. 1990;10:991–995. doi: 10.1161/01.ATV.10.6.991. [DOI] [PubMed] [Google Scholar]
- 9.Glutamic Acid. inNational Center for Biotechnology Information. PubChem Compound Database. https://pubchem.ncbi.nlm.nih.gov/compound/Glutamic-acid. Accessed 26 Apr 2020.
- 10.-Carboxyglutamic acid. inNational Center for Biotechnology Information. PubChem Compound Database. https://pubchem.ncbi.nlm.nih.gov/compound/4-Carboxyglutamic-acid#section=Structures. Accessed 26 Apr 2020.
- 11.Chou KC. Some remarks on protein attribute prediction and pseudo amino acid composition. J. Theor. Biol. 2011;273:236–247. doi: 10.1016/j.jtbi.2010.12.024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Chou KC. Using subsite coupling to predict signal peptides. Protein Eng. 2001;14:75–79. doi: 10.1093/protein/14.2.75. [DOI] [PubMed] [Google Scholar]
- 13.Arif M, Hayat M, Jan Z. iMem-2LSAAC: A two-level model for discrimination of membrane proteins and their types by extending the notion of SAAC into Chou's pseudo amino acid composition. J. Theor. Biol. 2018;442:11–21. doi: 10.1016/j.jtbi.2018.01.008. [DOI] [PubMed] [Google Scholar]
- 14.Contreras-Torres E. Predicting structural classes of proteins by incorporating their global and local physicochemical and conformational properties into general Chous PseAAC. J. Theor. Biol. 2018;454:139–145. doi: 10.1016/j.jtbi.2018.05.033. [DOI] [PubMed] [Google Scholar]
- 15.Feng P-M, Chen W, Lin H, Chou K-C. iHSP-PseRAAAC: Identifying the heat shock protein families using pseudo reduced amino acid alphabet composition. Anal. Biochem. 2013;442:118–125. doi: 10.1016/j.ab.2013.05.024. [DOI] [PubMed] [Google Scholar]
- 16.Javed F, Hayat M. Predicting subcellular localization of multi-label proteins by incorporating the sequence features into Chous PseAAC. Genomics. 2018;111:1325–1332. doi: 10.1016/j.ygeno.2018.09.004. [DOI] [PubMed] [Google Scholar]
- 17.Krishnan SM. Using Chous general PseAAC to analyze the evolutionary relationship of receptor associated proteins (RAP) with various folding patterns of protein domains. J. Theor. Biol. 2018;445:62–74. doi: 10.1016/j.jtbi.2018.02.008. [DOI] [PubMed] [Google Scholar]
- 18.Sankari ES, Manimegalai D. Predicting membrane protein types by incorporating a novel feature set into Chous general PseAAC. J. Theor. Biol. 2018;455:319–328. doi: 10.1016/j.jtbi.2018.07.032. [DOI] [PubMed] [Google Scholar]
- 19.Khan YD, Rasool N, Hussain W, Khan SA, Chou KC. iphosY-PseAAC: Identify phosphotyrosine sites by incorporating sequence statistical moments into PseAAC. Mol. Biol. Rep. 2018;45:2501–2509. doi: 10.1007/s11033-018-4417-z. [DOI] [PubMed] [Google Scholar]
- 20.Chou KC. Impacts of bioinformatics to medical chemistry. Med. Chem. 2015;11:218–234. doi: 10.2174/1573406411666141229162834. [DOI] [PubMed] [Google Scholar]
- 21.Chou KC. Impacts of bioinformatics to medical using pseudo-amino acid composition. Proteins. 2001;43:246–255. doi: 10.1002/prot.1035. [DOI] [PubMed] [Google Scholar]
- 22.Khan YD, Ahmad F, Anwar MW. A neuro-cognitive approach for iris recognition using backpropagation. World Appl. Sci. J. 2012;16:678–685. [Google Scholar]
- 23.Khan YD, Ahmed F, Khan SA. Situation recognition using image moments and recurrent neural networks. Neural Comput. Appl. 2013;24:1519–1529. doi: 10.1007/s00521-013-1372-4. [DOI] [Google Scholar]
- 24.Butt H, Khan SA, Jamil H, Rasool N, Khan YD. A prediction model for membrane proteins using moments based features. Biomed. Res. Int. 2016;2016:1–7. doi: 10.1155/2016/8370132. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Butt H, Rasool N, Khan YD. A treatise to computational approaches towards prediction of membrane protein and its subtypes. J. Membr. Biol. 2016;250:55–76. doi: 10.1007/s00232-016-9937-7. [DOI] [PubMed] [Google Scholar]
- 26.Khan YD, et al. An efficient algorithm for recognition of human actions. Sci. World J. 2014;2014:1–11. doi: 10.1155/2014/875879. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Khan YD, Khan SA, Ahmad F, Islam S. Iris recognition using image moments and k-means algorithm. Sci. World J. 2014;2014:1–9. doi: 10.1155/2014/723595. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Khan YD, Rasool N, Hussain W, Khan SA, Chou KC. iPhosT-PseAAC: Identify phosphothreonine sites by incorporating sequence statistical moments into PseAAC. Anal. Biochem. 2018;550:109–116. doi: 10.1016/j.ab.2018.04.021. [DOI] [PubMed] [Google Scholar]
- 29.Akmal MA, Rasool N, Khan YD. Prediction of N-linked glycosylation sites using position relative features and statistical moments. PLoS ONE. 2017 doi: 10.1371/journal.pone.0181966. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.sklearn.preprocessing.StandardScaler. scikit. https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html. Accessed 8 Mar 2020.
- 31.Wan S, Liang Y, Zhang Y, Guizani M. Deep multi-layer perceptron classifier for behavior analysis to estimate Parkinson’s disease severity using smartphones. IEEE Access. 2018;6:36825–36833. doi: 10.1109/ACCESS.2018.2851382. [DOI] [Google Scholar]
- 32.Gajoui KE, Allah FA, Oumsis M. Diacritical language OCR based on neural network: Case of Amazigh language. Procedia Comput. Sci. 2015;73:298–305. doi: 10.1016/j.procs.2015.12.035. [DOI] [Google Scholar]
- 33.Zhai X, Ali AAS, Amira A, Bensaali F. MLP neural network based gas classification system on Zynq SoC. IEEE Access. 2016;4:8138–8146. doi: 10.1109/ACCESS.2016.2619181. [DOI] [Google Scholar]
- 34.Chen J, Liu H, Yang J, Chou K-C. Prediction of linear B-cell epitopes using amino acid pair antigenicity scale. Amino Acids. 2007;33:423–428. doi: 10.1007/s00726-006-0485-9. [DOI] [PubMed] [Google Scholar]
- 35.Xu Y, Ding J, Wu L-Y, Chou K-C. iSNO-PseAAC: Predict cysteine S-nitrosylation sites in proteins by incorporating position specific amino acid propensity into pseudo amino acid composition. PLoS ONE. 2013;8:e55844. doi: 10.1371/journal.pone.0055844. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Chen W, Feng P-M, Lin H, Chou K-C. iRSpot-PseDNC: Identify recombination spots with pseudo dinucleotide composition. Nucleic Acids Res. 2013;41:e68. doi: 10.1093/nar/gks1450. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Porter J, Berkhahn J, Zhang L. A comparative analysis of read mapping and indel calling pipelines for next-generation sequencing data. In: Tran QN, Arabnia H, editors. Emerging Trends in Computational Biology, Bioinformatics, and Systems Biology. Amsterdam: Elsevier; 2015. pp. 521–535. [Google Scholar]
- 38.Chou K-C, Zhang C-T. Prediction of protein structural classes. Crit. Rev. Biochem. Mol. Biol. 1995;30:275–349. doi: 10.3109/10409239509083488. [DOI] [PubMed] [Google Scholar]
- 39.Ali F, Hayat M. Classification of membrane protein types using voting feature interval in combination with Chou’s pseudo amino acid composition. J. Theor. Biol. 2015;384:78–83. doi: 10.1016/j.jtbi.2015.07.034. [DOI] [PubMed] [Google Scholar]
- 40.Zhou G-P, Doctor K. Subcellular location prediction of apoptosis proteins. ProteinsStruct. Funct. Bioinform. 2002;50:44–48. doi: 10.1002/prot.10251. [DOI] [PubMed] [Google Scholar]
- 41.Mondal S, Pai PP. Chou’s pseudo amino acid composition improves sequence-based antifreeze protein prediction. J. Theor. Biol. 2014;356:30–35. doi: 10.1016/j.jtbi.2014.04.006. [DOI] [PubMed] [Google Scholar]
- 42.Feng K-Y, Cai Y-D, Chou K-C. Boosting classifier for predicting protein domain structural class. Biochem. Biophys. Res. Commun. 2005;334:213–217. doi: 10.1016/j.bbrc.2005.06.075. [DOI] [PubMed] [Google Scholar]
- 43.Nanni L, Brahnam S, Lumini A. Prediction of protein structure classes by incorporating different protein descriptors into general Chou’s pseudo amino acid composition. J. Theor. Biol. 2014;360:109–116. doi: 10.1016/j.jtbi.2014.07.003. [DOI] [PubMed] [Google Scholar]
- 44.Shen H-B, Yang J, Chou K-C. Euk-PLoc: An ensemble classifier for large-scale eukaryotic protein subcellular location prediction. Amino Acids. 2007;33:57–67. doi: 10.1007/s00726-006-0478-8. [DOI] [PubMed] [Google Scholar]
- 45.Wu Z-C, Xiao X, Chou K-C. iLoc-Plant: A multi-label classifier for predicting the subcellular localization of plant proteins with both single and multiple sites. Mol. BioSyst. 2011;7:3287. doi: 10.1039/c1mb05232b. [DOI] [PubMed] [Google Scholar]
- 46.Dehzangi A, et al. Gram-positive and gram-negative protein subcellular localization by incorporating evolutionary-based descriptors into Chou’s general PseAAC. J. Theor. Biol. 2015;364:284–294. doi: 10.1016/j.jtbi.2014.09.029. [DOI] [PubMed] [Google Scholar]
- 47.Qiu W-R, Xiao X, Chou K-C. iRSpot-TNCPseAAC: Identify recombination spots with trinucleotide composition and pseudo amino acid components. Int. J. Mol. Sci. 2014;15:1746–1766. doi: 10.3390/ijms15021746. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Kumar R, Srivastava A, Kumari B, Kumar M. Prediction of β-lactamase and its class by Chou’s pseudo-amino acid composition and support vector machine. J. Theor. Biol. 2015;365:96–103. doi: 10.1016/j.jtbi.2014.10.008. [DOI] [PubMed] [Google Scholar]
- 49.Chen J, Long R, Wang X-L, Liu B, Chou K-C. dRHP-PseRA: Detecting remote homology proteins using profile-based pseudo protein sequence and rank aggregation. Sci. Rep. 2016 doi: 10.1038/srep32333. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Ahmad K, Waris M, Hayat M. Prediction of protein submitochondrial locations by incorporating dipeptide composition into Chou’s general pseudo amino acid composition. J. Membr. Biol. 2016;249:293–304. doi: 10.1007/s00232-015-9868-8. [DOI] [PubMed] [Google Scholar]
- 51.Duchesnay, E. & Löfstedt, T. Statistics and Machine Learning in Python Release 0.2. (2018).
- 52.Adams, R. P. Model Selection and Cross Validation Evaluation Hygiene: The Train/Test Split, 1–8.
- 53.Anguita, D. Ghelardoni, L. Ghio, A. Oneto, L & Ridella, S. The ‘K’ in K-fold cross validation. inEuropean Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, 441–446 (2012).
- 54.Rodríguez JD, Pérez A, Lozano JA. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2010;32:569–575. doi: 10.1109/TPAMI.2009.187. [DOI] [PubMed] [Google Scholar]
- 55.Chapter 8 Bootstrap and Jackknife Estimation of Sampling. https://www.stat.washington.edu/jaw/COURSES/580s/581/LECTNOTES/ch8.pdf. Accessed 24 May 2019.
- 56.G Protein-Coupled Receptor 172A (GPR172A) ELISA Kit. Human GPR172A ELISA Kit (ABIN5654457). https://www.antibodies-online.com/kit/5654457/GProtein-CoupledReceptor172AGPR172AELISAKit/. Accessed 8 Mar 2020.
- 57.Lavergne C. A Jackknife method for estimation of variance components. Statistics. 1995;27:1–13. doi: 10.1080/02331889508802506. [DOI] [Google Scholar]