

Abstract
Deep learning models have shown their advantage in many different tasks, including neuroimage analysis. However, to effectively train a high-quality deep learning model, the aggregation of a significant amount of patient information is required. The time and cost for acquisition and annotation in assembling, for example, large fMRI datasets make it difficult to acquire large numbers at a single site. However, due to the need to protect the privacy of patient data, it is hard to assemble a central database from multiple institutions. Federated learning allows for population-level models to be trained without centralizing entities’ data by transmitting the global model to local entities, training the model locally, and then averaging the gradients or weights in the global model. However, some studies suggest that private information can be recovered from the model gradients or weights. In this work, we address the problem of multi-site fMRI classification with a privacy-preserving strategy. To solve the problem, we propose a federated learning approach, where a decentralized iterative optimization algorithm is implemented and shared local model weights are altered by a randomization mechanism. Considering the systemic differences of fMRI distributions from different sites, we further propose two domain adaptation methods in this federated learning formulation. We investigate various practical aspects of federated model optimization and compare federated learning with alternative training strategies. Overall, our results demonstrate that it is promising to utilize multi-site data without data sharing to boost neuroimage analysis performance and find reliable disease-related biomarkers. Our proposed pipeline can be generalized to other privacy-sensitive medical data analysis problems. Our code is publicly available at: https://github.com/xxlya/Fed_ABIDE/.
Keywords: Federated Learning, Domain Adaptation, Data Sharing, Privacy, rs-fMRI
Graphical Abstract
1. Introduction
Data has non-rivalrous value, a term from the economics literature (Weimer and Vining, 2017), meaning that it can be utilized by multiple parties at a time to create additional data products or services. Pooling data together will have synergistic effects. For example, for developing a deep neural network for image recognition tasks, a vast training set is needed that captures the complexity of the problem (in some cases as many as ten thousand images). However, similar data at scale tend not to be available in healthcare, resulting in a lack of generalizability and accuracy for models and concerns regarding the reproducibility of results. Sharing large amounts of medical data is essential for precision medicine, with one important example being functional MRI (fMRI) data related to certain neurological diseases or disorders. The time and cost for acquisition and annotation in gathering large fMRI datasets make it difficult to recruit large numbers at a single site. Deep learning models have shown their advantage in fMRI analysis (Suk et al., 2016; Shen et al., 2017). Without assembling data from a number of different locations, the typically limited amount of data available from a single site becomes an obstacle to building an accurate deep learning model for neuroimage analysis.
However, there are many concerns regarding medical data sharing. For example, patients might be concerned about sharing their medical data, due to the risk that it will be shared with employers or used for future health insurance decision-making if their data are stored and accessed by multiple users, even when deidentified (Roski et al., 2014). There are questions about whether deidentified data are truly anonymous. From a legal point of view, data sharing is regulated by different federal and state laws. The power of regulation might vary due to the content of the data, its identifiability, and the context of its use (Rosenbaum and Painter, 2005). Many governmental agencies have their own privacy and data-sharing policies (POLICY et al., 2003). In addition, health systems are concerned that competitors will be able to use their data when they compete for customers. Providers worry that if their health statistics are publicly available, they will lose patients or be sanctioned if they cannot assess their performance (Heitmueller et al., 2014).
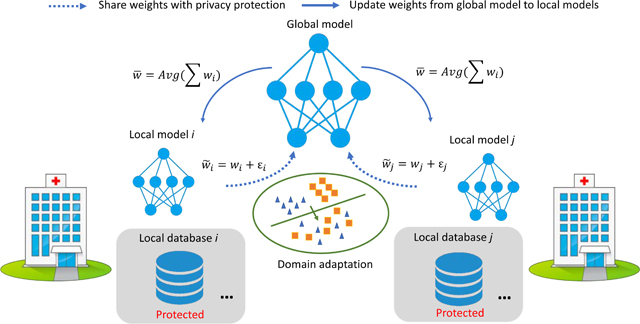
To tackle the data-sharing problem, Federated learning (Li et al., 2019a) was introduced to protect privacy by using training data distributed among multiple parties. Instead of transferring data directly to a centralized data warehouse for building machine learning models, in a federated learning setup, each party retains its data and performs decentralized computing. Hence, federated learning addresses privacy concerns and encourages multi-institution collaboration.
Another problem existing in utilizing data from different parties is domain shift. Diverse domains of data are common because institutions can have very different methods of data generation and collection. The scanners used in different institutions may be from different manufacturers, may be calibrated differently and may have different acquisition protocols specified. For example, in data from the Autism Brain Imaging Data Exchange (ABIDE I) (Di Martino et al., 2014), the University of Utah School of Medicine (USM) site used a 3T Siemens TrioTim MR scanner, the New York University (NYU) site used a 3T Siemens Allegra MR scanner, while the University of Michigan (UM) site used a 3T GE Signa MR scanner. Also, the instructions given to each subject were different at different sites. The USM site told participants to ”Keep your eyes open and remain awake, letting thoughts pass through your mind without focusing on any particular mental activity” while participants at the UM site looked at a fixation cross in the middle of the screen and participants at the NYU site were asked to look at a white cross-hair against a black background that was projected on a screen but some participants’ eyes were closed during scanning. Figure 1 shows the heterogeneous fMRI data distribution of NYU and USM sites, although both of the sites used the scanners from the same manufacturer. One of the challenges of imaging studies of brain disorders is to detect robust findings across sites.Recent studies (Yao et al., 2019; Wang et al., 2018) have shown promising results of utilizing domain adaptation techniques to assist heterogeneous data analysis, including the applications in medical image analysis areas (Chen et al., 2019; Yang et al., 2019a). Therefore, federated learning, together with domain adaptation methods, has the potential to extract reliable, robust neural patterns from brain imaging data of patients having different psychiatric disorders.
Fig. 1:

fMRI distribution of different sites
Our contributions are summarized as follows:
We formulate a new privacy-preserving pipeline for multi-site fMRI analysis and investigate various practical aspects of the federated model’s communication frequency and privacy-preserving mechanisms.
To the best of our knowledge, we investigate domain adaptation in federated learning for medical image analysis for the first time. Domain shift due to heterogeneous data distribution is a challenging issue when utilizing medical images from different institutions.
We propose to evaluate performance based on the biomarkers detected by the model, in addition to direct assessment of accuracy metrics.
Paper structure:
In Section 2, we summarize related work about federated learning and unsupervised domain adaptation, the two techniques we focus on in this paper. In Section 3, we introduce the methods used for our study. Specifically, in Section 3.1, we propose the privacy-preserving federated learning setup for multi-site fMRI analysis; in Section 3.2, we propose two domain adaptation methods to boost federated learning performance; and in Section 3.3, we propose the biomarker detection and evaluation methods. The experiments, results, and evaluation methods are presented in Section 4. We conclude the paper in Section 5.
2. Related Work
2.1. Federated Learning
Generally, federated learning can be achieved by two approaches: 1) each party training the model using private data and where only model parameters being transferred and 2) using encryption techniques to allow safe communications between different parties (Yang et al., 2019b). In this way, the details of the data are not disclosed in between each party. In this paper, we focus on the first approach, which has been studied in (Dean et al., 2012; Shokri and Shmatikov, 2015; McMahan et al., 2016).
Obtaining sufficient data is a major challenge in the field of medical imaging. Apart from data collection, labeling medical image data that require expert knowledge can be addressed by the collaboration between institutions. However, there are lots of potential legal and technical issues when sharing medical data to a centralized location, especially among international institutions. In the medical imaging field, multi-institutional deep learning without sharing patient data was firstly investigated in (Sheller et al., 2018). Later, another work (Li et al., 2019b) empirically studied privacy-preserving issues using a sparse vector technique and investigated model weights sharing schemes for imbalanced data. We note that the randomization mechanism for privacy protection and domain adaptation issues have not been studied in federated learning for medical images. We address these two issues in our study.
2.2. Domain Adaptation
Domain Adaptation aims to transfer the knowledge learned from a source domain to a target domain. Then, a model trained over a data set from a source domain is further refined to adapt to a data set from a different target domain. Unsupervised domain adaptation methods have been extensively studied (Gholami et al., 2018; Zhao et al., 2019; Hoffman et al., 2018; Long et al., 2015; Ganin and Lempitsky, 2014; Tzeng et al., 2017; Zhu et al., 2017; Long et al., 2018). However, these efforts cannot meet the requirements of federated settings: data are stored locally and cannot be shared, which hinders adaptive approaches in mainstream domains because they require access to source and target data (Tzeng et al., 2014; Long et al., 2017; Ghifary et al., 2016; Sun and Saenko, 2016; Ganin and Lempitsky, 2014; Tzeng et al., 2017). Federated domain adaptation has been recently proposed (Peng et al., 2019; Peterson et al., 2019). In our study, we investigate adopting those two federated domain adaptation methods in our multi-source and multi-target federated learning domain adaptation problem.
3. Methods
3.1. Basic privacy-preserving federated learning setup
In this section, we formulate multi-site fMRI analysis without data sharing in a federated learning framework. Then we introduce the randomized mechanism for privacy protection. Finally, we show the details of training such a privacy-preserving federated learning network step by step.
3.1.1. Problem definition
Let matrix denote the data held by the data owner site i. Define N sites {,....}, all of whom wish to train a deep learning model by consolidating their respective data {,....}. For medical imaging problems, usually, the data size at each site is limited to train an accurate deep learning model. A conventional method is to put all data together and use = ⋃ · · · ⋃ to train a model MIX. At the same time, some data sets may also contain label data. We denote the feature space as , the label space as and we use to denote the sample ID space. The feature space , label and sample IDs constitute the complete training dataset (, , ). In our multi-site fMRI classification scenario: is fMRI data, is the institution owning private fMRI data; is the extracted fMRI feature and label can be the diagnosis or phenotype we want to predict. In this setting, data sets share the same feature space but are different in samples. For example, different sites have different subjects. However, the features are all fMRI signals extracted from the same preprocessing pipeline. Therefore, we can summarize the data distribution as:
| (1) |
which belongs to the horizontal federated learning category where different data sets have large overlap on features while they have small overlap on samples (Yang et al., 2019b).
In this scenario, due to regulation and other issues, each medical institution will not share data with the other parties. A federated learning system is a learning process where the data owners collaboratively train a model FED, in which any data owner does not expose its data to others. In our problem setting, assume there is a central server for computing (not for data storage). All the different medical institutions (sites) use the same deep learning architecture for the same task. Each institution trains the deep learning model in-house and updates the model weight information to a central server at a particular frequency during training. The shared weights are blurred by additive random noise ε to protect data from inverse interpretation leakage. Once the central server receives all the weights, it summarizes them and updates the new weights to each institution. The simplified pipeline is depicted in Figure 2.
Fig. 2:

The simplified example of privacy-preserving federated learning strategy for fMRI analysis.
3.1.2. Privacy-preserving decentralized training
The simplified federated learning framework is depicted in Figure 2, which contains two key steps in decentralized optimization: 1) local update, and 2) communicating to a global server. The detailed training procedure is presented in Algorithm 1. The objective function in Algorithm 1 for training data in any site n is cross-entropy loss:
| (2) |
where yni is the label of ith subject in the training label set Yn = and pni is the corresponding model output, which estimates the probability of that label, given an input. All the training inputs and training labels are sampled from feature space and label space .
3.1.3. Randomized mechanism for privacy protection
Differential privacy (Dwork et al., 2014, 2006b) is a popular approach to privacy-preserving machine learning (Shokri and Shmatikov, 2015)
Algorithm 1.
Privacy-preserving federated learning for multi-site fMRI analysis
| Input: 1. X = {X1, . . ., XN}, fMRI data from N institutions/sites; 2. fw = {fwi, . . ., fwN}, local models within N sites, where wi is local model weights; 3. Y = {Yi, . . ., YN}, fMRI labels; 4. M(·), noise generator that is used for privacy-preservation (explained in the following section); 5. K, number of optimization iterations; 6. τ, global model updating pace, which means the global model and the private models communicate per τ steps in each optimization iteration; 7. {opt1(·),...,optN(·)}, optimizer returning updated model weights w.r.t. objective function . | ||
| 1: | ← randomize parameters | ▷ initialize local model |
| 2: | for k = 1 to K do | |
| 3: | t ← 0 | ▷ initialize pace counter |
| 4: | for n = 1 to N do | |
| 5: | ||
| 6: | end for | |
| 7: | t ← t + 1 | ▷ models communicate |
| 8: | if t%τ = 0 then | |
| 9: | ▷ update global model per τ steps | |
| 10: | for n = 1 to N do | |
| 11: | ▷ deploy weights to local model | |
| 12: | end for | |
| 13: | end if | |
| 14: | end for | |
| Return: global model | ||
and establishes a strong standard for privacy guarantees for aggregated database-based algorithms. Informally, differential privacy aims to provide a bound, ϵ, that the attacker could learn virtually nothing more about an individual than they would learn if it were absent from the dataset as the individual’s sensitive information is almost irrelevant in the outputs of the model. The bound ϵ represents the degree of privacy preference that can be controlled by each party. A lot of research has tried to protect differential privacy at the data level when a model is learned in a centralized manner (Shokri and Shmatikov, 2015; Abadi et al., 2016). To protect the data from inversion attack, such as inferring data from model weights, a differential privacy-preserving randomized mechanism can be incorporated into the learning process. Given a deterministic real-valued function h : → , h’s L1 sensitivity sh is defined as the maximum of the absolute distance ‖h() − h(′)‖1, where ‖ − ′‖1 = 1, meaning that there is only one data point difference between and ′ (Dwork et al., 2014) (Definition 3.1). In our case h computes the m weight parameters in the deep learning model. Introducing noise in the training process (inputs, parameters, or outputs) can limit the granularity of information shared and ensure ε-differential privacy (Dwork et al., 2006b) (Definition 1) for all S ⊆ Range(h), and then (Dwork et al., 2006a):
| (3) |
or
| (4) |
where the additional additive term δ is the probability of ϵ-differential privacy being broken. Here, we introduce two approaches: 1) Gaussian mechanism, and 2) Laplace mechanism, which can enjoy good privacy guarantees (Chaudhuri et al., 2019) by adding noise to the shared weights.
Gaussian Mechanism
The Gaussian mechanism adds noise with mean 0 and standard deviation shσ to a function h() with global sensitivity sh. h() will satisfy (ϵ, δ)-differential privacy if and ϵ < 1 (Dwork et al., 2014) (Theorem 3.22). Hereby, we linked the Gaussian noise parameter σ to the privacy parameters ϵ and δ.
Laplace Mechanism
The Laplace Distribution centered at 0 with scale b is the distribution with probability density function:
| (5) |
and the variance of the Laplace distribution is σ2 = 2b2. The Laplace mechanism adds Lap(sh/ϵ) noise to a function h() with global sensitivity sh and preserves (ϵ, 0)-difference privacy. Hereby, we linked the Laplace noise parameter b to the privacy parameters ϵ.
In our case, mapping function h is a deep learning model and it is not tractable to compute the sensitivity sh. For simplicity of discussion, sensitivity sh is assumed to be 1. From the mechanisms described above, we can control noise parameters to meet certain privacy requirement, as the noise parameters are linked to privacy parameters as shown above.
3.2. Boosting multi-site learning with domain adaptation
Although federated learning is promising for better privacy and efficiency, there is the additional issue that the data at each site likely have different distributions, leading to domain shift between the sites (Quionero-Candela et al., 2009). The main hypothesis here is that domain adaptation techniques can improve overall accuracy of different sites in a federated learning setting, and that holds even when noise is added for privacy-preservation, especially for the sites whose data distributions are quite different from the other sites. In this subsection, we investigate two domain adaptation methods: 1) Mixture of Experts (MoE), adaptation near the output layer, and 2) Adversarial domain alignment, adaptation on the data knowledge representation level.
3.2.1. Mixture of Experts (MoE) domain adaptation
Mixture of Experts (MoE) (Masoudnia and Ebrahimpour, 2014; Shazeer et al., 2017; Wang et al., 2018) is an approach to conditionally combine experts to process each input. In deep learning, experts mean deep learning models. An MoE layer for feed-forward neural networks is a trainable gating network that dynamically assigns gated weights to combine multiple networks. Then, all parts of the big model that contains all expert models and the MoE layer are trained jointly by back-propagation.
Mixing the outputs of a collaboratively-learned general model and a domain expert was proposed for domain adaptation (Peterson et al., 2019). Improving from the previous work (Peterson et al., 2019), we integrate randomized mechanism into MoE. Each participating party has an independent set of labeled training examples that they wish to keep private, drawn from a party-specific domain distribution. These users collaborate to build a general model for the task but maintain private, domain-adapted expert models. The final predictor is a weighted average of the outputs from the general and private models. These weights are learned using a MoE architecture (Masoudnia and Ebrahimpour, 2014), so the entire model can be trained with gradient descent. More specifically, given an input data x ∈ Xi, the output of the global model is which is learned using the strategy in Algorithm 1. In the binary classification setting, the output is the model’s predicted probability for the positive class. As shown in Figure 3a, we train another local model fϕi in the meantime, which is defined as a private model. The private model can have different architecture from and it does not communicate with the global model. The output of the private model is yP = fϕi (x). fϕi is trained using the regular deep learning setting, without including privacy-related noise. The final output that entity i uses to label data is
| (6) |
Fig. 3:

Domain adaptation strategies for our proposed federated learning setup.
The weight ai(x) is called a gating function in the MoE, and we use a non-linear layer to compute ai(x), where σ is the sigmoid function, and ψi and bi are learned weights by end-to-end training together with the federated learning architecture.
3.2.2. Adversarial domain alignment
In the federated setting, the data are locally stored in a privacy-preserving manner. For the domain adaptation problem, we have multiple source domains and want to generalize the domains into a common space of target data. Due to the data sharing limitation of federated learning, we cannot train a single model that has access to the source domain and target domain simultaneously. To address this issue, we employed federated adversarial alignment (Peng et al., 2019) that introduces two modules (a domain-specific local feature extractor, and a global discriminator) in the classification networks and divides optimization into two independent steps. Using this method (Figure 3b), for source site , we train a local feature extractor, Gs. For the target site , we train a local feature generator Gt. For each (, ) source-target domain pair, we train an adversarial domain discriminator D to align the distributions. First, domain discriminator D is trained to identify which domain the features come from, then the feature generators (Gs, Gt) are trained to confuse the discriminator D. In this setting of privacy preserving, the discriminator D only gets access to the output features with noise coverage of Gs and Gt, without leaking the original data. Specifically, the inputs of source discriminator D are M ◦ Gt(xt) and M ◦ Gs(xs), where M(·) is a noise generator. Therefore, the data-leakage of target site is prevented in training the discriminator D on the source side. Given the source domain data XS and target data XT, the objective for discriminating the source domain from the others Ds is defined as:
| (7) |
Algorithm 2.
Federated Adversarial Domain Alignment
| Input: 1. X = {X1, . . . , XN}, fMRI data from N institutions/sites; 2. local feature generators within N sites, where is the generator’s parameters of site n; 3. local classifiers within N sites, where is the classifier’s parameters of site n; 4. discriminators from embedded features, where is the discriminator parameters that identify the data from site n; 5. Y = {Y1,...,YN}, fMRI labels (HC or ASD); 6. M(·), noise generator; 7. K, number of optimization iterations; 8. τ, global model updating pace; 9. {, }, global model. | ||
| 1: | Initialize parameters {θG, θC, θD} | |
| 2: | for k = 1 to K do | |
| 3: | t ← 0 | ▷ initialize pace counter |
| 4: | for i = 1 to N do | |
| 5: | Sample mini-batch from source site and target site | |
| 6: | Compute gradient with cross-entropy classification loss ce (Eq. 2) to update | |
| 7: | Domain Alignment: | |
| 8: | Update with Eq. 7 and Eq. 8 respectively to align the domain distribution | |
| 9: | end for | |
| 10: | t ← t + 1 | ▷ models communicate |
| 11: | if t%τ = 0 then | |
| 12: | ||
| 13: | ▷ update global model per τ steps | |
| 14: | for n = 1 to N do | |
| 15: | ||
| 16: | ▷ deploy weights to local model | |
| 17: | end for | |
| 18: | end if | |
| 19: | end for | |
| Return: global model | ||
In the second step, LadvD remains unchanged, but LadvG is updated with the following objective:
| (8) |
By end-to-end training of the federated learning model with the alignment module, we can minimize the discrepancy between the source and target domains. The implementation details are described in Algorithm 2.
3.3. Evaluate model by interpreting biomarkers
The primary goal of psychiatric neuroimaging research is to identify objective and repeatable biomarkers that may inform the disease (Heinsfeld et al., 2018). Finding the biomarkers associated with ASD is extremely helpful in understanding the underlying roots of the disorder and can lead to earlier diagnosis and more targeted treatment. Alteration in brain functional connectivity is expected to provide potential biomarkers for classifying or predicting brain disorders (Du et al., 2018). Deep learning methods are promising tools for investigating the reliability of patterns of brain function across large and heterogeneous data sets (Varoquaux and Thirion, 2014).
We held the hypothesis that reliable biomarkers could be detected from a reliable model. The guided gradient-based explanation method (Simonyan et al., 2013; Springenberg et al., 2014) is perhaps the most straightforward and easiest approach for data feature importance interpretation. The advantage of gradient-based explanation method is easy to compute. By calculating the difference of the output w.r.t the model input then applying norm, a score can be obtained. The gradient-based score can be used to indicate the relative importance of the input feature since it represents the change in input space, which corresponds to the positive maximizing rate of change in the model output.
| (9) |
where c ∈ {0, . . . , − 1} is the correct class of input, is the total number of classes, and yc is the score for class c before softmax layer, xk is the kth feature of the input. can indicate the importance of feature k for classifying an input as class c. We use this method to interpret the important features (ROIs) as biomarkers.
Given the important biomarkers, first, we propose to examine their consistency, i.e., whether the biomarkers are robust across different datasets. Second, we should examine whether the biomarkers are meaningful. For the relatively important features selected, such as the features with the top K important scores, we can ”decode” them to associated functional keywords based on prior knowledge and compute the correlation score for the keyword with the biomarkers in class c. The informative biomarkers of the inputs in the different classes c should have different functional representations, which means we expect large |Δ| = | − | for the informative biomarkers, where c′ ∈ \c. The larger the difference, the more representative and informative the biomarkers.
4. Experiments and Results
4.1. Data
4.1.1. Participants
The study was carried out using resting-state fMRI (rs-fMRI) data from the Autism Brain Imaging Data Exchange dataset (ABIDE I preprocessed, (Di Martino et al., 2014)). ABIDE is a consortium that provides preciously collected rs-fMRI ASD and matched controls data for the purpose of data sharing in the scientific community. However, in reality, collecting data in a consortium like ABIDE is not easy as strict agreement need to be reached by different parties. Therefore, although the data were shared in ABIDE, we studied the multi-site data from the federated learning perspective. To ensure the deep learning model could perform on a single site, we downloaded Regions of Interests (ROIs) fMRI series of the top four largest sites (UM1, NYU, USM, UCLA1) from the preprocessed ABIDE dataset with Configurable Pipeline for the Analysis of Connectomes (CPAC), band-pass filtering (0.01 – 0.1 Hz), no global signal regression, parcellated by Harvard-Oxford (HO) atlas. Skipping subjects lacking filename, we downloaded 106, 175, 72, 71 subjects from UM1, NYU, USM, UCLA1 separately. HO parcellated each brain into 111 ROIs. Since some subjects did not contain complete ROIs, we removed the incomplete data, resulting in 88, 167, 52, 63 subjects for UM1, NYU, USM, UCLA1 separately. Due to a lack of sufficient data, we used sliding windows (with window size 32 and stride 1) to truncate raw time sequences of fMRI. After removing incomplete subjects, the compositions of four sites were shown in Table 1. We denoted UM for UM1 and UCLA for UCLA1. We summarized the phenotype information of the subjects under our study in Table 2.
Table 1:
Data summary of the dataset used in our study
| NYU | UM | USM | UCLA | |
|---|---|---|---|---|
| Total Subject | 167 | 88 | 52 | 63 |
| ASD Subject | 73 | 43 | 33 | 37 |
| HC Subject | 94 | 45 | 19 | 26 |
| ASD Percentage | 44% | 49% | 63% | 59% |
| fMRI Frames | 176 | 296 | 236 | 116 |
| Overlapping Trunc | 145 | 265 | 205 | 85 |
Table 2:
Data phenotype summary.
| SITE | AGE | ADOS | IQ | SEX | |
|---|---|---|---|---|---|
| ASD | UM | 12.4(2.2) | - | 102.8(18.8) | M36F7 |
| USM | 22.9(7.3) | 12.6(3.0) | 99.8(16.4) | M33F0 | |
| NYU | 14.7(7.1) | 11.5(4.1) | 107.4(16.5) | M65F8 | |
| UCLA | 13.0(2.7) | 10.4(3.6) | 103.5(13.5) | M 31 F 6 | |
| HC | UM | 14.1(3.4) | - | 106.7(9.6) | M32F 13 |
| USM | 20.8(8.2) | - | 117.1(14.4) | M 19 F 0 | |
| NYU | 15.2(5.9) | - | 112.6(13.5) | M 69 F 25 | |
| UCLA | 13.4(2.3) | - | 104.9(10.4) | M 22 F 4 | |
Values reported with mean (std) format. M: Male, F: Female, ADOS score: - means information not available
4.1.2. Data preprocessing
The task we performed on the ABIDE datasets was to identify autism spectrum disorders (ASD) or healthy control (HC). We used the mean time sequences of ROIs to compute the correlation matrix as functional connectivity. The functional connectivity provided an index of the level of co-activation of brain regions based on the time series of rs-fMRI brain imaging data. Each element of the correlation matrix was calculated using Pearson correlation coefficient, which ranged from −1 to 1: values close to 1 indicated that the time series were highly correlated and values close to −1 indicate that the time series are anti-correlated. Then, we applied the Fisher transformation on the correlation matrices to emphasize the strong correlations. As the correlation matrices were symmetric, we only kept the upper-triangle of the matrices and flattened the triangle values to vectors, with the purpose of using them for the inputs of multilayer perceptron (MLP) classifiers. The number of resultant features was defined by R(R − 1)/2, where R was the number of ROIs. Under the HO atlas (111 ROIs), the procedure resulted in 6105 features.
4.2. Federated training setup and hyper-parameters discussion
A multi-layer perceptron (MLP) 6105–16–2 (corresponding to 6105 nodes for the input (first) layer, 16 nodes for the hidden layer, and 2 nodes for the output layer) was used for classification. The outputs of the MLPs were the probability of the given input being classified as each class. We used cross-entropy as the objective function. We performed 5-fold cross-validation (subject-wise splitting), and each entry of the input vectors was normalized by training set mean and standard deviation (std) within each site. As we performed overlapping truncation for data augmentation in data processing, we used the majority voting method to evaluate the final classification performance. For example, we augmented m input instances for a single subject, and if more than m/2 instances were classified as ASD, then we assigned ‘ASD’ label to the subject. Adam optimization was applied with initial learning rate 1e-5 and reduced by 1/2 for every 20 epochs and stopped at the 50th epoch. In each epoch, we performed local updates multiple times instead of once based on communication pace τ. We set the total steps of each epoch as 60, and the batch size of each site was the number of training data over 60.
First, we investigated the effects of changing communication pace on classification accuracy, as communication between models would be costly. To select the best communication pace τ, we did not apply any noise on the shared weights in the experiment. As the results in Figure 4 show, there was no significant difference between the accuracies when τ varied from 5 to 30.
Fig. 4:

Investigate communication pace τ vs accuracy
Then, we investigated adding the randomization mechanism on shared weights to protect the data from inversion attack, such as inferring data from model weights, given local model weights. Here we tested the Gaussian and Laplace mechanism, which corresponded to L2 and L1 sensitivity. Institutions may want to specify the level of privacy they want to preserve, which would be reflected in the noise levels. For the Gaussian mechanism experiment, we generated Gaussian noise εn ∼ N(0, ασ) adding to local model weights, where σ was the standard deviation of the local model weights and a was the noise level. We varied α from 0.001 to 1. For the Laplace mechanism experiment, we generated Laplace noise adding to local model weights, where σ was the scale parameter, and a was the standard deviation of the local model weights. We varied α from 0.001 to 1. As the results in Figure 5 and Figure 6 show, there was a trade-off between model performance and noise level (privacy-preserving level). When the noise level was too high (α = 1 in our setup), corresponding to high privacy-preserving levels, the models failed in the classification task.
Fig. 5:

Investigate Gaussian mechanism vs accuracy
Fig. 6:

Investigate Laplace mechanism vs accuracy
4.3. Comparisons with different strategies
To demonstrate the proposed federated learning framework in Algorithm 1 (Fed) could improve multi-site fMRI classification, we compared the proposed methods (τ = 20 and α = 0.01) with four alternative, non-federated strategies: 1) training and testing within the single site (Single); 2) training using one site and testing on another site (Cross); 3) collecting multi-site data together for training (Mix) and 4) creating an ensemble model using the models from different sites (Ensemble). Ensemble method averaged the outputs from aSingle model that was trained within the site and a Cross model that was trained by another site. Single and Cross preserved data privacy, while could not incorporate the data. Mix could take use of all the data from different sites, while could not preserve data privacy. The classification performance of Mix was expected to perform better than Fed as it used more data information. To fairly compare the results, we tried to choose the best model parameters for different strategies by varying the model as little as possible. Because the sizes of the available training data for Single, Cross and Ensemble strategies were much smaller than those of Mix and Fed strategies, we changed the MLP architecture to 6105–8–2 to avoid overfitting, while all the other training settings and data splitting settings were the same as described in Section 4.2.
Considering the fact that data distribution was heterogeneous, we also tried to use the domain adaptation methods introduced in Section 3.2 to boost the classification performance of Fed. For the combination of federated training and MoE (Fed-MoE) strategy, we trained a private classifier simultaneously with the federated architecture. The same as Single, we used MLPs 6105-8-2 as the private models. The gate function was implemented by an MLP with two fully-connected (FC) layers 6105-8-1 and a sigmoid non-linearity layer. For the combination of federated training and adversarial alignment (Fed-Align) strategy, we used four discriminators D to discriminate whether the data came from the source domain. We treated the first two layers of the federated MLPs 6105–16 as a feature generator G, and each site had a different G. Following the randomized mechanism in Fed, we sent the generated features blurred by Gaussian noises εn ∼ N(0, 0.01σ) to the inputs of D. The input of the classifier C was a 16-dim vector. The global model was the concatenation of G − C. Only the G and C weights of local models were shared with the global model. For the whole network training, the setup was the same as training a Fed model, except that we started to propagate adversarial loss on D (Eq. 7) after training the G − C part for 5 epochs.
How to utilize data for training and testing in different classification strategies was explained in Figure 7. All the implemented model architectures were shown in the Appendix. The comparison results were shown in Table 9. In Cross, we denoted the site used for training as ‘tr<site>‘. As the testing data were all the other whole sites, there was no standard deviation (std) to report. Also, we ignored the performance of the site used for training. The other results were reported using the ‘mean (std)’ format. By comparing the mean accuracy only, we highlighted the best accuracy in Table 9. The reason why Cross results were better than Single was probably because more data were included in training (no data splitting). For example, the total number of training instances at the UCLA site with Single strategy was 85×63×0.8 (5-fold) = 4284, while using the Cross strategy training on the USM site then testing on the UCLA site included 205 × 52 = 10660 training instances. Ensemble results were not good, probably because the ensemble methods could not make use of the decisions made by different models and counter-productively weakened the prediction power. The mean accuracy of Fed was higher than the best Cross learning case for each single site. In addition, Fed was significantly better than Single by two sample t test with p < 0.001 for each site. We also observed that Fed-MoE (p = 0.003) and Fed-Align (p < 0.001) significantly improved accuracy on NYU site when comparing with Fed. The accuracy on UM site using Fed-Align was significantly better than the accuracy using Fed (p = 0.018).The accuracy on UCLA site using Fed-MoE showed potential to improve the classification results compared with using Fed (p = 0.094). Using domain adaptation methods did not improve the performance on the USM site, which was probably caused by the data distribution of the USM site. We validated the hypothesis in the following discussion.
Fig. 7:

Different classification strategies
4.4. Evaluate model from interpretation perspective
We tried to understand the model mechanism by interpreting how each model made a particular decision and how the adaptation methods affected the decision-making process.
4.4.1. Aligned feature embedding
We used t-SNE (Maaten and Hinton, 2008) to visualize the latent space embedded by the first fully connected layer in Figure 8a and Figure 8b for our federated learning model without and with adversarial domain alignment. We found the alignment method overall improved domain adaptation. In Figure 8a, we also noticed that the features of the USM site (blue crosses) mixed with other domains. We assumed that could be the reason why the adversarial domain alignment methods did not improve federated learning accuracy for the USM site.
Fig. 8:

t-SNE visualization of latent space.
4.4.2. MoE gating value
The core of MoE was to mix the outputs of a collaboratively-learned global model and a private model in each site. Over time, a site’s gate function a(x) learned whether to trust the global model or the private model more for a given input. The private model needed to perform well on only the subset of the data points for which the global model failed. While the global model still benefited from the data product (model weights) sharing but received weaker updates on these hard ”private” data points. This meant that users with unusual domains had a smaller effect on the global model, which might increase their ability to generalize (Ji et al., 2019). We show the gating value associated with a federated global model for each testing data point in Figure 9. Again, we noticed that the gating values were almost uniformly distributed in the range [0,1], which meant the MoE layer functioned as an inter-medium to coordinate the decisions of the private and global model, except that the gating values of USM site were skewed to 0s and 1s. This showed evidence for why Fed-MoE did not perform better than Fed on the USM site.
Fig. 9:

The histogram of MoE gated values assigned to federated global model.
4.4.3. Neural patterns: connectivity in the autistic brain
Note that we defined ”informativeness” as the difference of functional representations between ASD and HC groups and ”robustness” as the consistency of biomarker detection results across 4 sites. Whether informative and robust biomarkers can be interpreted is another dimension to evaluate a deep learning model apart from using accuracy-related metrics. Here, we used the guided back-propagation method (Eq. 9) to interpret feature importance on Fed and Single model separately. The features of inputs were the functional connectivity between brain ROIs. First, we calculated for each testing point. To get the ROI level evaluation, we built a symmetric grad matrix where the i jth entry is the gc of functional connectivity between ROI i and j. We summed over columns resulting in a 111-dim vector sc standing for the importance score of the 111 ROIs. We normalized by dividing max(sc) to bound it to [0, 1]. We averaged the results for all the test data points in each site. The ROIs with the top 10 important scores for classification (2 classes) and normalized importance scores on the ROIs were plotted for HC (Figure 10) and ASD (Figure 11). Fed detected robust biomarkers across 4 sites, while the biomarkers detected by Single were different across different sites. Further, we listed the correlations between the biomarkers with functional keyword maps in Table 4 by Neurosynth (Yarkoni et al., 2011). The biomarkers detected by Fed were more distinguishable than those of Single, as the differences between correlation values for HC and ASD group were larger than those of Single (see the |Δ| scores of Fed are larger than those of Single in Table 4). Therefore, we found the biomarkers detected by Fed were more informative. We could infer from Table 4 that the semantic, comprehension, social and attention-related functional connectivity was more salient in the HC group, while memory and reward-related functional connectivity was more salient in the ASD group. Hence, the biomarkers detected by Fed were more robust and informative. The names of the biomarkers of each group detected by Fed and Single were listed in the Appendix.
Fig. 10:

Interpreting brain biomarkers associated with identifying HC from federated learning model (Fed) and using single site data for training (Single). The colors stand for the relative importance scores of the ROIs and the values are denoted on the color bar. The names of the strategies and sites are denoted on the left-upper corners of each subfigure. Each row shows the results of NYU, UM, USM, UCLA site from top to bottom.
Fig. 11:

Interpreting brain biomarkers associated with identifying ASD from federated learning model (Fed) and using single site data for training (Single). The colors stand for the relative importance scores of the ROIs and the values are denoted on the color bar. The names of the strategies and sites are denoted on the left-upper corners of each subfigure. Each row shows the results of NYU, UM, USM, UCLA site from top to bottom.
Table 4:
Correlations between the detected biomarkers and functional keywords maps decoded by Neurosynth.
| Sementic | Comprehension | Social | Attention | Memory | Reward | ||
|---|---|---|---|---|---|---|---|
| Fed | HC | 0.054 | 0.096 | 0.099 | 0.088 | 0.009 | −0.078 |
| ASD | −0.048 | −0.035 | −0.081 | 0.007 | 0.031 | 0.017 | |
| |Δ| | 0.102 | 0.131 | 0.180 | 0.081 | 0.022 | 0.095 | |
| Single | HC | 0.050 | 0.043 | 0.069 | 0.053 | 0.022 | −0.062 |
| ASD | −0.029 | −0.005 | −0.094 | 0.005 | 0.041 | 0.010 | |
| |Δ| | 0.079 | 0.048 | 0.163 | 0.048 | 0.019 | 0.072 | |
|Δ| is the absolute difference between the scores of HC and ASC groups.
4.5. Limitation and discussion
Although, based on our empirical investigation that the communication pace, which controled how often the local and global model update the weight information, did not affect the classification performance, we could not draw the conclusion that the pace parameter was irrelevant. A more extensive range of pace values should be examined according to the application. Also, we used practical approaches to investigate privacy-preserving mechanisms. However, the sensitivity of the mapping function h : → m, the deep learning classifier in our case, was difficult to estimate. Hence, we did not explicitly give the bound ϵ. A recent study (Zhu et al., 2019) also demonstrated Gaussian and Laplace noise higher than a certain scale can be a good defense to reconstruction attack. According to the specific application and dataset, we can empirically estimate a suitable noise level from attacking perspective as well. In our experiments, we used the averaging method to incorporate models’ outputs for Ensemble. To achieve better performance for Ensemble, more advanced ensemble methods could be exploited, such as gradient tree boosting, stacking, and forest of randomized trees (Zhou, 2012). We evaluated the biomarkers at the ROI-level. The functional connectivity also could be used as biomarkers. More advanced deep learning models can be explored as well. In order to show the strong direct associations between the biomarkers and disease diagnosis or treatment outcome prediction, down-stream tasks such as regression to ADOS scores using the biomarkers are worthy of exploring. We found that domain adaptation methods were not always a beneficial addition to the federated model. Based on the results presented in Section 4.3 and Section 4.4, we found that domain adaption techniques improved the classification accuracy of some sites but not all (two out of four sites were better and one site kept the same for MoE and MoE by comparing mean accuracies). This could be because the current model updating strategy is not optimal. Going forward, we plan to examine the distribution of the latent features of different data owners first, then decide whether to adopt our proposed domain adaptation methods. In contrast to other FL applications, such as typing recommendations in Google and Apple, where there might be millions of FL participants, there are many fewer participants in multi-site medical data analysis. Hence, the number of FL participants might play a role here, especially if we use an averaging strategy to update the global model. Incorporating more advanced model-selection and updating strategies will help avoid including the wrong private model in updating (Mohri et al., 2019; Nishio and Yonetani, 2019).
5. Conclusion
In this work, we have presented a privacy-preserving federated learning framework for multi-site fMRI analysis. We have investigated the communication pace and the privacy-preserving randomized mechanisms for the problem of using brain functional connectivity to classify ASD and HC. To overcome the domain shift issue, we have proposed two strategies: MoE and adversarial domain alignment to boost federated learning model performance. We have also evaluated the deep learning model for neuroimaging from the biomarker detection perspective.
Our results have demonstrated the advantage of using a federated framework to utilize multi-site data without data sharing compared to alternative methods. We have shown federated learning performance can potentially be boosted by adding domain adaptation and discussed the condition of benefits. In addition, the proposed federated learning model has revealed possible brain biomarkers for identifying ASD. Our work also has broader implications into other disease areas, particularly rare diseases with fewer patients. In these situations, utilizing data across multiple sites is critical and required for meaningful conclusions.
Our approach brings new hope for accelerating deep learning applications in the field of medical imaging, where data isolation and the emphasis on data privacy have become challenges. It can establish a unified model for multiple medical institutions while protecting local data, allowing medical institutions to work together with the required data security.
Table 3:
Results of using different training strategies
| NYU | UM | USM | UCLA | |
|---|---|---|---|---|
| trNYU | - | 0.716 | 0.673 | 0.682 |
| trUM | 0.611 | - | 0.712 | 0.682 |
| trUSM | 0.641 | 0.625 | - | 0.730 |
| trUCLA | 0.575 | 0.648 | 0.750 | - |
| Single | 0.601(0.064) | 0.648(0.065) | 0.695(0.108) | 0.571(0.100) |
| Ensemble | 0.611(0.012) | 0.638(0.054) | 0.654(0.088) | 0.634(0.064) |
| Fed | 0.647(0.049) | 0.728(0.073) | 0.849(0.124) | 0.712(0.075) |
| Fed-MoE | 0.671(0.082) | 0.728(0.083) | 0.809(0.098) | 0.744(0.130) |
| Fed-Align | 0.676(0.071) | 0.751(0.053) | 0.829(0.091) | 0.712(0.089) |
| Mix | 0.671(0.035) | 0.740(0.063) | 0.829(0.137) | 0.710(0.128) |
Highlights.
A novel framework for multi-site fMRI analysis without data-sharing using privacy-preserving federated learning.
The first employment of domain adaptation techniques on federated learning formulation for medical image analysis.
Comparisons to baseline strategies and innovative model evaluation methods from the biomarker interpretation perspective.
New insights into utilizing multi-site medical data to improve both tasks performance and replicable and informative biomarker detection.
Potential solution to training deep learning models on multiple small, heterogeneous, privacy-sensitive medical datasets.
7. Acknowledgements
Data collection and sharing for this project was funded by the Autism Brain Imaging Data Exchange dataset (ABIDE) (Di Martino et al., 2014). Parts of this research was supported by National Institutes of Health (NIH) [R01NS035193, R01MH100028].
Appendix
Architecture of the models
We provide the detailed model architecture for each strategy we used in our study. For each fully connected (FC), we provide the input and output dimension. For drop-out (Dropout) layers, we provide the probability of an element to be zeroed. We denote batch normalization layers as (BN), relu layers as (ReLU) and softmax layers as Softmax.
Models for Single, Cross and Ensemble are shown in Table 5.
Table 5:
Model architecture for ABIDE rs-fMRI classification task under Single, Cross and Ensemble strategies.
| Layer | Configuration |
|---|---|
| MLPs | |
| 1 | Dropout (0.5), FC (6105, 8), ReLU, BN |
| 2 | Dropout (0.5), FC (8, 2), Softmax |
Models for Cross and Ensemble is shown in Table 6.
Table 6:
Model architecture for ABIDE rs-fMRI classification task under Fed and Mix strategies.
| Layer | Configuration |
|---|---|
| MLPs | |
| 1 | Dropout (0.5), FC (6105, 16), ReLU, BN |
| 2 | Dropout (0.5), FC (16, 2), Softmax |
Models for Fed-MoE strategy is shown in Table 7.
Table 7:
Model architecture for ABIDE rs-fMRI classification task under Fed-MoE strategy.
| Layer | Configuration | Layer | Configuration |
|---|---|---|---|
| Private Model | Global Model | ||
| 1 | Dropout (0.5), FC (6105,8), ReLU, BN | 1 | Dropout (0.5), FC (6105,16), ReLU, BN |
| 2 | Dropout (0.5), FC (8,2) | 2 | Dropout (0.5), FC (16,2) |
| Layer | Configuration | ||
| MoE | |||
| 1 | FC (2,1), Sigmoid | ||
Models for Fed-Align strategy is shown in Table 8
Names of the biomarkers
We list the top 10 important ROIs (plotted in Figure 10 and Figure 11 in descending order.
-
1. HC biomarkers detected by Fed:
Table 8:
Model architecture for ABIDE rs-fMRI classification task under Fed-Align strategy.
| Layer | Configuration |
|---|---|
| Feature Generator | |
| 1 | Dropout (0.5), FC (6105, 16), ReLU, BN |
| Domain Discriminator | |
| 1 | FC (6105, 8), ReLU |
| 2 | FC (8, 1), sigmoid |
| Classifier | |
| 1 | Dropout (0.5), FC (16, 2), Softmax |
NYU : ’Right Heschl’s Gyrus (includes H1 and H2)’ ’Right Inferior Temporal Gyrus’ ’Right Superior Frontal Gyrus’ ’Right Precentral Gyrus’ ’Left Intracalcarine Cortex’ ’Left Cingulate Gyrus’ ’Left Temporal Pole’ ’Right Superior Temporal Gyrus’ ’Right Middle Temporal Gyrus’ ’Left Planum Polare’
UM : ’Right Heschl’s Gyrus (includes H1 and H2)’ ’Right Inferior Temporal Gyrus’ ’Right Superior Frontal Gyrus’ ’Right Precentral Gyrus’ ’Left Intracalcarine Cortex’ ’Left Cingulate Gyrus’ ’Right Superior Temporal Gyrus’ ’Left Temporal Pole’ ’Right Middle Temporal Gyrus’ ’Left Planum Polare’
USM : ’Right Heschl’s Gyrus (includes H1 and H2)’ ’Right Inferior Temporal Gyrus’ ’Right Superior Frontal Gyrus’ ’Right Precentral Gyrus’ ’Left Intracalcarine Cortex’ ’Left Cingulate Gyrus’ ’Right Middle Temporal Gyrus’ ’Left Planum Polare’ ’Right Superior Temporal Gyrus’ ’Left Temporal Pole’
UCLA : ’Right Heschl’s Gyrus (includes H1 and H2)’ ’Right Superior Frontal Gyrus’ ’Right Inferior Temporal Gyrus’ ’Right Precentral Gyrus’ ’Left Intracalcarine Cortex’ ’Left Cingulate Gyrus’ ’Left Temporal Pole’ ’Right Superior Temporal Gyrus’ ’Right Middle Temporal Gyrus’ ’Left Planum Polare’
-
2. HC biomarkers detected by Single:
NYU : ’Right Middle Temporal Gyrus’ ’Right Occipital Pole’ ’Right Supramarginal Gyrus’ ’Left Paracingulate Gyrus’ ’Right Precentral Gyrus’ ’Right Frontal Orbital Cortex’ ’Right Temporal Pole’ ’Right Frontal Medial Cortex’ ’Right Parahippocampal Gyrus’ ’Left Parietal Operculum Cortex’
UM : ’Right Supramarginal Gyrus’ ’Right Middle Temporal Gyrus’ ’Left Inferior Temporal Gyrus’ ’Left Inferior Frontal Gyrus’ ’Left Paracingulate Gyrus’ ”Right Heschl’s Gyrus (includes H1 and H2)” ’Left Lingual Gyrus’ ’Right Superior Temporal Gyrus’ ’Left Frontal Orbital Cortex’ ’Left Superior Temporal Gyrus’
USM : ’Right Middle Temporal Gyrus’ ’Right Supramarginal Gyrus’ ’Left Superior Temporal Gyrus’ ’Right Occipital Pole’ ’Left Paracingulate Gyrus’ ’Right Precentral Gyrus’ ’Left Inferior Temporal Gyrus’ ’Left Middle Temporal Gyrus’ ’None’ ’Left Hippocampus’
UCLA : ’Right Supramarginal Gyrus’ ’Right Middle Temporal Gyrus’ ’Right Occipital Pole’ ’Right Precentral Gyrus’ ’Right Temporal Occipital Fusiform Cortex’ ’Left Lingual Gyrus’ ’Left Inferior Temporal Gyrus’ ’Left Paracingulate Gyrus’ ’Right Cingulate Gyrus’ ’Left Inferior Frontal Gyrus’
-
3. ASD biomarkers detected by Fed:
NYU : ’Left Accumbens’ ’Left Parahippocampal Gyrus’ ’Right Thalamus’ ”Right Heschl’s Gyrus (includes H1 and H2)” ’Right Pallidum’ ’Left Middle Frontal Gyrus’ ’Right Precentral Gyrus’ ’Right Parahippocampal Gyrus’ ’Left Cuneal Cortex’ ’Left Temporal Fusiform Cortex’
UM : ’Left Accumbens’ ’Left Frontal Operculum Cortex’ ’Right Thalamus’ ’Right Lateral Occipital Cortex’ ’Right Pallidum’ ’Left Postcentral Gyrus’ ’Left Juxtapositional Lobule Cortex (formerly Supplementary Motor Cortex)’ ’Right Middle Frontal Gyrus’ ’Right Occipital Fusiform Gyrus’ ’Left Central Opercular Cortex’
USM : ’Left Accumbens’ ’Left Frontal Operculum Cortex’ ’Right Thalamus’ ’Right Pallidum’ ’Right Lateral Occipital Cortex’ ’Left Juxtapositional Lobule Cortex (formerly Supplementary Motor Cortex)’ ’Left Postcentral Gyrus’ ’Right Middle Frontal Gyrus’ ’Left Central Opercular Cortex’ ’Right Occipital Fusiform Gyrus’
UCLA : ’Left Accumbens’ ’Left Frontal Operculum Cortex’ ’Right Thalamus’ ’Right Lateral Occipital Cortex’ ’Right Pallidum’ ’Left Juxtapositional Lobule Cortex (formerly Supplementary Motor Cortex)’ ’Left Postcentral Gyrus’ ’Right Middle Frontal Gyrus’ ’Right Occipital Fusiform Gyrus’ ’Left Central Opercular Cortex’
-
4. ASD biomarkers detected by Single:
NYU : ’Right Occipital Fusiform Gyrus’ ’Left Angular Gyrus’ ’Left Putamen’ ’Left Thalamus’ ’Left Supracalcarine Cortex’ ’Right Cingulate Gyrus’ ’Left Frontal Operculum Cortex’ ’Left Juxtapositional Lobule Cortex (formerly Supplementary Motor Cortex)’ ’Right Thalamus’ ’Left Accumbens’
UM : ’Left Supracalcarine Cortex’ ’Left Accumbens’ ’Right Middle Frontal Gyrus’ ’Left Temporal Fusiform Cortex’ ’Right Occipital Fusiform Gyrus’ ’Left Parahippocampal Gyrus’ ’Left Subcallosal Cortex’ ’Left Hippocampus’ ’Left Middle Frontal Gyrus’ ’Right Pallidum’
USM : ’Right Occipital Fusiform Gyrus’ ’Left Putamen’ ’Right Cingulate Gyrus’ ’Right Middle Frontal Gyrus’ ’Left Middle Frontal Gyrus’ ’Right Temporal Pole’ ’Left Caudate’ ’Right Pallidum’ ’Right Central Opercular Cortex’ ’Right Paracingulate Gyrus’
UCLA : ’Left Putamen’ ’Right Occipital Fusiform Gyrus’ ’Right Cingulate Gyrus’ ’Right Temporal Pole’ ’Right Central Opercular Cortex’ ’Left Caudate’ ’Right Paracingulate Gyrus’ ’Right Parahippocampal Gyrus’ ’Right Middle Frontal Gyrus’ ’Left Angular Gyrus’
Additional experiments using alternative atlas
Following the preprocessing pipeline in Section 4.1.2, we replaced the structural Harvard-Oxford (HO) atlas with a functional atlas, the Craddock 200 (CC200), which parcellates brain into 200 ROIs. We replicated the main experiment of our work as shown in Section 4.3, but changed the input dimension of each MLP from 6105 to 19900(= 200 × 100 − 100). The comparison results were shown in Appendix Table 9. Overall, the accuracies of using CC200 was lower than the accuracies of using HO. This could be caused by overfitting as the number of parameters required for training CC200 data is higher than HO due to the dimensionality of the input. In Cross, we denoted the site used for training as ‘tr<site>‘. As the testing data were all the other whole sites, there was no standard deviation (std) to report. Also, we ignored the performance of the site used for training. The other results were reported using the ‘mean (std)’ format. By comparing the mean accuracy only, we highlighted the best accuracy in Table 9. Fed-MoE outperformed Fed on NYU, UM and UCLA site and Fed-Align outperformed Fed on NYU, UM and UCLA site by comparing mean accuracies. All Fed and Fed+Domain Adaptation strategies showed significant improvement compared to Cross, Single and Ensemble strategies. The results showed the replicability of our method on a different atlas.
Table 9:
Results of using different training strategies with atlas CC200. Numbers shown are mean classification accuracies and corresponding stds.
| NYU | UM | USM | UCLA | |
|---|---|---|---|---|
| trNYU | - | 0.559 | 0.669 | 0.689 |
| trUM | 0.611 | - | 0.577 | 0.492 |
| trUSM | 0.635 | 0.693 | - | 0.587 |
| trUCLA | 0.580 | 0.681 | 0.750 | - |
| Single | 0.610(0.062) | 0.681(0.071) | 0.689(0.083) | 0.536(0.121) |
| Ensemble | 0.626(0.054) | 0.676(0.053) | 0.694(0.092) | 0.649(0.069) |
| Fed | 0.648(0.157) | 0.693(0.055) | 0.789(0.153) | 0.652(0.098) |
| Fed-MoE | 0.664(0.072) | 0.705(0.070) | 0.756(0.061) | 0.663(0.146) |
| Fed-Align | 0.683(0.097) | 0.694(0.109) | 0.712(0.053) | 0.667(0.106) |
| Mix | 0.652(0.052) | 0.690(0.092) | 0.752(0.090) | 0.725(0.130) |
Additional experiments on ASD sex classification
Following the preprocessing pipeline in Section 4.1.2, in an effort to illustrate that our approach works effectively on another problem, we present new results on gender classification for ASD subjects. We replicated the main experiment of our work as shown in Section 4.3, but excluded USM site as it only contained male ASDs. The comparison results were shown in Table 10. Strategy Basline was denoted as the random guess accuracy. We found obvious improvement in using federated related strategies and Mix strategy, whereas the other strategies that only could train the model using the data in a single site did not show improvement.
Fig. 12:

Interpreting brain biomarkers associated with identifying Male among ASD subjects from federated learning model (Fed) and using single site data for training (Single). The colors stand for the relative importance scores of the ROIs and the values are denoted on the color bar. The names of the strategies and sites are denoted on the left-upper corners of each subfigure. Each row shows the results of NYU, UM, UCLA site from top to bottom.
Table 10:
Results of ASD sex classification using different training strategies. Numbers shown are mean classification accuracies and corresponding stds.
| NYU | UM | UCLA | |
|---|---|---|---|
| trNYU | - | 0.837 | 0.838 |
| trUM | 0.877 | - | 0.865 |
| trUCLA | 0.890 | 0.814 | - |
| Single | 0.879(0.010) | 0.902(0.013) | 0.887(0.048) |
| Ensemble | 0.915(0.029) | 0.917(0.048) | 0.891(0.062) |
| Fed | 0.972(0.033) | 0.913(0.054) | 0.925(0.098) |
| Fed-MoE | 0.967(0.033) | 0.917(0.048) | 0.937(0.108) |
| Fed-Align | 0.973(0.028) | 0.906(0.048) | 0.955(0.054) |
| Mix | 0.983(0.029) | 0.925(0.052) | 0.975(0.059) |
| Baseline | 0.857 | 0.890 | 0.838 |
Following Section 4.4.3, we used gradient-based feature importance analysis method (Section 3.3) to calculate gc = for each testing point firstly. To get the ROI level evaluation, we built a symmetric grad matrix where the ijth entry was the gc of functional connectivity between ROI i and j. We summed over columns resulting in a 111-dim vector sc standing for the importance score of the 111 ROIs. We normalized sc = by dividing max(sc) to bound it to [0, 1]. We averaged the results for all the test data points in each site. The ROIs with the top 10 important scores for ASD subjects sex classification and normalized importance scores on the ROIs were plotted for male ASD (Figure 12). The sex effects on Frontal Gyrus and Angular Gyrus were pointed out in recent work (Alaerts et al., 2016) and our methods highlighted those ROIs in Figure 12.”
Footnotes
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Abadi M, Chu A, Goodfellow I, McMahan HB, Mironov I, Talwar K, Zhang L, 2016. Deep learning with differential privacy, in: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, ACM; pp. 308–318. [Google Scholar]
- Alaerts K, Swinnen SP, Wenderoth N, 2016. Sex differences in autism: a resting-state fmri investigation of functional brain connectivity in males and females. Social cognitive and affective neuroscience 11, 1002–1016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chaudhuri K, Imola J, Machanavajjhala A, 2019. Capacity bounded differential privacy, in: Advances in Neural Information Processing Systems, pp. 3469–3478. [Google Scholar]
- Chen C, Dou Q, Chen H, Qin J, Heng PA, 2019. Synergistic image and feature adaptation: Towards cross-modality domain adaptation for medical image segmentation, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 865–872. [Google Scholar]
- Dean J, Corrado G, Monga R, Chen K, Devin M, Mao M, Ranzato M, Senior A, Tucker P, Yang K, et al. , 2012. Large scale distributed deep networks, in: Advances in neural information processing systems, pp. 1223–1231. [Google Scholar]
- Di Martino A, Yan CG, Li Q, Denio E, Castellanos FX, Alaerts K, Anderson JS, Assaf M, Bookheimer SY, Dapretto M, et al. , 2014. The autism brain imaging data exchange: towards a large-scale evaluation of the intrinsic brain architecture in autism. Molecular psychiatry 19, 659. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Du Y, Fu Z, Calhoun VD, 2018. Classification and prediction of brain disorders using functional connectivity: promising but challenging. Frontiers in neuroscience 12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dwork C, Kenthapadi K, McSherry F, Mironov I, Naor M, 2006a. Our data, ourselves: Privacy via distributed noise generation, in: Annual International Conference on the Theory and Applications of Cryptographic Techniques, Springer; pp. 486–503. [Google Scholar]
- Dwork C, McSherry F, Nissim K, Smith A, 2006b. Calibrating noise to sensitivity in private data analysis, in: Theory of cryptography conference, Springer; pp. 265–284. [Google Scholar]
- Dwork C, Roth A, et al. , 2014. The algorithmic foundations of differential privacy. Foundations and Trends® in Theoretical Computer Science 9, 211–407. [Google Scholar]
- Ganin Y, Lempitsky V, 2014. Unsupervised domain adaptation by backpropagation. arXiv preprint arXiv:1409.7495. [Google Scholar]
- Ghifary M, Kleijn WB, Zhang M, Balduzzi D, Li W, 2016. Deep reconstruction-classification networks for unsupervised domain adaptation, in: European Conference on Computer Vision, Springer; pp. 597–613. [Google Scholar]
- Gholami B, Sahu P, Rudovic O, Bousmalis K, Pavlovic V, 2018. Unsupervised multi-target domain adaptation: An information theoretic approach. arXiv preprint arXiv:1810.11547. [DOI] [PubMed] [Google Scholar]
- Heinsfeld AS, Franco AR, Craddock RC, Buchweitz A, Meneguzzi F, 2018. Identification of autism spectrum disorder using deep learning and the abide dataset. NeuroImage: Clinical 17, 16–23. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heitmueller A, Henderson S, Warburton W, Elmagarmid A, Pentland AS, Darzi A, 2014. Developing public policy to advance the use of big data in health care. Health Affairs 33, 1523–1530. [DOI] [PubMed] [Google Scholar]
- Hoffman J, Mohri M, Zhang N, 2018. Algorithms and theory for multiple-source adaptation, in: Advances in Neural Information Processing Systems, pp. 8246–8256. [Google Scholar]
- Ji S, Pan S, Long G, Li X, Jiang J, Huang Z, 2019. Learning private neural language modeling with attentive aggregation, in: 2019 International Joint Conference on Neural Networks (IJCNN), IEEE; pp. 1–8. [Google Scholar]
- Li T, Sahu AK, Talwalkar A, Smith V, 2019a. Federated learning: Challenges, methods, and future directions. arXiv preprint arXiv:1908.07873. [Google Scholar]
- Li W, Milletarì F, Xu D, Rieke N, Hancox J, Zhu W, Baust M, Cheng Y, Ourselin S, Cardoso MJ, et al. , 2019b. Privacy-preserving federated brain tumour segmentation, in: International Workshop on Machine Learning in Medical Imaging, Springer; pp. 133–141. [Google Scholar]
- Long M, Cao Y, Wang J, Jordan MI, 2015. Learning transferable features with deep adaptation networks. arXiv preprint arXiv:1502.02791. [Google Scholar]
- Long M, Cao Z, Wang J, Jordan MI, 2018. Conditional adversarial domain adaptation, in: Advances in Neural Information Processing Systems, pp. 1640–1650. [Google Scholar]
- Long M, Zhu H, Wang J, Jordan MI, 2017. Deep transfer learning with joint adaptation networks, in: Proceedings of the 34th International Conference on Machine Learning-Volume 70, JMLR. org; pp. 2208–2217. [Google Scholar]
- Maaten L. v.d., Hinton G, 2008. Visualizing data using t-sne. Journal of machine learning research 9, 2579–2605. [Google Scholar]
- Masoudnia S, Ebrahimpour R, 2014. Mixture of experts: a literature survey. Artificial Intelligence Review 42, 275–293. [Google Scholar]
- McMahan H, Moore E, Ramage D, Agera y Arcas B, 2016. Federated learning of deep networks using model averaging. [Google Scholar]
- Mohri M, Sivek G, Suresh AT, 2019. Agnostic federated learning. arXiv preprint arXiv:1902.00146. [Google Scholar]
- Nishio T, Yonetani R, 2019. Client selection for federated learning with heterogeneous resources in mobile edge, in: ICC 2019–2019 IEEE International Conference on Communications (ICC), IEEE; pp. 1–7. [Google Scholar]
- Peng X, Huang Z, Zhu Y, Saenko K, 2019. Federated adversarial domain adaptation. arXiv preprint arXiv:1911.02054. [Google Scholar]
- Peterson D, Kanani P, Marathe VJ, 2019. Private federated learning with domain adaptation. arXiv preprint arXiv:1912.06733. [Google Scholar]
- POLICY IDCBT, THIS I, OR PVBOR, 2003. Cdc/atsdr policy on releasing and sharing data. [Google Scholar]
- Quionero-Candela J, Sugiyama M, Schwaighofer A, Lawrence ND, 2009. Dataset shift in machine learning. The MIT Press. [Google Scholar]
- Rosenbaum SJ, Painter MW, 2005. Assessing legal implications of using health data to improve health care quality and eliminate health care disparities. [Google Scholar]
- Roski J, Bo-Linn GW, Andrews TA, 2014. Creating value in health care through big data: opportunities and policy implications. Health affairs 33, 1115–1122. [DOI] [PubMed] [Google Scholar]
- Shazeer N, Mirhoseini A, Maziarz K, Davis A, Le Q, Hinton G, Dean J, 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538. [Google Scholar]
- Sheller MJ, Reina GA, Edwards B, Martin J, Bakas S, 2018. Multi-institutional deep learning modeling without sharing patient data: A feasibility study on brain tumor segmentation, in: International MICCAI Brain-lesion Workshop, Springer; pp. 92–104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shen D, Wu G, Suk HI, 2017. Deep learning in medical image analysis. Annual review of biomedical engineering 19, 221–248. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shokri R, Shmatikov V, 2015. Privacy-preserving deep learning, in: Proceedings of the 22nd ACM SIGSAC conference on computer and communications security, ACM; pp. 1310–1321. [Google Scholar]
- Simonyan K, Vedaldi A, Zisserman A, 2013. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv:1312.6034. [Google Scholar]
- Springenberg JT, Dosovitskiy A, Brox T, Riedmiller M, 2014. Striving for simplicity: The all convolutional net. arXiv preprint arXiv:1412.6806. [Google Scholar]
- Suk HI, Wee CY, Lee SW, Shen D, 2016. State-space model with deep learning for functional dynamics estimation in resting-state fmri. NeuroImage 129, 292–307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sun B, Saenko K, 2016. Deep coral: Correlation alignment for deep domain adaptation, in: European Conference on Computer Vision, Springer; pp. 443–450. [Google Scholar]
- Tzeng E, Hoffman J, Saenko K, Darrell T, 2017. Adversarial discriminative domain adaptation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7167–7176. [Google Scholar]
- Tzeng E, Hoffman J, Zhang N, Saenko K, Darrell T, 2014. Deep domain confusion: Maximizing for domain invariance. arXiv preprint arXiv:1412.3474. [Google Scholar]
- Varoquaux G, Thirion B, 2014. How machine learning is shaping cognitive neuroimaging. GigaScience 3, 28. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang X, Yu F, Dunlap L, Ma YA, Wang R, Mirhoseini A, Darrell T, Gonzalez JE, 2018. Deep mixture of experts via shallow embedding. arXiv preprint arXiv:1806.01531. [Google Scholar]
- Weimer DL, Vining AR, 2017. Policy analysis: Concepts and practice. Routledge. [Google Scholar]
- Yang J, Dvornek NC, Zhang F, Chapiro J, Lin M, Duncan JS, 2019a. Unsupervised domain adaptation via disentangled representations: Application to cross-modality liver segmentation, in: International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer; pp. 255–263. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang Q, Liu Y, Chen T, Tong Y, 2019b. Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST) 10, 12. [Google Scholar]
- Yao Y, Zhang Y, Li X, Ye Y, 2019. Heterogeneous domain adaptation via soft transfer network, in: Proceedings of the 27th ACM International Conference on Multimedia, pp. 1578–1586. [Google Scholar]
- Yarkoni T, Poldrack RA, Nichols TE, Van Essen DC, Wager TD, 2011. Large-scale automated synthesis of human functional neuroimaging data. Nature methods 8, 665. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao S, Li B, Yue X, Gu Y, Xu P, Hu R, Chai H, Keutzer K, 2019. Multi-source domain adaptation for semantic segmentation, in: Advances in Neural Information Processing Systems, pp. 7285–7298. [Google Scholar]
- Zhou ZH, 2012. Ensemble methods: foundations and algorithms. Chapman and Hall/CRC. [Google Scholar]
- Zhu JY, Park T, Isola P, Efros AA, 2017. Unpaired image-to-image translation using cycle-consistent adversarial networks, in: Proceedings of the IEEE international conference on computer vision, pp. 2223–2232. [Google Scholar]
- Zhu L, Liu Z, Han S, 2019. Deep leakage from gradients. arXiv:1906.08935. [Google Scholar]