

Abstract
Estimating temporal changes in a target population from phylogenetic or count data is an important problem in ecology and epidemiology. Reliable estimates can provide key insights into the climatic and biological drivers influencing the diversity or structure of that population and evidence hypotheses concerning its future growth or decline. In infectious disease applications, the individuals infected across an epidemic form the target population. The renewal model estimates the effective reproduction number, R, of the epidemic from counts of observed incident cases. The skyline model infers the effective population size, N, underlying a phylogeny of sequences sampled from that epidemic. Practically, R measures ongoing epidemic growth while N informs on historical caseload. While both models solve distinct problems, the reliability of their estimates depends on p-dimensional piecewise-constant functions. If p is misspecified, the model might underfit significant changes or overfit noise and promote a spurious understanding of the epidemic, which might misguide intervention policies or misinform forecasts. Surprisingly, no transparent yet principled approach for optimizing p exists. Usually, p is heuristically set, or obscurely controlled via complex algorithms. We present a computable and interpretable p-selection method based on the minimum description length (MDL) formalism of information theory. Unlike many standard model selection techniques, MDL accounts for the additional statistical complexity induced by how parameters interact. As a result, our method optimizes p so that R and N estimates properly and meaningfully adapt to available data. It also outperforms comparable Akaike and Bayesian information criteria on several classification problems, given minimal knowledge of the parameter space, and exposes statistical similarities among renewal, skyline, and other models in biology. Rigorous and interpretable model selection is necessary if trustworthy and justifiable conclusions are to be drawn from piecewise models. [Coalescent processes; epidemiology; information theory; model selection; phylodynamics; renewal models; skyline plots]
Inferring the temporal trends or dynamics of a target population is an important problem in ecology, evolution, and systematics. Reliable estimates of the demographic changes underlying empirical data sampled from an animal or human population, for example, can corroborate or refute hypotheses about the historical and ongoing influence of environmental or anthropogenic factors, or inform on the major forces shaping the diversity and structure of that population (Turchin 2003; Ho and Shapiro 2011). In infectious disease epidemiology, where the target population is often the number of infected individuals (infecteds), demographic fluctuations can provide insight into key shifts in the fitness and transmissibility of a pathogen and motivate or validate public health intervention policy (Rambaut et al. 2008; Churcher et al. 2014).
Sampled phylogenies (or genealogies) and incidence curves (or epi-curves) are two related but distinct types of empirical data that inform about the population dynamics and ecology of infectious disease epidemics. Phylogenies map the tree of ancestral relationships among genetic sequences that were sampled from the infected population (Drummond et al. 2005). They facilitate a retrospective view of epidemic dynamics by allowing estimation of the historical effective size or diversity of that population. Incidence curves chart the number of new infecteds observed longitudinally across the epidemic (Wallinga and Teunis 2004). They provide insight into the ongoing rate of spread of that epidemic, by enabling the inference of its effective reproduction number. Minimal examples of each empirical data type are given in Fig. 1(a)(i) and (b)(ii).
Figure 1.

Skyline and renewal model inference problems. The left panels (a) show how the reconstructed phylogeny of infecteds (i) leads to (branching) coalescent events, which form the Poisson count record of (ii). The timing of these observable events encodes information about the piecewise effective population size function to be inferred in (iii). The right panels (b) indicate how infecteds, which naturally conform to the Poisson count record of (iv) are usually only observed at the resolution of days or weeks, leading to the Poisson histogram record in (v). The number of infecteds in these histogram bins inform on the piecewise effective reproduction number in (vi). Both models feature data with size 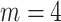 and involve
and involve 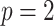 parameters to be estimated. See Materials and Methods for notation.
parameters to be estimated. See Materials and Methods for notation.
The effective reproduction number at time 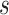 ,
, 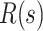 , is a key diagnostic of whether an outbreak is growing or under control. It defines how many secondary infections an infected will, on average, generate (Wallinga and Teunis 2004). The renewal or branching process model (Fraser 2007) is a popular approach for inferring
, is a key diagnostic of whether an outbreak is growing or under control. It defines how many secondary infections an infected will, on average, generate (Wallinga and Teunis 2004). The renewal or branching process model (Fraser 2007) is a popular approach for inferring 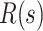 from incidence curves that generalizes the Lotka–Euler equation from ecology (Wallinga and Lipsitch 2007). Renewal models describe how fluctuations in
from incidence curves that generalizes the Lotka–Euler equation from ecology (Wallinga and Lipsitch 2007). Renewal models describe how fluctuations in 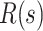 modulate the tree-like propagation structure of an epidemic and have been used to predict Ebola virus disease case counts and assess the transmissibility of pandemic influenza, for example (Fraser et al. 2011; Cori et al. 2013; Nouvellet et al. 2018). Here
modulate the tree-like propagation structure of an epidemic and have been used to predict Ebola virus disease case counts and assess the transmissibility of pandemic influenza, for example (Fraser et al. 2011; Cori et al. 2013; Nouvellet et al. 2018). Here 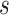 indicates discrete time, for example, days.
indicates discrete time, for example, days.
The effective population size at 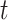 ,
, 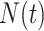 , is a popular proxy for census (or true) population size that derives from the genetic diversity of the target demography. When applied to epidemics,
, is a popular proxy for census (or true) population size that derives from the genetic diversity of the target demography. When applied to epidemics, 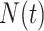 measures the number of infecteds contributing offspring (i.e., transmitting the disease) to the next generation (Ho and Shapiro 2011). The skyline plot model (Pybus et al. 2000) is a prominent means of estimating
measures the number of infecteds contributing offspring (i.e., transmitting the disease) to the next generation (Ho and Shapiro 2011). The skyline plot model (Pybus et al. 2000) is a prominent means of estimating 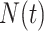 from phylogenies that extends the Kingman coalescent process from population genetics (Kingman 1982). Skyline models explain how variations in
from phylogenies that extends the Kingman coalescent process from population genetics (Kingman 1982). Skyline models explain how variations in 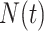 influence the shape and size of the infected genealogy and have informed on the historical transmission and origin of HIV, influenza and hepatitis C, among others (Pybus et al. 2001; Lemey et al. 2003; Rambaut et al. 2008). Here,
influence the shape and size of the infected genealogy and have informed on the historical transmission and origin of HIV, influenza and hepatitis C, among others (Pybus et al. 2001; Lemey et al. 2003; Rambaut et al. 2008). Here, 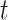 is continuous and usually in units of genealogical time.
is continuous and usually in units of genealogical time.
While renewal and skyline models depict very different aspects of an infectious disease, they possess some statistical similarities. Foremost is their approximation of 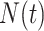 and
and 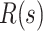 by
by 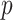 -dimensional, piecewise-constant functions (see Fig. 1(iii)). Here,
-dimensional, piecewise-constant functions (see Fig. 1(iii)). Here, 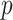 is the number of parameters to be inferred from the data and time is regressive for phylogenies but progressive for incidence curves. The choice of
is the number of parameters to be inferred from the data and time is regressive for phylogenies but progressive for incidence curves. The choice of 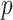 is critical to the quality of inference. Models with large
is critical to the quality of inference. Models with large 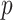 can better track rapid changes but are susceptible to noise and uncertainty (overfitting) (Cori et al. 2013). Smaller
can better track rapid changes but are susceptible to noise and uncertainty (overfitting) (Cori et al. 2013). Smaller 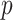 improves estimate precision but reduces flexibility, easily over-smoothing (underfitting) salient changes (Minin et al. 2008). Optimally selecting
improves estimate precision but reduces flexibility, easily over-smoothing (underfitting) salient changes (Minin et al. 2008). Optimally selecting 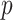 , in a manner that is justified by the available data, is integral to deriving reliable and sensible conclusions from these models.
, in a manner that is justified by the available data, is integral to deriving reliable and sensible conclusions from these models.
Surprisingly, no transparent, principled and easily computable 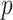 -selection strategy exists. In renewal models,
-selection strategy exists. In renewal models, 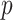 is often set by trial and error, or defined using heuristic sliding windows (Fraser 2007; Cori et al. 2013). Existing theory on window choice is limited, with (Cori et al. 2013) positing a bound on the minimum number of infecteds a window should contain for a given level of estimate uncertainty and (Nouvellet et al. 2018) initially proposing a “naïve-rational” squared error based window-sizing approach, which they subsequently found inferior to other subjective window choices examined in that study. In skyline models, this problem has been more actively researched because the classic skyline plot (Pybus et al. 2000), which forms the core of most modern skyline methods, overfits by construction, that is, it infers a parameter per data-point. Accordingly, various approaches for reducing
is often set by trial and error, or defined using heuristic sliding windows (Fraser 2007; Cori et al. 2013). Existing theory on window choice is limited, with (Cori et al. 2013) positing a bound on the minimum number of infecteds a window should contain for a given level of estimate uncertainty and (Nouvellet et al. 2018) initially proposing a “naïve-rational” squared error based window-sizing approach, which they subsequently found inferior to other subjective window choices examined in that study. In skyline models, this problem has been more actively researched because the classic skyline plot (Pybus et al. 2000), which forms the core of most modern skyline methods, overfits by construction, that is, it infers a parameter per data-point. Accordingly, various approaches for reducing 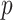 , by ensuring that each population size parameter is informed by groups of data points, have been proposed.
, by ensuring that each population size parameter is informed by groups of data points, have been proposed.
The generalized skyline plot (Strimmer and Pybus 2001) uses a small sample correction to the Akaike information criterion (AIC) to achieve one such grouping in an interpretable and computable fashion. However, basing analyses solely on the AIC can still lead to overfitting (Kass and Raftery 1995). The Bayesian skyline plot built on the generalized skyline by additionally incorporating a prior distribution that assumed an exponentially distributed autocorrelation between successive parameters (Drummond et al. 2005). This implicitly influenced group choices but is known to oversmooth or underfit (Minin et al. 2008). As a result, later approaches such as the Skyride and Skygrid reverted to the classic skyline plot and applied Gaussian–Markov smoothing prior distributions to achieve implicit grouping (Minin et al. 2008; Gill et al. 2012). However, these methods also raised concerns about underfitting and the relationship between model selection and smoothing prior settings is obscure (Parag et al. 2020a).
Other approaches to effective population size model selection are considerably more involved. The extended Bayesian skyline plot and the multiple change-point method use piecewise-linear functions and apply Bayesian stochastic search variable selection (Heled and Drummond 2008) and reversible jump MCMC (Opgen-Rhein et al. 2005) to optimize 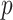 . These algorithms, while capable, are more computationally demanding, and lack interpretability (their results are not easily debugged and linear functions do not possess the biological meaningfulness of constant ones, which estimate the harmonic mean of time-varying population sizes, Pybus et al. 2000). Note that we assume phylogenetic data is available without error (i.e., we do not consider extensions of the above or subsequent methods to genealogical uncertainty) and limit the definition of skyline models to those with piecewise-constant functions. In Fig. A4 of the Appendix, we illustrate estimates from some of these approaches on an empirical HIV data set.
. These algorithms, while capable, are more computationally demanding, and lack interpretability (their results are not easily debugged and linear functions do not possess the biological meaningfulness of constant ones, which estimate the harmonic mean of time-varying population sizes, Pybus et al. 2000). Note that we assume phylogenetic data is available without error (i.e., we do not consider extensions of the above or subsequent methods to genealogical uncertainty) and limit the definition of skyline models to those with piecewise-constant functions. In Fig. A4 of the Appendix, we illustrate estimates from some of these approaches on an empirical HIV data set.
New 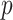 -selection metrics, which can balance between the interpretability of the generalized skyline and the power of more sophisticated Bayesian selection methods, are therefore needed. Here, we attempt to answer this need by developing and validating a minimum description length (MDL)-based approach that unifies renewal and skyline model selection. MDL is a formalism from information theory that treats model selection as equivalent to finding the best way of compressing observed data (i.e., its shortest description) (Rissanen 1978). MDL is advantageous because it includes both model dimensionality and parametric complexity within its definition of model complexity (Rissanen 1996). Parametric complexity describes how the functional relationship between parameters matters (Myung et al. 2006) and is usually ignored by standard selection criteria. However, MDL is generally difficult to compute (Grunwald 2007), which may explain why it has not penetrated the epidemiological or phylodynamics literature.
-selection metrics, which can balance between the interpretability of the generalized skyline and the power of more sophisticated Bayesian selection methods, are therefore needed. Here, we attempt to answer this need by developing and validating a minimum description length (MDL)-based approach that unifies renewal and skyline model selection. MDL is a formalism from information theory that treats model selection as equivalent to finding the best way of compressing observed data (i.e., its shortest description) (Rissanen 1978). MDL is advantageous because it includes both model dimensionality and parametric complexity within its definition of model complexity (Rissanen 1996). Parametric complexity describes how the functional relationship between parameters matters (Myung et al. 2006) and is usually ignored by standard selection criteria. However, MDL is generally difficult to compute (Grunwald 2007), which may explain why it has not penetrated the epidemiological or phylodynamics literature.
We overcome this issue by deriving a tractable Fisher information approximation (FIA) to MDL. This is achieved by recognizing that sampled phylogenies and incidence curves both sit within a Poisson point process framework and by capitalizing on the piecewise-constant structure of skyline and renewal models. The result is a pair of analogous FIA metrics that lead to adaptive estimates of 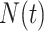 and
and 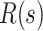 by selecting the
by selecting the 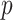 most justified by the observed Poisson data. These expressions decompose model complexity into clearly interpretable contributions and are as computable as the standard AIC and the Bayesian information criterion (BIC). We find, over a range of selection problems, that the FIA generally outperforms the AIC and BIC, emphasizing the importance of including parametric complexity. This improvement requires some knowledge about the piecewise parameter space domain.
most justified by the observed Poisson data. These expressions decompose model complexity into clearly interpretable contributions and are as computable as the standard AIC and the Bayesian information criterion (BIC). We find, over a range of selection problems, that the FIA generally outperforms the AIC and BIC, emphasizing the importance of including parametric complexity. This improvement requires some knowledge about the piecewise parameter space domain.
Materials and Methods
Phylogenetic Skyline and Epidemic Renewal Models
The phylogenetic skyline and epidemic renewal models are popular approaches for solving inference problems in infectious disease epidemiology. The skyline plot or model (Ho and Shapiro 2011) infers the hidden, time-varying effective population size, 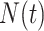 , from a phylogeny of sequences sampled from that infected population; while the renewal or branching process model (Fraser et al. 2011) estimates the hidden, time-varying effective reproduction number,
, from a phylogeny of sequences sampled from that infected population; while the renewal or branching process model (Fraser et al. 2011) estimates the hidden, time-varying effective reproduction number, 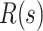 , from the observed incidence of an infectious disease. Here,
, from the observed incidence of an infectious disease. Here, 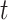 indicates continuous time, which is progressive (moving from past to present) in the renewal model, but reversed (retrospective) in the skyline, while
indicates continuous time, which is progressive (moving from past to present) in the renewal model, but reversed (retrospective) in the skyline, while 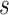 is its discrete equivalent. We use
is its discrete equivalent. We use 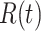 here initially as we work in continuous time before deriving the discretized version
here initially as we work in continuous time before deriving the discretized version 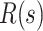 .
.
While both models solve different problems, they approximate their variable of interest, 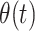 , with a
, with a 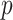 -dimensional piecewise-constant function, and assume a Poisson point process (PP) relationship between it and the observed data,
-dimensional piecewise-constant function, and assume a Poisson point process (PP) relationship between it and the observed data, 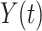 , as in Eq. (1).
, as in Eq. (1).
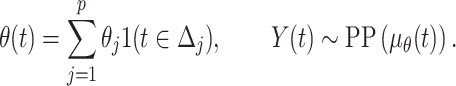 |
(1) |
Here, 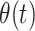 is either
is either 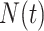 or
or 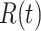 and
and 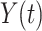 is either phylogenetic or incidence data, depending on the model of interest. The
is either phylogenetic or incidence data, depending on the model of interest. The 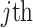 piecewise component of
piecewise component of 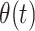 , which is valid over the interval
, which is valid over the interval 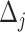 , is
, is 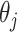 . The rate function,
. The rate function, 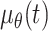 depends on
depends on 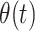 and allows us to treat the usually distinct skyline and renewal models within the same Poisson point process framework. We want to estimate the parameter vector
and allows us to treat the usually distinct skyline and renewal models within the same Poisson point process framework. We want to estimate the parameter vector 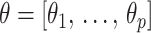 from the data over
from the data over 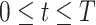 , denoted
, denoted 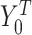 . We consider two fundamental mechanisms for observing
. We consider two fundamental mechanisms for observing 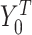 and then show how they apply to skyline and renewal models in turn.
and then show how they apply to skyline and renewal models in turn.
The first, known as a Poisson count record (Snyder and Miller 1991), involves having access to every event time of the Poisson process, that is, 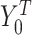 is observed directly. Eq. (2) gives the likelihood of these data, in which a total of
is observed directly. Eq. (2) gives the likelihood of these data, in which a total of 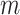 events occur.
events occur.
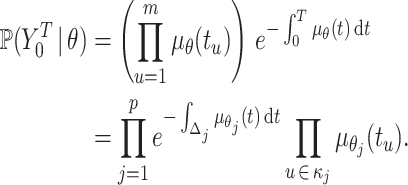 |
(2) |
The 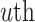 event time is
event time is 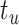 and
and 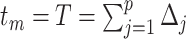 . The set
. The set 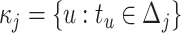 collects all event indices within the
collects all event indices within the 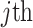 piecewise interval and
piecewise interval and 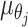 emphasizes that the parameter controlling the rate in
emphasizes that the parameter controlling the rate in 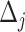 is
is 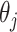 . We denote the portion of events falling within
. We denote the portion of events falling within 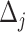 as
as 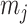 so that
so that 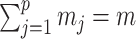 . The number of elements in
. The number of elements in 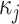 is therefore
is therefore 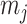 . The boundaries of
. The boundaries of 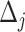 are defined by the times of the
are defined by the times of the 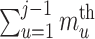 event (exclusive) and the
event (exclusive) and the 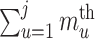 event (inclusive). The size of the data is also summarized by
event (inclusive). The size of the data is also summarized by 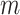 and
and 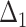 starts at 0.
starts at 0.
The second is called a Poisson histogram record (Snyder and Miller 1991) and applies when individual events are not observed. Instead only counts of the events occurring within time bins are available and the size of the data is now defined by the number of bins. We redefine 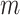 for this data type as the number of bins so that it again controls data size. The
for this data type as the number of bins so that it again controls data size. The 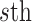 bin is defined on interval
bin is defined on interval 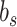 and has count
and has count 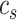 . We use
. We use 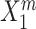 to denote the bin transformed version of
to denote the bin transformed version of 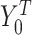 . The likelihood is then given by Eq. (3).
. The likelihood is then given by Eq. (3).
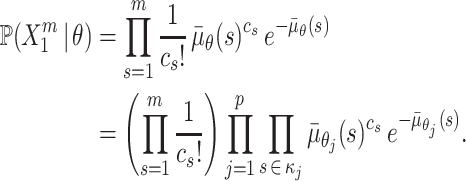 |
(3) |
Here, 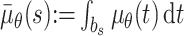 is the Poisson rate integrated across the
is the Poisson rate integrated across the 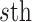 observation bin and
observation bin and 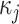 again defines the indices (of bins in this case) that are controlled by
again defines the indices (of bins in this case) that are controlled by 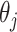 . The time interval over which
. The time interval over which 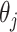 is valid is
is valid is 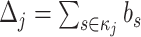 . Figure 1 illustrates the relationship between histogram and count records. We now detail how these two observation schemes apply to phylogenetic and incidence data and hence skyline and renewal models.
. Figure 1 illustrates the relationship between histogram and count records. We now detail how these two observation schemes apply to phylogenetic and incidence data and hence skyline and renewal models.
The skyline model is founded on the coalescent approach to phylogenetics (Kingman 1982). Here, genetic sequences (lineages) sampled from an infected population across time elicit a reconstructed phylogeny or tree, in which these lineages successively merge into their common ancestor. The observed branching or coalescent times of this tree form a Poisson point process that contains information about the piecewise effective population parameters 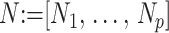 . Since the coalescent event times
. Since the coalescent event times 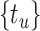 are observable, phylogenetic data correspond to a Poisson count record. The rate underlying the events for
are observable, phylogenetic data correspond to a Poisson count record. The rate underlying the events for 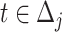 is
is 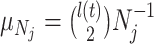 with
with 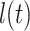 counting the lineages in the phylogeny at time
counting the lineages in the phylogeny at time 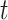 (this increases at sample event times and decrements at coalescent times).
(this increases at sample event times and decrements at coalescent times).
The log-likelihood of the observed, serially sampled tree data, denoted by count record 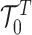 is then derived from Eq. (2) to obtain Eq. (4), which is equivalent to standard skyline log-likelihoods (Drummond et al. 2005), but with constant terms removed.
is then derived from Eq. (2) to obtain Eq. (4), which is equivalent to standard skyline log-likelihoods (Drummond et al. 2005), but with constant terms removed.
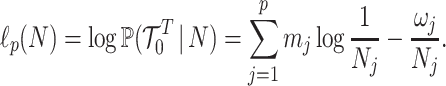 |
(4) |
Here, 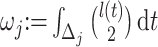 and
and 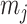 counts the number of coalescent events falling within
counts the number of coalescent events falling within 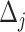 . The endpoints of
. The endpoints of 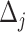 coincide with coalescent event times, as in (Pybus et al., 2000), (Drummond et al., 2005), and (Parag et al., 2020b). Figure 1a outlines the skyline coalescent inference problem and summarizes its notation. Since
coincide with coalescent event times, as in (Pybus et al., 2000), (Drummond et al., 2005), and (Parag et al., 2020b). Figure 1a outlines the skyline coalescent inference problem and summarizes its notation. Since 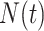 can have a large dynamic range (e.g., for exponentially growing epidemics), we will analyze the skyline model under the robust log transform (Parag and Pybus 2019), which ensures good statistical properties.
can have a large dynamic range (e.g., for exponentially growing epidemics), we will analyze the skyline model under the robust log transform (Parag and Pybus 2019), which ensures good statistical properties.
The maximum likelihood estimate (MLE) and Fisher information (FI) are important measures for describing how estimates of 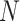 (or
(or 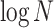 ) depend on
) depend on 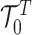 . We compute the MLE,
. We compute the MLE, 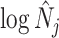 , and FI,
, and FI, 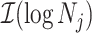 , of the skyline model by solving
, of the skyline model by solving 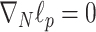 and
and 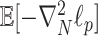 and then log-transforming, with
and then log-transforming, with 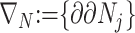 as the vector derivative operator (Lehmann and Casella 1998). The result is Eq. (5) (Parag and Pybus 2019).
as the vector derivative operator (Lehmann and Casella 1998). The result is Eq. (5) (Parag and Pybus 2019).
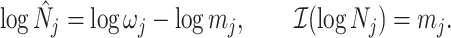 |
(5) |
For a given 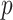 , the MLE controls the per-segment bias because as
, the MLE controls the per-segment bias because as 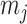 increases
increases 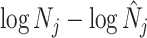 decreases. The FI defines the precision, that is, the inverse of the variance around the MLEs, and also (directly) improves with
decreases. The FI defines the precision, that is, the inverse of the variance around the MLEs, and also (directly) improves with 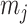 . We will find these two quantities to be integral to formulating our approach to
. We will find these two quantities to be integral to formulating our approach to 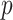 -model selection. Thus, the FI and MLE control the per-segment performance, while
-model selection. Thus, the FI and MLE control the per-segment performance, while 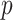 determines how well the overall piecewise function adapts to the underlying generating process.
determines how well the overall piecewise function adapts to the underlying generating process.
The renewal model is based on the classic (Lotka–Euler) renewal equation or branching process approach to epidemic transmission (Wallinga and Lipsitch 2007). This states that the number of new infecteds depends on past incidence through the generation time distribution, and the effective reproduction number 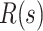 . As incidence is usually observed on a coarse temporal scale (e.g., days or weeks), exact infection times are not available. As a result, incidence data conform to a Poisson histogram record with the number of infecteds observed in the
. As incidence is usually observed on a coarse temporal scale (e.g., days or weeks), exact infection times are not available. As a result, incidence data conform to a Poisson histogram record with the number of infecteds observed in the 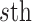 bin denoted
bin denoted 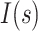 . For simplicity, we assume daily (unit) bins. The generation time distribution is specified by
. For simplicity, we assume daily (unit) bins. The generation time distribution is specified by 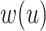 , the probability that an infected takes between
, the probability that an infected takes between  and
and 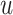 days to transmit that infection (Fraser 2007).
days to transmit that infection (Fraser 2007).
The total infectiousness of the disease is 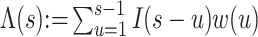 . We make the common assumptions that
. We make the common assumptions that 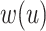 is known (it is disease specific) and stationary (does not change with time) (Cori et al. 2013). If an epidemic is observed for
is known (it is disease specific) and stationary (does not change with time) (Cori et al. 2013). If an epidemic is observed for 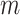 days then the historical incidence counts,
days then the historical incidence counts, 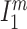 , constitute the histogram record informing on the piecewise parameters to be estimated,
, constitute the histogram record informing on the piecewise parameters to be estimated, 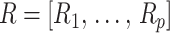 . The renewal equation asserts that
. The renewal equation asserts that 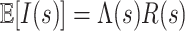 (Fraser 2007). Setting this as the integrated bin rate
(Fraser 2007). Setting this as the integrated bin rate  allows us to obtain the log-likelihood of Eq. (6) from Eq. (3).
allows us to obtain the log-likelihood of Eq. (6) from Eq. (3).
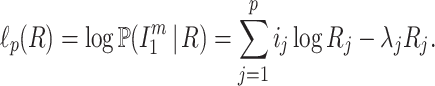 |
(6) |
Here, 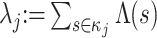 and
and 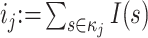 are sums across the indices
are sums across the indices 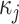 , which define the
, which define the 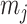 bins composing
bins composing 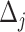 . Equation 6 is equivalent to the standard renewal log-likelihood (Fraser et al. 2011) but with the constant terms removed.
. Equation 6 is equivalent to the standard renewal log-likelihood (Fraser et al. 2011) but with the constant terms removed.
This derivation emphasizes the statistical similarity between count and histogram records (and hence skyline and renewal models) and allows generalization to variable width histogram records (e.g., irregularly timed epi-curves). Figure 1b illustrates the renewal inference problem and its associated notation. We can compute the relevant MLE and robust FI from Eq. (6) as Eq. (7) (Fraser et al. 2011; Parag and Pybus 2019).
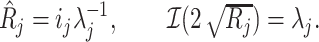 |
(7) |
As each 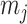 becomes large the per-segment bias
becomes large the per-segment bias 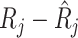 decreases. Using results from (Parag and Pybus, 2019), we find the square root transform of
decreases. Using results from (Parag and Pybus, 2019), we find the square root transform of 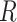 to be robust for renewal models, that is, it guarantees optimal estimation properties. We compute the FI under this parametrization to reveal that the total infectiousness controls the precision around our MLEs (via
to be robust for renewal models, that is, it guarantees optimal estimation properties. We compute the FI under this parametrization to reveal that the total infectiousness controls the precision around our MLEs (via 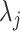 ). This will also improve as
). This will also improve as 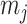 increases, but with the caveat that the parameters underlying bigger epidemics (specified by larger historical incidence values and controlled via
increases, but with the caveat that the parameters underlying bigger epidemics (specified by larger historical incidence values and controlled via 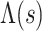 ) are easier to estimate than those of smaller ones.
) are easier to estimate than those of smaller ones.
In both models, we find a clear piecewise separation of MLEs and FIs. Per-segment bias and precision depend on the quantity of data apportioned to each parameter. This data division is controlled by 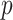 , which balances per-segment performance against the overall fit of the model to its generating process. Thus, model dimensionality fundamentally controls inference quality. Large
, which balances per-segment performance against the overall fit of the model to its generating process. Thus, model dimensionality fundamentally controls inference quality. Large 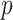 means more segments, which can adapt to rapid
means more segments, which can adapt to rapid 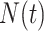 or
or 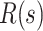 changes. However, this also rarefies the per-segment data (grouped sums like
changes. However, this also rarefies the per-segment data (grouped sums like 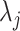 or
or 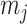 decrease) with both models becoming unidentifiable if
decrease) with both models becoming unidentifiable if 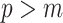 . Small
. Small 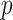 improves segment inference, but stiffens the model. We next explore information theoretic approaches to
improves segment inference, but stiffens the model. We next explore information theoretic approaches to 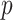 -selection that formally utilize both MLEs and FIs within their decision making.
-selection that formally utilize both MLEs and FIs within their decision making.
Model and Parametric Complexity
Our proposed approach to model selection relies on the MDL framework of (Rissanen, 1978). This treats modeling as an attempt to compress the regularities in the observed data, which is equivalent to learning about its statistical structure. MDL evaluates a 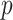 -parameter model,
-parameter model, 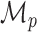 , in terms of its code length (in e.g., nats or bits) as
, in terms of its code length (in e.g., nats or bits) as 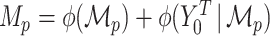 (Grunwald 2007). Here,
(Grunwald 2007). Here, 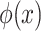 computes the length to encode
computes the length to encode 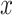 and
and 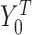 is the observed data.
is the observed data. 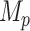 is the sum of the information required to describe
is the sum of the information required to describe 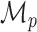 and the data given that
and the data given that 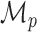 is chosen. More complex models have larger
is chosen. More complex models have larger 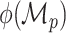 (more bits are needed to depict just the model), and smaller
(more bits are needed to depict just the model), and smaller 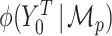 (as complex models should better fit the data, there is less remaining information to detail).
(as complex models should better fit the data, there is less remaining information to detail).
If 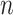 models are available to describe
models are available to describe 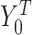 , then the model with
, then the model with 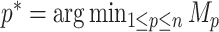 best compresses or most succinctly represents the data. The model with
best compresses or most succinctly represents the data. The model with 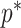 is known to possess the desirable properties of generalizability and consistency (Grunwald 2007). The first means that
is known to possess the desirable properties of generalizability and consistency (Grunwald 2007). The first means that 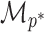 provides good predictions on newly observed data (i.e., it fits the underlying data generating process instead of a specific instance of data obtained from that process), while the second indicates that the selected
provides good predictions on newly observed data (i.e., it fits the underlying data generating process instead of a specific instance of data obtained from that process), while the second indicates that the selected 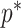 will converge to the true model index (if one exists) as data increase (Barron et al. 1998; Pitt et al. 2002). If
will converge to the true model index (if one exists) as data increase (Barron et al. 1998; Pitt et al. 2002). If 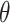 represents the
represents the 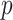 -parameter vector of
-parameter vector of 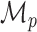 and
and 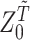 is a potential instance of data derived from the same generating process as
is a potential instance of data derived from the same generating process as 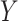 then the MDL code lengths can be reframed as
then the MDL code lengths can be reframed as 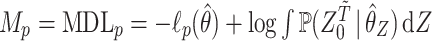 (Rissanen 1996).
(Rissanen 1996).
The first term of MDL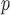 describes the goodness-of-fit of the model to the observed data, while the second term balances this against the fit to unobserved data (
describes the goodness-of-fit of the model to the observed data, while the second term balances this against the fit to unobserved data (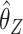 is the MLE of the parameters of
is the MLE of the parameters of 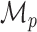 but with
but with 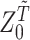 as data) from the same process. This is done over all possible data that could be obtained from that process (hence the integral with respect to
as data) from the same process. This is done over all possible data that could be obtained from that process (hence the integral with respect to 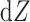 ) and measures the generalizability of the model. This generalizability term is usually intractable. We therefore use a well-known FI approximation from (Rissanen, 1996), which we denote FIA
) and measures the generalizability of the model. This generalizability term is usually intractable. We therefore use a well-known FI approximation from (Rissanen, 1996), which we denote FIA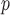 for
for 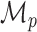 in Eq. (8), with “det” as the standard matrix determinant.
in Eq. (8), with “det” as the standard matrix determinant.
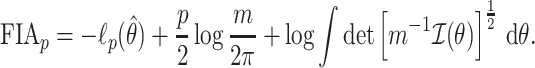 |
(8) |
The approximation of Eq. (8) is good, provided certain regularity conditions are met. These mostly relate to the FI being identifiable and continuous in 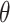 and are not issues for either skyline or renewal models (Myung et al. 2006). While we will apply the FIA within a class of renewal or skyline models, this restriction is unnecessary. The FIA can be used to select among any variously parametrized and non-nested models (Grunwald 2007).
and are not issues for either skyline or renewal models (Myung et al. 2006). While we will apply the FIA within a class of renewal or skyline models, this restriction is unnecessary. The FIA can be used to select among any variously parametrized and non-nested models (Grunwald 2007).
The FIA not only maintains the advantages of MDL, but also has strong links to Bayesian model selection (BMS). BMS compares models based on their posterior evidence, that is, BMS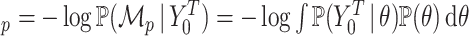 (Kass and Raftery 1995). BMS and MDL are considered the two most complete and rigorous model selection measures (Grunwald 2007). As with MDL, the BMS integral is often intractable and it can be difficult to disentangle and interpret how the formulation of
(Kass and Raftery 1995). BMS and MDL are considered the two most complete and rigorous model selection measures (Grunwald 2007). As with MDL, the BMS integral is often intractable and it can be difficult to disentangle and interpret how the formulation of 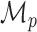 impacts its associated complexity according to these metrics (Pitt et al. 2002). Interestingly, if a Jeffreys prior distribution is used for
impacts its associated complexity according to these metrics (Pitt et al. 2002). Interestingly, if a Jeffreys prior distribution is used for 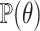 , then it can be shown that BMS
, then it can be shown that BMS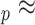 FIA
FIA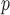 (via an asymptotic expansion) (Myung et al. 2006). Consequently, the FIA uniquely trades off the performance of BMS and MDL for some computational ease.
(via an asymptotic expansion) (Myung et al. 2006). Consequently, the FIA uniquely trades off the performance of BMS and MDL for some computational ease.
However, this tradeoff is not perfect. For many model classes the integral of the FI in Eq. (8) can be divergent or difficult to compute (Grunwald 2007). At the other end of the computability–completeness spectrum are standard metrics such as the AIC and BIC, which are quick and simple to construct, calculate, and interpret. These generally penalize a goodness-of-fit term (e.g., 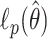 ) with the number of parameters
) with the number of parameters 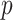 and may also consider the total size of the data
and may also consider the total size of the data 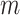 . Unfortunately, these methods often ignore the parametric complexity of a model, which measures the contribution of the functional form of a model to its overall complexity. Parametric complexity explains why two-parameter sinusoidal and exponential models have non-identical complexities, for example. This concept is detailed in (Pitt et al., 2002) and (Grunwald, 2007) and corresponds to the FI integral term in Eq (8).
. Unfortunately, these methods often ignore the parametric complexity of a model, which measures the contribution of the functional form of a model to its overall complexity. Parametric complexity explains why two-parameter sinusoidal and exponential models have non-identical complexities, for example. This concept is detailed in (Pitt et al., 2002) and (Grunwald, 2007) and corresponds to the FI integral term in Eq (8).
This provides the statistical context for our proposing the FIA as a meaningful metric for skyline and renewal models. In the Results section, we will show that the piecewise separable MLEs and FIs (Eqs 5 and 7) of these models not only ensure that the FI integral is tractable, but also guarantee that Eq. (8) is no more difficult to compute than the AIC or BIC. Consequently, our proposed adaptation of the FIA is able to combine the simplicity of standard measures such as the AIC and BIC while still capturing the more sophisticated and comprehensive descriptions of complexity inherent to the BMS and MDL by including parametric complexity. This point is embodied by the relationship between the FIA and BIC. As data size asymptotically increases, the parametric complexity becomes less important (it does not grow with 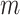 ) and FIA
) and FIA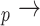 BIC
BIC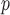 . The BIC is hence a coarser approximation to both the MDL and BMS, than the FIA (Myung et al. 2006).
. The BIC is hence a coarser approximation to both the MDL and BMS, than the FIA (Myung et al. 2006).
While the FIA achieves a favorable compromise among interpretability, completeness and computability in its description of complexity, it does depend on roughly specifying the domain of the FI integral. We will generally assume some arbitrary but sensible domain. However, when this is not possible the Qian–Kunsch approximation to MDL, denoted QK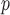 and given in Eq. (9), can be used (Qian and Kunsch 1998).
and given in Eq. (9), can be used (Qian and Kunsch 1998).
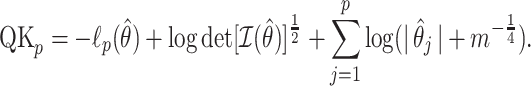 |
(9) |
This approximation trades off some interpretability and performance for the benefit of not having to demarcate the multidimensional domain of integration.
Lastly, we provide some intuition about Eq. (8), which balances fit via the maximum log-likelihood 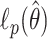 against model complexity, which can be thought of as a geometric volume defining the set of distinguishable behaviors (i.e., parameter distributions) that can be generated from the model. This volume is composed of two terms. The first,
against model complexity, which can be thought of as a geometric volume defining the set of distinguishable behaviors (i.e., parameter distributions) that can be generated from the model. This volume is composed of two terms. The first, 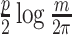 , shows, unsurprisingly, that higher model dimensionality,
, shows, unsurprisingly, that higher model dimensionality, 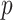 , expands the volume of possible behaviors. Less obvious is the fact that increased data size
, expands the volume of possible behaviors. Less obvious is the fact that increased data size 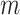 also enlarges this volume because distinguishability improves with inference resolution. The second term, which is parametric complexity, is invariant to transformations of
also enlarges this volume because distinguishability improves with inference resolution. The second term, which is parametric complexity, is invariant to transformations of 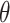 , independent of
, independent of 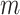 and is an explicit volume integral measuring how different functional relationships among the parameters, defined via the FI, influence the possible, distinguishable behaviors the model can describe (Grunwald 2007).
and is an explicit volume integral measuring how different functional relationships among the parameters, defined via the FI, influence the possible, distinguishable behaviors the model can describe (Grunwald 2007).
Results
The Insufficiency of Log-Likelihoods
The inference performance of both the renewal and skyline models, for a given data set, strongly depends on the chosen model dimensionality, 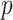 . As observed previously, current approaches to
. As observed previously, current approaches to 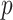 -selection utilize ad hoc rules or elaborate algorithms that are difficult to interrogate. Here, we emphasize why finding an optimal
-selection utilize ad hoc rules or elaborate algorithms that are difficult to interrogate. Here, we emphasize why finding an optimal 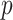 , denoted
, denoted 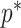 , is important and illustrate the pitfalls of inadequately balancing bias and precision. We start by proving that overfitting is a guaranteed consequence of depending solely on the log-likelihood for
, is important and illustrate the pitfalls of inadequately balancing bias and precision. We start by proving that overfitting is a guaranteed consequence of depending solely on the log-likelihood for 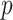 -selection. While this may seem obvious, early formulations of piecewise models did over-parametrize by setting
-selection. While this may seem obvious, early formulations of piecewise models did over-parametrize by setting 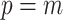 (Strimmer and Pybus 2001) and our proof can be applied more generally, for example, when selecting among models with
(Strimmer and Pybus 2001) and our proof can be applied more generally, for example, when selecting among models with 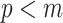 . Substituting the MLEs of Eq. (5) and Eq. (7) into Eq. (4) and Eq. (6), we get Eq. (10).
. Substituting the MLEs of Eq. (5) and Eq. (7) into Eq. (4) and Eq. (6), we get Eq. (10).
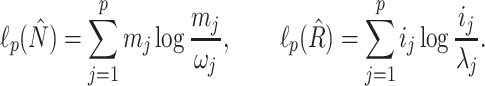 |
(10) |
Both the renewal and skyline log-likelihoods take the form 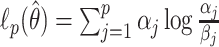 , due to their inherent and dominant piecewise-Poisson structure. Here,
, due to their inherent and dominant piecewise-Poisson structure. Here, 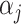 and
and 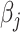 are grouped variables that are directly computed from the observed data (
are grouped variables that are directly computed from the observed data ( or
or 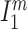 ). The most complex model supportable by the data is at
). The most complex model supportable by the data is at 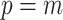 , with
, with 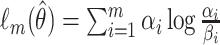 . As the data size (
. As the data size (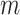 ) is fixed, we can clump the
) is fixed, we can clump the 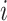 indices falling within the duration of the
indices falling within the duration of the 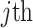 group
group 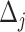 as
as 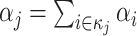 and
and 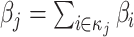 . The log-sum inequality from (Cover and Thomas, 2006) states that
. The log-sum inequality from (Cover and Thomas, 2006) states that 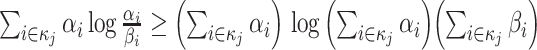 . Repeating this across all possible
. Repeating this across all possible 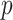 groupings results in Eq. (11).
groupings results in Eq. (11).
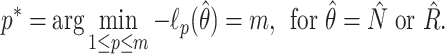 |
(11) |
Thus, log-likelihood based model selection always chooses the highest dimensional renewal or skyline model. This result also holds when solving Eq. (11) over a subset of all possible 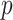 , provided smaller
, provided smaller 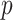 models are non-overlapping groupings of larger
models are non-overlapping groupings of larger 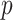 ones (Hanson and Fu 2004). Thus, it is necessary to penalize
ones (Hanson and Fu 2004). Thus, it is necessary to penalize 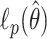 with some term that increases with
with some term that increases with 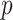 .
.
The highest 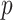 -model is most sensitive to changes in
-model is most sensitive to changes in 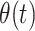 , but extremely noisy and likely to overfit the data. This noise is reflected in a poor FI. From Eq. (5) and Eq. (7) it is clear that grouping linearly increases the FI, hence smoothing noise. However, this improved precision comes with lower flexibility. At the extreme of
, but extremely noisy and likely to overfit the data. This noise is reflected in a poor FI. From Eq. (5) and Eq. (7) it is clear that grouping linearly increases the FI, hence smoothing noise. However, this improved precision comes with lower flexibility. At the extreme of  , for example,
, for example, 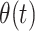 is approximated by a single, perennial parameter, and the log-likelihood
is approximated by a single, perennial parameter, and the log-likelihood 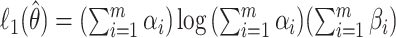 is unchanged for all combinations of data that produce the same grouped sums. This oversmooths and underfits. We will always select
is unchanged for all combinations of data that produce the same grouped sums. This oversmooths and underfits. We will always select 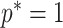 if our log-likelihood penalty is too sensitive to dimensionality.
if our log-likelihood penalty is too sensitive to dimensionality.
We now present some concrete examples of bad model selection. We use adjacent groupings of size 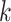 to control
to control 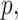 that is, every
that is, every 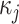 clumps
clumps 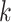 successive indices (the last index is
successive indices (the last index is 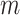 ). In Fig. 2(a), we examine skyline models with periodic exponential fluctuations ((i)–(ii)) and bottleneck variations ((iii)–(iv)). The periodic case describes seasonal epidemic oscillations in infecteds, while the bottleneck simulates the severe decline that results from a catastrophic event. In Fig. 2(b), we investigate renewal models featuring cyclical ((i)–(ii)) and sigmoidal ((iii)–(iv))
). In Fig. 2(a), we examine skyline models with periodic exponential fluctuations ((i)–(ii)) and bottleneck variations ((iii)–(iv)). The periodic case describes seasonal epidemic oscillations in infecteds, while the bottleneck simulates the severe decline that results from a catastrophic event. In Fig. 2(b), we investigate renewal models featuring cyclical ((i)–(ii)) and sigmoidal ((iii)–(iv)) 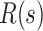 dynamics. The cyclical model depicts the pattern of spread for a seasonal epidemic (e.g., influenza), while the sigmoidal one might portray a vaccination policy that quickly leads to outbreak control.
dynamics. The cyclical model depicts the pattern of spread for a seasonal epidemic (e.g., influenza), while the sigmoidal one might portray a vaccination policy that quickly leads to outbreak control.
Figure 2.

Skyline and renewal model under and overfitting. Small 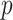 leads to smooth but biased estimates characteristic of underfitting ((i) and (iii) in (a) and (b)). Large
leads to smooth but biased estimates characteristic of underfitting ((i) and (iii) in (a) and (b)). Large 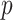 results in noisy estimates that respond well to changes. This is symptomatic of overfitting ((ii) and (iv) in (a) and (b)). The MLEs (
results in noisy estimates that respond well to changes. This is symptomatic of overfitting ((ii) and (iv) in (a) and (b)). The MLEs (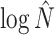 or
or 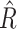 ) are in blue and the true
) are in blue and the true 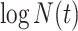 or
or 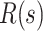 in black. Panel (a) shows cyclic and bottleneck skyline models at
in black. Panel (a) shows cyclic and bottleneck skyline models at 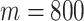 and (b) focuses on sinusoidal and sigmoidal renewal models at
and (b) focuses on sinusoidal and sigmoidal renewal models at 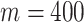 .
.
In both Fig. 2(a) and (b), we observe underfitting at low 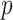 ((i) and (iii)) and overfitting at high
((i) and (iii)) and overfitting at high 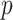 ((ii) and (iv)). The detrimental effects of choosing the wrong model are not only dramatic, but also realistic. For example, in the skyline examples the underfitted case corresponds to the fundamental Kingman coalescent model (Kingman 1982), which is often used as a null model in phylogenetics. Alternatively, the classic skyline (Pybus et al. 2000), which is at the core of many coalescent inference algorithms, is exactly as noisy as the overfitted case. Correctly, penalizing the log-likelihood is therefore essential for good estimation, and forms the subject of the subsequent section.
((ii) and (iv)). The detrimental effects of choosing the wrong model are not only dramatic, but also realistic. For example, in the skyline examples the underfitted case corresponds to the fundamental Kingman coalescent model (Kingman 1982), which is often used as a null model in phylogenetics. Alternatively, the classic skyline (Pybus et al. 2000), which is at the core of many coalescent inference algorithms, is exactly as noisy as the overfitted case. Correctly, penalizing the log-likelihood is therefore essential for good estimation, and forms the subject of the subsequent section.
Minimum Description Length Selection
Having clarified the impact of non-adaptive estimation, we develop and appraise various, easily computed, model selection metrics, in terms of how they penalize renewal and skyline log-likelihoods. The most common and popular metrics are the AIC and BIC (Kass and Raftery 1995), which we reformulate in Eqs 12 and 13, with 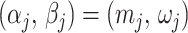 or
or 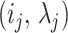 for skyline and renewal models, respectively.
for skyline and renewal models, respectively.
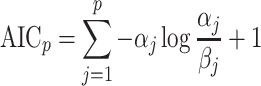 |
(12) |
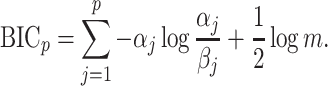 |
(13) |
By decomposing the AIC and BIC on a per-segment basis (for a model with 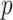 segments or dimensions), as in Eqs 12 and 13, we gain insight into exactly how they penalize the log-likelihood. Specifically, the AIC simply treats model dimensionality as a proxy for complexity, while the BIC also factors in the total dimension of the available data. A small-sample correction to the AIC, which adds a further
segments or dimensions), as in Eqs 12 and 13, we gain insight into exactly how they penalize the log-likelihood. Specifically, the AIC simply treats model dimensionality as a proxy for complexity, while the BIC also factors in the total dimension of the available data. A small-sample correction to the AIC, which adds a further 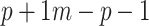 to the penalty in Eq. (12), was used in (Strimmer and Pybus, 2001) for skyline models. We found this correction inconsequential to our later simulations and so used the standard AIC only.
to the penalty in Eq. (12), was used in (Strimmer and Pybus, 2001) for skyline models. We found this correction inconsequential to our later simulations and so used the standard AIC only.
As discussed in the Materials and Methods section, these metrics are insufficient descriptions because they ignore parametric complexity. Consequently, we suggested the MDL approximations of Eqs 8 and 9. We now derive and specialize these expressions to skyline and renewal models. Adapting the FIA metric of Eq. (8) forms a main result of this work. Its integral term, 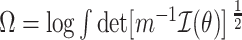 , can, in general, be intractable (Rissanen 1996). However, the piecewise structure of both the skyline and renewal models, which leads to orthogonal (diagonal) FI matrices, allows us to decompose
, can, in general, be intractable (Rissanen 1996). However, the piecewise structure of both the skyline and renewal models, which leads to orthogonal (diagonal) FI matrices, allows us to decompose 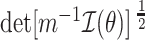 as
as 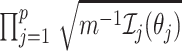 with
with 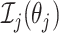 as the
as the 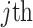 diagonal element of
diagonal element of 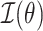 , which only depends on
, which only depends on 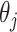 . Note that
. Note that 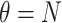 or
or 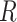 for the skyline and renewal model, respectively.
for the skyline and renewal model, respectively.
Using this decomposition, we partition 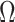 across each piecewise segment as
across each piecewise segment as 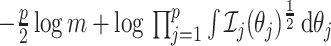 . The
. The 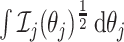 is known to be invariant to parameter transformations (Grunwald 2007). This is easily verified by using the FI change of variable formula (Lehmann and Casella 1998). This asserts that
is known to be invariant to parameter transformations (Grunwald 2007). This is easily verified by using the FI change of variable formula (Lehmann and Casella 1998). This asserts that 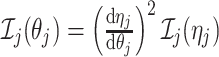 , with
, with 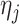 as some function of
as some function of 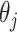 . The orthogonality of our piecewise-constant FI matrices allows this component-by-component transformation. Hence
. The orthogonality of our piecewise-constant FI matrices allows this component-by-component transformation. Hence 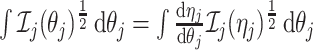 , which equals
, which equals 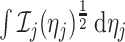 . We let
. We let 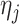 denote the robust transform of
denote the robust transform of 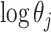 or
or 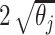 for the skyline or renewal model, respectively. Robust transforms make the integral more transparent by removing the dependence of
for the skyline or renewal model, respectively. Robust transforms make the integral more transparent by removing the dependence of 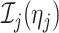 on
on 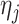 (Parag and Pybus 2019).
(Parag and Pybus 2019).
Hence, we use Eq. (5) (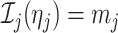 ) and Eq. (7) (
) and Eq. (7) (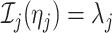 ) to further obtain
) to further obtain 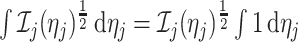 and
and 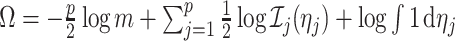 . The domain of integration for each parameter is all that remains to be solved. We make the reasonable assumption that each piecewise parameter,
. The domain of integration for each parameter is all that remains to be solved. We make the reasonable assumption that each piecewise parameter, 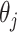 , has an identical domain. This is
, has an identical domain. This is 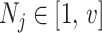 and
and 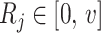 , with
, with 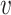 as an unknown model-dependent maximum. The minima of 1 and 0 are sensible for these models. This gives
as an unknown model-dependent maximum. The minima of 1 and 0 are sensible for these models. This gives 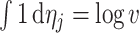 or
or 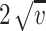 for the skyline or renewal model. Substituting into
for the skyline or renewal model. Substituting into  and Eq. (8) yields Eq. (14) and Eq. (15).
and Eq. (8) yields Eq. (14) and Eq. (15).
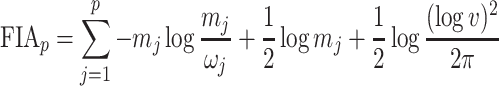 |
(14) |
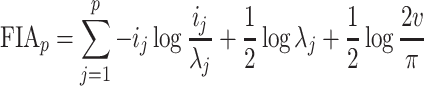 |
(15) |
Equations 14 and 15 present an interesting and more complete view of piecewise model complexity. Comparing to Eq. (13) reveals that the FIA further accounts for how the data are divided among segments, making explicit use of the robust FI of each model. This is an improvement over simply using the (clumped) data dimension 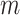 . Intriguingly, the maximum value of each parameter to be inferred,
. Intriguingly, the maximum value of each parameter to be inferred, 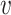 , is also central to computing model complexity. This makes sense as models with larger parameter spaces can describe more types of dynamical behaviors (Grunwald 2007). By comparing, these terms we can disentangle the relative contribution of the data and parameter spaces to complexity.
, is also central to computing model complexity. This makes sense as models with larger parameter spaces can describe more types of dynamical behaviors (Grunwald 2007). By comparing, these terms we can disentangle the relative contribution of the data and parameter spaces to complexity.
One limitation of the FIA is its dependence on the unknown 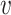 , which is assumed finite. This is reasonable as similar assumptions would be implicitly made to compute the BMS or MDL (in cases where they are tractable). The QK metric (Qian and Kunsch 1998), which also approximates the MDL, partially resolves this issue. We compute QK
, which is assumed finite. This is reasonable as similar assumptions would be implicitly made to compute the BMS or MDL (in cases where they are tractable). The QK metric (Qian and Kunsch 1998), which also approximates the MDL, partially resolves this issue. We compute QK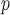 by substituting FIs and MLEs into Eq. (9). Expressions identical to Eqs 14 and 15 result, except for the
by substituting FIs and MLEs into Eq. (9). Expressions identical to Eqs 14 and 15 result, except for the 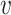 -based terms, which are replaced as in Eqs 16 and 17.
-based terms, which are replaced as in Eqs 16 and 17.
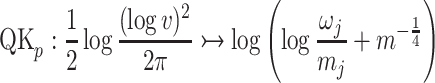 |
(16) |
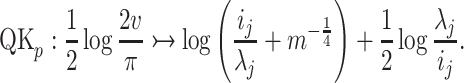 |
(17) |
These replacements require no knowledge of the parameter domain, but still approximate the parametric complexity of the model (Qian and Kunsch 1998). However, in gaining this domain independence we lose some performance (see later sections), and transparency. Importantly, both the FIA and QK are as easy to compute as the AIC or BIC. The similarity in the skyline and renewal model expressions reflects the significance of their piecewise-Poisson structure. We next investigate the practical performance of these metrics.
Adaptive Estimation: Epidemic Renewal Models
We validate our FIA approach on several renewal inference problems. We simulate incidence curves, 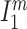 , via the renewal or branching process relation
, via the renewal or branching process relation 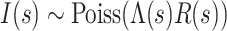 with
with 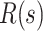 as the true effective reproduction number that we wish to estimate and Poiss indicating the Poisson distribution. We construct
as the true effective reproduction number that we wish to estimate and Poiss indicating the Poisson distribution. We construct 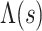 using a gamma generation time distribution that approximates the one used in (Nouvellet et al., 2018) for Ebola virus outbreaks. We initialize each epidemic with
using a gamma generation time distribution that approximates the one used in (Nouvellet et al., 2018) for Ebola virus outbreaks. We initialize each epidemic with 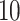 infecteds as in (Cori et al., 2013). We condition on the epidemic not dying out, and remove initial sequences of zero incidence to ensure model identifiability. We consider an observation period of
infecteds as in (Cori et al., 2013). We condition on the epidemic not dying out, and remove initial sequences of zero incidence to ensure model identifiability. We consider an observation period of 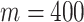 days, and select among models with
days, and select among models with 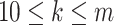 such that
such that 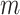 is divisible by
is divisible by 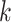 . Here
. Here 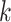 counts how many days are grouped to form a piecewise segment (i.e., the size of every
counts how many days are grouped to form a piecewise segment (i.e., the size of every 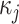 ), and model dimensionality,
), and model dimensionality, 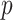 , is bijective in
, is bijective in 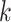 that is,
that is, 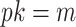 .
.
We apply the criteria developed above to select among possible 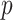 -parameter (or
-parameter (or 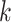 -grouped) renewal models. For the FIA, we set
-grouped) renewal models. For the FIA, we set 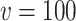 as a conservative upper bound on the reproduction number domain. We start by highlighting how the FIA (1) regulates between the over and underfitting extremes from Fig. 2(b), and (2) updates its selected
as a conservative upper bound on the reproduction number domain. We start by highlighting how the FIA (1) regulates between the over and underfitting extremes from Fig. 2(b), and (2) updates its selected 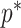 as the data increase. These points are illustrated in Fig. 3(a) and Fig. 3(b). Graphs (i) and (iii) exemplify (1) as the FIA ((iii)) reduces
as the data increase. These points are illustrated in Fig. 3(a) and Fig. 3(b). Graphs (i) and (iii) exemplify (1) as the FIA ((iii)) reduces 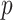 from the maximum chosen by the log-likelihood ((i)), leading to estimates that balance noise against dimensionality. Interestingly, the FIA chooses a minimum of segments for the sigmoidal fall in Fig. 3, and so pinpoints its key dynamics. As the observed data are increased (graphs (ii) and (iv) of Fig. 3(a) and 3(b)) the FIA adapts
from the maximum chosen by the log-likelihood ((i)), leading to estimates that balance noise against dimensionality. Interestingly, the FIA chooses a minimum of segments for the sigmoidal fall in Fig. 3, and so pinpoints its key dynamics. As the observed data are increased (graphs (ii) and (iv) of Fig. 3(a) and 3(b)) the FIA adapts 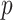 to reflect the improved resolution that is now justified, hence demonstrating (2). The increased data use
to reflect the improved resolution that is now justified, hence demonstrating (2). The increased data use 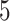 more, conditionally independent (on
more, conditionally independent (on 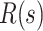 )
) 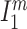 curves and have size
curves and have size 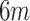 . The
. The 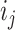 and
and 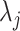 used now sum over all 6
used now sum over all 6 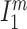 curves.
curves.
Figure 3.

Adaptive cyclical and sigmoidal estimation with FIA. In (a) and (b), graphs (i)–(ii) present optimal log-likelihood based 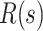 MLEs for
MLEs for 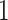 ((i)) and
((i)) and 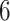 ((ii)) observed incidence data streams, simulated under renewal models with time-varying effective reproduction numbers. Graphs (iii)–(iv) give the FIA adaptive estimates at the same settings with
((ii)) observed incidence data streams, simulated under renewal models with time-varying effective reproduction numbers. Graphs (iii)–(iv) give the FIA adaptive estimates at the same settings with 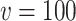 . Panels (a) and (b) examine cyclical and sigmoidal (also called logistic) reproduction number profiles, respectively.
. Panels (a) and (b) examine cyclical and sigmoidal (also called logistic) reproduction number profiles, respectively.
While the above examples provide practical insight into the merits of the FIA, they cannot rigorously assess its performance, since continuous 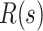 functions have no true
functions have no true 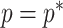 or
or 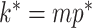 . We therefore study two problems in which a true
. We therefore study two problems in which a true 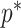 exists: a simple binary classification, and a more complex piecewise model search. In both, we benchmark the FIA against the AIC, BIC, and QK metric over the same set of simulated
exists: a simple binary classification, and a more complex piecewise model search. In both, we benchmark the FIA against the AIC, BIC, and QK metric over the same set of simulated 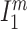 curves. We note that, when
curves. We note that, when 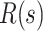 is piecewise-constant, increasing the number of conditionally independent curves improves the probability of recovering
is piecewise-constant, increasing the number of conditionally independent curves improves the probability of recovering 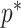 . We discuss the results of the first problem in the Appendix (see Fig. A1), where we show that the FIA most accurately identifies between a null model of an uncontrolled epidemic and an alternative model featuring rapid outbreak control. The FIA uniformly outperforms all other metrics at every
. We discuss the results of the first problem in the Appendix (see Fig. A1), where we show that the FIA most accurately identifies between a null model of an uncontrolled epidemic and an alternative model featuring rapid outbreak control. The FIA uniformly outperforms all other metrics at every 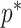 in this problem, with the QK a close second.
in this problem, with the QK a close second.
For the second and more complicated problem, we consider models involving piecewise-constant 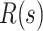 changes after every
changes after every 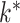 days, with
days, with 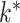 looping over
looping over 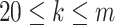 and
and 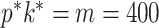 days. For every
days. For every 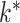 we generate
we generate 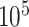 independent epidemics, allowing
independent epidemics, allowing 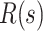 to vary in each run, with magnitudes uniformly drawn from
to vary in each run, with magnitudes uniformly drawn from 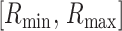 . Fig. 4(a) illustrates typical random telegraph
. Fig. 4(a) illustrates typical random telegraph 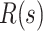 models at each
models at each 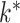 (these change in magnitude for each run). Key selection results are shown in Fig. 4(b) with
(these change in magnitude for each run). Key selection results are shown in Fig. 4(b) with 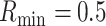 ,
, 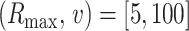 in (i) and
in (i) and 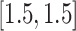 in (ii). In both cases, the FIA attains the best overall accuracy, that is, the largest sum of
in (ii). In both cases, the FIA attains the best overall accuracy, that is, the largest sum of 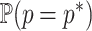 across
across 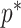 , followed by the QK (which overlaps the FIA curve in (i)), BIC and AIC. The dominance of both MDL-based criteria suggests that parametric complexity is important. However, the FIA can do worse than the BIC and QK when
, followed by the QK (which overlaps the FIA curve in (i)), BIC and AIC. The dominance of both MDL-based criteria suggests that parametric complexity is important. However, the FIA can do worse than the BIC and QK when 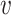 is large compared to
is large compared to 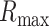 (or if
(or if 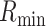 is notably above 0). We discuss these cases in the Appendix (see Fig. A3), explaining why the reduced
is notably above 0). We discuss these cases in the Appendix (see Fig. A3), explaining why the reduced 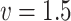 is used in (ii).
is used in (ii).
Figure 4.

Renewal model selection. We simulate 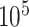 epidemics from renewal models with
epidemics from renewal models with 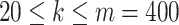 and
and 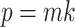 . We test the ability of several model selection criteria to recover the true
. We test the ability of several model selection criteria to recover the true 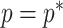 from among this set. Each epidemic has an independent, piecewise-constant
from among this set. Each epidemic has an independent, piecewise-constant 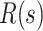 , examples of which are shown in (a). These models change in amplitude but not
, examples of which are shown in (a). These models change in amplitude but not 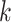 for every simulation. Panel b) shows the probability of detecting the true model as a function of
for every simulation. Panel b) shows the probability of detecting the true model as a function of 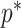 and (i) considers
and (i) considers 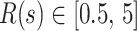 with
with 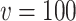 while (ii) uses
while (ii) uses 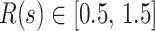 and
and 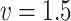 . The FIA performs best at every
. The FIA performs best at every 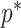 in (i) and overall in (ii).
in (i) and overall in (ii).
Adaptive Estimation: Phylogenetic Skyline Models
We verify the FIA performance on several skyline problems. We simulate serially sampled phylogenies with sampled tips spread evenly over some interval using the phylodyn R package of (Karcher et al., 2017). Increasing the sampling density within that interval increases overall data size 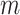 (each pair of sampled tips can produce a coalescent event). We define our
(each pair of sampled tips can produce a coalescent event). We define our 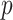 segments as groups of
segments as groups of 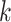 coalescent events. Skyline model selection is more involved because the end-points of the
coalescent events. Skyline model selection is more involved because the end-points of the 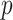 segments coincide with coalescent events. While this ensures statistical identifiability, it means that grouping is sensitive to phylogenetic noise (Strimmer and Pybus 2001), and that
segments coincide with coalescent events. While this ensures statistical identifiability, it means that grouping is sensitive to phylogenetic noise (Strimmer and Pybus 2001), and that 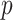 changes for a given
changes for a given 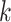 if
if 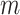 varies (
varies (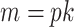 ). This can result in MLEs, even at optimal groupings, appearing delayed or biased relative to
). This can result in MLEs, even at optimal groupings, appearing delayed or biased relative to 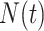 , when
, when 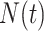 is not a grouped piecewise function. Methods are currently under being developed to resolve these biases (Parag et al. 2020b).
is not a grouped piecewise function. Methods are currently under being developed to resolve these biases (Parag et al. 2020b).
Nevertheless, we start by examining how our FIA approach mediates the extremes of Fig. 2(a). We restrict our grouping parameter to 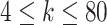 , set
, set 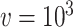 (
(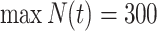 ) and apply the FIA of Eq. (14) to obtain Fig. 5(a) and (b). Two points are immediately visible: (1) the FIA ((iii)–(iv)) regulates the noise from the log-likelihood ((i)–(ii)), and (2) the FIA supports higher
) and apply the FIA of Eq. (14) to obtain Fig. 5(a) and (b). Two points are immediately visible: (1) the FIA ((iii)–(iv)) regulates the noise from the log-likelihood ((i)–(ii)), and (2) the FIA supports higher 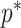 when the data are increased ((iv)). Specifically, the FIA characterizes the bottleneck of Fig. 5(b) using a minimum of segments but with a delay. As data accumulate, more groups can be justified and so the FIA is able to compensate for the delay. Note that the last 1–2 coalescent events are often truncated, as they can span half the time-scale, and bias all model selection criteria (Nordborg 2001). In the Appendix (see Fig. A4), we show how the sensitivity of the FIA to event density compares to other methods on empirical data (see the Materials and Methods section).
when the data are increased ((iv)). Specifically, the FIA characterizes the bottleneck of Fig. 5(b) using a minimum of segments but with a delay. As data accumulate, more groups can be justified and so the FIA is able to compensate for the delay. Note that the last 1–2 coalescent events are often truncated, as they can span half the time-scale, and bias all model selection criteria (Nordborg 2001). In the Appendix (see Fig. A4), we show how the sensitivity of the FIA to event density compares to other methods on empirical data (see the Materials and Methods section).
Figure 5.

Adaptive periodic and bottleneck estimation with FIA. For (a) and (b), graphs (i)–(ii) present inferred 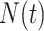 under optimal log-likelihood groupings, while (iii)–(iv) show corresponding estimates under the FIA at
under optimal log-likelihood groupings, while (iii)–(iv) show corresponding estimates under the FIA at 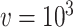 . Graphs (i) and (iii) feature
. Graphs (i) and (iii) feature 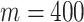 while (ii) and (iv) have
while (ii) and (iv) have 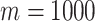 (data size increases). Panels (a) and (b) respectively consider periodically exponential and bottleneck population size changes, with phylogenies sampled approximately uniformly over
(data size increases). Panels (a) and (b) respectively consider periodically exponential and bottleneck population size changes, with phylogenies sampled approximately uniformly over 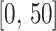 and
and 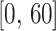 time units.
time units.
We consider two model selection problems involving a piecewise-constant 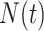 , to formally evaluate the FIA against the QK, BIC, and AIC. We slightly abuse notation by redefining
, to formally evaluate the FIA against the QK, BIC, and AIC. We slightly abuse notation by redefining 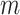 as the number of coalescent events per piecewise segment. The first is a binary hypothesis test between a Kingman coalescent null model (Kingman 1982) and an alternative with a single shift to
as the number of coalescent events per piecewise segment. The first is a binary hypothesis test between a Kingman coalescent null model (Kingman 1982) and an alternative with a single shift to 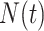 . We investigate this problem in the Appendix and show in Fig. A2 (i) that the FIA is, on average, better at selecting the true model than other criteria, with the QK a close second. Further, these metrics generally improve in accuracy with increased data. Closer examination also reveals that the FIA and QK have the best overall true positive and lowest false positive rates (Fig. A2(ii)).
. We investigate this problem in the Appendix and show in Fig. A2 (i) that the FIA is, on average, better at selecting the true model than other criteria, with the QK a close second. Further, these metrics generally improve in accuracy with increased data. Closer examination also reveals that the FIA and QK have the best overall true positive and lowest false positive rates (Fig. A2(ii)).
The second classification problem is more complex, requiring selection from among 5 possible square waves, with half-periods that are powers of 2. We define 15 change-point times at multiples of 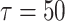 time units (i.e., there are 16 components) and allow
time units (i.e., there are 16 components) and allow 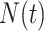 to fluctuate between maximum
to fluctuate between maximum 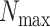 and
and 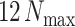 . At each change-point and 0, equal numbers of samples are introduced, to allow approximately
. At each change-point and 0, equal numbers of samples are introduced, to allow approximately 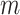 coalescent events per component (the phylogeny has
coalescent events per component (the phylogeny has 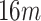 total events). The possible models are in Fig. 6(a). A similar problem, but for Gaussian MDL selection, was investigated in (Hanson and Fu, 2004). We simulate 200 phylogenies from each wave and compute the probability that each metric selects the correct model (i.e.,
total events). The possible models are in Fig. 6(a). A similar problem, but for Gaussian MDL selection, was investigated in (Hanson and Fu, 2004). We simulate 200 phylogenies from each wave and compute the probability that each metric selects the correct model (i.e., 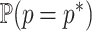 ) at
) at 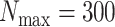 ((i)) and
((i)) and 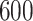 ((ii)) with
((ii)) with 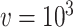 in Fig. 6(b). The group size (
in Fig. 6(b). The group size (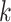 ) search space is
) search space is 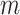 times the half-period of every wave.
times the half-period of every wave.
Figure 6.

Skyline model selection. We simulate 200 sampled phylogenies from each of the 5 square wave models of (a), with 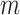 coalescent events per segment. Each square wave varies between
coalescent events per segment. Each square wave varies between 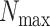 and
and 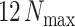 (ratios shown on y axes), and occurs with varying half-periods over 16 segments (x axes) of duration
(ratios shown on y axes), and occurs with varying half-periods over 16 segments (x axes) of duration 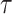 . Each phylogeny contains sampled tips at 0 and every multiple of
. Each phylogeny contains sampled tips at 0 and every multiple of 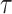 time units after. Panel (b) gives the probability that several model selection criteria select the true (
time units after. Panel (b) gives the probability that several model selection criteria select the true (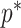 ) model from among these waves at
) model from among these waves at 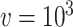 for
for 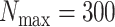 ((i)) and
((i)) and 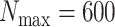 ((ii)). The FIA is the most accurate criterion on average and improves with
((ii)). The FIA is the most accurate criterion on average and improves with 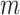 and as
and as 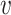 gets closer to the true
gets closer to the true 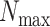 .
.
We find that the FIA has the best overall accuracy at both 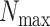 settings (i.e., the largest sum of
settings (i.e., the largest sum of 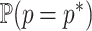 across
across 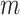 ), though the BIC is not far behind. The QK displays slightly worse performance than the BIC and the AIC is the worst (except at low
), though the BIC is not far behind. The QK displays slightly worse performance than the BIC and the AIC is the worst (except at low 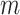 ). At
). At 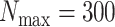 ((i)), there is a greater mismatch with
((i)), there is a greater mismatch with 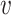 and so the FIA is not as dominant. As
and so the FIA is not as dominant. As 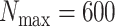 ((ii)) gets closer to
((ii)) gets closer to 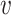 this issue dissipates. We discuss this dependence of FIA on
this issue dissipates. We discuss this dependence of FIA on 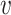 in the Appendix (see Fig. A3). Observe that the
in the Appendix (see Fig. A3). Observe that the 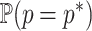 improves for most metrics as the sample phylogeny data size (
improves for most metrics as the sample phylogeny data size (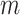 ) increases (consistency). The strong performance of the FIA confirms the impact of parametric complexity, while the suboptimal QK curves suggest that these advantages are sometimes only realizable when this complexity component is properly specified.
) increases (consistency). The strong performance of the FIA confirms the impact of parametric complexity, while the suboptimal QK curves suggest that these advantages are sometimes only realizable when this complexity component is properly specified.
Discussion
Identifying salient fluctuations in effective population size, 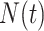 , and effective reproduction number,
, and effective reproduction number, 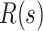 , is essential to understanding the retrospective and continuing behavior of an epidemic, at the population level. A significant swing in
, is essential to understanding the retrospective and continuing behavior of an epidemic, at the population level. A significant swing in 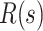 could inform on whether an outbreak is exponentially growing (e.g., if
could inform on whether an outbreak is exponentially growing (e.g., if 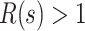 for a sustained period) or if enacted control measures are working (e.g., if
for a sustained period) or if enacted control measures are working (e.g., if  falls rapidly below
falls rapidly below 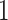 ) (Fraser et al. 2011; Cori et al. 2013). Similarly, sharp changes in
) (Fraser et al. 2011; Cori et al. 2013). Similarly, sharp changes in 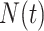 could evidence the historical impact of a public health policy (e.g., if
could evidence the historical impact of a public health policy (e.g., if 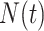 has a bottleneck or logistic growth) or corroborate hypotheses about past transmissions (e.g., if
has a bottleneck or logistic growth) or corroborate hypotheses about past transmissions (e.g., if 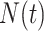 correlates with seasonal changes) (Rambaut et al. 2008; Pybus et al. 2001). Together,
correlates with seasonal changes) (Rambaut et al. 2008; Pybus et al. 2001). Together, 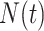 and
and 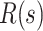 can provide a holistic view of the temporal dynamics of an epidemic, with their change-points signifying the impact of climatic, ecological, and anthropogenic factors (Ho and Shapiro 2011.
can provide a holistic view of the temporal dynamics of an epidemic, with their change-points signifying the impact of climatic, ecological, and anthropogenic factors (Ho and Shapiro 2011.
Piecewise-constant approaches, such as skyline plots and renewal models, are tractable and popular ways of separating insignificant fluctuations (the constant segments) from meaningful ones (the change points). However, the efficacy of these models requires principled and data-justified selection of their dimension, 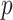 . Failure to do so, as in Fig. 2, could result in salient changes being misidentified (i.e., underfitting) or random noise being over-interpreted (i.e., overfitting). Existing approaches to
. Failure to do so, as in Fig. 2, could result in salient changes being misidentified (i.e., underfitting) or random noise being over-interpreted (i.e., overfitting). Existing approaches to 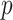 -selection for renewal models usually involve heuristics or trial and error (Cori et al. 2013). Skyline models feature a more developed set of
-selection for renewal models usually involve heuristics or trial and error (Cori et al. 2013). Skyline models feature a more developed set of 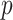 -selection methods but many of these, though widely used, are either computationally complex (e.g., involving sophisticated MCMC algorithms) (Heled and Drummond 2008) or difficult to interpret (e.g., when
-selection methods but many of these, though widely used, are either computationally complex (e.g., involving sophisticated MCMC algorithms) (Heled and Drummond 2008) or difficult to interpret (e.g., when 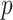 is implicitly controlled with smoothing prior distributions) (Ho and Shapiro 2011; Parag et al. 2020a).
is implicitly controlled with smoothing prior distributions) (Ho and Shapiro 2011; Parag et al. 2020a).
We therefore focused on finding a 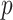 -selection metric that favorably compromises among simplicity, transparency, and performance. We started by proving that ascribing
-selection metric that favorably compromises among simplicity, transparency, and performance. We started by proving that ascribing 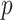 solely on the evidence of the log-likelihood (i.e., the model fit) guarantees overfitting (see Eq. (11)). Consequently, it is absolutely necessary to penalize the log-likelihood with a measure of model complexity. However, getting this measure wrong can just as easily lead to underfitting. This is a known issue in common skyline methods that apply smoothing prior distributions for example, where the prior-induced penalty is unclear (Minin et al. 2008). Standard metrics, such as the AIC and BIC, are easy to compute and offer transparent penalties; treating model complexity as either equivalent to
solely on the evidence of the log-likelihood (i.e., the model fit) guarantees overfitting (see Eq. (11)). Consequently, it is absolutely necessary to penalize the log-likelihood with a measure of model complexity. However, getting this measure wrong can just as easily lead to underfitting. This is a known issue in common skyline methods that apply smoothing prior distributions for example, where the prior-induced penalty is unclear (Minin et al. 2008). Standard metrics, such as the AIC and BIC, are easy to compute and offer transparent penalties; treating model complexity as either equivalent to 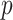 or
or 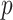 mediated by the observed data size (see Eqs 12 and 13). However, this description, while useful, is incomplete, and neglects parametric complexity (Rissanen 1996).
mediated by the observed data size (see Eqs 12 and 13). However, this description, while useful, is incomplete, and neglects parametric complexity (Rissanen 1996).
Parametric complexity describes how the functional relationship among parameters matters. MDL and BMS, which are the most powerful model selection methods, both account for parametric complexity but are often intractable (Grunwald 2007). The general FIA of Eq. (8) approximates both the MDL and BMS and defines this complexity as an integral across parameter space (Myung et al. 2006). Unfortunately, this integral is often difficult to evaluate, also rendering the FIA impractical. However, we found that the piecewise-constant nature of renewal and skyline models, together with their Poisson data structures, allowed us to analytically solve this integral and obtain Eqs 14 and 15. These expressions form our main results, are of similar computability to the AIC and BIC, and disaggregate model complexity into interpretable elements as follows for Eq. (15).
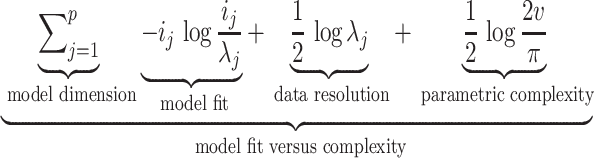 |
A similar breakdown exists for Eq. (14). Intriguingly, the parametric complexity now only depends on the unknown parameter domain maximum, 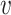 .
.
Knowledge of 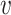 is the main cost of our metric. This parameter limit requirement is not unusual and can often improve estimates. In (Parag and Pybus, 2017) and (Parag and Pybus, 2018), this knowledge facilitated exact inference from sampled phylogenies, for example. Similar domain choices are also implicitly made when setting prior distributions on
is the main cost of our metric. This parameter limit requirement is not unusual and can often improve estimates. In (Parag and Pybus, 2017) and (Parag and Pybus, 2018), this knowledge facilitated exact inference from sampled phylogenies, for example. Similar domain choices are also implicitly made when setting prior distributions on 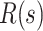 and
and 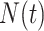 or practically performing MCMC sampling. In Fig. A3, we explored the effect of misspecifying
or practically performing MCMC sampling. In Fig. A3, we explored the effect of misspecifying 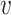 . While drastic mismatches between the true and assumed
. While drastic mismatches between the true and assumed 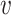 can be detrimental, we found that in some cases poor knowledge of
can be detrimental, we found that in some cases poor knowledge of 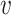 can be inconsequential. We adapted the QK metric (Qian and Kunsch 1998) to obtain Eqs 16 and 17 which, though less interpretable than the FIA, also somewhat account for parametric complexity and offer good performance should reasonable knowledge of
can be inconsequential. We adapted the QK metric (Qian and Kunsch 1998) to obtain Eqs 16 and 17 which, though less interpretable than the FIA, also somewhat account for parametric complexity and offer good performance should reasonable knowledge of 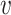 be unavailable.
be unavailable.
The FIA balances performance with simplicity. The MDL method it approximates has the desirable theoretical properties of generalizability (it mediates overfitting and underfitting) and consistency (it selects the true model with increasing probability as data accumulate) (Grunwald 2007). We therefore investigated whether the FIA maintained these properties. In Figs 3 and 5, we demonstrated that the FIA not only inherits the generalizability property, but also regulates its selections based on the available data. Higher data resolution supports larger 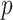 as both bias and variance can be simultaneously reduced under these conditions (van Erven and Grunwald 2012). Figures 4, 6, A1, and A2 confirmed the consistency of the FIA, in addition to benchmarking its performance against the comparable AIC and BIC. We found that the FIA consistently outperformed all other metrics, provided that
as both bias and variance can be simultaneously reduced under these conditions (van Erven and Grunwald 2012). Figures 4, 6, A1, and A2 confirmed the consistency of the FIA, in addition to benchmarking its performance against the comparable AIC and BIC. We found that the FIA consistently outperformed all other metrics, provided that 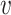 was not drastically misspecified.
was not drastically misspecified.
We recommend the FIA as a principled, transparent and computationally simple means of adaptively estimating informative changes in 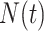 and
and 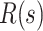 , and for diagnosing the relative contributions of different components of model complexity. We provide software for computing the FIA in the Supplementary Material. The FIA can be easily interfaced with the EpiEstim and projections packages (Cori et al. 2013; Nouvellet et al. 2018), which are common renewal model toolboxes for analyzing real epidemic data, to formalize the window size choices used in
, and for diagnosing the relative contributions of different components of model complexity. We provide software for computing the FIA in the Supplementary Material. The FIA can be easily interfaced with the EpiEstim and projections packages (Cori et al. 2013; Nouvellet et al. 2018), which are common renewal model toolboxes for analyzing real epidemic data, to formalize the window size choices used in 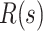 inference. Until now, these choices have been subjective. For skyline analyses, we propose the FIA as a useful diagnostic for verifying the
inference. Until now, these choices have been subjective. For skyline analyses, we propose the FIA as a useful diagnostic for verifying the 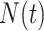 estimates generated by phylogenetic software such as BEAST or phylodyn (Karcher et al. 2017; Suchard et al. 2018). This can help validate or interrogate the outputs of common but complex MCMC methods. Comparing MCMC grouping choices to the FIA-optimized
estimates generated by phylogenetic software such as BEAST or phylodyn (Karcher et al. 2017; Suchard et al. 2018). This can help validate or interrogate the outputs of common but complex MCMC methods. Comparing MCMC grouping choices to the FIA-optimized 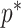 for example might help flag when known issues such as oversmoothing (underfitting) are biasing estimates (Minin et al. 2008; Parag et al. 2020a).
for example might help flag when known issues such as oversmoothing (underfitting) are biasing estimates (Minin et al. 2008; Parag et al. 2020a).
Sampled phylogenies and incidence curves, and hence skyline and renewal models, have often been treated separately in the epidemiological and phylodynamics literature. While they do solve different problems, we showed how refocusing on their shared piecewise-Poisson framework exposed their common complexity properties. Our information theoretic approach could also generate broad insight into other distinct models in genetics, molecular evolution, and ecology (Parag and Pybus 2019). The structured coalescent model is often used to estimate migration rate and population size changes from phylogeographic data (Beerli and Felsenstein 2001) while sequential Markovian coalescent methods are widely applied to infer demographic changes from metazoan genomes (Li and Durbin 2011). These models all involve Poisson count and histogram records and piecewise parameter sets and are promising candidates for future application of our metrics.
Appendix
Binary Model Selection
We examine the binary classification performance of the FIA, QK, BIC, and AIC for both renewal and skyline models. For the first, we set 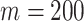 days and use a constant null model with
days and use a constant null model with 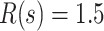 , to exemplify an uncontrolled epidemic. The alternative model changes to
, to exemplify an uncontrolled epidemic. The alternative model changes to 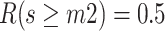 , simulating rapid control at
, simulating rapid control at 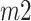 (inset of Fig. A1). We randomly generate
(inset of Fig. A1). We randomly generate 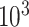 epidemics with some null model probability (
epidemics with some null model probability (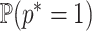 ) and compute the frequentist probability that each criterion selects the correct model (
) and compute the frequentist probability that each criterion selects the correct model (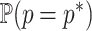 ) in Fig. A1. We find that the FIA uniformly outperforms all other criteria, with the QK as its closest competitor. The AIC performs poorly, as does
) in Fig. A1. We find that the FIA uniformly outperforms all other criteria, with the QK as its closest competitor. The AIC performs poorly, as does 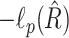 (not shown), because they are biased towards the more complex model. Relative metric performance is unchanged if we instead set
(not shown), because they are biased towards the more complex model. Relative metric performance is unchanged if we instead set 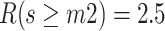 (an accelerating epidemic).
(an accelerating epidemic).
Figure A1.
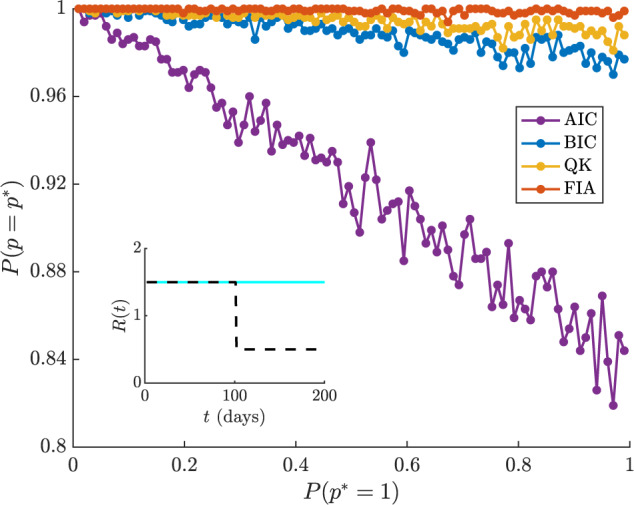
Binary renewal model selection. The consistency of several selection criteria is tested on a binary classification problem in which the null model 1 has no change in 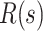 (solid, inset), while the alternative model 2 has a rapid decline (dashed, inset). We generate
(solid, inset), while the alternative model 2 has a rapid decline (dashed, inset). We generate 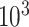 independent incidence curves randomly according to model 1 with probability
independent incidence curves randomly according to model 1 with probability 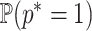 , and compute the ability of each criterion to decipher the correct model,
, and compute the ability of each criterion to decipher the correct model, 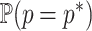 . The FIA outperforms other metrics at every
. The FIA outperforms other metrics at every 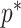 with QK a close second.
with QK a close second.
For the skyline problem, we test between a Kingman coalescent null model (Kingman 1982) with 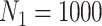 , and an alternative with a single shift to
, and an alternative with a single shift to 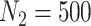 that simulates rapid change potentially due to some environmental driver at
that simulates rapid change potentially due to some environmental driver at 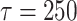 units. We set
units. We set 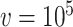 and generate 500 replicate phylogenies, with
and generate 500 replicate phylogenies, with 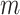 controlling the quantity of data available per piecewise component (so the total number of coalescent events is
controlling the quantity of data available per piecewise component (so the total number of coalescent events is 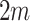 ). This is a slight abuse of previous definitions of
). This is a slight abuse of previous definitions of 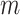 but is more useful here as we want
but is more useful here as we want 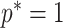 for the null model and
for the null model and 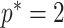 for the alternative. We introduce sampled tips at 0 and
for the alternative. We introduce sampled tips at 0 and 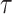 time units only. The grouping parameter search space is
time units only. The grouping parameter search space is 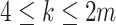 with
with 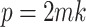 . Figure A2 presents our main results, showing that the FIA is, overall, more accurate (achieving a higher sum of
. Figure A2 presents our main results, showing that the FIA is, overall, more accurate (achieving a higher sum of 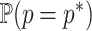 ) with the QK second. We find relative performance to be largely unchanged with
) with the QK second. We find relative performance to be largely unchanged with  and to hold when
and to hold when  is doubled. Observe that all metrics except the AIC (which is known to be inconsistent) improve with data size,
is doubled. Observe that all metrics except the AIC (which is known to be inconsistent) improve with data size, 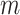 .
.
Figure A2.
Binary skyline model selection. We simulate 500 conditionally independent phylogenies from skyline models and test the classification ability of model selection criteria. The null model is a Kingman coalescent with  , and the alternative features a sharp fall to
, and the alternative features a sharp fall to  at
at 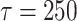 time units. The sampled tips of the phylogeny are introduced at
time units. The sampled tips of the phylogeny are introduced at  and
and 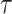 only. Graph (i) gives the probability of correct classification
only. Graph (i) gives the probability of correct classification 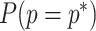 as a function of data size
as a function of data size 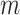 . The FIA performs best, on average, but the BIC is better at small
. The FIA performs best, on average, but the BIC is better at small 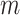 . Graph (ii) gives the true (TPR) and false positive rates (FPR) of the metrics. The FIA and QK have the best overall rates.
. Graph (ii) gives the true (TPR) and false positive rates (FPR) of the metrics. The FIA and QK have the best overall rates.
Figure A3.

FIA parameter space sensitivity. In (a), we repeat the simulations from Fig. 4(b)(ii) but at different 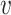 . The accuracy of the FIA clearly depends on the discrepancy between
. The accuracy of the FIA clearly depends on the discrepancy between 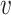 and
and 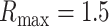 , and becomes inferior when
, and becomes inferior when 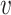 is dramatically above this maximum ((i)). In (b), we revisit the simulations of Fig. 6(a), but vary
is dramatically above this maximum ((i)). In (b), we revisit the simulations of Fig. 6(a), but vary 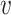 between
between  and
and 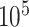 . The AIC, BIC, and QK from Fig. 6(a) are in cyan, while the best and worst case FIA values are in grey. While the FIA does depend on
. The AIC, BIC, and QK from Fig. 6(a) are in cyan, while the best and worst case FIA values are in grey. While the FIA does depend on 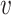 , interestingly, its performance is still superior on average, for both
, interestingly, its performance is still superior on average, for both 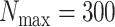 ((i)) and
((i)) and 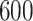 ((ii)).
((ii)).
Figure A4.

HIV demographic estimates. We estimate the effective population size history underlying an empirical HIV phylogeny with 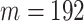 coalescent events. All tips of this tree are sampled in 1997 from the Democratic Republic of Congo. We plot the generalized skyline, the multiple change-point method and the FIA-optimized skyline estimates in (i), (ii), and (iv) in black against the classic skyline in grey. In (iii), we show the optimization over
coalescent events. All tips of this tree are sampled in 1997 from the Democratic Republic of Congo. We plot the generalized skyline, the multiple change-point method and the FIA-optimized skyline estimates in (i), (ii), and (iv) in black against the classic skyline in grey. In (iii), we show the optimization over 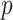 of the FIA (black) against its associated BIC (grey).
of the FIA (black) against its associated BIC (grey).
Weaknesses of Piecewise Model Selection
In Results section, we found the FIA to be a viable and top performing model selection strategy, when compared to standard metrics of similar computability such as the AIC and BIC. However, the FIA can do worse if the parameter maximum 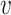 is large relative to the actual domain or space from which
is large relative to the actual domain or space from which 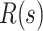 or
or 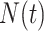 is drawn. In such cases, the incorrect parameter bounds can cause the FIA to overestimate the complexity of the generating renewal or skyline models. While the QK criterion offers a more stable and reasonably performing MDL alternative, it is less interpretable. Here, we examine the nature of this
is drawn. In such cases, the incorrect parameter bounds can cause the FIA to overestimate the complexity of the generating renewal or skyline models. While the QK criterion offers a more stable and reasonably performing MDL alternative, it is less interpretable. Here, we examine the nature of this 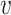 dependence, and discuss some general issues limiting piecewise model selection.
dependence, and discuss some general issues limiting piecewise model selection.
In Fig. 4(b)(ii), we showed the FIA outperforming other metrics for a model selection problem over piecewise 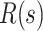 functions drawn within the artificial range
functions drawn within the artificial range 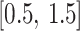 (the AIC was better at higher
(the AIC was better at higher 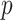 due to its tendency to overfit). We achieved this by setting
due to its tendency to overfit). We achieved this by setting 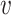 to the true
to the true 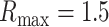 . However, when there is a significant mismatch between
. However, when there is a significant mismatch between 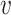 and
and 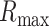 we find that the FIA is notably inferior to the QK and BIC. Figure A3(a) illustrates, at
we find that the FIA is notably inferior to the QK and BIC. Figure A3(a) illustrates, at 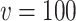 and
and 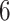 , how the magnitude of this mismatch influences relative performance. However, this effect is not always important, as seen in Fig. 4(b)(i), where
, how the magnitude of this mismatch influences relative performance. However, this effect is not always important, as seen in Fig. 4(b)(i), where 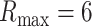 and
and 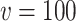 . The skyline model also has this FIA
. The skyline model also has this FIA 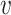 -dependence. We re-examine the square wave model selection problem of Fig. 6(b), but for
-dependence. We re-examine the square wave model selection problem of Fig. 6(b), but for 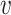 ranging between
ranging between 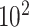 and
and 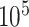 . Figure A3(b) plots the resulting changes in the FIA detection probability at
. Figure A3(b) plots the resulting changes in the FIA detection probability at 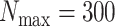 ((i)) and
((i)) and 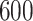 ((ii)). There we observe, that while the FIA is sensitive to
((ii)). There we observe, that while the FIA is sensitive to 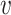 , it still performs well over the entire range. Thus, the FIA can sometimes be a choice selection metric, even in the absence of reasonable parameter space knowledge.
, it still performs well over the entire range. Thus, the FIA can sometimes be a choice selection metric, even in the absence of reasonable parameter space knowledge.
Lastly, we comment on some general issues limiting 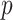 -selection performance of any metric on renewal and skyline models. The MLEs and FIs of the renewal model depend on the
-selection performance of any metric on renewal and skyline models. The MLEs and FIs of the renewal model depend on the 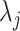 and
and 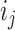 groups. As a result, epidemics with low observed incidence (i.e., likely to have
groups. As a result, epidemics with low observed incidence (i.e., likely to have  ) and diseases possessing sharp (low variance) generation time distributions (i.e., likely to feature
) and diseases possessing sharp (low variance) generation time distributions (i.e., likely to feature 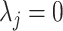 ) will be difficult to adaptively estimate. This is why we conditioned on the epidemic not dying out. Similarly, the MLEs and FIs of the skyline are sensitive to
) will be difficult to adaptively estimate. This is why we conditioned on the epidemic not dying out. Similarly, the MLEs and FIs of the skyline are sensitive to 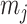 , meaning that it is necessary to ensure each group has coalescent events falling within its duration. Forcing segment end-points to coincide with coalescent events, as in (Drummond et al., 2005), guards against this identifiability problem (Parag and Pybus 2019). However, skyline model selection remains difficult even after averting this issue.
, meaning that it is necessary to ensure each group has coalescent events falling within its duration. Forcing segment end-points to coincide with coalescent events, as in (Drummond et al., 2005), guards against this identifiability problem (Parag and Pybus 2019). However, skyline model selection remains difficult even after averting this issue.
This follows from the random timing of coalescent events, which means that regular 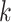 groupings can miss change-points, and that long branches can bias analysis (Parag et al. 2020b). These are known skyline plot issues and evidence why we truncated the last few events in the
groupings can miss change-points, and that long branches can bias analysis (Parag et al. 2020b). These are known skyline plot issues and evidence why we truncated the last few events in the 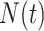 simulations. Further, there will always be limits to the maximum temporal precision attainable by
simulations. Further, there will always be limits to the maximum temporal precision attainable by 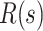 and
and 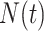 estimates under renewal and skyline models. It is impossible to infer changes in
estimates under renewal and skyline models. It is impossible to infer changes in  on a finer time scale than that of the observed incidence curve or estimate more
on a finer time scale than that of the observed incidence curve or estimate more  segments than the number of available coalescent events (Parag and Pybus 2019). This cautions against naively applying the criteria we have developed here. It is necessary to first understand and then prepare for these preconditions before sensible model selection results can be obtained. Practical model selection is rarely straightforward and the performance of most metrics is often only strictly guaranteed under asymptotic conditions (Grunwald 2007).
segments than the number of available coalescent events (Parag and Pybus 2019). This cautions against naively applying the criteria we have developed here. It is necessary to first understand and then prepare for these preconditions before sensible model selection results can be obtained. Practical model selection is rarely straightforward and the performance of most metrics is often only strictly guaranteed under asymptotic conditions (Grunwald 2007).
Empirical Case Study: HIV-1
We consider an empirical, ultrametric phylogeny composed of HIV-1 sequences sampled in 1997 from the Democratic Republic of Congo. This data set was previously examined in (Strimmer and Pybus, 2001). In Fig. A4, we illustrate several estimates of the effective population size underling this phylogeny. As a baseline, we plot the classic skyline plot (Pybus et al. 2000) for this phylogeny in grey on (i), (ii), and (iv). This represents the maximally parametrized skyline model and is known to overfit. Because the classic skyline converts every coalescent interval into a population size estimate, it also portrays where the events in the HIV tree are located. The clustering of estimates between 1940 and 1980 indicates that this period is considerably more informative (i.e., has a higher count record event density) than the time-regions around it.
We investigate two extremes of skyline model selection methodology. In Fig. A4(i), we consider the generalized skyline plot, which uses a small sample AIC. This method is simple, computable and improves on the noisy classic skyline by using 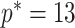 . However, it does require more extensive optimization than our metrics (it chooses groups based on their durations) and can be susceptible to overfitting (Kass and Raftery 1995). In (ii), we plot estimates from the multiple change-point method of (Opgen-Rhein et al., 2005). This approach is computationally intensive and lacks transparency but uses powerful reversible jump MCMC algorithms. Its output smooths over all demographic fluctuations.
. However, it does require more extensive optimization than our metrics (it chooses groups based on their durations) and can be susceptible to overfitting (Kass and Raftery 1995). In (ii), we plot estimates from the multiple change-point method of (Opgen-Rhein et al., 2005). This approach is computationally intensive and lacks transparency but uses powerful reversible jump MCMC algorithms. Its output smooths over all demographic fluctuations.
In (iv), we compute the FIA solution with 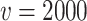 , which mediates between (i) and (ii). The FIA responds to the varying data-density across the tree by using notably more parameters than (i) in the 1940–1980 period, where it can be confident of a smooth trend, and fewer otherwise. This approach to group choice was theoretically supported in (Parag and Pybus 2019). In (iii), we compare the FIA (
, which mediates between (i) and (ii). The FIA responds to the varying data-density across the tree by using notably more parameters than (i) in the 1940–1980 period, where it can be confident of a smooth trend, and fewer otherwise. This approach to group choice was theoretically supported in (Parag and Pybus 2019). In (iii), we compare the FIA (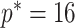 ) and BIC (
) and BIC (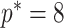 ) curves, where we find that they agree at small
) curves, where we find that they agree at small 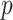 due to the large sample size in that region (the BIC is an asymptotic approximation to the FIA). However, at larger
due to the large sample size in that region (the BIC is an asymptotic approximation to the FIA). However, at larger 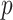 , where the space of parameter interactions is more notable, the parametric complexity terms matter.
, where the space of parameter interactions is more notable, the parametric complexity terms matter.
Supplementary material
Data (and code in Matlab) available from the Dryad Digital Repository: https://doi.org/10.5061/dryad.mpg4f4qv6.
Funding
K.V.P. and C.A.D. acknowledge joint funding from the UK Medical Research Council (MRC) and the UK Department for International Development (DFID) under the MRC/DFID Concordat agreement and the EDCTP2 programme supported by the European Union (grant MR/R015600/1). C.A.D. thanks the UK National Institute for Health Research Health Protection Research Unit (NIHR HPRU) in Modelling Methodology at Imperial College London in partnership with Public Health England (PHE) for funding (grant HPRU-2012-10080)
References
- Barron A., Rissanen J., Yu B. 1998. The minimum description length principle in coding and modeling. IEEE Trans. Inform. Theory 44:2743–2760. [Google Scholar]
- Beerli P., Felsenstein J. 2001. Maximum likelihood estimation of a migration matrix and effective population sizes in n subpopulations by using a coalescent approach. Proc. Natl. Acad. Sci. USA, 98:4563–4568. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Churcher T., Cohen J., Novotny J., Ntshalintshali N., Kunene S., and Cauchemez S. 2014. Measuring the path toward malaria elimination. Science 344:1230–1232. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cori A., Ferguson N., Fraser C., and Cauchemez S. 2013. A new framework and software to estimate time-varying reproduction numbers during epidemics. Am. J. Epidemiol. 178:1505–1512. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cover T. and Thomas J. 2006. Elements of information theory. 2nd ed New York: John Wiley and Sons. [Google Scholar]
- Drummond A., Rambaut A., Shapiro B., and Pybus O. 2005. Bayesian coalescent inference of past population dynamics from molecular sequences. Mol. Biol. Evol. 22:1185–1192. [DOI] [PubMed] [Google Scholar]
- Fraser C. 2007. Estimating individual and household reproduction numbers in an emerging epidemic. PLoS One 8:e758. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fraser C., Cummings D., Klinkenberg D., Burke D., and Ferguson N. 2011. Influenza transmission in households during the 1918 pandemic. Am. J. Epidemiol. 174:505–514. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gill M., Lemey P., Faria N., Rambaut A., Shapiro B., and Suchard M. 2012. Improving Bayesian population dynamics inference:a coalescent-based model for multiple loci. Mol. Biol. Evol. 30:713–724. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grunwald P. 2007. The minimum description length principle. Cambridge (MA): The MIT Press. [Google Scholar]
- Hanson A. and Fu P. 2004. Applications of MDL to selected families of models In: Advances in minimum description length:theory and applications. MIT Press. [Google Scholar]
- Heled J. and Drummond A. 2008. Bayesian inference of population size history from multiple loci. BMC Evol. Biol. 8(289). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ho S. and Shapiro B. 2011. Skyline-plot methods for estimating demographic history from nucleotide sequences. Mol. Ecol. Res. 11:423–434. [DOI] [PubMed] [Google Scholar]
- Karcher M., Palacios J., Lan S., Minin V. 2017. PHYLODYN:an R package for phylodynamic simulation and inference. Mol. Ecol. Res. 17:96–100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kass R. and Raftery A. 1995. Bayes factors. J. Am. Stat. Assoc. 90:773–795. [Google Scholar]
- Kingman J. 1982. On the genealogy of large populations. J. Appl. Prob. 19:27–43. [Google Scholar]
- Lehmann E. and Casella G. 1998. Theory of point estimation. 2nd ed Springer. [Google Scholar]
- Lemey P., Pybus O., Wang B., Saksena N., Salemi M., and Vandamme A. 2003. Tracing the origin and history of the HIV-2 epidemic. Proc. Natl. Acad. Sci. USA 100:6588–6592. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li H. and Durbin R. 2011. Inference of human population history from individual whole-genome sequences. Nature 475:493–496. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Minin V., Bloomquist E., and Suchard M. 2008. Smooth skyride through a rough skyline:Bayesian coalescent-based inference of population dynamics. Mol. Biol. Evol. 25:1459–1471. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Myung J., Navarro D., and Pitt M. 2006. Model selection by normalized maximum likelihood. J. Math. Psychol. 50:167–179. [Google Scholar]
- Nordborg M. 2001. Handbook of statistical genetics:coalescent theory. Chichester, UK: John Wiley and Sons. [Google Scholar]
- Nouvellet P., Cori A., Garske T., Blake I., Dorigatti I., Hinsley W., Jombart T., Mills H., Nedjati-Gilani G., Van Kerkhove M., Fraser C., Donnelly C., Ferguson N., and Riley S. 2018. A simple approach to measure transmissibility and forecast incidence. Epidemics 22:29–35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Opgen-Rhein R., Fahrmeir L., and Strimmer K. 2005. Inference of demographic history from genealogical trees using reversible jump Markov chain Monte Carlo. BMC Evol. Biol. 5(6). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Parag K., Pybus O. 2017. Optimal point process filtering and estimation of the coalescent process. J. Theor. Biol. 421:153–167. [DOI] [PubMed] [Google Scholar]
- Parag K., Pybus O. 2018. Exact Bayesian inference for phylogenetic birth-death models. Bioinformatics 34:3638–3645. [DOI] [PubMed] [Google Scholar]
- Parag K., Pybus O. 2019. Robust design for coalescent model inference. Syst. Biol. 68:730–743. [DOI] [PubMed] [Google Scholar]
- Parag K., Pybus O., Wu C. 2020a. Are skyline plot-based demographic estimates overly dependent on smoothing prior assumptions? BioRxiv 920215. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Parag K., du Plessis L., Pybus O. 2020b. Jointly inferring the dynamics of population size and sampling intensity from molecular sequences. Mol. Biol. Evol. (in press) doi: 10.1093/molbev/msaa016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pitt M., Myung I., Zhang S. 2002. Toward a method of selecting among computational models of cognition. Psych. Rev. 109:472–491. [DOI] [PubMed] [Google Scholar]
- Pybus O., Rambaut A., Harvey P. 2000. An integrated framework for the inference of viral population history from reconstructed genealogies. Genetics 155:1429–1437. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pybus O., Charleston M., Gupta S., Rambaut A., Holmes E., and Harvey P. 2001. The epidemic behavior of the hepatitis C virus. Science 292:2323–2325. [DOI] [PubMed] [Google Scholar]
- Qian G., Kunsch H. 1998. Some notes on Rissanen’s stochastic complexity. IEEE Trans. Inf. Theory 44:782–786. [Google Scholar]
- Rambaut A., Pybus O., Nelson M., Viboud C., Taubenberger J., and Holmes E. 2008. The genomic and epidemiological dynamics of human influenza A virus. Nature 453:615–619. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rissanen J. 1978. Modeling by shortest data description. Automatica 14:465–471. [Google Scholar]
- Rissanen J. 1996. Fisher information and stochastic complexity. IEEE Trans. Inf. Theory 42:40–47. [Google Scholar]
- Snyder D., Miller M. 1991. Random point processes in time and space. 2nd ed New York: Springer. [Google Scholar]
- Strimmer K., Pybus O. 2001. Exploring the demographic history of DNA sequences using the generalized skyline plot. Mol. Biol. Evol. 18:2298–2305. [DOI] [PubMed] [Google Scholar]
- Suchard M., Lemey P., Baele G., Ayres D., Drummond A., and Rambaut A. 2018. Bayesian phylogenetic and phylodynamic data integration using BEAST 1.10. Virus Evol. 4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Turchin P. 2003. Complex population dynamics:a theoretical/empirical synthesis. Princeton University Press. [Google Scholar]
- van Erven T. and Grunwald P. 2012. Catching up faster by switching sooner:a predictive approach to adaptive estimation with an application to the AIC–BIC dilemma. J. R. Stat. Soc. B, 74:361–417. [Google Scholar]
- Wallinga J. and Lipsitch M. 2007. How generation intervals shape the relationship between growth rates and reproductive numbers. Proc. R. Soc. B, 274:599–604. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wallinga J. and Teunis P. 2004. Different epidemic curves for severe acute respiratory syndrome reveal similar impacts of control measures. Am. J. Epidemiol. 160:509–516. [DOI] [PMC free article] [PubMed] [Google Scholar]