

Abstract
Protein–DNA interactions are dynamic, and these dynamics are an important aspect of chromatin‐associated processes such as transcription or replication. Due to a lack of methods to study on‐ and off‐rates across entire genomes, protein–DNA interaction dynamics have not been studied extensively. Here, we determine in vivo off‐rates for the Saccharomyces cerevisiae chromatin organizing factor Abf1, at 191 sites simultaneously across the yeast genome. Average Abf1 residence times span a wide range, varying between 4.2 and 33 min. Sites with different off‐rates are associated with different functional characteristics. This includes their transcriptional dependency on Abf1, nucleosome positioning and the size of the nucleosome‐free region, as well as the ability to roadblock RNA polymerase II for termination. The results show how off‐rates contribute to transcription factor function and that DIVORSEQ (Determining In Vivo Off‐Rates by SEQuencing) is a meaningful way of investigating protein–DNA binding dynamics genome‐wide.
Keywords: DNA binding dynamics, epigenetics, genomics, systems biology, transcription
Subject Categories: Chromatin, Epigenetics, Genomics & Functional Genomics; Methods & Resources
Using a new method (DIVORSEQ), genome‐wide off‐rates are determined for a DNA binding transcription factor. Abf1 exhibits site‐specific residence times that range from 4 to 33 min and which are associated with different functional characteristics.
Introduction
Processes that act on chromatin, such as transcription or replication, are controlled by molecular interactions. This includes proteins interacting with DNA. Protein–DNA interactions are dynamic, and these dynamics are likely important to achieve appropriate regulation of DNA‐dependent processes. During transcription for example, different types of transcription factors (TFs) are continuously interacting with chromatin in a variety of ways. Each brings different functions into play: opening or closing chromatin, creating loops, modifying or evicting nucleosomes, recruiting cofactors and, in the case of activation, ultimately causing formation of a pre‐initiation complex that includes RNA polymerase (Hahn & Young, 2011; de Laat & Dekker, 2012; Spitz & Furlong, 2012; Struhl & Segal, 2013; Friedman & Rando, 2015; Kubik et al, 2017; Lai & Pugh, 2017; Woo et al, 2017; Cramer, 2019; Brahma & Henikoff, 2020). TFs are therefore constantly moving off and onto different loci, probing for appropriate interactions, also under conditions of steady‐state transcriptional output (Hammar et al, 2014). The rates with which proteins interact with DNA, their on‐ and off‐rates, dictate the outcome of all kinds of regulatory programmes. Understanding how DNA‐dependent processes work at the molecular level therefore requires methods to measure the dynamics of protein–DNA binding interactions in a systematic manner.
Different methods have been applied to investigate protein–DNA interaction dynamics. Initial in vitro measurements showed very stable TF‐DNA binding that could last for more than an hour (Perlmann et al, 1990; Hoopes et al, 1992). This view was challenged by in vivo measurements showing much more dynamic interactions (Hager et al, 2009; Larson, 2011; Mueller et al, 2013; Voss & Hager, 2014; Coleman et al, 2015; Brignall et al, 2019; Elf & Barkefors, 2019), likely in part due to the presence of nucleosomes (Luo et al, 2014; Donovan et al, 2019a; Mivelaz et al, 2020). Direct visualization of protein–DNA interaction dynamics by fluorescence microscopy has been pivotal in forming the current view that binding of many proteins is indeed highly dynamic (McNally et al, 2000; Elbi et al, 2004; Karpova et al, 2004, 2008; Stavreva et al, 2004; Bosisio et al, 2006; Yao et al, 2006; Kloster‐Landsberg et al, 2012). These studies have also been crucial for showing the importance of dynamics and how this can be regulated through distinct mechanisms. A drawback of microscopy is scope however. Information is provided for only part of the nucleus collectively, or only for a single locus. It would be very useful to determine interaction dynamics at many different binding sites individually, preferably across an entire genome.
Genome‐wide protein–DNA binding can be measured by chromatin immunoprecipitation (ChIP) in vivo (Gilmour & Lis, 1984; Kuo & Allis, 1999; Park, 2009; Collas, 2010; Furey, 2012). On its own, ChIP only provides a static indication of the degree of binding during the time‐window of protein–DNA cross‐linking. ChIP cannot measure protein–DNA binding dynamics directly. Competition ChIP is a ChIP variant that uses inducible switching between two differentially tagged isoforms of the same protein and has been applied to measure turnover of nucleosomes and TFs (Dion et al, 2007; Rufiange et al, 2007; van Werven et al, 2009; Lickwar et al, 2012; Hasegawa & Struhl, 2019). Although limited by the induction kinetics of the competing isoform, competition ChIP has nevertheless highlighted the advantage of determining dynamics at different loci in a genome‐wide manner. It has revealed differences in dynamics between promoter classes, differences in nucleosome turnover between promoters and gene bodies and showed that differential TF turnover at different loci is an important basis of transcription regulation.
Binding dynamics are determined by TF concentrations, and by on‐ and off‐rates. On‐ and off‐rates are two distinct facets of dynamics. Both would be useful to measure separately since they are likely influenced and regulated by different molecular mechanisms. Having both would also enable the estimation of dissociation constants and the binding free energy. A second adaptation of ChIP has indeed focused on determining on‐rates by measuring the kinetics of binding during a formaldehyde cross‐linking time–course (Poorey et al, 2013). As a method, this is still under development (Zaidi et al, 2017) and has only been applied to a few binding sites and not genome‐wide as yet. Here, we devised a method that directly determines off‐rates and does so for all binding sites across a genome. This was achieved by applying anchor‐away to rapidly deplete unbound proteins from the nucleus (Haruki et al, 2008; Grimaldi et al, 2014), thereby removing the on‐rate contribution to binding levels. Monitoring the time‐dependent decay of protein–DNA binding across all genomic locations results in determination of off‐rates, also in the form of locus‐specific mean residence times. The method DIVORSEQ (Determining In Vivo Off‐Rates by SEQuencing) is applied here to Abf1, a Saccharomyces cerevisiae general regulatory factor akin to chromatin pioneering TFs in mammals (Zaret & Carroll, 2011; Kubik et al, 2017). Alongside roles in shaping chromatin architecture (Venditti et al, 1994; Lascaris et al, 2000; Yarragudi et al, 2004; Hartley & Madhani, 2009), several different functions have been attributed to Abf1, including involvement in transcription regulation (Gailus‐Durner et al, 1996), telomere binding (Enomoto et al, 1994; Pryde & Louis, 1999), DNA replication (Marahrens & Stillman, 1992), DNA repair (Reed et al, 1999) and RNA polymerase II roadblock termination (Roy et al, 2016; Candelli et al, 2018). Applying DIVORSEQ to Abf1 results in determination of off‐rates for 191 different binding sites, with estimated mean residence times ranging from 4.2 to 33 min. Sites with different off‐rates are associated with different functional characteristics that include their transcriptional dependency on Abf1, nucleosome positioning and the ability to roadblock RNA polymerase II thereby aiding transcription termination. The results emphasize that off‐rate is an important characteristic of TF function and indicate that DIVORSEQ is a useful method for investigating protein–DNA binding dynamics genome‐wide.
Results
Nuclear depletion of Abf1
To inducibly remove unbound Abf1 from the nucleus, an Abf1 anchor‐away strain (Haruki et al, 2008) was created in the Saccharomyces cerevisiae BY4742 background (de Jonge et al, 2017). Abf1 was tagged with an FK506 binding protein–rapamycin binding (FRB) domain for nuclear depletion, green fluorescent protein (GFP) to monitor cellular localization and a V5 epitope for ChIP (Southern et al, 1991). ABF1 deletion is lethal (Halfter et al, 1989; Rhode et al, 1989). To investigate whether tagging of Abf1 interferes with its function, growth of tagged strains was compared to the untagged background. Tagging Abf1 has only a slight effect on growth (Fig EV1A), indicating that tagging does not greatly interfere with Abf1 function, as has been observed before (Kubik et al, 2015). Because of its essential nature, cells are expected to cease growth when Abf1 is depleted from the nucleus. Indeed, upon inducing nuclear depletion, cells show a clear disruption of growth, leading to complete growth cessation (Fig EV1B). Because loss of growth is a downstream effect, the rate of growth cessation does not necessarily reflect the speed of nuclear depletion (de Jonge et al, 2017). To directly visualize depletion, cellular localization of Abf1 was monitored using fluorescence microscopy. As expected, nuclear depletion of Abf1 indeed occurs much more rapidly than growth cessation (Fig EV1C and D).
Figure EV1. Dynamics of Abf1 depletion.
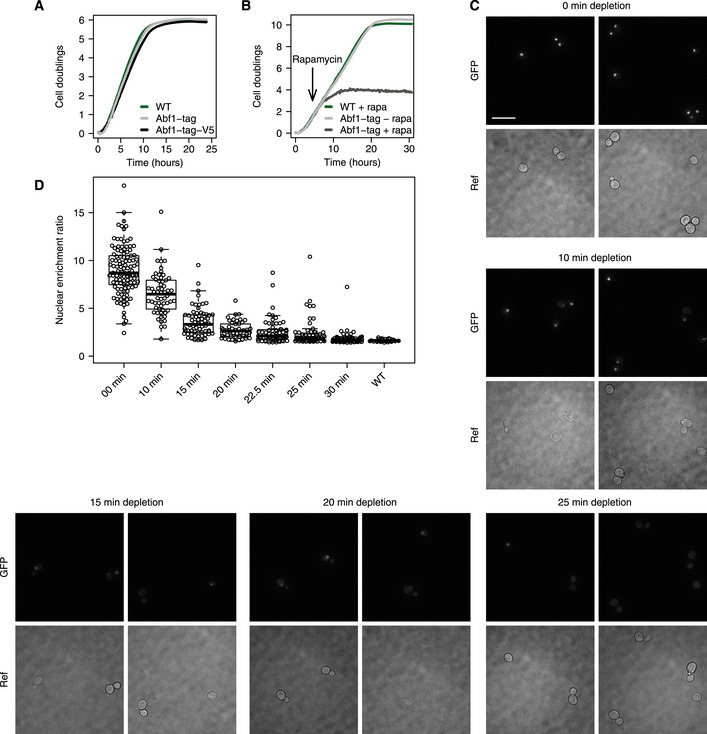
- Representative growth curves of the untagged parental background strain (WT), an ABF1 FRB‐GFP-tagged strain (Abf1‐tag) and an ABF1 FRB‐GFP-V5‐tagged strain (Abf1‐tag-V5). The WT strain is the parental BY4742/S288C strain of the Abf1 anchor‐away strains that have been genetically desensitized to rapamycin. The Abf1‐tag strain grows approximately 10% slower compared to the WT strain and the Abf1‐tag-V5 strain grows approximately 15% slower than the WT strain.
- Growth curves of the WT strain with rapamycin, and the ABF1 FRB‐GFP tagged strain with and without rapamycin, the inducing agent for nuclear depletion (Haruki et al, 2008). Rapamycin was added 4.5 h after the start of the experiment to induce nuclear depletion (arrow). Upon induction of depletion, clear disruption of growth is visible after approximately 3 h (t = 7.5 h) and cessation of growth is visible after approximately 8 h (t = 12.5 h).
- Representative fluorescence microscopy images of ABF1 FRB‐GFP-V5 cells before (0 min) and at several time points after (10, 15, 20 and 25 min) induction of nuclear depletion. Scale bar: 10 μm.
- Quantification of nuclear enrichment ratios of ABF1 FRB‐GFP and ABF1 FRB‐GFP-V5 cells during depletion (three biological replicates). Both DNA‐bound and free Abf1 contribute to the GFP signal and therefore the decrease in fluorescence represents the depletion speed of both unbound as well as bound Abf1. Dots represent individual cell measurements. The nuclear enrichment ratio was calculated as the maximum intensity divided by the median intensity of each cell. A WT strain without GFP was taken along as a control.
Determining in vivo off‐rates by sequencing: DIVORSEQ
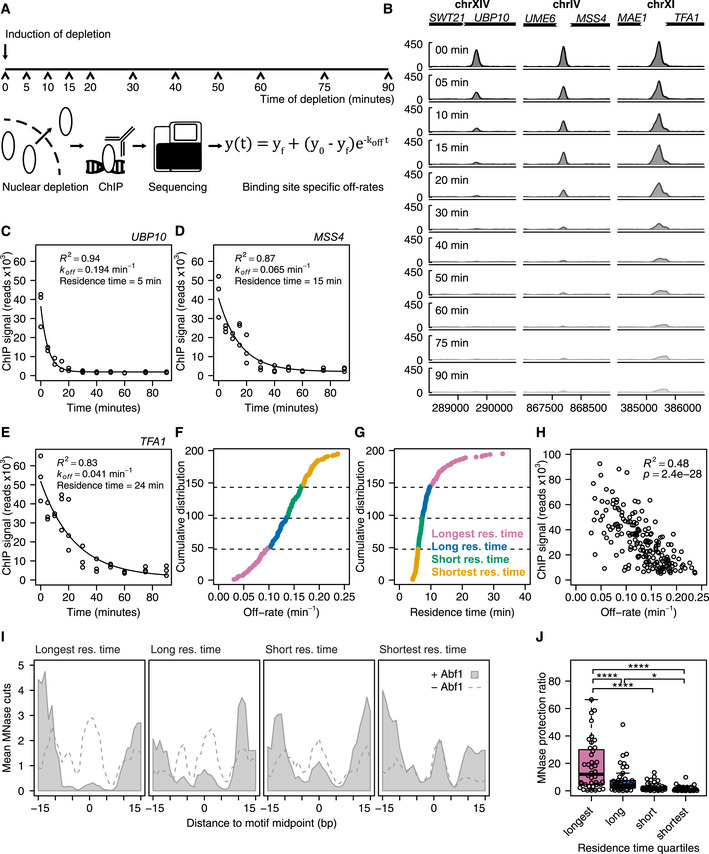
Having ascertained Abf1 depletion, we next determined whether the system can be used to measure TF mean residence times (defined as 1/k off) at different sites across the genome. As published elsewhere (preprint: de Jonge et al, 2019), first the ChIP protocol was extensively optimized at almost all steps, to yield results better comparable between different time points. Next, to determine off‐rates, Abf1 was depleted from the nucleus and its binding levels were measured genome‐wide using the optimized ChIP‐seq protocol at 11 time points during 90 min of depletion, all in biological triplicate (Fig 1A). The binding sites detected before depletion (t = 0) correspond well with previously published Abf1 binding sites (Kasinathan et al, 2014; Zentner et al, 2015; Rossi et al, 2018b). Over 90% of binding sites overlap with previously reported sites (Fig EV2A). As exemplified, different genomic locations show distinct rates of binding peak decay (Fig 1B), indicating different mean Abf1 residence times at these sites. Quantification and fitting the exponential decay model (Fig 1A) to the data (Fig 1C–E) yields an estimated site‐specific off‐rate that can also be expressed as an average TF residence time for that site. The examples (Fig 1B–E) were chosen to cover the wide range of different off‐rates/mean residence times observed. First, stringent peak filtering was performed to obtain only reliable signals, by selecting sites with strong binding (fold enrichment > 4) as well as sites that have a G/C residue at −8 bp from the motif (Fig EV2B) and therefore can efficiently be cross‐linked (Rossi et al, 2018a). Next, off‐rates and the corresponding mean residence times were obtained for these 191 selected Abf1 binding sites by fitting exponential decay models to the ChIP‐seq data of each individual binding peak. Almost all models closely match the actual binding data, with low residuals (Fig EV2C) and a median R 2 of 0.94 (Fig EV2D, lowest R 2 = 0.65). Based on these models, the off‐rates for Abf1 range between 0.030 and 0.24 min−1 (Fig 1F). This corresponds to a mean residence time of 4.2 min for the most dynamic Abf1 site, the divergent promoter of SRB2 and NCP1, and a mean residence time of 33 min for the promoter of OCA5 which has a very stable Abf1 binding peak (Fig 1G). This is the first indication that DIVORSEQ can measure mean residence times over a considerable range and that Abf1 has distinct mean residence times at different locations across the genome.
Figure 1. DIVORSEQ measures distinct mean residence times at different genomic sites.
-
ASchematic overview of the DIVORSEQ method. Unbound protein of interest is depleted from the nucleus, and at several time points during the depletion, binding levels are measured using ChIP‐seq. The decrease in binding levels is fitted using an exponential decay model and off‐rates and mean residence times are estimated for all binding sites across the genome.
-
BAbf1 binding during the depletion time–course at three Abf1 binding sites with different rates of binding decrease. The signal at each time point is the average of three biological replicates, except for the 10 min time point, where one time point was discarded.
-
C–EFit of the exponential decay model for the examples shown in (B). The estimates for off‐rates, mean residence time and goodness of fit are shown in the plots.
-
F, GCumulative distribution of the off‐rates (F) or mean residence times (G) of the 191 binding sites. The four different mean residence time quartiles are highlighted with different colours.
-
HRelationship between Abf1 binding levels before depletion and off‐rates for the 191 Abf1 binding sites.
-
IAverage in vivo MNase sensitivity of the mean residence time quartiles, plotted as the average number of MNase cuts at each position relative to the Abf1 binding motif (MacIsaac et al, 2006) before (grey fill) or after (dashed line) nuclear Abf1 depletion. The data were smoothed using a 3 bp window.
-
JExtent of MNase protection by Abf1 for each mean residence time quartile. The MNase protection ratio is the mean number of cuts in the region protected by Abf1 (−8 bp until +8 bp) after depletion of Abf1 (I, dashed line), divided by the mean number of cuts in the same region before depletion (I, light grey fill). Asterisks denote a significant difference between the quartiles, calculated using a one‐way ANOVA followed by Tukey's honest significant difference (HSD) test (*P < 0.05 and ****P < 0.0001).
Figure EV2. The exponential decay model closely fits the binding data.
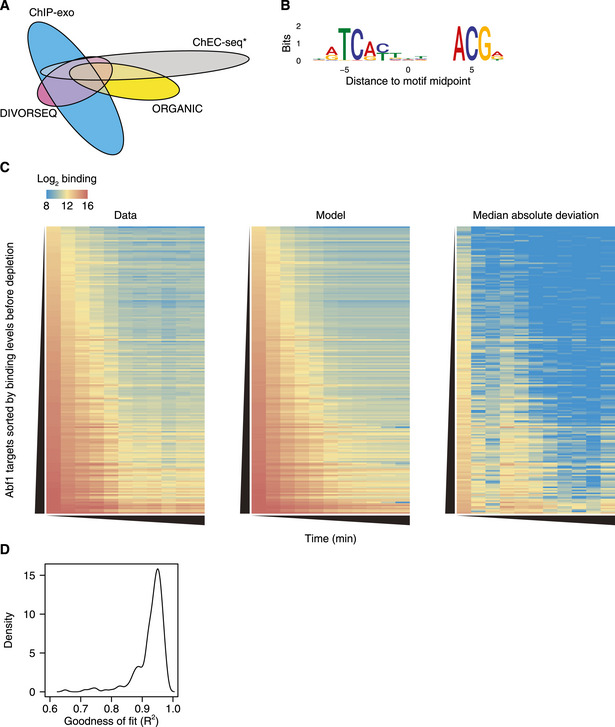
- Venn diagram showing the overlap between all unfiltered Abf1 binding sites detected here (n = 948) and published Abf1 binding sites detected using ORGANIC ChIP (Kasinathan et al, 2014; n = 1,068), binding sites detected using ChEC‐seq that were annotated both as “fast” and “high scoring” (Zentner et al, 2015; n = 1,583) and binding sites that were detected using ChIP‐exo v5 (Rossi et al, 2018b; n = 3,177).
- Heatmap representation of the average Abf1 binding at the 191 binding sites, quantified as the log2 number of reads in the peak (peak summit ± 50 bp). The rows are sorted on the binding levels before depletion, and the columns represent increasing time of depletion. From left to right: average binding data, fit and residuals of the fit (median absolute deviation) are shown.
- The distribution of the goodness of fit of the 191 Abf1 binding sites.
DIVORSEQ‐derived TF mean residence times correspond to MNase protection rates
To initially test whether DIVORSEQ‐derived off‐rates are realistic measures of Abf1 binding stability, two strategies were employed. First, mean residence times were compared to Abf1 binding at t = 0. Since off‐rates influence steady‐state binding levels, some degree of correspondence is expected. There is indeed correlation between the DIVORSEQ‐derived off‐rates and binding levels (Fig 1H), whereby sites with low off‐rates have higher Abf1 binding levels. That the correspondence is not complete is also expected because on‐rate contributes to steady‐state binding levels as well. These results therefore also indicate that the relative importance of on‐ and off‐rates may differ for different genomic binding sites. A second verification of the DIVORSEQ‐derived off‐rates was therefore also sought. This was based on an independently generated MNase cleavage dataset, derived from a strain expressing free MNase (Kubik et al, 2018). Since it is well known that TF occupancy can result in protection against MNase cleavage, it is expected that Abf1 binding sites with the lowest off‐rate should show the highest degree of MNase protection. This is indeed the case. Abf1 binding sites were divided into the four quartiles with the longest, long, short and shortest mean Abf1 residence times (Fig 1F and G). The average MNase cleavage is plotted for each quartile relative to the Abf1 binding motif (Fig 1I, grey area) and is indeed seen to increase in the four quartiles from left (longest mean residence times, least MNase cleavage) to right (shortest mean residence times, most cleavage). That protection against MNase cleavage in the quartiles with long mean Abf1 residence times is indeed dependent on Abf1 is demonstrated by an overall increase in MNase cleavage after prolonged Abf1 depletion (Fig 1I, dashed line). The extent of MNase protection is also shown for each individual site in each quartile (Fig 1J). DIVORSEQ‐derived Abf1 off‐rates correspond well to the degree of MNase protection. This indicates that the method performs as designed and provides meaningful data for a wide range of TF binding stabilities at different locations across the genome.
Increased Abf1 binding stability is associated with larger nucleosome‐free regions
Having established that the DIVORSEQ‐derived off‐rates are meaningful reflections of binding stability, we next asked whether there are mechanistic relationships between stability as measured in this manner and the roles of Abf1. Abf1 is important for shaping local chromatin architecture (Venditti et al, 1994; Lascaris et al, 2000; Yarragudi et al, 2004; Hartley & Madhani, 2009; Ganapathi et al, 2011; Krietenstein et al, 2016; Kubik et al, 2018) and contributes to the creation of nucleosome‐free regions (NFRs) by competing with nucleosomes and acting as a barrier that chromatin remodellers use to position surrounding nucleosomes. To investigate whether Abf1 binding stability is related to its role in creating NFRs, nucleosome positioning data (Kubik et al, 2015) were investigated in the context of different mean Abf1 residence times. Sites with more stable Abf1 binding (longer mean residence times, Fig 2, top) have larger NFRs (308 bp) compared to sites with shorter mean residence time sites (Fig 2, bottom, 272 bp). These results obviously fit well with the idea that more stably bound Abf1 can more efficiently repel nucleosomes. However, this does not rule out the converse whereby nucleosome remodelling and nucleosome competition causes increased Abf1 off‐rates at those sites with reduced mean residence times. Most importantly for the goals of our study, alongside the MNase protection data (Fig 1I and J), the NFR size associated differences shows that DIVORSEQ‐derived Abf1 off‐rates can be functionally meaningful in this manner too.
Figure 2. Nucleosomes architecture corresponds to mean residence times.
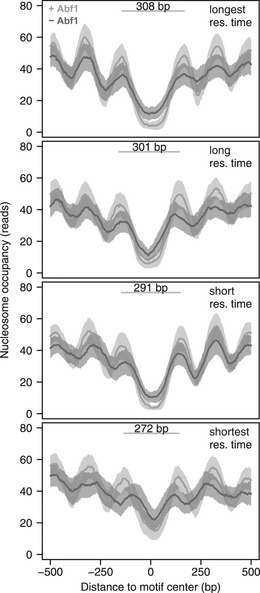
Average nucleosome occupancy of the mean residence time quartiles before (light grey) and after (dark grey) Abf1 depletion, centred on the Abf1 binding motif. Nucleosomes of all mean residence time quartiles reposition upon Abf1 depletion, which indicates that Abf1 contributes to the positioning of nucleosomes for all quartiles. The average distance between the midpoints of the −1 and +1 nucleosomes before depletion of Abf1 are indicated for each quartile. The confidence intervals are indicated by a transparent grey fill, calculated as the mean ± the standard error of the mean (SEM). Nucleosome binding data are from (Kubik et al, 2015).
Changes in mRNA synthesis rates match Abf1 binding dynamics
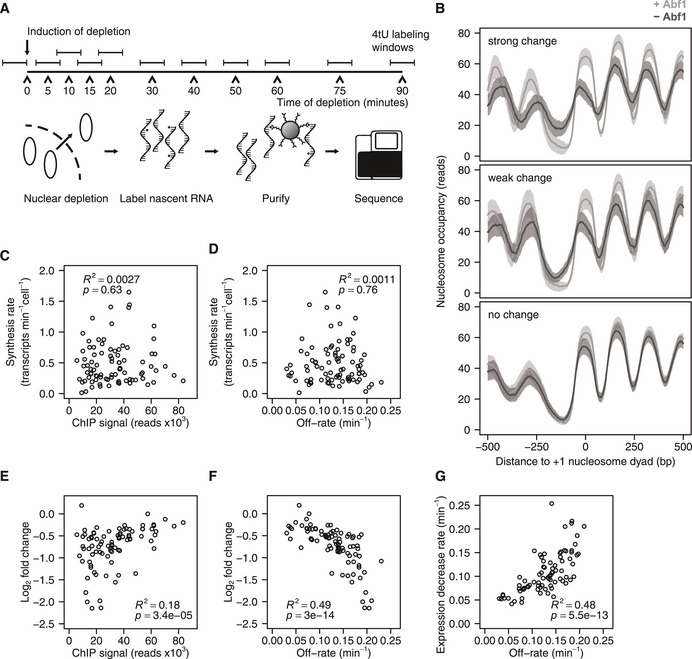
We next investigated whether Abf1 binding dynamics play a role in the function of Abf1 as a transcriptional regulator (Buchman & Kornberg, 1990; Gailus‐Durner et al, 1996; Miyake et al, 2002, 2004; Yarragudi et al, 2007; Paul et al, 2015; Kubik et al, 2018). Previous studies have shown that not all Abf1 bound promoters show transcriptional dependency on Abf1 (Schroeder & Weil, 1998; Yarragudi et al, 2007; Paul et al, 2015). This has been ascribed to either lower inherent propensity for nucleosome formation at some sites, binding too far away from a transcription start site, or redundancy with other TFs (Paul et al, 2015; Kubik et al, 2018). We therefore first determined which genes are dependent on Abf1 by measuring mRNA synthesis rates genome‐wide using 4‐thiouracil labelling of nascent transcripts (Sun et al, 2012) during a 90 min Abf1 depletion time–course, at the same times points that were used to determine off‐rates (Fig 3A). Approximately half of the genes with Abf1 promoter binding show a decrease in mRNA synthesis rates upon Abf1 depletion, in agreement with what has previously been described for Abf1 (Schroeder & Weil, 1998; Yarragudi et al, 2007; Paul et al, 2015). The non‐responsive genes show little, if any, concomitant change in nucleosome repositioning (Figs 3B and EV3A), also in agreement with previous studies (Kubik et al, 2018). The set of genes that do show Abf1‐dependency were next used to investigate the role of binding dynamics.
Figure 3. Dynamics of mRNA synthesis changes follow the dynamics of Abf1 dissociation.
-
ASchematic overview of the experiment set‐up for measuring promoter output dynamics by labelling nascent RNA. The protein of interest is depleted from the nucleus and nascent RNA is labelled for 6 min using 4‐thiouracil (4tU) at several time points during the depletion. Total RNA is extracted, nascent RNA is purified by biotinylating 4tU labelled RNA and the purified RNA is sequenced. Samples were taken such that the centre of the labelling period was the same as the time points that were used for DIVORSEQ.
-
BAverage nucleosome occupancy relative to +1 nucleosome dyad, of genes with Abf1 binding to the promoter that show strong changes (fold change > 2 at t = 20, top panel, n=44), weak changes (1.5 ≤ fold change ≤ 2 at t = 20, middle panel, n = 42) or no changes (fold change < 1.5 at t = 20, bottom panel, n = 112) in mRNA synthesis upon Abf1 depletion. Nucleosome occupancy is shown before (light grey) and after (dark grey) Abf1 depletion. The confidence intervals are indicated as in Fig 2 by a transparent grey fill, calculated as the mean ± SEM. Nucleosome binding data and +1 nucleosome positions are from (Kubik et al, 2015). Downregulated and Abf1 bound genes without an annotated +1 nucleosome were omitted from the plots.
-
C, DRelationship between steady‐state synthesis rates (Sun et al, 2012) and binding levels before depletion (C), or off‐rates (D). Genes are shown that are Abf1 bound and downregulated (fold change > 1.5 and P < 0.01 at 20 and 30 min of depletion, yielding 88 genes) and have available synthesis rates (n = 87).
-
E, FRelationship between log2 mRNA synthesis rate changes after 10 min of depletion and binding levels before depletion (E) or off‐rates (F). Genes are shown that are Abf1 bound and downregulated (fold change > 1.5 and P < 0.01 at 20 and 30 min of depletion, n = 88).
-
GRelationship between expression decrease rates of downregulated genes and off‐rates of the corresponding Abf1 binding site. The expression decrease rates were calculated by fitting the 4tU‐seq time data course using the same exponential decay model that was used for the off‐rates. The genes from (E‐F) are shown, except for the ones where the 4tU‐seq data could not be fitted with an exponential decay model (n = 82).
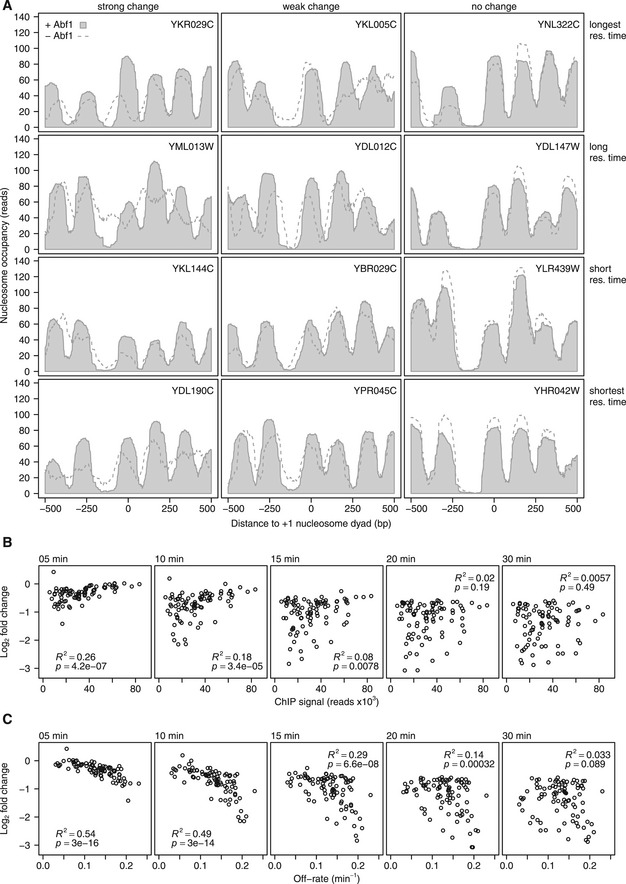
Figure EV3. Changes in mRNA synthesis correspond more closely to off‐rates than binding levels.
-
ANucleosome occupancy of example genes relative to the +1 nucleosome dyad. Genes are shown from each of the residence time quartiles (rows), with different expression changes (columns), with strong changes (fold change > 2 at t = 20, left), weak changes (1.5 ≤ fold change ≤ 2 at t = 20, middle) or no changes (fold change < 1.5 at t = 20, right). Nucleosome occupancy is shown before (light grey fill) and after (dashed line) Abf1 depletion. Nucleosome binding data and +1 nucleosome positions are from (Kubik et al, 2015).
-
BChange in mRNA synthesis rate versus Abf1 binding level before depletion of the corresponding binding site after 5, 10, 15, 20 and 30 min of depletion of downregulated genes (fold change > 1.5 and P < 0.01 at 20 and 30 min of depletion) with Abf1 binding in the promoter (n = 88). The panel for t = 10 min is also shown in Fig 3E.
-
CChange in mRNA synthesis rate versus the off‐rates of the corresponding binding sites for the same gene‐binding sites pairs as in (A) 5, 10, 15, 20 and 30 min after induction of depletion. The panel for t = 10 min is also shown in Fig 3F.
First, steady‐state synthesis rates (transcripts per minute per cell, Sun et al, 2012) were compared to steady‐state binding levels of Abf1. In contrast to what might be expected, there is virtually no relationship between the amount of Abf1 at a promoter and promoter activity at steady state (Fig 3C). Regardless of absolute binding levels, promoters with more stably bound Abf1 also do not show higher synthesis rates (Fig 3D). There is however some association between the steady‐state amount of bound Abf1 and the early changes in synthesis rates observed upon Abf1 depletion (Figs 3E and EV3B). The relationship between Abf1 presence and transcriptional dependency is markedly stronger when taking into account the DIVORSEQ‐derived off‐rates (Figs 3F and EV3C). Genes showing the largest change in promoter output are those with the highest off‐rates. This holds both for the 10 min time point analysed in Fig 3F, as well as when fitting an exponential decay model to the entire mRNA synthesis rate time–course (Fig 3G). For those genes that are dependent on Abf1 for transcriptional activity, there is a strong correspondence between the loss of Abf1 and the reduction in synthesis rate. The relationship between Abf1 and transcriptional output only becomes clear when plotting off‐rates (Fig 3F and G). This emphasizes the importance of methods to investigate interaction dynamics genome‐wide and the utility of DIVORSEQ for this purpose. As discussed later, our analyses agree with the idea that an Abf1‐dependent NFR is the most important determinant for setting up transcription, resulting in associated dependencies on Abf1 (Paul et al, 2015; Kubik et al, 2018; Fig 3B), but that fine‐tuning the absolute levels of steady‐state transcriptional output is further dependent on other contributing transcription (co‐)factors.
Stably bound sites are more efficient roadblocks for pervasive Pol II transcription
In addition to being a chromatin organizer, Abf1 has been shown to function as roadblock for pervasive transcription (Roy et al, 2016; Candelli et al, 2018). In this role, Abf1, like the other general regulatory factors Reb1 and Rap1, can block transcribing RNA polymerase II (Pol II). This collision causes Pol II to stall, to become ubiquitinylated and likely degraded (Colin et al, 2014; Candelli et al, 2018). An obvious hypothesis, as has indeed been suggested (Roy & Chanfreau, 2018), is that TF binding stability may contribute to roadblock function. To test this idea, data of actively transcribing Pol II (Schaughency et al, 2014) were analysed. The average Pol II presence relative to the Abf1 binding motif was plotted for each of the mean residence time quartiles (Fig 4A). A roadblock peak (Fig 4A, arrow) can be observed immediately upstream of the Abf1 motif for the quartile with the longest mean residence times, and this becomes less pronounced with shorter mean residence times. Quantification of roadblock efficiency at each individual site confirms that stronger roadblocks are observed in the quartile with the longest mean residence times (Fig 4B). In agreement with this, sites with stalled Pol II have significantly lower off‐rates compared to sites that do not (Fig 4C). More stably bound Abf1 is a more efficient roadblock for transcribing Pol II, further demonstrating the utility of genome‐wide off‐rate measurements for molecular mechanistical understanding.
Figure 4. Sites with long mean residence times function as a roadblock for pervasive transcription.
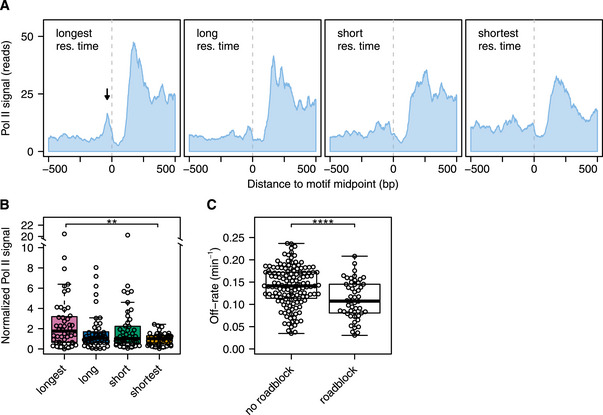
- Average RNA polymerase II binding for the different mean residence time quartiles. Binding profiles are centred on the Abf1 motif. The dotted line marks the midpoint of the Abf1 motif. All RNA polymerase II binding data were reoriented such that each motif is oriented in the same direction. RNA polymerase II binding is PAR‐CLIP (photoactivatable ribonucleoside‐enhanced cross‐linking and immunoprecipitation) data from (Schaughency et al, 2014).
- Quantification, by mean residence time quartile, of normalized Pol II binding levels at the roadblock peak. These levels are defined as the amount of roadblocked Pol II (located at −37 ± 5 bp) divided by the amount of upstream Pol II (from −300 to −100 bp). Asterisks denote a significant difference between the quartiles, calculated using a one‐way ANOVA followed by Tukey's HSD test (**P < 0.01).
- Difference in off‐rates between sites that are a roadblock (normalized Pol II signal > 2) and those that are not. The P‐value was calculated using a two‐tailed t‐test (****P < 0.0001).
Factors contributing to Abf1 binding stability
When applied to Abf1, DIVORSEQ indicates that there is a considerable range of off‐rates and that this contributes to different aspects of Abf1 function. The ability to determine mean residence times also allows for investigation into the factors that determine different off‐rates. The DNA binding motif is obviously an important factor for determining Abf1 binding stability. To evaluate the contribution of motif frequency, the number of Abf1 motifs in the vicinity of each Abf1 peak was counted. Although there are only a few peaks with multiple motifs, it is clear that most sites with more than one Abf1 binding motif have significantly longer mean residence times compared to sites with only a single binding motif (Fig 5A). Such increases in stability are likely caused by different types of cooperative effects associated with the presence of multiple motifs (Adams & Workman, 2020; Polach & Widom, 1996; Miller & Widom, 2003; Hager et al, 2009; Mirny, 2010).
Figure 5. Factors that contribute to Abf1 binding stability.
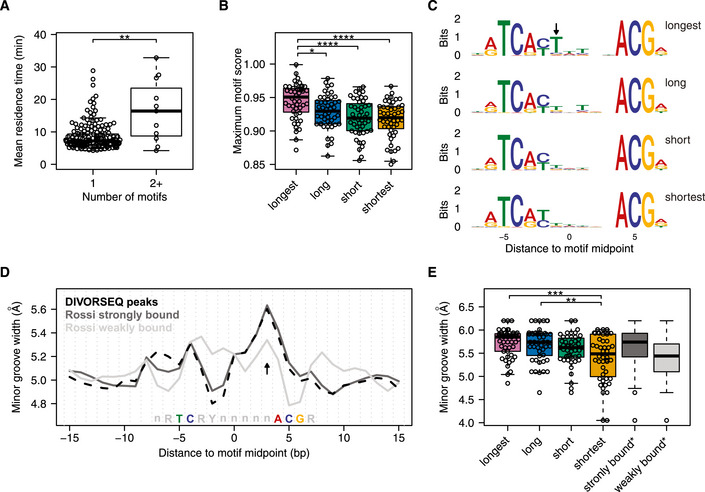
- Difference in mean residence times between sites with one motif and sites with two or more motifs. The P‐value was calculated using a Wilcoxon rank‐sum test (**P = 0.0066), rather than a t‐test (P = 0.022) as used in Fig 4C, since the group with 1 binding motif is not normally distributed.
- Difference in maximum motif score between the different mean residence time quartiles. When a site has more than one motif, the highest score was used.
- Sequence logos showing the representative binding motif of each mean residence time quartile. Motifs from the longest mean residence time quartile are enriched (P = 0.0046) for having a thymine at position −1 bp (arrow).
- Predicted minor groove width centred at the Abf1 binding motif of all 191 Abf1 sites found here (black, dashed line) and Abf1 binding motifs defined as strongly bound (dark grey line) and weakly bound (light grey line) by (Rossi et al, 2018a).
- Difference in predicted minor groove width between the mean residence time quartiles at position +3 bp from the motif midpoint (D, arrow). In addition, the minor groove width at this position of the Abf1 motifs defined as strongly and weakly bound by (Rossi et al, 2018a) are shown (n = 400 for each group). Asterisks in (B) and (E) denote adjusted P‐values calculated using a one‐way ANOVA followed by Tukey's HSD test between the mean residence time quartiles (*P < 0.05, **P < 0.01, ***P < 0.001, ****P < 0.0001).
Beside the number of motifs, the sequence composition of the binding motif is also likely to contribute to binding stability. To investigate how motif composition affects Abf1 binding stability, the motif score of each of the binding motifs was compared between the mean residence time groups. Binding sites with the longest mean residence time have a motif that is closer to the consensus compared to the other sites (Fig 5B), which indicates that having a stronger binding motif leads to more stable binding. Indeed, mutating the binding site of another well‐studied TF, Gal4, results in a shorter residence time (Donovan et al, 2019b). To investigate the contribution of motif sequence to Abf1 binding stability in more detail, the consensus motifs of the different mean residence time groups were compared to each other (Fig 5C). Although the consensus motifs of all four groups are similar, showing good correspondence to published motifs (MacIsaac et al, 2006; Kasinathan et al, 2014; Zentner et al, 2015; Rossi et al, 2018a), the longest mean residence time group has a significant enrichment (P = 0.0046) for a thymine in the variable part of the motif, at position −1 bp (Fig 5C, arrow). This suggests that having a thymine at this position is not needed for binding per se, but that it contributes to the binding stability of Abf1. In agreement with this, mutation of a thymine residue at this position reduces the binding levels of Abf1 in vitro (Gailus‐Durner et al, 1996).
DNA shape can also influence Abf1 binding levels (Zentner et al, 2015; Rossi et al, 2018a). Strongly and weakly bound Abf1 sites differ in their predicted minor groove width as estimated across naked DNA motifs (Rossi et al, 2018a). The Abf1 sites found here closely resemble the strongly bound sites in their minor groove width pattern (Fig 5D). Strikingly, the same analysis performed across the four groups of sites with different mean residence times reveals that in terms of minor groove width at position +3 bp (Fig 5D, arrow), the group with shortest mean Abf1 residence times most closely resembles the sites with low Abf1 binding levels (Rossi et al, 2018a), in having a smaller minor groove (Fig 5E). This suggests that the lower binding levels observed on sites with a reduced minor groove width at the +3 position is caused by a higher off‐rate. The extended genome‐wide survey of Abf1 binding stabilities demonstrates that factors influencing TF binding stability in vivo can also be advantageously studied by DIVORSEQ.
Discussion
The dynamics of proteins interacting with DNA are thought to play an important role in the regulation of chromatin‐associated processes such as transcription (Hager et al, 2009). To fully understand these processes at a molecular level requires an understanding of the underlying binding dynamics. DIVORSEQ quantifies protein–DNA binding dynamics in vivo by directly measuring off‐rates and mean residence times at multiple binding sites across an entire genome. Applying DIVORSEQ to the TF Abf1 shows that the method can measure meaningful differences in off‐rates spanning a wide range of values. Our results show how motif number, sequence and structure of the binding motif contribute to off‐rates and how this aspect of binding dynamics influences the roles of Abf1 as a chromatin organizing factor, a transcriptional regulator and a termination roadblock for RNA polymerase II at different sites across the genome.
Abf1 is a general regulatory factor, known to organize chromatin (Venditti et al, 1994; Lascaris et al, 2000; Yarragudi et al, 2004; Hartley & Madhani, 2009; Ganapathi et al, 2011; Krietenstein et al, 2016; Kubik et al, 2018). Our results show good correspondence between NFR size and binding stability (Fig 2). Sites with shorter mean Abf1 residence times have smaller NFRs. This could either be explained by stronger nucleosome exclusion through more stably bound Abf1, or conversely, by more stable binding of Abf1 in larger NFRs. Abf1 shapes the local chromatin architecture by competing with nucleosomes (Venditti et al, 1994; Yarragudi et al, 2004) and by acting as a barrier that chromatin remodellers use to position flanking nucleosomes (Krietenstein et al, 2016). It seems reasonable that Abf1 forms a more efficient barrier when it is more stably bound, thus repelling nucleosomes more efficiently, which would support the hypothesis that stable binding creates bigger NFRs. On the other hand, being a barrier means that chromatin remodellers actively position nucleosomes towards Abf1. Therefore, nucleosomes that are being positioned by remodellers may exert a force on Abf1 and destabilize its binding. In this hypothesis, competition with nucleosomes could reduce the residence time of Abf1, as has been shown for Rap1 (Lickwar et al, 2012; Mivelaz et al, 2020). Upon depletion of Abf1, nucleosomes become repositioned in all mean Abf1 residence time quartiles, but sites with the shortest mean residence time show the biggest reduction in NFR size (Fig 2). This fits with nucleosome positioning leading to shorter mean Abf1 residence times at these sites. Neither hypothesis can, nor need be excluded as yet. The observed correspondence between NFR size and Abf1 off‐rates at different sites highlights the advantage of such measurements as a starting point for detailed characterization of molecular mechanisms.
Besides organizing chromatin, Abf1 also functions as a transcriptional regulator (Buchman & Kornberg, 1990; Gailus‐Durner et al, 1996; Miyake et al, 2002, 2004; Yarragudi et al, 2007). Abf1 is known to be only a weak activator of transcription (Buchman & Kornberg, 1990; Levo et al, 2017), and the results presented here indicate that it mainly regulates transcription through repositioning nucleosomes, which is consistent with previous reports (Paul et al, 2015; Kubik et al, 2018). Our results fit with Abf1 stimulating transcription by creating an NFR that allows other regulatory factors to bind and whose activities may more directly dictate steady‐state expression levels. This offers an explanation for why there is little correlation between steady‐state mRNA synthesis rates and Abf1 binding levels or off‐rates (Fig 3C and 3D), but nevertheless good correlation between off‐rates and changes in mRNA synthesis rates upon depletion (Fig 3F). Removal of Abf1 causes NFR collapse for those promoters that have no redundant mechanisms of NFR upkeep (Fig 3B), resulting in cessation of promoter activity. This is in contrast to Rap1, which is known to directly contact TFIID (Garbett et al, 2007) and may directly recruit the transcription pre‐initiation complex itself. Such direct recruitment suggests that Rap1 is the main regulator of transcription of its targets, explaining correlation between Rap1 binding dynamics and steady‐state mRNA synthesis levels (Lickwar et al, 2012). As with the analysis of roadblock function for Abf1, different modes of regulator activity or function may therefore be revealed by detailed analyses of binding dynamics.
A limitation of DIVORSEQ is that analysis is in bulk, rather than at the single cell resolution available through microscopy (Hager et al, 2009; Larson, 2011; Mueller et al, 2013; Voss & Hager, 2014; Coleman et al, 2015; Brignall et al, 2019; Elf & Barkefors, 2019). This is offset by the advantage of determining off‐rates for many loci across the genome in parallel. Other methods that measure site‐specific in vivo binding dynamics include competition ChIP, which determines turnover and is limited by a slow induction of the competitor protein, as well as by the substantial carbon source perturbation required for induction (Schermer et al, 2005). DIVORSEQ directly measures off‐rates and has been designed for application alongside on‐rate measurement by cross‐linking kinetic analyses (Poorey et al, 2013), that has yet to be applied at the genomic scale (Zaidi et al, 2017). In theory, on‐rates can also be inferred from a combination of binding levels and off‐rates. Such inference will lead to large estimation errors and therefore direct measurement of on‐rates, for example by an approach like cross‐linking kinetic analysis is preferable.
Considerations that need to be made when applying DIVORSEQ include having sufficiently rapid removal of unbound proteins from the nucleus. Using anchor‐away (Haruki et al, 2008), an estimated 2,000 molecules can be depleted from the nucleus per minute (Warner, 1999). This implies that for highly abundant proteins such as Abf1, with an estimated 6,000 molecules (Ho et al, 2018), mean residence times will be determined at minute‐scale resolution. In other words the lower limit of detecting residence times is mainly determined by the number of TF molecules and the 4 min shortest residence time for Abf1 is the limit for applying DIVORSEQ in its current form to Abf1. The lower limit of residence times determined will be lower for less abundant proteins.
The timescale of minutes found here for Abf1 by DIVORSEQ may seem in contrast to the timescale of seconds that have frequently been reported for other TFs using microscopy based methods (McNally et al, 2000; Bosisio et al, 2006; Karpova et al, 2008; Loffreda et al, 2017; Donovan et al, 2019a). The microscopy based methods certainly also have their limitations such as sensitivity to the model used for fitting, bleaching and out‐of‐focus movement, making it challenging to accurately measure minute time scale residence times. Nevertheless, it is important to point out that minute‐scale residence times have been reported for several TFs previously (Yao et al, 2006; Hammar et al, 2014; Agarwal et al, 2017; Hansen et al, 2017; Donovan et al, 2019a; Mivelaz et al, 2020). It is possible that different approaches are suitable for different TFs with different ranges of residence times. This issue can best be addressed by comparing measurements of many different TFs by several different methods. Until such a comparison is carried out it is possible that some methods, including DIVORSEQ, should only be interpreted on a relative scale. Such relative measurements are of course still valuable for investigating biological meaningful differences in residence times.
That anchor‐away is sufficiently rapid for Abf1, is indicated by the excellent fit to first‐order kinetics observed and the wide range of different off‐rates obtained. Besides anchor‐away, other techniques that facilitate nuclear depletion could also be used (Klemm et al, 1997; Bayle et al, 2006; Busch et al, 2009), contingent on rapidity. A second consideration is that the ChIP or genomic location protocol requires results that are comparable between time points. Here we first extensively optimized almost all ChIP protocol steps to achieve this (preprint: de Jonge et al, 2019). Some limitations still remain. Abf1 can only be cross‐linked to sites with a guanine or cytosine at −8 bp from the binding motif centre (Rossi et al, 2018a). Sites without a guanidine or cytosine at this position were therefore excluded here although some nevertheless yielded low signals. These signals at sites without a G/C at position −8 bp from the motif did not deplete over time and are likely caused by small amounts of cytosolic Abf1 rebinding during the ChIP procedure. Therefore no reliable fits can be obtained for these sites and they were therefore excluded from all analyses. Combined with peak filtering for robust binding, this reduced the number of Abf1 sites for which off‐rate could be determined. Improvements to DIVORSEQ could therefore be aimed at preventing rebinding and/or applying assays that do not depend on cross‐linking (Zentner et al, 2015; Skene & Henikoff, 2017). These considerations aside, that the determined off‐rates are accurate is corroborated by the MNase protection levels at Abf1 sites with different off‐rates, as well as by the diverse aspects of previously established Abf1 function presented here for the first time in the context of a large number of genomic binding sites and their binding dynamics.
Materials and Methods
Strains
The strains used in this study are Saccharomyces cerevisiae anchor‐away strains (Haruki et al, 2008) that were recreated in the BY4742 background (de Jonge et al, 2017). Besides the FRB domain from mammalian target of rapamycin (mTOR), the anchor‐away tag consists of yeast enhanced green fluorescent protein (yEFGP) and a triple V5 tag. The parental BY4742 anchor‐away strain, which has an FPR1 deletion and a tor1‐1 mutation to desensitize the strain to rapamycin, was used as a wildtype control.
Growth conditions
Strains were streaked from −80°C stocks on appropriate selection plates (for the parental anchor‐away strain: YPD + Nourseothricin and for the Abf1‐aa strains: YPD + Nourseothricin + Hygromycin), and incubated at 30°C for 3 days. In the morning, liquid pre‐cultures were inoculated in 1.5 ml of synthetic complete (SC) medium: 2 g/l dropout mix complete and 6.71 g/l yeast nitrogen base without amino acids, carbohydrate & w/AS (YNB) from US Biologicals (Swampscott, USA) with 2% D‐glucose. In the afternoon, several pre‐cultures were combined, diluted to final volume of 20 ml and grown overnight. The growth conditions were identical for all experiments and pre‐cultures: in SC medium at 30°C, with shaking (230 rpm).
Anchor‐away depletion
At t = 0, Abf1 was depleted from the nucleus by addition of rapamycin (LC Laboratories #R‐5000; dissolved to 2mM in DMSO), to a final concentration of 7.5 μM. For the t = 0 time point, the same volume of DMSO instead of rapamycin was added and incubated for 90 min.
Chromatin immunoprecipitation
ChIP was performed as described in detail in (de Jonge et al, 2020) using biological triplicates. To summarize: cells were diluted in the morning to an optical density (OD) of 0.11–0.15 (WPA Biowave CO8000 Cell Density Meter) in 100 ml of SC medium, and grown for at least 2 doublings to an OD600 = 0.8, which corresponds to about 2 × 107 cells per ml. Additions of rapamycin and DMSO were staggered such that all time points were ready at the same OD (0.8). When this OD was reached, the cells were cross‐linked for 5 min by addition of 37% formaldehyde (Sigma‐Aldrich #252549) to a final concentration of 2%. The formaldehyde was quenched using a final concentration of 1.5M of Tris (tris(hydroxymethyl)aminomethane) for 1 min. Subsequently, the cells were pelleted by centrifugation at 3,220 g at 4°C for 3 min. The pellet was washed in 10 ml TBS (150 mM NaCl, 10 mM Tris pH 7.5) and pelleted again at 3,220 g for 3 min at 4°C. After resuspension in 1 ml MQ, cells were centrifuged at 3,381 g for 20 s at room temperature and the pellet was snap‐frozen in liquid nitrogen and stored at −80°C.
To lyse cells, the cells were resuspended in FA lysis buffer (50 mM HEPES‐KOH pH 7.5, 150 mM NaCl, 1 mM EDTA pH 8.0, 1% Triton X‐100, 0.1% Na‐deoxycholate, 0.1% SDS) containing the protease inhibitors aprotinin, pepstatin A, leupeptin and PMSF to a final volume of 2ml, transferred to 2‐ml screw‐cap tubes and disrupted using zirconium/silica beads 0.5 mm (BioSpec Products, #11079105z) by bead beating 7 times 3 min in a Genie Disruptor (Scientific Industries). The lysate was recovered and centrifuged at 1,503 g for 2 min at 4°C to remove cell debris. The supernatant was subsequently fragmented by sonicating the samples for 10 cycles of 15 s on, 30 s off using a Bioruptor Pico sonicator (Diagenode #B01060010).
For the immunoprecipitation, 450 μl of the fragmented chromatin was incubated with 1 μl of anti‐V5 antibody (Life Technologies #R96025) for 2 h at 4°C. A 20 μl aliquot was kept separate as an input control. The chromatin + antibody were subsequently bound for 20 min at room temperature to magnetic beads (Dynabeads protein G, Life Technologies #10004D) that were pre‐incubated with BSA. The beads were washed twice with PBS and twice using PBS‐T. During the last wash, the beads were transferred to fresh LoBind tubes (Eppendorf #0030108051). Cross‐links were reversed by incubating in TE/1% SDS (10 mM Tris pH 8.0, 1 mM EDTA pH 8.0, 1% SDS (w/v)) overnight at 65°C. The next morning, RNA was degraded by addition of RNAse A/T1 (Thermo Scientific #EN0551) at 37°C, and subsequently proteins were digested by addition of proteinase K (Roche #03115852001) at 37°C. After protein digestion, DNA was recovered using a Qiagen PCR purification cleanup kit (Qiagen #28106) by eluting in 30 μl buffer EB.
RNA labelling and extraction
For the 4tU‐seq time–course, 20 ml cultures were used, with biological triplicates for each time point. Rapamycin and DMSO additions were staggered such that all cultures were ready at the same OD (0.8). WT samples incubated with rapamycin or DMSO for 90 min were taken along as a controls. Three minutes before the cultures were ready, 4‐thiouracil (4tU; Sigma‐Aldrich #440736) was added to the cell cultures to a final concentration of 5 mM. Cells were incubated with 4tU for 6 min in total, such that the centre of the labelling period matched the time point of the ChIP time–course. Subsequently, cells were harvested by centrifugation at 3,220 g for 3 min, cell pellets were snap‐frozen immediately in liquid nitrogen and stored at −80°C.
To isolate total RNA, cells were resuspended in Acid Phenol Chloroform (Sigma #P1944) and immediately mixed with the same volume of TES buffer (10 mM Tris pH 7.5, 10 mM EDTA, 0.5% SDS). The samples were vortexed hard for 20 s, the tubes were covered in aluminium foil to keep the samples dark, and incubated in a 65°C water bath for 10 min. Next, the samples were transferred to 1.5 ml tubes and incubated in a thermomixer for 50 min at 65°C and 1,400 rpm, while covered with aluminium foil. After incubation, samples were centrifuged at 18,407 g for 20 min at 4°C. The water phase was recovered and phenol extraction was repeated once, followed by extraction using chloroform–isoamyl alcohol (25:1). The RNA was precipitated using sodium acetate (NaAc 3M, pH 5.2) and 100% ethanol (−20°C) by incubating at −20°C for at least 30 min. DTT was also added to a final concentration of 1 mM to prevent oxidation of the 4tU. The pellet was washed once with 80% ethanol and resuspended to a final concentration of 1 μg/μl in sterile MQ.
To recover nascent transcripts the protocol from (Dölken et al, 2008) was used with minor adaptations. In brief, 100 μg of cleaned RNA was heated to 60°C for 10 min and immediately put on ice for 2 min. The RNA was biotinylated by adding 200 μl Biotin‐HPDP (Thermo Fisher Scientific #21341) dissolved to 1 mg/ml in 30% DMF. Unbound biotin was removed using chloroform extraction. Biotinylated RNA was separated from total RNA using streptavidin‐conjugated magnetic beads and μMACs columns (Miltenyi Biotec #130‐074‐101). The beads were washed 6x using 65°C washing buffer (100 mM Tris pH 7.5, 10 mM EDTA, 1 M NaCl, 0.1% Tween‐20) and bound RNA was eluted using 200 μl of 100 mM DTT. The nascent RNA was purified using an RNeasy MinElute Cleanup Kit (Qiagen #74204).
Library preparation and sequencing
ChIP‐seq libraries were created using a combination of a NEXTflex Rapid DNA‐Seq Kit (Bioo Scientific #NOVA‐5144) and a NEXTflex Rapid Directional qRNA‐Seq Kit (Bioo Scientific #NOVA‐5130) to allow for incorporation of unique molecular identifiers (UMIs) (Kivioja et al, 2012) on both sides of each fragment. To improve speed and accuracy, a maximum of 8 libraries were prepared at the same time. To make the amount of starting material of the input samples similar to that of the IP samples, the input samples were diluted 1:300 prior to library prep. End‐repair and adenylation were carried using the NEXTflex Rapid DNA‐Seq Kit with half of the recommended volumes. The subsequent steps were carried out using the NEXTflex Rapid Directional qRNA‐Seq Kit with a quarter of the recommended volumes for the adapter ligation and half volumes for the PCR amplification. The initial volume used for each of the bead clean‐ups was adjusted to 50 μl by addition of MQ and bead ratios were kept as recommended. The number of PCR cycles used was the same for all ChIP and input samples (13 cycles) except for the WT IPs where 15 PCR cycles were used. Library yields were assessed using a High Sensitivity DNA bioanalyzer chip (Agilent) and equimolar amounts of library were pooled and sequenced paired‐end 2 × 75 bp on a NextSeq 500 system (Illumina).
4tU‐seq libraries were created using the NEXTflex Rapid Directional qRNA‐Seq Kit (Bioo Scientific #NOVA‐5130) with a slightly modified protocol. During step D of the protocol (i.e. bead cleanup after second strand synthesis) the beads were resuspended in 10 μl of resuspension buffer, and 8 μl was used for the next step. From this step onwards, half of all recommended volumes were used. The initial volume used for each of the bead clean‐ups was adjusted to 50 μl by addition of MQ and bead ratios were kept as recommended. Since the concentrations of labelled RNA differed after the purification, a qPCR was performed to estimate the number of PCR cycles needed for each sample after adapter ligation. The number of cycles that were used varied between 8 and 12 cycles. Library yields were assessed using a High Sensitivity DNA bioanalyzer chip (Agilent) and equimolar amounts of library were pooled and sequenced paired‐end 2 × 75 bp in two sequence runs on a NextSeq 500 system (Illumina).
Mapping
Reads from both the ChIP‐seq and 4tU‐seq experiments were aligned to the sacCer3 genome assembly (February 2011) using HISAT2 v2.0.5 (Kim et al, 2015). The settings for the ChIP‐seq samples were “‐-add-chrname ‐X 1000 ‐-score‐min L,0,‐0.2 -k 1 ‐-no-spliced‐alignment ‐5 12 ‐3 6” and for the 4tU‐seq samples the settings “‐-add-chrname ‐X 1000 ‐-score‐min L,0,‐0.175 ‐5 10 ‐3 10 ‐-dta ‐max-intronlen 1500 ‐-rna-strandness RF” were used. Subsequently, the bam files were filtered to keep only transcripts with a unique combination of UMIs using the custom scripts “addumis2bam.sh” and “uniqify‐umis.pl” available from https://github.com/wdejonge/DIVORSEQ.
Peak calling and filtering
The ChIP‐seq data were filtered to keep only uniquely mapping reads and subsequently peaks were called using MACS2 v2.1.1.20160309 (Zhang et al, 2008) with the settings “‐f BAMPE ‐g 1.25e7 ‐-keep‐dup all ‐-mfold 5 2000 ‐-call‐summits ‐q 0.001 ‐-fe-cutoff 2” using all three replicate t = 0 time points (no depletion) versus their corresponding inputs, yielding 948 Abf1 peaks.
To monitor the depletion, the initial binding levels need to be sufficiently strong to accurately measure a reduction in binding levels. Therefore, only binding peaks with a fold enrichment of at least 4 were considered (421 peaks). This also filters out apparent weak binding across open reading frames and tRNAs, which is a known artefact of ChIP (Park et al, 2013; Teytelman et al, 2013). In addition, it has been recently shown that Abf1 is only efficiently cross‐linked to sites with either a guanine or a cytosine at −8 bp from the centre of the Abf1 binding motif (Rossi et al, 2018a). For each binding peak, we searched for motifs (±100 bp from peak summit) that closely match the Abf1 consensus (at least 85% of the consensus motif score from (MacIsaac et al, 2006)) and determined whether there was a G/C or an A/T at −8 bp from each motif. Only peaks where all motifs found had a G/C at −8 bp from the motif midpoint were kept for further analysis (195 peaks). Four of these peaks were located in telomeric regions. Although the mean residence time estimates of these four peaks are probably accurate, we noticed that other characteristics were very distinct from other peaks (e.g. nucleosome organization, motif composition, RNA polymerase II binding). Therefore, these peaks were excluded, yielding a total of 191 Abf1‐binding sites that were analysed in greater detail.
Exponential decay fitting
To fit the exponential decay model, first the bam files were centred and smoothed with a 101 bp window, as described in (de Jonge et al, 2017). Subsequently, all samples were scaled to 1 million reads using genomecov from the bedtools2 suite v2.27 (Quinlan & Hall, 2010), which makes sure that total coverage across the genome is the same for all samples (1.01 × 108 bases). For each binding site (n = 191), the total coverage was calculated for each sample in a window ± 50 bp from the peak summit. Subsequently, the binding at all peaks was normalized to the background levels. This was achieved by first calculating the fraction of background reads of each sample, by dividing the number of reads not present in any of the 948 peaks by the total number of reads. The binding levels at each peak were then divided by this fraction of background reads, essentially equalizing the background level of each sample. These values were used to fit a first‐order exponential decay function using the nls function in R:
| (1) |
with y 0 the binding levels a t = 0 (i.e. before depletion), t the time since depletion, y f the final binding level and k off the decay rate of the binding levels. The use of a site‐specific y f is needed since different sites decay to a different background levels. The mean residence time is given by 1/k off and represents the average time Abf1 stays bound to a specific site. The fits were done in R with the nls function using the formula: “nls(ChIP ~SSasymp(time, yf, y0, log_koff), data = data)”, using all three replicates together to obtain a single fit per peak. The goodness of fit for each fit was assessed by calculating a pseudo‐R2, calculated as:
| (2) |
This yielded regressions with excellent R 2, with the lowest R 2 = 0.65 and the median R 2 = 0.94 (Fig EV2D). One of the 10 min depletion ChIP samples had much higher binding levels compared to the other 10 min samples, with a median absolute deviation more than six times as high. Upon removal of this sample all fits improved. This sample was therefore removed from all analyses. The 191 binding sites were divided into four mean residence time groups defined by the quartiles of their mean residence times (48 or 47 sites per quartile). An exponential decay model with the absolute binding levels was used rather than an exponential decay fit with log‐transformed data since such a linear model cannot estimate a baseline y f, yielding poor fits and inaccurate estimates for the off‐rates. Dataset EV1 contains for the 191 Abf1‐binding sites the coordinates of the 101 bp windows, the binding levels before and after 90 min of depletion, the estimates for y 0, y f, k off and the mean residence time as well as the number of motifs, motif scores and to which residence time quartile a binding site belongs to.
4tU‐seq expression analysis
The 4tU‐seq reads were assigned to genomic features using featureCounts from the subread package v1.6.5 (Liao et al, 2014). As an annotation file, transcription start site annotations from (van Bakel et al, 2013) were merged with the genome annotation from the Saccharomyces genome database (SGD; Cherry et al, 2012) containing ORFs, tRNAs, rRNAs and snRNAs. The counts from the two independent sequence runs were combined and differential expression of the genomic features (genes) was calculated using the DESeq2 package v1.10.1 (Love et al, 2014) in R. Only genes with a fold change of more than 1.5 with an adjusted P‐value < 0.01 after 20 min as well as 30 min of depletion were considered differentially expressed. The fold change in mRNA synthesis was calculated relative to t = 0.
To model the decrease rate of mRNA synthesis, absolute transcript counts were used at each time point. They were normalized to the median number of transcripts of all samples after filtering out rRNAs. Only genes that were significantly downregulated with Abf1 binding to the promoter were used (n = 88). Binding peaks were assigned to genes when the summit of that peak was found within the promoter (500 bp upstream of the transcription start site). As described for the ChIP‐seq data, a first‐order exponential decay function (Equation (1)) was used to model the changes in mRNA synthesis. In this case, y 0 is the expression level before depletion and k off is the rate with which the expression decreases to the final expression level y f. For six of the genes with robust changes in mRNA synthesis, no reliable fit could be obtained and these were therefore excluded from Fig 3G (n = 82).
External datasets
To assess what percentage of Abf1 binding peaks overlap with previously detected Abf1 binding sites, the peaks (peak summits ± 50 bp) detected here (n = 948) were compared to published datasets. Data from three different techniques were used: ORGANIC, ChEC‐seq and ChIP‐exo (Kasinathan et al, 2014; Zentner et al, 2015; Rossi et al, 2018b). For the ORGANIC data, the published bound Abf1 sites (n = 1,068) from the “10’ MNase 80mM” samples were used (Kasinathan et al, 2014). For the ChEC‐seq data, the Abf1 sites that were both classified as “fast” and “high scoring motif” (n = 1,583) were taken (Zentner et al, 2015). For the ChIP‐exo peaks, all sites detected using the ChIP‐exo protocol v5 (n = 3,177) were used (Rossi et al, 2018b).
To assess in vivo protection from MNase cleavage, the bigwig files “Abf1aa_V_freeMNase_ChEC” and “Abf1aa_R_freeMNase_ChEC” were downloaded from the gene expression omnibus (GEO) dataset GSE98259 (Kubik et al, 2018) and smoothed with a 3 bp window. The data were centred on the Abf1 binding motif, and the average number of cleavage sites per mean residence time quartile was calculated. Subsequently, the average number of cut sites was calculated in the area of the motif (−8 bp to +8 bp from the motif midpoint) both in the presence and absence of Abf1. The cleavage ratio was calculated by taking the number of cuts in the absence of Abf1 divided by the number of cuts in the presence of Abf1. Sites without cuts in either conditions (with or without rapamycin) were excluded from the quantification (Fig 1J).
To compare synthesis rates with off‐rates and binding levels, genome‐wide synthesis rates were taken from (Sun et al, 2012), by downloading them from the researchers’ website: https://www.mpibpc.mpg.de/13760807/Sc_turnover.zip.
To visualize nucleosome positioning before and after depletion of Abf1, the bigwig files “Abf1veh15” and “Abf1rapa15” were downloaded from GEO dataset GSE73337 (Kubik et al, 2015). The data were either centred on the Abf1 binding motif (Fig 2) or aligned on the +1 nucleosome (Figs 3B and EV3A), with +1 nucleosome positions taken from (Kubik et al, 2015). The average nucleosome occupancy was calculated for genes with Abf1 binding, an annotated +1 nucleosome and that were strongly downregulated (fold change > 2 at t = 20, n = 44), weakly downregulated (1.5 < fold change < 2 at t = 20, n = 42) or did not change (fold change < 1.5 at t = 20, n = 112) upon depletion of Abf1 (Fig 3B). In Fig 2, the average nucleosome occupancy was calculated per mean residence time quartile. The confidence intervals in Figs 2 and 3B are indicated by the shaded area which is calculated as the mean ± 2 × the standard error of the mean (SEM).
To visualize polymerase binding, the PAR‐CLIP (photoactivatable ribonucleoside‐enhanced cross‐linking and immunoprecipitation) data for both the plus and minus strand from sample “Rpb2‐HTB Control With Rapamycin” were downloaded from GEO dataset GSE56435 (Schaughency et al, 2014). As the Abf1 motif is strand‐specific, the data were reoriented accordingly, meaning that when the data had to be reoriented to match the orientation of the motif (as shown in Figs EV2B and 5C), the plus and minus strand were also swapped. To calculate the roadblock efficiency, the average binding in the roadblocked peak, located at −37 bp ± 5 bp from the Abf1 binding motif centre, was normalized by the amount of incoming transcription (defined as the average Pol II binding in the region from −300 bp until −100 bp upstream of the Abf1 binding motif). For the quantification shown in Fig 4C, a peak was considered to be a roadblock peak when it had upstream normalized Pol II binding > 2. With this cut‐off, approximately 25% of the peaks (49/191) were considered to be a roadblock for Pol II.
Motif scoring and DNA shape analysis
The position frequency matrix from (MacIsaac et al, 2006) was obtained from the YeTFaSCo database (de Boer & Hughes, 2011), multiplied by a factor 1,000 and converted to a position weight matrix (PWM). The region ± 100 bp of the summit of each binding peak was searched for a match of this PWM using the matchPWM function from the Biostrings v2.38.4 package in R, using a minimum motif score of 85%. Whenever a binding peak had more than one motif match, the highest score was assigned to this binding peak. For all aggregate plots, the data were aligned to the motif with the highest motif score with all motifs in the same orientation as shown in Figs EV2B and 5C. DNA shape analysis was done on the aligned motifs ± 40 bp from the motif midpoint using DNAshapeR v1.10.0 (Chiu et al, 2016). The DNA shape of the bound and unbound sites from (Rossi et al, 2018a) was calculated as described in (Rossi et al, 2018a), by taking for each of the 8 motifs the top 50 and bottom 50 bound peaks and showing the average of the top 400 and bottom 400 bound peaks. For further details, see (Rossi et al, 2018a).
Statistical analysis and data visualization
All statistical analyses were done using the statistical language R v3.2.2 except for the DNA shape and Venn diagram analyses which were done using R v3.5.1. The area‐proportional Venn diagrams were created using the eulerr package v6.0.0 in R v3.5.1.
To visualize the binding to different genomic loci in Fig 1B, the Sushi package v1.24.0 was used (Phanstiel et al, 2014). All boxplots were created using R's built‐in boxplot function, with default settings; here, the solid horizontal line represents the median, the box shows the interquartile range, and the whiskers are at the most extreme data point no further away from the closest quartile than 1.5 times the interquartile range. Differences between the four mean residence time quartiles were assessed using a one‐way ANOVA followed by Tukey's honest significant difference test (Figs 1J, 4B, 5B and D). The difference between the two groups in Fig 4C was tested using a two‐tailed t‐test and between the groups in Fig 5A using a Wilcoxon rank‐sum test, since one of the groups was deemed to deviate too much from normality.
Author contributions
WJJ, PK and FCPH involved in conceptualization. WJJ and MB involved in investigation. WJJ and PL involved in formal analysis. PL contributed to software. WJJ involved in data curation. PK and FCPH supervised the study and acquired funding. WJJ and FCPH contributed to writing—original draft. WJJ, MB, PL, PK and FCPH contributed to writing—review and editing.
Conflict of interest
The authors declare that they have no conflict of interest.
Supporting information
Expanded View Figures PDF
Dataset EV1
Review Process File
Acknowledgements
We thank the members of the Holstege and Kemmeren groups for their support and discussions. We thank Jeff DeMartino and Marit de Kort for technical assistance. This work was supported by the Netherlands Organisation for Scientific Research (NWO) grant 86411010 and by the European Research Council (ERC) grant 671174 DynaMech.
Mol Syst Biol. (2020) 16: e9885
Data availability
The datasets and computer code produced in this study are available in the following databases:
ChIP‐Seq data: Gene Expression Omnibus GSE151692 (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE151692).
RNA‐Seq data: Gene Expression Omnibus GSE151468 (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE151468).
Modeling computer scripts: GitHub (https://github.com/wdejonge/DIVORSEQ).
References
- Adams CC, Workman JL (2020) Binding of disparate transcriptional activators to nucleosomal DNA is inherently cooperative. Mol Cell Biol 15: 1405–1421 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Agarwal H, Reisser M, Wortmann C, Gebhardt JCM (2017) Direct observation of cell‐cycle‐dependent interactions between CTCF and chromatin. Biophys J 112: 2051–2055 [DOI] [PMC free article] [PubMed] [Google Scholar]
- van Bakel H, Tsui K, Gebbia M, Mnaimneh S, Hughes TR, Nislow C (2013) A compendium of nucleosome and transcript profiles reveals determinants of chromatin architecture and transcription. PLoS Genet 9: e1003479 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bayle JH, Grimley JS, Stankunas K, Gestwicki JE, Wandless TJ, Crabtree GR (2006) Rapamycin analogs with differential binding specificity permit orthogonal control of protein activity. Chem Biol 13: 99–107 [DOI] [PubMed] [Google Scholar]
- de Boer CG, Hughes TR (2011) YeTFaSCo: a database of evaluated yeast transcription factor sequence specificities. Nucleic Acids Res 40: D169–D179 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bosisio D, Marazzi I, Agresti A, Shimizu N, Bianchi ME, Natoli G (2006) A hyper‐dynamic equilibrium between promoter‐bound and nucleoplasmic dimers controls NF‐κB‐dependent gene activity. EMBO J 25: 798–810 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brahma S, Henikoff S (2020) Epigenome regulation by dynamic nucleosome unwrapping. Trends Biochem Sci 45: 13–26 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brignall R, Moody AT, Mathew S, Gaudet S (2019) Considering abundance, affinity, and binding site availability in the NF‐κB target selection puzzle. Front Immunol 10: 609 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buchman AR, Kornberg RD (1990) A yeast ARS‐binding protein activates transcription synergistically in combination with other weak activating factors. Mol Cell Biol 10: 887–897 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Busch A, Kiel T, Hübner S (2009) Quantification of nuclear protein transport using induced heterodimerization. Traffic 10: 1221–1227 [DOI] [PubMed] [Google Scholar]
- Candelli T, Challal D, Briand J‐B, Boulay J, Porrua O, Colin J, Libri D (2018) High‐resolution transcription maps reveal the widespread impact of roadblock termination in yeast. EMBO J 37: e97490 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cherry JM, Hong EL, Amundsen C, Balakrishnan R, Binkley G, Chan ET, Christie KR, Costanzo MC, Dwight SS, Engel SR et al (2012) Saccharomyces genome database: the genomics resource of budding yeast. Nucleic Acids Res 40: D700–D705 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chiu T‐P, Comoglio F, Zhou T, Yang L, Paro R, Rohs R (2016) DNAshapeR: an R/Bioconductor package for DNA shape prediction and feature encoding. Bioinformatics 32: 1211–1213 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Coleman RA, Liu Z, Darzacq X, Tjian R, Singer RH, Lionnet T (2015) Imaging transcription: past, present, and future. Cold Spring Harb Symp Quant Biol 80: 1–8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Colin J, Candelli T, Porrua O, Boulay J, Zhu C, Lacroute F, Steinmetz LM, Libri D (2014) Roadblock termination by Reb1p restricts cryptic and readthrough transcription. Mol Cell 56: 667–680 [DOI] [PubMed] [Google Scholar]
- Collas P (2010) The current state of chromatin immunoprecipitation. Mol Biotechnol 45: 87–100 [DOI] [PubMed] [Google Scholar]
- Cramer P (2019) Organization and regulation of gene transcription. Nature 573: 45–54 [DOI] [PubMed] [Google Scholar]
- Dion MF, Kaplan T, Kim M, Buratowski S, Friedman N, Rando OJ (2007) Dynamics of replication‐independent histone turnover in budding yeast. Science 315: 1405–1408 [DOI] [PubMed] [Google Scholar]
- Dölken L, Ruzsics Z, Rädle B, Friedel CC, Zimmer R, Mages J, Hoffmann R, Dickinson P, Forster T, Ghazal P et al (2008) High‐resolution gene expression profiling for simultaneous kinetic parameter analysis of RNA synthesis and decay. RNA 14: 1959–1972 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Donovan BT, Chen H, Jipa C, Bai L, Poirier MG (2019a) Dissociation rate compensation mechanism for budding yeast pioneer transcription factors eLife 8: e43008 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Donovan BT, Huynh A, Ball DA, Patel HP, Poirier MG, Larson DR, Ferguson ML, Lenstra TL (2019b) Live‐cell imaging reveals the interplay between transcription factors, nucleosomes, and bursting. EMBO J 38: e100809 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Elbi C, Walker DA, Romero G, Sullivan WP, Toft DO, Hager GL, DeFranco DB (2004) Molecular chaperones function as steroid receptor nuclear mobility factors. Proc Natl Acad Sci 101: 2876–2881 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Elf J, Barkefors I (2019) Single‐molecule kinetics in living cells. Annu Rev Biochem 88: 635–659 [DOI] [PubMed] [Google Scholar]
- Enomoto S, Longtine MS, Berman J (1994) Enhancement of telomere‐plasmid segregation by the X‐telomere associated sequence in Saccharomyces cerevisiae involves Sir2, Sir3, Sir4 and Abf1. Genetics 136: 757–767 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friedman N, Rando OJ (2015) Epigenomics and the structure of the living genome. Genome Res 25: 1482–1490 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Furey TS (2012) ChIP–seq and beyond: new and improved methodologies to detect and characterize protein–DNA interactions. Nat Rev Genet 13: 840–852 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gailus‐Durner V, Xie J, Chintamaneni C, Vershon AK (1996) Participation of the yeast activator Abf1 in meiosis‐specific expression of the HOP1 gene. Mol Cell Biol 16: 2777–2786 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ganapathi M, Palumbo MJ, Ansari SA, He Q, Tsui K, Nislow C, Morse RH (2011) Extensive role of the general regulatory factors, Abf1 and Rap1, in determining genome‐wide chromatin structure in budding yeast. Nucleic Acids Res 39: 2032–2044 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Garbett KA, Tripathi MK, Cencki B, Layer JH, Weil PA (2007) Yeast TFIID serves as a coactivator for Rap1p by direct protein‐protein interaction. Mol Cell Biol 27: 297–311 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gilmour DS, Lis JT (1984) Detecting protein‐DNA interactions in vivo: distribution of RNA polymerase on specific bacterial genes. Proc Natl Acad Sci USA 81: 4275–4279 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grimaldi Y, Ferrari P, Strubin M (2014) Independent RNA polymerase II preinitiation complex dynamics and nucleosome turnover at promoter sites in vivo . Genome Res 24: 117–124 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hager GL, McNally JG, Misteli T (2009) Transcription dynamics. Mol Cell 35: 741–753 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hahn S, Young ET (2011) Transcriptional regulation in Saccharomyces cerevisiae: transcription factor regulation and function, mechanisms of initiation, and roles of activators and coactivators. Genetics 189: 705–736 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Halfter H, Kavety B, Vandekerckhove J, Kiefer F, Gallwitz D (1989) Sequence, expression and mutational analysis of BAF1, a transcriptional activator and ARS1‐binding protein of the yeast Saccharomyces cerevisiae . EMBO J 8: 4265–4272 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hammar P, Walldén M, Fange D, Persson F, Baltekin O, Ullman G, Leroy P, Elf J (2014) Direct measurement of transcription factor dissociation excludes a simple operator occupancy model for gene regulation. Nat Genet 46: 405–408 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hansen AS, Pustova I, Cattoglio C, Tjian R, Darzacq X (2017) CTCF and cohesin regulate chromatin loop stability with distinct dynamics. eLife 6: e25776 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hartley PD, Madhani HD (2009) Mechanisms that specify promoter nucleosome location and identity. Cell 137: 445–458 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haruki H, Nishikawa J, Laemmli UK (2008) The anchor‐away technique: rapid, conditional establishment of yeast mutant phenotypes. Mol Cell 31: 925–932 [DOI] [PubMed] [Google Scholar]
- Hasegawa Y, Struhl K (2019) Promoter‐specific dynamics of TATA‐binding protein association with the human genome. Genome Res 29: 1939–1950 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ho B, Baryshnikova A, Brown GW (2018) Unification of protein abundance datasets yields a quantitative Saccharomyces cerevisiae proteome. Cell Syst 6: 192–205.e3 [DOI] [PubMed] [Google Scholar]
- Hoopes BC, LeBlanc JF, Hawley DK (1992) Kinetic analysis of yeast TFIID‐TATA box complex formation suggests a multi‐step pathway. J Biol Chem 267: 11539–11547 [PubMed] [Google Scholar]
- de Jonge WJ, Brok M, Kemmeren P, Holstege FCP (2019) An extensively optimized chromatin immunoprecipitation protocol for quantitatively comparable and robust results. bioRxiv 10.1101/835926 [PREPRINT] [DOI] [Google Scholar]
- de Jonge WJ, Brok M, Kemmeren P, Holstege FCP (2020) An optimized chromatin immunoprecipitation protocol for quantification of protein‐DNA interactions. STAR Protoc 1: 100020 [DOI] [PMC free article] [PubMed] [Google Scholar]
- de Jonge WJ, O'Duibhir E, Lijnzaad P, van Leenen D, Groot Koerkamp MJ, Kemmeren P, Holstege FC (2017) Molecular mechanisms that distinguish TFIID housekeeping from regulatable SAGA promoters. EMBO J 36: 274–290 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Karpova TS, Chen TY, Sprague BL, McNally JG (2004) Dynamic interactions of a transcription factor with DNA are accelerated by a chromatin remodeller. EMBO Rep 5: 1064–1070 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Karpova TS, Kim MJ, Spriet C, Nalley K, Stasevich TJ, Kherrouche Z, Heliot L, McNally JG (2008) Concurrent fast and slow cycling of a transcriptional activator at an endogenous promoter. Science 319: 466–469 [DOI] [PubMed] [Google Scholar]
- Kasinathan S, Orsi GA, Zentner GE, Ahmad K, Henikoff S (2014) High‐resolution mapping of transcription factor binding sites on native chromatin. Nat Methods 11: 203–209 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kim D, Langmead B, Salzberg SL (2015) HISAT: a fast spliced aligner with low memory requirements. Nat Methods 12: 357–360 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kivioja T, Vähärautio A, Karlsson K, Bonke M, Enge M, Linnarsson S, Taipale J (2012) Counting absolute numbers of molecules using unique molecular identifiers. Nat Methods 9: 72–74 [DOI] [PubMed] [Google Scholar]
- Klemm JD, Beals CR, Crabtree GR (1997) Rapid targeting of nuclear proteins to the cytoplasm. Curr Biol 7: 638–644 [DOI] [PubMed] [Google Scholar]
- Kloster‐Landsberg M, Herbomel G, Wang I, Derouard J, Vourc'h C, Usson Y, Souchier C, Delon A (2012) Cellular response to heat shock studied by multiconfocal fluorescence correlation spectroscopy. Biophys J 103: 1110–1119 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krietenstein N, Wal M, Watanabe S, Park B, Peterson CL, Pugh BF, Korber P (2016) Genomic nucleosome organization reconstituted with pure proteins. Cell 167: 709–721.e12 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kubik S, Bruzzone MJ, Jacquet P, Falcone J‐L, Rougemont J, Shore D (2015) Nucleosome stability distinguishes two different promoter types at all protein‐coding genes in yeast. Mol Cell 60: 422–434 [DOI] [PubMed] [Google Scholar]
- Kubik S, Bruzzone MJ, Shore D (2017) Establishing nucleosome architecture and stability at promoters: Roles of pioneer transcription factors and the RSC chromatin remodeler. BioEssays 39: 1600237 [DOI] [PubMed] [Google Scholar]
- Kubik S, O'Duibhir E, de Jonge WJ, Mattarocci S, Albert B, Falcone J‐L, Bruzzone MJ, Holstege FCP, Shore D (2018) Sequence‐directed action of RSC remodeler and general regulatory factors modulates +1 nucleosome position to facilitate transcription. Mol Cell 71: 89–102.e5 [DOI] [PubMed] [Google Scholar]
- Kuo MH, Allis CD (1999) In vivo cross‐linking and immunoprecipitation for studying dynamic Protein:DNA associations in a chromatin environment. Methods 19: 425–433 [DOI] [PubMed] [Google Scholar]
- de Laat W, Dekker J (2012) 3C‐based technologies to study the shape of the genome. Methods 58: 189–191 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lai WKM, Pugh BF (2017) Understanding nucleosome dynamics and their links to gene expression and DNA replication. Nat Rev Mol Cell Biol 18: 548–562 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Larson DR (2011) What do expression dynamics tell us about the mechanism of transcription? Curr Opin Genet Dev 21: 591–599 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lascaris RF, de Groot E, Hoen P‐B, Mager WH, Planta RJ (2000) Different roles for Abf1p and a T‐rich promoter element in nucleosome organization of the yeast RPS28A gene. Nucleic Acids Res 28: 1390–1396 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Levo M, Avnit‐Sagi T, Lotan‐Pompan M, Kalma Y, Weinberger A, Yakhini Z, Segal E (2017) Systematic investigation of transcription factor activity in the context of chromatin using massively parallel binding and expression assays. Mol Cell 65: 604–617.e6 [DOI] [PubMed] [Google Scholar]
- Liao Y, Smyth GK, Shi W (2014) featureCounts: an efficient general purpose program for assigning sequence reads to genomic features. Bioinformatics 30: 923–930 [DOI] [PubMed] [Google Scholar]
- Lickwar CR, Mueller F, Hanlon SE, McNally JG, Lieb JD (2012) Genome‐wide protein–DNA binding dynamics suggest a molecular clutch for transcription factor function. Nature 484: 251–255 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Loffreda A, Jacchetti E, Antunes S, Rainone P, Daniele T, Morisaki T, Bianchi ME, Tacchetti C, Mazza D (2017) Live‐cell p53 single‐molecule binding is modulated by C‐terminal acetylation and correlates with transcriptional activity. Nat Commun 8: 1–12 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Love MI, Huber W, Anders S (2014) Moderated estimation of fold change and dispersion for RNA‐seq data with DESeq2. Genome Biol 15: 550 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luo Y, North JA, Rose SD, Poirier MG (2014) Nucleosomes accelerate transcription factor dissociation. Nucleic Acids Res 42: 3017–3027 [DOI] [PMC free article] [PubMed] [Google Scholar]
- MacIsaac KD, Wang T, Gordon DB, Gifford DK, Stormo GD, Fraenkel E (2006) An improved map of conserved regulatory sites for Saccharomyces cerevisiae . BMC Bioinformatics 7: 113 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marahrens Y, Stillman B (1992) A yeast chromosomal origin of DNA replication defined by multiple functional elements. Science 255: 817–823 [DOI] [PubMed] [Google Scholar]
- McNally JG, Müller WG, Walker D, Wolford R, Hager GL (2000) The glucocorticoid receptor: rapid exchange with regulatory sites in living cells. Science 287: 1262–1265 [DOI] [PubMed] [Google Scholar]
- Miller JA, Widom J (2003) Collaborative competition mechanism for gene activation in vivo . Mol Cell Biol 23: 1623–1632 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mirny LA (2010) Nucleosome‐mediated cooperativity between transcription factors. Proc Natl Acad Sci 107: 22534–22539 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mivelaz M, Cao A‐M, Kubik S, Zencir S, Hovius R, Boichenko I, Stachowicz AM, Kurat CF, Shore D, Fierz B (2020) Chromatin fiber invasion and nucleosome displacement by the Rap1 transcription factor. Mol Cell 77: 488–500.e9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miyake T, Loch CM, Li R (2002) Identification of a multifunctional domain in autonomously replicating sequence‐binding factor 1 required for transcriptional activation, DNA replication, and gene silencing. Mol Cell Biol 22: 505–516 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miyake T, Reese J, Loch CM, Auble DT, Li R (2004) Genome‐wide analysis of ARS (autonomously replicating sequence) binding factor 1 (Abf1p)‐mediated transcriptional regulation in Saccharomyces cerevisiae . J Biol Chem 279: 34865–34872 [DOI] [PubMed] [Google Scholar]
- Mueller F, Stasevich TJ, Mazza D, McNally JG (2013) Quantifying transcription factor kinetics: at work or at play? Crit Rev Biochem Mol Biol 48: 492–514 [DOI] [PubMed] [Google Scholar]
- Park PJ (2009) ChIP–seq: advantages and challenges of a maturing technology. Nat Rev Genet 10: 669–680 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Park D, Lee Y, Bhupindersingh G, Iyer VR (2013) Widespread misinterpretable ChIP‐seq bias in yeast. PLoS ONE 8: e83506 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Paul E, Tirosh I, Lai W, Buck MJ, Palumbo MJ, Morse RH (2015) Chromatin mediation of a transcriptional memory effect in yeast. G3 (Bethesda) 5: 829–838 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Perlmann T, Eriksson P, Wrange O (1990) Quantitative analysis of the glucocorticoid receptor‐DNA interaction at the mouse mammary tumor virus glucocorticoid response element. J Biol Chem 265: 17222–17229 [PubMed] [Google Scholar]
- Phanstiel DH, Boyle AP, Araya CL, Snyder MP (2014) Sushi.R: flexible, quantitative and integrative genomic visualizations for publication‐quality multi‐panel figures. Bioinformatics 30: 2808–2810 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Polach KJ, Widom J (1996) A model for the cooperative binding of eukaryotic regulatory proteins to nucleosomal target sites. J Mol Biol 258: 800–812 [DOI] [PubMed] [Google Scholar]
- Poorey K, Viswanathan R, Carver MN, Karpova TS, Cirimotich SM, McNally JG, Bekiranov S, Auble DT (2013) Measuring chromatin interaction dynamics on the second time scale at single‐copy genes. Science 342: 369–372 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pryde FE, Louis EJ (1999) Limitations of silencing at native yeast telomeres. EMBO J 18: 2538–2550 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Quinlan AR, Hall IM (2010) BEDTools: a flexible suite of utilities for comparing genomic features. Bioinformatics 26: 841–842 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reed SH, Akiyama M, Stillman B, Friedberg EC (1999) Yeast autonomously replicating sequence binding factor is involved in nucleotide excision repair. Genes Dev 13: 3052–3058 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rhode PR, Sweder KS, Oegema KF, Campbell JL (1989) The gene encoding ARS‐binding factor I is essential for the viability of yeast. Genes Dev 3: 1926–1939 [DOI] [PubMed] [Google Scholar]
- Rossi MJ, Lai WKM, Pugh BF (2018a) Genome‐wide determinants of sequence‐specific DNA binding of general regulatory factors. Genome Res 28: 497–508 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rossi MJ, Lai WKM, Pugh BF (2018b) Simplified ChIP‐exo assays. Nat Commun 9: 1–13 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roy K, Gabunilas J, Gillespie A, Ngo D, Chanfreau GF (2016) Common genomic elements promote transcriptional and DNA replication roadblocks. Genome Res 26: 1363–1375 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roy K, Chanfreau GF (2018) A global function for transcription factors in assisting RNA polymerase II termination. Transcription 9: 41–46 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rufiange A, Jacques P‐É, Bhat W, Robert F, Nourani A (2007) Genome‐wide replication‐independent histone H3 exchange occurs predominantly at promoters and implicates H3 K56 acetylation and Asf1. Mol Cell 27: 393–405 [DOI] [PubMed] [Google Scholar]
- Schaughency P, Merran J, Corden JL (2014) Genome‐wide mapping of yeast RNA polymerase II termination. PLoS Genet 10: e1004632 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schermer UJ, Korber P, Hörz W (2005) Histones are incorporated in trans during reassembly of the yeast PHO5 promoter. Mol Cell 19: 279–285 [DOI] [PubMed] [Google Scholar]
- Schroeder SC, Weil PA (1998) Genetic tests of the role of abf1p in driving transcription of the yeast TATA box bindng protein‐encoding gene, SPT15. J Biol Chem 273: 19884–19891 [DOI] [PubMed] [Google Scholar]
- Skene PJ, Henikoff S (2017) An efficient targeted nuclease strategy for high‐resolution mapping of DNA binding sites. eLife 6: e21856 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Southern JA, Young DF, Heaney F, Baumgärtner WK, Randall RE (1991) Identification of an epitope on the P and V proteins of simian virus 5 that distinguishes between two isolates with different biological characteristics. J Gen Virol 72: 1551–1557 [DOI] [PubMed] [Google Scholar]
- Spitz F, Furlong EEM (2012) Transcription factors: from enhancer binding to developmental control. Nat Rev Genet 13: 613–626 [DOI] [PubMed] [Google Scholar]
- Stavreva DA, Müller WG, Hager GL, Smith CL, McNally JG (2004) Rapid glucocorticoid receptor exchange at a promoter is coupled to transcription and regulated by chaperones and proteasomes. Mol Cell Biol 24: 2682–2697 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Struhl K, Segal E (2013) Determinants of nucleosome positioning. Nat Struct Mol Biol 20: 267–273 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sun M, Schwalb B, Schulz D, Pirkl N, Etzold S, Larivière L, Maier KC, Seizl M, Tresch A, Cramer P (2012) Comparative dynamic transcriptome analysis (cDTA) reveals mutual feedback between mRNA synthesis and degradation. Genome Res 22: 1350–1359 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Teytelman L, Thurtle DM, Rine J, van Oudenaarden A (2013) Highly expressed loci are vulnerable to misleading ChIP localization of multiple unrelated proteins. Proc Natl Acad Sci USA 110: 18602–18607 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Venditti P, Costanzo G, Negri R, Camilloni G (1994) ABFI contributes to the chromatin organization of Saccharomyces cerevisiae ARS1 B‐domain. Biochim Biophys Acta 1219: 677–689 [DOI] [PubMed] [Google Scholar]
- Voss TC, Hager GL (2014) Dynamic regulation of transcriptional states by chromatin and transcription factors. Nat Rev Genet 15: 69–81 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Warner JR (1999) The economics of ribosome biosynthesis in yeast. Trends Biochem Sci 24: 437–440 [DOI] [PubMed] [Google Scholar]
- van Werven FJ, van Teeffelen HAAM, Holstege FCP, Timmers HTM (2009) Distinct promoter dynamics of the basal transcription factor TBP across the yeast genome. Nat Struct Mol Biol 16: 1043–1048 [DOI] [PubMed] [Google Scholar]
- Woo H, Ha SD, Lee SB, Buratowski S, Kim T (2017) Modulation of gene expression dynamics by co‐transcriptional histone methylations. Exp Mol Med 49: e326 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yao J, Munson KM, Webb WW, Lis JT (2006) Dynamics of heat shock factor association with native gene loci in living cells. Nature 442: 1050–1053 [DOI] [PubMed] [Google Scholar]
- Yarragudi A, Miyake T, Li R, Morse RH (2004) Comparison of ABF1 and RAP1 in chromatin opening and transactivator potentiation in the budding yeast Saccharomyces cerevisiae . Mol Cell Biol 24: 9152–9164 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yarragudi A, Parfrey LW, Morse RH (2007) Genome‐wide analysis of transcriptional dependence and probable target sites for Abf1 and Rap1 in Saccharomyces cerevisiae . Nucleic Acids Res 35: 193–202 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zaidi H, Hoffman EA, Shetty SJ, Bekiranov S, Auble DT (2017) Second‐generation method for analysis of chromatin binding with formaldehyde–cross‐linking kinetics. J Biol Chem 292: 19338–19355 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zaret KS, Carroll JS (2011) Pioneer transcription factors: establishing competence for gene expression. Genes Dev 25: 2227–2241 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zentner GE, Kasinathan S, Xin B, Rohs R, Henikoff S (2015) ChEC‐seq kinetics discriminates transcription factor binding sites by DNA sequence and shape in vivo . Nat Commun 6: 8733 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang Y, Liu T, Meyer CA, Eeckhoute J, Johnson DS, Bernstein BE, Nusbaum C, Myers RM, Brown M, Li W et al (2008) Model‐based analysis of ChIP‐Seq (MACS). Genome Biol 9: R137 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Expanded View Figures PDF
Dataset EV1
Review Process File
Data Availability Statement
The datasets and computer code produced in this study are available in the following databases:
ChIP‐Seq data: Gene Expression Omnibus GSE151692 (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE151692).
RNA‐Seq data: Gene Expression Omnibus GSE151468 (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE151468).
Modeling computer scripts: GitHub (https://github.com/wdejonge/DIVORSEQ).