

Summary
Machine learning has been heavily researched and widely used in many disciplines. However, achieving high accuracy requires a large amount of data that is sometimes difficult, expensive, or impractical to obtain. Integrating human knowledge into machine learning can significantly reduce data requirement, increase reliability and robustness of machine learning, and build explainable machine learning systems. This allows leveraging the vast amount of human knowledge and capability of machine learning to achieve functions and performance not available before and will facilitate the interaction between human beings and machine learning systems, making machine learning decisions understandable to humans. This paper gives an overview of the knowledge and its representations that can be integrated into machine learning and the methodology. We cover the fundamentals, current status, and recent progress of the methods, with a focus on popular and new topics. The perspectives on future directions are also discussed.
Subject Areas: Computer Science, Artificial Intelligence, Human-Centered Computing
Graphical Abstract
Highlights
-
•
Integrating knowledge into machine learning delivers superior performance
-
•
Knowledge is categorized and its representations are presented
-
•
Various methods to bridge human knowledge and machine learning are shown
-
•
Suggestions on approaches and perspectives on future research directions are provided
Computer Science; Artificial Intelligence; Human-Centered Computing
Introduction
Machine learning has been heavily researched and widely used in many areas from object detection (Zou et al., 2019) and speech recognition (Graves et al., 2013) to protein structure prediction (Senior et al., 2020) and engineering design optimization (Deng et al., 2020; Gao and Lu, 2020; Wu et al., 2018). The success is grounded in its powerful capability to learn from a tremendous amount of data. However, it is still far from achieving intelligence comparable to humans. As of today, there have been few reports on artificial intelligence defeating humans in sensory tasks such as image recognition, object detection, or language translation. Some skills are not acquired by machines at all, such as creativity, imagination, and critical thinking. Even in the area of games where humans may be beaten, machine behaves more like a diligent learner than a smart one, considering the amount of data requirement and energy consumption. What is worse, pure data-driven models can lead to unintended behaviors such as gradient vanishing (Hu et al., 2018; Su, 2018) or classification on the wrong labels with high confidence (Goodfellow et al., 2014). Integrating human knowledge into machine learning can significantly reduce the data required, increase the reliability and robustness of machine learning, and build explainable machine learning systems.
Knowledge in machine learning can be viewed from two perspectives. One is “general knowledge” related to machine learning but independent of the task and data domain. This involves computer science, statistics, neural science, etc., which lays down the foundation of machine learning. An example is the knowledge in neural science that can be translated to improving neural network design. The other is “domain knowledge” which broadly refers to knowledge in any field such as physics, chemistry, engineering, and linguistics with domain-specific applications. Machine learning algorithms can integrate domain knowledge in the form of equations, logic rules, and prior distribution into its process to perform better than purely data-driven machine learning.
General knowledge marks the evolution of machine learning in history. In 1943, the first neuron network mathematical model was built based on the understanding of human brain cells (McCulloch and Pitts, 1943). In 1957, perceptron was invented to mimic the “perceptual processes of a biological brain” (Rosenblatt, 1957). Although it was a machine instead of an algorithm as we use today, the invention set the foundation of deep neuron networks (Fogg, 2017). In 1960, the gradients in control theory were derived to optimize the flight path (Kelley, 1960). This formed the foundation of backpropagation of artificial neural networks. In 1989, Q-learning was developed based on the Markov process to greatly improve the practicality and feasibility of reinforcement learning (Watkins and Dayan, 1992). In 1997, the concept of long short-term memory was applied to a recurrent neural network (RNN) (Hochreiter and Schmidhuber, 1997). The development of these algorithms, together with an increasing amount of available data and computational power, brings the era of artificial intelligence today.
Domain knowledge plays a significant role in enhancing the learning performance. For instance, experts' rating can be used as an input of the data mining tool to reduce the misclassification cost on evaluating lending applications (Sinha and Zhao, 2008). An accurate estimation of the test data distribution by leveraging the domain knowledge can help design better training data sets. Human involvement is essential in several machine learning problems, such as the evaluation of machine-generated videos (Li et al., 2018). Even in areas where machine learning outperforms humans, such as the game of Go (Silver et al., 2017), learning from records of human experience is much faster than self-play at the initial stage.
Knowledge is more or less reflected in all data-based models from data collection to algorithm implementation. Here, we focus on typical areas where human knowledge is integrated to deliver superior performance. In Section Knowledge and Its Representations, we discuss the type of knowledge that has been incorporated in machine learning and its representations. Examples to embed such knowledge will be provided. In Section Methods to Integrate Human Knowledge, we introduce the methodology to incorporate knowledge into machine learning. For a broad readership, we start from the fundamentals and then cover the current status, remarks, and future directions with particular attention to new and popular topics. We do not include the opposite direction, i.e. improving knowledge-based models by data-driven approaches. Different from a review on related topics (Rueden et al., 2019), we highlight the methods to bridge machine learning and human knowledge, rather than focusing on the topic of knowledge itself.
Knowledge and Its Representations
Knowledge is categorized into general knowledge and domain knowledge as we mentioned earlier. General knowledge regarding human brains, learning process, and how it can be incorporated is discussed in Section Human Brain and Learning. Domain knowledge is specifically discovered, possessed and summarized by experts in certain fields. In some subject areas, domain knowledge is abstract or empirical, which makes it challenging to be integrated into a machine learning framework. We discuss some recent progresses on this form of knowledge in Section Qualitative Domain Knowledge. Meanwhile, the knowledge base is becoming more systematic and quantitative in various fields, particularly in science and engineering. We discuss how quantitative domain knowledge can be utilized in Section Quantitative Domain Knowledge.
Human Brain and Learning
Machine learning uses computers to automatically process data to look for patterns. It mimics the learning process of biological intelligence, especially humans. Many breakthroughs in machine learning are inspired by the understanding of learning from fields such as neuroscience, biology, and physiology. In this section, we review some recent works that bring machine learning closer to human learning.
For decades, constructing a machine learning system required careful design of raw data transformation to extract their features for the learning subsystem, often a classifier, to detect or classify patterns in the input. Deep learning (LeCun et al., 2015) relaxes such requirements by stacking multiple layers of artificial neural modules, most of which are subject to learning. Different layers could extract different levels of features automatically during training. Deep learning achieved record-breaking results in many areas. Despite dramatic increase in the size of networks, the architecture of current deep neural networks (DNNs) with learnable weights is still much simpler than the complex brain network with neurons (Herculano-Houzel, 2009) and synapses (Drachman, 2005).
Residual neural networks (ResNets) (He et al., 2016), built on convolutional layers with shortcuts between different layers, were proposed for image classification. The input of downstream layers also contains the information from upstream layers far away from them, in addition to the output of adjacent layers. Such skip connections have been observed in brain cells (Thomson, 2010). This technique helps ResNets to win first place on the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2015 classification task (He et al., 2016) and is widely used in other DNNs (Wu et al., 2019).
Dropout, motivated by “theory of the role of sex in evolution”, is a simple and powerful way to prevent overfitting of neural networks (Hinton et al., 2012; Srivastava et al., 2014). It is also analogous to the fact that neurons and connections in human brains keep growing and dying (breaking). At the training time, the connections of artificial neurons break randomly, and the remaining ones are scaled accordingly. This process can be regarded as training different models with shared weights. At the test time, the outputs are calculated by a single network without dropout, which can be treated as an average of different models. In recent years, dropout is proposed to be used at the test time to evaluate uncertainty (Gal and Ghahramani, 2016; Gal et al., 2017).
The focus of machine learning nowadays is on software or algorithms, yet some researchers start to redesign the hardware. Current computers, built on the von Neumann architecture, have a power consumption that is several orders of magnitude higher than biological brains. For example, International Business Machines Corporation (IBM)'s Blue Gene/P supercomputer simulated 1% of the human cerebral cortex and could consume up to 2.9 MW of power (Hennecke et al., 2012) while a human brain consumes only around 20 W (Modha, 2017). Neuromorphic systems were proposed and designed to improve energy efficiency. To name a few practical implementations, TrueNorth from IBM (Merolla et al., 2014; Modha, 2017) can solve problems from vision, audition, and multi-sensory fusion; Loihi from Intel (Davies et al., 2018) can solve the least absolute shrinkage and selection operator (LASSO) optimization orders of magnitude superior than the conventional central processing unit (CPU); NeuroGrid from Stanford University (Benjamin et al., 2014) offers affordable biological real-time simulations. In these brain-inspired systems, information is stored and processed at each neuron's synapses, which themselves are responsible for learning (Bartolozzi and Indiveri, 2007). There are various models to mimic neurons by circuits, such as the integrate-and-fire (I&F) model (Bartolozzi and Indiveri, 2007), the Hodgkin-Huxley model (Hodgkin and Huxley, 1952), and the Boolean logic gate design (Deshmukh et al., 2005). The majority of implementations use the I&F model, though their specific circuitry and behaviors vary (Nawrocki et al., 2016). As for materials, most systems utilize the standard silicon fabrication, which allows for integration with relatively mature technology and facilities. Recently, a few neuromorphic components or systems are made of new materials, such as organic or nanoparticle composites (Sun et al., 2018; Tuchman et al., 2020).
Qualitative Domain Knowledge
Along with the neuroscience-inspired fast development of deep learning architecture, knowledge from specific domains enlightens innovative machine learning algorithms. In its primitive format, knowledge is descriptive, intuitive, and often expressed by plain language. Such knowledge is usually based on observation, inference, and induction. Here, we group it as qualitative domain knowledge which requires intensive engagement and interpretation by humans with sophisticated skills. Although there is no universal way to bridge machine learning and qualitative knowledge, qualitative knowledge adds unique insights into the machine learning framework by using customized strategies. This integration offers two primary advantages. For one thing, qualitative knowledge is explained mainly by experts, which means that it highly relies on subjective interpretation. Machine learning consolidates the stringency of expert knowledge so that it can be directly validated by the large amount of raw data. Therefore, the qualitative knowledge can be built on a more statistically rigorous base. For another thing, machine learning models, such as the DNN, are subject to interpretability issues. Using qualitative domain knowledge in machine learning helps dig into the underlying theoretical mechanisms.
Qualitative knowledge can be further divided into three subgroups according to the degree of quantification. Here, we name them as Knowledge in Plain Language, Loosely Formed Knowledge, and Concretely Formatted Knowledge.
Knowledge in Plain Language
Tremendous qualitative knowledge is well established in different disciplines, especially for social science. Sociology has been developed for thousands of years, with modern theory focusing on globalization and micro-marco structures (Ritzer and Stepnisky, 2017). Political scientists proposed institutional theories to profile current governments (Peters, 2019). These theories are usually in the form of plain language. Traditionally, machine learning is far from these domains. However, many empirical theories actually provide good intuition to understand and design better machine learning models. For example, machine learning researchers found that some widely used DNN models have “shape bias” in word recognition (Ritter et al., 2017). This means that the shape of characters is more important than color or texture in visual recognition. At the same time, research in development psychology shows that humans tend to learn new words based on similar shape, rather than color, texture, or size (Nakamura et al., 2012a). This coincidence provides a new theoretical foundation to understand how the DNN identifies objects. Conversely, some unfavorable biases, such as those toward race and gender, should be eliminated (DeBrusk, 2018).
Loosely Formed Knowledge
Qualitative knowledge can be pre-processed in ways that it is expressed in more numerical formats for use in machine learning. One example is that empirical human knowledge in social science can be inserted into machine learning through qualitative coding (Chen et al., 2018). This technique assigns inferential labels to chunks of data, enabling later model development. For example, social scientists in natural language processing (NLP) use their domain knowledge to group and structure the code system in the postprocessing step (Crowston et al., 2012). Moreover, qualitative coding is able to infer relations among latent variables. Human-understandable input and output are crucial for interpretable machine learning. If the input space contains theoretically justified components by humans, the mapping to output has logical meanings, which is much more preferred compared with pure statistical relationship (Liem et al., 2018).
In addition to social science, qualitative knowledge in natural science can be integrated into machine learning as well. For example, physical theories could guide humans to create knowledge-induced features for Higgs boson discovery (Adam-Bourdarios et al., 2015). Another strategy is to transfer language-based qualitative knowledge into numerical information. In computational molecular design (Ikebata et al., 2017), a molecule is encoded into a string including information such as element types, bond types, and branching components. The string is further processed by NLP models. The final strategy is to use experts to guide the learning process to identify a potential search direction. For instance, in cellular image annotation (Kromp et al., 2016), expert knowledge progressively improves the model through an online multi-level learning.
Concretely Formatted Knowledge
Although qualitative knowledge is relatively loose in both social and natural science, there are some formalized ways to represent it. For example, logic rules are often used to show simple relationships, such as implication (A B), equivalence (A B), conjunction (A B), disjunction (A B), and so on. The simple binary relationship can be extended to include more entities by parenthesis association. It can be defined as a first order logic that each statement can be decomposed into a subject, a predicate, and their relationship. Logic rule–regularized machine learning models attract attention recently. For example, a “but” keyword in a sentence usually indicates that the clause after it dominates the overall sentiment. This first-order logic can be distilled into a neural network (Hu et al., 2016). In a material discovery framework called CombiFD, complex combinatorial prioris expressing whether the data points belong to the same cluster (Must-Link) or not (Cannot-Link) can be used as constraints in model training (Ermon et al., 2014).
Besides logic rules, invariance is another major format of qualitative knowledge which is not subject to change after transformation. An ideal strategy is to incorporate invariance in machine learning models, i.e., to build models invariant to input transformation, yet this is sometimes very difficult. Some details are shown in Section Symmetry of Convolutional Neural Networks. Besides models, one can leverage the invariant properties by preprocessing the input data. One way is to find a feature extraction method whose output is constant when the input is transformed within the symmetry space. For example, the Navier-Stokes equations obey the Galilean invariance. Consequently, seven tensors can be constructed from the velocity gradient components to form an invariant basis (Ling et al., 2016). The other way is to augment the input data based on invariance and feed the data to models (see Section Data Augmentation).
Quantitative Domain Knowledge
In scientific domains, a large amount of knowledge has been mathematically defined and expressed, which facilitates a quantitative analysis using machine learning. In the following sections, three groups of quantitative knowledge, in terms of their representation formats, are discussed: equation-based, probability-based, and graph-based knowledge.
Equation-Based Knowledge
Equality and inequality relationships can be established by algebraic and differential equations and inequations, respectively. They are the predominant knowledge format in physics, mathematics, etc. At the same time, there is increasing amount of equation-based knowledge in chemistry, biology, engineering, and other experiment-driven disciplines. A great benefit of equations in aforementioned areas is that most variables have physical meanings understandable by humans. Even better, many of them can be measured or validated experimentally. The insertion and refinement of expert knowledge in terms of equations can be static or dynamic. Static equations often express a belief or truth that is not subject to change so that they do not capture the change of circumstance. Dynamically evolving equations, such as those used in the control area, are being used to express continuously updating processes. Equations in different categories play diverse roles in the machine learning pipeline, so equation-based knowledge can be further divided into subgroups according to their complexity.
The simplest format is a ground-truth equation, expressing consensus such as . Since it cannot be violated, this type of equation is usually treated as constraints to regularize the training process in the format of Loss(x) = original_Loss(x)+, where is the equation-enforced regularization term and is the weight. For example, the object trajectory under gravity can be predicted by a convolutional neural network (CNN) without any labeled data, by just using a kinetic equation as the regularization term (Stewart and Ermon, 2017). The kinetic equation is easily expressed as a quadratic univariate equation of time or . In another study, a robotic agent is designed to reach an unknown target (Ramamurthy et al., 2019). The solid body property enforces a linear relationship of segments, which serves as a regularizer in the policy architectures. The confidence of ground truth influences the degree of regularization through a soft or hard hyperparameter. For a complicated task, an expert must choose the confidence level properly.
At the second level, the equation has concrete format and constant coefficients, with single or multiple unknown variables and their derivatives. The relationship among those variables is deterministic. This means that the coefficients of these equations are state independent. Particularly, ordinary differential equation (ODE) and partial differential equation (PDE) belong to this category, which are being researched extensively within machine learning. They have the generalized form of = 0. Although only few differential equations have explicit solutions, as long as their formats can be determined by domain knowledge, machine learning can numerically solve them. This strategy inspires data-driven PDE/ODE solvers (Samaniego et al., 2020). Prior knowledge, such as periodicity, monotonicity, or smoothness of underlying physical process, is reflected in the kernel function and its hyperparameters.
In its most complicated format, equations may not fully generalize domain knowledge when the system has characteristics of high uncertainty, continuous updating, or ambiguity. The coefficients are state dependent or unknown functionals. These issues can be partially addressed by building a hybrid architecture of machine learning and PDE, in which machine learning helps predict or resolve such unknowns. For example, PDE control can be formulated as a reinforcement learning problem (Farahmand et al., 2017). The most extreme condition is that the form of coefficient/equation is unknown, but it can still be learned by machine learning purely from harnessing the experimental and simulation data. For example, governing equations expressed by parametric linear operators, such as heat conduction, can be discovered by machine learning (Raissi et al., 2017). Maximum likelihood estimation (MLE) with Gaussian process priors is used to infer the unknown coefficients from the noisy data. In another example, researchers propose to estimate nonlinear parameters in PDEs using quantum-behaved particle swarm optimization with Gaussian mutation (Tian et al., 2015). Inverse modeling can also be used to reconstruct functional terms (Parish and Duraisamy, 2016).
Probability-Based Knowledge
Knowledge in the form of probabilistic relations is another major type of quantitative knowledge. A powerful tool used in machine learning is Bayes' theorem which regulates the conditional dependence. We have prior knowledge of the relations of variables and their distributions. Given data, we could adjust some probabilities to fit observations.
Some machine learning algorithms have the intrinsic structure to capture probabilistic relations. For example, parameters of the conditional distribution in Bayesian network can be learned from data or directly from encoded knowledge (Flores et al., 2011; Masegosa and Moral, 2013). Domain knowledge can also be directly used to determine probabilities. For instance, gene relations help build optimal Bayesian classification by mapping into a set of constraints (Boluki et al., 2017). For instance, if gene g2 and g3 regulate g1 with X1 = 1 when X2 = 1 and X3 = 0 according to the domain knowledge, the constraint can be enforced by
Graph-Based Knowledge
In both natural science and social science fields, a lot of knowledge has the “subject verb object” structure. A knowledge graph consists of entities and links among them. It can be expressed as a set of triples. The degree of their correlation can be numerically expressed and graphically visualized. Knowledge graphs are initially built by expert judgment from data. With growing size of data available, machine learning algorithms play an important role in constructing large knowledge graphs.
Google knowledge graph is an example that we access daily. It covers 570 million entities and 18 billion facts initially and keeps growing to have over 500 billion facts on ∼5 billion entities (Paulheim, 2017). For example, when you search basketball in Google, highly related NBA teams and stars will appear on the right. Another famous general knowledge-formed knowledge graph is ConceptNet, which connects words and phrases of natural language with labeled edges. It can be combined with word embeddings with a better understanding of the underlying meanings (Speer et al., 2016). Specific knowledge graphs are popular in different domains. In NLP, WordNet is a semantic network to link synonyms for highlighting their meanings rather than spelling. It can enhance the performance of search applications (Fellbaum, 2012). Medical and biologic fields have, for instance, MeSH (Lowe and Barnett, 1994). It is hierarchically organized vocabulary used for indexing, cataloging, and searching of biomedical and health-related information, upon which some machine learning models are built (Abdelaziz et al., 2017; Gan et al., 2019).
Knowledge graphs and machine learning mutually benefit each other. A graph may be incomplete when there are missing entities, relations, or facts and thus needs machine learning approaches to supplement the information. For example, knowledge graph can be trained together with tasks of recommendation to connect items (Cao et al., 2019). Human-computer interaction and knowledge discovery approach (Holzinger et al., 2013) can be used to identify, extract, and formalize useful data patterns from raw medical data. Meanwhile, knowledge graph helps human to understand the related fields to promote machine learning. For instance, a better understanding of biology and neuroscience leads to advanced machine learning algorithms and neuromorphic systems (Section Human Brain and Learning). Besides, machine learning models, such as neural networks, can be built upon knowledge graph, as is further discussed in Section Design of Neuron Connections.
Methods to Integrate Human Knowledge
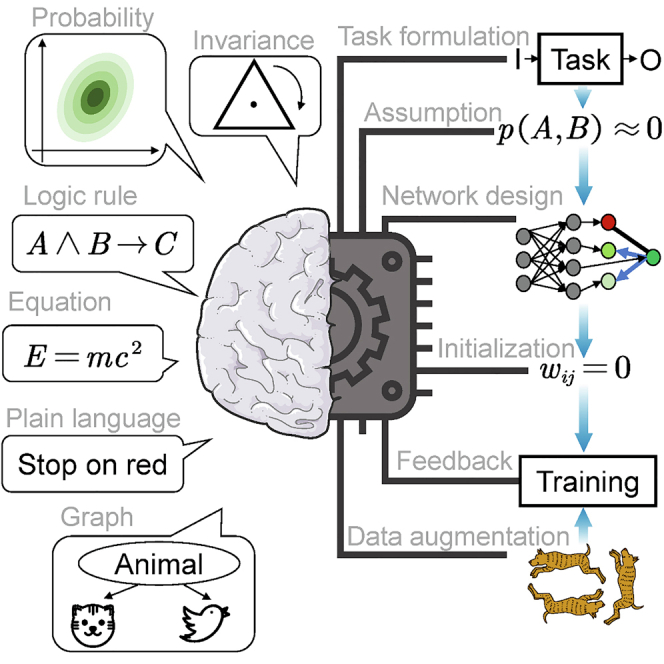
A complete process to design and implement a machine learning model consists of multiple steps. The first step is to formulate the appropriate tasks based on the goal. One needs to determine what the machine should learn, i.e., the inputs and outputs. After simplifying the problem by some assumptions, a model is built with unknown parameters to explain or correlate the inputs and outputs. Then, the model is initialized and trained by the collected data. After this, the machine learning model is ready for inference and evaluation. In practice, the process is not necessarily in such a chronological order but usually follows an iterative process. Some algorithms incorporate humans in the loop for feedback and evaluation. Human knowledge can be incorporated almost anywhere in this process. In the following sections, we review the methods to integrate human knowledge into machine learning. We organize them based on the sub-domains of machine learning field and group them according to their major contribution to the steps aforementioned. We should note that (1) there are numerous approaches, thus we focus on popular or emerging methods that could work efficiently across disciplines; (2) the methods are interwoven, namely, they may be used in several sub-domains and contribute to multiple steps; thus, we consider their main categories and detail them only in one place.
Task Formulation
Machine learning models, such as neural networks and support vector machines, take an array of numbers in the form of vectors or matrices as inputs and make predictions. For a given goal, there remains flexibility for humans to formulate the task, i.e., to determine the inputs and outputs of the machine learning models. Humans could combine similar tasks based on their background and shared information (Section Multitask Learning). Domain knowledge is necessary to understand and make use of the similarity of tasks. Also, we need to carefully decide the inputs of machine learning models (Section Features) to best represent the essence of the tasks. We can leverage expert knowledge in the domain or some statistical tools when engineering these features.
Multitask Learning
Humans do not learn individual tasks in a linear sequence, but they learn several tasks simultaneously. This efficient behavior is replicated in machine learning with multitask learning (MTL). MTL shares knowledge between tasks so they are all learned simultaneously with higher overall performance (Ruder, 2017a). By learning the tasks simultaneously, MTL helps to determine which features are significant and which are just noise in each task (Ruder, 2017a). Human knowledge is used in MTL to determine if a group of tasks would benefit from being learned together. For example, autonomous vehicles use object recognition to drive safely and arrive at the intended destination. They must recognize pedestrians, signs, road lines, other vehicles, etc. Machine learning could be trained to recognize each object individually with supervised learning, but human knowledge tells us that the objects share an environment. The additional context increases accuracy as MTL finds a solution that fits all tasks. MTL has also been used extensively for facial landmark detection (Ehrlich et al., 2016; Ranjan et al., 2017; Trottier et al., 2017; Zhang et al., 2014) and has even contributed to medical research through drug behavior prediction (Lee and Kim, 2019; Mayr et al., 2016; Yuan et al., 2016) and through drug discovery (Ramsundar et al., 2015). Object recognition is a common use of MTL due to its proven benefits when used alongside CNNs (Girshick, 2015; Li et al., 2016).
Currently, the two main methods of task sharing are hard and soft parameter sharing as shown in Figure 1. Hard parameter sharing is where some hidden layers are shared while the output layers remain task specific. In soft parameter sharing, each task has its own model and parameters, but the parameters are encouraged to be similar through the L2 norm regularization. Currently, hard parameter sharing is more common due to being more effective in reducing overfitting. Alternative methods to hard and soft parameter sharing have been proposed, such as deep relationship networks (Long et al., 2017), cross-stitch networks (Misra et al., 2016), and sluice networks (Ruder et al., 2019). Deep relationship networks use matrices to connect the task-specific layers so they also increase the performance alongside the shared layers. Cross-stitch networks attempt to find the optimal combination of shared and specific layers. Sluice networks combine several techniques to learn which layers should be shared. These methods aim to find a general approach that works broadly so that it can be easily used for all MTL problems. However, so far, the optimal task sharing method is different for each application. This means human knowledge on the application subject and on the various task sharing methods is a necessity to find the best method for the application. It has been found that MTL is unlikely to improve performance unless the tasks and the weighting strategies are carefully chosen (Gong et al., 2019). Continued research is needed for optimal strategies to choose and balance tasks.
Figure 1.

Illustration of Hard and Soft Parameter Sharing
(A) hard parameter sharing.
(B) soft parameter sharing.
Redrawn from (Ruder, 2017a).
Another important area in MTL is to gain benefits even in the case where only one task is important. Research shows that MTL can still be used in this situation by finding an appropriate auxiliary task to support the main task (Ruder, 2017a). Similar to finding the best task sharing method, significant human knowledge is needed to find an effective auxiliary task. Another approach is to use an adversarial auxiliary task which achieves the opposite purpose of the main task. By maximizing the loss function of the adversarial task, information can be gained for the main task. There are several other types of auxiliary tasks, but sometimes an auxiliary task is not even needed. In recent developments, MTL principles are utilized even in single task settings. Pseudo-task augmentation is where a single task is being solved; however, multiple decoders are used to solve the task in different ways (Meyerson and Miikkulainen, 2018). Each solving method is treated as a different task and implemented into MTL. This allows a task to be solved optimally as each method of solving the task learns from the other methods.
Features
“Features” in machine learning refer to variables that represent the property or characteristic of the observations. They could be statistics (e.g., mean, deviation), semantic attributes (e.g., color, shape), transformation of data (e.g, power, logarithm), or just part of raw data. “Feature engineering” is the process to determine and obtain input features to optimize machine learning performance. In this section, we will discuss the approaches in this process.
Feature engineering, especially feature creation, heavily relies on human knowledge and experience in the areas. For instance, in a credit card fraud detection task, there are many items associated with each transaction, such as transaction amount, merchant ID, and card type. A simple model treats each transaction independently and classifies the transactions by eliminating unimportant items (Brause et al., 1999). Later, people realize that costumer spending behaviors matter as well. Then, their indicators, such as transactions during the last give number of hours and countries, are aggregated (Whitrow et al., 2009). This methodology is further amended by capturing transaction time and its periodic property (Bahnsen et al., 2016). We could see from this example that it is an iterative process that interplays with feature engineering and model evaluation (Brownlee, 2014). Although the guidelines vary with specific areas, a rule of thumb is to find the best representation of the sample data to learn a solution.
In addition to domain knowledge, there are some statistical metrics in feature selection widely used in different areas. There are mainly two types of ideas (Ghojogh et al., 2019). One is called filter methods, which rank the features by their relevance (correlation of features with targets) or redundancy (whether the features share redundant information) and remove some by setting a threshold. This type includes linear correlation coefficient, mutual information, consistency-based filter (Dash and Liu, 2003), and many others. The other type is called wrapper methods. These methods train and test the model during searching. They look for the subset of features that correspond to the optimal model performance. Since the number of combinations grow exponentially with the number of features, it is a non-deterministic polynomial-time (NP) hard problem to find the optimal subset. One searching strategy, sequential selection methods, is to access the models sequentially (Aha and Bankert, 1996). The other strategy is to implement metaheuristic algorithms such as the binary dragonfly algorithm (Mafarja et al., 2017), genetic algorithm (Frohlich et al., 2003), and binary bat algorithm (Nakamura et al., 2012b). Wrapper methods can be applied to simple models instead of the original ones to reduce computation. For instance, Boruta (Kursa and Rudnicki, 2010) uses a wrapper method on random forests, which in essence can be regarded as a filter method. In addition to these two types, there exist other techniques such as embedded methods, clustering techniques, and semi-supervised learning (Chandrashekar and Sahin, 2014).
“Feature learning”, also called “representation learning”, is a set of techniques that allow machine to discover or extract features automatically. Since the raw data may contain redundant information, we normally want to extract features with lower dimension, i.e., to find a mapping where and usually . Thus, these methods are sometimes referred to as dimension reduction. Traditional ways are statistical methods to extract features. Unsupervised (unlabeled data) methods include principal component analysis (Wold et al., 1987), maximum variance unfolding (Weinberger and Saul, 2006), Laplacian eigenmap (Belkin and Niyogi, 2003; Chen et al., 2010), and t-distributed stochastic neighbor embedding (t-SNE) (Maaten and Hinton, 2008). Supervised (labeled data) methods include Fisher linear discriminant analysis (Fisher, 1936), its variant Kernel Fisher linear discriminant analysis (Mika et al., 1999), partial least squares regression (Dhanjal et al., 2008), and many approaches on supervised principal component analysis (Bair and Tibshirani, 2004; Barshan et al., 2011; Daniušis et al., 2016). Recent works are mostly based on neural networks, such as autoencoders (Baldi, 2012), CNNs, deep Boltzman machines (Salakhutdinov and Hinton, 2009). Even though these methods extract features automatically, prior knowledge can still be incorporated. For instance, to capture the features of videos with slow moving objects, we can represent the objects by a group of numbers (such as their positions in space and the pose parameters) rather than by a single scalar, and these groups tend to move together (Bengio et al., 2013; Hinton et al., 2011). Or we can deal with the moving parts and the static background separately (Li et al., 2018). Another example, which applies the principal of Multitask Learning, is to train an image encoder and text encoder simultaneously and correlate their extracted features (Reed et al., 2016). Other strategies to integrate knowledge include data manipulation and neural network design, as will be discussed in the following sections.
Model Assumptions
Machine learning models are built upon assumptions or hypotheses. Since “hypothesis” in machine learning field commonly refers to model candidates, we use the word “assumption” to denote explicit or implicit choices, presumed patterns, and other specifications on which models are based for simplification or reification. The assumptions could be probabilistic or deterministic. We first introduce probabilistic assumptions in Sections Preliminaries of Probabilistic Machine Learning, Variable Relation and Distribution, and then briefly discuss Deterministic Assumptions.
Preliminaries of Probabilistic Machine Learning
Mathematically, what are we looking for when we train a machine learning model? From the perspective of probability, two explanations have been proposed as shown in Equations (1) and (2) (Murphy, 2012). One is called MLE (maximum likelihood estimation) which means that the model maximizes the likelihood of the training data set,
| (Equation 1) |
where is the training data set and is the probability of data provided by the machine learning model whose parameter is . The machine learning model estimates the probability of observation, while the training process tries to find the parameter which best accords with the observation. The specific form of depends on models. For example, in supervised learning, we can rewrite the form as , i.e., the probability of label given input and model parameters , and we regard the label with the highest probability as the model's prediction.
The other strategy, maximum a posteriori (MAP), means to maximize the posterior probability of the model parameter,
| (Equation 2) |
MAP takes into account , the prior distribution of . From the equations above, we can observe that MLE is a special case of MAP where is uniform.
Variable Relation
A variable could be an instance (data point), a feature, or a state of the system. An assumption on variable relation used in almost all models is the independence of data instances; therefore, the probability of data sets is equal to the product of instance probabilities. For instance, in unsupervised learning we have .
When the variables are related, we could simplify the likelihood function by assuming partial independence. For instance, in image generation models, pixels are correlated to each other; thus, an image is associated with all pixels (). Pixel RNN (Oord et al., 2016a) assumes that pixel is only correlated to its previous pixels and independent of those afterward:
| (Equation 3) |
Under this assumption, pixels are generated sequentially by an RNN. As a simpler implementation, we can pay more attention to the local information and calculate a pixel value by the previous ones close to it (Oord et al., 2016b).
In the stochastic process of time series, Equation (3) is commonly used, and denotes the variable value at time . In this context, the approximation is more of knowledge than an assumption since it is hard to imagine that the future would impact the past. It can be simplified further by assuming that future probabilities are determined by their most recent values and then the variables , called states, form a Markov chain. A more flexible model, hidden Markov model (HMM), treats the states as hidden variables and the observations have a conditional probability distribution given the states. HMM is widely used in stock market, data analysis, speech recognition, and so forth (Mor et al., 2020). Such Markov property is also presumed in reinforcement learning (Section Reinforcement Learning), where the next state is determined by the current state and action.
In addition to sequential dependence, the relation between variables can be formulated as a directed acyclic graph or a Bayesian network in which nodes represent the variables and edges represent the probabilistic dependencies. Learning the optional structure of a Bayesian network is NP-hard problem, which means that it requires a huge amount of computation and may not converge to global optima. Prior knowledge of the variables can be incorporated by their dependencies, such as the existence or absence of an edge and even the probability distribution (Su et al., 2014; Xu et al., 2015). The results of learned networks get improved while computational cost is reduced.
Distribution
The distribution of variables is unknown and has to be assumed or approximated by sampling. A very popular and fundamental distribution is the Gaussian distribution, a.k.a. normal distribution. Its popularity is not groundless; instead, it is based on the fact that the mean of a large number of independent random variables, regardless of their own distributions, tends toward Gaussian distribution (central limit theorem). The real-world data are composed of many underlying factors, so the aggregate variables tend to have a Gaussian distribution in nature. Some models are named after it, such as Gaussian process (Ebden, 2015) and Gaussian mixture model (Shental et al., 2004). Independent component analysis (ICA) decomposes the observed data into several underlying components and sources (Hyvärinen, 2013). ICA assumes that the original components are non-Gaussian. In linear regression models, the least square method can be derived from Equation (1) while assuming the output has a Gaussian distribution with a mean of , namely where is the standard deviation. Further, by assuming the prior to be Gaussian with zero mean, regularized linear regression can be derived from Equation (2), whose loss function is penalized by the sum of the squares of the terms in .
Besides Gaussian, other types of distribution assumptions are applied as well. Student- process is used in regression to model the priors of functions (Shah et al., 2014). In many Bayesian models, priors must be given through either the training data or manual adjustment. Inaccurate priors would cause systemic errors of the models. For instance, in spam email classification by naive Bayesian classifiers, if assuming uniform distribution of spam and non-spam (50/50), then the classifier is prone to report a non-spam email as spam when applying it to real life where the ratio of spam emails is much smaller, say 2%. Conversely, assuming a 2% spam ratio, the classifier would miss spam emails when applying it to email accounts full of spam emails. Although methods have been proposed to alleviate this issue (Frank and Bouckaert, 2006; Rennie et al., 2003), classifiers would benefit from appropriate priors. Such training-testing mismatch problem also occurs in other machine learning models. To the best of our knowledge, there is no perfect solution to this problem; thus, the most efficient way is to design a distribution of training data close to test scenarios which requires knowledge from experts.
Deterministic Assumptions
Deterministic assumptions describe the properties and relations of objects. Some deterministic assumptions can also be expressed in a probabilistic way, such as variable independence. In addition to these, many are encoded in the “hypothesis space”: for an unknown function , we use a machine learning model to approximate the target function. Hypothesis space is the set of all the possible functions. This is the set from which the algorithm determines the model which best describes the target function according to the data. For instance, in artificial neural networks, the configuration of the networks, e.g., the number of layers, activation functions, and hyperparameters, is determined priorly. Then, all combinations of weights span the hypothesis space. Through training, the optimal combination of weights is calculated. The design of networks can be integrated with human knowledge, which is elaborated in the section below.
Network Architecture
Artificial neural network has been proved to be a very powerful tool to fit data. It is extensively used in many machine learning models especially after the emergence of deep learning (LeCun et al., 2015). Although ideally neural networks could adapt to all functions, adding components more specific to the domains can boost the performance. As mentioned in Section Deterministic Assumptions, the architecture of network regulates the hypothesis space. Using a specialized network reduces the size of hypothesis space and thus generalizes better with less parameters than universal networks. Therefore, we want to devise networks targeting at data and tasks.
There have been network structures proposed for specific tasks. For instance, RNNs are applied to temporal data, such as language, speech, and time series; capsule neural networks are proposed to capture the pose and spatial relation of objects in images (Hinton et al., 2011). In the following contents, we elaborate how symmetry is used in CNNs and how to embed different knowledge via customizing the neuron connections.
Symmetry of Convolutional Neural Networks
Symmetry, in a broad sense, denotes the property of an object which stays the same after a transformation. For instance, the label and features of a dog picture remain after rotation. In CNNs, symmetry is implemented by two concepts, “invariance” and “equivariance”. Invariance means the output stays the same when the input changes, i.e., where denotes the input, denotes the transformation, and denotes the feature mapping (e.g. convolution calculation). Equivariance means the output preserves the change of the input, i.e., where is another transformation that could equal . CNNs are powerful models for sensory data and especially images. A typical CNN for image classification is composed of mostly convolution layers possibly followed by pooling layers and fully connected ones for the last few layers. Convolution layers use filters to slide through images and calculate inner products with pixels to extract features to analyze each part of images. Such weight sharing characteristic not only greatly reduces the number of parameters but also provides them with inherent translation equivariance: the convolution output of a shifted image is the same as the shifted output of the original image. Basically, the CNN relies on convolution layers for equivariance and fully connected layers for invariance.
The inherent translation equivariance is limited: there are reports showing that the confidence of correct labels would decrease dramatically even with shift unnoticeable by human eyes. It is ascribed to the aliasing caused by down-sampling (stride) commonly used on convolution layers, and a simple fix is to add a blur filter before down-sampling layers (Zhang, 2019). Other symmetry groups are also considered, such as rotation, mirror, and scale. The principle of most works is to manipulate filters since they compute faster than data transformation. A simple idea is to use symmetric filters such as circular harmonics (Worrall et al., 2017) for rotation or log-radial harmonics (Ghosh and Gupta, 2019) for scale. Such equivariance or invariance is local, that is, only each pixel-filter operation has the symmetry property while the whole layer output, composed of multiple operations, does not. A global way is to traverse the symmetry space and represent with exemplary points (control points) (Cohen and Welling, 2016). For instance, in the previous dog example, we could rotate the filter by 90, 180, and 270° to calculate the corresponding feature maps. Thus, we can approximate the equivariance of rotation. Kernel convolution can be used to control the extent of symmetry, e.g. to distinguish “6” and “9” (Gens and Domingos, 2014). Overall, although invariant layers (Kanazawa et al., 2014) can also be constructed to incorporate symmetry, equivariant feature extraction as intermediate layers is preferred in order to preserve the relative pose of local features for further layers.
Design of Neuron Connections
By utilizing the knowledge of invariance and equivariance in the transformation, the CNN preforms well in image classification especially with some designed filters. From another perspective, we can also say that the CNN includes the knowledge of graphs. Imagine a pixel in a graph, which is connected to the other pixels around it. By pooling and weights sharing, the CNN generalizes the information of the pixel and its neighbors. This kind of knowledge is also applied in a graph neural network (GNN) (Gori et al., 2005; Wu et al., 2020) where the node's state is updated based on embedded neighborhood information. In the GNN, the neighbors are not necessarily the surrounding pixels but can be defined by designers. Thus, the GNN is able to represent the network nodes as low-dimensional vectors and preserve both the network topology structure and the node content information. Furthermore, the GNN can learn more informative relationship through differential pooling (Ying et al., 2018) and the variational evaluation-maximization algorithm (Qu et al., 2019).
Not only is the knowledge of general connections between nodes used in network design but also the specific relational knowledge in connections is beneficial. Encoding the logic graph (Fu, 1993) and hierarchy relationships (Deng et al., 2014) into the architecture, such as “” and “a A”, is also one way to build neural networks with Graph-Based Knowledge. With these encoding methods, some of the rules are learned from data and part of them are enforced by human knowledge. This idea is reflected in the cooperation of symbolic reasoning and deep learning, which is getting increasingly popular recently (Garnelo and Shanahan, 2019; Mao et al., 2019; Segler et al., 2018). Symbolic reasoning or symbolic artificial intelligence (AI) (Flasiński, 2016; Hoehndorf and Queralt-Rosinach, 2017) is a good example of purely utilizing graph-based knowledge where all the rules are applied by humans and the freedom of learning is limited, while in deep learning, the rules are automatically learned from data. Building symbolic concept into neural networks helps increase the network's interpreting ability and endow the networks with more possibilities, allowing more interactions between labels, for instance.
Aside from the knowledge of graphs, Equation-Based Knowledge can also be united with deep learning. For example, a general data-driven model can be added to a first-principle model (Zhou et al., 2017). The add-on neural networks will learn the complex dynamics which might be impossible to identify with pure physical models, e.g. learning the close-to-ground aerodynamics in the drone landing case (Shi et al., 2019). Another example in utilizing equation-based knowledge is using optimization equations in the layers through OptNet (Amos and Kolter, 2017), a network architecture which allows learning the necessary hard constraints. In these layers, the outputs are not simply linear combinations plus nonlinear activation functions but solutions (obtained by applying Karush-Kuhn-Tucker conditions) to constrained optimization problems based on previous layers.
In speech recognition, the words in a sentence are related, and the beginning of the sentence may have a huge impact on interpretation. This induces delays and requires accumulating information over time. Also, in many dynamical systems, especially those involving human reaction time, the effects of delays are important. The knowledge of delay is then introduced in the design of neural networks. For example, time-delay neural networks (Waibel et al., 1989) take information from a fixed number of delayed inputs and thus can represent the relations between sequential events. Neural networks with trainable delay (Ji et al., 2020) utilize the knowledge of delay's existence and learn the delay values from data. RNN (Graves et al., 2013; Zhang et al., 2019) is a network architecture in which neurons feedback in a similar manner to dynamical systems, where the subsequent state depends on the previous state. Through inferring the latent representations of states instead of giving label to each state, the RNN can be trained directly on text transcripts of dialogs. However, these end-to-end methods often lack constraints and domain knowledge which may lead to meaningless answers or unsafe actions. For instance, if a banking dialog system does not require the username and password before providing account information, personal accounts could be accessed by anyone. A hybrid code network (HCN) (Williams et al., 2017) is proposed to address this concern. The HCN includes four components: entity extraction module, RNN, domain-specific software, and action templates. The RNN and domain-specific software maintain the states, and the action templates can be a textual communication or an API call. This general network allows experts to express specific knowledge, achieves the same performance with less data, and retains the benefits of end-to-end training.
Data Augmentation
Machine learning, especially deep learning, is hungry for data. The problems with insufficient data include overfitting where the machine generalizes poorly and class imbalance where the machine does not learn what we want because real-world data sets only contain a small percentage of “useful” examples (Salamon and Bello, 2017). These problems can be addressed by data augmentation, a class of techniques to artificially increase the amount of data with almost no cost. The basic approaches are transforming, synthesizing, and generating data. From the perspective of knowledge, it teaches machine invariance or incorporates knowledge-based models. Some papers do not consider simulation as data augmentation, but we will discuss it here since in essence these techniques are all leveraging human knowledge to generate data. Data augmentation needs more computation than explicit ways (e.g. Section Symmetry of Convolutional Neural Networks), but it is widely used in many areas such as Image, Audio, time series (Wen et al., 2020), and NLP (Fadaee et al., 2017; Ma, 2019) owing to its flexibility, simplicity, and effectiveness. It is even mandatory in unsupervised representation learning (Chen et al., 2020; He et al., 2020).
Image
Some representative data augmentation techniques for images are illustrated in Figure 2. A fundamental approach is to apply affine transformation to geometries, i.e., cropping, rotating, scaling, shearing, and translating. Noise and blur filters can be injected for better robustness. Elastic distortions (Simard et al., 2003), designed for hand-written character recognition, are generated using a random displacement field in image space to mimic uncontrolled oscillations of muscles (Wong et al., 2016). Random erasing (Zhong et al., 2020) is analogous to dropout except that it is applied to input data instead of network architecture. Kernel filters are used to generate blurred or sharpened images. Some kernels (Kang et al., 2017) can swap the rows and columns in the windows. This idea of “swapping” is similar to another approach, mixing images. There are two ways to mix images, one is cropping and merging different parts of images (Summers and Dinneen, 2019), the other is overlapping images and averaging their pixel values (Inoue, 2018). They have both been demonstrated to improve performance, though the latter is counterintuitive.
Figure 2.

Illustration of Image Augmentation Techniques
Another perspective is to change the input data in color space (Shorten and Khoshgoftaar, 2019). Images are typically encoded by RGB (red, green, blue) color space, i.e. represented by three channels (matrices) indicating red, green, and blue. These values are dependent upon brightness and lightning conditions. Therefore, color space transformation, also called photometric transformation, can be applied. A quick transformation is to increase or decrease the pixel values of one or three channels by a constant. Other methods are, for instance, setting thresholds of color values and applying filters to change the color space characteristics. Besides RGB, there are other color spaces such as CMY (cyan, magenta, yellow), HSV (hue, saturation, value which denotes intensity), and CIELab. The performance varies with color spaces. For example, a study tested four color spaces in a segmentation task and found that CMY outperformed the others (Jurio et al., 2010). It is worthy to note that human judgment is important in the freedom of color transformation since some tasks are sensitive to colors, e.g. distinguishing between water and blood. In contrast to augmentation, another direction to tackle color variance is to standardize the color space such as adjusting the white balance (Afifi and Brown, 2019).
Deep learning can be used to generate data for augmentation. One way is adversarial training which consists of two or more networks with contrasting objectives. Adversarial attacking uses networks to learn augmentations to images that result in misclassifications of their rival classification networks (Goodfellow et al., 2014; Su et al., 2019). Another method is generative models, such as generative adversarial networks and variational auto-encoders. These models can generate images to increase the amount of data (Lin et al., 2018). Style Transfer (Gatys et al., 2015), best known for its artistic applications, serves as a great tool for data augmentation (Jackson et al., 2019). In addition to images in the input space, data augmentation can also be applied to the feature space, i.e., the intermediate layers of neural networks (Chawla et al., 2002; DeVries and Taylor, 2017).
Audio
There are many types of audio, such as music and speech, and accordingly many types of tasks. Although augmentation method varies with audio types and tasks, the principles are universal.
Tuning is frequently used by music lovers and professionals to play or post-process music. There is a lot of mature software for it. They can stretch time to shift pitch or change the speed without pitch shifting. More advanced tuning involves reverberation (sound reflection in a small space), echo, saturation (non-linear distortion caused by overloading), gain (signal amplitude), equalization (adjusting balance of different frequency components), compression, etc. These methods can all be used in audio data augmentation (Mignot and Peeters, 2019; Ramires and Serra, 2019). Unfavorable effects in tuning, such as noise injection and cropping, are used as well in audio data augmentation.
An interesting perspective is to convert audio to images on which augmentations are based. Audio waveforms are converted to spectrograms which represent the intensity of a given frequency (vertical axis) at a given time (horizontal axis). Then, we can modify the “image” by distorting in the horizontal direction, blocking several rows, or blocking several columns (Park, 2019). These augmentations help the networks to be robust against, respectively, time direction deformations, partial loss of frequency channels, or partial loss of temporal segments of the input audio. This idea was extended by introducing more policies such as vertical direction distortion (frequency warping), time length control, and loudness control (Hwang et al., 2020). Other techniques used in image augmentation, e.g., rotation and mixture, are attempted as well (Nanni et al., 2020).
Simulation
As humans create faster and more accurate knowledge-based models to simulate the world, using simulations to acquire a large amount of data becomes an increasingly efficient method for machine learning. The primary advantage of simulations is the ability to gather a large amount of data when doing so experimentally would be costly, time consuming, or even dangerous (Ruder, 2017b; Ruiz et al., 2018). In some cases, acquiring real-world data may even be impossible without already having some training through simulations.
One application that conveys the important role of human knowledge in simulation data is computer vision. Humans can use their visual knowledge to develop powerful visual simulations to train computers. Autonomous vehicles, for instance, can be trained by simulated scenarios. They can learn basic skills before running on the road and can also be exposed to dangerous scenes that are rare naturally. Open-source simulation environments and video games such as Grand Theft Auto V (Martinez et al., 2017) can be used to reduce the time and money required to build simulations. Besides autonomous vehicles, simulation data have been used for computer vision in unique works such as cardiac resynchronization therapy (Giffard-Roisin et al., 2018), injection molding (Tercan et al., 2018), and computerized tomography (CT) scans (Holmes et al., 2019). Each of these applications requires thorough human knowledge of the subject. Lastly, robotics is a field where simulation data are expected to play a significant role in future innovation. Training robotics in the real world is too expensive, and the equipment may be damaged (Shorten and Khoshgoftaar, 2019). By incorporating human models, simulation data can allow robotics to be trained safely and efficiently.
Improvement through future research will accelerate the adoption of this technique for more tasks. Human experience and knowledge-based models will make simulations in general more realistic and efficient. Therefore, simulation data will become even more advantageous for training. At the same time, data-driven research aims to find optimal simulations that provide the most beneficial data for training the real-world machine. For instance, reinforcement learning is used to quickly discover and converge to simulation parameters that provide the data which maximizes the accuracy of the real-world machine being trained (Ruiz et al., 2018). While data-driven methods will reduce the human knowledge necessary for controlling the simulation, they will not replace the necessity of human knowledge for developing the simulation in the first place.
Feedback and Interaction
As humans, we gain knowledge mostly from interactions with the environment. In some algorithms, the machine is designed to interact with humans. Including human-in-loop (Holzinger, 2016; Holzinger et al., 2019) can help interpret the data, promote the efficiency of learning, and enhance the performance.
A typical method that demonstrates how machines can interact with the environment, including humans and preset rules, is discussed in Section Reinforcement Learning. Knowledge can also be injected through the rewards as well. In Section Active Learning, machines may ask humans for data labeling or distribution. In Section Interactive Visual Analytics, machines interact with humans by bringing new knowledge through visualization while seeking manual tuning.
Reinforcement Learning
Reinforcement learning is a goal-directed algorithm (Sutton and Barto, 2018) which learns the optimal solution to a problem by maximizing the benefit obtained in interactions with the environment.
In reinforcement learning, the component which makes decisions is called “agent” and everything outside and influenced by the agent is “environment”. At time , the agent has some information about the environment which can be denoted as a “state” . According to the information, it will take an action under a policy , which is the probability of choosing when . This action will lead to the next state and a numerical reward . The transition between two states is given by interactions with the environment and is described by the environment model. If the probability of transition between states is given, we can solve the problem by applying model-based methods. When the model is unknown, which is usually the case in real life, we can also learn the model from the interactions and use the learned model to simulate the environmental behaviors if interactions are expensive.
The agent learns the optimal policy by maximizing the accumulated reward (usually in episodic problems and is called return) or average reward (in continuing problems). In general, the collected rewards can be evaluated by state value or action value . Based on different policy evaluation approaches, the methods used in reinforcement learning can be categorized into two types. One type is to evaluate the policy by the value function or . The value function is estimated through table (tabular methods) or approximator (function approximation methods). In the tabular methods, the exact values of those states or state-action pairs are stored in a table; thus, the tabular methods are usually limited by computation and memory (Kok and Vlassis, 2004). Function approximation (Xu et al., 2014) provides a way to bypass the computation and memory limit in high-dimensional problems. The states and actions are generalized into different features, then the value functions become functions of those features, and the weights in the function are learned through interactions. The other type is to evaluate the policy directly by an approximator. Apart from learning the value functions, an alternative approach in reinforcement learning is to express the policy with its own approximation, which is independent of the value function. These kinds of methods are called policy gradient methods, including actor-critic methods which learn approximations to both policy and value functions (Silver et al., 2014; Sutton et al., 2000). With these methods, the agent learns the policy directly.
Feedback from the human or the environment as a reward in reinforcement learning is essential since it is a goal-directed learning algorithm. There are many tasks for which human experience remains useful, and for those tasks, it would be efficient and preferable to obtain the knowledge from humans directly and quickly. Humans can participate in the training process of reinforcement learning in two ways, one is to indirectly shape the policy by constructing the reward function, while the other is to directly intervene with the policy during learning. In the former way, when the goal of some tasks is based on human satisfaction, we need humans to give the reward signal and ensure that the agent fulfills the goal as we expect (Knox and Stone, 2008). Including human rewards, the policy is pushed indirectly toward the optimal one under the human's definition, and the learning process is sped up (Loftin et al., 2016). Aside from giving reward manually after each action, human knowledge can also be used to design the reward function, e.g. give more positive weights to those important indicators in multi-goal problems (Hu et al., 2019). A recent work summarizes how to inject human knowledge into a tabular method with reward shaping (Rosenfeld et al., 2018). In the other way, guidelines from humans directly exist in the policy. Human feedback can modify the exploration policy of the agent and participate in the action selection mechanism (Knox and Stone, 2010, 2012). The feedback on policy can be not only a numerical number but also a label on the optimal actions (Griffith et al., 2013). By adding the label, human feedback changes the policy directly instead of influencing the policy through rewards. Recent works show that human feedback also depends on the agent's current policy which enables useful training strategies (MacGlashan et al., 2017), and involving humans in the loop of reinforcement learning gives improvement in learning performance (Lin et al., 2017).
Active Learning
Active learning, by selecting partial data to be annotated, aims to resolve the challenge that labeled data are more difficult to obtain than unlabeled data. During the training process, the learner poses “queries” such as some unlabeled instances to be labeled by an “oracle” such as a human. An example of active learning algorithm for classification is shown in Figure 3. Initially, we have some labeled data and unlabeled data. After training a model based on the labeled data, we can search for the most informative unlabeled data and query the oracle to obtain its label. Eventually, we can have an excellent classifier with only few additional labeled data. In this scenario, the learner makes a decision on the query after evaluating all the instances; thus, it is called “pool-based sampling”. Other scenarios include “stream-based selective sampling” (each unlabeled data point is examined one at a time with the learner evaluating the informativeness and deciding whether to query or discard) and “query synthesis” (the learner synthesizes or creates its own instance).
Figure 3.

Pseudocode of an Active Learning Example
Rephrased from (Settles, 2012)
There are many ways to define how informative a data point is, namely, “query strategies” vary. As illustrated in Figure 4, effective query strategies help the trained model outperform the one trained by random sampling. Therefore, it is a major issue in active learning to apply optimal query strategy, which has the following categories (Settles, 2012): (1) uncertainty sampling, which measures the uncertainty of the model's prediction on data points; (2) query by disagreement, which trains different models and checks their differences; (3) error and variance reduction, which directly looks into the generalization error of the learner. Besides, there are many other variants, such as density or diversity methods (Settles and Craven, 2008; Yang et al., 2015), which consider the repressiveness (reflection on input distribution) of instances in uncertainty sampling, clustering-based approaches (Dasgupta and Hsu, 2008; Nguyen and Smeulders, 2004; Saito et al., 2015) which cluster unlabeled data and query the most representative instances of those clusters, and min-max framework (Hoi et al., 2009; Huang et al., 2010) which minimizes the maximum possible classification loss. More versatile methods include combining multiple criteria (Du et al., 2015; Wang et al., 2016; Yang and Loog, 2018), choosing strategies automatically (Baram et al., 2004; Ebert et al., 2012), and training models to control active learning (Bachman et al., 2018; Konyushkova et al., 2017; Pang et al., 2018).
Figure 4.

An Illustration of Active Learning: Choosing Data to Inquire for Better Estimation When Labeled Data Are Not Sufficient
Data shown are randomly generated from two Gaussian distributions with different means. Drawn based on the concept in (Settles, 2012).
(A) Correct labels of the binary classification problem. The line denotes the decision boundary.
(B) A model trained by random queries.
(C) A model trained by active queries.
In addition to asking the oracle to label instances, queries may seek for more advanced domain knowledge. A simple idea is to solicit information about features. For instance, besides instance-label queries, a text classifier (Raghavan et al., 2006) may query the relevance between features (words) and classes, e.g. “is ‘puck’ discriminate to determine whether documents are about basketball or hockey?” Then, the vectors of instances are scaled to reflect the relative importance of features. Another way is to set constraints based on high-level features (Druck et al., 2009; Small et al., 2011). The oracle may be queried on possibilities, e.g. “what is the percentage of hockey documents when the word ‘puck’ appears?” The learning algorithm then tries to adjust the model to match the label distributions over the unlabeled pool. Other methods to incorporate features include adjusting priors in naive Bayes models (Settles, 2011), mixing models induced from rules and data (Attenberg et al., 2010), and label propagation in graph-based learning algorithms (Sindhwani et al., 2009). Humans sometimes do a poor job in answering such questions, but it is found that specifying many imprecise features may result in better models than fewer more precise features (Mann and McCallum, 2010).
Although most of active learning work is on classification, the principals also apply to regression (Burbidge et al., 2007; Willett et al., 2006). Recent work focuses on leveraging other concepts for larger data sets (e.g., image data), such as deep learning (Gal et al., 2017), reinforcement learning (Liu et al., 2019), and adversary networks (Sinha et al., 2019).
Interactive Visual Analytics
Visual analytics (VA) is a field where information visualization helps people understand the data and concepts in order to make better decisions. One core in VA is dimension reduction which can be well addressed through machine learning (Sacha et al., 2016). Applying the interactive VA, which allows users to give feedback in the modeling-visualizing loop, will make machine learning tools more approachable in model understanding, steering, and debugging (Choo and Liu, 2018).
In the combination of machine learning and VA, human knowledge plays an indispensable role as interactions and feedback to the system (Choo et al., 2010). Interactions and feedback can happen either in the visualization part or the machine learning part. In the former part, visualization systems satisfy users' requirements through interacting with them and assisting users in having a better understanding of the data analyzed by some machine learning methods. For instance, principle component analysis (PCA) is a powerful machine learning method which transforms the data from the input space to the eigenspace and reduces the dimension of the data by choosing the most representative components. However, for many users, PCA works as a “black box” and it is difficult to decipher the relationships in the eigenspace. Interactive PCA (Jeong et al., 2009) provides an opportunity for the users to give feedback on system visualization, and these interactions are reflected immediately in other views so that the user can identify the dimension in both the eigenspace and the original input space. In the machine learning part, interactions and feedback from humans help machine learning methods to generate more satisfying and explainable results and make the results easier to visualize as well. A good example of utilizing human interactions in machine learning methods is the application in classification (Fails and Olsen, 2003; Ware et al., 2001). These interactive classifiers allow users to view, classify, and correct the classifications during training. Readers can refer to a recent comment (Holzinger et al., 2018) on explainable AI.
The mutual interaction between human knowledge and the visualization or the model is an iterative process. A better visualization leads the users to learn more practical information. After the users gain some knowledge regarding the model and data, they can utilize the knowledge to further improve the model and even the learning algorithm (Hohman et al., 2018). This iterative process has a steering effect on the model, which can be viewed as the parameter evolution in dynamical systems shown in Equation (4) (Dıaz et al., 2016; Endert et al., 2017):
| (Equation 4) |
where is the model under the machine learning algorithm, is the visualization of that model, and is the input including the new input data and users' feedback . The feedback is based on users' knowledge as well as the visualization . Training of the model is complete when the dynamical system settles down at a certain equilibrium, .
Some progress has been made in this interdisciplinary area to help machine learning become more accessible. Semantic interaction (Endert et al., 2012) is an approach that enables co-reasoning between the human and the analytic models used for visualization without directly controlling the models. Users can manipulate the data during visualization, and the model is steered by their actions. In this case, interactions happen with the help of visualization and affect both model and visual results. Interactive visual tools can also be built for understanding and debugging current machine learning models (Bau et al., 2019; Karpathy et al., 2015; Zeiler and Fergus, 2014). The language model visual inspector system (Rong and Adar, 2016) is able to explore the word embedding models. It allows the users to track how the hidden layers are changing and inspect the pairs of words. The reinforcement learning VA systems, DQNViz (Wang et al., 2018) and ReLVis (Saldanha et al., 2019), allow users to gain insight about the behavior pattern between training iterations in discrete and continuous action space, respectively. As the users explore the machine learning algorithms better, they can compare different methods and adjust the model faster.
In the meanwhile, increasing the understandability of machine learning makes those algorithms more trustworthy and actionable and extends the application to more areas. An example is visualizing CNNs for autonomous driving where visualization serves as a debugging tool for real-time CNN-based systems. This is done by visualizing the regions of the input image which have the highest influence on the output (Bojarski et al., 2016). A recent paper (Endert et al., 2017) gives a summary of literature on how interactive VA is involved with the machine learning domains of dimension reduction, clustering, classification, and regression. It also shows some application domains in the field of integrating machine learning with VA, text analytics, and biological data analytics.
Parameter Initialization
In essence, all the machining learning problems are optimization problems where we minimize the error/loss or maximize the benefit/probability from an initial start point. A bad initialization may lead to a slow converging path or even a sub-optimal result. In the following sections, we will introduce some works which apply human knowledge to initialization. We introduce how an agent learns from expert behaviors in Pre-training in Reinforcement Learning and how to use trained models by Transfer Learning. Although transfer learning is not limited to initialization, we categorize it here considering that fine-tuning pre-trained models is a widely used technique of transfer learning.
Pre-training in Reinforcement Learning
Many reinforcement problems must be solved in a large state/action space, especially for the continuous state action problems (Lazaric et al., 2008). Learning in a high-dimensional space requires huge amounts of data and learning time. Also, in many optimization methods, such as gradient-descent method and Newton's method, the initialization plays a critical role and may determine whether we are able to find the optimal value function/policy. Thus, equipping a pre-trained function as initialization in reinforcement learning becomes popular these days. Supervised learning is often used at the beginning stage of reinforcement learning, and the domain knowledge from humans is embedded in this way of initialization.
Pre-training can be applied to policy learning, value function learning, environment model learning, or a combination of them. In policy learning, humans can act as a trainer to teach agents the target parameterized policy through demonstration. A study provides a comprehensive survey of many different approaches to learning from demonstrations (Argall et al., 2009), and these approaches allow the agent to have a good initial policy before fine-tuning with interactive feedback. In the training of AlphaGO with DNNs and tree search (Silver et al., 2016), a supervised learning policy network is pre-trained directly from human expert moves. Then, a reinforce learning policy is trained to improve it by optimizing the final outcomes. In robot navigation, reinforce learning is capable of learning the fuzzy rules automatically but suffers from a heavy learning phase and insufficiently learned rules. Including supervised learning results as initialization in value function learning helps solve the issue and becomes one of the main approaches for this problem (Fathinezhad et al., 2016; Navarro-Guerrero et al., 2012; Ye et al., 2003). Learning a model of state dynamics can result in a pre-trained hidden layer structure that reduces the training time in reinforce learning problems (Anderson et al., 2015), and learning the deep Q networks from human demonstrators also helps to give a relatively good initial model and predict the dynamics (Gabriel et al., 2019). There are many other applications of smart initialization on policy gradient methods (Yun et al., 2017) and Q-learning methods (Burkov and Chaib-Draa, 2007; Song et al., 2012), which speed up the learning and level up the performance (Finn et al., 2016).
Transfer Learning
Transfer learning is where knowledge is learned from a “source task” and applied to a “target task” (Pan and Yang, 2009). This method is inherently dependent on human knowledge to determine suitable source tasks to transfer. The transferred knowledge can be data, neural networks, weights, etc. The ideal situation to use transfer learning is when the source task has more data available than the target task. However, transfer learning can yield benefits even when the source task does not have as much data. As shown in Figure 5, traditionally in machine learning, the data is specific to the task being trained. By transferring knowledge from the already trained source task, less data specific to the target task are needed and the training time is reduced. The context provided from the source task increases the initial performance, rate of improvement, and final performance (Brownlee, 2017) while reducing the training time and the data needed. This efficiency has led to significant commercial use of transfer learning (Ruder, 2017b).
Figure 5.

Illustration of Traditional Machine Learning and Transfer Learning
(A) Tasks in traditional machine learning do not share knowledge.
(B) Tasks in transfer learning share knowledge. Target task can reuse the knowledge of source tasks.
Drawn based on the concept in (Pan and Yang, 2009).
The role of human knowledge in transfer learning can be understood through the NLP problem of training a DNN for children's automatic speech recognition (ASR) (Shivakumar and Georgiou, 2020). There is a plethora of general speech data available, yet there is a lack of data specific to child speech recognition. It would be costly and time consuming to acquire data to train a child ASR algorithm from scratch. Instead, the data, neural networks, and weights from general ASR training can be transferred. Then, the weights can be fine-tuned for child ASR by using the limited amount of data specific to child ASR. The machine cannot know which source tasks would be beneficial to train the target task, so human knowledge is required to determine compatible and effective source tasks. Transfer learning is also used for image recognition where a human finds a source task to quickly train the target task before fine-tuning it with new visual data. This has been used in a wide variety of applications such as plant identification (Ghazi et al., 2017), structural damage detection (Gao and Mosalam, 2018; Gopalakrishnan et al., 2017), human behavior recognition (Kaya et al., 2017; Sargano et al., 2017), and even medical research (Burlina et al., 2017; Christodoulidis et al., 2016; Karri et al., 2017).
New methods of incorporating human knowledge with transfer learning are being researched to achieve higher efficiency and broader application. One of them is using simulation data. As we have mentioned in Section Simulation, machine learning can be trained with simulations before being fine-tuned with real-world data.
Another method that benefits from human knowledge is “heterogeneous transfer learning” (Day and Khoshgoftaar, 2017). Most commercial transfer learning methods are homogeneous, which means that the source and target tasks have the same feature space. For instance, in computer vision, the simulation looks different from the real world but the feature space is the same since they are both inputting pixels. In heterogeneous transfer learning, the feature spaces are different. For instance, the inputs are texts of two different languages, or one input is texts while the other is images. Heterogeneous transfer, by correlating different feature spaces, allows the source task to come from a wider variety of data. Extensive human knowledge on the subject is required to correlate the feature spaces effectively. The complexity of this correlation makes it difficult to scale heterogeneous transfer learning for broad use because each application of heterogeneous transfer learning requires a different subject of human knowledge. Other heterogeneous transfer learning techniques are being attempted to solve this problem, such as deep semantic mapping (Zhao et al., 2019) and hybrid heterogeneous transfer learning (Zhou et al., 2014, 2019).
Lastly, the importance of human knowledge for transfer learning is apparent by the poor performance that can occur without it. Sometimes the performance may actually be worse than if the target task was trained alone. This is known as negative transfer and occurs when the source tasks are poorly suited for the target tasks (Wang et al., 2019). It appears in human learning as well, e.g., learning to throw a baseball may be harder after learning to throw a football due to muscle memory making it difficult to adapt to a new throwing motion. Currently, preventing negative transfer requires effective human intuition or experience. Research is conducted to develop methods that will quantitatively eliminate negative performance, including using a discriminator gate to assign different weights to each source task (Wang et al., 2019) and using an iterative method that detects the source of the negative transfer to reduce class noise (Gui et al., 2018).
Conclusions
In this paper, we give a comprehensive review on integrating human knowledge into machine learning. Knowledge is categorized into general knowledge and domain knowledge, and its representations are introduced together with the works that leverage them. We focus on some new and popular topics and group the methods by their major contribution to the machine learning pipeline. In conclusion, based on existing methods, we propose the following suggestions on improving the machine learning performance with knowledge:
-
1.
Devise the inputs and outputs of models to make better use of resources. Aggregate tasks to learn together by Multitask Learning if they share data or information; an auxiliary task can be attempted even if only a single task is important. Use Features that could best represent the essence of tasks; the features can be manually engineered, selected by statistic metrics, or automatically learned by machine learning models.
-
2.
Examine model assumptions to capture major factors. Set Variable Relation such as independence based on prior knowledge. The Distribution of unknown variables in models can be obtained by empirical data, expert intuition or Gaussian. Try to match the distribution of training data with test scenarios.
-
3.
If using neural networks, tailor the architecture to be suitable for the tasks. If possible, incorporate some known properties, such as Symmetry of Convolutional Neural Networks. Logic, equations, and temporal nature can be, respectively, reflected in the structure of networks by, for instance, combining with symbolic AI, designing special layers/architectures, and using RNNs.
-
4.
Augment data to incorporate invariant properties or knowledge-based models. Augmentation can be done by transforming, manipulating, or synthesizing the original data. Image and Audio data have been discussed in details, and their augmentation share similar principles. Simulations built upon knowledge-based models can be used to generate data.
-
5.
Design algorithms to include humans in the loop. The interaction between machine and environment can be modeled and optimized in Reinforcement Learning . Humans can be asked to label data or provide distribution (Active Learning). Interactive Visual Analytics can be used to help humans understand machine learning results and then adjust models during or after training.
-
6.
Find better initialization to reflect known results. This could be achieved by learning from expert behaviors before allowing machine to automatically learn from the environment (Pre-training in Reinforcement Learning). Transfer Learning can be used to distill knowledge from relevant tasks.
For future works, we highlight the following directions:
-
1.
Models are dedicated and specific to tasks rather than universal. We witnessed the emergence of CNNs for images and RNNs for natural language. They are intuitively and empirically better than fully connected networks. General knowledge inspires us to leverage math and brains to propose more efficient mechanisms, such as attention (Vaswani et al., 2017). Domain knowledge captures the nature of the tasks, and more customized components can be incorporated.
-
2.
More nodes are added to end-to-end learning for human interaction, feedback, and intervention. Despite convenient data preparation, the black box approach of end-to-end learning makes it difficult to explain and control. We can regulate the intermediate results or network layers (Zhang et al., 2018) to produce models more understandable and controllable by humans.
-
3.
Existing results are reused for new targets. Humans can use the skills and insights across multiple tasks and even disciplines; some abilities are innate. Similarly, machines do not need to be trained from scratch. Given a new task, we can transfer or distill the knowledge from previous tasks or models.
-
4.
Higher level features such as conceptual understanding and math theorems are incorporated. Currently, the knowledge integrated in machine learning is relatively concrete and mostly at the instance level, e.g. expressing each theorem as a constraint. Despite the efforts and achievements to make knowledge generic and broad, we have not seen a successful model to grasp abstract concepts or systematic theories. We believe integrating higher level features is an essential path toward strong artificial intelligence and would change the paradigm to integrate knowledge.
Designing and implementing machine learning algorithms is an iterative process. This requires humans to analyze the models and knowledge integration to take advantage of human understanding of the real world. This review may help current and prospective users of machine learning to understand these fields and inspire them to build more efficient models.
Acknowledgments
We gratefully acknowledge the support by the Ford Motor Company.
Author Contributions
X.J. drafted Design of Neuron Connections, Reinforcement Learning, Interactive Visual Analytics, and Pre-training in Reinforcement Learning. C.R. drafted Multitask Learning, Simulation, and Transfer Learning. J.Z. drafted Qualitative Domain Knowledge and Quantitative Domain Knowledge. C.D. drafted other sections and edited the manuscript. W.L. supervised this review and revised the manuscript.
References
- Abdelaziz I., Fokoue A., Hassanzadeh O., Zhang P., Sadoghi M. Large-scale structural and textual similarity-based mining of knowledge graph to predict drug–drug interactions. J. Web Semant. 2017;44:104–117. [Google Scholar]
- Adam-Bourdarios C., Cowan G., Germain C., Guyon I., Kégl B., Rousseau D. NIPS 2014 Workshop on High-Energy Physics and Machine Learning. 2015. The Higgs boson machine learning challenge; pp. 19–55. [Google Scholar]
- Afifi M., Brown M.S. Proceedings of the IEEE International Conference on Computer Vision. IEEE; 2019. What else can fool deep learning? Addressing color constancy errors on deep neural network performance; pp. 243–252. [Google Scholar]
- Aha D.W., Bankert R.L. Learning from Data. Springer; 1996. A comparative evaluation of sequential feature selection algorithms; pp. 199–206. [Google Scholar]
- Amos B., Kolter J.Z. Optnet: differentiable optimization as a layer in neural networks. arXiv. 2017 arXiv:1703.00443 [Google Scholar]
- Anderson C.W., Lee M., Elliott D.L. 2015 International Joint Conference on Neural Networks. IEEE; 2015. Faster reinforcement learning after pretraining deep networks to predict state dynamics; pp. 1–7. [Google Scholar]
- Argall B.D., Chernova S., Veloso M., Browning B. A survey of robot learning from demonstration. Rob. Auton. Syst. 2009;57:469–483. [Google Scholar]
- Attenberg J., Melville P., Provost F. Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer; 2010. A unified approach to active dual supervision for labeling features and examples; pp. 40–55. [Google Scholar]
- Bachman P., Sordoni A., Trischler A. Proceedings of Machine Learning Research. 2018. Learning algorithms for active learning.arXiv:1708.00088 [Google Scholar]
- Bahnsen A.C., Aouada D., Stojanovic A., Ottersten B. Feature engineering strategies for credit card fraud detection. Expert Syst. Appl. 2016;51:134–142. [Google Scholar]
- Bair E., Tibshirani R. Semi-supervised methods to predict patient survival from gene expression data. Plos Biol. 2004;2:e108. doi: 10.1371/journal.pbio.0020108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baldi P. Proceedings of ICML Workshop on Unsupervised and Transfer Learning. 2012. Autoencoders, unsupervised learning, and deep architectures; pp. 37–49. [Google Scholar]
- Baram Y., Yaniv R.E., Luz K. Online choice of active learning algorithms. J. Mach. Learn. Res. 2004;5:255–291. [Google Scholar]
- Barshan E., Ghodsi A., Azimifar Z., Jahromi M.Z. Supervised principal component analysis: visualization, classification and regression on subspaces and submanifolds. Pattern Recognit. 2011;44:1357–1371. [Google Scholar]
- Bartolozzi C., Indiveri G. Synaptic dynamics in analog VLSI. Neural Comput. 2007;19:2581–2603. doi: 10.1162/neco.2007.19.10.2581. [DOI] [PubMed] [Google Scholar]
- Bau D., Zhu J.-Y., Strobelt H., Zhou B., Tenenbaum J.B., Freeman W.T., Torralba A. Visualizing and understanding generative adversarial networks. arXiv. 2019 arXiv:1901.09887 [Google Scholar]
- Belkin M., Niyogi P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput. 2003;15:1373–1396. [Google Scholar]
- Bengio Y., Courville A.C., Vincent P. Representation learning: a review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013;35:1798–1828. doi: 10.1109/TPAMI.2013.50. [DOI] [PubMed] [Google Scholar]
- Benjamin B.V., Gao P., McQuinn E., Choudhary S., Chandrasekaran A.R., Bussat J.-M., Alvarez-Icaza R., Arthur J.V., Merolla P.A., Boahen K. Neurogrid: a mixed-analog-digital multichip system for large-scale neural simulations. Proc. IEEE. 2014;102:699–716. [Google Scholar]
- Bojarski M., Choromanska A., Choromanski K., Firner B., Jackel L., Muller U., Zieba K. Visualbackprop: efficient visualization of CNNS. arXiv. 2016 arXiv:1611.05418 [Google Scholar]
- Boluki S., Esfahani M.S., Qian X., Dougherty E.R. Incorporating biological prior knowledge for Bayesian learning via maximal knowledge-driven information priors. BMC Bioinformatics. 2017;18:552. doi: 10.1186/s12859-017-1893-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brause R., Langsdorf T., Hepp M. Proceedings of the 11th International Conference on Tools with Artificial Intelligence. IEEE); 1999. Neural data mining for credit card fraud detection; pp. 103–106. [Google Scholar]
- Brownlee J. 2014. Discover Feature Engineering, How to Engineer Features and How to Get Good at it.https://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/ [Google Scholar]
- Brownlee J. 2017. A Gentle Introduction to Transfer Learning for Deep Learning.https://machinelearningmastery.com/transfer-learning-for-deep-learning/ [Google Scholar]
- Burbidge R., Rowland J.J., King R.D. International Conference on Intelligent Data Engineering and Automated Learning. Springer; 2007. Active learning for regression based on query by committee; pp. 209–218. [Google Scholar]
- Burkov A., Chaib-Draa B. Proceedings of the 6th International Joint Conference on Autonomous Agents and Multiagent Systems. 2007. Reducing the complexity of multiagent reinforcement learning; pp. 1–3. [Google Scholar]
- Burlina P., Pacheco K.D., Joshi N., Freund D.E., Bressler N.M. Comparing humans and deep learning performance for grading AMD: a study in using universal deep features and transfer learning for automated AMD analysis. Comput. Biol. Med. 2017;82:80–86. doi: 10.1016/j.compbiomed.2017.01.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cao Y., Wang X., He X., Hu Z., Chua T.-S. The World Wide Web Conference. 2019. Unifying knowledge graph learning and recommendation: towards a better understanding of user preferences; pp. 151–161. [Google Scholar]
- Chandrashekar G., Sahin F. A survey on feature selection methods. Comput. Electr. Eng. 2014;40:16–28. [Google Scholar]
- Chawla N.V., Bowyer K.W., Hall L.O., Kegelmeyer W.P. SMOTE: synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002;16:321–357. [Google Scholar]
- Chen C., Zhang L., Bu J., Wang C., Chen W. Constrained Laplacian eigenmap for dimensionality reduction. Neurocomputing. 2010;73:951–958. [Google Scholar]
- Chen N.C., Drouhard M., Kocielnik R., Suh J., Aragon C.R. Using machine learning to support qualitative coding in social science: shifting the focus to ambiguity. ACM TiiS. 2018;8:1–20. [Google Scholar]
- Chen T., Kornblith S., Norouzi M., Hinton G. A simple framework for contrastive learning of visual representations. arXiv. 2020 arXiv:2002.05709 [Google Scholar]
- Choo J., Liu S. Visual analytics for explainable deep learning. IEEE Comput. Graph Appl. 2018;38:84–92. doi: 10.1109/MCG.2018.042731661. [DOI] [PubMed] [Google Scholar]
- Choo J., Lee H., Kihm J., Park H. 2010 IEEE Symposium on Visual Analytics Science and Technology. IEEE; 2010. iVisClassifier: an interactive visual analytics system for classification based on supervised dimension reduction; pp. 27–34. [Google Scholar]
- Christodoulidis S., Anthimopoulos M., Ebner L., Christe A., Mougiakakou S. Multisource transfer learning with convolutional neural networks for lung pattern analysis. IEEE J. Biomed. Health Inform. 2016;21:76–84. doi: 10.1109/JBHI.2016.2636929. [DOI] [PubMed] [Google Scholar]
- Cohen T., Welling M. International Conference on Machine Learning. 2016. Group equivariant convolutional networks; pp. 2990–2999. [Google Scholar]
- Crowston K., Allen E.E., Heckman R. Using natural language processing technology for qualitative data analysis. Int. J. Soc. Res. Methodol. 2012;15:523–543. [Google Scholar]
- Daniušis P., Vaitkus P., Petkevičius L. Hilbert–Schmidt component analysis. Proc. Lith. Math. Soc. Ser. A. 2016;57:7–11. [Google Scholar]
- Dasgupta S., Hsu D. Proceedings of the 25th International Conference on Machine Learning. 2008. Hierarchical sampling for active learning; pp. 208–215. [Google Scholar]
- Dash M., Liu H. Consistency-based search in feature selection. Artif. Intell. 2003;151:155–176. [Google Scholar]
- Day O., Khoshgoftaar T.M. A survey on heterogeneous transfer learning. J. Big Data. 2017;4:29. [Google Scholar]
- DeBrusk C. MIT Sloan Management Review; 2018. The Risk of Machine-Learning Bias (And How to Prevent it) [Google Scholar]
- Davies M., Srinivasa N., Lin T.H., Chinya G., Cao Y., Chody S.H., Dimou G., Joshi P., Imam N., Jain S. Loihi: a neuromorphic manycore processor with on-chip learning. IEEE Micro. 2018;38:82–99. [Google Scholar]
- Deng C., Wang Y., Qin C., Lu W. Self-directed online machine learning for topology optimization. arXiv. 2020 doi: 10.1038/s41467-021-27713-7. arXiv:2002.01927 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deng J., Ding N., Jia Y., Frome A., Murphy K., Bengio S., Li Y., Neven H., Adam H. European Conference on Computer Vision. Springer; 2014. Large-scale object classification using label relation graphs; pp. 48–64. [Google Scholar]
- Deshmukh A., Morghade J., Khera A., Bajaj P. International Conference on Knowledge-Based and Intelligent Information and Engineering Systems. Springer; 2005. Binary neural networks–a CMOS design approach; pp. 1291–1296. [Google Scholar]
- DeVries T., Taylor G.W. Dataset augmentation in feature space. arXiv. 2017 arXiv:1702.05538 [Google Scholar]
- Dhanjal C., Gunn S.R., Shawe-Taylor J. Efficient sparse kernel feature extraction based on partial least squares. IEEE Trans. Pattern Anal. Mach. Intell. 2008;31:1347–1361. doi: 10.1109/TPAMI.2008.171. [DOI] [PubMed] [Google Scholar]
- Dıaz I., Cuadrado A.A., Verleysen M. 24th European Symposium on Artificial Neural Networks. 2016. A statespace model on interactive dimensionality reduction; pp. 647–652. [Google Scholar]
- Drachman D.A. Do we have brain to spare? Neurology. 2005;64:2004–2005. doi: 10.1212/01.WNL.0000166914.38327.BB. [DOI] [PubMed] [Google Scholar]
- Druck G., Settles B., McCallum A. Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. 2009. Active learning by labeling features; pp. 81–90. [Google Scholar]
- Du B., Wang Z., Zhang L., Zhang L., Liu W., Shen J., Tao D. Exploring representativeness and informativeness for active learning. IEEE Trans. Cybern. 2015;47:14–26. doi: 10.1109/TCYB.2015.2496974. [DOI] [PubMed] [Google Scholar]
- Ebden M. Gaussian processes: a quick introduction. arXiv. 2015 arXiv:1505.02965 [Google Scholar]
- Ebert S., Fritz M., Schiele B. 2012 IEEE Conference on Computer Vision and Pattern Recognition. 2012. Ralf: a reinforced active learning formulation for object class recognition; pp. 3626–3633. [Google Scholar]
- Ehrlich M., Shields T.J., Almaev T., Amer M.R. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2016. Facial attributes classification using multi-task representation learning; pp. 47–55. [Google Scholar]
- Endert A., Fiaux P., North C. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. 2012. Semantic interaction for visual text analytics; pp. 473–482. [Google Scholar]
- Endert A., Ribarsky W., Turkay C., Wong B.W., Nabney I., Blanco I.D., Rossi F. The state of the art in integrating machine learning into visual analytics. Comput. Graphics Forum. 2017;36:458–486. [Google Scholar]
- Ermon S., Bras R.L., Suram S.K., Gregoire J.M., Gomes C., Selman B., Dover R.B.V. Pattern decomposition with complex combinatorial constraints: application to materials discovery. arXiv. 2014 arXiv:1411.7441 [Google Scholar]
- Fails J.A., Olsen D.R. Proceedings of the 8th International Conference on Intelligent User Interfaces. 2003. Interactive machine learning; pp. 39–45. [Google Scholar]
- Fadaee M., Bisazza A., Monz C. Data augmentation for low-resource neural machine translation. arXiv. 2017 arXiv:1705.00440 [Google Scholar]
- Farahmand A., Nabi S., Nikovski D.N. 2017 American Control Conference. IEEE; 2017. Deep reinforcement learning for partial differential equation control; pp. 3120–3127. [Google Scholar]
- Fathinezhad F., Derhami V., Rezaeian M. Supervised fuzzy reinforcement learning for robot navigation. Appl. Soft Comput. 2016;40:33–41. [Google Scholar]
- Fellbaum C. WordNet. In: Chapelle C., editor. The Encyclopedia of Applied Linguistics. Blackwell Publishing Ltd.; 2012. pp. 1–8. [Google Scholar]
- Finn C., Yu T., Fu J., Abbeel P., Levine S. Generalizing skills with semi-supervised reinforcement learning. arXiv. 2016 arXiv:1612.00429 [Google Scholar]
- Fisher R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936;7:179–188. [Google Scholar]
- Flasiński M. Introduction to Artificial Intelligence. Springer; 2016. Symbolic artificial intelligence; pp. 15–22. [Google Scholar]
- Flores M.J., Nicholson A.E., Brunskill A., Korb K.B., Mascaro S. Incorporating expert knowledge when learning Bayesian network structure: a medical case study. Artif. Intell. Med. 2011;53:181–204. doi: 10.1016/j.artmed.2011.08.004. [DOI] [PubMed] [Google Scholar]
- Fogg A. 2017. A History of Machine Learning and Deep Learning.https://www.import.io/post/history-of-deep-learning/ [Google Scholar]
- Frank E., Bouckaert R.R. European Conference on Principles of Data Mining and Knowledge Discovery. Springer; 2006. Naive Bayes for text classification with unbalanced classes; pp. 503–510. [Google Scholar]
- Frohlich H., Chapelle O., Scholkopf B. Proceedings. 15th IEEE International Conference on Tools with Artificial Intelligence. 2003. Feature selection for support vector machines by means of genetic algorithm; pp. 142–148. [Google Scholar]
- Fu L.M. Knowledge-based connectionism for revising domain theories. IEEE Trans. Syst. Man. Cybern. Syst. 1993;23:173–182. [Google Scholar]
- Gabriel V., Du Y., Taylor M.E. Pre-training with non-expert human demonstration for deep reinforcement learning. Knowl. Eng. Rev. 2019;34:e10. [Google Scholar]
- Gal Y., Ghahramani Z. International Conference on Machine Learning. 2016. Dropout as a Bayesian approximation: representing model uncertainty in deep learning; pp. 1050–1059. [Google Scholar]
- Gal Y., Islam R., Ghahramani Z. Deep Bayesian active learning with image data. arXiv. 2017 arXiv:1703.02910 [Google Scholar]
- Gan J., Cai Q., Galer P., Ma D., Chen X., Huang J., Bao S., Luo R. Mapping the knowledge structure and trends of epilepsy genetics over the past decade: a co-word analysis based on medical subject headings terms. Medicine. 2019;98:e16782. doi: 10.1097/MD.0000000000016782. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gao T., Lu W. Physical model and machine learning enabled electrolyte channel design for fast charging. J. Electrochem. Soc. 2020;167:110519. [Google Scholar]
- Gao Y., Mosalam K.M. Deep transfer learning for image-based structural damage recognition. Comput. Aided Civil Infrastruct. Eng. 2018;33:748–768. [Google Scholar]
- Garnelo M., Shanahan M. Reconciling deep learning with symbolic artificial intelligence: representing objects and relations. Curr. Opin. Behav. Sci. 2019;29:17–23. [Google Scholar]
- Gatys L.A., Ecker A.S., Bethge M. A neural algorithm of artistic style. arXiv. 2015 arXiv:1508.06576 [Google Scholar]
- Gens R., Domingos P.M. Advances in Neural Information Processing Systems. 2014. Deep symmetry networks; pp. 2537–2545. [Google Scholar]
- Ghazi M.M., Yanikoglu B., Aptoula E. Plant identification using deep neural networks via optimization of transfer learning parameters. Neurocomputing. 2017;235:228–235. [Google Scholar]
- Ghojogh B., Samad M.N., Mashhadi S.A., Kapoor T., Ali W., Karray F., Crowley M. Feature selection and feature extraction in pattern analysis: a literature review. arXiv. 2019 arXiv:1905.02845 [Google Scholar]
- Ghosh R., Gupta A.K. Scale steerable filters for locally scale-invariant convolutional neural networks. arXiv. 2019 arXiv:1906.03861 [Google Scholar]
- Giffard-Roisin S., Delingette H., Jackson T., Webb J., Fovargue L., Lee J., Rinaldi C.A., Razavi R., Ayache N., Sermesant M. Transfer learning from simulations on a reference anatomy for ECGI in personalized cardiac resynchronization therapy. IEEE. Trans. Biomed. Eng. 2018;66:343–353. doi: 10.1109/TBME.2018.2839713. [DOI] [PubMed] [Google Scholar]
- Girshick R. Proceedings of the IEEE International Conference on Computer Vision. 2015. Fast R-CNN; pp. 1440–1448. [Google Scholar]
- Gong T., Lee T., Stephenson C., Renduchintala V., Padhy S., Ndirango A., Keskin G., Elibol O.H. A comparison of loss weighting strategies for multi task learning in deep neural networks. IEEE Access. 2019;7:141627–141632. [Google Scholar]
- Goodfellow I.J., Shlens J., Szegedy C. Explaining and harnessing adversarial examples. arXiv. 2014 arXiv:1412.6572 [Google Scholar]
- Gopalakrishnan K., Khaitan S.K., Choudhary A., Agrawal A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build Mater. 2017;157:322–330. [Google Scholar]
- Gori M., Monfardini G., Scarselli F. Proceedings of 2005 IEEE International Joint Conference on Neural Networks. 2005. A new model for learning in graph domains; pp. 729–734. [Google Scholar]
- Graves A., Mohamed A., Hinton G. 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. 2013. Speech recognition with deep recurrent neural networks; pp. 6645–6649. [Google Scholar]
- Griffith S., Subramanian K., Scholz J., Isbell C.L., Thomaz A.L. Policy shaping: integrating human feedback with reinforcement learning. In: Burges C.J.C., Bottou L., Welling M., Ghahramani Z., Weinberger K.Q., editors. Advances in Neural Information Processing Systems. Curran Associates; 2013. pp. 2625–2633. [Google Scholar]
- Gui L., Xu R., Lu Q., Du J., Zhou Y. Negative transfer detection in transductive transfer learning. Int. J. Mach. Learn. Cybern. 2018;9:185–197. [Google Scholar]
- He K., Fan H., Wu Y., Xie S., Girshick R. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. Momentum contrast for unsupervised visual representation learning; pp. 9729–9738. [Google Scholar]
- He K., Zhang X., Ren S., Sun J. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016. Deep residual learning for image recognition; pp. 770–778. [Google Scholar]
- Hennecke M., Frings W., Homberg W., Zitz A., Knobloch M., Böttiger H. Measuring power consumption on IBM Blue gene/P. Comput. Sci. Res. Dev. 2012;27:329–336. [Google Scholar]
- Herculano-Houzel S. The human brain in numbers: a linearly scaled-up primate brain. Front. Hum. Neurosci. 2009;3:31. doi: 10.3389/neuro.09.031.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hinton G.E., Krizhevsky A., Wang S.D. International Conference on Artificial Neural Networks. Springer; 2011. Transforming auto-encoders; pp. 44–51. [Google Scholar]
- Hinton G.E., Srivastava N., Krizhevsky A., Sutskever I., Salakhutdinov R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv. 2012 arXiv:1207.0580 [Google Scholar]
- Hochreiter S., Schmidhuber J. Long short-term memory. Neural Comput. 1997;9:1735–1780. doi: 10.1162/neco.1997.9.8.1735. [DOI] [PubMed] [Google Scholar]
- Hodgkin A.L., Huxley A.F. A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 1952;117:500. doi: 10.1113/jphysiol.1952.sp004764. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hoehndorf R., Queralt-Rosinach N. Data science and symbolic AI: synergies, challenges and opportunities. Data Sci. 2017;1:27–38. [Google Scholar]
- Hohman F., Kahng M., Pienta R., Chau D.H. Visual analytics in deep learning: an interrogative survey for the next frontiers. IEEE Trans. Vis. Comput. Graph. 2018;25:2674–2693. doi: 10.1109/TVCG.2018.2843369. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hoi S.C., Jin R., Zhu J., Lyu M.R. Semisupervised SVM batch mode active learning with applications to image retrieval. ACM Trans. Inf. Syst. 2009;27:1–29. [Google Scholar]
- Holmes T.W., Ma K., Pourmorteza A. 15th International Meeting on Fully Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine. International Society for Optics and Photonics; 2019. Combination of CT motion simulation and deep convolutional neural networks with transfer learning to recover Agatston scores; p. 110721Z. [Google Scholar]
- Holzinger A. Interactive machine learning for health informatics: when do we need the human-in-the-loop? Brain Inform. 2016;3:119–131. doi: 10.1007/s40708-016-0042-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holzinger A., Kieseberg P., Weippl E., Tjoa A.M. International Cross-Domain Conference for Machine Learning and Knowledge Extraction. Springer; 2018. Current advances, trends and challenges of machine learning and knowledge extraction: from machine learning to explainable AI; pp. 1–8. [Google Scholar]
- Holzinger A., Plass M., Kickmeier-Rust M., Holzinger K., Crişan G.C., Pintea C.-M., Palade V. Interactive machine learning: experimental evidence for the human in the algorithmic loop. Appl. Intell. 2019;49:2401–2414. [Google Scholar]
- Holzinger A., Stocker C., Ofner B., Prohaska G., Brabenetz A., Hofmann-Wellenhof R. International Workshop on Human-Computer Interaction and Knowledge Discovery in Complex, Unstructured, Big Data. Springer; 2013. Combining HCI, natural language processing, and knowledge discovery-potential of IBM content analytics as an assistive technology in the biomedical field; pp. 13–24. [Google Scholar]
- Hu Y., Huber A., Anumula J., Liu S.-C. Overcoming the vanishing gradient problem in plain recurrent networks. arXiv. 2018 arXiv:1801.06105 [Google Scholar]
- Hu Y., Nakhaei A., Tomizuka M., Fujimura K. Interaction-aware decision making with adaptive strategies under merging scenarios. arXiv. 2019 arXiv:1904.06025 [Google Scholar]
- Hu Z., Ma X., Liu Z., Hovy E., Xing E. Harnessing deep neural networks with logic rules. arXiv. 2016 arXiv:1603.06318 [Google Scholar]
- Huang S.-J., Jin R., Zhou Z.-H. Active learning by querying informative and representative examples. In: Lafferty J.D., Williams C.K.I., Shawe-Taylor J., Zemel R.S., Culotta A., editors. Advances in Neural Information Processing Systems. Curran Associates; 2010. pp. 892–900. [Google Scholar]
- Hwang Y., Cho H., Yang H., Oh I., Lee S.-W. Mel-spectrogram augmentation for sequence to sequence voice conversion. arXiv. 2020 arXiv:2001.01401 [Google Scholar]
- Hyvärinen A. Independent component analysis: recent advances. Philos. T. R. Soc. A. 2013;371:20110534. doi: 10.1098/rsta.2011.0534. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ikebata H., Hongo K., Isomura T., Maezono R., Yoshida R. Bayesian molecular design with a chemical language model. J. Comput. Aided Mol. Des. 2017;31:379–391. doi: 10.1007/s10822-016-0008-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Inoue H. Data augmentation by pairing samples for images classification. arXiv. 2018 arXiv:1801.02929 [Google Scholar]
- Jackson P.T., Abarghouei A.A., Bonner S., Breckon T.P., Obara B. CVPR Workshops. 2019. Style augmentation: data augmentation via style randomization; pp. 83–92. [Google Scholar]
- Jeong D.H., Ziemkiewicz C., Fisher B., Ribarsky W., Chang R. iPCA: An Interactive System for PCA-based Visual Analytics. Comput. Graphics Forum. 2009;28:767–774. [Google Scholar]
- Ji X.A., Molnar T.G., Avedisov S.S., Orosz G. Feed-forward neural network with trainable delay. In: Bayen A., Jadbabaie A., Pappas G.J., Parrilo P., Recht B., Tomlin C., Zeilinger M., editors. Proceedings of the 2nd Conference on Learning for Dynamics and Control. PLMR; 2020. pp. 127–136. [Google Scholar]
- Jurio A., Pagola M., Galar M., Lopez-Molina C., Paternain D. International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems. Springer; 2010. A comparison study of different color spaces in clustering based image segmentation; pp. 532–541. [Google Scholar]
- Kanazawa A., Sharma A., Jacobs D. Locally scale-invariant convolutional neural networks. arXiv. 2014 arXiv:1412.5104 [Google Scholar]
- Kang G., Dong X., Zheng L., Yang Y. Patchshuffle regularization. arXiv. 2017 arXiv:1707.07103 [Google Scholar]
- Karpathy A., Johnson J., Fei-Fei L. Visualizing and understanding recurrent networks. arXiv. 2015 arXiv:1506.02078 [Google Scholar]
- Karri S.P.K., Chakraborty D., Chatterjee J. Transfer learning based classification of optical coherence tomography images with diabetic macular edema and dry age-related macular degeneration. Biomed. Opt. Express. 2017;8:579–592. doi: 10.1364/BOE.8.000579. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kaya H., Gürpınar F., Salah A.A. Video-based emotion recognition in the wild using deep transfer learning and score fusion. Image Vis. Comput. 2017;65:66–75. [Google Scholar]
- Kelley H.J. Gradient theory of optimal flight paths. ARS J. 1960;30:947–954. [Google Scholar]
- Knox W.B., Stone P. 2008 7th IEEE International Conference on Development and Learning. 2008. Tamer: training an agent manually via evaluative reinforcement; pp. 292–297. [Google Scholar]
- Knox W.B., Stone P. Proceedings of the International Conference on Autonomous Agents and Multiagent Systems. 2010. Combining manual feedback with subsequent MDP reward signals for reinforcement learning; pp. 5–12. [Google Scholar]
- Knox W.B., Stone P. Proceedings of the International Conference on Autonomous Agents and Multiagent Systems. 2012. Reinforcement learning from simultaneous human and MDP reward; pp. 475–482. [Google Scholar]
- Kok J.R., Vlassis N. Annual Machine Learning Conference of Belgium and the Netherlands. 2004. Sparse tabular multiagent Q-learning; pp. 65–71. [Google Scholar]
- Konyushkova K., Sznitman R., Fua P. Learning active learning from data. In: Guyon I., Luxburg U.V., Bengio S., Wallach H., Fergus R., Vishwanathan S., Garnett R., editors. Advances in Neural Information Processing Systems. Curran Associates; 2017. pp. 4225–4235. [Google Scholar]
- Kromp F., Ambros I., Weiss T., Bogen D., Dodig H., Berneder M., Gerber T., Taschner-Mandl S., Ambros P., Hanbury A. 2016 International Conference on Pattern Recognition. IEEE; 2016. Machine learning framework incorporating expert knowledge in tissue image annotation; pp. 343–348. [Google Scholar]
- Kursa M.B., Rudnicki W.R. Feature selection with the Boruta package. J. Stat. Softw. 2010;36:1–13. [Google Scholar]
- Lazaric A., Restelli M., Bonarini A. Reinforcement learning in continuous action spaces through sequential Monte Carlo methods. In: Platt J.C., Koller D., Singer Y., Roweis S.T., editors. Advances in Neural Information Processing Systems. Curran Associates; 2008. pp. 833–840. [Google Scholar]
- LeCun Y., Bengio Y., Hinton G. Deep learning. Nature. 2015;521:436–444. doi: 10.1038/nature14539. [DOI] [PubMed] [Google Scholar]
- Lee K., Kim D. In-silico molecular binding prediction for human drug targets using deep neural multi-task learning. Genes. 2019;10:906. doi: 10.3390/genes10110906. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li X., Zhao L., Wei L., Yang M.-H., Wu F., Zhuang Y., Ling H., Wang J. Deepsaliency: multi-task deep neural network model for salient object detection. IEEE Trans. Image Process. 2016;25:3919–3930. doi: 10.1109/TIP.2016.2579306. [DOI] [PubMed] [Google Scholar]
- Li Y., Min M.R., Shen D., Carlson D.E., Carin L. AAAI Conference on Artificial Intelligence. 2018. Video generation from text; pp. 7065–7072. [Google Scholar]
- Liem C.C., Langer M., Demetriou A., Hiemstra A.M., Wicaksana A.S., Born M.P., König C.J. Psychology meets machine learning: interdisciplinary perspectives on algorithmic job candidate screening. In: Escalante H., Escalera S., Guyon I., Baró X., Güçlütürk Y., Güçlü U., Gerven M.V., editors. Explainable and Interpretable Models in Computer Vision and Machine Learning. Springer; 2018. pp. 197–253. [Google Scholar]
- Lin Z., Harrison B., Keech A., Riedl M.O. Explore, exploit or listen: combining human feedback and policy model to speed up deep reinforcement learning in 3d worlds. arXiv. 2017 arXiv:1709.03969 [Google Scholar]
- Lin Z., Shi Y., Xue Z. IDSGAN: generative adversarial networks for attack generation against intrusion detection. arXiv. 2018 arXiv:1809.02077 [Google Scholar]
- Ling J., Jones R., Templeton J. Machine learning strategies for systems with invariance properties. J. Comput. Phys. 2016;318:22–35. [Google Scholar]
- Liu Z., Wang J., Gong S., Lu H., Tao D. Proceedings of the IEEE International Conference on Computer Vision. 2019. Deep reinforcement active learning for human-in-the-loop person re-identification; pp. 6122–6131. [Google Scholar]
- Loftin R., Peng B., MacGlashan J., Littman M.L., Taylor M.E., Huang J., Roberts D.L. Learning behaviors via human-delivered discrete feedback: modeling implicit feedback strategies to speed up learning. Auton. Agent Multi Agent Syst. 2016;30:30–59. [Google Scholar]
- Long M., Cao Z., Wang J., Philip S.Y. Learning multiple tasks with multilinear relationship networks. In: Guyon I., Luxburg U.V., Bengio S., Wallach H., Fergus R., Vishwanathan S., Garnett R., editors. Advances in Neural Information Processing Systems. Curran Associates; 2017. pp. 1594–1603. [Google Scholar]
- Lowe H.J., Barnett G.O. Understanding and using the medical subject headings (MeSH) vocabulary to perform literature searches. JAMA. 1994;271:1103–1108. [PubMed] [Google Scholar]
- Ma E. 2019. Data Augmentation in NLP.https://towardsdatascience.com/data-augmentation-in-nlp-2801a34dfc28 [Google Scholar]
- Maaten L.van der, Hinton G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008;9:2579–2605. [Google Scholar]
- MacGlashan J., Ho M.K., Loftin R., Peng B., Roberts D., Taylor M.E., Littman M.L. Interactive learning from policy-dependent human feedback. arXiv. 2017 arXiv:1701.06049 [Google Scholar]
- Mafarja M.M., Eleyan D., Jaber I., Hammouri A., Mirjalili S. 2017 International Conference on New Trends in Computing Sciences. IEEE; 2017. Binary dragonfly algorithm for feature selection; pp. 12–17. [Google Scholar]
- Mann G.S., McCallum A. Generalized expectation criteria for semi-supervised learning with weakly labeled data. J. Mach. Learn. Res. 2010;11:955–984. [Google Scholar]
- Mao J., Gan C., Kohli P., Tenenbaum J.B., Wu J. The neuro-symbolic concept learner: interpreting scenes, words, and sentences from natural supervision. arXiv. 2019 arXiv:1904.12584 [Google Scholar]
- Martinez M., Sitawarin C., Finch K., Meincke L., Yablonski A., Kornhauser A. Beyond grand theft auto V for training, testing and enhancing deep learning in self driving cars. arXiv. 2017 arXiv:1712.01397 [Google Scholar]
- Masegosa A.R., Moral S. An interactive approach for Bayesian network learning using domain/expert knowledge. Int. J. Approx. Reason. 2013;54:1168–1181. [Google Scholar]
- Mayr A., Klambauer G., Unterthiner T., Hochreiter S. DeepTox: toxicity prediction using deep learning. Front. Environ. Sci. 2016;3:80. [Google Scholar]
- McCulloch W.S., Pitts W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biol. 1943;5:115–133. [PubMed] [Google Scholar]
- Merolla P.A., Arthur J.V., Alvarez-Icaza R., Cassidy A.S., Sawada J., Akopyan F., Jackson B.L., Imam N., Guo C., Nakamura Y. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science. 2014;345:668–673. doi: 10.1126/science.1254642. [DOI] [PubMed] [Google Scholar]
- Meyerson E., Miikkulainen R. Pseudo-task augmentation: from deep multitask learning to intratask sharing-and back. arXiv. 2018 arXiv:1803.04062 [Google Scholar]
- Mignot R., Peeters G. An analysis of the effect of data augmentation methods: experiments for a musical genre classification task. Trans. Int. Soc. Music Inf. Retr. 2019;2:97–110. [Google Scholar]
- Mika S., Ratsch G., Weston J., Scholkopf B., Mullers K.-R. Neural Networks for Signal Processing IX: Proceedings of the 1999 IEEE Signal Processing Society Workshop. IEEE; 1999. Fisher discriminant analysis with kernels; pp. 41–48. [Google Scholar]
- Misra I., Shrivastava A., Gupta A., Hebert M. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016. Cross-stitch networks for multi-task learning; pp. 3994–4003. [Google Scholar]
- Modha D.S. 2017. Introducing a Brain-Inspired Computer.https://www.research.ibm.com/articles/brain-chip.shtml [Google Scholar]
- Mor B., Garhwal S., Kumar A. A systematic review of hidden markov models and their applications. Arch. Comput. Methods Eng. 2020 doi: 10.1007/s11831-020-09422-4. [DOI] [Google Scholar]
- Murphy K.P. MIT press; 2012. Machine Learning: A Probabilistic Perspective. [Google Scholar]
- Nakamura K., Kuo W.-J., Pegado F., Cohen L., Tzeng O.J., Dehaene S. Universal brain systems for recognizing word shapes and handwriting gestures during reading. Proc. Natl. Acad. Sci. 2012;109:20762–20767. doi: 10.1073/pnas.1217749109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nakamura R.Y., Pereira L.A., Costa K.A., Rodrigues D., Papa J.P., Yang X.-S. 25th SIBGRAPI Conference on Graphics, Patterns and Images. IEEE; 2012. BBA: a binary bat algorithm for feature selection; pp. 291–297. [Google Scholar]
- Nanni L., Maguolo G., Paci M. Data augmentation approaches for improving animal audio classification. Ecol. Inform. 2020;57:101084. [Google Scholar]
- Navarro-Guerrero N., Weber C., Schroeter P., Wermter S. Real-world reinforcement learning for autonomous humanoid robot docking. Rob. Auton. Syst. 2012;60:1400–1407. [Google Scholar]
- Nawrocki R.A., Voyles R.M., Shaheen S.E. A mini review of neuromorphic architectures and implementations. IEEE Trans. Electron. Devices. 2016;63:3819–3829. [Google Scholar]
- Nguyen H.T., Smeulders A. Proceedings of the 21st International Conference on Machine Learning. 2004. Active learning using pre-clustering; p. 79. [Google Scholar]
- Oord A.van den, Kalchbrenner N., Espeholt L., Vinyals O., Graves A. Conditional image generation with pixelcnn decoders. In: Lee D.D., Sugiyama M., Luxburg U.V., Guyon I., Garnett R., editors. Advances in Neural Information Processing Systems. Curran Associates; 2016. pp. 4790–4798. [Google Scholar]
- Oord A.van den, Kalchbrenner N., Kavukcuoglu K. Pixel recurrent neural networks. arXiv. 2016 arXiv:1601.06759 [Google Scholar]
- Pan S.J., Yang Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009;22:1345–1359. [Google Scholar]
- Pang K., Dong M., Wu Y., Hospedales T. Meta-learning transferable active learning policies by deep reinforcement learning. arXiv. 2018 arXiv:1806.04798 [Google Scholar]
- Parish E.J., Duraisamy K. A paradigm for data-driven predictive modeling using field inversion and machine learning. J. Comput. Phys. 2016;305:758–774. [Google Scholar]
- Park D.S. 2019. SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition.https://ai.googleblog.com/2019/04/specaugment-new-data-augmentation.html [Google Scholar]
- Paulheim H. Knowledge graph refinement: a survey of approaches and evaluation methods. Semantic web. 2017;8:489–508. [Google Scholar]
- Peters B.G. Edward Elgar Publishing; 2019. Institutional Theory in Political Science: The New Institutionalism. [Google Scholar]
- Qu M., Bengio Y., Tang J. GMNN: graph Markov neural networks. arXiv. 2019 arXiv:1905.06214 [Google Scholar]
- Raghavan H., Madani O., Jones R. Active learning with feedback on features and instances. J. Mach. Learn. Res. 2006;7:1655–1686. [Google Scholar]
- Raissi M., Perdikaris P., Karniadakis G.E. Machine learning of linear differential equations using Gaussian processes. J. Comput. Phys. 2017;348:683–693. [Google Scholar]
- Ramamurthy R., Bauckhage C., Sifa R., Schücker J., Wrobel S. International Conference on Artificial Neural Networks. Springer; 2019. Leveraging domain knowledge for reinforcement learning using MMC architectures; pp. 595–607. [Google Scholar]
- Ramires A., Serra X. Data augmentation for instrument classification robust to audio effects. arXiv. 2019 arXiv:1907.08520 [Google Scholar]
- Ramsundar B., Kearnes S., Riley P., Webster D., Konerding D., Pande V. Massively multitask networks for drug discovery. arXiv. 2015 arXiv:1502.02072 [Google Scholar]
- Ranjan R., Patel V.M., Chellappa R. Hyperface: a deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017;41:121–135. doi: 10.1109/TPAMI.2017.2781233. [DOI] [PubMed] [Google Scholar]
- Reed S., Akata Z., Yan X., Logeswaran L., Schiele B., Lee H. Generative adversarial text to image synthesis. arXiv. 2016 arXiv:1605.05396 [Google Scholar]
- Rennie J.D., Shih L., Teevan J., Karger D.R. Proceedings of the 20th International Conference on Machine Learning. 2003. Tackling the poor assumptions of naive bayes text classifiers; pp. 616–623. [Google Scholar]
- Ritter S., Barrett D.G., Santoro A., Botvinick M.M. Cognitive psychology for deep neural networks: a shape bias case study. arXiv. 2017 arXiv:1706.08606 [Google Scholar]
- Ritzer G., Stepnisky J. Sage publications; 2017. Modern Sociological Theory. [Google Scholar]
- Rong X., Adar E. Proceedings of ICML Workshop on Visualization for Deep Learning. 2016. Visual tools for debugging neural language models. [Google Scholar]
- Rosenblatt F. Cornell Aeronautical Laboratory; 1957. The Perceptron, a Perceiving and Recognizing Automaton. [Google Scholar]
- Rosenfeld A., Cohen M., Taylor M.E., Kraus S. Leveraging human knowledge in tabular reinforcement learning: a study of human subjects. Knowl. Eng. Rev. 2018;33:e14. [Google Scholar]
- Ruder S. An overview of multi-task learning in deep neural networks. arXiv. 2017 arXiv:1706.05098 [Google Scholar]
- Ruder S. 2017. Transfer Learning-Machine Learning’s Next Frontier.https://ruder.io/transfer-learning/ [Google Scholar]
- Ruder S., Bingel J., Augenstein I., Søgaard A. Proceedings of the AAAI Conference on Artificial Intelligence. 2019. Latent multi-task architecture learning; pp. 4822–4829. [Google Scholar]
- Rueden L.von, Mayer S., Beckh K., Georgiev B., Giesselbach S., Heese R., Kirsch B., Pfrommer J., Pick A., Ramamurthy R. Informed machine learning-A taxonomy and survey of integrating knowledge into learning systems. arXiv. 2019 arXiv:1903.12394 [Google Scholar]
- Ruiz N., Schulter S., Chandraker M. Learning to simulate. arXiv. 2018 arXiv:1810.02513 [Google Scholar]
- Sacha D., Zhang L., Sedlmair M., Lee J.A., Peltonen J., Weiskopf D., North S.C., Keim D.A. Visual interaction with dimensionality reduction: a structured literature analysis. IEEE Trans. Vis. Comput. Graph. 2016;23:241–250. doi: 10.1109/TVCG.2016.2598495. [DOI] [PubMed] [Google Scholar]
- Saito P.T., Suzuki C.T., Gomes J.F., Rezende P.J.de, Falcão A.X. Robust active learning for the diagnosis of parasites. Pattern Recognit. 2015;48:3572–3583. [Google Scholar]
- Salakhutdinov R., Hinton G. Deep Boltzmann machines. In: Dyk D.V., Welling M., editors. Proceedings of the Twelfth International Conference on Artificial Intelligence and Statistics. PMLR; 2009. pp. 448–455. [Google Scholar]
- Salamon J., Bello J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017;24:279–283. [Google Scholar]
- Saldanha E., Praggastis B., Billow T., Arendt D.L. EuroVis. 2019. ReLVis: visual analytics for situational awareness during reinforcement learning experimentation; pp. 43–47. [Google Scholar]
- Samaniego E., Anitescu C., Goswami S., Nguyen-Thanh V.M., Guo H., Hamdia K., Zhuang X., Rabczuk T. An energy approach to the solution of partial differential equations in computational mechanics via machine learning: concepts, implementation and applications. Comput. Methods Appl. Mech. Eng. 2020;362:112790. [Google Scholar]
- Sargano A.B., Wang X., Angelov P., Habib Z. 2017 International Joint Conference on Neural Networks. IEEE; 2017. Human action recognition using transfer learning with deep representations; pp. 463–469. [Google Scholar]
- Segler M.H., Preuss M., Waller M.P. Planning chemical syntheses with deep neural networks and symbolic AI. Nature. 2018;555:604–610. doi: 10.1038/nature25978. [DOI] [PubMed] [Google Scholar]
- Senior A.W., Evans R., Jumper J., Kirkpatrick J., Sifre L., Green T., Qin C., Žídek A., Nelson A.W., Bridgland A. Improved protein structure prediction using potentials from deep learning. Nature. 2020;577:706–710. doi: 10.1038/s41586-019-1923-7. [DOI] [PubMed] [Google Scholar]
- Settles B. Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. 2011. Closing the loop: fast, interactive semi-supervised annotation with queries on features and instances; pp. 1467–1478. [Google Scholar]
- Settles B. Active learning. Synth. Lect. Artif. Intell. Mach. Learn. 2012;6:1–114. [Google Scholar]
- Settles B., Craven M. Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing. 2008. An analysis of active learning strategies for sequence labeling tasks; pp. 1070–1079. [Google Scholar]
- Shah A., Wilson A., Ghahramani Z. Student-t processes as alternatives to Gaussian processes. In: Kaski S., Corander J., editors. Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics. PLMR; 2014. pp. 877–885. [Google Scholar]
- Shental N., Bar-Hillel A., Hertz T., Weinshall D. Computing Gaussian mixture models with EM using equivalence constraints. In: Thrun T., Saul L.K., Schölkopf B., editors. Advances in Neural Information Processing Systems. MIT Press; 2004. pp. 465–472. [Google Scholar]
- Shi G., Shi X., O’Connell M., Yu R., Azizzadenesheli K., Anandkumar A., Yue Y., Chung S.J. 2019 International Conference on Robotics and Automation. IEEE; 2019. Neural lander: stable drone landing control using learned dynamics; pp. 9784–9790. [Google Scholar]
- Shivakumar P.G., Georgiou P. Transfer learning from adult to children for speech recognition: evaluation, analysis and recommendations. Comput. Speech Lang. 2020;63:101077. doi: 10.1016/j.csl.2020.101077. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shorten C., Khoshgoftaar T.M. A survey on image data augmentation for deep learning. J. Big Data. 2019;6:60. doi: 10.1186/s40537-021-00492-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Silver D., Huang A., Maddison C.J., Guez A., Sifre L., Driessche G.V.D., Schrittwieser J., Antonoglou I., Panneershelvam V., Lanctot M. Mastering the game of Go with deep neural networks and tree search. Nature. 2016;529:484–489. doi: 10.1038/nature16961. [DOI] [PubMed] [Google Scholar]
- Silver D., Lever G., Heess N., Degris T., Wierstra D., Riedmiller M. Proceedings of the 31st International Conference on Machine Learning. 2014. Deterministic policy gradient algorithms; pp. 1387–1395. [Google Scholar]
- Silver D., Schrittwieser J., Simonyan K., Antonoglou I., Huang A., Guez A., Hubert T., Baker L., Lai M., Bolton A. Mastering the game of go without human knowledge. Nature. 2017;550:354–359. doi: 10.1038/nature24270. [DOI] [PubMed] [Google Scholar]
- Simard P.Y., Steinkraus D., Platt J.C. Proceedings of the Seventh International Conference on Document Analysis and Recognition. 2003. Best practices for convolutional neural networks applied to visual document analysis; pp. 958–963. [Google Scholar]
- Sindhwani V., Melville P., Lawrence R.D. Proceedings of the 26th Annual International Conference on Machine Learning. 2009. Uncertainty sampling and transductive experimental design for active dual supervision; pp. 953–960. [Google Scholar]
- Sinha A.P., Zhao H. Incorporating domain knowledge into data mining classifiers: an application in indirect lending. Decis. Support Syst. 2008;46:287–299. [Google Scholar]
- Sinha S., Ebrahimi S., Darrell T. Proceedings of the IEEE International Conference on Computer Vision. 2019. Variational adversarial active learning; pp. 5972–5981. [Google Scholar]
- Small K., Wallace B.C., Brodley C.E., Trikalinos T.A. Proceedings of the 28th International Conference on International Conference on Machine Learning. 2011. The constrained weight space svm: learning with ranked features; pp. 865–872. [Google Scholar]
- Song Y., Li Y., Li C., Zhang G. An efficient initialization approach of Q-learning for mobile robots. Int. J. Control. Autom. 2012;10:166–172. [Google Scholar]
- Speer R., Chin J., Havasi C. Conceptnet 5.5: an open multilingual graph of general knowledge. arXiv. 2016 arXiv:1612.03975 [Google Scholar]
- Srivastava N., Hinton G., Krizhevsky A., Sutskever I., Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014;15:1929–1958. [Google Scholar]
- Stewart R., Ermon S. Proceedings of the 31st AAAI Conference on Artificial Intelligence. 2017. Label-free supervision of neural networks with physics and domain knowledge; pp. 2576–2582. [Google Scholar]
- Su C., Borsuk M.E., Andrew A., Karagas M. 2014 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology. 2014. Incorporating prior expert knowledge in learning Bayesian networks from genetic epidemiological data; pp. 1–5. [Google Scholar]
- Su J. GAN-QP: a novel GAN framework without gradient vanishing and Lipschitz constraint. arXiv. 2018 arXiv:1811.07296 [Google Scholar]
- Su J., Vargas D.V., Sakurai K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019;23:828–841. [Google Scholar]
- Summers C., Dinneen M.J. n 2019 IEEE Winter Conference on Applications of Computer Vision. 2019. Improved mixed-example data augmentation; pp. 1262–1270. [Google Scholar]
- Sun J., Fu Y., Wan Q. Organic synaptic devices for neuromorphic systems. J. Phys. D Appl. Phys. 2018;51:314004. [Google Scholar]
- Sutton R.S., Barto A.G. MIT press; 2018. Reinforcement Learning: An Introduction. [Google Scholar]
- Sutton R.S., McAllester D.A., Singh S.P., Mansour Y. Policy gradient methods for reinforcement learning with function approximation. In: Solla S.A., Leen T.K., Müller K., editors. Advances in Neural Information Processing Systems. Neural Information Processing Systems Foundation; 2000. pp. 1057–1063. [Google Scholar]
- Tercan H., Guajardo A., Heinisch J., Thiele T., Hopmann C., Meisen T. Transfer-learning: bridging the gap between real and simulation data for machine learning in injection molding. Proced. CIRP. 2018;72:185–190. [Google Scholar]
- Thomson A.M. Neocortical layer 6, a review. Front. Neuroanat. 2010;4:13. doi: 10.3389/fnana.2010.00013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tian N., Ji Z., Lai C.-H. Simultaneous estimation of nonlinear parameters in parabolic partial differential equation using quantum-behaved particle swarm optimization with Gaussian mutation. Int. J. Mach. Learn. Cybern. 2015;6:307–318. [Google Scholar]
- Trottier L., Giguere P., Chaib-draa B. Multi-task learning by deep collaboration and application in facial landmark detection. arXiv. 2017 arXiv:1711.00111 [Google Scholar]
- Tuchman Y., Mangoma T.N., Gkoupidenis P., Burgt Y.van de, John R.A., Mathews N., Shaheen S.E., Daly R., Malliaras G.G., Salleo A. Organic neuromorphic devices: past, present, and future challenges. MRS Bull. 2020;45:619–630. [Google Scholar]
- Vaswani A., Shazeer N., Parmar N., Uszkoreit J., Jones L., Gomez A.N., Kaiser Ł., Polosukhin I. Attention is all you need. In: Guyon I., Luxburg U.V., Bengio S., Wallach H., Vishwanathan S., Garnett R., editors. Advances in Neural Information Processing Systems. Curran Associates; 2017. pp. 5998–6008. [Google Scholar]
- Waibel A., Hanazawa T., Hinton G., Shikano K., Lang K.J. Phoneme recognition using time-delay neural networks. IEEE Trans. Signal Process. 1989;37:328–339. [Google Scholar]
- Wang J., Gou L., Shen H.-W., Yang H. Dqnviz: a visual analytics approach to understand deep Q-networks. IEEE Trans. Vis. Comput. Graph. 2018;25:288–298. doi: 10.1109/TVCG.2018.2864504. [DOI] [PubMed] [Google Scholar]
- Wang Z., Dai Z., Póczos B., Carbonell J. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019. Characterizing and avoiding negative transfer; pp. 11293–11302. [Google Scholar]
- Wang Z., Du B., Zhang L., Zhang L. A batch-mode active learning framework by querying discriminative and representative samples for hyperspectral image classification. Neurocomputing. 2016;179:88–100. [Google Scholar]
- Ware M., Frank E., Holmes G., Hall M., Witten I.H. Interactive machine learning: letting users build classifiers. Int. J. Hum. Comput. 2001;55:281–292. [Google Scholar]
- Watkins C.J., Dayan P. Q-learning. Mach. Learn. 1992;8:279–292. [Google Scholar]
- Weinberger K.Q., Saul L.K. AAAI Proceedings of the 21st National Conference on Artificial Intelligence. 2006. An introduction to nonlinear dimensionality reduction by maximum variance unfolding; pp. 1683–1686. [Google Scholar]
- Wen Q., Sun L., Song X., Gao J., Wang X., Xu H. Time series data augmentation for deep learning: a survey. arXiv. 2020 arXiv:2002.12478 [Google Scholar]
- Whitrow C., Hand D.J., Juszczak P., Weston D., Adams N.M. Transaction aggregation as a strategy for credit card fraud detection. Data Min. Knowl. Discov. 2009;18:30–55. [Google Scholar]
- Willett R., Nowak R., Castro R.M. Faster rates in regression via active learning. In: Weiss Y., Schölkopf B., Platt J.C., editors. Advances in Neural Information Processing Systems. MIT Press; 2006. pp. 179–186. [Google Scholar]
- Williams J.D., Asadi K., Zweig G. Hybrid code networks: practical and efficient end-to-end dialog control with supervised and reinforcement learning. arXiv. 2017 arXiv:1702.03274 [Google Scholar]
- Wold S., Esbensen K., Geladi P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987;2:37–52. [Google Scholar]
- Wong S.C., Gatt A., Stamatescu V., McDonnell M.D. 2016 International Conference on Digital Image Computing: Techniques and Applications. IEEE; 2016. Understanding data augmentation for classification: when to warp? pp. 1–6. [Google Scholar]
- Worrall D.E., Garbin S.J., Turmukhambetov D., Brostow G.J. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017. Harmonic networks: deep translation and rotation equivariance; pp. 5028–5037. [Google Scholar]
- Wu B., Han S., Shin K.G., Lu W. Application of artificial neural networks in design of lithium-ion batteries. J. Power Sourc. 2018;395:128–136. [Google Scholar]
- Wu Z., Pan S., Chen F., Long G., Zhang C., Philip S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020 doi: 10.1109/TNNLS.2020.2978386. [DOI] [PubMed] [Google Scholar]
- Wu Z., Shen C., Hengel A.V.D. Wider or deeper: revisiting the ResNet model for visual recognition. Pattern Recognit. 2019;90:119–133. [Google Scholar]
- Xu J.-G., Zhao Y., Chen J., Han C. A structure learning algorithm for Bayesian network using prior knowledge. J. Comput. Sci. Technol. 2015;30:713–724. [Google Scholar]
- Xu X., Zuo L., Huang Z. Reinforcement learning algorithms with function approximation: recent advances and applications. Inf. Sci. 2014;261:1–31. [Google Scholar]
- Yang Y., Loog M. A variance maximization criterion for active learning. Pattern Recognit. 2018;78:358–370. [Google Scholar]
- Yang Y., Ma Z., Nie F., Chang X., Hauptmann A.G. Multi-class active learning by uncertainty sampling with diversity maximization. Int. J. Comput. Vis. 2015;113:113–127. [Google Scholar]
- Ye C., Yung N.H., Wang D. A fuzzy controller with supervised learning assisted reinforcement learning algorithm for obstacle avoidance. IEEE Trans. Syst. Man. Cybern. Syst. 2003;33:17–27. doi: 10.1109/TSMCB.2003.808179. [DOI] [PubMed] [Google Scholar]
- Ying Z., You J., Morris C., Ren X., Hamilton W., Leskovec J. Hierarchical graph representation learning with differentiable pooling. In: Bengio S., Wallach H., Larochelle H., Grauman K., Cesa-Bianchi N., Garnett R., editors. Advances in Neural Information Processing Systems. Curran Associates; 2018. pp. 4800–4810. [Google Scholar]
- Yuan H., Paskov I., Paskov H., González A.J., Leslie C.S. Multitask learning improves prediction of cancer drug sensitivity. Sci. Rep. 2016;6:31619. doi: 10.1038/srep31619. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yun S., Choi J., Yoo Y., Yun K., Choi J.Y. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017. Action-decision networks for visual tracking with deep reinforcement learning; pp. 2711–2720. [Google Scholar]
- Zeiler M.D., Fergus R. European Conference on Computer Vision. Springer; 2014. Visualizing and understanding convolutional networks; pp. 818–833. [Google Scholar]
- Zhang Q., Wu Y.N., Zhu S.-C. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018. Interpretable convolutional neural networks; pp. 8827–8836. [Google Scholar]
- Zhang R. Making convolutional networks shift-invariant again. arXiv. 2019 arXiv:1904.11486 [Google Scholar]
- Zhang Z., Kag A., Sullivan A., Saligrama V. Equilibrated recurrent neural network: neuronal time-delayed self-feedback improves accuracy and stability. arXiv. 2019 arXiv:1903.00755 [Google Scholar]
- Zhang Z., Luo P., Loy C.C., Tang X. European Conference on Computer Vision. Springer; 2014. Facial landmark detection by deep multi-task learning; pp. 94–108. [Google Scholar]
- Zhao L., Chen Z., Yang L.T., Deen M.J., Wang Z.J. Deep semantic mapping for heterogeneous multimedia transfer learning using co-occurrence data. ACM Trans. Multimedia Comput. Commun. Appl. 2019;15:1–21. [Google Scholar]
- Zhong Z., Zheng L., Kang G., Li S., Yang Y. Proceedings of the 34th AAAI Conference on Artificial Intelligence. 2020. Random erasing data augmentation; pp. 13001–13008. [Google Scholar]
- Zhou J.T., Pan S.J., Tsang I.W. A deep learning framework for hybrid heterogeneous transfer learning. Artif. Intell. 2019;275:310–328. [Google Scholar]
- Zhou J.T., Pan S.J., Tsang I.W., Yan Y. Proceedings of the 38th AAAI Conference on Artificial Intelligence. 2014. Hybrid heterogeneous transfer learning through deep learning; pp. 2213–2219. [Google Scholar]
- Zhou S., Helwa M.K., Schoellig A.P. IEEE 56th Annual Conference on Decision and Control. 2017. Design of deep neural networks as add-on blocks for improving impromptu trajectory tracking; pp. 5201–5207. [Google Scholar]
- Zou Z., Shi Z., Guo Y., Ye J. Object detection in 20 years: a survey. arXiv. 2019 arXiv:1905.05055 [Google Scholar]