

Abstract
Mixed outcome endpoints that combine multiple continuous and discrete components are often employed as primary outcome measures in clinical trials. These may be in the form of co‐primary endpoints, which conclude effectiveness overall if an effect occurs in all of the components, or multiple primary endpoints, which require an effect in at least one of the components. Alternatively, they may be combined to form composite endpoints, which reduce the outcomes to a one‐dimensional endpoint. There are many advantages to joint modeling the individual outcomes, however in order to do this in practice we require techniques for sample size estimation. In this article we show how the latent variable model can be used to estimate the joint endpoints and propose hypotheses, power calculations and sample size estimation methods for each. We illustrate the techniques using a numerical example based on a four‐dimensional endpoint and find that the sample size required for the co‐primary endpoint is larger than that required for the individual endpoint with the smallest effect size. Conversely, the sample size required in the multiple primary case is similar to that needed for the outcome with the largest effect size. We show that the empirical power is achieved for each endpoint and that the FWER can be sufficiently controlled using a Bonferroni correction if the correlations between endpoints are less than 0.5. Otherwise, less conservative adjustments may be needed. We further illustrate empirically the efficiency gains that may be achieved in the composite endpoint setting.
Keywords: latent variable modeling, mixed outcome endpoints, sample size estimation
1. INTRODUCTION
Sample size estimation plays an integral role in the design of a study. The objective is to determine the minimum sample size that is large enough to detect, with a specified power, a clinically meaningful treatment effect. Although it is crucial that investigators have enough patients enrolled to detect this effect, overestimating the sample size also has ethical and practical implications. Namely, in a placebo‐controlled trial, more patients are subjected to a placebo arm than is necessary, therefore withholding access to potentially beneficial drugs from them and delaying access to future patients. 1 , 2 , 3 Furthermore it results in longer, more expensive trials, using resources that could be allocated elsewhere.
One vital aspect of sample size determination is the primary endpoint. Typically this is a single outcome, however in some instances there may be multiple outcomes of interest and so various combinations of these outcomes can be selected as the primary endpoint, depending on the hypothesis of interest. Assuming we have three outcomes of interest and , one option is a co‐primary endpoint, which takes the form of the multivariate endpoint . This means that an intervention is deemed to be effective overall if it is shown to be effective in each of , and . Alternatively multiple primary endpoints may be of interest, which take the multivariate form , where an intervention is deemed effective if it is shown to be effective in at least one of , or . Another possibility is a composite endpoint, involving some function that maps the multivariate outcome to a univariate outcome for inference, for example . In this case the outcomes within the composite may be assigned equal or differing degrees of relevance depending on clinical importance. 4 Alternatively, the composite endpoint may combine outcomes by labeling patients as ‘responders’ or ‘non‐responders’ based on whether they exceed predefined thresholds in each of the outcomes. For instance, we let a response indicator if , and , where denotes the response cutpoints. Note that the composite case is distinct from the others in that it combines the parameters and hence test statistics for each outcome into one, rather than these remaining separate for each outcome. This will have implications for sample size estimation.
For each of these endpoints, the individual outcomes may be a mix of multiple continuous, ordinal, and binary measures. One possible way to jointly model the outcomes is using a latent variable framework, arising in the graphical modeling literature, in which discrete outcomes are assumed to be latent continuous variables subject to estimable thresholds and modeled using a multivariate normal distribution. 5 , 6 By employing this framework we can take account of the correlation between the outcomes, improve the handling of missing data in individual components and potentially increase efficiency. Furthermore, in the case of multiple primary outcomes, it may reduce the severity of multiple testing corrections required by accounting for correlation between endpoints.
A barrier to adopting these techniques is a lack of consensus on sample size determination. A recent and comprehensive overview of the existing literature for sample size calculation in clinical trials with co‐primary and multiple primary endpoints is provided by Sozu et al. 7 The review found many proposals for power and sample size calculations for multiple continuous outcomes. In the co‐primary case, some of these were based on assuming that the endpoints were bivariate normally distributed, 8 , 9 and extended for the case of more than two endpoints. 10 , 11 Other work focused on testing procedures 12 , 13 and controlling the type I error rate. 14 , 15 , 16 , 17 Similar ideas were investigated for multiple primary endpoints. 14 , 17 , 18 , 19
Approaches to sample size estimation for composite endpoints have focused primarily on the case of multiple binary components. 20 , 21 , 22 , 23 , 24 , 25 In the case of binary co‐primary endpoints, five methods of power and sample size calculation based on three association measures have been introduced. 26 Additionally, sample size calculation for trials using multiple risk ratios and odds ratios for treatment effect estimation is discussed by Hamasaki et al, 27 and Song 28 explores co‐primary endpoints in non‐inferiority clinical trials. Consideration has also been given to the case where two co‐primary endpoints are both time‐to‐event measures where effects are required in both endpoints, 29 , 30 , 31 and at least one of the endpoints. 32 , 33 Furthermore, composites comprised of time‐to‐event measures are common, in which the composite reflects time‐to‐first‐event variable. 34 Sample size estimation in this case has been considered by Sugimoto et al. 35
The mixed outcome setting has received substantially less consideration. One paper considers overall power functions and sample size determinations for multiple co‐primary endpoints that consist of mixed continuous and binary variables. 36 They assume that response variables follow a multivariate normal distribution, where binary variables are observed in a dichotomized normal distribution, and use Pearson's correlations for association. A modification was suggested by Wu and de Leon 37 which involved using latent‐level tests and pairwise correlations, and provided increased power. These methods focus on the co‐primary endpoint case, where effects are required in all outcomes. The case of multiple primary or composite endpoints where the components are measured on different scales has not been considered, each of which will require distinct hypotheses. In practice, if a mixed outcome composite is selected as the primary endpoint in a trial then the sample size calculation may be based on an overall binary endpoint or collapsed to form multiple binary endpoints however this will result in a large loss in efficiency. 38
In this article we build on the existing work for co‐primary continuous and binary endpoints to include any combination of continuous, ordinal, and binary outcomes for co‐primary, multiple primary, and composite endpoints. We propose a framework based on the same latent variable model and show how it may be tailored to each of the three endpoints to facilitate sample size estimation. The article will proceed as follows: in Section 2 we introduce the latent variable model, detailing how it can be used in each context, and specify hypothesis tests for each of the three combinations of mixed outcomes; in Section 3 we propose power calculations and sample size estimation techniques in each case; in Section 4 we illustrate the methods on a four dimensional endpoint consisting of two continuous, one ordinal and one binary outcome using a numerical example based on the MUSE trial; 39 and in Section 5 we simulate the empirical power for each test and the FWER for the union‐intersection test. We conclude with a discussion and recommendations for practice in Section 6, and introduce user‐friendly software and documentation for implementation in Section 7.
2. ENDPOINTS AND HYPOTHESIS TESTING
2.1. Latent variable framework
Let and represent the number of patients in the treatment group and the control group respectively and let K be the number of outcomes measured for each patient. Let be vector of K responses for patient i on the treatment arm and the vector of K responses for patient i on the control arm. Without loss of generality, the first elements of and are observed as continuous variables, the next are observed as ordinal and the remaining are observed as binary. For instance, for a three dimensional endpoint with one continuous, one ordinal and one binary measure, , and . We use the biserial model of association by Tate, 40 which is based on latent continuous measures manifesting as discrete variables. Formally, we say that and have latent variables and respectively, where and , where , and denotes the p covariates included in the model for outcome k. Likewise are the corresponding quantities for the control arm. Then for let and , where and are the association measures between the endpoints. For , and . The latent variables can be related to the observed variables by:
and
-
We set and the intercepts and equal to zero for in order to estimate the cut‐points. Additionally, for so that the intercepts can be estimated for the outcomes observed as binary. The mixed outcomes are then combined as follows.
2.2. Co‐primary endpoint
In this case, a treatment must be shown to be effective as measured by each of the outcomes in order to be deemed effective overall. We generalize previous work for mixed continuous and binary outcomes to include ordinal outcomes, as shown below. 36 , 37 In many clinical trials the hypothesis of interest is based on superiority, namely that the proposed treatment will perform better than the control treatment. The null hypothesis is that the difference in treatment effects for the treatment arm and control arm is less than or equal to zero. This is straightforward to formalize in the case of one endpoint but less so when there are multiple co‐primary endpoints, particularly when they are measured on different scales. The hypothesis of interest is as shown in (1)
| (1) |
where and is the effect of the intervention in the treatment and control arm respectively. For we can specify and for the treatment and control group.
We can generalize this assumption to account for the ordinal endpoints based on the fact that for . The definition of treatment effect for ordinal outcomes may be modified to include multiple ordinal levels by selecting the appropriate thresholds. For instance, . As the latent means are estimable by maximum likelihood, in the treatment group and in the control group.
We can proceed by specifying that the hypothesis in (1) holds if and only if the hypothesis
| (2) |
holds, where , and . The maximum likelihood estimates and can be used for a test of and the variance of this test statistic can be obtained using the inverse of the Fisher information matrix.
2.3. Multiple primary endpoint
Multiple primary endpoints conclude a treatment is effective if it is shown to work in at least one of the outcomes. We would expect the sample size required to be reduced compared with the co‐primary endpoint case which would require power to detect treatments in all outcomes. We can allow for sample size estimation for multiple primary endpoints as follows.
The hypothesis of interest, accounting for the fact that a significant effect in only one outcome is required, is shown below.
| (3) |
As before, and can be determined for using the relevant thresholds.
| (4) |
The difference in latent means and their variance are estimated using the maximum likelihood estimates and Fisher information matrix, as before.
2.4. Composite endpoint
A review conducted by Wason et al 41 showed that composite responder endpoints are widely used and identified many clinical areas in which they are common, such as oncology, rheumatology, cardiovascular, and circulation. The latent variable framework may be used to model the underlying structure of these mixed outcome composite endpoints to greatly improve efficiency. 38 The joint distribution of the continuous, ordinal, and binary outcomes is modeled using the latent variable structure as before. However, in this case the endpoint of interest is a composite responder endpoint and so the required quantity is some function of the probability of response in the treatment group and in the control group .
For instance, an overall responder index can be formed for patient i, where if and 0 otherwise, where the quantities are predefined responder thresholds. Generalizations where response only requires a certain number of the components to meet the thresholds are possible, but involve more complex sums. Note that this definition of response is distinct from that commonly found in composites formed from survival endpoints or binary composites typical in cardiovascular studies. We can specify and , the probability of response for patient i in the treatment arm and control arm respectively, as shown in (5),
| (5) |
where is the vector of model parameters and we assume that and . As in the case of co‐primary and multiple primary endpoints, the assumptions allow us to estimate latent means for the observed discrete components using the model parameters.
In the mixed outcome composite endpoint setting, note that although we are exploiting the latent multivariate Gaussian structure for efficiency gains we are ultimately still interested in a one dimensional endpoint, such as the difference in response probabilities between the treatment and control arms of the trial. This is distinct from the co‐primary and multiple primary endpoints cases, where the overall hypothesis test must be based on some union or intersection of the hypotheses for the individual outcomes. For the composite endpoint we can formulate the hypothesis as shown in (6),
| (6) |
where and are as in (5). For sample size estimation, we require the distribution of under , which we can assume to be . The hypothesis can therefore be stated as
| (7) |
where , , and is the K‐dimensional multivariate normal distribution function, with mean vector and covariance matrix . Estimates of the quantities can be obtained using the maximum likelihood estimates for the model parameters, as in the co‐primary and multiple primary endpoint settings, so that and , where is the K‐dimensional vector of mean values in the treatment arm and is the corresponding vector for the control arm. Using a Taylor series expansion, we can obtain the quantity using the fact that . Then, , where is the vector of partial derivatives of with respect to each of the parameter estimates. We can obtain and covariance matrix by fitting the model to pilot trial data.
3. SAMPLE SIZE ESTIMATION
3.1. Co‐primary endpoints
To construct the power function, we define the required quantities as follows. Let and denote the difference in sample means for the continuous and discrete outcomes respectively. We assume , , and let denote the 100th standard normal percentile, where is the prespecified significance level. We define the z score as and for the observed continuous and latent continuous measures respectively. The test statistic can then be defined as shown below.
| (8) |
| (9) |
A useful property of is that it is asymptotically multivariate normal under regularity conditions. 11 The power function for the joint co‐primary endpoints is as shown in (10) and hence can be approximated by (11).
| (10) |
for .
| (11) |
Assuming it is possible to rearrange (11) to obtain a sample size formula in terms of n as shown below. 7
| (12) |
where the sample size depends on the number of outcomes and is the solution of
| (13) |
Alternatively, we can input different values for n in (11) to achieve the required power.
3.2. Multiple primary endpoints
Using the and defined for co‐primary endpoints and assuming , we can define the overall power as in (14).
| (14) |
In order to obtain an appropriate power function we rely on the inclusion‐exclusion principle as follows.
A closed form expression for the overall power is shown in (15).
| (15) |
We then input different values for n to achieve the required power. Note when using the union‐intersection test for multiple primary endpoints that a correction must be applied to control the family‐wise error rate (FWER). Approaches used for multiple primary continuous endpoints, such as Bonferroni and Holm corrections, may also be implemented in this setting.
3.3. Composite endpoints
As the endpoint of interest is specified in terms of the overall one dimensional composite endpoint, we can use the formula assumed when employing the standard test of proportions technique. As , we can assume that and , so that . The power is deduced in the standard way, as demonstrated below.
| (16) |
Note that , however to obtain a formula in terms of the required sample size we will need to separate n from the variance estimate. By fitting the model to pilot trial data we can obtain an estimate for , as the value of n will be known in this instance and n can be obtained using (17).
| (17) |
This is similar to the sample size equation used for the binary method, however is not derived in the standard way and is obtained using latent means as opposed to provided directly.
4. NUMERICAL APPLICATION
4.1. MUSE trial
We illustrate the technique for sample size determination using the MUSE trial. 39 The trial was a phase IIb, randomized, double‐blind, placebo‐controlled study investigating the efficacy and safety of anifrolumab in adults with moderate to severe systemic lupus erythematosus (SLE). Patients (n=305) were randomized (1:1:1) to receive anifrolumab (300 or 1000 mg) or placebo, in addition to standard therapy every 4 weeks for 48 weeks. The primary endpoint in the study was the percentage of patients achieving an SLE Responder Index (SRI) response at week 24, with sustained reduction of oral corticosteroids (10 mg/day and less than or equal to the dose at week 1 from week 12 through 24). SRI is comprised of a continuous Physician's Global Assessment (PGA) measure, a continuous SLE Disease Activity Index (SLEDAI) measure and an ordinal British Isles Lupus Assessment Group (BILAG) measure. 42 The study had a target sample size of 100 patients per group based on providing 88% power at the two‐sided 0.10 alpha level, to detect at least 20% absolute improvement in SRI(4) response rate at week 24 for anifrolumab relative to placebo. The investigators assumed a 40% placebo response rate.
4.2. Model
In this case are SLEDAI, PGA, BILAG and the corticosteroid tapering indicator respectively and where,
| (18) |
and the ordinal and binary components may be related to their latent variables as shown in (19). The thresholds are estimated from the data.
| (19) |
We can use the MUSE trial to design future studies where we assume that the endpoints of interest are co‐primary, multiple primary and composite endpoints. The overall power functions for each are shown below.
where for and for . In the composite setting where is estimated using the delta method. For the calculation we apply the Bonferroni correction, such that each outcome is assessed at the level.
4.3. Computation
We have conducted the computations in R version 4.0.2. We define functions to evaluate the power for each of the endpoints using a combination of the pnorm and pmvnorm functions. Sample size is obtained by inserting values for n until the desired power is achieved. Details of our source code and a web app for implementation is included in the Software section. Code to obtain the results shown in this article can be obtained at https://github.com/martinamcm/mcmenamin_2021_multsamp. Considerations and instructions for fitting the latent variable model are discussed in detail McMenamin et al. (2021). 38
4.4. Results
The power is largest for the multiple primary endpoint, where 80% is achieved for n=37 patients in each arm. The power for the composite endpoint is similar to that of PGA, the component with the highest effect size. As we would expect the power is considerably lower for co‐primary endpoints, which would require n=325 for 80% power (Figure 1).
FIGURE 1.
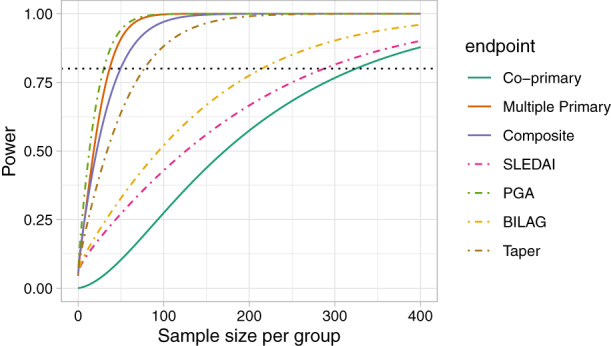
Power function for individual SLEDAI (continuous), PGA (continuous), BILAG (ordinal), and Taper (binary) outcomes and the power functions with when they are treated as co‐primary, multiple primary, and composite endpoints using data from the MUSE trial
Table 1 shows the sample sizes required in each group, for the co‐primary and multiple primary endpoints to obtain an overall power of at least 80% to detect a difference of 0.88 in SLEDAI, 0.38 in PGA, 0.24 in BILAG and 0.40 in the taper outcome based on the values observed in the trial. We allow for uncertainty in the variance of the continuous measures by setting and . The sample sizes required for each individual endpoint are also shown, based on achieving a power of at least 80%. Allowing for uncertainty in the variance of the SLEDAI outcome varies the required sample size for the co‐primary endpoint but not the multiple primary endpoint. The opposite is true when the assumed variance of the PGA outcome is changed, namely affecting the sample size required for the multiple primary endpoint but not the co‐primary. This is intuitive given that the treatment effect observed in the SLEDAI outcome is smallest and is largest for the PGA outcome. For the co‐primary and composite endpoints the power is largest when the correlation between the endpoints is high whereas for multiple primary endpoints the power is largest for zero correlation between endpoints (Figure 2).
TABLE 1.
Sample sizes for the co‐primary and multiple primary endpoints for overall power , , using the MUSE trial data
| SLEDAI | PGA | BILAG | Taper | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
| 0.88 | 18 | 0.38 | 0.35 | (0.97,0.95) | 0.24 | (0.54,0.38) | 0.40 | 403 | 46 | 365 | 39 | 273 | 99 | ||||||||||||||
| 0.88 | 19 | 0.38 | 0.35 | (0.97,0.95) | 0.24 | (0.54,0.38) | 0.40 | 419 | 46 | 386 | 39 | 273 | 99 | ||||||||||||||
| 0.88 | 20 | 0.38 | 0.35 | (0.97,0.95) | 0.24 | (0.54,0.38) | 0.40 | 435 | 46 | 406 | 39 | 273 | 99 | ||||||||||||||
| 0.88 | 18 | 0.38 | 0.45 | (0.97,0.95) | 0.24 | (0.54,0.38) | 0.40 | 403 | 55 | 365 | 49 | 273 | 99 | ||||||||||||||
| 0.88 | 18 | 0.38 | 0.55 | (0.97,0.95) | 0.24 | (0.54,0.38) | 0.40 | 403 | 63 | 365 | 60 | 273 | 99 | ||||||||||||||
| 0.88 | 18 | 0.38 | 0.65 | (0.97,0.95) | 0.24 | (0.54,0.38) | 0.40 | 403 | 70 | 365 | 71 | 273 | 99 | ||||||||||||||
Note: are sample sizes required per group for the individual endpoints for a power of at least .
FIGURE 2.
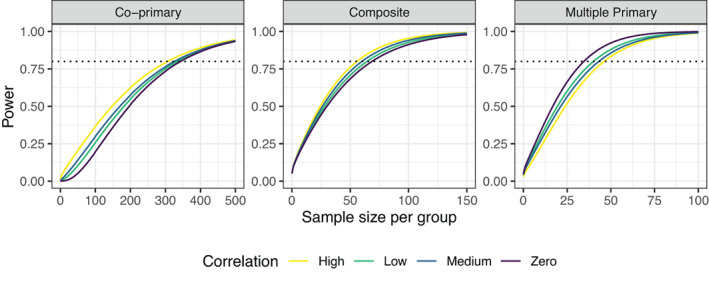
Overall power to detect the treatment effects assumed from the MUSE trial for the systemic lupus erythematosus co‐primary, multiple primary, and composite endpoints for different sample sizes per group and differing correlations between outcomes, where Low = 0.3, Medium = 0.5, and High = 0.8
We assume that a future trial in SLE is to be conducted using the composite responder endpoint, allowing for uncertainty in . The estimated variance for the risk difference from the trial dataset is with correlation parameters . For a risk difference of 0.14, the required sample size per group is 50, compared to 135 for 88% power in the standard binary method. If the method were to be employed for increased power, rather than a decrease in required sample size, the estimated power of the latent variable method is over 99.99% for sample sizes giving 88% power at the 0.05 one‐sided alpha level in the binary method. The empirical power is shown for the latent variable method in 1000 simulated datasets, which is approximately 88% for each sample size, as required. Note that the sample size for composite endpoints are highly dependent on the responder threshold chosen, which will be predefined by clinicians.
5. EMPIRICAL PERFORMANCE OF SAMPLE SIZES
The behavior of the sample sizes obtained for each of the endpoints can be shown empirically. Assuming the four dimensional SLE endpoint, we calculate the empirical power by simulating 100 000 datasets from the multivariate normal distribution and applying the corresponding tests for both the observed and latent continuous outcomes. The key concern for the co‐primary endpoints is that the method gives the appropriate power whereas for multiple primary endpoints we must ensure the family‐wise error rate is controlled.
The sample sizes required for each of the three endpoints and the corresponding empirical power is shown for effect sizes observed in the MUSE trial with low, medium, and high correlation assumed between endpoints (Table 2). The empirical power derived is approximately equal to the desired power of 80% for all endpoints. As is well recognized in the multiple testing literature, the type I error rate must be controlled when multiple primary endpoints are tested using the union‐intersection test. The degree to which the type I error rate is inflated depends on the number of outcomes and the correlation between outcomes, where lower correlation between outcomes and larger number of outcomes result in larger inflations (Figure 3). The performance of the Bonferroni correction in this setting is shown, where it is conservative in the case of high correlation between endpoints. As the maximum correlation between outcomes in the MUSE trial endpoint used in the numerical example is 0.5, we expect the sample sizes shown for this application to be a good estimate. If very large positive correlations between the endpoints are expected the required sample size from this approach may be overestimated. The code to obtain these empirical results is provided in the ‘Software’ section.
TABLE 2.
Sample sizes and empirical power (%) for for the co‐primary, multiple primary, and composite endpoints for overall power , , with observed and latent effect sizes and correlation equal to 0.3, 0.5, 0.8 where correlations are assumed to be equal between all endpoints
|
|
|
|
|
|
Co‐primary | Multiple primary | Composite | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.12 | 0.12 | 0.12 | 0.12 | 0.0 | 1766 (80.1) | 591 (80.0) | 1031 (80.1) | |||||
| 0.3 | 1692 (80.0) | 744 (80.1) | 883 (80.0) | |||||||||
| 0.5 | 1617 (80.0) | 867 (80.1) | 687 (80.0) | |||||||||
| 0.8 | 1439 (80.0) | 1117 (80.0) | 589 (79.9) | |||||||||
| 0.35 | 0.35 | 0.15 | 0.15 | 0.0 | 917 (79.9) | 105 (80.1) | 201 (79.9) | |||||
| 0.3 | 894 (80.0) | 122 (79.9) | 156 (80.0) | |||||||||
| 0.5 | 870 (80.0) | 134 (80.0) | 115 (80.1) | |||||||||
| 0.8 | 815 (80.1) | 153 (80.0) | 92 (80.0) | |||||||||
| 0.12 | 0.35 | 0.55 | 0.10 | 0.0 | 1772 (80.2) | 61 (80.3) | 81 (80.0) | |||||
| 0.3 | 1736 (80.2) | 67 (80.5) | 72 (80.1) | |||||||||
| 0.5 | 1700 (80.0) | 70 (79.9) | 67 (80.2) | |||||||||
| 0.8 | 1625 (80.2) | 74 (80.6) | 58 (80.1) |
FIGURE 3.
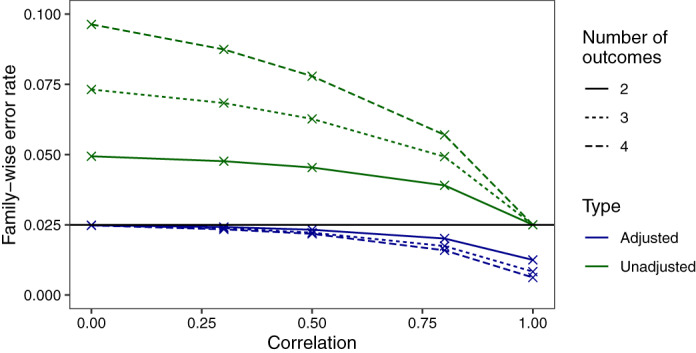
Family‐wise error rate (FWER) of the multiple primary endpoints shown both unadjusted and adjusted using the Bonferroni correction. FWERs are shown for outcomes and correlations are constrained to be equal between all outcomes
6. DISCUSSION
The work in this article demonstrated the various ways in which a latent variable framework may be employed for mixed continuous, ordinal, and binary outcomes. We illustrated sample size determination in the case of mixed continuous, ordinal, and binary co‐primary outcomes. We extended this to allow for sample size determination in the case of mixed multiple primary endpoints and proposed a technique to estimate the sample size when using a latent variable model for the underlying structure of a mixed composite endpoint. For co‐primary and multiple primary endpoints the resulting hypothesis is based on an intersection or union of the hypotheses for the individual outcomes and so is multivariate in nature. However, for composite responder endpoints the hypothesis of interest is stated in relation to the overall responder endpoint and so is univariate. Sample size estimation in this case can make use of the standard power and sample size functions but requires the distribution of the test statistic under the alternative hypothesis which we approximate using latent‐level means and a Taylor series expansion.
We applied the methods to a numerical example based on a phase IIb study. For the correlation structure observed in the MUSE trial, the sample size required for the co‐primary endpoint was greater than that required for the individual endpoint with the lowest effect size. Alternatively, the sample size required for the multiple primary endpoint changes based on the variance assumed for the outcome with the largest treatment effect, however is similar to that required by the individual endpoint. The sample size required for the composite endpoint was between that required for the individual outcome with the largest and second largest effect size. Given that in the composite case we are concerned with the overall binary response endpoint, we compared the sample sizes required for the endpoint using the latent variable model with the standard binary method which we showed offered a large gain in efficiency. Results of the simulated scenarios agree with previous findings that the inclusion of the ordinal component with five levels is only responsible for a very small proportion of the precision gains. Given that the inclusion of the ordinal component substantially increases complexity and computational demand, it may be sufficient to combine any ordinal components with the binary outcome if necessary. Detailed simulation results for the composite endpoint are shown in the Supplementary Material.
One practical consideration when calculating the sample size for a trial using the latent variable model is the need to specify a large number of parameters, even in the case of only a few outcomes. Estimates for the parameters could be obtained by fitting the model to pilot data however this is potentially challenging and restrictive for a number of reasons. First, it requires that a pilot or earlier phase trial must have already taken place. Furthermore, the pilot data could be fundamentally different to the future trial and observed effects may be imprecise. Therefore, placing too much emphasis on the existing data may lead to problems in the main trial. In theory, it is possible to specify the required covariance parameters without data however this would be difficult in practice. Additionally, in the case of composite endpoints, we cannot define the variance in terms of the model parameters only, as the treatment effect is defined for the one‐dimensional composite and so is a function of the parameters. This means that the full covariance matrix of the estimated parameters is required for the Taylor series derivation. An alternative when there is no data available is to apply the method using the sample size required to achieve 80% power for the binary method and avail of the large increase in power. Alternatively, we can directly specify based on expert elicitation, as is sometimes the case in practice for standard one‐dimensional endpoints. Allowing for uncertainty in the quantities and choosing conservative values should provide an appropriate sample size estimate.
It is possible to extend this approach to use adaptive sample size re‐estimation, or an internal pilot to allow for reductions in the required sample size in the trial as we collect more information about the treatment effect variability.
SOFTWARE
The code to obtain the results in this article is available at https://github.com/martinamcm/mcmenamin_2021_multsamp. A Shiny application for implementing the method is available at https://martinamcm.shinyapps.io/multsampsize/. Documentation and example data are available at https://github.com/martinamcm/MultSampSize.
Supporting information
Data S1: Supplementary Material
ACKNOWLEDGEMENTS
This research was supported by the NIHR Cambridge Biomedical Research Centre (BRC‐1215‐20014) and the Medical Research Council (MC_UU_00002/5). The funding bodies did not have any role in the design or analysis of the study, interpretation of data or writing the manuscript.
McMenamin ME, Barrett JK, Berglind A, Wason JMS. Sample size estimation using a latent variable model for mixed outcome co‐primary, multiple primary and composite endpoints. Statistics in Medicine. 2022;41(13):2303–2316. doi: 10.1002/sim.9356
Funding information Medical Research Council, MC_UU_00002/5; NIHR Cambridge Biomedical Research Centre, BRC‐1215‐20014
REFERENCES
- 1. Altman D. Statistics and ethics in medical research: III how large a sample? Br Med J. 1980;281:1336‐1338. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Moher D, Dulberg C, Wells G. Statistical power, sample size, and their reporting in randomized controlled trials. JAMA. 1994;272:122‐124. [PubMed] [Google Scholar]
- 3. Wittes J. Sample size calculations for randomized controlled trials. Epidemiol Rev. 2002;24:39‐53. [DOI] [PubMed] [Google Scholar]
- 4. Pocock SJ, Ariti CA, Collier TJ, Wang D. The win ratio: a new approach to the analysis of composite endpoints in clinical trials based on clinical priorities. Eur Heart J. 2012;33(2):176‐182. [DOI] [PubMed] [Google Scholar]
- 5. Ashford J, Sowden R. Multivariate probit analysis. Biometrics. 1970;26:535‐546. doi: 10.2307/2529107 [DOI] [PubMed] [Google Scholar]
- 6. Chib S, Greenberg E. Analysis of multivariate probit models. Biometrika. 1998;85(2):347‐361. doi: 10.1093/biomet/85.2.347 [DOI] [Google Scholar]
- 7. Sozu T, Sugimoto T, Hamasaki T, Evans S. Sample Size Determination in Clinical Trials with Multiple Endpoints. New York, NY: Springer; 2015. [Google Scholar]
- 8. Sozu T, Kanou T, Hamada C, Yoshimura I. Power and sample size calculations in clinical trials with multiple primary variables. Jpn J Biometr. 2006;27:83‐96. [Google Scholar]
- 9. Xiong C, Yu K, Gao F, Yan Y, Zhang Z. Power and sample size for clinical trials when efficacy is required in multiple endpoints: application to Alzheimer's treatment trial. Clin Trials. 2005;2:387‐393. doi: 10.1191/1740774505cn112oa [DOI] [PubMed] [Google Scholar]
- 10. Sozu T, Sugimoto T, Hamasaki T. Sample size determination in superiority clinical trials with multiple co‐primary correlated endpoints. J Biopharm Stat. 2011;21:650‐668. doi: 10.1002/sim.3972 [DOI] [PubMed] [Google Scholar]
- 11. Sugimoto T, Sozu T, Hamasaki T. A convenient formula for sample size calculations in clinical trials with multiple co‐primary continuous endpoints. Pharm Stat. 2012;11:118‐128. doi: 10.1002/pst.505 [DOI] [PubMed] [Google Scholar]
- 12. Eaton M, Muirhead R. On a multiple endpoints testing problem. J Stat Plan Infer. 2007;137:3416‐3429. doi: 10.1016/j.jspi.2007.03.021 [DOI] [Google Scholar]
- 13. Julious S, McIntyre N. Sample sizes for trials involving multiple correlated must‐win comparisons. Pharm Stat. 2012;11:177‐185. doi: 10.1002/pst.515 [DOI] [PubMed] [Google Scholar]
- 14. Senn S. Disappointing dichotomies. Pharm Stat. 2003;2:239‐240. doi: 10.1002/pst.90 [DOI] [Google Scholar]
- 15. Chuang‐Stein C, Stryszak P, Dmitrienko A, Offen W. Challenge of multiple co‐primary endpoints: a new approach. Stat Med. 2007;26:1181‐1192. doi: 10.1002/sim.2604 [DOI] [PubMed] [Google Scholar]
- 16. Kordzakhia G, Siddiqui O, Huque M. Method of balanced adjustment in testing co‐primary endpoints. Stat Med. 2010;29:2055‐2066. doi: 10.1002/sim.3950 [DOI] [PubMed] [Google Scholar]
- 17. Hung H, Wang S. Some controversial multiple testing problems in regulatory applications. J Biopharm Stat. 2009;19:1‐11. doi: 10.1080/10543400802541693 [DOI] [PubMed] [Google Scholar]
- 18. Dmitrienko A, Tamhane A, Bretz F. Multiple Testing Problems in Pharmaceutical Statistics. Boca Raton, FL: Chapman & Hall/CRC Press; 2010. [Google Scholar]
- 19. Gong J, Pinheiro J, DeMets D. Estimating significance level and power comparisons for testing multiple endpoints in clinical trials. Control Clin Trials. 2000;21:323‐329. doi: 10.1016/S0197-2456(00)00049-0 [DOI] [PubMed] [Google Scholar]
- 20. Sander A, Rauch G, Kieser M. Blinded sample size recalculation in clinical trials with binary composite endpoints. J Biopharm Stat. 2017;27(4):705‐715. [DOI] [PubMed] [Google Scholar]
- 21. Rauch G, Kieser M. Multiplicity adjustment for composite binary endpoints. Methods Inf Med. 2012;51(4):309‐317. [DOI] [PubMed] [Google Scholar]
- 22. Ruse M, Ritz C, Hothorn L. Simultaneous inference of a binary composite endpoint and its components. J Biopharm Stat. 2016;3406:1‐14. [DOI] [PubMed] [Google Scholar]
- 23. Marsal J, Ferreira‐González I, GPMDGGG SB. The use of a binary composite endpoint and sample size requirement: influence of endpoints overlap. Am J Epidemiol. 2017;185(9):832‐841. [DOI] [PubMed] [Google Scholar]
- 24. Roig MB, Gómez G. A new approach for sizing trials with composite binary endpoints using anticipated marginal values and accounting for the correlation between components. Stat Med. 2019;38(11):1935‐1956. [DOI] [PubMed] [Google Scholar]
- 25. Roig MB, Gómez G. Selection of composite binary endpoints in clinical trials. Biometr J. 2018;60(2):246‐261. [DOI] [PubMed] [Google Scholar]
- 26. Sozu T, Sugimoto T, Hamasaki T. Sample size determination in clinical trials with multiple co‐primary binary endpoints. Stat Med. 2010;29:2169‐2179. doi: 10.1002/sim.3972 [DOI] [PubMed] [Google Scholar]
- 27. Hamasaki T, Evans S, Sugimoto T, Sozu T. Power and sample size determination for clinical trials with two correlated binary relative risks. Technical report, ENAR Spring Meeting; 2012; Washington DC.
- 28. Song J. Sample size for simulataneous testing of rate differences in non‐inferiority trials with multiple endpoints. Comput Stat Data Anal. 2009;53:1201‐1207. doi: 10.1016/j.csda.2008.10.028 [DOI] [Google Scholar]
- 29. Hamasaki T, Sugimoto T, Evans S, Sozu T. Sample size determination for clinical trials with co‐primary outcomes: exponential event‐times. Pharma Stat. 2013;12:28‐34. doi: 10.1002/pst.1545 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Sugimoto T, Hamasaki T, Sozu T. Sample size determination in clinical trials with two correlated co‐primary time‐to‐event endpoints. Paper presented at: Proceedings of the 7th International Conference on Multiple Comparison Procedures; 2011; Washington DC.
- 31. Sugimoto T, Sozu T, Hamasaki T, Evans S. A logrank test‐based method for sizing clinical trials with two co‐primary time‐to‐events endpoints. Biostatistics. 2013;14:409‐421. doi: 10.1093/biostatistics/kxs057 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Sugimoto T, Hamasaki T, Sozu T, Evans S. Sample size determination in clinical trials with two correlated time‐to‐event endpoints as primary contrast. Proceedings of the 6th FDA‐DIA Forum; 2012; Washington, DC.
- 33. Sugimoto T, Hamasaki T, Evans S, Sozu T. Sizing clinical trials when comparing bivariate time‐to‐event outcomes. Stat Med. 2017;36(9):1363‐1382. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Ferreira‐González I, Permanyer‐Miralda G, Domingo‐Salvany A, et al. Problems with use of composite end points in cardiovascular trials: systematic review of randomised controlled trials. BMJ. 2007;334(7597):786. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35. Gómez G, Lagakos S. Statistical considerations when using a composite endpoint for comparing treatment groups. Stat Med. 2013;32:719‐738. [DOI] [PubMed] [Google Scholar]
- 36. Sozu T, Sugimoto T, Hamasaki T. Sample size determination in clinical trials with multiple co‐primary endpoints including mixed continuous and binary variables. Biometr J. 2012;54:716‐729. doi: 10.1002/bimj.201100221 [DOI] [PubMed] [Google Scholar]
- 37. Wu B, de Leon A. Letter to the Editor re: "Sample size determination in clinical trials with multiple co‐primary endpoints including mixed continuous and binary variables", by T Sozu, T. Sugimoto, and T. Hamasaki. Biometr J. 2013;55(5):807‐812. doi: 10.1002/bimj.201200254 [DOI] [PubMed] [Google Scholar]
- 38. McMenamin M, Barrett JK, Berglind A, Wason JM. Employing a latent variable framework to improve efficiency in composite endpoint analysis. Stat Methods Med Res. 2021;30(3):702–716. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. Furie R, Khamashta M, Merrill J, et al. Anifrolumab, an anti interferon alpha receptor monoclonal antibody, in moderate‐to‐severe systemic lupus erythematosus. Arthritis Rheumatol. 2017;69(2):376‐386. doi: 10.1002/art.39962 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Tate R. The theory of correlation between two continuous variables when one is dichotomized. Biometrika. 1955;42(1‐2):205‐216. doi: 10.2307/2333437 [DOI] [Google Scholar]
- 41. Wason J, McMenamin M, Dodd S. Analysis of responder‐based endpoints: improving power through utilising continuous components. Trials. 2020;21:427. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. Luijten K, Tekstra J, Bijlsma J, Bijl M. The systemic lupus erythematosus responder index (SRI): a new SLE disease activity assessment. Autoimmun Rev. 2012;11(5):326‐329. doi: 10.1016/j.autrev.2011.06.011 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data S1: Supplementary Material