

Abstract
Advances in Machine Learning and availability of state-of-the-art computational resources, along with digitized healthcare data, have set the stage for extensive application of artificial intelligence in the realm of diagnosis, prognosis, clinical decision support, personalized treatment options, drug development, and the field of biomedicine. Here, we discuss the application of Machine Learning algorithms in patient healthcare and dermatological domains along with the ethical complexities that are involved. In scientific studies, ethical challenges were initially not addressed proportionally (as assessed by keyword counts in PubMed) and just more recently (since 2016) this has started to improve. Few pioneering countries have created regulatory guidelines around how to respect matters of (1) privacy, (2) fairness, (3) accountability, (4) transparency and (5) conflict of interest when developing novel medical Machine Learning applications. While there is a strong promise of emerging medical applications to ultimately benefit both the patients and the medical practitioners, it is important to raise awareness on the five key ethical issues and incorporate them into medical practice in the near future.
KEY WORDS: Best practices, ethics, electronic health records, machine learning
Introduction
In the past 5-10 years, successful applications of Analytics, Machine Learning, and more broadly Artificial Intelligence, have made great strides within industrial and academic contexts. Fueled by advancements in computing hardware resources, sensor technologies, and vast collections of annotated data sets, the possible set of applications has become limitless and already accounts for a multi-billion dollar industry.[1] Healthcare and medical applications, along with manufacturing and financial applications, have been at the forefront of both innovating and benefiting vertical domains. As a testament to these developments in the academic sector, empirical evidence is given below in terms of the number of publications in the PubMed database since 2013, displayed in Table 1 and Figure 1 below.
Table 1.
Counts of publications from Pubmed using keywords
| Topic Searches with Keywords | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019* |
|---|---|---|---|---|---|---|---|
| A=ML | 1,662 | 2,044 | 2,801 | 3,271 | 4,415 | 6,568 | 5,526 |
| B=ML+medic | 496 | 733 | 1,139 | 1,397 | 2,031 | 3,059 | 2,801 |
| C=ML+ethic | 0 | 6 | 9 | 15 | 29 | 59 | 61 |
| D=ML+medic+ethic | 0 | 5 | 6 | 11 | 19 | 39 | 47 |
| E=ML+dermat | 11 | 32 | 50 | 44 | 58 | 115 | 104 |
*2019 data through end of October 2019 only. ML-Machine Learning; medic-medical field; ethic-ethics; dermat-dermatology
Figure 1.
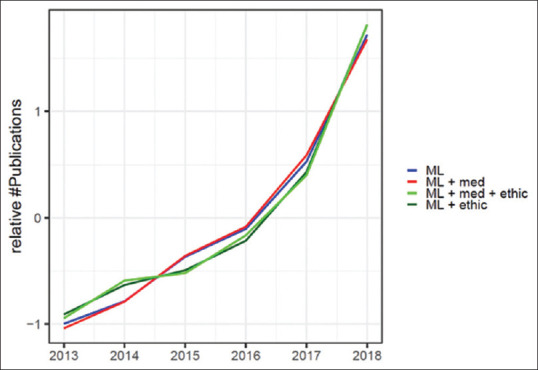
Trends in academic publication counts in the Pubmed Database from 2013 through 2018 with relevant keywords in their topic search patterns. The counts were normalized by the standard score (z-score) for better visual comparison of trends. Z-scores were calculated by subtracting annual search counts by its sample mean and dividing by the sample standard deviation for each topic search
An analysis of recent academic publications in medical sciences with relevant keywords regarding to Machine Learning and Ethics shows the following [Table 1, Figure 1]:
We see a strong positive trend for publications with keyword set A = “Machine Learning” in the past 5 years (i.e., noted as ML in Figure 1 and Table 1)
The trend in publications with keywords B = “Machine Learning + medic” virtually matches A (i.e., trend for the subset of Machine Learning publications in the Medical field)
The trends in topic searches C = “Machine Learning + ethic and D = “Machine Learning + medic* + ethic” are facing upwards as well, albeit they are lagging behind A and B in the years 2013-2015
The ethics related topic searches C and D started with zero publication in 2013, but have caught up in recent years (since 2016)
Applications of Machine Learning in the field of medicine include but are not limited to, patient diagnosis, prognosis of the course of a disease following its onset, supporting the work of a clinician, providing patients with personalized treatment options and drug development, more specifically in the prediction of absorption, distribution, metabolism, excretion, and toxicology properties.[2,3]
To predict whether a new patient with a skin lesion has skin cancer or not, prior studies[4] leveraged a data set of 129,450 clinical images of skin lesions to train a Machine Learning algorithm. Images were classified into one of two categories: malignant melanomas versus benign. The model is capable of classifying skin cancer with a level of competence comparable to 21 board-certified dermatologists. Similarly, a kaggle challenge showed that dermatoscopic image analysis with Machine Learning methods can separate melanoma from non-melanoma samples.[5] Students fulfilling the challenge could reach Matthews Correlation coefficients of 0.5 and higher, meaning a strong positive relationship between their models and a doctor's prediction. These results strongly underpinned the potential of Machine Learning methods to significantly expand access to vital medical care.
Table 2 below provides a summary of research that has been conducted in this field.
Table 2.
Literature review
| Study Name and Year | Medical Vertical | Data | ML Method | Result |
|---|---|---|---|---|
| Fujisawa et al. (2019)[6] | Skin cancer classification | 6,009 clinical images | Deep Convolutional Neural Network | Accuracy: 76.5% Sensitivity: 96.3% Specificity: 89.5% |
| Esteva et al. (2017)[3] | Classification of skin lesions | 129,450 clinical images | Convolutional Neural Network | AUC between 0.91 and 0.96 |
| Masood et al. (2013)[7] | Skin cancer | Skin images | Support Vector Machine, Discriminant Analysis, Decision Trees, Logistic Regression | Varying levels of accuracy, often not benchmarked against one another or a reference data set. Need for better validation data was pointed out. Note: studies included from as early as 1993 |
| Fjell et al. (2009)[8] | Identifying, new antibacterial agents | silico library of approximately 100,000 peptides | Artificial Neural Networks | Accuracy: 94% |
Other benefits demonstrated by case studies that are using ML in medical context include:
Generally high/improved sensitivity and specificity;
Algorithms may pick up on some features in images that humans may not pick up; (Acknowledging that the reverse is also true due to fundamental differences in the cognition of artificial systems and humans)
Particularly useful for patients with many potentially suspicious lesions (due to the automated nature of Machine Learning);
Potentially extending the reach of dermatologists outside the clinic with smartphone subscriptions;
Cost effectiveness;
Universal access to lifesaving diagnostic care
In the presence of antibiotic resistance, the ability to detect new antibacterial agents in a cost effective manner
The ability to detect patterns at the genetic level which may be impossible for humans to detect.
It is also noteworthy that decision support systems that can be based on Machine Learning algorithms are already embedded in the software of many advanced dermatology imaging products in the market,[9] serving as a second opinion to the clinicians. (NB: Rule based decision systems can work without any Machine Learning). Finally, it is important to note that such systems have been designed for more than a couple of decades as the above example studies document.
While the applications of Machine Learning are limitless, it is important to understand that there are associated ethical dilemmas and to acknowledge the responsibilities of reporting unbiased interpretations and conclusions. This paper aims to bring attention to the ethics, limitations, and common pitfalls in the application of Machine Learning algorithms in the field of patient healthcare. In particular, attention will be given to the common challenges faced in classification problems, such as data collection and pre-processing, the training of Machine Learning algorithms, the use of appropriate metrics for reporting model performance, and finally model interpretation.
How Does Machine Learning Work: The Machine Learning Workflow
The first step for any Machine Learning task in any field is identifying and formulating the goal of the research problem to be solved. Different problem formulations and learning paradigms are available: supervised, unsupervised, semi-supervised or reinforcement learning. Usually, the data collection or data sourcing of existing records happens in the next step, with the intention of training a model that can make predictions.
Some factors to consider when gathering data are: size of the data set (to assess representativeness and data sampling rates), and the quality of the data (considering measurement error or noise, high quality data usually leads to better model performance). Raw data or measurement sets often need to be pre-processed such that they can be consumed by a Machine Learning algorithm (e.g., imputation of missing values, data type conversions, unit conversions). The data is then split into a training set, a validation set and a testing set. Typically, the testing data set is an independent holdout sample that is not evaluated until training is complete. Feature engineering (through variable transformation or combination) and feature selection (the process of reducing the number of input variables when developing a predictive model) are performed at this stage as well.
When deciding upon which algorithm(s) to select, there are several factors to consider, such as the type of features available from the data: numerical/categorical/ordinal variables, text data, images etc., complexity of the model relative to the type and size of the available data, and run time of the algorithm. For best performance, the Machine Learning algorithms chosen should be sensitive to the type of data available for training. For example, when working with medical data in the form of images, it is currently standard to use Deep Neural Networks. Deep Neural Networks are a form of neural network with many hidden layers.
There are several metrics that one can use to evaluate the performance of a model. Some examples are: accuracy, Fβ score, AUC (area under the curve) score, precision and recall. It is important to choose a metric that is consistent with the field of study in which the Machine Learning algorithm is employed. In the healthcare industry standard, metrics for model performance evaluation include: sensitivity, also known as true positive rate (TPR), and specificity, also known as true negative rate (TNR). For example, a Machine Learning practitioner may need to decide whether false positives are worse than true negatives. Within a dermatological context, we normally want to minimize the true negatives. In context, this means screening examinations for melanoma can be repeated at a low cost and at no risk to the patient.
In summary, the main advantages of the application of Machine Learning algorithms in medical sciences are:
Scalability: While a medical practitioner may take a few minutes to view a single image to classify it a machine can view hundreds of images in seconds.
Assisting practitioners in decision making. It can serve as a second opinion and reinforce the decision of the practitioner.
In some cases, Machine Learning algorithms may be able to provide an initial diagnosis to a patient from the comfort of their own home through mobile applications.
The Basis for Machine Learning in Healthcare: Electronic Health Records
The availability of digital health data is the basis to apply Machine Learning algorithm for medical applications. The main digital data sources are the electronic health record (EHR) or electronic medical record (EMR). The data elements included in an electronic health/medical record can vary a lot. It can be something as basic as the name and date of birth or more details around for example historical doctor's office visit records including all diagnoses. Here we would like to focus on implementations of EHRs that would allow the use of Machine Learning. This means they must contain information in a digital format. Therefore, several data standards were developed. A well-known international standard is the HL7 (Health Level 7) standard. This standard includes multiple concepts to store images within. Mainly, it recommends storing images under the DICOM (Digital Imaging and Communications in Medicine) standard.[10] A supplement for dermoscopic images shall be included in this standard.[11] The FHIR (Fast Healthcare Interoperable Resources) standard is an implementation of the HL7 Standard.[12] Thirty two percent of the certified health IT developer's software in the U.S. uses the FHIR Standard.[13] Since 2018, the FHIR standard is also available on the iPhone.[14] India introduced its own standard in 2016.[15]
Currently many countries do not have a standardized way of sharing EHRs. Dornan et al.[16] showed that many Asian countries have medical records implemented. However, these data collections are not interconnected among the medical institutions, which makes them unusable for Machine Learning analysis. The OpenMRS software is aiming to become the best EHR software by 2030.[17] As it is open-source and free of use, it was implemented in >20 countries already. This would allow the participating countries to share the medical records amongst each other and also share some principles on how to apply Machine Learning successfully.
One of the few countries with a coverage of electronic health records above 95% is Estonia. The eHealth system covers 99% of prescriptions, doctor's letters, and diagnosis reports inside Estonia.[18] Germany is planning to implement centralized EHRs with the introduction of an electronic patient record;[19] in China, there are case studies to connect the decentralized systems.[20] In 2009 and 2012, the Ministry of Health of China even provided a technical guideline on how to share medical records, which is not yet implemented due to many different systems all over the country. Neither having difficulties due to decentralization, 66% of all patients already have created electronic records until 2012.
In the USA, individual companies created large EHR collections. For example, Cerner currently has a market share of about 28% on EHR IT systems here.[21] Together with Amazon, Cerner plans to analyze these collections with Machine Learning.[22] Foundation Medicine and Flatiron are both examples of companies that collected and curated EHRs in a specific field. Both companies created data collections of cancer patients that are large and clean enough to find immediate use in Machine Learning applications.[23]
To allow analyzing such EHRs with Machine Learning, central databases or at least central data collections are necessary. For dermatoscopic data there are several data collections of which by far the largest is the XiangYaDerm data collection[24] with 107,565 skin images. It can be compared to the Skin Imaging Collection (ISIC) from Europe which contains 23,906 images.[25] One of the largest collections of images with billions of images is the VistA Imaging service of the U.S. Government of Veterans Health.[26] However, this is not open for public use.
Ethical Challenges around Machine Learning Applications
Recent survey data around the usage of patient data for Machine Learning applications in healthcare and medicine indicate that there are substantial ethical and regulatory challenges associated with privacy, fairness, accountability, transparency and conflicts of interest,[27] more recently supported by Park et al[28] Successfully addressing these will foster the future of Machine Learning in medicine and its positive impact on healthcare.
Privacy
Data privacy, data ownership and secondary use of data challenges arise mainly from electronic health records. In the large countries of the world, policies exist to handle such problems. Developers of medical predictive models must understand regulatory rules that apply and these can vary by the geography of the source of the data. The policies in place are given in Table 3.
Table 3.
Data protection guidelines
| Name | Region | Purpose | Released |
|---|---|---|---|
| General Data Protection Regulation (GDPR)[29] | EU | Give individuals control over their personal data more broadly and as such it is not just limited to Health Data | 2018 |
| Health Insurance Probability and Accountability Act (HIPAA)[30] | U.S. | Provide privacy standards to protect patients’ medical records and other health information | 2003 |
| Indian Medical Council Act[31] | India | Defining privacy between patient and doctor | 1952 (updated 2001) |
| Digital Information Security in Healthcare Act[32] | India | Ensure electronic health data privacy, confidentiality, security and standardization | 2020 (proposed) |
| Act on the Protection of Personal Information (APPI)[33] | Japan | Data protection for patients | 2017 |
While the same ethical issues exist in countries with lower financial resources, they should be dealt with differently due to differences in culture, literacy rate, and patient-provider relationships. Were et al. proposes a reconsideration of the EHR implementation in such countries to clear ethical issues first.[34]
Fairness
Selective bias can be caused by: a) the measurements themselves (say, when an instrument works better or worse for some individual groups than others), b) the what/when/how/where the data were collected (e.g., geographically discriminating bias against individuals from countries with less access to medical facility / heathcare), c) removing missing values in adjacent data columns.
Transparency and conflict of interest
Machine Learning implementers have the ethical responsibility of recording and reporting model performance metrics appropriately. For instance, in the case of target imbalance in a classification problem, reporting accuracy as a metric of performance is usually misleading. It is also important to distinguish the entire model's performance compared to the confidence range of one single output (e.g., patient infected vs. not infected). Another fact to keep in mind is that the “best” performing model is highly dependent on the data set, the size and features, and type of variables of the data set. The “best” model for a particular research problem may not be able to carry over equally satisfying performance for another data set or a related, but slightly different research problem.
The interpretation step of Machine Learning models can pose an ethical challenge to developers in two ways: Machine Learning applications have the potential to model complex relationships between medical response variables and images, yet they are also known for their “black-box” nature. This is because the mathematical functions that result from model training to represent the problem solution can be very complex. Therefore, the resulting model can be hard to interpret in itself. (NB: the interpretability of Machine Learning models has recently been a very active field of research[35,36]) Secondly, there is also a challenge with regard to a lack of understanding of the algorithms inner-workings, although we note that this can equally apply to developers, practitioners and patients in one way or another.
Accountability
Accountability implies a set of norms to evaluate the conduct of an individual or entity. Accountability involves a relationship between entities where one of them has the obligation to justify his actions. Machine Learning algorithms create a new situation, where the actor of the algorithm is not capable of predicting the future machine behavior anymore and thus cannot be held morally responsible or liable for it.[37] Currently, there is no legal solution for this gap. Increasing applications of Machine Learning will drive governments to find solutions for those legal gaps.
In practice, the following are some of the regulations in effect to address ethical challenges. Recently, few countries and federations have started introducing such regulations on the use of Machine Learning. Here we will focus on China, the USA, the European Union and India. In China, the “New Generation Artificial Intelligence Development Plan” enforces the use of Machine Learning in several industrial sectors. Since 2019 China's Ministry of Science and Technology published principles of next-generation artificial intelligence (AI) governance, pledging to develop responsible AI in China.[38] Additionally a consortium of different universities and industry leaders, like Alibaba, published the Beijing AI principles which deal in 3 chapters with general suggestions for the ethical use of AI. In the USA, only California has endorsed the Asilomar AI Principles.[39] A bill on ethical use of AI in the entire United States was introduced in the Congress, but not yet ratified.[40] The EU enforced and ratified the “Ethics guidelines for trustworthy AI”[41] in 2019. The guidelines contain 4 ethical principles (Respect of Human Authority, Fairness, Prevention of Harm, Explicability) and 7 requirements that need to be fulfilled by artificial intelligence applications. In India the National Institute for Transforming India (NITI) has published guidelines for a national strategy on AI already, in 2018.[42] The strategy contains a large section on AI privacy, transparency and ethical use of AI. The organization was mandated to implement the strategy in 2019.[43] Since then, NITI has been working on a large database for cancer data and another one for Diabetic Retinopathy.[44]
Where Do We Stand Today? What is the Future of Machine Learning in Medical Sciences?
Our analysis of recently published relevant work addressing ethical challenges in Machine Learning in medical sciences show a positive trend in previous years since 2016. Despite them still being a small number of studies in total, they are catching up and are now growing proportionally to the broader medical Machine Learning studies. As shown, governments show increased interest in regulating Machine Learning, too.
As concerns around the topic of ethics of Machine Learning in medical sciences continue to grow, we propose the following common rules and best practices that should be followed:
Improving collaboration between people collecting data, model developers, and medical practitioners is necessary
Data collection and storage need to be standardized on a global scale to improve application of Machine Learning
Improving regulations around data privacy and possibly setting up guidelines to protect patient privacy on a global scale
Introducing standards on avoiding biases in data collection, or if biases are apparent, how to remove them from the training data set
Practitioners of Machine Learning should report and make available all possible metrics that apply to a specific Machine Learning model to facilitate comparisons across studies
For the purposes of research and development, particularly those resulting in publications or other platforms for education, authors are encouraged to use public data sets for model development or make their datasets available for public use by storing in a repository
Practitioners of Machine Learning are also encouraged to disclose all data cleaning techniques used and disclose methods and algorithms used for model training which will allow easy comparison across multiple studies
Schools of Medicine should also consider offering a course as a part of modernizing curriculum that highlights some of the challenges and concerns of the application of artificial intelligence in patient diagnosis similar to the way medical students are taught how to read an MRI scan or X-ray plate.[45]
The future of the application of Machine Learning in medical sciences looks promising. Emerging medical applications that can benefit from Machine Learning in the future include:
The development of language translators for better communication between patient and doctor leading to better diagnosis[46,47]
Creating mobile applications that allow patients to submit images or enter symptoms resulting in patient diagnosis remotely[48]
Automatic detection of tumors in either MRI scans or dermoscopic images[3,5]
The development of treatments for neglected and rare diseases.
Financial support and sponsorship
Nil.
Conflicts of interest
There are no conflicts of interest.
References
- 1.International Data Corporation (IDC) Market research report on revenue in Big Data and Analytics solutions. [Last accessed on 2019 Oct 14]. Available from: https://wwwidccom/getdocjspcontainerId= prUS44998419 .
- 2.Davenport TO, Kalakota R. The potential for artificial intelligence in healthcare. Future Healthc J. 2019;6:94–8. doi: 10.7861/futurehosp.6-2-94. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Esteva A, Kuprel B, Novoa RA, Ko J, Swetter SM, Blau HM, et al. Dermatologist-level classification of skin cancer with deep neural networks. Nature. 2017;542:115–8. doi: 10.1038/nature21056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Chen Y, Cheng C, Lai C, Hsu C, Syu H. Identifying patients in target customer segments using a two-stage clustering-classification approach: A hospital-based assessment. Comput Biol Med. 2012;42:213–21. doi: 10.1016/j.compbiomed.2011.11.010. [DOI] [PubMed] [Google Scholar]
- 5.IMA205 Challenge Classify images as either melanoma or non-melanoma. [Last accessed on 2020 Mar 09]. Available from: https://wwwkagglecom/c/ima205challenge/data .
- 6.Fujisawa Y, Otomo Y, Ogata Y, Nakamura Y, Fujita R, Ishitsuka Y, et al. Deep-learning-based, computer-aided classifier developed with a small dataset of clinical images surpasses board-certified dermatologists in skin tumour diagnosis. Br J Dermatol. 2019;180:373–81. doi: 10.1111/bjd.16924. [DOI] [PubMed] [Google Scholar]
- 7.Masood A, Al-Jumaily AA. Computer aided diagnostic support system for skin cancer: A review of techniques and algorithms. Int J Biomed Imaging. 2013;2013:323268. doi: 10.1155/2013/323268. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Fjell C, Jenssen H, Hilpert K, Cheung W, Panté N, Hancock R, et al. Identification of novel antibacterial peptides by chemoinformatics and machine learning. J Med Chem. 2009;52:2006–15. doi: 10.1021/jm8015365. [DOI] [PubMed] [Google Scholar]
- 9.Janda M, Horsham C, Koh U, Gillespie N, Loescher LJ, Vagenas D, et al. Redesigning skin cancer early detection and care using a new mobile health application: Protocol of the SKIN research project, a randomised controlled trial. Dermatology. 2019;235:11–8. doi: 10.1159/000493729. [DOI] [PubMed] [Google Scholar]
- 10.DICOM Standard definition. [Last accessed on 2020 Mar 09]. Available from: https://wwwdicomstandardorg/wgs/wg-19/
- 11.DICOM WORKING GROUP 19 Dermatology minutes. 2019. [Last accessed on 2020 Mar 09]. Available from: http://dicom.nema.org/Dicom/minutes/WG-19/2019/WG-19-2019-12-17-Min-tcon.pdf .
- 12.Lehne M, Luijten S, Vom Felde Genannt Imbusch P, Thun S. The use of FHIR in digital health-A review of the scientific literature. Stud Health Technol Inform. 2019;267:52–8. doi: 10.3233/SHTI190805. [DOI] [PubMed] [Google Scholar]
- 13.Posnack S, Barker W. Heat Wave: The U.S. is Poised to Catch FHIR in 2019. [Last accessed on 2020 Mar 09]. Available from: https://www.healthit.gov/buzz-blog/interoperability/heat-wave-the-u-s-is-poised-to-catch-fhir-in-2019 .
- 14.Apple announces effortless solution bringing health records to iPhone. 2018. [Last accessed on 2020 Mar 09]. Available from: https://www.apple.com/newsroom/2018/01/apple-announces-effortless-solution-bringing-health-records-to-iPhone/
- 15.Ministry of Health and Family Welfare, Government of India. 2016. Dec, [2018 Mar 25] Electronic Health Record (EHR) Standards for India. [Last accessed on 2020 Mar 09]. Available from: https://www.nhp.gov.in/NHPfiles/EHR-Standards-2016-MoHFW.pdfwebcite .
- 16.Dornan L, Pinyopornpanish K, Jiraporncharoen W, Hashmi W, Dejkriengkraikul N, Angkurawaranon C. Utilisation of electronic health records for public health in Asia: A review of success factors and potential challenges. Biomed Res Int. 2019;2019:7341841. doi: 10.1155/2019/7341841. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.How Might We…. Make OpenMRS the Best EHR in the world by 2030? [Last accessed on 2020 Mar 09]. Available from: https://openmrs.org/2019/01/howmight-we-make-openmrs-the-best-ehr-in-the-world-by-2030/
- 18.Paimre M. Do Elderly People Enjoy the Fruits of Estonia's e-Health System 2019. [Last accessed on 2020 Mar 09]. Available from: https://wwwresearchgatenet/profile/Marianne_Paimre/publication/332037022_Do_Elderly_People_Enjoy_the_Fruits_of_Estonia's_E-Health_System/links/5cf168ca299bf1fb184e6f9a/Do-Elderly-People-Enjoy-the-Fruits-of-Estonias-E-Health-Systempdf .
- 19.Bertram N, Püschner F, Gonçalves ASO, Binder S, Amelung V. Einführung einer elektronischen Patientenakte in Deutschland vor dem Hintergrund der internationalen Erfahrungen. In: Klauber J, Geraedts M, Friedrich J, Wasem J, editors. Krankenhaus-Report 2019. Berlin, Heidelberg: Springer; 2019. [Google Scholar]
- 20.Wang Z. Data integration of electronic medical record under administrative decentralization of medical insurance and healthcare in China: A case study. Isr J Health Policy Res. 2019;8:24. doi: 10.1186/s13584-019-0293-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Roth M. In EMR Market Share Wars, Epic and Cerner Triumph Yet Again. 2019. [Last accessed on 2020 Mar 09]. Available from: https://www.healthleadersmedia.com/innovation/emr-market-sharewars-epic-and--cerner-triumph-yet-again .
- 22.Pifer R. Amazon, Cerner team up on AI, Machine Learning. 2019. [Last accessed on 2020 Mar 09]. Available from: https://www.healthcaredive.com/news/amazon-cerner-team-up-on-ai-machine-learning/559847/
- 23.Das R. The Flatiron Health Acquisition Is A Shot In The Arm For Roche's Oncology Real-World Evidence Needs. 2018. [Last accessed on 2020 Mar 09]. Available from: https://wwwforbescom/sites/reenitadas/2018/02/26/flatiron-health-acquisition-a-shot-in-the-arm-for-roches-oncology-real-world-evidence-needs/#19ae323b3f60 .
- 24.Xie B, He X, Zhao S, Li Y, Su J, Zhao X, et al. XiangyaDerm: A Clinical Image Dataset of Asian Race for Skin Disease. [Last accessed on 2020 Mar 09];Aided Diagnosis Lecture Notes in Computer Science. 2019 doi: 101007/978-3-030-33642-4_3. [Google Scholar]
- 25.Celebi ME, Codella N, Halpern A. Dermoscopy image analysis: Overview and future directions. IEEE J Biomed Health Inform. 2019;23:474–8. doi: 10.1109/JBHI.2019.2895803. [DOI] [PubMed] [Google Scholar]
- 26.VA Medical Imaging Reaches Record Level, 2009. [Last accessed on 2020 Mar 09]. Available from: https://wwwvagov/health/IMAGING/docs/vista_imaging_nrpdf .
- 27.Vayena E, Blasimme A, Cohen IG. Machine learning in medicine: Addressing ethical challenges. PLoS Med. 2018;15:e1002689. doi: 10.1371/journal.pmed.1002689. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Park SH, Kim Y-H, Lee JY, Yoo S, Kim CJ. Ethical challenges regarding artificial intelligence in medicine from the perspective of scientific editing and peer review. Sci Ed. 2019;6:91–8. [Google Scholar]
- 29.Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) (Text with EEA relevance) [Last accessed on 2019 Mar 09]. Available from: http://data.europa.eu/eli/reg/2016/679/oj .
- 30.Pub. L. 104-191 Health Insurance Portability and Accountability Act of 1996. [Last accessed on 2020 Jun 14]. Available from: //uslaw.link/citation/us-law/public/104/191 .
- 31.Indian Medical Council Act 2001. [Last accessed on 2020 Mar 09]. Available from: https://wwwmciindiaorg .
- 32.Digital Information Security in Healthcare Act, 2019. [Last accessed on 2020 Mar 09]. Available from: https://www.nhp.gov.in/NHPfiles/R_4179_1521627488625_0.pdf .
- 33.Act on the Protection of Personal Information 2017. [Last accessed on 2020 Mar 09]. Available from: https://wwwppcgojp/files/pdf/Act_on_the_Protection_of_Personal_Informationpdf .
- 34.Were MC, Eric MM. Ethics of implementing Electronic Health Records in developing countries: Points to consider. AMIA Annu Symp Proc. 2011;2011:1499–505. [PMC free article] [PubMed] [Google Scholar]
- 35.Hall P, Gill N. Introduction to Machine Learning Interpretability O'Reilly Media, Incorporated. 2018 [Google Scholar]
- 36.Tulio Ribeiro M, Singh S, Guestrin C. “Why Should I Trust You”: Explaining the Predictions of Any Classifier, 2016, arXiv, arXiv: 160204938 [Google Scholar]
- 37.Matthias A. The responsibility gap: Ascribing responsibility for the actions of learning automata. Ethics Inf Technol. 2004;6:175–83. [Google Scholar]
- 38.Xiang B. China issues principles of next generation AI governance, newscn, 2019. [Last accessed on 2020 Mar 09]. Available from: http://wwwxinhuanetcom/english/2019-06/18/c_138152819htm .
- 39.Asilomar AI Principles 2017. [Last accessed on 2020 Mar 09]. Available from: https://futureoflifeorg/ai-principles/
- 40.All Information (Except Text) for H. R2231-Algorithmic Accountability Act of 2019. [Last accessed on 2020 Mar 09]. Available from: https://wwwcongressgov/bill/116th-congress/house-bill/2231/all-info .
- 41.Ethics Guidelines for Trustworthy AI 2020. [Last accessed on 2020 Mar 09]. Available from: https://eceuropaeu/futurium/en/ai-alliance-consultation .
- 42.National strategy for artificial intelligence 2018. [Last accessed on 2020 Mar 09]. Available from: https://nitigovin/writereaddata/files/document_publication/NationalStrategy-for-AI-Discussion-Paperpdf .
- 43.Governance Principles for a New Generation of Artificial Intelligence: Develop Responsible Artificial Intelligence 2019. [Last accessed on 2020 Mar 09]. Available from: https://mpweixinqqcom/s/JWRehPFXJJz_mu80hlO2kQ .
- 44.Here is Why We are Excited About India's National Strategy for Artificial Intelligence 2019. [Last accessed on 2020 Mar 09]. Available from: https://wwwintelimentcom/blog/our-thinking/here-is-why-we-are-excited-about-indias-national-strategy-for-artificial-intelligence/
- 45.Kumar GR, Madhavi S, Karthikeyan K, Thirunavakarasu MR. Role of clinical images based teaching as a supplement to conventional clinical teaching in dermatology. Indian J Dermatol. 2015;60:556–61. doi: 10.4103/0019-5154.169125. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Panayiotou A, Gardner A, Williams S, Zucchi E, Mascitti-Meuter M, Goh AM, et al. Language translation apps in health care settings: Expert opinion. JMIR Mhealth Uhealth. 2019;7:e11316. doi: 10.2196/11316. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Sarkar R. Healthtech start-up mfine allows users to consult doctors online Business Standard. 2018. [Last accessed on 2020 Jun 14]. Available from: 2018: https://wwwbusiness-standardcom/article/companies/healthtech-start-up-mfine-allows-users-to-consult-doctors-online-118052000593_1html .
- 48.Peltola MK, Lehikoinen JS, Sippola LT, Saarilahti K, Mäkitie AA. A novel digital patient-reported outcome platform for head and neck oncology patients-A pilot study. Clin Med Insights Ear Nose Throat. 2016;9:1–6. doi: 10.4137/CMENT.S40219. [DOI] [PMC free article] [PubMed] [Google Scholar]