

Abstract
We analyze adolescent BMI and middle-age systolic blood pressure (SBP) repeatedly measured on women enrolled in the Fels longitudinal study (FLS) between 1929 and 2010 to address three questions: Do adolescent-specific growth rates in BMI and menarche affect middle-age SBP? Do they moderate the aging effect on middle-age SBP? Have the effects changed over historical time? To address the questions, we propose analyzing a growth curve model (GCM) that controls for age, birth-year cohort and historical time. However, several complications in the data make the GCM analysis non-standard. First, the person-specific adolescent BMI and middle-age SBP trajectories are unobservable. Second, missing data are substantial on BMI, SBP and menarche. Finally, modeling the latent trajectories for BMI and SBP, repeatedly measured on two distinct sets of unbalanced time points, are computationally intensive. We adopt a bivariate GCM for BMI and SBP with correlated random coefficients. To efficiently handle missing values of BMI, SBP and menarche assumed missing at random, we estimate their joint distribution by maximum likelihood via the EM algorithm where the correlated random coefficients and menarche are multivariate normal. The estimated distribution will be transformed to the desired GCM for SBP that includes the random coefficients of BMI and menarche as covariates. We demonstrate unbiased estimation by simulation. We find that adolescent growth rates in BMI and menarche are positively associated with and moderate the aging effect on SBP in middle age, controlling for age, cohort and historical time, but the effect sizes are at most modest. The aging effect is significant on SBP, controlling for cohort and historical time, but not vice versa.
Keywords: longitudinal data, growth curve model, mixed model, hierarchical model, maximum likelihood
1. Introduction
The Fels longitudinal study (FLS) collected the lifetime repeated measurements on growth, health and body composition of 2,567 participants enrolled in yearly cohorts of 20 to 35 from 1929 to 2010. The participants were scheduled to be examined every six months for the first 18 years and every two years for the rest of their life spans. Each examination took extensive anthropometric measurements and recorded a health inventory (Sun et al. 2007, 2008). Via a growth curve model (GCM) with person-specific growth trajectories, also known as a hierarchical, multilevel, random coefficients or linear mixed model (Raudenbush and Bryk 2002; Goldstein 2003), we link growth in adolescent BMI and person-specific (age at) menarche to the course of middle-age systolic blood pressure (SBP) for 835 female participants where 459 women were enrolled at birth producing 85% of the repeated measurements while others were family members, spouses and relatives. In this paper, we consider BMI and SBP as the biomarkers of obesity and health, respectively.
Figure 1 plots all observed BMI and SBP of the participants against age where 5,694 adolescent BMIs and 1,196 middle-age SBPs are nested within 552 and 436 individuals, respectively. It superimposes the scatterplots with person-specific longitudinal spaghetti plots. BMI and SBP are standardized to have mean 0 and variance 1. Every participant has at least one observation in adolescence or middle age. The spaghetti plots reveal that some growth patterns in BMI are higher overall, accelerate earlier or decelerate earlier than others. We analyze the impact of the growth patterns on progression of middle-age SBP. Because the 835 female participants consist of 98% European Americans and a tiny fraction of minority participants including African American, Asian, multiracial and other individuals and because the minority effect is not significant on either BMI or SBP outcome in preliminary analysis, we do not consider the race covariate.
Figure 1:

Scatter and spaghetti plots superimposed for the unbalanced repeated measurements of adolescent BMI and middle-age SBP against age from 835 FLS female participants enrolled over time across multiple birth year cohorts.
The examination schedule implies that those enrolled at age 10 or earlier can have up to 18 adolescent measurements between 10 and 19 years of age and up to 10 middle-age measurements between 45 and 65 years of age, depending on how old they are as of 2010. Some relatives, spouses and family members of the participants enrolled in the FLS during adolescence or later produced their measurements afterward. It is, however, unreasonable to take all these repeated measurements as complete data for analysis because only 18% of the 835 participants have at least one measurement in both adolescence and middle age. Instead, we realistically take the measurements at the time points of actual visits to a clinic for examination and menarche as complete data and assume data missing at random (MAR, Rubin 1976). As the spaghetti plots in Figure 1 show, the actual timings of examinations varied, and BMI appears semi-regularly measured while SBP looks more sparse and unbalanced.
Family relocations due to job transfers or newly acquired jobs, sickness of participants or family members accompanied to scheduled examinations, or other family emergencies or situations may have caused participants to miss scheduled examinations or attrite. During the scheduled examinations, 12% of the adolescents and 18% of adults failed to have their BMI and SBP measured, respectively, for some reasons. Menarche was either identified at a scheduled examination or obtained from participants’ recollections, but missing otherwise. It seems plausible that the missing patterns are not related to missing values themselves. As a reviewer pointed out, however, it is possible for an adolescent to have a high BMI worsened since the last examination and fail to participate in the next scheduled examination because of embarrassment or anxiety. As the reviewer also commented, participants who have adolescent BMI measurements but who have no SBP measurement as adults are likely to be unhealthy and have high SBP in middle age. The missing BMI and SBP will be associated with missing probability to violate the MAR assumption. However, because the missing rates on BMI and SBP are modest, because 40% of the female participants having adolescent BMI measurements are younger than middle age as of 2010, and because most adolescents appear to have attended most follow-ups in the spaghetti plots, even if some missing BMI and SBP are NMAR, they will not seriously affect our analysis.
We leverage the FLS data collected longitudinally on individuals enrolled over time to estimate the age, cohort and historical time effects separately. In large-scale single cohort studies such as the Dunedin Longitudinal Study and the Environmental-Risk Longitudinal Twin Study (Caspi et al. 2016; Moffitt et al. 2011), age and historical time are perfectly correlated. The confounded effects of age and childhood factors may explain only modest effect sizes of childhood risk factors on adult health outcomes reported (Felitti et al. 1998; Roberts et al. 2007; Moffitt et al. 2011; Caspi et al. 2016). On the contrary, age and cohort are perfectly collinear in a cross-sectional study of multiple birth year cohorts such as National Growth and Health Studies (Ren and Shin 2016). The multi-cohort FLS enables us to control for temporal, cohort and historical sources of SBP, and estimate the main effects of growth rates in adolescent BMI and menarche, and the growth rates-by-age and menarche-by-age interaction effects on middle-age SBP by a multilevel GCM. These effects may also change over cohorts and time.
Researchers have studied the impact of longitudinal growth patterns in childhood obesity on adult health or the effects of childhood covariates on a longitudinal adult outcome in linear and nonlinear mixed models (Eriksson et al. 1999; Law et al. 2002; Ferreira et al. 2005; Nooyens et al. 2007; Sabo et al. 2012; McLeod et al. 2018; Sabo et al. 2014). Kim et al. (2016) analyzed FLS longitudinal childhood BMI to predict the person-specific timing of the BMI rebound, and subsequently analyzed the impact of the timing on a longitudinal adult cardiac outcome. Sabo et al. (2017) analyzed the FLS childhood BMI to predict child-specific ages and BMIs at the BMI rebound and maximum BMI growth, and subsequently estimated the effects of the predicted childhood covariates on longitudinal adulthood blood pressure outcomes. These studies have assessed the impact of either adult characteristics on a longitudinal childhood outcome or childhood covariates on a longitudinal adult outcome.
In structural equation models (Bollen 1989), a longitudinal model for the repeated measurements of an outcome nested within individuals may be efficiently estimated by latent growth modeling where age variables are considered as fixed factor loadings and random coefficients are latent variables (Willett and Sayer 1994; MacCallum et al. 1997; Bauer 2003; Bollen and Curan 2006; Preacher et al. 2008; Grimm and Ram 2009; Ram and Grimm 2015). Growth-mixture modeling extends the latent growth model to identify unobserved subpopulations exhibiting different growth trajectories (Wang and Bodner 2007). These approaches model longitudinal outcomes measured on a common set of time points.
In the joint modeling approach (Gueorguieva 2001; Ivanova et al. 2016), a mixture of discrete and continuous longitudinal outcomes may be modeled in a joint mixed model. Data MAR in the model may be imputed by univariate sequential regression models (Raghunathan et al. 2001), also known as multiple imputation by fully conditional specification (van Buuren et al. 2006; van Buuren 2011). A multilevel GCM given data MAR may also be efficiently estimated by maximum likelihood (ML) or Bayesian methods (Liu et al. 2000; Schafer and Yucel 2002; Goldstein and Browne 2002; Goldstein et al. 2009; Goldstein and Kounali 2009; Shin and Raudenbush 2007, 2010, 2020; Ren and Shin 2016). These approaches typically apply to longitudinal outcomes measured at a common set of time points.
In this paper, we estimate a nonstandard multilevel GCM for middle-age SBP that introduces challenges. First, the key covariates are unobservable adolescent-specific growth rates in BMI that have to be estimated from sample data. Sample average growth rates, for example, are unreliable measurements of the true growth rates that are known to introduce bias in the estimated effects of the growth rates (Lüdtke et al. 2008; Shin and Raudenbush 2010, 2020; Grilli and Rampichini 2011). Furthermore, missing data are substantial on BMI, SBP and menarche. Finally, longitudinal mj BMIs in adolescence and nj SBPs in middle age are measured at two separate sets of unbalanced time points nested within each person, and subjects may have measurements in either adolescence or middle age, or both. To handle missing data efficiently, we may express, as a special case of the joint modeling approach, a bivariate multilevel GCM for BMI and SBP and a linear model for menarche jointly where correlated person-specific random coefficients and menarche are multivariate normal and the variance covariance structure is appropriately constrained. Computationally efficient estimation of the joint model, however, involves derivation of new estimators and considerable amount of programming in a way that fully leverage the longitudinal structure. Our method is tailored to the structure with one set of outcomes repeatedly measured at unbalanced time points during childhood and another set longitudinally measured at separate unbalanced time points as an adult within each individual, thereby achieving computational efficiency.
Viewing BMI, SBP, menarche and random coefficients as complete data, we analyze all observed data to estimate the joint model efficiently by ML via the EM algorithm (Dempster et al. 1977; Dempster et al. 1981; Shin and Raudenbush 2007). At convergence, we compute standard errors by the approximate Fisher score (Hedeker and Gibbons 1994; Raudenbush et al. 2000; Olsen and Schafer 2001). Subsequently, by the delta method (Casella and Berger 2002), we transform the estimated joint model to the desired GCM for SBP that includes the random coefficients of adolescent BMI and menarche as covariates. An alternative is to draw multiple imputation of completed data, including the random coefficients, from the estimated joint model and estimate the desired GCM given the multiple imputation (Shin and Raudenbush 2007). This approach requires a cumbersome extra step of multiple imputation. We choose the delta method that demanded less programming than the alternative. We will demonstrate unbiased estimation by simulation. Our findings may provide important policy implications to promote adult health based on juvenile obesity history.
Although FLS has not selected participants with respect to factors known to be associated with body composition, health, and other related conditions (Roche 1992), the participants are far from being randomly assigned to levels of key covariates, BMI growth rates and menarche. Furthermore, with adolescence far apart from middle age in time, there can be a number of confounders of the key covariates that we have not considered such as socioeconomic and environmental covariates unavailable in FLS. Consequently, the effect we mention in this paper is associational, not causal.
The Fels data set is not publically available. However, the data set analyzed in this paper will be available from the second author upon reasonable request. The next section introduces our model. Section 3 explains how to estimate the model and compute standard errors given data MAR. Section 4 evaluates the accuracy and precision of the estimation by simulation. Section 5 presents analysis of the multi-cohort FLS sample data. The final section discusses the limitations and future extensions of the approach.
2. Model
Following Raudenbush and Bryk (2002), we express the repeated measurements of middle-age SBP Rij and adolescent BMI Ctj for adult occasion i and adolescent occasion t within person j in a level-1 model
| (1) |
| (2) |
where is a polynomial in adult age aij for vectors ARij of age terms and βRj of person-specific age effects (e.g. and ), BRij is a vector of known covariates (e.g. historical time) having fixed effects γR1, is a polynomial in adolescent age atj for vectors ACtj of age terms and βCj of adolescent-specific age effects (e.g. and ), BCtj is a vector of known covariates having fixed effects γC1 (e.g. and historical time), and occasion-specific random errors ϵRij and ϵCtj are independent for i = 1, ⋯, nj, t = 1, ⋯, mj and j = 1, ⋯, J. With adolescence and middle age far apart within each person, it appears reasonable that occasion-specific random errors ϵRij and ϵCtj are uncorrelated given the person-specific growth trajectories βRj and βCj and time-varying covariates. That is, given the covariates, SBP and BMI are dependent on each other only through the dependence between the trajectories.
The aging effects βRj on SBP vary between individuals according to a level-2 model
| (3) |
for a matrix ΓR0 of fixed effects; a vector of known covariates W2j (e.g. cohort), partially observed covariates Y2j (e.g. menarche) and unobservable growth rates βCj in adolescent BMI; and a vector of random effects νj independent of random errors and Uj. Conditional on νj and covariates, SBP and BMI are independent. Although the growth trajectories may also vary differently across subpopulations to produce non-constant variances of random coefficients, for example, between males and females, we believe that the constant variance covariance matrix τ is plausible within our analysis of females, controlling for Uj. Equations (1) and (3) imply our desired GCM (Raudenbush and Bryk 2002)
| (4) |
for a matrix of fixed effects ΓR0 including the effects of aging moderated by Uj, the fixed effects γR1 of BRij, and the random effects vj of ARij independent of ϵRij.
Estimation of GCM (4) is difficult because (Rij, Ctj, Y2j) are partially observed and because latent trajectories βCj are unobservable. We introduce efficient and unbiased estimation below. For a positive integer n, let In be an n-by-n identity matrix, 1n be a vector of n unities, a diagonal matrix , probability density function (pdf) f (A) and conditional pdf f (A|B).
3. Efficient Estimation
For efficient estimation by all observed data, we estimate the joint distribution of (Rij, Ctj, Y2j) MAR given known covariates. We view q random coefficients and p2 variables Y2j as level-2 complete data in a model
| (5) |
for , a matrix of covariates having fixed effects , random effects and having distinct elements ϕT for and . Each outcome in may control for a different subset of W2j as we do in Section 6. Let .
We aggregate and to view and as complete data and observed values of as observed data for person j, and estimate the joint model given known covariates by the EM algorithm. We aggregate Equations (1) and (2) as the level-1 model f (Y1j|β1j)
| (6) |
of person j where A1j = diag{ARj, ACj}, , B1j = diag{BRj, BCj}, , and for , , , , and . Let and .
Equations (5) and (6) imply a linear mixed model
| (7) |
for , , , and where and . The parameters are θ = (θR, θC, θ2).
3.1. The EM Algorithm
We view complete data as (Y1j, b1j, Y2j) for individual j, equivalent to (ϵ1j, b1j, b2j) = (ϵ1j, bj) given known covariates and θ for ϵ1j = Y1j − A1jβ1j − B1jγ1 and b2j = Y2j − X22jγ22. This approach simplifies expressions for the complete data likelihood, E-step, M-step and standard error estimation. The complete data likelihood is
For the E step, we define matrix O2j of ones and zeros to select observed data Yo2j = O2jY2j ∼ N (0, T22j) from Y2j for (Shin and Raudenbush 2007). Likewise, we define ORj, OCj and O1j = diag{ORj, OCj} to find observed data Roj = ORjRj of length noj, Coj = OCjCj of length moj, and . Equation (7) implies f (Yoj)
| (8) |
where , Xoj = diag{Xo1j, Xo22j}, Zoj = diag{Ao1j, O2j}, and for Xo1j = O1jX1j, Xo22j = O2jX22j, Ao1j = O1jA1j, ϵo1j = O1jϵ1j and . For simplicity of notation, let and . The observed-data joint model f (Yoj) implies
| (9) |
for the E components , ,
where , and for and k, l = 1,2.
Given θ from the previous iteration, we compute the expected complete-data ML
where , and .
Let be of length No. Then, the log-likelihood is
3.2. Standard Errors
At ML , we express the log-likelihood and score for
where Yj = (Yoj, Ymj) for kj missing values Ymj, and estimate by the approximate Fisher score (Bock and Lieberman 1970; Raudenbush el al. 2000; Olsen and Schafer 2001). Let and for , and . Based on the posterior distributions (9), we compute where
for , and . Next, we transform the estimated joint model to the desired GCM by the delta method. Specifically, each parameter δ of the GCM is a function g(θ) of θ. We take the first-order Taylor-series approximation of to estimate and associated standard error.
To find the initial values of θ, we estimate two GCMs f (Rij, Y2j) and f (Ctj, Y2j) given known covariates, implied from the joint model in Equations (1), (2) and (5), by efficient ML estimation (Shin and Raudenbush 2007); use estimated f (Rij), cov(Rij, Y2j) and f (Ctj, Y2j); and set cov(Rij, Ctj) to zero. We estimated all models via a C program written by the first author1, and simulated data and implemented the delta method within the R environment (R Core Team 2017) on a Dell XPS PC with Intel’s i7 processor. In our experience with this estimation method so far, added random coefficients increase computational burden noticeably, but added time points do not.
4. Simulation Study
To assess our estimation, we simulate in sequence Wj ∼ Bernoulli(0.5) simulating a dummy indicator of a group of birth-year cohorts, simulating the standardized menarche and a vector of four correlated random coefficients describing the linear growth trajectories of adolescent BMI and middle-age SBP at level 2 for , , having variances equal to 1 and covariances equal to 0.2 so that in Equation (5). Given β1j, we simulate SBP at age aij = −9, −3, 3, 9 centered at the midyear 55 of middle age in Equation (1) and BMI at age atj = −4.5, −3.5, ⋯, 3.5, 4.5 centered at the midyear 14.5 of adolescence in Equation (2). Sample sizes are nj = 4, mj = 10 and J = 500 to reflect comparatively sparse middle-age SBP of FLS sample data analyzed in the next section. We simulate 1,000 data sets.
Next, we draw missing values of Rij, Ctj and Y2j. For each simulated data set, we simulate missing indicators MRij, MCtj and MY 2j of Rij, Ctj and Y2j, respectively, according to the following mechanisms
for independent uj ∼ N (0, 1) and νj ∼ N (0, 1) such that MRij ∼ Bernoulli(pij), MCtj ∼ Bernoulli(ptj) and MY 2j ∼ Bernoulli(pj). We simulated δ0 = −1.5 and δ1 = −1.5 to obtain pij = 0.15 (0.07 for Wj = 1 and 0.22 for Wj = 0), δ0 = −2 and δ1 = −1 to yield ptj = 0.11 (0.07 for Wj = 1 and 0.16 for Wj = 0), and δ0 = −1 and δ1 = 0.8 to simulate pj = 0.36 (0.45 for Wj = 1 and 0.27 for Wj = 0) on average. Missing values are MAR because MRij, MCtj and MY 2j depend on known Wj. The missing rates closely reflect those of SBP, BMI and menarche in the FLS sample. As a result, 4.1, 17.0, 48.5, 126.1, and 304.4 individuals have 0, 1, 2, 3 and 4 SBPs observed, respectively, on average in the 1,000 observed data sets.
From the simulated bivariate distribution of BMI and SBP given Y2j and Wj, we compute and show the implied simulated GCM (4) for SBP conditional on the random coefficients βC0j and βC1j of BMI, Wj and Y2j under column heading “simulated” in Table 1. Next, we illustrate our approach for estimation of the joint model f (Rij, Ctj, Y2j|aij, atj, Wj) in Equations (1), (2) and (5), i.e., Equation (7) by the EM algorithm and the subsequent delta method transforming the estimates to yield the estimated simulated GCM (4). We repeated our approach to estimate the simulated GCM (4) given each of the 1,000 simulated data sets to produce average estimates with associated average standard errors, biases and mean squared errors under heading “complete data EM” in Table 1. The average estimates are really close to the simulated parameters with the standard errors in parentheses, biases and mean squared errors comparatively very small.
Table 1:
Model (4) simulated 1,000 times for nj = 4, mj = 10 and J = 500 with simulated parameters under heading simulated. Complete data EM and observed data EM list the average estimates and standard errors (se) by the EM algorithm, bias and mean squared errors (mse) given completely observed data and data MAR, respectively.
| simulated | complete data EM | observed data EM | |||
|---|---|---|---|---|---|
| estimate (se) | bias, mse | estimate (se) | bias, mse | ||
| 1 | 0.67 | 0.66 (0.11) | −0.005, 0.012 | 0.66 (0.13) | −0.004, 0.015 |
| Wj | 0.67 | 0.67 (0.13) | 0.007, 0.016 | 0.67 (0.14) | 0.008, 0.020 |
| βC0j | 0.17 | 0.17 (0.05) | 0.001, 0.003 | 0.17 (0.06) | 0.000, 0.004 |
| βC1j | 0.17 | 0.17 (0.05) | 0.001, 0.003 | 0.17 (0.06) | 0.000, 0.003 |
| Y2j | 0.67 | 0.66 (0.08) | −0.003, 0.007 | 0.67 (0.11) | −0.001, 0.011 |
| aij | 0.67 | 0.66 (0.10) | −0.004, 0.010 | 0.66 (0.10) | −0.005, 0.011 |
| aijWj | 0.67 | 0.67 (0.12) | 0.004, 0.013 | 0.67 (0.12) | 0.004, 0.014 |
| aijβC0j | 0.17 | 0.17 (0.05) | −0.001, 0.002 | 0.17 (0.05) | −0.001, 0.003 |
| aijβC1j | 0.17 | 0.17 (0.05) | 0.002, 0.002 | 0.17 (0.05) | 0.001, 0.002 |
| aijY2j | 0.67 | 0.66 (0.08) | −0.002, 0.005 | 0.67 (0.09) | 0.000, 0.007 |
| 1.00 | 1.00 (0.00) | 0.000, 0.000 | 1.00 (0.00) | 0.000, 0.000 | |
| τ00 | 0.93 | 0.92 (0.08) | −0.011, 0.006 | 0.92 (0.09) | −0.011, 0.008 |
| τ01 | 0.13 | 0.14 (0.05) | 0.002, 0.002 | 0.13 (0.06) | 0.002, 0.003 |
| τ11 | 0.93 | 0.92 (0.06) | −0.009, 0.004 | 0.92 (0.07) | −0.009, 0.004 |
| σRR | 1.00 | 1.00 (0.05) | −0.002, 0.002 | 1.00 (0.05) | −0.002, 0.003 |
Given partially observed data, we again obtain the average estimates of the simulated GCM (4) by our approach and list them under heading “observed data EM” in Table 1. The average estimates are very close to the simulated parameters. Consequently, the biases appear very small near the counterparts under complete data EM. The standard errors and mean squared errors are 5% to 28% and 0 to 57% larger, respectively, than those of complete data EM to reflect added uncertainty due to missing data. Estimation of the joint model by the EM algorithm took only a few seconds to converge to ML in average 22 iterations.
5. Data Analysis
We now analyze the 835 female participants of FLS. Controlling for age, birth year cohort, and historical time as a visit year to a clinic for measurement, we estimate a multilevel GCM in Equation (4) for the effects of growth rates in adolescent BMI and menarche on middle-age SBP. The covariates may also strengthen or weaken the effect of aging on SBP. We discuss the statistical significance of an estimate at a significance level 0.05.
Table 2 summarizes sample data. At level 1, adolescent BMI and middle-age SBP range 12.32 to 46.61 and 75 to 210, missing 12% and 18% of the values, respectively. Age is centered at midyear 14.5 of adolescence (10 to 19 years of age) and 55 of middle age (45 to 65 years of age). Onset is 1 from diagnosis of a cancer and 0 otherwise. Visit years start from 1930 in adolescence and 1942 in middle age. We denote the last two digits of visit years ranging aa to bb by a dummy indicator “vyraa_bb.” In middle age, vyr42_50 has a single SBP observed, and vyr91_00 and vyr01_10 show no difference in mean SBP by the t test so that we analyze vyr42_60, vyr61_70, vyr71_80, vyr81_90 and vyr91_10. In adolescence, we analyze vyr30_40 to vyr01_10 shown in Table 2. At level 2, menarche ranges 9 to 17 years of age, missing 37%. Birth year cohorts range 1889 to 1963 in middle age, and 1912 to 1997 in adolescence. We denote the last two digits of birth years ranging aa to bb by a dummy indicator “byraa_bb.” A single SBP is observed in byr89_00, and no evidence of differences was found in mean SBP between byr00_10 and byr10 20 and in mean BMI between byr80_90 and byr90_97 by the t tests. Thus, we analyze byr_20, referring to birth years from 1989 to 1920 in middle age and from 1912 to 1920 in adolescence, to byr80_97 shown in Table 2. We standardize BMI and SBP to have mean 0 and variance 1, and center menarche at midpoint 13 years of age.
Table 2:
FLS female data summary for analysis. “vyr” and “byr” stand for visit year and birth year, respectively.
| Level | Mean(sd, missing) | Mean(sd, missing) | ||
|---|---|---|---|---|
| 1 | SBP | 119.50 (18.44,18%) | BMI | 19.74 (3.53,12%) |
| age | −1.21 ( 5.71, 0%) | age | −0.56 (2.47, 0%) | |
| onset | 0.10 ( 0.30, 0%) | onset | 1E-3 (0.03, 0%) | |
| vyr42_60 | 0.07 ( 0.26, 0%) | vyr30_40 | 0.03 (0.18, 0%) | |
| vyr61_70 | 0.17 ( 0.38, 0%) | vyr41_50 | 0.19 (0.40, 0%) | |
| vyr71_80 | 0.10 ( 0.30, 0%) | vyr51_60 | 0.16 (0.36, 0%) | |
| vyr81_90 | 0.07 ( 0.26, 0%) | vyr61_70 | 0.16 (0.36, 0%) | |
| vyr91_10 | 0.58 ( 0.49, 0%) | vyr71_80 | 0.18 (0.38, 0%) | |
| vyr81_90 | 0.11 (0.31, 0%) | |||
| vyr91_00 | 0.11 (0.31, 0%) | |||
| vyr01_10 | 0.07 (0.25, 0%) | |||
| 2 | menarche | 12.73 (1.20,37%) | ||
| byr_20 | 0.20 (0.40, 0%) | |||
| byr21_30 | 0.06 (0.24, 0%) | |||
| byr31_40 | 0.12 (0.33, 0%) | |||
| byr41_50 | 0.11 (0.32, 0%) | |||
| byr51_60 | 0.17 (0.38, 0%) | |||
| byr61_70 | 0.12 (0.32, 0%) | |||
| byr71_80 | 0.07 (0.26, 0%) | |||
| byr81_97 | 0.14 (0.35, 0%) |
For efficient estimation of the GCM by all observed data, we estimate the joint distribution of Rij =SBP, Ctj =BMI and Y2j =menarche given known covariates in Equations (1), (2) and (5) for , with the latest vyr91_10 as the reference level, , BCtj having adolescent onset and seven visit year indicators with the latest vyr01_10 as the reference, and W2j having 1 for the intercept followed by the seven cohort indicators with the latest byr81_97 as the reference. In middle age, birth years range up to 1963 with 9 individuals in byr61_70 and no difference in mean SBP found between byr51_60 and byr61_70 so that we analyze byr51_70 as the reference and set the effects of later cohorts on βRj to zero. Preliminary analysis by efficient ML estimation of two hierarchical models f (Rij, Y2j) and f (Ctj, Y2j) given known covariates implied by the joint model (Shin and Raudenbush 2007) not only provided the initial values of θ, but also enabled a series of likelihood ratio tests (LRT) that supported the first-degree polynomial βR0j + βR1jaij in middle age and the third-degree polynomial in adolescence (Stram and Lee 1994).
We attempted to simplify the joint model having 93 parameters, consisting of 63 fixed effects, 28 parameters in ϕT, and 2 error variances σCC and σRR. We identified and dropped eight BMIs and one SBP influential on the estimates by plotting the empirical Bayes estimates of random effects, and found some cohort effects different from zero on all random coefficients but βR1j by LRT producing the p-value 0.31. With no cohort effects on βR1j, we tested if the aging effect on SBP is randomly varying by testing var(βR1j) = 0. We also tested if the cubic age effect on BMI is random by testing var(βC3j) = 0. The large-sample distribution of the LRT statistics is a mixture (Stram and Lee 1994). The LRT statistics yield respective p-values 0.0002 and 0 in support of the random coefficients. Likewise, we found other age coefficients on BMI randomly varying.
Next, we transformed the full model to the desired GCM given known covariates where and are Y2j and βCj centered at the respective birth-year means from in Equation (5). Consequently, the cohort effects on βRj are marginal in the sense that they control for neither menarche nor BMI growth rates. The joint model also yields f (Y2j) and given known covariates.
We show the estimated parameters of , and in Table 3. The estimates of f (Y2j) under column heading “f (Y2j)” reveal that the average age at menarche is 12.47 years old in byr81_97 (the intercept −0.53 plus the centered age 13 of menarche), younger than those in earlier cohorts although the cohort gaps are significant only in byr_20, byr51_60 and byr61_70. The estimates of in the subsequent column under heading “” reveal that for a 14.5 year-old adolescent, the expected BMI in byr81_97 is 0.67 standard deviations (SD) above the mean BMI and higher than those in earlier cohorts with the significant gaps in byr31_40 and later cohorts, and BMI decreases 0.39 SD for each year delayed in menarche on average controlling for onset and visit years. The linear age effect in byr81_97 is positive and higher than those in byr31_40 and byr51_60, and the quadratic and cubic age effects are negative and near zero in byr81_90, respectively, with no significant gaps across cohorts on average, controlling for the covariates in the model. The person-specific linear and quadratic growth rates βC1j and βC2j in BMI are positively and cubic rate βC3j is negatively associated with menarche, ceteris paribus.
Table 3:
Estimates (standard errors) of f (Y2j), and .
| Covariates | f (Y2j) | Covariates | ||
|---|---|---|---|---|
| 1 | −0.53 (0.11)++ | 0.67 (0.08)++ | 1 | 0.03 (0.11) |
| byr_20 | 1.74 (0.56)++ | −3.12 (9.80) | byr_20 | 0.47 (0.36) |
| byr21_30 | 0.40 (0.27) | −0.45 (0.38) | byr21_30 | 0.43 (0.29) |
| byr31_40 | 0.15 (0.16) | −0.66 (0.17)++ | byr31_40 | 0.16 (0.19) |
| byr41_50 | 0.32 (0.16) | −0.44 (0.21)+ | byr41_50 | −0.03 (0.14) |
| byr51_60 | 0.49 (0.14)++ | −0.48 (0.16)++ | βC0j | 0.10 (0.21) |
| byr61_70 | 0.52 (0.15)++ | −0.39 (0.15)++ | βC1j | 0.78 (2.29) |
| byr71_80 | 0.18 (0.16) | −0.43 (0.19)+ | βC2j | 0.54 (6.95) |
| Y2j | −0.39 (0.05)++ | βC3j | 8.99 (68.2) | |
| atj | 0.20 (0.02)++ | Y2j | 0.01 (0.10) | |
| atjbyr_20 | 4.85 (11.7) | aij | 0.05 (0.01)++ | |
| atjbyr21_30 | −0.04 (0.08) | aijβC0j | −0.01 (0.02) | |
| atjbyr31_40 | −0.06 (0.03)+ | aijβC1j | 0.18 (0.16) | |
| atjbyr41_50 | −0.01 (0.03) | aijβC2j | 0.21 (0.96) | |
| atjbyr51_60 | −0.06 (0.03)+ | aijβC3j | 2.58 (5.02) | |
| atjbyr61_70 | 0.00 (0.03) | aijY2j | −0.01 (0.01) | |
| atjbyr71_80 | −0.04 (0.03) | onset | −0.00 (0.15) | |
| atjY2j | 0.03 (0.01)++ | vyr42 60 | −0.33 (0.78) | |
| −0.02 (0.00)++ | vyr61 70 | −0.58 (0.32) | ||
| −2.36 (4.18) | vyr71 80 | −0.05 (0.25) | ||
| −0.005 (0.02) | vyr81 90 | −0.26 (0.16) | ||
| −0.004 (0.01) | ||||
| 0.001 (0.01) | ||||
| 0.002 (0.01) | ||||
| −0.001 (0.01) | ||||
| 0.004 (0.01) | ||||
| 0.004 (0.002)+ | ||||
| 0.000 (0.001) | ||||
| 0.330 (0.470) | ||||
| −0.003 (0.005) | ||||
| −0.000 (0.002) | ||||
| −0.002 (0.002) | ||||
| 0.000 (0.002) | ||||
| −0.003 (0.002) | ||||
| −0.000 (0.002) | ||||
| −0.002 (0.001)++ | ||||
| onset | −0.10 (0.15) | |||
| vyr30_40 | 0.02 (0.17) | |||
| vyr41_50 | 0.04 (0.11) | |||
| vyr51_60 | 0.05 (0.09) | |||
| vyr61_70 | −0.01 (0.07) | |||
| vyr71_80 | 0.00 (0.07) | |||
| vyr81_90 | 0.03 (0.06) | |||
| vyr91_00 | −0.04 (0.04) | |||
| T22 or var(βCj) | 0.95 | 0.67 0.02 −5E-3 4E-4* | τ | 0.51 0.02 |
| 0.02 −7E-4 −7E-4 | 0.001 | |||
| 6E-4 7E-5 | ||||
| 4E-5 | ||||
| σCC | 0.036 | σRR | 0.401 |
p-value < .05;
p-value < .01;
xE − y = x × 10−y
The estimated parameters of the desired GCM in Equation (4) appear in the last column under heading “”. For a 55 year-old woman, the growth rates in adolescent BMI and menarche are positively associated with SBP controlling for cohorts, onset and historical time, but these associations are statistically insignificant. The aging effect is positive and significant on SBP, but not significantly moderated by the growth rates in adolescent BMI and menarche, ceteris paribus. Women in earlier cohorts (earlier visit years) have higher (lower) expected SBP than do those in byr41_70 (vyr91_10), controlling for age, onset and historical time (cohorts). However, the effect sizes are at most modest. Overall, the aging effect is significant on SBP, controlling for cohorts and historical time, but the cohort and temporal effects are not, controlling for age. To check if we might have found the aging effect by chance, we used the Bonferroni adjustment for testing 21 fixed effects to confirm that the aging effect is indeed significant.
Figure 2 graphs the predicted growths in adolescent BMI and middle-age SBP controlling for onset and historical time of measurement, respectively. Most strikingly, BMI is not only higher at the beginning of, but also grows faster throughout adolescence in byr81_97 than in previous cohorts such that the differences between byr81_97 and other cohorts grow to range 0.66 to 1.08 SDs at age 19. On the contrary, we see that the predicted progression of middle-age SBP barely changes across the cohorts up to byr61_70. This may be because the middle-age measurements in byr81_97 are yet unavailable. When they become available, the impact of the rapid growth in adolescent BMI on middle-age health can be more pronounced.
Figure 2:
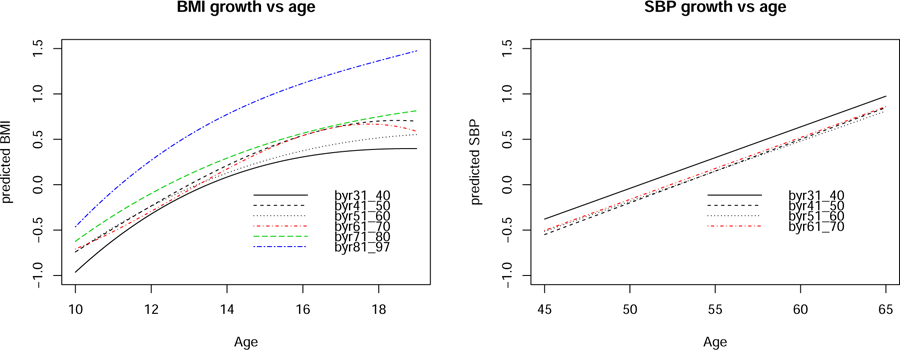
Predicted growth in adolescent BMI and middle-age SBP controlling for onset and historical time of a visit.
Figure 3 exhibits the normal probability plots of the level-2 and −1 residuals from the joint model that produced the estimates in Table 3. Modest heavy tails are noticeable in some level-2 plots, in particular, for those of the random intercepts. This may be because as many as 296 adolescents and 139 adults have only zero to 2 repeated measurements observed in BMI and SBP, respectively, essentially downsizing effective sample sizes for the model fit. This may also be because of omitted covariates we were unable to control such as socioeconomic and environmental covariates unavailable in FLS. A nonnormal model more flexible with heavy tails might have resulted in an improved fit. Other than the moderate heavy tails, the residuals do not appear to deviate severely from the assumed model.
Figure 3:
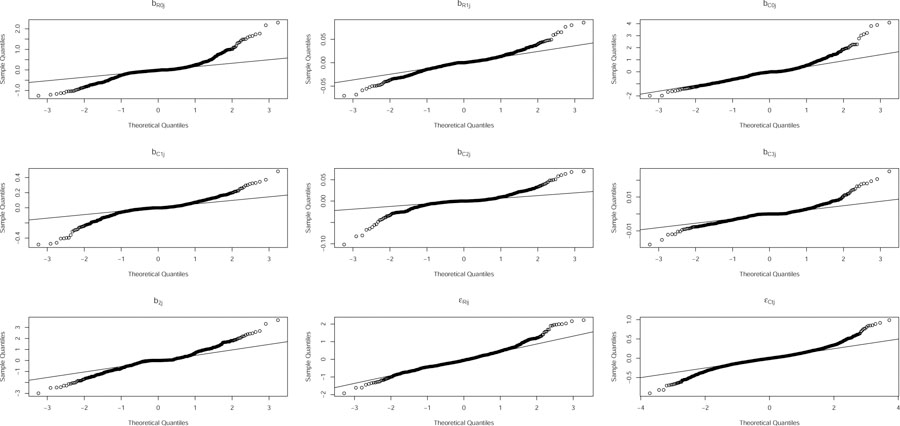
Residual plots of the joint model that produced estimates in Table 3.
We repeated the analysis with an extra covariate, indicating if an individual was taking medication at the time of measurement, added to BRij and BCtj of the joint model. The total number of visits on medication happened at 22 adolescent and 53 middle-age occasions. Neither the significant effect of the covariate was found on either BMI or SBP, nor did the added covariate change the estimates in Table 3 in a notable way.
6. Discussion
We analyzed the repeated measurements of adolescent BMI and middle-age SBP nested within 835 female participants of FLS to estimate the lasting effects of growth rates in BMI and menarche, including the growth rates-by-age and menarche-by-age interaction effects, on SBP later in middle age via a multilevel GCM, controlling for onset of cancer, age, birth year cohort, and historical time of measurement. Estimation of the GCM was nonstandard and computationally intensive because BMI and SBP were repeatedly measured on two distinct sets of unbalanced time points nested within each participant, and missing values were substantial on BMI, SBP and menarche.
For efficient estimation by all observed data, we estimated the multilevel joint distribution of SBP, BMI and menarche assumed MAR given known covariates by ML via the EM algorithm. A series of likelihood ratio tests revealed that the coefficients of the linear, quadratic and cubic age terms on BMI and linear age on SBP vary randomly across individuals and that cohort effects are significant on menarche and random coefficients except the random slope of age on SBP. We transformed the estimated joint model to the desired GCM by the delta method. Because we analyzed FLS female participants who are mostly white, our findings are most appropriately applicable to European Americans. We illustrated unbiased estimation by our method via simulation.
The estimated mean growth trajectory in adolescent BMI is much higher among individuals born in 1981 to 1997 than those in earlier cohorts such that the mean differences are most striking, ranging 0.66 to 1.08 SDs on average, by age 19 as shown in Figure 2. Because middle-age measurements of those born in 1981 or later are not yet available, we are unable to show the impact on middle-age SBP. When they become available, we anticipate that the impact will strengthen quite remarkably.
We found only modest effect sizes of growth rates in adolescent BMI and menarche on SBP in our analysis. That may be because we have ignored an important family level. Because 376 family members and relatives who accompanied 459 participants enrolled at birth to clinics for measurement were also measured, analysis of the repeated measurements of individuals nested within families would have resulted in more efficient estimates, which will be an important future analysis.
Because FLS started collecting socioeconomic covariates such as income and education quite recently since the year 2002, we could not control for the effects of such covariates. The omitted covariates may have contributed to the modest effect sizes we found. A valuable future research is to reanalyze the GCM, combining FLS with other longitudinal samples that have collected extensive socioeconomic covariates. Our missing data method can be extended to handle such analysis of multiple samples.
The FLS female sample comprises 1,196 occasions of 436 subjects to give 2.7 occasions per middle-age female. In addition, missing data are substantial on BMI, SBP and menarche. Consequently, the FLS female sample sizes may not have provided adequate power to detect the desired effects. Furthermore, adolescence and middle age may be too distant to reveal significant associations between BMI and SBP, possibly, due to confounders. In near future, we want to reanalyze the model in a way that increases sample sizes and also in a way that involves closer timeframes. For example, we may estimate the effects of growth rates in teenagers’ obesity on an earlier adulthood outcome by the entire sample.
Adolescent obesity may also be too distant in time to reveal direct effects on middle-age health. What we have found in this paper may be the evidence of a lack of the direct effects of growth rates in adolescent obesity on middle-age health, and important mediators may exist in closer future. For example, it is plausible that the effects of adolescent obesity on middle-age health are mediated by a near-future health outcome in earlier adulthood. Although we have illustrated the impact of a univariate BMI in adolescence on a univariate SBP in middle age, extension to multivariate health outcomes is straightforward.
Under our current model, we assumed constant variances σRR and σCC of occasion-specific or within-person random errors of middle-age SBP and adolescent BMI, respectively. In near future, we want to estimate non-constant error variances σRRj and σCCj of person j such that the person-specific random coefficients of SBP are correlated with the within-person variances log(σRRj) and log(σCCj) (Hedeker et al. 2008). We will also consider the non-constant variances of the SBP and BMI growth trajectories, for example, across males and females in an extended FLS analysis.
Acknowledgements
We really appreciate two anonymous reviewers for their helpful comments that greatly improved our manuscript. This research was supported by the National Institutes of Health through grants R01AG048801 and UL1TR002649, by the Institute of Education Sciences, U.S. Department of Education, through grant R305D130033, and by the Virginia Commonwealth University Presidential Research Quest Fund. The views expressed in this publication are those of the authors and not necessarily those of the National Institute for Health or the Institute of Education Sciences.
Footnotes
Conflict of Interest
The authors have declared no conflict of interest.
Convergence to ML is taken to be less than 10−6 in the difference between loglikelihood values of two consecutive iterations.
References
- Bock RD and Lieberman M (1970). Fitting a Response Model for n Dichotomously Scored Items. Psychometrika, 35, 179–197. [Google Scholar]
- Bauer DJ (2003). Estimating Multilevel Linear Models as Structural Equation Models, Journal of Educational and Behavioral Statistics, 28, 135–167. [Google Scholar]
- Bollen KA (1989). Structural equations with latent variables. New York: John Wiley & Sons. [Google Scholar]
- Bollen KA and Curran PJ (2006). Latent curve models: A structural equation perspective, Hoboken, NJ: Wiley [Google Scholar]
- Caspi A, Houts RM, Belsky DW, Harrington H, Hogan S, Ramrakha S, Poulton R and Moffitt TE (2016). Childhood forecasting of a small segment of the population with large economic burden, Nature Human Behavior, 1, 1–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Casella G and Berger RL (2002). Statistical Inference, Belmont, CA: Duxbury [Google Scholar]
- Dempster AP, Laird NM, and Rubin DB (1977). Maximum Likelihood From Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society: Series B, 76, 1–38. [Google Scholar]
- Dempster AP, Rubin DB and Tsutakawa RK (1981). Estimation in Covariance Components Models. Journal of the American Statistical Association, 76, 341–353. [Google Scholar]
- Eriksson JG, Forsen T, Tuomilehto J, Winter PD, Osmond C and Barker DJ (1999). Catch-up growth in childhood and death from coronary heart disease: longitudinal study. BMJ, 318, 427–431. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Felitti VJ, Anda RF, Nordenberg D, Williamson DF, Spitz AM, Edwards V, Koss MP and Marks JS (1998). Relationship of childhood abuse and household dysfunction to many of the leading causes of death in adults. The Adverse Childhood Experiences (ACE) Study. American Journal of Preventive Medicine, 14, 245–258. [DOI] [PubMed] [Google Scholar]
- Ferreira I, Twisk JW, van Mechelen W, Kemper HC,Stehouwer CD (2005) Development of fatness, fitness, and lifestylefrom adolescence to the age of 36 years: determinants of the metabolic syndrome in young adults. The Amsterdam growth and health longitudinal study. Arch. Intern. Med, 165, 42–48. [DOI] [PubMed] [Google Scholar]
- Goldstein H and Browne W (2002). Multilevel factor analysis modeling using Markov Chain Monte Carlo estimation In Marcoulides G and Moustaki I eds. Quantitative methodology series. Latent variable and latent structure models, Mahwah, NJ, US: Lawrence Erlbaum Associates Publishers, 225–243. [Google Scholar]
- Goldstein H (2003). Multilevel Statistical Models, London: Edward Arnold. [Google Scholar]
- Goldstein H, Carpenter J, Kenward MG and Levin KA (2009). Multilevel models with multivariate mixed response types, Statistical Modeling, 9, 173–197. [Google Scholar]
- Goldstein H and Kounali D (2009). Multilevel multivariate modeling of childhood growth, numbers of growth measurements and adult characteristics, Journal of the Royal Statistical Society: Series A, 172, 599–613. [Google Scholar]
- Grilli L and Rampichini C (2011). The role of sample cluster means in multilevel models: A view on endogeneity and measurement error issues. Methodology: European Journal of Research Methods for the Behavioral and Social Sciences, 7, 121–133. [Google Scholar]
- Grimm KJ and Ram N (2009). Nonlinear Growth Models in Mplus and SAS. Structural Equation Modeling, 16, 676–701. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gueorguieva R (2001). A multivariate generalized linear mixed model for joint modeling of clustered outcomes in the exponential family, Statistical Modeling, 1, 177–193. [Google Scholar]
- Hedeker D and Gibbons RD (1994). Application of Random-Effects Pattern-Mixture Models for Missing Data in Longitudinal Studies, Psychological Methods, 2, 64–78. [Google Scholar]
- Hedeker D, Mermelstein RJ and Demirtas H (2008). An Application of a Mixed-Effects Location Scale Model for Analysis of Ecological Momentary Assessment (EMA) Data. Biometrics, 64(2), 627–634. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ivanova A, Molenberghs G and Verbeke G (2016). Mixed models approaches for joint modeling of different types of responses, Journal of Biopharmaceutical Statistics, 26, 601–618. [DOI] [PubMed] [Google Scholar]
- Kim N, Sabo RT, Wang A, Sabo CS and Sun SS (2016). Effects of Curtailed Juvenile State on Cardiac Structure and Function in Adulthood: The Fels Longitudinal Study, Journal of Child Obesity, 1, 1–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Law CM, Shiell AW, Newsome CA, Syddall HE, Shinebourne EA, Fayers PM, Martyn CN and de Swiet M (2002). Fetal, Infant, and Childhood Growth and Adult Blood Pressure. Circulation, 105, 1088–1092. [DOI] [PubMed] [Google Scholar]
- Liu M, Taylor JMG, and Belin TR (2000). Multiple Imputation and Posterior Simulation for Multivariate Missing Data in Longitudinal Studies. Biometrics, 56 1157–63. [DOI] [PubMed] [Google Scholar]
- Lüdtke O, Marsh HW, Robitzsch A, Trautwein U, Asparouhov T, and Muthén B (2008). The Multilevel Latent Covariate Model: A New, More Reliable Approach to Group-Level Effects in Contextual Studies, Psychological Methods, 13, 203–229. [DOI] [PubMed] [Google Scholar]
- MacCallum RC, Kim C, Malarkey W and Kielcolt-Glaser J (1997). Studying multivariate change using multilevel models and latent curve models. Multivariate Behavioral Research, 32, 215–253. [DOI] [PubMed] [Google Scholar]
- McLeod GF, Fergusson DM, Horwood LJ, Boden JM and Carter FA (2018). Childhood predictors of adult adipose: findings from a longitudinal study, The New Zealand Medical Journal, 131(1472), 10–20. [PubMed] [Google Scholar]
- Moffitt TE, Arsenate L, Bel sky D, Dickson N, Han cox RJ, Harrington H, et al. (2011). A gradient of childhood self-control predicts health, wealth, and public safety. Proceedings of the National Academy of Sciences USA, 108, 2693–98. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nooyens ACJ, Koppes LLJ, Visscher TLS, Twisk JWR, Kemper HCG, Schuit AJ, van Mechelen W, Seidell JC (2007). Adolescent skinfold thickness is a better predictor of high body fatness in adults than is body mass index: the Amsterdam Growth and Health Longitudinal Study, The American Journal of Clinical Nutrition, 85, 1533–9. [DOI] [PubMed] [Google Scholar]
- Olsen MK and Schafer JL (2001). A Two-Part Random-Effects Model for Semi continuous Longitudinal Data, Journal of the American Statistical Association, 96, 730–745. [Google Scholar]
- Preacher KJ, Switchman AL, Malacca RC and Briggs NE (2008). Latent Growth Curve Modeling. Sage: Thousand Oaks, CA. [Google Scholar]
- R Core Team (2017). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria: URL https://www.R-project.org/. [Google Scholar]
- Raghunathan T, Lepkowski J, Van Hoewyk J and Solenberger P (2001). A Multivariate Technique for Multiply Imputing Missing Values Using a Sequence of Regression Models. Survey Methodology, 27, 85–95. [Google Scholar]
- Ram N and Grimm KJ (2015). Growth Curve Modeling and Longitudinal Factor Analysis In Lerner RM (Ed.), Handbook of child psychology and developmental science (pp. 1–31). Hoboken, NJ: John Wiley & Sons, Inc. [Google Scholar]
- Raudenbush SW, Yang M, Yosef M (2000). Maximum Likelihood for Generalized Linear Models with Nested Random Effects via High-Order, Multivariate Laplace Approximation. Journal of Computational and Graphical Statistics, 9, 141–157. [Google Scholar]
- Raudenbush SW and Bryk AS (2002). Hierarchical Linear Models. Newbury Park, CA: Sage. [Google Scholar]
- Ren C and Shin Y (2016) Longitudinal Latent Variable Models Given Incompletely Observed Biomarkers and Covariates, Statistics in Medicine, 35, 4729–45. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roberts BW, Kuncel NR, Shiner R, Caspi A and Goldberg LR (2007). The power of personality: the comparative validity of personality traits, socioeconomic status, and cognitive ability for predicting important life outcomes. Perspectives on Psychological Science, 2, 313–345. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roche A (1992). Growth, maturation and body composition: the Fels longitudinal study 1929–1991. United Kingdom: Cambridge University Press. [Google Scholar]
- Rubin DB (1976). Inference and missing data. Biometrika, 63, 581–592. [Google Scholar]
- Sabo RT, Lu Z, Daniels S and Sun SS (2012). Serial Childhood BMI and associations With Adult Hypertension and Obesity: the Fels Longitudinal study, Obesity, 20, 1741–43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sabo RT, Yen M, Daniels S and Sun SS (2014). Associations between Childhood Body Size, Composition, Blood Pressure and Adult Cardiac Structure: The Fels Longitudinal Study, PLoS ONE, 9, 1–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sabo RT, Wang A, Deng Y, Sabo CS and Sun SS (2017). Relationships between childhood growth parameters and adult blood pressure: the Fels Longitudinal Study, Journal of Developmental Origins of Health and Disease, 8, 113–122. [DOI] [PubMed] [Google Scholar]
- Schafer JL and Yucel RM (2002). Computational Strategies for Multivariate Linear Mixed-Effects Models with Missing Values. Journal of Computational and Graphical Statistics, 11, 437–457. [Google Scholar]
- Shin Y and Raudenbush SW (2007). Just-Identified Versus Over-Identified Two-Level Hierarchical Linear Models with Missing Data. Biometrics, 63, 1262–68. [DOI] [PubMed] [Google Scholar]
- Shin Y and Raudenbush SW (2010). A Latent Cluster Mean Approach to The Contextual Effects Model with Missing Data. Journal of Educational and Behavioral Statistics, 35, 26–53. [Google Scholar]
- Shin Y and Raudenbush SW (2020). Income Equality in Achievement among US Elementary Schools: A Random Coefficients Model with Data MAR. Manuscript in preparation.
- Stram DO and Lee J (1994). Variance Components Testing in the Longitudinal Mixed Effects Model. Biometrics, 50, 1171–77. [PubMed] [Google Scholar]
- Sun SS, Grave GD, Siervogel RM, Pickoff A, Arslanian S, and Daniels SR (2007). Systolic Blood Pressure in Childhood Predicts Hypertension and the Metabolic Syndrome Later in Life. Pediatrics, 119, 237–46. [DOI] [PubMed] [Google Scholar]
- Sun SS, Liang R, Huang TT, Daniels SR, Arslanian S, Liu K, Grave GD, and Siervogel RM (2008). Childhood obesity predicts adult metabolic syndrome: the Fels Longitudinal Study. The Journal of Pediatrics, 152, 191–200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van Buuren S, Brand J, Groothuis-Oudshoorn C, and Rubin D (2006). Fully conditional specification in multivariate imputation. Journal of Statistical Computation and Simulation, 76, 1049–64 [Google Scholar]
- van Buuren S (2011). Multiple imputation of multilevel data In Hox JJ and Roberts JK (Eds.), The Handbook of Advanced Multilevel Analysis, Chapter 10, pp. 173–196. Milton Park, UK: Routledge. [Google Scholar]
- Wang M and Bodner T (2007). Growth Mixture Modeling: Identifying and Predicting Unobserved Subpopulations with Longitudinal Data. Organizational Research Methods, 10, 635–656. [Google Scholar]
- Willett JB and Sayer AG (1994). Using covariance structure analysis to detect correlates and predictors of individual change over time. Psychological Bulletin, 116, 363–381. [Google Scholar]