

Abstract
Respondent driven sampling (RDS) is a sampling method designed for hard-to-sample groups with strong social ties. RDS starts with a small number of arbitrarily selected participants (“seeds”). Seeds are issued recruitment coupons, which are used to recruit from their social networks. Waves of recruitment and data collection continue until reaching a sufficient sample size. Under the assumptions of random recruitment, with-replacement sampling, and a sufficient number of waves, the probability of selection for each participant converges to be proportional to their network size. With recruitment noncooperation, however, recruitment can end abruptly, causing operational difficulties with unstable sample sizes. Noncooperation may void the recruitment Markovian assumptions, leading to selection bias. Here, we consider two RDS studies: one targeting Korean immigrants in Los Angeles and in Michigan; and another study targeting persons who inject drugs in Southeast Michigan. We explore predictors of coupon redemption, associations between recruiter and recruits, and details within recruitment dynamics. While no consistent predictors of noncooperation were found, there was evidence that coupon redemption of targeted recruits was more common among those who shared social bonds with their recruiters, suggesting that noncooperation is more likely to be a feature of recruits not cooperating, rather than recruiters failing to distribute coupons.
Keywords: Respondent driven sampling, sampling hard-to-reach population, nonresponse error
1. Introduction
Respondent driven sampling (RDS) is a new sampling method first introduced in 1997 to address the lack of feasible approaches for capturing rare, elusive and/or hard-to-reach groups (Heckathorn 1997). RDS, as a variant of snowball sampling, is entirely different than traditional sampling. In traditional sampling, researchers control the recruitment process by selecting participants in a randomized fashion from established frames and recruiting sampled participants individually and independently. Although not universal, incentives are often provided for participation as a token of appreciation (Singer 2002). On the other hand, RDS starts with a handful of participants (seeds) directly recruited by researchers. After collecting data from the seeds, researchers issue recruitment coupons to them, who then distribute the coupons to and recruit their peers from their own social networks. The peers participate in the study by redeeming the coupons and, just like the seeds, are issued coupons for recruiting their own peers. This recruitment process continues in waves. Although there is no standard, RDS coupons include a serial number that links a recruit to his/her recruiter and are used as a means to incentivize recruitment (i.e., in addition to study participation incentives, participants are given recruitment incentives based on the number of redeemed coupons). The recruitment process in RDS is essentially controlled by participants, is incentivized and is based on chain-referrals, where each seed forms his/her own chain. Naturally, word of mouth (WOM) comes into play in RDS (Hathaway et al. 2010).
RDS is neither the only option nor a perfect method for reaching rare, elusive and/or hard-to-reach groups, as illustrated in Lee et al. (2014) and Wagner and Lee (2014). It depends on the study goals, as well as the characteristics of the target groups. Obviously, one may consider screening probability samples potentially stratified by characteristics related to the target rare group (Kalsbeek 2003; Kalton and Anderson 1986). However, this is resource-intensive and becomes more so when the target groups are geographically dispersed. For rare groups with stigmatized characteristics (e.g., illicit substance users), this screening method may be ineffective. If there are certain access points in the geography or cyberspace (e.g., gay dating apps, ethnic groceries) frequented by a large share of target rare groups, those points may be leveraged for sampling (e.g., time and location sampling). When the target groups are difficult to reach through conventional methods or existing venues but are connected with each other in some fashion, RDS may become effective. With a social network being the basic premise of RDS, if members of the target group are not networked, RDS is inapplicable.
2. Recruitment Cooperation in Respondent Driven Sampling
Success in implementing RDS depends on participants’ cooperation with recruitment requests. Noncooperation directly leads to recruitment chains dying out and causes samples to stop growing in size. This forces researchers to make design changes to meet the target sample size. For example, an RDS study, the Chicago Health and Life Experiences of Women, reports slow data collection, forcing them to improvise design features (e.g., adding more seeds) (Bostwick et al. 2015; Martin et al. 2015). Noncooperation with RDS recruitment is compound in nature and can be attributed to four sources: 1) participants’ network sizes (degree); 2) participants’ willingness to recruit their peers which can be manifested through their acceptance of coupons from the researchers and/or their act of giving out coupons; 3) their peers’ acceptance of coupons; and 4) coupon recipients’ willingness to participate (Lee et al. 2012; Gile et al. 2015; Lee et al. 2017). Naturally, participants with small networks are likely to have fewer eligible peers than those with larger networks. This can be ascertained to some extent by directly asking the network size. The latter three sources are typically unknowable until the data collection ends. This turns RDS sample sizes into a random variable for which researchers have little information, making them neither predictable nor controllable (World Health Organization and UNAIDS 2013; Centers for Disease Control and Prevention, CDC 2015; Lee et al. 2018). Examples of such difficulties are plentiful in the field (e.g., LGBTQ in Washington D.C. in Tucker et al. 2015; Polish migrants in Great Britain in Luthra 2011); however, they remain as anecdotes reported mostly at professional meetings and are rarely found in the peer-reviewed literature. Exacerbated by the lack of transparency and inadequate reporting of RDS studies (Hafeez 2012; White et al. 2015), when facing unforeseen challenges in RDS operations, researchers will be left on their own to make design changes on the spur of the moment in hopes of making RDS “work” (Martin et al. 2015). This approach is neither replicable nor informative for effective RDS designs.
Recruitment cooperation has profound implications for inferences. However, it is largely overlooked in the extant RDS literature which rests on strong assumptions (Lee 2009; Gile and Handcock 2010; White et al. 2015; Heckathorn and Cameron 2017; Lee et al. 2017). Arguably, the most important assumption is that RDS recruitment chains follow a Markov process, where the future and past states are independent given the present. Figures 1 (A, B) illustrates two different RDS scenarios of a sample size 20 coming from two chains. In Figure 1A, chains start with seeds’ characteristics (black or white color), which are lost in the process of recruiting through ten waves, and the characteristics of the overall sample becomes independent of the seeds. On the other hand, the two chains in Figure 1B are different in their sizes and much shorter at four and two waves, with chains “remembering” the characteristics of their own seeds. Chains that are long and similar in their length and size (e.g., Figure 1A) are likely to follow a Markov process. Noncooperation, particularly differential noncooperation, produces chains like Figure 1B, violating this assumption (Strömdahl et al. 2015). This dependence needs to be accounted for in computing sampling variance. Although noted as a critical gap in RDS inferences (Heckathorn and Cameron 2017), variance estimation becomes less of a concern if the design facilitates the chains to grow like Figure 1A.
Fig. 1 (A, B).
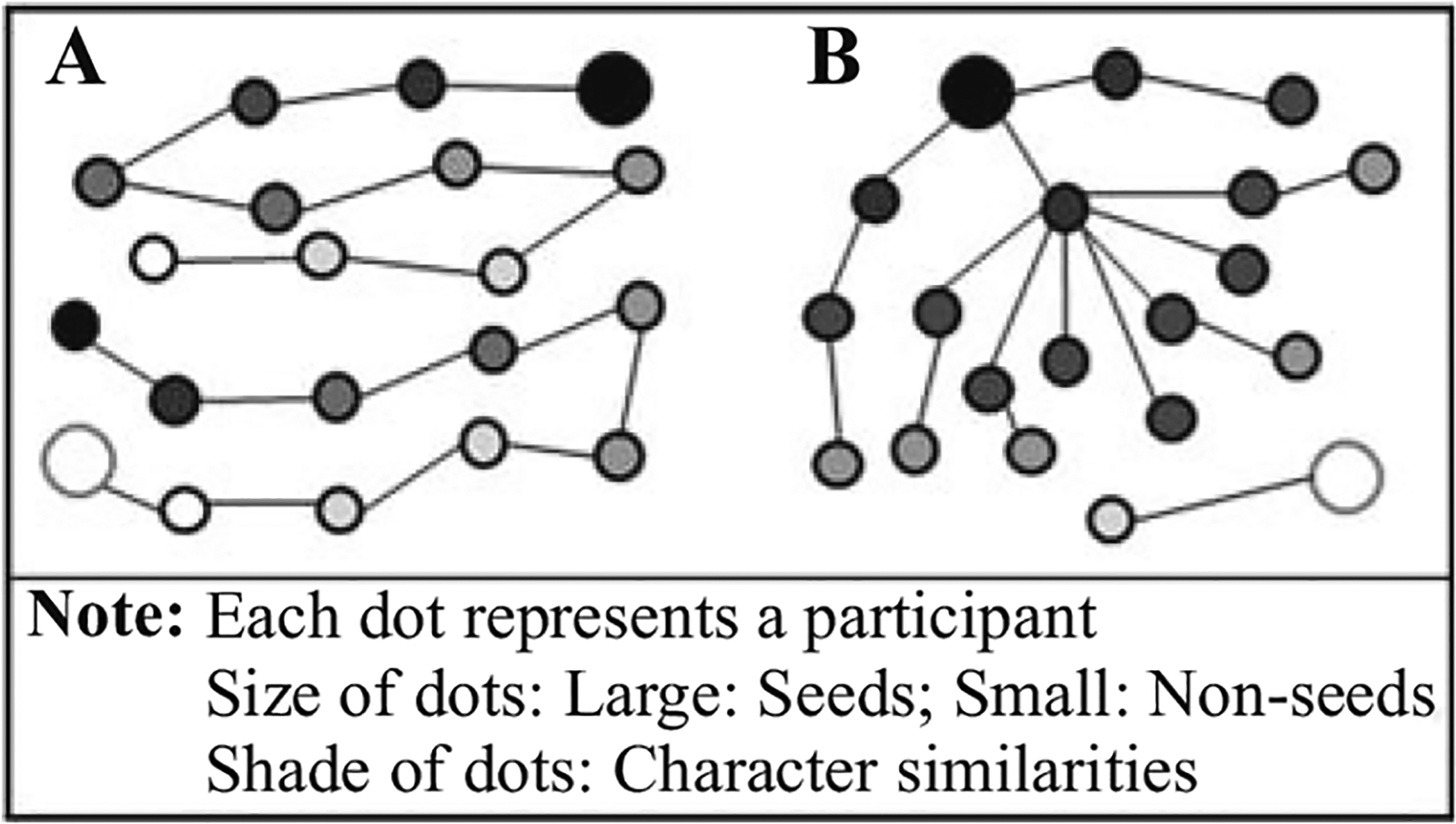
Two types of recruitment chains with two seeds.
While noncooperation and sampling are conceptualized separately in traditional sampling (Groves 1989), noncooperation in RDS directly influences the sampling mechanism (Lee 2009). It is imperative for inferences to reflect design and operational glitches (Shadish and Cook 1999). For instance, in probability sampling, estimators incorporate design fully (e.g., selection probability, stratification) and attempt to correct for nonresponse based on the extensive literature on its mechanism (e.g., Groves and Couper 1998; Kalton and Flores-Cervantes 2003). While the same should hold for RDS, existing RDS inference approaches rely mostly on the network sizes and structures (McCreesh et al. 2013; Tomas and Gile 2011; Gile and Handcock 2015; Li et al. 2017), and are rather blind to the realities of recruitment noncooperation (Gile et al. 2015) despite its nonrandomness (Abramovitz et al. 2009; Lee et al. 2017) and undesirable effects (Stein et al. 2018). Hence, poor inference properties of existing RDS estimators for real-world data (Lu et al. 2012; Verdery et al. 2015; Selvaraj et al. 2016) are not surprising.
This study uses data from two RDS studies that targeted distinctive rare groups using different administration modes. These studies embedded similar features to allow us to examine the dynamics of RDS recruitment, in particular the mechanisms of recruitment noncooperation, which have not been carefully examined in the extant literature.
3. Data and Methods
3.1. Data
3.1.1. Study 1: Positive Attitudes Towards Health
We conducted the Positive Attitudes Towards Health (PATH), an in-person RDS study targeting persons who inject drugs (PWID) in Southeast Michigan in the United States, from May to November 2017.
The overall study protocol closely resembled the PWID component of the National HIV Behavioral Surveillance by the Centers for Disease Control and Prevention (CDC 2015). Seeds were recruited through recruitment flyers and cards distributed through PWID and at-risk population service agencies around Wayne, Macomb and St. Clair counties Interested individuals were instructed to call the research team, who then conducted a short screening interview and scheduled an in-person visit with eligible persons. Specifically, PWID who were at least 18 years old, who resided in the three counties noted above, and who injected within the six months were eligible. The data collection sites were Detroit, Warren, Roseville and St. Clair. Upon each visit, interviewers conducted another screening interview that included checking for physical injection marks and administered the main survey as an audio computer-assisted-self-interview (A-CASI). After the main survey, recruitment coupons were issued to participants who were also provided with instructions regarding peer recruitment for the PATH and a recruitment instruction card. Three coupons were issued per participant unless they indicated knowing fewer than three PWID in the area, in which case they were given a number of coupons up to the number of eligible people they know (i.e., one coupon if they knew one other person, two if they knew two). Reminder calls regarding recruitment were given to the participants 7, 10 and 12 days after the main survey. Roughly two weeks after the main interview, all participants to whom at least one coupon was issued were invited back to the site for a follow-up survey also done in A-CASI and for a recruitment incentive payment. Participants were offered USD 30 for completing the main survey, USD 5 for the follow-up survey and USD 10 for each successful recruit. Overall, 410 PWIDs participated in PATH, and 172 participated in the follow-up. Socio-demographic characteristics of the PATH participants are provided in Table A1 (Appendix, Section 11).
3.1.2. Study 2: Health and Life Study of Koreans
A web-based RDS was implemented through the Health and Life Study of Koreans (HLSK) which targeted Korean immigrants (i.e., Koreans born outside of the United States) living in Los Angeles County (LA) and the State of Michigan (MI). The recruitment was done through RDS chain referrals. Unlike the PATH, the majority of the operation was done over the web. Most seeds were recruited via online ads and some referrals through various Korean and Korean American organizations. Eligible seeds were invited to the main survey by the study team and given a unique number required to access the questionnaire. Toward the end of the main survey, participants were notified about the peer recruitment. Shortly after the main survey, two coupons were issued, unless participants reported knowing fewer than two foreign-born Koreans in the target area. Coupons included unique numbers for the recruits to use for accessing questionnaires. When coupons were not redeemed, we sent reminders to the participants 7, 10 and 12 days after the main survey to encourage them to distribute coupons. Two weeks after the main survey, participants were invited to a follow-up survey. A total of 639 Koreans participated in the main survey and 266 in its follow-up survey. Note that among 639 main completes, eight were Korean immigrants whose postal addresses are outside of Louisiana and Michigan. Additionally, there were two participants whose survey responses were not properly stored in the software and, hence, were excluded from the analysis of survey responses. Table A1 (Appendix) provides socio-demographic characteristics of the HLSK participants.
3.1.3. Features Specific to Recruitment Process in Study 1 and Study 2
In order to examine dynamics of peer-referral recruitment processes in both PATH and HLSK, we implemented special features as described in Figure 2. In the main survey, all participants were asked how many study-eligible persons they knew (“social network size”) and about the age, gender and relationship of the persons to whom they intended to distribute coupons (i.e., intended recruits). Specifically for non-seeds (i.e., participants recruited by someone else), we asked about the characteristics of their recruiters, including age, gender, relationship type, closeness and contact patterns. It should be noted that the social network size was examined in various ways in each survey. In addition to the standard measures that simply asked how many target group members a participant knew, both surveys asked how many of them were participants’ family members, how many of them participants interacted with more than once a week, and how many of them participants felt close to.
Fig. 2.
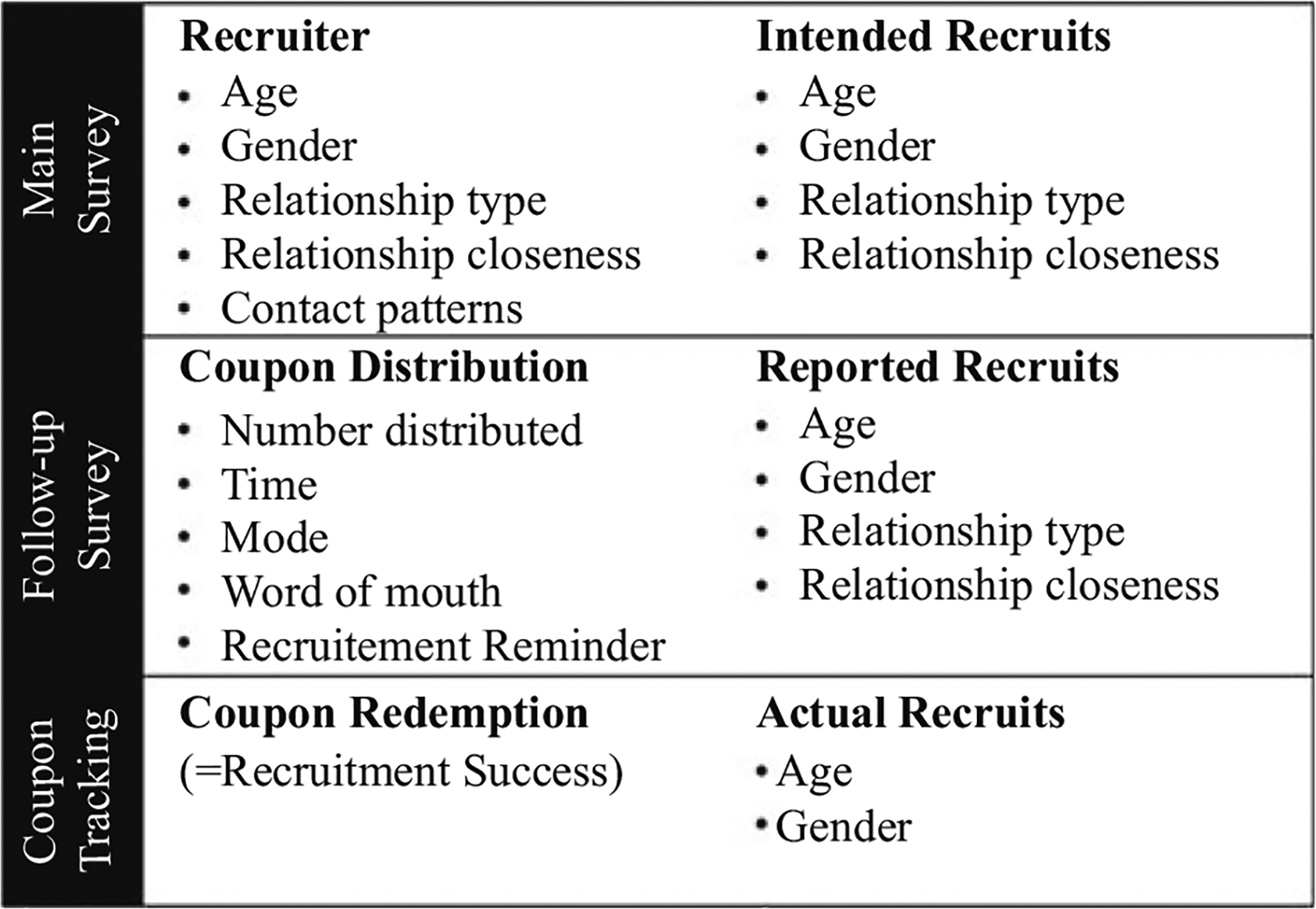
Features for recruitment noncooperation examination in PATH and HLSK.
The follow-up survey included questions detailing the actual coupon distribution process, rather than the intended distribution. Specifically, we asked for the number of coupons each participant actually distributed; the characteristics (age, gender and relationship) of the persons to whom coupons were distributed (i.e., reported recruits); the timing and mode of coupon distribution; the type of message used when distributing coupons (“What did you tell (RECRUIT) about the study?”); whether they knew the participation status of the reported recruits; and for HLSK, utility of the recruitment reminder.
As part of the sample management, we tracked each of the issued coupons and the redemption status through which participants’ recruitment success can be ascertained. From this, the links between participants and their recruiters and between participants and their actual recruits can be established. Because characteristics of actual recruits can be accessed from the main survey, they can be added to our analysis. Within each study, when the main, follow-up and the tracking data are combined, data about the characteristics of intended, attempted and actual recruits become available.
3.2. Analysis Procedures
The analysis will focus on five aspects of peer recruitment in RDS. Because similar features were implemented in PATH and HLSK, all analysis will be done using both surveys to broaden the applicability.
First, we will examine the progress of the main survey data collection by plotting the number of recruited seeds, the number of issued coupons and the number of completed interviews (i.e., participants) separately for each data collection site over time as well as visualizing the overall recruitment chain structures that denote each participant as a node and each recruiter-recruit relationship as an edge. In particular, the recruitment network diagrams will be compared to Figures 1 (A, B). Here, visualized recruitment networks will allow us to assess the plausibility of the Markov process assumption in Studies 1 and 2.
The second analysis will focus on the coupon use, including the distribution and the redemption. From coupon tracking data, we will examine the number of issued and successfully redeemed coupons. Further, the follow-up survey included questions about participants’ coupon distribution and their knowledge about distributed coupons’ redemption status. This allows us to examine, for the follow-up participants, whether the number of distributed coupons reported in the follow-up survey is greater than, smaller than or equal to the number of redeemed coupons. By linking knowledge about the coupon redemption status from the follow-up survey and the true redemption status ascertained from coupon tracking, we will examine how participants’ knowledge compares to the actual success.
Recruitment success among all participants who were issued coupons will be examined in a multivariate model as a function of participant characteristics, including socio-demographics in Table A1 (Appendix), social network size and drug use for the PATH or ethnic identity for the HLSK. In particular, we will use the ratio of the number of redeemed coupons over issued coupons as a dependent variable in a quasibinomial regression. This is to avoid any confounding imposed by the number of issued coupons on recruitment success and to account for overdispersion. In these models, we tested all versions of social networks described in Subsection 3.1.3 as an independent variable. The best model fit was observed through likelihood ratio tests for the following versions of social networks: for the PATH, the number of PWID that participants interacted more than once a week; and for the HLSK, the number of foreign-born Koreans to whom participants felt close. For the PATH, we also tested models with participants’ drug use. This did not improve the ability to explain recruitment success. We present results from the best fitting models.
The third analysis will involve triangulating data from the main survey, the follow-up survey and coupon tracking, and examining profiles of intended (from the main survey), reported (from the main survey) and actual recruits (from coupon tracking and the main survey). We will compare profiles of all intended recruits reported by all participants and actual recruits ascertained from coupon linkage, focusing on age and sex. Intended recruits will be further compared by participants’ recruitment success in order to examine whether successful recruiters target different types of peers than unsuccessful recruiters through χ2 independence tests. For the follow-up participants, the profiles will be compared between their intended and reported recruits. Further, for the follow-up participants who also were successful at recruitment, age and sex of their intended, reported and actual recruits will be compared. There is no way to link intended, reported and actual recruits individually as we will have no data on all intended or reported recruits who did not participate. Instead, we will focus on the profile of the recruits. Note that the data on intended, reported and actual recruits will each be stacked at the recruit level in the analysis of recruit profiles.
The social relationship between recruiters and recruits will be our fourth analysis. For all participants, the main survey asked the type of relationship and the closeness that participants have with their intended recruits; and for any non-seed participants (i.e., actual recruits), the main survey also asked the relationship type and closeness with their recruiter. These allow us to compare the relationship between recruiters and their intended recruits and between actual recruits and their recruiters. As done with recruit profiles, intended recruits will be further compared by participants’ recruitment success in order to examine whether social relationship matters for successful recruitment through χ2 independence tests. For the follow-up participants, the relationship type and closeness will be compared between their intended and reported recruits.
The last analysis step will examine the dynamics within the coupon distribution process ascertained through the follow-up survey: in particular, the coupon distribution timing since issuance, and its mode and WOM participants used during coupon distribution. For the HLSK, we will also examine whether participants received recruitment reminders and whether they reminded the reported recruits about participating in the survey.
To date, there is no comprehensive analysis on RDS recruitment cooperation. Therefore, our analysis will take a descriptive approach to provide detailed information in the recruitment process that can be ascertained from our triangulated data. The next four sections will include results from each analysis step along with implications. These implications will be summarized in the last section along with comparisons of two RDS studies in our analysis.
4. Data Collection Progress
Figures 3 (A, B) include the number of seeds, issued coupons and participants (i.e., seeds and redeemed coupons) over the data collection periods of the PATH and the HLSK. The PATH started its data collection in the first week of May and continued until the first week of November 2017. A total of 410 participants (286 Detroit, 104 St. Clair, 20 Macomb) stemming from 46 seeds (22 Detroit, 14 St. Clair, 10 Macomb) were interviewed, meaning 364 were recruited via coupons. Most seeds were recruited at the beginning of the data collection, and very few were added in the second half. It is notable that, even though the number of seeds did not differ greatly across sites, the number of non-seeds did. Especially in Macomb, after two months into data collection, only ten recruits were generated from ten seeds with no in-person visits scheduled. Due to low productivity, data collection was suspended in Macomb as of August 2017.
Fig. 3A.
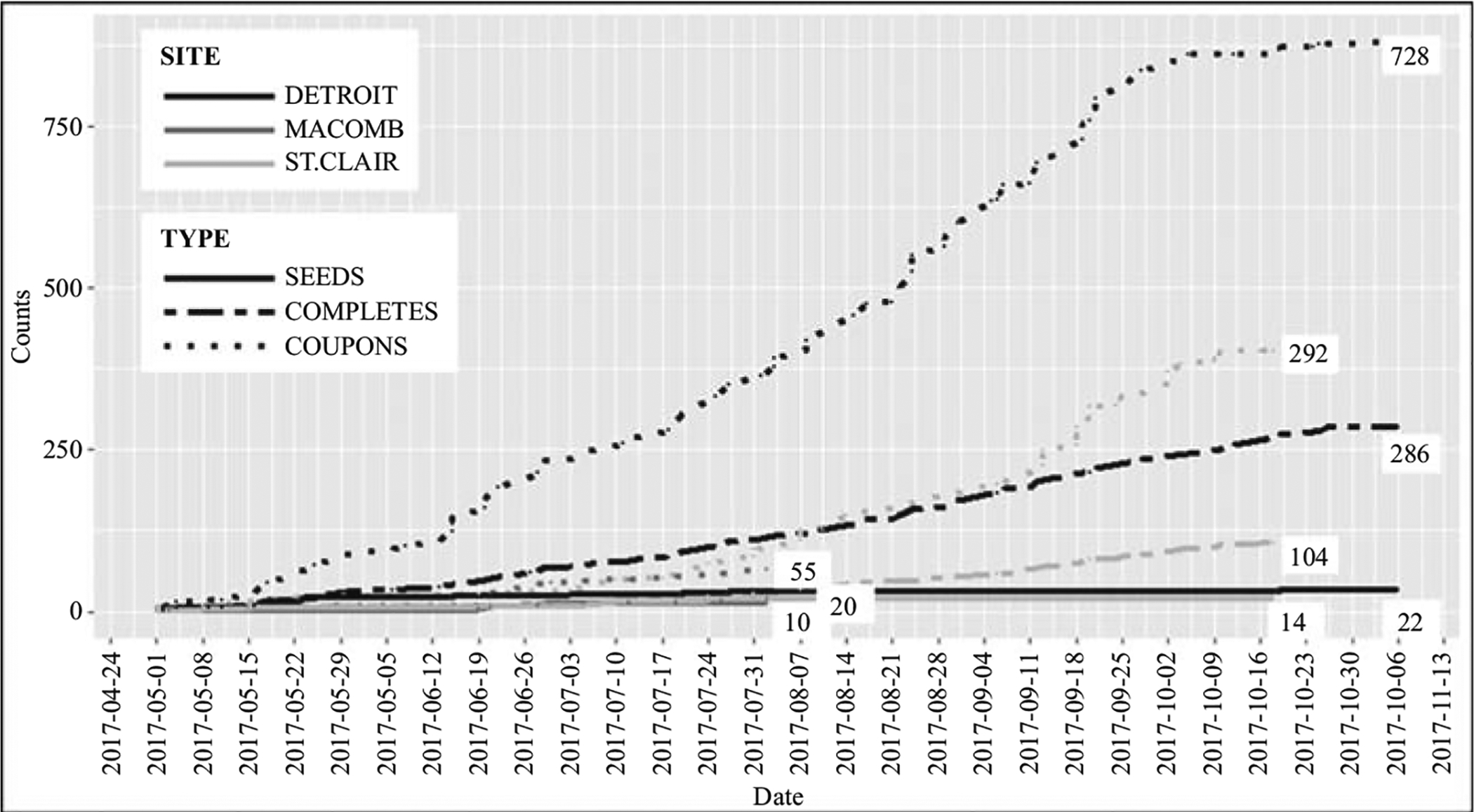
Data collection progress, positive attitudes towards health.
Fig. 3B.
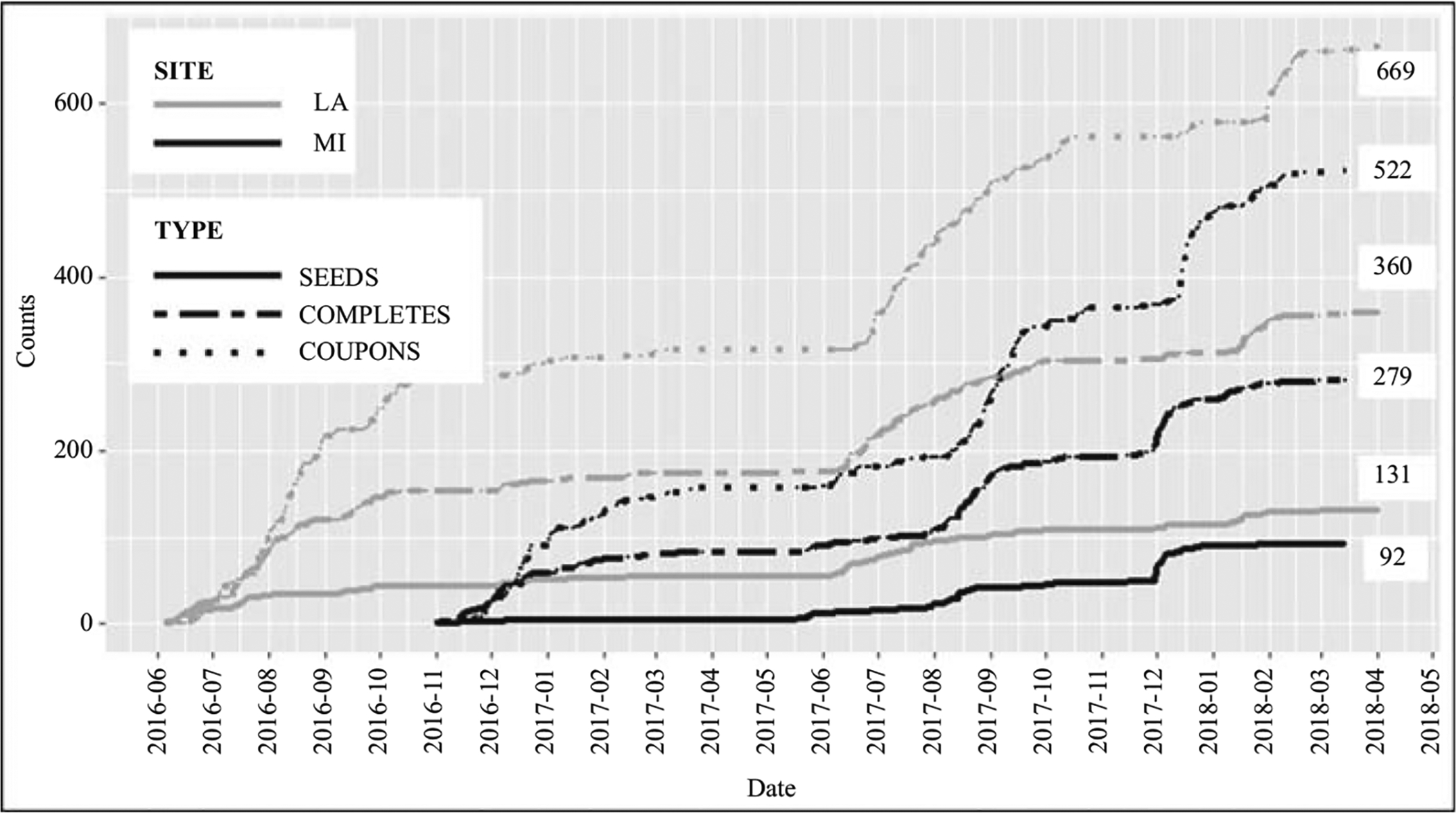
Data collection progress, health and life study of Koreans.
The HLSK started in June 2016 with a small number of seeds in Louisiana. Michigan was added in November 2016. The data collection continued until late March 2018. From a total of 223 seeds (131 Louisiana, 92 Michigan), 411 recruits (229 Louisiana, 187 Michigan) were generated through coupons, resulting in a total sample size of 639 (360 Louisiana, 279 Michigan). Unlike the PATH, the number of completes did not grow gradually. Rather, the sample size growth plateaued at points and chains died out. To increase the number of completes, we were required to add seeds. We added seeds in batches when the data collection progress was lagging behind. This can be seen from the correspondence between counts of seeds and increases in completes in Figure 3B.
Figure 4A provides structures of all 46 chains in the PATH. There was a large variation in chain lengths and sizes. Among 46 chains, about half (24) did not generate any additional participant after seeds. The longest chain lasted for 14 waves after the seeds. The sample size per chain was distributed positively skewed with a mean of 8.9, a median of 1 and a maximum of 78. This skewed distribution of chain length and chain sample size held true across sites. Out of 223 chains in the HLSK shown in Figure 4B, nearly half (112 chains) died at the seed. The longest chain in Louisiana recruited through nine waves after seeds and in Michigan through 12 waves. More than three quarters of chains recruited three or fewer participants, but 17 Koreans were recruited from the longest chains in Louisiana and 48 in Michigan. Clearly, both recruitment chains resemble Figure 1B rather than 1A. Not surprisingly, the correlation coefficient between chain lengths and sizes in the PATH and HLSK were estimated around 0.90.
Fig. 4 (A, B).

Recruitment chain graphs.
Overall, our data collection progress shows that chains grow in a way that far from meets the Markov process assumption. The sample size growth is also shown to be unpredictable. Within the same RDS survey of PWID that used the same data collection protocols, some sites were less productive than others. This resulted in a closing of the least productive site. In a Web RDS study, it was necessary to add more seeds in the middle of the data collection to continue the data collection and meet the target sample size.
5. Coupon Distribution and Redemption
A total of 1,075 coupons were issued to 367 PATH participants. Among them, 364 coupons were redeemed (i.e., successful recruitment), producing a 33.9% coupon redemption rate. In the HLSK, among the 1,191 coupons issued to 607 participants, 416 were redeemed (a 34.9% redemption rate). At the respondent level, 56.9% of the PATH participants and 46.8% of the HLSK participants successfully recruited one or more peers.
In Table 1, the number of redeemed coupons at the participant level is shown in relation to the number of issued coupons. In both PATH and HLSK, the majority of participants (349 out of 410 in PATH; 584 out of 639 in HLSK) received the maximum number of coupons. However, the rate of all issued coupons being redeemed was low. In the PATH, 5.0% of those issued one coupon, 10.0% of those issued two coupons and 12.9% of those issued three coupons had all coupons successfully redeemed. In the HLSK, 43.5% of those issued one coupon and 22.6% of those two coupons had all coupons successfully redeemed. For the remaining participants, redeemed coupons were fewer than the issued.
Table 1.
Number of issued coupons and redeemed coupons per respondent.
| No. issued Coupons | PATH | No. issued coupons | HLSK | |||||
|---|---|---|---|---|---|---|---|---|
| No. redeemed coupons % | No. redeemed coupons % | |||||||
| 0 (n = 158) |
1 (n = 99) |
2 (n = 65) |
3 (n = 45) |
0 (n = 355) |
1 (n = 152) |
2 (n = 132) |
||
| 0 (n = 43) | - | - | - | - | 0 (n = 32) | - | - | - |
| 1 (n = 8) | 50.0 | 50.0 | - | - | 1 (n = 23) | 56.5 | 43.5 | - |
| 2 (n = 10) | 70.0 | 20.0 | 10.0 | - | 2 (n = 584) | 53.1 | 24.3 | 22.6 |
| 3 (n = 349) | 42.1 | 26.7 | 18.3 | 12.9 | ||||
Information about how many coupons were distributed can be ascertained for the follow-up participants. It should be noted that follow-up participation was significantly related to recruitment success as 89.5% of the PATH follow-up participants successfully recruited one or more peers, whereas 28.2% of non-participants did so (t = 15.4, p < 0.001). The corresponding rates for the HLSK were 63.2% for follow-up participants and 32.8% for nonparticipants (t = 7.7, p < 0.001). In the follow-up survey, 91.1% and 74.0% of the PATH and the HLSK participants, respectively, reported distributing the same number of coupons as issued. Table 2 compares the number of redeemed coupons ascertained from coupon tracking against the number of distributed coupons reported in the follow-up survey, as well as against the number of distributed coupons that participants knew to have been redeemed by the coupon recipient peer(s). As one would expect from Figure 3, as well as based on the principles of nonresponse, more coupons were distributed than redeemed for 65.6% of the PATH participants and for 44.5% of the HLSK participants. When using participants’ knowledge about the redemption status of the coupons they distributed, only a small proportion of the participants reported not knowing the status (2.9% for the PATH; 6.2% for the HLSK). In fact, the majority of the follow-up participants’ knowledge matched with the actual redemption status (64.0% for the PATH; 66.9% for the HLSK). PATH participants were more likely to underreport than overreport the redemption status (25.6% underreport versus 7.6% overreport), whereas HLSK participants were more likely to overreport than underreport (16.7% overreport versus 10.2% underreport). Table 3 includes the results of quasibinomial regression models that predicted the probability of an issued coupon being redeemed. In the PATH, age was the only predictor with marginal significance (p = 0.070): coupons distributed by participants in the oldest category (61 years old or older) were more likely to be redeemed than those distributed by participants aged 18–40 years old. In the HLSK, successful coupon redemption was associated with marital status, interview language and network size measured by the number of peers to whom participants felt close significantly at p < 0.050, and with age, sex, and employment status marginally significantly at p < 0.100. In particular, the probability of a coupon being redeemed was higher for coupons distributed by married participants than those not married; by participants who took the survey in Korean rather than English; and by participants with larger network sizes. Marginally lower coupon redemption probabilities were observed from participants who were aged 50–59 years old (ref: 18–29 years old), male or employed, compared to their counterparts.
Table 2.
Comparison of number of distributed coupons reported in the follow-up survey versus redeemed coupons from coupon tracking and number of distributed coupons reported as redeemed by peers in the follow-up survey versus redeemed coupons from coupon tracking.
| PATH % | HLSK % | |
|---|---|---|
| No. coupons reported as distributed is | (n = 157) | (n = 265) |
| Greater than No. redeemed coupons | 65.6 | 44.5 |
| Equal to No. redeemed coupons | 34.4 | 53.6 |
| Smaller than No. redeemed coupons | - | 1.9 |
| No. coupons reported as used by the peer(s) is | (n = 172) | (n = 275) |
| Greater than No. redeemed coupons | 7.6 | 16.7 |
| Equal to No. redeemed coupons | 64.0 | 66.9 |
| Smaller than No. redeemed coupons | 25.6 | 10.2 |
| Don’t know | 2.9 | 6.2 |
Table 3.
Quasibinomial regression predicting of recruitment success.
| PATH | HLSK | ||||||
|---|---|---|---|---|---|---|---|
| Coeff | SE | p val. | Coeff | SE | p val. | ||
| Intercept | −0.573 | 0.482 | 0.236 | Intercept | −0.760 | 0.267 | 0.005 |
| Age (ref: 18–40 years) | Age (ref: 18–29 years) | ||||||
| 41–60 years | 0.387 | 0.304 | 0.203 | 30–39 years | 0.200 | 0.249 | 0.424 |
| 61+ years | 0.623 | 0.343 | 0.070 | 40–49 years | −0.125 | 0.273 | 0.649 |
| 50–59 years | −0.600 | 0.317 | 0.059 | ||||
| 60+ years | −0.540 | 0.404 | 0.182 | ||||
| Male vs. female | −0.244 | 0.200 | 0.223 | Male versus female | −0.307 | 0.166 | 0.064 |
| Non-Hispanic White versus other race | −0.336 | 0.293 | 0.252 | ||||
| Living alone versus not education (ref: high school graduate) | 0.005 | 0.226 | 0.983 | Not married versus married Education (ref: college degree) | −0.488 | 0.219 | 0.026 |
| Less | −0.113 | 0.216 | 0.602 | Less | 0.158 | 0.196 | 0.418 |
| More | −0.065 | 0.240 | 0.706 | More | 0.234 | 0.193 | 0.228 |
| Employed versus unemployed | −0.118 | 0.298 | 0.691 | Employed versus unemployed | −0.324 | 0.166 | 0.052 |
| Income ≤ versus > USD20K | −0.277 | 0.308 | 0.369 | Income ≤ versus > USD50K | 0.079 | 0.169 | 0.642 |
| Interviewed in English versus Korean | −0.436 | 0.182 | 0.017 | ||||
| Site: Detroit versus other | −0.127 | 0.265 | 0.631 | Site: Michigan versus Los Angeles | 0.043 | 0.163 | 0.790 |
| Network sizea | 0.007 | 0.006 | 0.288 | Network sizeb | 0.033 | 0.015 | 0.030 |
| Ethnic identity (ref: Korean) | |||||||
| Korean American | 0.098 | 0.189 | 0.603 | ||||
| Other | −0.043 | 0.396 | 0.914 | ||||
Number of PWID that participants know and interacted with more than once a week.
Number of foreign-born Korean adults in Los Angeles/Michigan that participants know and feel close to.
Between the PATH and the HLSK, the redemption rate of a given coupon was around 30%. There was a systematic pattern in recruitment success as participants’ certain socio-demographics as well as social network sizes were significant in predicting the probability of coupons issued to them being redeemed by their peers. Network sizes as currently measured in RDS were not effective in predicting recruitment success. Rather, network sizes that were restricted by certain social relationship (e.g., closeness) were effective for such predictions. Follow-up surveys indicated that, even though most participants distributed all coupons issued to them, not all coupons were redeemed and participants’ knowledge about the redemption status was relatively accurate. For follow-up survey nonrespondents, it is possible that they knew that their recruitment effort was not successful either because they did not distribute coupons or the coupon recipient peer(s) did not participate, which further prompted them to be less motivated to participate in the follow-up.
6. Recruitment Intention and Behavior
Table 4 provides age and sex profiles of intended recruits reported in the main survey along with the profiles of intended recruits reported by those who were successful at recruitment and the profiles of actual recruits. In the PATH, intended recruits overall were younger than actual recruits: less than one out of five (16.8%) of the intended recruits were aged 60 or older, but almost half (41.8%) of the actual recruits were in that age category. When comparing intended recruits’ age between successful recruiters and unsuccessful recruiters, there was a significant difference in age as the latter intended to recruit younger PWID (χ2 = 36.9; df = 4; p < 0.001). Sex was distributed similarly between intended and actual recruits and between successful recruiters’ intended recruits and unsuccessful recruiters’ intended recruits. In the HLSK, age and sex profiles were similar between intended and actual recruits, and there was no significant difference in intended recruits’ profiles between successful and unsuccessful recruiters.
Table 4.
Profile of intended recruits and actual recruits.
| PATH | HLSK | |||||
|---|---|---|---|---|---|---|
| Intended recruits of all recruiters % (n = 1074) |
Intended recruits of successful recruiters % (n = 616) |
Actual recruits % (n = 354) |
Intended recruits of all recruiters % (n = 1138) |
Intended recruits of successful recruiters % (n = 539) |
Actual recruits % (n = 415) |
|
| Age | ||||||
| 18–29 years | 13.3 | 10.7 | 8.2 | 32.6 | 30.4 | 34.1 |
| 30–39 years | 20.0 | 16.1 | 11.0 | 25.2 | 26.4 | 25.4 |
| 40–49 years | 16.0 | 14.9 | 13.8 | 20.8 | 21.0 | 21.0 |
| 50–59 years | 33.8 | 38.2 | 25.1 | 15.4 | 16.1 | 14.0 |
| 60+ years | 16.8 | 20.2 | 41.8 | 5.9 | 6.1 | 5.6 |
| Gender | ||||||
| Male | 62.4 | 63.2 | 63.3 | 43.4 | 42.9 | 41.2 |
| Female | 36.4 | 35.9 | 36.7 | 56.6 | 57.1 | 58.8 |
| Othera | 1.2 | 1.0 | - | |||
Gay, Lesbian, Bisexual, Transgender, Something else.
For follow-up participants, intended and reported recruits were similar with respect to age and sex consistently in the PATH and the HLSK (results not shown). Among follow-up participants who also successfully recruited, there was no difference across intended, reported and actual recruits in terms of these profiles in the HLSK; in the PATH, sex was similar, but age was different with the actual recruits being much older than intended as well as reported recruits, similar to Table 4. Overall, participants appeared to have distributed coupons to whom they intended. However, successful recruiters may target different types of peer(s). For example, age of the recipients mattered in the PATH as older recipients appeared to have participated at a higher rate than the counterparts.
7. Social Relationship within RDS Recruitment
The relationship between participants and their intended recruits and between participants and their actual recruiters is described in Table 5. PATH participants intended to recruit those that were not family members (94.2%), someone they felt close to (65.1%) and with whom (57.6%), and these patterns were not different between participants who were and were not successful at recruitment. This may make sense given that injection drug use was a key determinant of eligibility for the PATH. However, when examining participants’ relationship with their recruiters, there was an increase in the close relationship, as well as in the co-injection compared to their relationship with intended recruits. This may mean that while PATH participants may have distributed or intended to distribute coupons to peers to whom they did not necessarily feel close to and did not inject drugs together, it was the coupon recipients who felt close to the recruiters or who did drugs with the recruiters that were more likely to participate than their counterparts. The fact that 93.6% of the PATH participants reported that they had contact with their recruiter last week may provide evidence of this.
Table 5.
Participants’ relationship with intended recruits and actual recruiters.
| PATH | HLSK | |||||
|---|---|---|---|---|---|---|
| Intended recruits of all recruiters % (n = 1075) |
Intended recruits of successful recruiters % (n = 616) |
Recruiters % (n = 357) |
Intended recruits of all recruiters % (n = 1138) |
Intended recruits of successful recruiters % (n = 539) |
Recruiters % (n = 415) |
|
| Relationship type | ||||||
| Family | 5.9 | 5.5 | 8.2 | 28.0 | 36.1 | 53.4 |
| Spouse | 1.0 | 0.8 | 1.7 | 10.6 | 15.3 | 21.6 |
| Parent | 0.4 | 0.5 | 0.3 | 7.0 | 11.0 | 7.7 |
| Sibling | 1.6 | 1.1 | 3.1 | 5.8 | 5.2 | 7.9 |
| Other | 2.9 | 3.1 | 3.1 | 4.6 | 4.7 | 24.0 |
| Non-family | 94.2 | 94.5 | 91.9 | 72.0 | 63.9 | 46.6 |
| Friend | 73.6 | 73.2 | 71.7 | 50.0 | 41.0 | 31.0 |
| Romantic partner | 1.8 | 1.0 | 1.1 | 4.0 | 4.7 | 3.8 |
| Acquaintance | 18.3 | 19.6 | 19.1 | 14.3 | 10.8 | 1.7 |
| Colleague | 0.5 | 0.7 | - | 7.7 | 7.5 | 6.3 |
| Feel close to | 65.1 | 67.1 | 81.2 | 88.8 | 92.3 | 87.0 |
| Inject together | 57.6 | 58.8 | 68.9 | - | - | - |
| Contact within last week | - | - | 93.6 | - | - | 78.4 |
With the HLSK, there was little to no difference in closeness between participants’ relationship with intended recruits (also further divided by successful recruiters and unsuccessful recruiters) and with recruiters. However, the relationship type differed. About 28.0% of the intended recruits were family members, but it was 36.1% for successful recruiters and 20.5% for unsuccessful recruiters (χ2 = 37.1; df = 2; p < 0.001). Further, more than half (53.4%) of the participants reported that their recruiters were family members: 21.6% spouses, 7.7% parents, 7.9% siblings and 24.0% other family members (e.g., children). This means that recruitment coupons were redeemed at a higher rate when distributed to participants’ families than to non-families.
Relationship types that follow-up participants had with their intended recruits were similar to those with reported recruits in both studies (results not shown).
Social relationship appears to matter in RDS recruitment, but may matter differently depending on the target group. For PWID, relationship closeness and substance co-injection mattered; but for Korean immigrants, it was the relationship type––non-family peers were recruited less successfully than family members.
8. Dynamics within Recruitment Process
Most follow-up participants reported that they distributed coupons within a week after issuance (96.2% for the PATH; 77.4% for the HLSK). In particular, 70.5% of the PATH participants distributed coupons within three days, and nearly all PATH participants reported distributing coupons in person. For the HLSK, the mode most frequently used for coupon distribution was Kakao talk, an extremely popular messaging app among Koreans, at 48.9%, followed by email (41.1%), text (24.2%), in-person (12.6%), phone conversation (4.3%), and others (1.7%), with 27.3% of the participants distributing coupons in more than one mode. WOM strategies used during recruitment in the PATH in order was: payment for participation (88.5%), survey topic (71.8%), payment for recruitment (62.2%), survey length (51.9%), study importance (20.5%) and something else (14.1%); and in the HLSK: payment (87.0%), Korean focus (72.6%), Web mode (50.9%), survey length (36.1%), study importance (20.9%) and something else (4.4%). Even though the recruitment reminders were sent to all HLSK participants whose issued coupons were not redeemed, 81.3% reported receiving the reminders. Among those who reported receiving reminders, 84.5% said they reminded their recruits about participation.
9. Implications for Fitness of RDS
One may wonder which of the two populations examined in this study fits better for RDS. Fitness, of course, should consider angles beyond the recruitment and recruitment processes that this study addresses. Assessing fitness of RDS for recruitment success requires subjecting populations to the same data collection protocols. Since data collection in our study followed different protocols (e.g., Web vs. in-person mode; a URL to access questionnaires vs. visiting an office; electronic versus paper coupons; up to two vs. three issued coupons), it is difficult to assess the fitness of RDS from the recruitment perspectives. Rather, our study offers important implications for RDS that may improve its general fitness, regardless of target populations. In particular, with coupon redemption rates around 30% commonly observed between two applications of RDS in this, as well as in other studies (e.g., Lee et al. 2017), at least three coupons need to be issued to each participant in order to prevent chains dying out. Otherwise, to meet operational goals, one may be forced to make unplanned protocol changes in the middle of data collection. However, issuing three coupons only guarantees no interruption in the overall recruitment on average and does not guarantee individual recruitment chains resembling Figure 1A. The systematic nature of recruitment noncooperation, discussed more in the next section, opens a door for integrating adaptive survey design to RDS. Creating recruitment chains like Figure 1A is difficult under current practices of RDS, where researchers have little to no control over the recruitment process. The adaptive survey design framework (Schouten et al. 2017) allows RDS operations to respond to the incoming data, such as survey data, coupon tracking data and paradata (e.g., interviewer observations). By capitalizing on the incoming data that allows predicting recruitment propensities at the individual level, researchers may change designs/protocols influential for producing chains like Figure 1A under the rules set prior to the data collection. This data-driven design adaptation approach may facilitate improved fitness of RDS across population types, so long as the target groups are networked.
10. Discussion
This study used data from two RDS studies (one targeting PWID in-person and the other targeting an ethnic minority group over the Web) and examined data collection progress, coupon use, profiles of intended versus actual recruits, social relationship between recruits and recruiters, and details of dynamics in the recruitment process. In both RDS studies, the coupon redemption rate was around 30%. Moreover, the recruitment success/cooperation differed systematically based on participants’ characteristics. The lack of consistency in these patterns between the two RDS studies may suggest that the RDS recruitment cooperation is dependent on the target population and the context of survey administration.
Those who participated in the follow-up reported distributing most issued coupons to whom they intended. More often than not, participants knew their peers’ coupon redemption status accurately. Interestingly, recruitment and recruitment success appeared to have been influenced by social relationship. The majority of recruiters were those with whom recruits had contacted within a week prior to their participation. For PWID, relationship closeness and whether using drugs together mattered for coupon recipients’ participation. For Korean immigrants, coupons distributed to families were far more likely to be redeemed than those to non-families. Age and gender of intended recruits largely did not matter for the participation pattern, except for the study of PWID where older coupon recipients participated at a higher level than younger recipients.
Further, the timing of coupon distribution left little gap from the issuance, as most were reported to have been distributed within a week after their issuance in person for the in-person RDS and using a messaging app, email or text for the Web RDS. Incentive payment was the most prominent message participants told their peers during the recruitment process.
By no means does this study illustrate a complete picture of recruitment noncooperation in RDS. It uses information from the follow-up survey, which only about 40% of the participants completed. Albeit partial, the follow-up offers information about what happens between coupon issuance and redemption. For example, it provides answers to whether it is the RDS participants not distributing coupons or the coupon recipients not participating in the study that lead to recruitment noncooperation. Our study shows it is likely to be the latter potentially dictated by coupon recipients’ perceived, as well as actual relationship with their coupon distributors. However, it is entirely possible that follow-up nonparticipants do not distribute coupons.
Taken together, this study suggests that “social networks” relevant to RDS recruitment may well be different than those discussed in the social network literature. In turn, this means that, without improving our ability to measure degrees specific to the chain-referral recruitment, weights used in RDS-specific estimators (e.g., Volz and Heckathorn 2008) are bound to be irrelevant and ineffective. Clearly, there are design features that participants highlight in their recruitment effort (e.g., incentives). Thorough investigations on participants’ messaging and ways to leverage the design features affecting recruitment success also used in the messaging will allow us better design RDS studies. Moreover, as discussed with Figures 1A and 1B, two RDS studies of the same sample size starting from the same number of seeds do not mean the same recruitment chain structures. As done with response rate calculations in survey research (American Association for Public Opinion Research 2016), needs for methodological transparency of RDS studies need to be recognized, and guidelines fostering such transparency need to be materialized (White et al. 2015).
Acknowledgments:
We thank Dr. Julie Roddy, local health departments in Southeast Michigan, Dr. Minsung Kwon, Dr. Jungran Kim and research assistants (Jae-Kyung Ahn, Karen Seo, Jenni Kim, Daayun Chung, Celina Yim, Hannah Sim and Christine Kim) for their contributions to the data collection. This research was supported by the US National Science Foundation (grant number: SES-1461470) and the US National Institutes of Health (grant number: 1-R01 AG060936-01; 1-R21 AG062844-01).
11. Appendix
Table A1.
Sample characteristics.
| PATH % (n = 410) |
HLSK % (n = 637*) |
||
|---|---|---|---|
| Age | Age | ||
| 18–40 years | 22.7 | 18–29 years | 36.9 |
| 41–60 years | 38.8 | 30–39 years | 24.3 |
| 61 + years | 38.5 | 40–49 years | 20.9 |
| 50–59 years | 12.9 | ||
| 60+ years | 5.0 | ||
| Gender | Gender | ||
| Male | 63.7 | Male | 39.4 |
| Female | 36.3 | Female | 60.6 |
| Race/ethnicity | |||
| Non-Hispanic White | 29.8 | ||
| Other | 70.2 | ||
| Living arrangement | Marital status | ||
| Living alone | 73.8 | Married | 54.6 |
| Not living alone | 26.2 | Not married | 45.4 |
| Education | Education | ||
| Less than high school | 38.1 | Less than college degree | 30.0 |
| High school graduate | 35.1 | College degree | 40.0 |
| More than high school | 26.8 | More than college degree | 30.0 |
| Employment status | Employment status | ||
| Employed | 11.5 | Employed | 55.4 |
| Unemployed | 88.5 | Unemployed | 44.6 |
| Annual household income | Annual household income | ||
| ≤ USD 20,000 | 90.1 | ≤ USD 50,000 | 57.2 |
| > USD 20,000 | 9.9 | > USD 50,000 | 42.8 |
| Interview language | |||
| English | 32.8 | ||
| Korean | 67.2 | ||
| Site | Site | ||
| Detroit | 69.5 | Los Angeles | 56.2 |
| Macomb | 4.6 | Michigan | 43.8 |
| St. Clair | 26.9 | ||
This excludes two participants whose survey responses were not properly stored in the data.
12. References
- Abramovitz D, Volz EM, Strathdee SA, Patterson TL, Vera A, and Frost SD. 2009. “Using Respondent Driven Sampling in a hidden Population at Risk of HIV Infection: Who Do HIV-positive Recruiters Recruit?” Sexually Transmitted Diseases 36(12): 750–756. DOI: 10.1097/OLQ.0b013e3181b0f311. [DOI] [PMC free article] [PubMed] [Google Scholar]
- American Association for Public Opinion Research. 2016. Standard definitions: Final dispositions of case codes and outcome rates for surveys. 9th edition. AAPOR; Available at: https://www.aapor.org/AAPOR_Main/media/publications/Standard-Definitions20169theditionfinal.pdf (accessed September 2019). [Google Scholar]
- Bostwick WB, Hughes TL, and Everett B. 2015. “Health behavior, status, and outcomes among a community-based sample of lesbian and bisexual women.” LGBT Health 2(2): 121–126. DOI: 10.1089/lgbt.2014.0074. [DOI] [PMC free article] [PubMed] [Google Scholar]
- CDC. 2015. National HIV Behavioral Surveillance: Injection Drug Use – Round 4 (NHBS-IDU4): Operations Manual. Available at: https://www.cdc.gov/hiv/pdf/statistics/systems/nhbs/NHBS-IDU4-Operations-Manual-2015.pdf (accessed April 2018). [Google Scholar]
- Gile KJ and Handcock MS. 2010. “Respondent-driven sampling: an assessment of current methodology.” Sociological Methodology 40(1): 286–327. DOI: 10.1111/j.1467-9531.2010.01223.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gile KJ and Handcock MS. 2015. “Network model-assisted inference from respondent-driven sampling data.” Journal of the Royal Statistical Society Series A, (Statistics in Society) 178(3): 619–639. DOI: 10.1111/rssa.12091. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gile KJ, Johnston LG, and Salganik MJ. 2015. “Diagnostics for respondent-driven sampling.” Journal of the Royal Statistical Society: Series A (Statistics in Society) 178(1): 241–269. DOI: 10.1111/rssa.12059. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Groves RM 1989. Survey Errors and Survey Costs. New York: John Wiley & Sons. [Google Scholar]
- Groves RM and Couper MP. 1998. Nonresponse in household interview surveys. New York: John Wiley & Sons. [Google Scholar]
- Hafeez S 2012. A review of the proposed STROBE-RDS reporting checklist as an effective tool for assessing the reporting quality of RDS studies from the developing world. London, UK: LSHTM. [Google Scholar]
- Hathaway AD, Hyshka E, Erickson PG, Asbridge M, Brochu S, Cousineau MM, Duff C, and Marsh D. 2010. “Whither RDS? An investigation of respondent driven sampling as a method of recruiting mainstream marijuana users.” Harm Reduction Journal 7(1): 15 DOI: 10.1186/1477-7517-7-15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heckathorn DD 1997. “Respondent-driven sampling: A new approach to the study of hidden populations.” Social Problems 44: 174–199. DOI: 10.2307/3096941. [DOI] [Google Scholar]
- Heckathorn DD and Cameron CJ. 2017. “Network sampling: From snowball and multiplicity to respondent-driven sampling.” Annual Review of Sociology 43: 101–119. DOI: 10.1146/annurev-soc-060116-053556. [DOI] [Google Scholar]
- Kalsbeek WD 2003. “Sampling minority groups in health surveys.” Statistics in Medicine 22: 1527–1549. [DOI] [PubMed] [Google Scholar]
- Kalton G and Anderson DW. 1986. “Sampling rare populations.” Journal of Royal Statistical Society, Series A 149(1): 65–82. DOI: 10.2307/2981886. [DOI] [Google Scholar]
- Kalton G and Flores-Cervantes I. 2003. “Weighting methods.” Journal of Official Statistics 19(2): 81–97. Available at: https://www.scb.se/contentassets/ca21efb41-fee47d293bbee5bf7be7fb3/weighting-methods.pdf (accessed February 2020). [Google Scholar]
- Lee S 2009. “Understanding respondent driven sampling from a total survey error perspective.” Survey Practice 2(6) 1–6. DOI: 10.29115/SP-2009-0029. [DOI] [Google Scholar]
- Lee S, Ong AR, and Elliott M. 2018. “Two applications of respondent driven sampling: Ethnic minorities and illicit substance users.” Paper presented at the Workshop on Improving Health Research for Small Populations. National Academy of Sciences, Engineering and Medicine, Washington, DC, U.S.A. January 2018 Available at: http://sites.nationalacademies.org/cs/groups/dbassesite/documents/webpage/dbasse_185285.pdf (accessed September 2019). [Google Scholar]
- Lee S, Suzer-Gurtekin ZT, Wagner J, and Valliant R. 2017. “Total survey error and respondent driven sampling: Focus on nonresponse and measurement errors in the recruitment process and the network size reports and implications for inferences.” Journal of Official Statistics 33(2): 335–366. DOI: 10.1515/jos-2017-0017. [DOI] [Google Scholar]
- Lee S, Suzer-Gurtekin ZT, Wagner J, and Valliant R. 2012. “Exploring error properties of respondent driven sampling.” Paper presented at the Joint Statistical Meeting, San Diego, CA, U.S.A. July 2012. [Google Scholar]
- Lee S, Wagner J, Valliant R, and Heeringa S. 2014. “Recent developments of sampling hard-to-reach populations: an assessment” In Hard to Survey Populations, edited by Tourangeau R, Edwards B, Johnson T, and Wolter K: 424–444. Cambridge, UK: Cambridge University Press. [Google Scholar]
- Li J, Valente TW, Shin HS, Weeks M, Zelenev A, Moothi G, Mosher H, Heimer R, Robles E, Palmer G, and Obidoa C. 2017. “Overlooked threats to respondent driven sampling estimators: peer recruitment reality, degree measures, and random selection assumption.” AIDS and Behavior 22(7): 2340–2359. DOI: 10.1007/s10461-017-1827-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lu X, Bengtsson L, Britton T, Camitz M, Kim BJ, Thorson A, and Liljeros F. 2012. “The sensitivity of respondent-driven sampling.” Journal of the Royal Statistical Society: Series A (Statistics in Society) 175(1): 1–26. DOI: 10.1111/j.1467-985X.2011.00711.x. [DOI] [Google Scholar]
- Luthra R 2011. “RDS for Migration Studies? A Review and Invitation to Discuss.” Paper presented at the Workshop on Design, Implementation, and Analysis: An Exploration of Respondent Driven Sampling, London, UK. [Google Scholar]
- Martin K, Johnson TP, and Hughes TL. 2015. “Using respondent driven sampling to recruit sexual minority women.” Survey Practice 8(2): 273 Available at: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5066809/ (accessed April 2020). [PMC free article] [PubMed] [Google Scholar]
- McCreesh N, Copas A, Seeley J, Johnston LG, Sonnenberg P, Hayes RJ, Frost SDW, and White RG. 2013. “Respondent driven sampling: determinants of recruitment and a method to improve point estimation.” PLoS ONE 8(10): e78402 DOI: 10.1371/journal.pone.0078402. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Selvaraj V, Boopathi K, Paranjape P, and Mehendale S. 2016. “A single weighting approach to analyze respondent-driven sampling data.” The Indian Journal of Medical Research 144(3): 447–459. DOI: 10.4103/0971-5916.198665. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schouten B, Peytchev A, and Wagner J. 2017. Adaptive Survey Design. Boca Raton, FL: CRC Press. [Google Scholar]
- Shadish WR and Cook TD. 1999. “Design rules: More steps towards a complete theory of quasi-experimentation.” Statistical Science 294–300. [Google Scholar]
- Singer E 2002. “The use of incentives to reduce nonresponse in household surveys” In Survey Nonresponse, edited by Groves RM, Dillman DA, Eltinge JL, and Little RJA, 163–178. New York, NY: Wiley; 163–177 [Google Scholar]
- Stein ML, Buskens V, van der Heijden PGM, van Steenbergen JE, Wong A, Bootsma MCJ, and Kretzschmar MEE. 2018. “A stochastic simulation model to study respondent-driven recruitment.” PLoS One 13(11): e0207507 DOI: 10.1371/journal.pone.0207507. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strömdahl S, Lu X, Bengtsson L, Liljeros F, and Thorson A. 2015. “Implementation of Web-based respondent driven sampling among men who have sex with men in Sweden.” PLoS ONE 10(10): e0138599 DOI: 10.1371/journal.pone.0138599. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tomas A and Gile KJ. 2011. “The effect of differential recruitment, non-response and non-recruitment on estimators for respondent-driven sampling.” Electronic Journal of Statistics 5: 899–934. DOI: 10.1214/11-EJS630. [DOI] [Google Scholar]
- Tucker C, Cohen MP, KewalRamani A, and Eyster S. 2015. “Surveying the District of Columbia GLBT community using respondent-driven sampling.” Paper presented at the annual meeting of the American Association for Public Opinion Research, May 2015 Available at: http://www.aapor.org/AAPOR_Main/media/AnnualMeetingProceedings/2015/A3-3-Tucker.pdf (accessed September 2019). [Google Scholar]
- Verdery AM, Merli MG, Moody J, Smith J, and Fisher JC. 2015. “Respondent-driven sampling estimators under real and theoretical recruitment conditions of female sex workers in China.” Epidemiology 26(5): 661–665. DOI: 10.1097/EDE.0000000000000335. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Volz E and Heckathorn DD. 2008. “Probability based estimation theory for respondent driven sampling.” Journal of Official Statistics 24(1): 79–97. DOI: https://www.scb.se/contentassets/ca21efb41fee47d293bbee5bf7be7fb3/probability-based-estimation-theory-for-respondent-driven-sampling.pdf (accessed May 2020). [Google Scholar]
- Wagner J and Lee S. 2014. “Sampling rare populations” In Handbook of Health Survey Methods, edited by Johnson TP, 77–104. Hoboken, N.J.: Wiley. [Google Scholar]
- White RG, Hakim AJ, Salganik MJ, Spiller MW, Johnston LG, Kerr L, Kendall C, Drake A, Wilson D, Orroth K, Egger M, and Hladik W. 2015. “Strengthening the reporting of observational studies in epidemiology for respondent-driven sampling studies: “STROBE-RDS” statement.” Journal of Clinical Epidemiology 68(12): 1463–1471. DOI: 10.1016/j.jclinepi.2015.04.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- World Health Organization and UNAIDS. 2013. Introduction to HIV/AIDS and sexually transmitted infection surveillance: Module 4: Introduction to Respondent Driven Sampling. Geneva, Switzerland: Available at: http://applications.emro.who.int/dsaf/EMRPUB_2013_EN_1539.pdf (accessed June 2017). [Google Scholar]