

Abstract
Measuring conditional dependence is an important topic in econometrics with broad applications including graphical models. Under a factor model setting, a new conditional dependence measure based on projection is proposed. The corresponding conditional independence test is developed with the asymptotic null distribution unveiled where the number of factors could be high-dimensional. It is also shown that the new test has control over the asymptotic type I error and can be calculated efficiently. A generic method for building dependency graphs without Gaussian assumption using the new test is elaborated. We show the superiority of the new method, implemented in the R package pgraph, through simulation and real data studies.
Keywords: conditional dependence, distance covariance, factor model, graphical model, projection
JEL classification: C13, C14
1. Introduction
Rapid development in technology continuously floods us with high-dimensional data nowadays. One interesting question we wish to answer is their conditional dependency structure. Mathematically, let z = (z(1), …, z(d)) be a d-dimensional random vector, which represents our data. We would like to know whether for or if there are other factors f associated with z, then whether . For visualization, a graph is often used to represent such a conditional dependence structure: vertices represent observed variables and edges indicate conditional dependence. Producing such a graph can help us understand data and has been an important topic in fields including economics, finance, signal processing, bioinformatics and network modeling (Wainwright and Jordan, 2008).
Intrinsically, if we look at the nodes pair by pair, this is a testing problem. In general, we can write our goal as testing whether x and y are independent given f, i.e.,
| (1) |
where x, y and f are random vectors with possibly different dimensions. For such conditional independence tests, there has been abundant literature, especially in econometrics. Linton and Gozalo (1997) proposed two nonparametric tests based on a generalization of the empirical distribution function; however, a complicated bootstrap procedure is needed to calculate critical values of the test, which limits its applications. Su and White (2007, 2008, 2014) and Wang et al. (2015) proposed conditional independence tests based on Hellinger distance, empirical likelihood, conditional moments and conditional characteristic function, respectively. However, as many of the recently available datasets are of high-dimension, the computation for these tests becomes prohibitive. Another related work is Sen and Sen (2014), where the focus is on testing the independence between the error and the predictor variables in the linear regression problem.
Our starting point is a relatively “general” model on {x, y, f}. In particular, suppose are i.i.d. realizations of , which are generated from the following model:
| (2) |
where f is the K-dimensional common factors, Gx and Gy are general mappings from to and , respectively. The observed data are {(xi, yi, fi), i = 1, …, n}. Here, for simplicity and tractability, we assume independence between (ϵx, ϵy) and f. Such kind of models shed light for another route to solve the issues, nonparametric regression. The idea is intuitive: to test (1) is the same as testing under (2), which naturally leads to a two-step procedure. Since {(ϵi,x, ϵi,y), i = 1, …, n} are not observed, in Step 1, we estimate the residuals. In this regard, we assume the dimensions p and q to be fixed while the number of factors K could diverge to infinity. Step 2, we apply an independence test on the estimated residuals. These two steps constitute our new conditional independence test and we will unveil the asymptotic properties for this new test statistic. Let’s briefly preview the procedure in the following two paragraphs.
In Step 1, ideally, a fully nonparametric projection on f (e.g., local linear regression (Fan, 1992)) would consistently recover the random errors asymptotically under certain smoothness assumptions on Gx and Gy, when K is fixed. However, it becomes challenging when K diverges due to the curse of dimensionality if no structural assumptions are made on Gx and Gy. As a result, in this paper, we will study two cases where Gx and Gy are linear functions (factor models) in Section 2.2 and where Gx and Gy are additive functions in Section 2.5 when K diverges. Further relaxed models might be available for future work, but we don’t focus on them in this paper.
To complete our proposal, after estimating the residuals in Step 1, we still need to find a suitable measure of dependence between random variables/vectors in Step 2. In this regard, many different measures of dependence have been proposed. Some of them rely heavily on Gaussian assumptions, such as Pearson correlation, which measures linear dependence and the uncorrelatedness is equivalent to independence only when the joint distribution is Gaussian; or Wilks Lambda (Wilks, 1935), where normality is adopted to calculate the likelihood ratio. To deal with non-linear dependence and non-Gaussian distribution, statisticians have proposed rank-based correlation measures, including Spearman’s ρ and Kendall’s τ, which are more robust than Pearson correlation against deviations from normality. However, these correlation measures are usually only effective for monotonic types of dependence. In addition, under the null hypothesis that two variables are independent, no general statistical distribution of the coefficients associated with these measures has been derived. Other related works include Hoeffding (1948), Blomqvist (1950), Blum et al. (1961), and some methods described in Hollander et al. (2013) and Anderson (1962). Taking these into consideration, distance covariance (Székely et al., 2007) was introduced to address these deficiencies. The major benefits of distance covariance are: first, zero distance covariance implies independence, and hence it is a true dependence measure. Second, distance covariance can measure the dependence between any two vectors which potentially are of different dimensions. Recently, Huo and Székely (2016) proposed a fast computation method for distance covariance. Due to these advantages, we will focus on distance covariance in this paper as our measure of dependence.
So far, we complete a rough description of the newly proposed conditional dependence measure; and we are able to build conditional dependency graphs by conducting this test edge by edge. We would like to make two remarks here to help readers connect the dots between our work and some other existing related topics/works.
First, let us look at the connection to undirected graphical models. Undirected graphical models (UGM) has been a popular topic in econometrics in the past decade. It studies the “internal” conditional dependency structure of a multivariate random vector. To be more explicit, again let z = (z(1), …, z(d)) be the d-dimensional random vector of interest. We denote the undirected graph corresponding to z by (V, E), where vertices V correspond to components of z and edges E = {eij, 1 ≤ i ≠ j ≤ d} indicate whether node z(i) and z(j) are conditionally independent given the remaining nodes. In particular, the edge eij is absent if and only if . Therefore, UGM is a nature application of our measure if we take f = z \ {z(i), z(j)} in our test. One intensively studied sub-field is GGM (Gaussian graphical model) where z is assumed to follow a multivariate Gaussian distribution with mean µ and covariance matrix Σ. This extra assumption is desirable since then the precision matrix Ω = (wij)d×d = Σ−1 captures exactly the conditional dependency graph; that is, wij = 0 if and only if eij is absent (Lauritzen, 1996; Edwards, 2000). Therefore, under the Gaussian assumption, this problem reduces to the estimation of precision matrix, where a rich literature on model selection and parameter estimation can be found in both low-dimensional and high-dimensional settings, including Dempster (1972), Drton and Perlman (2004), Meinshausen and Bühlmann (2006), Friedman et al. (2008), Fan et al. (2009), Cai et al. (2011), Liu (2013), Chen et al. (2014), Ren et al. (2015), Jankova and Van De Geer (2015) and Yu and Bien (2017). With simple derivations, it’s easy to check that GGM fits into our framework with G being linear and ϵ having Gaussian distributions. Therefore, with linear projection in Step 1 and distance covariance in Step 2, our proposed conditional measure solves GGM. It’s worth noting that, indeed, in Step 2, choosing Pearson correlation will solve GGM as well; choosing distance covariance gives more flexibility since we don’t assume normality on ϵ and potentially we can solve non-Gaussian UGMs. Another interesting work is Voorman et al. (2013), where a semi-parametric method was introduced for graph estimation.
Second, we examine the link to factor models. As explained in the last paragraph, UGM is a case with f being internal factors, in other words, part of the interested vector z. Another scenario of our framework is the case when f are external, and this is closely related to factor models. As an example, in the Fama-French three factors model, the excessive return of each stock can be considered as one node in the graph we want to build and f are the chosen three-factors. This example will be further elaborated in Section 5. Therefore, the factors f are considered as external since they are not part of the individual stock returns. Another interesting application is discussed in Stock and Watson (2002), where external factors are aggregated macroeconomic variables, and the nodes are disaggregated macroeconomic variables.
With the above two remarks, we see our proposed test cover some of the existing topics as by-products. We summarize the main contribution of this paper here. First, under model (2), we propose a computationally efficient conditional independence test. Both the response vectors and the common factors can be of different dimensions and the number of the factors could grow to infinity with sample size. Second, we apply this test to build conditional dependency graph (internal factors) and covariates-adjusted dependency graph (external factors).
The rest of this paper is organized as follows. In Section 2, we present our new procedure for testing conditional independence via projected distance covariance (P-DCov) and describe how to construct conditional dependency graphs based on the proposed test. Section 3 gives theoretical properties including the asymptotic distribution of the test statistic under the null hypothesis as well as the type I error guarantee. Section 4 contains extensive numerical studies and Section 5 demonstrates the performance of P-DCov via a financial data set. We conclude the paper with a short discussion in Section 6. Several technical lemmas and all proofs are relegated to the appendix.
2. Methods
2.1. A brief review of distance covariance
First, we introduce some notations. For a random vector z, ‖z‖ and ‖z‖1 represent its Euclidean norm and ℓ1 norm, respectively. A collection of n i.i.d. observations of z is denoted as {z1, …, zn}, where represents the k-th observation. For any matrix M, ‖M‖F, ‖M‖ and ‖M‖max denote its Frobenius norm, operator norm and max norm, respectively. ‖M‖a,b is the (a, b) norm defined as the ℓb norm of the vector consisting of column-wise ℓa norm of M. Furthermore, a ∧ b represents min{a, b} and a ∨ b represents max{a, b}.
As an important tool, distance covariance is briefly reviewed in this section with further details available in Székely et al. (2007). We introduce several definitions as follows.
Definition 1. (w-weighted L2 norm) Let , for any positive integer d, where Γ is the Gamma function. Then for function γ defined on , the w-weighted L2 norm of γ is defined by
Definition 2. (Distance covariance) The distance covariance between random vectors and with finite first moments is the nonnegative number defined by
where gx, gy and gx,y represent the characteristic functions of x, y and the joint characteristic function of x and y, respectively.
Suppose we observe random sample {(xk, yk) : k = 1, …, n} from the joint distribution of (x, y). We denote X = (x1, x2, …, xn) and Y = (y1, y2, …, yn).
Definition 3. (Empirical distance covariance) The empirical distance covariance between samples X and Y is the nonnegative random variable defined by
where
With above definitions, Lemma 1 depicts the consistency of as an estimator of . Lemma 2 shows the asymptotic distribution of under the null hypothesis that x and y are independent. Corollary 1 reveals properties of the test statistic proposed in Székely et al. (2007).
Lemma 1. (Theorem 2 in Székely et al. (2007)) Assume that , then almost surely
Lemma 2. (Theorem 5 in Székely et al. (2007)) Assume that x and y are independent, and , then as n → ∞,
where represents convergence in distribution and ζ(·, ·) denotes a complex-valued centered Gaussian random process with covariance function
in which u = (τ, ρ), u0 = (τ 0, ρ0).
Corollary 1. (Corollary 2 in Székely et al. (2007)) Assume that .
If x and y are independent, then as n → ∞, with , where and {λj} are non-negative constants depending on the distribution of (x, y);.
If x and y are dependent, then as n → ∞, .
2.2. Conditional independence test via projected distance covariance (P-DCov)
Here, we consider the case where Gx and Gy are linear in (2), which leads to the following factor model setup:
| (3) |
where Bx and By are factor loading matrices of dimension p × K and q × K respectively, and f is the K-dimensional vector of common factors. Here, we assume p and q are fixed, the number of common factors K could grow to infinity and the matrices Bx and By are sparse to reflect that x and y only depend on several important factors. As a result, we will impose regularization on the estimation of Bx and By. Now, we are in the position to propose a test for problem (1). We first provide an estimate for the idiosyncratic components ϵx and ϵy, and then calculate distance covariance between the estimates. More generally, we project x and y onto the space orthogonal to the linear space spanned by f and evaluate the dependency between the projected vectors. The conditional independence test is summarized in the following steps.
Step 1: Estimate factor loading matrices Bx and By by the penalized least square (PLS) estimators and defined as follows.
| (4) |
| (5) |
where X = (x1, x2, …, xn), Y = (y1, y2, …, yn), F = (f1, f2, …, fn), pλ(·) is the penalty function with penalty level λ.
Step 2: Estimate the error vectors ϵi,x and ϵi,y by
Step 3: Define the estimated error matrices and Calculate the empirical distance covariance between and as
Step 4: Define the P-DCov test statistic as .
Step 5: With a predetermined significance level α, we reject the null hypothesis when T (x, y, f) > (Φ−1(1 − α/2))2.
Theoretical properties of the proposed conditional independence test will be studied in Section 3. In the above method, we implicitly assume that the number of variables K is large so that the penalized least-squares methods are used. When the number of variables K is small, we can take λ1 = λ2 = 0 so that no penalization is imposed.
We would like to point out that after getting the estimated error matrices and , one could apply other dependency measures including Hilbert Schmidt independence criterion (Gretton et al., 2005) and Heller-Heller-Gorfine test (Heller et al., 2012).
2.3. Building graphs via conditional independence test
Now we explore a specific application of our conditional independence test to graphical models. To identify the conditional independence relationship in a graphical model, i.e., , we assume
| (6) |
where represents all coordinates of zk other than and , and β1,ij and β2,ij are d − 2 dimensional regression coefficients. Under model (6), we decide whether edge eij will be drawn through directly testing , where is the linear space spanned by f.
More specifically, for each node pair {(i, j) : 1 ≤ i < j ≤ d}, we define T(i,j) = T(z(i), z(j), z(−i,−j)) using the same steps as in Section 2.2 as the test for the current null hypothesis:
| (7) |
We now summarize the testing results by a graph in which nodes represent variables in z and the edge eij between node i and node j is drawn only when H0,ij is rejected at level α.
In (6), the factors are created internally via the observations on remaining nodes z \ {z(i), z(j)}. In financial applications, it is often desirable to build graphs when conditioning on external factors. In such cases, it is straightforward to change the factors in (6) to external factors.
We will demonstrate the two different types of conditional dependency graphs via examples in Sections 4 and 5.
2.4. Graph estimation with FDR control
Through the graph building process described in Section 2.3, we can carry out P-DCov tests simultaneously and we wish to control the false discovery rate (FDR) at a pre-specified level 0 < α < 1. Let RF and R be the number of falsely rejected hypotheses and the number of total rejections, respectively. The false discovery proportion (FDP) is defined as RF / max{1, R} and the FDR is the expectation of FDP.
In the literature, various procedures have been proposed for conducting large-scale multiple hypothesis testing via FDR control. Liu (2013) proposed a procedure for estimating large Gaussian graphical models with FDR control. Fan et al. (2018) proposed factor-adjusted tests by estimating the latent factors that drive the dependency of these tests. In this work, we will follow the most commonly used Benjamini and Hochberg (BH) procedure developed in the seminal work of Benjamini and Hochberg (1995), where P-values of all marginal tests are compared. More specifically, let be the ordered P-values of the hypotheses given in (7). Let , and we reject the s hypotheses H0,ij with the smallest P-values. We will demonstrate the performance of this strategy via the real data example in Section 5.
2.5. Extension to functional projection
In the P-DCov described in Section 2.2, we assume the conditional dependency of x and y given factor f is expressed via a linear form of f. In other words, we are projecting x and y onto the space orthogonal to and evaluate the dependence between the projected vectors. Although this linear projection assumption makes the theoretical development easier and delivers the main idea of this work, a natural extension is to consider a nonlinear projection. In particular, we consider the following additive generalization (Stone, 1985) of the factor model setup:
| (8) |
where are unknown vector-valued functions we would like to estimate. In (8), we consider the additive space spanned by factor f. By this extension, we could identify more general conditional dependency structures between x and y given f. This is a special case of (2), but avoids the issue of curse of dimensionality.
In the high-dimensional setup where K is large, we can use a sparse additive model (Ravikumar et al., 2009; Fan et al., 2011) to estimate the unknown functions. The conditional independence test described in Section 2.2 could be modified by replacing the linear regression with the (penalized) additive model regression. We will investigate the P-DCov method coupled with the sparse additive model (Ravikumar et al., 2009) in numerical studies.
Remark 1. (8) is the additive generalization of (3) with homoscedastic noises, i.e., the covariance matrix of ϵx and ϵy are constant across different samples. Following Rigby and Stasinopoulos (1996) and Rigby and Stasinopoulos (2005), we can further extend (8) to accommodate heteroscedastic noises. In particular, we consider the following model
| (9) |
where ϵx and ϵy are the idiosyncratic errors, , and . Adapting the model described in (1a), (1b) and (1c) in Rigby and Stasinopoulos (1996), we assume the standard deviation functions are modeled via transformed additive models:
| (10) |
where g1 and g2 are link functions, and are linear or non-parametric functions of fk corresponding to or , respectively.
We can then use the algorithms developed in Rigby and Stasinopoulos (1996) and Rigby and Stasinopoulos (2005) to get a new set of error estimates, in place of Steps 1 and 2 of our original P-DCov test. Subsequently, we can follow Steps 3 to 5 of the P-DCov test on the estimated errors. This leads to a generalized P-DCov test with heteroskedastic errors. We skip the details to keep the paper concise.
3. Theoretical Results
In this section, we derive the asymptotic properties of our conditional independence test. First, we introduce several assumptions on ϵx, ϵy and f.
Condition 1. , , .
Condition 2. Let us assume that the densities of ‖ϵ1,x − ϵ2,x‖ and ‖ϵ1,y − ϵ2,y‖ are bounded on [0, C0], for some positive constant C0. In other words, there exists a positive constant M,
where hu(·) represents the probability density function for random variable u.
Remark 2. Conditions 1 and 2 impose mild moment and distributional assumptions on random errors ϵx and ϵy. We use the following two simple examples to provide some intuitions regarding Condition 2. Assume , for i = 1, 2, we have and hence . Therefore,
It is easy to observe that, with C0 = 1 and M = 1, Condition 2 is satisfied. Now instead of an identity covariance matrix, let us consider the other extreme case with all coordinates copies or negative copies of one variable (the case where all correlations equal 1 or −1). Then . Therefore,
Again, with C0 = 1 and , Condition 2 is satisfied.
To better understand when the proposed projection method works, we give the following high-level assumptions, whose justifications are noted below.
Condition 3. There exist constants C1 > 1 and γ > 0, such that for any C2 > 1, with probability greater than , we have for any n,
where the sequence an = o{n−1/4 ∧ (n(1+γ) log n)−1/3}.
Condition 4. Let Bx,l denote the l-th row of Bx, and similarly we define , By,l and . We assume for any fixed l,
where sequences en and an in Condition 3 satisfy .
Remark 3. Conditions 3 and 4 are mild. They are imposed to ensure the quality of the projection and guarantee the theoretical properties regarding our conditional independence test. For example, one could directly call the results from penalized least squares for high-dimensional regression (Belloni et al., 2011; Bühlmann and Van De Geer, 2011; Hastie et al., 2015) and robust estimation (Belloni and Chernozhukov, 2011; Wang, 2013; Fan et al., 2017). We now discuss two special examples as follows.
(K is fixed) In this fixed dimensional case, it is straightforward to verify that the projection based on ordinary least squares satisfies the two conditions.
(Sparse Linear Projection) Let and . Note that the graphical model case corresponds to p = 1. We apply the popular L1-regularized least squares for each dimension of x regressing on the factor F. Here, we further assume the true regression coefficient bj is sparse for each j with , and |Sj| = sj. From Theorem 11.1, Example 11.1 and Theorem 11.3 in Hastie et al. (2015), and since are i.i.d., we have with probability going to 1, , and . Then, we have with probability going to 1, for each i = 1, …, n and j = 1, …, p,
| (11) |
where smax = maxj sj. It is now easy to verify that Conditions 3 and 4 are satisfied even under the ultra-high-dimensional case where log K = o(na), 0 < a < 1/3. We would like to omit the details here for brevity about the specification of various constants.
Theorem 1. Under Conditions 1 and 3,
In particular, when ϵx and ϵy are independent, .
Theorem 1 shows that the sample distance covariance between the estimated residual vectors converges to the distance covariance between the population error vectors. It enables us to use the distance covariance of the estimated residual vectors to construct the conditional independence test as described in Section 2.2.
Theorem 2. Under Conditions 1–4, and the null hypothesis that (or equivalently ),
where ζ is a zero-mean Gaussian process defined analogously as in Lemma 2.
Theorem 2 provides the asymptotic distribution of the test statistic T (x, y, f) under the null hypothesis, which is the basis of Theorem 3.
Corollary 2. Under the same conditions of Theorem 2,
where and {λj} are non-negative constants depending on the distribution of (x, y); .
Theorem 3. Consider the test that rejects conditional independence when
| (12) |
where Φ(·) is the cumulative distribution function of . Let αn(x, y, f) denote its associated type I error. Then under Conditions 1–4, for all 0 < α ≤ 0.215,
,
Part (i) of Theorem 3 indicates the proposed test with critical region (12) has an asymptotic significance error at most α. Part (ii) of Theorem 3 implies that there exists a pair (ϵx, ϵy) such that the pre-specified significant level α is achieved asymptotically. In other words, the size of testing is α.
Remark 4. When the sample size n is small, the theoretical critical value in (12) could sometimes be too conservative in practice (Székely et al., 2007). Therefore, we recommend using random permutation to get a reference distribution for the test statistic T (x, y, f) under H0. Random permutation is used to decouple ϵi,x and ϵi,y so that the resulting pair (ϵπ(i),x, ϵi,y) follows the null model, where {π(1), …, π(n)} are a random permutation of indices {1, …, n}. Here, we set the number of permutations as in Székely et al. (2007). Consequently, we can also estimate the P-value associated with the conditional independence test based on the quantiles of the test statistics over R(n) random permutations.
4. Monte Carlo Experiments
In this section, we investigate the performance of P-DCov with five simulation examples. In Example 4.1, we consider a factor model and test the conditional independence between two vectors x and y given their common factor f, via P-DCov. In Examples 4.2, we investigate the classical Gaussian graphical model. In Example 4.3, we consider the case of general graphical model without the Gaussian assumption. In Example 4.4, we consider the case of dependency graph with the contribution of external factors. In Example 4.5, we consider a general graphical model with external factors.
Example 4.1. [High-dimensional factor model] Let p = 5, q = 10 and K = 1000. The rows of Bx and rows of By are drawn independently from , where z1 is a 3-dimensional vector with elements i.i.d. from Unif [2, 3] and z2 = 0K−3. are i.i.d. from . We generate n i.i.d. copies from log-normal distribution (heavy-tail) where Σ is an equal correlation matrix of size (p + q) × (p + q) with Σjk = ρ when j ≠ k and Σjj = 1. ϵi,x and ϵi,y are the centered version of the first p coordinates and the last q coordinates of ri. Then, and are generated according to xi = Bxfi + ϵi,x and yi = Byfi + ϵi,y correspondingly.
In Example 4.1, we consider a high-dimensional factor model with sparse structure. Note that the errors are generated from a heavy tail distribution to demonstrate the proposed test works beyond Gaussian errors. We assume each coordinate of x and y only depends on the first three factors. We calculate T (x, y, f) in the P-DCov test, and T0(x, y, f) in which we replace and by the true ϵi,x and ϵi,y as an oracle test to compare with. To get reference distributions of T (x, y, f) and T0(x, y, f), we follow the permutation procedure as described in Section 3. In this example, we set the significance level α = 0.1. We vary the sample size from 100 to 300 with increment of 20 and show the empirical power based on 2000 repetitions for both T (x, y, f) and T0(x, y, f) in Figure 1 for ρ ∈ {0.1, 0.2, 0.3, 0.4}. In the implementation of penalized least squares in Step 1, we use R package glmnet with the default tuning parameter selection method (10-fold cross-validation) and perform least square on the selected variables to reduce estimation bias of these estimated parameters (Belloni et al., 2013). It is worth mentioning that an alternative approach to reduce the estimation bias is the de-biased lasso method (Zhang and Zhang, 2014; Van de Geer et al., 2014). Here, we decided to use the least square post model selection approach due to its simplicity and computational efficiency.
Figure 1:
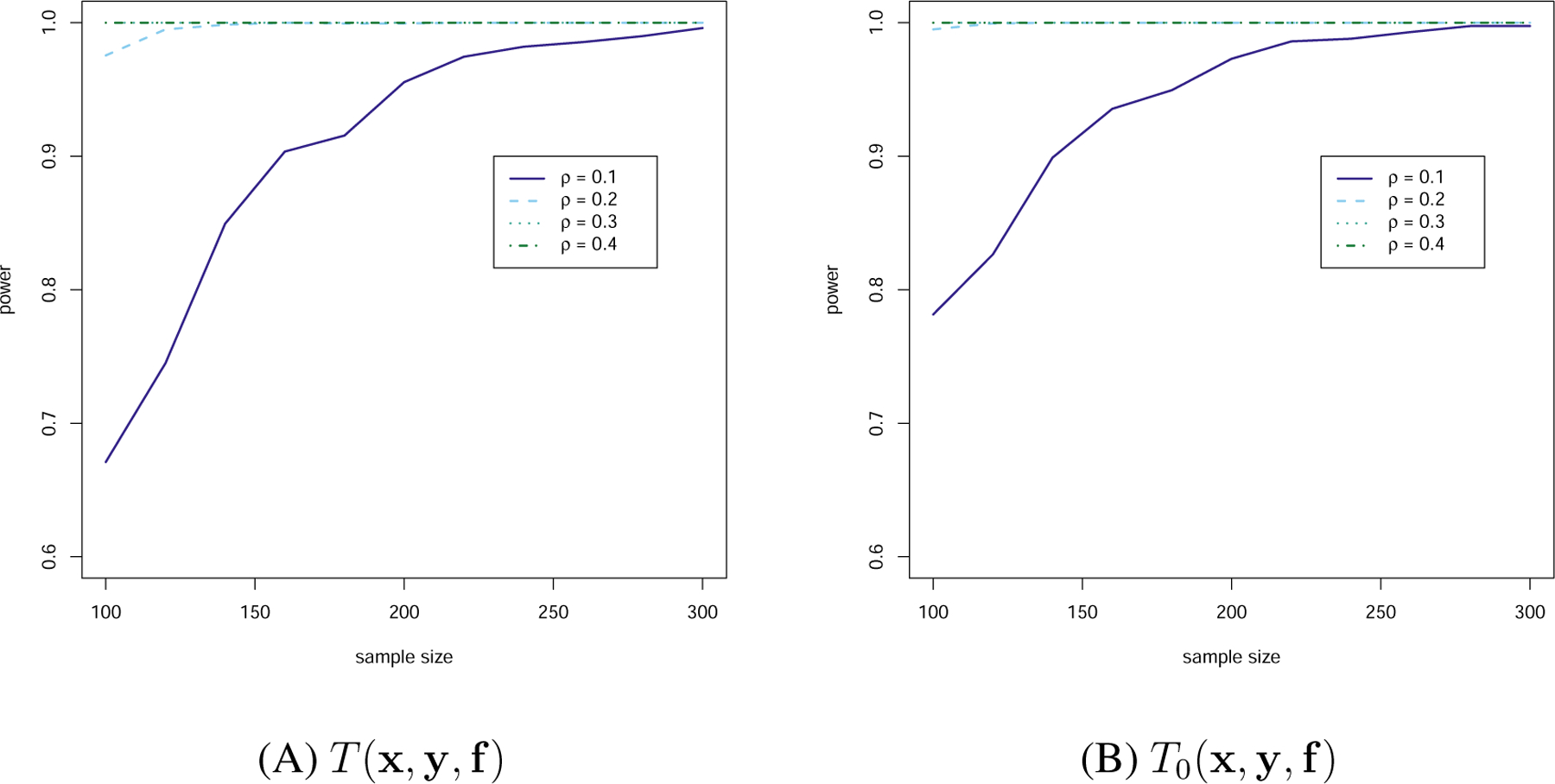
Power-sample size graph of Example 1
From Figure 1, it is clear that as the sample size or ρ increases, the empirical power also increases in general. Also, comparing the panels (A) and (B) in Figure 1, we see that when the sample size is small, the P-DCov test has smaller power than the oracle test, however, the difference between them becomes negligible as the sample size increases. This is consistent with our theory regarding the asymptotic distribution of the test statistics. When ρ = 0, Table 1 reports the empirical type I error for both P-DCov as well as the oracle version. It is clear that the type I error of P-DCov is under good control as the sample size increases.
Table 1:
Type I error of Example 1
| Test based on and | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| n | 100 | 120 | 140 | 160 | 180 | 200 | 220 | 240 | 260 | 280 | 300 |
| 0.119 | 0.114 | 0.116 | 0.100 | 0.098 | 0.097 | 0.092 | 0.102 | 0.094 | 0.091 | 0.096 | |
| Test based on ϵx and ϵy | |||||||||||
| n | 100 | 120 | 140 | 160 | 180 | 200 | 220 | 240 | 260 | 280 | 300 |
| 0.086 | 0.102 | 0.104 | 0.094 | 0.092 | 0.091 | 0.096 | 0.103 | 0.098 | 0.092 | 0.095 | |
Example 4.2. [Gaussian graphical model] We consider a Gaussian graphical model with precision matrix Ω = Σ−1, where Ω is a tridiagonal matrix of size d × d, and is associated with the autoregressive process of order one. We set d = 100 and the (i, j)-element in Σ to be σi,j = exp(−|si − sj|), where . In addition,
In this example, we would like to compare the proposed P-DCov with the state-of-the-art approaches for recovering Gaussian graphical models. In terms of recovering structure Ω, we compare lasso.dcov (projection by lasso followed by distance covariance), sam.dcov (projection by sparse additive model followed by distance covariance), lasso.pearson (projection by lasso followed by Pearson correlation), sam.pearson (projection by sparse additive model followed by Pearson correlation) with three popular estimators corresponding to the lasso, adaptive lasso and scad penalized likelihoods (called graphical.lasso, graphical.alasso and graphical.scad on the graph) for the precision matrix (Friedman et al., 2008; Fan et al., 2009). Here, lasso.dcov and sam.dcov are two examples of our P-DCov methods. We use R package SAM to fit the sparse additive model. To evaluate the performances, we construct receiver operating characteristic (ROC) curves for each method with sample sizes n = 100 and n = 300. The process of constructing the ROC curves involves conducting the P-DCov test for each pair of nodes and record the corresponding P-values. In each of the ROC curve, true positive rates (TPR) are plotted against false positive rates (FPR) at various thresholds of those P-values (“TP” means the true entry of the precision matrix is nonzero and estimated as nonzero; “FP” means the true entry of the precision matrix is zero but estimated as nonzero). We follow the implementation in Fan et al. (2009) for the three penalized likelihood estimators. The average results over 100 replications of different methods are reported in Figure 2. The associated AUC (Area Under the Curve) for each method is also displayed in the legend of the figure.
Figure 2:
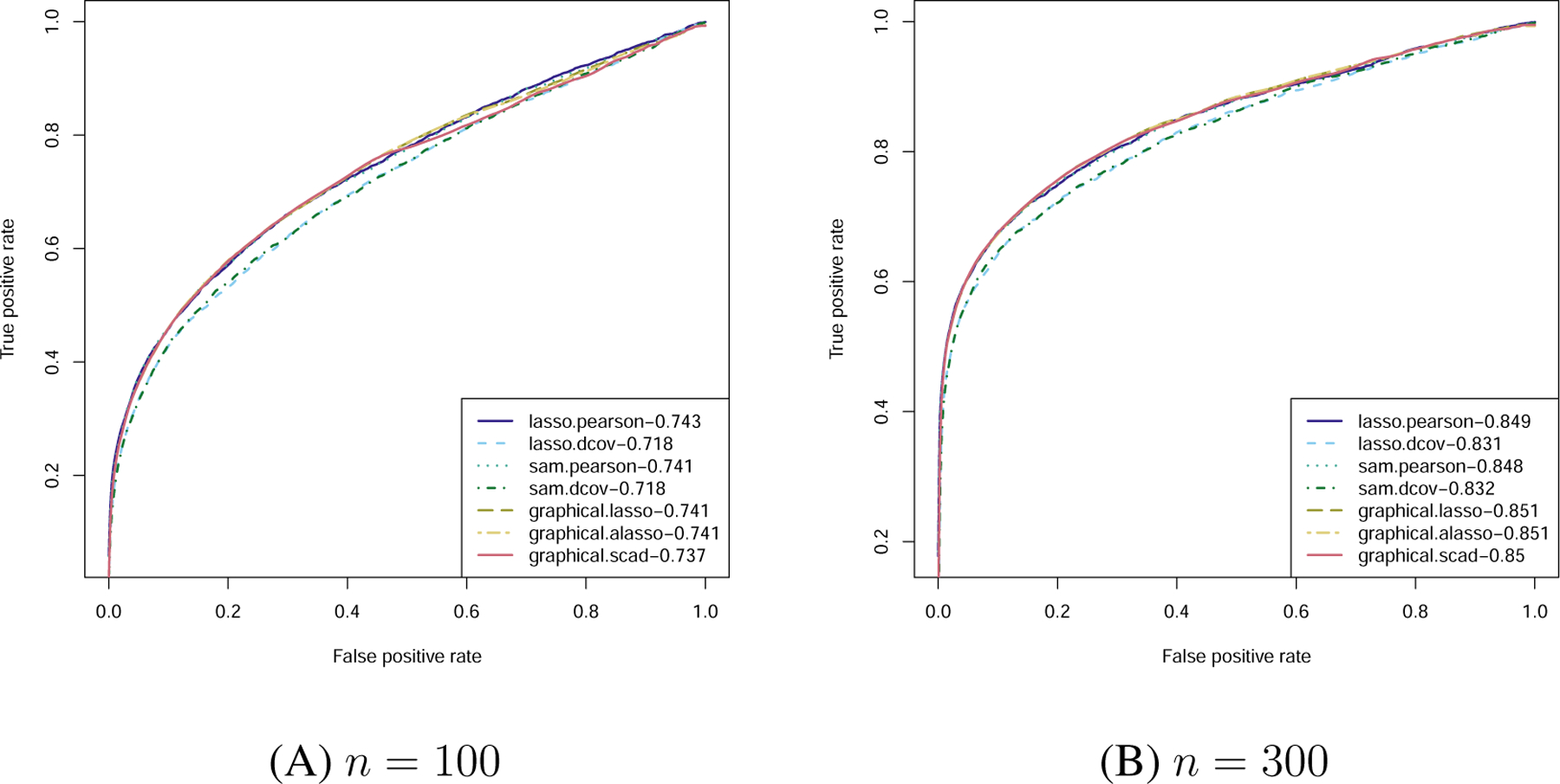
ROC curves for Gaussian graphical models with AUCs in legends.
We observe that lasso.pearson and sam.pearson perform similarly to the penalized likelihood methods when n = 100. On the other hand, lasso.dcov and sam.dcov lead to slightly smaller AUC value due to the use of the distance covariance, which is expected for the Gaussian model. This shows that we do not pay a big price for using the more complicated distance covariance and sparse additive model.
Example 4.3. [A general graphical model] We consider a general graphical model with a combination of multivariate t distribution and multivariate Gaussian distribution. The dimension of x is d = 100. In detail, where x1 follows a 20 dimensional multivariate t distribution with degrees of freedom 5, location parameter 0 and identity covariance matrix, x2 follows the same Gaussian graphical model as in Example 4.2 except the dimension is now 10, and . In addition, x1, x2, and x3 are mutually independent.
To generate a multivariate t-distribution, we first generate a random vector w20 from the standard multivariate Gaussian distribution and an independent random variable and then set . One important fact about the multivariate t distribution is that the zero element in the precision matrix does not imply conditional independence like the case of Gaussian graphical models (Finegold and Drton, 2009). Indeed, for x1, we actually have the fact that and are dependent given for any pair 1 ≤ i ≠ j ≤ 20. On the contrary, the Gaussian likelihood based methods will falsely claim that all the components of x1 are independent, because the corresponding elements in Ω are 0.
The average ROC curve results are rendered in Figure 3. As expected, by using the new projection based distance covariance method for testing conditional independence, lasso.dcov outperforms all the other methods in terms of AUC, with a more evident advantage when n = 300. One interesting observation is that: in the region where FPR is very low, the likelihood based methods actually outperform P-DCov methods. One possible reason is that the likelihood based methods are more capable of capturing the conditional dependency structure within x2 as it follows a Gaussian graphical model.
Figure 3:
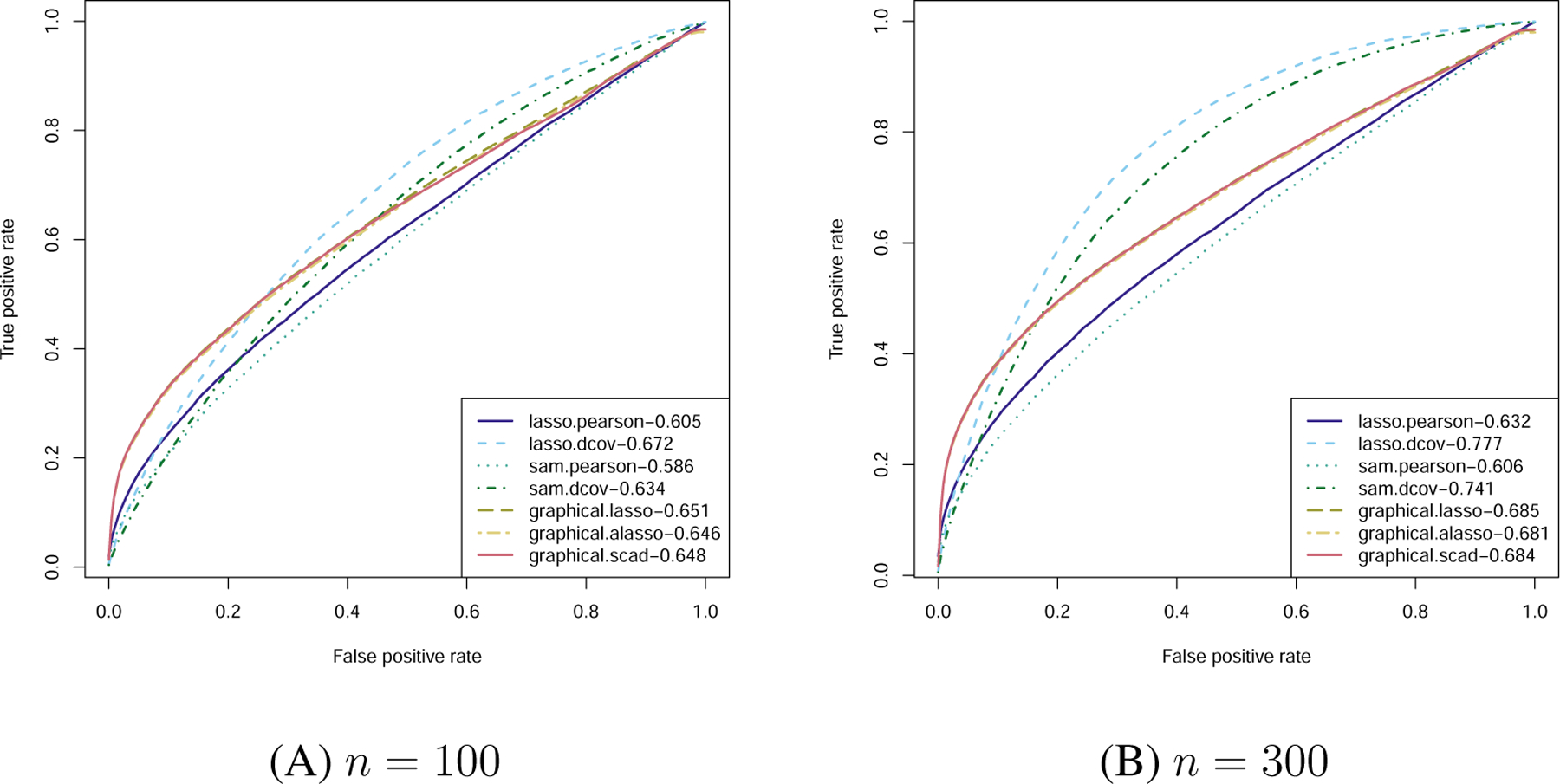
ROC curves for a general graphical model with AUCs in legends.
Example 4.4. [Dependency graph with external factors] We consider a dependency graph with the contribution of external factors. In particular, we generate , where Ω is the same tridiagonal matrix used in Example 4.2 except the dimension is now 30 and , then the observation x = u + Qg(f) where Q30×300 is a sparse coefficient matrix that dictates how each dimension of x depends on the factor g(f). In particular, we let with the generation of follows the setting in Cai et al. (2013). For each element , we first generate a Bernoulli distribution with success probability 0.2 to determine whether is 0 or not. If is not 0, we then generate . Here we consider two forms of g(·), namely g(f) = f and g(f) = f2.
Now, we report results regarding the average ROC curves for lasso.pearson, lasso.dcov, sam.pearson and sam.dcov. The results for both g(f) = f and g(f) = f2 are depicted in Figure 4. Note that we are not building a conditional dependency graph among x, but a dependency graph of x conditioning on the external factor f. There are some insightful observations from the figure. First of all, by looking at the first case when g(f) = f, it is clear that lasso.pearson is the best as it takes advantage of the sparse linear structure paired with the Gaussian distribution of the residual. By using the distance covariance as a dependency measure, or by using the sparse additive model as a projection method, it is reassuring that we do not lose much efficiency. Second, for the case when g(f) = f2 and n = 300, we can see a substantial advantage of the sparse additive model based methods as they can capture this nonlinear contribution of the factors to the dependency structure of x.
Figure 4:
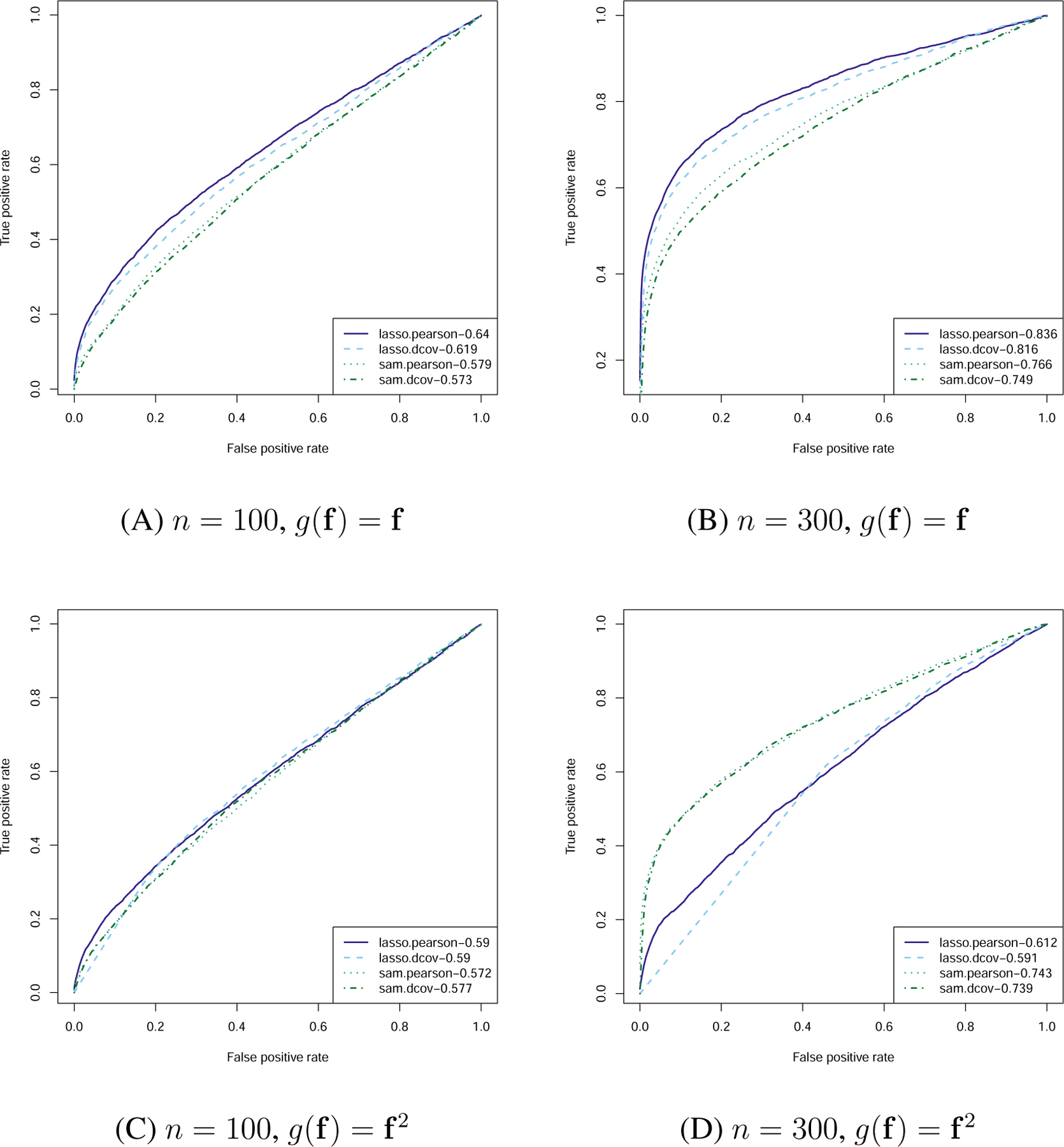
ROC curves for factor based dependency graph with AUCs in legends.
Example 4.5. [A general graphical model with external factors] We consider a general conditional dependency graph with the contribution of external factors by combining the ingredients of Examples 4.3 and 4.4. In particular, we generate with x1 and x2 generated from Example 4.3 and , then set x = u + Qg(f) where Q is the same as Example 4.4. We also consider g(f) = f and g(f) = f2.
In this example, we would like to investigate the performance of a two-step projection method. In particular, we first project x onto the space spanned by f and denote the residual by . Then we explore the conditional dependency structure of and given by projecting them onto the space orthogonal to the space (linearly or additively) spanned by . Here, we compare the performances of methods using the external factor and those that ignore them. The average ROC curves are rendered in Figure 5.
Figure 5:

ROC curves for a general graphical model with external factors (AUCs in legends).
From Figure 5, we see that first of all, when g(f) = f, the methods using external factors outperform their counterparts without using the information with the best method being lasso.dcov. Second, when we have nonlinear factors, using the factors do not necessarily help when we only consider linear projection. For example, the performances of lasso.pearson and lasso.pearson.f in panel (c) illustrates this point. On the other hand, by using sparse additive model based projection, we have a substantial gain over all the remaining methods especially for n = 300.
5. Real Data Analysis
We collect daily excess returns of 90 stocks among the S&P 100 index, which are available between August 19, 2004 and August 19, 2005. We chose the starting date as Google’s Initial Public Offering date, and consider one year of daily excess returns since then. In particular, we consider the following Fama-French three factors model (Fama and French, 1993)
for i = 1, …, 90 and t = 1, …, 252. At time t, rit represents the return for stock i, rft is the risk-free rate, and MKTt, SMBt and HMLt constitute market, size and value factors, respectively.
5.1. Individual stocks
In the first experiment, we study the conditional dependency on all pairs of stocks, with the conditioning set being the Fama-French three factors in Section 5.1.1. Then, we further add the industry factor to the conditioning set in Section 5.1.2.
5.1.1. Fama-French three-factors effect
We perform P-DCov test with FDR control on all pairs of stocks and study the dependence between stocks conditioning on the Fama-French three factors. Under significance level α = 0.01, we found out that 15.46% of the pairs of stocks are conditionally dependent given the three factors, which implies that the three factors may not be sufficient to explain the dependencies among stocks. As a comparison, we also implemented the conditional independence test with the distance covariance based test replaced by Pearson correlation based test. It turns out the 9.34% of the pairs are significant under the same significance level. This shows the P-DCov test is more powerful than the Pearson correlation test in discovering significant pairs that are conditionally dependent.
We then investigate the top 5 pairs of stocks that correspond to the largest test statistic values using the P-DCov test. They are (BHI, SLB), (CVX, XOM), (HAL, SLB), (COP, CVX), and (BHI, HAL). Interestingly, all six stocks involved are closely related to the oil industry. This reveals the high level of dependence among oil industry stocks that cannot be well explained by the Fama-French three factors model. In addition, we examine the stock pairs that are conditionally dependent under the P-DCov test but not under the Pearson correlation test. The two most significant pairs are (C, USB) and (MRK, PFE). The first pair is in the financial industry (Citigroup and U.S. Bancorp) and the second pair is pharmaceutical companies (Merck & Co. and Pfizer). This shows that by using the proposed P-DCov, some interesting conditional dependency structures could be recovered. This is consistent with the findings that the within-sector correlations are still present even after adjusting for Fama-French factors and 10 industrial factors (Fan et al., 2016).
5.1.2. Industry factor effect
For the top 5 stock pairs with the largest test statistics after conditioning on the Fama-French three factors in Section 5.1.1, we would like to evaluate how much of the conditional dependency comes from the industry group effect. In particular, as these stocks all come from the energy industry, we computed the corresponding test statistics before and after further conditioning on the energy group (XLE), in addition to the Fama-French three factors. We summarized the results in Table 2, where columns “woXLE (stat)” and “wXLE (stat)” contain values of the test statistic before and after further conditioning on XLE respectively for each pair. The columns “woXLE (p-value)” and “wXLE (p-value)” contain the corresponding p-values. From the table, we first see that after conditioning on XLE in additional to the Fama-French three factors, all five stock pairs become less dependent with much smaller test statistic values, which agrees with intuition since we remove the impact of industry factor with the additional conditioning. A second observation is that, while the five pairs of stocks are listed in decreasing order in terms of distance covariance before conditioning on the industry factor (in columns containing “woXLE”), the order of these pairs changed after conditioning (in columns containing “wXLE”). This implies that the industry effects may play quite different roles for these pairs of stocks, when we evaluate distance covariances. After carefully investigating the five pairs, we found that CVX, XOM, and COP are oil companies which are directly impacted by XLE, whereas BHI, SLB, and HAL are energy service companies. This may explain that compared with (CVX, XOM) and (COP, CVX), (BHI, SLB), (HAL, SLB) and (BHI, HAL) have a relatively larger test statistic after conditioning on the industry factor XLE in additional to the Fama-French three factors. Some other possible issues that may affect the conditional dependency include the liquidity of stocks (Haugen and Baker, 1996).
Table 2:
The conditional independence test statistics and their associated p-values before and after conditioning on the energy group effect (XLE) for the 5 pairs of stocks.
| Stock Pair | woXLE (stat) | woXLE (p-value) | wXLE (stat) | wXLE (p-value) |
|---|---|---|---|---|
| (BHI, SLB) | 46.92 | 1e–6 | 15.09 | 1e–6 |
| (CVX, XOM) | 35.71 | 1e–6 | 1.86 | 0.043 |
| (HAL, SLB) | 34.81 | 1e–6 | 5.19 | 2.7e–5 |
| (COP, CVX) | 34.12 | 1e–6 | 1.00 | 0.389 |
| (BHI, HAL) | 33.67 | 1e–6 | 6.41 | 2e–6 |
5.2. Stock groups by industry
One advantage of our proposed procedure is that P-DCov can investigate dependence between two multivariate vectors, not necessarily of the same dimension, conditioning on external factors. As an illustration, beyond studying the relationship of stocks within industrial sectors as in Section 5.1.1, we explore dependency structures between industrial sectors conditioning on the Fama-French three factors. In particular, we group the stocks in S&P 100 into 32 industrial groups based on the “Sectoring by industry groups” information provided on https://www.nasdaq.com. Each of the industrial group now contains a few stocks, with a full list provided in Table 6 in Appendix. We perform P-DCov test on all pairs of industrial groups conditioning on the same Fama-French three factors in Section 5.1.1. Table 3 presents the pairs of industrial groups (containing more than 2 stocks) which attain the smallest P-value of 1e-6, and for readers’ convenience, we list the stocks corresponding to each selected groups in Table 4. A few interesting findings are the following. Industry ‘Conglomerates’ (containing stocks of General Electric, Honeywell, 3M and United Technologies Corporation), is conditionally dependent of both ‘Aerospace’ (containing stocks of Boeing, General Dynamics and Raytheon) and ‘Transportation’ (containing stocks of FedEx, Norfolk Southern and UPS-United Parcel Service). A plausible explanation is that the companies in sector ‘Conglomerates’ may produce supplies such as components/gadgets for sector ‘Aerospace’ and ‘Transportation’ and therefore the returns of these industrial sectors might be dependent. Similarly, ‘Large Cap Pharma’ (containing stocks of Bristol-Myers Squibb, Johnson & Johnson, Merck & Co and Pfizer) is conditionally dependent of ‘Medical Products’ (containing stocks of Abbott Laboratories, Baxter International and Medtronic) and ‘Soap and Cleaning Products’ (containing stocks of Colgate-Palmolive and Procter & Gamble). The first relationship can be explained as Pharmaceutical versus Health care and the second is due to the fact that companies in ‘Soap and Cleaning Products’ are big suppliers of the Pharmaceutical companies in terms of their commonly used commodities. Lastly, based on the industrial division provided by Nasdaq, sector ‘Finance’ contains mainly investment banks while sector ‘Banks’ contains the usual regional and commercial banks. It is reasonable to believe these two sectors are closely dependent. The rest of the pairs are detected as significant although we cannot provide an obvious explanation. Nevertheless, since the Fama-French three factors are conditioned out, the discovered conditional dependencies can be subtle. We will leave them to experts for further investigation.
Table 6:
The industry groups and their associated stocks.
| Metal Products | AA |
| Medical | AMGN |
| Steel | ATI |
| Cosmetics & Toiletries | AVP |
| Medical Products | ABT BAX MDT |
| Utility | AEP AES ETR EXC SO |
| Insurance | AIG ALL CI HIG |
| Finance | AXP COF GS MS |
| Aerospace | BA GD RTN |
| Banks | BAC C JPM RF USB WFC |
| Large Cap Pharma | BMY JNJ MRK PFE |
| Beverages | CCU KO |
| Machinery | CAT |
| Soap and Cleaning Products | CL PG |
| Cable TV | CMCSA |
| Oil | COP CVX HAL SLB WMB XOM |
| Food | CPB |
| Computer | CSCO HPQ IBM MSFT ORCL PEP |
| Media Conglomerates | DIS |
| Auto | F |
| Transportation | FDX NSC UPS |
| Conglomerates | GE HON MMM UTX |
| Internet | GOOG |
| Building Prds Retail | HD |
| Semi General | INTC TXN |
| Paper & Related Products | IP |
| Retail | MCD TGT WMT |
| Tobacco | MO |
| Industrial Robotics | ROK |
| Wireless National | S T VZ |
| Building Products | WY |
| Business Services | XRX |
Table 3:
Pairs of stock groups with the smallest P-value 1e–6.
| Conglomerates | Aerospace |
| Large Cap Pharma | Medical Products |
| Soap and Cleaning Products | Large Cap Pharma |
| Conglomerates | Transportation |
| Banks | Finance |
| Banks | Medical Products |
| Conglomerates | Banks |
| Banks | Utility |
| Soap and Cleaning Products | Banks |
| Wireless National | Banks |
Table 4:
The stocks corresponding to each selected industry.
| Banks | BAC C JPM RF USB WFC |
| Large Cap Pharma | BMY JNJ MRK PFE |
| Soap and Cleaning Products | CL PG |
| Conglomerates | GE HON MMM UTX |
| Wireless National | S T VZ |
| Medical Products | ABT BAX MDT |
| Utility | AEP AES ETR EXC SO |
| Finance | AXP COF GS MS |
| Aerospace | BA GD RTN |
| Transportation | FDX NSC UPS |
After looking at the interesting pairs corresponding to the smallest P-values, we apply FDR control with α = 0.01 and selected 27 important pairs with results presented in Tables 5 and 6. Similar messages can be discovered and we leave out the detailed discussions due to the large number of pairs.
Table 5:
The selected important pairs of industry groups with FDR control under α = 0.01.
| Banks | Medical Products |
| Banks | Utility |
| Banks | Medical |
| Banks | Finance |
| Large Cap Pharma | Medical Products |
| Large Cap Pharma | Medical |
| Soap and Cleaning Products | Cosmetics & Toiletries |
| Soap and Cleaning Products | Banks |
| Soap and Cleaning Products | Large Cap Pharma |
| Conglomerates | Aerospace |
| Conglomerates | Banks |
| Conglomerates | Transportation |
| Retail | Building Prds Retail |
| Wireless National | Banks |
| Building Products | Paper & Related Products |
| Banks | Insurance |
| Building Products | Conglomerates |
| Conglomerates | Utility |
| Conglomerates | Machinery |
| Paper & Related Products | Conglomerates |
| Building Products | Transportation |
| Large Cap Pharma | Banks |
| Business Services | Computer |
| Soap and Cleaning Products | Medical Products |
| Semi General | Computer |
| Conglomerates | Medical Products |
| Paper & Related Products | Metal Products |
6. Discussion
In this work, we proposed a general framework for testing conditional independence via projection and showed a new way to create dependency graphs. A few future directions worth exploration. Firstly, the current theoretical results assume that contribution of factors is sparse linear. How to extend the theory to the case of sparse additive model projection would be an interesting future work. The second potential direction is to extend the methodology and theory to the case where the dimensions of x and y grow with n.
Furthermore, the proposed methodology could be generalised to test the conditional independency of multiple random vectors {X1, …, XN} given a common factor f by taking advantage of a recent result by Böttcher et al. (2019), which developed a new dependency measure for multiple random vectors. A preliminary description of the extension is as follows.
Estimate the errors by the projection methods described in the current paper. Denote the corresponding estimates as .
- With a predetermined significance level α, we reject the null hypothesis if the normalized total multivariance (see Test B in Section 4.5 of Böttcher et al. (2019) for details) satisfies
where is the normalized total multivariance function specified in definition 4.17 in Böttcher et al. (2019).
The detailed impact of the estimated error on the asymptotic distribution of the test statistic is worth further investigation.
An R package pgraph for implementing the proposed methodology is available on CRAN.
Acknowledgement
The authors would like to thank the Editor, the AE and anonymous referees for their insightful comments which greatly improved the scope of this paper. This work was partially supported by National Science Foundation grants NSF grant DMS-1308566, NSF CAREER grant DMS-1554804, NSF DMS-1662139 and DMS-1712591 and National Institutes of Health grant R01-GM072611-14.
Appendix
Lemma 3. Under Condition 3, we have and .
Proof. From Condition 3, it is obvious that . Let and . Then, we have
As a result, the lemma is proved.□
For the remaining proofs, we apply Taylor expansion to at and get
| (13) |
where and , for and .
of Theorem 1. Using the Taylor expansion in (13), we have the following decomposition
where
| (14) |
| (15) |
| (16) |
By Condition 3, we have . Therefore,
Another fact we easily observe is that: , since is uniformly bounded over all (i, j) pairs and so is .
As a result, we know . This combined with Lemma 1 leads to
□
Remark: The result of Theorem 1 cannot be implied from that of Theorem 2, since independence between ϵx and ϵy is not assumed.
Lemma 4. For the ci,j,x and ci,j,y defined in (13), we have the following approximation error bound on the normalized version.
| (17) |
| (18) |
Proof. It suffices to show (17). First, we will show
| (19) |
Denote by α1 and α2 the angle between ci,j,x and ϵi,x−ϵj,x, and the angle between and ϵi,x − ϵj,x, respectively. It is easy to see that 0 ≤ α1 ≤ α2 ≤ π, and hence cos α1 ≥ cos α2. By cosine formula,
Therefore, (19) is proved and it remains to show that
| (20) |
Left hand side of (20) can be rewritten as
Combining (19) and (20), the lemma is proved. □
Lemma 5. Under Conditions 1 and 2, and the null hypothesis that , for any γ > 0,
Proof. We will only show the first result involving ϵx with the other one follows similarly. For any δ > 0, let
Then for ∀ ϵ > 0,
| (21) |
due to the Condition 2 that the density function of ‖ϵi,x − ϵj,x‖ is pointwise bounded.
Therefore, , which leads to
| (22) |
On the other hand,
| (23) |
where is the density of ‖ϵi,x − ϵj,x‖. In the above derivation, the first inequality can be easily seen from (21) and the second inequality utilizes Condition 2.
Therefore, is bounded in L1 and since nγ → ∞, converges to 0 in L1 and hence in probability, i.e.,
| (24) |
This, combined with (22) yields
| (25) |
This completes the proof of Lemma 5. □
To prove Theorem 2, we first introduce two propositions.
Proposition 1. Under Conditions 1 and 2, and the null hypothesis that ,
Proof. From (14), we rewrite T1 as
with Ai,j,y self-defined by the equation.
Let us consider term
| (26) |
We can separate the above quantity into three parts. It is easy to see that Di,j,x are identically distributed with respect to different pairs of (i, j) when i ≠ j. Let us define the following three sets of index quadruples:
I1 = {(i, j, k, l)|there are four distinct values in {i, j, k, l}}.
I2 = {(i, j, k, l)|i ≠ j, k ≠ l, and there are three distinct values in {i, j, k, l}}.
I3 = {(i, j, k, l)|i ≠ j, k ≠ l, and there are two distinct values in {i, j, k, l}}.
Let us suppose , for (i, j, k, l) ∈ I1;, for (i, j, k, l) ∈ I2., for (i, j, k, l) ∈ I3. By Condition 3, we know c1, c2 and c3 are all of order . Also, . Then we have
| (27) |
On the other hand, we observe that by definition and Ai,j,y = Aj,i,y, so we have
By Condition 1, we know all the second order terms of distances of differences (‖ϵi,y − ϵj,y‖2, ‖ϵi,y−ϵj,y‖·‖ϵi,y−ϵk,y‖ as examples) have bounded expectation, and thus all the second order terms of Ai,j,y’s also have bounded expectations. Therefore, . Finally, since ,
This combined with our previous calculations leads to . As a result, we have . Together with Chebychev’s inequality, we know and equivalently, T1 = Op(an/n). Similarly, we could show that T2 = Op(an/n). □
Proposition 2. Under Conditions 1, 2, 3, and 4, and the null hypothesis that ,
Proof. Recall that
with Bi,j,y self-defined in the above equation. We can easily see that , for any j. Let Bmax = maxi,j |Bi,j,y|, then we define . In this way, we know and for any j. By Condition 3, we know that Bmax = Op(an). Also, since all are non-negative, by Cauchy-Schwartz, we can upper bound with the case when have the same values across i. Thus, .
Then we can rewrite T3 in the following form:
Let us look at T31 first. If we denote D and as the matrix of dimension n × n composed of elements Di,j,x and , we know that
| (28) |
Then, let us proceed to term T32. Here, we write Di,j,x in another form as a sum of two terms and bound them separately.
| (29) |
As a result, we know
By Lemma 4, we know
| (30) |
where .
Together with Lemma 5, the first term in T32 has rate
The second term in T32 can be rewritten in terms of trace:
| (31) |
| (32) |
where W is self-defined and W (i, j) is the element on the i-th row and j-column of matrix W. Let us take (i, j) = (1, 1) as an example, and look at . We easily see that , due to facts: and ϵi,x and ϵi,x are mutually independent of f with any observation indices; and . Furthermore,
Similar to the reasoning in Proposition 1, we have n4 terms in I1. But in this scenario, due to independence, therefore we know
As a result, we know |W (1, 1)| = Op(n−1/2), and thus maxi,j |W (i, j)| = Op(n−1/2 log K). Furthermore, we can bound the term in (31) with rate Op(n−1/2anen log K).
Combining T31 and T32, we know . □
Proof of Theorem 2. Recall the notations we used in the proof of Theorem 1,
By Propositions 1 and 2, Conditions 3 and 4, we have for any γ > 0,
Combined with Lemma 2, the theorem is proved. □
Proof of Corollary 2. The result follows directly from the proofs of Theorems 1 and 2 and an application of Slutsky’s theorem. □
Proof of Theorem 3. The proof of Theorem 3 follows similarly as Theorem 6 in Székely et al. (2007). Here we omit the details for brevity. □
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Anderson TW, 1962. An introduction to multivariate statistical analysis. Wiley; New York. [Google Scholar]
- Belloni A, Chernozhukov V, 2011. L1-penalized quantile regression in high-dimensional sparse models. The Annals of Statistics 39, 82–130. [Google Scholar]
- Belloni A, Chernozhukov V, Wang L, 2011. Square-root lasso: pivotal recovery of sparse signals via conic programming. Biometrika 98, 791–806. [Google Scholar]
- Belloni A, Chernozhukov V, et al. , 2013. Least squares after model selection in high-dimensional sparse models. Bernoulli 19, 521–547. [Google Scholar]
- Benjamini Y, Hochberg Y, 1995. Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society. Series B (Methodological), 289–300.
- Blomqvist N, 1950. On a measure of dependence between two random variables. The Annals of Mathematical Statistics, 593–600.
- Blum J, Kiefer J, Rosenblatt M, 1961. Distribution free tests of independence based on the sample distribution function. The Annals of Mathematical Statistics, 485–498.
- Böttcher B, Keller-Ressel M, Schilling RL, 2019. Distance multivariance: New dependence measures for random vectors. The Annals of Statistics 47, 2757–2789. [Google Scholar]
- Bühlmann P, Van De Geer S, 2011. Statistics for high-dimensional data: methods, theory and applications. Springer Science & Business Media.
- Cai T, Liu W, Luo X, 2011. A constrained L1 minimization approach to sparse precision matrix estimation. Journal of the American Statistical Association 106, 594–607. [Google Scholar]
- Cai TT, Li H, Liu W, Xie J, 2013. Covariate-adjusted precision matrix estimation with an application in genetical genomics. Biometrika 100, 139–156. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen S, Witten DM, Shojaie A, 2014. Selection and estimation for mixed graphical models. Biometrika 102, 47–64. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dempster AP, 1972. Covariance selection. Biometrics, 157–175.
- Drton M, Perlman MD, 2004. Model selection for gaussian concentration graphs. Biometrika 91, 591–602. [Google Scholar]
- Edwards D, 2000. Introduction to graphical modelling. Springer. [Google Scholar]
- Fama EF, French KR, 1993. Common risk factors in the returns on stocks and bonds. Journal of Financial Economics 33, 3–56. [Google Scholar]
- Fan J, 1992. Design-adaptive nonparametric regression. Journal of the American statistical Association 87, 998–1004. [Google Scholar]
- Fan J, Feng Y, Song R, 2011. Nonparametric independence screening in sparse ultra-high dimensional additive models. Journal of the American Statistical Association 106, 544–557. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan J, Feng Y, Wu Y, 2009. Network exploration via the adaptive lasso and scad penalties. The Annals of Applied Statistics 3, 521. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan J, Furger A, Xiu D, 2016. Incorporating global industrial classification standard into portfolio allocation: A simple factor-based large covariance matrix estimator with high frequency data. Journal of Business & Economic Statistics, 489–503.
- Fan J, Ke Y, Sun Q, Zhou WX, 2018. Farm-test: Factor-adjusted robust multiple testing with false discovery control. Journal of American Statistical Association, to appear. [DOI] [PMC free article] [PubMed]
- Fan J, Li Q, Wang Y, 2017. Robust estimation of high-dimensional mean regression. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 79, 247–265. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Finegold MA, Drton M, 2009. Robust graphical modeling with t-distributions, in: Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, AUAI Press; pp. 169–176. [Google Scholar]
- Friedman J, Hastie T, Tibshirani R, 2008. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 9, 432–441. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van de Geer S, Bühlmann P, Ritov Y, Dezeure R, et al. , 2014. On asymptotically optimal confidence regions and tests for high-dimensional models. The Annals of Statistics 42, 1166–1202. [Google Scholar]
- Gretton A, Bousquet O, Smola A, Schölkopf B, 2005. Measuring statistical dependence with hilbert-schmidt norms, in: International conference on algorithmic learning theory, Springer; pp. 63–77. [Google Scholar]
- Hastie T, Tibshirani R, Wainwright M, 2015. Statistical learning with sparsity: the lasso and generalizations. CRC Press. [Google Scholar]
- Haugen RA, Baker NL, 1996. Commonality in the determinants of expected stock returns. Journal of Financial Economics 41, 401–439. [Google Scholar]
- Heller R, Heller Y, Gorfine M, 2012. A consistent multivariate test of association based on ranks of distances. Biometrika 100, 503–510. [Google Scholar]
- Hoeffding W, 1948. A non-parametric test of independence. The Annals of Mathematical Statistics, 546–557.
- Hollander M, Wolfe DA, Chicken E, 2013. Nonparametric statistical methods. John Wiley & Sons. [Google Scholar]
- Huo X, Székely GJ, 2016. Fast computing for distance covariance. Technometrics 58, 435–447. [Google Scholar]
- Jankova J, Van De Geer S, 2015. Confidence intervals for high-dimensional inverse covariance estimation. Electronic Journal of Statistics 9, 1205–1229. [Google Scholar]
- Lauritzen SL, 1996. Graphical models. Oxford University Press. [Google Scholar]
- Linton O, Gozalo P, 1997. Conditional independence restrictions: testing and estimation. V Cowles Foundation Discussion Paper 1140. [Google Scholar]
- Liu W, 2013. Gaussian graphical model estimation with false discovery rate control. The Annals of Statistics 41, 2948–2978. [Google Scholar]
- Meinshausen N, Bühlmann P, 2006. High-dimensional graphs and variable selection with the lasso. The Annals of Statistics, 1436–1462.
- Ravikumar P, Lafferty J, Liu H, Wasserman L, 2009. Sparse additive models. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 71, 1009–1030. [Google Scholar]
- Ren Z, Sun T, Zhang CH, Zhou HH, 2015. Asymptotic normality and optimalities in estimation of large gaussian graphical models. The Annals of Statistics 43, 991–1026. [Google Scholar]
- Rigby R, Stasinopoulos D, 1996. A semi-parametric additive model for variance heterogeneity. Statistics and Computing 6, 57–65. [Google Scholar]
- Rigby RA, Stasinopoulos DM, 2005. Generalized additive models for location, scale and shape. Journal of the Royal Statistical Society: Series C (Applied Statistics) 54, 507–554. [Google Scholar]
- Sen A, Sen B, 2014. Testing independence and goodness-of-fit in linear models. Biometrika 101, 927–942. [Google Scholar]
- Stock JH, Watson MW, 2002. Macroeconomic forecasting using diffusion indexes. Journal of Business & Economic Statistics 20, 147–162. [Google Scholar]
- Stone CJ, 1985. Additive regression and other nonparametric models. The Annals of Statistics 13, 689–705. [Google Scholar]
- Su L, White H, 2007. A consistent characteristic function-based test for conditional independence. Journal of Econometrics 141, 807–834. [Google Scholar]
- Su L, White H, 2008. A nonparametric hellinger metric test for conditional independence. Econometric Theory 24, 829–864. [Google Scholar]
- Su L, White H, 2014. Testing conditional independence via empirical likelihood. Journal of Econometrics 182, 27–44. [Google Scholar]
- Székely GJ, Rizzo ML, Bakirov NK, 2007. Measuring and testing dependence by correlation of distances. The Annals of Statistics 35, 2769–2794. [Google Scholar]
- Voorman A, Shojaie A, Witten D, 2013. Graph estimation with joint additive models. Biometrika 101, 85–101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wainwright MJ, Jordan MI, 2008. Graphical models, exponential families, and variational inference. Foundations and Trends® in Machine Learning 1, 1–305. [Google Scholar]
- Wang L, 2013. The l1 penalized lad estimator for high dimensional linear regression. Journal of Multivariate Analysis 120, 135–151. [Google Scholar]
- Wang X, Pan W, Hu W, Tian Y, Zhang H, 2015. Conditional distance correlation. Journal of the American Statistical Association 110, 1726–1734. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilks S, 1935. On the independence of k sets of normally distributed statistical variables. Econometrica, Journal of the Econometric Society, 309–326.
- Yu G, Bien J, 2017. Learning local dependence in ordered data. Journal of Machine Learning Research 18, 1–60. [Google Scholar]
- Zhang CH, Zhang SS, 2014. Confidence intervals for low dimensional parameters in high dimensional linear models. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 76, 217–242. [Google Scholar]