

Abstract
Background
There is little consensus on how to sample hospitalizations and analyze multiple variables to model readmission risk. The purpose of this study was to compare readmission rates and the accuracy of predictive models based on different sampling and multivariable modeling approaches.
Methods
We conducted a retrospective cohort study of 17,284 adult diabetes patients with 44,203 discharges from an urban academic medical center between 1/1/2004 and 12/31/2012. Models for all-cause 30-day readmission were developed by four strategies: logistic regression using the first discharge per patient (LR-first), logistic regression using all discharges (LR-all), generalized estimating equations (GEE) using all discharges, and cluster-weighted (CWGEE) using all discharges. Multiple sets of models were developed and internally validated across a range of sample sizes.
Results
The readmission rate was 10.2% among first discharges and 20.3% among all discharges, revealing that sampling only first discharges underestimates a population’s readmission rate. Number of discharges was highly correlated with number of readmissions (r = 0.87, P < 0.001). Accounting for clustering with GEE and CWGEE yielded more conservative estimates of model performance than LR-all. LR-first produced falsely optimistic Brier scores. Model performance was unstable below samples of 6000–8000 discharges and stable in larger samples. GEE and CWGEE performed better in larger samples than in smaller samples.
Conclusions
Hospital readmission risk models should be based on all discharges as opposed to just the first discharge per patient and utilize methods that account for clustered data.
Supplementary Information
The online version contains supplementary material available at 10.1186/s12874-020-01162-0.
Keywords: Logistic models, Patient readmission, Predictive modeling, Sampling strategies, Clustering
Background
Recent interest in value-based care has focused attention on quality metrics in healthcare delivery. One metric, the all-cause emergency (unplanned) 30-day hospital readmission rate, has received considerable attention because it may be related to poor care, and hospitals in the US with excess readmission rates are subject to financial penalties [1, 2]. To better understand and ultimately prevent readmissions, numerous studies have examined readmission risk factors and/or developed multivariable predictive models [3–5].
Despite this growing body of literature, there is little consensus on how to sample hospitalizations and analyze multiple variables to model readmission risk. It is possible that different sampling strategies may yield different readmission rates. For example, the 30-day readmission rate for patients diagnosed with diabetes reported in the literature ranges from 10.0%, in which only the first hospitalization per patient was included as an observation, to 20.4%, in which all hospitalizations were considered as observations [6, 7]. While some variation is expected due to differences in populations across studies, sampling strategy may independently affect observed readmission rates.
In addition to variation in sampling methods, there are also multiple approaches to multivariable modeling. The most common approach is logistic regression, which treats each observation (hospital discharge) as independent [4, 5]. While this model is the least computationally demanding and the most familiar, the assumption of independence may not be valid for multiple hospitalizations of an individual patient during a given study period. The readmission risk of a patient at the time of discharge #1 is likely related to the readmission risk of the same patient at the time of discharge #2. In this case, the patient may be considered as a cluster of 2 hospital discharges. Simulation studies show that analytical approaches on clustered data that do not take into account the effects of clustering often yield erroneous results [8, 9].
One method that accounts for longitudinal correlations of data within clusters is generalized estimating equations (GEE) [10]. In the GEE approach, the intra-cluster correlation is modeled to determine the weight that should be assigned to data from each cluster [11]. If the outcome is independent of cluster size (i.e., cluster size is uninformative), then this approach is valid. However, if the outcome is related to cluster size, as is likely with readmission risk and number of discharges, then GEE may generate misleading parameter estimates. For example, people with poor dental health are likely to have fewer teeth than those with good dental health because factors that lead to poor dental health also lead to tooth loss. Therefore, in a study investigating risk factors for tooth disease, the number of teeth per person (cluster size) would be informative [11]. Cluster-weighted GEE (CWGEE) has been proposed as a valid approach to analyzing clustered data with an informative cluster size [11]. While some examples of the GEE approach exist in the readmission literature [7, 12, 13], to our knowledge, CWGEE has not been used in this context.
Herein, we compare readmission rates and predictive model accuracy of different sampling and multivariable modeling approaches in a dataset of diabetes patients previously used to develop a readmission risk prediction model [7].
Methods
A cohort of 17,284 patients discharged from an urban academic medical center (Boston Medical Center) between 1/1/2004 and 12/31/2012 were selected, and 44,203 discharges from this cohort comprised the complete dataset. Inclusion criteria for index discharges were diabetes defined by an International Classification of Diseases, Ninth Revision, Clinical Modification (ICD-9-CM) code of 250.xx associated with hospital discharge or the presence of a diabetes-specific medication on the pre-admission medication list. Index discharges were excluded for patient age < 18 years, discharge by transfer to another hospital, discharge from an obstetric service (indicating pregnancy), inpatient death, outpatient death within 30 days of discharge, or incomplete data. Readmission documented within 8 h of a discharge was merged with the index admission to avoid counting in-hospital transfer as a readmission.
The primary outcome was all-cause readmission within 30 days of discharge. The same 46 variables previously used to develop a readmission risk prediction model were evaluated as predictors of the primary outcome to construct and validate all prediction models (see Table, Supplemental Digital Content 1, which presents patient characteristics on the variables analyzed) [7].
Five different measures of performance were assessed for each model.
Diagnostic discrimination (C statistic): the area under the receiver operating characteristic curve (AUC), for which higher values represent better discrimination [14]. Discrimination is the ability of a model to distinguish high-risk individuals from low-risk individuals [15]. The C statistic is the most commonly used performance measure of generalized linear regression models [16].
Correlation: the correlation between the observed outcome (readmission) and the value predicted by the model [17]. Unlike the C statistic, correlation represents a summary measure of the predictive power of a generalized linear model.
Coefficient of discrimination (D): the absolute value of the difference between model successes (the mean predicted probability of readmission, p^, for readmitted patients) and model failures (p^ for non-readmitted patients) [18]. This is a measure of overall model performance with a more intuitive interpretation for binary outcomes than the more familiar coefficient of determination (R2).
Brier score: the mean squared deviation between the predicted probability of readmission and the observed readmission rate. An overall score that captures both calibration and discrimination aspects, the Brier score can range from 0 for a perfect model to 0.25 for a noninformative model with a 50% incidence of the outcome. When the outcome incidence is lower, the maximum score for a noninformative model is lower [16, 19].
Scaled Brier score: the Brier score scaled by its maximum score (Briermax) according to the eq. 1- Brier score / Briermax [16, 20]. Unlike the Brier score, the scaled Brier score is not dependent on the incidence of the outcome. For the scaled Brier score, a higher score represents greater accuracy. Briermax is defined as mean(p)*(1-mean(p)) where mean(p) is the average probability of a positive outcome. The scaled Brier score is similar to Pearson’s R2 statistic [16]. The Brier score and scaled Brier score were chosen as measures to highlight potential differences seen when the incidence of readmission varies due to the sampling methods described below.
Sampling was performed by two methodologies. The first method included only the first index discharge per patient during the study period (first discharges). The second method included all index discharges per patient (all discharges), regardless of whether the hospitalization was a readmission relative to a prior discharge. The study sample was then divided randomly into a training sample and a validation sample [15]. The training sample, which comprised 60% of the patients in the study cohort, was used to develop the statistical prediction models. The validation sample contained the remaining 40% of the patients and was used to evaluate the performance of the prediction models.
Characteristics of the study population were described and compared between the training and validation samples. Categorical variables were presented as number (%) while continuous variables were presented as mean (standard deviation) or median (interquartile range). For the first discharge per patient dataset, the validation sample was compared to the training sample by Chi-square tests for categorical variables and two sample t-tests or Wilcoxon rank-sum tests for continuous variables. For the all discharges dataset, the validation sample was compared to the training sample by univariate generalized linear model for all variables. When analyzing all discharges, only current and prior observations available at the time of each index discharge were used for modeling.
The models can be described in mathematical terms as follows. Suppose the ith patient has ni observations where i = 1, 2, … N and jth discharge where j = 1, 2, …ni. Suppose Xij is the 46-vector of covariates and Yij is the vector of discharges where Yij = 1 of ith subject at jth discharge readmitted within 30 days and Yij = 0 otherwise. Xij can be constant over time such as gender or time-varying such as age. We further define a general class of models that specify the potential relation between readmission Y and covariates X as f (E(Y | X)) = η, where f (.) is a link function, such as the logit function, that determines the relationship between Y and X; E (Y | X) denotes the conditional mean of Y given X; and η is a function of covariates, usually a linear function such that η = α + β X where α and β are log odds ratios. We fit the readmission prevalence model assuming a logit link to estimate the effect of covariates β as logit(E(Y|X)) = α + β X. Then the probability of readmission within 30 days is P((Y = 1) = exp.(α + β X)/[1 + exp.(α + β X)]. This probability is estimated and used to compare performance of four statistical approaches described below.
The four approaches used to predict readmission were: 1) logistic regression using the first discharges, 2) logistic regression using all discharges, 3) GEE logistic regression with an exchangeable correlation structure using all discharges, and 4) CWGEE logistic regression with an exchangeable correlation structure using all discharges. CWGEE logistic regression is an extension of GEE logistic regression that accounts for cluster size when the outcome among observations in a cluster is dependent on the cluster size (i.e., when cluster size is informative) [11]. For each approach, univariate analyses were performed for all variables to determine those associated with 30-day readmission (P < 0.1). Multivariable models with best subset selection were performed to determine the adjusted associations of the variables with all-cause 30-day readmission [21, 22]. Variables associated with 30-day readmission at the P < 0.05 level in the multivariable models were retained.
To examine the effects of sample size on model performance, we conducted resampling studies across a range of sample sizes from 2000 to 17,000 patients by intervals of 1000. We randomly sampled each subset from the complete cohort of 17,284 patients. Each subset was then randomly divided 60% for model development and 40% for validation. For each dataset, the models were developed and compared as described above. Changes in model performance measures over sample size are displayed by line charts and compared by analysis of covariance. Lastly, we examined the relationship between the log of the number of discharges per patient (cluster size) and the number of readmissions per patient by Pearson correlation. In addition, correlations between the number of discharges per patient and predicted readmission rates were assessed. All statistical analyses were conducted using SAS 9.4 (SAS Institute, Cary, NC) and Stata 14.0 (StataCorp, College Station, TX). Institutional Review Board approval was obtained from Boston Medical Center and Temple University.
Results
There were 17,284 patients with 44,203 discharges, of which 9034 (20.4%) were associated with 30-day readmission for any cause. The study cohort is well-distributed across middle to older adult age and sex (See Supplementary Table 1, Additional File 1). A majority of the patients are unmarried, English-speaking, insured by Medicare or Medicaid, lived within 5 miles of the hospital, educated at a high-school level or less, disabled, retired, or unemployed, and overweight or obese. This is an ethnically diverse sample, with 37.4% black, 14.7% Hispanic, and 39.7% white. The distribution of characteristics is similar between training and validation sets, with only 3 variables showing statistically significant differences despite absolute differences of < 2% (race/ethnicity [P = 0.03], serum sodium [P = 0.01], and COPD or asthma [P = 0.049]). Likewise, the distribution of characteristics is similar between training and validation sets of all discharges, with only 2 variables showing statistically significant differences despite absolute differences of < 2% (pre-admission sulfonylurea use [P = 0.032], and serum sodium [P = 0.029], (See Supplementary Table 2, Additional File 2).
The readmission rate is 10.2% in the sample of first discharges and 20.3% in the sample of all discharges. The AUCs are comparable among logistic regression with first discharges, logistic regression using all discharges, and GEE using all discharges, ranging from 0.803–0.821 (See Supplementary Table 3, Additional File 3, which compares performance of the four modeling methods in the whole cohort). CWGEE using all discharges yielded a lower AUC than logistic regression with first discharges and logistic regression with all discharges. Logistic regression with all discharges resulted in the highest coefficient of discrimination, followed by the GEE, first discharge and WGEE models. Analyzing all discharges both with and without GEE produced the highest predictive power by correlation, while the first discharge showed the least predictive power. Analysis of the first discharges yielded the smallest (best) Brier score while the other three methods yielded comparably higher (worse) Brier scores. Analysis of the first discharges generated the smallest (worst) scaled Brier score, which is borderline different from the largest (best) scaled Brier score produced by logistic regression with all discharges.
The observed rates of readmission were stable with increasing sample size from 2000 to 17,000 patients for the first discharges and all discharges samples. With sample sizes less than 6000, the AUCs, coefficients of discrimination, correlations and Brier scores were variable (Figs. 1,2,3 and 4). These measures of model performance were relatively stable at sample sizes of 6000 to 17,000. The scaled Brier scores were relatively stable at sample sizes of 8000 to 17,000. The AUCs were comparable among the four approaches, with the first discharges models generally having the greatest AUC and CWGEE having the smallest AUC over the sample size range (Fig. 1). The coefficients of discrimination were greatest for the analysis of all discharges using logistic regression and generally smallest with CWGEE and first discharges (Fig. 2). The correlations were highest for logistic regression with all discharges and lowest for the first discharges (Fig. 3). The first discharges analysis yielded the lowest (best) Brier score by a substantial margin compared to the other 3 methods, which were comparable across all samples sizes (Fig. 4). In contrast, the first discharges approach generally produced the lowest (worst) scaled Brier score and all discharges logistic regression yielded the highest (best) across samples sizes (Fig. 5).
Fig. 1.
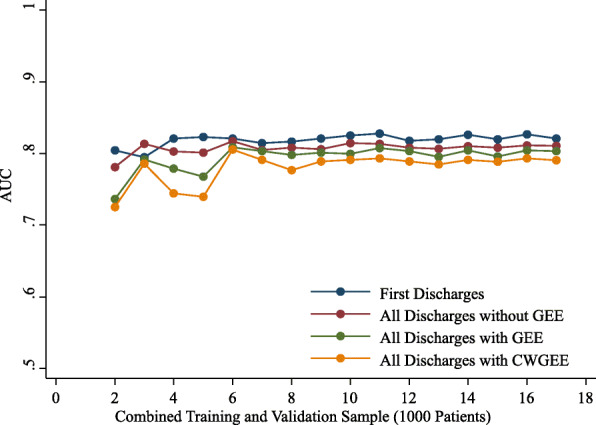
AUC of models tested in validation samples of adult patients with diabetes. The x-axis shows the size of the initial cohort from which training and validation samples were drawn. Boston, Massachusetts, 2004–2012. GEE = generalized estimating equations. CWGEE = cluster-weighted generalized estimating equations. AUC = Receiver operating characteristic area under the curve
Fig. 2.
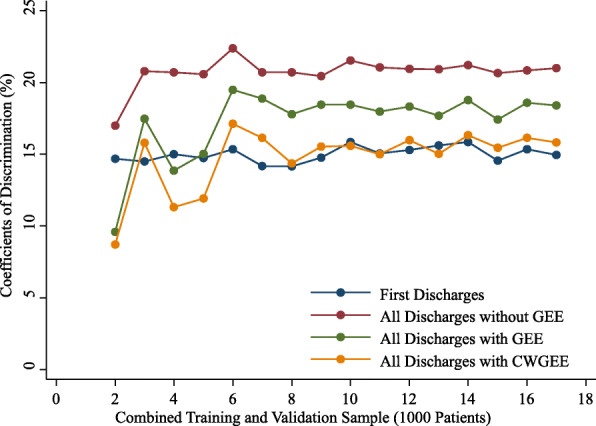
Coefficients of discrimination of models tested in validation samples of adult patients with diabetes. The x-axis shows the size of the initial cohort from which training and validation samples were drawn. Boston, Massachusetts, 2004–2012. GEE = generalized estimating equations. CWGEE = cluster-weighted generalized estimating equations
Fig. 3.
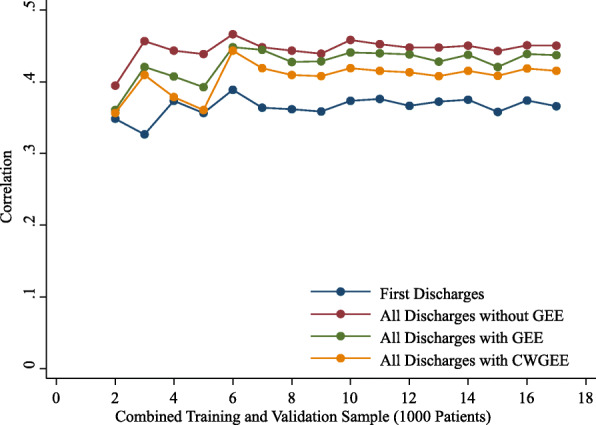
Correlation measures of models tested in validation samples of adult patients with diabetes. The x-axis shows the size of the initial cohort from which training and validation samples were drawn. Boston, Massachusetts, 2004–2012. GEE = generalized estimating equations. CWGEE = cluster-weighted generalized estimating equations
Fig. 4.
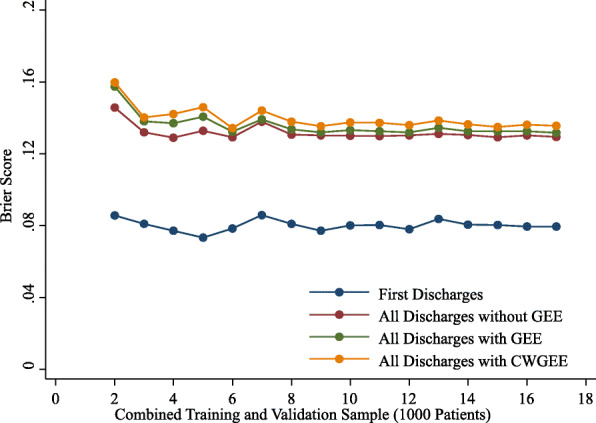
Brier scores of models tested in validation samples of adult patients with diabetes. The x-axis shows the size of the initial cohort from which training and validation samples were drawn. Boston, Massachusetts, 2004–2012. GEE = generalized estimating equations. CWGEE = cluster-weighted generalized estimating equations
Fig. 5.
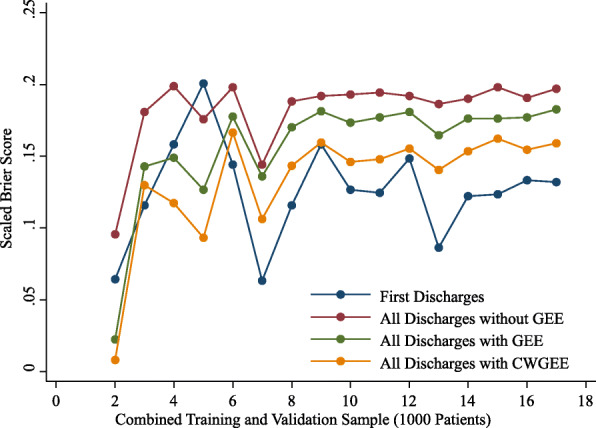
Scaled Brier scores of models tested in validation samples of adult patients with diabetes. The x-axis shows the size of the initial cohort from which training and validation samples were drawn. Boston, Massachusetts, 2004–2012. GEE = generalized estimating equations. CWGEE = cluster-weighted generalized estimating equations
There were no statistically significant readmission rate changes over sample size for both the first discharges (P = 0.48) and all discharges (P = 0.24). The slopes for AUC, coefficients of discrimination, correlations, Brier score, and scaled Brier score were flat for both first discharges and all discharges logistic regression (See Supplementary Table 4, Additional File 4, which compares change over sample size across the model performance measures). However, the slopes for these measures were significantly different from zero for GEE and CWGEE. As sample size increases, the AUC, coefficients of discrimination, correlation measures, and scaled Brier scores increase for GEE and CWGEE, indicating more predictive accuracy. Similarly, the Brier scores decrease for GEE and CWGEE as the sample size increases, indicating greater predictive accuracy.
The distribution of discharges per patient is presented in Supplementary Table 5, Additional File 5. There are 9780 (56.6%) patients with one discharge, 2936 (17.0%) with 2 discharges, and 4568 (26.4%) with at least three discharges. A total of 919 (13.3%) patients experienced one readmission and 686 (9.9%) had 2 or more readmissions. As expected, the number of discharges is positively correlated with the number of readmissions (r = 0.87, P < 0.001). The correlation coefficients between number of discharges and predicted readmission rates for all discharges logistic regression, GEE and CWGEE are 0.44, 0.38 and 0.31, respectively. Furthermore, the risk of readmission increases as the number of discharges increases (r = 0.45, P < 0.001, Fig. 6).
Fig. 6.
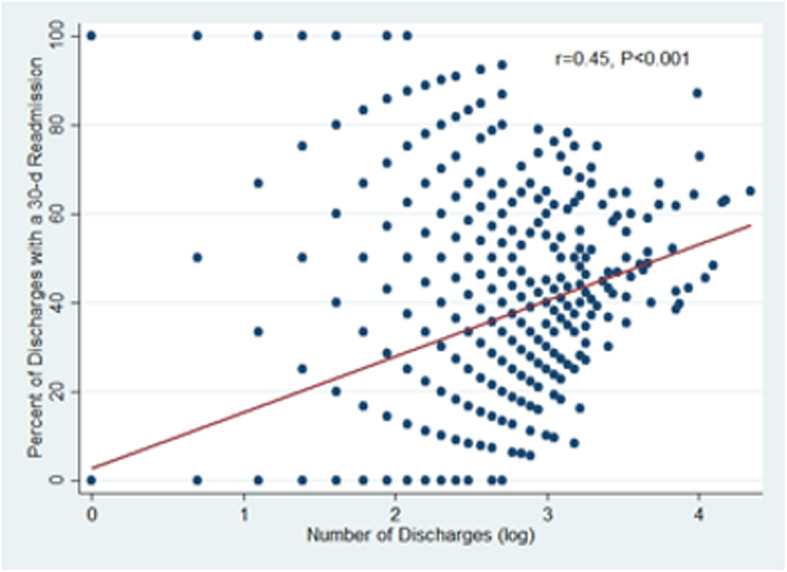
Percent of discharges followed by a readmission within 30 days by number of discharges per patient. The risk of readmission increases as the number of discharges increases (r = 0.45, P < 0.001 by Pearson correlation with log-transformed number of discharges)
Discussion
This study explored the impact of different sampling and multivariable modeling approaches on readmission risk prediction. We found that sampling only the first discharge per patient substantially underestimates the readmission rate relative to all discharges and is associated with misleading measures of model performance, particularly the Brier score. As expected, the number of readmissions per patient and the risk of readmission is highly correlated with the number of discharges per patient. In resampling studies across a range of sample sizes, most measures of model performance are unstable below a sample size of 6000 and stabilize at sample sizes of 6000 or greater. We also found that the accuracy of GEE and CWGEE is better in larger samples than in smaller samples. Lastly, we showed that using modeling approaches that account for clustering (GEE) and cluster size (CWGEE) yield generally more conservative measures of model performance than logistic regression.
Multiple methods for sampling hospitalizations and analyzing risk factors are used in studies that model predictors of readmission risk. Sampling only the first discharge per patient is a commonly used approach [6, 23–32]. This approach eliminates clusters of multiple hospitalizations per patient, enabling the valid analysis of such data by logistic regression. One disadvantage of sampling the first discharges, however, is that informative data from subsequent discharges are excluded. We show that models based on all discharges perform better on most measures of model performance than models based on first discharges. A second disadvantage of sampling only the first discharges is that the observed readmission rate is substantially lower than the readmission rate observed for all discharges during the study. In our study, the readmission rate in the sample with all discharges was nearly double the readmission rate in the first discharges sample. This occurs because excluding repeat discharges per patient minimizes the influence of patients with multiple discharges, who are at higher risk of readmission.
Such variation in observed readmission rates by different sampling methods is reflected in the literature. For example, among studies modeling readmission risk factors of patients with diabetes, we identified 14 English-language papers on PubMed published before 2019 that reported models of all-cause 30-day readmission risk [6, 7, 12, 23–28, 33–37]. Among the 7 studies that sampled all discharges in their respective datasets [7, 12, 33–37], the mean readmission rate was 18.9% with a range of 16.0–21.5%. Among the 7 studies that sampled only first discharges [6, 23–28], the mean readmission rate was 13.5% with a range of 10.0–17.1%. Given that in clinical practice a provider may be treating a patient experiencing their first hospitalization or one of many hospitalizations, we believe it is more generalizable to sample all discharges for analysis so the entire experience of the study population is captured. Although studies that sample only first discharges can provide insights into readmission risk factors, reports of readmission rates in these samples should not be broadly interpreted to represent the readmission rate for the target population. We believe this is an important methodological insight that has not been previously published.
As with approaches to sampling hospitalizations, multiple methods of modeling readmission risk are used. The most common multivariable modeling approach by far is logistic regression [4, 5]. Interestingly, logistic regression is utilized in some studies that sample all discharges without acknowledging the probable violation of the independence assumption [13, 34, 37]. In addition, some studies of readmission risk factors that utilize logistic regression do not report how hospitalizations were sampled [38–40]. The most often utilized statistical modeling approach to account for correlations within clustered hospitalization data is GEE [7, 12, 33, 41]. We are unaware of any readmission risk models that employ CWGEE.
While some studies have compared readmission risk models generated by different methods [42, 43], few have explored broader methodologic issues involved with analyzing readmissions. One study found that the LACE+ model, which was derived in a patient-level sample based on one randomly selected hospitalization per patient, performed worse in the parent sample that included all hospitalizations of the patients [44]. The authors concluded that frequent hospital utilizers probably have characteristics that were not adequately captured in the patient-level model and that capturing these characteristics may improve readmission models. Another study showed that readmission risk model performance varied by restricting samples to different reasons for readmission, that different types of data (visit history and laboratory results) contributed more predictive value than other types of data, and that limiting the cohort to patients whose index admission and readmission diagnoses matched was associated with worse model performance compared with a cohort that did not match admission and readmission diagnoses [45]. Lastly, simulation studies outside the readmission literature show that analytical approaches on clustered data that do not take into account the effects of clustering often yield erroneous results [8, 9].
Our study has some limitations. First, 30-day readmissions that may have occurred at other hospitals were not captured. However, in our cohort the 30-day readmission rate was 20.4%, which is one of the highest readmission rates reported among patients with diabetes. Therefore, it seems unlikely that a significant number of patients were readmitted elsewhere. Second, no external validation was conducted because the data were drawn from a single center. Although it is possible that the specific models generated in our study population would yield different results in other populations, the types of administrative and clinical data analyzed are likely to be generalizable to most hospitals. Therefore we believe the general concepts revealed by our findings are broadly applicable to analyses of readmissions in hospital cohorts across other settings and other chronic conditions than diabetes. Finally, we did not assess calibration by the commonly used Hosmer-Lemeshow goodness-of-fit test [46]. The standard approach with this test compares observed and predicted outcomes by decile of predicted probability. However, this test can give different results depending on the number of groups used [46]. In addition, performance of the test varies by sample size [46, 47], and 4 of the 5 measures of model performance we used incorporate calibration.
These limitations are balanced by a number of strengths. We analyzed a large enough cohort to examine performance of different modeling approaches across a broad range of sample sizes. Furthermore, this was a population well-characterized on 46 different variables used for modeling procedures. In addition, our analyses on the effects of different sampling and modeling approaches on model performance are novel in the field of readmission risk prediction.
Conclusions
This study demonstrates the impact of different methodological approaches to analyzing hospital readmission data. All discharges in a cohort of hospitalized patients should be analyzed because sampling only the first discharge per patient produces low population estimates of readmission rates and misleading results with Brier scores. Studies should therefore transparently report how discharges are sampled. In addition, the number of readmissions per patient and the risk of readmission is highly correlated with the number of discharges per patient. Not surprisingly, modeling methods that account for clustering and cluster size yield different, generally more conservative, estimates of model performance. Researchers should be aware of the pitfalls associated with these measures of model performance and modeling procedures. Future studies of readmission risk may generate more valid results if they include all discharges and utilize modeling methods that account for clustered data.
Supplementary Information
Additional file 1: Supplementary Table 1. Characteristics of Patients With Diabetes at the Time of the First Hospital Discharge by Training and Validation Samples, Boston, Massachusetts, 2004–2012.
Additional file 2: Supplementary Table 2. Characteristics of hospitalized patients with diabetes for all discharges by training and validation samples.
Additional file 3: Supplementary Table 3. Performance of Logistic Regression Using First Discharges (n = 6913), All Discharges (n = 17,801), All Discharges With GEE, and All Discharges With CWGEE to Predict All-Cause 30-Day Readmission Among Adults With Diabetes, Boston, Massachusetts, 2004–2012.
Additional file 4: Supplementary Table 4. Change Over Sample Size of Logistic Regression Model Performance Measures Using First Discharges (n = 6913), All Discharges (n = 17,801), All Discharges With GEE, and All Discharges With CWGEE to Predict All-Cause 30-Day Readmission in Validation Sample of Adults With Diabetes, Boston, Massachusetts, 2004–2012.
Additional file 5: Supplementary Table 5. Distribution of the Number of Discharges Per Patient (N = 17,801) in Sample of Adults With Diabetes, Boston, Massachusetts, 2004–2012.
Acknowledgements
An abstract of this work was presented as a poster at the 78th Scientific Sessions of the American Diabetes Association in June, 2018, Orlando, Florida.
Abbreviations
- CWGEE
Cluster-weighted generalized estimating equations
- GEE
Generalized estimating equations
- ICD-9-CM
International Classification of Diseases, Ninth Revision, Clinical Modification
- LR-first
Logistic regression using the first discharge per patient
- LR-all
Logistic regression using all discharges
- AUC
Area under the receiver operating characteristic curve
Authors’ contributions
HZ conducted the data analysis, interpretation of results, and was a major contributor to the writing of the manuscript. ST conducted the literature review and was a major contributor to the writing of the manuscript. SHG and SGF helped planned the study and critically reviewed the manuscript for important intellectual content. DJR planned and supervised the study and was a major contributor to the writing of the manuscript. All authors read and approved the final manuscript.
Authors’ information
Not applicable.
Funding
This work was supported by the National Institute of Diabetes and Digestive and Kidney Diseases of the National Institutes of Health (Grant K23DK102963 to D.J.R.). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Availability of data and materials
The data that support the findings of this study are available from Boston Medical Center but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of Boston Medical Center.
Ethics approval and consent to participate
Institutional Review Board approval was obtained from Boston Medical Center (H-31845) and Temple University (20658). A waiver of informed consent was provided for this retrospective analysis of a limited data set.
Consent for publication
Not applicable.
Competing interests
The authors declare no conflict of interest.
Footnotes
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Benbassat J, Taragin M. Hospital readmissions as a measure of quality of health care: advantages and limitations. Arch Intern Med. 2000;160(8):1074–1081. doi: 10.1001/archinte.160.8.1074. [DOI] [PubMed] [Google Scholar]
- 2.Kocher RP, Adashi EY. Hospital readmissions and the affordable care act: paying for coordinated quality care. JAMA. 2011;306(16):1794–1795. doi: 10.1001/jama.2011.1561. [DOI] [PubMed] [Google Scholar]
- 3.Leppin AL, Brito JP, Mair FS, et al. Preventing 30-day hospital readmissions: a systematic review and meta-analysis of randomized trials. JAMA Intern Med. 2014;174(7):1095–1107. doi: 10.1001/jamainternmed.2014.1608. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Kansagara D, Englander H, Salanitro A, et al. Risk prediction models for hospital readmission: a systematic review. JAMA. 2011;306(15):1688–1698. doi: 10.1001/jama.2011.1515. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Zhou H, Della PR, Roberts P, Goh L, Dhaliwal SS. Utility of models to predict 28-day or 30-day unplanned hospital readmissions: an updated systematic review. BMJ Open. 2016;6(6):e011060. doi: 10.1136/bmjopen-2016-011060. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Eby E, Hardwick C, Yu M, et al. Predictors of 30 day hospital readmission in patients with type 2 diabetes: a retrospective, case-control, database study. Curr Med Res Opin. 2015;31(1):107–114. doi: 10.1185/03007995.2014.981632. [DOI] [PubMed] [Google Scholar]
- 7.Rubin DJ, Handorf EA, Golden SH, Nelson DB, McDonnell ME, Zhao H. Development and validation of a novel tool to predict hospital readmission risk among patients with diabetes. Endocr Pract. 2016;22(10):1204–1215. doi: 10.4158/E161391.OR. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Bouwmeester W, Twisk JW, Kappen TH, van Klei WA, Moons KG, Vergouwe Y. Prediction models for clustered data: comparison of a random intercept and standard regression model. BMC Med Res Methodol. 2013;13:19. doi: 10.1186/1471-2288-13-19. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Galbraith S, Daniel JA, Vissel B. A study of clustered data and approaches to its analysis. J Neurosci. 2010;30(32):10601–10608. doi: 10.1523/JNEUROSCI.0362-10.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Liang K-Y, Zeger SL. Longitudinal data analysis using generalized linear models. Biometrika. 1986;73(1):13–22. doi: 10.1093/biomet/73.1.13. [DOI] [Google Scholar]
- 11.Williamson JM, Datta S, Satten GA. Marginal analyses of clustered data when cluster size is informative. Biometrics. 2003;59(1):36–42. doi: 10.1111/1541-0420.00005. [DOI] [PubMed] [Google Scholar]
- 12.Rubin DJ, Recco D, Turchin A, Zhao H, Golden SH. External validation of the diabetes early re-admission risk indicator (DERRI()) Endocr Pract. 2018;24(6):527–541. doi: 10.4158/EP-2018-0035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Donzé J, Aujesky D, Williams D, Schnipper JL. Potentially avoidable 30-day hospital readmissions in medical patients: derivation and validation of a prediction model. JAMA Intern Med. 2013;173(8):632–638. doi: 10.1001/jamainternmed.2013.3023. [DOI] [PubMed] [Google Scholar]
- 14.Chambless LE, Diao G. Estimation of time-dependent area under the ROC curve for long-term risk prediction. Stat Med. 2006;25(20):3474–3486. doi: 10.1002/sim.2299. [DOI] [PubMed] [Google Scholar]
- 15.Altman DG, Vergouwe Y, Royston P, Moons KGM. Prognosis and prognostic research: validating a prognostic model. BMJ. 2009;338:1432–1435. doi: 10.1136/bmj.b1432. [DOI] [PubMed] [Google Scholar]
- 16.Steyerberg EW, Vickers AJ, Cook NR, et al. Assessing the performance of prediction models: a framework for traditional and novel measures. Epidemiology. 2010;21(1):128–138. doi: 10.1097/EDE.0b013e3181c30fb2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Zheng B, Agresti A. Summarizing the predictive power of a generalized linear model. Stat Med. 2000;19(13):1771–1781. doi: 10.1002/1097-0258(20000715)19:13<1771::AID-SIM485>3.0.CO;2-P. [DOI] [PubMed] [Google Scholar]
- 18.Tjur T. Coefficients of determination in logistic regression models—a new proposal: the coefficient of discrimination. Am Stat. 2009;63(4):366–372. doi: 10.1198/tast.2009.08210. [DOI] [Google Scholar]
- 19.BRIER GW. Verification forecasts expressed in terms of probability. Mon Weather Rev. 1950;78(1):1–3. doi: 10.1175/1520-0493(1950)078<0001:VOFEIT>2.0.CO;2. [DOI] [Google Scholar]
- 20.Wu Y-C, Lee W-C. Alternative performance measures for prediction models. PLoS One. 2014;9(3):e91249. doi: 10.1371/journal.pone.0091249. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Furnival GM, Wilson RW., Jr Regressions by leaps and bounds. Technometrics. 1974;16(4):499–511. doi: 10.1080/00401706.1974.10489231. [DOI] [Google Scholar]
- 22.Hanley JA, Negassa A, Edwardes MD, Forrester JE. Statistical analysis of correlated data using generalized estimating equations: an orientation. Am J Epidemiol. 2003;157(4):364–375. doi: 10.1093/aje/kwf215. [DOI] [PubMed] [Google Scholar]
- 23.Bennett KJ, Probst JC, Vyavaharkar M, Glover SH. Lower rehospitalization rates among rural Medicare beneficiaries with diabetes. J Rural Health. 2012;28(3):227–234. doi: 10.1111/j.1748-0361.2011.00399.x. [DOI] [PubMed] [Google Scholar]
- 24.Collins J, Abbass IM, Harvey R, et al. Predictors of all-cause-30-day-readmission among Medicare patients with type 2 diabetes. Curr Med Res Opin. 2017;33(8):1517–1523. doi: 10.1080/03007995.2017.1330258. [DOI] [PubMed] [Google Scholar]
- 25.Healy SJ, Black D, Harris C, Lorenz A, Dungan KM. Inpatient diabetes education is associated with less frequent hospital readmission among patients with poor glycemic control. Diabetes Care. 2013;36(10):2960–2967. doi: 10.2337/dc13-0108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.King C, Atwood S, Lozada M, et al. Identifying risk factors for 30-day readmission events among American Indian patients with diabetes in the four corners region of the southwest from 2009 to 2016. PLoS One. 2018;13(8):e0195476. doi: 10.1371/journal.pone.0195476. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Png ME, Yoong J, Chen C, et al. Risk factors and direct medical cost of early versus late unplanned readmissions among diabetes patients at a tertiary hospital in Singapore. Curr Med Res Opin. 2018:1–10. [DOI] [PubMed]
- 28.Raval AD, Zhou S, Wei W, Bhattacharjee S, Miao R, Sambamoorthi U. 30-day readmission among elderly Medicare beneficiaries with type 2 diabetes. Population Health Management. 2015;18(4):256–264. doi: 10.1089/pop.2014.0116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Billings J, Dixon J, Mijanovich T, Wennberg D. Case finding for patients at risk of readmission to hospital: development of algorithm to identify high risk patients. BMJ. 2006;333(7563):327. doi: 10.1136/bmj.38870.657917.AE. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Howell S, Coory M, Martin J, Duckett S. Using routine inpatient data to identify patients at risk of hospital readmission. BMC Health Serv Res. 2009;9:96. doi: 10.1186/1472-6963-9-96. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Krumholz HM, Wang K, Lin Z, et al. Hospital-readmission risk — isolating hospital effects from patient effects. N Engl J Med. 2017;377(11):1055–1064. doi: 10.1056/NEJMsa1702321. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Silverstein MD, Qin H, Mercer SQ, Fong J, Haydar Z. Risk factors for 30-day hospital readmission in patients >/=65 years of age. Proc (Bayl Univ Med Cent) 2008;21(4):363–372. doi: 10.1080/08998280.2008.11928429. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Albrecht JS, Hirshon JM, Goldberg R, et al. Serious mental illness and acute hospital readmission in diabetic patients. Am J Med Qual. 2012;27(6):503–508. doi: 10.1177/1062860612436576. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Enomoto LM, Shrestha DP, Rosenthal MB, Hollenbeak CS, Gabbay RA. Risk factors associated with 30-day readmission and length of stay in patients with type 2 diabetes. J Diabetes Complicat. 2017;31(1):122–127. doi: 10.1016/j.jdiacomp.2016.10.021. [DOI] [PubMed] [Google Scholar]
- 35.Holscher CM, Hicks CW, Canner JK, et al. Unplanned 30-day readmission in patients with diabetic foot wounds treated in a multidisciplinary setting. J Vasc Surg. 2018;67(3):876–886. doi: 10.1016/j.jvs.2017.07.131. [DOI] [PubMed] [Google Scholar]
- 36.Ostling S, Wyckoff J, Ciarkowski SL, et al. The relationship between diabetes mellitus and 30-day readmission rates. Clin Diabetes Endocrinol. 2017;3(1):3. doi: 10.1186/s40842-016-0040-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Robbins JM, Webb DA. Diagnosing diabetes and preventing rehospitalizations: the urban diabetes study. Med Care. 2006;44(3):292–296. doi: 10.1097/01.mlr.0000199639.20342.87. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Caughey GE, Pratt NL, Barratt JD, Shakib S, Kemp-Casey AR, Roughead EE. Understanding 30-day re-admission after hospitalisation of older patients for diabetes: identifying those at greatest risk. Med J Aust. 2017;206(4):170–175. doi: 10.5694/mja16.00671. [DOI] [PubMed] [Google Scholar]
- 39.Najafian A, Selvarajah S, Schneider EB, et al. Thirty-day readmission after lower extremity bypass in diabetic patients. J Surg Res. 2016;200(1):356–364. doi: 10.1016/j.jss.2015.06.061. [DOI] [PubMed] [Google Scholar]
- 40.Escobar GJ, Ragins A, Scheirer P, Liu V, Robles J, Kipnis P. Nonelective Rehospitalizations and Postdischarge mortality: predictive models suitable for use in real time. Med Care. 2015;53(11):916–923. doi: 10.1097/MLR.0000000000000435. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Karunakaran A, Zhao H, Rubin DJ. Predischarge and Postdischarge risk factors for hospital readmission among patients with diabetes. Med Care. 2018;56(7):634–642. doi: 10.1097/MLR.0000000000000931. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Welchowski T, Schmid M. A framework for parameter estimation and model selection in kernel deep stacking networks. Artif Intell Med. 2016;70:31–40. doi: 10.1016/j.artmed.2016.04.002. [DOI] [PubMed] [Google Scholar]
- 43.Povalej Brzan P, Obradovic Z, Stiglic G. Contribution of temporal data to predictive performance in 30-day readmission of morbidly obese patients. PeerJ. 2017;5:e3230. doi: 10.7717/peerj.3230. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.van Walraven C, Wong J, Forster AJ, Hawken S. Predicting post-discharge death or readmission: deterioration of model performance in population having multiple admissions per patient. J Eval Clin Pract. 2013;19(6):1012–1018. doi: 10.1111/jep.12012. [DOI] [PubMed] [Google Scholar]
- 45.Walsh C, Hripcsak G. The effects of data sources, cohort selection, and outcome definition on a predictive model of risk of thirty-day hospital readmissions. J Biomed Inform. 2014;52:418–426. doi: 10.1016/j.jbi.2014.08.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Hosmer DW, Hosmer T, Le Cessie S, Lemeshow S. A comparison of goodness-of-fit tests for the logistic regression model. Stat Med. 1997;16(9):965–980. doi: 10.1002/(SICI)1097-0258(19970515)16:9<965::AID-SIM509>3.0.CO;2-O. [DOI] [PubMed] [Google Scholar]
- 47.Kramer AA, Zimmerman JE. Assessing the calibration of mortality benchmarks in critical care: the Hosmer-Lemeshow test revisited. Crit Care Med. 2007;35(9):2052–2056. doi: 10.1097/01.CCM.0000275267.64078.B0. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Additional file 1: Supplementary Table 1. Characteristics of Patients With Diabetes at the Time of the First Hospital Discharge by Training and Validation Samples, Boston, Massachusetts, 2004–2012.
Additional file 2: Supplementary Table 2. Characteristics of hospitalized patients with diabetes for all discharges by training and validation samples.
Additional file 3: Supplementary Table 3. Performance of Logistic Regression Using First Discharges (n = 6913), All Discharges (n = 17,801), All Discharges With GEE, and All Discharges With CWGEE to Predict All-Cause 30-Day Readmission Among Adults With Diabetes, Boston, Massachusetts, 2004–2012.
Additional file 4: Supplementary Table 4. Change Over Sample Size of Logistic Regression Model Performance Measures Using First Discharges (n = 6913), All Discharges (n = 17,801), All Discharges With GEE, and All Discharges With CWGEE to Predict All-Cause 30-Day Readmission in Validation Sample of Adults With Diabetes, Boston, Massachusetts, 2004–2012.
Additional file 5: Supplementary Table 5. Distribution of the Number of Discharges Per Patient (N = 17,801) in Sample of Adults With Diabetes, Boston, Massachusetts, 2004–2012.
Data Availability Statement
The data that support the findings of this study are available from Boston Medical Center but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of Boston Medical Center.