

Abstract
Deep learning models are often trained on datasets that contain sensitive information such as individuals’ shopping transactions, personal contacts, and medical records. An increasingly important line of work therefore has sought to train neural networks subject to privacy constraints that are specified by differential privacy or its divergence-based relaxations. These privacy definitions, however, have weaknesses in handling certain important primitives (composition and subsampling), thereby giving loose or complicated privacy analyses of training neural networks. In this paper, we consider a recently proposed privacy definition termed f-differential privacy [18] for a refined privacy analysis of training neural networks. Leveraging the appealing properties of f-differential privacy in handling composition and subsampling, this paper derives analytically tractable expressions for the privacy guarantees of both stochastic gradient descent and Adam used in training deep neural networks, without the need of developing sophisticated techniques as [3] did. Our results demonstrate that the f-differential privacy framework allows for a new privacy analysis that improves on the prior analysis [3], which in turn suggests tuning certain parameters of neural networks for a better prediction accuracy without violating the privacy budget. These theoretically derived improvements are confirmed by our experiments in a range of tasks in image classification, text classification, and recommender systems. Python code to calculate the privacy cost for these experiments is publicly available in the TensorFlow Privacy library.
1. Introduction
In many applications of machine learning, the datasets contain sensitive information about individuals such as location, personal contacts, media consumption, and medical records. Exploiting the output of the machine learning algorithm, an adversary may be able to identify some individuals in the dataset, thus presenting serious privacy concerns. This reality gave rise to a broad and pressing call for developing privacy-preserving data analysis methodologies. Accordingly, there have been numerous investigations in the scholarly literature of many fields—statistics, cryptography, machine learning, and law—for the protection of privacy in data analysis.
Along this line, research efforts have repeatedly suggested the necessity of a rigorous and versatile definition of privacy. Among other things, researchers have questioned whether the use of a privacy definition gives interpretable privacy guarantees, and if so, whether this privacy definition allows for high accuracy of the private model among alternative definitions. In particular, anonymization as a syntactic and ad-hoc privacy concept has been shown to generally fail to guarantee privacy. Examples include the identification of a homophobic individual in the anonymized Netflix Challenge dataset [45] and the identification of the health records of the then Massachusetts governor in public anonymized medical datasets [56].
In this context, (ε, δ)-differential privacy (DP) arose as a mathematically rigorous definition of privacy [23]. Today, this definition has developed into a firm foundation of private data analysis, with its applications deployed by Google [26], Apple [5], Microsoft [16], and the US Census Bureau [4]. Despite its impressive popularity in both the scholarly literature and the industry, (ε, δ)-DP is not versatile enough to handle composition, which is perhaps the most fundamental primitive in statistical privacy. For example, the training process of deep neural networks is in effect the composition of many primitive building blocks known as stochastic gradient descent (SGD). Under a modest privacy budget in the (ε, δ)-DP sense, however, it was not clear how to maintain a high prediction accuracy of deep learning. This requires a tight privacy analysis of composition in the (ε, δ)-DP framework. Indeed, the analysis of the privacy costs in deep learning was refined only recently using a sophisticated technique called the moments accountant [3].
Ideally, we hope to have a privacy definition that allows for refined privacy analyses of various algorithms in a principled manner, without resorting to sophisticated techniques. Having a refined privacy analysis not only enhances the trustworthiness of the models but can also be leveraged to improve the prediction accuracy by trading off privacy for utility. One possible candidate is f-differential privacy, a relaxation of (ε, δ)-DP that was recently proposed by Dong, Roth, and Su [18]. This new privacy definition faithfully retains the hypothesis testing interpretation of differential privacy and can losslessly reason about common primitives associated with differential privacy, including composition, privacy amplification by subsampling, and group privacy. In addition, f-DP includes a canonical single-parameter family that is referred to as Gaussian differential privacy (GDP). Notably, GDP is the focal privacy definition due to a central limit theorem that states that the privacy guarantees of the composition of private algorithms are approximately equivalent to telling apart two shifted normal distributions.
The main results of this paper show that f-DP offers a rigorous and versatile framework for developing private deep learning methodologies1. Our guarantee provides protection against an attacker with knowledge of the network architecture as well as the model parameters, which is in the same spirit as [53, 3]. In short, this paper delivers the following messages concerning f-DP:
Closed-form privacy bounds.
In the f-DP framework, the overall privacy loss incurred in training neural networks admits an amenable closed-form expression. In contrast, the privacy analysis via the moments accountant must be done by numerical computation [3], and the implicit nature of this earlier approach can hinder our understanding of how the tuning parameters affect the privacy bound. This is discussed in Section 3.1.
Stronger privacy guarantees.
The f-DP approach gives stronger privacy guarantees than the earlier approach [3], even in terms of (ε, δ)-DP. This improvement is due to the use of the central limit theorem for f-DP, which accurately captures the privacy loss incurred at each iteration in training the deep learning models. This is presented in Section 3.2 and illustrated with numerical experiments in Section 4.1.
Improved prediction accuracy.
Leveraging the stronger privacy guarantees provided by f-DP, we can trade a certain amount of privacy for an improvement in prediction performance. This can be realized, for example, by appropriately reducing the amount of noise added during the training process of neural networks so as to match the target privacy level in terms of (ε, δ)-DP. See Section 3.2 and Section 4.2 for the development of this utility improvement.
The remainder of the paper is structured as follows. In Section 1.1 we provide a brief review of related literature. Section 2 introduces f-DP and its basic properties at a minimal level. Next, in Section 3 we analyze the privacy cost of training deep neural networks in terms of f-DP and compare it to the privacy analysis using the moments accountant. In Section 4, we present numerical experiments to showcase the superiority of the f-DP approach to private deep learning in terms of test accuracy and privacy guarantees. The paper concludes with a discussion in Section 5.
1.1. Related Work
There are continued efforts to understand how privacy degrades under composition. Developments along this line include the basic composition theorem and the advanced composition theorem [22, 24]. In a pioneering work, [32] obtained an optimal composition theorem for (ε, δ)-DP, which in fact served as one of the motivations for the f-DP work [18]. However, it is #P hard to compute the privacy bounds from their composition theorem [44]. More recently, [17] derived sharp composition bounds on the overall privacy loss for exponential mechanisms.
From a different angle, a substantial recent effort has been devoted to relaxing differential privacy using divergences of probability distributions to overcome the weakness of (ε, δ)-DP in handling composition [21, 11, 43, 12]. Unfortunately, these relaxations either lack a privacy amplification by subsampling argument or present a quite complex argument that is difficult to use [8, 57]. As subsampling is inherently used in training neural networks, therefore, it is difficult to directly apply these relaxations to the privacy analysis of deep learning.
To circumvent these technical difficulties associated with (ε, δ)-DP and its divergence-based relaxations, Abadi et al. [3] invented a technique termed the moments accountant to track detailed information of the privacy loss in the training process of deep neural networks. Using the moments accountant, their analysis significantly improves on earlier privacy analysis of SGD [14, 55, 10, 53, 61] and allows for meaningful privacy guarantees for deep learning trained on realistically sized datasets. This technique has been extended to a variety of situations by follow-up work [41, 48]. In contrast, our approach to private deep learning in the f-DP framework leverages some powerful tools of this new privacy definition, nevertheless providing a sharper privacy analysis, as seen both theoretically and empirically in Sections 3 and 4.
For completeness, we remark that different approaches have been put forward to incorporate privacy considerations into deep learning, without leveraging the iterative and subsampling natures of training deep learning models. This line of work includes training a private model by an ensemble of “teacher” models [47, 46], the development of noised federated averaging algorithms [42], and analyzing privacy costs through the lens of the optimization landscape of neural networks [59].
2. Preliminaries
2.1. f-Differential Privacy
In the differential privacy framework, we envision an adversary that is well-informed about the dataset except for a single individual, and the adversary seeks to determine whether this individual is in the dataset on the basis of the output of an algorithm. Roughly speaking, the algorithm is considered private if the adversary finds it hard to determine the presence or absence of any individual.
Informally, a dataset can be thought of as a matrix, whose rows each contain one individual’s data. Two datasets are said to be neighbors if one can be derived by discarding an individual from the other. As such, the sizes of neighboring datasets differ by one2. Let S and S′ be neighboring datasets, and ε ⩾ 0, 0 ⩽ δ ⩽ 1 be two numbers, and denote by M a (randomized) algorithm that takes as input a dataset.
Definition 2.1 ([23, 22]).
A (randomized) algorithm M gives (ε, δ)-differential privacy if for any pair of neighboring datasets S, S′ and any event E,
To achieve privacy, the algorithm M is necessarily randomized, whereas the two datasets in Definition 2.1 are deterministic. This privacy definition ensures that, based on the output of the algorithm, the adversary has a limited (depending on how small ε, δ are) ability to identify the presence or absence of any individual, regardless of whether any individual opts in to or opts out of the dataset.
In essence, the adversary seeks to tell apart the two probability distributions M(S) and M(S′) using a single draw. In light of this observation, it is natural to interpret what the adversary does as testing two simple hypotheses:
The connection between differential privacy and hypothesis testing was, to our knowledge, first noted in [58], and was later developed in [32, 39, 9]. Intuitively, privacy is well guaranteed if the hypothesis testing problem is hard. Following this intuition, the definition of (ε, δ)-DP essentially uses the worst-case likelihood ratio of the distributions M(S) and M(S′) to measure the hardness of testing the two simple hypotheses.
Is there a more informative measure of the hardness? In [18], the authors propose to use the trade-off between type I error (the probability of erroneously rejecting H0 when H0 is true) and type II error (the probability of erroneously accepting H0 when H1 is true) in place of a few privacy parameters in (ε, δ)-DP or divergence-based DP definitions. To formally define this new privacy definition, let P and Q denote the distributions of M(S) and M(S′), respectively, and let ϕ be any (possibly randomized) rejection rule for testing H0 : P against H1 : Q. With these in place, [18] defines the trade-off function of P and Q as
Above, and are type I and type II errors of the rejection rule ϕ, respectively. Writing f = T(P, Q), the definition says that f(α) is the minimum type II error among all tests at significance level α. Note that the minimum can be achieved by taking the likelihood ratio test, according to the Neymann–Pearson lemma. As is self-evident, the larger the trade-off function is, the more difficult the hypothesis testing problem is (hence more privacy). This motivates the following privacy definition.
Definition 2.2 ([18]).
A (randomized) algorithm M is f-differentially private if
for all neighboring datasets S and S′.
In this definition, both T and f are functions that take α ∈ [0, 1] as input and the inequality holds pointwise for all 0 ⩽ α ⩽ 1, and we abuse notation by identifying M(S) and M(S′) with their associated distributions. This privacy definition is easily interpretable due to its inherent connection with the hypothesis testing problem. By adapting a result due to Wasserman and Zhou [58], (ε, δ)-DP is a special instance of f-DP in the sense that an algorithm is (ε, δ)-DP if and only if it is fε,δ-DP with
| (1) |
The more intimate relationship between the two privacy definitions is that they are dual to each other: briefly speaking, f-DP ensures (ε, δ(ε))-DP with δ(ε) = 1 + f*(−eε) for every ε ⩾ 03.
Next, we define a single-parameter family of privacy definitions within the f-DP class for a reason that will be apparent later. Let for μ ⩾ 0. Note that this tradeoff function admits a closed-form expression Gμ(α) = Φ(Φ−1(1−α)−μ), where Φ is the cumulative distribution function of the standard normal distribution.
Definition 2.3 ([18]).
A (randomized) algorithm M is μ-Gaussian differentially private (GDP) if
for all neighboring datasets S and S′.
In words, μ-GDP says that determining whether any individual is in the dataset is at least as difficult as telling apart the two normal distributions and based on one draw. The Gaussian mechanism serves as a template to achieve GDP. Consider the problem of privately releasing a univariate statistic θ(S). The Gaussian mechanism adds noise to the statistic θ, which gives μ-GDP if σ = sens(θ)/μ. Here the sensitivity of θ is defined as sens(θ) = supS,S′ |θ(S)− θ(S′)|, where the supremum is over all neighboring datasets.
2.2. Properties of f-Differential Privacy
Composition.
Deep learning models are trained using the composition of many SGD updates. Broadly speaking, composition is concerned with a sequence of analyses on the same dataset where each analysis is informed by the explorations of prior analyses. A central question that every privacy definition is faced with is to pinpoint how the overall privacy guarantee degrades under composition. Formally, letting M1 be the first algorithm and M2 be the second, we define their composition algorithm M as M(S) = (M1(S), M2(S, M1(S))). Roughly speaking, the composition is to “release all information that is learned by the algorithms.” Notably, the second algorithm M2 can take as input the output of M1 in addition to the dataset S. In general, the composition of more than two algorithms follows recursively.
To introduce the composition theorem for f-DP, [18] defines a binary operation ⊗ on trade-off functions. Given trade-off functions f = T(P, Q) and g = T(P′, Q′), let f ⊗ g = T(P × P′, Q × Q′). This definition depends on the distributions P, Q, P′, Q′ only through f and g. Moreover, ⊗ is commutative and associative. Now the composition theorem can be readily stated as follows. Let Mt be ft-DP conditionally on any output of the prior algorithms for t = 1, …, T. Then their T-fold composition algorithm is f1 ⊗ ⋯ ⊗ fT-DP. This result shows that the composition of algorithms in the f-DP framework is reduced to performing the ⊗ operation on the associated trade-off functions. As an important fact, the privacy bound f1 ⊗ ⋯ ⊗ fT in general cannot be improved. Put more precisely, one can find an ft-DP mechanism Mt for t = 1, …, T such that their composition is precisely f1 ⊗ ⋯ ⊗ fT-DP (see the discussion following Theorem 4 in [18]).
More profoundly, a central limit theorem phenomenon arises in the composition of many “very private” f-DP algorithms in the following sense: the trade-off functions of small privacy leakage accumulate to Gμ for some μ under composition. Informally, assuming each ft is very close to Id(α) = 1 − α, which corresponds to perfect privacy, then we have
| (2) |
if the number of iterations T is sufficiently large4. This central limit theorem approximation is especially suitable for the privacy analysis of deep learning, where the training process typically takes at least tens of thousands of iterations. The privacy parameter μ depends on some functionals such as the Kullback–Leibler divergence of the trade-off functions. The central limit theorem yields a very accurate approximation in the settings considered in Section 4 (see numerical confirmation in Appendix A). For a rigorous account of this central limit theorem for differential privacy, see Theorem 6 in [18]. We remark that a conceptually related article [54] developed a central limit theorem for privacy loss random variables.
At a high level, this convergence-to-GDP result brings GDP to the focal point of the family of f-DP guarantees, implying that GDP is to f-DP as normal random variables to general random variables. Furthermore, this result serves as an effective approximation tool for approximating the privacy guarantees of composition algorithms. In contrast, privacy loss cannot be losslessly tracked under composition in the (ε, δ)-DP framework.
Subsampling.
In training neural networks, the gradient at each iteration is computed from a mini-batch that is subsampled from the training examples. Intuitively, an algorithm applied to a subsample gives stronger privacy guarantees than applied to the full sample. Looking closely, this privacy amplification is due to the fact that an individual enjoys perfect privacy if not selected in the subsample. A concrete and pressing question is, therefore, to precisely characterize how much privacy is amplified by subsampling in the f-DP framework.
Consider the following sampling scheme: for each individual in the dataset S, include his or her datum in the subsample independently with probability p, which is sometimes referred to as the Poisson subsampling [57]. The resulting subsample is denoted by Samplep(S). For the purpose of clearing up any confusion, we remark that the subsample Samplep(S) has a random size and as an intermediate step is not released. Given any algorithm M, denote by M ◦ Samplep the subsampled algorithm.
The subsampling theorem for f-DP states as follows. Let M be f-DP, write fp for pf+(1−p)Id, and denote by the inverse5 of fp. It is proved in Appendix A that the subsampled algorithm M ◦ Samplep satisfies
| (3) |
if S can be obtained by removing one individual from S′. Likewise,
As such, the two displays above say that the trade-off function of M ◦ Samplep on any neighboring datasets is lower bounded by , which however is in general non-convex and thus is not a trade-off function. This suggests that we can boost the privacy bound by replacing with its double conjugate , which is the greatest convex lower bound of and is indeed a trade-off function. Taken together, all the pieces show that the subsampled algorithm M ◦ Samplep is .
Notably, the privacy bound is larger than f and cannot be improved in general. In light of the above, the f-DP framework is flexible enough to nicely handle the analysis of privacy amplification by subsampling. In the case where the original algorithm M is (ε, δ)-DP, this privacy bound strictly improves on the subsampling theorem for (ε, δ)-DP [38].
3. Algorithms and Their Privacy Analyses
3.1. NoisySGD and NoisyAdam
SGD and Adam [33] are among the most popular optimizers in deep learning. Here we introduce a new privacy analysis of a private variant of SGD in the f-DP framework and then extend the study to a private version of Adam.
Letting S = {x1, …, xn} denote the dataset, we consider minimizing the empirical risk
where θ denotes the weights of the neural networks and ℓ(θ, xi) is a loss function. At iteration t, a mini-batch It is selected from {1, 2, …, n} with subsampling probability p, thereby having an approximate size of pn. Taking learning rate ηt and initial weights θ0, the vanilla SGD updates the weights according to
To preserve privacy, [14, 55, 10, 3] introduce two modifications to the vanilla SGD. First, a clip step is applied to the gradient so that the gradient is in effect bounded. This step is necessary to have a finite sensitivity. The second modification is to add Gaussian noise to the clipped gradient, which is equivalent to applying the Gaussian mechanism to the updated iterates. Formally, the private SGD algorithm is described in Algorithm 1. Herein I is the identity matrix and ∥ · ∥2 denotes the ℓ2 norm. Formally, we present this in Algorithm 1, which we henceforth refer to as NoisySGD. As a contribution of the present paper, NoisySGD uses the Poisson subsampling, as opposed to the uniform sampling used in [18]. For completeness, we remark that there is another possible subsampling method: shuffling (randomly permuting and dividing data into folds at each epoch). We emphasize that different subsampling mechanisms produce different privacy guarantees.

The analysis of the overall privacy guarantee of NoisySGD makes heavy use of the compositional and subsampling properties of f-DP. We first focus on the privacy analysis of the step that computes θt+1 from θt. Let M denote the gradient update and write Samplep(S) for the mini-batch It (we drop the subscript t for simplicity). This allows us to use M ◦ Samplep(S) to represent what NoisySGD does at each iteration. Next, note that adding or removing one individual would change the value of by at most R in the ℓ2 norm due to the clipping operation, that is, has sensitivity R. Consequently, the Gaussian mechanism with noise standard deviation σR ensures that M is . With a few additional arguments, in Appendix B we show that NoisySGD is min{f, f−1}**-DP with f = (pG1/σ + (1 − p)Id)⊗T. As a remark, it has been empirically observed in [3, 6] that the performance of the private neural networks is not sensitive to the choice of the clipping norm bound R (see more discussion in [48, 60]).
To facilitate the use of this privacy bound, we now derive an analytically tractable approximation of min{f, f−1}** using the privacy central limit theorem in a certain asymptotic regime, which further demonstrates the mathematical coherence and versatility of the f-DP framework. The central limit theorem shows that, in the asymptotic regime where for a constant ν > 0 as T → ∞,
where . Thus, the overall privacy loss in the form of the double conjugate satisfies
| (4) |
As such, the central limit theorem demonstrates that NoisySGD is approximately . Denoting by B = pn the mini-batch size, the privacy parameter equals . Intuitively, this reveals that NoisySGD gives good privacy guarantees if is small and σ is not too small.
As an aside, we remark that this new privacy analysis is different from the one performed in Section 5 of [18]. Therein, the authors consider Algorithm 1 with uniform subsampling and obtain a privacy bound that is different from the one in the present paper.
Next, we present a private version of Adam [33] in Algorithm 2, which we refer to as NoisyAdam and can be found in [2]. This algorithm has the same privacy bound as NoisySGD in the f-DP framework. In short, this is because the momentum mt and ut are deterministic functions of the noisy gradients and no additional privacy cost is incurred due to the post-processing property of differential privacy. In passing, we remark that the same argument applies to AdaGrad [20] and therefore it is also asymptotically GDP in the same asymptotic regime.

3.2. Comparisons with the Moments Accountant
It is instructive to compare the moments accountant with our privacy analysis performed in Section 3.1 using the f-DP framework. Developed in [3], the moments accountant gives a tight one-to-one mapping between ε and δ for specifying the overall privacy loss in terms of (ε, δ)-DP under composition, which is beyond the reach of the advanced composition theorem [24]. In slightly more detail, the moments accountant uses the moment generating function of the privacy loss random variable to track the privacy loss under composition. As abuse of notation, this paper uses functions δMA = δMA(ε) and εMA = εMA(δ) to denote the mapping induced by the moments accountant in both directions6. For self-containedness, the appendix includes a formal description of the two functions.
Although NoisySGD and NoisyAdam are our primary focus, our following discussion applies to general iterative algorithms where composition must be addressed in the privacy analysis. Let algorithm Mt be ft-DP for t = 1, …, T and write M for their composition. On the one hand, the moments accountant technique ensures that M is (ε, δMA(ε))-DP for any ε or, put equivalently, is (εMA, δ)-DP7. On the other hand, the composition algorithm is f1 ⊗ ⋯ ⊗ fT-DP from the f-DP viewpoint and, following from the central limit theorem (2), this composition can be shown to be approximately GDP in a certain asymptotic regime. For example, both NoisySGD and NoisyAdam presented in Algorithm 1 and Algorithm 2, respectively, asymptotically satisfy μCLT-GDP with privacy parameter
| (5) |
In light of the above, it is tempting to ask which of the two approaches yields a sharper privacy analysis. In terms of f-DP guarantees, it must be the latter, which we refer to as the CLT approach, because the composition theorem of f-DP is tight and, more importantly, the privacy central limit theorem is asymptotic exact. To formally state the result, note that the moments accountant asserts that the private optimizer is (ε, δMA(ε))-DP for all ε ⩾ 0, which is equivalent to by recognizing (1) (see also Proposition 2.11 in [18]). Roughly speaking, the following theorem says that asymptotically) promises no more privacy guarantees than the bound of μCLT-GDP given by the CLT approach. This simple result is summarized by the following theorem and see Appendix B for a formal proof of this result.
Theorem 1 (Comparison in f-DP).
Assume that converges to a positive constant as T → ∞. Then, both NoisySGD and NoisyAdam satisfy
for every 0 ⩽ α ⩽ 1.
Remark 1.
For ease of reading, we point out that, in the (ε, δ)-DP framework, the smaller ε, δ are, the more privacy is guaranteed. In contrast, in the f-DP framework, the smaller f is, the less privacy is guaranteed.
From the (ε, δ)-DP viewpoint, however, the question is presently unclear. Explicitly, the duality between f-DP and (ε, δ)-DP shows that μ-GDP implies (ε, δ(ε; μ))-DP for all ε ⩾ 0, where8
| (6) |
The question is, therefore, reduced to the comparison between δMA(ε) and δCLT(ε) ≔ δ(ε; μCLT) or, equivalently, between εMA(δ) and εCLT(δ) ≔ ε(δ; μCLT)9.
Theorem 2 (Comparison in (ε, δ)-DP).
Under the assumptions of Theorem 1, the f-DP framework gives an asymptotically sharper privacy analysis of both NoisySGD and NoisyAdam than the moments accountant in terms of (ε, δ)-DP. That is,
for all 7 ε ⩾ 0.
In words, the CLT approach in the f-DP framework allows for an asymptotically smaller δ than the moments accountant at the same ε. It is worthwhile mentioning that the inequality in this theorem holds for any finite T if δ is derived by directly applying the duality to the (exact) privacy bound f1 ⊗ ⋯ ⊗ fT. Equivalently, the theorem says that lim supT→∞ (εCLT(δ) − εMA(δ)) < 0 for any δ10. As such, by setting the same δ in both approaches, say δ = 10−5, the f-DP based CLT approach shall give a smaller value of ε.
From a practical viewpoint, this refined privacy analysis allows us to trade privacy guarantees for improvement in utility. More precisely, recognizing the aforementioned conclusion that δ(ε; μCLT) ≡ δCLT(ε) < δMA(ε) (for sufficiently large T) and that δ(ε; μ) increases as μ increases, one can find such that
| (7) |
Put differently, we can carefully adjust some parameters in Algorithm 1 and Algorithm 2 in order to let the algorithms be . For example, we can reduce the scale of the added noise from σ to a certain , which can be solved from (7) and
| (8) |
Note that this is adapted from (5).
Figure 1 shows the flowchart of the privacy analyses using the two approaches and their relationship. In addition, numerical comparisons are presented in Figure 2, consistently demonstrating the superiority of the CLT approach.
Figure 1:
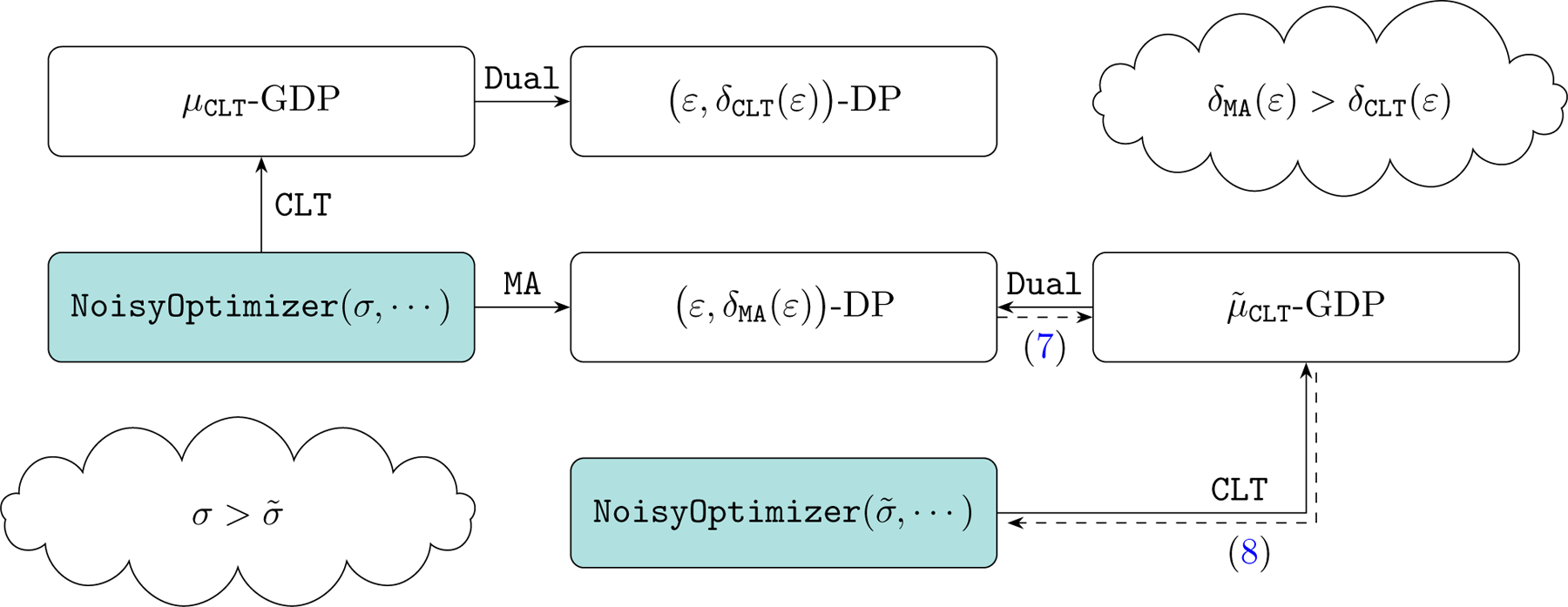
An illustration of the CLT approach in the f-DP framework and the moments accountant in the (ε, δ)-DP framework. NoisyOptimizer(σ, …) using the moments accountant gives the same privacy guarantees in terms of (ε, δ)-DP as using the CLT approach (the ellipses denote omitted parameters). Note that the duality formula (6) is used in solving from (7).
Figure 2:

Tradeoffs between ε and δ for both CLT and MA, which henceforth denotes the moments accountant. The settings follows the MNIST experiment in Section 4 with σ = 0.7, p = 256/60000. The bottom two plots assume δ = 10−5. Note ε and δ in the CLT are related via (6) with μ = μCLT. The bottom right plot is consistent with the conclusion shown in the cloud icon of Figure 1.
4. Results
In this section, we use NoisySGD and NoisyAdam to train private deep learning models on datasets for tasks ranging from image classification (MNIST), text classification (IMDb movie review), recommender systems (MovieLens movie rating), to regular binary classification (Adult income). Note that these datasets all contain sensitive information about individuals, and this fact necessitates privacy consideration in the training process. Code to reproduce the results using the TensorFlow Privacy library is available at https://github.com/tensorflow/privacy/tree/master/research/GDP_2019.
4.1. The f-DP Perspective
This section demonstrates the utility and practicality of the private deep learning methodologies with associated privacy guarantees in terms of f-DP. In Section 4.2, we extend the empirical study to the (ε, δ)-DP framework. Throughout the experiments, the parameter δ we use always satisfies δ < 1/n, where n is the number of training examples.
MNIST.
The MNIST dataset [35] contains 60,000 training images and 10,000 test images. Each image is in 28 × 28 gray-scale representing a handwritten digit ranging from 0 to 9. We train neural networks with the same architecture (two convolutional layers followed by one dense layer) as in [2, 3] on this dataset. Throughout the experiment, we set the subsampling probability to p = 256/60000 and use a constant learning rate η.
Table 1 displays the test accuracy of the neural networks trained by NoisySGD as well as the associated privacy analyses. The privacy parameters ε in the last two columns are both with respect to δ = 10−5. Over all six sets of experiments with different tuning parameters, the CLT approach gives a significantly smaller value of ε than the moments accountant, which is consistent with our discussion in Section 3.2. The point we wish to emphasize, however, is that f-DP offers a much more comprehensive interpretation of the privacy guarantees than (ε, δ)-DP. For instance, the model from the third row preserves a decent amount of privacy since it is not always easy to tell apart and . In stark contrast, the (ε, δ)-DP viewpoint is too conservative, suggesting that for the same model not much privacy is left, due to a very large “likelihood ratio” eε in Definition 2.1: it equals e7.10 = 1212.0 or e5.07 = 159.1 depending on which approach is chosen. This shortcoming of (ε, δ)-DP cannot be overcome by taking a larger δ, which, although gives rise to a smaller ε, would undermine the privacy guarantee from a different perspective.
Table 1:
Experimental results for NoisySGD and their privacy analyses on MNIST. The accuracy is averaged over 10 independent runs. The hyperparameters in the first three rows are the same as in [2]. The μ in the 6th row is calculated using (5), which carries over to the 7th row via (6) with δ = 10−5. The number of epochs is equal to T × mini-batch size/n = pT.
| η | R | σ | Epochs | Test accuracy (%) | CLT μ | CLT ε | MA ε |
|---|---|---|---|---|---|---|---|
| 0.25 | 1.5 | 1.3 | 15 | 95.0 | 0.23 | 0.83 | 1.19 |
| 0.15 | 1.0 | 1.1 | 60 | 96.6 | 0.57 | 2.32 | 3.01 |
| 0.25 | 1.5 | 0.7 | 45 | 97.0 | 1.13 | 5.07 | 7.10 |
| 0.25 | 1.5 | 0.6 | 62 | 97.6 | 2.00 | 9.98 | 13.27 |
| 0.25 | 1.5 | 0.55 | 68 | 97.8 | 2.76 | 14.98 | 18.72 |
| 0.25 | 1.5 | 0.5 | 100 | 98.0 | 4.78 | 31.12 | 32.40 |
For all experiments described in Table 1, Figure 3 illustrates the privacy bounds given by the CLT approach and the moments accountant both in terms of trade-off functions. The six plots in the first and third rows are with respect to δ = 10−5, from which the f-DP framework is seen to provide an analyst with substantial improvements in the privacy bounds. Note that the first row in Figure 3 corresponds to the first three rows in Table 1, and the third row in Figure 3 corresponds to the last three rows in Table 1. For the model corresponding to 96.6% test accuracy, concretely, the minimum sum of type I and type II errors in the sense of hypothesis testing is (at least) 77.6% by the CLT approach, whereas it is merely (at least) 9.4% by the moments accountant. For completeness, we show the optimal trade-off functions over all pairs of ε, δ given by the moments accountant in the middle row. The gaps between the two approaches exist, as predicted by Theorem 1, and remain significant.
Figure 3:
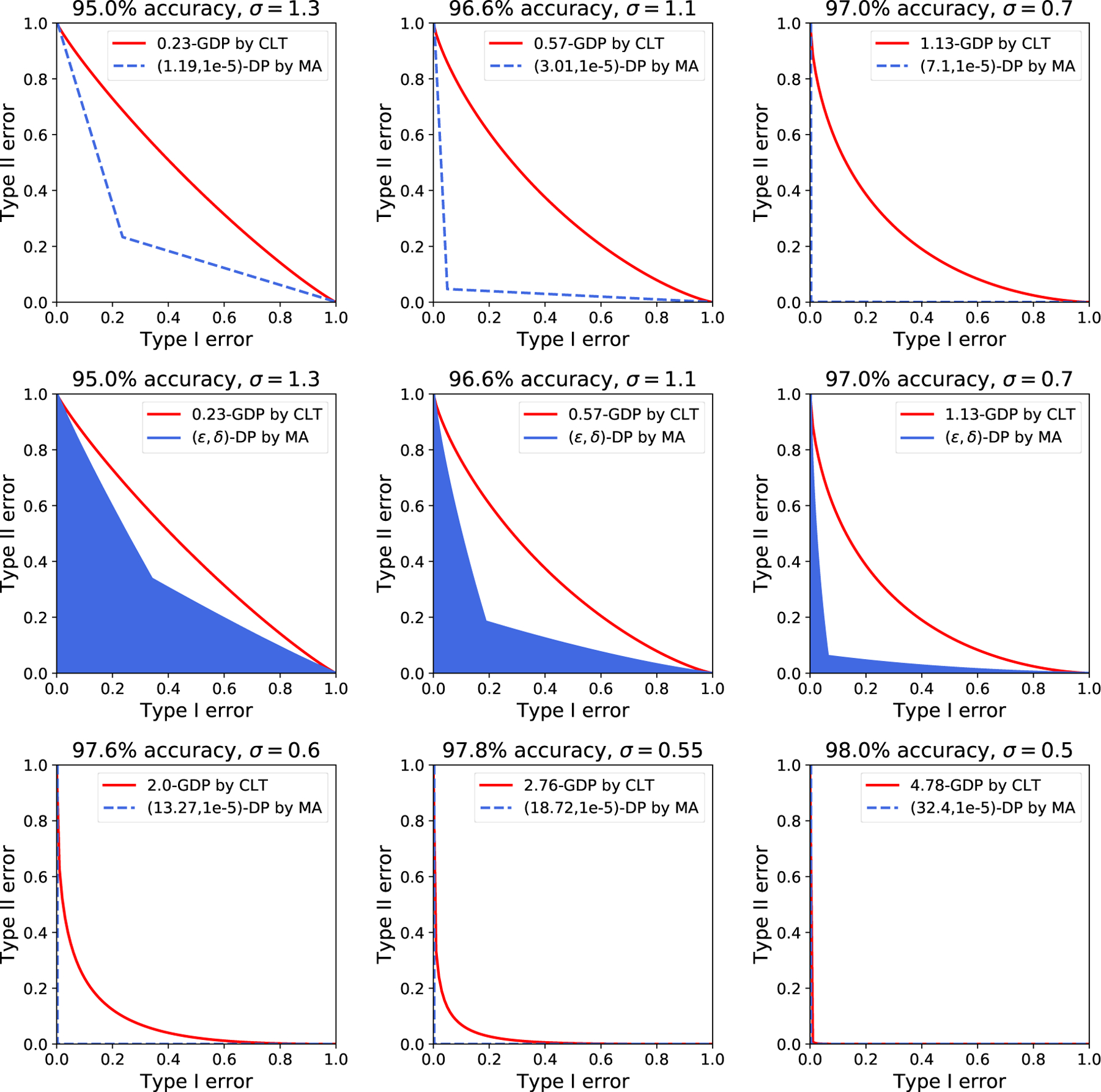
Comparisons between the two ways of privacy analysis on MNIST in terms of the tradeoff between type I and type II errors, in the same setting as Table 1. The plots are different from Figure 7 in [18]. The (ε, δ)-DP guarantees are plotted according to (1). The blue regions in the plots from the second row correspond to all pairs of (ε, δ) computed by MA. The blue regions are not noticeable in the third row.
Next, we extend our experiments to other datasets to further test f-DP for training private neural networks. The experiments compare private models under the privacy budget μ ≤ 2 to their non-private counterparts and some popular baseline methods. For simplicity, we focus on shallow neural networks and leave the investigation of complex architectures for future research.
Adult income.
Originally from the UCI repository [19], the Adult income dataset has been preprocessed into the LIBSVM format [13]. This dataset contains 32,561 examples, each of which has 123 features and a label indicating whether the individual’s annual income is more than $50,000 or not. We randomly choose 10% of the examples as the test set (3,256 examples) and use the remaining 29,305 examples as the training set.
Our model is a single-layer multi-perceptron with 16 neurons and the ReLU activation. We set σ = 0.55, p = 256/29305, η = 0.15, R = 1, and use NoisySGD as our optimizer. The results displayed in Table 2 show that our private model achieves comparable performance to the baselines in the MLC++ library [34] in terms of test accuracy.
Table 2:
Results for NoisySGD on the Adult income dataset. The ε parameters are with respect to δ = 10−5.
IMDb.
We use the IMDb movie review dataset [40] for binary sentiment classification (positive or negative reviews). The dataset contains 25,000 training and 25,000 test examples. In our experiments, we prepocess the dataset by only including the top 10,000 frequently used words and discard the rest. Next, we set every example to have 256 words by truncating the length or filling with zeros if necessary.
In our neural networks, the input is first embedded into 16 units and then is passed through a global average pooling. The intermediate output is fed to a fully-connected layer with 16 neurons, followed by a ReLU layer. We set σ = 0.56, p = 512/25000, η = 0.02, R = 1, and use NoisyAdam as our optimizer, which is observed to converge much faster than NoisySGD in this training task. We use the (non-private) two-layer LSTM RNN model in the Tensorflow tutorials [1] as a baseline model. Table 3 reports the experimental results. Notably, the private neural networks perform comparably to the baseline model, at the cost of only one percent drop in test accuracy compared to the non-private counterpart.
Table 3:
Results for NoisyAdam on the IMDB dataset, with δ = 10−5 used in the privacy analyses.
| Models | Epochs | Test accuracy (%) | CLT μ | CLT ε | MA ε |
|---|---|---|---|---|---|
| private networks | 9 | 83.8 | 2.07 | 10.43 | 15.24 |
| non-private networks | 20 | 84.7 | — | — | — |
| LSTM-RNN [30] | 10 | 85.4 | — | — | — |
MovieLens.
The MovieLens movie rating dataset [28] is a benchmark dataset for recommendation tasks. Our experiments consider the MovieLens 1M dataset, which contains 1,000,209 movie ratings from 1 star to 5 stars. In total, there are 6,040 users who rated 3,706 different movies. For this multi-class classification problem, the root mean squared error (RMSE) is chosen as the performance measure. It is worthwhile to mention that, as each user only watched a small fraction of all the movies, most (user, movie) pairs correspond to missing ratings. We randomly sample 20% of the examples as the test set and take the remainder as the training set.
Our model is a simplified version of the neural collaborative filtering in [29]. The network architecture consists of two branches. The left branch applies generalized matrix factorization to embed the users and movies using five latent factors. The output of the user embedding is multiplied by the item embedding. In the right branch, we use 10 latent factors for embedding. The embedding from both branches are then concatenated, which is fed to a fully-connected output layer. We set σ = 0.6, p = 1/80, η = 0.01, and R = 5 in NoisyAdam.
Table 4 presents the numerical results of our neural networks as well as baseline models in the Suprise library [31] in their default settings. The difference in RMSE between the non-private networks and the private one is relatively large for the MovieLens 1M dataset. Nevertheless, the private model still outperforms many popular non-private models, including the user-based collaborative filtering and nonnegative matrix factorization.
Table 4:
Results for NoisyAdam on the MovieLens 1M dataset, with δ = 10−6 used in the privacy analyses. CF stands for collaborative filtering.
| Models | Epochs | RMSE | CLT μ | CLT ε | MA ε |
|---|---|---|---|---|---|
| private networks | 20 | 0.915 | 1.94 | 10.61 | 15.39 |
| non-private networks | 20 | 0.893 | — | — | — |
| SVD | — | 0.873 | — | — | — |
| NMF | — | 0.916 | — | — | — |
| user-based CF [52] | — | 0.923 | — | — | — |
| global average | — | 1.117 | — | — | — |
4.2. The (ε, δ)-DP Perspective
While we hope that the f-DP perspective has been conclusively demonstrated to be advantageous, this section shows that the CLT approach continues to bring considerable benefits even in terms of (ε, δ)-DP. Specifically, by making use of the comparisons between the CLT approach and the moments accountant in Section 3.2, we can add less noise to the gradients in NoisySGD and NoisyAdam while achieving the same (ε, δ)-DP guarantees provided by the moments accountant. With less added noise, conceivably, an optimizer would have a higher prediction accuracy.
Figure 4 illustrates the experimental results on MNIST. In the top two plots, we set the noise scales to σ = 1.3, , which are both shown to give (1.34, 10−5)-DP at epoch 20 using the moments accountant and the CLT approach, respectively. The test accuracy associated with the CLT approach is almost always higher than that associated with the moments accountant. In addition, another benefit of taking the CLT approach is that it gives rise to stronger privacy protection before reaching epoch 20, as shown by the right plot. For the bottom plots, although the improvement in test accuracy at the end of training is less significant, the CLT approach leads to much faster convergence at early epochs. To be concrete, the numbers of epochs needed to achieve 95%, 96%, and 97% test accuracy are 18, 26, and 45, respectively, for the neural networks with less noise, whereas the numbers of epochs are 23, 33, and 64, respectively, using noise level that is computed by the moments accountant. In a similar vein, the moments accountant gives a test accuracy of 92% for the first time when ε = 4 and the CLT approach achieves 96% under the same privacy budget.
Figure 4:
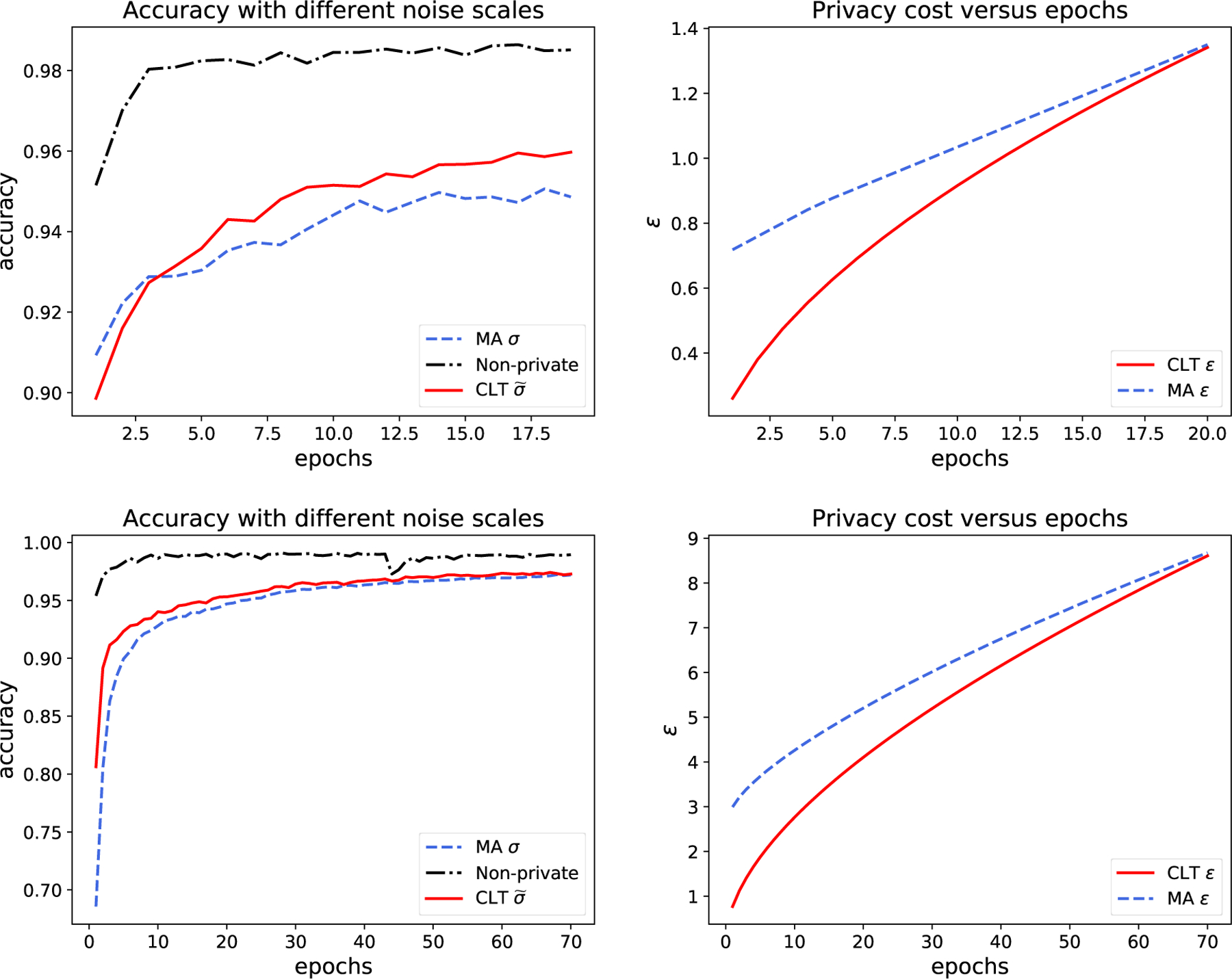
Experimental results from one run of NoisySGD on MNIST with different noise scales but the same (ε, δ)-DP guarantees. The top plots use p = 256/60000, η = 0.15, R = 1.5, and σ = 1.3, . The CLT approach with and the moments accountant with σ = 1.3 give (1.34, 10−5)-DP at the 20th epoch (μCLT = 0.35). The bottom plots use the same parameters except for σ = 0.7, , and η = 0.15. Both approaches give (8.68, 10−5)-DP at epoch 70 (μCLT = 1.78). The right plots show the privacy loss during the training process in terms of the ε spending with respect to δ = 10−5.
5. Discussion
In this paper, we have showcased the use of f-DP, a very recently proposed privacy definition, for training private deep learning models using SGD or Adam. Owing to its strength in handling composition and subsampling and the powerful privacy central limit theorem, the f-DP framework allows for a closed-form privacy bound that is sharper than the one given by the moments accountant in the (ε, δ)-DP framework. By numerical experiments, we show that the trained neural networks can be quite private from the f-DP viewpoint (for instance, 1.13-GDP11) but are not in the (ε, δ)-DP sense due to over conservative privacy bounds (for instance, (7.10, 10−5)-DP) computed in the (ε, δ)-DP framework. This in turn suggests that one can add less noise during the training process while having the same privacy guarantees as using the moments accountant, thereby improving model utility.
We conclude this paper by offering several directions for future research. As the first direction, we may consider using time-dependent noise scales and learning rates in NoisySGD and NoisyAdam for a better tradeoff between privacy loss and utility in the f-DP framework. Note that [37] has made considerable progress using concentrated differential privacy along this line. More generally, a straightforward but interesting problem is to extend this work to complex neural network architectures with a variety of optimization strategies. For example, can we develop some guidelines for choosing an optimizer among NoisySGD, NoisyAdam, and others for a given classification problem under some privacy constraint? Empirically, deep learning models are very sensitive to hyperparameters such as mini-batch size in terms of test accuracy. Therefore, from a practical standpoint, it would be of great importance to incorporate hyperparameter tuning into the f-DP framework [27]. Inspired by [36], another interesting direction is to explore the possible relationship between f-DP guarantees and adversarial robustness of neural networks. Given f-DP’s good interpretability and powerful toolbox, it is worthwhile investigating whether, from a broad perspective, its superiority over earlier differential privacy relaxations would hold in general private statistical and machine learning tasks. We look forward to more research efforts to further the theory and extend the use of f-DP.
Figure 5:
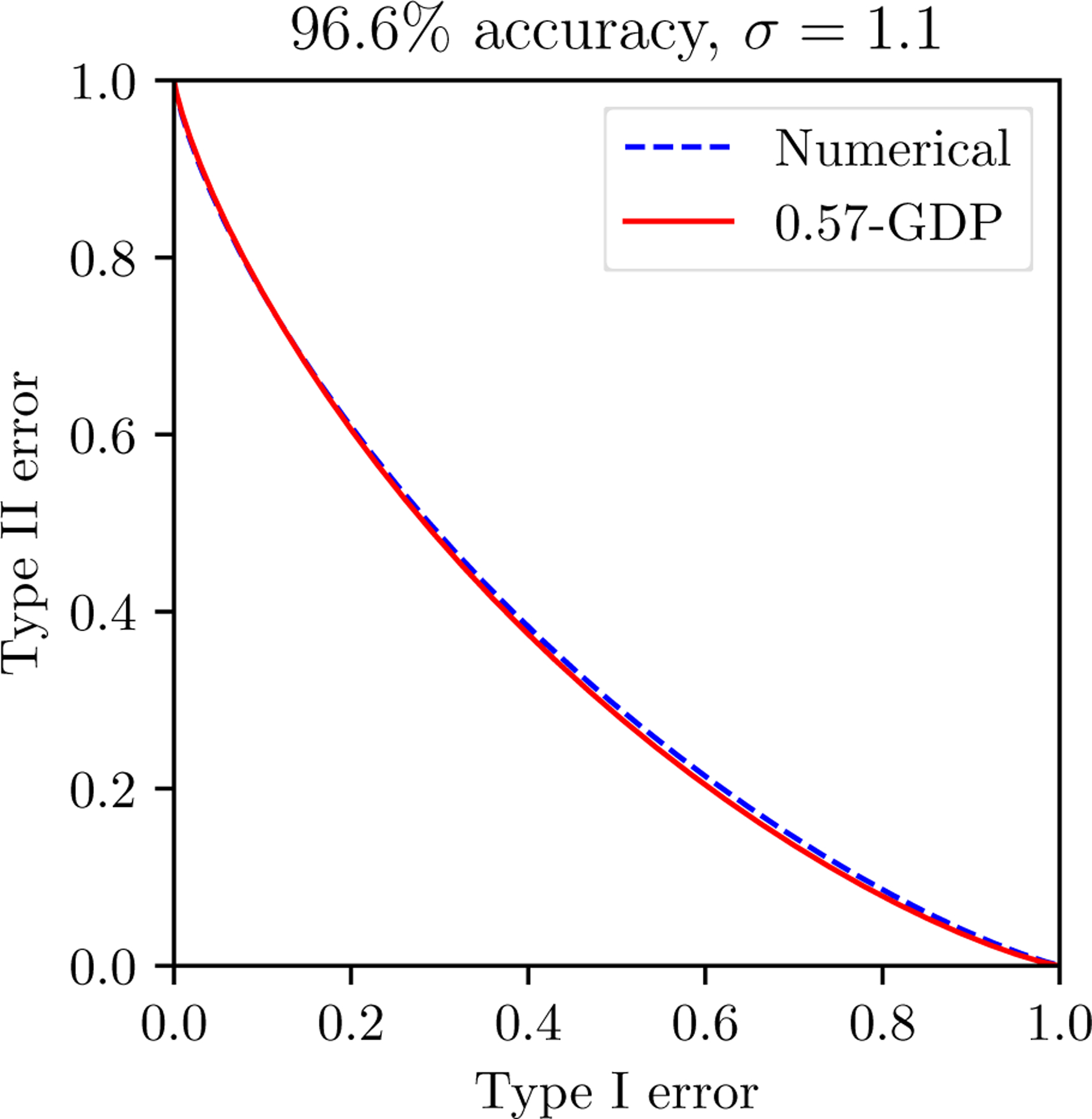
(pG1/σ + (1 − p)Id)⊗T (blue dashed) is numerically computed and compared with the GDP limit (red solid) predicted by CLT. The two are almost identical at merely epoch one.
Acknowledgments
We are grateful to David Durfee, Ryan Rogers, Aaron Roth, and Qinqing Zheng for stimulating discussions in the early stages of this work. We would also like to thank two anonymous referees for their constructive comments that improved the presentation of the paper. This work was supported in part by NSF through CAREER DMS-1847415, CCF-1763314, and CCF-1934876, the Wharton Dean’s Research Fund, and NIH through R01GM124111 and RF1AG063481.
A. Omitted Details in Section 2
We present Equation (3) as the following proposition, which is given in Section 2 but not in the foundational work [18].
Proposition A.1.
If M is f-DP, and S′ = S ∪ {x0}, then
Proof.
We first write the two distributions M ◦ Samplep(S) and M ◦ Samplep(S′) as mixtures.
Without loss of generality, we can assume S = {x1, …, xn} and S′ = {x0, x1, …, xn}. An outcome of the process Samplep when applied to S is a bit string . Bit bi dependes on whether xi is selected into the subsample. We use to denote the subsample determined by . When each bi is sampled from a Bernoulli(p) distribution independently, can be identified with Samplep(S). Let be the probability that appears. More specifically, if k out of n entries of is one, then . With this notation, M ◦Samplep(S) can be written as the following mixture:
Similarly, M ◦ Samplep(S) can also be written as a mixture, with an additional bit indicating the presence of x0. Alternatively, we can divide the components into two groups: one with x0 present, and the other with x0 absent. Namely,
Note that and are neighbors, i.e. M ◦ Samplep(S′) is the mixture of neighboring distributions. The following lemma is the perfect tool to deal with it.
Lemma A.2.
Let I be an index set. For all i ∈ I, Pi and Qi are distributions that reside on a common sample space. (θi)i∈I is a collection of non-negative numbers that sums to 1. If f is a trade-off function and T(Pi, Qi) ⩾ f for all i, then
To apply the lemma, let the index be , Pi be and Qi be . Condition T(Pi, Qi) ⩾ f is the consequence of M being f-DP. The conclusion simply translates to
which is what we want. The proof is complete. □
Proof of Lemma A.2.
Let P = ∑θiPi and Q = (1 − p)∑θiPi + p∑θiQi. Suppose ϕ satisfies . That is,
It is easy to see that
We know that T(Pi, Qi) ⩾ f. Hence . So
Since f is convex, Jensen’s inequality implies
Next we use a figure to justify the claim we made in Section 2.2 that “CLT approximation works well for SGD”. Recall that we argued in Section 3 that Algorithms 1 and 2 are min{f, f−1}**-DP where
This function converges to Gμ with as T → ∞ provided . In the following figure, we numerically compute f (blue dashed) and compare it with the predicted limit Gμ (red solid). More specifically, the configuration is designed to illustrate the fast convergence in the setting of the second line of Table 1, i.e. noise scale σ = 1.1, final GDP parameter μ = 0.57 and test accuracy 96.6%. Originally the algorithm runs 60 epochs, i.e. ≈ 14k iterations. To best illustrate that convergence appears in early stage, the numerical evaluation uses a much smaller Tnumeric = 234, i.e. only one epoch. In order to make the final limit consistent, we also enlarge the sample probability to pnumeric so that remain the same.
We have to remark that when σ is small, gets large and yields challenges in the numerical computation of (pG1/σ + (1 − p)Id)⊗T. We leave rigorous and complete study to future work.
B. Omitted Details in Section 3
B.1. Privacy Property of Algorithms 1 and 2
Theorem 3.
Algorithms 1 and 2 are both min{f, f−1}**-DP with f = (pG1/σ + (1 − p)Id)⊗T.
Proof.
The proof is mostly done in the main text, except the composition step. Let V be the vector space that all θt live in and be the gradient update. We have already proved (using Proposition A.1) that for both Algorithms 1 and 2, if S′ = S∪{x0}, then satisfies
Note that we cannot say M is fp-DP because T(M(S′), M(S)) is not necessarily lower bounded by fp. So we need a more specific composition theorem than stated in [18].
Theorem 4 (Refined Composition).
Suppose M1 : X → Y, M2 : X × Y → Z satisfy the following conditions for any S, S′ such that S′ = S ∪ {x0}:
T(M1(S), M(S′)) ⩾ f;
T(M2(S, y), M2(S′, y)) ⩾ g for any y ∈ Y.
Then the composition M2 ◦ M1 : X → Y × Z satisfies
for any S, S′ such that S′ = S ∪ {x0}.
The theorem can be identically proved as Theorem 3.2 in [18].
Taking Algorithm 1 as an example, since
is simply the composition of T copies of , the above composition theorem implies that
Moreover, T(NoisySGD(S), NoisySGD(S′)) ⩾ f−1. The two inequality let us conclude that any trade-off function of neighboring distributions must be lower bounded by at least one of f and f−1, hence min{f, f−1}, hence min{f, f−1}**. In other words, NoisySGD is min{f, f−1}**-DP.
For NoisyAdam, we argued that its privacy property is the same as NoisySGD in each iteration, so the above argument also applies, and we have the same conclusion. □
B.2. Justifying CLT for Algorithms 1 and 2
The main purpose of this section is to show the following theorem
Theorem 5.
Suppose p depends on T and . Then we have the following uniform convergence as T → ∞
where .
This theorem is the corollary of the following more general CLT on composition of subsample mechanisms and Lemma B.1 below.
Theorem 6.
Suppose f is a trade-off function such that (1) f(0) = 1, (2) f(x) > 0, for all x < 1 and (3) . Let fp = pf+(1−p)Id as usual. Furthermore, assume as T → ∞ for some constant ν > 0. Then we have the uniform convergence
as T → ∞, where .
Lemma B.1.
We have
In order to prove Theorem 6, we need an even more general CLT. The first privacy CLT was introduced in [18]. However, that version is valid only when each component trade-off function is symmetric, which is not true for pG1/σ + (1 − p)Id. In order to state the general CLT that applies to asymmetric trade-off functions, we need to introduce the following functionals:
Theorem 7.
Let be a triangular array of (possibly asymmetric) trade-off functions and assume the following limits for some constants K ⩾ 0 and s > 0 as n → ∞:
;
max1⩽i⩽n kl(fni) → 0, ;
, ;
, .
Then, we have
uniformly for all α ∈ [0, 1].
Proof of this theorem exactly mimics that of Theorem 3.5 in [18], which we omit here for its length and tediousness.
Next, we apply the asymmetric CLT to (pf + (1 − p))⊗T and prove Theorem 6. We start by collecting the necessary expressions into the following lemma. All of them are straightforward.
Lemma B.2.
Let g(x) = −f′(x) − 1 = |f′(x)| − 1. Then
Proof of Theorem 6.
It suffices to compute the limits in the asymmetric Central Limit Theorem 7, namely
Since T ~ p−2, we can consider and so on.
As in Lemma B.2, let g(x) = −f′(x)−1 = |f′(x)|−1. The assumption expressed in terms of g is simply
In particular, it implies |g(x)|k is integrable in [0, 1] for k = 2, 3, 4. In addition, by Lemma B.2,
For the functional kl, by Lemma B.2,
| (9) |
Changing the order of the limit and the integral in (9) is approved by the dominated convergence theorem. To see this, notice that log(1 + x) ⩽ x. The integrand in (9) satisfies
We already argued that g(x)2 is integrable, so it works as a dominating function and the limit is justified. When , we have
So the constant K in Theorem 7 is ν2 · χ2(f).
For the functional κ2 we have
By a similar dominating function argument,
Adding in the limit , we know s2 in Theorem 7 is ν2 · χ2(f).
The same argument involving |g(x)|3 and g(x)4 applies to the functional κ3 and respectively and yields
Note the different power in p in the denominator. It means κ3(fp) = o(p2) and hence T·κ3(fp) → 0 when .
Hence all the limits in Theorem 7 check and we have a Gμ limit where
This completes the proof. □
We finish the section by proving the formula in Lemma B.1.
Proof of Lemma B.1.
The best calculation is done via better understanding. We point out that the functional χ2 is doing nothing more than computing the famous χ2-divergence. Recall that Neyman χ2-divergence (reverse Pearson) of P, Q is defined as
Lemma B.3.
If f = T(P, Q) and f(0) = 1, f(x) > 0, for all x < 1, then χ2(f) = χ2(P∥Q).
This lemma is a straightforward corollary of Proposition B.4 in [18], which gives expressions for all F-divergence12. In particular, if f = T(P, Q) and f(0) = 1, f(x) > 0, ∀x < 1, then F-divergence of P, Q can be computed from their trade-off function as follows:
Neyman χ2-divergence corresponds to , so
With this formula, computing χ2(G1/σ) is straightforward:
B.3. Proof of Theorems 1 and 2
Recall that Theorems 1 and 2 compare our CLT approach to moments accountant (MA) from two different perspectives: f-DP perspective in Theorem 1 and (ε, δ)-DP perspective in Theorem 2. We first show that Theorem 1 can be derived from Theorem 2. Then we prove a refined version of Theorem 2. To be more precise about the statement, let us first expand the notations used in the main text.
Let δMA(ε; σ, p, T) be the δ value computed by moment accountant method (described in detail below) for NoisySGD algorithm with subsampling probability p, iteration T and noise scale σ. Similarly, δCLT(ε; σ, ν) denotes the δ value computed for the same algorithm using central limit theorem assuming .
Let . It is supported by at α. Theorem 2 says this supporting function is smaller than that of at α by a strict gap. Taking the limit, lim supT→∞ fT (α) has at least that much gap from , which proves Theorem 1.
Theorem 2 is a straightforward corollary of the following proposition. Note that the inequality is reversed compared to the statement of Theorem 2 so that the gap is positive, which also turns lim sup into lim inf.
Proposition B.4.
where .
Let us first describe how the two methods compute δ from ε.
where αGM(λ; σ, p) is a scaled version of the Rényi divergence of Gaussian mixtures. More specifically, let and . We further denote the Gaussian mixture pQ + (1 − p)P by GMp,σ. The
In [3], it has been shown that Algorithm 1 (hence also the Adam variant, Algorithm 2) with subsampling probability p, iteration T and noise scale σ is (ε, δ)-DP for each ε ⩾ 0 if δ = δMA(ε; σ, p, T). To evaluate the infimum, the domain is discretized13. This results in the numerical moment accountant method that is actually implemented. Since δnMA(ε; σ, p, T) ⩾ δMA(ε; σ, p, T), Algorithm 1 is also (ε, δ)-DP with δ = δnMA(ε; σ, p, T).
On the other hand, δCLT(ε; σ, ν) is obtained by first observing Algorithm 1 is asymptotically μCLT-GDP with and then convert GDP to (ε, δ)-DP via Equation (6), i.e. Algorithm 1 asymptotically satisfies (ε, δ)-DP where
We have just explained how MA and CLT works. Next we prove Proposition B.4
Proof of Proposition B.4.
Let fT = (pGμ+(1−p)Id)⊗T. We need a lemma (whose proof is provided later) that relates the Rényi divergence to the trade-off function fT.
Lemma B.5.
Let xT ∈ (0, 1) be the point such that (or if readers worry about diffesrentiability). We have
It is clear that for 0 ⩽ x ⩽ xT.
On the other hand, using Lemma B.5, we get
In summary, we have
| (10) |
Setting , we would like to take limit on both sides of (10). First notice that fT converge pointwise to , which we have already proven in Appendix B.2. The limit of xT is taken care of in the following lemma:
Lemma B.6.
Combining these results, we can take limits on both sides of (10):
This finishes the proof. □
Proof of Lemma B.5.
The Rényi divergence can also be computed from the trade-off function, just like the χ2-divergence. In fact, under the same assumptions as in Lemma B.1, we have
Alternatively,
| (11) |
This identity will be the bridge between αGM and fT.
On one hand, αGM(λ; σ, p) is the maximum of two Rényi divergences, so
Consequently,
The last step is the tensorization identity of Rényi divergence.
On the other hand, notice that pGμ + (1 − p)Id = T(P, GMp,σ) where we continue the use of notations , and GMp,σ = pQ + (1 − p)P. We have
Using (11), we have
Proof of Lemma B.6.
By definition, . The convexity of fT implies .
Since fT converges uniformly to in [0, 1], we have uniform convergence . By convexity of these functions, the convergence also implies the convergence of derivatives (See Theorem 25.7 of [51]), namely,
Therefore,
Let be the limit. Using the convexity again, we have
We can solve for x* using the expression of Gμ (6). After some algebra, we have
The proof is complete. □
Footnotes
It is noteworthy that training deep learning models has served as an important benchmark in testing a privacy definition since the tightness of its privacy analysis crucially depends on whether the definition can tightly account for composition and subsampling.
Alternatively, the neighboring relationship can be defined for datasets of the same size and differing by one individual.
Here, f* is the convex conjugate, which is defined as f*(x) = supα αx − f(α).
If for i = 1, …, T, then the T-fold composition is exactly Gμ with .
For any trade-off function f = T(P, Q), its inverse f−1 = T(Q, P).
We omit the dependence of the functions on the specification of the composition algorithm such as p, σ, T as in NoisySGD and NoisyAdam.
The moments accountant can be applied in the f-DP framework. In fact, the moments accountant is defined via a certain moment generating function, which is equivalent to the Rényi divergence. The Rényi divergence can be uniquely deduced from a trade-off function. See Section 2.3 in [18].
Here, ε(δ; μ) is the inverse function of δ(ε; μ).
Write and set εCLT(δ) = 0 for . Apply the same adjustment for εMA.
This means that undermining the privacy guarantee is harder than or of the same hardness as testing H0 : μ = 0 against H1 : μ = 1.13 based on the observation .
We use capital F to avoid confusion with the notation of trade-off function.
Code in tensorflow/privacy discretizes at [1.25, 1.5, 1.75, 2., 2.25, 2.5, 3., 3.5, 4., 4.5, 5, 6, 7, …, 63, 64, 128, 256, 512].
References
- [1].IMDB Tensorflow RNN tutorial. www.tensorflow.org/tutorials/text/text_classification_rnn.
- [2].Tensorflow Privacy library. github.com/tensorflow/privacy.
- [3].Abadi M, Chu A, Goodfellow I, McMahan HB, Mironov I, Talwar K, and Zhang L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pages 308–318. ACM, 2016. [Google Scholar]
- [4].Abowd JM. The US Census Bureau adopts differential privacy. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2867–2867. ACM, 2018. [Google Scholar]
- [5].D. P. T. Apple. Learning with privacy at scale. Technical report, Apple, 2017. [Google Scholar]
- [6].Bagdasaryan E, Poursaeed O, and Shmatikov V. Differential privacy has disparate impact on model accuracy. In Advances in Neural Information Processing Systems, pages 15453–15462, 2019. [Google Scholar]
- [7].Balle B and Wang Y-X. Improving the gaussian mechanism for differential privacy: Analytical calibration and optimal denoising. In International Conference on Machine Learning, pages 403–412, 2018. [Google Scholar]
- [8].Balle B, Barthe G, and Gaboardi M. Privacy amplification by subsampling: Tight analyses via couplings and divergences. In Advances in Neural Information Processing Systems, pages 6280–6290, 2018. [Google Scholar]
- [9].Balle B, Barthe G, Gaboardi M, Hsu J, and Sato T. Hypothesis testing interpretations and renyi differential privacy. arXiv preprint arXiv:1905.09982, 2019. [Google Scholar]
- [10].Bassily R, Smith A, and Thakurta A. Private empirical risk minimization: Efficient algorithms and tight error bounds. In 2014 IEEE 55th Annual Symposium on Foundations of Computer Science, pages 464–473. IEEE, 2014. [Google Scholar]
- [11].Bun M and Steinke T. Concentrated differential privacy: Simplifications, extensions, and lower bounds. In Theory of Cryptography Conference, pages 635–658. Springer, 2016. [Google Scholar]
- [12].Bun M, Dwork C, Rothblum GN, and Steinke T. Composable and versatile privacy via truncated cdp. In Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing, pages 74–86. ACM, 2018. [Google Scholar]
- [13].Chang C-C and Lin C-J. Libsvm: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology (TIST), 2(3):27, 2011. [Google Scholar]
- [14].Chaudhuri K, Monteleoni C, and Sarwate AD. Differentially private empirical risk minimization. Journal of Machine Learning Research, 12(Mar):1069–1109, 2011. [PMC free article] [PubMed] [Google Scholar]
- [15].Cover T and Hart P. Nearest neighbor pattern classification. IEEE Transactions on Information Theory, 13(1):21–27, 1967. [Google Scholar]
- [16].Ding B, Kulkarni J, and Yekhanin S. Collecting telemetry data privately. In Proceedings of Advances in Neural Information Processing Systems 30 (NIPS 2017), 2017. [Google Scholar]
- [17].Dong J, Durfee D, and Rogers R. Optimal differential privacy composition for exponential mechanisms and the cost of adaptivity. arXiv preprint arXiv:1909.13830, 2019. [Google Scholar]
- [18].Dong J, Roth A, and Su WJ. Gaussian differential privacy. arXiv preprint arXiv:1905.02383, 2019. [Google Scholar]
- [19].Dua D and Graff C. UCI machine learning repository, 2017. URL http://archive.ics.uci.edu/ml.
- [20].Duchi J, Hazan E, and Singer Y. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(Jul):2121–2159, 2011. [Google Scholar]
- [21].Dwork C and Rothblum GN. Concentrated differential privacy. arXiv preprint arXiv:1603.01887, 2016. [Google Scholar]
- [22].Dwork C, Kenthapadi K, McSherry F, Mironov I, and Naor M. Our data, ourselves: Privacy via distributed noise generation. In Annual International Conference on the Theory and Applications of Cryptographic Techniques, pages 486–503. Springer, 2006. [Google Scholar]
- [23].Dwork C, McSherry F, Nissim K, and Smith A. Calibrating noise to sensitivity in private data analysis. In Theory of cryptography conference, pages 265–284. Springer, 2006. [Google Scholar]
- [24].Dwork C, Rothblum GN, and Vadhan S. Boosting and differential privacy. In Foundations of Computer Science (FOCS), 2010 51st Annual IEEE Symposium on, pages 51–60. IEEE, 2010. [Google Scholar]
- [25].Dwork C, Talwar K, Thakurta A, and Zhang L. Analyze gauss: optimal bounds for privacy-preserving principal component analysis. In Proceedings of the forty-sixth annual ACM Symposium on Theory of Computing, pages 11–20. ACM, 2014. [Google Scholar]
- [26].Erlingsson Ú, Pihur V, and Korolova A. Rappor: Randomized aggregatable privacy-preserving ordinal response. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, pages 1054–1067. ACM, 2014. [Google Scholar]
- [27].Gupta A, Ligett K, McSherry F, Roth A, and Talwar K. Differentially private combinatorial optimization. In Proceedings of the twenty-first annual ACM-SIAM Symposium on Discrete Algorithms, pages 1106–1125. Society for Industrial and Applied Mathematics, 2010. [Google Scholar]
- [28].Harper FM and Konstan JA. The movielens datasets: History and context. Acm Transactions on Interactive Intelligent Systems (TIIS), 5(4):19, 2016. [Google Scholar]
- [29].He X, Liao L, Zhang H, Nie L, Hu X, and Chua T-S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, pages 173–182. International World Wide Web Conferences Steering Committee, 2017. [Google Scholar]
- [30].Hochreiter S and Schmidhuber J. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997. [DOI] [PubMed] [Google Scholar]
- [31].Hug N. Surprise, a Python library for recommender systems. http://surpriselib.com, 2017.
- [32].Kairouz P, Oh S, and Viswanath P. The composition theorem for differential privacy. IEEE Transactions on Information Theory, 63(6):4037–4049, 2017. [Google Scholar]
- [33].Kingma DP and Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. [Google Scholar]
- [34].Kohavi R, Sommerfield D, and Dougherty J. Data mining using/spl mscr//spl lscr//spl cscr/++ a machine learning library in c++. In Proceedings Eighth IEEE International Conference on Tools with Artificial Intelligence, pages 234–245. IEEE, 1996. [Google Scholar]
- [35].LeCun Y and Cortes C. MNIST handwritten digit database. 2010. URL http://yann.lecun.com/exdb/mnist/.
- [36].Lecuyer M, Atlidakis V, Geambasu R, Hsu D, and Jana S. Certified robustness to adversarial examples with differential privacy. In 2019 IEEE Symposium on Security and Privacy (SP), pages 656–672. IEEE, 2019. [Google Scholar]
- [37].Lee J and Kifer D. Concentrated differentially private gradient descent with adaptive per-iteration privacy budget. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1656–1665. ACM, 2018. [Google Scholar]
- [38].Li N, Qardaji W, and Su D. On sampling, anonymization, and differential privacy or, k-anonymization meets differential privacy. In Proceedings of the 7th ACM Symposium on Information, Computer and Communications Security, pages 32–33. ACM, 2012. [Google Scholar]
- [39].Liu C, He X, Chanyaswad T, Wang S, and Mittal P. Investigating statistical privacy frameworks from the perspective of hypothesis testing. Proceedings on Privacy Enhancing Technologies, 2019(3): 233–254, 2019. [Google Scholar]
- [40].Maas AL, Daly RE, Pham PT, Huang D, Ng AY, and Potts C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150. Association for Computational Linguistics, 2011. [Google Scholar]
- [41].McMahan B, Andrew G, Mironov I, Papernot N, Kairouz P, Chien S, and Erlingsson Ú. A general approach to adding differential privacy to iterative training procedures. arXiv preprint arXiv:1812.06210, 2018. [Google Scholar]
- [42].McMahan HB, Ramage D, Talwar K, and Zhang L. Learning differentially private recurrent language models. arXiv preprint arXiv:1710.06963, 2017. [Google Scholar]
- [43].Mironov I. Rényi differential privacy. In 2017 IEEE 30th Computer Security Foundations Symposium (CSF), pages 263–275. IEEE, 2017. [Google Scholar]
- [44].Murtagh J and Vadhan S. The complexity of computing the optimal composition of differential privacy. In Theory of Cryptography Conference, pages 157–175. Springer, 2016. [Google Scholar]
- [45].Narayanan A and Shmatikov V. Robust de-anonymization of large sparse datasets. In 2008 IEEE Symposium on Security and Privacy, pages 111–125. IEEE, 2008. [Google Scholar]
- [46].Papernot N, Abadi M, Erlingsson U, Goodfellow I, and Talwar K. Semi-supervised knowledge transfer for deep learning from private training data. arXiv preprint arXiv:1610.05755, 2016. [Google Scholar]
- [47].Papernot N, Song S, Mironov I, Raghunathan A, Talwar K, and Erlingsson Ú. Scalable private learning with pate. arXiv preprint arXiv:1802.08908, 2018. [Google Scholar]
- [48].Pichapati V, Suresh AT, Yu FX, Reddi SJ, and Kumar S. AdaCliP: Adaptive clipping for private SGD. arXiv preprint arXiv:1908.07643, 2019. [Google Scholar]
- [49].Quinlan JR. Induction of decision trees. Machine learning, 1(1):81–106, 1986. [Google Scholar]
- [50].Quinlan JR. C4. 5: programs for machine learning. Elsevier, 2014. [Google Scholar]
- [51].Rockafellar RT. Convex analysis, volume 28 Princeton University Press, 1970. [Google Scholar]
- [52].Sarwar BM, Karypis G, Konstan JA, Riedl J, et al. Item-based collaborative filtering recommendation algorithms. Www, 1:285–295, 2001. [Google Scholar]
- [53].Shokri R and Shmatikov V. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC conference on computer and communications security, pages 1310–1321. ACM, 2015. [Google Scholar]
- [54].Sommer D, Meiser S, and Mohammadi E. Privacy loss classes: The central limit theorem in differential privacy. 2018. [Google Scholar]
- [55].Song S, Chaudhuri K, and Sarwate AD. Stochastic gradient descent with differentially private updates. In 2013 IEEE Global Conference on Signal and Information Processing, pages 245–248. IEEE, 2013. [Google Scholar]
- [56].Sweeney L. Weaving technology and policy together to maintain confidentiality. The Journal of Law, Medicine & Ethics, 25(2–3):98–110, 1997. [DOI] [PubMed] [Google Scholar]
- [57].Wang Y-X, Balle B, and Kasiviswanathan SP. Subsampled Renyi differential privacy and analytical moments accountant. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 1226–1235, 2019. [Google Scholar]
- [58].Wasserman L and Zhou S. A statistical framework for differential privacy. Journal of the American Statistical Association, 105(489):375–389, 2010. [Google Scholar]
- [59].Xiang L, Yang J, and Li B. Differentially-private deep learning from an optimization perspective. In IEEE INFOCOM 2019-IEEE Conference on Computer Communications, pages 559–567. IEEE, 2019. [Google Scholar]
- [60].Xu Z, Shi S, Liu AX, Zhao J, and Chen L. An adaptive and fast convergent approach to differentially private deep learning. arXiv preprint arXiv:1912.09150, 2019. [Google Scholar]
- [61].Zhang J, Zheng K, Mou W, and Wang L. Efficient private ERM for smooth objectives. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, pages 3922–3928. AAAI Press, 2017. [Google Scholar]