

Abstract
The optimal control of sugar content and its associated technology is important for producing high-quality crops more stably and efficiently. Model-based reinforcement learning (RL) indicates a desirable action depending on the type of situation based on trial-and-error calculations conducted by an environmental model. In this paper, we address plant growth modeling as an environmental model for the optimal control of sugar content. In the growth process, fruiting plants generate sugar depending on their state and evolve via various external stimuli; however, sugar content data are sparse because appropriate remote sensing technology is yet to be developed, and thus, sugar content is measured manually. We propose a semisupervised deep state-space model (SDSSM) where semisupervised learning is introduced into a sequential deep generative model. SDSSM achieves a high generalization performance by optimizing the parameters while inferring unobserved data and using training data efficiently, even if some categories of training data are sparse. We designed an appropriate model combined with model-based RL for the optimal control of sugar content using SDSSM for plant growth modeling. We evaluated the performance of SDSSM using tomato greenhouse cultivation data and applied cross-validation to the comparative evaluation method. The SDSSM was trained using approximately 500 sugar content data of appropriately inferred plant states and reduced the mean absolute error by approximately 38% compared with other supervised learning algorithms. The results demonstrate that SDSSM has good potential to estimate time-series sugar content variation and validate uncertainty for the optimal control of high-quality fruit cultivation using model-based RL.
1. Introduction
Several studies have been performed to evaluate advanced cultivation techniques for stable and efficient production of high-quality crops based on farmers' experience and intuition [1–4]. For example, water stress cultivation of tomato plants is a technique that increases their sugar content by reducing irrigation. The technique requires sensitive irrigation control to provide the appropriate water stress throughout the cultivation period. A fine balance must be achieved because insufficient water stress does not improve sugar content while excessive water stress causes permanent withering. Such a technique is currently limited to expert farmers, and there have been some studies conducted to estimate water stress indirectly from soil moisture or climatic environmental factors such as temperature, humidity, and sunlight [5–10]. Recent studies have attempted to assess water stress with deep neural networks by monitoring plant motion caused by withering [11, 12]. Those studies contributed to the quantification of water stress to improve water stress cultivation to some extent. However, the purpose of water stress cultivation is to raise the sugar content, and a technique to directly control the sugar content flexibly is of interest. In this regard, our final goal is to develop a method to determine the optimal action to achieve the desired sugar content of greenhouse tomato plants at harvest stably and efficiently. In this study, we aim to develop a plant growth model to estimate time-series sugar content variation employing reinforcement learning, as the first step toward the final goal.
Reinforcement learning (RL) [13–15] acquires an optimal strategy through the experience of an agent performing an action in an environment and has demonstrated high flexibility and nontask-dependent representation capabilities. There are two types of RL: model-free RL [16, 17] and model-based RL [18, 19]. Model-free RL does not use the environmental information (state transition of the environment) to predict how the environment changes and what type of reward is obtainable when the environment is modified. By contrast, model-based RL uses the information of the state transition of the environment. Therefore, model-based RL is better than model-free RL at judging behavior based on a long-term plan with regard to a future state. Namely, model-based RL is expected to perform well in determining optimal actions to achieve the desired sugar content at harvesting.
The training of model-based RL involves two steps: (1) modeling an environment and (2) planning to learn the optimal policy for the model. In this paper, we focus on modeling an environment and developing a plant growth model for the optimal control of water stress cultivation. The model-based RL's environmental model is often a probabilistic model evaluated based on the standard deviation, because the plant states and the surrounding environment data are time-series data and generally contain a significant amount of noise [20]. The noise is affected not only by external factors but also by internal factors such as nonlinearly distributed plant growth. For example, nondestructively measured sugar content data based on spectroscopy varies depending on the location of the measurement point on a fruit because of the uneven internal structure of a fruit. Thus, we need to select a robust model that can properly handle such noisy data.
Among probabilistic models, the generative model is known as the most suitable for plant growth modeling, because generative models assign low probability to outliers. By contrast, discriminative models process the training dataset without considering the effects of noise. The generative model not only is robust to noise but also has good characteristics for predicting future states [20] and for generalization performance [21].
When model-based RL is used for the optimal cultivation of high sugar content fruits, it is necessary to predict future plant conditions from the cultivation environment based on present conditions. Moreover, it is important that the modeling method can be applied to different plant varieties and specific environments as well as to various environments. Therefore, we use the generative model to achieve high generalization performance of plant growth modeling, which requires predictability of the future states. In particular, we try to make the generative models much more robust and flexible by using sequential deep generative models combined with a state-space model (SSM, a typical generative model for time-series data) and because deep neural networks have fewer restrictions.
The variational autoencoder (VAE) [22] is a deep generative model for nonsequential data, and the parameters are optimized via stochastic gradient variational Bayes (SGVB) [23]. The stochastic recurrent networks (STORN) [23] are highly structured generative processes that are difficult to fit to deterministic by combining the elements of the VAE. Additionally, STORN is able to generate high-dimensional sequences such as music by including recurrent neural networks (RNN) in the structure of VAE and represents stochastic sequential modeling by inputting a sequence independently sampled from the posterior to a standard RNN. The variational RNN (VRNN) was proposed by Chung et al. [24] as a model similar to STORN. The main difference is that the prior of the latent variable depends on all previous information via a hidden state in the RNN. The introduction of temporal information has been shown to help in modeling highly structured sequences. VAE is also applied for optimal control. Watter et al. [25] addressed the local optimal control of high-dimensional nonlinear dynamic systems. Considering optimal control as the identification of the low-dimensional latent space, their proposed model Embed to Control (E2C) is trained while compressing high-dimensional observations such as images. Their results showed that E2C exhibits strong performance in various control tasks. Krishnan et al. [26] modeled the change of a patient's state over time using temporal generative models called Deep Kalman Filters (DKF). Unlike previous methods, DKF incorporates action variables to express factors external to patients, such as prescribing medication or performing surgery. In particular, structured variational inference is introduced in DKF to cater to the unique problems of living organisms, such as considering that a patient's states vary slowly and that external factors may have long-term effects on patients. These phenomena are similar to plant growth modeling.
The methods described above require a comparatively large-scale dataset to model complex generative processes. On the other hand, creating a large-scale dataset for the time-series sugar content of fruits is not temporally or financially easy because it is necessary to use a sensor to make gentle contact with the fruit manually. In addition, because measurements are performed manually, it is necessary to establish the methods based on various considerations such as measurement time, position, repetition of measurements, and measurement of the surrounding tomatoes to reduce the variance of the measurement value. By contrast, it is common to measure the fruit juice of representative fruits at the time of harvest (destructive measurement). Once the destructive measurement is performed, it is not possible to measure the same fruit over time. For these reasons, the data collection interval required for sugar content is longer than that of automatically sensed data such as temperature, humidity, and solar radiation. In particular, creating a large-scale dataset for time-series crop condition and quality is also not easy using manual measurements because of the workload and cost factors. Thus, it is important to develop a suitable method even though the amount of available data is not large.
In this study, we propose a novel sequential deep generative model called a semisupervised deep state-space model (SDSSM) to evaluate such defective data. SDSSM is similar to DKF in that a deep neural network is used for enforcement of the representation capability of SSM. On the other hand, the major difference is that SDSSM is trained by semisupervised learning to achieve a balance between high generalization performance and high representation power, even if some types of training data are sparse.
2. Materials and Methods
2.1. Plant Growth Model
2.1.1. Overview of SDSSM
Based on the general SSM, we assume the following generative processes for plant growth modeling:
| (1) |
| (2) |
where zt and xt are latent variables and observed variables, respectively, at time step t. The probabilistic models are shown in Figure 1. In our task, the latent variable zt denotes the plant states. We assume that the water content and the duration of plant growth, which are particularly strongly related to sugar content, are plant states.
Figure 1.
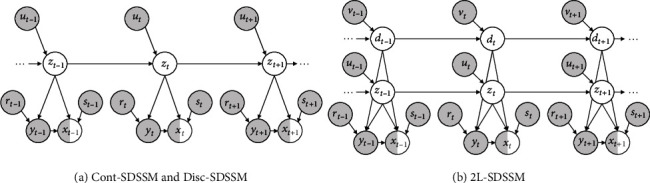
Graphical representations of proposed models.
Regarding these two states as single-type states with continuous variation, we set a normal distribution to the latent variables zt according to the previous studies of deep generative models, where a normal distribution was adopted for continuous values. The observed variables xt indicate the sugar content and are assumed to follow a normal distribution considering the continuous variation of sugar content. Moreover, we introduce the action variables ut, rt, and st to the system model and observation model, respectively.
The action variable ut is added to the process of the state transition considering that plant states vary according not only to previous states but also with external factors such as temperature. In fact, the accumulated temperature is well-known in the agricultural domain as the growth indicator for plants. The action variable st is added to the process of the emission because sugar is produced via photosynthesis based on a plant's state and its surrounding environmental variables such as carbon dioxide (CO2) concentration. The detailed settings of each random variable are discussed in Section 2.2.2.
Training the generative model based on Equations (1) and (2) using SGVB requires a large amount of data owing to the assumption of the complex generative process: there are implicitly two types of states in the single latent space, and the state transition and emission of the observation are strongly nonlinear. Deep generative models trained by semisupervised learning have recently demonstrated significantly improved generalization capabilities in comparison to previous methods and perform very well even for very small datasets [21, 27, 28].
In particular, conditional VAE (CVAE) is a typical deep generative model trained by semisupervised learning, and the generative model and learning algorithm are based on VAE. VAE learns the parameters simultaneously with the inference of the latent states using only observations. On the other hand, CVAE introduces labels for observations as latent variables to improve the quality of prediction by exploring information in the data density. However, CVAE does not assume missing observations. To explore missing observations efficiently, we take a different approach to CVAE by applying a probabilistic model of SDSSM, as shown in Figure 1(a). Formally, we assume the following generative model:
| (3) |
where yt is an additional observed variable that follows a normal distribution and is generated from the same latent variable zt as is xt, and rt is the action variable added to the emission of the observation yt. Thus, we assume that observation yt is a generative process similar to observation xt. The difference between observations appears through the nonlinear functions having different forms and inputs. In particular, sharing latent variables allows one to infer the latent states complementarily to the other observations, even when one observation is missing. Therefore, SDSSM learns the complex latent space as efficiently as other deep generative models, even when the training dataset includes few observations. Here, the functions μz, σz, μy,σy, μx, and σx are arbitrary nonlinear functions parameterized by deep neural networks (DNNs) as follows:
| (4) |
where DNNz, DNNx, and DNNy are deep neural networks that have weight matrices wz, wx, and wy, respectively. Thus, the parameters of the generative model are θ = {wz, wx, wy}. According to Kingma and Welling [29], we assume that μz, μx, and μy denote the mean and σz, σx, and σy indicate a diagonal covariance matrix. To ensure definite positivity, the outputs from deep neural networks for the diagonal covariance matrix are taken using their logarithm.
2.1.2. Learning SDSSM Using SGVB
We maximize the marginal log-likelihood based on the labeled dataset (Dl) and the unlabeled dataset (Du) to optimize the parameters θ and φ in the generative model. The labeled dataset (Dl = {(xt1(l), yt1(l), ut1(l), st1(l), rt1(l)) ⋯ (xtm(l), ytm(l), utm(l), stm(l), rtm(l))}) does not include missing values, whereas the unlabeled dataset (Du = {(yt1(u), ut1(u), st1(u), rt1(u)) ⋯ (ytn(u), utn(u), stn(u), rtn(u))}) includes missing values of observations xt. Note that the labeled data is xt. Here, the superscript l represents labeled and the superscript u represents unlabeled. We treat xt in the labeled dataset as observed variables and xt in the unlabeled dataset as latent variables. In the following, we omit the dependence of p and q on ut, vt, st, and rt. The marginal log-likelihood on the labeled dataset is as follows:
| (5) |
Note that we describe x1, x2, ⋯, xT at each time step t (t = 1, 2,…, T) as x1:T. Following the principle of SGVB, we maximize the evidence lower bound (ELBO) with respect to parameters θ and φ instead of maximizing the marginal log-likelihood directly. We derive a labeled ELBO ℒl(x, y; θ, φ) by introducing the recognition model into Equation (14) and using Jensen's inequality:
| (6) |
where qφ is the posterior approximation of latent variable zt, called the recognition model. In general, SGVB approximates the true posterior without factorization. There is an assumption that the true posterior distribution is factorized to a simpler form using a mean-field approximation in the framework of variational inference. Relaxing the constraint contributes to the improvement of the representation capability.In the case of sequential data, the Kullback–Leibler (KL) divergence terms in ELBO often have no analytic form. The gradients of the KL terms are derived by sampling estimation so that insufficient sampling leads to high-variance estimations [26]. Fraccaro et al. [30] derived low-variance estimators of the gradients using true factorization of the posterior distribution according to the Markov property. On the basis of their work, we factorize the recognition model as follows:
| (7) |
We set the initial latent state to zero:z0 = 0. The studies mentioned above derived a similar form, such that a latent state at time step t is conditioned by previous latent states and by the sequential observations and action variables from time step t to T. In our case, the form (including the future sequence of observations xt) cannot be calculated owing to the assumption that the observations are missing. However, Krishnan et al. [26] demonstrated that the sequence from the initial time step 0 to time step t contains sufficient information. Drawing on their work, we factorize the recognition model as follows:
| (8) |
Based on the decomposed recognition models, the labeled ELBO ℒl(x, y; θ, φ) is defined as follows:
| (9) |
where qφ(zt) = qφ(zt | zt−1, xt, yt). The expectations with respect to qφ(zt) and qφ(zt−1) in Equation (9) are estimated via Monte Carlo sampling after applying the reparameterization trick. KL denotes a Kullback–Leibler divergence. All KL terms in Equation (9) can be computed analytically. Additionally, we add the weight coefficient β for the KL divergence and gradually increase it from a small number during training to facilitate flexible modeling by the explicit avoidance of restrictions.In the unlabeled dataset, we are interested in the marginal log-likelihood logpθ(y1:T), which is derived by marginalizing out not only zt but also xt. We obtain an unlabeled ELBO from the marginal log-likelihood in the same way as we obtained the labeled ELBO. The unlabeled ELBO is decomposed as follows by applying d-separation to the graphical model:
| (10) |
Unlike the labeled dataset, an unlabeled ELBO has two recognition models, qφ(z1:T | x1:T, y1:T) and qφ(x1:T | y1:T), because the two latent variables, zt and xt, are included. The former has the same form as the recognition model of the labeled ELBO. On the other hand, the latter is factorized as follows, following a similar approach to the labeled dataset:
| (11) |
Using this decomposed recognition model, an unlabeled ELBO is eventually defined as
| (12) |
where H[qφ(xt | yt)] denotes the entropy of the recognition model qφ(xt | yt). The unlabeled ELBO ℒu(x, y; θ, φ) includes the labeled ELBO ℒl(x, y; θ, φ), and all probability models except for the recognition model qφ(xt | yt) are shared by the labeled ELBO and unlabeled ELBO. An expectation in the unlabeled ELBO is estimated via Monte Carlo sampling from the recognition model qφ(xt | yt). We derive an objective function by summing the labeled and unlabeled ELBOs as follows:
| (13) |
where α denotes a small positive constant. Because the recognition model qφ(xt | yt) has only an unlabeled ELBO, it does not acquire label information during training. In accordance with Krishnan et al. [26], we add a regression term to the objective function to train the recognition model using both the labeled dataset and the unlabeled dataset. The objective function is differentiable owing to the differentiable labeled and unlabeled ELBOs, and the parameters θ and φ are optimized simultaneously by stochastic gradient descent via back-propagation.
2.1.3. Extension of SDSSM
We propose two additional types of extensions to SDSSM depending on some assumptions of the latent space. We call the SDSSM described above a continuous SDSSM (Cont-SDSSM) to distinguish it from the other two models. There are two main plant states that are strongly related to sugar content.
The first is the growth stage [31]. The products of photosynthesis, such as organic acid and sugar content, are accumulated in the fruit, and the ratio of accumulated components varies depending on the growth stage with the transition in metabolism. Therefore, the growth stage is considered essential for plant growth modeling. Second, the sugar content also varies depending on the water content in the plant because insufficient water content often suppresses photosynthesis. Regarding these complicated state transitions with continuous variation, Cont-SDSSM uses single latent variables that follow a normal distribution. We have to consider the appropriate distribution to model the complex transitions and highly structured generative processes based on a plant's growth and surrounding environmental data.
As another approach for modeling the plant states, we design a simpler model called discrete SDSSM (Disc-SDSSM), which represents only the growth stage without considering the water content. In Disc-SDSSM, the forms of generative model, recognition model, and objective function are the same as those in Cont-SDSSM. The major difference is that the latent states follow a categorical distribution because the growth stage is defined as the plant growth class before the harvest, e.g., the flowering stage and ripening stage, which implies discrete growth. We use a Gumbel-Softmax distribution as the posterior of the latent states zt (instead of a normal distribution) to obtain differentiable categorical samples via the categorical reparameterization trick [32]. Formally, the generative model is defined as follows:
| (14) |
where πz is an arbitrary nonlinear function parameterized by deep neural networks as follows: πz = NNz(zt−1, ut).As a different approach to representing plant states, we design a generative model called two latent SDSSM (2L-SDSSM), as shown in Figure 1(b). 2L-SDSSM uses two types of latent variables, zt and dt, to clearly separate the two plant states. The generative model is defined as follows:
| (15) |
where zt denotes the water content in the plants, dt denotes the growth stage, and vt is an action variable playing the same role as the action variable ut in Cont-SDSSM. The random variables zt and dt are mutually independent latent variables that follow a normal distribution and category distribution, respectively. We sample random latent variables dt from a Gumbel-Softmax distribution via the categorical reparameterization trick, which is similar to our handling of Disc-SDSSM. The labeled and unlabeled ELBOs have different forms owing to differences in the generative model as follows:
| (16) |
where qφ(zt) = qφ(zt | zt−1, xt, yt), qφ(dt) = qφ(dt | dt−1, xt, yt), and qφ(xt) = qφ(xt | yt).
2.2. Experiments
2.2.1. Experimental Dataset
We grew tomato plants (Solanum lycopersicum L.) in a greenhouse at the Shizuoka Prefectural Research Institute of Agriculture and Forestry in Japan from August 28 to November 18, 2017. There were 16 cultivation beds in the greenhouse, as shown in Figure 2(c), and we cultivated 24 individual tomato plants in each cultivation bed, as shown in Figure 2(a). The tomatoes were grown by three-step dense-planting hydroponic cultivation. Under the three-step dense-planting hydroponic cultivation (Figure 2(b)), the quantity and timing of irrigation greatly affects the quality (sugar content) of tomatoes.
Figure 2.
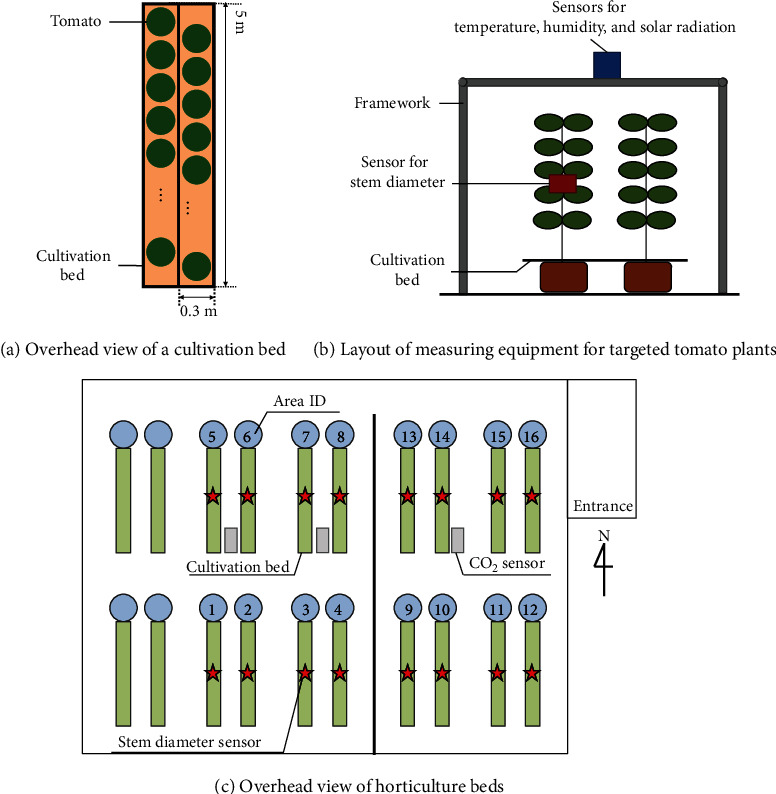
Experimental environment.
To collect data, we installed sensors in the greenhouse to measure the temperature, humidity, solar radiation, CO2 concentration, and stem diameter. The stem diameter was measured by laser displacement sensors (HL-T1010A, Panasonic Corporation) of the target tomato plants. The stem diameter decreases with exposure to high solar radiation in the daytime and increases with decreased exposure to solar radiation in the evening. In addition, the maximum daily stem-shrinkage of the stem diameter is susceptible to a vapor-pressure deficit [33]. All sensor data were collected every minute, and the daily averaged values were used for the model inputs. In addition, we measured the sugar content of the fruits of the target tomato plants on which the stem diameter sensors were installed. The sugar content was measured every three days by a hand-type near-infrared spectrometer (CD-H100, Chiyoda Corporation), and the measurements were conducted in each step of the three-step dense-planting hydroponic cultivation. We used the average sugar content value of 10 time measurements for each fruit in which stem diameter sensors were installed.
2.2.2. SDSSM Variable Settings
The three models (Cont-SDSSM, Disc-SDSSM, and 2L-SDSSM) used for the estimation of sugar content are analyzed through comparative evaluations. This is to reveal the performance of the proposed SDSSM. The variables for the proposed models are listed in Table 1. In this paper, each variable of the proposed three models is set as listed in Table 1; xt is sugar content, yt is stem diameter; vector ut is temperature, solar radiation, vapor-pressure deficit (VPD), the elapsed date from flowering, and accumulated temperature (which is the total temperature from the flowering date to the present); and vector st is the CO2 concentration, solar radiation, and step ID of three-step dense-planting hydroponic cultivation to indicate to which step of the tomato the data belong. The action variables rt are not used in any models in this experiment. The settings of each variable in Disc-SDSSM are similar to those of Cont-SDSSM. The difference is that vt includes the elapsed date from flowering and the accumulated temperature. 2L-SDSSM has similar settings to Cont-SDSSM, and the differences are that ut includes temperature, solar radiation, and VPD, while vt includes the elapsed date from flowering and the accumulated temperature.
Table 1.
Variables in the proposed models.
| Variable | Cont-SDSSM | Disc-SDSSM | 2L-SDSSM |
|---|---|---|---|
| x t | Sugar content | Sugar content | Sugar content |
| y t | Stem diameter | Stem diameter | Stem diameter |
| u t | Temperature, solar radiation, VPD, elapsed date1, accumulated temperature2 | Elapsed date1, accumulated temperature2 | Temperature, solar radiation, VPD |
| v t | — | — | Elapsed date1, accumulated temperature2 |
| s t | CO2 concentration, solar radiation, step ID | CO2 concentration, solar radiation, step ID | CO2 concentration, solar radiation, step ID |
1Number of days after flowering. 2Summation of daily temperatures from the flowering date to the present.
An overview of the information flow at time step t in the graphical model (Figure 1) of the proposed method is shown in Figure 3 by using probability distributions. In addition, Figure 4 shows the inputs and outputs of each probability distribution for the neural network architectures. Cont-SDSSM and Disc-SDSSM include five types of neural networks corresponding to five types of probability distributions: pθ(xt), pθ(yt), pθ(zt), qφ(xt), and qφ(zt). 2L-SDSSM has seven types of neural networks corresponding to its seven types of probability distributions: pθ(xt), pθ(yt), pθ(zt), pθ(dt), qφ(xt), qφ(zt), and qφ(dt).
Figure 3.
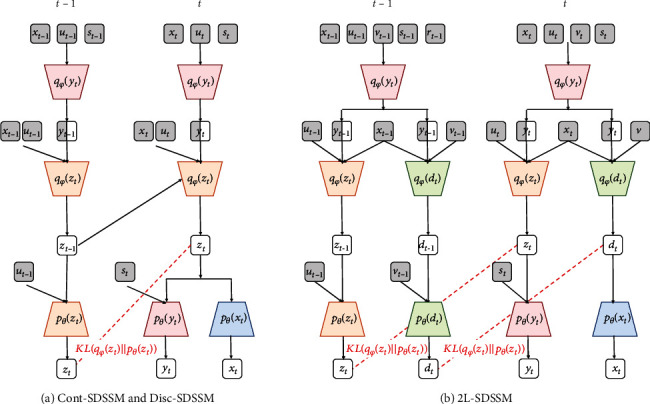
Overview of information flow at time step t of the proposed models.
Figure 4.
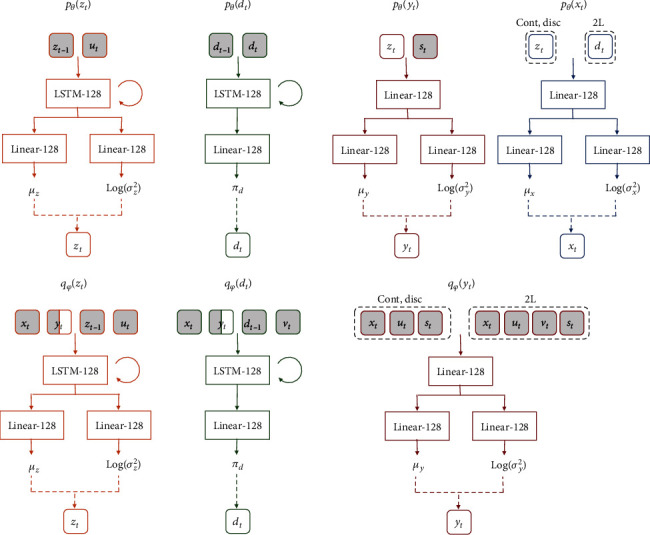
Network architectures showing each neural network in the proposed models.
These seven types of neural networks have the same basic architecture: a hidden layer converts the input nonlinearly, and then the outputs are converted to a mean vector and diagonal covariance log-parameterization matrix through a single separate hidden layer. The neural networks have hidden layers structured as follows: fully connected layers, rectified linear unit (ReLU) layers [34], and batch normalization layers [35]. The neural networks that emit latent states zt or dt use a long short-term memory (LSTM) [36, 37] as the first hidden layer instead of a fully connected layer. In this case, LSTM has a forget gate, input gate, and output gate, which makes it possible to consider long-term time series. Therefore, LSTM is used as the first hidden layer. All hidden layers have 128 units, and all weights are initialized using He et al.'s initialization [38] to accelerate convergence. All random variables of Cont-SDSSM follow a normal distribution. On the other hand, the random latent variabledtis categorically distributed. This is because categorical distribution has only one parameter, π; Disc-SDSSM and 2L-SDSSM have two consistent hidden layers without the branch structure used for Cont-SDSSM.
2.2.3. Experimental Conditions
We verified the performance of the proposed methods through two types of evaluations. In the first evaluation, we compared semisupervised SDSSMs to supervised SDSSMs trained using only labeled data via supervised learning to verify the effectiveness of our semisupervised learning approach. In this experiment, the supervised Cont-SDSSM, Disc-SDSSM, and 2L-SDSSM are called Cont-SV (SV denotes supervised), Disc-SV, and 2L-SV, respectively. In addition, the semisupervised Cont-SDSSM, Disc-SDSSM, and 2L-SDSSM are called Cont-SSV (SSV denotes semisupervised), Disc-SSV, and 2L-SSV, respectively.
In the second evaluation, we compared semisupervised SDSSMs with typical deep neural networks, the multilayer perceptron (MLP) and stacked LSTM (sLSTM). This is to investigate the performance of the proposed models for the optimal estimation of sugar content. We expected that the proposed models fit all of the observed data rather than local data because the KL terms in ELBO perform a regularization function. On the other hand, both MLP and sLSTM which were trained on a small dataset can easily result in overfitting. Therefore, we applied dropout [39] to each layer in the MLP and sLSTM to reduce overfitting.
We trained each model using the collected tomato dataset. We divided the dataset into training data, validation data, and test data to train and evaluate the models appropriately. In addition, to validating the robustness of the proposed methods, cross-validation was conducted using data sets of 16 cultivation beds divided into four patterns, as shown in Table 2. The hyperparameters were tuned by using random sampling. The hyperparameter such as learning rate, optimization algorithms, dimension size of latent variables for SDSSMs, sequence length, and dropout rate were the same for all the compared models.
Table 2.
Data used for cross-validation.
| Dataset pattern | Training (data size (labeled size) (cultivation bed no.)) | Validation (data size (labeled size) (cultivation bed no.)) | Test (data size (labeled size) (cultivation bed no.)) |
|---|---|---|---|
| A | 2,241 (382) (3, 4, 5, 6, 7, 11, 13, 14, 15) | 747 (123) (8, 12, 16) | 996 (167) (1, 2, 9, 10) |
| B | 2,241 (345) (1, 5, 7, 8, 9, 13, 14, 15, 16) | 747 (131) (2, 6, 10) | 996 (154) (3, 4, 11, 12) |
| C | 2,241 (361) (1, 2, 3, 4, 7, 9, 10, 11, 15) | 747 (123) (8, 12, 16) | 996 (189) (5, 6, 13, 14) |
| D | 2,241 (381) (1, 3, 4, 5, 9, 11, 12, 13, 14) | 747 (131) (2, 6, 10) | 996 (161) (7, 8, 15, 16) |
When training SDSSMs, we gradually increased the weight coefficient for the KL terms in ELBO by 0.0001 after each epoch (starting from 0 to 1). The mean absolute error (MAE), root mean squared error (RMSE), relative absolute error (RAE), and relative squared error (RSE) were used as the error indicators. In this study, all the models were tuned using the validation data, and the models which showed the lowest MAE were selected as the best models with the most optimal hyperparameters. In this experiment, we implemented all source codes using Python. We used Chainer [40] to implement a deep neural network architecture and scikit-learn [41] to preprocess the dataset. This evaluation was performed on a PC with an Intel Core i7-5820K Processor, GeForce GTX 1080, and 64 GB of memory. The training process time depends largely on the values of the hyperparameters, the tuning method, and the number of epochs. For example, when we used the training data for pattern C in Table 2, which had the largest number of test labeled contents for training, it took approximately 4.6 s to complete 1 epoch, so it took approximately 1 h to create one model converge. Regarding the inference time, it took approximately 5.33 s to infer the test data in 2L-SDSSM when it was repeatedly measured 100 times using the same test data (pattern C in Table 2).
3. Results and Discussion
Figure 5 shows the average errors of each supervised SDSSM (Cont-SV, Disc-SV, and 2L-SV), the semisupervised SDSSMs (Cont-SSV, Disc-SSV, and 2L-SSV), MLP, and sLSTM for the four types of test data. The results demonstrate that all semisupervised SDSSMs reduced the estimation errors for all error indicators. In particular, the MAE of Cont-SV is 1.25, whereas that of Cont-SSV is 0.78; the MAE reduction rate of Cont-SSV versus Cont-SV is approximately 38%. Similarly, the MAE reduction rates of the semisupervised SDSSMs versus the supervised SDSSMs are approximately 30% for Disc-SSV and 9% for 2L-SSV. Moreover, both the RAE and RSE of all semisupervised SDSSMs are less than 1. Therefore, all semisupervised SDSSMs perform better than the naive models which output the average of the true values as the estimation values. The MAEs of typical deep neural networks, such as MLP and LSTM, are larger than those of Cont-SSV and less than those of Disc-SSV and 2L-SSV. Although the error indicators of MLP and sLSTM appear to better than other models, further analysis is needed.
Figure 5.
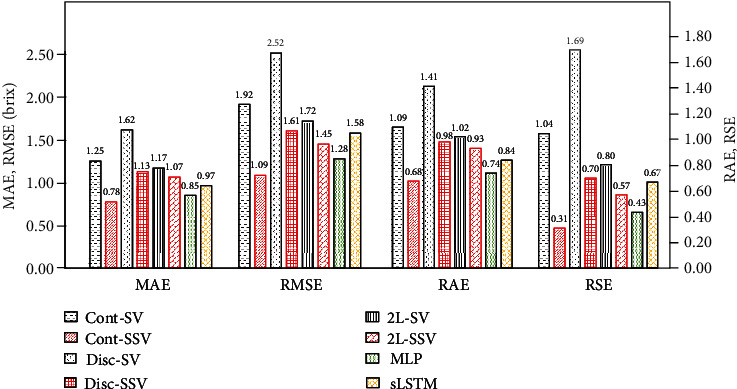
Error indicators of Cont-SV, Cont-SSV, Disc-SV, Disc-SSV, 2L-SV, 2L-SSV, MLP, and sLSTM.
Figure 6 shows the true values, estimated values, and standard deviations of estimated values of time-series sugar content in the area 10 output by supervised SDSSMs, semisupervised SDSSMs, MLP, and sLSTM trained on dataset pattern A. The standard deviations of Cont-SDSSM and 2L-SDSSM are so low that they are not clearly visible. The results show that our semisupervised approach (Cont-SSV, Disc-SSV, and 2L-SSV) estimates the sugar contents better because of the improved generalization performance. Although there are few sugar content data before October (the other dataset patterns show a similar tendency because we collected sugar content data in the same manner over the entire area), the semisupervised SDSSMs clearly identify the variation patterns in other periods with their effective use of unlabeled data. From middle October to late October in Figure 6, although each supervised SDSSM (Cont-SV, Disc-SV, and 2L-SV) appears to be able to estimate better compared to the semisupervised SDSSMs, each supervised SDSSM's RMSE in Figure 5 is higher than that of each semisupervised SDSSM.
Figure 6.
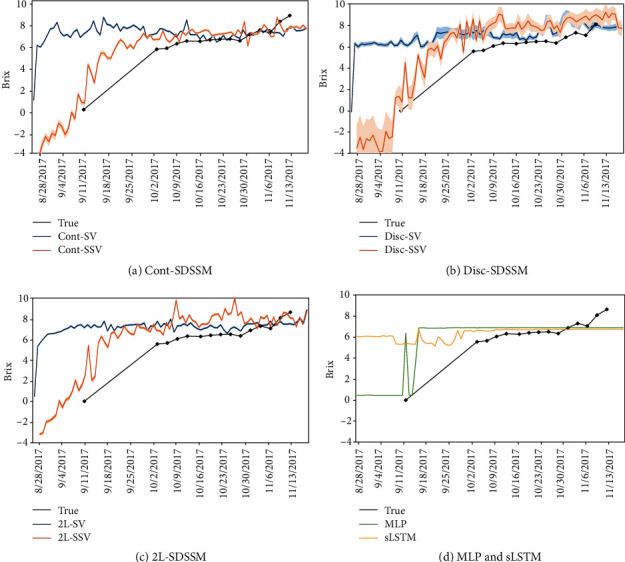
True and estimated values of the sugar content (brix) with the standard deviations for supervised SDSSMs, semisupervised SDSSMs, MLP, and sLSTM.
SDSSMs also output the variance and the estimation values. The averages of the standard deviations of the estimated values for all test plots in Table 2 are approximately 0.076 for Cont-SV, 0.28 for Disc-SV, 0.082 for 2L-SV, 0.17 for Cont-SSV, 1.04 for Disc-SSV, and 0.12 for 2L-SSV. In particular, the standard deviation of Disc-SSV is larger than those of the others, as clearly shown in Figure 6. A large standard deviation indicates output instability in the estimation for sugar content. The instability, however, is not a significant problem in a model for model-based RL when the standard deviation and estimation error are positively correlated. This is because the agent of the model-based RL explores an environmental model while considering the uncertainty of the estimation based on the standard deviation of the estimation value. Therefore, estimating the uncertainty correctly allows the agent to learn efficiently. MLP and LSTM look like they produce the same tendency as the supervised SDSSMS, and the estimated values in the period during October are relatively close to the true values, resulting in small errors, as shown in Figure 6(d). Considering only the numerical values, the MLP and LSTM look like they produce higher estimates than the supervised SDSSMs. However, as can be seen from Figure 6(d), the MLP and LSTM are overfitted to a particular dataset in the period after October even though dropout was applied in both cases, and the generalization performance is low.
Figure 7 shows scatter plots of the standard deviations and the absolute errors for the compared models with the test dataset of pattern A in Table 1. Our proposed method is based on a generative model, which outputs both estimation values and standard deviations. Therefore, our proposed methods can evaluate the uncertainty of estimates by using the standard deviation. These results indicate that Cont-SSV and Disc-SSV significantly improve the correlation coefficient compared to supervised SDSSMs such as Cont-SV and Disc-SV. The correlation coefficient of 2L-SSV is still negative and is likely to cause incorrect exploration, although 2L-SSV slightly improves the correlation coefficient compared to 2L-SV. Conceivably, the significantly high correlation of 0.47 for Disc-SSV demonstrates that its standard deviations can assist agents to better seek an appropriate model and promote learning of the optimal control to achieve high sugar content.
Figure 7.
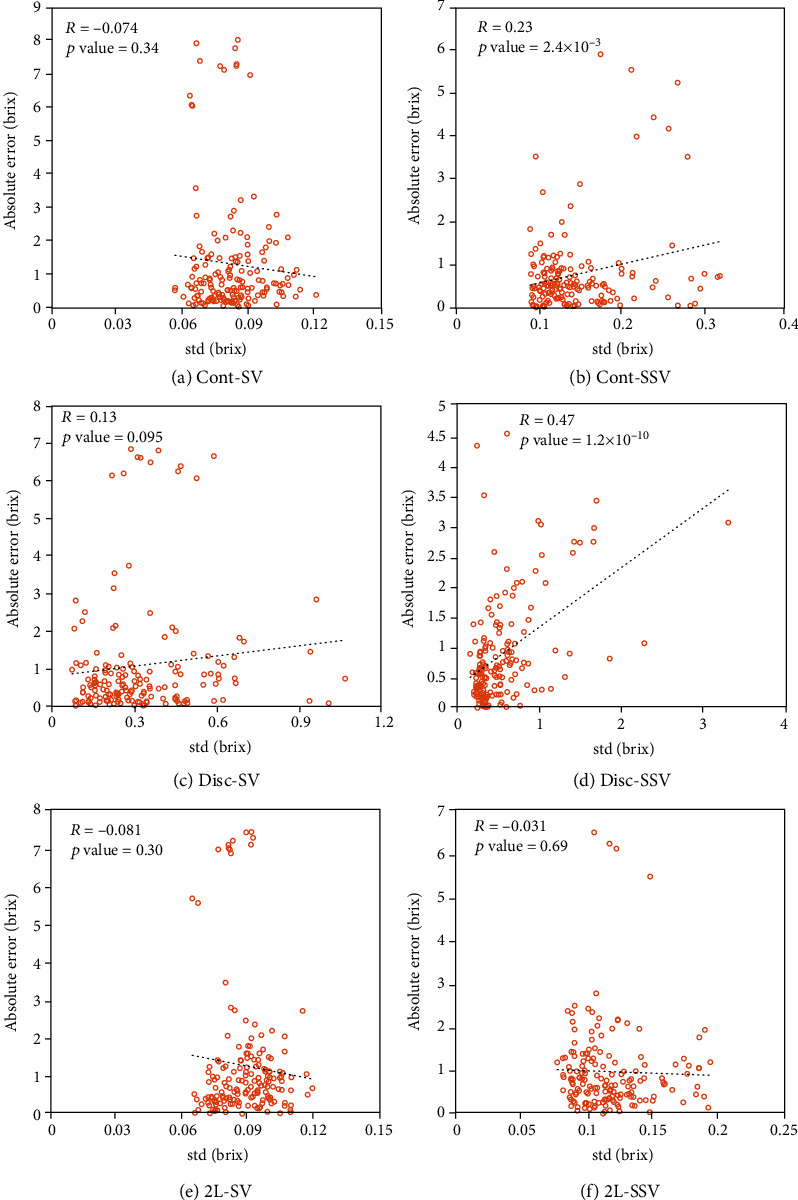
Scatter plots of standard deviations and absolute errors of supervised SDSSMs and semisupervised SDSSMs.
Figure 8 shows the principal component and stem diameter or the difference in stem diameter (DSD) in the model learned using the dataset of pattern A in Table 1 as a scatter diagram on the x-axis and y-axis, respectively. The DSD is one of the water stress indicators and is expressed as the difference between the maximum stem diameter (SD) observed thus far and the current stem diameter (SDi) as follows: DSDi = max(SD0, ⋯, SDi) − SDi. The maximum value continuously updates with plant growth. By calculating the decrease from the maximum stem diameter, the variation due to plant growth is ignored, and only the amount of water stress can be quantified from the stem diameter. This figure demonstrates that each principal component of the semisupervised Cont-SSV has a higher correlation with the stem diameter and DSD compared with Cont-SV. In particular, in Cont-SSV, the stem diameter has a significantly high correlation of approximately -0.9 with the first component, as shown in Figure 8(b), and DSD has a significantly high correlation of approximately 0.52 with the second component, as shown in Figure 8(h). This result suggests that Cont-SSV represents both plant growth and plant water content in the latent space owing to the reasonable inference achieved by using two observation variables sharing latent variables in our semisupervised learning model.
Figure 8.
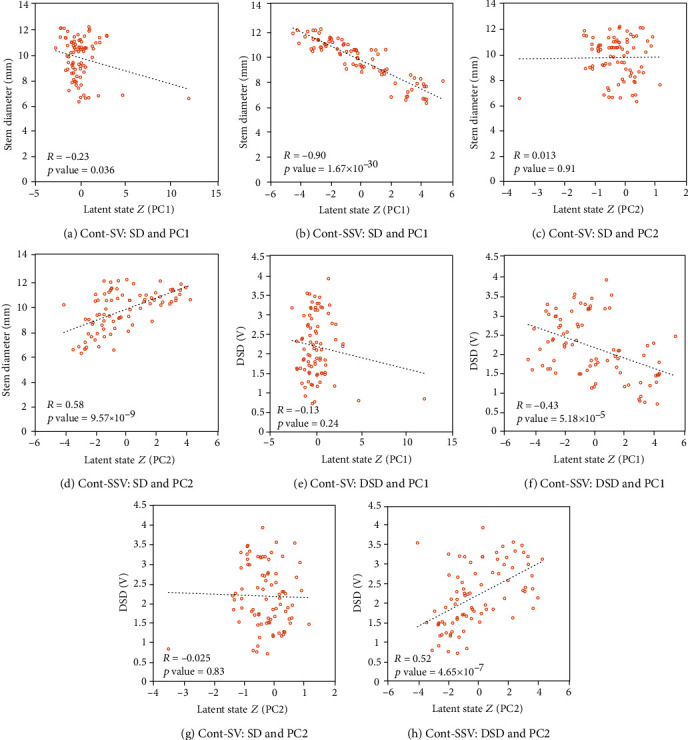
Scatter plots showing principal components and stem diameter or DSD.
Additionally, the latent space is represented as a linear combination of these two plant states. This result confirms the assumption that the two types of latent variables are independent of each other. Cont-SSV and Disc-SSV have different natures, and Cont-SSV has better estimation accuracy, but Disc-SSV estimates the uncertainty better.
The results indicate that our three types of proposed models (Cont-SSV, Disc-SSV, and 2L-SSV) work better than the same models with supervised learning and other typical deep neural networks. In particular, Cont-SSV has good potential to estimate sugar content with high accuracy and valid uncertainty. Considering the appropriate representation of the latent states, it is believed that Cont-SSV will perform well as an environmental model of model-based RL for the optimal control of sugar content.
4. Conclusion
We have proposed a novel plant growth model using a semisupervised deep state-space model (SDSSM) for model-based reinforcement learning to determine the optimal control of sugar content. There have been several studies on tomato growth modeling [42, 43], but we could not find any similar study for modeling time-series tomato sugar content. SDSSM is a sequential deep generative model that uses structured variational inference to model the slow dynamics of living organisms (such as plant growth). In particular, SDSSM was trained using our semisupervised learning method that complementarily infers the latent states by introducing two observation variables to efficiently utilize sugar content data which is difficult to collect.
Additionally, we designed three types of SDSSMs under different assumptions regarding each latent space. The experimental results demonstrated that the introduction of two observation variables sharing latent variables improved the generalization performance and enabled all SDSSMs to track the variation of sugar content appropriately. Moreover, tomatoes grown during the experiment had a maximum brix rating of 10.73 and minimum brix rating of 4.67. The average brix rating was 6.81. The highest accuracy model is 0.78 in MAE; thus, our model has a potential to estimate time-series sugar content variation with high accuracy.
We have designed a combined model (2L-SDSSM); however, the combined model was not the highest accuracy model. Therefore, we still need to consider other ways to combine the two models more appropriately, i.e., assuming the independence of two latent states. In a future study, we intend to improve the 2L-SDSSM which is the combination of two different latent variables. Furthermore, we will improve time-series data (sensor data of the temperature, humidity, solar radiation, CO2 concentration, stem diameter, and plant growth) in a greenhouse different from that used in this study. We will continue to verify the performance of our model by comparing our model with typical machine learning and typical deep neural networks.
Acknowledgments
This work was supported by JST PRESTO Grant Number JPMJPR15O5, Japan. Additionally, we greatly appreciate the support of Mr. Maejima and Mr. Imahara who provided the data collection location, Shizuoka Prefectural Research Institute of Agriculture and Forestry.
Appendix
A. Plant Growth Model Design
A.1 State-Space Model
The state-space model (SSM) is a generative model that represents time series based on two types of models: one is the system model and the other is the observation model. SSM models a sequence of observed variables x1, x2, ⋯, xT and a corresponding sequence of latent variables z1, z2, ⋯, zT at each time step t (t = 1, 2, ⋯, T). The probabilistic model is shown in Figure 9(a), and a general expression of the model is
| (A.1) |
where the system model is the conditional probability distribution of the latent state zt conditioned on the previous latent state zt−1 and the observation model is the conditional probability distribution of xt conditioned on the corresponding latent state zt at time step t. The variables θ and φ denote the parameter vectors of the system model and the observation model, respectively. The system model is initialized by z0 = p(z0). We use available arbitrary probability distributions in both the system model and the observation model. Some SSMs with specific distributions and constraints have unique names. For example, one of the simplest models, called a linear Gaussian model (LGM) [44], can be written mathematically as
| (A.2) |
where vector ϵt and vector ωt are random variables representing the state and observation noises, respectively. In addition, xt and zt are vectors. Both of these noises are independent of each other, the corresponding latent state zt, and the conditional probability distribution of xt. Both of these noise sources are a Gaussian distribution with zero covariance matrix representing the mean Q and R, each independent of the time step. At and Bt denote coefficient matrices. LGMs can fit with time-series data and are utilized for many applications whose observations and latent states have a linear transition and a normal distribution, respectively.
Figure 9.
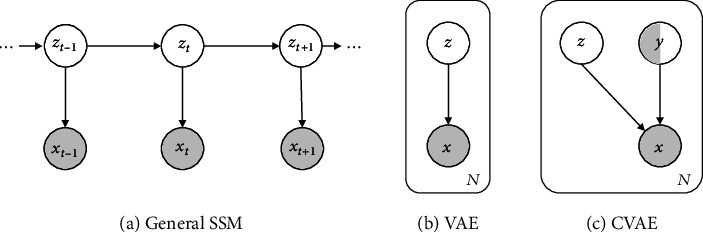
Graphical models of SSM, VAE, and CVAE.
Additionally, there are methods available to model time-series data with nonlinear transitions, e.g., the extended Kalman filter [45] and the quadrature particle filter [46]. Raiko et al. [47] and Valpola and Karhunen [22] attempted to estimate an intractable posterior of the complex generative model using nonlinear dynamic factor analysis, which is impractical for large-scale datasets owing to the inherent quadratic scale regarding observed dimensions. Recently, Kingma and Welling [29] introduced stochastic gradient variational Bayes (SGVB) and a learning algorithm named a variational autoencoder (VAE) to obtain a tractable posterior.
A.2 Variational Autoencoder
The variational autoencoder (VAE) [22] is a deep generative model for nonsequential data. The parameters are optimized via SGVB [23], and the probabilistic model is shown in Figure 9(b). In particular, conditional VAE (CVAE), as shown in Figure 9(c), is a typical deep generative model trained by semisupervised learning [21]. The N in the plate (the part surrounded by the frame) shown in Figure 9 means thatNnodes are omitted and only the representative nodes are shown in Figures 9(b) and 9(c). The details will be discussed later in this section. In the VAE, the generative process can be written mathematically as
| (A.3) |
The latent variable z is obtained from a prior p(z). The observed variable x is drawn from a probability distribution pθ(x | z) conditioned on z with the parameter vector θ, and the posterior pθ(z | x) is assumed to be intractable. The parameter is estimated simultaneously with the latent states through maximization of the following marginal log-likelihood:
| (A.4) |
When the posterior is intractable, the standard expectation-maximization (EM) algorithm and variational inference do not work well because the EM algorithm needs to compute the posterior and variational inference requires closed-form solutions of the expectations of the joint probability density function. Additionally, sampling-based EM algorithms require sufficient time to obtain the posterior when the data size is large. In SGVB, the approximate posterior qφ(z | x) with parameter φ is introduced, and we consider the following evidence lower bound (ELBO) ℒ(x; θ, φ) as would be the case for the variational inference. ELBO is an objective function used to optimize the parameters θ and φ.
| (A.5) |
KL denotes a Kullback–Leibler divergence. In addition, parameter φ denotes the parameter of qφ(z | x) that approximates pθ(x). In fact, in the VAE, φ represents the neural network's weights and bias, and these parameters are optimized via back-propagation. The difference in variational inference is the use of differentiable Monte Carlo expectations instead of applying the mean-field assumption. Formally, the reformulation of the ELBO is as follows:
| (A.6) |
where z is sampled via a reparameterization trick (z(l) = μ + σε(l) and ϵ(l) ~ N(0, I)) to acquire a differentiable ELBO instead of sampling from the posterior qφ(z | x) (which is not differentiable with respect to φ). Specifically, the reparameterization trick represents a sampling z ~ qφ(z | x) as a deterministic transformation gφ(ϵ, x) by adding a random noise ϵ ~ p(ϵ) to input x. By using the reparameterization trick, the expectation term can be written mathematically as Eqφ(z | x)[f(z)]≅1/L∑l=1Lf(gφ(ϵ(l), x)) where f(z) = logpθ(x | z) and ϵ(l) ~ p(ϵ). This expectation is differentiable with respect to θ and φ. For example, when a latent variable z is distributed according to a Gaussian distribution N(z | μ, σ2), the ELBO is as follows:
| (A.7) |
The likelihood pθ(x | z) and posterior qφ(z | x) are represented by neural networks, and the parameters are optimized via back-propagation.
Conflicts of Interest
The authors declare that there is no conflict of interest regarding the publication of this article.
Authors' Contributions
S. Shibata conceived the idea. S. Shibata and R. Mizuno designed the experimental procedures in detail, evaluated the idea, and preformed data analysis. S. Shibata, R. Mizuno, and H. Mineno provided important help during the experimental section and writing of this paper. H. Mineno directed the research. All of the authors participated in the preparation of the manuscript.
References
- 1.Wang X., Meng Z., Chang X., Deng Z., Li Y., Lv M. Determination of a suitable indicator of tomato water content based on stem diameter variation. Scientia Horticulturae. 2017;215:142–148. doi: 10.1016/j.scienta.2016.11.053. [DOI] [Google Scholar]
- 2.Sano M., Nakagawa Y., Sugimoto T., et al. Estimation of water stress of plant by vibration measurement of leaf using acoustic radiation force. Acoustical Science and Technology. 2015;36(3):248–253. doi: 10.1250/ast.36.248. [DOI] [Google Scholar]
- 3.Sánchez-Molina J. A., Rodríguez F., Guzmán J. L., Ramírez-Arias J. A. Water content virtual sensor for tomatoes in coconut coir substrate for irrigation control design. Agricultural Water Management. 2015;151:114–125. doi: 10.1016/j.agwat.2014.09.013. [DOI] [Google Scholar]
- 4.Prasad R., Ranjan K. R., Sinha A. K. AMRAPALIKA: an expert system for the diagnosis of pests, diseases, and disorders in Indian mango. Knowledge-Based Systems. 2006;19(1):9–21. doi: 10.1016/j.knosys.2005.08.001. [DOI] [Google Scholar]
- 5.Richards L. A., Gardner W. Tensiometers for measuring the capillary tension of soil water. Journal of the American Society of Agronomy. 1936;28(1):352–358. doi: 10.2134/agronj1936.00021962002800050002x. [DOI] [Google Scholar]
- 6.Topp G. C., Davis J. L., Annan A. P. Electromagnetic determination of soil water content: measurements in coaxial transmission lines. Water Resources Research. 1980;16(3):574–582. doi: 10.1029/WR016i003p00574. [DOI] [Google Scholar]
- 7.Patanè C., Cosentino S. L. Effects of soil water deficit on yield and quality of processing tomato under a Mediterranean climate. Agricultural Water Management. 2010;97(1):131–138. doi: 10.1016/j.agwat.2009.08.021. [DOI] [Google Scholar]
- 8.Othman M. F., Shazali K. Wireless sensor network applications: a study in environment monitoring system. Procedia Engineering. 2012;41:1204–1210. doi: 10.1016/j.proeng.2012.07.302. [DOI] [Google Scholar]
- 9.Park D. H., Park J. W. Wireless sensor network-based greenhouse environment monitoring and automatic control system for dew condensation prevention. Sensors. 2011;11(4):3640–3651. doi: 10.3390/s110403640. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Ibayashi H., Kaneda Y., Imahara J., Oishi N., Kuroda M., Mineno H. A reliable wireless control system for tomato hydroponics. Sensors. 2016;16(5):p. 644. doi: 10.3390/s16050644. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Shibata S., Kaneda Y., Mineno H. Motion-specialized deep convolutional descriptor for plant water stress estimation. In: Boracchi G., Iliadis L., Jayne C., Likas A., editors. Engineering Applications of Neural Networks. Vol. 744. Cham: Springer; 2017. pp. 3–14. (EANN 2017. Communications in Computer and Information Science). [DOI] [Google Scholar]
- 12.Kaneda Y., Shibata S., Mineno H. Multi-modal sliding window-based support vector regression for predicting plant water stress. Knowledge-Based Systems. 2017;134:135–148. doi: 10.1016/j.knosys.2017.07.028. [DOI] [Google Scholar]
- 13.Hernández-del-Olmo F., Gaudioso E., Dormido R., Duro N. Tackling the start-up of a reinforcement learning agent for the control of wastewater treatment plants. Knowledge-Based Systems. 2017;144:9–15. doi: 10.1016/j.knosys.2017.12.019. [DOI] [Google Scholar]
- 14.Deisenroth M. P., Neumann G., Peters J. A survey on policy search for robotics. Foundations and Trends in Robotics. 2013;2(1-2):1–142. doi: 10.1561/2300000021. [DOI] [Google Scholar]
- 15.Zhang X., Yu T., Yang B., Cheng L. Accelerating bio-inspired optimizer with transfer reinforcement learning for reactive power optimization. Knowledge-Based Systems. 2017;116:26–38. doi: 10.1016/j.knosys.2016.10.024. [DOI] [Google Scholar]
- 16.Van Hasselt H., Guez A., Silver D. Deep reinforcement learning with double Q-learning. Thirtieth AAAI Conference on Artificial Intelligence; 2016; Phoenix, USA. pp. 2094–2100. [Google Scholar]
- 17.Mnih V., Badia A. P., Mirza M., et al. Asynchronous methods for deep reinforcement learning. International Conference on Machine Learning; 2016; New York City, USA. pp. 1928–1937. [Google Scholar]
- 18.Deisenroth M., Rasmussen C. E. PILCO: a model-based and data-efficient approach to policy search. Proceedings of the 28th International Con-ference on Machine Learning; 2011; Bellevue, WA, USA. pp. 465–472. [Google Scholar]
- 19.Poupart P., Vlassis N. Model-based Bayesian reinforcement learning in partially observable domains. Proceedings of the International Symposium on Artificial Intelligence and Mathematics; 2008; Fort Lauderdale, USA. pp. 1–2. [Google Scholar]
- 20.Längkvist M., Karlsson L., Loutfi A. A review of unsupervised feature learning and deep learning for time-series modeling. Pattern Recognition Letters. 2014;42:11–24. doi: 10.1016/j.patrec.2014.01.008. [DOI] [Google Scholar]
- 21.Kingma D. P., Mohamed S., Rezende D. J., Welling M. Semi-supervised learning with deep generative models. Advances in neural information processing systems; 2014; Montreal, Canada. pp. 3581–3589. [Google Scholar]
- 22.Valpola H., Karhunen J. An unsupervised ensemble learning method for nonlinear dynamic state-space models. Neural Computation. 2002;14(11):2647–2692. doi: 10.1162/089976602760408017. [DOI] [Google Scholar]
- 23.Bayer J., Osendorfer C. Learning stochastic recurrent networks. Proceedings of Workshop on Advances in Variational Inference; 2014; Montreal, Canada. [Google Scholar]
- 24.Chung J., Kastner K., Dinh L., Goel K., Courville A. C., Bengio Y. A recurrent latent variable model for sequential data. Proceedings of the Advances in Neural Information Processing Systems; 2015; Montreal, Canada. pp. 2962–2970. [Google Scholar]
- 25.Watter M., Springenberg J., Boedecker J., Riedmiller M. Embed to control: a locally linear latent dynamics model for control from raw images. Proceedings of the Advances in Neural Information Processing Systems; 2015; Montreal, Canada. pp. 2746–2754. [Google Scholar]
- 26.Krishnan R. G., Shalit U., Sontag D. Deep Kalman Filters. https://arxiv.org/abs/1511.05121.
- 27.Maaløe L., Sønderby C. K., Sønderby S. K., Winther O. Auxiliary deep generative models. https://arxiv.org/abs/1602.05473.
- 28.Salimans T., Goodfellow I., Zaremba W., Cheung V., Radford A., Chen X. Improved techniques for training gans. Proceedings of the Advances in Neural Information Processing; 2016; Barcelona Spain. pp. 2234–2242. [Google Scholar]
- 29.Kingma D. P., Welling M. Auto-encoding variational Bayes. https://arxiv.org/abs/1312.6114.
- 30.Fraccaro M., Sønderby S. K., Paquet U., Winther O. Sequential neural models with stochastic layers. Proceedings of the Advances in Neural Information Processing Systems; 2016; Barcelona Spain. pp. 2199–2207. [Google Scholar]
- 31.Meier U. Growth stages of mono-and dicotyledonous plants: BBCH-monograph. http://pub.jki.bund.de/index.php/BBCH/issue/view/161, 2001.
- 32.Jang E., Gu S., Poole B. Categorical reparameterization with gumbel-softmax. https://arxiv.org/abs/1611.01144.
- 33.Zhang D., Du Q., Zhang Z., Jiao X., Song X., Li J. Vapour pressure deficit control in relation to water transport and water productivity in greenhouse tomato production during summer. Science Reports. 2017;7(1, article 43461) doi: 10.1038/srep43461. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Nair V., Hinton G. E. Rectified linear units improve restricted Boltzmann machines. Proceedings of the 27th International Conference on Machine Learning (ICML-10); 2010; Haifa, Israel. pp. 807–814. [Google Scholar]
- 35.Ioffe S., Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. https://arxiv.org/abs/1502.03167.
- 36.Hochreiter S., Schmidhuber J. Long short-term memory. Neural Computation. 1997;9(8):1735–1780. doi: 10.1162/neco.1997.9.8.1735. [DOI] [PubMed] [Google Scholar]
- 37.Gers F. A., Schmidhuber J., Cummins F. Learning to forget: continual prediction with LSTM. Neural Computation. 1999;12(10):2451–2471. doi: 10.1162/089976600300015015. [DOI] [PubMed] [Google Scholar]
- 38.He K., Zhang X., Ren S., Sun J. Delving deep into rectifiers: surpassing human-level performance on imagenet classification. 2015 IEEE International Conference on Computer Vision (ICCV); 2015; Santiago, Chile. pp. 1026–1034. [DOI] [Google Scholar]
- 39.Srivastava N., Hinton G., Krizhevsky A., Sutskever I., Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research. 2014;15(1):1929–1958. [Google Scholar]
- 40.Tokui S., Oono K., Hido S., Clayton J. Chainer: a next-generation open source framework for deep learning. Proceedings of the Workshop on Machine Learning Systems in the Advances in Neural Information Processing Systems; 2015; Montreal, Canada. pp. 1–6. [Google Scholar]
- 41.Pedregosa F., Varoquaux G., Gramfort A., et al. Scikit-learn: machine learning in python. Journal of Machine Learning Research. 2011;12:2825–2830. [Google Scholar]
- 42.Sun L., Yang Y., Hu J., Porter D., Marek T., Hillyer C. Respiration climacteric in tomato fruits elucidated by constraint-based modeling. ISPA/IUCC. 2017;213:1726–1739. doi: 10.1111/nph.14301. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Kang M., Wang F.-Y. From parallel plants to smart plants: intelligent control and management for plant growth. IEEE/CAA Journal of Automatica Sinica. 2017;4:161–166. doi: 10.1109/jas.2017.7510487. [DOI] [Google Scholar]
- 44.Roweis S., Ghahramani Z. A unifying review of linear Gaussian models. Neural Computation. 1999;11(2):305–345. doi: 10.1162/089976699300016674. [DOI] [PubMed] [Google Scholar]
- 45.Jazwinski A. H. Stochastic Processes and Filtering Theory. Courier Corporation; 2007. [Google Scholar]
- 46.Liang-qun L., Wei-xin X., Zong-xiang L. A novel quadrature particle filtering based on fuzzy c-means clustering. Knowledge-Based Systems. 2016;106:105–115. doi: 10.1016/j.knosys.2016.05.034. [DOI] [Google Scholar]
- 47.Raiko T., Tornio M., Honkela A., Karhunen J. Independent Component Analysis and Blind Signal Separation. Vol. 3889. Berlin, Heidelberg: Springer; 2006. State inference in variational Bayesian nonlinear state-space models; pp. 222–229. (ICA 2006. Lecture Notes in Computer Science). [DOI] [Google Scholar]