

Abstract
We introduce an estimation method of covariance matrices in a high-dimensional setting, i.e., when the dimension of the matrix, p, is larger than the sample size n. Specifically, we propose an orthogonally equivariant estimator. The eigenvectors of such estimator are the same as those of the sample covariance matrix. The eigenvalue estimates are obtained from an adjusted profile likelihood function derived by approximating the integral of the density function of the sample covariance matrix over its eigenvectors, which is a challenging problem in its own right. Exact solutions to the approximate likelihood equations are obtained and employed to construct estimates that involve a tuning parameter. Bootstrap and cross-validation based algorithms are proposed to choose this tuning parameter under various loss functions. Finally, comparisons with two well-known orthogonally equivariant estimators are given, which are based on Monte-Carlo risk estimates for simulated data and misclassification errors in real data analyses.
Keywords: adjusted profile likelihood, high-dimensional inference, covariance matrix estimation, singular Wishart distribution
1. Introduction
Many multivariate methods require an estimate of the covariance matrix. In this paper, we are interested in the problem of estimating the covariance matrix of a multivariate normal distribution, , using a sample of mutually independent draws X1, …, Xn, from it, when n is less than the dimension p of Σ. This problem has received much attention in the recent past because of an increasing number of applications where measurements are collected on a large number of variables, often greater than the available experimental units. The sample covariance matrix is not a good estimator in this case. In the general framework where both p and n go to infinity in such a way that their ratio p/n converges to a positive finite constant (often referred to as the large-dimensional asymptotic regime), the sample covariance matrix, its eigenvalues and its eigenvectors cease to be consistent. Some alternative estimators have thus been proposed in the literature. Ledoit and Wolf (2015) propose estimators of the eigenvalues of the covariance matrix in the large-dimensional framework that are consistent, in the sense that the mean squared deviation between the estimated eigenvalues and the population eigenvalues converges to zero almost surely. Their method is based on a particular discretization of a version of the Marčenko-Pastur equation that links the limiting spectral distribution of the sample eigenvalues and that of the population eigenvalues (Ledoit and Wolf, 2017). This method is then used to derive estimators of the covariance matrix itself that are asymptotically optimal with respect to a given loss function in the space of orthogonally equivariant estimators (Ledoit and Wolf, 2018). Additional results by these same authors have very recently appeared when our paper was under review (Ledoit and Wolf, 2020). Estimators that are derived in the large-dimensional asymptotic regime are proposed also by El Karoui (2008), Mestre (2008), Yao et al. (2012), among others. Estimators that deal with the case p > n and are derived in a decision-theoretic framework are those of Konno (2009), and, more recently, Tsukuma (2016). There is a vast literature on estimation of Σ where structural assumptions on Σ are made such as ordering or sparsity, for example Bickel and Levina (2008); Bien and Tibshirani (2011); Naul and Taylor (2017); Won et al. (2013).
In this paper, we propose an estimator for the covariance matrix that is equivariant under orthogonal transformations. In particular, these transformations include rotations of the variable axes. Equivariant estimation of the covariance matrix under the orthogonal group has been studied extensively (e.g., Dey and Srinivasan (1985); Ledoit and Wolf (2015); Takemura (1984)) since the pioneering work of Stein (1975, 1986). In this study, we follow our previous work Banerjee et al. (2016), where we describe estimators that are valid when n > p, and extend it to the case when p > n. Because of the property of equivariance, the eigenvectors of the covariance matrix are estimated by those of , to which we refer as the sample covariance matrix in this paper. Thus, the estimation problem is completed by providing estimates of the eigenvalues. These estimates are obtained from an adjusted profile likelihood function of the population eigenvalues, which is derived by approximating the integral of the density function of S over its eigenvectors (corresponding to the non-zero eigenvalues). This approximation is however not the large-n (Laplace) approximation of such integral, which results in the modified profile likelihood of Barndorff-Nielsen (1983), but it is an approximation suggested in Hikami and Brézin (2006) useful for large p. Our estimates are a mixture of an exact critical point of such a likelihood function, which is in fact a maximum when some conditions are satisfied, and an approximate critical point whose components are a modification of the non-zero sample eigenvalues by terms of order 1/p. The tuning parameter κ is determined from the data and controls the shrinkage of the eigenvalues. We will describe two algorithms to determine κ: one based on bootstrap and one based on cross-validation. High-dimensional estimators are generally derived under an asymptotic regime in which both n and p increase in such a way that their ratio tends to a constant. In our case, n is kept fixed, and the high-dimensionality of the estimator comes into play because we consider a large-p approximation of the marginal density of the eigenvalues of S.
In a variety of finite-sample simulation scenarios, we compare our estimator to two Ledoit-Wolf estimators, which are also orthogonally equivariant and have previously been shown to better many other estimators under some loss functions. Figures 3 and 4 summarize the results of our comparison, in terms of risk evaluated with respect to nine loss functions. To assess how our covariance matrix estimator estimates the eigenvalues of the population covariance matrix, we also compare the eigenvalues of our estimator with Ledoit-Wolf consistent estimator of the population eigenvalues themselves, under loss functions that depend only on the eigenvalues. Figure 5 displays such a comparison. Finally, comparison of covariance matrix estimators is also carried out using two real data applications of breast cancer data and leukemia data: in a linear discriminant analysis of these data, we use plugged-in estimates of the covariance matrix in the classifier and demonstrate that our estimator leads to lower misclassification errors in the breast cancer data and similar misclassification errors in the leukemia data. The two Ledoit-Wolf covariance matrix estimators are optimal asymptotically under two loss functions, but we show that finite sample improvements and improvements under other loss functions are indeed possible. Since the tuning parameter κ of our estimator can be chosen by minimizing risk estimates with respect to any loss function, our estimator can be used with any loss function appropriate to a statistical application.
Figure 3: PRIAL comparison with LW1.
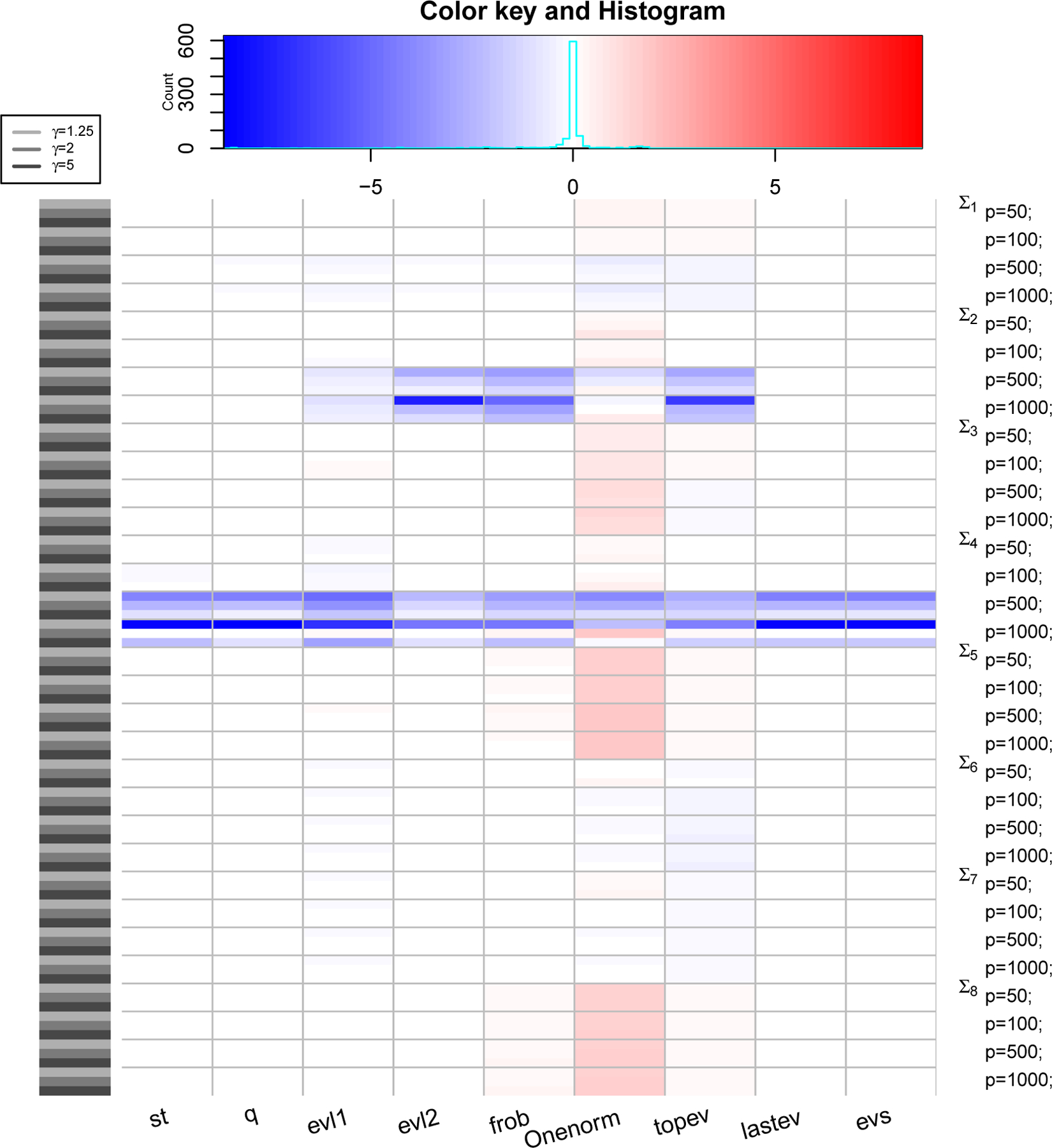
The heatmap shows values of PRIAL of with respect to for various simulation scenarios based on covariance structure, values of p and γ (rows) and various loss functions (columns). Top panel shows counts and histogram of various PRIAL values. PRIAL values are scaled column-wise for visual clarity. Red (blue) shades mean PRIAL > 0 (PRIAL < 0) indicating our estimator is better (worse) than LW1.
Figure 4: PRIAL comparison with LW2.
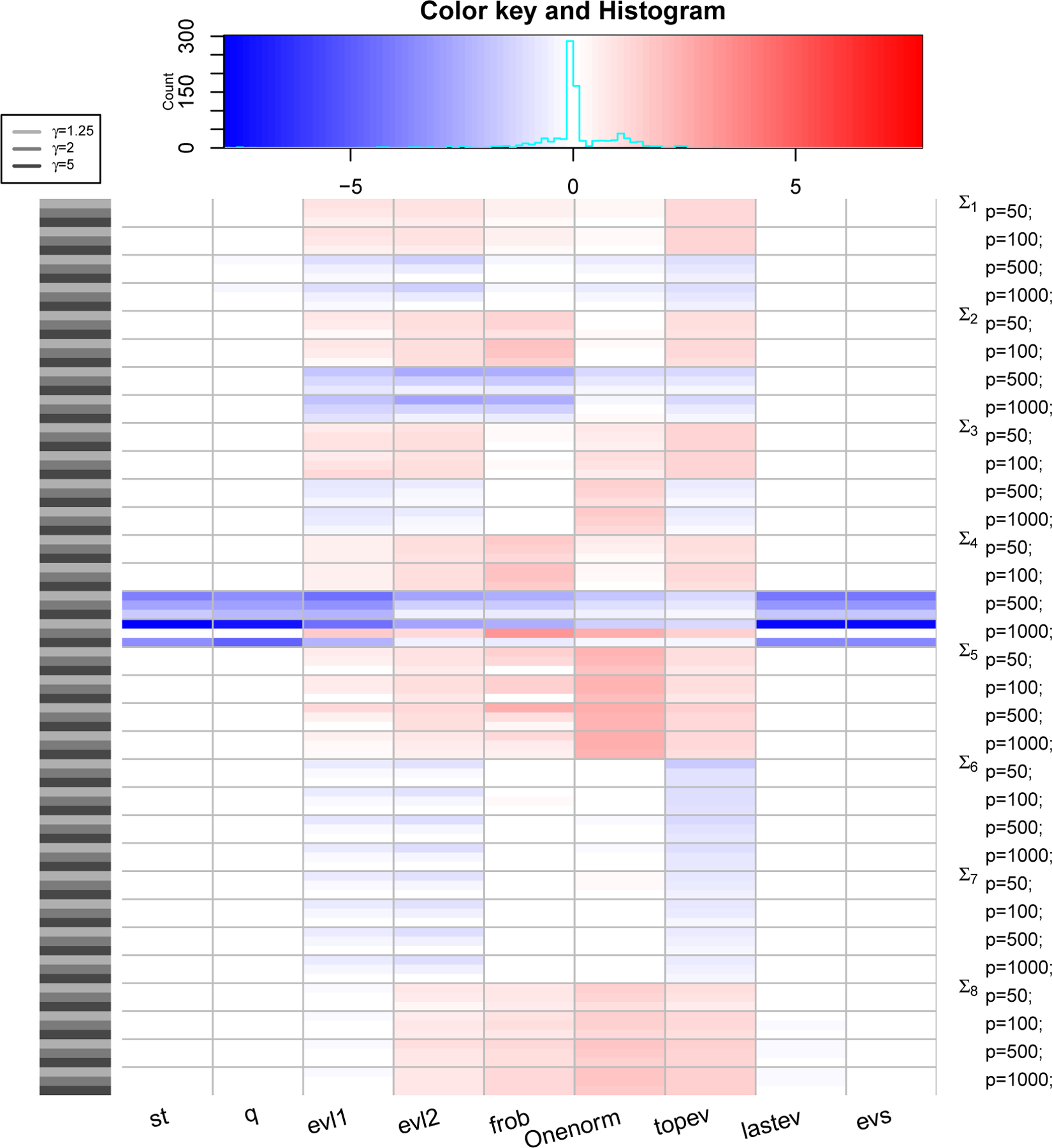
The heatmap shows values of PRIAL of with respect to for various simulation scenarios based on covariance structure, values of p and γ (rows) and various loss functions (columns). Top panel shows counts and histogram of various PRIAL values. PRIAL values are scaled column-wise for visual clarity. Red (blue) shades mean PRIAL > 0 (PRIAL < 0) indicating our estimator is better (worse) than LW2.
Figure 5: PRIAL comparison with LW3.
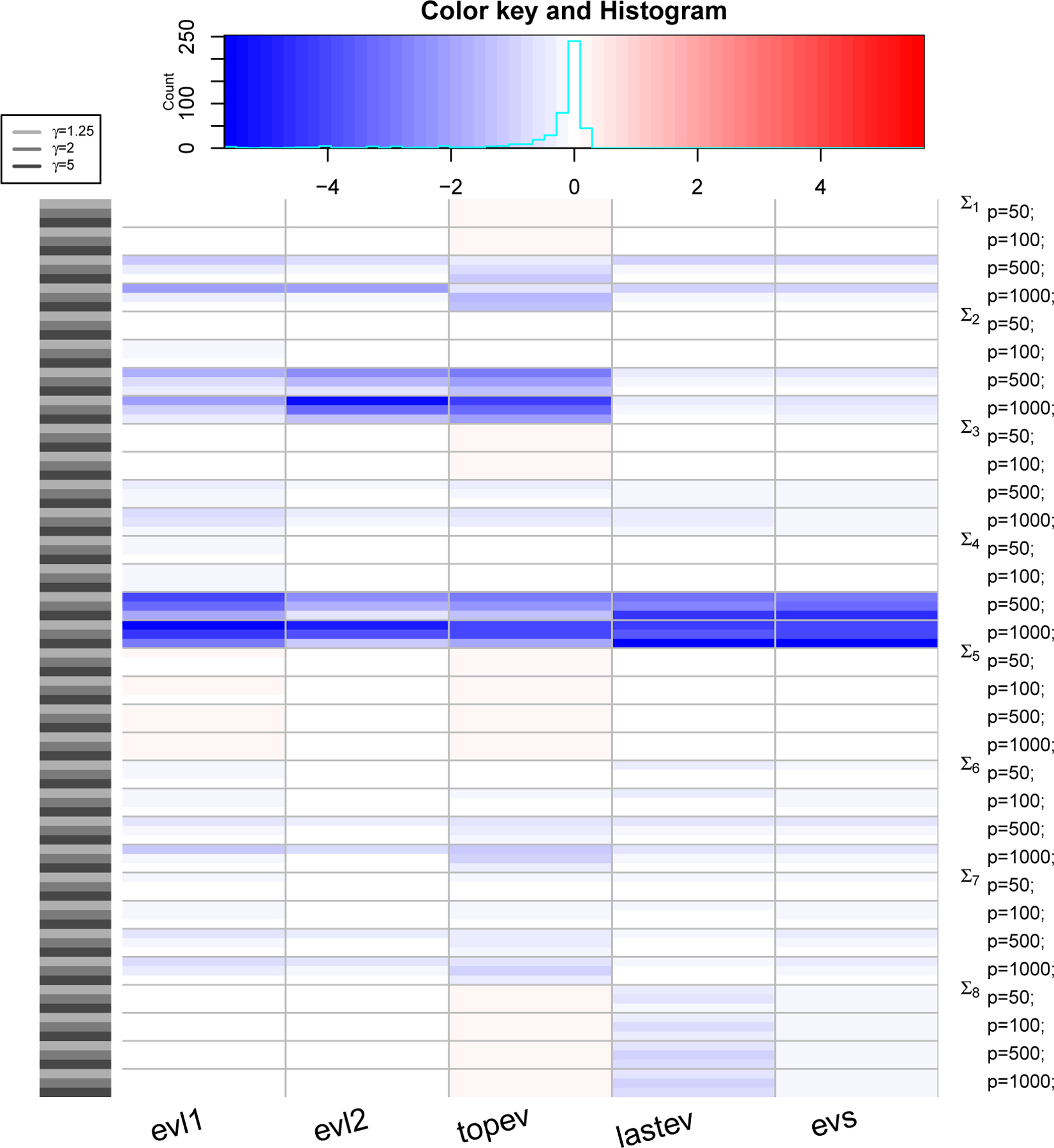
The heatmap shows values of PRIAL of with respect to for various simulation scenarios based on covariance structure, values of p and γ (rows) and various loss functions (columns). Top panel shows counts and histogram of various PRIAL values. PRIAL values are scaled column-wise for visual clarity. Red (blue) shades mean PRIAL > 0 (PRIAL < 0) indicating our estimator is better (worse) than LW3.
This paper is organized as follows. In Section 2, we introduce the adjusted profile likelihood that is used to obtain our estimator, which is introduced and discussed in Section 3. Section 4 and Section 5 present some numeric assessment of the performance of our estimator in simulated and real data respectively.
2. Marginal Density and Likelihood Function
In this section, we introduce some notations, review the singular Wishart distribution, derive an approximation to the marginal density of the sample eigenvalues and then obtain an adjusted profile likelihood for the eigenvalues of the population covariance matrix. Consider the case of mutually independent draws X1, …, Xn from a multivariate p-dimensional normal distribution , with Σ a p × p maximum-rank positive definite matrix. Assume p > n, and let S be the p × p sample covariance matrix X⊤X, with X the matrix whose rows are the vectors . S is positive semi-definite and of maximum rank, with distinct positive eigenvalues: ℓ1 > ℓ2 > … > ℓn > 0. Geometrically, S is an interior point of an (n+1)n/2-dimensional face of the closed convex cone of semi-positive definite p × p symmetric matrices (Barvinok, 2002). Uhlig (1994) showed that S has a distribution specified by the density
| (1) |
where , L = diag(ℓ1, …, ℓn) is the diagonal matrix of the non-zero eigenvalues of S, etr(.) = exp(tr(.)), and (dS) is the volume element on the space of positive semi-definite p × p symmetric matrices of rank n, with n distinct positive eigenvalues. This distribution, which extends the usual (n > p) Wishart distribution, is often called (non-central) singular Wishart distribution, but some authors (Srivastava and Khatri, 1979) prefer the name non-singular pseudo-Wishart distribution. It corresponds to the case 7 of the classification scheme of Díaz-García et al. (1997) (described in Table 1 therein), where generalizations are considered that include the cases when Σ and S have non-maximum rank and when the samples are not independent. The method we will present can be also extended to the case when S does not have maximum rank. For example, in some applications, one may wish to center the observations to have mean zero. The resulting matrix S constructed from the centered data will have rank less than n.
Table 1:
Error rates for LDA analysis of breast cancer data
| Estimator | Reference () | MCR | Sens | Spec |
|---|---|---|---|---|
| LW1 | - | 0.275 | 0.385 | 0.842 |
| LW2 | - | 0.333 | 0.538 | 0.711 |
| 0.392 | 0.538 | 0.658 | ||
| LW1 | 0.235 | 0.462 | 0.868 | |
| LW2 | 0.176 | 0.538 | 0.921 | |
| - | 0.216 | 0.538 | 0.868 |
Consider now the singular value decomposition of with U ∈ O(n) an orthogonal n × n matrix, L = diag(ℓ1, …, ℓn) as defined above and H1 the matrix whose n columns are the corresponding n eigenvectors of S. These n eigenvectors are uniquely determined up to column multiplication by ±1. The formulae below assume that one of these 2n choices has been made. H1 is a point in the Stiefel manifold, , of all orthonormal n-frames in . The joint density of H1 and L is
where
∧ is the exterior product, (dL) = dℓ1 ∧ ⋯ ∧ dℓn, and is the Haar measure of normalized as follows
Even if we have written the densities of S and of H1, L as differential forms, we need not keep track of the sign of the form, if we define the integrals to be positive. In the following, when the measure is clear, we will revert to using the term density for the scalar part.
We are interested in obtaining an estimator for Σ that belongs to the class of orthogonally equivariant estimators. This equivariance is intended in the usual meaning. Namely, consider the action of the orthogonal group O(p) on the sample space that is defined by X ↦ XG⊤, or equivalently, by S ↦ GSG⊤. We require , which is the same way as Σ transforms Σ ↦ GΣG⊤. Under such action, p(S) is invariant and so is the measure (dS). This equivariance implies that the eigenvectors of are the same as those of S. This is to say that the estimators are of the form , where the elements of the diagonal matrix are functions of the non-zero eigenvalues of S and the orthogonal matrix H = [H1 : H2] is that of the eigenvectors of S (Stein, 1986). In the case in which p > n, the zero eigenvalue has multiplicity (p − n), so that the corresponding eigenvectors of S given by the (p − n) columns H2 = (hn+1, …, hp), are unique only up to an orthogonal transformation of the last (p − n) coordinate axes. Namely, we can consider H2 or H2 · P with any orthogonal matrix P ∈ O(p − n). In general each different choice (of P) will lead to a different estimator of Σ. However, if the estimates of the smallest (p − n) eigenvalues of Σ are identical, all such choices will be immaterial, in the sense that they will lead to the same . The estimates of the last (p − n) eigenvalues that we propose are indeed identical, so that one can use as estimates of all the eigenvectors of Σ whatever representative of the class of the eigenvectors of S a numerical routine outputs.
To find the eigenvalue estimates, we follow our previous paper Banerjee et al. (2016), and consider the marginal density of the sample roots of :
where
The integral Jn cannot be computed in closed form. However, in Appendix A, we derive a useful approximation. Namely,
Proposition 1.
For large p, the integral Jn is approximated by the following expression
with for 1 ≤ i ≤ n and for i > n.
Remark.
The following condition 0 ≤ (li − lj)(λi − λj)/λiλj < p is employed in the proof of the proposition.
Remark.
This approximate formula is valid even when some of the population eigenvalues are equal. It is also interesting to notice that when Σ = μIp is proportional to the identity matrix, the value of Jn obtained using such formula is equal to the exact value of the integral, which can be computed to be times the volume of the Stiefel manifold, which is omitted in the formula above (see Appendix A). In the following, however, we assume the population eigenvalues to be distinct except when stated otherwise.
Employing such an approximation, we then obtain an approximate log-likelihood function for the true eigenvalues λ
| (2) |
The first two terms of this function are the profile log-likelihood function for the parameters λ, which is the partially maximized log-likelihood function of (λ, V), where V is replaced by the maximum likelihood estimator for fixed λ. We show in Appendix C that is a solution to the equation V⊤H1 = M, where M is a p × n matrix such that Mij = ±δij, with δij the Kronecker delta. The other terms in can thus be interpreted as an adjustment to the profile log-likelihood.
3. The Proposed Estimator
In this section, we derive an estimator for the eigenvalues of the population covariance matrix and discuss its properties.
Our starting point is , the function given in (2), which can be considered as a pseudo-(log)likelihood, of which our goal is to find the maximum points. We note that this function of is not concave on the whole domain , for all given values of (ℓ1, …, ℓn). The critical points are the solutions to the following equations
| (3) |
where ℓi = 0 when i = n + 1, …, p. Exact solutions to (3) satisfy what we can call a trace condition: , which is desirable since E(S) = nΣ.
A solution to (3) is seen to be given by , for i = 1, …, p. This results in a diagonal estimator for the covariance matrix . However there is no guarantee that such a solution may be a maximum of for all given values of (ℓ1, …, ℓn). Indeed, for some data (sample eigenvalues) the Hessian matrix evaluated at this solution can have positive eigenvalues. However, one can notice that is a genuine maximum of the likelihood function at order 1 in 1/p. Namely, it is a maximum of
which is obtained by expanding to first order the logarithm in (2). Furthermore, is also the maximum of the exact likelihood function when the true covariance matrix is proportional to the identity matrix, which can be computed exactly, without the need of any approximation, as remarked earlier. The advantage of the solution is that it shrinks the highest and pushes up the lowest eigenvalue. Indeed, the general theorem of van der Vaart (1961) tells us that the highest eigenvalue ℓi/n is upward biased and (obviously in this p > n case) the lowest eigenvalue downward biased. The disadvantage is that the shrinkage may be too extreme. It is perhaps not surprising that the eigenvalue estimates are degenerate. In our derivation, the sample size n is fixed and p is large, thus there may not be enough information in the sample to obtain a different estimate for each eigenvalue. To deal with the degeneracy of the estimates, we construct approximate solutions to the equations (3). We look for with an expansion of the form ai + fi/p + O(p−2), for i = 1, …, n. There is no reason a priori why solutions should take this form. However, the solution is of this form, with ai = 0 and fi the same for all i = 1, …, n. Our goal is to perturb the exact solution away from having all components equal, keeping the resulting estimates ordered and satisfying the trace condition. We find
which are a modification of the eigenvalues ℓi/n of the (usual) sample covariance matrix S/n (in our conventions ℓi are the eigenvalues of S = X⊤X) with a correction term of order 1/p. We do not use such an approximate solution as the estimate of our eigenvalues (it would lead to a non-invertible estimator of the covariance matrix, for one thing). We employ as a perturbation of the true solution . In fact, what we propose as an estimator is a linear combination of and , controlled by a tuning parameter κ. Namely,
| (4) |
where 0 ≤ κ < 1. The parameter κ controls the shrinkage of the eigenvalue estimate and is to be determined from the data. When κ is zero, the shrinkage is highest, and we recover the solution to the ML equations, with all the eigenvalues being equal and, accordingly, is proportional to the identity Ip. When κ tends to one we get with distinct estimates of the first n eigenvalues. There is no guarantee that is a maximizer for (2). For these reason, one could try to maximize (2) numerically. We did consider numerical solutions to (3) using Newton’s method and a constraint of positivity on the solutions. The resulting roots were always found to be close to with the last (p − n) values negligible. Furthermore, when used in place of , in the estimator (4), these numerical components had similar estimates of risk compared to our estimator (4) in the simulation study conducted in Section 4.2 (results not shown), but added an un-necessary computational step.
The last (p − n) estimates of the eigenspectrum (4) are all equal. As observed in Section 2, this property guarantees that any chosen basis for the eigenspace corresponding to the zero eigenvalues of S will give rise to the same estimator . In fact, this property should be required of any orthogonally equivariant estimators of Σ in the p > n setting, although it has not been explicitly mentioned before, and it also holds for the non-linear estimators of Ledoit and Wolf (2015). Our proposed estimators for the true eigenvalues have the following additional properties proven in Appendix B.
Proposition 2 (The properties of the eigenvalue estimates).
For κ, such that 0 ≤ κ < 1, the estimates given in (4) have the following properties
Thus the corresponding estimator of Σ will be positive definite. In addition, because of the ordering of the estimates, there is no additional step, such as re-ordering or isotonization, that often is necessary. The computational burden of obtaining the proposed estimates only stems from finding the singular value decomposition of the data matrix X or the eigenspectrum of S, and by the evaluation of the parameter κ, which we discuss in Section 3.1.
The formulae presented so far have been obtained under the assumption that the data matrix X or S = X⊤X were of maximum rank n. In some applications one may wish to center the data, , and consider the matrix in place of S. All formulae can be applied to these situations, if we replace n with the rank q of the rescaled matrix in the corresponding maximum rank equations. A sketch of their derivation is given in Appendix D.
3.1. Selecting the Tuning Parameter κ
The tuning parameter κ, 0 ≤ κ < 1, of needs to be determined from data. Selection of tuning parameters in an unsupervised setting is a difficult problem, and there is no method which is always satisfactory. In the context of covariance estimation, tuning parameters are often determined by minimizing estimates of risks (see for example Bickel and Levina (2008) for a cross-validation approach and Yi and Zou (2013) for an approach using Stein’s unbiased estimate of risk). This is also the approach we follow to choose κ, although our estimates of risk differ. Namely, we consider some loss function and compute the corresponding risk as follows:
| (5) |
where the expectation is over the data distribution. When , the risk can be seen as a function of κ. The “oracle” κ is then .
It is noteworthy that estimating the risk and estimating the tuning parameter that minimizes that risk, are not necessarily the same problem. The estimation of the risk is complicated by the fact that the true population matrix Σ is unknown in practice. We propose two methods to estimate the risk of the estimator under a loss L: one method relies on a bootstrap re-sampling scheme and the other on cross-validation.
κ-selection via bootstrap
To estimate the risk via bootstrap, we randomly choose n rows with replacement from our data matrix X. Let Xb be such a sample and be the corresponding sample covariance matrix. We then compute the reduced rank estimator, , as described in Appendix D and evaluate the loss with respect to a reference estimator for a grid of values of κ ∈ [0, 1). This procedure is iterated B times. The risk estimate is taken to be
and the optimal κ determined as
The choice of the reference estimator in our proposed κ-selection procedure requires discussion. We have considered using S and (matrix estimator corresponding to ) as reference estimators. However, since these estimators are singular, they may not be used when computing loss functions that require their inversions (such as Stein’s loss function or the quadratic loss function, see Section 4). In these cases, we have flipped the role of the reference estimator and the estimator at hand when computing the loss functions. As an alternative approach, we have used as reference estimator a non-singular extension of , which we call , where the zero eigenvalues are replaced with the smallest non-zero eigenvalue estimate. Our simulation studies (not shown here) indicate that the second strategy of using a non-singular estimator performs better than the first approach in selecting κ. We should emphasize that the choice of κ closest to the κ′ depends largely on the reference estimator and a better reference estimator will lead to a much improved estimator.
κ-selection via cross-validation
A second method estimates the risk using cross-validation (CV). Different losses lead to different estimates, and we have implemented this method for Stein’s, quadratic and Frobenius loss functions (see Section 4.1 for definition of these loss functions). First, consider the Frobenius loss, or actually its square, for reasons that we will be readily apparent:
We can now ignore terms that do not depend on κ since we wish to minimize with respect to κ. Observing further that
where the expectation E* is taken with respect to the distribution of x*, an independent sample from , we obtain the following leave-one-out cross-validation estimate of the risk
where is the estimator obtained removing the i-th row from X. If n is not very small, one can consider K-fold CV instead of leave-one-out CV, to ease the computational burden. When the loss function is quadratic or Stein’s, we reverse the role of Σ and and consider rather than . We can express the traces involving Σ and the inverse of as expectation with respect to samples of , and we are able to obtain the estimates of risks, or, more accurately, of functions that have the same minimum as the risks, since terms that do not depend on κ can be ignored. More precisely, the quadratic loss with the reversed role of Σ and is
Ignoring terms that do not depend on κ, the leave-one-out cross-validation estimate of the risk under the quadratic loss is
The Stein’s loss , which is now twice the KL-divergence of normal densities with covariance matrix Σ and , is equal, up to terms that do not depend on κ, to
from which one obtains the leave-one-out cross-validation risk estimate
Numerical comparison of κ-selecting methods
We conducted a simulation study (see Section 4.2 for details) to evaluate these two strategies and compare the corresponding values of κ with the “oracle” κ′. We considered nine different loss functions (see Section 4.1), eight different covariance structures and p = 50, 100, 500, 1000 with . The results of this study are shown in Figures 1 and 2 where each panel corresponds to a loss function, the horizontal axis of each panel represents various combinations of the true covariance structure Σ, γ and p, and the vertical axis of each panel represents the chosen κ for the two proposed methods (CV in dashed line and bootstrap in dotted line) and the “oracle” κ′ (in solid line) which is determined using the true matrix Σ. Figure 1 has true covariance structures Σ1 to Σ4 and Figure 2 has true covariance structures Σ5 to Σ8. Note that the leave-one-out CV is only available for three out of the nine loss functions (i.e., Frobenius, Stein’s and quadratic). The leave-one-out CV estimates the oracle κ′ almost perfectly for the Frobenius loss and also works well for Stein’s and quadratic loss functions. The bootstrap method on the other hand works reasonably well in choosing κ for most loss functions except the ones that depend on the smallest eigenvalues entirely. We have observed in our simulations that when the bootstrap estimate is quite different from the oracle κ′, the risk curves are quite flat, i.e., and are quite similar and there is little risk improvement with different choices of κ.
Figure 1: κ-selection for Σ1 to Σ4:
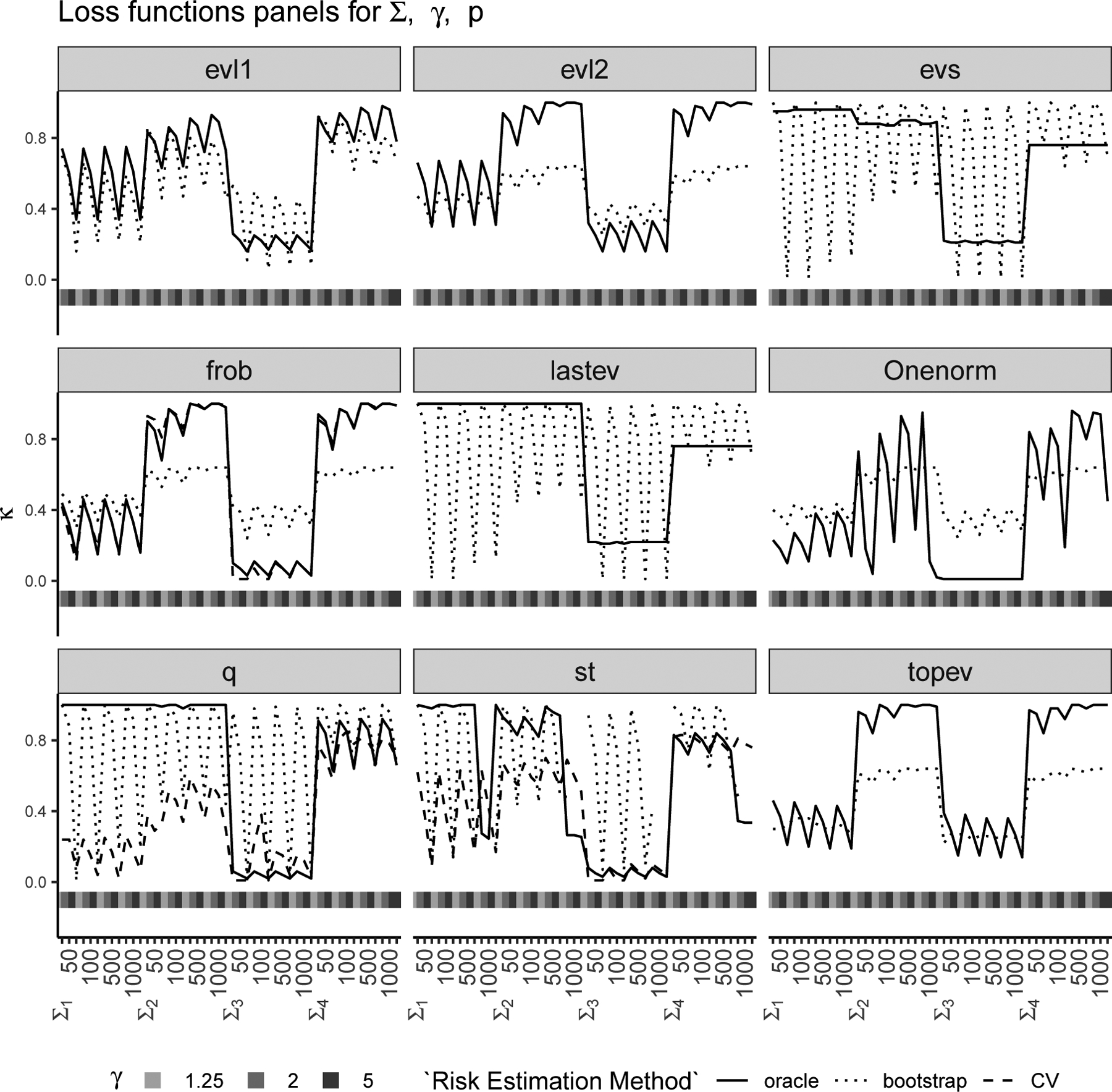
Chosen via bootstrap (dotted line) and CV (dashed line) are compared with oracle κ′ (solid line) with nine loss functions (each panel) for various combinations of true Σ (Σ1 to Σ4), γ = p/n and p (see Section 4).
Figure 2: κ-selection for Σ5 to Σ8:
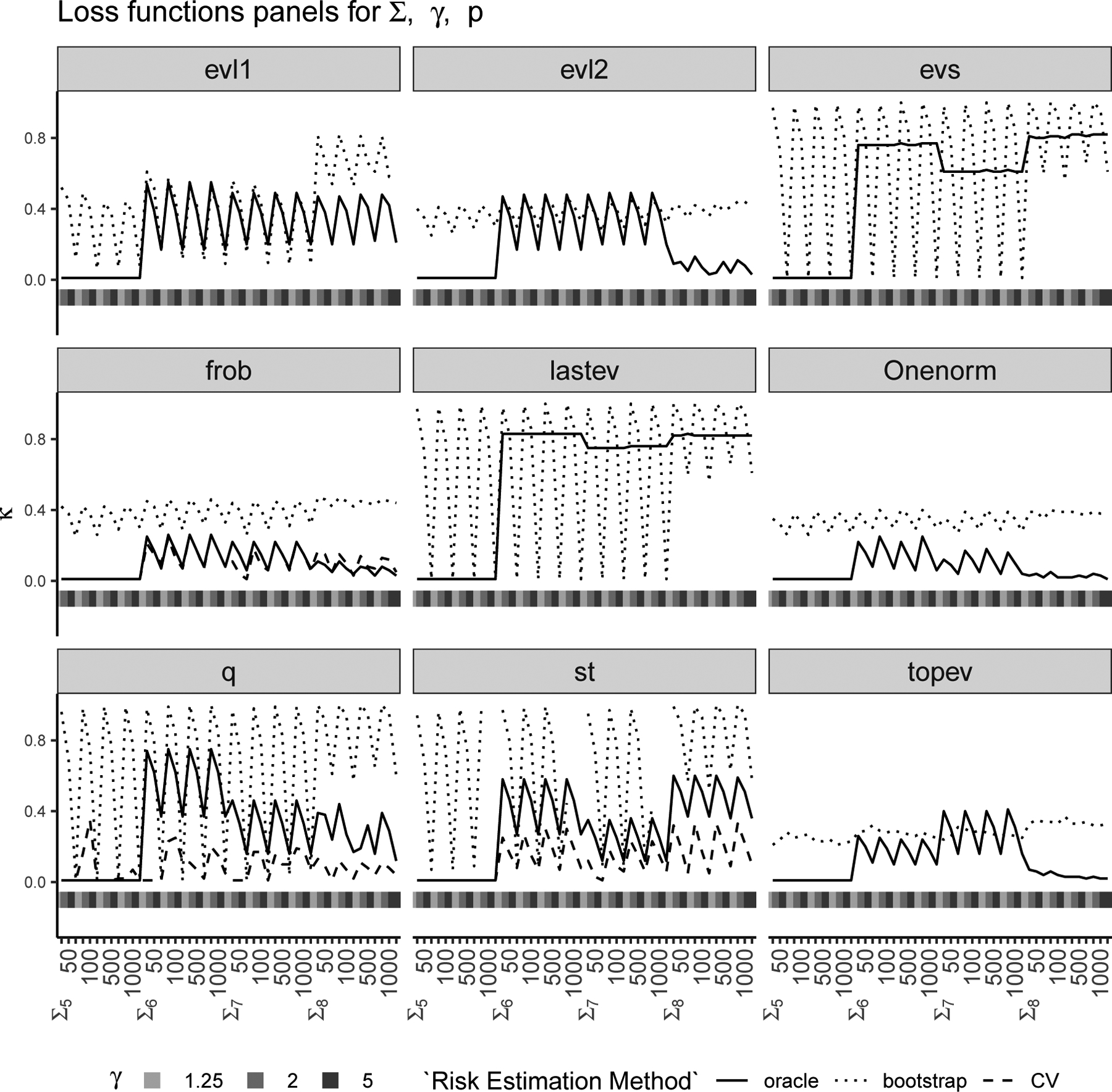
Chosen via bootstrap (dotted line) and CV (dashed line) are compared with oracle κ′ (solid line) with nine loss functions (each panel) for various combinations of true Σ (Σ5 to Σ8), γ = p/n and p (see Section 4).
As noted earlier, the choice of κ depends largely on the reference estimator. When analyzing real data, we recommend the analyst to choose a loss function that is appropriate for the applied problem. If any of Stein’s, quadratic or Frobenius (i.e., st, q or frob) loss functions is an appropriate choice, we recommend using the CV-method to select κ as it does not depend on a reference estimator. For any other loss function, we would recommend using other estimators as reference (e.g., the estimators of Ledoit and Wolf) in addition to .
4. Numerical Risk Comparisons with Other Estimators
In this section we perform Monte Carlo simulations to evaluate our proposed estimator with respect to various loss functions. Specifically, we compare it with the two non-linear shrinkage estimators of Ledoit and Wolf, one which is asymptotically optimal under Frobenius loss (LW1) and one which is asymptotically optimal under Stein’s loss (LW2). Ledoit and Wolf’s nonlinear shrinkage estimators are of the form , and thus orthogonally equivariant, with . The function is the nonlinear function responsible for shrinking the sample eigenvalues. Its form depends on which loss function is asymptotically minimized (Ledoit and Wolf, 2018). We refer the reader to Section 3.2 of Ledoit and Wolf (2015) for the specific form of when the loss is Frobenius and to Sections 5 and 6 of Ledoit and Wolf (2018) for its explicit form when the loss is Stein’s. In addition, we compare our eigenvalue estimates with those of the Ledoit-Wolf consistent estimator of the population eigenvalues (Ledoit and Wolf, 2015), which we call LW3. The comparison is carried out under the loss functions that only depend on eigenvalues: loss functions 3, 4, 7, 8, and 9 in the Section 4.1 below.
4.1. Loss Functions
The comparison of the estimators is carried out using the Monte Carlo estimates of risk as defined in eq. (5) with respect to the nine loss functions defined below. We choose a variety of loss functions, some of which depend on the complete covariance matrix and its estimate, and others depend only on the eigenvalues and their estimates. To an applied statistician, the type of loss function is determined by the context of the application which could involve the estimation of eigenvalues, an important characteristic of the covariance matrix. Thus, the reader will get a sense of overall performance of an estimator under various loss functions. We also refer the reader to our previous paper Banerjee et al. (2016) for a detailed description of most of these loss functions.
Stein’s (entropy) loss ;
the quadratic loss ;
L1 eigenvalue loss ;
L2 eigenvalue loss ;
Frobenius loss , with ;
Matrix L1-norm, the max of the L1 norm of the columns of , ;
L1 loss on the largest eigenvalue ;
L1 loss on the smallest eigenvalue ;
L1 loss on the smallest quartile of the eigenvalues .
We notice that, for our estimator , the oracle κ′ is chosen as described in Section 3.1.
4.2. Simulation Study
We construct eight covariance structures to represent typical applications. The matrix Σ1 has widely spaced eigenvalues, Σ2 has one large eigenvalue and mimics a typical principal components analysis covariance structure, Σ3 is a time series example, Σ4 is a spiked covariance structure, Σ5 is the identity matrix, Σ6 has eigenvalues drawn from a U-shaped beta distribution, Σ7 has eigenvalues drawn from a linearly decreasing beta density and Σ8 has eigenvalues of 1, 3 and 10 distributed with a frequency of 20%, 40% and 40% respectively. Namely,
Σ1 = diag(p2, ⋯, 22, 12);
, where λi ~ U(1, p/2), λ(i) are the ordered λi’s, , with U(a, b) being the uniform distribution over the [a, b] interval;
Σ3 = AR(1), the first-order autoregressive covariance matrix, where σij = 4 × 0.7|i−j| for i ≠ j and σii = 42 for i = 1, ⋯, p;
Σ4 = diag(2p, p, 1, ⋯, 1);
Σ5 = Ip where Ip is the p-dimensional identity matrix;
Σ6 = diag(λi) where and F (α, β)is the cumulative distribution function (c.d.f) of a beta distribution with parameters (α, β); the choice of α = 0.5, β = 0.5 draws eigenvalues from a U-shaped density with more mass on large (around 10) and small (around 1) eigenvalues as the support of the beta density has been shifted to [1, 10];
Σ7 is similar to Σ6 with (α = 1, β = 2) for the shape parameters of the beta c.d.f reflecting a linearly decreasing triangle with the highest density at 1 and lowest density at 10;
Σ8 has 20% of its eigenvalues equal to 1, 40% equal to 3 and the remaining 40% equal to 10.
For each covariance structure Σj (j = 1, 2, 3, 4, 5, 6, 7, 8) four values of p are considered p = 50, 100, 500, 1000. For all eight covariance structures and their various dimensions, three values of n are chosen corresponding to p/n = γ = 1.25, 2, 5. We generate n vectors , i = 1, ⋯ , n, for the first seven covariance structures. For the eighth case, we generate n vectors from a p-variate Student t distribution with four degrees of freedom so that Σ8 is used to test robustness to deviations from normality. We evaluate all nine loss functions, denoted henceforth by st, q, evl1, evl2, frob, Onenorm, topev, lastev and evs, on our estimator and compare the latter with LW1 (nonlinear shrinkage estimator that is optimal under Frobenius loss) and LW2 (nonlinear shrinkage estimator optimal under Stein’s loss) (see Section 4.1). Additionally, we evaluate the five loss functions (evl1, evl2, topev, lastev, evs) that depend only on eigenvalues to compare our estimator with LW3 (the Ledoit-Wolf consistent estimator of population eigenvalues). Risk estimates are based on 1000 repetitions for each simulation scenario.
As a measure of comparison, we use the Proportion Reduction in Integrated Average Loss (PRIAL) of our estimator over , which is LW1 (k = 1) or LW2 (k = 2). Namely, for a loss function L(.), PRIAL is defined similarly to that in Lin and Perlman (1985):
| (6) |
where the sum (over i) is over all datasets. For LW3, we replace with , with , and Σ with λ in (6) to compute the PRIAL. Figure 3, 4 and 5 are heatmaps of PRIAL with respect to LW1, LW2 and LW3 respectively. The rows correspond to various simulation scenarios (covariance structure, p and γ) just described and the columns correspond to various loss functions, described in Section 4.1. The red (blue) shades in the heatmap indicate positive (negative) PRIAL and the white represents zero PRIAL. The more intense the hue is, the larger the absolute value of the PRIAL. A positive PRIAL means our estimator compares favorably with LW1/LW2/LW3, negative PRIAL means the opposite and zero PRIAL means the estimators are comparable. Our estimator has positive PRIAL in 40.4%, 45.7% and 36.9% of all simulation scenarios when compared to LW1, LW2 and LW3 respectively.
It seems difficult to arrive at a general conclusion on which estimator (LW1, LW2, LW3 or ours) is preferable for which covariance structure or which loss function although they perform similarly for the majority of scenarios. Since LW1 is asymptotically optimal under the Frobenius loss function, one should expect LW1 to be better than our estimator with the Frobenius loss. Figure 3 confirms this, except in the case in which the true covariance matrix is the identity (Σ5) and in the case of t-distributed data with covariance matrix Σ8 when our estimator has an advantage. The exception with the identity matrix is also expected because our approximate solution with κ = 0 is a true maximum of the marginal likelihood function. For p ≥ 500, LW1 outperforms our estimator when the true structure is spiked (Σ4) under all loss functions and when the true structure represents a PCA-like situation (Σ2) under frob, Onenorm and topev loss functions. It is also expected that LW2, which is optimal under Stein’s loss function, would outperform our estimator using Stein’s loss. However, we observe in Figure 4 that, under the Stein’s loss function, LW2 is better than our estimator only for the spiked covariance structure (Σ4). On the other hand, our estimator tends to outperform LW2 with Σ8 (robust case) and Σ5 (identity) under multiple loss functions. If we compare estimators with respect to the true covariance matrix over all loss functions, LW1 and LW2 are better than our estimator for the spiked covariance structure (Σ4), while our estimator is better than LW1 and LW2 when data are generated from a non-normal distribution with fat-tails (Σ8) and it seems preferable to LW1 and LW2, when the true covariance matrix is the identity (Σ5). When we compare our eigenvalue estimators with LW3 (Figure 5), we see a similar pattern: the estimators perform comparably for the majority of scenarios, with LW3 outperforming our eigenvalue estimates for the spiked covariance structure (Σ4) when p ≥ 500 under all eigenvalue loss functions and for Σ2 when p ≥ 500 under the evl2 and topev.
5. Linear Discriminant Analysis (LDA) on Breast Cancer and Leukemia Data
In this section we apply our estimator to two-class classification problems using LDA in breast cancer and leukemia data. Specifically, we plug-in our estimator (and also LW1 and LW2) for the common covariance matrix of both classes in the discriminant function of LDA. In the first application we consider a breast cancer dataset. Hess et al. (2006) proposed a 31-probeset multi-gene predictor of pathologic complete response (pCR) to chemotherapy in an experiment with 133 patients with stage I-III breast cancer. Following Hess et al. (2006), we split the samples into a training set of size 82 and a test set of size 51. We develop our classifier on a subset of the training data so that n < p = 31 by randomly selecting 20 patients and preserving the ratio of the two classes. We then evaluate and compare discrimination metrics, such as misclassification rate (MCR), sensitivity (Sens) and specificity (Spec), of the classifier that uses our estimator with those of the classifiers that use LW1 and LW2 as the plug-in estimators for the common-covariance matrix. The comparisons are presented in Table 1. To choose κ for our estimator , we follow the procedures described in Section 3.1 with nine loss functions and as the reference estimator for the bootstrap-based method and the three loss functions for the CV-based method. The combination of the κ-selection method and the corresponding loss function that was chosen is described in Table 1. In addition, we also use LW1 and LW2 as the reference estimators in determining κ for the bootstrap-based method. Our estimator has comparable but higher MCR and lower sensitivity and specificity compared to LW1 and LW2 when we use as the reference estimator to choose κ. However, when we use LW1 as the reference estimator our estimator improves MCR by 4%, sensitivity by 7.7 % and specificity by 2.6% compared with LW1. Similarly, when using LW2 as the reference estimator in choosing κ, our estimator improves MCR by 15.7% and specificity by 21%. The estimator identified by the κ that minimizes the criterion via cross-validation as described in Section 3.1 also performs well.
In the second application we analyze the leukemia data set of Golub et al. (1999), consisting of gene expression measurements on 72 leukemia patients, 47 ALL and 25 AML. We retain p = 3571 of the 7148 gene expression levels for the analysis. This smaller data set can be downloaded from T. Hastie’s website https://web.stanford.edu/~hastie/CASI_files/DATA/leukemia.html. A training set and a validation set are then obtained by randomly selecting samples from the two classes but preserving the proportion of the classes as in the original data, with the training set comprising 31 ALL and 17 AML patients. We consider all LDA-classifiers as described in the breast cancer example, which employ our estimator, LW1, and LW2. All these estimators achieve perfect classification of the samples in the validation set.
6. Summary and Conclusion
Estimation of the covariance matrix is encountered in many statistical problems and has received much attention recently. When p is comparable to n or even greater, the sample covariance matrix is a poor and ill-conditioned estimator primarily due to an overspread eigenspectrum. Several alternative estimators have been considered in the literature for such scenarios, some of which are asymptotically optimal with respect to certain loss functions and others are derived under strong structural assumptions on the covariance matrix (e.g., sparsity). Often, estimators are valid in the regime in which both n and p go to infinity in such a way that their ratio is finite.
In this paper, we consider the class of orthogonally equivariant estimators and propose an estimator that is valid when p > n. This work is an extension of our previous work on equivariant estimation when p < n. Equivariance under orthogonal transformations reduces the problem of estimating the covariance matrix to that of the estimation of its eigenvalues. To this end, we find a modification of the profile likelihood function of eigenvalues by integrating out the sample eigenvectors. The integration result is approximate and valid for large p. The critical point of this pseudo-likelihood function, a maximum under certain conditions, is in an estimator with all components equal, thereby resulting in extreme shrinkage. To get distinct eigenvalue estimates, we perturb by introducing an approximate solution to the likelihood equations along with a tuning parameter κ. The tuning parameter, κ ∈ [0, 1), is selected by minimizing the risk, with respect to a loss function. We can find estimates of the risk using a bootstrap re-sampling scheme, which can be applied to any problem with any loss function. The κ selected with this method depends on the choice of a reference estimator, necessary to evaluate the loss function. Our estimator improves risk when a good estimator is employed as a reference estimator. Alternatively, a cross-validation estimate of the risk can be used, which was implemented for Frobenius, quadratic, and Stein’s loss functions. We compare finite sample properties of our proposed estimator with two covariance matrix estimators of Ledoit and Wolf (Figure 3 and 4) using Monte Carlo estimates of risk with respect to nine different loss functions and eight different covariance structures. We also compare the estimates of the population eigenvalues obtained by our method with those of a consistent estimator for population eigenvalues proposed by Ledoit and Wolf (Figure 5). Furthermore, we demonstrate in a real breast cancer example that our estimator can substantially improve risk.
The encouraging finite sample properties of our estimator reported here suggest that our method of constructing an orthogonally equivariant estimator on the marginal distribution of the sample eigenvalues may provide improved estimation of the covariance matrix, which is needed in many statistical applications.
Acknowledgments
SB was supported by NIMH (National Institute of Mental Health) grant number P50 MH113838 for this work. Many thanks to Yiyuan Wu and Elizabeth Mauer for their assistance with the Figures.
Appendix A
In this appendix we prove Proposition 1. To do this, we first review a result that is fundamental in deriving the approximation. Consider the integral
where (dH) is the Haar measure of the group O(p), X and Y are p × p symmetric matrices with eigenvalues x = (x1, …, xp) and y = (y1, …, yp) respectively. In Hikami and Brézin (2006), this integral and some of its generalizations (to the unitary and symplectic groups), known often as Harish-Chandra-Itzykson-Zuber integrals, are expressed in a form that involves the variables τij = (xi −xj)(yi −yj), using the expansion about the saddle points of the integrand. Specifically, for the orthogonal group,
| (7) |
where the matrix τ is the symmetric matrix with entries τij. The function f can be expanded as a power series of τ
with the term fs being of order s in τ. The solution (7) is obtained from a differential equation obeyed by the integral I. The power series in τ for the integral I is also obtained from the expression of I in terms of zonal polynomials. The term fs of the expansion of f is a polynomial of degree s in the τ variables. Each monomial enjoys a graphical representation, as a graph that has p nodes and an edge that connects two nodes i, j if the variable τij appears in the monomial. In particular, is represented as an edge of multiplicity q, that is, as q lines between the nodes i, j. The total number of lines in such graph, and thus the sum of the multiplicities of all the edges, is s. The details can be found in Hikami and Brézin (2006), but a few example can make the discussion clearer. In the term of order 1,
each monomial τij is represented by a graph in which two distinct nodes i, j are joined by a simple (i.e., with multiplicity 1) edge and the remaining nodes are singletons. Terms of order 2
are represented by three (types of) graphs with two edges: the first sum is associated with graphs that consist of p − 2 singletons and two nodes joined by an edge of multiplicity two; the second sum with graphs with p − 3 singletons and a connected component with 3 nodes and two simple edges; the third sum with graphs with p − 4 singletons and two connected components, each having two nodes and one simple edge. The coefficients cs of the monomials of degree s in τ have different forms in general. However, for large p all coefficients are of the same form (Hikami and Brézin, 2006). Namely,
where g is the degeneracy factor due to the multiplicities of the edges in the graph. For a graph with q edges with multiplicities (q1, …, qq), the degeneracy is
For example, the coefficients c2 for the monomials of degree 2 in f2(τ) above are in the large p limit 3/2p2 for the first and 1/p2 for the other two. Because of this formula, one can obtain the following large p expression for f
The details of its derivation are omitted in Hikami and Brézin (2006). We present them here. To make the notation more compact, let us use a bold symbol, a, say, for an unordered pair of integers (ia, ja). In other words, we are using a vector notation for the P = p(p − 1)/2 distinct elements of τ, whose diagonal elements are zero. By applying the Taylor expansion of the inverse of the square root, we find
| (8) |
where the last sum is over the vectors s = (s1, …, sP) such that 0 ≤ si ≤ s, with . Noticing that singletons in the graph just contribute 1, one now recognizes immediately that in (8) for each s = 0, 1, …, the sum is over all possible graphs with p nodes and with at most s edges whose multiplicities sum to s. These are exactly the graphs associated with the expansion of f. Since the Taylor series we have employed is convergent when −1 < 2τij/p < 1, the above result assumes 0 ≤ 2τij < p (since τij is non-negative). We can thus write (7) for large p as
| (9) |
We use the approximation (9) in the following
Proof of Proposition 1.
We follow some steps as in Theorem 9.5.4 of Muirhead (2009). Consider first the integral
where H ∈ O(p), (H⊤dH) is the Haar measure in O(p) (whose integral gives the volume of O(p)) and with ℓ repeated (p − n) times. Partition H = [H1 : H2], where and thus H2 is a matrix of order p × (p − n) whose columns are orthonormal and orthogonal to those of H1. Since , we have
where L = diag(ℓ1, …, ℓn). Using lemma 9.5.3 in Muirhead (2009), it follows
where and
Since the integrand function is bounded and is compact, in the limit ℓ → 0, we recover the integral of interest
with ℓ1 > ℓ2 > … > ℓn > 0. Applying the large-p form (9) of the integral, we obtain
and hence the result, ignoring the ratio . □
Appendix B
Proof of Proposition 2 (The properties of the eigenvalue estimates).
-
Let a = 1, …, n, and define ψa,b = p + n(ℓa − ℓb)2/ℓaℓb and ℓa − ℓa+1 = da. Clearly, da > 0 and ψab > p. Then
where we have used the fact that ψa+1, b > ψa,b for b ≤ a and ψa,b > ψa+1, b for b ≥ a + 1.Hence for all κ ∈ [0, 1], and .
It follows immediately from the fact that . □
Appendix C
In this appendix, using standard arguments (Muirhead, 2009), we compute the profile log-likelihood for the eigenvalues λ of the covariance matrix Σ. Let Σ = VΛV⊤ be the spectral decomposition of Σ. The log-likelihood function obtained from (1) is
Since , when A satisfies the condition A⊤A = I, with equality when A is one of the 2n matrices M of dimensions p × n with components Mij = ±δij, where δij is the Kronecker delta, we obtain
and thus the expression on the right-hand side is the profile log-likelihood . Thus the maximizer of the log-likelihood for a fixed value of Λ is a solution to V⊤H1 = M. Since V is orthogonal, then , where Mn is the n × n matrix of the first n rows of M and P ∈ O(p − n) any orthogonal matrix.
Appendix D
In this appendix we extend our algorithm to the case in which rank(S) = q ≤ n, with q distinct positive eigenvalues. In the rank-q case, the density of S and the measure are obtained from those in the maximum rank case by replacing n with q (Díaz-García et al., 1997). Namely,
where , with L = diag(ℓ1, …, ℓq), and the volume form written in terms of the Haar measure on is
Accordingly, all non-maximum rank formulae, from the marginal density of the eigenvalues to the ML equations, are obtained by replacing n with q in the corresponding maximum rank equations. Thus, an exact solution to the ML equations gives all estimates to be , and our proposed estimates have the form
with 0 ≤ κ < 1. Such estimates can be shown to be positive and ordered by following the same steps as in the proof of Proposition 2.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Contributor Information
Samprit Banerjee, Division of Biostatistics, Weill Medical College of Cornell University.
Stefano Monni, Department of Mathematics, American University of Beirut.
References
- Banerjee S, Monni S, and Wells MT (2016). A regularized profile likelihood approach to covariance matrix estimation. Journal of Statistical Planning and Inference, 179:36–59. [Google Scholar]
- Barndorff-Nielsen OE (1983). On a formula for the conditional distribution of the maximum likelihood estimator. Biometrika, 70:343–365. [Google Scholar]
- Barvinok A (2002). A Course in Convexity, volume 54 of Graduate Studies in Mathematics. American Mathematical Society. [Google Scholar]
- Bickel PJ and Levina E (2008). Regularized estimation of large covariance matrices. The Annals of Statistics, 36:199–227. [Google Scholar]
- Bien J and Tibshirani R (2011). Sparse estimation of a covariance matrix. Biometrika, 98:807–820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dey DK and Srinivasan C (1985). Estimation of a covariance matrix under Stein’s loss. The Annals of Statistics, 13:1581–1591. [Google Scholar]
- Díaz-García JA, Jáimez RG, and Mardia K (1997). Wishart and pseudo-Wishart distributions and some applications to shape theory. Journal of Multivariate Analysis, 63:73–87. [Google Scholar]
- El Karoui N (2008). Spectrum estimation for large dimensional covariance matrices using random matrix theory. The Annals of Statistics, 36:2757–2790. [Google Scholar]
- Golub TR, Slonim DK, Tamayo P, Huard C, Gaasenbeek M, Mesirov JP, Coller H, Loh ML, Downing JR, Caligiuri MA, Bloomfield CD, and Lander ES (1999). Molecular classification of cancer: class discovery and class prediction by gene expression monitoring. Science, 286:531–537. [DOI] [PubMed] [Google Scholar]
- Hess KR, Anderson K, Symmans WF, Valero V, Ibrahim N, Mejia JA, Booser D, Theriault RL, Buzdar AU, Dempsey PJ, et al. (2006). Pharmacogenomic predictor of sensitivity to preoperative chemotherapy with paclitaxel and fluorouracil, doxorubicin, and cyclophosphamide in breast cancer. Journal of Clinical Oncology, 24(26):4236–4244. [DOI] [PubMed] [Google Scholar]
- Hikami S and Brézin E (2006). WKB-expansion of the HarishChandra-Itzykson-Zuber integral for arbitrary β. Progress of Theoretical Physics, 116:441–502. [Google Scholar]
- Konno Y (2009). Shrinkage estimators for large covariance matrices in multivariate real and complex normal distributions under an invariant quadratic loss. Journal of Multivariate Analysis, 100:2237–2253. [Google Scholar]
- Ledoit O and Wolf M (2015). Spectrum estimation: A unified framework for covariance matrix estimation and PCA in large dimensions. Journal of Multivariate Analysis, 139:360–384. [Google Scholar]
- Ledoit O and Wolf M (2017). Numerical implementation of the QuEST function. Computational Statistics & Data Analysis, 115:199–223. [Google Scholar]
- Ledoit O and Wolf M (2018). Optimal estimation of a large-dimensional covariance matrix under Stein’s loss. Bernoulli, 24(4B):3791–3832. [Google Scholar]
- Ledoit O and Wolf M (2020). Shrinkage estimation of large covariance matrices: Keep it simple, statistician? Technical Report ECON Working Paper 327, Department of Economics, University of Zurich; Available at https://www.econ.uzh.ch/en/research/workingpapers.html. [Google Scholar]
- Lin SP and Perlman MD (1985). A Monte Carlo comparison of four estimators of a covariance matrix. Multivariate Analysis VI. [Google Scholar]
- Mestre X (2008). Improved estimation of eigenvalues and eigenvectors of covariance matrices using their sample estimates. IEEE Transactions on Information Theory, 54:5113–5129. [Google Scholar]
- Muirhead RJ (2009). Aspects of Multivariate Statistical Theory Wiley Series in Probability and Statistics. Wiley. [Google Scholar]
- Naul B and Taylor J (2017). Sparse Steinian covariance estimation. Journal of Computational and Graphical Statistics, 26:355–366. [Google Scholar]
- Srivastava MS and Khatri CG (1979). An Introduction to Multivariate Statistics. North-Holland, Amsterdam. [Google Scholar]
- Stein C (1975). Estimation of a covariance matrix Rietz lecture, 39th Annual Meeting, IMS. [Google Scholar]
- Stein C (1986). Lectures on the theory of estimation of many parameters. Journal of Soviet Mathematics, 34(1):1373–1403. [Google Scholar]
- Takemura A (1984). An orthogonally invariant minimax estimator of the covariance matrix of a multivariate normal population. Tsukuba J. Math, 8:367–376. [Google Scholar]
- Tsukuma H (2016). Estimation of a high-dimensional covariance matrix with the Stein loss. Journal of Multivariate Analysis, 148:1–17. [Google Scholar]
- Uhlig H (1994). On singular Wishart and singular multivariate beta distributions. The Annals of Statistics, 22:395–405. [Google Scholar]
- van der Vaart HR (1961). On certain characteristics of the distribution of the latent roots of a symmetric random matrix under general conditions. The Annals of Mathematical Statistics, 32:864–873. [Google Scholar]
- Won J-H, Lim J, Kim S-J, and Rajaratnam B (2013). Condition-number-regularized covariance estimation. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 75(3):427–450. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yao J, Kammoun A, and Najim J (2012). Eigenvalue estimation of parameterized covariance matrices of large dimensional data. IEEE Transactions on Signal Processing, 60:5893–5905. [Google Scholar]
- Yi F and Zou H (2013). SURE-tuned tapering estimation of large covariance matrices. Computational Statistics & Data Analysis, 58:339–351. The Third Special Issue on Statistical Signal Extraction and Filtering. [Google Scholar]