

Abstract
We introduce probability estimation, a broadly applicable framework to certify randomness in a finite sequence of measurement results without assuming that these results are independent and identically distributed. Probability estimation can take advantage of verifiable physical constraints, and the certification is with respect to classical side information. Examples include randomness from single-photon measurements and device-independent randomness from Bell tests. Advantages of probability estimation include adaptability to changing experimental conditions, unproblematic early stopping when goals are achieved, optimal randomness rates, applicability to Bell tests with small violations, and unsurpassed finite-data efficiency. We greatly reduce latencies for producing random bits and formulate an associated rate-tradeoff problem of independent interest. We also show that the latency is determined by an information-theoretic measure of nonlocality rather than the Bell violation.
Randomness is a key enabling resource for computation and communication. Besides being required for Monte-Carlo simulations and statistical sampling, private random bits are needed for initiating authenticated connections and establishing shared keys, both common tasks for browsers, servers and other online entities [1]. Public random bits from “randomness beacons” have applications to fair resource sharing [2] and can seed private randomness sources based on quantum mechanics [3]. Common requirements for random bits are that they are unpredictable to all before they are generated, and private to the users before they are published.
Quantum mechanics provides natural opportunities for generating randomness. The best known example involves measuring a two-level system that is in an equal superposition of its two levels. A disadvantage of such schemes is that they require trust in the measurement apparatus, and undiagnosed failures are always a possibility. This disadvantage is overcome by a loophole-free Bell test [4, 5], which can generate output whose randomness can be certified solely by statistical tests of setting and outcome frequencies. The devices preparing the quantum states and performing the measurements may come from an untrusted source. This strategy for certified randomness generation is known as device-independent randomness generation (DIRG).
Loophole-free Bell tests have been realized with nitrogen-vacancy (NV) centers [6], with atoms [7] and with photons [8, 9], enabling the possibility of full experimental implementations of DIRG. However, for NV centers and atoms, the rate of trials is too low, and for photons, the violation per trial is too small. As a result, previously available DIRG protocols [3, 10–18] are not ready for implementation with current loophole-free Bell tests. These protocols do not achieve good finite-data efficiency and therefore require an impractical number of trials. Experimental techniques will improve, but for many applications of randomness generation, including randomness beacons and key generation, it is desirable to achieve finite-data efficiency that is as high as possible, since these applications often require short blocks of fresh random bits with minimum delay or latency.
Excellent finite-data efficiency was achieved by a method that we described and implemented in Refs. [19, 20], which reduced the time required for generating 1024 low-error random bits with respect to classical side information from hours to minutes for a state-of-the-art photonic loophole-free Bell test. The method in Refs. [19, 20] is based on the prediction-based ratio (PBR) analysis [21] for hypothesis tests of local realism. Specifically, in Refs. [19, 20] we established a connection between the PBR-based p-value and the amount of randomness certified against classical side information. The basis for success of the method of Refs. [19, 20] motivates our development of probability estimation for randomness certification, with better finite-data efficiency and with broader applications.
In the probability estimation framework, the amount of certified randomness is directly estimated without relying on hypothesis tests of local realism. To certify randomness, we first obtain a bound on the conditional probability of the observed outcomes given the chosen settings, valid for all classical side information. Then we show how to obtain conditional entropy estimates from this bound to quantify the number of extractable random bits [22]. By focusing on data-dependent probability estimates, we are able to take advantage of powerful statistical techniques to obtain the desired bound. The statistical techniques are based on test supermartingales [23] and Markov’s bounds. Probability estimation inherits several features of the theory of test supermartingales. For example, probability estimation has no independence or stationarity requirement on the probability distribution of trial results. Also, probability estimation supports stopping the experiment early, as soon as the randomness goal is achieved.
Probability estimation is broadly applicable. In particular it is not limited to device-independent scenarios and can be applied to traditional randomness generation with quantum devices. Such applications are enabled by the notion of models, which are sets of probability distributions that capture verified, physical constraints on device behavior. In the case of Bell tests, these constraints include the familiar non-signaling conditions [24, 25]. In the case of two-level systems such as polarized photons, the constraints can capture that measurement angles are within a known range, for example.
In this paper, we first describe the technical features of probability estimation and the main results that enable its practical use. We propose a general information-theoretic rate-tradeoff problem that closely relates to finite-data efficiency. We then show how the general theoretical concepts are instantiated in experimentally relevant examples involving Bell-test configurations. We demonstrate advantages of probability estimation such as its optimal asymptotic randomness rates and show large improvements in finite-data efficiency, which corresponds to great reductions in latency.
Theory.
Consider an experiment with “inputs” Z and “outputs” C. The inputs normally consist of the random choices made for measurement settings but may include choices of state preparations such as in the protocols of Refs. [26, 27]. The outputs consist of the corresponding measurement outcomes. In the cases of interest, the inputs and outputs are obtained in a sequence of n time-ordered trials, where the i’th trial has input Zi and output Ci, and and . We assume that Zi and Ci are countable-valued. We refer to the trial inputs and outputs collectively as the trial “results”, and to the trials preceding the upcoming one as the “past”. The party with respect to which the randomness is intended to be unpredictable is represented by an external classical system, whose initial state before the experiment may be correlated with the devices used. The classical system carries the side information E, which is assumed to be countable-valued. After the experiment, the joint of Z, C and E is described by a probability distribution μ. The upper-case symbols introduced in this paragraph are treated as random variables. As is conventional, their values are denoted by the corresponding lower-case symbols.
The amount of extractable uniform randomness in C conditional on both Z and E is quantified by the (classical) smooth conditional min-entropy where ϵ is the “error bound” (or “smoothness”) and μ is the joint distribution of Z, C and E. One way to define the smooth conditional min-entropy is with the conditional guessing probability Pguess(C|ZE)μ defined as the average over values z and e of the maximum conditional probability maxc μ(c|ze). The ϵ-smooth conditional min-entropy is the greatest lower bound of −log2 Pguess(C|ZE)μ′ for all distributions μ′ within total-variation distance ϵ of μ. Our goal is to obtain lower bounds on with probability estimation.
The application of probability estimation requires a notion of models. A model for an experiment is defined as the set of all probability distributions of Z and C achievable in the experiment conditionally on values e of E. If a joint distribution μ of Z, C and E satisfies that for all e, the conditional distributions μ(CZ|e), considered as distributions of Z and C, are in , we say that the distribution μ satisfies the model .
To apply probability estimation to an experiment consisting of n time-ordered trials, we construct the model for the experiment as a chain of models for each individual trial i in the experiment. The trial model is defined as the set of all probability distributions of trial results CiZi achievable at the i’th trial conditionally on both the past trial results and the side information E. For example, for Bell tests, may be the set of non-signaling distributions with uniformly random inputs. Let and be the results before the i’th trial. The sequences z≤i and c≤i are defined similarly. The chained model consists of all conditional distributions μ(CZ|e) satisfying the following two conditions. First, at each trial i the conditional distributions μ(CiZi|c<iz<ie) for all c<i, z<i and e are in the trial model . Second, at each trial i the input Zi is independent of the past outputs C<i given E and the past inputs Z<i. The second condition prevents leaking information about the past outputs through the future inputs, which is necessary for certifying randomness in the outputs C conditional on both the inputs Z and the side information E. In the common situation where the inputs are chosen independently with distributions known before the experiment, the second condition is always satisfied.
Since the model consists of all conditional distributions μ(CZ|e) regardless of the value e, the analyses in the next paragraph apply to the worst-case conditional distribution over e. To simplify notation we normally write the distribution μ(CZ|e) conditional on e as μe(CZ), abbreviated as μe.
To estimate the conditional probability μe(c|z), we design trial-wise probability estimation factors (PEFs) and multiply them. Consider a generic trial with trial model , where for generic trials, we omit the trial index. Let β > 0. A PEF with power β for is a function F : cz ↦ F(cz) ≥ 0 such that for all , , where denotes the expectation functional. Note that F(cz) = 1 for all cz defines a valid PEF with each positive power. For each i, let Fi be a PEF with power β for the i’th trial, where the PEF can be chosen adaptively based on the past results c<iz<i. Other information from the past may also be used, see Ref. [28]. Let T0 = 1 and The final value Tn of the running product Ti, where n is the total number of trials in the experiment, determines the probability estimate. Specifically, for each value e of E, each μe in the chained model , and ϵ > 0, we have
| (1) |
where denotes the probability according to the distribution μe and U(CZ) = (ϵTn)−1/β. The proof of Eq. (1) is given in Appendix C1. The meaning of Eq. (1) is as follows: For each e and each , the probability that C and Z take values c and z for which U(C = c, Z = z) ≤ μe (C = c|Z = z) is at most ϵ. This defines U(CZ) = (ϵTn)−1/β as a level-ϵ probability estimator.
A main theorem of probability estimation is the connection between probability estimators and conditional min-entropy estimators, which is formalized as follows:
Theorem 1. Suppose that the joint distribution μ of Z, C and E satisfies the chained model . Let 1 ≥ κ, ϵ > 0 and 1 ≥ p ≥ 1/|Rng(C)|, where |Rng(C)| is the number of possible outputs. Define {ϕ} to be the event that Tn ≥ 1/(pβϵ), and let . Then the smooth conditional min-entropy satisfies
The probability of the event {ϕ} can be interpreted as the probability that the experiment succeeds, and κ is an assumed lower bound on the success probability. The theorem is proven in Appendix C2.
When constructing PEFs, the power β > 0 must be decided before the experiment and cannot be adapted. Thm. 1 requires that p, ϵ and κ also be chosen beforehand, and success of the experiment requires Tn ≥ 1/(pβ ϵ), or equivalently,
| (2) |
Since log2(Tn) = ∑i log2(Fi), before the experiment we choose PEFs in order to aim for large expected values of the logarithms of the PEFs Fi. Consider a generic next trial with results CZ and model . Based on prior calibrations or the frequencies of observed results in past trials, we can determine a distribution that is a good approximation to the distribution of the next trial’s results CZ. Many experiments are designed so that each trial’s distribution is close to ν. The PEF can be optimized for this distribution but, by definition, is valid regardless of the actual distribution of the next trial in . Thus, one way to optimize PEFs before the next trial is as follows:
| (3) |
The objective function is strictly concave and the constraints are linear, so there is a unique maximum, which can be found by convex programming. More details are available in Appendix E.
Before the experiment, one can also optimize the objective function in Eq. (3) with respect to the power β. During the experiment ϵ and β are fixed, so it suffices to maximize . If during the experiment, the running product Ti with i < n exceeds the target 1/(pβ ϵ), we can set future PEFs to F(CZ) = 1, which is a valid PEF with power β. This ensures that Tn = Ti and is equivalent to stopping the experiment after trial i. Since the target needs to be set conservatively in order to make the actual experiment succeed with high probability, this can result in a significant reduction in the number of trials actually executed.
A question is how PEFs perform asymptotically for a stable experiment. This question is answered by determining the rate per trial of entropy production assuming constant ϵ and κ independent of the number of trials. In view of Thm. 1, after n trials the entropy rate is given by (−log2(p) + log2(κ1+1/β))/n. Considering Eq. (2), when n is large the entropy rate is dominated by log2(Tn)/(nβ), which is equal to . Therefore, if each trial has distribution ν and each trial model is the same , then in the limit of large n the asymptotic entropy rate witnessed by a PEF F with power β is given by . Define the rate
| (4) |
where the supremum is over PEFs F with power β for . The maximum asymptotic entropy rate at constant ϵ and κ witnessed by PEFs is g0 = supβ>0 g(β). The rate g(β) is non-increasing in β (see Appendix D), so g0 is determined by the limit as β goes to zero. A theorem proven in Ref. [28] is that g0 is the worst-case conditional entropy H(C|ZE) over joint distributions of CZE allowed by with marginal ν. Since this is a tight upper bound on the asymptotic randomness rate [29], probability estimation is asymptotically optimal and we identify g0 as the asymptotic randomness rate. We also remark that probability estimation enables exponential expansion of input randomness [28].
For finite data and applications requiring fresh blocks of randomness, the rate g0 is not achieved. To understand why, consider the problem of certifying a fixed number of bits b of randomness at error bound ϵ and with as few trials as possible, where each trial has distribution ν. In view of Thm. 1, the PEF optimization problem in Eq. (3), and the definition of g(β) in Eq. (4), n needs to be sufficiently large so that
| (5) |
The left-hand side is maximized at positive β, whereas g(β) increases to g0 as β goes to zero. As a result the best actual rate b/n is less than g0.
Setting κ = 1 in Eq. (5) shows that the number of trials n must exceed −log2(ϵ)/(βg(β)) before randomness can be produced, which suggests that the maximum of βg(β) is a good indicator of finite-data performance. Another way to arrive at this quantity is to consider ϵ = 2−γn, where γ > 0 is the “certificate rate”. Given ν and the trial model, we can ask for the maximum certificate rate for which it is possible to have positive entropy rate at κ = 1. It follows from Eq. (5) with κ = 1 that this rate is at most
| (6) |
We propose a general information-theoretic rate-tradeoff problem given trial model and : For a given certificate rate γ, determine the supremum of the entropy rates achievable by protocols. Eq. (5) implies lower bounds on the resulting tradeoff curve.
Our protocol assumes classical-only side information. There are more costly DIRG protocols that handle quantum side information [11, 13–17], but verifying that side information is effectively classical only requires confirming that the quantum devices used in the experiment have no long-term quantum memory. Verifying the absence of long-term quantum memory in current experiments is possibly less difficult than ensuring that there are no backdoors or information leaks in the experiment’s hardware and software.
Applications.
We consider DIRG with the standard two-party, two-setting, two-outcome Bell-test configuration [30]. The parties are labeled A and B. In each trial, a source prepares a state shared between the parties, and each party chooses a random setting (their input) and obtains a measurement outcome (their output). We write Z = XY, where X and Y are the inputs of A and B, and C = AB, where A and B are the respective outputs. For this configuration, A, B, X, Y ∈ {0,1}.
Consider the trial model consisting of distributions of ABXY with uniformly random inputs and satisfying non-signaling [24]. We begin by determining and comparing the asymptotic randomness rates witnessed by different methods. The rates are usually quantified as functions of the expectation of the C-HSH Bell function (Eq. G4) for (the classical upper bound). We prove in Appendix G that the maximum asymptotic randomness rate for any is equal to , and the rate g0 witnessed by PEFs matches this value. Most previous studies, such as Refs. [3, 10, 12, 18, 31–33], estimate the asymptotic randomness rate by the singletrial conditional min-entropy Hmin(AB|XY E). We determine that when . As decreases to 2 the ratio of g0 to Hmin(AB|XYE) approaches 1.386, demonstrating an improvement at small violations.
Next, we investigate finite-data performance. We consider three different families of quantum-achievable distributions of trial results. For the first family νE,θ, A and B share the unbalanced Bell state |Φθ⟩ = cos θ|00⟩ + sin θ|11⟩ with θ ∈ (0, π/4] and apply projective measurements that maximize . This determines νE,θ. This family contains the goal states for many experiments suffering from detector inefficiency. For the second family νW,p, A and B share a Werner state with and again apply measurements that maximize . Werner states are standard examples in quantum information and are among the worst states for our application. In experiments with photons, measurements are implemented with imperfect detectors. For the third family νP,η, A and B use detectors with efficiency η ∈ (2/3, 1) to implement the measurements and to close the detection loophole [34]. They choose the unbalanced Bell state |Φθ⟩ and measurements such that an information-theoretic measure of nonlocality, the statistical strength for rejecting local realism [35–37], is maximized.
For each family of distributions, we determine the maximum certificate rate γPEF as given in Eq. (6). For this, we consider the trial model , but we note that γPEF does not depend on the specific constraints on the quantum-achievable conditional distributions (see Appendix F). As an indicator of finite-data performance, γPEF depends not only on , but also on the distribution ν. To illustrate this behavior, we plot the rates γPEF as a function of for each family of distributions in Fig. 1. To obtain these plots, we note that is a monotonic function of the parameter θ, p or η for each family. We also find that γPEF is given by the statistical strength of the distribution ν for rejecting local realism (see Appendix F for a proof). Conventionally, experiments are designed to maximize , but in general, the optimal state and measurements maximizing are different from those maximizing the statistical strength [36, 37].
FIG. 1:
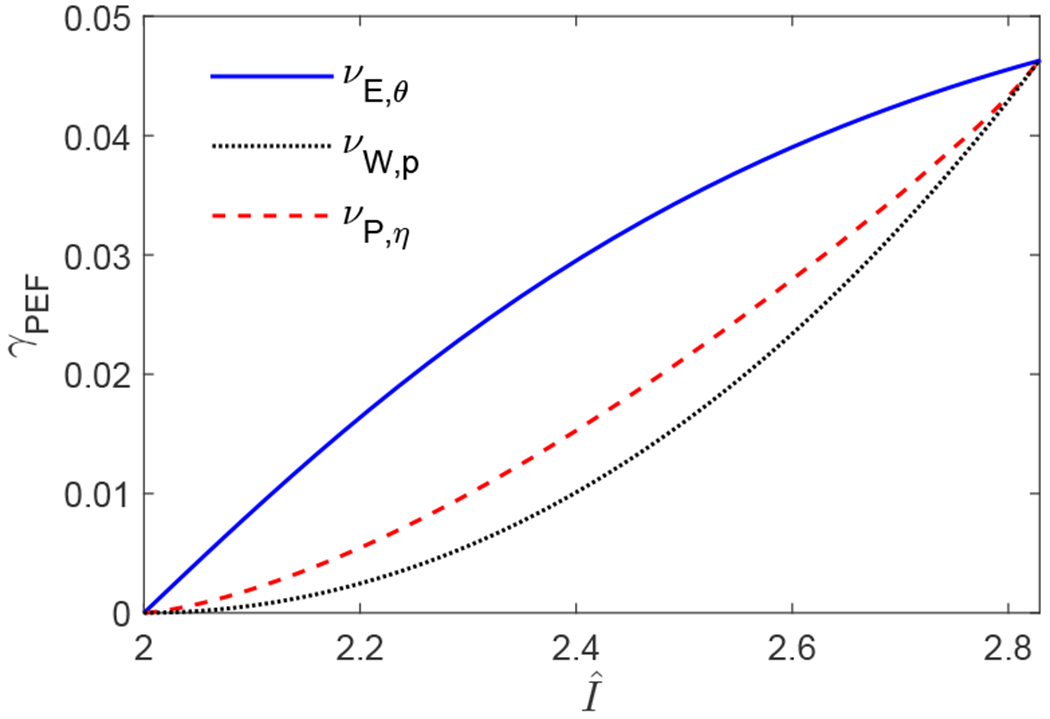
Maximum certificate rates γPEF (Eq. (6)) as a function of for each family of distributions.
We further determine the minimum number of trials, nPEF,b, required to certify b bits of ϵ-smooth conditional min-entropy with a given distribution ν of trial results. From Eq. (5), we get
where for simplicity we allow non-integer values for nPEF,b. We can upper bound nPEF,b by means of the simpler-to-compute certificate rate γPEF given in Eq. (6). For the trial model , γPEF is achieved when β is above a threshold β0 that depends on ν (see Appendix F). From γPEF and β0, we can determine the upper bound
on nPEF,b. The minimum number of trials required can be determined for other published protocols, which usually certify conditional min-entropy from . (An exception is Ref. [18] but the minimum number of trials required is worse.) We consider the protocol “PM” of Ref. [3] and the entropy accumulation protocol “EAT” of Ref. [17]. From Thm. 1 of Ref. [3] with κ = 1 and b ↘ 0, we obtain a lower bound
For the EAT protocol, we determine an explicit lower bound nEAT,b in Appendix H. This lower bound applies for b ≥ 0 and ϵ, κ, ∈ (0, 1], and is valid with respect to quantum side information for the trial model consisting of quantum-achievable distributions.
We compare the three protocols over a broad range of for b ↘ 0, ϵ = 10−6, and κ = 1. For each family of distributions above, we compute the improvement factors given by and . For νW,p the improvement factors depend weakly on increases from 3.89 at at , while fEAT increases from 84.97 at at . For νE,θ and νP,η, the improvement factors can be much larger and depend strongly on , monotonically decreasing with as shown in Fig. 2. The improvement is particularly notable at small violations which are typical in current photonic loophole-free Bell tests. We remark that similar comparison results were obtained with other choices of the values for ϵ and κ.
FIG. 2:
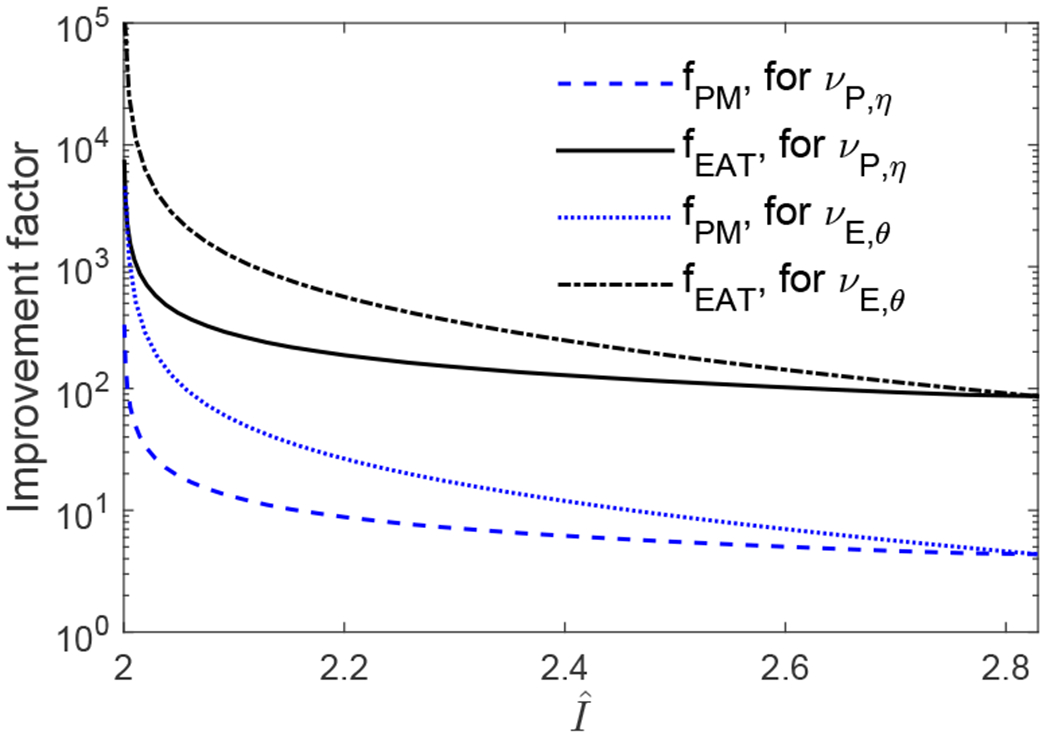
Improvement factors as a function of .
The large latency reduction with probability estimation persists for certifying blocks of randomness. For randomness beacons, good reference values are b = 512 and ϵ = 2−64. We also set κ = 2−64. Setting κ = ϵ is a common conservative choice, but we remark that soundness for randomness generation can be defined with a better tradeoff between ϵ and κ [28]. We consider the trial model of distributions with uniformly random inputs, satisfying both non-signaling conditions [24] and Tsirelson’s bounds [38]. Consider the state-of-the-art photonic loophole-free Bell test reported in Ref. [20]. With probability estimation, the number of trials required for the distribution inferred from the measurement statistics is 4.668 × 107, which would require about 7.78 minutes of running time in the referenced experiment. With entropy accumulation [17], 2.887 × 1011 trials taking 802 hours would be required. For atomic experiments, we can use the distribution inferred from the measurement statistics in Ref. [7], for which probability estimation requires 7.354 × 104 trials, while entropy accumulation [17] requires 5.629 × 106. The experiment of Ref. [7] observed 1 to 2 trials per minute, so probability estimation would have needed at least 612.8 hours of data collection, which while impractical is still less than the 5.35 years required by entropy accumulation [17].
Finally, we briefly discuss the performance of probability estimation on DIRG with published Bell-test experimental data. The first experimental demonstration of conditional min-entropy certification for DIRG is reported in Ref. [10]. The method therein certifies the presence of 42 random bits at error bound ϵ = 10−2 against classical side information, where the trial model consists of quantum-achievable distributions with uniform inputs. (The lower bound of the protocol success probability κ = 1 was used implicitly in Ref. [10], so κ = 1 in the following comparison.) For the same data but with the less restrictive trial model , probability estimation certifies the presence of at least nine times more random bits with ϵ = 10−2. With ϵ = 10−6 probability estimation can still certify the presence of 80 random bits, while other methods fail to certify any random bits. For the loophole-free Bell-test data reported in Ref. [9] and analyzed in our previous work Ref. [19], the presence of 894 random bits at ϵ = 10−3 was certified against classical side information with the trial model . Further, 256 private random bits within 10−3 (in terms of the total-variation distance) of uniform were extracted in Ref. [19]. With probability estimation we can certify the presence of approximately two times more random bits at ϵ = 10−3. The presence of four times more bits can be certified if we use the more restrictive trial model . Furthermore, we can certify randomness even when the input distribution is not precisely known, which was an issue in the experiment of Ref. [9]. Applications to other experimental distributions, complete analyses of the mentioned experiments, and details on handling input choices whose probabilities are not precisely known are in Ref. [28].
In conclusion, probability estimation is a powerful and flexible framework for certifying randomness in data from a finite sequence of experimental trials. Implemented with probability estimation factors, it witnesses optimal asymptotic randomness rates. For practical applications requiring fixed-size blocks of random bits, it can reduce the latencies by orders of magnitude even for high-quality devices. Latency is a notable problem for device-independent quantum key generation (DIQKD). If probability estimation can be extended to accommodate security against quantum side information, the latency reductions may be extendable to DIQKD by means of existing constructions [17].
Finally we remark that if the trial results are explainable by local realism, no device-independent randomness would be certified by probability estimation. The reason is as follows. For simplicity we assume that the input distribution is fixed and known [52]. Consider a generic trial with results CZ and model . Let be the set of distributions of CZ explainable by local realism, which is a convex polytope with a finite number of extremal distributions σLR,k, k = 1, 2, …, K. Since is a subset of , by definition a PEF F with power β satisfies the condition
| (7) |
for each k. For each extremal distribution σLR,k in and each cz, the value of σLR,k,(c|z) is either 0 or 1, from which it follows that σLR,k(c|z)β σLR,k(cz) = σLR,k(cz). Eq. (7) now becomes
| (8) |
Since any local realistic distribution can be written as a convex mixture of extremal distributions σLR,k, k = 1, 2, …, K, Eq. (8) implies that for all distributions
| (9) |
By the concavity of the logarithm function and Eq. (9) we get that
Hence, the asymptotic entropy rate in Eq. (4) cannot be positive if the distribution of trial results is explainable by local realism. Furthermore, Eq. (9) shows that the PEF F is a test factor for the hypothesis test of local realism [21] (see Appendix B for the formal definition of test factors). So, if a finite sequence of trial results is explainable by local realism and Fi is a PEF with power β for the i’th trial, according to Ref. [21] the success event Tn ≥ 1/(pβ ϵ) with in Thm. 1 for randomness certification would happen with probability at most pβ ϵ.
Acknowledgments
We thank D. N. Matsukevich for providing the experimental data for Ref. [10], Bill Munro, Carl Miller, Kevin Coakley, and Paulina Kuo for help with reviewing this paper. This work includes contributions of the National Institute of Standards and Technology, which are not subject to U.S. copyright.
Appendix
Appendix A: Notation
Much of this work concerns stochastic sequences, that is, sequences of random variables (RVs). RVs are functions on an underlying probability space. The range of an RV is called its value space and may be thought of as the set of its observable values or realizations. Here, all RVs have countable value spaces. We truncate sequences of RVs so that we only consider finitely many RVs at a time. With this the underlying probability space is countable too. We use upper-case letters such as A, B, …, X, Y, … to denote RVs. The value space of an RV such as X is denoted by Rng(X). The cardinality of the value space of X is |Rng(X)|. Values of RVs are denoted by the corresponding lower-case letters. Thus x is a value of X, often thought of as the particular value realized in an experiment. When using symbols for values of RVs, they are implicitly assumed to be members of the range of the corresponding RV. In many cases, the value space is a set of letters or a set of strings of a given length. We use juxtaposition to denote concatenation of letters and strings. Stochastic sequences are denoted by capital bold-face letters, with the corresponding lower-case bold-face letters for their values. For example, we write and . Our conventions for indices are that we generically use N to denote a large upper bound on sequence lengths, n to denote the available length and i,j,k,l,m as running indices. By convention, A≤0 is the empty sequence of RVs. Its value is constant. When multiple stochastic sequences are in play, we refer to the collection of i’th RVs in the sequences as the data from the i’th trial. We typically imagine the trials as happening in time and being performed by an experimenter. We refer to the data from the trials preceding the upcoming one as the “past”. The past can also include initial conditions and any additional information that may have been obtained. These are normally implicit when referring to or conditioning on the past.
Probabilities are denoted by . If there are multiple probability distributions involved, we disambiguate with a subscript such as in or simply ν(…), where ν is a probability distribution. We generally reserve the symbol μ for the global, implicit probability distribution, and may write μ(…) instead of or . Expectations are similarly denoted by or . If ϕ is a logical expression involving RVs, then {ϕ} denotes the event where ϕ is true for the values realized by the RVs. For example, {f(X) > 0} is the event {x : f(x) > 0} written in full set notation. The brackets {…} are omitted for events inside or . As is conventional, commas separating logical expressions are interpreted as conjunction. When the capital/lower-case convention can be unambiguously interpreted, we abbreviate “X = x” as “x”. For example, with this convention, . Furthermore, we omit commas in the abbreviated notation, so . RVs or functions of RVs appearing outside an event but inside or after the conditioner in result in an expression that is itself an RV. We can define these without complications because of our assumption that the event space is countable. Here are two examples. is a function of the RVs X and Y and can be described as the RV whose value is whenever the values of X and Y are x and y, respectively. Similarly is the RV defined as a function of Y, with value whenever Y has value y. Note that X plays a different role before the conditioners in than it does in , as is not a function of X, but only of Y. We comment that conditional probabilities with conditioners having probability zero are not well-defined, but in most cases can be defined arbitrarily. Typically, they occur in a context where they are multiplied by the probability of the conditioner and thereby contribute zero regardless. An important context involves expectations, where we use the convention that when expanding an expectation over a set of values as a sum, zero-probability values are omitted. We do so without explicitly adding the constraints to the summation variables. We generally use conditional probabilities without explicitly checking for probability-zero conditioners, but it is necessary to monitor for well-definedness of the expressions obtained.
To denote general probability distributions, usually on the joint value spaces of RVs, we use symbols such as μ, ν, σ, with modifiers as necessary. As mentioned, we reserve the unmodified μ for the distinguished global distribution under consideration, if there is one. Other symbols typically refer to probability distributions defined on the joint range of a subset of the available RVs. We usually just say “distribution” instead of “probability distribution”. The terms “distributions on Rng(X)” and “distributions of X” are synonymous. If ν is a joint distribution of RVs, then we extend the conventions for arguments of to arguments of ν, as long as all the arguments are determined by the RVs for which ν is defined. For example, if ν is a joint distribution of X, Y, and Z, then ν(x|y) has the expected meaning, as does the RV ν(X|Y) in contexts requiring no other RVs. Further, ν(X) and ν(XY) are the marginal distributions of X and XY, respectively, according to ν.
In our work, probability distributions are constrained by a “model”, which is defined as a set of distributions and denoted by letters such as or . The models for trials to be considered here are usually convex and closed.
The total-variation (TV) distance between ν and ν′ is defined as
| (A1) |
where ⟦ϕ⟧ for a logical expression ϕ denotes the {0,1}-valued function evaluating to 1 iff ϕ is true. True to its name, the TV distance satisfies the triangle inequality. Here are three other useful properties: First, if ν and ν′ are joint distributions of X and Y and the marginals satisfy ν(Y) = ν′(Y), then the TV distance between ν and ν′ is the average of the TV distances of the Y-conditional distributions:
| (A2) |
Second, if for all y, the conditional distributions ν(X|y) = ν′(X|y), then the TV distance between ν and ν′ is given by the TV distance between the marginals on Y:
| (A3) |
Third, the TV distance satisfies the data-processing inequality. That is, for any stochastic process on Rng(X) and distributions ν and ν′ of X, . We use this property only for functions , but for general forms of this result, see Ref. [39]. The above properties of TV distances are well known, specific proofs can be found in Refs. [20, 28].
When constructing distributions close to a given one in TV distance, which we need to do for the proof of Thm. 1 in the main text, it is often convenient to work with subprobability distributions. A subprobability distribution of X is a sub-normalized non-negative measure on Rng(X), which in our case is simply a non-negative function on Rng(X) with weight . For expressions not involving conditionals, we use the same conventions for subprobability distributions as for probability distributions. When comparing subprobability distributions, means that for all x, , and we say that “dominates” .
Lemma 2. Let be a subprobability distribution of X of weight w = 1 − ϵ. Let ν and ν′ be distributions of X satisfying and . Then TV(ν, ν′) ≤ ϵ.
Proof. Calculate
Lemma 3. Assume that p ≥ 1/|Rng(X)|. Let ν be a distribution of X and a subprobability distribution of X with weight w = 1 − ϵ and . Then there exists a distribution ν′ of X with , ν′ ≤ p, and TV(ν, ν′) ≤ ϵ.
Proof. Because p ≥ 1/|Rng(X)|, that is, ∑x p ≥ 1, and for all x, , there exists a distribution with . Since ν′ and ν are distributions dominating and by Lem. 2, TV(ν, ν′) ≤ ϵ.
Appendix B: Test Supermartingales and Test Factors
Definition 4. A test supermartingale [23] with respect to a stochastic sequence R and model is a stochastic sequence with the properties that 1) T0 = 1, 2) for all i Ti ≥ 0, 3) Ti is determined by R≤i and the governing distribution, and 4) for all distributions in , . The ratios Fi = Ti/Ti−1 with Fi = 1 if Ti−1 = 0 are called the test factors of T.
Here R captures the relevant information that accumulates in a sequence of trials. It does not need to be accessible to the experimenter. Between trials i and i + 1, the sequence R≤i is called the past. In the definition, we allow for Ti to depend on the governing distribution μ. With this, for a given μ, Ti is a function of R≤i Below, when stating that RVs are determined, we implicitly include the possibility of dependence on μ without mention. The μ-dependence can arise through expressions such as for some G, which is determined by R≤i given μ. One way to formalize this is to consider μ-parameterized families of RVs. We do not make this explicit and simply allow for our RVs to be implicitly parameterized by μ. We note that the governing distribution in a given experiment or situation is fixed but usually unknown with most of its features inaccessible. As a result, many RVs used in mathematical arguments cannot be observed even in principle. Nevertheless, they play important roles in establishing relationships between observed and inferred quantities.
Defining Fi = 1 when Ti−1 = 0 makes sense because given {Ti−1 = 0}, we have {Ti = 0} with probability 1. The sequence satisfies the conditions that for all i, 1) Fi ≥ 0, 2) Fi is determined by R≤i and 3) for all distributions in , . We can define test supermartingales in terms of such sequences: Let F be a stochastic sequence satisfying the three conditions. Then the stochastic sequence with members T0 = 1 and Ti = Π1≤j≤i Fj for i ≥ 1 is a test supermartingale. It suffices to check that . This follows from
where we pulled out the determined quantity Ti from the conditional expectation. In this work, we construct test supermartingales from sequences F with the above properties. We refer to any such sequence as a sequence of test factors, without necessarily making the associated test supermartingale explicit. We extend the terminology by calling an RV F a test factor with respect to if F ≥ 0 and for all distributions in . Note that F = 1 is a valid test factor.
For an overview of test supermartingales and their properties, see Ref. [23]. The notion of test supermartingales and proofs of their basic properties are due to Ville [40] in the same work that introduced the notion of martingales. The name “test supermartingale” appears to have been introduced in Ref. [23]. Test supermartingales play an important theoretical role in proving many results in martingale theory, including that of proving tail bounds for large classes of martingales. They have been studied and applied to Bell tests [21, 41, 42].
The definition implies that for a test supermartingale T, for all n, . This follows inductively from and T0 = 1. An application of Markov’s inequality shows that for all ϵ > 0,
| (B1) |
Thus, a large final value t = Tn of the test supermartingale is evidence against in a hypothesis test with as the (composite) null hypothesis. Specifically, the RV 1/T is a p-value bound against , where in general, the RV U is a p-value bound against if for all distributions in , .
One can produce a test supermartingale adaptively by determining the test factors Fi+1 to be used at the next trial. If the i’th trial’s data is Ri, including any incidental information obtained, then Fi+1 is expressed as a function of R≤i and data from the (i + 1)’th trial (a “past-parameterized” function of Ri+1), and constructed to satisfy Fi+1 ≥ 0 and for any distribution in the model . Note that inbetween trials, we can effectively stop the experiment by assigning all future Fi+1 = 1, which is a valid test factor, conditional on the past. This is equivalent to constructing the stopped process relative to a stopping rule. This argument also shows that the stopped process is still a test supermartingale.
More generally, we use test supermartingales for estimating lower bounds on products of positive stochastic sequences G. Such lower bounds are associated with unbounded-above confidence intervals. We need the following definition:
Definition 5. Let U, V, X be RVs and 1 ≥ ϵ ≥ 0. I = [U, V] is a confidence interval for X at level ϵ with respect to if for all distributions in we have . The quantity is called the coverage probability.
As noted above, the RVs U, V and X may be μ-dependent. For textbook examples of confidence intervals such as in Ch. 2.4.3 of Ref [43], X is a parameter determined by μ, and U and V are obtained according to a known distribution for an estimator of X. The quantity e in the definition is a significance level, which corresponds to a confidence level of (1 − ϵ). The following technical lemma will be used in the next section.
Lemma 6. Let F and G be two stochastic sequences with Fi ∈ [0, ∞), Gi ∈ (0, ∞], and Fi and Gi determined by R≤i. Define T0 = 1, and U0 = 1, , and suppose that for all , . Then [Tnϵ, ∞) is a confidence interval for Un at level ϵ with respect to .
Proof. The assumptions imply that the sequence forms a sequence of test factors with respect to and generate the test supermartingale T/U, where division in this expression is term-by-term. Therefore, by Eq. (B1),
| (B2) |
so [Tnϵ, ∞) is a confidence interval for Un at level ϵ.
Appendix C: Proof of Main Results
In this section, we show how to perform probability estimation and how to certify smooth conditional min-entropy by probability estimation.
1. Probability Estimation by Test Supermartingales: Proof of Main Text Eq. (1)
We consider the situation where CZ is a time-ordered sequence of n trial results, and the classical side information is represented by an RV E with countable value space. In an experiment, Z and C are the inputs and outputs of the quantum devices, and the side information E is carried by an external classical system E. Before the experiment, the initial state of E may be correlated with the quantum devices. At each trial of the experiment, we allow arbitrary one-way communication from the system E to the devices. For example, E can initialize the state of the quantum devices via a one-way communication channel. We also allow the possibility that the device initialization at a trial by E depends on the past inputs preceding the trial. This implies that the random inputs Z can come from publicrandomness sources, as first pointed out in Ref. [3]. However, at any stage of the experiment the information of the outputs C cannot be leaked to the system E. After the experiment, we observe Z and C, but not the side information E.
A model for an experiment is defined as the set of joint probability distributions of CZ that satisfy the known constraints and consists of all achievable probability distributions of CZ conditional on values e of E. Thus we say that a joint distribution μ of CZ and E satisfies the model if for each value e.
We focus on probability estimates with lower bounds on coverage probabilities that do not depend on E. Our specific goal is to prove Eq. (1) in the main text. We will show that the probability bound of U(CZ) = (Tnϵ)−1/β in Eq. (1) of the main text is an instance of what we call an “ϵ-uniform probability estimator”:
Definition 7. Let 1 ≥ ϵ ≥ 0. The function U : Rng(CZ) → [0, ∞) is a level-ϵ E-uniform probability estimator for (ϵ-UPE or with specifics, ) if for all e and distributions μ satisfying the model , we have . We omit specifics such as if they are clear from context.
We can obtain ϵ-UPEs by constructing test supermartingales. In order to achieve this goal, we consider models of distributions of CZ constructed from a chain of trial models , where the trial model is defined as the set of all achievable distributions of Ci+1Zi+1 conditional on both the past results c≤iz≤i and the value e of E. The chained model consists of all conditional distributions μ(CZ|e) satisfying the following two properties. First, for all i, c≤iz≤i, and e, the conditional distributions
Second, the joint distribution μ of CZ and E satisfies that Zi+1 is independent of C≤i conditionally on both Z≤i and E. The second condition is needed in order to be able to estimate ZE-conditional probabilities of C and corresponds to the Markov-chain condition in the entropy accumulation framework [17].
In many cases, the trial models do not depend on the past outputs c≤i, but probability estimation can take advantage of dependence on the past inputs z≤i. Such dependence captures the possibility that at the (i + 1)’th trial the device initialization by the external classical system E depends on the past inputs z≤i. In applications involving Bell-test configurations, the trial models capture constraints on the input distributions and on non-signaling or quantum behavior of the devices. For simplicity, we write , leaving the conditional parameters implicit. Normally, models for individual trials are convex and closed. If they are not, we note that our results generally extend to the convex closures of the trial models used.
For chained models , we can construct ϵ-UPEs from products of “probability estimation factors” according to the following definition, see also the paragraph containing Eq. (1) in the main text.
Definition 8. Let β > 0, and let be any model, not necessarily convex. A probability estimation factor (PEF) with power β for is a non-negative RV F = F(CZ) such that for all , .
We emphasize that a PEF is a function of the trial results CZ, but not of the side information E.
Consider the model constructed as a chain of trial models . Let Fi be PEFs with power β > 0 for , past-parameterized by C≤i and Z≤i. Define T0 = 1, for i ≥ 1, and
| (C1) |
Then, U(CZ) satisfies the inequality in Eq. (1) of the main text as proven in the following theorem, and is therefore an ϵ-UPE. To simplify notation in the following theorem, we normally write the distribution μ(CZ|e) conditional on e as μe(CZ), abbreviated as μe.
Theorem 9. Fix β > 0. For each value e of E, each , and ϵ > 0, the following inequality holds:
| (C2) |
Note that β cannot be adapted during the trials. On the other hand, before the i’th trial, we can design the PEFs Fi for the particular constraints relevant to the i’th trial.
Proof. We first observe that for each value e of E,
| (C3) |
This follows by induction with the identity
by conditional independence of Zj+1 on C≤j given Z≤j and E = e.
We claim that for each e, Fi+1μe(Ci+1|Zi+1Z≤iC≤i)β is a test factor determined by C≤i+1Z≤i+1. To prove this claim, for all c≤iz≤i, the distributions . With Fi+1 = Fi+1(Ci+1Zi+1; c≤iz≤i), we obtain the bound
where we invoked the assumption that Fi+1 is a PEF with power β for . By arbitrariness of c≤iz≤i, and because the factors Fi+1μe(Ci+1|Z≤iC≤i)β are determined by C≤i+1Z≤i+1, the claim follows. The product of these test factors is
| (C4) |
with . To obtain the last equality above, we used Eq. (C3). Thus, for each e, the sequence Q0 = 1 and Qi = Tiμe(C≤i|Z≤i)β for i > 0 satisfies the supermartingale property . We remark that as a consequence, . By induction this gives . Thus, considering that , Tn is a PEF with power β for , that is, chaining PEFs yields PEFs for chained models.
In Lem. 6, if we replace Ti and Ui there by Ti and μe(C≤i|Z≤i)−β here, then from Eq. (B2) and manipulating the inequality inside , we get the inequality in Eq. (C2).
That Fi+1 can be parameterized in terms of the past as Fi+1 = Fi+1 (Ci+1Zi+1; C≤iZ≤i) allows for adapting the PEFs based on CZ, but no other information can be used. To adapt the PEF Fi+1 based on other past information besides C≤iZ≤i, we need a “soft” generalization of probability estimation as detailed in Ref. [28].
2. Smooth Min-Entropy by Probability Estimation: Proof of Main Text Thm. 1
We want to generate bits that are near-uniform conditional on E and often other variables such as Z. For our analyses, E is not particularly an issue because our results hold uniformly for all values of E, that is, conditionally on {E = e} for each e. However this is not the case for Z. For this subsection, it is not necessary to structure the RVs as stochastic sequences, so below we use C and Z in place of C and Z.
Definition 10. The distribution μ of CZE has ϵ-smooth average ZE-conditional maximum probability p if there exists a distribution ν of CZE with TV(ν, μ) ≤ ϵ and ∑ze maxc(ν(c|ze))ν(ze) ≤ p. The minimum p for which μ has ϵ-smooth average ZE-conditional maximum probability p is denoted by . The quantity is the (classical) ϵ-smooth ZE-conditional min-entropy.
We denote the ϵ-smooth ZE-conditional min-entropy evaluated conditional on an event {ϕ} by . We refer to the smoothness parameters as “error bounds”. Observe that the definitions are monotonic in the error bound. For example, if and ϵ′ ≥ ϵ, then . The quantity ∑ze maxc(ν(c|ze))ν(ze) in the definition of can be recognized as the (average) maximum guessing probability of C given Z and E (with respect to ν), whose negative logarithm is the guessing entropy defined, for example, in Ref. [44].
A summary of the relationships between smooth conditional min-entropies and randomness extraction with respect to quantum side information is given in Ref. [22] and can be specialized to classical side information. When so specialized, the definition of the smooth conditional min-entropy in, for example, Ref. [22] differs from the one above in that Ref. [22] uses one of the fidelity-related distances. One such distance reduces to the Hellinger distance h for probability distributions for which .
The Z-conditional maximum probabilities with respect to E = e can be lifted to the ZE-conditional maximum probabilities, as formalized by the next lemma.
Lemma 11. Suppose that for all e, , and let and . Then .
Proof. For each e, let νe witness . Then TV(νe,μ(CZ|e)) ≤ ϵe and ∑z maxc(νe(c|z))νe(z) ≤ pe. Define ν by ν(cze) = νe(cz)μ(e). Then the marginals ν(E) = μ(E), so we can apply Eq. (A2) for
Furthermore,
as required for the conclusion. □
The level of a probability estimator relates to the smoothness parameter for smooth min-entropy via the relationships established below.
Theorem 12. Suppose that U is an and that the distribution μ of CZE satisfies the model . Let p ≥ 1/|Rng(C)| and κ = μ(U ≤ p). Then .
Proof. Let κe = μ(U ≤ p|e). Below we show that for all values e of E, . Once this is shown, we can use
| (C5) |
and Lem. 11 to complete the proof. For the remainder of the proof, e is fixed, so we simplify the notation by universally conditioning on {E = e} and omitting the explicit condition. Further, we omit e from suffixes. Thus κ = κe from here on.
Let κz = μ(U ≤ p|z). We have ∑z κzμ(z) = κ and
| (C6) |
Define the subprobability distribution by . By the definition of ϵ-UPEs, we get that the weight of satisfies
| (C7) |
Define . The weight of satisfies
| (C8) |
| (C9) |
To obtain the last inequality above, we used Eq. (C7). Thus is a subprobability distribution of weight at least 1 − ϵ/κ. We use to construct the distribution ν witnessing the conclusion of the theorem. For each cz we bound
| (C10) |
where in the second step we used Eq. (C6). Define by , with if μ(z|U ≤ p) = 0, and let . We show below that wz ≤ 1, and so the definition of extends the conditional probability notation to the subprobability distribution with the understanding that the conditionals are with respect to μ given {U ≤ p}. Applying the first two steps of Eq. (C10) and continuing from there, we have
| (C11) |
Since μ(C|z, U ≤ p) is a normalized distribution, the above equation implies that wz ≤ 1. For each z, we have that (Eq. (C10)), p/κz ≥ p ≥ 1/|Rng(C)|, and μ(C|z, U ≤ p) dominates (Eq. (C11)). Hence, we can apply Lem. 3 to obtain distributions νz of C such that , νz ≤ p/κz, and TV(νz, μ(C|z, U ≤ p)) ≤ 1 − wz. Now we can define the distribution ν of CZ by ν(cz) = νz(c)μ(z|U ≤ p). By Eq. (A2), we get
| (C12) |
where in the last step we used Eq. (C9). For the average maximum probability of ν, we get
| (C13) |
where to obtain the last line we used Eq. (C6). The above two equations show that for an arbitrary value e of E, , which together with the argument at the beginning of the proof establishes the theorem. □
The above theorem implies Thm. 1 in the main text as a corollary.
Corollary 13. Suppose that the distribution μ of CZE satisfies the chained model . Let 1 ≥ p ≥ 1/|Rng(C)| and 1 ≥ κ′, ϵ > 0. Define {ϕ} to be the event that U ≤ p, where U is given in Eq. (C1). Let . Then the smooth conditional min-entropy satisfies
Proof. We observe that the event that U ≤ p is the same as the event that U′ ≤ p/κ1/β, where U′ = (Tnϵκ)−1/β and Tn is defined as above Eq. (C1). By Thm. 9, U′ is an ϵκ-UPE. In Thm. 12, if we replace U and p there by U′ and p/κ1/β here, then we obtain . Since κ′ ≤ κ, we also have . According to the definition of the smooth conditional min-entropy in Def. 10, we get the lower bound in the corollary. □
We remark that, to obtain uniformly random bits, Cor. 13 can be composed directly with “classical-proof” strong extractors in a complete protocol for randomness generation. The error bounds from the corollary and those of the extractor compose additively [28]. Efficient randomness extractors requiring few seed bits exist, see Refs. [45, 46]. Specific instructions for ways to apply them for randomness generation can be found in Refs. [19, 20, 28].
Appendix D: Properties of PEFs
Here we prove the monotonicity of the functions g(β) and βg(β): As β increases, the rate g(β) as defined in Eq. (4) of the main text is monotonically non-increasing, and βg(β) is monotonically non-decreasing. These are the consequence of the following lemma:
Lemma 14. If F is a PEF with power β for the trial model , then for any 0 < γ ≤ 1, F is a PEF with power β/γ for , and Fγ is a PEF with poiver γβ for .
Proof. For an arbitrary distribution , we have 0 ≤ σ(c|z) ≤ 1 for all cz. By the monotonic property of the exponential function x ↦ ax with 0 ≤ a ≤ 1, we get that σ(c|z)β/γ ≤ σ(c|z)β for all cz. Therefore, if a non-negative RV F satisfies that
then
Hence, if F is a PEF with power β for , then F is a PEF with power β/γ for .
On the other hand, by the concavity of the function x ↦ xγ with 0 < γ ≤ 1, we can apply Jensen’s inequality to get
for all distributions . Hence Fγ is a PEF with power γβ for .
The property that βg(β) is monotonically non-decreasing in β follows directly from Lem. 14 and the definition of g(β) in Eq. (4) of the main text. On the other hand, to prove that g(β) is monotonically non-increasing in β, we also need to use the equality that
The monotonicity of the function g(β) (or βg(β)) helps to determine the maximum asymptotic randomness rate g0 = supβ>0 g(β) (or the maximum certificate rate γPEF = supβ>0 βg(β)), as one can analyze the PEFs with powers β only in the limit where β goes to 0 (or where β goes to the infinity).
Appendix E: Numerical Optimization of PEFs
We provide more details here on how to perform the optimizations (such as the optimization in Eq. (3) of the main text) required to determine the power β and the PEFs Fi to be used at the i’th trial. We claim that to verify that the PEF F satisfies the first constraint in Eq. (3) of the main text for all , it suffices to check this constraint on the extremal members of the convex closure of . The claim follows from the next lemma, Carathéodory’s theorem, and induction on the number of terms in a finite convex combination.
Lemma 15. Let F ≥ 0 and β > 0. Suppose that the distribution σ can be expressed as a convex combination of two distributions: For all cz, σ(cz) = λσ1(cz) + (1 − λ)σ2(cz) with λ ∈ [0, 1]. If the distributions σ1 and σ2 satisfy ∑cz F(cz)σi(c|z)β σi(cz) ≤ 1, then σ satisfies ∑cz F(cz)σ(c|z)βσ(cz) ≤ 1.
Proof. We start by proving that for every cz, the following inequality holds:
| (E1) |
If σ1(z) = σ2(z) = 0, we recall our convention that probabilities conditional on z are zero, and so for every c, σ1(c|z) = σ2(c|z) = σ(c|z) = 0. Hence, Eq. (E1) holds immediately (as an equality). If σ1(z) = 0 < σ2(z), then for every c, σ1(c|z) = 0 and σ(cz) = (1 − λ)σ2(cz). In this case, one can verify that Eq. (E1) holds. By symmetry, Eq. (E1) also holds in the case that σ2(z) = 0 < σ1(z). Now consider the case that σ1(z) > 0 and σ2(z) > 0. Let xi = σi(cz) and yi = σi(z), and consider the function
so f(0) = σ2(c|z)βσ2(cz), f(1) = σ1(c|z)βσ1(cz), and f(λ) = σ(c|z)βσ(c|z). If we can show that f(λ) is convex in λ on the interval [0,1], Eq. (E1) will follow. Since f(λ) is continuous for λ ∈ [0,1] and smooth for λ ∈ (0,1), it suffices to show that f″(λ) ≥ 0 as follows:
which is a non-negative multiple of a square. Having demonstrated Eq. (E1), we can complete the proof of the lemma as follows:
Suppose that the trial model is a convex polytope with a finite number of extremal distributions σk(CZ), k = 1,2, …, K. In view of the claim before Lem. 15, the optimization problem in Eq. (3) of the main text is equivalent to
| (E2) |
Given the values of n, β, ϵ, ν, and σk with k = 1, 2, …, K, the objective function in Eq. (E2) is a concave function of F(CZ), and each constraint on F(CZ) is linear. Hence, the above optimization problem can be solved by any algorithm capable of optimizing nonlinear functions with linear constraints on the arguments. In our implementation, we use sequential quadratic programming. Due to numerical imprecision, it is possible that the returned numerical solution does not satisfy the first constraint in Eq. (E2) and the corresponding PEF is not valid. In this case, we can multiply the returned numerical solution by a positive factor smaller than 1, whose value is given by the reciprocal of the largest left-hand side of the above first constraint at the extremal distributions σk(CZ), k = 1, 2, …, K. Then, the re-scaled solution is a valid PEF. We remark that if the trial model is not a convex polytope but there exists a good approximation with a convex polytope, then we can enlarge the model to for an effective method to determine good PEFs.
Consider device-independent randomness generation (DIRG) in the CHSH Bell-test configuration [30] with inputs Z = XY and outputs C = AB, where A, B, X, Y ∈ {0,1}. If the input distribution is fixed with for all xy, then we need to characterize the set of input-conditional output distributions . If we consider all distributions satisfying non-signaling conditions [24], then the associated trial model is the nonsignaling polytope, which is convex and has 24 extreme points [25]. If we consider only the distributions achievable by quantum mechanics, then the associated trial model is a proper convex subset of the above non-signaling polytope. The quantum set has an infinite number of extreme points. In our analysis of the Bell-test results reported in Refs. [9, 10], we simplified the problem by considering instead the set of distributions satisfying nonsignaling conditions [24] and Tsirelson’s bounds [38], which includes all the distributions achievable by quantum mechanics. For a fixed input distribution with for all xy, the associated trial model is a convex polytope with 80 extreme points [28]. If the input distribution is not fixed but is contained in a convex polytope, the associated trial model is still a convex polytope (see Ref. [28] for more details). Therefore, for DIRG based on the CHSH Bell test [30], the optimizations for determining the power β and the PEFs Fi can be expressed in the form in Eq. (E2) and hence solved effectively.
Appendix F: Relationship between Certificate Rate and Statistical Strength
We prove that for DIRG in the CHSH Bell-test configuration, the maximum certificate rate γPEF witnessed by PEFs at a distribution ν of trial results is equal to the statistical strength of ν for rejecting local realism as studied in Refs. [35–37]. To prove this, we first simplify the optimization problem for determining γPEF. Then, we show that the simplified optimization problem is the same as that for determining the statistical strength. The argument generalizes to any convex-polytope model whose extreme points are divided into the following two classes: 1) classical deterministic distributions satisfying that given the inputs, the outputs are deterministic (here we require that for every cz there exists a distribution in the model where the outcome is c given z), and 2) distributions that are completely non-deterministic in the sense that for no input is the output deterministic. The argument further generalizes to models contained in such a model, provided it includes all of the classical deterministic distributions of the outer model.
In order to determine γPEF = supβ>0 βg(β), considering the monotonicity of the function βg(β) proved in Sect. D and the definition of g(β) in Eq. (4) of the main text, we need to solve the following optimization problem at arbitrarily large powers β:
| (F1) |
To simplify this optimization, we first consider the case that the trial model is the set of non-signaling distributions with a fixed input distribution where for all z. The model is a convex polytope and has 24 extremal distributions [25], among which there are 16 deterministic local realistic distributions, denoted by σLR, i = 1, 2, …, 16, and 8 variations of the Popescu-Rohrlich (PR) box [24], denoted by σPRj, j = 1, 2, …, 8. According to the discussion in Sect. E, the optimization problem in Eq. (F1) is equivalent to
| (F2) |
where we used the fact that σLRi(c|z) is either 0 or 1. Only the second constraint in Eq. (F2) depends on the power β. The distributions σPRj satisfy that σPRj(c|z) < 1 for all cz. Hence σPRj)β → 0 for all cz as β → ∞. Because there are finitely many constraints and values of cz, the second constraint becomes irrelevant for sufficiently large β. Let be the minimum β for which the second constraint is implied by the first. The threshold is independent of the specific input distribution. To see this, the last factors in the sums on the left-hand sides of the constraints in Eq. (F2) are of the form σ(cz), which can be written as σ(c|z)σ(z) with a fixed σ(z). We can define and optimize over instead, thus eliminating the fixed input distribution from the problem. Then the first constraint on implies that . Since ∑i σLRi(c|z) ≥ 4 for each cz, this constraint implies the second provided that σPRj(c|z)1+β ≤ 1/4, which holds for each j and cz for sufficiently large β. Particularly, since σPRj(c|z) is either 0 or 1/2 [25], we obtain that . Furthermore, by numerical optimization for a sample of large-enough β we find that . Therefore, when the optimization problem in Eq. (F2) is independent of β and becomes
| (F3) |
This optimization problem is identical to the one for designing the optimal test factors for the hypothesis test of local realism [21, 41, 47]. In Ref. [21] it is proven that the optimal value of the optimization problem in Eq. (F3) is equal to the statistical strength for rejecting local realism [35–37], which is defined as
Here, σLR is an arbitrary local realistic distribution and DKL(ν|σLR) is the Kullback-Leibler divergence from σLR to ν [48]. Therefore, when we have βg(β) = s. Considering that the function βg(β) is monotonically non-decreasing in β, we have shown that
Now we consider the case where the trial model is the set of quantum-achievable distributions with a fixed input distribution where for all z. Since the set of quantum-achievable distributions is a proper subset of the non-signaling polytope, the constraints on F(CZ) imposed by quantum-achievable distributions are a subset of the constraints imposed by non-signaling distributions. Moreover, the set of quantum-achievable distributions contains all local realistic distributions. Therefore, in the quantum case, when , the constraints on F(CZ) are also implied by the constraints associated with the local realistic distributions. Consequently the maximum certificate rate γPEF is also equal to the statistical strength s. We remark that as a consequence, if we set to be the threshold such that when all quantum constraints on F(CZ) are implied by those imposed by the local realistic distributions, then .
We remark that β0 = inf[β|βg(β) = s} is typically strictly less than and depends on both the distribution ν as well as the trial model . One way to understand this behavior is as follows: When , the second constraint in Eq. (F2) is relevant; however, if β is still large enough, it is possible that the constraint does not affect the optimal solution of the optimization problem (F2). By numerical optimization, we find that for the CHSH Bell-test configuration β0 is typically less than 0.2 when the trial model includes all non-signaling distributions with the uniform distribution for inputs.
Appendix G: Analytic Expressions for Asymptotic Randomness Rates
In this section we derive the asymptotic randomness rates for the trial model consisting of non-signaling distributions according to two different methods for DIRG protocol based on the CHSH Bell test [30]. We first consider the maximum asymptotic rate g0 witnessed by PEFs. Then, we derive the single-trial conditional min-entropy for comparison.
Suppose that the distribution of each trial’s inputs XY and outputs AB is , where is the model for each trial. The maximum asymptotic rate g0 is equal to the worst-case conditional entropy that is consistent with the distribution ν(ABXY) [28]. That is, the rate g0 is given by the following minimization:
| (G1) |
where σ is the joint distribution of A, B, X, Y and E, and σ(ABXY) is its marginal. By the assumption that the value space of E is countable, we can also express the above minimization as
| (G2) |
where σe is the distribution of A, B, X and Y conditional on E = e according to σ, and ωe is the probability of the event E = e. By the concavity of the conditional entropy, if any of the σe contributing to the sum in Eq. (G2) is not extremal in , we can replace it by a convex combination of extremal distributions to decrease the value of the sum. Thus, we only have to consider extremal distributions in the above minimization.
For the rest of this section we let consist of non-signaling distributions for the CHSH Bell-test configuration with a fixed input distribution where for all xy. As explained in the previous section, is a convex polytope with 24 extreme points. Considering the argument below Eq. (G2), the number of terms in the sum of Eq. (G2) is at most 24. As in the previous section, we can divide the 24 extreme points into the two classes consisting of the 16 deterministic local realistic distributions σLRi, i = 1, 2, …, 16, and the 8 variations of the PR box σPRj, j = 1, 2, …, 8. Because the σLRi are deterministic conditional on the inputs, if σe = σLRi then the conditional entropy satisfies HσLRi (AB|XY, E = e) = 0. For each PR box σPRj, the conditional probabilities σPRj (AB|XY) are either 0 or 1/2 [25]. Thus, if σe = σPRj, the conditional entropy satisfies HσPRj (AB|XY, E = e) = 1. Hence, the minimization problem in Eq. (G2) becomes
| (G3) |
We need to find the minimum total probability of PR boxes in a representation of the distribution ν as a convex combination of the 16 local realistic distributions and the 8 PR boxes. To help solve this problem, we consider the violation of the CHSH Bell inequality [30]. Recall that there is only one PR box that can violate a particular CHSH Bell inequality [25], where ICHSH is the CHSH Bell function
| (G4) |
and A, B, X, Y ∈ {0,1}. Let σPR1 be the violating PR box. The expectation of ICHSH according to σPR1 is maximal, that is, . Without loss of generality, . The probability ωPR1 in the convex decomposition of ν satisfies the inequality , or equivalently, . Hence, according to Eq. (G3), we have .
We next show that . For this, we directly use the result of Ref. [49]. According to Ref. [49], for any non-signaling distribution σ(ABXY), if , then the distribution σ(ABXY) can be decomposed as σ(ABXY) = ωPR1 σPR1 + ∑iωLRiσLRi, where , ωLRi ≥ 0, and ∑iωLRi = 1 − ωPR1. Specializing to the distribution ν(ABXY), we get that for .
FIG. 3:
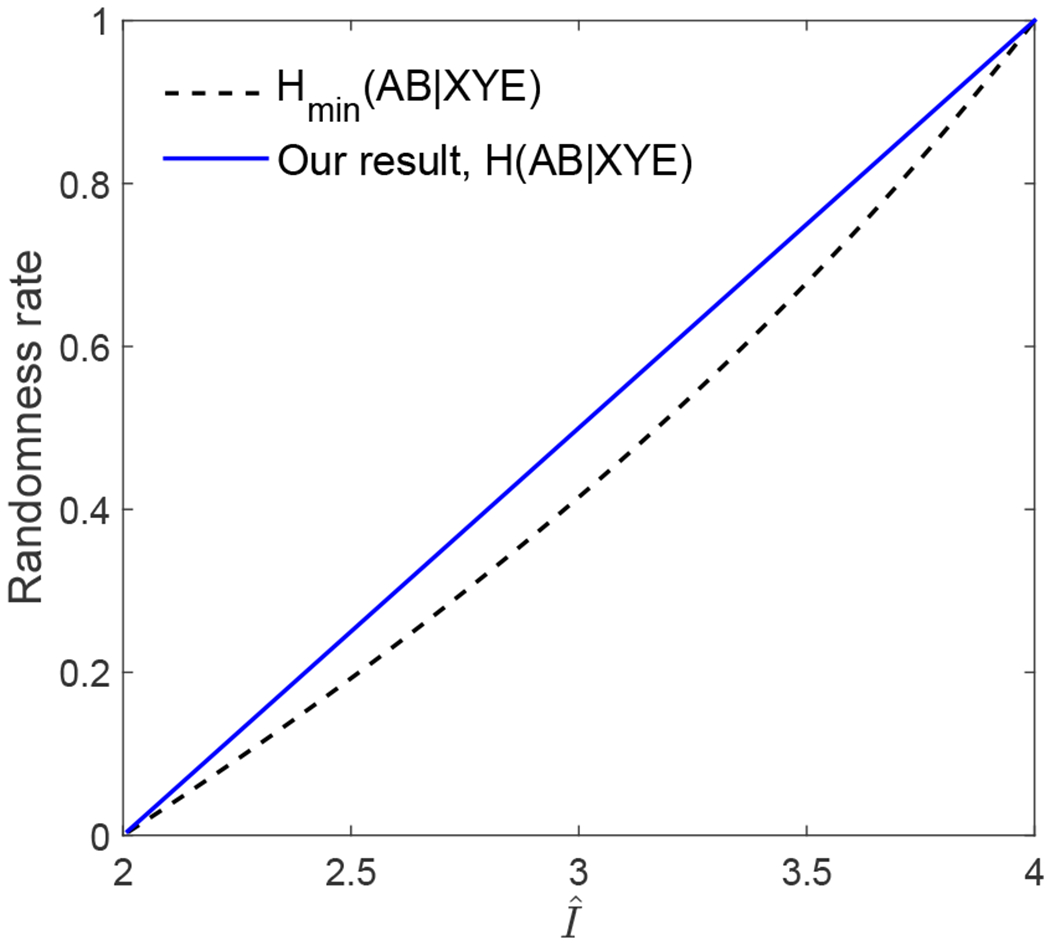
Asymptotic randomness rates as a function of . Results according to both our method (the solid curve) and Refs. [3, 10, 12, 18, 31–33] (the dashed curve) are shown. Our method witnesses the maximum asymptotic rate H(AB|XY E), which is the worst-case conditional entropy.
The arguments above show that given , the maximum asymptotic randomness rate witnessed by PEFs is
| (G5) |
independent of the particular distribution ν realizing .
We also numerically evaluated the maximum asymptotic rate according to g0 = supβ>0 g(β) with g(β) given by Eq. (4) of the main text. The numerical results are presented in Fig. 3, which are consistent with the analytic expression in Eq. (G5).
Next, we consider the quantification of the asymptotic randomness rate by the single-trial conditional min-entropy Hmin(AB|XY E), which is a lower bound and is studied in Refs. [3, 10, 12, 18, 31–33]. The single-trial conditional min-entropy is defined by
| (G6) |
where Pguess(AB|XYE) is the average guessing probability of the output AB given the input XY and the side information E, as defined in Ref. [33]. According to Refs. [32, 33], the guessing probability at xy is given by the following maximization:
| (G7) |
If a σe contributing to the sum in Eq. (G7) is not extremal in the set , we can replace it by a convex combination of extremal distributions to increase the value of the sum. Thus, we only have to consider extremal distributions σe in the above maximization. Applying the argument that led from Eq. (G2) to Eq. (G3), we obtain
| (G8) |
Since only need to minimize the total probability of PR boxes ∑jωPRj in the convex decomposition of the distribution ν. Prom the derivation of g0 that gave Eq. (G5), we conclude that for . Therefore regardless of the particular input xy. Furthermore, the specific convex decomposition over E that achieves the maximum in Eq. (G8) is the same for all the possible inputs. Hence we also have independent of the input distribution. Therefore the single-trial conditional min-entropy is
| (G9) |
which is plotted in Fig. 3.
The results of this section are summarized in the following theorem:
Theorem 16. Suppose that the trial model consists of non-signaling distributions with a fixed input distribution where for all xy. For any , both the maximum asymptotic randomness rate g0 witnessed by PEFs and the single-trial conditional min-entropy Hmin(AB|XY E) depend only on and are given by and .
Appendix H: Entropy Accumulation
Consider DIRG in the CHSH Bell-test configuration. In this section, the input distribution at each trial is assumed to be uniform. Define the winning probability at a trial by where with ν the distribution of trial results. Entropy accumulation [17] is a framework for estimating (quantum) conditional min-entropy with respect to quantum side information and can be applied to the CHSH Bell-test configuration. The following theorem from Ref. [17] implements the framework:
Theorem 17. Let , and 1 ≥ κ, ϵ > 0. Suppose that after n trials the joint quantum state of the inputs XY, the outputs AB and the quantum side information E is ρ. Define {ϕ} to be the event that the experimentally observed winning probability is higher than or equal to ωexp, and suppose that . Denote the joint quantum state conditional on {ϕ} by ρ|ϕ. Then the (quantum) smooth conditional min-entropy evaluated at ρ|ϕ satisfies
where η is defined by
with h(x) = −x log2(x) − (1 − x) log2 (1 − x) be the binary entropy function.
The function fmin in the theorem is referred to as a min-tradeoff function. The parameter pt in the theorem is free, and can be optimized over its range before running the protocol based on the chosen parameters n, ωexp, ϵ and κ. So the optimal entropy rate is ηopt(ωexp, n, ϵ, κ) = maxpt η(pt, ωexp, n, ϵ, κ).
According to Thm. 17, in order to certify b bits of entropy given ωexp, ϵ and κ, we need that ηη(pt, ωexp, n, ϵ, κ) ≥ b. Equivalently, n ≥ nEAT,b(pt) where
| (H1) |
Including the optimization over pt gives the minimum number of identical trials required:
| (H2) |
To compute nEAT,b, we set the parameter ωexp to the winning probability according to the distribution ν of trial results in a stable experiment.
We finish with several remarks on the comparison between entropy accumulation and probability estimation. First, Thm. 17 based on entropy accumulation holds with respect to quantum side information, while Cor. 13 (Thm. 1 in the main text) based on probability estimation holds with respect to classical side information. Second, in principle both entropy accumulation and probability estimation can witness asymptotically tight bounds on the smooth conditional min-entropies with respect to the assumed side information. Entropy accumulation can witness the maximum asymptotic entropy rate with respect to quantum side information, if an optimal min-tradeoff function is available. However, it is unknown how to obtain such min-tradeoff functions. In particular, the min-tradeoff function fmin (p, pt) is not optimal for the CHSH Bell-test configuration considered here. A min-tradeoff function is required to be a bound on the single-trial conditional von Neumann entropy H(AB|XY E). That fmin (p, pt) is not optimal is due to the following: 1) fmin (p, pt) is designed according to a bound on the single-trial conditional von Neumann entropy H(A|XY E) derived in Refs. [50, 51]. A tight bound on H(A|XY E) is generally not a tight bound on H(AB|XY E). 2) The bound on H(A|XY E) derived in Refs. [50, 51] is tight if the only information available is the winning probability. However, in practice one can access the full measurement statistics rather than just the winning probability. In contrast to entropy accumulation, probability estimation is an effective method for approaching the maximum asymptotic entropy rate (with respect to classical side information) considering the full measurement statistics and the model constraints. In general, the maximum rate with respect to quantum side information is lower than that with respect to classical side information, as accessing quantum side information corresponds to a more powerful attack. Third and as demonstrated in the main text, probability estimation performs significantly better with finite data.
References
- [1].Paar Christof and Pelzl Jan, Understanding Crypotgraphy (Springer-Verlag Berlin Heidelberg, New York, 2010). [Google Scholar]
- [2].Fischer MJ, “A public randomness service,” in SECRYPT 2011 (2011) pp. 434–438. [Google Scholar]
- [3].Pironio S and Massar S, “Security of practical private randomness generation,” Phys. Rev. A 87, 012336 (2013). [Google Scholar]
- [4].Colbeck R, Quantum and Relativistic Protocols for Secure Multi-Party Computation, Ph.D. thesis, University of Cambridge; (2007). [Google Scholar]
- [5].Colbeck R and Kent A, “Private randomness expansion with untrusted devices,” J. Phys. A: Math. Theor 44, 095305 (2011). [Google Scholar]
- [6].Hensen B et al. , “Loophole-free Bell inequality violation using electron spins separated by 1.3 km,” Nature 526, 682 (2015). [DOI] [PubMed] [Google Scholar]
- [7].Rosenfeld W, Burchardt D, Garthoff R, Redeker K, Ortegel N, Rau M, and Weinfurter H, “Event-ready Bell-test using entangled atoms simultaneously closing detection and locality loopholes,” Phys. Rev. Lett 119, 010402 (2017). [DOI] [PubMed] [Google Scholar]
- [8].Giustina M, Marijn AM, Versteegh, Soren Wengerowsky, Johannes Handsteiner, Armin Hochrainer, Kevin Phelan, Fabian Steinlechner, Johannes Kofler, Jan-Ake Larsson, Carlos Abellan, Waldimar Amaya, Valerio Pruneri, Mitchell Morgan W., Joorn Beyer, Thomas Gerrits, Lita Adriana E., Shalm Lynden K., Sae Woo Nam, Thomas Scheidl, Rupert Ursin, Bernhard Wittmann, and Anton Zeilinger, “Significant-loophole-free test of Bell’s theorem with entangled photons,” Phys. Rev. Lett 115, 250401 (2015). [DOI] [PubMed] [Google Scholar]
- [9].Shalm LK, Meyer-Scott E, Christensen BG, Bierhorst P, Wayne MA, Stevens MJ, Gerrits T, Glancy S, Hamel DR, Allman MS, Coakley KJ, Dyer SD, Hodge C, Lita AE, Verma VB, Lambrocco C, Tortorici E, Migdall AL, Zhang Y, Kumor DR, Farr WH, Marsili F, Shaw MD, Stern JA, Abellan C, Amaya W, Pruneri V, Jennewein T, Mitchell MW, Kwiat PG, Bienfang JC, Mirin RP, Knill E, and Nam SW, “Strong loophole-free test of local realism,” Phys. Rev. Lett 115, 250402 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Pironio S, Acin A, Massar S, Boyer A, de la Giroday, Matsukevich DN, Maunz P, Olmschenk S, Hayes D, Luo L, Manning TA, and Monroe C, “Random numbers certified by Bell’s theorem,” Nature 464, 1021–4 (2010). [DOI] [PubMed] [Google Scholar]
- [11].Vazirani U and Vidick T, “Certifiable quantum dice - or, exponential randomness expansion,” in STOC’12 Proceedings of the 44th Annual ACM Symposium on Theory of Computing (2012) p. 61. [Google Scholar]
- [12].Fehr S, Gelles R, and Schaffner C, “Security and composability of randomness expansion from Bell inequalities,” Phys. Rev. A 87, 012335 (2013). [Google Scholar]
- [13].Miller CA and Shi Y, “Robust protocols for securely expanding randomness and distributing keys using untrusted quantum devices,” J. ACM 63, 33 (2016). [Google Scholar]
- [14].Miller CA and Shi Y, “Universal security for randomness expansion from the spot-checking protocol,” SIAM J. Comput 46, 1304–1335 (2017). [Google Scholar]
- [15].Chung K-M, Shi Y, and Wu X, “Physical randomness extractors: Generating random numbers with minimal assumptions,” (2014), arXiv:1402.4797 [quant-ph]. [Google Scholar]
- [16].Coudron M and Yuen H, “Infinite randomness expansion with a constant number of devices,” in STOC’14 Proceedings of the 46th Annual ACM Symposium on Theory of Computing (2014) pp. 427–36. [Google Scholar]
- [17].Arnon-Friedman R, Dupuis F, Fawzi O, Renner R, and Vidick T, “Practical device-independent quantum cryptography via entropy accumulation,” Nat. Commun 9, 459 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Nieto-Silleras O, Bamps C, Silman J, and Pironio S, “Device-independent randomness generation from several Bell estimators,” New J. Phys 20, 023049 (2018). [Google Scholar]
- [19].Bierhorst P, Knill E, Glancy S, Mink A, Jordan S, Rommal A, Liu Y-K, Christensen B, Nam SW, and Shalm LK, “Experimentally generated random numbers certified by the impossibility of superluminal signaling,” (2017), arXiv:1702.05178. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].Bierhorst P, Knill E, Glancy S, Zhang Y, Mink A, Jordan S, Rommal A, Liu Y-K, Christensen B, Nam SW, , Stevens MJ, and Shalm LK, “Experimentally generated random numbers certified by the impossibility of superluminal signaling,” Nature 556, 223–226 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Zhang Y, Glancy S, and Knill E, “Asymptotically optimal data analysis for rejecting local realism,” Phys. Rev. A 84, 062118 (2011). [Google Scholar]
- [22].Konig R, Renner R, and Schaffner C, “The operational meaning of min- and max-entropy,” IEEE Trans. Inf. Theory 55, 4337–4347 (2009). [Google Scholar]
- [23].Shafer G, Shen A, Vereshchagin N, and Vovk V, “Test martingales, Bayes factors and p-values,” Statistical Science 26, 84–101 (2011). [Google Scholar]
- [24].Popescu S and Rohrlich D, “Quantum nonlocality as an axiom,” Found. Phys 24, 379–85 (1994). [Google Scholar]
- [25].Barrett J, Linden N, Massar S, Pironio S, Popescu S, and Roberts D, “Nonlocal correlations as an information-theoretic resource,” Phys. Rev. A 71, 022101 (2005). [Google Scholar]
- [26].Lunghi Tommaso, Bohr Brask Jonatan, Ci Wen Lim Charles, Lavigne Quentin, Bowles Joseph, Martin Anthony, Zbinden Hugo, and Brunner Nicolas, “Self-testing quantum random number generator,” Phys. Rev. Lett 114, 150501 (2015). [DOI] [PubMed] [Google Scholar]
- [27].Van Himbeeck Thomas, Woodhead Erik, Cerf Nicolas J., Garcla-Patron Raul, and Pironio Stefano, “Semi-device-independent framework based on natural physical assumptions,” Quantum 1, 33 (2017). [Google Scholar]
- [28].Knill E, Zhang Y, and Bierhorst P, “Quantum randomness generation by probability estimation with classical side information,” (2017), arXiv:1709.06159. [Google Scholar]
- [29].Tomamichel M, Colbeck R, and Renner R, “A fully quantum asymptotic equipartition property,” IEEE Trans. Inf. Theory 55, 5840–5847 (2009). [Google Scholar]
- [30].Clauser JF, Horne MA, Shimony A, and Holt RA, “Proposed experiment to test local hidden-variable theories,” Phys. Rev. Lett 23, 880–884 (1969). [Google Scholar]
- [31].Acin Antonio, Massar Serge, and Pironio Stefano, “Randomness versus non-locality and entanglement,” Phys. Rev. Lett 108, 100402 (2012). [DOI] [PubMed] [Google Scholar]
- [32].Nieto-Silleras O, Pironio S, and Silman J, “Using complete measurement statistics for optimal device-independent randomness evaluation,” New J. Phys 16, 013035 (2014). [Google Scholar]
- [33].Bancal J-D, Sheridan L, and Scarani V, “More randomness from the same data,” New J. Phys 16, 033011 (2014). [Google Scholar]
- [34].Eberhard PH, “Background level and counter efficiencies required for a loophole-free Einstein-Podolsky-Rosen experiment,” Phys. Rev. A 47, R747–R750 (1993). [DOI] [PubMed] [Google Scholar]
- [35].van Dam W, Gill RD, and Grunwald PD, “The statistical strength of non-locality proofs,” IEEE Trans. Inf. Theory. 51, 2812–2835 (2005). [Google Scholar]
- [36].Acin Antonio, Gill Richard, and Gisin Nicolas, “Optimal Bell tests do not require maximally entangled states,” Phys. Rev. Lett 95, 210402 (2005). [DOI] [PubMed] [Google Scholar]
- [37].Zhang Yanbao, Knill Emanuel, and Glancy Scott, “Statistical strength of experiments to reject local realism with photon pairs and inefficient detectors,” Phys. Rev. A 81, 032117 (2010). [Google Scholar]
- [38].Cirelson BS, “Quantum generalizations of Bell’s inequality,” Lett. Math. Phys 4, 93 (1980). [Google Scholar]
- [39].Pardo MC and Vajda Igor, “About distances of discrete distributions satisfying the data processing theorem of information theory,” IEEE Trans. Inf. Theory 43, 1288–1293 (1997). [Google Scholar]
- [40].Ville J, Etude Critique de la Notion de Collectif (Gauthier-Villars, Paris, 1939). [Google Scholar]
- [41].Zhang Y, Glancy S, and Knill E, “Efficient quantification of experimental evidence against local realism,” Phys. Rev. A 88, 052119 (2013). [Google Scholar]
- [42].Christensen BG, Hill A, Kwiat PG, Knill E, Nam SW, Coakley K, Glancy S, Shalm LK, and Zhang Y, “Analysis of coincidence-time loopholes in experimental Bell tests,” Phys. Rev. A 92, 032130 (2015). [Google Scholar]
- [43].Shao Jun, Mathematical Statistics, 2nd ed (Springer, New York, 2003). [Google Scholar]
- [44].Konig R and Terhal B, “The bounded-storage model in the presence of a quantum adversary,” IEEE Trans. Inf. Theory 54, 749–62 (2008). [Google Scholar]
- [45].Trevisan L, “Extractors and pseudorandom generators,” Journal of the ACM 48, 860–79 (2001). [Google Scholar]
- [46].Mauerer W, Portmann C, and Scholz VB, “A modular framework for randomness extraction based on trevisan’s construction,” (2012), arXiv:1212.0520, code available on github. [Google Scholar]
- [47].Knill E, Glancy S, Nam SW, Coakley K, and Zhang Y, “Bell inequalities for continuously emitting sources,” Phys. Rev. A 91, 032105 (2015). [Google Scholar]
- [48].Kullback S and Leibler RA, “On information and sufficiency,” Ann. Math. Statist 22, 79 (1951). [Google Scholar]
- [49].Bierhorst P, “Geometric decompositions of Bell poly-topes with practical applications,” J. Phys. A: Math. Theor 49, 215301 (2016). [Google Scholar]
- [50].Acin Antonio, Brunner Nicolas, Gisin Nicolas, Massar Serge, Pironio Stefano, and Scarani Valerio, “Device-independent security of quantum cryptography against collective attacks,” Phys. Rev. Lett 98, 230501 (2007). [DOI] [PubMed] [Google Scholar]
- [51].Pironio Stefano, Acin Antonio, Brunner Nicolas, Gisin Nicolas, Massar Serge, and Scarani Valerio, “Device-independent quantum key distribution secure against collective attacks,” New J. Phys 11, 045021 (2009). [Google Scholar]
- [52].The argument can be generalized to the case that the input distribution is not precisely known after considering the construction of the corresponding PEFs detailed in Ref. [28].