

Abstract
Successful navigation of the Covid-19 pandemic is predicated on public cooperation with safety measures and appropriate perception of risk, in which emotion and attention play important roles. Signatures of public emotion and attention are present in social media data, thus natural language analysis of this text enables near-to-real-time monitoring of indicators of public risk perception. We compare key epidemiological indicators of the progression of the pandemic with indicators of the public perception of the pandemic constructed from million unique Covid-19-related tweets from 12 countries posted between 10th March and 14th June 2020. We find evidence of psychophysical numbing: Twitter users increasingly fixate on mortality, but in a decreasingly emotional and increasingly analytic tone. Semantic network analysis based on word co-occurrences reveals changes in the emotional framing of Covid-19 casualties that are consistent with this hypothesis. We also find that the average attention afforded to national Covid-19 mortality rates is modelled accurately with the Weber–Fechner and power law functions of sensory perception. Our parameter estimates for these models are consistent with estimates from psychological experiments, and indicate that users in this dataset exhibit differential sensitivity by country to the national Covid-19 death rates. Our work illustrates the potential utility of social media for monitoring public risk perception and guiding public communication during crisis scenarios.
Keywords: Risk perception, Twitter, Covid-19, Natural language processing, Psychophysics, Regression analysis, Linguistic networks, Network partitions
Introduction
The Covid-19 pandemic has brought about widespread disruption to human life. In many countries, public gatherings have been broadly forbidden, mass restrictions on human movement have been introduced, and entire industries have been paralysed in attempting to lower the peak stress on healthcare systems (Hale et al. 2020). However, the degree to which these restrictions have been enforced by law has varied over time and by location, and their success in mitigating public health risks depends on the extent of cooperation on the part of the public.
A key determinant of the public’s behaviour and their cooperation with state-imposed social restrictions is the public’s emotional response to, and their perception of the the risk presented by, the pandemic. However, the evolution of emotions and risk perception in response to disasters is not well-understood, and there is a need for more longitudinal data on such responses with which this understanding can be improved (Burns and Slovic 2012). Our goal is thus to contribute to bettering this understanding, and we do so by exploring the empirical relationships present between the progression of the Covid-19 pandemic and the public’s perception of the risk posed by the pandemic.
We explain our findings in terms of the existing body of literature surrounding public perception of risk, disasters, and human suffering in cognitive psychology. In particular, we draw from psychophysics, the field that studies the relationship between stimulus and subjective sensation and perception (Gescheider 1997). The search for psychophysical “laws” of perception has existed since at least the mid-19th Century with the proposing of the Weber–Fechner law (Fechner et al. 1966), which posits that the smallest perceptible change in a physical stimulus of magnitude s is proportional to s. Thus, the perceived magnitude p of such stimuli follows
| 1 |
In the continuum limit, this implies that p grows logarithmically with the physical magnitude s of the stimulus. More recently, empirical studies by Stevens (1975) supported, instead, a power law relationship between human perception of a stimulus and the physical magnitude of the stimulus:
| 2 |
Summers et al. (1994) extended this concept to human sensitivity to war death statistics and found that a power law with exponent best fit the data. A number of further studies have corroborated the extension of these psychophysical laws describing the subjective perception of physical magnitudes to the subjective evaluations of human fatalities (Slovic 2010; Fetherstonhaugh et al. 1997; Friedrich et al. 1999). In all of these, perception is a concave function of the stimulus, meaning that the larger the stimulus magnitude, the more it has to change in absolute terms to be equally noticeable. Thus, perception is considered relative rather than absolute, implying that our judgments are comparative in nature. This observation has been shown to account for deviations from rationality in economic decision-making (Weber 2004).
These proposed psychophysical laws of human perception present an opportunity for monitoring a population’s response to a disaster scenario such as the Covid-19 pandemic. By evaluating the goodness of fit of these models to data on the perception of the progression of the pandemic, and determining the parameter values of such fits, we can describe the sensitivity of populations to the state of such crises, with important implications for risk communication and disaster management.
To this end, we make use of a massive Twitter dataset consisting of user-posted textual data to study the public’s emotional and perceptual responses to the current public health crisis. Twitter provides convenient access to the conversation amongst members of the public across the globe on a plethora of topics, and many authors are studying several aspects of the public’s response to the pandemic with it. Twitter is a particularly appropriate tool under conditions of physical distancing requirements and furlough schemes, where online communication has become more than ever a central feature of everyday life. Moreover, results from psycholinguistics and advances in natural language processing techniques enable the extraction of psychologically meaningful attributes and the reconstruction of cognitive structures (e.g. semantic networks) from textual data. With this dataset, our general approach is to offer a quantitative, spatiotemporal comparison between indicators of the state of the pandemic and the topics and psychologically meaningful linguistic features present in the discussion surrounding Covid-19 on social media on a country-by-country basis, for a selection of countries.
Related work
Our work is novel in that, to our knowledge, it is the first to use a large social media dataset spanning multiple countries to model the perceptual response of countries’ citizens to the pandemic in the context of risk perception. To date, empirical validation of the aforementioned psychophysical laws has largely taken place in controlled laboratory settings, in which decisions, actions, and scenarios are artificial or hypothetical. Our work thus contributes to the body of literature surrounding risk perception by investigating these laws in a naturalistic setting.
However, there have been numerous authors using social media to analyse the public response to the Covid-19 pandemic. This includes work that has focused on the psychological burden of the social restrictions. For instance, Stella et al. (2020) use the circumplex model of affect (Posner et al. 2005) and the NRC lexicon (Mohammad and Turney 2010) to give a descriptive analysis of the public mood in Italy from a Twitter dataset collected during the week following the introduction of lockdown measures. In addition, Venigalla et al. (2020) has developed a web portal for categorising tweets by emotion in order to track mood in India on a daily basis.
Others have instead focused on negative emotions, as in the work of Schild et al. (2020), where they study the rise of hate speech and sinophobia as a result of the outbreaks. More specifically on perception, Dryhust et al. (2020) measured the perceived risk of the Covid-19 pandemic by conducting surveys at a global scale () and compared countries, finding that factors such as individualistic and pro-social values and trust in government and science were significant predictors of risk perception. de Bruin and Bennett (2020) perform similar work in the USA. The closest work we have been able to find to our own are those of Barrios and Hochberg (2020) and Aiello et al. (2020), where both research pieces focus on the current pandemic using data from the USA. In the former, they combine internet search data with daily travel data to show that regions in the USA with a greater proportion of Trump voters exhibit behaviours that are consistent with a lower perceived risk during the Covid-19 pandemic. In the latter, they assess the epidemic psychology using Covid-19 Twitter data in the USA according to several linguistic features present in the tweets. They identify three psychological phases consistent with the refusal-suspended reality-acceptance stages of grief. Despite the above, we have been unable to find work that combines large-scale social media data with linguistic analysis to offer a spatiotemporal, quantitative analysis of emotion and risk perception during the Covid-19 pandemic across multiple countries.
Beyond the Covid-19 pandemic, our work is related to a small but growing body of literature on the use of data science in understanding human emotion and risk perception. In such work, natural language analysis has succeeded in supporting established linguistic theories such as the importance of the distribution of words in a vocabulary as a proxy for knowledge (Harris 1954), and regarding the relation between the uncertainty of events and the emotional response to their outcome (Feather 1963; Verinis et al. 1968). For instance, using textual data from Twitter, Bhatia found that unexpected events elicit higher affective responses than those which are expected (Bhatia et al. 2019). In another instance, the same author conducted experiments with 300 participants and predicted the perceived risk of several risk sources using a vector-space representation of natural language, concluding that the word distribution of language successfully captures human perception of risk (Bhatia 2019). Similar work has been conducted by Jaidka et al. (2020) in the area of monitoring public well-being, in which they compare word-based and data-driven methods for predicting ground-truth survey results for subjective well-being of US citizens on a county-level basis using a 1.5 billion Tweet dataset constructed from 2009 to 2015.
The remainder of this paper is laid out as follows. In “Data”, we present the dataset used in the subsequent analysis. In “Analysing the public's perception of the pandemic”, we provide further details on the approach followed to explore the relationships between indicators of the state of the pandemic and the public’s perception of the pandemic, and discuss possible explanations for our observations by drawing on psychological literature. In “Discussion and conclusions”, we summarise and offer concluding remarks, along with a discussion of the limitations of the current work and suggestions for avenues of future work.
Data
Twitter dataset
In the following analysis, we make use of the set of tweets gathered by Banda et al. (2020), which are obtained and mantained using the Twitter free Stream API.1 At the time of writing, this dataset consists of million original tweets spanning from March 11, 2020 to June 14, 2020. By original we mean that we do not consider retweets, which is standard for natural language processing (Go et al. 2009; Banda et al. 2020). Data is collected according to the following query filters2: “COVID19”, “CoronavirusPandemic”, “COVID-19”, “2019nCoV”, “CoronaOutbreak”, “coronavirus”, “WuhanVirus”, “covid19”, “coronaviruspandemic”, “covid-19”, “2019ncov”, “coronaoutbreak”, “wuhanvirus”.
For our analysis, we consider only the English and Spanish tweets with a non-empty self-reported location field. We process every self-reported location using OpenStreetMaps (https://planet.osm.org) and remove non-sensical locations (e.g. “Mars”, “Everywhere”, “Planet Earth”). This allows us to group the remaining tweets by country and proceed with our analysis on a country-by-country basis. To assure the statistical significance of our analysis, we keep the countries with the highest number of tweets for each language, resulting in a geolocated Twitter dataset of million original tweets posted by million users on 12 different countries, which we summarise in Table 1.
Table 1.
Per-country summary of the Covid-19-related Twitter dataset constructed from the repository maintained by Banda et al. (2020)
| Language | Number of tweets | Unique users | |
|---|---|---|---|
| Argentina | Spanish | 846,706 | 194,818 |
| Australia | English | 701,072 | 97,027 |
| Canada | English | 1,209,712 | 195,507 |
| Chile | Spanish | 342,013 | 60,235 |
| Colombia | Spanish | 466,477 | 103,845 |
| India | English | 1,806,685 | 344,894 |
| Mexico | Spanish | 1,133,350 | 187,064 |
| Nigeria | English | 754,152 | 133,797 |
| South Africa | English | 354,613 | 78,447 |
| Spain | Spanish | 1,697,049 | 274,010 |
| UK | English | 3,490,703 | 631,017 |
| USA | English and Spanish | 6,297,720 | 1,397,410 |
| Total | 19,072,850 | 3,699,071 |
All tweets are original, i.e. all retweets are removed
Epidemiological data
We measure the progression of the pandemic with the number of Covid-19 confirmed cases and deaths for all the countries in our analysis. The data was made publicly available by Our World in Data repository (Max Roser et al. 2020). In particular, we take the daily Covid-19 cases and deaths, both in linear and logarithmic scale, since these are four epidemiological indicators that are most frequently used to summarise the state of the pandemic, and are therefore frequently encountered by the public.
Analysing the public’s perception of the pandemic
In this section, we study the public’s perception of the pandemic on a country-by-country basis, using the countries with the highest number of tweets in the observation period (see Table 1). We do this on a country-by-country basis since the pandemic has often evoked nation-level responses, making nation-level analysis the most natural geographic scale. Our broad approach is to inspect and compare the linguistic features of the tweets released by users in the Twitter dataset described in “Twitter dataset” section with the epidemiological data described in “Epidemiological data” section.
Defining perception from linguistic inquiry
Our goal is to explore the public’s perception of the pandemic. To do this, we analyse the linguistic features present in the textual data generated by Twitter users, and map these features to psychologically meaningful categories that are indicative of the Twitter users’ perception. Here, we are assuming that the words used by these Twitter users are indicative of their internal cognitive and emotional states (Tausczik and Pennebaker 2010), which is supported in (Bhatia 2019) where they predict the perception of risk using text data. Thus, we quantify the linguistic content of each tweet using the Linguistic Inquiry and Word Count (LIWC) program (Pennebaker et al. 2015). LIWC has been widely adopted in several text data analyses, and it has proven successful in applications ranging from measuring the perception of emotions (Yin et al. 2014) to predicting the German federal elections using Twitter (Tumasjan et al. 2010). Moreover, it has recently been used to successfully identify the early-epidemic psychological stages of grief in the current pandemic (Aiello et al. 2020).
LIWC operates as text analysis program that reports the number of words in a document belonging to a set of predefined linguistically and psychologically meaningful categories3 (Tausczik and Pennebaker 2010). For our purposes, a document is a tweet posted on date t and from a user based in country i. LIWC represents documents as an unordered set of words, and a LIWC category l is similarly a set of words associated with concept l. For a given document , the linguistic score for category l is the percentage of words in that belong to l:
| 3 |
There are many such categories l, including Family, Work, and Motion. We capitalise such category titles, and use the titles to refer to either the set of words associated with that category or to refer to the category itself. Linguistic scores from Eq. (3) for individual tweets will be noisy, as they are short documents. Moreover, we are interested in the average response of the population of a country. For this reason, we group the tweets by country i and by date t, and denote these sets of tweets as . We then compute the National Linguistic Score (NLS) for category l as the average of the linguistic scores over documents in relative to an empirically observed Twitter base rate :
| 4 |
The base rates for the use of words on Twitter associated with category l are given in (Pennebaker et al. 2015). Using Eq. (4) for all the selected linguistic categories, we construct multidimensional country-level time series that represent the evolution of the public perception of the pandemic, similar to the linguistic profiles introduced by (Tumasjan et al. 2010). These perception dynamics are influenced by each user in our dataset, which may include bots and institutional or public relations accounts. We discuss the possible implications of this aspect of our data in “Discussion and conclusions” section.
In Fig. 1, we show the collection of NLSs for a selection of relevant linguistic categories. We observe clear trends that, in most cases, are synchronized between countries and languages. In particular, most categories associated with emotion—notably Affect, Anger, Anxiety, Positive emotion, Negative emotion, and Swear words [swearing is associated with frustration and anger (Jay and Janschowitz 2008)]—have their highest scores in mid-to-late March, when the World Health Organisation (WHO) announced the pandemic status of Covid-19 and most Western countries introduced more stringent social restrictions (Hale et al. 2020). These scores decay thereafter, indicating a relaxation of the emotional response in the conversation. This is consistent with results reported by Bhatia regarding the affective response to unexpected events (Bhatia et al. 2019) and with those of Aiello et al. (2020) where the Death NLS of the USA rises from late March on. A qualitatively similar trend can be seen in the Social processes panel, the category involving “all non-first-person-singular personal pronouns as well as verbs that suggest human interaction (talking, sharing)” (Pennebaker et al. 2015).
Fig. 1.

Time series for the National Linguistic Scores (NLSs) [see Eq. (4)] for the countries as indicated by the legend. Each panel shows the individual linguistic categories. The units on the y-axis represent the percentage change of the NLSs for our data with respect to the LIWC baselines for Twitter
We also observe that health-related categories such as Death and Health show an overall rising trend, with Death rising most rapidly throughout March. These categories, with the exception of Positive Emotion and Health, peak again in the USA at the end of May, coinciding with the murder of George Floyd and the subsequent Black Lives Matter protests. Such universal trends are not apparent by visual inspection in the Money, Risk, and Sadness panels. An additional feature of these plots is the absolute scale of these values: in all cases, there is a significant percentage change from their baseline values, with large percentage increases observed initially in the use of words associated with Anxiety and later with Death, and a moderate percentage increase in the use of words associated with Risk.
Comparing the public’s perception with epidemiological data
In this section, we explore the relationship between the NLSs described in “Defining perception from linguistic inquiry” section, which we use as a proxy for the public’s perception, and the intensity of the pandemic, which we assume is the stimulus triggering this perception. Our measure of the intensity of the pandemic is the number of Covid-19 cases and deaths from the data described in “Epidemiological data” section.
A straightforward way of approaching this relationship is by computing the correlations between the NLSs and the epidemiological data in a per-country basis, and we show the average across countries of these per-country correlations in Fig. 2. On the one hand, we observe significant negative correlations in emotionally charged categories (eg. Swear words, Anger, Anxiety, Affective processes), indicating a decay in emotion as the pandemic intensifies. Conversely, categories related with health and mortality (Death, Health) and analytical thinking (Analytic) show significant positive correlation.4
Fig. 2.

Correlation coefficients between epidemiological indicators and NLSs [see Eq. (4)] averaged across all countries. * “Risk” and “Analytic” are only available for the English-language LIWC. These two categories are thus averages across English-language countries only
Psychophysical numbing
We believe the trends we observe in Fig. 1 and the correlations we observe in Fig. 2 are consistent with the notion of psychophysical numbing. This term was introduced by Robert Jay Lifton (1982), and developed by Paul Slovic (Slovic 2010); Fetherstonhaugh et al. 1997) in the context of human perception of genocides and their associated death tolls, to describe the paradoxical phenomenon in which people exhibit growing indifference towards human suffering as the number of humans suffering increases. By inspecting the correlations between the NLSs and the epidemiological indicators, we find that as the pandemic intensifies—in the sense of an increasing number of cases and deaths reported daily—our emotional response diminishes, as expected from a psychophysical numbing phenomenon.
Specifically, we observe negative correlations between almost all components of the NLSs associated with affect—Affective processes, Anger, Anxiety, Negative emotion, Positive emotion, and Swear words—and the epidemiological data.5 By inspecting Fig. 1, we see that every country exhibits similar downward trends in these components and, with the exception of Anxiety, are all significantly lower than their baseline values throughout the observation period.
This unusually low and decreasing Affect word count is accompanied, conversely, with a growing awareness of the morbidity of the situation in that we observe significant positive correlations between the Death NLSs and the daily national cases and deaths, indicating that the decrease in affect occurs simultaneously with and despite an attentional shift towards Covid-19 related mortality. We also observe a simultaneous increase in the Analytic component of each English-language dataset6 over this same period, indicating a movement towards more logical and analytical, rather than intuitive and emotional, thinking.
The potential implication of this is that the public is less perceptive of the risk that the pandemic poses to public health, since their emotional response is reduced and reducing (Sandman 1993). For example, Van Bavel et al. (2020) and Loewenstein et al. (2001) describe that risk perception is driven more by association and affect-based processes than analytic and reason-based processes, with the affect-based processes typically prevailing when there is disagreement between the two modes of thinking. The negative correlations between the intensity of the pandemic and affective processes, together with its positive correlation with the prevalence of analytic processes, suggests that public risk communication could be adjusted to re-balance the degree of affective and analytic thinking amongst members of the public to achieve favourable risk avoidance behaviour and, consequently, favourable public health outcomes.
Analysing the emotional framing of Covid-19 casualties with semantic networks
To support our claim that these observations are attributable to psychophysical numbing, we construct word co-occurrence networks using tweets in our dataset. Word co-occurrence networks are a class of linguistic networks in which nodes are words appearing in a body of text and an edge is placed between a pair of words with a weight given by some function of the number of co-occurrences of that pair in the text. Empirical word co-occurrence networks have been used in cognitive network science as approximate reconstructions of the author’s latent cognitive structures, e.g. semantic or conceptual networks (Siew et al. 2019), with a given corpus deemed to be an empirical manifestation of such structures.
For example, Kenett et al. (2014) reconstruct participants’ internal semantic networks on the basis of their responses in a free word association task, reporting that participants that were found independently to have lower creativity scores also had less well-connected semantic networks—specifically, a higher modularity, average shortest path length, and diameter, and a lower small-world-ness (Humphries and Gurney 2008)—than participants scoring more highly in creativity.
In the context of the Covid-19 pandemic, Stella et al. (2020) use word and hashtag co-occurrence networks in conjunction with word-to-emotion mappings to uncover complex emotional profiles amongst Twitter users posting from Italy during the first week of lockdown. More generally, a plethora of models for inferring semantic relationships between words in natural language processing tasks are based on some notion of word co-occurrence (Jones et al. 2020). The semantic proximity of a pair of words in such models has also been shown to possess predictive power regarding the subjective probability participants assign to hypothetical real-world events involving that pair of concepts (Bhatia 2016). For a more complete review of the use of linguistic networks in the study of human cognition, we refer the interested reader to (Siew et al. 2019).
Given the well-established utility of word co-occurrence analysis in providing a view of authors’ internal cognitive structures, we employ such an approach on —the set of words in either the Death or Affect categories—in an attempt to approximate the Twitter users’ internal semantic relationships between these two concepts.7 Specifically, we hypothesise that, if the psychophysical numbing effect is legitimate, the modular structure of these networks will separate Death-related and Affect-related words more decidedly at larger daily death counts than at lower death counts. This would indicate that conversation regarding Covid-19-related mortality evokes a weaker emotional response at higher daily death counts.
Given a set of tweets, the word co-occurrence network is represented by a weighted adjancency matrix in which the nodes are words belonging to . Entry counts the number of co-occurrences between words i and j across all tweets in , and is computed as
| 5 |
where counts the number of instances of word k in tweet . We ignore self-edges by imposing , since it is the relationship between distinct words that is of interest. (See “Appendix 3.1” for further details on the construction of these networks.)
Qualitative overview of the death-affect partition
We identify three main periods for which we construct network snapshots of word co-occurrences (see Fig. 3a, c). The first period spans 11th March to 9th April 2020, in which the WHO declared Covid-19’s pandemic status and governments generally imposed social restrictions. The second period spans 10th April to 23rd May, during which most Covid-19 cases either underwent exponential growth or flattened out for some countries in Europe. The final period spans 24th May to 13th June, during which most countries were at the peak daily rate of Covid-19 cases or where in a stage of decreasing number of daily cases. Moreover, the Black Lives Matter protests were triggered by the murder of George Floyd in the USA in this period. In constructing these networks, we weight each country equally by taking a random sample of approximately 300,000 tweets from each country.
Fig. 3.

Snapshots of the word co-occurrences associated with Death (green labels) and Affect (red labels) for English-language tweets aggregated across all analyzed countries in three different time windows (see sub-captions). The nodes are coloured according to their community label as obtained by maximising modularity with the Louvain algorithm (Blondel et al. 2008). We filtered edges with weight below 20 co-occurrences for visualisation purposes
In Fig. 3a–c, we visualise these three snapshots for the English-language tweets. From these we observe that two clusters emerge in all cases: a left-hand cluster consisting mainly of Death-related words and a right-hand cluster consisting primarily of Affect-related words. We also observe that the relative sizes of these clusters vary over time: the Death-cluster grows in size as the pandemic progresses, and remains separated from the Affect-based cluster. This indicates that the evolving structure of these networks may be consistent with our hypothesis of psychophysical numbing: throughout, Covid-19 casualties appear not to evoke a strong emotional response.
However, we find that a number of the most highly connected nodes in these Death clusters are Affect-related words: in the first network, the Affect-related words “panic”, “positive”, and “isolat*” appear; in the second, the words “care”, and “fail*” also appear; and in the third, “protests” appears. While such words are normally associated with affective processes, we argue that some of these are more readily understood in terms of their association with Covid-19-specific topics that are less indicative of an affective experience in this context than they might be more generally. For example, “positive” is used very frequently in the context of the pandemic in relation to individuals “testing positive” for the virus. In Table 2, we address five of these words, providing what we believe are the most plausible explanations for their association with conversation surrounding mortality during the Covid-19 pandemic.
Table 2.
Words belonging to the Affect LIWC category that appear in the primarily Death-based clusters in the three snapshot word co-occurrence networks shown in Fig. 3a–c. The middle and right columns indicate in which snapshots they are most prominent, and the likely explanation for their association with the concept of death during the pandemic
| Word | Figures | Interpretation |
|---|---|---|
| Positive | 3a–c | Used in reference to the number of people that have tested positive for Covid-19 |
| Isolat* | 3a, b | Used in discussion surrounding symptomatic and at-risk individuals self-isolating |
| Care | 3b, c | Used in relation to: the health care system; the death care industry; the admission of Covid-19 patients to intensive care units; and deaths occurring in care homes for the elderly |
| Panic | 3a | Panic-buying of household goods, e.g. toilet paper, hand-sanitiser |
| Protests | 3c | George Floyd’s death and subsequent Black Lives Matter protests |
Altogether, this initial examination indicates that words associated with a subjective emotional/affective experience and words related to death may be well-separated in this Twitter data, which is consistent with the notion of psychophysical numbing as an explanation for the trends and correlations observed in Figs. 1 and 2. For completeness, we include the equivalent co-occurrence graphs for the Spanish-language tweets in “Appendix 3.2”, about which similar statements can be made.
Our discussion has so far been qualitative given that the aforementioned network snapshots (i) vary considerably in size, (ii) represent the aggregate conversation of the tweets across countries in our dataset, and (iii) involve crude aggregation over large time periods. In the next section, we address these issues by investigating the change in a number of network measures over time and discuss the extent to which they support our hypothesis of psychophysical numbing.
Quantitative analysis of the death-affect partition
To further probe this hypothesis of psychophysical numbing, we seek network measures that describe the strength of association between the concept of death and affective processes. Since the primary tenet of psychophysical numbing is that “the more who die, the less we care”, our investigation is focused on the degree to which conversation around Covid-19 mortality evokes the use of affective language, which is our proxy for “degree of caring”. In particular, we are interested in whether the emotional framing of such conversation changes as the daily death rates change in each country, where a less emotional conversation at higher daily death rates would support our hypothesis.
For this purpose, we investigate the dynamics of the following network measures over a sequence of comparable snapshots for each country:
- the weighted modularity for the partition induced by assigning nodes to their respective LIWC categories, i.e. Death or Affect. We compute the weighted modularity following Newman (2004) as
where is the weighted adjacency matrix of a network at snapshot t, is the strength of node/word i, is the total strength of the network, represents the community assignment of node i under partition , and is the Dirac delta function.6 - the fraction of the total strength of node “death*” (“muert*”) that can be attributed to its connections with other nodes in the Death category:
The range of is bounded between 0 and 1, being 0 when all of the neighbours of node “death*” (“muert*”) are in the Affect category and 1 when all of its neighbours are in the Death category.7
We henceforth omit the explicit time-dependence of and to simplify notation. The first measure tracks the quality of separation of the Death and Affect categories in these semantic networks. A larger indicates a better separation between Death and Affect in the empirical word co-occurrences. This is relevant to our investigation of psychophysical numbing in the following sense: if the numbing effect is genuine, we should expect that is larger at larger values of the daily number of deaths and lower at lower values of the daily number of deaths. This would indicate that conversation around Covid-19-related deaths evokes affective responses less strongly for larger death rates. If a weakening association between the concept of death and affective processes is an accurate measure of growing apathy and indifference—of the “collapse of compassion” (Cameron and Payne 2011)—then observing a positive correlation between and the daily national number of deaths would provide evidence supporting our hypothesis of psychophysical numbing.
The second is a local measure of the strength of association between the concept of Covid-19 deaths—represented with the word “death*” (“muert*”) in a tweet—and the affective processes within those tweets. A high value suggests a weak evocation of affective responses during conversation around Covid-19-related deaths.
To perform this analysis, we compute a sequence of higher-frequency snapshots than those in Fig. 3a–c, where labels each of the T snapshots for a given country. Each snapshot represents, on average, the tweets contained in 3 consecutive days and, for each country, each snapshot has roughly the same number of tweets (see “Appendix 3.1” for details on the construction of these networks). With this construction, each network contains approximately the same number of nodes, edges, and network total strength, enabling a fair comparison of the network measures—Eqs. (6) and (7)—over time.
In Fig. 4, we plot the z-scores of these network measures and of the log of the daily number of deaths, , for each country, and report the Pearson correlation coefficients and of and with , respectively, in parenthesis above each plot. In general, we observe similar dynamics for both and . This is sensible, since both are measures of the relative strength of association within the two communities induced by the Death and Affect word sets. Furthermore, we observe a number of instances—most notably, Canada, Colombia, Mexico, the UK, and the USA—in which there is a relatively strong correlation between these network measures and . These correlations are, however, weaker in other countries to varying degrees.
Fig. 4.

Panel plot time series for the network measures (orange) and (green) [see Eqs. (6) and (7) respectively], and the log of the national daily deaths (blue). Each panel represents a country, and in parentheses we show the Pearson correlation coefficients between these network measures and the log of the national daily deaths. Data is smoothed with a 3-day moving average and standardised by their z-scores
To verify that the observed and can be attributed to the empirical word co-occurrences, we compute the same correlations for corresponding sequences of null network models. For our null model, we take the weighted version of the configuration model described in (Britton et al. 2011). Here, a realisation of the null model at random seed j involves assigning node i stubs, where
| 8 |
and p(d) is the empirical degree distribution at time t. The k-th stub for node i is then assigned a weight
| 9 |
where is the empirical distribution of weights for nodes with degree d. Stubs with the same weight are then joined with uniform probability.
As a baseline, we compute a sequence
of null model ensembles for each country at each snapshot t, where labels each of the J realisations of the null model. Here, we take realisations per snapshot. We then compute the average network measure over each ensemble for both and , here denoted and respectively. Similarly, we write the correlation coefficients as and . We report these coefficients, along with the correlation coefficients for the empirical networks, in Fig. 5.
Fig. 5.

Correlation coefficients between the log of daily national death counts and the network measures and [see Eqs. (6) and (7) respectively]. We indicate null model counterparts with superscripts “null” (see main text for details)
We find that, in most cases, the correlation coefficients are higher for the empirical word co-ocurrences than for the null model counterparts. In particular, each of Australia, Canada, Colombia, South Africa, the UK, and the USA have . This difference is also present for Nigeria, although it is smaller in this instance. For the remaining countries, however, the differences are either negligible or in the opposite direction. Overall, nonetheless, we see that the average across countries of is low, whereas the average across countries of is almost three times larger, and that for nine cases out of twelve.
A similar pattern is observed for and . In some instances—namely Australia, Colombia, South Africa, the UK, and the USA—we observe an increase in the correlation coefficients of the original sequence of snapshots relative to the corresponding sequences of null snapshots. This indicates that these increases in can be attributed to the empirical word co-occurrences. The difference is smaller but nonetheless in the correct direction for Chile, Mexico, and Nigeria. For the remaining countries, the difference is negligible.
Discussion of the semantic network analysis
Overall, our semantic network analysis provides evidence in favour of our hypothesis of psychophysical numbing, although this evidence is not definitive. We have seen that, for most countries, the separation between words associated with Death and Affect in our approximate semantic networks—as measured by and —becomes more pronounced as the national daily deaths rise, and that this relationship is generally weaker in the null model realisations.
There are nonetheless some exceptions to this statement. In particular, we find for Chile and Mexico that the difference between and is marginal, but that both versions of the correlation coefficients are high. We also report low correlations between these network measures and the time series of daily deaths for Argentina, India, and Spain. For the case of Spain, however, there are two exogenous death-related events contributing to this anomalous behaviour and low correlation values (see “Appendix 2” for details). For the case of India, there is evidence suggesting that Twitter users posting from India have a strong preference for using Hindi in the expression of negative sentiment and emotion, but English in the expression of positive emotion (Rudra et al. 2016). Our use of an English-language dictionary for evaluating the emotional content of such tweets may therefore bias our results, and a more thorough analysis including tweets and dictionaries in both Hindi and English [or in “Hinglish”, the blending of the two (Mathur et al. 2019)] should be performed in future. This is a specific case of a more general problem regarding the use of a single dictionary to analyse texts from different world regions, which typically differ in dialect.
For the remaining countries in our dataset, however, the empirical co-occurrences yield stronger correlations between the network measures and the national daily deaths than in the case of the baseline models, providing support for our psychophysical numbing hypothesis. Our observations thus indicate that psychophysical numbing may be a genuine effect for many Twitter users, but that other factors are possibly contributing to our results. Some of these factors are methodological issues with this work. First, we saw in Fig. 3a–c that LIWC is unable to account for context, and that there are a number of words that are classically associated with affective processes that are more appropriately associated with concepts surrounding mortality in the context of the pandemic. Second, in analysing word co-occurrences, we only retain tweets that contain at least two distinct words in the set Death Affect by construction. We have evaluated separately the proportion of tweets in each snapshot that contribute to our word co-occurrence networks, and have seen that this usually corresponds to between 10-20% of tweets for each snapshot, with between 20-30% of tweets involving the use of only one word in Death Affect. As such, this potentially leads to a systematic overestimation of the relative strength of association between words in Death Affect. Finally, as with most studies of organic social media data, it is hard to control for exogenous factors that form part of the Covid-19 conversation (e.g. Black Lives Matter protests, death-related news). It is thus important to treat such evidence as complementary to classical laboratory-based, controlled psychological experiments.
Modeling attention to Covid-19 casualties
In the previous section, we demonstrated our finding that as the pandemic intensifies, the proportion of words that appear in the set of Tweets posted in each country that indicate emotion diminishes over time. This indicates that the actual emotional response to the pandemic diminishes as the intensity of the pandemic increases, implying a psychophysical numbing effect. We supported this explanation by showing that the word co-occurrence networks induced by our set of tweets host a community structure that separates words in the Death and Affect dictionaries, suggesting that people do not talk about Covid-19 deaths in a highly emotional tone. We built on this analysis by tracking a number of measures of this supposed separation in higher-frequency sequences of snapshots for each country, observing that these network measures behaved consistently with our hypothesis of psychophysical numbing for a number of countries.
The following sections model the relationship between the progression of the Covid-19 pandemic and the Twitter users’ perception using grounded theories of psychophysical numbing. Until this point, we have used the emotional framing of the conversation around Covid-19 mortality as an indication of the degree of concern or indifference towards these casualties. However, one could argue that attention itself is equally indicative of the degree of concern experienced by individuals regarding such casualties. Indeed, both are recognised as key components to risk perception and the perception of threats (Slovic 2010). For this reason, we investigate the relationship between the typical perceptual response of individuals to a stimulus, in this case the daily number of reported deaths nationally, and seek to describe this relationship using established psychophysical laws, as in previous lab-based psychological experiments e.g. Stevens (1957).
The Weber–Fechner law
Our analysis suggests that the public’s perception of the progression of the pandemic is logarithmic or, at least, sublinear. From Fig. 2, we observe that the correlation magnitudes between NLSs and epidemiological data are generally larger in absolute value whenever the latter are taken in logarithmic scale. To exemplify this observation, we show in Fig. 6 the z-scores8 of the Death NLSs and of the logarithm of the daily number of deaths and cases within each country.
Fig. 6.

Panel time series for (blue), the logarithm of the daily deaths (orange), and the logarithm of the daily cases (green). Each panel presents a different country, with the country name provided in the subplot title. The correlation between and the national daily death rate is given in parentheses for each country. Data is smoothed with a 3-day moving average and standardized with their z-score to make them visually comparable. Black vertical lines represent peaks in the death discourse caused by exogenous events not related to psychophysical numbing (see “Appendix 2” for details) which we remove from the time series
The general correspondence between all three normalised features in each country is striking.9 We propose that this can be explained in terms of the Weber–Fechner law (Fechner et al. 1966), which is a quantitative statement with its origins in psychology and psychophysics regarding humans’ perceived magnitude p of a stimulus with physical magnitude s. It states that a human’s perception of the magnitude of a stimulus varies as the logarithm of the physical magnitude s of the stimulus, meaning we are more sensitive to ratios when comparing different physical magnitudes than we are to absolute differences. In the continuum limit, Eq. (1) gives the following functional form for the Weber–Fechner law:
| 10 |
where k and are real-valued parameters and R(t) the residual. Parameter k determines the sensitivity of perception to changes in the stimulus s, while determines the minimum threshold that the stimuli s must overcome in order to be perceived. The residual term R(t) is a random variable representing noise not directly captured by the stimulus. For instance, exogenous events can trigger abrupt peaks in the Death score. This is the case, for example, with the murder of George Floyd in the USA, or the peak in Nigeria around April 17th 2020, triggered by a number of prominent African figures dying from Covid-19 around that day, including the Nigerian President’s top aide (see “Appendix 2” for details on these exogenous peaks).
In order to test the Weber–Fechner law, we fit a linear regression model to , the Death NLS time series in country i, and , the daily number of deaths in the same country, and summarize the results of these fits in Table 3. We find that Eq. (10) accurately models the data, with significant coefficients (p-value ) for all countries except Spain. The sensitivity parameter k has the same order of magnitude for all significant countries. However, the country with the lowest k is times less sensitive than the highest, indicating that Twitter users in different countries may react differently to the evolution of the pandemic. The minimum stimuli threshold , in the other hand, is always small: most countries, except for the USA and the UK, need only one Covid-19 death in a given day in order to be perceived. Conversely, the USA and UK need approximately 5 and 6 deaths to be perceived, which is small compared to the thousands of daily deaths registered in these countries during the observation period.
Table 3.
Results from the fit of the Weber–Fechner law [see Eq. (10)] to the observed relationship between the Death NLS and the logarithm of the daily number of deaths in each country (see Fig. 6)
| Weber–Fechner law | 95% CI | NRMSE | ||||||
|---|---|---|---|---|---|---|---|---|
| Country | () | () | () | |||||
| Argentina | 1.044 | 0.0080 | 0.758 – 1.329 | 7.29 | 0.0 | 0.421 | 0.113 | 75 |
| Australia | 1.042 | 0.1047 | 0.508 – 1.576 | 3.94 | 0.0003 | 0.275 | 0.171 | 43 |
| Canada | 0.596 | 0.4477 | 0.508 – 0.683 | 13.53 | 0.0 | 0.683 | 0.105 | 87 |
| Chile | 0.575 | 0.0001 | 0.412 – 0.737 | 7.05 | 0.0 | 0.395 | 0.149 | 78 |
| Colombia | 0.604 | 0.0011 | 0.436 – 0.772 | 7.18 | 0.0 | 0.414 | 0.144 | 75 |
| India | 0.332 | 0.0061 | 0.264 – 0.4 | 9.69 | 0.0 | 0.543 | 0.128 | 81 |
| Mexico | 0.846 | 0.0300 | 0.742 – 0.95 | 16.2 | 0.0 | 0.775 | 0.101 | 78 |
| Nigeria | 0.457 | 0.0003 | 0.168 – 0.747 | 3.16 | 0.0025 | 0.147 | 0.222 | 60 |
| South Africa | 0.282 | 0.0001 | 0.127 – 0.436 | 3.64 | 0.0005 | 0.171 | 0.183 | 66 |
| Spain | − 0.016 | Inf | − 0.198 – 0.165 | − 0.18 | 0.8593 | 0 | 0.198 | 82 |
| UK | 0.752 | 5.241 | 0.61 – 0.894 | 10.54 | 0.0 | 0.555 | 0.143 | 91 |
| USA | 0.788 | 4.2478 | 0.672 – 0.905 | 13.43 | 0.0 | 0.677 | 0.126 | 88 |
Overall, this model best describes the relationship between the daily number of deaths local to each country and the Death NLS.
Power-law perception
An alternative functional form for the relationship between human perception p of a stimulus and the physical magnitude s of the stimulus is a power law relationship
| 11 |
where and are parameters determining the perception from a stimulus of unit magnitude and the growth rate of the perception as a function of the stimulus magnitude, and is a residual term. This form has been shown to outperform the Weber–Fechner law in characterising human perception in a number of empirical studies (Stevens 1975). We also therefore report the results of this model fit to the relationship between the Death NLS and national daily death counts for each country i, reporting our results in Table 4.
Table 4.
The results from the fit of a power law [see Eq. (11)] to the relationship between the Death NLS and the national daily death count
| Power law | 95% CI | * | NRMSE | |||||
|---|---|---|---|---|---|---|---|---|
| Country | () | () | () | |||||
| Argentina | 0.164 | 2.21 | 0.121–0.208 | 7.59 | 0.0 | 0.411 | 0.114 | 75 |
| Australia | 0.363 | 0.99 | 0.181–0.546 | 4.02 | 0.0002 | 0.259 | 0.173 | 43 |
| Canada | 0.288 | 0.37 | 0.252–0.323 | 16.29 | 0.0 | 0.678 | 0.106 | 87 |
| Chile | 0.085 | 2.47 | 0.06–0.109 | 6.97 | 0.0 | 0.382 | 0.151 | 78 |
| Colombia | 0.112 | 1.81 | 0.083–0.142 | 7.57 | 0.0 | 0.425 | 0.143 | 75 |
| India | 0.126 | 0.77 | 0.101–0.15 | 10.33 | 0.0 | 0.558 | 0.126 | 81 |
| Mexico | 0.141 | 1.52 | 0.126–0.157 | 18.04 | 0.0 | 0.78 | 0.1 | 78 |
| Nigeria | 0.104 | 1.56 | 0.037–0.172 | 3.09 | 0.0031 | 0.143 | 0.223 | 60 |
| South Africa | 0.087 | 1.11 | 0.037–0.136 | 3.52 | 0.0008 | 0.16 | 0.184 | 66 |
| Spain | 0.014 | 2.14 | − 0.03 to 0.059 | 0.64 | 0.5241 | − 0.042 | 0.202 | 82 |
| UK | 0.356 | 0.16 | 0.302–0.409 | 13.21 | 0.0 | 0.514 | 0.149 | 91 |
| USA | 0.309 | 0.21 | 0.279–0.339 | 20.54 | 0.0 | 0.608 | 0.139 | 88 |
This is the best model in some cases, though it is outperformed by the Weber–Fechner law most times. *While we fit this model assuming a log-log relationship between p and s, we compute with linear p to make it comparable to the model implied by the Weber–Fechner law [see Eq. (14) in “Appendix 1” for details]. This may cause negative values of as is the case for Spain
In all cases, we observe sublinear exponents for the perception of the daily deaths data, with significant exponents (p-value ) ranging between 0.085 and 0.36. These exponents are of the same order of magnitude as the of 0.32 reported in (Summers et al. 1994), where in several laboratory experiments they measure psychophysical numbing in participants’ perception of death statistics. As discussed previously, the data for Spain is unusual for a number of reasons, thus the model does not accurately describe the data in this instance. These results suggest that Twitter users in certain countries are more sensitive to change in the number of deaths than others.
Model comparison
Both the Weber–Fechner law and power-law relationships between the Death NLS and the daily number of reported deaths accurately model the data. Each captures the phenomenon in which “the first few fatalities in an ongoing event elicit more concern than those occurring later on” (Olivola 2015). By way of comparison, we present in Table 5 the normalised root mean squared errors (NRMSE), defined as
| 12 |
for these models, in addition to a linear model between and as a baseline “null” model. Here, is the model residual, and n is the sample size. The models are directly comparable in this sense, since each involves only two parameters. Bhatia (2016) performed a similar model comparison to test psychophysical laws for subjective probability judgements of real-world events, in that case finding that the linear relationship was the best. In our case, however, a linear relationship between s and p is significantly worse than the present concave models of perception [see “Appendix 1” for the results of the linear model], reinforcing our hypothesis of psychophysical numbing.
Table 5.
Comparison of the normalised root mean squared error (NRMSE) [see Eq. (12)] between the models of attention
| NRMSE country | Power law | Weber–Fechner law | Linear relationship |
|---|---|---|---|
| Argentina | 0.114 | 0.113 | 0.116 |
| Australia | 0.173 | 0.171 | 0.175 |
| Canada | 0.106 | 0.105 | 0.117 |
| Chile | 0.151 | 0.149 | 0.17 |
| Colombia | 0.143 | 0.144 | 0.145 |
| India | 0.126 | 0.128 | 0.125 |
| Mexico | 0.1 | 0.101 | 0.133 |
| Nigeria | 0.223 | 0.222 | 0.218 |
| South Africa | 0.184 | 0.183 | 0.188 |
| Spain | 0.202 | 0.198 | 0.193 |
| UK | 0.149 | 0.143 | 0.166 |
| USA | 0.139 | 0.126 | 0.179 |
| Mean | 0.151 | 0.149 | 0.16 |
| Proportion of best fits | 16.7% | 58.3% | 25% |
| Proportion of second-best fits | 66.7% | 33.3% | 0 % |
We compare the power law model of Eq. (11), the Weber–Fechner model of Eq. (10), and a linear relationship between variables, which we use as a benchmark model. Lower values indicate better-fitting models; italics indicate the best model for that country. Note that, overall, the Weber–Fechner law outperforms the other models. For further details, see Figs. 8 and 9 in “Appendix 1”
While the Weber–Fechner law is better than the power law model overall, the difference in their goodness of fit—as measured by the NRMSE—is marginal. Both are reasonable descriptions of the observed relationship, and similar conclusions can be drawn from both.
In particular, the parameters k and from the Weber–Fechner law and power law, respectively, are analogous in their interpretation as the measure of the sensitivity of the nation’s Twitter users to changes in the national Covid-19 daily death rate. To illustrate this, we rank the countries in our dataset in order of sensitivity to changes in the local death rate, as measured separately by these two parameters, and plot the correlation between the countries’ ranks in Fig. 7. Here, low rank indicates high sensitivity to changes in the number of daily deaths nationally. The correlation between the two methods of ranking—according to k, the Weber–Fechner law slope parameters, and according to , the power law model exponents—is high, with correlation coefficient 0.77. This shows that the sensitivity of each country is relatively robust between models. By both measures, therefore, Twitter users tweeting in English and Spanish from Australia and Argentina, respectively, appear to be the most sensitive to changes in the national daily death rate, while Twitter users posting in English from South Africa, India, and Nigeria and in Spanish from Spain and Chile appear to be the least sensitive to these changes.
Fig. 7.
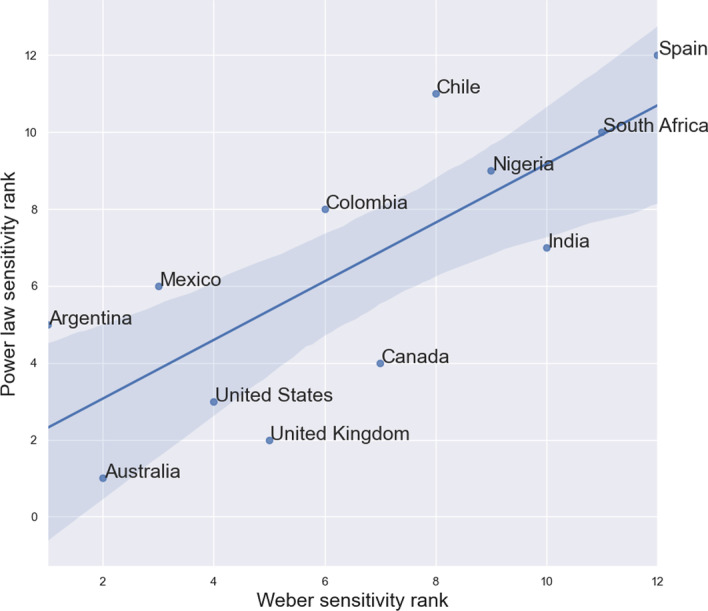
Comparison of the rank of each country as determined by their k and parameters in the Weber–Fechner and power-law fits, respectively, which determine the sensitivity of Twitter users tweeting from each country to changes in the number of daily reported deaths. Low rank indicates high sensitivity relative to the remaining countries. The correlation between countries’ ranks from both measures is high at 0.77
Discussion and conclusions
We explored the country-by-country relationship between the linguistic features present in a large set of tweets posted in relation to the Covid-19 pandemic, and the progression/intensity of the pandemic as measured by the daily number of cases and deaths in each country in our dataset. By considering the change, relative to a baseline, in the percentage of words present in each tweet that are associated with a number of psychologically meaningful categories—here called linguistic scores—we observed significant trends that we believe are indicative of a psychophysical numbing effect (Slovic 2010).
We found that the National Linguistic Scores [NLSs, see Eq. (4)] associated with emotion and affect decrease as the pandemic intensifies. This is in spite of a greater attentional focus on death and mortality and a simultaneous increase in use of words indicating analytic reasoning. We showed, by constructing word co-occurrence networks on different time periods of the pandemic, that words related to death co-occur more frequently with other words related to death than they do with words indicating affect and emotion. We constructed network measures of this separation between the concepts of death and emotion—namely the weighted modularity of the partition induced by the Death and the Affect LIWC dictionaries, and the fraction of strength of the “death*” (muert*) node attributable to connections with other nodes in the Death category—and showed that this separation became more pronounced at larger daily death rates for a number of countries. This is consistent with the notion of psychophysical numbing, which we believe may explain these observations.
We also showed that the psychophysical laws of Weber–Fechner and of power law perception in humans accurately model the relationship between the frequency of words related to death and the actual daily number of Covid-19 deaths in each country. We estimated sub-linear exponents in the power law perception function that are of similar values to values previously estimated from psychological experiments (Summers et al. 1994). These exponents, together with parameter k of the Weber–Fechner law [see Eq. (10)], tell us how sensitive the Twitter users in each country are to their national Covid-19 daily deaths, and were seen to vary by country, indicating inter-country differences in risk perception and sensitivity to death rates. Such sensitivities were consistent across models (see Fig. 7) suggesting that these measures are robust features of the data.
Overall, our results indicate that two key factors contributing to risk perception—attention and emotion (Slovic 2010)—may be evolving in line with that predicted by psychophysical numbing amongst members of the public. In general, both measures of the degree of concern towards Covid-19-related casualties expressed by the Twitter users in our dataset appear to decrease as the number of Covid-19-related casualties increases. This potentially reflects a collapse of compassion and a concavity in the value assigned to human lives as the number of potential casualties grows.
Our findings illustrate the signaling power of Twitter, and demonstrate its potential use as a tool for monitoring public perception of risk during large-scale crisis scenarios. With the modelling and visualisation approaches we employ in this paper, policy-makers and public officials could track in near-to-real-time the public’s attitudes towards threats to public well-being and the prevalence of factors important to public perception of risk, including degree of outrage and relative attentional focus on the threat. Our findings also imply a functional form for agent perception of the system state in models of opinion dynamics. This will be instrumental for developing coupled opinion dynamics-epidemiological models, in which the bidirectional relationships between human perception, human behaviour, and epidemic progression are modelled endogenously.
A natural extension to this work would involve nowcasting and/or forecasting of certain economic indicators. It has also been limited in that we assumed that only the national death rate is a significant predictor of perception. A more complete analysis should account for the effect of other countries’ death statistics as a driver of local perception, or more broadly an advancement of a process-level explanation of the cross-cultural differences we observe in the sensitivity to death statistics. This analysis could also be enhanced by relating these measures of risk perception to behavioural data, which—since “people’s behavior is mediated by their perceptions of risk” (Weber 2004)—may be useful for understanding the role of emotions in driving behaviours that are conducive to public health during crises. Further, a deconstruction of the aggregate indicators we have developed to the state and regional level may be necessary to more accurately characterise the relationship between local crisis progression and human risk perception.
It is important to acknowledge that additional factors may be at play and contributing to our findings. In particular, our dataset is a large social media dataset in which non-human accounts – for instance, bots, institutional accounts, and companies’ public relations accounts—coexist with human accounts. Such public relations and institutional accounts can be subject to editorial constraints on the kind of language used, and therefore may not reflect any true underlying subjective experience. The use of tweets from such non-human accounts may nonetheless be appropriate. Indeed, it is widely accepted that news media play a significant role in shaping public attention and opinion, e.g. via the Cultivation or Agenda-Setting theories of consumer-media relations (Bryant and Miron 2006; Mccombs and Shaw 1972). With almost half of all UK adults consuming news through social media in 2020 (https://www.ofcom.org.uk/research-and-data/tv-radio-and-on-demand/news-media/news-consumption), for example, the inclusion of news and institutional accounts may act as a proxy for public attention and opinion at large.
With regard to bots: previous large-scale studies of Twitter data have demonstrated the influence bots can have on the exposure of human accounts to emotional content (Stella et al. 2018) and the extent to which they can distort the discussion on certain topics (Bessi and Ferrara 2016). More recently and in the context of the current pandemic, bots have been shown to have a significant role in promoting political conspiracy theories (Ferrara 2020). By ignoring retweets and using unique original tweets only, we mitigate to some extent the potential effect of bots, which have previously been shown to engage in retweeting behaviour significantly more frequently than they do the creation of original content (Bessi and Ferrara 2016). It is nonetheless likely that, even if the hypothesised psychophysical numbing effect is genuine, our observations are partly attributable to the nature of content generated by these non-human accounts.
Furthermore, we stress that the results presented in this paper may be indicative only of the responses of Twitter users posting from each of these countries in each of these languages, so extrapolating these results to the broader population will only be possible with a better understanding of the biases present in, and representativeness of, the dataset at hand. While the demography of Twitter users has been to some extent mapped for the USA [see e.g. Greenwood et al. (2016)] and the UK [see e.g. Sloan (2017)], it is difficult to find similar studies for the remaining countries in our dataset, and thus to interpret these country-level differences in terms of potentially differing demographic representation on Twitter. We nonetheless advance this as a factor that possibly contributes to our results.
We also reiterate that our analysis has been crude in that we make use of a single dictionary for each language when extracting linguistic features from our data. This ignores important differences in dialect and language use between different nationalities and cultures, and can result in the systematic omission of certain linguistic features (Rudra et al. 2016; Mathur et al. 2019) which may also contribute to the observed differences between countries. Further important differences between countries which may help to account for the observed results are differences in the importance of religion in each of the considered countries. The set of countries under consideration here span the full spectrum of importance assigned to religion (Hackett et al. 2018), and attitudes towards death and the framing of mortality may vary accordingly by country. Despite these difficulties inherent to the empirical analysis of social media data, we nonetheless hope that our work inspires further investigations into the use of natural language processing and cognitive network science to investigate the prevalence of psychophysical numbing in naturalistic contexts.
Acknowledgements
The authors would like to thank Mirta Galesic, Rodrigo Leal Cervantes, Rita Maria del Rio Chanona, François Lafond, and J. Doyne Farmer for helpful feedback, and to the Oxford INET Complexity Economics group for stimulating discussions. The authors also thank the anonymous reviewers whose suggestions significantly improved the quality of the final paper.
Abbreviations
- LIWC
Linguistic Inquiry and Word Count
- WHO
World Health Organization
- NLS
National linguistic score
Appendix 1: Further model comparison
In this section, we present further results of our models to give a more complete overview of their quality. Besides the Weber–Fechner law and power law models [see Eqs. (10) and (11)], we use the following linear relationship between s and p as our benchmark model
| 13 |
where a and b are parameters. We summarize our results for the linear model in Table 6.
Table 6.
Results for the linear model defined in Eq. (13)
| Country | a | b | 95% CI (a) | (a) | (a) | NRMSE | ||
|---|---|---|---|---|---|---|---|---|
| Argentina | 0.057 | 2.603 | 0.04–0.074 | 6.79 | 0.0 | 0.387 | 0.116 | 75 |
| Australia | 0.192 | 0.912 | 0.087–0.298 | 3.67 | 0.0007 | 0.247 | 0.175 | 43 |
| Canada | 0.005 | 0.759 | 0.005–0.006 | 11.46 | 0.0 | 0.607 | 0.117 | 87 |
| Chile | 0.005 | 2.969 | 0.003–0.007 | 4.58 | 0.0 | 0.216 | 0.17 | 78 |
| Colombia | 0.016 | 2.147 | 0.011–0.02 | 7.11 | 0.0 | 0.409 | 0.145 | 75 |
| India | 0.002 | 1.074 | 0.002–0.003 | 10.14 | 0.0 | 0.566 | 0.125 | 81 |
| Mexico | 0.003 | 2.428 | 0.002–0.003 | 10.97 | 0.0 | 0.613 | 0.133 | 78 |
| Nigeria | 0.047 | 1.589 | 0.021–0.073 | 3.61 | 0.0006 | 0.184 | 0.218 | 60 |
| South Africa | 0.006 | 1.295 | 0.002–0.01 | 2.95 | 0.0045 | 0.119 | 0.188 | 66 |
| Spain | 0 | 2.248 | − 0.0–0.001 | 1.98 | 0.0506 | 0.047 | 0.193 | 82 |
| UK | 0.001 | 0.877 | 0.001–0.001 | 7.69 | 0.0 | 0.399 | 0.166 | 91 |
| USA | 0 | 1.235 | 0.0–0.001 | 6.84 | 0.0 | 0.352 | 0.179 | 88 |
For all models, we compute the values
| 14 |
where is the model residual, is the variance of p(t), and n is the sample size. The values for all models are summarized in Table 7. (Note that as the power law model implies a log-normal residual, the values can be negative.) From this table we see that, once again, the Weber–Fechner law is generally a better fit to the data across all countries, but that the power law and Weber–Fechner models are often comparable and significantly better than the linear model.
Table 7.
Comparison of between the models of attention
| Country | Power law | Weber–Fechner law | Linear relationship |
|---|---|---|---|
| Argentina | 0.411 | 0.421 | 0.387 |
| Australia | 0.259 | 0.275 | 0.247 |
| Canada | 0.678 | 0.683 | 0.607 |
| Chile | 0.382 | 0.395 | 0.216 |
| Colombia | 0.425 | 0.319 | 0.28 |
| India | 0.558 | 0.397 | 0.477 |
| Mexico | 0.78 | 0.775 | 0.613 |
| Nigeria | 0.143 | 0.004 | 0.007 |
| South Africa | 0.16 | 0.171 | 0.119 |
| Spain | − 0.042 | 0 | 0.047 |
| UK | 0.514 | 0.555 | 0.399 |
| USA | 0.608 | 0.556 | 0.24 |
| Mean | 0.36 | 0.379 | 0.303 |
| Proportion of best fits | 41.7% | 50% | 8.33% |
| Proportion of second-best fits | 66.7% | 33.3% | 0% |
We also show in Figs. 8 and 9 scatterplots of the Death NLSs against the logarithm of the daily number of deaths in each country, with the y-axis in linear- and log-scales, respectively. Red lines indicate the line of best fit, with the slope equal to k and in Eqs. 10 and 11, respectively.
Fig. 8.

Scatter plots for the Weber–Fechner law model fit [see Eq. (10)], where each panel shows a different country with their corresponding NRMSE [see Eq. (12)] in parenthesis (the lower the better)
Fig. 9.

Scatter plot for the power law model fit [see Eq. (11)], where each panel shows a different country with their corresponding NRMSE [see Eq. (12)] in parenthesis (the lower the better)
Appendix 2: National Linguistic Scores
Appendix 2.1: Exogenous peaks in the National Linguistic Scores
In this section, we address significant deviations in the National Linguistic Scores from our proposal of psychophysical numbing as an explanation for their trends over the observation period, and suggest possible explanations for their occurrence, see Table 8. We stress that the following table might be prone to error although we double checked every peak.
Table 8.
A list of plausible explanations for anomalous peaks observed in Fig. 1
| Country | Date | Category | Description |
|---|---|---|---|
| USA | June 2, 2020 | Anger | Donald Trump responding near the White House to the protests against the murder of George Floyd (Collinson 2020) |
| Australia, Nigeria, UK | June 6–7, 2020 | Anger | Worldwide protests against the murder of George Floyd in the USA (https://edition.cnn.com/2020/06/06/world/gallery/intl-george-floyd-protests/index.html) |
| Chile | May 13–15, 2020 | Anger | Chilean Health Ministry announces total lockdown (https://www.minsal.cl/ministerio-de-salud-decreta-cuarentena-total-para-la-ciudad-de-santiago-y-seis-comunas-aledanas/) |
| Argentina | March 20, 2020 | Death | President Alberto Fernandez announces total national lockdown (https://elpais.com/sociedad/2020-03-20/argentina-entra-en-cuarentena-obligatoria-hasta-el-31-de-marzo.html) |
| Australia | May 20–26, 2020 | Death | New Covid-19 deaths after several days without casualties. Moreover, the murder of George Floyd in the USA took place on May 25 (https://www.nbcnews.com/news/us-news/man-dies-after-pleading-i-can-t-breathe-during-arrest-n1214586) |
| Canada | May 2, 2020 | Death | Unknown |
| Colombia | March 22, 2020 | Death | Shootout in a prison triggered by prisoners demanding better hygiene conditions for Covid-19 results in 23 deaths (https://www.efe.com/efe/america/sociedad/matanza-de-23-presos-y-83-heridos-sacude-a-una-colombia-temerosa-del-covid-19/20000013-4201992) |
| India | March 29, 2020 | Death | Unknown |
| Nigeria | April 18, 2020 | Death | Many important African political figures die from Covid-19 this day (https://www.africanews.com/2020/06/25/africa-s-prominent-coronavirus-deaths/) |
| Spain | May 25, 2020 | Death | Correction in Covid-19 data repositories show negative daily deaths (https://www.eldiario.es/sociedad/espana-registra-fallecidos-ultimas-diagnostica_1_5972351.html) |
| Spain | June 1, 2020 | Death | First day in Spain without Covid-19 deaths (https://www.elfinanciero.com.mx/mundo/espana-registra-su-primer-dia-sin-muertes-por-covid-19) |
| UK | April 10, 2020 | Death | The UK surpasses 10,000 Covid-19 deaths (https://www.bbc.com/news/uk-52264145) |
| USA | May 25, 2020 | Death | Murder of George Floyd (https://www.nbcnews.com/news/us-news/man-dies-after-pleading-i-can-t-breathe-during-arrest-n1214586) |
Most of these peaks arise from the murder of George Floyd and the consequent protests. We focused mainly on the Death and emotionally-charged categories as these are the ones that are most related to the psychophysical numbing effect we describe in the main text
Appendix 3: Word co-occurrence analysis
Appendix 3.1: Further technical details on co-occurrence network construction
In constructing the word co-occurrence networks presented in “Psychophysical numbing” section, we perform basic text preprocessing, including taking the lower-case form of all letters, removing URLs, removing punctuation, and removing the following small set of stopwords from the vocabulary:
to, today, too, has, have, like.
We retain hashtags, since LIWC also recognises hashtags and because hashtags are an essential aspect to communications on Twitter. It is also necessary to account for the fact that a number of “words” appearing in the LIWC dictionary are in fact regular expressions to which many complete words in the Twitter dataset map. For example, the “word” “isolat*” appears in the English LIWC dictionary, to which each of the following words would map: “isolate”, “isolated”, “isolating”. Thus, construction of the word co-occurrence networks involves a two-step procedure: first, constructing the raw word co-occurrence networks , in which the nodes are words exactly as they appear in the Twitter dataset; and then reducing this to a quotient graph by contracting nodes in that are matched by the same regular expression in the LIWC dictionary. More formally: the LIWC dictionary implies an equivalence relation on the vocabulary implied by the Twitter dataset, such that for words if both v and u are matched by the same regular expression in the LIWC dictionary. The weights of edges between nodes and in are then taken to be
| 15 |
where is the weight of edge (x, y) in G. Note that and if (x, y) is not an edge in G.
To construct the higher-frequency sequences of snapshots, we impose a minimum document frequency of ( for Spanish tweets) for each term in the vocabulary in order to reduce the effect of noise. In Table 9, we summarise the approximate number of tweets per snapshot for each country. The number of tweets per snapshot for each country was chosen in order that each country had approximately the same number of data points separated by approximately 3 days, and such that edge effects did not yield a final snapshot with a disproportionately low number of tweets. While this ultimately led to some snapshots representing aggregation over longer periods than others, this yielded sequences of networks that are comparable in terms of their total strength and order, enabling reasonably fair comparison of the modularities of the partition induced by the Death and Affect LIWC categories.
Table 9.
Number of tweets taken per snapshot for each country
| Country | Argentina | Australia | Canada | Chile |
|---|---|---|---|---|
| Country | Colombia | India | Mexico | Nigeria |
|---|---|---|---|---|
| Country | South Africa | Spain | UK | USA |
|---|---|---|---|---|
Appendix 3.2: Word co-occurrence networks for Spanish-language tweets
For completeness, we provide here the word co-occurrence graphs for the Spanish language tweets (see Fig. 10). We omit a discussion of the results, since similar conclusions can be drawn from these as in the English counterparts.
Fig. 10.

Snapshots of the word co-occurrences associated with death (“muerte”, green labels) and affect (“afecto”, red labels) for Spanish-language tweets aggregated across all analyzed countries in three different time windows (see sub-captions). The nodes are coloured based on the community labels obtained by maximising modularity using the Louvain algorithm (Blondel et al. 2008). We filtered edges with weight below 20 co-occurrences for visualisation purposes
Appendix 4: Covid-19 epidemiological data
We include this section as a reference for the actual number of deaths in each country for the period we analysed throughout the paper, which we present in Fig. 11.
Fig. 11.
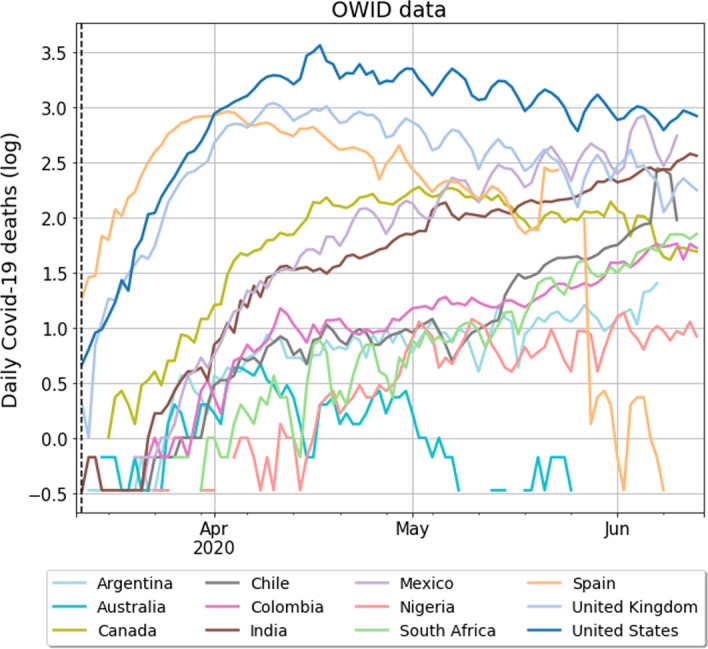
Log of daily deaths related to Covid-19 for each of the countries in our analysis (see legend) from March 11 to June 14, 2020
Authors' contributions
BK and JD both conceived the idea, carried out the analysis, and wrote the final manuscript. All authors read and approved the final manuscript.
Funding
JD is supported by the EPSRC Centre For Doctoral Training in Industrially Focused Mathematical Modelling (EP/L015803/1) in collaboration with Improbable Worlds Limited. BK acknowledges funding from the Conacyt-SENER: Sustentabilidad Energética scoloraship.
Availability of data and materials
The Twitter data used in the manuscript is collected and maintained by Banda et al. at the Panacea Lab (Banda et al. 2020), and it is available at their website http://www.panacealab.org/covid19. The data on Covid-19 confirmed cases and deaths were obtained from the “Coronavirus Pandemic (COVID-19)” page of the Our World in Data website (Max Roser et al. 2020), and the stable URL for this data is https://covid.ourworldindata.org/data/owid-covid-data.csv.
Competing interests
The authors declare that they have no competing interests.
Footnotes
The free Stream API randomly samples around of the total tweets for the given queries.
A number of publicly available Twitter datasets have emerged in relation to the pandemic. We chose to work with this dataset since it used the most generic query terms among all the publicly available datasets we considered, and we wanted the least amount of bias possible for our analysis.
For the English-language tweets, we make use of the 2015 English dictionary. For the Spanish-language tweets, the most recent dictionary is the 2007 edition, which has fewer categories than the 2015 English dictionary.
When analysing these correlations, we found that, overall, the cumulative cases and deaths correlate better with most linguistic categories than the daily data. However, while this is sensible in the early stages of the pandemic, it is unlikely to remain the case over a long time horizon due to humans’ finite memory. We therefore proceeded with our comparison using the daily epidemiological data alone for this reason.
The only exception is the cross-country average of the Sadness component of the NLSs, which is positively correlated with the epidemiological indicators and appears to be driven only from Argentina’s, Chile’s, and Colombia’s increasing use of words related to Sadness. The remaining countries remain stationary at a lower-than-baseline value for this component.
Unfortunately, the Spanish LIWC dictionary does not yet have an Analytic category.
The Affect category contains all the words related with affective processes. This includes the words in Anger, Anxiety, Positive and Negative emotion, and Swear words, which are all significantly correlated with Death and daily deaths.
Recall that the z-score of a sequence of observations is given by , where and are the mean and standard deviation of , respectively.
We note that the correspondence is weaker for Australia, Nigeria, and South Africa due to the relatively low number of cases in these countries (see Fig. 11 in the “Appendix” for reference). The correspondence is also weaker in Spain because it contains two exogenous peaks not related to psychophysical numbing. See “Appendix 2” for a discussion of these peaks for Spain and other countries, which we remove from the time series.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Equal contribution
Contributor Information
Joel Dyer, Email: joel.dyer@maths.ox.ac.uk.
Blas Kolic, Email: blas.kolic@maths.ox.ac.uk.
References
- Africa’s top virus deaths. https://www.africanews.com/2020/06/25/africa-s-prominent-coronavirus-deaths/. Accessed 7 July 2020
- Aiello LM, Quercia D, Zhou K, Constantinides M, Šćepanović S, Joglekar S (2020) How epidemic psychology works on social media: evolution of responses to the covid-19 pandemic. arXiv preprint arXiv:2007.13169
- Argentina entra en cuarentena obligatoria hasta el 31 de marzo, El Pas, Mar 2020. https://elpais.com/sociedad/2020-03-20/argentina-entra-en-cuarentena-obligatoria-hasta-el-31-de-marzo.html
- Banda JM, Tekumalla R, Wang G, Yu J, Liu T, Ding Y, Chowell G (2020) A large-scale COVID-19 Twitter chatter dataset for open scientific research—an international collaboration [DOI] [PMC free article] [PubMed]
- Barrios JM, Hochberg YV (2020) Risk perception through the lens of politics in the time of the COVID-19 pandemic. NBER working paper no. 27008
- Bessi A, Ferrara E (2016) Social bots distort the 2016 U.S. presidential election online discussion. First Monday, 21 Nov 2016. https://firstmonday.org/ojs/index.php/fm/article/view/7090
- Bhatia S (2016) Vector space semantic models predict subjective probability judgments for real-world events. In: CogSci
- Bhatia S. Predicting risk perception: new insights from data science. Manag Sci. 2019;65(8):3800–3823. doi: 10.1287/mnsc.2018.3121. [DOI] [Google Scholar]
- Bhatia S, Mellers B, Walasek L. Affective responses to uncertain real-world outcomes: sentiment change on Twitter. PLoS ONE. 2019;14(2):e0212489. doi: 10.1371/journal.pone.0212489. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blondel VD, Guillaume J-L, Lambiotte R, Lefebvre E. Fast unfolding of communities in large networks. J Stat Mech Theory Exp. 2008;2008:P10008. doi: 10.1088/1742-5468/2008/10/P10008. [DOI] [Google Scholar]
- Britton T, Deijfen M, Liljeros F. A weighted configuration model and inhomogeneous epidemics. J Stat Phys. 2011;145(5):1368–1384. doi: 10.1007/s10955-011-0343-3. [DOI] [Google Scholar]
- Bryant J, Miron D. Theory and research in mass communication. J Commun. 2006;54:662–704. doi: 10.1111/j.1460-2466.2004.tb02650.x. [DOI] [Google Scholar]
- Burns WJ, Slovic P. Risk perception and behaviors: anticipating and responding to crises. Risk Anal. 2012;32(4):579–582. doi: 10.1111/j.1539-6924.2012.01791.x. [DOI] [PubMed] [Google Scholar]
- Cameron CD, Payne BK. Escaping affect: how motivated emotion regulation creates insensitivity to mass suffering. J Personal Soc Psychol. 2011;100(1):1–15. doi: 10.1037/a0021643. [DOI] [PubMed] [Google Scholar]
- Collinson S (2020) Trump responds to protests with a strongman act. CNN Politics, Jun 2020. https://edition.cnn.com/2020/06/02/politics/donald-trump-george-floyd-protest-military/index.html
- Coronavirus: ’sombre day’ as UK deaths hit 10,000, BBC, Apr 2020. https://www.bbc.com/news/uk-52264145
- de Bruin WB, Bennett D (2020) Relationships between initial COVID-19 risk perceptions and protective health behaviors: a national survey. Am J Prev Med [DOI] [PMC free article] [PubMed]
- Dryhurst S, Schneider CR, Kerr J, Freeman ALJ, Recchia G, Marthe van der Bles A, Spiegelhalter D, van der Linden S (2020) Risk perceptions of COVID-19 around the world. J Risk Res
- Espaa registra su primer da sin muertes por covid-19, El Financiero, Jun 2020. https://www.elfinanciero.com.mx/mundo/espana-registra-su-primer-dia-sin-muertes-por-covid-19
- Feather N (1963) The effect of differential failure on expectation of success, reported anxiety, and response uncertainty. J Personal [DOI] [PubMed]
- Fechner GT, Howes DH, Boring EG. Elements of psychophysics. New York: Holt, Rinehart and Winston; 1966. [Google Scholar]
- Ferrara E (2020) What types of covid-19 conspiracies are populated by twitter bots? First Monday, 25 May 2020
- Fetherstonhaugh D, Slovic P, Johnson S, Friedrich J. Insensitivity to the value of human life: a study of psychophysical numbing. J Risk Uncertain. 1997;14:283–300. doi: 10.1023/A:1007744326393. [DOI] [Google Scholar]
- Friedrich J, Barnes P, Chapin K, Dawson I, Garst V, Kerr D. Psychophysical numbing: When lives are valued less as the lives at risk increase. J Consum Psychol. 1999;8:277–299. doi: 10.1207/s15327663jcp0803_05. [DOI] [Google Scholar]
- Gescheider GA. Psychophysics: the fundamentals. 3. London: Erlbaum; 1997. [Google Scholar]
- Go A, Bhayani R, Huang L. Twitter sentiment classification using distant supervision. CS224N Project Rep Stanf. 2009;1(12):2009. [Google Scholar]
- Greenwood S, Perrin A, Duggan M (2016) Social media update 2016. Pew Research Center, November 2016
- Hackett C, Kramer S, Schiller A (2018) The age gap in religion around the world, Pew Research Center, June 2018
- Hale T, Webster S, Petherick A, Phillips T, Kira B (2020) COVID-19 government response tracker, Blavatnik School of Government. Data use policy: creative commons attribution CC BY standard
- Harris ZS. Distributional structure. Word. 1954;10(2–3):146–162. doi: 10.1080/00437956.1954.11659520. [DOI] [Google Scholar]
- Humphries MD, Gurney K. Network small-world-ness’: a quantitative method for determining canonical network equivalence. PLoS ONE. 2008;3(4):1–10. doi: 10.1371/journal.pone.0002051. [DOI] [PMC free article] [PubMed] [Google Scholar]
- ’I can’t breathe’: man dies after pleading with officer attempting to detain him in minneapolis. NBC News, May 2020. https://www.nbcnews.com/news/us-news/man-dies-after-pleading-i-can-t-breathe-during-arrest-n1214586
- Jaidka K, Giorgi S, Schwartz HA, Kern ML, Ungar LH, Eichstaedt JC. Estimating geographic subjective well-being from Twitter: a comparison of dictionary and data-driven language methods. PNAS. 2020;117(19):10165–10171. doi: 10.1073/pnas.1906364117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jay T, Janschowitz K. The pragmatics of swearing. J Politeness Res. 2008;4:267–288. doi: 10.1515/JPLR.2008.013. [DOI] [Google Scholar]
- Jones MN, Willits J, Dennis S, Busemeyer JR, Wang Z, Townsend JT, Eidels A (2020) Models of semantic memory of a single chapter of a title in Oxford handbooks online for personal use (for details see Privacy Policy and Legal Notice). Models of semantic memory the oxford handbook of computational and mathematical psychology, September, 2020
- Kenett YN, Anaki D, Faust M. Investigating the structure of semantic networks in low and high creative persons. Front Hum Neurosci. 2014;8:407. doi: 10.3389/fnhum.2014.00407. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lifton RJ (1982) Beyond psychic numbing: a call to awareness. Am J Orthopsych 52(4) [DOI] [PubMed]
- Loewenstein G, Weber E, Hsee C, Welch E. Risk as feelings. Psychol Bull. 2001;127:267–286. doi: 10.1037/0033-2909.127.2.267. [DOI] [PubMed] [Google Scholar]
- Matanza de 23 presos y 83 heridos sacude a una colombia temerosa del covid-19, Agencia EFE, Mar 2020. https://www.efe.com/efe/america/sociedad/matanza-de-23-presos-y-83-heridos-sacude-a-una-colombia-temerosa-del-covid-19/20000013-4201992
- Mathur P, Sawhney R, Ayyar M, Shah R (2019) Did you offend me? Classification of offensive tweets in Hinglish language, pp 138–148
- Max Roser EO-O, Ritchie H, Hasell J (2020) Coronavirus pandemic (COVID-19). Our world in data. https://ourworldindata.org/coronavirus
- Mccombs ME, Shaw DL. THE agenda-setting function of mass media. Public Opin Q. 1972;36:176–187. doi: 10.1086/267990. [DOI] [Google Scholar]
- Ministerio de salud decreta cuarentena total para la ciudad de santiago y seis comunas aledaas, Ministerio de Salud, May 2020. https://www.minsal.cl/ministerio-de-salud-decreta-cuarentena-total-para-la-ciudad-de-santiago-y-seis-comunas-aledanas/
- Mohammad SM, Turney PD (2010) Emotions evoked by common words and phrases: using mechanical Turk to create an emotion lexicon. In: Proceedings of the NAACL HLT 2010 workshop on computational approaches to analysis and generation of emotion in text, pp 26–34
- Newman MEJ. Analysis of weighted networks. Phys Rev E. 2004;70:056131. doi: 10.1103/PhysRevE.70.056131. [DOI] [PubMed] [Google Scholar]
- News consumption in the UK: 2020 report, Ofcom (2020). https://www.ofcom.org.uk/research-and-data/tv-radio-and-on-demand/news-media/news-consumption
- Olivola C. The cognitive psychology of sensitivity to human fatalities: implications for life-saving policies. Policy Insights Behav Brain Sci. 2015;2(1):141–146. doi: 10.1177/2372732215600887. [DOI] [Google Scholar]
- OpenStreetMap contributors, Planet dump retrieved from https://planet.osm.org (2017)
- Pennebaker JW, Boyd RL, Jordan K, Blackburn K (2015) The development and psychometric properties of LIWC2015
- Posner J, Russell JA, Peterson BS. The circumplex model of affect: an integrative approach to affective neuroscience, cognitive development, and psychopathology. Dev Psychopathol. 2005;17(3):715–734. doi: 10.1017/S0954579405050340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Protests across the globe after George Floyd’s death. CNN World, Jun 2020. https://edition.cnn.com/2020/06/06/world/gallery/intl-george-floyd-protests/index.html
- Rudra K, Rijhwani S, Begum R, Bali K, Choudhury M, Ganguly N (2016) Understanding language preference for expression of opinion and sentiment: what do Hindi–English speakers do on twitter? In: Proceedings of the 2016 conference on empirical methods in natural language processing, pp 1131–1141
- Sandman PM. Responding to community outrage: strategies for effective risk communication. Fairfax: American Industrial Hygiene Association; 1993. [Google Scholar]
- Sanidad elimina casi 2.000 fallecidos del balance total tras una revisin de los casos, El Diario, May 2020. https://www.eldiario.es/sociedad/espana-registra-fallecidos-ultimas-diagnostica_1_5972351.html
- Schild L, Ling C, Blackburn J, Stringhini G, Zhang Y, Zannettou S (2020) Go eat a bat, Chang!”: an early look on the emergence of sinophobic behavior on web communities in the face of COVID-19. arXiv e-prints arXiv:2004.04046
- Siew CS, Wulff DU, Beckage NM, Kenett YN (2019) Cognitive network science: a review of research on cognition through the lens of network representations, processes, and dynamics. Complexity
- Sloan L (2017) Who tweets in the United Kingdom? Profiling the twitter population using the British social attitudes survey 2015. Soc Media Soc 3(1)
- Slovic P. “If I look at the mass I will never act”: psychic numbing and genocide. Dordrecht: Springer; 2010. [Google Scholar]
- Sri Manasa Venigalla A, Vagavolu D, Chimalakonda S (2020) Mood of India during Covid-19—an interactive web portal based on emotion analysis of twitter data. arXiv e-prints arXiv:2005.02955
- Stella M, Ferrara E, De Domenico M. Bots increase exposure to negative and inflammatory content in online social systems. Proc Natl Acad Sci USA. 2018;115(49):12435–12440. doi: 10.1073/pnas.1803470115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stella M, Restocchi V, De Deyne S. #lockdown: network-enhanced emotional profiling at the times of COVID-19. Big Data Cogn Comput. 2020;4(2):14. doi: 10.3390/bdcc4020014. [DOI] [Google Scholar]
- Stevens SS. On the psychophysical law. Psychol Rev. 1957;64(3):153–181. doi: 10.1037/h0046162. [DOI] [PubMed] [Google Scholar]
- Stevens SS. Psychophysics. New York: Wiley; 1975. [Google Scholar]
- Summers C, Slovic P, Hine D, Zuliani D (1994) Psychophysical numbing: an empirical basis for perceptions of collective violence. Collective violence: harmful behavior in groups and governments
- Tausczik YR, Pennebaker JW. The psychological meaning of words: LIWC and computerized text analysis methods. J Lang Soc Psychol. 2010;29(1):24–54. doi: 10.1177/0261927X09351676. [DOI] [Google Scholar]
- Tumasjan A, Sprenger TO, Sandner PG, Welpe IM (2010) Predicting elections with twitter: what 140 characters reveal about political sentiment. In: Fourth international AAAI conference on weblogs and social media
- Van Bavel JJ, Baicker K, Boggio PS, Capraro V, Cichocka A, Cikara M, Crockett MJ, Crum AJ, Douglas KM, Druckman JN et al (2020) Using social and behavioural science to support COVID-19 pandemic response. Nat Hum Behav 1–12 [DOI] [PubMed]
- Verinis JS, Brandsma JM, Cofer CN. Discrepancy from expectation in relation to affect and motivation: tests of McClelland’s hypothesis. J Person Soc Psychol. 1968;9(1):47. doi: 10.1037/h0025672. [DOI] [PubMed] [Google Scholar]
- Weber EU. Perception matters: psychophysics for economists. Psychol Econ Decis. 2004;2:163–176. [Google Scholar]
- Yin D, Bond SD, Zhang H. Anxious or angry? Effects of discrete emotions on the perceived helpfulness of online reviews. MIS Q. 2014;38(2):539–560. doi: 10.25300/MISQ/2014/38.2.10. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The Twitter data used in the manuscript is collected and maintained by Banda et al. at the Panacea Lab (Banda et al. 2020), and it is available at their website http://www.panacealab.org/covid19. The data on Covid-19 confirmed cases and deaths were obtained from the “Coronavirus Pandemic (COVID-19)” page of the Our World in Data website (Max Roser et al. 2020), and the stable URL for this data is https://covid.ourworldindata.org/data/owid-covid-data.csv.