

Abstract
Background
Concept extraction, a subdomain of natural language processing (NLP) with a focus on extracting concepts of interest, has been adopted to computationally extract clinical information from text for a wide range of applications ranging from clinical decision support to care quality improvement.
Objectives
In this literature review, we provide a methodology review of clinical concept extraction, aiming to catalog development processes, available methods and tools, and specific considerations when developing clinical concept extraction applications.
Methods
Based on the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, a literature search was conducted for retrieving EHR-based information extraction articles written in English and published from January 2009 through June 2019 from Ovid MEDLINE In-Process & Other Non-Indexed Citations, Ovid MEDLINE, Ovid EMBASE, Scopus, Web of Science, and the ACM Digital Library.
Results
A total of 6,686 publications were retrieved. After title and abstract screening, 228 publications were selected. The methods used for developing clinical concept extraction applications were discussed in this review.
Keywords: concept extraction, natural language processing, information extraction, electronic health records, machine learning, deep learning
Graphical abstract
1. Introduction
Electronic health records (EHRs) have been widely viewed to have great potential to advance clinical research and healthcare delivery (1). To achieve the goal of “meaningful use”, transforming routinely generated EHR data into actionable knowledge requires systematic approaches (2). However, a significant portion of clinical information remains locked away in free text (3). The solution to this is to replace these manual methods with autonomous computational extraction. The field of research related to this topic, commonly referred to as information extraction (IE), a subdomain of natural language processing (NLP), seeks to address the challenges of computationally extracting information from free-text narratives (4, 5). Specifically, we define the process of automatically extracting pre-defined clinical concepts from unstructured text as clinical concept extraction, which includes concept mention detection and concept encoding. Concept mention detection generally adopts the named entity recognition (NER) (6, 7) technology in the general domain, which focuses on detecting concept mentions in the text. Concept encoding aims to map the mentions to concepts in standard terminologies or those defined by downstreaming applications (5, 8, 9). Concept extraction has been adopted to extract clinical information from text for a wide range of applications ranging from supporting clinical decision making (3) to improving the quality of care (10). A review done by Meystre et al. in 2008 observed an increasing utilization of NLP in the clinical domain and a major challenge in advancing clinical NLP due to the unavailability of a large amount of clinical text (11). A summary of EHR-based clinical concept extraction applications can be found in Wang et al (5).
For illustrative purposes, an example of a typical clinical concept extraction task is presented in Figure 1, where the goal is to identify patients with silent brain infarcts (SBIs) from neuroimaging reports for stroke research. Silent brain infarcts, defined as old infarcts found through neuroimaging exams (CT or MRI) without a history of stroke, have been considered a major priority for new studies on stroke prevention by the American Heart Association and American Stroke Association. However, identification of SBIs is significantly impeded since discovery of them is an incidental finding: there are no International Classification of Diseases (ICD) codes for SBI, and it is generally not included in a patient’s problem list or any structured EHR field. Concept extraction is therefore necessary for the identification of SBI-related findings from neuroimaging reports. We can infer a case of SBI based on acuity (chronic), location (left basal ganglia lacunar), and the number of infarcts (one) from the sentence “A chronic lacunar infarct is also noted”.
Figure 1.

An example of using concept extraction for stroke research.
Methods for developing clinical concept extraction applications have been largely translated from the general NLP domain (4), and can typically be stratified into rule-based approaches and statistical approaches with four categories: rule-based, traditional machine learning (non-deep-learning variants), deep learning, or hybrid approaches. For example, an early attempt of clinical concept extraction, the Medical Language Processing project, was adapted from the Linguistic String Project aiming to extract symptoms, medications, and possible side effects from medical records (12, 13) leveraging a semantic lexicon and a large collection of rules. The rise of statistical NLP in the 1990s (14) and recent advances in deep learning technologies (15–17) have influenced the methods adopted for clinical concept extraction. Despite these advances, methods for clinical concept extraction are generally buried within the methods section of the literature due to the complexity and heterogeneity associated with EHR data and the diverse range of applications. No singular method has proven to be globally effective.
Here, we provide a review of the methodologies behind clinical concept extraction, cataloguing development processes, available methods and tools, and specific considerations when developing clinical concept extraction applications. This systematic review of the concept extraction task aims to address the following questions: 1) what are the keys steps involved in the development of a clinical concept extraction application; 2) what are the trends and associations of clinical concept extraction research over different approaches; and 3) what are the unresolved barriers, challenges and future directions.
2. Method
This review was conducted following a process compliant with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines (18). A literature search was conducted, retrieving EHR-based concept extraction articles that were written in English and published from January 2009 through June 2019. Literature databases surveyed included Ovid MEDLINE In-Process & Other Non-Indexed Citations, Ovid MEDLINE, Ovid EMBASE, Scopus, Web of Science, and the ACM Digital Library. The implementations of search patterns were consistent across the different databases. The search query was designed and implemented by an experienced librarian (LJP) as: (“clinic” or “clinical” or “electronic health record” or “electronic health records” or “electronic medical record” or “electronic medical records” or “electronic patient record” or “electronic patient records” or “EHR” or “EMR” or “EPR” or “ATR”) AND (“information extraction” OR “concept extraction” OR “named entity extraction” OR “named entity recognition” OR “text mining” OR “natural language processing”) AND (NOT “information retrieval”). A detailed description of the search strategies used is provided in the Appendix.
A total of 10,441 articles were retrieved from five libraries, of which 6,686 articles were found to be unique. The articles were then filtered manually based on the title, abstract, and method sections to keep articles with EHR-based clinical information extraction from English text. After this screening process, 928 articles were considered for subsequent categorization. We conducted additional manual review to keep articles with methodology description focusing on clinical concept extraction. The final inclusion criteria for the target papers are as follows 1) using concept extraction methods, 2) applied to EHR data in English, 3) providing a methodological contribution via: a) presenting novel methods for clinical concept extraction, including introducing a new model, data processing framework, NLP pipeline, etc., or b) applying existing methods to a new domain or task. Articles without full text or methology description were excluded. Following this screening process, 228 articles were selected and categorized based on the methods used. A comprehensive full-text review of all 228 studies was performed by the study team. During the full-text review, the following information were extracted manually: method type (e.g. rule based, machine learning), domain (e.g. disease study area), sub-domain, data type, performance (e.g. f1-score and AUC), and overall summary of methology. A flow chart of this article selection process is shown in Figure 2.
Figure 2.

Overview of article selection process.
3. Results
Figure 3 shows the number of articles and associated methods available in our surveyed literature from January 2009 to June 2019. An upward trend in published clinical concept extraction research is observed, suggesting a strong need for harvesting information and knowledge from EHRs to support various clinical, operational, and research activities.
Figure 3.

Trend view of clinical concept extraction research over different approaches.
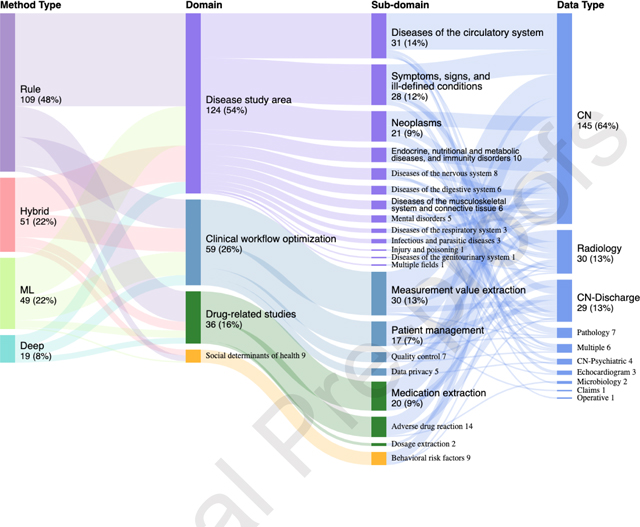
A comprehensive mapping of each method to its associated application was illustrated in Figure 4 through a sunburst plot where the targets for concept extraction were categorized into four primary domains (i.e., diseases, drugs, clinical workflows, and social determinants of health) based on the focus of collected studies and clinical perspectives. The four domains were based on the focus of collected studies (frequency), clinical perspectives (importance) and the past clinical NLP shared tasks. We subsequently classified the four domains to more detailed sub-domains. The “Diseases” sub-domain was classified based on the ICD-9 classification system (19) given its stability and wide coverage in clinical practice. The sub-domain for clinical workflow optimization, drug and social behavior-related studies were determined by clinical perspectives and the uniqueness of the category.
Figure 4.

Overview of the method utilization.
Among the 228 surveyed articles, rule-based approaches were the most widely used approach for concept extraction (48%), followed by hybrid (22%), traditional machine learning (22%), and deep learning (8%). Despite the overall low utilization rate, adoption of deep learning techniques has increased drastically since 2017. We also observed that the three disease sub-domains with the highest coverage were (i) diseases of the circulatory system, neoplasms, and endocrine, (ii) nutritional and (iii) metabolic diseases, and immunity disorders. Six disease areas have the lowest coverage: (i) certain conditions originating in the perinatal period, (ii) complications of pregnancy, childbirth, and the puerperium, (iii) congenital anomalies, (iv) diseases of the skin and subcutaneous tissue, (v) diseases of the blood and blood-forming organs, and (vi) injury and poisoning. The popularity of the sub-domains was contributed to by many reasons. Particularly, we found shared-tasks can promote research activities in specific sub-domains. In addition, the disease sub-domains that cannot be addressed by disease classification codes alone were more likely to adopt concept extraction techniques. For example, incidental findings such as leukoaraiosis and asymptomatic lesions were reported to adopt concept extraction when ICD codes were not available (20, 21).
Under the clinical workflow domain, we observed that measurement, patient identification, and quality were broadly studied. The clinical note was the most utilized data type (78%), followed by radiology reports (13%) and pathology reports (3%). On the other hand, microbiology reports, claims, and operative reports were the least utilized data type.
Based on the performance of past shared tasks and evaluation on benchmarking datasets, we summarized the state of the art performance over each domain as of June 2019. The contextual pre-trained language models, such as Bidirectional Encoder Representations from Transformers (BERT), leveraged the bidirectional training of transformers, an attention mechanism that learns contextual relations between words, resulting in state-of-the-art results in six concept extraction tasks. Hybrid and traditional machine learning achieved the best performance on two tasks. In Table 1 we summarize a list of past shared tasks with the state-of-the-art methods.
Table 1.
Benchmark of clinical concept extraction tasks
| Domain | Task Description | F-measure | Method | Model |
|---|---|---|---|---|
| Clinical workflow optimization | Automatic de-identification and identification of medical risk factors related to coronary artery disease in the narratives of longitudinal medical records of diabetic patients | 93.0 | Deep learning | BioBERT (22) |
| i2b2 2006 1B de-identification: Automatic de-identification of personal health information | 94.6 | Deep learning | BioBERT (22) | |
| Drug-related studies | i2b2 2010/VA : Medical problem extraction | 90.3 | Deep learning | BERT-large (23) |
| i2b2 2009 medication challenge: Identification of medications, dosages, routes, frequencies, durations, and reasons | 85.7 | Hybrid | CRF, SVM, Context Engine(24) | |
| Disease study area | ShARe/CLEFE 2013: Named entity recognition in clinical notes | 77.1 | Deep learning | BERT-base (P+M) (25) |
| SemEval 2014 Task 7: Identification and normalization of diseases and disorders in clinical reports | 80.7 | Deep learning | BERT-large (23) | |
| SemEval 2014 Task 14: Named entity recognition and template slot filling for clinical texts | 81.7 | Deep learning | BERT-large (23) | |
| Social determinants of health | I2B2 2006: Smoking identification challenge | 90.0 | Machine learning | SVM (26) |
The steps involved in the development of a clinical concept extraction application can be divided into three key components: 1) task formulation, 2) model development, and 3) experiment and evaluation (Figure 5). In the following subsections, we provide a detailed review of methods used for each of them. In section 3.1, we describe how to formulate a task in two different settings. Section 3.2 provides an overview of the approaches and summarizes the features for model development and the specific methods for concept extraction. Section 3.3 discusses methods for performing experiment and evaluation.
Figure 5.

The development process of clinical concept extraction applications.
3.1. Task formulation
All studies were categorized into one of two experimental settings: shared-task and practice. The shared-task setting is defined as either participation in or usage of resources produced from a shared-task to conduct concept extraction-related research. The practice setting (e.g. General Internal Medicine, Orthopaedic Medicine) involves direct use of the EHR for concept extraction in real-world scenarios. Among a total of 228 articles, 63 (28%) were categorized as belonging to a shared task setting and 165 (72%) were categorized as belonging to a practice setting. The overall prevalence proportions for rule-based, hybrid, traditional machine learning, and deep learning were 35%, 32%, 18%, and 15% respectively in the shared task setting and 51%, 20%, 23%, and 6% respectively in the practice setting. A comparison between the two settings revealed a substantial difference in relative usage of statistical approaches and rule-based approaches: the practice setting had a much higher usage of rule-based approaches whereas deep learning and other statistical approaches had a higher prevalence of usage in the shared task setting.
Per the first author affiliations from 156 articles indexed in PubMed, 87 (56%) were affiliated with an academic institution, 50 (32%) with a medical center, 9 (6%) with an industry-based research institution, and 6 (4%) with a technology company. The remaining 3 authors (2%) were affiliated with a healthcare company, a medical library, and a pharmaceutical company.
3.1.1. Shared-task setting -
Shared-tasks have successfully engaged NLP researchers in the advancement, adoption, and dissemination of novel NLP methods. Furthermore, because shared-task corpora are usually made accessible with well-defined evaluation mechanisms and public availability, they are usually regarded as standard benchmarks. Well-known tasks focusing on clinical concept extraction include the Informatics for Integrating Biology and the Bedside (i2b2) challenges (27–31), the Conference and Labs of the Evaluation Forum (CLEF) eHealth challenges (32, 33), the Semantic Evaluation (SemEval) challenges (32–34), BioCreative/OHNLP (35–38), and the National NLP Clinical Challenge (n2c2) (39).
The winning system in many past shared tasks typically used a hybrid approach, combining supervised traditional machine learning or deep learning for concept extraction with feature representation trained through unsupervised learning algorithms. The current state-of-the-art models use the long short-term memory (LSTM) (40) variant of bidirectional recurrent neural networks (BiRNN) with a subsequent conditional random field (CRF) decoding layer (15, 22, 23, 41). The convolution neural network (CNN)-based network, such as Gate-Relation Network (GRN), also performs well in tasks requiring long-term context information (42).
Recently, contextual pre-trained language models, such as Bidirectional Encoder Representations from Transformers (BERT), leverage bidirectional training of transformers, an attention mechanism that learns contextual relations between words, resulting in state-of-the-art results in the concept extraction task (15) (22) (23) (25).
3.1.2. Practice setting –
Compared with the shared-task setting, the development of concept extraction applications in practice settings is more variant, costly, and time consuming. Tasks in practice settings can be much more specialized or ill-defined depending on the disease and use-case. Furthermore, there is an additional need for study teams to create the fully-annotated corpora themselves (whereas the corpora are provided in shared tasks), which can be expensive and time consuming. However, it is a necessary step to ensure rigorous evaluation of any developed technologies.
There are some variations in the process of creating gold standard corpora in practice settings due to the heterogeneity of data caused by variations in institutional processes and clinical workflows. Based on our review, we determined that the typical tasks involved in this process included annotation task formulation, data collection and cohort screening, annotation guideline development, annotation training, annotation production, and corpus adjudication (43–46) (Figure 6). Formulation of a task in a practice setting involved definition of points of interest (see Table 3 - Description), execution of a literature review, consultation with domain experts, and identification of study stakeholders such as abstractors and annotators with specialized knowledge. This step was then followed by definition and/or creation of a study population or cohort. For example, a concept extraction application of geriatric syndromes was developed based on the cohort of 18,341 people who were 1) 65 years or older, 2) received health insurance coverage between 2011 and 2013 and 3) were enrolled in a regional Medicare Advantage Health Maintenance Organization (47). Once the cohort definition was finalized, data was screened and retrieved. Studies have found the usefulness of leveraging open-source informatics technologies such as i2b2 or customized application programming interface and SQL queries for automatic screening and retrieval (48). Subsequent to dataset definition and creation, development of a detailed annotation guideline specifying the common conventions and standards was necessary, ensuring that definitions created are scientifically valid and robust. Notably, this step involves prototyping a baseline guideline, performing trial annotation runs, calculating inter-annotator agreement (IAA), and consensus building.
Figure 6.

Data collection and corpus annotation process.
Table 3.
An overview of features used for concept extraction.
| Feature Categories | Feature Types | Description | Features | Examples |
|---|---|---|---|---|
| Linguistic features | Lexicon-based feature | A dictionary or the vocabulary of a language | Bag-of-words (BoW); | “periprosthetic, joint, infection” (71, 77, 107) |
| Orthographic features | A set of conventions for writing a language | Spelling; capitalization; hyphenation; punctuation; special characters | “igA”; “Pauci-immune vasculitis”; “BRCA1/2” (71, 108) | |
| Morphologic feature | Structure and formation of words | Prefix; suffix | “Omni” is the prefix of “Omnipaque” (91) | |
| Syntactic feature | Syntactic patterns presented in the text | Part-of-Speech, constituency parsing, dependency parsing, sequential representation (e.g. Inside–outside–beginning (IOB), B-beginning, I-intermediate, E-end, S-single word entity and O-outside (BIESO)) | “Communicating [verb] by [preposition] sinus tract [noun]” “Patient [O] has [O] an [O] acute [B] infarct [I] in [I] the [I] right [I] frontal [I] lobe [E]” (108, 109) |
|
| Semantic feature | Semantic patterns presented in the text (whether a word is semantically related to the target words) | Synonym; hyponym/hypernym (etc.), frame semantics | “Loosing” is semantically related to “subsidence”, “lucency”, and “radiolucent lines” (68, 71) | |
| Domain knowledge features | Conceptual feature | Semantic categories and relationships of words | Classifications and taxonomies, thesauri, ontologies: | ICD9/10, NCI Thesaurus, UMLS, UMLS Semantic Network, use case-specific code systems or controlled terminologies (71) |
| Statistical features | Graphic feature | Node and edge for each word in a document | Graph-of-Words (GOW) | Bi-directional representation: “grade” - “3”, “3” - “grade” (110) |
| Statistical corpus features | Features generated through basic statistical methods | Word length, TF-IDF, semantic similarity, distributional semantics, co-occurrence | “word1: parameter1, word2: parameter2” (70, 71) | |
| Vector-based representation of text | One-hot encoding Word embedding Sentence encoding Paragraph encoding Document encoding | Word2vec/doc2vec, BERT, one-hot character-level encoding. | Vector representations of text (81, 82, 84) | |
| General document features | Pattern and rule-based feature | A label for a note if certain rules satisfied | Logic (if–then) rules and expert systems | If “Metal” and “Polyethylene” then “Metal-on-Polyethylene bearing surfaces” (58, 111) |
| Contextual feature | Context information | Negated; status; hypothetical; experienced by someone other than the patient | “Patient [experiencer] does not [negation] have history of [status] infection” (58, 59) | |
| Document structural feature | Structural and organizational patterns presented in the text and document | Section information; indentation; semi-structured information | “Family History [section]: CVD Diabetes Hypertension” (71, 112) | |
Determining the appropriate number of annotators and the size of corpus for annotation is critical and often challenged by the resources available. In general, the process requires at least two annotators with (clinical) domain expertise to independently perform the annotation (49–51). Having only one annotator in the study is not recommended since data validity and reliability cannot be measured and ensured (51). For multi-site studies, the process requires at least two annotators from both sides in order to help estimate inter-institutional and intra-institutional variation (52). Based on the analysis of 18 articles with exclusive discussion of gold standard development process, 4 (22%) studies used a single annotator, 10 (56%) studies reported of using two annotators and one adjudicator, 3 (17%) studies reported of using multiple annotator but did not specify the number, and 1 (6%) study with no mention of annotator. The median, minimal and maximal number of annotated clinical documents were 251, 100 and 8,321 respectively. Most studies choose 200 to 600 documents as the study data size. Among these, 30% to 60% were randomly sampled for double annotation and IAA assessment. Process iteration was used to save the annotation cost and increase effectiveness. For example, Mayer et al reported of having two annotators to perform the initial annotation on 15 documents for training and consensus development. During the second iteration, another 30 new documents were applied and IAA was calculated. The process was repeated until the IAA reached to 0.85 (53).
Proper training and education were utilized to reduce practice inconsistency and ensure a shared understanding of study design, objectives, concept definition, and informatics tools. The training materials generated included an initial annotation guideline walkthrough; demos and instructions on how to download, install, and use the annotation software; case studies; and practice annotations. Annotation production is typically organized into several iterations with a significant amount of overlap in the data annotated by each individual annotator to ensure the ability to determine IAA. Finally, in cases where annotators disagree, conflicts were adjudicated by subject matter experts. All the issues encountered during the gold standard creation process were documented. We encourage interested readers to read articles by Albright et al. (49) and South et al. (54) for more information on the standard annotation process for concept extraction.
3.2. Model Development
This section provides an overview of the specific approaches for model development and summarizes features used for concept extraction. Based on our review, there are five model development approaches which are summarized in Table 2 with relevant references.
Table 2.
Comparison of model develoment approaches.




Designing computer systems to process text requires preparing the text in such a way that a computer can understand and perform operations on it. We broadly break these features down into categories of linguistic features, domain knowledge features, statistical features, and general document features, as summarized in Table 3. Features such as part of speech tagging, bag-of-words, and language models are used to give models more information on how to complete its task. Different approaches also tend to use different features. For example, the top three frequently used features for traditional machine learning and hybrid approaches are lexicon features (24%), syntactic features (20%), and ontologies (13%). The most intuitive text representation for the machine learning approach is a naïve one-hot encoding of the entire dictionary of words. Such a data representation presents several problems. First, there are over 180,000 words in the English dictionary, not including domain specific vocabulary (106). The vector space that the words are mapped to is both highly dimensional and extremely sparse, leading to inefficient and expensive computation. Second, such a representation assumes each “variable” is independent of the others, removing any semantic and synthetic features which may be beneficial for concept extraction tasks. For example, “cardiac” and “heart” would be represented by two independent variables, and therefore any concept extraction system could not easily learn their semantic similarities. Consequently, it is common to engineer data representations which encode semantic and syntactic similarities. Many rule-based systems are dependent on explicitly created features which tend to be more interpretable to humans. Alternatively, the latest techniques in deep learning create features which are often abstract (e.g. word embeddings or language models) and implicitly encode the semantic or synthetic features. Such features are very difficult to use by rule-based systems, but can greatly improve deep learning systems by reducing the dimensionality of the search space.
Medical concept normalization is an essential process in order to take advantage of rich clinical information from large and complex free-form text. Medical concept normalization aims at mapping medical mentions to a corresponding medical concept in standardized ontologies such as Unified Medical Language System (UMLS) or controlled vocabularies such as SNOMED CT. The well-established clinical NLP tools such as MedLEE (113), MetaMap (114), cTAKES (115) and MedTagger (116) can achieve normalization using diverse approaches like a dictionary-lookup method and rule-based methods applying pattern recognition. In-depth studies explored specific medical concept normalization. For example, DNorm proposed a machine learning approach (pairwise learning-to-rank) to normalize mentions within a pre-defined lexicon (117). Hao et al. used heuristic rule-based approach to extract temporal expression and normalized them using the TIMEX standard (118). Lin et al. Proposed the strategy of contextual alias registry (CAR) and Chronological Order of Temporal Expressions (COTE) by focusing on domain-specific contextual alias dates and chronological order of clinical notes for temporal normalization (119). However, these mentioned-methods are not yet sufficient to autonomously deliver a comprehensive information of patient condition due to the complexity of clinical information and variations within medical domains (120). In sections 3.2.1. – 3.2.4., we are going to discuss the specific methods of applying feature extraction and normailization techniques for concept extraction.
Rule-based approach
Symbolic rule-based concept extraction methodologies use a comprehensive set of rules and keyword-based features to identify pre-defined patterns in text (58, 121). The rule-based approach has been adopted in many clinical applications due to their transparency and tractability, i.e. effectiveness of implementing domain specific knowledge. One particular advantage of using rule-based approaches is that the solution provides reliable results in a timely and low-cost manner, given the benefit of not needing to manually annotate a large amount of training examples (4). Based on specific tasks, the combination of rules and well-curated dictionaries can result in promising performance. Many tasks have used rule-based matching methods to varying levels of success (60, 122, 123). For example, in the 2014 i2b2/UTHealth de-identification challenge, the top four performing teams (including the winning team) used rule-based methodologies (124). In previous i2b2 challenges, the 2009 medication challenge reported 10 rule-based systems in the top 20 systems (30). In the i2b2/UTHealth Cardiac risk factors challenge, Cormack et al. demonstrated that a pattern matching system can achieve competitive performance with diverse lexical resources (61).
Ruleset development is an iterative process that requires manual effort to hand craft features based on clinical criteria, domain knowledge and/or expert opinions. The following steps were summarized based on the reported utilization and importance: (1) existing rule-based system adoption, (2) assessment of existing knowledge resources, and (3) development and refinement of features and logic rules.
First, the top performing rule-based applications often utilize existing NLP systems (frameworks) (56, 58, 60, 62, 125). There are many different NLP systems that have been developed at different institutions that are utilized to convert clinical narratives into structured data, including MedLEE (113), MetaMap (114), KnowledgeMap (126), cTAKES (115), HiTEX (127), and MedTagger (116). A comprehensive summary of NLP systems can be found in Wang et al (5). Second, adopting existing resources such as clinical criteria, guidelines, and clinical corpora can substantially reduce development efforts. The most common strategy is to leverage well curated clinical dictionaries and knowledge bases. The dictionary acts as a domain or task specific knowledge base, which can be easily modified, updated, and aggregated (128). Well-established medical terminologies and ontologies such as Unified Medical Language System (UMLS) Metathesaurus (129), Medical Subject Headings (MeSH) (130), and MEDLINE®, have been used as the basis for clinical information extraction tasks as they already contain well-defined concepts associated with multiple terms (131). This approach works best in tasks and situations where modifier detection and the recognition of complex dependencies in the document are not necessary (132, 133). Since the common features being exploited are morphologic, lexical and syntactic, dictionary-based methods are highly interpretable, adoptable, and customizable. In the 2014 i2b2/UTHealth challenge, Khalifa and Meystre leveraged UMLS dictionary lookup to identify cardiovascular risk factors and achieved an F-measure of 87.5% (60). Table 4 summarizes a list of dictionaries and knowledge bases that were used in our surveyed papers.
Table 4.
An overview of the dictionaries and knowledge bases used for clinical concept extraction.
| Dictionary/Knowledge base | Description | Link | Examples |
|---|---|---|---|
| Unified Medical Language System (UMLS) | Biomedical thesaurus organized by concept and it links similar names for the same concept | https://www.nlm.nih.gov/research/umls/knowledge_sources/metathesaurus/ | (123, 134–137) |
| Wikipedia | PHI Category Description Source | https://en.wikipedia.org/wiki/ | (138) |
| MeSH (Medical Subject Headings) | MeSH is the controlled vocabulary based on PubMed articles indexing developed by NLM | https://www.ncbi.nlm.nih.gov/mesh | (122, 123, 139) |
| ICD-O-3 | International Classification of Diseases for Oncology | https://www.who.int/classifications/icd/adaptations/oncology/en/ | (140) |
| RadLex | Radiology lexicon | http://www.radlex.org/ | (123) |
| BodyParts3D | Anatomical concepts | https://dbarchive.biosciencedbc.jp/en/bodyparts3d/download.html | (123) |
| NCI Database | Cancer related information | https://cactus.nci.nih.gov/download/nci/ | (122) |
| Berman taxonomy | Tumor taxonomy | https://www.ncbi.nlm.nih.gov/pmc/articles/PMC535937/bin/1471-2407-4-88-S1.gz | (140) |
| CTCAE | Common Terminology Criteria for Adverse Events | https://ctep.cancer.gov/protocolDevelopment/electronic_applications/ctc.htm | (141) |
Third, in many situations, singularly relying on dictionaries cannot fully capture all the patterns necessary to completely capture a concept. Customized rules are created to address complex patterns. The creation of customized rules is an iterative process involving multiple subject matter experts. At each iteration, the rules are applied to a reference standard corpus, and its results are evaluated. Based on the evaluation performance, domain experts review false positive mentions with the given context to determine the reasons (e.g. family history, negated and hypothetical sentences). The false negative mentions are usually caused by missing keywords and negation errors, and can be addressed by refining existing rules or establishing new. This pattern was then repeated until it reached to a reasonable performance (e.g. maximal F-measure with balanced precision and recall). For example, Cormack et al. leveraged data-driven rule-based approach by starting with high recall rules and refining them to increase precision while maintaining recall with contextual patterns based on observations (61). Kelahan et al. extracted impression text and assigned positive and negative labels to sentences based on manual rules. The final label of the radiology report wass determined based on the frequency of sentence labels (64).
3.2.1. Traditional machine learning approach
Advances in methods have revitalized interest in statistical machine learning approaches for NLP, for which the non-deep-learning variants are typically referred to as “traditional” machine learning. Traditional machine learning is capable of learning patterns without explicit programming through learning the association of input data and labeled outputs (142–145). The learning function is inferred from the data, with the form of the function limited only by the assumptions made by the learning algorithm. Although feature engineering can be complex, the ability to process and learn from large document corpora greatly reduces the need to manually review documents and also has the possibility of developing more accurate models. However, in contrast to deep learning methods which learn from text in the sequential format in which it is stored, traditional machine learning approaches require more human intervention in the form of feature engineering (Table 3).
The process of developing traditional machine learning models can be summarized into the following steps: data pre-processing, feature extraction, modeling, optimization, and evaluation. Raw text is difficult for today’s computers to understand. In particular, non-deep learning methods were developed to learn from categorical or numerical data. Therefore, it is common to pre-process the text into a format that is readily computable. There are a wide variety of different pre-processing methods which have been proposed, however they are outside the scope of this manuscript. Standard pre-processing techniques include sentence segmentation that splits text into sentences, tokenization that divides a text or set of text into its individual words, stemming that reduces a word to its word stem, POS marking up a word in a text (corpus) as corresponding to a particular part of speech, and dependency parsing. The NLTK and the Stanford CoreNLP were the two most popular toolkits for performing data pre-processing (73, 76, 107, 146–148).
The majority of traditional machine learning approaches leverage a bag-of-words model for the word representation (70, 107, 109, 149–151). The bag-of-words model often tokenizes words into a sparse, high dimensional one-hot space. Although simple, this approach introduces sparsity, greatly increases the size of data, and also removes any sense of semantic similarity between words. Building on top of an existing bag of words feature, Yoon et al. proposed graph-of-words, a new text representation approach based on graph analytics which overcomes these limitations by modeling word co-occurrence (110). Chen et al. proposed a clustering method using Latent Dirichlet Allocation (LDA) to summarize sentences for feature representation (152). Another approach to text representation is to automatically learn abstract, low-dimensional representation of the words. Common approaches to this are continuous bag of words (CBOW) (79, 135) or Word2vec (81, 83–85). Recently, advanced embedding and language representations have further improved state-of-the-art clinical concept extraction. Word embeddings (153) capture latent syntactic and semantic similarities, but cannot incorporate context dependent semantics present at sentence or even more abstract levels. Peter et al. addressed this issue through training a neural language model which was able to capture the semantic roles of words in context. They found that the addition of the neural language model embeddings to word embeddings yielded state-of-the-art results for named-entity recognition and chunking (41). From a more abstract approach, Akbik et al. proposed character-level neural language modeling to capture not only the latent syntactic and semantic similarities between words, but also capture linguistic concepts such as sentences, subclauses, and sentiment (154). Many of these embeddings can be used in conjunction with others. For example, Liu et al. used both token-level and character-level word embeddings as the input layer (81). Choosing the appropriate embedding for the task can have large effects on the end model performance (81, 135).
The labeling for concept extraction is typically more complex compared to the standard classification or regression task. This is because entities in text are varying in length, location of text, and context. Commonly reported labeling for traditional machine learning include boundary detection-based classification and sequential labeling. Boundary detection aimed at detecting the boundaries of the target type of information. For example, the BIO tags use B for beginning, I for inside, and O for outside of a concept. Sequential labeling based extraction methods transforms each sentence into a sequence of tokens with a corresponding property or label. One particular advantage of sequential labeling is the consideration of the dependencies of the target information. Despite that, classification-based extraction is more commonly used than sequential labeling based extraction. From the review, 15 articles were found to utilize boundary detection-based classification approaches and 10 articles reported utilizing a sequential learning approach.
Frequently used traditional machine learning models for clinical concept extraction include conditional random fields (CRF) (155), the Support Vector Machine (SVM) (156), Structural Support Vector Machines (SSVMs) (157), Logistic Regression (LR) (158), the Bayesian model, and random forests (159). Among the aforementioned models, CRFs and the SVM are the two most popular models for clinical concept extraction (71). CRFs can be thought of as a generalization of LR for sequential data. SVMs use various kernels to transform data into a more easily discriminative hyperspace. Structural Support Vector Machines is an algorithm that combines the advantages of both CRFs and SVMs (71). When Tang et al. compared SSVMs and CRF using the data sets from 2010 i2b2 NLP challenge, the SSVMs achieved better performance than the CRFs using the same features (71). The summarized traditional machine learning approaches can be found in Table 5.
Table 5.
Summary of traditional machine learning (non-deep learning) approaches.
| Learning Task | Tag Examples | Word Representation | Model Examples | Examples |
|---|---|---|---|---|
| Boundary detection-based classification | Word position tag (e.g. BIO, BIESO); Binary outcome tag (e.g. 0, 1) |
Flat or naive representation; clustering-based word representation; distributional word representation | SVM; SSVM, Naïve Bayes; Decision Trees; AdaBoost; RandomForests; MIRA(160) | (55, 146, 161, 162) |
| Sequential learning | Word level tag (e.g. POS) | Sequential representation | CRF; Hidden Markov Model (HHM); Maximum Entropy | (73, 160, 163–165) |
| Markov Models (MEMMs) | ||||
3.2.2. Deep learning approach
Deep learning is a subfield of machine learning that focuses on automatic learning of features in multiple levels of abstract representations (17, 166, 167). The algorithms are largely focused around neural networks such as recurrent neural networks (RNN) (168–170), CNNs (42, 171–173) and transformers (174), although there are a few other niche approaches. Deep learning has led to revolutionary developments in many fields including computer vision (175, 176), robotics (177, 178), and NLP (17, 84, 179). In contrast to traditional machine learning paradigms, deep learning minimizes the need to engineer explicit data representations such as bag-of-words or n-grams.
Many of the deep learning applications in concept extraction have used either variants of RNNs or CNNs. CNNs rely on convolutional filters to capture spatial relationships in the inputs and pooling layers to minimize computational complexity. Although these have been found to be exceptionally useful for computer vision tasks, CNNs may have a difficult time capturing long distance relationships that are common in text (180). RNNs are neural networks which explicitly model connections along a sequence, making RNNs uniquely suited for tasks that require long-term dependency to be captured (181, 182). Conventional RNNs are, however, limited in modeling capability by the length of text (and therefore limited in the maximum distance between words) due to problems with vanishing gradients. Variants such as LSTM (40) and gated recurrent unit (GRU) (183) have been developed to address this issue by separating the propagation of the gradient and control of the propagation through “gates”. While shown to be effective, these only diminish the issue rather than completely solve it, being still limited to sequence lengths on the order of 10s-100s of words long (181). Furthermore, training these models is computationally intensive and difficult to parallelize as the weights need to be trained in series. Recently, the transformer architecture has been proposed to solve many of these problems. The transformer architecture circumvents the need to sequentially process text by processing the entire sequence at once through a set of matrix multiplications, allowing the network to memorize what element in the sequence is important (174). If the sequences are lengthy, the memory requirements for training are substantial. Breaking up the sequence into smaller pieces and adding subsequent layers is therefore needed to allow the model to accommodate long sequences of text without crippling memory constraints. Thus, transformers can effectively model relationships with long word distance and are much more computationally efficient compared to RNN variants. Models based on this architecture such as BERT (15) and GPT (184) have yielded significant improvements for state-of-the-art performance in many NLP tasks (25).
Meanwhile, using a deep learning model does not preclude using a traditional machine learning model. Although deep learning models are powerful feature extractors, other models may have specific attributes which suit particular needs of the problem. This is evident as many of the researchers combined conditional random field (CRF) with various deep neural networks (word embeddings input) to improve the performance on NER, such as Bi-LSTM-CRF (44%), Bi-LSTM-Attention-CRF (22%), and CNN-CRF (22%). This is to take advantage of their relative strengths: long distance modeling of RNNs and CRF’s ability to jointly connect output tags. Choosing the correct algorithm that is appropriate for both the research setting and dataset is key to produce a successful model. Interested readers can refer to a recent review by Wu et al (17) for a more in-depth overview.
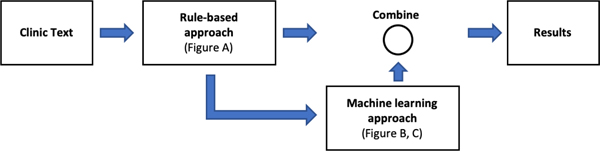
3.2.3. Hybrid approach
Hybrid approaches combine both rule- and machine learning-based approaches into one system, potentially offering the advantages of both and minimizing their respective weaknesses. There are two major hybrid approaches, as shown in Section 3.2 - Table 2. Depending on how traditional machine learning approaches were leveraged, we named these two architectures as either terminal hybrid approaches or supplemental hybrid approaches. In a terminal hybrid approach, rule-based systems are used for feature extraction, where the outputs became features used as input for the machine learning system, and the machine learning system is then a terminal step that selects optimal features. We found that the terminal hybrid approaches used in 31 out of 51 studies were in this category. For example, Wang and Akella (91) used NLP features, such as semantic, syntactic, and sequential features, as input to a supervised traditional machine learning model to extract disorder mentions from clinical notes. Other applications of hybrid systems include automatic de-identification of psychiatric notes (185, 186) and detection of clinical note sections (187). Section 3.2 - Table 3 lists the available NLP features used in the included studies.
In supplemental hybrid approaches, machine learning approaches are used to patch deficiencies in extraction of entities that have poor performance when extracted by purely rule-based approaches. In one study, such a supplemental hybrid system was incorporated with a user interface for interactive concept extraction (188). In another example, Meystre et al. (105) leveraged a traditional machine learning classifier to extract congestive heart failure medications as a supplement to the rule-based system that extracted mentions and values of left ventricular ejection fraction, amongst other concepts, for an assessment of treatment performance measures. Using a hybrid approach may have the benefit of achieving high performance. Although traditional machine learning systems tend to do best when the task dataset has well-balanced outcomes, many concept extraction tasks’ datasets are highly imbalanced, therefore making learning difficult. Farkas and Szarvas added specific “trigger words” as rules to improve their traditional machine learning de-identification system (189). Explicitly crafting the rules for these “trigger words” effectively created a “balanced” outcome, improving the algorithm’s ability to correctly learn patterns. Yang and Garibaldi leveraged a dictionary-based method to supply a CRF model for medication concept recognition. The hybrid model was ranked fifth out of the 20 participating teams on the 2014 i2b2 challenge (101). In a study to automatically extract heart failure treatment performance metrics, the hybrid system outperformed both rule- and traditional machine learning-based approaches (190).
3.3. Experiment and Evaluation
Rigorously evaluating model performance is a crucial process for developing valid and reliable concept extraction applications. Evaluation is usually performed at one of several levels: a patient level, a document level, a concept level, or a defined episode level (with temporality). The specific level selected with which evaluation was performed was typically determined based on the specific task or application. For example, patient level detection may be sufficient if the task is to detect patients with a disease or a disease phenotype. On the other hand, identification of the time of presentation likely requires an evaluation with a finer level of granularity. Determination of an evaluation method, as with any concept extraction task, should be made in consultation with clinical subject matter experts and in the context of the application.
The evaluation can be performed by construction of a confusion matrix or a contingency table to derive error ratios. Commonly used ratios measure the number of true positives (the predicted label occurs in the gold-standard label set), false positives (the predicted label does not occur in the gold-standard label set), false negatives (the label occurs in the gold-standard set but was not a predicted label), and true negatives (the total number of occurrences that are not predicted to be a given label minus the false positives of that label). From these measures, the standardized evaluation metrics, including sensitivity or recall, specificity, precision, or positive predictive value (PPV), negative predictive value (NPV), and f-measure, can then be determined based on the error ratios. Because traditional machine learning or deep learning models also provide probabilities, performance can be evaluated using the area under the ROC curve (AUC) and the area under the precision-recall curve (PRAUC).
A majority of concept extraction methods are evaluated using the hold-out method, where the model is trained on training (and possible validation) sets and evaluated on the held-out test set. Cross validation (CV) can also be used to estimate the prediction error of a model by iteratively training part of the data and leaving the rest for testing. However, applying CV for error estimation on tuned models using CV may yield a biased result (191). The nested-cross-validation that uses two independent loops of CV for parameter tuning and error estimation can reduce the bias of the true error estimation (192).
For multiclass prediction or classification, micro-average and macro-average are two methods of weight prioritization. The micro-average calculates the score by aggregating the individual rates (e.g. true positive, false positive, and false negative). In the task of epilepsy phenotype extraction, Cui et al. reported the micro-average to reflect each individual class under an imbalanced category distribution (56). The macro-average calculates the metrics score (e.g. precision and recall) by each class first and then averages by the number of classes. In the evaluation of CEGS N-GRID 2016 shared task, macro-average was used to equally evaluate multiclass symptom severity (193).
In addition, mean squared error was also used for evaluating multiclass prediction or classification tasks. Another important aspect of evaluation, Cohen’s kappa coefficient, is used to measure the inter- or intra-annotator agreement. Human annotators are imperfect, and therefore various problems may be more or less difficult to annotate. This can be due to fatigue, variation in interpretations, or annotator skill. This measure can be important to giving context on the performance of the model, as well as on the difficulty of the concept extraction task. An extensive summary of evaluation methods for clinical NLP can be found in Velupillai et al. (194).
4. Discussion
Given that methods for clinical concept extraction are generally buried within the methods section of the literature, here, we have provided a review of the methodologies behind clinical concept extraction applications based on a total of 228 articles. Our review aims to provide some guidance on method selection for clinical concept extraction tasks. However, the actual method adopted for a specific task can be impacted by five factors: data and resource availability, domain adaptation, model interpretability, system customizability, and practical implementation. In the following, we discuss each of them in detail.
Data and resource availability
In clinical concept extraction tasks, the availability of data is a key consideration for determining the type of methods. For example, the amount of data used to train machine learning, specifically deep learning methods may impact the reliability and robustness of the model. Rule-based systems have less of a demand for training data and can be more appropriate when the data set is relatively small. Alternatively, when large amounts of labeled data are available and the task has a significant degree of ambiguity, machine learning approaches can be considered. From section 3.1, it is apparent that machine learning is used more than rule-based approaches in shared-task settings, possibly due in part to the readily available deidentified and annotated health-related data (e.g. MIMIC, i2b2 corpus). The availability of clinical and external subject matter expertise is another consideration. For the rule-based approaches, developing rules may require substantial manual effort such as iterative chart review and manual feature crafting. It may be challenging to involve clinicians to help with case validation and shared-decision making. However, large amounts of a priori knowledge about the domain and clinical problem (e.g. clear concept definition, well-documented abstraction protocol) and availability of clinical experts are favorable indicators for success of the rules-based approach.
Domain adaptation
One way to leverage available resources is through transfer learning, an approach to reuse a model trained over a prior task as the pre-trained model for a new task, has been widely used in deep learning and NLP specifically (195, 196). A popular example of pre-trained models is BERT (15), which applies a transformer model (174) over huge narratives to generate a robust language representation model. Meanwhile, multi-concept learning plays an important role in learning tasks jointly and provides significant insights to accelerate domain adaptation. This learning strategy could also be referred as multitask learning, aiming to make use of features from multiple datasets or different data modalities to improve the generalization performance of models (197). In the biomedical domain specifically, some biomedical named entity recognition (BioNER) tasks were done by leveraging the multitask learning strategy. For example, based on 15 cross-domain biomedical datasets including the category of anatomy, chemical, disease, gene/protein, and species, Crichton et al. utilized a convolutional layer and a fully connected layer as a shared component and a task-specific component respectively to complete a BioNER task (198). In another study, building upon the embedding layers, Bi-LSTM layer and CRF layer, Wang et al. built a novel multitask model with the cross-sharing structure and ran it over heterogeneous gene, protein, and disease datasets to assist BioNER (199). Multimodal-based multitask learning is also a research direction to conduct prediction jointly incorporating different collected data modalities (e.g., claims data, free text notes, images, and genome sequences). For example, Weng et al. developed an innovative representation learning framework to co-learn features derived from patch-level pathological images, slide-level pathological images, pathology reports as well as case-level structured data (200). In addition, Nagpal developed different multitask models (i.e., Multitask Multilayer Perceptron, Recurrent Multitask Network, and Deep Multimodal Fusion Multitask Network) to jointly model different data modalities from EHRs, including ICD codes and unstructured clinical notes (201)
Model interpretability
Considering that many models will eventually be implemented for clinical use, the evaluation of a successful model may not solely rely on performance, but also on the interpretability, which refers to the model’s capability to explain why a certain decision is made (202). In a practice setting, these explanations may serve as important criteria for safety and bias evaluations, and are usually referred to as a key factor of “user trust” (203, 204). There are two categories of interpretability: intrinsic interpretability and post-hoc interpretability (205). Intrinsic interpretability emphasizes models with certain architectures that can be self-explained. Models with intrinsic interpretability include rule-based approaches, decision trees, linear models, and attention models (202). These models are widely used in the clinical domain compared to state-of-the-art deep learning approaches, due to their explanatory capabilities, the transparency of model components, and the interpretability of model parameters and hyperparameters (206). For example, Mowery et al. used regular expressions along with different semantic modifiers to conduct concept extraction of carotid stenosis findings. Based on the clinical definition of carotid disease, semantic patterns were organized into laterality (e.g. right, left), severity (e.g. critical or non-critical), and neurovascular anatomy (e.g. internal carotid artery) (112). The semantic pattern successfully captured important findings with high interpretability. With the advancement of deep learning models, there has been a surge of interest in interpreting black-box models through post-hoc interpretability. This can be achieved by creating an additional model to help independently interpret an existing model. Successful techniques such as a model-agnostic approach allow explanations to be generated without accessing the internal model. However, the trade-off between interpretability and model performance needs to be considered when deciding which method to use.
System customizability
Customizability measures how easily each model can be adapted when a concept definition is changed or there is an update to clinical guidelines. The rule-based approaches allow the model to be modified and refined based on existing implementation. For example, Sohn et al. applied a refinement process when deploying an existing pattern matching algorithm to a different clinical site to achieve high performance (207). Davis et al. adopted four previously published algorithms for the identification of patients with multiple sclerosis using the rules combined with multiple features including ICD-9 codes, text keywords, and medication lists (125). The final updated algorithm was shared on PheKB, a publicly available phenotype knowledgebase for building and validating phenotype algorithms (208). Xu et al. leveraged existing algorithms from the eMERGE (electronic Medical Records and Genomics) network to identify patients with type 2 diabetes mellitus (209). Regarding traditional machine learning and deep learning models, it is difficult to make customizations explicitly due to their data-driven nature. In order to accommodate the models to specific clinical problems, incorporating knowledge-driven perspectives (e.g., sublanguage analysis and biomedical ontology) with the models are commonly adopted to customize the models implicitly. For example, Shen et al., combined surgical site infection features generated by sublanguage analysis with decision tree, random forest, and support vector machines to mine postsurgical complication patients automatically from unstructured clinical notes (210). Casteleiro et al., combined the Word2vec model with knowledge formalized in the cardiovascular disease ontology (CVDO) to provide a customized solution to extract more pertinent cardiovascular disease-related terms from biomedical literatures (211). The HPO2Vec+ framework provides a way to generate customized node embeddings for the Human Phenotype Ontology (HPO) based on different selections of knowledge repositories, in order to accelerate rare disease differential diagnosis by analyzing patient phenotypic characterization from clinical narratives (212).
Practical implementation
When the models are carefully evaluated, they will be implemented for clinical and research use. The implementation process is highly dependent on institutional infrastructure, system requirements, data usage agreements, and research and practice objectives. A majority of the articles implemented the models into different standalone tools with the advantage of flexibility, low development cost, and low maintenance effort. For example, Fernandes et al. implemented a suicide ideation model by developing an additional platform to host the traditional machine learning component (213). Others have implemented the model into their institutional IT infrastructure, which includes an ETL process for document or HL7 message retrieval, a parser that does document pre-processing, an engine to host and run rule-based or traditional machine learning models, and a database to store extracted results (214).
Open challenges
Beyond the aforementioned factors which impact the specific tasks, there are several open challenges which impact the overall field of clinical concept extraction. Like many AI tasks, reproducibility and system portability of proposed solutions are often in question. However, these questions are further challenged by the stringent privacy and security requirements posed by the regulations surrounding protected health information, thereby limiting ability to share data or produce fruitful collaborations (215). The lack of multi-institutional data is further exacerbated by the cost of annotating data, lack of detailed study protocols, and sometimes severe differences in EHR data between institutions (52). As the result, it has been shown that NLP algorithms developed in one institution for a study may not perform well when reused in the same institution or deployed to a different institution or for different studies. For example, Wagholikar et al. evaluated the performance of an NLP tagging system from two sites. The performance degrades when the tagger was ported to a different hospital (216). The differences in EHR systems, physician training, and data documentation standards are the source of significant clinical document variability and non-optimal performance of concept extraction systems.
Potential solutions such as federated learning have some advantages in dealing with data privacy issues (217). In a federated learning regime, several individual institutions (workers) collaborate to create a single model hosted at a centralized location (server) without the need to share data. Instead, the model is iteratively sent to the nodes to incrementally improve the results of the model. The trained models are then iteratively aggregated in the server. In this way, neither the server, nor other nodes have to see any data not residing at that specific node. However, this type of model development is limited to machine learning methods. Furthermore, the centralized model is typically developed using a centralized test set which as mentioned earlier, often does not approximate well to the data at individualized nodes.
Limitations
There are some limitations in our study. First, this study may be biased and has the potential of missing relevant articles published due to the search strings and databases selected in this review. Secondly, we only included articles written in English with the focus on clinical information extraction. Articles written in other languages would also provide valuable information. Thirdly, our review did not include methods based on non-English EHRs. Finally, our study also suffers the inherent ambiguity associated with data element collection and normalization due to subjectivity introduced in the review process.
Supplementary Material
Acknowledgements
We gratefully acknowledge Larry J. Prokop for implementing search strategies, and Katelyn Cordie and Luke Carlson for editorial support.
Funding
This work was made possible by National Institute of Health (NIH) grant number 1U01TR002062–01 and R21AI142702.
Footnotes
Competing Interests
The authors have no competing interests to declare.
Publisher's Disclaimer: This is a PDF file of an article that has undergone enhancements after acceptance, such as the addition of a cover page and metadata, and formatting for readability, but it is not yet the definitive version of record. This version will undergo additional copyediting, typesetting and review before it is published in its final form, but we are providing this version to give early visibility of the article. Please note that, during the production process, errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- 1.Jones SS, Rudin RS, Perry T, Shekelle PG. Health information technology: an updated systematic review with a focus on meaningful use. Ann Intern Med. 2014;160(1):48–54. [DOI] [PubMed] [Google Scholar]
- 2.Friedman CP, Wong AK, Blumenthal D. Achieving a nationwide learning health system. Science translational medicine. 2010;2(57):57cm29–57cm29. [DOI] [PubMed] [Google Scholar]
- 3.Demner-Fushman D, Chapman WW, McDonald CJ. What can natural language processing do for clinical decision support?. [Review] [132 refs]. Journal of Biomedical Informatics. 2009;42(5):760–72. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Cowie J, Wilks Y. Information extraction. Handbook of Natural Language Processing. 2000;56:57. [Google Scholar]
- 5.Wang Y, Wang L, Rastegar-Mojarad M, Moon S, Shen F, Afzal N, et al. Clinical information extraction applications: A literature review. Journal of Biomedical Informatics. 2018;77:34–49. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Nadeau D, Sekine S. A survey of named entity recognition and classification. Lingvisticae Investigationes. 2007;30(1):3–26. [Google Scholar]
- 7.Marsh E, Perzanowski D, editors. MUC-7 evaluation of IE technology: Overview of results. Seventh Message Understanding Conference (MUC-7): Proceedings of a Conference Held in Fairfax, Virginia, April 29-May 1, 1998; 1998. [Google Scholar]
- 8.Torii M, Wagholikar K, Liu H. Using machine learning for concept extraction on clinical documents from multiple data sources. Journal of the American Medical Informatics Association. 2011;18(5):580–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Si Y, Wang J, Xu H, Roberts K. Enhancing clinical concept extraction with contextual embeddings. Journal of the American Medical Informatics Association. 2019;26(11):1297–304. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Harkema H, Chapman WW, Saul M, Dellon ES, Schoen RE, Mehrotra A. Developing a natural language processing application for measuring the quality of colonoscopy procedures. Journal of the American Medical Informatics Association. 2011;18(Supplement_1):i150-i6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Meystre SM, Savova GK, Kipper-Schuler KC, Hurdle JF. Extracting information from textual documents in the electronic health record: a review of recent research. Yearb. 2008;17(01):128–44. [PubMed] [Google Scholar]
- 12.Sager N. Natural Language Information Processing: A Computer Grammmar of English and Its Applications: Addison-Wesley Longman Publishing Co., Inc.; 1981. [Google Scholar]
- 13.Sager N, Friedman C, Lyman MS. Medical language processing: computer management of narrative data: Addison-Wesley Longman Publishing Co., Inc.; 1987. [Google Scholar]
- 14.Manning CD, Manning CD, Schütze H. Foundations of statistical natural language processing: MIT press; 1999. [Google Scholar]
- 15.Devlin J, Chang M-W, Lee K, Toutanova K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:181004805. 2018. [Google Scholar]
- 16.Xiao C, Choi E, Sun J. Opportunities and challenges in developing deep learning models using electronic health records data: a systematic review. Journal of the American Medical Informatics Association. 2018;25(10):1419–28. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Wu S, Roberts K, Datta S, Du J, Ji Z, Si Y, et al. Deep learning in clinical natural language processing: a methodical review. 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Moher D, Liberati A, Tetzlaff J, Altman DG. Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. Ann Intern Med. 2009;151(4):264–9. [DOI] [PubMed] [Google Scholar]
- 19.Slee VNJAoim. The International classification of diseases: ninth revision (ICD-9). 1978;88(3):424–6. [DOI] [PubMed] [Google Scholar]
- 20.Oliveira L, Tellis R, Qian Y, Trovato K, Mankovich G. Identification of Incidental Pulmonary Nodules in Free-text Radiology Reports: An Initial Investigation. Stud Health Technol Inform. 2015;216:1027. [PubMed] [Google Scholar]
- 21.Dutta S, Long WJ, Brown DF, Reisner AT. Automated detection using natural language processing of radiologists recommendations for additional imaging of incidental findings. Annals of Emergency Medicine. 2013;62(2):162–9. [DOI] [PubMed] [Google Scholar]
- 22.Si Y, Wang J, Xu H, Roberts K. Enhancing Clinical Concept Extraction with Contextual Embedding. arXiv preprint arXiv:190208691. 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Alsentzer E, Murphy JR, Boag W, Weng W-H, Jin D, Naumann T, et al. Publicly available clinical BERT embeddings. arXiv preprint arXiv:190403323. 2019. [Google Scholar]
- 24.Patrick J, Li M, editors. A cascade approach to extracting medication events. Proceedings of the Australasian Language Technology Association Workshop 2009; 2009. [Google Scholar]
- 25.Peng Y, Yan S, Lu Z. Transfer Learning in Biomedical Natural Language Processing: An Evaluation of BERT and ELMo on Ten Benchmarking Datasets. arXiv preprint arXiv:190605474. 2019. [Google Scholar]
- 26.Clark C, Good K, Jezierny L, Macpherson M, Wilson B, Chajewska U. Identifying smokers with a medical extraction system. Journal of the American Medical Informatics Association. 2008;15(1):36–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Uzuner Ö, Luo Y, Szolovits P. Evaluating the state-of-the-art in automatic de-identification. Journal of the American Medical Informatics Association. 2007;14(5):550–63. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Uzuner Ö, Goldstein I, Luo Y, Kohane I. Identifying patient smoking status from medical discharge records. Journal of the American Medical Informatics Association. 2008;15(1):14–24. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Uzuner Ö. Recognizing obesity and comorbidities in sparse data. Journal of the American Medical Informatics Association. 2009;16(4):561–70. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Uzuner Ö, Solti I, Cadag E. Extracting medication information from clinical text. Journal of the American Medical Informatics Association. 2010;17(5):514–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Uzuner O, Bodnari A, Shen S, Forbush T, Pestian J, South BR. Evaluating the state of the art in coreference resolution for electronic medical records. Journal of the American Medical Informatics Association. 2012;19(5):786–91. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Pradhan S, Elhadad N, Chapman W, Manandhar S, Savova G, editors. Semeval-2014 task 7: Analysis of clinical text. Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014); 2014. [Google Scholar]
- 33.Elhadad N, Pradhan S, Gorman S, Manandhar S, Chapman W, Savova G, editors. SemEval-2015 task 14: Analysis of clinical text. Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015); 2015. [Google Scholar]
- 34.Bethard S, Savova G, Chen W-T, Derczynski L, Pustejovsky J, Verhagen M, editors. Semeval-2016 task 12: Clinical tempeval. Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016); 2016. [Google Scholar]
- 35.Liu S, Wang Y, Liu H. Selected articles from the BioCreative/OHNLP challenge 2018. Springer; 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Rastegar-Mojarad M, Liu S, Wang Y, Afzal N, Wang L, Shen F, et al. , editors. BioCreative/OHNLP Challenge 2018. Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics; 2018: ACM. [Google Scholar]
- 37.Wang Y, Afzal N, Liu S, Rastegar-Mojarad M, Wang L, Shen F, et al. Overview of the BioCreative/OHNLP Challenge 2018 Task 2: Clinical Semantic Textual Similarity. 2018;2018. [Google Scholar]
- 38.Liu S, Mojarad MR, Wang Y, Wang L, Shen F, Fu S, et al. Overview of the BioCreative/OHNLP 2018 Family History Extraction Task. [Google Scholar]
- 39.Stubbs A, Filannino M, Soysal E, Henry S, Uzuner Ö. Cohort selection for clinical trials: n2c2 2018 shared task track 1. Journal of the American Medical Informatics Association. 2019;26(11):1163–71. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Hochreiter S, Schmidhuber JJNc. Long short-term memory. 1997;9(8):1735–80. [DOI] [PubMed] [Google Scholar]
- 41.Peters ME, Ammar W, Bhagavatula C, Power R. Semi-supervised sequence tagging with bidirectional language models. arXiv preprint arXiv:170500108. 2017. [Google Scholar]
- 42.Chen H, Lin Z, Ding G, Lou J, Zhang Y, Karlsson B, editors. GRN: Gated Relation Network to Enhance Convolutional Neural Network for Named Entity Recognition. Proceedings of AAAI; 2019. [Google Scholar]
- 43.Developing a framework for detecting asthma endotypes from electronic health records. American Journal of Respiratory and Critical Care Medicine. 2014;Conference:American Thoracic Society International Conference, ATS 2014. San Diego, CA United States. Conference Publication: (var.pagings). 189 (no pagination).
- 44.Fu S, Leung LY, Wang Y, Raulli A-O, Kallmes DF, Kinsman KA, et al. Natural Language Processing for the Identification of Silent Brain Infarcts From Neuroimaging Reports. JMIR Med Inform. 2019;7(2):e12109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Chase HS, Mitrani LR, Lu GG, Fulgieri DJ. Early recognition of multiple sclerosis using natural language processing of the electronic health record. BMC Med Inf Decis Mak. 2017;17(1):24. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Wu ST, Wi CI, Sohn S, Liu H, Juhn YJ, editors. Staggered NLP-assisted refinement for clinical annotations of chronic disease events. 10th International Conference on Language Resources and Evaluation, LREC 2016; 2016: European Language Resources Association (ELRA). [Google Scholar]
- 47.Chen T, Dredze M, Weiner JP, Hernandez L, Kimura J, Kharrazi HJJmi. Extraction of Geriatric Syndromes From Electronic Health Record Clinical Notes: Assessment of Statistical Natural Language Processing Methods. 2019;7(1):e13039. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Murphy SN, Weber G, Mendis M, Gainer V, Chueh HC, Churchill S, et al. Serving the enterprise and beyond with informatics for integrating biology and the bedside (i2b2). 2010;17(2):124–30. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Albright D, Lanfranchi A, Fredriksen A, Styler WF IV, Warner C, Hwang JD, et al. Towards comprehensive syntactic and semantic annotations of the clinical narrative. 2013;20(5):922–30. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Fu S, Carlson LA, Peterson KJ, Wang N, Zhou X, Peng S, et al. Natural Language Processing for the Evaluation of Methodological Standards and Best Practices of EHR-based Clinical Research. AMIA Summits Transl Sci Proc. 2020;2020:171. [PMC free article] [PubMed] [Google Scholar]
- 51.Gilbert EH, Lowenstein SR, Koziol-McLain J, Barta DC, Steiner J. Chart reviews in emergency medicine research: where are the methods? Annals of emergency medicine. 1996;27(3):305–8. [DOI] [PubMed] [Google Scholar]
- 52.Fu S, Leung LY, Raulli A-O, Kallmes DF, Kinsman KA, Nelson KB, et al. Assessment of the impact of EHR heterogeneity for clinical research through a case study of silent brain infarction. BMC Med Informatics Decis Mak. 2020;20:1–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Mayer J, Shen S, South BR, Meystre S, Friedlin FJ, Ray WR, et al. , editors. Inductive creation of an annotation schema and a reference standard for de-identification of VA electronic clinical notes. AMIA Annual Symposium Proceedings; 2009: American Medical Informatics Association. [PMC free article] [PubMed] [Google Scholar]
- 54.South BR, Shen S, Jones M, Garvin J, Samore MH, Chapman WW, et al. , editors. Developing a manually annotated clinical document corpus to identify phenotypic information for inflammatory bowel disease BMC Bioinformatics; 2009: BioMed Central. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Khalifa A, Velupillai S, Meystre S, editors. UtahBMI at SemEval-2016 task 12: Extracting temporal information from clinical text. 10th International Workshop on Semantic Evaluation, SemEval 2016; 2016: Association for Computational Linguistics (ACL). [Google Scholar]
- 56.Cui L, Sahoo SS, Lhatoo SD, Garg G, Rai P, Bozorgi A, et al. Complex epilepsy phenotype extraction from narrative clinical discharge summaries. Journal of Biomedical Informatics. 2014;51:272–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Murtaugh MA, Gibson BS, Redd D, Zeng-Treitler Q. Regular expression-based learning to extract bodyweight values from clinical notes. Journal of biomedical informatics. 2015;54:186–90. [DOI] [PubMed] [Google Scholar]
- 58.Childs LC, Enelow R, Simonsen L, Heintzelman NH, Kowalski KM, Taylor RJ. Description of a rule-based system for the i2b2 challenge in natural language processing for clinical data. Journal of the American Medical Informatics Association. 2009;16(4):571–5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Nelson RE, Grosse SD, Waitzman NJ, Lin J, DuVall SL, Patterson O, et al. Using multiple sources of data for surveillance of postoperative venous thromboembolism among surgical patients treated in Department of Veterans Affairs hospitals, 2005–2010. 2015;135(4):636–42. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Khalifa A, Meystre S. Adapting existing natural language processing resources for cardiovascular risk factors identification in clinical notes. Journal of biomedical informatics. 2015;58:S128–S32. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Cormack J, Nath C, Milward D, Raja K, Jonnalagadda SR. Agile text mining for the 2014 i2b2/UTHealth Cardiac risk factors challenge. Journal of biomedical informatics. 2015;58:S120–S7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Sevenster M, Van Ommering R, Qian Y. Automatically correlating clinical findings and body locations in radiology reports using MedLEE. Journal of digital imaging. 2012;25(2):240–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Yang H. Automatic extraction of medication information from medical discharge summaries. Journal of the American Medical Informatics Association. 2010;17(5):545–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Kelahan LC, Fong A, Ratwani RM, Filice RW. Call Case Dashboard: Tracking R1 Exposure to High-Acuity Cases Using Natural Language Processing. Journal of the American College of Radiology. 2016;13(8):988–91. [DOI] [PubMed] [Google Scholar]
- 65.Jonnagaddala J, Liaw S-T, Ray P, Kumar M, Chang N-W, Dai H-JJJobi. Coronary artery disease risk assessment from unstructured electronic health records using text mining. 2015;58:S203–S10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Deléger L, Grouin C, Zweigenbaum PJJotAMIA. Extracting medical information from narrative patient records: the case of medication-related information. 2010;17(5):555–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Mork JG, Bodenreider O, Demner-Fushman D, Dogan RI, Lang FM, Lu Z, et al. Extracting Rx information from clinical narrative. Journal of the American Medical Informatics Association. 2010;17(5):536–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Denny JC, Peterson JF, Choma NN, Xu H, Miller RA, Bastarache L, et al. Extracting timing and status descriptors for colonoscopy testing from electronic medical records. 2010;17(4):383–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Xu H, Jiang M, Oetjens M, Bowton EA, Ramirez AH, Jeff JM, et al. Facilitating pharmacogenetic studies using electronic health records and natural-language processing: a case study of warfarin. 2011;18(4):387–91. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Sarker A, Gonzalez G. Portable automatic text classification for adverse drug reaction detection via multi-corpus training. Journal of biomedical informatics. 2015;53:196–207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Tang B, Cao H, Wu Y, Jiang M, Xu H, editors. Recognizing clinical entities in hospital discharge summaries using Structural Support Vector Machines with word representation features BMC Med Informatics Decis Mak; 2013: BioMed Central. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Sordo M, Rocha BH, Morales AA, Maviglia SM, Oglio ED, Fairbanks A, et al. Modeling decision support rule interactions in a clinical setting. Stud Health Technol Inform. 2013;192:908–12. [PubMed] [Google Scholar]
- 73.Jiang J, Guan Y, Zhao C, editors. WI-ENRE in CLEF eHealth Evaluation Lab 2015: Clinical Named Entity Recognition Based on CRF. CLEF (Working Notes); 2015. [Google Scholar]
- 74.Akkasi A, Varoglu E. Improving Biochemical Named Entity Recognition Using PSO Classifier Selection and Bayesian Combination Methods. IEEE/ACM Trans Comput Biol Bioinformatics. 2017;14(6):1327–38. [DOI] [PubMed] [Google Scholar]
- 75.Henriksson A, Kvist M, Dalianis H. Detecting Protected Health Information in Heterogeneous Clinical Notes. Stud Health Technol Inform. 2017;245:393–7. [PubMed] [Google Scholar]
- 76.Urbain J. Mining heart disease risk factors in clinical text with named entity recognition and distributional semantic models. Journal of biomedical informatics. 2015;58:S143–S9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Esuli A, Marcheggiani D, Sebastiani FJJobi. An enhanced CRFs-based system for information extraction from radiology reports. 2013;46(3):425–35. [DOI] [PubMed] [Google Scholar]
- 78.Roberts K, Rink B, Harabagiu SM, Scheuermann RH, Toomay S, Browning T, et al. , editors. A machine learning approach for identifying anatomical locations of actionable findings in radiology reports. AMIA Annual Symposium Proceedings; 2012: American Medical Informatics Association. [PMC free article] [PubMed] [Google Scholar]
- 79.Liu Z, Yang M, Wang X, Chen Q, Tang B, Wang Z, et al. Entity recognition from clinical texts via recurrent neural network. BMC Med Inf Decis Mak. 2017;17(Suppl 2):67. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Li P, Huang H, editors. UTA DLNLP at SemEval-2016 task 12: Deep learning based natural language processing system for clinical information identification from clinical notes and pathology reports. 10th International Workshop on Semantic Evaluation, SemEval 2016; 2016: Association for Computational Linguistics (ACL). [Google Scholar]
- 81.Liu Z, Tang B, Wang X, Chen Q. De-identification of clinical notes via recurrent neural network and conditional random field. Journal of Biomedical Informatics. 2017;75S:S34–S42. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Wu Y, Xu J, Jiang M, Zhang Y, Xu H, editors. A study of neural word embeddings for named entity recognition in clinical text. AMIA Annual Symposium Proceedings; 2015: American Medical Informatics Association. [PMC free article] [PubMed] [Google Scholar]
- 83.Tran T, Kavuluru R. Predicting mental conditions based on “history of present illness” in psychiatric notes with deep neural networks. Journal of Biomedical Informatics. 2017;75S:S138–S48. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Gehrmann S, Dernoncourt F, Li Y, Carlson ET, Wu JT, Welt J, et al. Comparing deep learning and concept extraction based methods for patient phenotyping from clinical narratives. PLoS ONE. 2018;13(2):e0192360. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Luu TM, Phan R, Davey R, Chetty G, editors. A multilevel NER framework for automatic clinical name entity recognition. 17th IEEE International Conference on Data Mining Workshops, ICDMW 2017; 2017: IEEE Computer Society. [Google Scholar]
- 86.Wei W-Q, Tao C, Jiang G, Chute CG, editors. A high throughput semantic concept frequency based approach for patient identification: a case study using type 2 diabetes mellitus clinical notes. AMIA annual symposium proceedings; 2010: American Medical Informatics Association. [PMC free article] [PubMed] [Google Scholar]
- 87.Yadav K, Sarioglu E, Choi HA, Cartwright WB IV, Hinds PS, Chamberlain JM. Automated outcome classification of computed tomography imaging reports for pediatric traumatic brain injury. Academic emergency medicine. 2016;23(2):171–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Sordoa M, Topazb M, Zhongb F, Murralid M, Navathed S, Rochaa RA. Identifying patients with depression using free-text clinical documents. 2015. [PubMed] [Google Scholar]
- 89.Zheng C, Rashid N, Wu YL, Koblick R, Lin AT, Levy GD, et al. Using natural language processing and machine learning to identify gout flares from electronic clinical notes. Arthritis care & research; 2014;66(11):1740–8. [DOI] [PubMed] [Google Scholar]
- 90.Leaman R, Khare R, Lu Z. NCBI at 2013 ShARe/CLEF eHealth Shared Task: disorder normalization in clinical notes with DNorm. Radiology. 2011;42(21.1):1,941. [Google Scholar]
- 91.Wang C, Akella R. A hybrid approach to extracting disorder mentions from clinical notes. AMIA Summits on Translational Science Proceedings. 2015;2015:183. [PMC free article] [PubMed] [Google Scholar]
- 92.Yu S, Liao KP, Shaw SY, Gainer VS, Churchill SE, Szolovits P, et al. Toward high-throughput phenotyping: unbiased automated feature extraction and selection from knowledge sources. Journal of the American Medical Informatics Association. 2015;22(5):993–1000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 93.Patrick J, Li M. High accuracy information extraction of medication information from clinical notes: 2009 i2b2 medication extraction challenge. Journal of the American Medical Informatics Association. 2010;17(5):524–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 94.Tang B, Wu Y, Jiang M, Chen Y, Denny JC, Xu H. A hybrid system for temporal information extraction from clinical text. Journal of the American Medical Informatics Association. 2013;20(5):828–35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Agarwal A, Baechle C, Behara R, Zhu X. A Natural language processing framework for assessing hospital readmissions for patients with COPD. IEEE journal of biomedical and health informatics. 2018;22(2):588–96. [DOI] [PubMed] [Google Scholar]
- 96.Karystianis G, Nevado AJ, Kim CH, Dehghan A, Keane JA, Nenadic G. Automatic mining of symptom severity from psychiatric evaluation notes. International journal of methods in psychiatric research. 2018;27(1):e1602. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 97.Castro SM, Tseytlin E, Medvedeva O, Mitchell K, Visweswaran S, Bekhuis T, et al. Automated annotation and classification of BI-RADS assessment from radiology reports. Journal of biomedical informatics. 2017;69:177–87. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 98.Yim W-w, Evans HL, Yetisgen M. Structuring Free-text Microbiology Culture Reports For Secondary Use. AMIA Summits on Translational Science Proceedings. 2015;2015:471. [PMC free article] [PubMed] [Google Scholar]
- 99.Khor R, Yip W-K, Bressel M, Rose W, Duchesne G, Foroudi F. Practical implementation of an existing smoking detection pipeline and reduced support vector machine training corpus requirements. Journal of the American Medical Informatics Association. 2013;21(1):27–30. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 100.Xu Y, Hong K, Tsujii J, Chang EI-C. Feature engineering combined with machine learning and rule-based methods for structured information extraction from narrative clinical discharge summaries. Journal of the American Medical Informatics Association. 2012;19(5):824–32. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 101.Yang H, Garibaldi JM. A hybrid model for automatic identification of risk factors for heart disease. Journal of biomedical informatics. 2015;58:S171–S82. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 102.Meystre SM, Thibault J, Shen S, Hurdle JF, South BR. Textractor: a hybrid system for medications and reason for their prescription extraction from clinical text documents. Journal of the American Medical Informatics Association. 2010;17(5):559–62. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 103.Yang H, Spasic I, Keane JA, Nenadic G. A text mining approach to the prediction of disease status from clinical discharge summaries. Journal of the American Medical Informatics Association. 2009;16(4):596–600. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 104.Wu ST, Kaggal VC, Dligach D, Masanz JJ, Chen P, Becker L, et al. A common type system for clinical natural language processing. Journal of biomedical semantics. 2013;4(1):1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 105.Meystre SM, Kim Y, Gobbel GT, Matheny ME, Redd A, Bray BE, et al. Congestive heart failure information extraction framework for automated treatment performance measures assessment. Journal of the American Medical Informatics Association. 2016;24(e1):e40–e6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 106.McCrum R, Cran W, MacNeil R, MacNeil R. The story of English: Faber & Faber; London; 1986. [Google Scholar]
- 107.Hoogendoorn M, Szolovits P, Moons LMG, Numans ME. Utilizing uncoded consultation notes from electronic medical records for predictive modeling of colorectal cancer. Artificial Intelligence in Medicine. 2016;69:53–61. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 108.Aramaki E, Miura Y, Tonoike M, Ohkuma T, Masuichi H, Waki K, et al. Extraction of adverse drug effects from clinical records. MedInfo. 2010;160:739–43. [PubMed] [Google Scholar]
- 109.Doan S, Xu H. Recognizing Medication related Entities in Hospital Discharge Summaries using Support Vector Machine. Proc. 2010;2010:259–66. [PMC free article] [PubMed] [Google Scholar]
- 110.Yoon HJ, Roberts L, Tourassi G, editors. Automated histologic grading from free-text pathology reports using graph-of-words features and machine learning. 4th IEEE EMBS International Conference on Biomedical and Health Informatics, BHI 2017; 2017: Institute of Electrical and Electronics Engineers Inc. [Google Scholar]
- 111.Wyles CC, Tibbo ME, Fu S, Wang Y, Sohn S, Kremers WK, et al. Use of natural language processing algorithms to identify common data elements in operative notes for total hip arthroplasty. JBJS. 2019;101(21):1931–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 112.Mowery DL, Chapman BE, Conway M, South BR, Madden E, Keyhani S, et al. Extracting a stroke phenotype risk factor from Veteran Health Administration clinical reports: an information content analysis. J Biomed Semantics. 2016;7(1):26. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 113.Friedman C, Alderson PO, Austin JH, Cimino JJ, Johnson SB. A general natural-language text processor for clinical radiology. Journal of the American Medical Informatics Association. 1994;1(2):161–74. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 114.Aronson AR, Lang F-M. An overview of MetaMap: historical perspective and recent advances. Journal of the American Medical Informatics Association. 2010;17(3):229–36. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 115.Savova GK, Masanz JJ, Ogren PV, Zheng J, Sohn S, Kipper-Schuler KC, et al. Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): architecture, component evaluation and applications. Journal of the American Medical Informatics Association. 2010;17(5):507–13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 116.Liu H, Bielinski SJ, Sohn S, Murphy S, Wagholikar KB, Jonnalagadda SR, et al. An information extraction framework for cohort identification using electronic health records. AMIA Summits Transl Sci Proc. 2013;2013:149. [PMC free article] [PubMed] [Google Scholar]
- 117.Leaman R, Khare R, Lu Z. NCBI at 2013 ShARe/CLEF eHealth Shared Task: disorder normalization in clinical notes with DNorm. Radiology. 2011;42(21.1):1–941. [Google Scholar]
- 118.Hao T, Pan X, Gu Z, Qu Y, Weng H. A pattern learning-based method for temporal expression extraction and normalization from multi-lingual heterogeneous clinical texts.[Erratum appears in BMC Med Inform Decis Mak. 2018. April 13;18(1):25; PMID: 29653522]. BMC Med Inf Decis Mak. 2018;18(Suppl 1):22. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 119.Lin YK, Chen H, Brown RA. MedTime: a temporal information extraction system for clinical narratives. Journal of Biomedical Informatics. 2013;46(8). [DOI] [PubMed] [Google Scholar]
- 120.Vetulani Z, Uszkoreit H. Human Language Technology. Challenges of the Information Society: Third Language and Technology Conference, LTC 2007, Poznan, Poland, October 5–7, 2007, Revised Selected Papers: Springer; 2009. [Google Scholar]
- 121.Clancey WJ. The epistemology of a rule-based expert system—a framework for explanation. Artificial intelligence. 1983;20(3):215–51. [Google Scholar]
- 122.Quimbaya AP, Múnera AS, Rivera RAG, Rodríguez JCD, Velandia OMM, Peña AAG, et al. , editors. Named Entity Recognition over Electronic Health Records Through a Combined Dictionary-based Approach. Conference on ENTERprise Information Systems / International Conference on Project MANagement / Conference on Health and Social Care Information Systems and Technologies, CENTERIS / ProjMAN / HCist 2016; 2016: Elsevier B.V. [Google Scholar]
- 123.Xu Y, Hua J, Ni Z, Chen Q, Fan Y, Ananiadou S, et al. Anatomical entity recognition with a hierarchical framework augmented by external resources. PloS one. 2014;9(10):e108396. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 124.Yang H, Garibaldi JM. Automatic detection of protected health information from clinic narratives. Journal of biomedical informatics. 2015;58:S30–S8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 125.Davis MF, Sriram S, Bush WS, Denny JC, Haines JL. Automated extraction of clinical traits of multiple sclerosis in electronic medical records. Journal of the American Medical Informatics Association. 2013;20(e2):e334–e40. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 126.Denny JC, Irani PR, Wehbe FH, Smithers JD, Spickard A III, editors. The KnowledgeMap project: development of a concept-based medical school curriculum database. AMIA Annual Symposium Proceedings; 2003: American Medical Informatics Association. [PMC free article] [PubMed] [Google Scholar]
- 127.Goryachev S, Sordo M, Zeng QT, editors. A suite of natural language processing tools developed for the I2B2 project. AMIA Annual Symposium Proceedings; 2006: American Medical Informatics Association. [PMC free article] [PubMed] [Google Scholar]
- 128.Rindflesch TC, Tanabe L, Weinstein JN, Hunter L. EDGAR: extraction of drugs, genes and relations from the biomedical literature Biocomputing 2000: World Scientific; 1999. p. 517–28. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 129.Bodenreider OJNar. The unified medical language system (UMLS): integrating biomedical terminology. 2004;32(suppl_1):D267–D70. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 130.Lipscomb CEJBotMLA. Medical subject headings (MeSH). 2000;88(3):265. [PMC free article] [PubMed] [Google Scholar]
- 131.Carrell DS, Schoen RE, Leffler DA, Morris M, Rose S, Baer A, et al. Challenges in adapting existing clinical natural language processing systems to multiple, diverse health care settings. Journal of the American Medical Informatics Association. 2017;24(5):986–91. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 132.Farkas R, Szarvas G, Hegedűs I, Almási A, Vincze V, Ormándi R, et al. Semi-automated construction of decision rules to predict morbidities from clinical texts. Journal of the American Medical Informatics Association. 2009;16(4):601–5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 133.Wang Y, Patrick J, editors. Cascading classifiers for named entity recognition in clinical notes. Proceedings of the workshop on biomedical information extraction; 2009: Association for Computational Linguistics. [Google Scholar]
- 134.Ebersbach M, Herms R, Eibl M, editors. Fusion methods for ICD10 code classification of death certificates in multilingual corpora. 18th Working Notes of CLEF Conference and Labs of the Evaluation Forum, CLEF 2017; 2017: CEUR-WS. [Google Scholar]
- 135.Pandey C, Ibrahim Z, Wu H, Iqbal E, Dobson R, editors. Improving RNN with atention and embedding for adverse drug reactions. 7th International Conference on Digital Health, DH 2017; 2017: Association for Computing Machinery. [Google Scholar]
- 136.Smith KL, Sarker A, Nikfarjam A, Malone D, Gonzalez-Hernandez G. Mining adverse events in twitter: Experiences of adalimumab users. Value in Health. 2017;20 (5):A51. [Google Scholar]
- 137.Liu YC, Ku LW, editors. CLEFeHealth 2014 normalization of information extraction challenge using multi-model method. 2014 Cross Language Evaluation Forum Conference, CLEF 2014; 2014: CEUR-WS. [Google Scholar]
- 138.Bui DDA, Wyatt M, Cimino JJ. The UAB Informatics Institute and 2016 CEGS N-GRID de-identification shared task challenge. Journal of Biomedical Informatics. 2017;75S:S54–S61. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 139.Deng N, Du NK, Feng YN, Wang ZY, Duan HL, Liu F. Exploring the genotype-phenotype associations of colorectal cancer using vector space model. Journal of Investigative Medicine. 2017;65 (Supplement 7):A3. [Google Scholar]
- 140.Kasthurirathne SN, Dixon BE, Gichoya J, Xu H, Xia Y, Mamlin B, et al. Toward better public health reporting using existing off the shelf approaches: The value of medical dictionaries in automated cancer detection using plaintext medical data. Journal of Biomedical Informatics. 2017;69:160–76. [DOI] [PubMed] [Google Scholar]
- 141.Dehghan A, Ala-Aldeen K, Blaum C, Liptrot T, Kennedy J, Tibble D, et al. Automated classification of radiation oesophagitis from free text clinical narratives. Lung Cancer. 2017;103 (Supplement 1):S57–S8. [Google Scholar]
- 142.Sebastiani F. Machine learning in automated text categorization. ACM computing surveys (CSUR). 2002;34(1):1–47. [Google Scholar]
- 143.Freitag D. Machine learning for information extraction in informal domains. Machine learning. 2000;39(2–3):169–202. [Google Scholar]
- 144.Alpaydin E. Introduction to machine learning: MIT press; 2009. [Google Scholar]
- 145.Hastie T, Tibshirani R, Friedman J, Franklin J. The elements of statistical learning: data mining, inference and prediction. The Mathematical Intelligencer. 2005;27(2):83–5. [Google Scholar]
- 146.Zhang Y, Jiang M, Wang J, Xu H. Semantic Role Labeling of Clinical Text: Comparing Syntactic Parsers and Features. AMIA Annu Symp Proc. 2016;2016:1283–92. [PMC free article] [PubMed] [Google Scholar]
- 147.Loper E, Bird S. NLTK: the natural language toolkit. arXiv preprint cs/0205028. 2002. [Google Scholar]
- 148.Manning CD, Surdeanu M, Bauer J, Finkel JR, Bethard S, McClosky D, editors. The Stanford CoreNLP natural language processing toolkit. Proceedings of 52nd annual meeting of the association for computational linguistics: system demonstrations; 2014. [Google Scholar]
- 149.Sohn S, Larson DW, Habermann EB, Naessens JM, Alabbad JY, Liu H. Detection of clinically important colorectal surgical site infection using Bayesian network. J Surg Res. 2017;209:168–73. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 150.Rochefort CM, Verma AD, Eguale T, Lee TC, Buckeridge DL. A novel method of adverse event detection can accurately identify venous thromboembolisms (VTEs) from narrative electronic health record data. Journal of the American Medical Informatics Association. 2014;22(1):155–65. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 151.Gaebel J, Kolter T, Arlt F, Denecke K. Extraction Of Adverse Events From Clinical Documents To Support Decision Making Using Semantic Preprocessing. Stud Health Technol Inform. 2015;216:1030. [PubMed] [Google Scholar]
- 152.Chen Y, Lask TA, Mei Q, Chen Q, Moon S, Wang J, et al. An active learning-enabled annotation system for clinical named entity recognition. BMC Med Inf Decis Mak. 2017;17(Suppl 2):82. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 153.Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J, editors. Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems; 2013. [Google Scholar]
- 154.Akbik A, Blythe D, Vollgraf R, editors. Contextual string embeddings for sequence labeling. Proceedings of the 27th International Conference on Computational Linguistics; 2018. [Google Scholar]
- 155.Lafferty J, McCallum A, Pereira FC. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. 2001. [Google Scholar]
- 156.Cortes C, Vapnik VJMl. Support-vector networks. 1995;20(3):273–97. [Google Scholar]
- 157.Tsochantaridis I, Joachims T, Hofmann T, Altun YJJomlr. Large margin methods for structured and interdependent output variables. 2005;6(Sep):1453–84. [Google Scholar]
- 158.Kleinbaum DG, Dietz K, Gail M, Klein M, Klein M. Logistic regression: Springer; 2002. [Google Scholar]
- 159.Breiman L. Random forests. Machine learning. 2001;45(1):5–32. [Google Scholar]
- 160.Kim Y, Garvin JH, Heavirland J, Meystre SM, editors. Improving heart failure information extraction by domain adaptation. Medinfo; 2013. [PubMed] [Google Scholar]
- 161.Kreuzthaler M, Schulz S, editors. Detection of sentence boundaries and abbreviations in clinical narratives. BMC Med Informatics Decis Mak; 2015: BioMed Central. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 162.Turner CA, Jacobs AD, Marques CK, Oates JC, Kamen DL, Anderson PE, et al. Word2Vec inversion and traditional text classifiers for phenotyping lupus. BMC Med Inf Decis Mak. 2017;17(1):126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 163.Li Q, Zhai H, Deleger L, Lingren T, Kaiser M, Stoutenborough L, et al. A sequence labeling approach to link medications and their attributes in clinical notes and clinical trial announcements for information extraction. 2013;20(5):915–21. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 164.Gung J, editor Using Relations for Identification and Normalization of Disorders: Team CLEAR in the ShARe/CLEF 2013 eHealth Evaluation Lab. CLEF (Working Notes); 2013. [Google Scholar]
- 165.Forsyth AW, Barzilay R, Hughes KS, Lui D, Lorenz KA, Enzinger A, et al. Machine Learning Methods to Extract Documentation of Breast Cancer Symptoms From Electronic Health Records. J Pain Symptom Manage. 2018;27:27. [DOI] [PubMed] [Google Scholar]
- 166.LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521(7553):436. [DOI] [PubMed] [Google Scholar]
- 167.Chen D, Liu S, Kingsbury P, Sohn S, Storlie CB, Habermann EB, et al. Deep learning and alternative learning strategies for retrospective real-world clinical data. NPJ digital medicine. 2019;2(1):43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 168.Rumelhart DE, Hinton GE, Williams RJJn. Learning representations by back-propagating errors. 1986;323(6088):533–6. [Google Scholar]
- 169.Cocos A, Fiks AG, Masino AJ. Deep learning for pharmacovigilance: recurrent neural network architectures for labeling adverse drug reactions in Twitter posts. Journal of the American Medical Informatics Association. 2017;24(4):813–21. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 170.Jauregi Unanue I, Zare Borzeshi E, Piccardi M. Recurrent neural networks with specialized word embeddings for health-domain named-entity recognition. Journal of Biomedical Informatics. 2017;76:102–9. [DOI] [PubMed] [Google Scholar]
- 171.LeCun Y, Bottou L, Bengio Y, Haffner PJPotI. Gradient-based learning applied to document recognition. 1998;86(11):2278–324. [Google Scholar]
- 172.Tan LK, Liew YM, Lim E, McLaughlin RA. Convolutional neural network regression for short-axis left ventricle segmentation in cardiac cine MR sequences. Med Image Anal. 2017;39:78–86. [DOI] [PubMed] [Google Scholar]
- 173.Rios A, Kavuluru R. Convolutional neural networks for biomedical text classification: application in indexing biomedical articles. Proceedings of the 6th ACM Conference on Bioinformatics, Computational Biology and Health Informatics; Atlanta, Georgia: ACM; 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 174.Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. , editors. Attention is all you need. Advances in neural information processing systems; 2017. [Google Scholar]
- 175.Voulodimos A, Doulamis N, Doulamis A, Protopapadakis E. Deep learning for computer vision: A brief review. Computational intelligence and neuroscience. 2018;2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 176.Guo Y, Liu Y, Oerlemans A, Lao S, Wu S, Lew MS. Deep learning for visual understanding: A review. Neurocomputing. 2016;187:27–48. [Google Scholar]
- 177.Pierson HA, Gashler MS. Deep learning in robotics: a review of recent research. Advanced Robotics. 2017;31(16):821–35. [Google Scholar]
- 178.Garcia-Garcia A, Orts-Escolano S, Oprea S, Villena-Martinez V, Garcia-Rodriguez J. A review on deep learning techniques applied to semantic segmentation. arXiv preprint arXiv:170406857. 2017. [Google Scholar]
- 179.Kundeti SR, Vijayananda J, Mujjiga S, Kalyan M, editors. Clinical named entity recognition: Challenges and opportunities. 4th IEEE International Conference on Big Data, Big Data 2016; 2016: Institute of Electrical and Electronics Engineers Inc. [Google Scholar]
- 180.Zhang D, Wang DJapa. Relation classification via recurrent neural network. 2015. [Google Scholar]
- 181.Hochreiter SJIJoU, Fuzziness, Systems K-B. The vanishing gradient problem during learning recurrent neural nets and problem solutions. 1998;6(02):107–16. [Google Scholar]
- 182.Chung J, Gulcehre C, Cho K, Bengio Y, editors. Gated feedback recurrent neural networks. International conference on machine learning; 2015. [Google Scholar]
- 183.Cho K, Van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. 2014. [Google Scholar]
- 184.Radford A, Narasimhan K, Salimans T, Sutskever I. Improving language understanding by generative pre-training. URL https://s3-us-west-2amazonawscom/openaiassets/researchcovers/languageunsupervised/languageunderstandingpaperpdf. 2018. [Google Scholar]
- 185.Lee H-J, Wu Y, Zhang Y, Xu J, Xu H, Roberts KJJobi. A hybrid approach to automatic de-identification of psychiatric notes. 2017;75:S19–S27. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 186.Dehghan A, Kovacevic A, Karystianis G, Keane JA, Nenadic GJJobi. Learning to identify Protected Health Information by integrating knowledge-and data-driven algorithms: A case study on psychiatric evaluation notes. 2017;75:S28–S33. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 187.Denny JC, Spickard A III, Johnson KB, Peterson NB, Peterson JF, Miller RAJJotAMIA. Evaluation of a method to identify and categorize section headers in clinical documents. 2009;16(6):806–15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 188.Zheng S, Lu JJ, Ghasemzadeh N, Hayek SS, Quyyumi AA, Wang FJJmi. Effective information extraction framework for heterogeneous clinical reports using online machine learning and controlled vocabularies. 2017;5(2):e12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 189.Szarvas G, Farkas R, Busa-Fekete RJJotAMIA. State-of-the-art anonymization of medical records using an iterative machine learning framework. 2007;14(5):574–80. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 190.Meystre SM, Kim Y, Heavirland J, Williams J, Bray BE, Garvin J. Heart Failure Medications Detection and Prescription Status Classification in Clinical Narrative Documents. Stud Health Technol Inform. 2015;216:609–13. [PMC free article] [PubMed] [Google Scholar]
- 191.Simon R, Radmacher MD, Dobbin K, McShane LM. Pitfalls in the use of DNA microarray data for diagnostic and prognostic classification. Journal of the National Cancer Institute. 2003;95(1):14–8. [DOI] [PubMed] [Google Scholar]
- 192.Varma S, Simon R. Bias in error estimation when using cross-validation for model selection. BMC Bioinformatics. 2006;7(1):91. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 193.Filannino M, Stubbs A, Uzuner O. Symptom severity prediction from neuropsychiatric clinical records: Overview of 2016 CEGS N-GRID shared tasks Track 2. Journal of Biomedical Informatics. 2017;75S:S62–S70. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 194.Velupillai S, Suominen H, Liakata M, Roberts A, Shah AD, Morley K, et al. Using clinical Natural Language Processing for health outcomes research: Overview and actionable suggestions for future advances. Journal of biomedical informatics. 2018;88:11–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 195.Ruder S, Peters ME, Swayamdipta S, Wolf T, editors. Transfer learning in natural language processing. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Tutorials; 2019. [Google Scholar]
- 196.Mou L, Meng Z, Yan R, Li G, Xu Y, Zhang L, et al. How transferable are neural networks in nlp applications? arXiv preprint arXiv:160306111. 2016. [Google Scholar]
- 197.Zhang Y, Yang Q. A survey on multi-task learning. arXiv preprint arXiv:170708114. 2017. [Google Scholar]
- 198.Crichton G, Pyysalo S, Chiu B, Korhonen A. A neural network multi-task learning approach to biomedical named entity recognition. BMC Bioinformatics. 2017;18(1):368. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 199.Wang X, Lyu J, Dong L, Xu K. Multitask learning for biomedical named entity recognition with cross-sharing structure. BMC Bioinformatics. 2019;20(1):427. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 200.Weng W-H, Cai Y, Lin A, Tan F, Chen P-HC. Multimodal Multitask Representation Learning for Pathology Biobank Metadata Prediction. arXiv preprint arXiv:190907846. 2019. [Google Scholar]
- 201.Nagpal C. Deep Multimodal Fusion of Health Records and Notes for Multitask Clinical Event Prediction. [Google Scholar]
- 202.Du M, Liu N, Hu XJCotA. Techniques for interpretable machine learning. 2019;63(1):68–77. [Google Scholar]
- 203.Ahmad MA, Eckert C, Teredesai A, editors. Interpretable machine learning in healthcare. Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics; 2018: ACM. [Google Scholar]
- 204.Ribeiro MT, Singh S, Guestrin C, editors. Why should i trust you?: Explaining the predictions of any classifier. Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining; 2016: ACM. [Google Scholar]
- 205.Molnar C. Interpretable machine learning: Lulu. com; 2019. [Google Scholar]
- 206.Lipton ZC. The mythos of model interpretability. arXiv preprint arXiv:160603490. 2016. [Google Scholar]
- 207.Sohn S, Wang Y, Wi C-I, Krusemark EA, Ryu E, Ali MH, et al. Clinical documentation variations and NLP system portability: a case study in asthma birth cohorts across institutions. Journal of the American Medical Informatics Association. 2017;30:30. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 208.Kirby JC, Speltz P, Rasmussen LV, Basford M, Gottesman O, Peissig PL, et al. PheKB: a catalog and workflow for creating electronic phenotype algorithms for transportability. Journal of the American Medical Informatics Association. 2016;23(6):1046–52. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 209.Xu H, Aldrich MC, Chen Q, Liu H, Peterson NB, Dai Q, et al. Validating drug repurposing signals using electronic health records: a case study of metformin associated with reduced cancer mortality. Journal of the American Medical Informatics Association. 2014;22(1):179–91. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 210.Shen F, Larson DW, Naessens JM, Habermann EB, Liu H, Sohn S. Detection of surgical site infection utilizing automated feature generation in clinical notes. Journal of Healthcare Informatics Research. 2019;3(3):267–82. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 211.Casteleiro MA, Demetriou G, Read W, Prieto MJF, Maroto N, Fernandez DM, et al. Deep learning meets ontologies: experiments to anchor the cardiovascular disease ontology in the biomedical literature. J Biomed Semantics. 2018;9(1):13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 212.Shen F, Peng S, Fan Y, Wen A, Liu S, Wang Y, et al. HPO2Vec+: Leveraging heterogeneous knowledge resources to enrich node embeddings for the Human Phenotype Ontology. Journal of biomedical informatics. 2019;96:103246. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 213.Fernandes AC, Dutta R, Velupillai S, Sanyal J, Stewart R, Chandran DJSr. Identifying suicide ideation and suicidal attempts in a psychiatric clinical research database using natural language processing. 2018;8(1):7426. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 214.Wen A, Fu S, Moon S, El Wazir M, Rosenbaum A, Kaggal VC, et al. Desiderata for delivering NLP to accelerate healthcare AI advancement and a Mayo Clinic NLP-as-a-service implementation. 2019;2(1):1–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 215.Chapman WW, Nadkarni PM, Hirschman L, D’avolio LW, Savova GK, Uzuner O. Overcoming barriers to NLP for clinical text: the role of shared tasks and the need for additional creative solutions. BMJ Group BMA House, Tavistock Square, London, WC1H 9JR; 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 216.Wagholikar K, Torii M, Jonnalagadda S, Liu H. Feasibility of pooling annotated corpora for clinical concept extraction. AMIA Summits Transl Sci Proc. 2012;2012:38. [PMC free article] [PubMed] [Google Scholar]
- 217.Li T, Sahu AK, Talwalkar A, Smith V. Federated learning: Challenges, methods, and future directions. IEEE Signal Processing Magazine. 2020;37(3):50–60. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.