

Abstract
With the current focus of survey researchers on “big data” that are not selected by probability sampling, measures of the degree of potential sampling bias arising from this nonrandom selection are sorely needed. Existing indices of this degree of departure from probability sampling, like the R-indicator, are based on functions of the propensity of inclusion in the sample, estimated by modeling the inclusion probability as a function of auxiliary variables. These methods are agnostic about the relationship between the inclusion probability and survey outcomes, which is a crucial feature of the problem. We propose a simple index of degree of departure from ignorable sample selection that corrects this deficiency, which we call the standardized measure of unadjusted bias (SMUB). The index is based on normal pattern-mixture models for nonresponse applied to this sample selection problem and is grounded in the model-based framework of nonignorable selection first proposed in the context of nonresponse by Don Rubin in 1976. The index depends on an inestimable parameter that measures the deviation from selection at random, which ranges between the values zero and one. We propose the use of a central value of this parameter, 0.5, for computing a point index, and computing the values of SMUB at zero and one to provide a range of the index in a sensitivity analysis. We also provide a fully Bayesian approach for computing credible intervals for the SMUB, reflecting uncertainty in the values of all of the input parameters. The proposed methods have been implemented in R and are illustrated using real data from the National Survey of Family Growth.
Keywords: Measures of selection bias, National Survey of Family Growth, Nonignorable sample selection, Nonprobability sampling, Sampling bias
1. INTRODUCTION
Classical methods of scientific probability sampling and corresponding “design-based” frameworks for making statistical inferences about populations have long been used to advance knowledge about populations. The random selection of elements from a population of interest into a probability sample, where all population elements have a known nonzero probability of selection, ensures that the elements included in the sample are representative of the larger population, mirroring the population in expectation. Random sampling is an example of an ignorable selection mechanism under the theoretical framework for missing data mechanisms originally introduced by Rubin (1976), provided that design variables are appropriately incorporated in the analysis. Unfortunately, the modern survey research environment has had a severe negative impact on these “tried and true” methods of survey research: it has become harder and harder to contact sampled units, survey response rates continue to decline in all modes of administration (face-to-face, telephone, etc.; Brick and Williams 2013; Williams and Brick 2018), and the costs of collecting and maintaining scientific probability samples are steadily rising (Presser and McCulloch 2011). These problems raise a significant question: to what extent can samples be treated like probability samples when only a small fraction of the original sample has responded, and the response mechanism may in fact not be ignorable?
Because of the problems and costs associated with classical probability samples, researchers in the health sciences and other fields are turning to the “big data” generated from nonprobability samples of population elements (Eysenbach and Wyatt 2002; Braithwaite, Emery, de Lusignan, and Sutton 2003; Bowen, Bradford, and Powers 2007; Miller, Johnston, Dunn, Fry, and Degenhardt 2010; Brooks-Pollock, Tilston, Edmunds, and Eames 2011; Heiervang and Goodman 2011; Shlomo and Goldstein 2015; Wang, Rothschild, Goel, and Gelman 2015). These “infodemiology” data might be scraped from social media platforms such as Twitter (Chew and Eysenbach 2010; McNeil, Brna, and Gordon 2012; Bosley, Zhao, Hill, Shofer, Asch, et al. 2013; Myslín, Zhu, Chapman, and Conway 2013; Thackeray, Burton, Giraud-Carrier, Rollins, Draper 2013; Thackeray, Neiger, Burton, Thackeray 2013; Zhang, Campo, Janz, Eckler, Yang, et al. 2013; Aslam, Tsou, Spitzberg, An, Gawron, et al. 2014; Gabarron, Serrano, Wynn, and Lau 2014; Harris, Moreland-Russell, Choucair, Mansour, Staub, et al. 2014; Lee, DeCamp, Dredze, Chisolm, and Berger 2014; Mishori, Singh, Levy, and Newport 2014; Nagar, Yuan, Freifeld, Santillana, Nojima, et al. 2014; Nascimento, DosSantos, Danciu, DeBoer, van Holsbeeck, et al. 2014; O’Connor, Jackson, Goldsmith, and Skirton 2014; Reavley and Pilkington 2014; Nwosu, Debattista, Rooney, and Mason 2015; McCormick, Lee, Cesare, Shojaie, and Spiro 2017) or collected from commercial databases and online searches (to name a few potential sources; Shlomo and Goldstein 2015; DiGrazia 2017). Online surveys are other common sources of “big data” (Eysenbach and Wyatt 2002; Braithwaite et al. 2003; Evans, Wiggins, Mercer, Bolding, and Elford 2007; Brooks-Pollock et al. 2011; Heiervang and Goodman 2011), and annual academic conferences on survey research are currently dedicating entire sessions to research on online surveys of nonprobability samples (e.g., a session at the 2015 Annual Conference of the European Survey Research Association titled “Representativeness of Surveys Using Internet-Based Data Collection”).
Researchers have started to use these data sources and tools to collect information about underlying populations (Koh and Ross 2006; Evans et al. 2007; Myslín et al. 2013; Zhang et al. 2013; Nascimento et al. 2014), given that these data are inexpensive, and a researcher can easily collect large quantities of information from existing data sources or online data collection. However, these are ultimately nonprobability samples, and classical design-based methods of inference have at best questionable validity when applied to data from these samples. The protection of ignorable selection conveyed by probability sampling no longer applies; nonprobability samples may lead to estimates that are substantially biased, depending on the features of the population elements that self-select into the sample (Pasek and Krosnick 2011; Yeager, Krosnick, Chang, Javitz, Levendusky, et al. 2011).
Rubin (1976) originally described the key theoretical notion of the ignorability of a missing data mechanism. The key aspect of nonignorability is that the probability of missingness does depend on missing data, even after conditioning on observed data. This definition can also be applied to sample selection (Rubin 1978; Little 2003). Probability sampling ensures that the sample selection mechanism is ignorable; but ignorability of nonprobability samples is a strong assumption that is often invalid. Inferences based on nonignorable samples paint a potentially biased picture of the target population, so survey researchers need theoretically sound measures of how far nonprobability selection mechanisms deviate from ignorability. A 2013 task force on nonprobability sampling from the American Association for Public Opinion Research (AAPOR) called for more research into appropriate models for data collected from nonprobability samples (Baker, Brick, Bates, Battaglia, Couper, et al. 2013). More recently, Pasek (2016) proposed general approaches using existing methods for empirically assessing whether a given nonprobability sample will mirror a probability sample (i.e., is the nonprobability sample selection ignorable?). We build on this recent work by using Rubin’s framework to develop a principled, easy-to-use index of nonignorable selection bias and methods of adjusting population inferences for this bias.
Our proposed index is based on work by Andridge and Little (2009, 2011), who developed proxy pattern-mixture models (PMMs) for nonignorable nonresponse in surveys. These authors used a model-based approach to develop adjusted estimators of means when nonresponse is potentially nonignorable and proposed sensitivity analysis to examine the sensitivity of inferences to the extent that survey nonresponse is nonignorable. West and Little (2013) adapted this approach in evaluating the ability of PMMs to repair the nonresponse bias in survey estimates when missingness depends on the true value of an unobserved auxiliary variable U, but a variable Z is fully observed and serves as a noisy proxy for U. West, Wagner, Gu, and Hubbard (2015) also discussed this approach in the context of “big” data sets obtained from commercial vendors. In this article, we adapt PMMs to the selection bias problem in nonprobability samples, where the missing data problem arises from the fact that not everyone in a population of interest self-selects into a given nonprobability sample. These methods provide a bias correction for estimates of survey means as a function of a parameter measuring the degree of deviation from ignorability; see (9) below.
One widely considered alternative measure of survey representativeness in surveys subject to nonresponse is the “R-indicator” (Schouten, Cobben, and Bethlehem 2009; Schouten, Bethlehem, Beullens, Kleven, Loosveldt, et al. 2012), which measures the variability in the probability of responding to a survey as a function of auxiliary covariates available for an entire sample. Low variability in response propensities as a function of the auxiliary covariates suggests more balance (in terms of the covariates used) in the final set of respondents. Särndal and Lundström (Särndal and Lundström 2010; Särndal 2011) proposed variants of the R-indicator, including the coefficient of variation of nonresponse adjustment factors applied to existing sampling weights based on a calibration adjustment. In this case, if there is greater variability in the adjustments, there is a higher risk of selection bias due to nonresponse. While these indicators have attractive properties and can be applied to the problems of sample selection as well as nonresponse, they require a well-specified model for selection, and most importantly, they are agnostic with regard to specific survey variables of interest, failing to reflect the fact that selection bias depends on the strength of the relationship of selection with the survey variable.
Another major limitation of measures using the R-indicator is that their variability depends on response across values of the available auxiliary variables and therefore does not reflect nonignorable selection. The measure H1 in Särndal and Lundström (2010), unlike the R-indicator, is tailored to each survey variable Y and, like our proposed measure, is based on a regression of each survey variable Y on the auxiliary variables. However, unlike our approach, it assumes that the regression equation estimated on the selected cases applies to the nonselected cases and, as such, assumes that the selection mechanism is ignorable. This measure also relies on survey weights accounting for unequal probabilities of selection and nonresponse adjustment, which is not the context considered for this study. For these reasons, we did not evaluate this measure in this study.
In simulation experiments, Nishimura et al. found that the R-indicator was not an effective indicator of nonresponse bias when the missing data mechanism was nonignorable (Nishimura, Wagner, and Elliott 2016). These authors did find that when the estimated fraction of missing information (or FMI; Wagner 2010), which is an outcome-specific measure that is a byproduct of a model-based multiple imputation analysis, is greater than the nonresponse rate associated with a given estimate, this may indicate potential nonignorable nonresponse bias (Nishimura et al. 2016). Their results suggested that the FMI may be worthy of additional consideration but that additional indicators of potential selection bias are still needed (especially for nonignorable mechanisms). Our proposed indices fill this need since they focus on nonignorable selection bias and are based on models for the selection mechanism and the survey variable(s) of interest and as such reflect differential effects of selection for different substantive variables.
The remainder of the article is organized as follows: In section 2, we review Rubin’s (1976) framework for ignorable and nonignorable nonresponse, relating it to sample selection and probability sampling. In section 3, we present our proposed index for measuring departures from ignorable selection for a continuous survey variable and discuss associated sensitivity analyses to assess the impact of deviations from ignorable selection. In section 4, we apply our index and other alternatives (like the FMI) to real data from the National Survey of Family Growth (NSFG), treating the full NSFG sample as a hypothetical population and smartphone users in the NSFG as a nonprobability sample. We conclude in section 5 with a summary of our proposed approach, and we outline possible future extensions to non-normal survey variables and estimands other than means.
2. RUBIN’S MISSING DATA FRAMEWORK APPLIED TO SAMPLE SELECTION
In a landmark article for the modeling of data with missing values, Rubin (1976) defined joint models for the data and the missingness mechanism and defined sufficient conditions under which the missingness mechanism can be ignored for likelihood and frequentist inference. This framework is applied to sample selection in Rubin (1978), the first chapter of Rubin (1987), and Little (2003), with the indicator for response being replaced by the indicator for selection into the sample.
We define the following notation, with vectors or matrices of values of variables in boldface:
We initially adopt a model-based (more specifically, Bayesian) framework and assume a model for the joint distribution of the survey variables Y and the sample inclusion indicator S. We assume a selection model, where this joint distribution is factored into the marginal distribution of Y and the conditional distribution of S given Y, that is,
| (1) |
In (1), is the density for Y given Z indexed by unknown parameters , and is the density for S, given Z and Y, indexed by unknown parameters . The full likelihood based on the joint model for Y and S is then
| (2) |
The corresponding posterior distributions for and , given the full likelihood in (2), are then
| (3) |
where is a prior distribution for the parameters. In many models, , so the posterior distribution of the nonsampled data depends on S and only through the parameters.
The specification of the model for the inclusion indicators S is difficult because the mechanisms leading to inclusion are often not well understood. The likelihood ignoring the selection mechanism is based on a model for Y given Z and is
| (4) |
which does not require a model for S. The corresponding posterior distributions for and , given the likelihood in (4), are then
| (5) |
When the full posterior distributions (3) reduce to these simpler posterior distributions (5), the selection mechanism is called ignorable for Bayesian inference about and .
Two general and simple sufficient conditions for ignoring the data collection mechanism are
The parameters that control selection into the sample are typically assumed to be unrelated to the parameters of the model for Y, so it is reasonable to assign and independent prior distributions, as Bayesian Distinctness implies.
It is easy to show that these conditions together imply that
so the model for the data collection mechanism does not affect inferences about the parameter or the finite population quantities Q.
A special form of SAR is probability sampling, where the probability of selection is known and does not depend on the survey outcomes:
| (6) |
Note that the right side of (6) does not include an unknown parameter , since the selection mechanism in probability sampling is known and under the control of the sampler. Probability sampling is stronger than SAR in three important respects: first, it is automatically valid (in terms of guaranteeing ignorability), and not an assumption, if probability sampling is used to select the sample and there is complete response; second, it implies that, conditional on Z, inclusion is independent of Y and also any other unobserved variables that might be included in a model, such as latent variables in a factor analysis; third, probability sampling implies that selection is independent of the observed values of Y, , whereas SAR only requires independence of S and after conditioning on and Z, which is a weaker condition. Also, ignorability is specific to the particular survey variable Y, unlike probability sampling, which guarantees ignorability for any variable, whether or not observed.
These facts imply that probability sampling is highly desirable. However, as indicated in the Introduction, it is an ideal that is rarely attained. The weaker SAR condition is more relevant to nonrandom selection mechanisms and is the basis for our adjusted indices of nonignorable selection, which we describe in the next section.
3. AN INDEX OF SELECTION BIAS FOR THE MEAN OF A CONTINUOUS VARIABLE
We assume that the nonprobability sample has data , where i is the unit of analysis, the sample is of size n, is a vector of auxiliary variables for which summary statistics are available for the population (from administrative data or some other external source, denoted by A), and is a continuous variable of interest. In general, subject matter considerations should be employed to “design” the best vector of auxiliary variables given the variables of primary interest (Särndal and Lundström 2010). To be useful, this vector should be predictive of the variables of interest, and summary information for these variables needs to be available at the population level (from A). In the absence of good auxiliary variables in a given nonprobability sample, one could use data fusion techniques to link auxiliary variables with these required properties from another independent sample (Kamakura and Wedel 1997; Saporta 2002; Van Der Puttan, Kok, and Gupta 2002; ZuWallack, Dayton, Freedner-Maguire, Karriker-Jaffe, and Greenfield 2015).
We consider first the development of an index of bias for the mean of a continuous survey variable Y. First, we regress Y on the auxiliary variables Z, using the data in the nonprobability sample. Let X be the best predictor of Y from a multiple regression of Y on all the auxiliary variables Z. In particular, X could be the linear predictor of Y based on the additive linear regression of Y on Z. X is scaled as discussed below (7). We assume that one is able to compute asymptotically unbiased summary measures of X at the population level from A, regardless of its form. As is the case with all model-based methods, the use of X as the “best” predictor of Y requires careful diagnostic assessment of the regression of Y on Z to assess the model fit and make sure that there is not strong evidence of model misspecification. We rescale X to
| (7) |
where are respectively the variances of Y and X for the selected cases, S = 1; then and Y have the same variance given S = 1. We call the auxiliary proxy for Y.
Our proposed index is based on maximum likelihood (ML) estimates for a normal proxy pattern-mixture model (PMM) (Little 1994; Andridge and Little 2011) relating Y and X. Suppose that S = 1 for units in the sample, S = 0 for units not in the sample, and for j = 0 or 1,
| (8) |
where N2() is a bivariate normal distribution, is unknown scalar parameter, g is an unknown function, and is the rescaled best predictor of Y, as in (7). Here, “nonselection” (S = 0) corresponds to “missing” (M = 1) in the nonresponse setting of Andridge and Little (2011), and that article uses the alternative parameterization rather than . Since is a proxy for Y, we assume here that . The parameter is a measure of the “degree of nonrandom selection,” after conditioning on .
One can extend the missingness mechanism in (8) to a more general form. First, write Z = (X, U), where U is the set of available auxiliary variables other than X. Without loss of generality, we can transform U to be orthogonal to X for selected cases, S = 1. Since X is the best linear predictor of Y, the mean of Y does not depend on U for S = 1. In Andridge and Little (2011), the exclusion of U from the proxy pattern-mixture model in (8) was rationalized informally. In Appendix 1, we show more formally that if, for nonselected cases S = 0, X is also the best predictor of Y, and U is orthogonal to X, then maximum likelihood (ML) or Bayes for the normal PMM (8) are also valid under a more general mechanism:
| (9) |
where g is an arbitrary function of its two arguments. This more general form in (9) increases the realism of the model by allowing the selection mechanism to depend on U and V.
Following Andridge and Little (2011), the ML estimate of the population mean of Y for a given for the model (8) is
| (10) |
Where is the mean of X in the whole population, and for units in the sample (S = 1), are the means of X and Y, are the variances of X and Y, and is the correlation of X and Y. Because X is the best predictor of Y, we can define it in such a way that it has a positive correlation with Y; consequently, we restrict to be greater than 0. We note that the term arises from the rescaling of the proxy X to have the same variance as Y in the sample. A useful feature of ML estimation for the model defined in (8) is that the ML estimates are valid for all functions g, so a specific form for g does not need to be specified; see Andridge and Little (2011) for more discussion of this point.
It follows from (10) that a measure of unadjusted bias (MUB) of the sample mean is
| (11) |
The bias measure in (11) is dependent on the scale of Y and does not readily allow comparisons of the size of bias between Y variables. Scaling the measure to increase comparability is useful. For positive variables, one approach is to express MUB as a fraction of the mean. A more broadly useful approach is to standardize the bias by dividing by the standard deviation of Y in the sample, . This leads to a standardized measure of unadjusted bias (SMUB):
| (12) |
To define a single index of selection bias, we need to choose a value of the unknown . As seen in (8), when , selection depends on X and Y only through X, and since X is fully observed, the data are SAR. At the other extreme, when , selection depends on X and Y only through the survey variable Y. In the absence of knowledge about the value of , we suggest defining the index at , which is an intermediate value of that corresponds to selection depending on + Y. This leads to a very simple standardized measure:
| (13) |
To reflect sensitivity to the choice of , a simple approach is to compute the interval (SMUB[0], SMUB[1]), where
| (14) |
from substituting in (12). All three measures can be easily computed using the R function nisb(), which is available in the supplementary materials online or via the GitHub repository located at github.com/bradytwest/IndicesOfNISB.
We make nine remarks regarding the measures in (13) and (14). First, we note that SMUB(0), SMUB(0.5), and SMUB(1) do not require the presence of microdata for the population elements not included in the nonprobability sample. Part of the appeal of these indices is that they only require knowledge of the aggregate population mean for X. This in turn requires knowledge of the population means of the auxiliary variables Z.
Second, the three bias measures SMUB(0), SMUB(0.5), and SMUB(1) correspond to the sensitivity analysis for nonresponse proposed by Andridge and Little (2011).
Third, the expression
| (15) |
measures the difference in the mean of Y when from the adjusted mean obtained when and is thus a standardized measure of adjusted bias (SMAB). That is, it measures the potential bias of the adjusted mean of Y that accounts for the known auxiliary variables and is caused by deviations from SAR. Such a measure is clearly desirable, but we caution that it is strongly dependent on the assumptions underlying the model (8); without some such model assumptions, there is no way of predicting the bias due to deviations from SAR. As per (15), SMUB() can be rewritten as SMUB(0) + SMAB(), which means that SMAB captures the portion of the overall bias in an unadjusted estimate that exists after adjustment for the known auxiliary variables (given a choice of ), assuming that selection is only a function of X (or SAR). In this sense, the ability of SMAB to indicate this “residual” selection bias due to deviations from SAR strongly depends on the auxiliary variables used to make the initial adjustment. This result shows how our general approach is less restrictive than existing measures that assume SAR and essentially set to 0, including the R-indicator or the measure H1 in Särndal and Lundström (2010). Therefore, SMUB() serves as a more robust overall indicator of the selection bias in an unadjusted estimate computed from a given nonprobability sample and should be used to identify variables that would likely benefit from adjustment procedures.
Fourth, SMUB(1) is unstable when is close to zero; that is, the proxy variable X is not a good predictor of Y. The bias in such cases cannot be reliably estimated from the sample.
Fifth, intuitively, the measures in (13)–(14) capture relevant features of the sample selection problem: measures the strength of the best proxy as a predictor of Y (larger being better), and measures how much the sample deviates from the population on the mean of X, which is the best proxy for Y (smaller being better). Also,
where is the mean of X for the nonselected part of the population and f is the fraction of the population sampled. Our measures, therefore, also reflect the fraction f of the population included in the sample, with a higher f leading to a smaller value of the measure, other factors being equal. A nonprobability sample would be considered “good” in a loose sense if X and Y are strongly correlated and is close to , meaning that the sample is “representative” on a variable X that is a good proxy for Y. A nonprobability sample is “bad” if X and Y are weakly correlated, and is far from , meaning that the sample is not representative with respect to X, and the ability to adjust for the bias is weak. There are intermediate cases, but in short, good samples will have lower absolute values on these indices, and bad samples will have higher absolute values on these indices.
Sixth, the central measure SMUB(0.5) is closely related to the Bias Effect Size proposed by Biemer and Peytchev (2011), when applied to the best predictor of the survey variable Y. The difference is that their numerator is the difference in the means of X for selected and nonselected units, whereas the numerator in (15) is this difference multiplied by (1- f) and, as such, incorporates the impact of the nonselection rate (see the fifth point mentioned previously). Our indices have a more formal justification in terms of bias under the normal pattern-mixture model, and they are defined for choices of other than 0.5.
Seventh, the strengths of are that it is relatively simple, and unlike previous proposals, it does not assume SAR. However, there is no perfect measure, and our measure has limitations. It is founded on the normal model in (8) and in particular on the assumption that selection depends on and Y only through the linear combination . The bivariate normality assumption for the variables of interest leads to the straightforward result in (10) and provides a clear theoretical basis for development and evaluation of the indices proposed here. Because is founded on a normal model, it is less suitable for nonnormal outcomes. Extensions of the pattern-mixture model to nonnormal outcomes are possible (Andridge and Little 2009, 2018), but resulting measures are less straightforward, and our application later on suggests that still has value for nonnormal variables. Negative values of are not considered, although they are technically possible, and is close to zero when the sample and population means of X are close, even though selection bias is clearly still possible in that situation. In particular, the auxiliary variables cannot include variables used for stratification in sample selection, since these have the same means in the sample and population by design.
Eighth, if the sample with S = 1 is the responding component of a probability sample of the population subject to frame errors and nonresponse, then the component of the model for nonselected cases, S = 0, should more realistically be confined to the subpopulation of nonrespondents and individuals outside the sampling frame. It can be shown, however, that the resulting ML estimate of the bias for that model is similar to the estimate from the model (7), at least when the sample design is with equal probability.
Ninth, a refinement of our measures is to incorporate measures of sampling uncertainty. This is possible if we have the sample mean and variance of X for the nonsampled population, which in turn requires the sample mean and covariance matrix of Z in the nonsampled population. If only the means of Z are available, as would often be the case, we need to assume that the population covariance matrix of Z is the same for sampled and nonsampled units, allowing this matrix to be estimated from the sampled cases. As in Andridge and Little (2011), one approach to incorporating parameter uncertainty is to assign the parameters of the pattern-mixture model (8) a prior distribution and compute the posterior distribution of the bias of and, hence, of the SMUB. The interval can then be replaced by a credible interval from the posterior distribution of SMUB. If desired, a formal test of the null hypothesis of no selection bias is obtained by checking whether this interval includes zero. Appendix 2 outlines how to compute draws from the posterior distribution of SMUB when is assigned a beta prior distribution,
where is the incomplete beta function, and other parameters in the model (8) are assigned relatively noninformative Jeffreys’ prior distributions. The choice yields a uniform prior distribution for , which reflects limited knowledge about this parameter. We have developed an R function, nisb_bayes(), that implements this Bayesian approach. This function can also be found in the supplementary materials online or via the GitHub repository located at github.com/bradytwest/IndicesOfNISB.
4. APPLICATION: SMARTPHONE USERS IN THE NSFG
To illustrate the utility of our proposed index in practice, we applied the index to real data from the NSFG. The NSFG is an ongoing national probability survey of women and men age 15–49, using a continuous cross-sectional sample design. We analyzed sixteen quarters (four years) of NSFG data, collected from September 2012 to August 2016. During this time period, two questions (on internet access and smartphone ownership) were added to the NSFG. Specifically, the NSFG recorded an indicator of whether the randomly selected individual responding to the survey in a sample household currently owned a smartphone (Couper, Gremel, Axinn, Guyer, Wagner, et al. 2018). For purposes of this illustration, we treated the full set of NSFG respondents in this data set as a hypothetical “population,” enabling the calculation of “true” values of selected population parameters (means and proportions) describing the distributions of key NSFG variables. We analyzed males and females separately and considered smartphone (SPH) users as a nonprobability sample arising from the larger NSFG “population.” We note that the selection fractions for this hypothetical illustration were quite different from zero; the typical selection fraction for most nonprobability samples selected from large populations would be a number close to zero. For variables measured on males, the selection fraction was 0.788 (6,942 smartphone users out of 8,809 males), and for variables measured on females, the selection fraction was 0.817 (8,981 smartphone users out of 10,991 females).
For each of several NSFG variables important to data users, we then identified all males or females in the NSFG “population” (defined by both SPH and non-SPH cases) with complete data on both the variable of interest and several auxiliary variables. We selected auxiliary variables Z that 1) may be available in aggregate (at the population level) or for each unit in a given population in other nonprobability surveys and 2) could be used to predict each variable of interest in the NSFG. These auxiliary variables included age, race/ethnicity, marital status, education, household income, region of the United States (based on definitions from the US Census Bureau), current employment status, and presence of children under the age of 16 in the household. Specifically, we computed our proposed index of selection bias for the following survey variables Y, which we again assumed to be measured for the SPH sample only: lifetime parity, or number of live births (females only); age at first sex (males and females); number of sexual partners in the past year (first analyzed “as is” for both males and females and then top-coded at seven for females) and number of sexual partners in the lifetime (males and females, again both “as-is” and top-coded at seven); and number of months worked in the past year (males and females).
For each of these survey variables (and separately for males and females), we initially regressed the variable on all of the auxiliary variables Z described previously (using the SPH respondents only), and we then used the estimated coefficients to compute the linear predictor X for a given survey variable Y (for both the SPH respondents only and all cases in the overall NSFG “population”). For purposes of this illustration, we also treated recoded binary indicators representing the auxiliary variables as additional survey variables of interest (Y), assumed to be measured on SPH respondents only. In these analyses, we only regressed the binary indicators on all other auxiliary variables (i.e., excluding the auxiliary variable used to form the binary indicator from the set of predictors) when computing the linear predictor X because the previously described survey variables Y (e.g., number of sexual partners in the lifetime) generally would not be available as auxiliary variables for a full population. This allowed for multiple illustrations of the computation of our indices and also allowed us to assess the ability of our index (and its proposed “interval”) to reflect actual bias in a parameter estimate computed based on a nonprobability sample when the variable of interest does not follow a normal distribution.
Because the means of the Y variables were also available for the entire NSFG “population,” we were able to assess how well our indices predicted the actual bias in the estimates based on the SPH sample. For evaluation purposes, we computed the standardized true estimated bias (STEB), defined as the difference between the SPH estimate and the true population parameter, scaled by the standard deviation of the population measures. These bias measures were used as benchmarks for our proposed index. Measures based on the R-indicator would be of limited use here, since they do not vary with the survey variable. An alternative variable-specific measure of selection bias is the fraction of missing information (FMI), and we also assess how well this measure predicted STEB, compared with our proposed index. The FMI is a function of the multiple R-squared of the regression of Y on Z, which is one of the elements that affects our proposed index, but it does not reflect deviations from ignorable sample selection.
4.1 Results
Table 1 presents, for each of the survey means of interest (for males and females), the computed values of the proposed SMUB(0.5) index, the corresponding (SMUB[0], SMUB[1]) interval, and the 95 percent Bayesian credible interval for SMUB based on a uniform prior distribution for . We also present values of based on the SPH sample and the STEB measures for each mean. The estimates in table 1 are displayed in descending order by the estimates of based on the SPH sample. We also display scatter plots of SMUB(0), SMUB(0.5), SMUB(1), and FMI against the STEB in figures 1–4, together with Pearson correlations. The dots in the scatter plots represent the indices of all the survey variables of interest and the corresponding values of the benchmarks. We fitted ordinary least squares regression lines to the data in these plots, which are shown in red, and included 45-degree lines (y = x), which are dashed and would represent perfect correspondence of the index values with the STEB measures. We also plot the indices against the benchmarks restricting to those survey variables where the best predictor has some predictive power, defined as > 0.4 (see the shaded points and black fitted lines in figure 1).
Table 1.
Computed Values of the SMUB(0.5) Index, the Proposed (SMUB[0], SMUB[1]) Intervals, and 95 Percent Bayesian Credible Intervals for the SMUB(0) and SMUB Indices (the Latter Assuming a Uniform Prior for ) for Selected Survey Means Based on NSFG Measures Collected on the SPH Sample, in Addition to Measures of Standardized True Estimated Bias (STEB) for Each Estimated Meana
| NSFG Variable Label | Gender | STEB | SMUB(0) | SMUB(0.5) | SMUB(1) | Proposed Interval Cover STEB? | 95% Credible Interval for SMUB(0) | Interval Cover STEB? | 95% Credible Interval for SMUBb | Interval Cover STEB? | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| # of months worked last year | F | 0.791 | 69 | 55 | 70 | 88 | Y | (48, 62) | N | (53, 91) | Y |
| # of months worked last year | M | 0.785 | 90 | 73 | 93 | 118 | Y | (64, 83) | N | (70, 122) | Y |
| Number of live births | F | 0.705 | −43 | −33 | −47 | −66 | Y | (−39, −26) | N | (−69, −31) | Y |
| Never been married (binary) | M | 0.646 | −24 | −17 | −27 | −42 | Y | (−25, −9) | Y | (−48, −12) | Y |
| Never been married (binary) | F | 0.590 | −3 | −3 | −5 | −8 | Y | (−9, 4) | Y | (−16, 5) | Y |
| Age = 30–44 (binary) | M | 0.581 | −4 | 32 | 55 | 94 | N | (24, 39) | N | (30, 97) | N |
| Lifetime sex partners (top-coded) | M | 0.543 | 36 | 14 | 26 | 48 | Y | (6, 23) | N | (9, 56) | Y |
| Age = 30–44 (binary) | F | 0.532 | −15 | 17 | 31 | 59 | N | (11, 22) | N | (15, 61) | N |
| Currently employed (binary) | M | 0.532 | 86 | 37 | 69 | 130 | Y | (29, 45) | N | (36, 131) | Y |
| Lifetime sex partners (top-coded) | F | 0.530 | 19 | 2 | 4 | 7 | N | (−4, 8) | N | (−7, 17) | N |
| Children present in HU (binary) | M | 0.476 | −12 | −5 | −10 | −20 | Y | (−12, 3) | Y | (−32, 3) | Y |
| Currently employed (binary) | F | 0.406 | 63 | 26 | 64 | 156 | Y | (20, 31) | N | (26, 152) | Y |
| Age at first sex | M | 0.375 | 22 | 32 | 85 | 226 | N | (23, 40) | N | (31, 218) | N |
| Children present in HU (binary) | F | 0.371 | −19 | −21 | −56 | −152 | N | (−26, −15) | Y | (−146, −21) | N |
| “Other” race (binary) | F | 0.365 | 17 | 23 | 63 | 172 | N | (17, 28) | Y | (23, 166) | N |
| Age at first sex | F | 0.363 | 10 | 19 | 52 | 143 | N | (12, 24) | N | (18, 138) | N |
| “Other” race (binary) | M | 0.329 | 12 | 30 | 91 | 276 | N | (22, 37) | N | (31, 261) | N |
| # of sex partners in last year | M | 0.298 | 27 | 8 | 28 | 95 | Y | (0, 16) | N | (5, 101) | Y |
| Education: “Some coll.” (binary) | M | 0.267 | 50 | 10 | 38 | 143 | Y | (3, 18) | N | (9, 139) | Y |
| Life sex partners | F | 0.258 | −1 | −2 | −9 | −34 | N | (−7, 4) | Y | (−49, 6) | Y |
| Education: “Some coll.” (binary) | F | 0.251 | 29 | 3 | 12 | 47 | Y | (−3, 8) | N | (−1, 55) | Y |
| Life sex partners | M | 0.242 | 9 | −1 | −2 | −9 | N | (−8, 7) | N | (−44, 34) | Y |
| Region = “south” (binary) | F | 0.230 | 14 | −7 | −30 | −130 | N | (−13, −1) | N | (−124, −6) | N |
| Region = “south” (binary) | M | 0.215 | 26 | −3 | −13 | −62 | N | (−10, 6) | N | (−84, 10) | N |
| # of sex partners in last year, top-coded | F | 0.213 | 16 | 2 | 8 | 37 | Y | (−5, 8) | N | (−11, 56) | Y |
| Income: $20K–$59, 999 (binary) | M | 0.207 | 10 | −6 | −30 | −146 | N | (−13, 2) | N | (−148, −4) | N |
| # of sex partners in last year | F | 0.175 | −5 | 2 | 11 | 64 | N | (−5, 8) | Y | (−8, 83) | Y |
| Income: $20K–$59, 999 (binary) | F | 0.134 | 11 | 1 | 9 | 70 | Y | (−5, 7) | N | (-15, 95) | Y |
aValues of STEB, SMUB(0), SMUB(0.5), and SMUB(1) have been multiplied by 1,000 in the table.
bComputed using a Uniform(0,1) prior distribution for .
Figure 1.
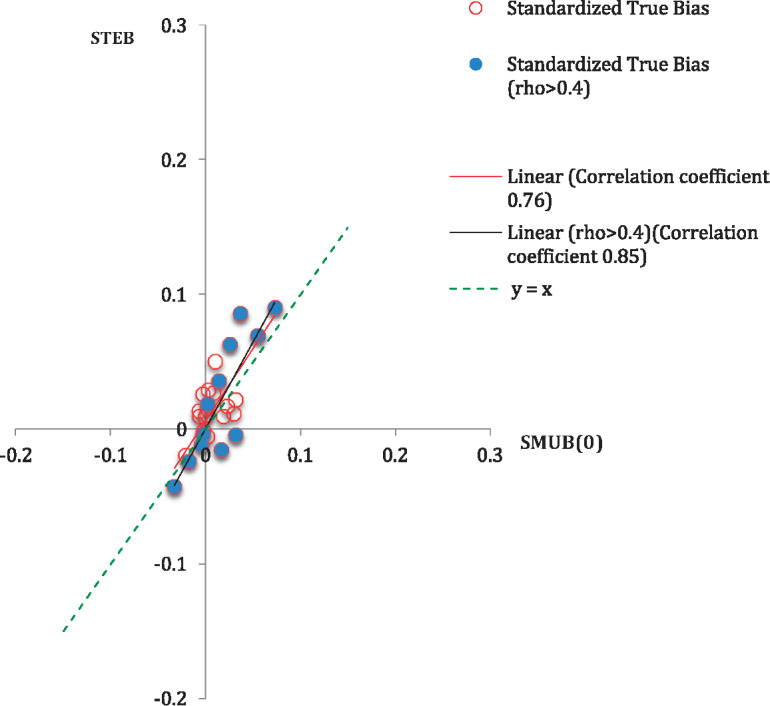
Scatterplot of STEB Against SMUB(0), Including Measures of Linear Association. note: rho =.
Figure 2.
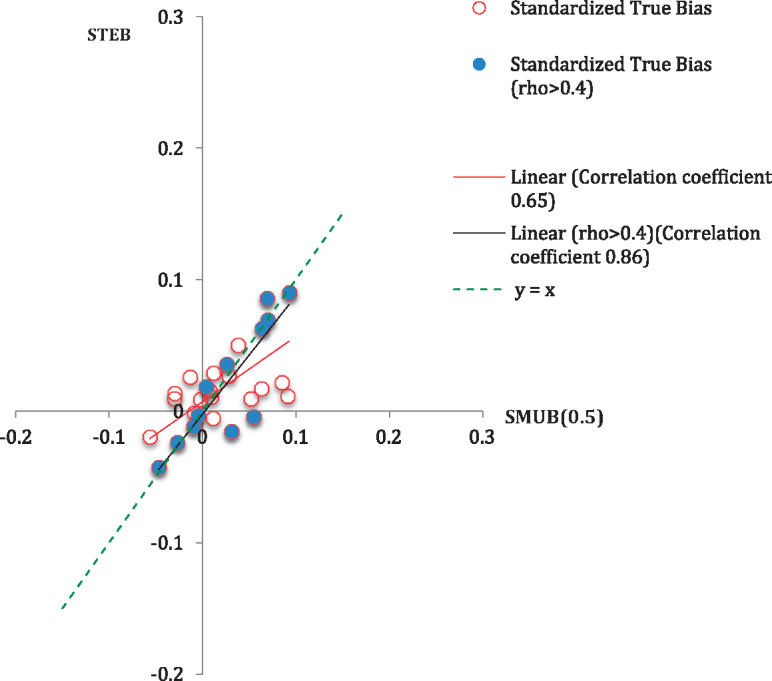
Scatterplot of STEB Against SMUB(0.5), Including Measures of Linear Association. note: rho =.
Figure 3.
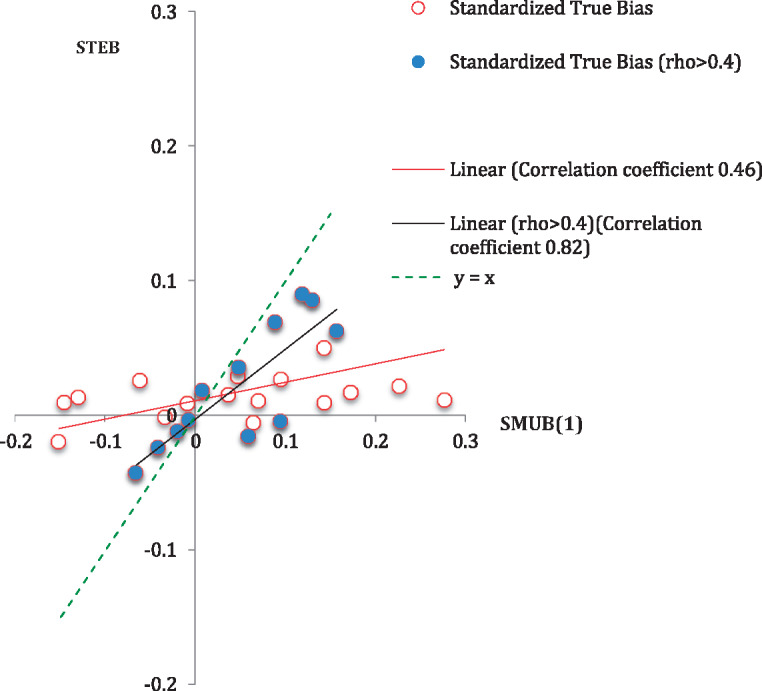
Scatterplot of STEB Against SMUB(1), Including Measures of Linear Association. note: rho =.
We make the following observations from table 1 and figures 1–4. First, for survey variables with estimates of greater than 0.4, our index does quite well. All three SMUB indices had strong linear associations with the STEB that we use as the benchmark. The particularly strong performance of SMUB(0) in this illustration when is greater than 0.4 likely reflects a selection mechanism for SPH respondents that is close to ignorable (i.e., SAR), but our compromise choice, SMUB(0.5), also does well. The correlations of SMUB with the STEB were much stronger than those found for the FMI (figure 4). Nine of the twelve intervals (SMUB[0], SMUB[1]) and nine of the twelve Bayesian credible intervals covered the STEB.
Figure 4.
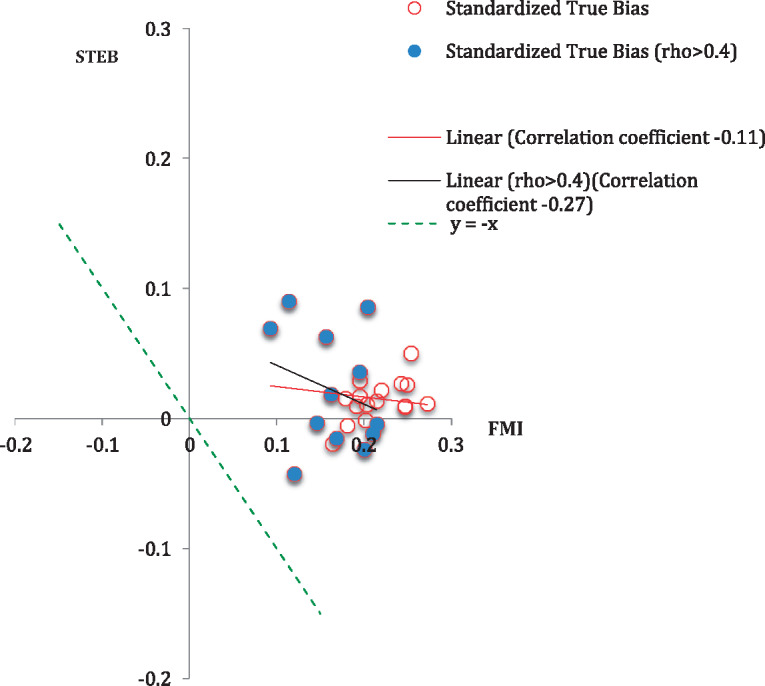
Scatterplot of STEB Against FMI, Including Measures of Linear Association. note: rho =.
Second, for survey variables with correlations less than 0.4, the index tends to deviate more from STEB in these cases, and only five of the sixteen intervals (SMUB[0], SMUB[1]) and eight of the sixteen Bayesian intervals covered the STEB. We note that when the correlation is low, the Bayesian credible intervals are considerably wider than the intervals (SMUB[0], SMUB[1]) that ignore sampling variability and thus are more likely to include the STEB. Whether 0.4 is a useful cutoff in general requires more study in other applications.
Third, the Bayesian intervals for SMUB(0), which correspond to the SAR case, performed poorly relative to the more general Bayesian intervals for SMUB that incorporated random draws of from a Uniform(0, 1) distribution. Only seven of the twenty-eight Bayesian intervals for SMUB(0) covered the STEB, despite the relatively high correlation of SMUB(0) with STEB noted previously. The Bayesian intervals based on a prior distribution for are wider and have much better coverage of the STEB, particularly when X and Y have a strong correlation. This suggests that making some allowance for uncertainty in , either by assigning a prior distribution or by a sensitivity analysis for different values of , is better than approaches that assume SAR (i.e., = 0).
For further insight on this performance, we note that our index does well when the estimated bias SMUB(0) (which adjusts for the auxiliary variables) has the same sign as the STEB and is smaller than the STEB in absolute value. In such cases, fourteen of the sixteen intervals (SMUB[0], SMUB[1]) cover the STEB. In other cases, SMUB(0) and SMUB(1) fails to cover the STEB since the interval extends in the wrong direction. We expect that adjustment of the sample mean based on strong auxiliary predictors tends to reduce bias, and this is the setting in which our approach does well. However, adjustment for auxiliary predictors that are poor predictors of the outcome often does not reduce the bias, and in these cases, our indices are less effective.
We note that two of the three intervals for correlations greater than 0.4 that do not cover the STEB are for binary age indicators, perhaps reflecting the fact that binary outcomes violate the normality assumption of the underlying PMM in (8).
We also present an illustration of our proposed Bayesian approach, assuming that one is able to compute sufficient statistics for the Z variables for cases not included in the nonprobability sample (as was the case in our NSFG example). After executing the nisb_bayes() code described in the online supplementary materials, a plot similar to figure 5 will be generated automatically, presenting draws of SMUB as a function of draws of the parameter, predictions of SMUB as a function of the parameter, and 95 percent credible intervals for these predictions. From the first row of table 1 (the mean number of months worked in the past twelve months for females), the STEB associated with selection into the SPH sample was 0.069 (multiplied by 1,000 in the table), the 95 percent credible interval for SMUB based on the resulting posterior draws of SMUB was (0.053, 0.091), and the median of the posterior draws was 0.069. Figure 5 indicates that a choice of 0.5 for the parameter does a good job of reflecting the STEB for this particular mean and that our proposed interval clearly covers the STEB, allowing for uncertainty in the value of the parameter.
Figure 5.

Scatterplot of Drawn Values of SMUB Versus Drawn Values of the Parameter for the Mean of Number of Months Worked in the Past Twelve Months (Females), Following Our Proposed Bayesian Approach in the Presence of Sufficient Statistics on Z for Nonsampled Cases.
Finally, we evaluate the performance of the proposed SMAB index in table 2. The standardized adjusted bias (SAB) is computed as the difference between the adjusted mean and the true mean, divided by the standard deviation of the true values for the “population.” Correlations of the SMAB(0.5) and SMAB(1) values with SAB were poor (−0.057 and −0.110) and improved substantially for cases with > 0.4 (0.462 and 0.484, respectively). This result underscores our earlier remark about the importance of the underlying model used for the initial adjustment when using the SMAB index to indicate selection bias in adjusted estimates; the index will perform poorly when the initial adjustments assuming SAR are poor. The overall coverage of the SAB values by the Bayesian intervals for SMAB is identical to the coverage of the STEB values by the Bayesian intervals for SMUB in table 1. This suggests that the SMAB index can still do reasonably well at capturing the SAB when allowing for sampling variance in the input estimates.
Table 2.
Computed Values of the SMAB(0.5) and SMAB(1) Indices and 95 Percent Bayesian Credible Intervals for the SMAB Index, Along with Measures of Standardized Adjusted Bias (SAB) for Each Mean Estimated from the NSFG Dataa
| NSFG Variable Label | Gender | SABb | SMAB (0.5) | SMAB (1) | 95% Credible Interval for SMABc | Credible Interval Cover SAB? | |
|---|---|---|---|---|---|---|---|
| # of months worked last year | F | 0.791 | 15 | 15 | 33 | (1, 33) | Y |
| # of months worked last year | M | 0.785 | 20 | 20 | 45 | (1, 45) | Y |
| Number of live births | F | 0.705 | −10 | −14 | −33 | (−33, 0) | Y |
| Never been married (binary) | M | 0.646 | −6 | −10 | −24 | (−26, 0) | Y |
| Never been married (binary) | F | 0.590 | −1 | −2 | −5 | (−9, 2) | Y |
| Age = 30–44 (binary) | M | 0.581 | −35 | 23 | 62 | (1, 62) | N |
| Life sex partners (top-coded) | M | 0.543 | 22 | 12 | 34 | (0, 38) | Y |
| Age = 30–44 (binary) | F | 0.532 | −32 | 15 | 42 | (1, 43) | N |
| Currently employed (binary) | M | 0.532 | 51 | 32 | 93 | (1, 91) | Y |
| Life sex partners (top-coded) | F | 0.530 | 17 | 2 | 5 | (−4, 11) | N |
| Children present in HU (binary) | M | 0.476 | −6 | −5 | −16 | (−23, 2) | Y |
| Currently employed (binary) | F | 0.406 | 38 | 38 | 131 | (1, 125) | Y |
| Age at first sex | M | 0.375 | −9 | 53 | 194 | (2, 185) | N |
| Children present in HU (binary) | F | 0.371 | 2 | −35 | −13 | (−125, −1) | N |
| “Other” race (binary) | F | 0.365 | −5 | 40 | 149 | (1, 142) | N |
| Age at first sex | F | 0.363 | −9 | 33 | 124 | (1, 118) | N |
| “Other” race (binary) | M | 0.329 | −17 | 61 | 246 | (2, 230) | N |
| # of sex partners in last year | M | 0.298 | 19 | 20 | 86 | (1, 91) | Y |
| Education: “Some coll.” (binary) | M | 0.267 | 40 | 28 | 133 | (1, 127) | Y |
| Life sex partners | F | 0.258 | 1 | −6 | −32 | (−45, 4) | Y |
| Education: “Some coll.” (binary) | F | 0.251 | 26 | 9 | 44 | (0, 50) | Y |
| Life sex partners | M | 0.242 | 10 | −2 | −8 | (−40, 31) | Y |
| Region = “south” (binary) | F | 0.230 | 20 | −23 | −123 | (−117, −1) | N |
| Region = “south” (binary) | M | 0.215 | 29 | −10 | −59 | (−79, 8) | N |
| # of sex partners in last year, top-coded | F | 0.213 | 14 | 6 | 35 | (−10, 53) | Y |
| Income: $20K–$59, 999 (binary) | M | 0.207 | 17 | −24 | −139 | (−141, −1) | N |
| # of sex partners in last year | F | 0.175 | −6 | 9 | 62 | (−8, 80) | Y |
| Income: $20K–$59, 999 (binary) | F | 0.134 | 10 | 8 | 69 | (−14, 92) | Y |
aValues of SAB, SMAB(0.5) and SMAB(1) have been multiplied by 1,000 in the table.
bWe first computed adjusted estimates of the means (assuming SAR) by (i) imputing the values of each variable of interest 100 times for each nonselected case, using the aforementioned auxiliary variables as covariates, and then (ii) applying Rubin’s combining rules to form a point estimate of the adjusted mean. Next, we computed the standardized adjusted bias (SAB) as the difference between the adjusted mean and the true mean, divided by the standard deviation of the true values for the “population.” Finally, we computed SMAB(0.5), SMAB(1), and a 95% Bayesian credible interval for SMAB (assuming a uniform prior for ); SMAB(0) is by definition zero.
Computed using a Uniform(0,1) prior distribution for .
5. SUMMARY AND FUTURE WORK
We have proposed a variable-specific index of nonignorable selection bias for nonprobability samples, namely the standardized measure of unadjusted bias (SMUB). This model-based and variable-specific index is easy to compute and allows for case-level or aggregate information for an entire population. The index is based on comparisons between the sample and population distributions of auxiliary variables that have not been matched in the estimation, neither by stratification or weighting. The proposed index is therefore suitable for nonprobability samples, which seldom rely on stratified sampling and do not permit the computation of weights based on known probabilities of selection. Although the nonprobability sampling literature has proposed weighted estimators based on pseudo-randomization approaches (Elliott and Valliant 2017), these weights are generally global in nature and not variable-specific, meaning that any bias correction engendered by these weights will not be tailored for individual variables. We have also described a Bayesian approach for describing uncertainty in the index, given case-level information for an entire population (or at least aggregate information for population members that are not selected for a nonprobability sample). All methods have been implemented in R, and these functions are available in the online supplementary materials.
Using real data from the NSFG, we have shown that the index is a good indicator of the actual bias in estimates based on nonprobability samples when the administrative proxy X is somewhat predictive of the survey variable of interest Y, as measured in our application by a correlation greater than 0.4. In situations where this correlation is weak, we suggest that any approach based on information in the auxiliary variables is likely to be ineffective because these variables do not provide much pertinent information for that survey variable. We emphasize that our proposed indices of selection bias are variable-specific, and the NSFG illustration suggests that intervals based on SMUB can provide a good sense of variables that may be particularly prone to selection bias. Depending on the magnitude of the X-Y correlations and how far away the intervals are from zero, our indices allow us to identify variables for which descriptive estimates should be interpreted with caution because of the risk of potential selection bias.
The proposed index is based on a normal pattern-mixture model (see [8]), and its performance is dependent on the extent to which this model is realistic. In particular, it is best suited to normal survey variables, although our illustration shows that it can still be useful qualitatively for nonnormal variables. Andridge and Little (2009, 2018) develop proxy PMMs for nonignorable nonresponse in binary survey variables, providing similar indices of nonignorable selection bias for estimated proportions. Work in progress includes simulation assessments of this method, and the development of indices of selection bias for regression coefficients.
In forming our Bayesian credible intervals for the proposed index, we used uniform priors for the parameter capturing dependence of sample selection on X and Y; we feel that this is a reasonable choice in the absence of any information about this parameter, but alternative priors may improve the overall performance of these intervals in terms of coverage of the true bias. Finally, since our setting is situations where the sample is not collected by probability sampling and summary auxiliary data are available for the population, complex design elements available for the sample, like sampling weights, are not generally relevant. The situation where the auxiliary data X are available for a probability sample rather than the population—and thus are subject to sampling error—will also be addressed in future work.
SUPPLEMENTARY MATERIALS
Supplementary materials are available online at academic.oup.com/jssam.
Supplementary Material
Appendix 1: Refining the Proxy Pattern-Mixture Model of Andridge and Little (2011)
As in section 3, write S = selection indicator; Y = survey variable, measured only when S = 1; and Z = auxiliary variables, measured for S = 0 and 1.
Assume best predictor of Y for respondents. Let auxiliary proxy for Y, or X scaled to have the same variance as Y given S = 1. Write Z = (X, U), U = auxiliary variables orthogonal to X, so
Assume that for nonselected cases S = 0, X is also the best predictor of Y, and U is also orthogonal to X. Then we show that ML or Bayes for the normal PMM in (8) is also ML or Bayes under the more general bivariate normal pattern-mixture model that conditions on U:
where g is an arbitrary function of its two arguments.
Assume that:
where that is, is the best predictor of Y for nonsampled as well as sampled units; and
U is orthogonal to X for nonsampled units, so
Then, for r = 0, 1, so (*) reduces to
| (**) |
Since (X, Y) do not depend on U given S, we can simplify the notation by dropping the subscript u in the parameters, replacing (**) by which is the model of Eq. (8). So ML or Bayes under this model is the same as ML or Bayes under (*).
Appendix 2: Simulating the posterior distribution of the population mean of Y
A. Expressions for the posterior mean and variance of the population mean of Y, assuming that the best predictor X is known:
Pattern-mixture model: Transform Y to , assuming
where s = 1 for sampled cases, 0 for non-sampled cases, = set of all parameters
By properties of the normal distribution, the slope, intercept, and residual variance of the regression of X on V given s = j are:
Then (***) implies that S and X are conditionally independent given V, and hence
These constraints just identify the model, and imply that:
For non-sampled values vi of V, and their average :
where n(0) and are respectively the number and the mean of X for non-selected cases.
Hence posterior mean and variance of are:
The corresponding posterior mean and variance of the overall mean v are:
where n(1) is the number of selected cases, and is the sampling fraction (assumed to be very close to zero in most cases).
B. Simulating draws of the mean of Y and SMUB from their posterior distributions.
Draw from posterior distribution of regression of Y on Z given sample data
Define
Draw from prior distribution of
Replace in above by X(d),
= sample means of X(d) for selected and non-selected cases
S (d) = sample covariance matrix of (X(d), Y) for selected cases
= sample variance of X(d) for non-selected cases
Draw , IW = inverse Wishart
Positive definite covariance matrix check:
If then discard and redraw.
Repeat for d = 1,…D to simulate posterior distribution of and SMUB(d), hence estimate posterior mean and variance as sample mean and variance of draws.
Financial support for this study was provided by a grant from the National Institutes for Health (1R21HD090366-01A1). The authors do not have any conflicts of interest involving the research reported here. The National Survey of Family Growth (NSFG) is conducted by the Centers for Disease Control and Prevention's (CDC’s) National Center for Health Statistics (NCHS), under contract #200-2010-33976 with University of Michigan’s Institute for Social Research with funding from several agencies of the U.S. Department of Health and Human Services, including CDC/NCHS, the National Institute of Child Health and Human Development (NICHD), the Office of Population Affairs (OPA), and others listed on the NSFG webpage (see http://www.cdc.gov/nchs/nsfg/). The views expressed here do not represent those of NCHS nor the other funding agencies.
REFERENCES
- Andridge R. R., Little R. J. (2009), “Extensions of Proxy Pattern-Mixture Analysis for Survey Nonresponse,” In JSM Proceedings, Survey Research Methods Section. Alexandria, VA: American Statistical Association. 2468–2482.
- Andridge R. R., Little R. J. (2011), “ Proxy Pattern-Mixture Analysis for Survey Nonresponse,” Journal of Official Statistics, 27, 153–180. [Google Scholar]
- Andridge R. R., Little R. J. (2018), “ Proxy Pattern-Mixture Analysis for a Binary Variable Subject to Nonresponse,” Journal of Official Statistics. Under Review [Google Scholar]
- Aslam A. A., Tsou M.-H., Spitzberg B. H., An L., Gawron J. M., Gupta D. K., Peddecord K. M., et al. (2014), “ The Reliability of Tweets as a Supplementary Method of Seasonal Influenza Surveillance,” Journal of Medical Internet Research, 16, e250. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baker R., Brick J. M., Bates N. A., Battaglia M., Couper M. P., Dever J. A., Gile K. J., Tourangeau R. (2013), “Report of the AAPOR Task Force on Nonprobability Sampling.” Available at https://www.aapor.org/AAPOR_Main/media/MainSiteFiles/NPS_TF_Report_Final_7_revised_FNL_6_22_13.pdf
- Biemer P., Peytchev A. (2011), “A Standardized Indicator of Survey Nonresponse Bias Based on Effect Size,” paper presented at the International Workshop on Household Survey Nonresponse, Bilbao, Spain, September 5, 2011.
- Bosley J. C., Zhao N. W., Hill S., Shofer F. S., Asch D. A., Becker L. B., Merchant R. M. (2013), “ Decoding Twitter: Surveillance and Trends for Cardiac Arrest and Resuscitation Communication,” Resuscitation, 84, 206–212. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bowen D. J., Bradford J., Powers D. (2007), “ Comparing Sexual Minority Status Across Sampling Methods and Populations,” Women and Health, 44, 121–134. [DOI] [PubMed] [Google Scholar]
- Braithwaite D., Emery J., de Lusignan S., Sutton S. (2003), “ Using the Internet to Conduct Surveys of Health Professionals: A Valid Alternative?,” Family Practice, 20, 545–551. [DOI] [PubMed] [Google Scholar]
- Brick J. M., Williams D. (2013), “ Explaining Rising Nonresponse Rates in Cross-Sectional Surveys,” The Annals of the American Academy of Political and Social Science, 645, 36–59. [Google Scholar]
- Brooks-Pollock E., Tilston N., Edmunds W. J., Eames K. T. D. (2011), “ Using an Online Survey of Healthcare-Seeking Behaviour to Estimate the Magnitude and Severity of the 2009 H1N1v Influenza Epidemic in England,” BMC Infectious Diseases, 11, 68. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chew C., Eysenbach G. (2010), “ Pandemics in the Age of Twitter: Content Analysis of Tweets during the 2009 H1N1 Outbreak,” PLoS One, 5, e14118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Couper M. P., Gremel G., Axinn W. G., Guyer H., Wagner J., West B. T. (2018), “New Options for National Population Surveys: The Implications of Internet and Smartphone Coverage,” Social Science Research, available at https://www.sciencedirect.com/science/article/pii/S0049089X17307871. [DOI] [PMC free article] [PubMed]
- DiGrazia J. (2017), “ Using Internet Search Data to Produce State-Level Measures: The Case of Tea Party Mobilization,” Sociological Methods and Research, 46, 898–925. [Google Scholar]
- Elliott M. R., Valliant R. (2017), “ Inference for Nonprobability Samples,” Statistical Science, 32, 249–264. [Google Scholar]
- Evans A. R., Wiggins R. D., Mercer C. H., Bolding G. J., Elford J., Ross M. W. (2007), “ Men Who Have Sex with Men in Great Britain: Comparison of a Self-Selected Internet Sample with a National Probability Sample,” Sexually Transmitted Infections, 83, 200–205. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eysenbach G., Wyatt J. (2002), “ Using the Internet for Surveys and Health Research,” Journal of Medical Internet Research, 4, e13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gabarron E., Serrano J. A., Wynn R., Lau A. Y. (2014), “ Tweet Content Related to Sexually Transmitted Diseases: No Joking Matter,” Journal of Medical Internet Research, 16, e228. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Harris J. K., Moreland-Russell S., Choucair B., Mansour R., Staub M., Simmons K. (2014), “ Tweeting for and against Public Health Policy: Response to the Chicago Department of Public Health’s Electronic Cigarette Twitter Campaign,” Journal of Medical Internet Research, 16, e238. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heiervang E., Goodman R. (2011), “ Advantages and Limitations of Web-Based Surveys: Evidence from a Child Mental Health Survey,” Social and Psychiatric Epidemiology, 46, 69–76. [DOI] [PubMed] [Google Scholar]
- Kamakura W. A., Wedel M. (1997), “ Statistical Data Fusion for Cross-Tabulation,” Journal of Marketing Research, 34, 485–498. [Google Scholar]
- Koh A. S., Ross L. K. (2006), “ Mental Health Issues: A Comparison of Lesbian, Bisexual, and Heterosexual Women,” Journal of Homosexuality, 51, 33–57. [DOI] [PubMed] [Google Scholar]
- Lee J. L., DeCamp M., Dredze M., Chisolm M. S., Berger Z. D. (2014), “ What are Health-Related Users Tweeting? A Qualitative Content Analysis of Health-Related Users and Their Messages on Twitter,” Journal of Medical Internet Research, 16, e237. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Little R. J. A. (1994), “ A Class of Pattern-Mixture Models for Normal Incomplete Data,” Biometrika, 81, 471–483. [Google Scholar]
- Little R. J. A. (2003), “The Bayesian Approach to Sample Survey Inference,” in Analysis of Survey Data, eds. Chambers R. L., Skinner C. J., pp. 49–57, New York: Wiley. [Google Scholar]
- McCormick T. H., Lee H., Cesare N., Shojaie A., Spiro E. S. (2017), “ Using Twitter for Demographic and Social Science Research: Tools for Data Collection and Processing,” Sociological Methods and Research, 46, 390–421. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McNeil K., Brna P. M., Gordon K. E. (2012), “ Epilepsy in the Twitter Era: A Need to Re-Tweet the Way We Think about Seizures,” Epilepsy and Behavior, 23, 127–130. [DOI] [PubMed] [Google Scholar]
- Miller P. G., Johnston J., Dunn M., Fry C. L., Degenhardt L. (2010), “ Comparing Probability and Nonprobability Sampling Methods in Ecstasy Research: Implications for the Internet as a Research Tool,” Substance Use and Misuse, 45, 437–450. [DOI] [PubMed] [Google Scholar]
- Mishori R., Singh L. O., Levy B., Newport C. (2014), “ Mapping Physician Twitter Networks: Describing How They Work as a First Step in Understanding Connectivity, Information Flow, and Message Diffusion,” Journal of Medical Internet Research, 16, e107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Myslín M., Zhu S.-H., Chapman W., Conway M. (2013), “ Using Twitter to Examine Smoking Behavior and Perceptions of Emerging Tobacco Products,” Journal of Medical Internet Research, 15, e174. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nagar R., Yuan Q., Freifeld C. C., Santillana M., Nojima A., Chunara R., Brownstein J. S. (2014), “ A Case Study of the New York City 2012–2013 Influenza Season with Daily Geocoded Twitter Data from Temporal and Spatiotemporal Perspectives,” Journal of Medical Internet Research, 16, e236. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nascimento T. D., DosSantos M. F., Danciu T., DeBoer M., van Holsbeeck H., Lucas S. R., Aiello C., et al. (2014), “ Real-Time Sharing and Expression of Migraine Headache Suffering on Twitter: A Cross-Sectional Infodemiology Study,” Journal of Medical Internet Research, 16, e96. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nishimura R., Wagner J., Elliott M. (2016), “ Alternative Indicators for the Risk of Non-Response Bias: A Simulation Study,” International Statistical Review, 84, 43–62. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nwosu A. C., Debattista M., Rooney C., Mason S. (2015), “ Social Media and Palliative Medicine: A Retrospective 2-Year Analysis of Global Twitter Data to Evaluate the Use of Technology to Communicate about Issues at the End of Life,” BMJ Support Palliat Care, 5, 207–212. [DOI] [PubMed] [Google Scholar]
- O’Connor A., Jackson L., Goldsmith L., Skirton H. (2014), “ Can I Get a Re-Tweet Please? Health Research Recruitment and the Twittersphere,” Journal of Advanced Nursing, 70, 599–609. [DOI] [PubMed] [Google Scholar]
- Pasek J. (2016), “ When Will Nonprobability Surveys Mirror Probability Surveys? Considering Types of Inference and Weighting Strategies as Criteria for Correspondence,” International Journal of Public Opinion Research, 28, 269–291. [Google Scholar]
- Pasek J., Krosnick J. A. (2011), “Measuring Intent to Participate and Participation in the 2010 Census and Their Correlates and Trends: Comparisons of RDD Telephone and Nonprobability Sample Internet Survey Data,” Statistical Research Division of the U.S. Census Bureau, 15.
- Presser S., McCulloch S. (2011), “ The Growth of Survey Research in the United States: Government-Sponsored Surveys, 1984–2004,” Social Science Research, 40, 1019–1024. [Google Scholar]
- Reavley N. J., Pilkington P. D. (2014), “ Use of Twitter to Monitor Attitudes toward Depression and Schizophrenia: An Exploratory Study,” PeerJ, 2, e647. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rubin D. B. (1976), “ Inference and Missing Data (with Discussion),” Biometrika, 63, 581–592. [Google Scholar]
- Rubin D. B. (1978), “ Bayesian Inference for Causal Effects: the Role of Randomization,” Annals of Statistics, 6, 34–58. [Google Scholar]
- Rubin D. B. (1987), Multiple Imputation for Nonresponse in Surveys, New York, NY: John Wiley & Sons. [Google Scholar]
- Saporta G. (2002), “ Data Fusion and Data Grafting,” Computational Statistics and Data Analysis, 38, 465–473. [Google Scholar]
- Särndal C.-E. (2011), “ The 2010 Morris Hansen Lecture Dealing with Survey Nonresponse in Data Collection, in Estimation,” Journal of Official Statistics, 27, 1–21. [Google Scholar]
- Särndal C.-E., Lundström S. (2010), “ Design for Estimation: Identifying Auxiliary Vectors to Reduce Nonresponse Bias,” Survey Methodology, 36, 131–144. [Google Scholar]
- Schouten B., Bethlehem J., Beullens K., Kleven Ø., Loosveldt G., Luiten A., Rutar K., Shlomo N., Skinner C. (2012), “ Evaluating, Comparing, Monitoring, and Improving Representativeness of Survey Response through R-Indicators and Partial R-Indicators,” International Statistical Review, 80, 382–399. [Google Scholar]
- Schouten B., Cobben F., Bethlehem J. (2009), “ Indicators for the Representativeness of Survey Response,” Survey Methodology, 35, 101–113. [Google Scholar]
- Shlomo N., Goldstein H. (2015), “ Editorial: Big Data in Social Research,” Journal of the Royal Statistical Society, Series A, 178, 787–790. [Google Scholar]
- Thackeray R., Burton S. H., Giraud-Carrier C., Rollins S., Draper C. R. (2013), “ Using Twitter for Breast Cancer Prevention: An Analysis of Breast Cancer Awareness Month,” BMC Cancer, 13, 508. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thackeray R., Neiger B. L., Burton S. H., Thackeray C. R. (2013), “ Analysis of the Purpose of State Health Departments’ Tweets: Information Sharing, Engagement, and Action,” Journal of Medical Internet Research, 15, e255. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van Der Puttan P., Kok J. N., Gupta A. (2002), “Data Fusion Through Statistical Matching,” MIT Sloan School of Management, Working Paper 4342-02, available at http://papers.ssrn.com/abstract=297501.
- Wagner J. (2010), “ The Fraction of Missing Information as a Tool for Monitoring the Quality of Survey Data,” Public Opinion Quarterly, 74, 223–243. [Google Scholar]
- Wang W., Rothschild D., Goel S., Gelman A. (2015), “ Forecasting Elections with Non-Representative Polls,” International Journal of Forecasting, 31, 980–991. [Google Scholar]
- West B. T., Little R. J. A. (2013), “ Nonresponse Adjustment of Survey Estimates Based on Auxiliary Variables Subject to Error,” Journal of the Royal Statistical Society, Series C, 62, 213–231. [Google Scholar]
- West B. T., Wagner J., Gu H., Hubbard F. (2015), “ The Utility of Alternative Commercial Data Sources for Survey Operations and Estimation: Evidence from the National Survey of Family Growth,” Journal of Survey Statistics and Methodology, 3, 240–264. [Google Scholar]
- Williams D., Brick J. M. (2018), “ Trends in US Face-to-Face Household Survey Nonresponse and Level of Effort,” Journal of Survey Statistics and Methodology, 6, 186–211. [Google Scholar]
- Yeager D. S., Krosnick J. A., Chang L., Javitz H. S., Levendusky M. S., Simpser A., Wang R. (2011), “ Comparing the Accuracy of RDD Telephone Surveys and Internet Surveys Conducted with Probability and Nonprobability Samples,” Public Opinion Quarterly, 75, 709–747. [Google Scholar]
- Zhang N., Campo S., Janz K. F., Eckler P., Yang J., Snetselaar L. G., Signorini A. (2013), “ Electronic Word of Mouth on Twitter about Physical Activity in the United States: Exploratory Infodemiology Study,” Journal of Medical Internet Research, 15, e261. [DOI] [PMC free article] [PubMed] [Google Scholar]
- ZuWallack R., Dayton J., Freedner-Maguire N., Karriker-Jaffe K. J., Greenfield T. K. (2015), “Combining a Probability Based Telephone Sample with an Opt-in Web Panel,” paper presented at the 2015 Annual Conference of the American Association for Public Opinion Research, Hollywood, Florida, May 2015.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.