

Abstract
We consider a single-index regression model, uniquely constrained to estimate interactions between a set of pretreatment covariates and a treatment variable on their effects on a response variable, in the context of analyzing data from randomized clinical trials. We represent interaction effect terms of the model through a set of treatment-specific flexible link functions on a linear combination of the covariates (a single index), subject to the constraint that the expected value given the covariates equals 0, while leaving the main effects of the covariates unspecified. We show that the proposed semiparametric estimator is consistent for the interaction term of the model, and that the efficiency of the estimator can be improved with an augmentation procedure. The proposed single-index regression provides a flexible and interpretable modeling approach to optimizing individualized treatment rules based on patients’ data measured at baseline, as illustrated by simulation examples and an application to data from a depression clinical trial.
Keywords: individualized treatment rule, precision medicine, projection-pursuit regression, single-index model, treatment effect modifier
1 |. INTRODUCTION
In precision medicine, a critical concern is to characterize individuals’ heterogeneity in treatment responses in order to enable individual-specific treatment decisions to be made (Murphy, 2003; Robins, 2004). Furthermore, estimating treatment and pretreatment covariate interactions in the setting of randomized clinical trials may provide valuable information for understanding the factors involved in heterogeneous treatment responses. In this paper, we propose a simple and flexible regression method specifically focused on estimating the interaction effects between a treatment variable and pretreatment covariates on a treatment response.
Since the seminal papers of Murphy (2003) and Robins (2004), much research has been done on development of individualized treatment rules based on pretreatment covariates. Regression-based methodologies are intended to optimize the individualized treatment rules by estimating treatment-specific mean response functions (eg, Qian and Murphy, 2011; Zhang et al., 2012; Lu et al., 2011; Petkova et al., 2019) while attempting to maintain robustness with respect to model misspecification. Machine learning approaches for developing individualized treatment rules are often framed in the context of classification problems (Zhang et al., 2012; Zhao et al., 2019); for example, the outcome weighted learning (eg, Zhao et al., 2012, 2015; Song et al., 2015) based on support vector machines, tree-based classification (eg, Laber and Zhao, 2015), and the methods of Kang et al. (2014) based on adaptive boosting, among others. Although the classification approaches are appealing in many settings, here we focus on familiar regression approaches that are frequently utilized in practice, and allow for ready interpretation.
Qian and Murphy (2011) show that the optimal individualized treatment rules (in terms of maximizing the mean treatment response) depends only on the treatment and pretreatment covariates’ interaction effects, and not on the main effects of the pretreatment covariates present in the mean response function. However, if the model inadequately represents the interaction effects, the estimated individualized treatment rule may perform poorly (Murphy, 2005; Qian and Murphy, 2011). The primary focus of this paper is to develop a semiparametric regression method for estimating the interaction effect term of the mean response function, which reduces concerns regarding misspecification of the interaction effects.
Qian and Murphy (2011) approximate the mean response function using a rich linear model with a penalized least squares criterion. However, this approach is generally not robust to misspecification of the main effect term of the model and is also restricted to a parametric regression. Also, if the main effect is responsible for a relatively large proportion of the variance in the outcome compared to the interaction effect, consistent estimation of the interaction effect is difficult. Addressing this issue, Tian et al. (2014) proposed an approach to consistently estimate the treatment-by-covariate interaction effect without having to specify the main effect. However, their approach is applicable only to the (generalized) linear model framework and only when there are exactly two treatments. In realistic situations, a linear model may be too restrictive to describe complex interactions. Zhang et al. (2012) proposed a robust approach to estimating an optimal individualized treatment rule, within a class of rules defined by a (possibly misspecified) regression model. However, their method is computationally feasible only in low-dimensional settings. Song et al. (2017) proposed a semiparametric regression model to estimate an optimal individualized treatment rule, but their approach is limited to a monotone interaction effect structure and to binary treatment conditions.
A primary contribution of this paper is in generalizing the work of Tian et al. (2014) to allow for a semi-parametrically defined interaction effect and also for more than two treatments in the context of randomized clinical trials. We do this by extending a single-index model (eg, Stoker, 1986) to allow treatment-specific nonparametric link functions (Park et al., 2020) in order to capture the treatment-by-covariates interaction effects, while allowing for an unspecified main effect of the covariates. The result is a simple and flexible regression model for the interaction effects.
2 |. CONSTRAINED SINGLE-INDEX MODELS
In the context of randomized clinical trials, we consider pretreatment covariates and a categorical treatment variable T ∈ {1, … , L} (with L levels) that has associated randomization probabilities (π1, … , πL). We let be the potential outcome if the patient received treatment T = t (t = 1, … , L); we only observe Y = Y(T), T, and X. Throughout the paper, we assume, without loss of generality, that E[Y|T = t] = 0 (t = 1, … , L), that is, the main effect for T is centered at 0 (this is only to suppress the treatment-specific intercepts in regression models in order to simplify the exposition, and can be achieved by removing the treatment level t-specific means from Y) and that X is centered at zero.
The focus of this paper is on modeling interactions between X and T on their effects on Y. We assume Y = E[Y|X, T] + ϵ, where ϵ is a zero-mean independent noise with finite variance. Let us assume that the nested mean model associated with the interaction effects has a single-index model structure with a set of treatment t-specific link functions, for a single-index coefficient :
| (1) |
where μ(X) represents an unspecified main effect of X. In model (1), the treatment t-specific functions ft(·) are general smooth univariate functions. To obtain an identifiable representation, without loss of generality, the treatment t-specific functions (f1, … , fL) in model (1) are assumed to satisfy a condition: (almost surely). This condition indicates that there are only L − 1 unrestricted functions ft among the L interaction functions (f1, … , fL); that is, the Lth function fL in (1) is identified by the other (L − 1) functions: (almost surely).
In model (1), the single-index coefficient α0 is identifiable only up to scale and sign due to the nonparametric nature of the link functions ft (t = 1, … , L) and therefore, without loss of generality, we assume α0 ∈ Θ, where
The semiparametric model (1) captures the variability in X related to the treatment effects via a single index and its interactions with the treatment via treatment-specific link functions (f1, … , fL). Interaction effects are determined by the distinct shapes of the unspecified functions (f1, … , fL). There are several reasons we consider a single-index in (1) (as opposed to treatment-specific L indices). First, the common single index provides a parsimonious one-dimensional composite treatment effect modifier (defined as a linear combination of X) that allows an intuitive visualization for the interaction effect. Besides its parsimonious appeal, the single-dimensional reduction model (1) naturally and directly extends the linear model-based approach (eg, Tian et al., 2014) in the L = 2 setting. If L = 2 and we restrict the unspecified interaction function ft(·) in model (1) to a prespecified linear form , then the semiparametric model (1) reduces to the modified covariates model assumed in Tian et al. (2014) (see also Murphy, 2003; Lu et al., 2011; Shi et al., 2016, 2018; Jeng et al., 2018):
| (2) |
for some which assumes a linear form for the T-by-X interaction effects.
For model (1), to estimate the interaction effect terms in the presence of the unspecified main effect μ(X), we propose to utilize a working model:
| (3) |
for α ∈ Θ, subject to the constraint:
| (4) |
almost surely, for all α ∈ Θ. The constraint (4) is imposed on the treatment t-specific smooth link-functions (g1, … , gL) of the working model (3). Even if (3) does not generally provide a good approximation to the underlying model (1), in Section 3.3 we will show, through the consistency results (Theorem 1 and Corollary 1), that (3) is a useful model for estimating the interaction effect terms of model (1).
In a least squares framework for model (3)
| (5) |
the condition (4) ensures that the cross-product term E[μ(X)gT(α⊤X)|X] vanishes to 0, and the part relevant to the estimation of the working model (3) is independent of the unspecified main effect μ(X). This independence implies that optimization of the unspecified component μ(X) and the working model (3) can be performed separately. As model (3) does not require specification of μ(X), working with (3) sidesteps issues that would arise if μ(X) were to be misspecified.
We call model (3) a constrained single-index model with multiple (ie, treatment t-specific) link functions, which is the main working model of this paper.
3 |. ESTIMATION
3.1 |. A criterion for fitting themodel
To optimize the constrained working model (3), we consider a constrained least squares criterion:
| (6) |
where α ∈ Θ and each function gt is in a suitable function space in L2(R).
Proposition 1.
For each fixed α, the minimizer (g1, … , gL) of the constrained minimization problem (6) satisfies
| (7) |
almost surely.
The proof of Proposition 1 is in Section A.1 of the Supporting Information. Proposition 1 suggests that solving (6) to optimize model (3) can be split into the following two iterative steps. First, for a fixed α, find the link-functions (g1, … , gL) from expression (7). Second, for a fixed (g1, … , gL), solve
| (8) |
These two steps can be iterated until convergence to obtain a solution of (6). To obtain a sample counterpart of this population solution, we can insert sample estimates into this population algorithm, as is done in Hastie and Tibshirani (1999). We will provide the details of this estimation procedure in Section 3.2, and establish the consistency of the estimator in Section 3.3.
3.2 |. A cubic spline estimator of the model
To obtain a sample counterpart of the population solution of (6), we approximate the objective function of (6) based on sample {(Yi, Ti, Xi), i = 1, … , n} (assumed to be independently and identically distributed across i). In particular, we use a nonparametric regression technique to approximate the solution (g1, … , gL) in (7) for each fixed α ∈ Θ. Although other nonparametric regression methods can also be used, in this paper we focus on a cubic B-spline (de Boor, 2001) representation of the solution (g1, … , gL) in (7) for each fixed α. Specifically, given each α, the functions gt is represented by
| (9) |
for some vector , where is a set of (dt + 4) cubic B-spline basis functions (de Boor (2001)) defined on the range of the candidate single-index {(α⊤Xi), i = 1, … , n}. We use dt to denote the number of interior knots (placed with equal distance between neighboring knots). The number dt depends on the treatment group sample size: . Furthermore, let us represent the conditional expectation E[Y|α⊤X] in expression (7) by E[Y|α⊤X] = B0(α⊤X)⊤β0 for some vector , where is a set of (d0 + 4) cubic B-spline basis functions defined on the range of the candidate single-index {(α⊤Xi), i = 1, … , n}. We use d0 number of interior knots (placed with equal distance between neighboring knots), and the number d0 depends on the sample size n.
Let denote the treatment t-specific n × dt design matrix, where the ith row is the 1 × dt vector Bt(α⊤Xi)⊤ if Ti = t and is a row of zeros if Ti ≠ t (i = 1, … , n) (t = 1, … , L). Let denote the n × d0 design matrix in which the ith row is the 1 × d0 vector B0(α⊤Xi)⊤ (i = 1, … , n). Then, for each fixed α ∈ Θ, we approximate the minimizer (g1, … , gL) in (7) by the method of least squares (see Section A.2 of the Supporting Information for a derivation):
| (10) |
where Y denotes the n × 1 vector of the observed responses. We define the estimator for α0 of model (1) by
| (11) |
where (g1, … , gL) are given in (10). Let us define the associated estimators for the treatment-specific functions (f1, … , fL) of model (1) by
| (12) |
We use iteratively re-weighted least squares to solve (11), repeating the following two steps:
Given a current estimate α ∈ Θ, compute the functions (g1, … , gL) in (10).
Given (g1, … , gL), approximately solve (11), based on a linear approximation to at the current estimate of α.
The iteration between the two steps continues until convergence of α ∈ Θ. We next elaborate Step 2 of this iterative procedure. For each (the kth) iterative step, the objective function in (11) is approximated based on a linear approximation of at the current (the kth) iterate, say α(k) ∈ Θ:
| (13) |
where the modified responses and the modified regressors :
| (14) |
and we minimize the right-hand side of (13) over . The minimizer α(k+1) is then scaled to satisfy α(k+1) ∈ Θ. The algorithm terminates, when ∥(α(k+1) − α(k))/α(k+1)∥ is less than a prespecified convergence tolerance.
Remark 1.
The objective function of the modified covariates model (2) (Tian et al., 2014) is
| (15) |
in which the terms Xi(Ti + π1 − 2) are called modified covariates. By comparing the right-hand side of (13) to (15), the modified regressors, , take the role of the modified covariates of Tian et al. (2014) in updating α for each (the kth) iterative step. For any set of arbitrary functions (g1, … , gL) satisfying the constraint (4), we have E[ġT(α(k)⊤X)X|X] = 0 (almost surely) for any α(k) ∈ Θ, which is analogous to the condition: E[X(T + π1 − 2)|X] = 0 (almost surely) satisfied by the modified covariates model (2). These conditions, satisfied by the models, make the parts relevant to the optimization of α in (13) and (15) independent of the unspecified μ(X) of the underlying models (1) and (2), respectively, as in (5). This orthogonality is attractive, as the estimation of the unspecified function μ(X) and the single-index coefficient α0 can be performed separately, independently of each another. If we restrict the treatment t-specific functions gt to gt(u) := u(t + π1 − 2), the objective function of (11) reduces to (15).
Remark 2.
As the weights that define the modified regressors in (14) depend on the values Xi and the shape of the link-functions (through the first derivatives ), the iterative procedure of optimizing α that utilizes the right-hand side of (13) accounts for the nonlinear interactions captured by the flexible link-functions (g1, … , gL). This is in contrast to the constant weights (Ti + π1 − 2) applied to Xi in defining the modified covariates of Tian et al. (2014).
3.3 |. Consistency and asymptotic normality of the estimator
We establish the consistency of the estimator in (11) for α0 and the estimators in (12) for ft, where α0 and ft are given in model (1). The theoretical results rely on those of Wang and Yang (2009), where cubic B-splines are used to approximate the link function of their single-index model. In Wang and Yang (2009), instead of imposing the true mean function to be a function only of a single-index , that is, for some single-index coefficient θ0 ∈ Θ, the authors develop a root-n consistent cubic spline estimator of the single-index coefficient of a single-index model that is robust against deviations from the exact single-index regression relationship. Specifically, their target single-index coefficient θ0 ∈ Θ is defined in terms of the optimal L2 (single-index based) approximation to the response , rather than in terms of an exact single-index relationship . In what follows, we adopt the results and assumptions of Wang and Yang (2009), and obtain uniformly consistent estimators of the conditional expectations E[Y|α⊤X, T = t] (t = 1, … , L) and E[Y|α⊤X] appearing on the right-hand side of (7) (uniformly over α ∈ Θ), and establish the root-n consistency of in (11) for α0 of model (1); cubic spline smoothing of Y(= Y(t)) on results in uniformly consistent estimators in (12) for ft (t = 1, … , L). We state our assumptions.
Assumption 1.
The response , where E[ϵi|Xi, Ti] = 0 and , in which the standard deviation functions σt(·) (t = 1, … , L) are bounded below and above by positive constants, defined on a bounded domain.
Assumption 2.
The function E[(Y − fT(α⊤X))2] is locally convex at α = α0.
Assumption 3.
The functions μ(·) and ft(·) in (1) have fourth-order continuous derivatives.
Assumption 4.
The covariate X is bounded, that is, ∥X∥ ≤ c, for some c > 0. The density function of X has a fourth-order continuous derivative, and is bounded above and below by positive constants, defined on a bounded domain.
Assumption 5.
The number of interior knots dt used in representing the function satisfies . The number of interior knots d0 used in representing the function satisfies n1/6 ≪ d0 ≪ n1/5(log(n))−(2/5).
Assumption 1 on the standard deviation functions σt(·) and Assumption 3 on the underlying regression functions are typical in the nonparametric smoothing literature; see, for instance, Hardle et al. (1993); Xia et al. (2002). Assumption 4 on the distribution of X is also assumed in Wang and Yang (2009). Assumption 5 gives the requirement for the numbers of interior knots for the cubic spline spaces in approximating the conditional expectations specified on the right-hand side of (7), and is needed to ensure the uniform convergence of the approximated criterion function in (11) to its population counterpart in (8) over α ∈ Θ. The strong consistency of in (11) to α0 and in (12) to ft are given below.
Theorem 1.
Under Assumptions 1–5, , almost surely.
Corollary 1.
Under Assumptions 1–5,
| (16) |
In (16), without loss of generality, we take the domain of the functions and ft to be [0,1], as α⊤X (α ∈ Θ) is bounded under Assumption 4. We next consider the asymptotic normality of . In the working model (3), any vector can be expressed as: , for some vector . Let J(ϕ) denote the p × (p − 1) Jacobian transformation matrix from to α ∈ Θ, whose (i, j)th element is given by ∂αi/∂ϕj = −αiϕj/K2, for (i = 1; j = 1, … , p − 1), and ∂αi/∂ϕj = −αiϕj/K2 + 1/K, for (i = 2, … , p; j = 1, … , p − 1), where K = (1 + ∥ϕ∥2)1/2. As the relation α = c(ϕ) is one-to-one, the parameter vector corresponding to the coefficient α0 ∈ Θ of model (1) can be specified. Let us define the (p − 1) × (p − 1) covariance matrix , in which , where α0 = c((ϕ0). Let A0 denote the (p − 1) × (p − 1) matrix of the first derivative of E[Ψ(Yi, Ti, Xi|ϕ)] with respect to evaluated at ϕ = ϕ0. The asymptotic normality of the estimator is given below.
Theorem 2.
Under Assumptions 1–5, in distribution, where J0 is the Jacobian function J(ϕ) evaluated at ϕ = ϕ0.
The proofs of Theorem 1 and 2 and Corollary 1 are in Section A.3 of the Supporting Information. Although the convergence rate of the nonparametric component in (12) to ft (t = 1, … , L) is slower than root-n (see (A.11) of the Supporting Information Section A.3) under Assumption 5 on the numbers of interior knots dt and d0, the parametric component α0 can be estimated at a root-n rate by letting the numbers of interior knots of the spline smoothing to increase with the sample size at an appropriate rate (Assumption 5). This indicates that the model can be estimated in two stages: estimation of α0 by the root-n consistent ; spline smoothing of Y on for each T = t (t = 1, … , L) to obtain an estimator (as given in (12)) of ft. Under Assumptions 1–5, Theorem 2 states that root-n rate asymptotic normality for is achievable, and that the estimator is as efficient as if the true nonparametric functions ft (t = 1, … , L) in model (1) were known and used as the link functions gt (t = 1, … , L) of the working model (3). However, is generally not the most efficient estimator (although a root-n consistent estimator). This is because is based on a generally misspecified working model (3) that includes only the T-by-X interaction effect component and omits the main effect term. Analogous to the efficiency augmentation of Tian et al. (2014), the efficiency of the estimator can be improved by incorporating a main effect component of X to the estimation of α0 (see Section A.4 of the Supporting Information).
3.4 |. An illustration of the consistency of
In this subsection, we illustrate the effect of the constraint (4) on the consistency of for α0 using a simulation experiment. For the purpose of illustration, we consider a simple case of p = 2 and L = 2. We generate {(Yi, Ti, Xi), i = 1, … n}, where Ti takes a value in {1, 2} with equal probability, independently of , where Xi,1,Xi,2 ~ independent unif[−π/2, π/2]. Given Ti and Xi, we generate Yi from model (1), that is, , with additive Gaussian noise ϵi, where (see Assumption 1). We set n = 250. We consider two simulation settings. In setting “A,” the T-by-X interaction effect specified in model (1) is nonlinear, and it is defined by
In setting “B,” the interaction effect is linear, as defined by
In both settings “A” and “B,” we take the main effect component in model (1) to be μ(X; δ) = δ cos(η⊤X), where the parameter δ ∈ {1, 2, 4} regulates the contribution of the X main effect to the variance of Y. In both settings, the contribution of μ(X; δ) to the variance of Y is about 0.85, 3.5, and 14 times greater than that of the interaction effect , for δ = 1, δ = 2, and δ = 4, respectively. In both settings, corresponds to the index of interest (as it is associated with the T-by-X interaction effects) and η⊤X corresponds to a “nuisance” index (as it is associated only with the X main effects). We set and . For the purpose of visualization, we parameterize vectors in terms of an angle θ ∈ [−π/2, π/2) such that α = (cos(θ), sin(θ))⊤. We identify the vectors α0 and η (in Cartesian coordinates) with the angles θ1 = π/4 and θ2 = −π/4 (in polar coordinates), respectively.
In this simulation example, as a function of θ ∈ [−π/2, π/2), we illustrate the squared error criterion (ie, the objective function of (11)) (reparametrized with respect to θ) of the constrained working model (3). In addition, we illustrate the squared error criterion of the unconstrained working model, which is model (3) but without enforcing the constraint (4). For comparison, we also include the modified covariates squared error criterion (15) (reparametrized with respect to θ, by setting α = γ(cos(θ), sin(θ))⊤, in which is “profiled out” for each value of θ under the squared error criterion).
We simulate 200 data sets and average the values of these three criterion functions for each value of θ ∈ [−π/2, π/2) (evaluated on a dense grid). Then each of the averaged criterion functions is scaled to have height 1. In Figure 2, the resulting averaged criterion functions are displayed for setting “A” on the top row, and the setting “B” on the bottom row.
FIGURE 2.
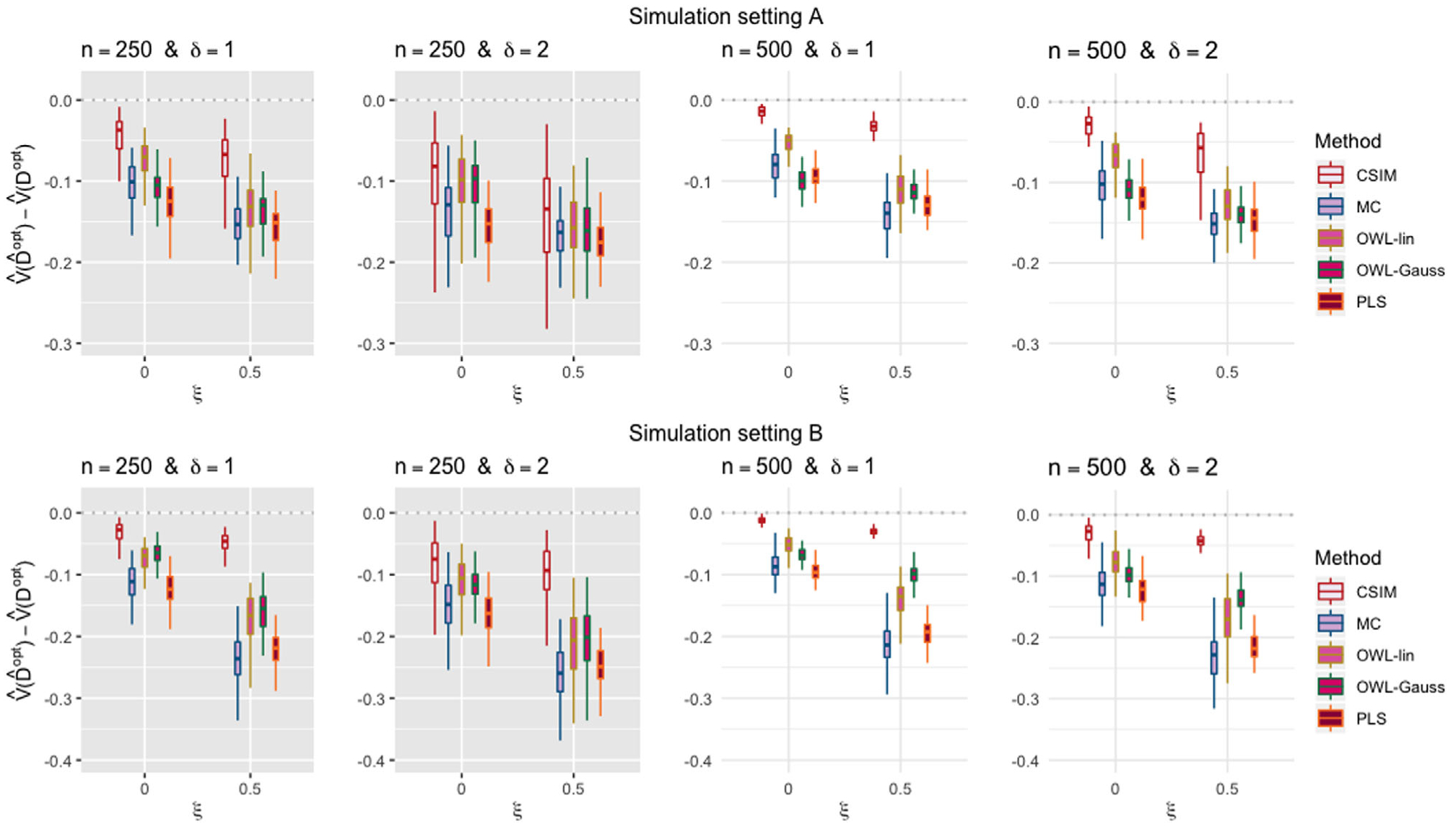
Boxplots comparing five approaches to estimating , given each scenario indexed by ξ ∈ {0, 0.5} and δ ∈ {1, 2}, for the simulation setting “A” in the top panels and the setting “B” in the bottom panels. For each scenario, from left to right, estimation approaches for : (1) the constrained single-index model (red); (2) the modified covariates model (green); (3) the outcome weighted learning with a linear kernel (violet); (4) the outcome weighted learning with a Gaussian kernel (purple); (5) the penalized spline least squares approach (dark purple). The case with ξ = 0 (or ξ = 0.5) corresponds to the correctly specified (or misspecified) single-index interaction model scenario; δ = 1 (or δ = 2) corresponds to the moderate (or large) main effect scenario. The dotted horizontal line represents the optimal value corresponding to .
In Figure 1, for all three cases of δ = 1, δ = 2, and δ = 4, the constrained criterion (the red solid lines) has a “correct” global minimum at θ1 = π/4, implying that the minimization of this constrained criterion would lead to correctly identifying the T-by-X interaction effect coefficient α0. The unconstrained criterion (the green dotted lines) has a correct minimum at θ1 = π/4 for the case δ = 1 (ie, when the main effect is relatively small), however, as the main effect intensity parameter δ increases (from δ = 1 to δ = 2 and to δ = 4), the unconstrained criterion function takes its global minimum at the nuisance angle θ2 = −π/4, implying that the minimization of the unconstrained criterion would lead to an inconsistent estimate of α0. Under the linear interaction effect (setting “B”), the constrained single-index regression criterion takes the consistent global minimum at θ1 = π/4 for all three cases of δ = 1, δ = 2, and δ = 4. On the other hand, the unconstrained criterion has its global minimum at the nuisance angle θ2 = −π/4, for the cases δ = 2 and δ = 4 (ie, when the main effect dominates the interaction effect).
FIGURE 1.
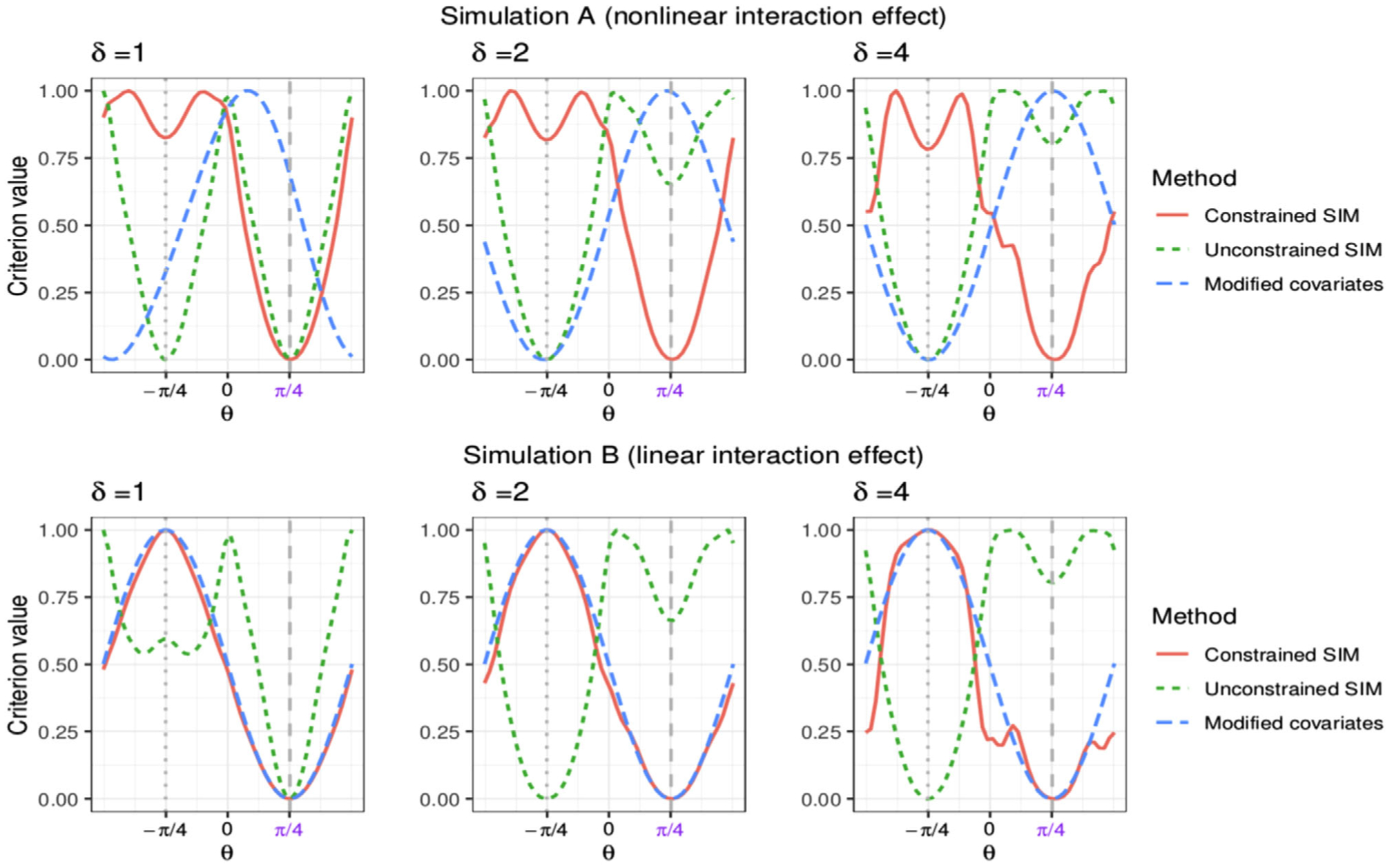
The averaged criterion functions of θ ∈ [−π/2, π/2) averaged over 200 simulated data sets. The vector α0 corresponds to the angle θ1 = π/4 that is indicated by the gray dashed vertical line, and the “nuisance” vector η corresponds to the angle θ2 = −π/4 indicated by the gray dotted vertical line. The criteria and their corresponding line styles: (1) the constrained single-index criterion (the red solid curves); (2) the unconstrained single-index criterion (the green dotted curves); (3) the modified covariates criterion (the blue dashed curves).
This example has illustrated that the proposed constrained single-index regression criterion consistently takes its global minimum near the “signal” direction α0 associated with the T-by-X interaction effect, even when the interaction effect signal is weak, unlike the case of the unconstrained criterion. In the linear interaction scenario (setting “B”), the modified covariates model (2) also produces a consistent estimate of the “signal” direction α0 as, in this case, the modified covariates model is correctly specified and is a special case of the proposed constrained single-index model (1). However, when the interaction effect is nonlinear (scenario “A”), the modified covariates criterion does not provide relevant information for modeling the T-by-X interaction effects, as it takes its global minimum away from α0.
4 |. SIMULATION STUDIES
In this section, we perform numerical studies to illustrate the performance of the proposed approach to optimizing individualized treatment rules, in comparison with alternative approaches including the modified covariates approach of Tian et al. (2014) and the outcome weighted learning method of Zhao et al. (2012).
We consider p = 10 with n ∈ {250, 500}. We generate covariates consisting of independent unif[−π/2, π/2] variates (a correlated covariate case is considered in Supporting Information Section B.5), and the treatment variable Ti takes a value in {1, 2} with equal probability, independently of Xi. We generate the treatment outcome from (1) the simulation setting “A”:
| (17) |
where the first term μ(X; δ) : = 0.8δ cos(η⊤X) (δ = 1, 2) corresponds to the main effect of X, and the second term corresponds to the T-by-X interaction effect, determined by a bell-shaped (ie, Gaussian) surface over two one-dimensional indices, and , which nonlinearly modifies the effect of the variable T on the outcome Y. We also consider (2) the simulation setting “B”:
| (18) |
where the first term μ(X; δ) := δ cos(η⊤X) (δ = 1, 2) determines the X main effect, and the second term fT(X; ξ) : = (−1)T{cos((α0 + α1I(T=2)ξ)⊤Xi − π/8) −0.5} (ξ = 0, 0.5) determines the T-by-X interaction effect, which is defined based on different single indices for each treatment, that is, for T = 1 and (α0 + α1ξ)⊤X for T = 2, when ξ ≠ 0.
Both models (17) and (18) are indexed by a pair (ξ, δ): the parameter ξ ∈ {0, 0.5} determines whether the T-by-X interaction effect term fT(X; ξ) in models (17) and (18) has an intrinsic one-dimensional structure over the single index or whether it deviates from a single-index model structure (ξ = 0.5); the parameter δ ∈ {1, 2} in μ(X; δ) controls the contribution of the X main effect on the variance of Y, where δ = 1 represents a relatively moderate X main effect (contributing about the same variance as the interaction effect does) and δ = 2 a relatively large X main effect (about 4 times greater than the interaction effect), respectively. In both (17) and (18), we use additive noise ϵi (see Assumption 1) that follows the mean zero Gaussian distribution with standard deviation 0.5. In models (17) and (18), we set the vectors η = (−1, 1, −1, 1, −1, 1, 0, 0, 0, 0)⊤, α0 = (1, 0.5, 0.25, 0.125, 0, 0, 0, 0, 0, 0)⊤, and α1 = (1, 1, 1, 1, 1, 1, 0, 0, 0)⊤, with each of these length p(= 10) vectors normalized to have unit norm. Without loss of generality, we assume that a larger value of Y is preferred.
For the case of a single decision time point, an individualized treatment rule, which we denote as , is a rule that maps an individual with (baseline) characteristics X to one of the L available treatment options. One natural measure for the effectiveness of is called the value (V) of (Qian and Murphy (2011)) defined as the expected mean response when everyone in the population receives treatment according to the rule , that is, . The optimal individualized treatment rule, which we denote as , resulting in the largest value of V is: . Accordingly, the estimators for are: and , for models (1) and (2), respectively. Here, the estimators and for model (1) correspond to the proposed estimators (11) and (12), and the estimator for model (2) corresponds to the minimizer of (15).
The methods for estimating under comparison include:
The proposed method of using model (3), estimated through the procedure described in Section 3.2. We use the numbers of interior knots and d0 = [n1/5.5], which satisfy Assumption 5. Here, [u] denotes the integer part of u.
The modified covariates method of Tian et al. (2014) of using model (2), estimated by minimizing (15).
The outcome weighted learning method (Zhao et al., 2012) based on a linear kernel, implemented in the R-package DTRlearn. To improve its efficiency, we employ the augmented outcome weighted learning approach of Liu et al. (2018). The tuning parameter κ in Zhao et al. (2012) is chosen from the grid of (0.25, 0.5, 1, 2, 4) (the default setting of DTRlearn) based on a fivefold cross-validation.
The same approach as in (3) but based on a Gaussian radial basis function kernel instead of a linear kernel. The inverse bandwidth parameter in Zhao et al. (2012) is chosen from the grid of (0.01, 0.02, 0.04, … , 0.64, 1.28) and κ is chosen from the grid of (0.25, 0.5, 1, 2, 4), based on a fivefold cross-validation.
A penalized additive cubic spline least squares (PLS) approach. We implement this method by estimating E[Y|X, T = t] via an additive regression for each treatment separately. The implementational detail is given in Section B.4 of Supporting Information.
For each simulation run, we estimate from each of the five methods based on a training set (of size n), and for evaluation of these methods, we evaluate the value for each estimate , using a Monte Carlo approximation based on a random sample of size 103, denoted as . As we know the true data-generating model in simulation studies, the optimal can be determined for each simulation run. Given each estimate of , we report , as the performance measure of . A larger value of the measure indicates better performance.
In Figure 2, we present the boxplots, obtained from 100 simulation runs, of the normalized values (normalized by the optimal values ) of the decision rules estimated from the five approaches, for each combination of n ∈ {250, 500}, ξ ∈ {0, 0.5} (corresponding to correctly specified or misspecified single-index interaction effect models, respectively) and δ ∈ {1, 2} (corresponding to moderate or large main effects, respectively), for the simulation setting “A” in the top panels and the setting “B” in the bottom panels.
The results in Figure 2 indicate that the proposed constrained single-index model outperforms all other approaches in estimating . With substantial nonlinearity in the interaction effect term of the models (17) and (18), the modified covariates method, which assumes a restricted linear model on the interaction term, is clearly outperformed by the proposed model that utilizes a set of flexible link functions to accommodate the nonlinear treatment effect modification. The estimated values of the outcome weighted learning with a linear kernel and a Gaussian kernel, respectively, are similar to each other, but both are outperformed by the constrained single-index regression, even when the true interaction model deviates from a single-index model (when ξ = 0.5). When n = 500 (ie, with a relatively large sample size) and ξ = 0.5 (ie, when the underlying model deviates from the exact single-index structure), the penalized additive spline approach (PLS), due to its large model space, outperforms the modified covariates method slightly; however, the approach is clearly outperformed by the proposed single-index method that is robust to the main effect model misspecification and also allows nonlinear interactions. When the X main effect dominates the T-by-X interaction effect (ie, when δ = 2), although the increased magnitude of the main effect dampens the performance of all approaches to optimizing treatment decisions, the constrained single-index regression consistently targets to model the interaction effect-related variability, and its performance is near optimal when n = 500.
5 |. APPLICATION TO DATA FROM A DEPRESSION RANDOMIZED CLINICAL TRIAL
The development of the constrained single-index model method was motivated by a randomized clinical trial comparing an antidepressant (T = 2) and placebo (T = 1) for treating major depressive disorder. The primary purpose of the study is the development of a biosignature, called a differential treatment response index, defined as a combination of multiple biomarkers that can be used for optimization of an individualized treatment rule for patients with major depressive disorder (Trivedi et al., 2016). In major depressive disorder, each patient characteristic often has at most a weak modifying effect. Therefore, the proposed single-index modeling approach that creates a differential treatment response single-index that collectively exhibits a stronger, and possibly nonlinear, interaction with the treatment is a very clinically significant endeavor.
Of the 166 subjects, 88 were randomized to placebo and 78 to drug. Pretreatment clinical characteristics X = (X1, … , X5)⊤ include: X1 = age at evaluation; X2 = severity of depressive symptoms measured by the Hamilton rating scale at baseline; X3 = logarithm of duration (in month) of the current major depressive episode. In addition, patients underwent neuropsychiatric testing at baseline to assess reaction time, X4 = median choice reaction time and cognitive control, X5 = Flanker accuracy, as these behavioral characteristics are believed to correspond to biological phenotypes related to response to antidepressants (Trivedi et al., 2016). For the purposes of regularization, all pretreatment covariates are centered and scaled to have mean 0 and unit variance. The outcome Y is the improvement in symptoms severity (assessed by the Hamilton rating scale for depression) from baseline to week 8 taken as the difference (week 0 to week 8), and thus larger values of the outcome are considered desirable.
The estimated single-index coefficients of the proposed model (1) and their 95% normal approximation bootstrap confidence intervals based on 500 bootstrap replications (see Supporting Information Section B.6 for the coverage proportions of the bootstrap confidence intervals assessed by simulations) are given by , , , , and , respectively. The estimated treatment t-specific functions (with 95% confidence bands, given ) are illustrated in the first two panels of Figure 3.
FIGURE 3.
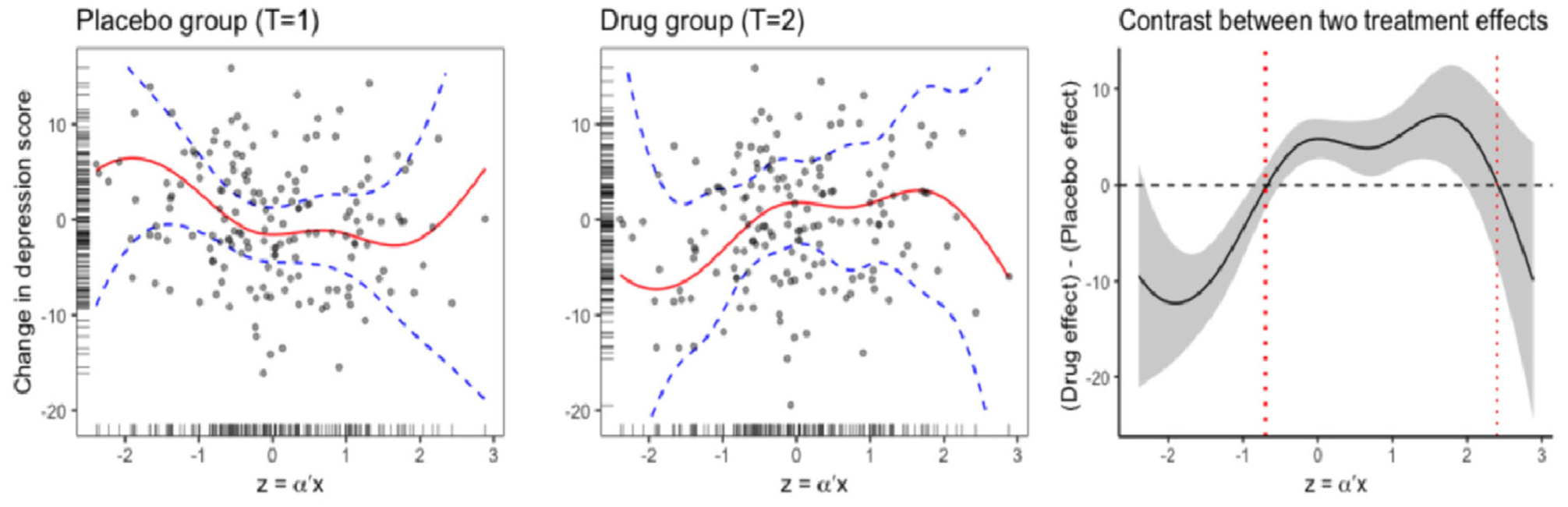
Depression randomized clinical trial: scatter plots of the outcome against the estimated single index z = α⊤X, for the placebo group (T = 1, in the left panel) and the drug group (T = 2, in the middle panel); the estimated treatment-specific curve (with 95% confidence bands) for each group is overlaid (the red solid curve). In the right panel, the contrast between the estimated two treatment effects (drug - placebo) as a function of the estimated single-index is displayed.
The right panel of Figure 3 displays the contrast between the two estimated treatment effects (drug - placebo) versus the estimated single-index. This indicates that the superiority of the drug over placebo does not linearly increase with z = α⊤X, but rather, it appears to plateau out with some nonlinear patterns to the right of the zero crossing point near z = −0.7, and it has another zero crossing point near z = 2.4. As implied by the contrast plot in Figure 3, an individualized treatment rule based on the single-index z = α⊤X can be constructed by assigning patients with the index −0.7 < z < 2.4 to the active drug.
To evaluate the performance of the individualized treatment rules estimated from five different approaches described in Section 4, we randomly split the data set at a ratio of 5 to 1 into a training set and a testing set (of size ñ), replicated 500 times, each time obtaining based on the training set and estimating the value of , , by an inverse probability weighted estimator (Murphy, 2005) based on the testing set (of size ñ). For the modified covariates method, we use a linear model with covariates X for efficiency augmentation. For comparison, we also include two naïve rules: treating all patients with placebo; and treating all patients with the active drug, each regardless of the individual patient’s characteristics X.
As Figure 4 shows, the proposed constrained single-index regression for estimating outperforms all other alternatives in terms of the average estimated values. In particular, the approach outperforms the modified covariates method and the outcome weighted learning with a linear kernel, illustrating the utility of the flexible treatment-specific link functions in approximating the nonlinear interactions. The method also outperforms the penalized additive spline least squares approach, suggesting that estimating and utilizing an optimal linear combination (a single-index α⊤X) of biomarkers that collectively exhibits a stronger (and possibly nonlinear) interaction with the treatment is practically an appealing approach to optimizing treatment decision rules. In this example, the outcome weighted learning with a Gaussian kernel does not perform well.
FIGURE 4.
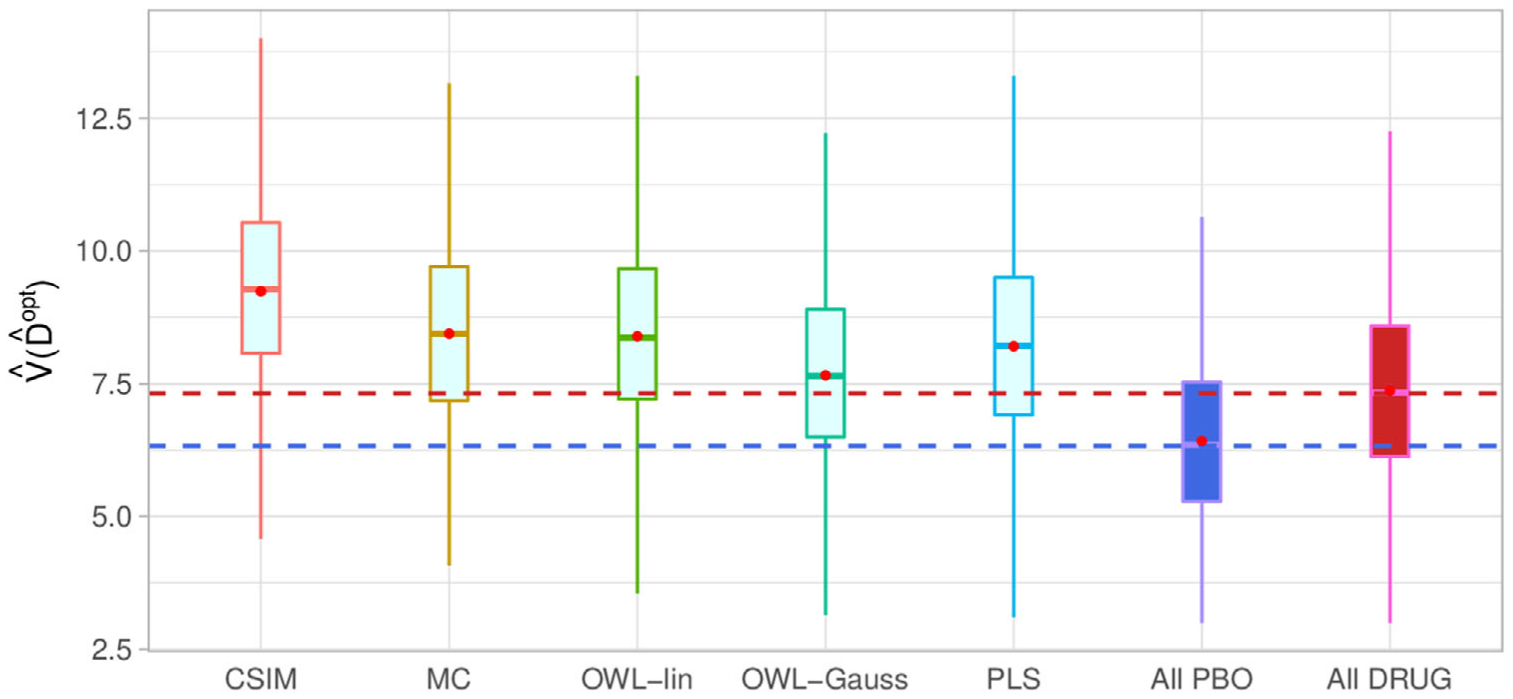
Depression randomized clinical trial: boxplots of the estimated values of the individualized treatment rules estimated from seven approaches, obtained from 500 randomly split testing sets. From left to right, estimation approaches to : (1) the constrained single-index model; (2) the modified covariates model; (3) outcome weighted learning with a linear kernel; (4) outcome weighted learning with a Gaussian kernel; (5) the penalized spline least squares approach; (6) treating all patients with placebo; (7) treating all patients with the active drug.
The proposed single-index regression provides a visualization of the estimated single-index as shown in the panels of Figure 3, and the relative importance of each pretreatment covariate in terms of characterizing the heterogeneous treatment responses can be indicated by the coefficients (α1, … α5)⊤. The practical utility of the proposed methodology is highlighted here by noting that the difference between the values of the treatment decision rule based on the new method and the values of the naïve rule that treats everyone with the drug is almost twice as large as the difference between the efficacies of the drug and placebo.
6 |. DISCUSSION
The proposed method is primarily designed to analyze data from randomized clinical trials. A limitation of the proposed method can occur when applying it to an observational study, where the covariates and treatment assignment can be correlated, in which case the estimator might not yield the optimal decision rule. However, the working model (3), with the link functions (g1, … , gL) as defined in (7), can still be useful in fitting the T-by-X interaction effect term of model (1). If there are estimators (g1, … , gL), for each fixed α, that asymptotically satisfy (7), then, in the objective function (6), the part relevant to the estimation of the coefficient α0 of model (1) is asymptotically separated from the X main effect term μ(X) of model (1), as in (5), resulting in robustness against misspecification of the X main effects in estimating the T-by-X interactions. We can utilize an iterative optimization procedure to optimize both α and (g1, … , gL). For each fixed α, estimators of (g1, … , gL) that asymptotically satisfy (7) are relatively easy to obtain. For example, we can first compute unconstrained estimators, denoted as , of the conditional expectations , based on a one-dimensional (along the axis α⊤X) nonparametric smoother for each treatment T = t (t = 1, … , L), and then remove the component in the fitted corresponding to the main effect of α⊤X, by fitting a one-dimensional nonparametric smoother (along the axis α⊤X), denoted as , to the fitted . Then, for each fixed α, we can take as such estimators (g1, … , gL), which approximately satisfy (7). See Supporting Information Section A.6 for a justification for the robustness of this procedure against misspecification of μ(·). However, when T depends on X, the fitted T-by-X interaction effect term might result in biased causal effect estimates, as described in Supporting Information Section A.7.
In many applications, only a subset of measurements may be useful in determining an optimal treatment decision rule. Also, high-dimensional settings can lead to instabilities and issues of overfitting. Forthcoming work will introduce a regularization method that can both avoid overfitting and choose among multiple potential covariates by obtaining a sparse estimate of the single-index coefficient α0. In this paper, the theoretical results are developed with a B-spline basis approximation, with the number of knots used as the tuning parameters. In finite samples, the choice of the number of knots can be crucial and delicate. At present an ad hoc choice of and d0 = [n1/55] is used for the number of knots, which is likely to be sub-optimal in practice (note that one can set or d0 = C[n1/55] with an arbitrary C > 0 while still achieving the requirements in Assumption 5). In practice, a penalized spline approximation, for example, P-splines (Eilers and Marx, 1996), can be considered, which is relatively robust to the choice of the number of knots. Although in Section 3.3, Assumption 4 does not allow discrete-valued covariates, our simulation experiment (see Supporting Information Section B.2) where the covariates X include a binary variable suggests that estimation in practice is rather insensitive to departure from this assumption. Generally, multiple local optima exist in the squared error criterion in (11) (and also its population counterpart in (6) with respect to α, where gt is defined in (7)), and in such cases the estimates can be sensitive to the choice of initialization. We assume (in Assumption 1) the local convexity of the criterion function near α = α0, and this implies that the algorithm will converge if the initial estimate is close to α0. Otherwise, the estimate can be sub-optimal. One way to mitigate this problem is to consider multiple initial points for α0 in estimation (as in Supporting Information Section B.2 and B.3). In this paper, we use a linear estimate based on the modified covariates linear model (2) (scaled to be in Θ) as an initial estimate, and the estimate , optimized to incorporate possibly nonlinear interactions, provides a significant improvement over the modified covariate initial estimate, as illustrated by the simulations in Section 4.
Future directions of this work also include an extension of the proposed regression to a multiple-index regression for modeling interactions. For example, when L = 2, model (1) can be extended to a partially linear single-index model (eg, Lian and Liang, 2016; Xia et al., 1999) by adding a modified covariate (Tian et al., 2014) linear component to the single-index interaction component. We will also investigate the incorporation of functional covariates and longitudinal outcomes.
Supplementary Material
ACKNOWLEDGMENTS
We are grateful to the editor, the associate editor, and two referees for their insightful comments and suggestions. One referee specifically suggested the direction that clarifies a limitation of the proposed method that can occur when applying it to an observational study setting. This work was supported by National Institute of Health (NIH) grant 5 R01 MH099003.
Footnotes
DATA AVAILABILITY STATEMENT
The data that support the findings in this paper are available from the corresponding author upon reasonable request.
SUPPORTING INFORMATION
Web Appendices A (Technical details of mathematical results) and B (Results from simulation studies) referenced in Sections 3–6 are available with this paper at the Biometrics website on Wiley Online Library. An R code demonstrating the method described in this article is also available there. The R package simml (Park et al., 2019) available on CRAN (R Development Core Team, 2019) provides an implementation of the proposed method.
REFERENCES
- de Boor C (2001)A Practical Guide to Splines. New York, N: Springer. [Google Scholar]
- Eilers P and Marx B (1996) Flexible smoothing with B-splines and penalties. Statistical Science, 11, 89–121. [Google Scholar]
- Hardle W, Hall P and Ichimura H (1993) Optimal smoothing in single-index models. Annals of Statistics, 21, 157–178. [Google Scholar]
- Hastie T and Tibshirani R (1999) Generalized Additive Models. Chapman & Hall. [DOI] [PubMed] [Google Scholar]
- Jeng X, Lu W and Peng H (2018) High-dimensional inference for personalized treatment decision. Electronic Journal of Statistics, 12, 2074–2089. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kang C, Janes H and Huang Y (2014) Combining biomarkers to optimize patient treatment recommendations. Biometrics, 70, 696–707. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laber EB and Zhao Y (2015) Tree-based methods for individualized treatment regimes. Biometrika, 102, 501–514. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lian H and Liang H (2016) Separation of linear and index covariates in partially linear single-index models. Journal of Multivariate Analysis, 143, 56–70. [Google Scholar]
- Liu Y, Wang Y, Kosorok MR, Zhao Y and Zeng D (2018) Augmented outcome-weighted learning for estimating optimal dynamic treatment regimens. Statistics in Medicine, 37, 3776–3788. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lu W, Zhang H and Zeng D (2011) Variable selection for optimal treatment decision. Statistical Methods in Medical Research, 22, 493–504. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Murphy SA (2003) Optimal dynamic treatment regimes. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 65, 331–355. [Google Scholar]
- Murphy SA (2005) A generalization error for Q-learning. Journal of Machine Learning, 6, 1073–1097. [PMC free article] [PubMed] [Google Scholar]
- Park H, Petkova E, Tarpey T and Ogden RT (2019) simml: a single-index model with multiple-links. R package version 0.1.0 [DOI] [PMC free article] [PubMed]
- Park H, Petkova E, Tarpey T and Ogden RT (2020) A single-index model with multiple-links. Journal of Statistical Planning and Inference, 205, 115–128. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Petkova E, Park H, Ciarleglio A, Ogden R and Tarpey T (2019) Optimising treatment decision rules through generated effect modifiers: a precision medicine tutorial. BJPsych Open, 6, 1–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Qian M and Murphy SA (2011) Performance guarantees for individualized treatment rules. The Annals of Statistics, 39, 1180–1210. [DOI] [PMC free article] [PubMed] [Google Scholar]
- R Development Core Team (2019) R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. [Google Scholar]
- Robins J (2004) Optimal Structural Nested Models for Optimal Sequential Decisions. New York, NY: Springer. [Google Scholar]
- Shi C, Fan A, Song R and Lu W (2018) High-dimensional A learning for optimal dynamic treatment regimes. The Annals of Statistics, 46, 925–957. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shi C, Song R and Lu W (2016) Robust learning for optimal treatment decision with np-dimensionality. Electronic Journal of Statistics, 10, 2894–2921. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Song R, Kosorok M, Zeng D, Zhao Y, Laber EB and Yuan M (2015) On sparse representation for optimal individualized treatment selection with penalized outcome weighted learning. Stat, 4, 59–68. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Song R, Luo S, Zeng D, Zhang H, Lu W and Li Z (2017) Semiparametric single-index model for estimating optimal individualized treatment strategy. Electronic Journal of Statistics, 11, 364–384. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stoker TM (1986) Consistent estimation of scaled coefficients. Econometrica, 54, 1461–1481. [Google Scholar]
- Tian L, Alizadeh A, Gentles A and Tibshrani R (2014) A simple method for estimating interactions between a treatment and a large number of covariates. Journal of the American Statistical Association, 109, 1517–1532. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Trivedi M, McGrath P, Fava M, Parsey R, Kurian B, Phillips M, Pquendo M, Bruder G, Pizzagalli D, Toups M, Cooper C, Adams P, Weyandt S, Morris D, Grannemann B, Ogden R, Buckner R, McInnis M, Kraemer H, Petkova E, Carmody T and Weissman M (2016) Establishing moderators and biosignatures of antidepressant response in clinical care: rationale and design. Journal of Psychiatric Research, 78, 11–23. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang L and Yang L (2009) Spline estimation of single-index models. Statistica Sinica, 19, 765–783. [Google Scholar]
- Xia Y, Tong H and Li W (1999) On extended partially linear single-index models. Biometrika, 86, 831–842. [Google Scholar]
- Xia Y, Tong H, Li W and Zhu L (2002) An adaptive estimation of dimension reduction space. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 64, 363–410. [Google Scholar]
- Zhang B, Tsiatis AA, Davidian M, Zhang M and Laber E (2012) Estimating optimal treatment regimes from classification perspective. Stat, 1, 103–114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang B, Tsiatis AA, Laber EB and Davidian M (2012) A robust method for estimating optimal treatment regimes. Biometrics, 68, 1010–1018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao Y, Laber E, Ning Y, Saha S and Sands B (2019) Efficient augmentation and relaxation learning for individualized treatment rules using observational data. Journal of Machine Learning Research, 20, 1–23. [PMC free article] [PubMed] [Google Scholar]
- Zhao Y, Zeng D, Rush AJ and Kosorok MR (2012) Estimating individualized treatment rules using outcome weighted learning. Journal of the American Statistical Association, 107, 1106–1118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao Y, Zheng D, Laber EB and Kosorok MR (2015) New statistical learning methods for estimating optimal dynamic treatment regimes. Journal of the American Statistical Association, 110, 583–598. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.