Abstract
Population stratification continues to bias the results of genome-wide association studies (GWAS). When these results are used to construct polygenic scores, even subtle biases can cumulatively lead to large errors. To study the effect of residual stratification, we simulated GWAS under realistic models of demographic history. We show that when population structure is recent, it cannot be corrected using principal components of common variants because they are uninformative about recent history. Consequently, polygenic scores are biased in that they recapitulate environmental structure. Principal components calculated from rare variants or identity-by-descent segments can correct this stratification for some types of environmental effects. While family-based studies are immune to stratification, the hybrid approach of ascertaining variants in GWAS but reestimating effect sizes in siblings reduces but does not eliminate stratification. We show that the effect of population stratification depends not only on allele frequencies and environmental structure but also on demographic history.
Research organism: None
Introduction
Population structure refers to patterns of genetic variation that arise due to non-random mating. If these patterns are correlated with environmental factors, they can lead to spurious associations and biased effect size estimates in genome-wide association studies (GWAS). Approaches such as genomic control (GC) (Devlin and Roeder, 1999), principal component analysis (PCA) (Price et al., 2006), linear mixed models (LMMs) (Kang et al., 2010; Loh et al., 2015) and linkage disequilibrium score regression (LDSC) (Bulik-Sullivan et al., 2015a) have been developed to detect and correct for this stratification. However, these approaches do not necessarily remove all stratification, particularly when multiple studies are meta-analyzed (Berg et al., 2019; Sohail et al., 2019). Large GWAS in relatively homogeneous populations, such as the UK Biobank (UKB) (Bycroft et al., 2018), should alleviate many of these concerns. However, such populations still exhibit fine-scale population structure (Leslie et al., 2015; Karakachoff et al., 2015; Kerminen et al., 2017; Haworth et al., 2019; Raveane et al., 2019; Bycroft et al., 2019; Byrne et al., 2020). The extent to which this fine structure impacts GWAS inference in practice is largely unknown, and it is not clear whether existing methods adequately correct for it. This question has become increasingly acute in light of the recent focus on polygenic scores for disease risk prediction (Torkamani et al., 2018; Knowles and Ashley, 2018). Polygenic scores for many physical and behavioral traits exhibit geographic clustering within the UK even after stringent correction for population structure (Haworth et al., 2019; Abdellaoui et al., 2019). Although some of this variation may be attributed to recent migration patterns (Abdellaoui et al., 2019), it could also reflect residual stratification in effect size estimates (Lawson et al., 2020).
To address these questions, we investigated the effect of population structure on GWAS in a simulated population with a similar degree of structure to the UK Biobank. We considered the fact that different demographic histories can give rise to the same overall degree of population structure (in terms of statistics such as and the genomic inflation factor, λ). This is relevant because the degree to which common and rare variants are impacted by, and are thus informative about, population structure depends on demographic history. It is therefore important to understand the demographic history of GWAS populations in order to assess the consequences of stratification.
Results
Rare variants capture recent population structure
We leveraged recent advances in our understanding of human history to simulate GWAS under different realistic demographic models. We simulated population structure using a six-by-six lattice-grid arrangement of demes with two different symmetric stepping-stone migration models (Figure 1). First, a model where the structure extends infinitely far back in time (perpetual structure model; e.g. Mathieson and McVean, 2012) and second, a model where the structure originated 100 generations ago (recent structure model). This second model is motivated by the observation from ancient DNA that Britain experienced an almost complete population replacement within the last 4,500 years (Olalde et al., 2018), providing an upper bound for the establishment of present-day geographic structure in Britain. We set the migration rates in the two models to match the degree of population structure in the UK Biobank, measured by the average between regions (Leslie et al., 2015) and the genomic inflation factor for a GWAS of birthplace in individuals with ‘White British’ ancestry from the UK Biobank (Haworth et al., 2019).
Figure 1. The ability of PCA to capture population structure depends on the frequency of the variants used and the demographic history of the sample.
Panels show the first and second principal components (PCs) of the genetic relationship matrix constructed from either common (upper row) or rare (lower row) variants. Each point is an individual (N = 9,000) and their color represents the deme in the grid (upper left) from which they were sampled. Both common (minor allele frequency >0.05) and rare (minor allele count = 2, 3, or 4) variants can be informative when population structure is ancient (left column; represents the time in generations in the past at which structure disappears) but only rare variants are informative about recent population structure (right column; generations). Number of variants used for PCA: 200,000 (upper row), 1 million (lower left), and ≈750,000 (lower right).
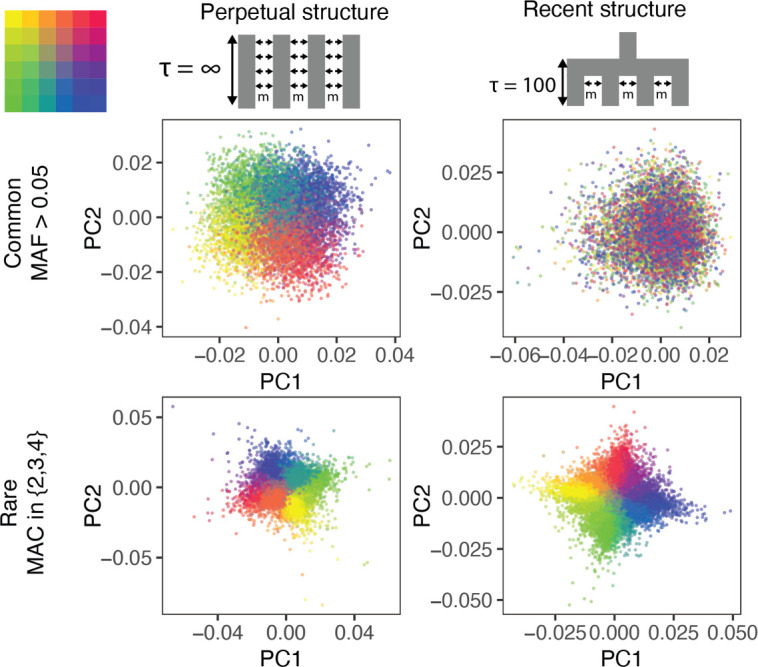
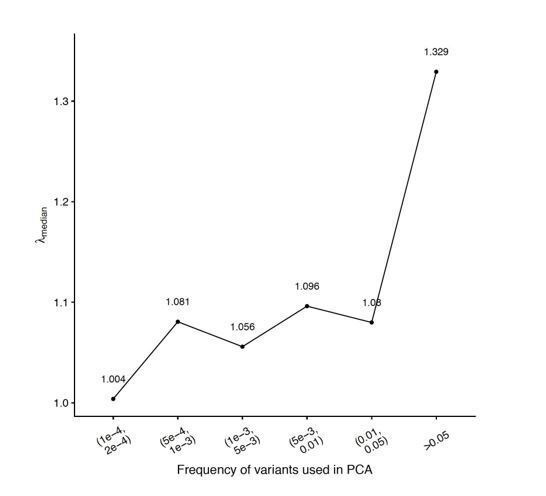
Figure 1—figure supplement 1. Collinearity between common- and rare-PCs under different demographic models.

Figure 1—figure supplement 2. PCA on imputed rare variants and IBD-sharing provide an alternative to rare-PCA when sequence data are not available.

Population structure in the two models is qualitatively different, even though is the same. When structure is recent, it is driven largely by rare variants which tend to have a more recent origin (Gravel et al., 2011; Fu et al., 2013; O'Connor et al., 2015) and are therefore less likely to be shared among demes. Common variants, because they are older and usually predate the onset of structure in our model, are more likely to be shared among demes and have not drifted enough in 100 generations to capture the spatial structure effectively. Therefore, recent structure is captured by the principal components of rare variants (rare-PCA) but not common variants (common-PCA) (Figure 1). In fact, 100 common-PCs altogether explain only 3% of the variance in rare-PC1 (Figure 1—figure supplement 1). In comparison, when population structure is perpetual, both common and rare variants carry information about spatial structure (Figure 1, Figure 1—figure supplements 1, 100 common-PCs explain 50% of the variance in rare-PC1). The two models discussed here represent somewhat extreme demographic scenarios and in reality, the degree to which common and rare variants capture independent aspects of population structure will depend on how the structure varies through time (Figure 1—figure supplement 1).
PCA with rare variants requires sequence data. When only genotype data are available, imputed rare variants can be used Figure 1—figure supplement 2. However, the practical utility of this approach would depend on the imputation accuracy which in turn depends on the population, the imputation algorithm and the reference panel (Das et al., 2018). Another alternative is to carry out PCA on haplotype or identity-by-descent (IBD) sharing, which is also informative about recent population structure (Figure 1—figure supplement 2).
The impact of population stratification depends on demographic history
That common variants fail to capture recent population structure has important implications for GWAS. Most GWAS use PCA or LMMs, both of which rely on the genetic relatedness matrix (GRM) to describe population structure. Since rare variants are not well-represented on SNP arrays, the GRM is usually constructed from common variants. This will lead to insufficient correction if common variants do not adequately capture recent population structure. To test this, we simulated a GWAS (N = 9,000) of a non-heritable phenotype (i.e. ) with an environmental component that is either smoothly (e.g. latitude) or sharply (e.g. local effects) distributed in space (Figure 2). We calculated GRMs using either common (minor allele frequency, MAF > 0.05) or rare variants (minor allele count, MAC = 2, 3, or 4), and included the first 100 PCs in the model to correct for population structure.
Figure 2. Test statistic inflation under two different demographic histories.
(A) Perpetual structure and (B) recent structure. Upper and lower rows show results for smoothly and sharply distributed environmental risk, respectively, whereas columns show different methods of correction. The simulated phenotype has no genetic contribution so any deviation from the diagonal represents inflation in the test statistic. Each panel shows QQ plots for -log10 p-value for common (orange) and rare (blue) variants. Insets show inflation () in the tail (99.9th percentile) of the distribution. Results are averaged across 20 simulations of the phenotype.

Figure 2—figure supplement 1. QQplots for linear mixed model association of non-heritable phenotypes carried out with GCTA-LOCO for genotypes generated under the recent structure model.

When population structure is recent, smooth environmental effects lead to an inflation in common, but not rare, variants and this inflation can only be corrected with rare- but not common-PCs (Figure 2B, top row). This is a consequence of the fact that rare variants carry more information about recent structure than common variants (Figure 1). We find similar results using LMMs instead of PCA (Figure 2—figure supplement 1). Therefore, in studies with recent structure, such as the UKB, neither PCA- nor LMM-based methods will fully correct for stratification as long as the GRM is derived from common variants. In contrast, under the perpetual structure model, both common and rare variants may be inflated due to smooth environmental effects (Figure 2A, top row), but this inflation is largely corrected with either common- or rare-PCs (Figure 2A, top row).
Local environmental effects largely impact rare variants only (Mathieson and McVean, 2012; Figure 2A, lower row) and the inflation due to local effects cannot be fully corrected using either common- or rare-PCs (Figure 2A and B, lower row). This is because local environmental effects cannot be represented by a linear combination of the first hundred principal components. Importantly, local effects only impact a small subset of variants—those clustered in the affected deme(s)—resulting in inflation only in the tails of the test statistic distribution (Figure 2). This pattern of inflation cannot be detected using standard genomic inflation, which assumes that stratification impacts enough variants to shift the median of the test statistic (Devlin and Roeder, 1999), making it difficult to distinguish between true associations and residual stratification.
Burden tests are relatively robust to local environmental effects
In practice, single rare variant association tests are often underpowered. To circumvent this, many studies aggregate information across multiple rare variants in a gene. Because they aggregate across rare variants, such tests have the potential to be affected by rare variant stratification (Mathieson and McVean, 2012). To study this, we examined the behavior of a simple gene burden statistic—the total number of rare derived alleles (frequency < 0.001) in each gene. We find that for a gene of average size (total exon length of ≈1.3 kb, mean of 16 rare variants), burden tests are robust to local effects under both perpetual and recent structure models (Figure 3). Because the burden statistic involves averaging over many variants, it behaves more like a common variant than a rare variant in terms of its spatial distribution (Figure 3—figure supplement 1). Thus, it is still susceptible to confounding by smoothly distributed environmental effects, but this can be corrected by common-PCA in the perpetual structure model or rare-PCA in either model (Figure 3).
Figure 3. Gene burden tests are relatively robust to stratification.
QQ plots of expected and observed -log10p-value under the (A) perpetual and (B) recent structure models for the association of rare variant burden across a gene with total exon length of 1.3 kb (gene length of 7 kb) and non-heritable phenotype with a smooth (upper) or sharp (lower) distribution of environmental effects. Orange and green lines show results for a gene with and without recombination, respectively. Inset shows inflation in the tail (99.9%) of the test statistic distribution.

Figure 3—figure supplement 1. Gini curves showing geographic clustering of (A) variant frequency and (B) gene burden.

More generally, the spatial distribution of gene burden depends on the number of variants and the recombination distance across which it is aggregated. Gene burden should become geographically less localized with an increase in the number of aggregated rare variants as each is likely to arise in an independent branch of the genealogy (Figure 3—figure supplement 1). As genetic distance between mutations increases, recombination decouples genealogies on which they arise, further reducing the probability of multiple mutations occurring on the same branch. Conversely, the rare variant burden aggregated across few variants in genes with little recombination behaves more like a single rare variant and is susceptible to local effects (Figure 3B lower row).
Polygenic scores capture residual environmental stratification
Polygenic scores—constructed by summing the effects of large numbers of associated variants—offer a simple way to make genetic risk predictions. At least in European ancestry populations, they can explain a substantial proportion of the phenotypic variance in complex traits like height (Yengo et al., 2018), BMI (Yengo et al., 2018), and coronary artery disease risk (Khera et al., 2018). However, their practical utility is limited by lack of transferability between populations (Scutari et al., 2016; Martin et al., 2017; Kerminen et al., 2019; Wang et al., 2020b) and between subgroups within populations (Mostafavi et al., 2020). This may be due in part to stratification in polygenic scores. To understand the behavior of polygenic scores under the perpetual and recent structure models, we simulated GWAS (N = 9000) of a heritable phenotype with a genetic architecture similar to that of height. We used GWAS effect sizes to calculate polygenic scores in an independent sample (N = 9000) and subtracted the true genetic values for each individual to examine the spatial bias in polygenic scores due to stratification.
Under both perpetual and recent structure models, residual polygenic scores are spatially structured, recapitulating environmental effects even when 100 common-PCs are used as covariates in the GWAS (Figure 4). LMMs perform similarly (Figure 4—figure supplement 1). This is due to the fact that when population stratification is not fully corrected, the effect sizes of variants that are correlated with the environment tend to be over- or under-estimated depending on the direction and strength of correlation (Figure 4—figure supplement 2). Stratification in residual polygenic scores is minimal when the causal variants are known, but not when the score is constructed from the most significant SNPs (‘lead SNPs’) (Figure 4, Figure 4—figure supplement 3)—almost always the case in practice. Thus, picking the most significant SNPs (clumping and thresholding) tends to enrich for variants that are more structured than the causal variants, and improvements through statistical fine-mapping are marginal (Figure 4—figure supplement 3). Polygenic scores will be especially prone to residual stratification when constructed using SNPs that do not reach genome-wide significance. At such loci, the causal effects are likely to be small relative to the effect of stratification, leading to false identification of more structured variants.
Figure 4. Residual stratification in effect size estimates translates to residual stratification in polygenic score in the (A) recent and (B) perpetual structure models.
The simulated phenotype in the training sample has a heritability of 0.8, distributed over 2,000 causal variants. Each small square is colored with the mean residual polygenic score for that deme in the test sample, averaged over 20 independent simulations of the phenotype. In each panel, the rows represent different methods of PCA correction and columns represent two different methods of variant ascertainment. ‘Causal’ refers to causal variants with p-value < 5×10−4, and ‘Lead SNP’ refers to a set of variants, where each represents the most significantly associated SNP with a p-value < 5×10−4 in a 100 kb window around the causal variant. The simulated environment is shown on the left. For the sharp effect, the affected deme is highlighted with an asterisk.

Figure 4—figure supplement 1. Spatial distribution of residual polygenic scores based on effect sizes from linear mixed models carried out in GCTA-LOCO.

Figure 4—figure supplement 2. Hexagonal bin plots illustrating the residual confounding in variant effect sizes due to stratification.

Figure 4—figure supplement 3. Bias and prediction accuracy in polygenic scores as a function of variant ascertainment schemes.

The effect of stratification in more complex models
In reality, genetic structure in most studies is more complex than either model discussed above. Most populations are genetically heterogeneous, and each genome is shaped by processes such as ancient and recent admixture, non-random mating, and selection, all of which vary both spatially and temporally. The present-day population of Britain, for example, is the result of a complex history of migration and admixture (Leslie et al., 2015; Olalde et al., 2018). Thus, restricting analysis even to the ‘White British’ subset of UK Biobank involves population structure on multiple time scales. To study these effects, we simulated under a model based on the demographic history of Europe and geographic structure of England and Wales, while maintaining the same degree of structure as the previous models (Figure 5, Table 1). In addition to recent geographic structure, we simulated an admixture event 100 generations ago between two populations, each of which are themselves the result of mixtures between several ancient populations (Figure 5). We varied the admixture fraction from the two source populations to create a North-South ancestry cline and sampled individuals to mimic uneven sampling in the UK Biobank (Figure 5, Materials and methods).
Figure 5. Residual stratification in polygenic scores under a complex demographic model, geographic structure representing England and Wales, and non-uniform sampling.
(A) Illustration of the simulated demography. (B) Maps depicting the spatial distribution of residual polygenic scores, as in Figure 4, averaged across 20 simulations of the phenotype. Columns: ‘Smooth’ and ‘Sharp’ refer to environmental effects and ‘Causal‘ and ‘Lead SNP’ refer to sets of variants that were used to construct polygenic scores. Rows: Different methods of correction for population structure. WHG and EHG: Western and Eastern Hunter Gatherers; EF: Early Farmers.

Figure 5—figure supplement 1. Spatial distribution of residual polygenic scores under the ‘complex’ structure model when individuals are sampled uniformly across demes.

Figure 5—figure supplement 2. Example of how one might empirically minimize the inflation in test statistic in a genome-wide association study (GWAS) without knowledge of the demographic history.

Figure 5—figure supplement 3. PCs computed from a single genetic relatedness matrix (GRM) constructed from common and rare variants together are different in how they capture population stratification than PCs computed from GRMs constructed separately from common and rare variants.

Table 1. Mean observed FST for different migration rate under each demographic model.
| Model | Migration rate1 | Mean FST (95% C.I.) | λ (Latitude) | λ (Longitude) |
|---|---|---|---|---|
| Recent | 0.001 | 3.8e-03 (3.7e-03 - 4e-03) | 3.5649 | 3.7808 |
| Recent | 0.0025 | 2.6e-03 (2.5e-03–2.7e-03) | 3.4733 | 3.6425 |
| Recent | 0.005 | 1.6e-03 (1.5e-03–1.7e-03) | 3.0914 | 3.1357 |
| Recent | 0.0075 | 1.5e-03 (1.4e-03–1.6e-03) | 3.4661 | 3.3344 |
| Recent | 0.01 | 1.1e-03 (1e-03–1.2e-03) | 3.0629 | 3.0675 |
| Recent | 0.015 | 7.9e-04 (7.2e-04–8.6e-04) | 2.8256 | 2.5172 |
| Recent | 0.02 | 7e-04 (6.3e-04–7.7e-04) | 2.4668 | 2.6838 |
| Recent | 0.025 | 5.1e-04 (4.4e-04–5.9e-04) | 2.2173 | 2.6485 |
| Recent | 0.03 | 4e-04 (3.3e-04–4.6e-04) | 2.4842 | 2.2036 |
| Recent | 0.05* | 2.3e-04 (1.7e-04–2.9e-04) | 1.6754 | 1.8486 |
| Perpetual | 0.06 | 2.5e-04 (1.9e-04–3.1e-04) | 1.8101 | 1.7606 |
| Perpetual | 0.07* | 2.0e-04 (1.4e-04–2.6e-04) | 1.6640 | 1.6381 |
| Perpetual | 0.08 | 1.7e-04 (1.1e-04–2.3e-04) | 1.5905 | 1.6658 |
| Complex | 0.05 | 3.2e-04 (2.5e-04–3.8e-04) | 2.6425 | 1.7480 |
| Complex | 0.06 | 2.8e-04 (2.1e-04–3.4e-04) | 2.1651 | 1.8637 |
| Complex | 0.07 | 2.5e-04 (1.8e-04–3.1e-04) | 1.9318 | 1.7012 |
| Complex | 0.08* | 1.5e-04 (9.7e-05–2.1e-04) | 1.6520 | 1.5214 |
| Complex | 0.09 | 1.7e-04 (1.1e-04–2.2e-04) | 1.6841 | 1.3892 |
| Complex | 0.1 | 1.7e-04 (1.2e-04–2.3e-04) | 1.5943 | 1.4719 |
| Complex | 0.12 | 1.3e-04 (7.3e-05–1.8e-04) | 1.4442 | 1.4395 |
| Complex | 0.15 | 7.9e-05 (2.7e-05–1.3e-04) | 1.2536 | 1.3123 |
Proportion of migrants in and out of a deme per generation. Selected migration rate indicated with * for each model.
The results under this model are very similar to the recent structure model in that when the environmental effect is smoothly distributed, it cannot be corrected using common-PCA as population structure is largely recent (Figure 5). Note also that correction is not complete even with rare-PCA as seen from the biased polygenic scores of individuals from Cornwall, in the south-west of England (lower left deme in Figure 5B). This is not due to reduced migration in the region (‘edge effects’) but rather to uneven sampling (only 17 individuals sampled from Cornwall as opposed to 250 under uniform sampling). The bias disappears when individuals are sampled uniformly (Figure 5—figure supplement 1). Thus, our ability to correct for stratification and the utility of polygenic scores also depends on the sampling design of the GWAS. As with the other models, local effects cannot be corrected using either common- or rare-PCA (Figure 5).
Polygenic scores based on effect sizes reestimated in siblings are not immune to stratification
Sibling-based studies test for association between siblings’ phenotypic and genotypic differences. These, and other family-based association tests, are robust to population stratification as any difference in siblings’ genotypes is due to Mendelian segregation and therefore uncorrelated with environmental effects. We simulated sibling pairs under the recent structure model and confirmed that polygenic scores constructed using SNPs and their effect sizes from the sibling-based tests were uncorrelated with environmental variation (Figure 6 lower row).
Figure 6. Comparison of stratification and predictive accuracy of polygenic scores between standard and sibling-based association tests under the recent structure model.
Phenotypes simulated as in Figure 4. (A) Spatial distribution of polygenic scores generated using (top) effects of variants discovered in a standard genome-wide association study (GWAS; middle) variants ascertained in a standard GWAS but with effect sizes reestimated in sib-based design, (bottom) variants ascertained and effect sizes estimated in sib-based design. In each case, the effect is averaged over 20 simulations. (B) Bias and (C) predictive accuracy of polygenic scores for 20 simulations of the smooth environmental effect.

Figure 6—figure supplement 1. Spatial distribution of residual polygenic scores when the environment is sharply distributed (risk location indicated with *).
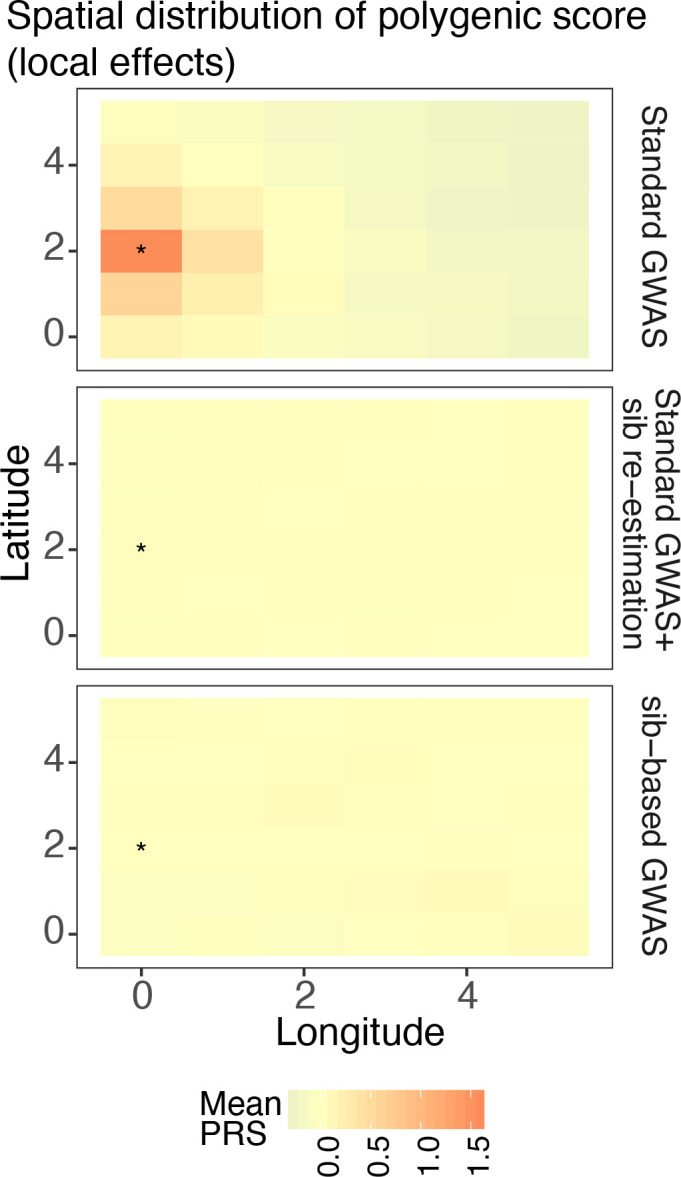
Figure 6—figure supplement 2. Bias (A) and prediction accuracy (B) of polygenic scores calculated using different variant ascertainment and effect size estimation schemes.

In practice, however, sample sizes for sibling-based studies are much smaller than standard GWAS. A possible hybrid approach is to first ascertain significantly associated SNPs in a standard GWAS and then reestimate effect sizes in siblings. However, this approach is not completely immune to stratification. To demonstrate, we took the significant lead SNPs from a standard GWAS, reestimated their effect sizes in an independent set of 9,000 sibling pairs simulated under the same demographic model, and then generated polygenic scores in a third, independent, sample of 9,000 unrelated individuals. Polygenic scores generated this way are still correlated with the environmental effect when it is smoothly distributed, although less than when effect sizes from the discovery GWAS are used (Figure 6). Even though the sibling reestimated effects are unbiased, stratification in the polygenic score persists because the frequencies of the lead SNPs are systematically correlated with the environment. This is less pronounced for local effects because stratification is driven by variants that are rare in the discovery sample and often absent in the test sample (Figure 6—figure supplement 1).
One argument in favor of the hybrid approach is that it balances the trade-off between bias and prediction accuracy. We show that the predictive accuracy of this approach is indeed higher than if both variants and effects were discovered in either standard or sibling GWAS (Figure 6). However, this is not an effect of the hybrid approach specifically but that of reestimation in general. Reestimating effect sizes in an independent cohort of unrelated individuals produces similar improvements in bias and prediction accuracy of polygenic scores (Figure 6—figure supplement 2).
Discussion
The effect of population structure on GWAS depends on the amount of structure, the frequency of the variants tested and the distribution of confounding environmental effects. Here, we demonstrated that it also depends on the demographic history of the population in a way that is not fully captured by the degree of structure as summarized by and genomic inflation. Consequently, to fully correct for population structure, it is necessary to know not only the degree of realized structure, but also the demographic history that generated it.
Generally, PCA (or mixed models) based on common variants will inadequately capture and correct population structure with a recent origin. This might partly explain why polygenic scores derived from studies such as the UK Biobank (Haworth et al., 2019; Abdellaoui et al., 2019) and FINNRISK (Kerminen et al., 2019) exhibit geographic clustering. In such cases, PCA based on rare variants, which are more informative about recent population history (Gravel et al., 2011; Fu et al., 2013; O'Connor et al., 2013; O'Connor et al., 2015; Mathieson and McVean, 2015), would be more effective. Haplotype sharing (Lawson et al., 2012) or identity-by-descent (IBD) segments are similarly informative about recent history (Palamara et al., 2012; Ralph and Coop, 2013; Saada et al., 2020), and provide an alternative to rare variant PCA when sequence data are not available, or when there are relatively few rare variants to adequately capture the structure, for example in exome sequence data.
This still leaves the question of exactly which frequency of variants (or length of IBD segments) to use. The structure in most studies exists on multiple time scales, even in relatively homogeneous populations (Byrne et al., 2020). In such cases, sets of PCs derived from variants in different frequency bins, or from IBD segments of different lengths, may be needed. PCs can be chosen based on visual inspection for significant axes of population structure (e.g. Figure 5—figure supplement 2A–C). However, even among the PCs that exhibit population structure, not all will contribute to the phenotype unless they are correlated with the confounding environmental effect(s), the distribution of which is a priori unknown. An empirical solution to this problem is to carry out a set of preliminary GWAS, each with different sets of PCs and use the summary statistics with the smallest inflation (Figure 5—figure supplement 2D). By letting the model learn the weights of PCs derived from different frequency bins, this approach has the added benefit of allowing for non-linearity in the contribution of stratification at different time scales. For example, under our complex model, using both common- and rare-PCs corrects for structure better than models where either rare- or common-PCs were used alone (Figure 5—figure supplement 3).
PCA- or LMM-based corrections are only effective when environmental effects are smoothly distributed with respect to ancestry or when they can be expressed as a linear function of the GRM. Sharply distributed effects (e.g. local environment or batch effects) may not be fully corrected with any method, regardless of the demographic history of the population. Such confounders are an important concern for rare variant studies. Because local effects lead to inflation in the tails of the test statistic distribution, single rare variant associations should always be treated with caution. Fortunately, burden tests are more robust to local effects than single rare variant tests, although, the degree to which burden statistics will be sensitive to local effects depends on the number of variants and the recombination distance between them—short genes with fewer variants will be more sensitive to local effects.
Even imperfect correction for population structure is probably sufficient to limit the number of genome-wide false positive associations in GWAS. But when information is aggregated across a large number of marginally associated variants, even small overestimates in effect sizes can lead to substantial bias in polygenic scores. Essentially some of the predictive power of polygenic scores will derive from predicting environmental structure rather than genetic effects. Comparison of polygenic scores derived from standard GWAS and sibling-based studies suggests that this effect can be substantial (Mostafavi et al., 2020), and it may also contribute to inflated estimates of heritability and genetic correlation (Browning and Browning, 2011). Even though family-based studies are immune to stratification, we show that the practice of discovering associations in a standard GWAS and then reestimating their effects in siblings improves prediction and reduces, but does not eliminate, bias in polygenic scores if there is inadequate correction in the original GWAS. However, this is largely because of the advantages of reestimating effect sizes in a different sample, rather than specifically because of the use of siblings.
Our study focused on population structure arising from ancient admixtures and geographic structure because these are relatively well-understood and easy to model. However, our results generalize to any type of population structure, for example due to social stratification or assortative mating. What we refer to as local environmental effects also includes socially structured factors such as cultural practices. Ultimately, no single approach can completely correct for population stratification and replication in within-family studies and populations of different ancestry will provide greater confidence. To facilitate the evaluation of any residual population stratification in summary statistics, we recommend that studies report the following: (i) Summary statistics for all methods of correction attempted (e.g. PCA or LMMs where the GRM is constructed from variants in different frequency bins); (ii) Summary statistics for association with any available demographic variables such as birthplace (e.g. Haworth et al., 2019); (iii) Summaries of the distribution of polygenic scores (for a subset of the data not used in the original GWAS) with respect to geography, ancestry, and principal components (e.g. Kerminen et al., 2019). These summaries will be helpful for downstream evaluation of the robustness of polygenic predictions.
Materials and methods
Simulations of population structure
We used msprime (Kelleher et al., 2016) to simulate genotypes in a 6×6 grid of demes and modeled the demographic history in three different ways: (i) where the structure extends infinitely far back in time (‘perpetual’), (ii) where all demes collapse into a single population 100 generations in the past (‘recent’), and (iii) a more complex model that is loosely based on the demographic history of Europe (Lazaridis, 2018; Figure 5; ‘complex’). We fixed the effective population size of all demes and the merged ancestral population sizes to 10,000 diploid individuals.
For the perpetual and recent models, we parameterized the degree of structure in the data with a fixed, symmetric migration rate among demes (m) chosen to match the degree of structure observed in Britain. To select an appropriate value for m, we simulated a 10 Mb genome (10 chromosomes of 1 Mb each) with mutation and recombination rates of 1× 10−8 per-base per-generation, for 9,000 individuals (250 per-deme) for a range of migration rates under each demographic model (Table 1). We estimated mean across all demes with the Weir and Cockerham estimator (Weir and Cockerham, 1984) using an LD-pruned (PLINK –indep-pairwise 100 10 0.1; Purcell et al., 2007; Chang et al., 2015) set of common variants (MAF > 0.05). We used the ratio of averages approach (Bhatia et al., 2013) to calculate and estimated genomic inflation on birthplace () by carrying out GWAS on an individual’s x and y coordinates in the grid, similar to the GWAS on longitude and latitude in Haworth et al., 2019. The migration rate was chosen for each model separately to roughly match the mean observed among regions in Britain (≈ 0.0007) (Leslie et al., 2015) and reported for the UKB (Haworth et al., 2019). Because genomic inflation scales linearly with sample size (Bulik-Sullivan et al., 2015b), we matched the expected value given our sample size of 9K using:
| (1) |
Where is the observed value () given a sample size of 300,000 as in Haworth et al., 2019. Plugging this in, we get an expected value of 1.36. To match this approximately, we set the migration rate to a fixed value of 0.05 and 0.07 for the ‘recent’ and ‘perpetual’ models, respectively (Table 1).
We parameterized the ‘complex’ model with two migration rates, m1 and m2, where m1 represents the migration rate between the source populations mixing 100 generations before present (2.5kya) and m2 represents the migration rate between adjacent demes in the grid (Figure 5). We selected m1 and m2 in a step-wise manner, first setting m1 = 0.004 (representing the between the two source populations) to match the maximum between regions in Britain. We then set m2 = 0.08 (representing subsequent mixing and isolation by distance) to match the mean between regions in Britain (Leslie et al., 2015; Table 1). In all cases, after selecting the appropriate migration parameters, we re-simulated genotypes under each model for a larger genome of 200 Mb (20 chromosomes of 10 Mb each), which we used for all further analysis.
Geographic structure in England and Wales
We downloaded the Nomenclature of Territorial Units for Statistics level 2 (NUTS2) map for 35 regions in England and Wales (version 2015) from data.gov.uk and assigned each individual of ‘White British’ ancestry in the UKB to a region based on their birthplace. We calculated the proportion of individuals sampled from each region and used these as weights in our simulations to mimic the sampling distribution in the UKB. To generate a migration matrix between regions, we generated an adjacency matrix for the NUTS2 districts using the ‘simple features’ (sf) R package (Pebesma, 2018), where an entry is one if two districts abut and zero otherwise, and multiplied this matrix by the migration parameter .
Simulation of phenotypes
To study the effect of stratification on test statistic inflation, we simulated non-heritable phenotypes of an individual from deme as , where is the mean environmental effect in deme . For the smooth effect, we chose such that the difference between the northern and southernmost demes was 2σ. For the sharp effect, we set for one affected deme and zero otherwise. To test the impact of population structure on effect size estimation and polygenic score prediction, we simulated heritable phenotypes using the model described in Schoech et al., 2019. We selected 2,000 variants across the 200 Mb genome (one variant chosen uniformly at random in each 100 kb window) and sampled their effect sizes as where is the frequency-independent component of genetic variance, is the allele frequency of the variant, and is a scaling factor. We set based on an estimate for height (Schoech et al., 2019) and such that the overall genetic variance underlying the trait, . We calculated the genetic value for each individual, , where is the number of derived alleles individual carries at variant , and added environmental effects as described above. We generated 20 random iterations of both heritable and non-heritable phenotypes.
GWAS
We simulated 18,000 individuals (500 from each deme) under each demographic model and split the sample into two equally sized sets, a training set on which GWAS and PCA were carried out, and a test set for polygenic score predictions. Common-PCA and rare-PCA were carried out using PLINK (Chang et al., 2015) on a set of 200,000 common (MAF > 5%) and one million rare (minor allele count = 2, 3, or 4) variants, respectively, sampled from all variants generated under each model. To carry out PCA on identity-by-descent (IBD) sharing, we called long (>10 cM) pairwise IBD segments using GERMLINE (Gusev et al., 2009) with default parameters and generated an IBD-sharing GRM, in which each entry represents the total fraction of the haploid genome (100 Mb) shared by individual pairs. We calculated eigenvectors (PCs) of the IBD-sharing GRM using GCTA (Yang et al., 2011).
We performed GWAS using –glm in PLINK 2.0 with 100 PCs as covariates (Chang et al., 2015). As indicated in the main text, we also used as a set of 50 common- and 50 rare-PCs, computed separately, as covariates in the same model to correct for structure existing on multiple time scales.
We fitted LMMs using GCTA-LOCO (Yang et al., 2011) where the GRM was based on the same common or rare variants used for PCA. GCTA’s LOCO (leave one chromosome out) algorithm fits a model where the GRM is constructed from SNPs that are not present on the same chromosome as the variant being tested to avoid proximal contamination. We also included the top 100 PCs as fixed effects in the mixed models.
We calculated genomic inflation () for non-heritable phenotypes as where is the percentile of the observed association test statistic and is the quantile function of the distribution with 1 degree of freedom.
Sibling-based tests
We conducted structured matings by sampling pairs of individuals from the same deme and generated the haplotypes of each child by sampling haplotypes, with replacement, from each parent without recombination. We generated heritable phenotypes as described in the previous section for each sibling and modeled the effect of each variant as
where is the difference in siblings’ phenotypic values and is the difference in the number of derived alleles at the variant.
Polygenic scores
We calculated polygenic scores for each individual as where is the estimated effect size and is the number of derived alleles for the variant (either causal or lead SNP). To study patterns of residual stratification, we subtracted individuals’ true (simulated) genetic values (), which themselves can be structured, from polygenic scores. We averaged residual polygenic scores across 20 random iterations of causal variant selection, effect size generation, and GWAS to minimize stochastic variation. Predictive accuracy of polygenic scores was measured as the proportion of variance in individuals’ genetic values that can be explained by their polygenic score.
Gene burden
We simulated genes, each with eight exons of length 160 bp separated by introns of length 6,938 bp, representing an average gene in the human genome (Piovesan et al., 2019). We simulated 100,000 genes for the ‘recent’ model with and without recombination and for the ‘perpetual’ model with no recombination. For the ‘perpetual’ model with recombination, we simulated 50,000 genes. We calculated gene burden as the total count of derived alleles (frequency < 0.001) across all exons in the gene for each individual. Even though introns do not directly contribute to gene burden, they serve as spacers to allow for recombination between exons. In genes without recombination, introns only add to the computational cost and, therefore, we did not simulate them. To ensure that differences in structure in gene burden between models was driven by differences in demographic history and not differences in the number of rare variants, we first calculated the mean (16) and standard deviation (4) of the number of rare variants under the ‘recent’ model and sampled from this distribution when simulating under the ‘perpetual’ model. The geographic clustering of burden was measured using Gini curves and the Gini coefficient.
where is the cumulative gene burden in the deme sorted in increasing order of gene-burden and is the number of demes. The Gini coefficient ranges from zero, indicating that the burden is uniformly distributed in space, to one, indicating that the burden is concentrated in a single deme (Figure 3—figure supplement 1).
Imputation and fine-mapping
We performed imputation using Beagle 5.1 (Browning et al., 2018). We imputed the genotypes of rare variants (MAF < 0.001) in a sample of 9,000 individuals using the phased sequences of an independent 9,000 individuals as reference. Both reference and test sets were simulated under the recent structure model.
We fine-mapped variants using SuSiE (Wang et al., 2020a) separately on 100 Kb windows, each of which carried a single causal variant. We restricted fine-mapping to windows where at least one variant had a p-value 10−4 and picked the variant with the highest posterior inclusion probability to construct polygenic scores.
Code availability
We carried out all analyses with code written in Python 3.5, R 3.5.1, and shell scripts, which are all available at https://github.com/Arslan-Zaidi/popstructure; Zaidi, 2020; copy archived at swh:1:rev:1509a53ee491e3e01320c174ff55f9426da8923f.
Acknowledgements
This research was supported by NIGMS award number R35GM133708. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. The UK Biobank Resource was used under Application 33923.
Funding Statement
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Contributor Information
Arslan A Zaidi, Email: aazaidi@pennmedicine.upenn.edu.
Iain Mathieson, Email: mathi@pennmedicine.upenn.edu.
George H Perry, Pennsylvania State University, United States.
George H Perry, Pennsylvania State University, United States.
Funding Information
This paper was supported by the following grant:
National Institute of General Medical Sciences R35GM133708 to Iain Mathieson.
Additional information
Competing interests
No competing interests declared.
Author contributions
Conceptualization, Formal analysis, Investigation, Visualization, Methodology, Writing - original draft, Writing - review and editing.
Conceptualization, Supervision, Funding acquisition, Investigation, Methodology, Project administration, Writing - review and editing.
Additional files
Data availability
The data used in this study were generated through simulations. The code for these simulations is freely available at https://github.com/Arslan-Zaidi/popstructure (copy archived at https://archive.softwareheritage.org/swh:1:rev:1509a53ee491e3e01320c174ff55f9426da8923f/) and can be used to reproduce all simulations and carry out all analyses in the manuscript.
References
- Abdellaoui A, Hugh-Jones D, Yengo L, Kemper KE, Nivard MG, Veul L, Holtz Y, Zietsch BP, Frayling TM, Wray NR, Yang J, Verweij KJH, Visscher PM. Genetic correlates of social stratification in great britain. Nature Human Behaviour. 2019;3:1332–1342. doi: 10.1038/s41562-019-0757-5. [DOI] [PubMed] [Google Scholar]
- Berg JJ, Harpak A, Sinnott-Armstrong N, Joergensen AM, Mostafavi H, Field Y, Boyle EA, Zhang X, Racimo F, Pritchard JK, Coop G. Reduced signal for polygenic adaptation of height in UK biobank. eLife. 2019;8:e39725. doi: 10.7554/eLife.39725. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bhatia G, Patterson N, Sankararaman S, Price AL. Estimating and interpreting FST: the impact of rare variants. Genome Research. 2013;23:1514–1521. doi: 10.1101/gr.154831.113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Browning BL, Zhou Y, Browning SR. A One-Penny imputed genome from Next-Generation reference panels. The American Journal of Human Genetics. 2018;103:338–348. doi: 10.1016/j.ajhg.2018.07.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Browning SR, Browning BL. Population structure can inflate SNP-based heritability estimates. The American Journal of Human Genetics. 2011;89:191–193. doi: 10.1016/j.ajhg.2011.05.025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bulik-Sullivan B, Finucane HK, Anttila V, Gusev A, Day FR, Loh PR, Duncan L, Perry JR, Patterson N, Robinson EB, Daly MJ, Price AL, Neale BM, Genetic Consortium for Anorexia Nervosa of the Wellcome Trust Case Control Consortium 3. ReproGen Consortium. Psychiatric Genomics Consortium An atlas of genetic correlations across human diseases and traits. Nature Genetics. 2015a;47:1236–1241. doi: 10.1038/ng.3406. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bulik-Sullivan BK, Loh PR, Finucane HK, Ripke S, Yang J, Patterson N, Daly MJ, Price AL, Neale BM, Schizophrenia Working Group of the Psychiatric Genomics Consortium LD score regression distinguishes confounding from polygenicity in genome-wide association studies. Nature Genetics. 2015b;47:291–295. doi: 10.1038/ng.3211. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bycroft C, Freeman C, Petkova D, Band G, Elliott LT, Sharp K, Motyer A, Vukcevic D, Delaneau O, O'Connell J, Cortes A, Welsh S, Young A, Effingham M, McVean G, Leslie S, Allen N, Donnelly P, Marchini J. The UK biobank resource with deep phenotyping and genomic data. Nature. 2018;562:203–209. doi: 10.1038/s41586-018-0579-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bycroft C, Fernandez-Rozadilla C, Ruiz-Ponte C, Quintela I, Carracedo Á, Donnelly P, Myers S. Patterns of genetic differentiation and the footprints of historical migrations in the iberian peninsula. Nature Communications. 2019;10:551. doi: 10.1038/s41467-018-08272-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Byrne RP, van Rheenen W, van den Berg LH, Veldink JH, McLaughlin RL, Project MinE ALS GWAS Consortium Dutch population structure across space, time and GWAS design. Nature Communications. 2020;11:4556. doi: 10.1038/s41467-020-18418-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang CC, Chow CC, Tellier LC, Vattikuti S, Purcell SM, Lee JJ. Second-generation PLINK: rising to the challenge of larger and richer datasets. GigaScience. 2015;4:7. doi: 10.1186/s13742-015-0047-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Das S, Abecasis GR, Browning BL. Genotype imputation from large reference panels. Annual Review of Genomics and Human Genetics. 2018;19:73–96. doi: 10.1146/annurev-genom-083117-021602. [DOI] [PubMed] [Google Scholar]
- Devlin B, Roeder K. Genomic control for association studies. Biometrics. 1999;55:997–1004. doi: 10.1111/j.0006-341X.1999.00997.x. [DOI] [PubMed] [Google Scholar]
- Fu W, O'Connor TD, Jun G, Kang HM, Abecasis G, Leal SM, Gabriel S, Rieder MJ, Altshuler D, Shendure J, Nickerson DA, Bamshad MJ, Akey JM, NHLBI Exome Sequencing Project Analysis of 6,515 exomes reveals the recent origin of most human protein-coding variants. Nature. 2013;493:216–220. doi: 10.1038/nature11690. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gravel S, Henn BM, Gutenkunst RN, Indap AR, Marth GT, Clark AG, Yu F, Gibbs RA, Bustamante CD, 1000 Genomes Project Demographic history and rare allele sharing among human populations. PNAS. 2011;108:11983–11988. doi: 10.1073/pnas.1019276108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gusev A, Lowe JK, Stoffel M, Daly MJ, Altshuler D, Breslow JL, Friedman JM, Pe'er I. Whole population, genome-wide mapping of hidden relatedness. Genome Research. 2009;19:318–326. doi: 10.1101/gr.081398.108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haworth S, Mitchell R, Corbin L, Wade KH, Dudding T, Budu-Aggrey A, Carslake D, Hemani G, Paternoster L, Smith GD, Davies N, Lawson DJ, J Timpson N. Apparent latent structure within the UK biobank sample has implications for epidemiological analysis. Nature Communications. 2019;10:333. doi: 10.1038/s41467-018-08219-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kang HM, Sul JH, Service SK, Zaitlen NA, Kong SY, Freimer NB, Sabatti C, Eskin E. Variance component model to account for sample structure in genome-wide association studies. Nature Genetics. 2010;42:348–354. doi: 10.1038/ng.548. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Karakachoff M, Duforet-Frebourg N, Simonet F, Le Scouarnec S, Pellen N, Lecointe S, Charpentier E, Gros F, Cauchi S, Froguel P, Copin N, Le Tourneau T, Probst V, Le Marec H, Molinaro S, Balkau B, Redon R, Schott JJ, Blum MG, Dina C, D.E.S.I.R. Study Group. D E S I R Study Group Fine-scale human genetic structure in western france. European Journal of Human Genetics. 2015;23:831–836. doi: 10.1038/ejhg.2014.175. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kelleher J, Etheridge AM, McVean G. Efficient coalescent simulation and genealogical analysis for large sample sizes. PLOS Computational Biology. 2016;12:e1004842. doi: 10.1371/journal.pcbi.1004842. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kerminen S, Havulinna AS, Hellenthal G, Martin AR, Sarin AP, Perola M, Palotie A, Salomaa V, Daly MJ, Ripatti S, Pirinen M. Fine-Scale genetic structure in Finland. G3: Genes, Genomes, Genetics. 2017;7:3459–3468. doi: 10.1534/g3.117.300217. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kerminen S, Martin AR, Koskela J, Ruotsalainen SE, Havulinna AS, Surakka I, Palotie A, Perola M, Salomaa V, Daly MJ, Ripatti S, Pirinen M. Geographic variation and Bias in the polygenic scores of complex diseases and traits in Finland. The American Journal of Human Genetics. 2019;104:1169–1181. doi: 10.1016/j.ajhg.2019.05.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Khera AV, Chaffin M, Aragam KG, Haas ME, Roselli C, Choi SH, Natarajan P, Lander ES, Lubitz SA, Ellinor PT, Kathiresan S. Genome-wide polygenic scores for common diseases identify individuals with risk equivalent to monogenic mutations. Nature Genetics. 2018;50:1219–1224. doi: 10.1038/s41588-018-0183-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Knowles JW, Ashley EA. Cardiovascular disease: the rise of the genetic risk score. PLOS Medicine. 2018;15:e1002546. doi: 10.1371/journal.pmed.1002546. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lawson DJ, Hellenthal G, Myers S, Falush D. Inference of population structure using dense haplotype data. PLOS Genetics. 2012;8:e1002453. doi: 10.1371/journal.pgen.1002453. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lawson DJ, Davies NM, Haworth S, Ashraf B, Howe L, Crawford A, Hemani G, Davey Smith G, Timpson NJ. Is population structure in the genetic biobank era irrelevant, a challenge, or an opportunity? Human Genetics. 2020;139:23–41. doi: 10.1007/s00439-019-02014-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lazaridis I. The evolutionary history of human populations in Europe. Current Opinion in Genetics & Development. 2018;53:21–27. doi: 10.1016/j.gde.2018.06.007. [DOI] [PubMed] [Google Scholar]
- Leslie S, Winney B, Hellenthal G, Davison D, Boumertit A, Day T, Hutnik K, Royrvik EC, Cunliffe B, Lawson DJ, Falush D, Freeman C, Pirinen M, Myers S, Robinson M, Donnelly P, Bodmer W, Wellcome Trust Case Control Consortium 2. International Multiple Sclerosis Genetics Consortium The fine-scale genetic structure of the british population. Nature. 2015;519:309–314. doi: 10.1038/nature14230. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Loh PR, Tucker G, Bulik-Sullivan BK, Vilhjálmsson BJ, Finucane HK, Salem RM, Chasman DI, Ridker PM, Neale BM, Berger B, Patterson N, Price AL. Efficient Bayesian mixed-model analysis increases association power in large cohorts. Nature Genetics. 2015;47:284–290. doi: 10.1038/ng.3190. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Martin AR, Gignoux CR, Walters RK, Wojcik GL, Neale BM, Gravel S, Daly MJ, Bustamante CD, Kenny EE. Human demographic history impacts genetic risk prediction across diverse populations. The American Journal of Human Genetics. 2017;100:635–649. doi: 10.1016/j.ajhg.2017.03.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mathieson I, McVean G. Differential confounding of rare and common variants in spatially structured populations. Nature Genetics. 2012;44:243–246. doi: 10.1038/ng.1074. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mathieson I, McVean G. Demography and the age of rare variants. PLOS Genetics. 2015;10:e1004528. doi: 10.1371/journal.pgen.1004528. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mostafavi H, Harpak A, Agarwal I, Conley D, Pritchard JK, Przeworski M. Variable prediction accuracy of polygenic scores within an ancestry group. eLife. 2020;9:e48376. doi: 10.7554/eLife.48376. [DOI] [PMC free article] [PubMed] [Google Scholar]
- O'Connor TD, Kiezun A, Bamshad M, Rich SS, Smith JD, Turner E, Leal SM, Akey JM, NHLBIGO Exome Sequencing Project. ESP Population Genetics, Statistical Analysis Working Group Fine-scale patterns of population stratification confound rare variant association tests. PLOS ONE. 2013;8:e65834. doi: 10.1371/journal.pone.0065834. [DOI] [PMC free article] [PubMed] [Google Scholar]
- O'Connor TD, Fu W, Mychaleckyj JC, Logsdon B, Auer P, Carlson CS, Leal SM, Smith JD, Rieder MJ, Bamshad MJ, Nickerson DA, Akey JM, NHLBI GO Exome Sequencing Project. ESP Population Genetics and Statistical Analysis Working Group, Emily Turner Rare variation facilitates inferences of fine-scale population structure in humans. Molecular Biology and Evolution. 2015;32:653–660. doi: 10.1093/molbev/msu326. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Olalde I, Brace S, Allentoft ME, Armit I, Kristiansen K, Booth T, Rohland N, Mallick S, Szécsényi-Nagy A, Mittnik A, Altena E, Lipson M, Lazaridis I, Harper TK, Patterson N, Broomandkhoshbacht N, Diekmann Y, Faltyskova Z, Fernandes D, Ferry M, Harney E, de Knijff P, Michel M, Oppenheimer J, Stewardson K, Barclay A, Alt KW, Liesau C, Ríos P, Blasco C, Miguel JV, García RM, Fernández AA, Bánffy E, Bernabò-Brea M, Billoin D, Bonsall C, Bonsall L, Allen T, Büster L, Carver S, Navarro LC, Craig OE, Cook GT, Cunliffe B, Denaire A, Dinwiddy KE, Dodwell N, Ernée M, Evans C, Kuchařík M, Farré JF, Fowler C, Gazenbeek M, Pena RG, Haber-Uriarte M, Haduch E, Hey G, Jowett N, Knowles T, Massy K, Pfrengle S, Lefranc P, Lemercier O, Lefebvre A, Martínez CH, Olmo VG, Ramírez AB, Maurandi JL, Majó T, McKinley JI, McSweeney K, Mende BG, Modi A, Kulcsár G, Kiss V, Czene A, Patay R, Endrődi A, Köhler K, Hajdu T, Szeniczey T, Dani J, Bernert Z, Hoole M, Cheronet O, Keating D, Velemínský P, Dobeš M, Candilio F, Brown F, Fernández RF, Herrero-Corral AM, Tusa S, Carnieri E, Lentini L, Valenti A, Zanini A, Waddington C, Delibes G, Guerra-Doce E, Neil B, Brittain M, Luke M, Mortimer R, Desideri J, Besse M, Brücken G, Furmanek M, Hałuszko A, Mackiewicz M, Rapiński A, Leach S, Soriano I, Lillios KT, Cardoso JL, Pearson MP, Włodarczak P, Price TD, Prieto P, Rey PJ, Risch R, Rojo Guerra MA, Schmitt A, Serralongue J, Silva AM, Smrčka V, Vergnaud L, Zilhão J, Caramelli D, Higham T, Thomas MG, Kennett DJ, Fokkens H, Heyd V, Sheridan A, Sjögren KG, Stockhammer PW, Krause J, Pinhasi R, Haak W, Barnes I, Lalueza-Fox C, Reich D. The beaker phenomenon and the genomic transformation of northwest Europe. Nature. 2018;555:190–196. doi: 10.1038/nature25738. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Palamara PF, Lencz T, Darvasi A, Pe'er I. Length distributions of identity by descent reveal fine-scale demographic history. The American Journal of Human Genetics. 2012;91:809–822. doi: 10.1016/j.ajhg.2012.08.030. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pebesma E. Simple features for R: standardized support for spatial vector data. The R Journal. 2018;10:439–446. doi: 10.32614/RJ-2018-009. [DOI] [Google Scholar]
- Piovesan A, Antonaros F, Vitale L, Strippoli P, Pelleri MC, Caracausi M. Human protein-coding genes and gene feature statistics in 2019. BMC Research Notes. 2019;12:315. doi: 10.1186/s13104-019-4343-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Price AL, Patterson NJ, Plenge RM, Weinblatt ME, Shadick NA, Reich D. Principal components analysis corrects for stratification in genome-wide association studies. Nature Genetics. 2006;38:904–909. doi: 10.1038/ng1847. [DOI] [PubMed] [Google Scholar]
- Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MA, Bender D, Maller J, Sklar P, de Bakker PI, Daly MJ, Sham PC. PLINK: a tool set for whole-genome association and population-based linkage analyses. The American Journal of Human Genetics. 2007;81:559–575. doi: 10.1086/519795. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ralph P, Coop G. The geography of recent genetic ancestry across Europe. PLOS Biology. 2013;11:e1001555. doi: 10.1371/journal.pbio.1001555. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Raveane A, Aneli S, Montinaro F, Athanasiadis G, Barlera S, Birolo G, Boncoraglio G, Di Blasio AM, Di Gaetano C, Pagani L, Parolo S, Paschou P, Piazza A, Stamatoyannopoulos G, Angius A, Brucato N, Cucca F, Hellenthal G, Mulas A, Peyret-Guzzon M, Zoledziewska M, Baali A, Bycroft C, Cherkaoui M, Chiaroni J, Di Cristofaro J, Dina C, Dugoujon JM, Galan P, Giemza J, Kivisild T, Mazieres S, Melhaoui M, Metspalu M, Myers S, Pereira L, Ricaut FX, Brisighelli F, Cardinali I, Grugni V, Lancioni H, Pascali VL, Torroni A, Semino O, Matullo G, Achilli A, Olivieri A, Capelli C. Population structure of modern-day italians reveals patterns of ancient and archaic ancestries in southern europe. Science Advances. 2019;5:eaaw3492. doi: 10.1126/sciadv.aaw3492. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Saada JN, Kalantzis G, Shyr D, Robinson M, Gusev A, Palamara PF. Identity-by-descent detection across 487,409 British samples reveals fine-scale population structure, evolutionary history, and trait associations. bioRxiv. 2020 doi: 10.1101/2020.04.20.029819. [DOI] [PMC free article] [PubMed]
- Schoech AP, Jordan DM, Loh PR, Gazal S, O'Connor LJ, Balick DJ, Palamara PF, Finucane HK, Sunyaev SR, Price AL. Quantification of frequency-dependent genetic architectures in 25 UK Biobank traits reveals action of negative selection. Nature Communications. 2019;10:790. doi: 10.1038/s41467-019-08424-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Scutari M, Mackay I, Balding D. Using genetic distance to infer the accuracy of genomic prediction. PLOS Genetics. 2016;12:e1006288. doi: 10.1371/journal.pgen.1006288. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sohail M, Maier RM, Ganna A, Bloemendal A, Martin AR, Turchin MC, Chiang CW, Hirschhorn J, Daly MJ, Patterson N, Neale B, Mathieson I, Reich D, Sunyaev SR. Polygenic adaptation on height is overestimated due to uncorrected stratification in genome-wide association studies. eLife. 2019;8:e39702. doi: 10.7554/eLife.39702. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Torkamani A, Wineinger NE, Topol EJ. The personal and clinical utility of polygenic risk scores. Nature Reviews Genetics. 2018;19:581–590. doi: 10.1038/s41576-018-0018-x. [DOI] [PubMed] [Google Scholar]
- Wang G, Sarkar A, Carbonetto P, Stephens M. A simple new approach to variable selection in regression, with application to genetic fine mapping. Journal of the Royal Statistical Society: Series B. 2020a;82:1273–1300. doi: 10.1111/rssb.12388. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang Y, Guo J, Ni G, Yang J, Visscher PM, Yengo L. Theoretical and empirical quantification of the accuracy of polygenic scores in ancestry divergent populations. Nature Communications. 2020b;11:3865. doi: 10.1038/s41467-020-17719-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Weir BS, Cockerham CC. Estimating f-statistics for the analysis of population structure. Evolution. 1984;38:1358–1370. doi: 10.1111/j.1558-5646.1984.tb05657.x. [DOI] [PubMed] [Google Scholar]
- Yang J, Lee SH, Goddard ME, Visscher PM. GCTA: a tool for genome-wide complex trait. The American Journal of Human Genetics. 2011;88:76–82. doi: 10.1016/j.ajhg.2010.11.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yengo L, Sidorenko J, Kemper KE, Zheng Z, Wood AR, Weedon MN, Frayling TM, Hirschhorn J, Yang J, Visscher PM, GIANT Consortium Meta-analysis of genome-wide association studies for height and body mass index in ∼700000 individuals of ancestry. Human Molecular Genetics. 2018;27:3641–3649. doi: 10.1093/hmg/ddy271. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zaidi A. popstructure. swh:1:rev:1509a53ee491e3e01320c174ff55f9426da8923fSoftware Heritage. 2020 https://archive.softwareheritage.org/swh:1:rev:1509a53ee491e3e01320c174ff55f9426da8923f/