

Abstract
During the unprecedented coronavirus disease 2019 (COVID-19) challenge, non-pharmaceutical interventions became a widely adopted strategy to limit physical movements and interactions to mitigate virus transmissions. For situational awareness and decision-support, quickly available yet accurate big-data analytics about human mobility and social distancing is invaluable to agencies and decision-makers. This paper presents a big-data-driven analytical framework that ingests terabytes of data on a daily basis and quantitatively assesses the human mobility trend during COVID-19. Using mobile device location data of over 150 million monthly active samples in the United States (U.S.), the study successfully measures human mobility with three main metrics at the county level: daily average number of trips per person; daily average person-miles traveled; and daily percentage of residents staying home. A set of generalized additive mixed models is employed to disentangle the policy effect on human mobility from other confounding effects including virus effect, socio-demographic effect, weather effect, industry effect, and spatiotemporal autocorrelation. Results reveal the policy plays a limited, time-decreasing, and region-specific effect on human movement. The stay-at-home orders only contribute to a 3.5%-7.9% decrease in human mobility, while the reopening guidelines lead to a 1.6%-5.2% mobility increase. Results also indicate a reasonable spatial heterogeneity among the U.S. counties, wherein the number of confirmed COVID-19 cases, income levels, industry structure, age and racial distribution play important roles. The data informatics generated by the framework are made available to the public for a timely understanding of mobility trends and policy effects, as well as for time-sensitive decision support to further contain the spread of the virus.
Keywords: Human mobility, Non-pharmaceutical interventions, COVID-19, Mobile device location data, Generalized additive mixed model
1. Introduction
Starting from December 2019 (Li et al., 2020) the fast-spreading Coronavirus disease 2019 (COVID-19) pandemic has globally infected 6,057,091 people and claimed 369,085 lives as of May 31st, 2020 (CSSE, 2020), deteriorating into one of the worst global health crises seen in decades. The first confirmed case of COVID-19 in the U.S. emerged in Washington State on January 21st, 2020. After exponential growth, the number of confirmed cases has increased to over 1.75 million within four months (CSSE, 2020). On March 13th, 2020, two days after the World Health Organization (WHO) announced COVID-19 as a pandemic, the U.S. government proclaimed a national state of emergency concerning the COVID-19 outbreak (TRUMP, 2020), indicating the combat with the virus in the U.S. was officially declared.
The outbreak of COVID-19 has posed unprecedented challenges for the government. Aside from medical measures, non-pharmaceutical interventions to restrict human movement have proven to be crucial to delaying and containing the spread of the virus (Chinazzi et al., 2020, Kraemer et al., 2020). This includes but is not limited to travel bans and restrictions, early detection, physical isolation, social distancing, and stay-at-home (Fang et al., 2020, Leung et al., 2020). In the U.S., the first stay-at-home order began in California on March 19th, 2020 and has quickly swept the nation. By mid-April 2020, stay-at-home orders were instituted across all but 8 states, indicating at least 316 million people were being urged to stay home, reduce unnecessary contact, and keep social distance (Sarah Mervosh, 2020). The restrictions did not last long, however. On April 16th, 2020, the guidelines for reopening America were released by the White House; after that, all lockdown states began to reopen in some way. As of May 1st, 2020, 18 states had lifted their stay-at-home orders or partially reopened certain regions or businesses (Yuriria Avila et al., 2020).
Understanding how human mobility varies under the pandemic, as well as how its responses to different directives are incredibly valuable but remain challenging due to the lack of ground truth data and the complexity of various confounding effects (Fang et al., 2020). Mobile device location-based service (LBS) data are believed to be a valuable source to provide near real-time human movement information and approximate population-level mobility patterns (Alexander et al., 2015, Chen et al., 2016, Ni et al., 2018). Unlike traditional small-sample, active-solicited survey data, LBS data are collected passively, with much higher penetration and temporal resolution (Chen et al., 2016). Different types of LBS data have been examined in prior literature, including call detain record (Chen et al., 2016), social media data (Rashidi et al., 2017), GPS-based trajectories (Dabiri and Heaslip, 2018), and smart cards transactions (Zou et al., 2018). Prior studies also demonstrated the capability of using LBS data in capturing human mobility patterns (Jiang et al., 2017), identifying activity locations (Zou et al., 2018), detecting transport modes (Dabiri and Heaslip, 2018), inferring trip purposes (Alexander et al., 2015), and deriving origin–destination matrices (Ni et al., 2018).
During the COVID-19 pandemic, several studies have used LBS data to monitor the population flow across cities and countries, and further explored the relationship between human movement and COVID-19 transmission (C2SMART, C.S.U.T.C., 2020, Chinazzi et al., 2020, De Vos, 2020, Engle et al., 2020, Jia et al., 2020, Kraemer et al., 2020, Tian et al., 2020, Xiong et al., 2020a, Zuo et al., 2020). Most studies believe there is a highly positive correlation between human movement and virus infection; thus, the travel restriction can effectively mitigate and delay the spread of infections (Chinazzi et al., 2020, Kraemer et al., 2020, Xiong et al., 2020a). For example, Jia et al. used mobile phone data to capture the population outflow from Wuhan, the epidemic epicenter of COVID-19 in China. They built a spatiotemporal “risk source” model leveraging population flow data to predict infections and identify high-risk locations (Jia et al., 2020). Similarly, several studies incorporated the population flow into typical epidemiological models, such as susceptible-infectious-recovered (SIR) model (Leung et al., 2020) and susceptible-exposed-infectious-recovered (SEIR) model (Chinazzi et al., 2020, Tian et al., 2020). Their results consistently indicated a higher estimation accuracy after considering human mobility variation. Besides researchers, plenty of commercial companies such as Google, Apple, Cuebiq, and SafeGraph have also utilized LBS data to produce valuable information about mobility and economic trends during the pandemic (Apple, 2020, Cuebiq, 2020, Google, 2020, SafeGraph, 2020). As for policy effects, though limited, a few early studies quantified the policy effect on human mobility change during the COVID-19 pandemic (Engle et al., 2020, Fang et al., 2020, Xiong et al., 2020b). Fang et al. employed a set of difference-in-differences (DID) models to examine the effect of Wuhan lockdown on human mobility reduction, controlling for other exogenous effects like panic effect, virus effect, and the Spring Festival effect (Fang et al., 2020). Another study developed several regression models to estimate how individual miles traveled is affected by the number of cases and stay-at-home orders across U.S. counties (Fang et al., 2020). Their results showed that the stay-at-home order contributes to only a 7.87% reduction in average traveled distance per person.
Largely due to the limited time into the pandemic and availability of data resources and analytical algorithms, several major knowledge gaps exist and are worthy of attention. First, most prior LBS-based studies used only the daily travel distance to measure human mobility (Fang et al., 2020). Admittedly, daily travel distance requires minimum effort and algorithm development for computation. However, this metric alone is insufficient to describe the overall mobility change (Zhang et al., 2020). The most critical missing metric could be the number of residents staying home that directly reflect the individual-level compliance to social distancing and stay-at-home orders. Second, most models regarding the policy effects on human mobility were oversimplified. Critical confounding factors, such as the effect of socio-demographics, weather, industry types, political parties, and spatiotemporal autocorrelation, are largely ignored (Engle et al., 2020, Yabe et al., 2020). Also, most prior studies considered stay-at-home orders as spatially homogeneous. However, the orders vary in different regions in detailed terms and the strictness and should be treated differently (Chinazzi et al., 2020, Mervosh, 2020). Last but not least, a comprehensive policy assessment of both the stay-at-home orders and the re-opening guidelines is still lacking. Despite seeing the decreasing then increasing mobility trend from various sources, we still do not know the exact effectiveness of these policy decisions, which would be crucial in the preparation for the future spike(s) as well as other highly contagious diseases. To fill these important research gaps, a data-driven and longitudinal analytical framework is in imperative need. Our approach captures individual mobility in greater detail with the emerging LBS data, validated data algorithms, and cloud-computing technology. Then, a longitudinal modeling approach is developed to quantitatively assess the policy effectiveness with explicitly specified spatiotemporal patterns and time-varying marginal effects.
2. An overview of the big-data driven analytical framework
The proposed big-data-driven analytical framework is illustrated in Fig. 1 . The framework has three major layers, interpreted in the following subsections.
Fig. 1.

A Big-Data Driven Analytical Framework for Understanding Human Mobility Trend and Policy Decision Support during COVID-19 Pandemic.
2.1. Data and analytics
A data panel of emerging mobile device location data representing person movements for the entire U.S. is developed, incorporating over 20 million anonymous individuals daily (over 150 million monthly) active mobile devices. Devices consist of iOS and Android operating systems combining various location data sources such as GPS, Wi-Fi, beacons, and network. All first-party data is collected from anonymized users who have opted-in with complete anonymity regarding their personal identity and personal details to provide access to their location data through a GDPR-compliant framework (GDPR, 2020). Besides, the data also employs privacy-preserving techniques (referred to as “up-leveling”) to reduce the risk of re-identification, such as aggregating the inferred home and work locations to the census block group level. More details of the dataset as well as the county-level data that we used to train and test our models can be found in Supplementary Section I.
To fully capture all covariates, county attributes, public health measures, political parties, weather conditions, industry types, etc. are integrated into the data source. A set of previously developed and validated data analytics algorithms are integrated to identify activity locations, derive weighted trip rosters, and calculate and validate the human mobility metrics (Zhang et al., 2020). First, a heuristic rule-based methodology is employed to identify activity locations and integrated with Point-of-Interest (POI) information. Sensitive locations such as the home and work are anonymized at the census block group level to protect privacy. Then, a rule-based recursive algorithm is used to identify trips from raw location points. This algorithm checks every point in the sequence sorted by devices and timestamps to identify if it belongs to the same trip as its previous point based on speed, time, and distance threshold. Next, a multi-level weighting procedure expands the observed trips to the entire U.S. population, using device-level and trip-level weights to ensure data representativeness in the total population. Finally, based on the weighted trip roster, various human mobility metrics are calculated via a post-processing step. The details of the data preprocessing methods can be found in the Supplementary Section I.
The execution of the analytics on all the mobile device location data is conducted daily via cloud computing and service solutions. 1.2–3.4 billion data records are generated daily, which is impractical to process with regular computing setup. Hence, a cloud-based distributed cluster-computing framework (Spark) built on EMR (Amazon Elastic MapReduce) is employed to address the computation problem. Using a cluster with a configuration of one c5.18xlarge master node and ten c5.12xlarge cores nodes, the average computation time of deriving the daily weighted trip rosters is reduced from 36 h on a local server (192 GB Memory, 28 cores, Intel® Xeon® CPU E5-2697 v3 @ 2.60 GHz) to 1 h on the EMR cluster.
Results and computational algorithms have been validated based on a variety of independent datasets such as the National Household Travel Survey (NHTS) and the American Community Survey (ACS), and peer-reviewed by an external expert panel in a U.S. Department of Transportation Federal Highway Administration’s Exploratory Advanced Research Program project (Zhang and Ghader, 2020). By running the algorithm on our data and comparing the trip lengths and travel times with the reported travel distances and travel times from the 2017 national household travel survey, a satisfactory match is observed (see more details related to the overall validation results in another paper by the authors, (Zhang et al., 2020)). Moreover, we compared national mobility trends during the COVID-19 calculated by our methods and by other data sources including Apple, Google, and SafeGraph and found high consistency. Validation results suggest our data sources and algorithms are convinced to represent the population-level mobility trend in the U.S. More details of the validation results can be found in Supplementary Section I.
2.2. Algorithms
From the Data and Analytics layer, three person-level metrics are derived to measure human mobility: 1) daily average number of trips per person; 2) daily average person-miles traveled; 3) daily percentage of residents staying home. If an anonymized individual in the sample did not make any trip with one trip end more than one mile away from home location, this anonymized individual is considered as staying at home. A trip with both trip ends at home (e.g., jogging three miles) does not violate our staying-at-home criteria. Then, with a set of longitudinal statistical models, the effects of stay-at-home orders and reopening guidelines were analyzed. A generalized additive mixed model (GAMM) is selected for its best goodness-of-fit and versatility in handling linear and nonlinear effects, random effects, and spatiotemporal autocorrelations.
2.3. Applications
The applications of the framework are profound. Ingesting over 60 TB of data and utilizing over 75,000 CPU hours of computation, this framework provides timely ground-truth information on how people in the U.S. move during the COVID-19 outbreak. The mobility informatics are analyzed daily at the national, state, and county levels in the U.S. and made available to the general public via the COVID-19 impact analysis platform (https://data.covid.umd.edu/). Then, the longitudinal models are used to evaluate the effectiveness of policies across regions with heterogeneous socio-demographics. The outputs of the models and analytics can help agencies monitor and improve their policy effectiveness, as well as enable cross-disciplinary research and collaborations.
There are several platforms developed by other research teams/agencies. One notable platform (C2SMART-COVID19) investigates the impact of COVID-19 on mobility and sociability using multi-source data such as transit ridership, corridor travel time, bikesharing trips, and traffic incidents (C2SMART, 2020). Their results reveal unprecedented mobility plummeting across different transport modes and regions (Zuo et al., 2020). For comparison, the C2SMART-COVID19 platform collects multisource transportation-related data, such as transit ridership, corridor travel time, bikesharing trips to provide insights on the change of transportation system. The data used mainly focuses on several big cities like New York, Seattle, Chicago, and some cities in China. On the contrary, using mobile device location data, our platform mainly focuses on measuring human behavior changes (i.e. Trips/person, Miles/person) across all counties and states in the U.S.
Other agencies like the Centers for Disease Control and Prevention (CDC), MOBS Lab at Northeastern University, GeoDS Lab at the University of Wisconsin, Madison also developed several platforms to reveal the mobility trends during the pandemic (CDC, 2020, Gao et al., 2020, MOBSLab, 2020). Specifically, CDC shows “Change in Incidence” in their COVID-data-tracker that measures the percentage change of the number of visits to different interests utilizing data from Google, Cuebiq, and SafeGraph (CDC, 2020). The MOBS Lab developed a dashboard that measures the percentage change of county-level average mobility and contact patterns with their baseline values in January and February (MOBSLab, 2020). GeoDS Lab provides two mobility-related metrics at the county-level based on the SafeGraph data, namely Mobility (Median of Max Travel Distance) Over Time and Home Dwell Time (Gao et al., 2020). Compared with these platforms, our platform estimates the absolute value of typical travel statistics (i.e. Trips/person, Miles/person) with our multi-level weighting process, which can provide more useful information to decision-makers and transportation researchers.
3. Data analytics and variable description
Using billions of raw location points collected daily, the analytical framework develops various mobility informatics to inform the general public and support decision making. Among the informatics, three fundamental metrics were employed to describe human mobility.
1) Daily average number of trips per person (Trip per person): Total number of identified and weighted trips on each day in each county divided by the county population; trips with length lower than 300 m are dropped.
2) Daily average person-miles traveled (Person-miles traveled): Total weighted person-miles traveled on each day in each county across all travel modes divided by the county population.
3) Daily proportion of residents staying home (Proportion of staying home): Proportion of county residents staying at home (i.e., no trips with a non-home trip end more than one mile away from home).
During the COVID-19 pandemic, various mobility indexes have been calculated using different data sources based on different algorithms (Apple, 2020, C2SMART, C.S.U.T.C., 2020, Cuebiq, 2020, Google, 2020, SafeGraph, 2020). We choose Trip per person, Person-miles traveled, and Proportion of staying home to build our models as these three metrics describe the mobility change from various perspectives. The number of trips per person reflects the travel frequency, the travel miles per person reflects the travel distance, and the percentage of staying at home directly quantifies the response to the stay-at-home orders and reopening guidelines. This paper will focus on the analyses of those metrics. Our future research will explore the travel behavioral changes using other mobility metrics such as travel time and radius of gyration (C2SMART, C.S.U.T.C., 2020, Zuo et al., 2020).
The descriptive analysis of the spatiotemporal human mobility change is reported in this section. Fig. 2 a visualize the daily varying patterns of Trip per person, Person-miles traveled, and Proportion of staying home. The buffer in grey represents the standard-deviation intervals of the metrics across all counties. The bar plots represent the daily number of new confirmed COVID-19 cases in the nation. A sharp decrease regarding Trip per person and Person-miles traveled is observed during the period between the first stay-at-home order (March 19th, 2020) and the first reopening order (April 20th, 2020), while the Proportion of staying home and the number of new confirmed cases increases rapidly. After the first reopening order was issued, human mobility gradually recovered regardless of a large number of daily new COVID-19 cases.
Fig. 2.

(a) Daily varying pattern of three human mobility metrics and (b) changes of metrics from February 1st, 2020 to May 31st, 2020 compared with January 2020. Note: On February 17th, 2020 (Washington's Birthday) and May 25th, 2020 (Memorial Day), fluctuations are observed across the nation due to the holiday effects, we fix the outliers with linear interpolation.
Similar patterns can be found in Fig. 2b, which presents the changes of human mobility metrics using January 2020 as the benchmark (holiday excluded). Before the pandemic, a slightly heavier Trip per person and Person-miles traveled are observed, reflecting a monthly and seasonal mobility pattern. After the nation entered the emergency, the mobility started to deteriorate and reached a plateau within two weeks (March 12th, 2020 to March 24th, 2020). During the week (April 5th, 2020 to April 12th, 2020) when the last stay-at-home order was released, people averagely reduced 0.60 trips and 11.62 miles traveled per day, and 15.73% more residents choose to stay at home. The human mobility reduction only lasted for around 30 days (March 12th, 2020 to April 12th, 2020), and then a strong “mobility resistance” phenomenon across the nation was observed (Xiong et al., 2020b). By early May, people's mobility rapidly recovered to 85.56% of the typical status in January 2020, albeit the number of confirmed cases kept growing and more than half of the states were still executing stay-at-home orders. It is also worth mentioning a time lag is observed between the policy release and the human mobility change. A nationwide mobility reduction started since March 12th, 2020, i.e. one week earlier than the time when the first stay-at-home order was released. During that week without any stay-at-home orders, people had already reduced their number of trips by 0.61 and number of travel miles by 10.45 across the nation. A similar phenomenon is observed regarding reopening orders. A human mobility rebound started from April 12th, 2020; however, the first reopening order wasn't issued until April 20th, 2020.
Fig. 3 illustrates the percentage change in the three mobility metrics across all contiguous counties. Two phases are compared: (1) one week after the first stay-at-home order (March 20th to March 27th); and (2) one week after the first reopening order (April 20th to April 27th). Similar to the trend revealed in Fig. 2, a nationwide decreasing pattern is observed in the first phase while resilience is observed in the second phase. Compared with January 2020, during phase one, Trip per person is estimated to drop by 12.52%, Person-miles traveled is decreased by 24.96%, and Proportion of staying home is increased by 39.61%. In the second phase, human mobility rebounded. Trip per person, Person-miles traveled and Proportion of staying home recovered to 93.5%, 77.0%, and 120.4% of the benchmark, respectively. Person-miles traveled presents a more dramatic change. One explanation is that people canceled longer-distance commute and other travels and conducted more trips with shorter-distance during the pandemic (Xiong et al., 2020b). For example, long-distance commute trips are greatly reduced due to telecommuting, and at the same time, short-distance outdoor exercises around home locations may increase. Another interesting finding is that regions with more COVID-19 cases present greater reductions in human mobility, such as New York, New Jersey, Massachusetts, Illinois, and California, indicating the virus is effective in persuading people to travel less.
Fig. 3.

Percentage change in three human mobility metrics across U.S. counties in different periods (i.e. March 20th, 2020 to March 27th, 2020; April 20th, 2020 to April 27th, 2020) compared with January 2020. Note: All analyses are based on contiguous United States (i.e. Hawaii and Alaska are excluded).
4. Models
4.1. Generalized additive mixed model
This section provides a detailed description of the generalized additive mixed model (GAMM) (Wood, 2003) that this study employed to examine different effects on human mobility change. GAMM is a semi-parametric model with a linear predictor involving a series of additive non-parametric smooth functions of covariates. Compared to the classical ordinary least squares (OLS) regression, GAMM is more flexible with fewer assumptions, which is useful when data cannot meet OLS assumptions, such as independence, normality, and homogeneity. Additionally, a noticeable advantage of GAMM lies in its capability and flexibility to handle different formats of nonlinear effects (Wood, 2003). By changing the spline functions, various effects can be captured under one model framework, such as random effects, interaction relationships, and spatiotemporal autocorrelations (Hu et al., 2018, Wang et al., 2020).
As a longitudinal analysis with repeated observations over time for each county, the non-independence among the repeated observations and the temporal heterogeneous variability should be carefully addressed. Mixed (also named multi-level) models are widely used to handle the panel data (Wolfinger and O'connell, 1993). However, traditional mixed models are linear-based and fail to reach high performance when data has significant nonlinear fluctuations. Hence, a GAMM structure was involved to handle the panel data, with several additive smooth terms besides the linear fixed effect to address the heterogeneous covariance structures. There are various types of GAMM in terms of distributions, additive terms, and model specifications. We test different combinations of distribution families and smoothing functions under the GAMM structure and choose the optimal model based on the smallest AIC. We also compare the coefficients generated by different GAMMs and found consistent signs and values, which further confirmed the model's robustness. The details of comparison and selection can be found in Supplementary Section II. We finally assume the dependent variables follow the Gaussian distribution and include various additive terms with different smoothing functions as follows (Wood, 2017):
-
1)
Nonlinear random effects across all counties and states to capture the unobserved heterogeneity (Smooth term: smoothers with parametric terms penalized by a ridge penalty).
-
2)
Temporal patterns, including an average pattern and a seasonal weekly pattern (Smooth term: thin plate regression splines).
-
3)
Autoregressive term to address the temporal autocorrelations existing in residual.
-
4)
Spatial interactions to address the spatial autocorrelations existing in residual (Smooth term: the interaction smoother exclude the basic functions associated with the main effects of the marginal smooths).
The formulation of GAMM is as follows:
| (2) |
| (3) |
where is the dependent variable in county i on day t; is the link function, here we use the identity links assuming the dependent variables follow a Gaussian distribution; is the overall intercept; is the kth coefficient of fixed effects; K is the total number of fixed effects; refers to the kth fixed covariate in county i on day t; L is the total number of covariates that present nonlinear features; is a low rank isotropic smooth function and denotes the lth covariate with nonlinear effects; and are the rth pair of interaction covariate in county i on day t; R and S are the numbers of variables with interactive effects; are the interaction smooth functions with penalties on each null space component; is the random effect vector of county i assumed to follow a Gaussian distribution; is the random effect vector of state I that county i belong to assumed to follow a Gaussian distribution; is the spline function penalized by a ridge penalty varies across different counties; is the error term; is an autoregressive term for county i with order P (here P = 1), with expression shown in Eq. (3): where is the vector of the dependent variable in county i on day t; is the intercept; is the coefficient of the pth lagged variable; is the white-noise in the time-series.
The estimation of GAMM is implemented in the open-source platform R (Wood, 2017). The variance components are estimated by the fast-Restricted Maximum Likelihood Estimation computation (fREML), which is widely used in estimating random-effect models. The large number of observations extremely slowed down the traditional estimation methods. Hence, this study employed an alternative approach based on the discretization of covariate values and C code level parallelization (Li and Wood, 2020, Wood et al., 2017). Each time when fitting model covariates, it takes only a discrete set of values substantially smaller than the sample size. The method reduced the computing time by two to three orders with a very low approximation error.
4.2. Spatiotemporal autocorrelation check
This study addresses the spatiotemporal autocorrelations respectively by adding a time autoregressive term (AR1) and a spatial coordinate interaction term (Wood, 2017). It is important to check the residual whether the spatiotemporal autocorrelations are well solved. We first fit a model with uncorrelated errors (i.e., the regular GAM model, Eq. (7)), and then use the autocorrelation function (ACF) and the Moran’s I to check whether spatiotemporal autocorrelations are statistically significant. Moran’s I was calculated based on queen neighbors with equal weighting using the R ‘spdep’ package.
Results show a significant one-lag autocorrelation in time series (Fig. 4 a). For the spatial distribution of the residuals in modeling Δ Trip per person, the Moran’s I statistic is 0.3652 (P-value = 0.0000), indicating a statistically significant high clustering of similar values, which can be overserved from the residual visualization on the map (Fig. 4c). After including the AR1 term and the spatial interaction term, the spatiotemporal autocorrelations are successfully reduced. The one-lag serial autocorrelation is eliminated (Fig. 4b), and the Moran’s I decreased to 0.0735 with not statistical significance (P-value = 0.2049), indicating the null hypothesis (i.e. random spatial distribution) cannot be rejected. The residuals now present a pattern that is more random across the nation (Fig. 4d). We also check the spatiotemporal autocorrelations in residuals of models with other dependent variables and find similar results.
Fig. 4.

Residuals of the Uncorrelated GAM model and the GAMM model in Modeling Δ Trip per person from February 1st, 2020 to May 31st, 2020.
4.3. Variables
The dependent variables are the differences of the three metrics, i.e., Trip per person, Person-miles traveled, and Proportion of staying home, compared to the benchmark. We set the benchmark as the average value in the same days of the week in January 2020 (New Year’s Day and Martin Luther King are excluded):
 |
(3) |
where 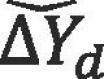 is the dependent variable on day d (i.e., Δ Trip per person, Δ Person-miles traveled, or Δ Proportion of staying home); is the corresponding value of the metric on day d;
is the day of the week of day d; is the average value of the metric in days belonging to in January 2020. The summary of the dependent variables is reported in Table 1
. The average of daily trips per person in January 2020 is 3.326, which is consistent with the results of 2017 NHTS (3.37 daily trips per person in the U.S.), indicating our models generate reasonable trip roasters. The average of Δ Trip per person and Δ Person-miles traveled are negative, while the Δ Proportion of staying home is positive, indicating people travel less and stay at home more compared with January 2020. The large SD (standard deviation), on the other hand, implies that mobility changes are highly heterogeneous across different counties and days.
is the dependent variable on day d (i.e., Δ Trip per person, Δ Person-miles traveled, or Δ Proportion of staying home); is the corresponding value of the metric on day d;
is the day of the week of day d; is the average value of the metric in days belonging to in January 2020. The summary of the dependent variables is reported in Table 1
. The average of daily trips per person in January 2020 is 3.326, which is consistent with the results of 2017 NHTS (3.37 daily trips per person in the U.S.), indicating our models generate reasonable trip roasters. The average of Δ Trip per person and Δ Person-miles traveled are negative, while the Δ Proportion of staying home is positive, indicating people travel less and stay at home more compared with January 2020. The large SD (standard deviation), on the other hand, implies that mobility changes are highly heterogeneous across different counties and days.
Table 1.
Summary of Dependent and Independent Variables Used in the Models (From February 1st, 2020 to May 31st, 2020).
| Variables | Description | Mean | SD | Min. | Max. | |
|---|---|---|---|---|---|---|
| Dependent Variables | ||||||
| Δ Trip per person | Daily average number of trips per person compared with January 2020 (Mean: 3.326 SD:0.466) | −0.209 | 0.405 | −1.264 | 0.798 | |
| Δ Person-miles traveled | Daily average person-miles traveled compared with January 2020 (Mean: 42.952 SD:10.572) | −5.686 | 9.715 | –32.060 | 31.399 | |
| Δ Proportion of staying home | Daily average proportion of residents staying at home compared with January 2020 (Mean: 0.199 SD:0.055) | 0.048 | 0.062 | −0.088 | 0.229 | |
| Independent Variables | ||||||
| Policy | Stay-at-home order | Categorical Variables. 0: No Stay-at-home order (Reference); 1: Stay-at-home order issued without penalty or specifying enforcement (32.54%); 2: Stay-at-home order issued and enforced with a warning, and a possible fine for the repeated offense (29.35%); 3: Stay-at-home order issued and enforced with fines and possible jail time (28.55%). | – | – | 0.000 | 3.000 |
| FEMA | If COVID-19 Emergency Declaration issued, 1; else 0. | 0.277 | 0.448 | 0.000 | 1.000 | |
| Reopening order | If (partial) reopening order is issued, 1; else 0 (Reference). | 0.218 | 0.413 | 0.000 | 1.000 | |
| ARG | If the Guideline for Opening Up America Again issued, 1; else 0. | 0.361 | 0.480 | 0.000 | 1.000 | |
| COVID-19 | New cases | Daily number of newly confirmed COVID-19 cases in the county (1,000). | 0.003 | 0.025 | 0.000 | 2.155 |
| Sum cases | Daily number of accumulated confirmed COVID-19 cases in the county (1,000). | 0.127 | 1.154 | 0.000 | 77.925 | |
| Adj. new cases | Daily number of newly confirmed COVID-19 cases in the adjacent counties (1,000). | 0.020 | 0.089 | 0.000 | 4.462 | |
| Adj. sum cases | Daily number of accumulated confirmed COVID-19 cases in adjacent counties (1,000). | 0.803 | 4.878 | 0.000 | 200.167 | |
| National new cases | Daily number of newly confirmed COVID-19 cases in the nation (1,000). | 14.551 | 12.859 | 0.000 | 36.590 | |
| Temporal | Week | The day of the week, from 0 (Monday) to 6 (Sunday). | – | – | 0.000 | 6.000 |
| Weekend | If the day is weekend, 1; else 0 (Reference). | 0.290 | 0.454 | 0.000 | 1.000 | |
| Time Index | The difference in the day from the current date to February 1st, 2020. | – | – | 0.000 | 120.000 | |
| Socio-Demographic | Population density | Population density, in 103 persons/sq. mile. | 0.233 | 0.945 | 0.000 | 25.591 |
| Employment density | Job density, in 103 jobs/sq. mile. | 0.125 | 1.319 | 0.000 | 67.846 | |
| Male | The proportion of males. | 0.500 | 0.023 | 0.421 | 0.790 | |
| Age_0_24 | The proportion of people aged between 0 and 24. | 0.312 | 0.047 | 0.105 | 0.612 | |
| Age_25_40 | The proportion of people aged between 25 and 40. | 0.176 | 0.029 | 0.067 | 0.346 | |
| Age_40_65 | The proportion of people aged between 40 and 65. | 0.328 | 0.030 | 0.149 | 0.499 | |
| Race-White | The proportion of White not Hispanic or Latino. | 0.767 | 0.198 | 0.007 | 1.000 | |
| Race-Hispanics | The proportion of White Hispanic or Latino. | 0.066 | 0.112 | 0.000 | 0.944 | |
| Race-African American | The proportion of African American. | 0.093 | 0.147 | 0.000 | 0.874 | |
| Race-Asian | The proportion of Asian. | 0.013 | 0.023 | 0.000 | 0.359 | |
| Median income | The median household income, in $103/household. | 51.402 | 13.605 | 20.188 | 136.268 | |
| Army personnel | The proportion of people in armed forces. | 0.003 | 0.016 | 0.000 | 0.520 | |
| College students | The proportion of residents enrolled in college or graduate school. | 0.050 | 0.039 | 0.000 | 0.536 | |
| Incarcerated ratio | The proportion of population incarcerated. | 0.004 | 0.008 | 0.000 | 0.167 | |
| Political parties | Democrats | The proportion of Democrats in presidential candidate vote totals. | 0.316 | 0.151 | 0.031 | 0.909 |
| Republicans | The proportion of Republicans in presidential candidate vote totals. | 0.632 | 0.155 | 0.041 | 0.946 | |
| Non-voters | The proportion of non-voters. | 0.557 | 0.077 | 0.208 | 0.871 | |
| Industry (weighted by number of employees in each establishment) | Agriculture | The proportion of agriculture, forestry, fishing, hunting, mining, quarrying, oil and gas extraction, and construction sectors. | 0.090 | 0.075 | 0.000 | 1.000 |
| Retail | The proportion of retail trade and wholesale trade sectors. | 0.256 | 0.104 | 0.000 | 1.000 | |
| Educational | The proportion of educational, professional, scientific, and technical services. | 0.045 | 0.037 | 0.000 | 0.486 | |
| Finance | The proportion of finance and insurance services. | 0.053 | 0.031 | 0.000 | 0.500 | |
| Transportation | The proportion of transportation and warehousing services. | 0.064 | 0.049 | 0.000 | 1.000 | |
| Entertainment | The proportion of arts, entertainment, and recreation services. | 0.009 | 0.012 | 0.000 | 0.277 | |
| Accommodation | The proportion of food and accommodation services | 0.151 | 0.081 | 0.000 | 1.000 | |
| Health care | The proportion of health care and social assistance services. | 0.146 | 0.088 | 0.000 | 1.000 | |
| Manufacturing | The proportion of manufacturing industry. | 0.101 | 0.110 | 0.000 | 0.776 | |
| Weather | Precipitation | Daily precipitation, in mm. | 3.363 | 8.532 | 0.000 | 197.900 |
| Max. Temperature | Daily maximum temperature, in Celsius. | 16.516 | 8.968 | –22.667 | 222.800 | |
| Min. Temperature | Daily minimum temperature, in Celsius. | 4.437 | 8.415 | −36.700 | 27.250 | |
a. Italic texts: excluded variables due to multicollinearity.
b. All analyses are based on contiguous United States (i.e. Hawaii and Alaska are excluded) from February 1st, 2020 to May 31st, 2020.
c. To address the low-sampling biases, only counties with at least 1% daily sampling ratio are included in this study.
d. The adjacent counties are calculated based on the queen relationship, i.e., the county share at least one border or one vertex is defined as an adjacent county.
e. Data source:
1. The county-level socio-demographics are obtained from the 2017 American Community Survey (ACS) 5-year estimates. The industry types are from the 2018 Annual Economic Surveys. The incarcerated data are from the Bureau of Justice Statistics (BJS). The 2018 election data are from the MIT election lab (Lab, 2018).
2. The weather conditions are obtained from the US National Weather Service Forecast Office.
3. The county-level policy information are collected from different government announcements (see (Sarah Mervosh, 2020; Yuriria Avila, 2020) for a summary).
4. The virus data are from the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University (CSSE, 2020).
f. On February 17th, 2020 (Washington's Birthday) and May 25th, 2020 (Memorial Day), abnormal data fluctuations are observed across the nation due to the holiday effects, we fix the outliers with linear interpolation.
Government directives, such as “staying-at-home” orders and “reopening” guidelines, certainly have a direct effect on human mobility and is the focus of this study. In addition, various other factors may contribute to the mobility change (Fang et al., 2020) and their confounding effects have to be incorporated. First, the daily-updating facts about the coronavirus transmissions can exert a deterrent effect on people and lead to curtailed human movement even without a mandatory stay-at-home order. Second, human mobility is greatly heterogeneous across different individuals with different socio-demographic features and regions with different governor approving rate (Engle et al., 2020, Qiu et al., 2020). Third, human mobility itself has the temporal and seasonal patterns, i.e., the weekly patterns, the monthly patterns, and some abnormal fluctuation caused by holidays, games, and other big events (Jia et al., 2020). Fourth, considering nearly every state/county governor has issued stay-at-home orders that outline industries deemed “essential” (i.e. services still need to operate during the pandemic), different industry types may exert significantly different impacts on human mobility change (Engle et al., 2020). Last, weather conditions also significantly affect people’s daily travel (Qiu et al., 2020). Lower temperatures and greater precipitations may make people reluctant to venture out.
To capture these confounding effects, various independent variables are included and categorized into seven types, including policies, COVID-19-related features, temporal features, socio-demographics, political parties, industry structure, and weather conditions. The summary of variables is reported in Table 1. The variance inflation factor (VIF) is used to check for multicollinearity, and variables with VIF values greater than 5.0 were excluded (Italic texts in Table 1). It is worth mentioning that highly multicollinearity is observed between the number of new confirmed cases and cumulative cases. Similar high multicollinearity is observed between stay-at-home orders and the COVID-19 Emergency Declaration, between reopening orders and the Guideline for Opening Up America Again, and between proportion of democrats and proportion of Republicans. Based on the smallest Akaike information criterion (AIC), we kept the new confirmed cases, the stay-at-home orders, the reopening orders, and the proportion of democrats in final models reported in the next section.
5. Results
5.1. Model selection
Several benchmark models are tested and compared with GAMM, including the linear fixed model (expressed by Eq. (4)), the linear mixed model with random intercepts (Eq. (5)), the linear mixed model with random intercepts and slopes (Eq. (6)), and the generalized additive models (Eq. (7)). Akaike Information Criterion (AIC) and Conditional R2 are used to compare the performances of different models and the results are presented in Table 1 . Conditional R2 is a Pseudo-R2 designed for generalized mixed-effect models, which can be interpreted as a variance explained by both fixed and random effects. Conditional R2 is estimated using the R ‘MuMIn’ package (Nakagawa et al., 2017). The benchmark models are expressed as follows:
| (4) |
| (5) |
| (6) |
| (7) |
where is the vector of the dependent variable in county i on day t; is the identity link function; is the overall intercept; is the mth coefficient of the covariate ; is the random effect of the intercept of county i; is the random effect of the slope of county i; M is the total number of covariates; is the error term; is an autoregressive term for county i with order P (here P = 1).
As shown in Table 2 , GAMM presents the lowest AIC and highest Conditional R2 among all models with different dependent variables, followed by the GAM without the AR1 and spatial interaction terms. The superior model performance of GAMM benefits from its flexible functional form of handling the linear and non-linear mixtures as well as its incorporation of spatiotemporal correlations.
Table 2.
Goodness-of-Fit Comparison of Different Models.
| Model | Dependent Variable | AIC | Conditional R2 |
|---|---|---|---|
| Linear fixed model | Δ Trip per person | 151,880 | 0.444 |
| Δ Person-miles traveled | 2,355,000 | 0.402 | |
| Δ Proportion of staying home | −1,180,677 | 0.507 | |
| Linear mixed model with random intercepts | Δ Trip per person | 22,267 | 0.454 |
| Δ Person-miles traveled | 2,294,352 | 0.449 | |
| Δ Proportion of staying home | −1,289,007 | 0.525 | |
| Linear mixed model with random intercepts and slopes | Δ Trip per person | 17,203 | 0.484 |
| Δ Person-miles traveled | 2,290,676 | 0.460 | |
| Δ Proportion of staying home | −1,295,881 | 0.550 | |
| Generalized additive model (GAM) | Δ Trip per person | −5,494 | 0.644 |
| Δ Person-miles traveled | 2,269,168 | 0.539 | |
| Δ Proportion of staying home | −1,344,796 | 0.682 | |
| Generalized additive mixed model (GAMM) | Δ Trip per person | −38,403 | 0.652 |
| Δ Person-miles traveled | 2,263,476 | 0.545 | |
| Δ Proportion of staying home | −1,362,065 | 0.708 |
5.2. Inferential analysis
The results of GAMMs are reported in Table 3 . Goodness-of-fit indexes (adjusted R squares) are 0.652, 0.708, and 0.545 for the three models, indicating that the GAMMs fitted the data well. The goodness-of-fit for Δ Person-miles traveled model is worse than the other two models, the reason may because: first, due to the noise and missing data in GPS points, the person-miles are more overdispersion and noisy compared with the other two metrics, which makes it more difficult to predict; and second, some unobserved variables related to the person-miles are not captured in the independent variables. For example, the commercial/delivery drivers may have longer driving distance, however, in this study we did not have these labels due to the anonymous user’s information.
Table 3.
Estimation Results of the Generalized Additive Mixed Models for Human Mobility (From February 1st, 2020 to May 31st, 2020).
| Δ Trip per person | Δ Proportion of staying home | Δ Person-miles traveled | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parametric coefficients: | |||||||||||||
| Estimate | Std. Error | P-value | Estimate | Std. Error | P-value | Estimate | Std. Error | P-value | |||||
| (Intercept) | −0.152 | 0.095 | 0.110 | 0.065 | 0.011 | 0.000 | *** | −3.404 | 2.309 | 0.140 | |||
| COVID-19 | New cases | −0.550 | 0.019 | 0.000 | *** | 0.115 | 0.003 | 0.000 | *** | −2.680 | 0.554 | 0.000 | *** |
| Adj. new cases | −0.252 | 0.006 | 0.000 | *** | 0.051 | 0.001 | 0.000 | *** | −4.138 | 0.164 | 0.000 | *** | |
| National new cases | −0.001 | 0.000 | 0.000 | *** | 0.000 | 0.000 | 0.000 | *** | −0.051 | 0.008 | 0.000 | *** | |
| Policy | Stay-at-home order: 1 | −0.064 | 0.003 | 0.000 | *** | 0.007 | 0.000 | 0.000 | *** | −0.491 | 0.077 | 0.000 | *** |
| Stay-at-home order: 2 | −0.083 | 0.003 | 0.000 | *** | 0.011 | 0.000 | 0.000 | *** | −1.327 | 0.076 | 0.000 | *** | |
| Stay-at-home order: 3 | −0.095 | 0.003 | 0.000 | *** | 0.014 | 0.000 | 0.000 | *** | −1.845 | 0.083 | 0.000 | *** | |
| Reopening order | 0.049 | 0.005 | 0.000 | *** | −0.009 | 0.001 | 0.000 | *** | 0.364 | 0.152 | 0.017 | * | |
| Weather | Precipitation | −0.002 | 0.000 | 0.000 | *** | 0.000 | 0.000 | 0.000 | *** | −0.033 | 0.002 | 0.000 | *** |
| Max. Temperature | 0.009 | 0.000 | 0.000 | *** | −0.001 | 0.000 | 0.000 | *** | 0.033 | 0.003 | 0.000 | *** | |
| Socio-demographics | Population density | 0.004 | 0.003 | 0.127 | −0.001 | 0.000 | 0.042 | * | 0.112 | 0.063 | 0.076 | . | |
| Male | 0.369 | 0.106 | 0.001 | *** | −0.084 | 0.013 | 0.000 | *** | 9.645 | 6.591 | 0.144 | ||
| Age_0_24 | −0.154 | 0.098 | 0.115 | −0.001 | 0.012 | 0.899 | 2.018 | 2.380 | 0.397 | ||||
| Age_25_40 | −0.567 | 0.112 | 0.000 | *** | 0.112 | 0.013 | 0.000 | *** | −5.287 | 2.737 | 0.053 | . | |
| Age_40_65 | −0.399 | 0.133 | 0.003 | ** | 0.025 | 0.016 | 0.118 | 2.302 | 3.234 | 0.477 | |||
| Race-White | 0.012 | 0.036 | 0.747 | −0.005 | 0.004 | 0.218 | 1.970 | 1.267 | 0.120 | ||||
| Race-Hispanics | −0.052 | 0.040 | 0.195 | 0.008 | 0.005 | 0.090 | . | −0.545 | 0.979 | 0.578 | |||
| Race-African American | 0.094 | 0.038 | 0.012 | * | −0.015 | 0.005 | 0.001 | *** | 3.408 | 0.907 | 0.000 | *** | |
| Race-Asian | −0.137 | 0.130 | 0.293 | 0.066 | 0.015 | 0.000 | *** | −0.365 | 3.174 | 0.909 | |||
| Median income | −0.002 | 0.000 | 0.000 | *** | 0.000 | 0.000 | 0.000 | *** | −0.067 | 0.006 | 0.000 | *** | |
| Army personnel | −0.193 | 0.131 | 0.141 | 0.016 | 0.016 | 0.310 | −6.743 | 3.191 | 0.035 | * | |||
| College students | −0.409 | 0.085 | 0.000 | *** | 0.091 | 0.010 | 0.000 | *** | −6.771 | 2.073 | 0.001 | ** | |
| Incarcerated ratio | 0.227 | 0.236 | 0.335 | −0.028 | 0.028 | 0.320 | 6.456 | 5.769 | 0.266 | ||||
| Political parties | Democrats | −0.155 | 0.032 | 0.000 | *** | 0.019 | 0.004 | 0.000 | *** | −1.204 | 0.575 | 0.036 | * |
| Non-voters | 0.065 | 0.052 | 0.211 | −0.013 | 0.008 | 0.121 | 3.109 | 2.800 | 0.270 | ||||
| Industry | Agriculture | 0.033 | 0.045 | 0.460 | −0.003 | 0.005 | 0.595 | 0.170 | 1.106 | 0.878 | |||
| Retail | 0.022 | 0.015 | 0.149 | −0.008 | 0.005 | 0.131 | −0.791 | 0.526 | 0.133 | ||||
| Educational | −0.215 | 0.077 | 0.006 | ** | 0.020 | 0.009 | 0.027 | * | −1.746 | 0.891 | 0.050 | * | |
| Finance | −0.092 | 0.038 | 0.017 | * | 0.023 | 0.009 | 0.015 | * | −6.973 | 1.922 | 0.000 | *** | |
| Transportation | −0.045 | 0.056 | 0.420 | 0.013 | 0.007 | 0.048 | * | −0.253 | 1.378 | 0.854 | |||
| Entertainment | −0.333 | 0.158 | 0.034 | * | 0.075 | 0.021 | 0.000 | *** | 2.954 | 1.345 | 0.028 | * | |
| Accommodation | −0.066 | 0.042 | 0.116 | −0.005 | 0.005 | 0.316 | −1.090 | 1.020 | 0.285 | ||||
| Health care | 0.105 | 0.045 | 0.020 | * | −0.003 | 0.001 | 0.008 | ** | 0.445 | 0.227 | 0.049 | * | |
| Manufacturing | −0.016 | 0.040 | 0.682 | −0.003 | 0.005 | 0.543 | −0.979 | 0.971 | 0.313 | ||||
| Temporal | Weekend | 0.156 | 0.028 | 0.000 | *** | −0.019 | 0.005 | 0.000 | *** | 1.213 | 0.622 | 0.051 | . |
| Smooth terms: | |||||||||||||
| e.d.f | F | P-value | e.d.f | F | P-value | e.d.f | F | P-value | |||||
| s (Time Index) | 8.998 | 9.000 | 0.000 | *** | 8.997 | 9.000 | 0.000 | *** | 8.993 | 9.000 | 0.000 | *** | |
| s (Week) | 4.974 | 5.000 | 0.000 | *** | 4.985 | 5.000 | 0.000 | *** | 4.957 | 4.999 | 0.000 | *** | |
| s (County) | 2828.020 | 3019.000 | 0.000 | *** | 2752.011 | 3019.000 | 0.000 | *** | 2773.656 | 3019.000 | 0.000 | *** | |
| s (State) | 23.815 | 48.000 | 0.000 | *** | 27.026 | 48.000 | 0.000 | *** | 22.600 | 48.000 | 0.000 | *** | |
| s (Latitude, Longitude) | 23.086 | 23.260 | 0.000 | *** | 24.363 | 24.580 | 0.000 | *** | 20.834 | 21.107 | 0.000 | *** | |
| Model fit: | |||||||||||||
| R-sq.(adj) | 0.652 | 0.708 | 0.545 | ||||||||||
| fREML | −15732 | −678050 | 1,137,400 | ||||||||||
aSignificance codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1.
bs () refers to a spline function.
Two parts are included in the results: the parametric coefficients, corresponding to the linear fixed effects, and the nonparametric smooth terms, corresponding to the nonlinear effects. P-values are reported for both linear effects and nonlinear effects, and variables with P-values smaller than 0.1 are considered as statistically significant. Most of the estimated coefficients related to COVID-19, policy, and weather are statistically significant, with several exceptions for those related to socio-demographic, political parties, and industry types. In terms of the linear effects, the estimated coefficients are robust among the three mobility models. And reasonable inferences can be summarized. For instance, the models all find a negative effect on Δ Trip per person and Δ Person-miles traveled and a positive effect on Δ Proportion of staying home from the daily new confirmed COVID-19 cases in the county, the new cases in adjacent counties, and the national new cases. Regarding the effect of weather conditions, results indicate the amount of rainfall negatively contributes to human movement change while high temperature presents positive impacts. For temporal features, the weekend variable presents a positive relationship with human movement change, indicating during the weekend the human mobility presents less reduction compared with the pre-pandemic period.
Regarding the effectiveness of policies, as we expected, stay-at-home orders negatively influence Δ Trip per person and Δ Person-miles traveled, and positively influence Δ Proportion of staying home. However, we find the extent of policy impact rather limited. Compared to counties without a stay-at-home order, residents in a county with an effective order will only reduce additional 0.064 (±0.003) trips and 0.491 (±0.077) miles-traveled, and see 0.7% more residents staying home. On the other hand, the strictness of policy enforcement does amplify the effects on human mobility changes. Compared with counties with a stay-at-home order that does not incur penalties or particular enforcements, those enforced with warnings and fines will see a further reduction of 0.031 (±0.000) trips and 1.354 (±0.006) miles-traveled for each person each day, and 0.7% more residents staying home. Again, this agrees with what we find in Fig. 2 that a reactive – as opposed to proactive – order seemed to be the case during the COVID-19 onset. As soon as infections first began to appear in significant numbers in a state or county (i.e., early to mid-March), mobility measures began to decrease quickly without any government measures. Those who wanted and were able to limit their travels quickly adopted social distancing practices. After about two weeks into the pandemic (mid to late-March), mobility measures stopped decreasing despite skyrocketing infection numbers and stay-at-home orders thus experiencing a “mobility resistance”. Nevertheless, the much higher policy impact with stronger enforcement indicates that there is room for agencies to seek further improvement on the effectiveness of stay-at-home orders, should there be a foreseeable second spike of COVID-19 or any other highly contagious disease outbreak.
Also as expected, the reopening guidelines have a positive effect on human mobility. The magnitude of that effect is found to be limited, and even more so than the stay-at-home orders. Reopening guidelines lead to 0.049 (±0.005) more trips, 0.364 (±0.152) more miles-traveled and reduce 0.9% of residents staying home. The reopening guidelines are advisory and only generate a mild effect on mobility changes. Nevertheless, this does not mean people are cautious in venturing out. People voluntarily began to travel more. Between April 23rd and May 1st, 2020, more than a dozen states announced partial reopening. During the same period, Proportion of staying home decreased from 31% to 26%, a 17% drop nationwide. This widespread mobility increase can be explained by various time-dependent factors such as the gradually decreasing number of daily infections, the warm weather drawing people outside, and the fact that people are warned out by self-quarantine.
For socio-demographic variables, we find that the median household income, the proportion of people aged between 25 and 65, and the proportion of college students all present negative and statistically significant relationships with Δ Trip per person and Δ Person-miles traveled, while present positive relationships with Δ Proportion of staying home. In other words, counties with higher income, higher proportions of 25 to 65 age groups, or more residents enrolled in college and graduate schools are more likely to reduce more trips and stay at home more during the pandemic. The racial distribution in counties also indicates statistically different mobility responses. Counties with higher proportions of African American people travel significantly more and stay home less often than other ethnic groups. The coefficients of most other variables are only found significant in some of the models or are insignificant in all models. Notable findings include counties with more males and higher population density are found with higher “mobility resistance” during the COVID-19 crisis. Moreover, for political parties, the proportion of democrats present a significantly negative relationship with mobility decline. Alternatively, counites with more democrats are more likely to follow stay-at-home orders and restrict their travels during the pandemic.
Variables related to industry types deserve more discussions. We found several industry types present consistent significances in three models. Specifically, the proportion of health care and social assistance services present positive and statistically significant relationships with Δ Trip per person and Δ Person-miles traveled, while present negative relationships with Δ Proportion of staying home. On the contrary, the proportion of educational, professional, scientific, and technical establishments, the proportion of finance and insurance services, and the proportion of arts, entertainment, and recreation services present opposite relationships. Other industry types are found only significant in some models or are insignificant in all models. Findings revealed by our models regarding the relationships among different industries and human mobility change are highly consistent with the definitions of “essential” jobs in most stay-at-home orders. Counties with more essential industries are more likely to have less reduction in human mobility since more residents have to go to work and keep commuting (Engle et al., 2020).
As for nonlinear effects, the estimated degrees of freedom (e.d.f.) are all largely greater than 1.0, suggesting a strong and statistically significant nonlinear relationship between the selected variables and the dependent variables. Fig. 6 presents the nonlinearities of the time-varying pattern of three dependent variables using the smooth spline estimation, which can be deemed as the impact from other unobserved time-varying factors represented as follows:
-
1)
A slight mobility drop is captured both near February 15th and near May 23rd, corresponding to the Presidents’ Day weekend and the Memorial Day weekend, respectively.
-
2)
A mobility increase is then captured, with a tipping point near March 7th, four days before WHO defined the COVID-19 as a pandemic. In line with others’ findings (Google, 2020, SafeGraph, 2020), we argue this is due to a model-unobserved pre-pandemic panic such that people were stocking up goods for the possible lock-down.
-
3)
A sharp decrease occurs between March 7th and March 22nd, followed by a rebound. This “mobility resistance” phenomenon could be due to people’s fatigue of self-quarantine. The rebound of the daily trips is much steeper than the miles-traveled. One explanation is that the increased trips are mainly short-distance trips, such as running errands near home locations.
-
4)
The county ID and the state ID are included as factor variables capturing the individual random effects across all counties and all states. All models show high e.d.f. with significance, capturing the unobserved county-specific and state-specific heterogeneity.
Fig. 6.

Estimated spline function from February 1st, 2020 to May 31st, 2020. (a) Δ Trip per person; (b) Δ Person-miles traveled; (c) Δ Proportion of staying home.
5.3. Time-varying marginal effect
Table 3 has already reported the average effects of different policies on human mobility. In this section, we further analyzed the time-varying marginal effect of the stay-at-home and reopening orders. To do so, the estimated models are employed to predict human mobility change assuming the absence of stay-at-home orders or reopening policies. This counterfactual prediction is then compared with the actual observation of human mobility change. The results are visualized in Fig. 5 . In each sub-figure, the black curve represents the model prediction of human mobility change, the purple curve represents the counterfactuals of human mobility change assuming the absence of any mobility restriction policies, the dashed blue curve indicates the observation of human mobility change, and the buffer indicates the SD interval across different counties.
Fig. 5.

The time-varying marginal effect of stay-at-home and reopening orders from February 1st, 2020 to May 31st, 2020.
As shown, the policies present very limited marginal effects. The effects of reopening orders are even more negligible compared to stay-at-home orders. In addition, the difference between the counterfactual and prediction is decreasing over time, indicating a gradually vanishing marginal effect. The figures also present a “belated directives” phenomenon across the nation (visualized in Fig. 5 as the “gap” between the time of mobility change began and first stay-at-home order or reopening order released; The time gap for stay-at-home orders on average is 12 days and for reopen guidelines is 19 days). A dramatic increase or decrease in human mobility is already in place even before the first issuance of stay-at-home orders or reopening guidelines. Under this circumstance, the stay-at-home orders only contribute to a 3.5%-7.9% decrease in human mobility, while the reopening guidelines lead to a 1.6%-5.2% mobility increase.
6. Conclusion and discussion
This study presents a big-data-driven approach to analyzing and modeling human mobility trends under non-pharmaceutical interventions during the COVID-19 pandemic. Ingesting over 60 TB of anonymized mobile device location data and utilizing over 75,000 CPU hours of computation, the analytical framework provides timely ground-truth information on how people in the U.S. move before and during the outbreak. Then, with a set of longitudinal models, the effects of stay-at-home orders and reopening guidelines are analyzed, controlling for various cofounding effects including the infection statistics, socio-demographics, industry type, political parties, weather effect, and spatiotemporal autocorrelation. Results are deemed statistically significant, accurate, and robust. Findings can help governments monitor mobility trends and improve their policy effectiveness across regions with heterogeneous socio-demographics. Outputs can also be directly integrated into epidemics models to support epidemiologist better understand and predict virus transmission.
The main contributions of this study can be summarized in four aspects:
-
•
Methodologically, the study has developed a big-data-driven analytical framework using the emerging mobile device location data sources. The framework leverages the state-of-the-art and industry-leading big-data analytical infrastructure, cloud computing, and proven algorithms and successfully derives useful and timely human mobility data products and informatics. For the first time, trip-level human mobility analytics have been derived across the U.S. counties using over 150 million monthly active samples.
-
•
Empirically, the study is also among the first to quantify the time-dependent effect of different policies on human mobility, including the non-pharmaceutical mobility restrictions and reopening guidelines during the COVID-19 crisis. Through longitudinal modeling practices, our empirical findings reveal a much smaller than expected, region-specific, and time-decreasing policy effect.
-
•
Besides policy effects, this study also examines various confounding effects on human mobility, including COVID-19 cases, socio-demographics, weather conditions, industry types, political parties, and spatiotemporal interactions. Results indicate a reasonable spatiotemporal heterogeneity among the U.S. counties, wherein the number of confirmed COVID-19 cases, income levels, “essential” businesses, age and racial distribution, political parties, and weather conditions play important roles.
-
•
The study also contributes to broader general interests. Through a daily updated web portal (https://data.covid.umd.edu), the big-data-driven framework delivers mobility informatics to the public. Many agencies, private-sector businesses, and researchers have adopted the data products in their decision processes and studies. It adds to the growing body of evidence suggesting the mobility perturbation during pandemic. It also enables various research directions once integrating the trip-ends with proper point-of-interest data. To this point, other public data sources, neither SafeGraph nor Google’s indices (Google, 2020, SafeGraph, 2020), etc., offer trip-level details.
The most surprising empirical finding in this study is that policies, including the stay-at-home orders and the reopening guidelines, play rather limited roles in influencing human mobility. Our models only attribute 3.5%-7.9% mobility decrease to the stay-at-home orders, while 1.6%-5.2% mobility increase is attributed to the reopening guidelines. In comparison, 1000 more confirmed cases in the county could lead to 1.45–7.95 times greater effect on mobility. Results are consistent with several existing studies (Engle et al., 2020, Xiong et al., 2020b). People curtail their travel frequency mainly due to the threat from viruses and the fear of being infected, rather than the obligation from the policies. We argue the reason for the limited policy effect in four folds. First, a “belated directives” phenomenon is found across the nation. The stay-at-home orders and reopening guidelines were announced too late since people have already started to change their activities. Second, most stay-at-home orders were non-compulsory. 32.5% of counties issued their announcements without mentioning any penalty or specifying particular enforcements; and a long list of essential businesses and activity exceptions were allowed to remain active during the pandemic. Third, the desire for mobility has led to stronger resistance to policies. Our data analysis has found a “mobility resistance” phenomenon that the mobility reduction only lasted for less than a month and then a rapid rebound happened, regardless of the growing number of infections and the executive stay-at-home orders. Our models also revealed a time-decreasing marginal effect of policies on human mobility, which further proved the “mobility resistance” phenomenon. Last but not least, some other individual-level unobserved factors may also serve as critical factors for mobility change. For example, company-level work-from-home policies, which sometimes are placed earlier than the government's stay-at-home orders, may significantly contribute to the reduction of commuting trips of their employees. These timely local polices seize the effects of government policies and further make such government policies ineffective.
Other important findings lie in various confounding effects. Results indicate that the wealthier and less African American communities were staying home more often, which is consistent with prior studies (Cuebiq, 2020, De Vos, 2020, Hu and Chen, 2020, Jennifer Valentino-DeVries, 2020, Sun et al., 2020). Counties with lower income levels and more African American population are more vulnerable to job losses, more likely to belong to essential workforce, and thus may need to go out and keep working (Hu and Chen, 2020, Sun et al., 2020). Other reasons, like the higher risk aversion tendency or better access to information, may also contribute to the result (De Vos, 2020). Evidence can also be found from results related to the effects of different industry types. Counties with higher proportion of essential businesses, such as health care and social assistance correspond to less mobility decline, while counties with more “inessential” industries such as educational, scientific, and technical services, finance and insurance services, and arts, entertainment, and recreation services, present significantly greater declines in human mobility. Findings are consistent with reports based on other data sources (Google, 2020, SafeGraph, 2020). In addition, counties with more people aged between 25 and 65 and more people enrolled in colleges or graduate schools are found to reduce the most activities during the pandemic. A large proportion of people in this age bracket belong to the commuting workforce and switched to the work-from-home mode under the restriction of stay-at-home orders. And similarly, college students reduced their daily activities on campus significantly since most universities have closed and switched to distant learning. Lastly, people in the counties with higher proportions of democrats are found more conservative in venturing out when facing the COVID-19. One explanation is that in the early stages most blue states such as NY, NJ, CA, IL, and MN suffered the most precipitous increase in COVID-19 cases, passing more negative messages about the virus and aggravating the panic effects.
Lessons learned from this study are that the government should seek further improvement to the policy timeliness, strictness, equity, and effectiveness. Restricting human movement has already shown inspiring effects on containing virus spread in many countries (Chinazzi et al., 2020, Kraemer et al., 2020). It is critical to effectively control human mobility, especially when an effective vaccine is still under development. In response to a foreseeable second spike or any other devastating contagion in the future, agencies could increase enforcement of policies, and reinforce the importance of non-pharmaceutical interventions among the public through educational campaigns. The mobility informatics generated by this study could further help agencies identify community hotspots that attract more travelers from epicenters and with higher infection risks. Finally, attention should also be focused on underserved and vulnerable population, especially the lower-income group, to help them address challenges in following the stay-at-home orders and the new social-distancing norm. For example, enhancing the wages of essential jobs and allocating more travel subsidies to make them affordable to use less-risked transport modes.
Several limitations are recognized and deserve further research. First of all, in addition to understanding the human mobility changes, it is equally important to evaluate how human mobility contributes to the virus transmissions (Chinazzi et al., 2020, Kraemer et al., 2020), for example, examining the lag effect of mobility inflow on the number of COVID-19 cases. Second, considering that the GAMM is a statistical technique mainly designed to examine the relationship rather than causal impact, our immediate next step is to employ causal inference models including difference-in-difference and Bayesian structural time series (Scott and Varian, 2013, Scott and Varian, 2014) to check the robustness of our findings. During the causal inference process, more detailed information, such as the company-level work-from-home policies, can be considered. Third, one limitation of this method is the mobile device location data might not be able to capture the travel behaviors of the younger, older, and lower-income population. Further study can employ an additional weighting and validation process on top of the sample results using land use and sociodemographic information. Last but not least, this study focuses on the modeling of fundamental mobility measurements such as number of trips, distance traveled, and stay-at-home behavior. It would be interesting to explore more mobility metrics, such as travel time and radius of gyration, as well as fine-grained point-based metrics (i.e., number of individual contacts, Yabe et al., 2020) in order to more comprehensively evaluate the community transmissions of the virus and the effectiveness of social distancing policies.
CRediT authorship contribution statement
Songhua Hu: Writing - original draft, Methodology, Formal analysis. Chenfeng Xiong: Conceptualization, Methodology, Writing - original draft. Mofeng Yang: Investigation, Validation, Writing - review & editing. Hannah Younes: Writing - review & editing. Weiyu Luo: Data curation, Visualization, Writing - review & editing. Lei Zhang: Supervision, Conceptualization.
Acknowledgment
We would like to thank and acknowledge our partners and data sources in this effort: (1) Amazon Web Service and its Senior Solutions Architect, Jianjun Xu, for providing cloud computing and technical support; (2) computational algorithms developed and validated in a previous USDOT Federal Highway Administration’s Exploratory Advanced Research Program project; (3) various mobile device location data provider partners; and (4) partial financial support from the U.S. Department of Transportation’s Bureau of Transportation Statistics.
Footnotes
Supplementary data to this article can be found online at https://doi.org/10.1016/j.trc.2020.102955.
Appendix A. Supplementary data
The following are the Supplementary data to this article:
References
- Alexander L., Jiang S., Murga M., González M.C. Origin–destination trips by purpose and time of day inferred from mobile phone data. Transport. Res. Part C: Emerg. Technol. 2015;58:240–250. [Google Scholar]
- Apple, 2020. Mobility Trends Reports, https://covid19.apple.com/mobility.
- C2SMART, C.S.U.T.C., 2020. C2SMART COVID-19 Data Dashboard. C2SMART University Transportation Center, http://c2smart.engineering.nyu.edu/covid-19-dashboard/.
- CDC, 2020. CDC COVID Data Tracker, https://covid.cdc.gov/covid-data-tracker/#mobility.
- Chen C., Ma J., Susilo Y., Liu Y., Wang M. The promises of big data and small data for travel behavior (aka human mobility) analysis. Transport. Res. Part C: Emerg. Technol. 2016;68:285–299. doi: 10.1016/j.trc.2016.04.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chinazzi, M., Davis, J.T., Ajelli, M., Gioannini, C., Litvinova, M., Merler, S., y Piontti, A.P., Mu, K., Rossi, L., Sun, K., 2020. The effect of travel restrictions on the spread of the 2019 novel coronavirus (COVID-19) outbreak. Science 368, 6489, 395–400. [DOI] [PMC free article] [PubMed]
- CSSE, J., 2020. COVID-19 Data Repository by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University. The Johns Hopkins University Center for Systems Science and Engineering, https://github.com/CSSEGISandData/COVID-19.
- Cuebiq, 2020. Cuebiq's COVID-19 Mobility Insights, https://help.cuebiq.com/hc/en-us/articles/360041285051-Cuebiq-s-COVID-19-Mobility-Insights.
- Dabiri S., Heaslip K. Inferring transportation modes from GPS trajectories using a convolutional neural network. Transport. Res. Part C: Emerg. Technol. 2018;86:360–371. [Google Scholar]
- De Vos J. The effect of COVID-19 and subsequent social distancing on travel behavior. Transport. Res. Interdisc. Perspect. 2020;100121 doi: 10.1016/j.trip.2020.100121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Engle, S., Stromme, J., Zhou, A., 2020. Staying at home: mobility effects of covid-19. Available at SSRN.
- Fang, H., Wang, L., Yang, Y., 2020. Human mobility restrictions and the spread of the novel coronavirus (2019-ncov) in china. National Bureau of Economic Research. [DOI] [PMC free article] [PubMed]
- Gao S., Rao J., Kang Y., Liang Y., Kruse J. Mapping county-level mobility pattern changes in the United States in response to COVID-19. SIGSPATIAL Special. 2020;12(1):16–26. [Google Scholar]
- GDPR, 2020. Complete guide to GDPR compliance, https://gdpr.eu/.
- Google, 2020. See how your community is moving around differently due to COVID-19, https://www.google.com/covid19/mobility/.
- Hu S., Chen P. Who left riding transit? Examining socioeconomic disparities in the impact of COVID-19 on ridership. Transport. Res. Part D: Transp. Environ. 2020;90 [Google Scholar]
- Hu S., Chen P., Lin H., Xie C., Chen X. Promoting carsharing attractiveness and efficiency: An exploratory analysis. Transport. Res. Part D: Transp. Environ. 2018;65:229–243. [Google Scholar]
- Jennifer Valentino-DeVries, D.L.a.G.J.X.D., 2020. Location Data Says It All: Staying at Home During Coronavirus Is a Luxury. The New York Times, https://www.nytimes.com/interactive/2020/04/03/us/coronavirus-stay-home-rich-poor.html.
- Jia J.S., Lu X., Yuan Y., Xu G., Jia J., Christakis N.A. Population flow drives spatio-temporal distribution of COVID-19 in China. Nature. 2020:1–5. doi: 10.1038/s41586-020-2284-y. [DOI] [PubMed] [Google Scholar]
- Jiang S., Ferreira J., Gonzalez M.C. Activity-based human mobility patterns inferred from mobile phone data: A case study of Singapore. IEEE Trans. Big Data. 2017;3(2):208–219. [Google Scholar]
- Kraemer M.U., Yang C.-H., Gutierrez B., Wu C.-H., Klein B., Pigott D.M., Du Plessis L., Faria N.R., Li R., Hanage W.P. The effect of human mobility and control measures on the COVID-19 epidemic in China. Science. 2020;368(6490):493–497. doi: 10.1126/science.abb4218. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lab, M.E., 2018. https://electionlab.mit.edu/data.
- Leung K., Wu J.T., Liu D., Leung G.M. First-wave COVID-19 transmissibility and severity in China outside Hubei after control measures, and second-wave scenario planning: a modelling impact assessment. The Lancet. 2020 doi: 10.1016/S0140-6736(20)30746-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li Q., Guan X., Wu P., Wang X., Zhou L., Tong Y., Ren R., Leung K.S., Lau E.H., Wong J.Y. Early transmission dynamics in Wuhan, China, of novel coronavirus–infected pneumonia. N. Engl. J. Med. 2020 doi: 10.1056/NEJMoa2001316. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li Z., Wood S.N. Faster model matrix crossproducts for large generalized linear models with discretized covariates. Statist. Comput. 2020;30(1):19–25. [Google Scholar]
- MOBSLab, 2020. Mobility, commuting, and contact patterns across the United States during the COVID-19 outbreak, https://covid19.gleamproject.org/mobility.
- Nakagawa S., Johnson P.C., Schielzeth H. The coefficient of determination R 2 and intra-class correlation coefficient from generalized linear mixed-effects models revisited and expanded. J. R. Soc. Interface. 2017;14(134):20170213. doi: 10.1098/rsif.2017.0213. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ni L., Wang X.C., Chen X.M. A spatial econometric model for travel flow analysis and real-world applications with massive mobile phone data. Transport. Res. Part C: Emerg. Technol. 2018;86:510–526. [Google Scholar]
- Qiu Y., Chen X., Shi W. Impacts of social and economic factors on the transmission of coronavirus disease 2019 (COVID-19) in China. J. Popul. Econom. 2020;1 doi: 10.1007/s00148-020-00778-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rashidi T.H., Abbasi A., Maghrebi M., Hasan S., Waller T.S. Exploring the capacity of social media data for modelling travel behaviour: Opportunities and challenges. Transport. Res. Part C: Emerg. Technol. 2017;75:197–211. [Google Scholar]
- SafeGraph, 2020. The Impact of Coronavirus (COVID-19) on Foot Traffic, https://www.safegraph.com/dashboard/covid19-commerce-patterns.
- Sarah Mervosh, D.L.a.V.S., 2020. See Which States and Cities Have Told Residents to Stay at Home. The New York Times, https://www.nytimes.com/interactive/2020/us/coronavirus-stay-at-home-order.html.
- Scott S.L., Varian H.R. National Bureau of Economic Research; 2013. Bayesian variable selection for nowcasting economic time series. [Google Scholar]
- Scott S.L., Varian H.R. Predicting the present with bayesian structural time series. Int. J. Mathem. Modell. Numer. Optim. 2014;5(1–2):4–23. [Google Scholar]
- Sun, Q., Zhou, W., Kabiri, A., Darzi, A., Hu, S., Younes, H., Zhang, L., 2020. COVID-19 and Income Profile: How People in Different Income Groups Responded to Disease Outbreak, Case Study of the United States. arXiv preprint arXiv:2007.02160.
- Tian H., Liu Y., Li Y., Wu C.-H., Chen B., Kraemer M.U., Li B., Cai J., Xu B., Yang Q. An investigation of transmission control measures during the first 50 days of the COVID-19 epidemic in China. Science. 2020;368(6491):638–642. doi: 10.1126/science.abb6105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- TRUMP, D.J., 2020. Proclamation on Declaring a National Emergency Concerning the Novel Coronavirus Disease (COVID-19) Outbreak, https://www.whitehouse.gov/presidential-actions/proclamation-declaring-national-emergency-concerning-novel-coronavirus-disease-covid-19-outbreak/.
- Wang T., Hu S., Jiang Y. Predicting shared-car use and examining nonlinear effects using gradient boosting regression trees. Int. J. Sustain. Transport. 2020:1–15. [Google Scholar]
- Wolfinger, R., O'connell, M., 1993. Generalized linear mixed models a pseudo-likelihood approach. J. Statist. Comput. Simul., 48, 3-4, 233–243.
- Wood S.N. Thin plate regression splines. J. Royal Statist. Soc.: Ser. B (Statist. Methodol.) 2003;65(1):95–114. [Google Scholar]
- Wood S.N. CRC Press; 2017. Generalized additive models: an introduction with R. [Google Scholar]
- Wood S.N., Li Z., Shaddick G., Augustin N.H. Generalized additive models for gigadata: modeling the UK black smoke network daily data. J. Am. Stat. Assoc. 2017;112(519):1199–1210. [Google Scholar]
- Xiong C., Hu S., Yang M., Luo W., Zhang L. Mobile device data reveal the dynamics in a positive relationship between human mobility and COVID-19 infections. Proc. Natl. Acad. Sci. 2020;117(44):27087–27089. doi: 10.1073/pnas.2010836117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xiong C., Hu S., Yang M., Younes H., Luo W., Ghader S., Zhang L. Mobile device location data reveal human mobility response to state-level stay-at-home orders during the COVID-19 pandemic in the USA. J. R. Soc. Interface. 2020;17(173):20200344. doi: 10.1098/rsif.2020.0344. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yabe, T., Tsubouchi, K., Fujiwara, N., Wada, T., Sekimoto, Y., Ukkusuri, S.V., 2020. Non-Compulsory Measures Sufficiently Reduced Human Mobility in Japan during the COVID-19 Epidemic. arXiv preprint arXiv:2005.09423. [DOI] [PMC free article] [PubMed]
- Yuriria Avila, B.H., Alex Leeds Matthews, Brian Perlman and Jugal K. Patel, 2020. See How All 50 States Are Reopening. The New York Times, https://www.nytimes.com/interactive/2020/us/states-reopen-map-coronavirus.html.
- Zhang, L., Ghader, S., 2020. Data Analytics and Modeling Methods for Tracking and Predicting Origin-Destination Travel Trends Based on Mobile Device Data, https://cms7.fhwa.dot.gov/research/projects/data-analytics-modeling-methods-tracking-predicting-origin-destination-travel-trends-based-mobile.
- Zhang, L., Ghader, S., Pack, M.L., Xiong, C., Darzi, A., Yang, M., Sun, Q., Kabiri, A., Hu, S., 2020. An interactive COVID-19 mobility impact and social distancing analysis platform. medRxiv. [DOI] [PMC free article] [PubMed]
- Zou Q., Yao X., Zhao P., Wei H., Ren H. Detecting home location and trip purposes for cardholders by mining smart card transaction data in Beijing subway. Transportation. 2018;45(3):919–944. [Google Scholar]
- Zuo, F., Wang, J., Gao, J., Ozbay, K., Ban, X.J., Shen, Y., Yang, H., Iyer, S., 2020. An Interactive Data Visualization and Analytics Tool to Evaluate Mobility and Sociability Trends During COVID-19. arXiv preprint arXiv:2006.14882.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.