

Abstract
Strategy extraction is of great importance for quantified Boolean formulas (QBF), both in solving and proof complexity. So far in the QBF literature, strategy extraction has been algorithmically performed from proofs. Here we devise the first QBF system where (partial) strategies are built into the proof and are piecewise constructed by simple operations along with the derivation. This has several advantages: (1) lines of our calculus have a clear semantic meaning as they are accompanied by semantic objects; (2) partial strategies are represented succinctly (in contrast to some previous approaches); (3) our calculus has strategy extraction by design; and (4) the partial strategies allow new sound inference steps which are disallowed in previous central QBF calculi such as Q-Resolution and long-distance Q-Resolution. The last item (4) allows us to show an exponential separation between our new system and the previously studied reductionless long-distance resolution calculus. Our approach also naturally lifts to dependency QBFs (DQBF), where it yields the first sound and complete CDCL-style calculus for DQBF, thus opening future avenues into CDCL-based DQBF solving.
Keywords: QBF, DQBF, Resolution, Proof complexity
Introduction
Proof complexity investigates the resources for proving logical theorems, focussing foremost on the minimal size of proofs needed in a particular calculus. Since its inception the field has enjoyed strong connections to computational complexity (cf. [17, 20]) and to first-order logic [19, 38]).
During the past decade, proof complexity has emerged as a key tool to model and analyse advances in the algorithmic handling of hard problems such as SAT and beyond. While traditionally perceived as a computationally hard problem, SAT solvers have been enormously successful in tackling huge industrial instances [42, 56] and hard combinatorial problems [32]. As each run of a solver on an unsatisfiable formula can be understood as a proof of unsatisfiability, each solver implicitly defines a proof system. This connection turns proof complexity into the main theoretical approach towards understanding the power and limitations of solving, with bounds on proof size directly corresponding to bounds on solver running time [17, 43].
The algorithmic success story of solving has not stopped at SAT, but is currently extending to even more computationally complex problems such as quantified Boolean formulas (QBF), which is complete, and dependency QBFs (DQBF), which is even complete [1]. While quantification does not increase expressivity, (D)QBFs can encode many problems far more succinctly, including application domains such as automated planning [18, 22], verification [6, 41], synthesis [24, 40] and ontologies [37].
The past 15 years have seen huge advances in QBF solving. While some of the main innovations in SAT solving, including the development of conflict-driven clause learning (CDCL), revolutionised SAT in the late 1990s [53], this development in QBF is happening now. Consequently, QBF proof complexity has received considerable attention in recent years.
Compared with QBF, solving in DQBF [26] is at its very beginnings, both in implementations (2018 was the first year that saw a DQBF track in the QBF competition [48]) as well as in its accompanying theory [52].
Strategy extraction is one of the distinctive features of QBF and DQBF, manifest in both solving [5, 49] and proof complexity. For solving it guarantees that together with the true/false answer the solver can produce a model (or countermodel) of the (D)QBF. This is an important step in the solving workflow, since a model (or countermodel) may encode a solution (or a counterexample) to the given problem. For example, a model for a QBF encoding a synthesis problem defines an implementation meeting the desired specification [31]. Determining truth merely implies the existence of such a system.
On the proof complexity side, this implies that proof calculi modelling QBF solving should allow strategy extraction in the sense that from a refutation of a false QBF, a countermodel of the QBF can be efficiently constructed. This feature—without analogue in the propositional domain—enables strong lower-bound techniques in QBF proof complexity [9, 11, 12], exploiting the fact that formulas requiring hard strategies cannot have short proofs in calculi with efficient strategy extraction.
As in SAT versus propositional proof complexity, one of the prime challenges in QBF and DQBF is to create compelling proof-theoretic models that capture central features of (D)QBF solving and at the same time remain amenable to a proof-theoretic analysis. While there exist several orthogonal approaches in QBF solving with quite different associated proof calculi, we will focus here on the paradigm of quantified conflict-driven constraint learning (QCDCL) [59]. An interesting feature of QCDCL is that it combines conflict learning with solution learning. Whereas a CDCL SAT solver can terminate upon finding a single solution (i.e. a satisfying assignment), a QCDCL QBF solver will repeatedly learn and manipulate solutions, aiming to determine the truth of the input QBF.1 Meanwhile, the solver also employs conflict learning, aiming to determine falsity. Here we focus on the conflict learning side. Proof-theoretically its most basic model is Q-Resolution [35], which as in propositional resolution operates on clauses (of prenex QBFs).
Q-Resolution () uses the resolution rule of propositional resolution and augments this with a universal reduction rule that allows to eliminate universal variables from clauses. Combining these two rules requires some technical care: without any side-conditions the two rules result in an unsound system. Typically this is circumvented by prohibiting the derivation of universal tautologies. It was noted early on that in solving this is needlessly prohibitive [59] and universal tautologies can be permitted under certain side-conditions. Later formalised as the proof system long-distance Q-Resolution () [3], it was even shown that exponentially shortens proofs in comparison to [23], thus demonstrating the appeal of the approach for solving. In fact, when enabling long-distance steps in QBF solving, universal reduction is not strictly needed and this reductionless approach was adopted in the QBF solver GhostQ [36]. To model this solving paradigm, Bjørner, Janota, and Klieber [15] introduced the calculus of reductionless .
The interplay between long-distance resolution and universal reduction steps becomes even more intriguing in DQBF. In [2] it was shown that lifting (using the rules of resolution and universal reduction) to DQBF results in an incomplete proof system, whereas lifting (using long-distance resolution steps together with universal reduction) becomes unsound [13].
Naturally, the intriguing question of why and how deriving ‘universal tautologies’ in long-distance steps might help solving has attracted attention among theoreticians and practitioners alike. Instead of a universal tautology , most formalisations of long-distance resolution actually use the concept of a ‘merged’ literal . While it is clear (and implicit in the literature) that merged literals correspond to partial strategies for u rather than universal tautologies, a formal semantic account of long-distance steps (and stronger calculi using merging [12]) was only recently given by Suda and Gleiss [54], where partial strategies are constructed for each individual proof inference. However, as already noted in [54], the models considered in [54] fail to have efficient strategy extraction in the sense that the constructed (partial) strategies may need exponential-size representations.
Our contributions
A. The new calculus of Merge Resolution. Starting from the reductionless system of [15] and its role of modelling QCDCL solving, we develop a new calculus that we call Merge Resolution (). Like reductionless , the system only uses a resolution rule and does not permit universal reduction steps. Reductionless and are therefore both refutational calculi that finish as soon as they derive a purely universal clause.
As the prime novel feature of we build partial strategies into proofs. We achieve this by computing explicit representations of strategies in a variant of binary decision diagrams (called merge maps here), which are updated and refined at each proof step by simple operations. These merge maps are part of the proof. As a consequence, has efficient strategy extraction by design.
This is in contrast to all previous existing QBF calculi in the literature, where strategies are algorithmically constructed from proofs. In particular, this also applies to the approaches taken in [23, 54] for and in [15] for reductionless . But also the choice of our representation as merge maps matters: as [15, 54] both represent (partial) strategies as trees, the constructed strategies may grow exponentially in the proof size, thus losing the property of efficient strategy extraction desired for practice. In contrast, in our model merge maps are always linear in the size of the clause derivations.
B. Exponential separation of from reductionless . Including merge maps explicitly into proofs also has another far-reaching advantage: it allows resolution steps not only forbidden in , but even disallowed in . In a nutshell, allows resolution steps only when universal variables quantified left of the pivot have constant and equal strategies in both parent clauses. In we have explicit representations of strategies and thus can allow resolution steps as long as the strategies in both parent clauses are isomorphic to each other, a property that we can check efficiently for merge maps.
This last mentioned advantage of allowing resolution steps in forbidden in (reductionless) manifests in shorter proofs. We show this by explicitly giving an example of a family of QBFs that admit linear-size proofs in (Theorem 29), but require exponential size in reductionless (Theorem 28). The separating formulas are a variant of the equality formulas introduced in [9]. While the original formulas from [9] are hard for , but easy in , we here consider a ‘squared’ version, for which we naturally use resolution steps for clauses with associated non-constant winning strategies, allowed in , but forbidden in .
This demonstrates that is exponentially stronger than reductionless , thus also pointing towards potential improvements in QCDCL solving. While the simulation of reductionless by is almost immediate and also the upper bound in is comparatively straightforward, the lower bound is a technically involved argument specifically tailored towards the squared equality formulas.
C. A sound and complete CDCL-style calculus for DQBF. As our final contribution we show that the new QBF system of naturally lifts to a sound and complete calculus for DQBF. As shown in [2], the lifting of to DQBF is incomplete, whereas the combination of universal reduction and long-distance steps presents soundness issues, both in DQBF [13] as well as in the related framework of dependency schemes [7, 8].
Here we show that our framework of overcomes both these soundness and completeness issues and therefore has exactly the right strength for a natural DQBF resolution calculus. In fact, it is the first DQBF CDCL-style system in the literature2 and as such paves the way towards CDCL-style solving in DQBF. Again, by design our DQBF system has efficient strategy extraction.
Preliminaries
Propositional logic Let be a countable set of Boolean variables. A literal is a Boolean variable or its negation , a clause is a set of literals, and a CNF is a set of clauses. For a literal l, we define if or ; for a clause C, we define ; for a CNF we define .
An assignment to a set of Boolean variables is a function , conventionally represented as a set of literals in which z (resp. ) represents the assignment (resp. ). The set of all assignments to Z is denoted . Given a subset , is the restriction of to . The CNF is obtained from by removing any clause containing a literal in , and removing the negated literals from the remaining clauses. We say that falsifies if contains the empty clause, and that is unsatisfiable if it is falsified by each .
Given two clauses and and a literal l such that and , we define the resolvent . (Note that .) A resolution refutation of a CNF is a sequence of clauses in which is the empty clause and, for each , either (a) or (b) for some and .
Quantified Boolean formulas A quantified Boolean formula (QBF) in prenex conjunctive normal form (PCNF) is denoted , where (a) is the quantifier prefix, in which the are pairwise disjoint finite sets of Boolean variables, for each , and for each , and (b) the matrix is a CNF over .
The existential (resp. universal) variables of , typically denoted X (resp. U), is the set obtained as the union of the for which (resp. ). The prefix defines a binary relation on , such that holds iff , , and , in which case we say that is right of z and z is left of . For each , we define , i.e. the existential variables left of u.
QBF semantics Semantics for QBFs is neatly described by the two-player evaluation game. Over the course of a game, the variables of a QBF are assigned 0/1 values in the order of the prefix, with the -player (-player) choosing the values for the existential (universal) variables. When the game concludes, the players have constructed a total assignment to the variables. The -player wins iff falsifies .
A strategy dictates how the -player should respond to every possible move of the -player. A strategy h for a QBF is a set of functions . Additionally h is winning if, for each , the restriction of by contains the empty clause. We use the terms ‘winning strategy’ and ‘countermodel’ interchangeably. A QBF is called false if it has a countermodel, and true if it does not.
A partial strategy for a universal variable u is a function from some subset of into .
QBF proof systems We deal with line-based refutational QBF systems that typically employ axioms and inference rules to prove the falsity of QBFs. We say that is complete if there exists a refutation of every false QBF, sound if there exists no refutation of any true QBF. We call a proof system if it is sound, complete, and polynomial-time checkable. Given two QBF proof systems and , p-simulates if there exists a polynomial-time procedure that takes a -refutation and outputs a -refutation of the same QBF [20].
Reductionless long-distance Q-Resolution
In this section we recall the definition of reductionless , prove that it is refutationally complete, and demonstrate that it does not have polynomial-time strategy extraction in either of the computational models of [15, 54]. The system appeared first in [15, Fig. 1], where it was referred to as -resolution.
Definition 1
(reductionless [15]) In reductionless , a derivation from a QBF is a sequence of clauses in which at least one of (a) or (b) holds for each :
Axiom. is a clause from the matrix ;
Long-distance resolution. There exist integers and an existential pivot such that and, for each , if , then .
The final clause is the conclusion of , and is a refutation of iff contains no existential variables.
A pair of complementary universal literals appearing in a clause is referred to singly as a merged literal. It is clear from a wealth of literature3 that merged literals are ‘placeholders’ for partial strategies, the exact representation left implicit in the structure of the derivation.
We illustrate the rules of the calculus by showing that the equality formulas [9] have linear-size refutations.
Definition 2
(equality formulas [9]) The equality family is the QBF family whose instance has the prefix and the matrix consisting of the clauses for , and .
Example 3
We construct linear-size reductionless refutations in two stages. First, resolve each pair , of clauses over pivot to obtain . Note that it is allowed to introduce the merged literal since variable is right of the pivot . Second, resolve the successively against the long clause over pivot , to obtain a full set of merged literals . Here, even though is left of the pivot , the appearance of the merged literal in the resolvent is allowed, since variable is absent from one of the antecedents. The derivation is a refutation since the conclusion C contains no existential literals.
We now show that this calculus is indeed complete. Given a false QBF with a countermodel h, we construct a canonical reductionless refutation based on the ‘full binary tree’ representation of a countermodel [51]. For each , there exists some in the matrix falsified by . The set of all such may be successively resolved over existential pivots in reverse prefix order, finally producing a clause containing no existentials. Merged literals never block resolution steps in this construction, as they only ever appear to the right of the pivot variable.
Example 4
Consider the QBF with the prefix and the matrix consisting of the clauses
It is easy to see that the unique countermodel for this QBF essentially sets u and v equal to x and y, respectively. Formally, the countermodel consists of the functions and , where and , for each and .
Figure 1 shows the full binary tree depiction of this countermodel and its associated reductionless refutation. Notice that each path from root to leaf in the countermodel tree specifies a total assignment that falsifies the corresponding axiom clause. Notice also that the existential resolution pivots on each path from an axiom to the conclusion occur in reverse prefix order, matching the pattern of the full binary tree countermodel. The prefix order inherent to the countermodel tree also ensures that each long-distance resolution step is valid.
Fig. 1.

The full binary tree depiction of a countermodel and its associated reductionless refutation
Lemma 5
Every false QBF has a reductionless refutation.
Proof
Let be a false QBF with countermodel h. Let denote the existential variables of in prefix order; that is, for each with , is not right of . Let define the natural lexicographic ordering of the total assignments to X, as in
 |
We define a sequence in which each , and the clauses are defined recursively as follows: For , is any clause in falsified by (at least one such clause exists by definition of countermodel); for and , if this resolvent exists, otherwise
It is readily verified by downwards induction on that each contains no complementary universal literals in variables left of . Moreover, it is easy to see that the conclusion contains no existential literals. Removing duplicate clauses from produces a reductionless refutation of .
Soundness and polynomial-time checkability of reductionless are immediate, as the system uses a subset of the rules of the classical long-distance Q-resolution proof system [3].
The computational model of Bjørner et al. [15]. In tandem with reductionless , the authors of [15] introduced a computational model based on tree-like branching programs. The model is used to explicitly construct the partial strategies represented implicitly by merged literals.
We demonstrate that tree-like branching programs constructed in this way cannot represent strategies efficiently; that is, the system does not have polynomial-time strategy extraction in the associated model (even for partial strategies). The following example shows a linear-size derivation whose explicit strategy grows exponentially large.
Example 6
Consider the following proof fragment, in reductionless , with a prefix . Alongside each proof line is the strategy for the universal variable u, as built by the Build function in [15]. In a nutshell, Build traverses the subderivation of the current step, and represents the pattern of merges on u as a tree-like branching program that queries the (existential) resolution pivots.
| Line | Obtained as | Clause | Strategy as built in [15] |
|---|---|---|---|
| axiom | 0 | ||
| axiom | 1 | ||
| axiom | 0 | ||
| axiom | |||
| axiom | |||
| axiom | |||
Observe that the final strategy at line 12 represents the strategy corresponding to line 3 twice. By nesting such a proof fragment from lines to with fresh copies of the existential variables (v, x, y, z) k times, we can construct a reductionless proof fragment with O(k) lines, where the strategy built by the Build function from [15] has size exponential in k.
The computational model of Suda and Gleiss [54]. The authors of [54] proposed a model of partial strategies based on so-called policies (a policy is a set of assignments specifying an ordered decision tree.) They noted that the equality formulas have linear-size refutations in the strong QBF system [12], whereas policies witnessing their falsity must be exponentially large, therefore does not admit polynomial-time strategy in policies. The same is true for reductionless , since Example 3 shows that the equality formulas also have linear-size refutations there.
The computational model of policies is not even suitable for strategy extraction in the weak system level-ordered [34].4 Versions of the equality formulas in which the prefix is rearranged () have linear-size level-ordered refutations, whereas winning strategies represented as policies must be large. The argument is the same as for the equality formulas [54], and derives from the implicit use of tree-like structures.
That neither model is suitable for efficient strategy extraction shows that using either inside the derivation would result in an artificial, exponential size blow-up. The root of the issue is tree-like models versus DAG-like proofs. The DAG-like computational model that we introduce in the following section is tightly knitted to the refutation, yielding linear-time strategy extraction for free.
Merge resolution
In this section we introduce Merge Resolution (, Sect. 4.2), and prove that it is sound and complete for QBF (Sect. 4.3). The salient feature of is the built-in partial strategies, represented as merge maps. Given the problems with the computational models of [15, 54], the principal technical challenge is to find a suitable way to define and combine partial strategies devoid of an artificial proof-size inflation.
Merge maps
Our computational model A merge map is a branching program that queries a set of existential variables and outputs an assignment to some universal variable, i.e. a literal in , where stands for ‘no assignment’. As we intend to tie the DAG structure of the merge maps to the DAG structure of the proof, we will label query nodes with natural numbers based on the proof line indexing (we elaborate on this later). Hence, from a technical standpoint it makes sense to define a merge map as a function from the index set of its nodes.
Definition 7
(merge map) A merge map M for a Boolean variable u over a finite set X of Boolean variables is a function from a finite set N of natural numbers satisfying, for each , either or , where .
A triple of the form represents the instruction ‘if then goto a else goto b’, whereas the literals represent output values. The exact computation is formalised below.
Definition 8
(computed function) Let M be a merge map for u over X with domain N. The function computed by M is the function
mapping to the output of the following algorithm:
We depict merge maps pictorially as DAGs. The nodes are the domain elements, and the leaf nodes as well as the directed edges are labelled by literals. In a merge map M, if M(i) is a literal l, then node i is labeled l. If , then the DAG has the edge labeled and the edge labeled x. The DAG naturally describes a deterministic branching program computing a Boolean function.
Figure 2 shows a merge map represented as a function, and its corresponding depiction as a branching program.
Fig. 2.

Function and branching program representations of a merge map M
Relations Merge Resolution uses two relations to determine preconditions for the binary operations. Firstly, we give the power to identify merge maps with equivalent representations, up to indexing. We term equivalent representations ‘isomorphic’.
Definition 9
(isomorphism) Two merge maps and for u over X with domains and are isomorphic (written ) iff there exists a bijection such that the following hold for each :
if is a literal in then ;
if is the triple (x, a, b) then .
Proposition 10
Any two isomorphic merge maps compute the same function.
Proof
Let and be merge maps, let f be a bijection satisfying the properties of Definition 9, and let . The computation of as in Definition 8 is identical to that of , except that each natural number is replaced with f(a). The proposition follows.
Our second relation, consistency, simply identifies whether or not two merge maps agree on the intersection of their domains.
Definition 11
(consistency) Two merge maps and for u over X with domains and are consistent (written ) iff for each .
Example 12
For the merge maps depicted in Fig. 3, isomorphism and consistency (or lack thereof) are as given in the table below.
Fig. 3.
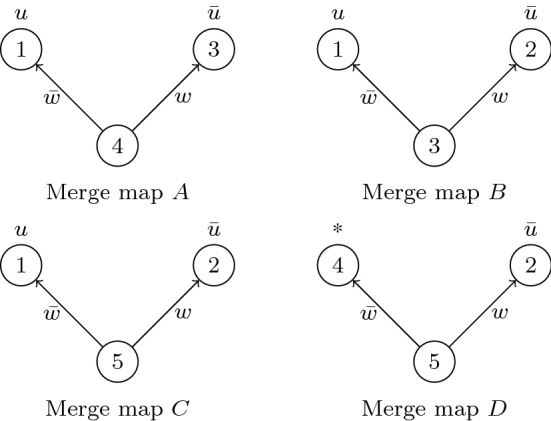
Relations on merge maps
| Relation | Isomorphic | Not isomorphic |
|---|---|---|
| Consistent | ; | ; |
| Not consistent | ; | ; |
It is easy to see that both relations can be computed in time polynomial in . (To check isomorphism, step through the two merge maps starting from their maximal domain elements . Using memoization, iteratively build the bijection-witnessing isomorphism. Any suitable data structure that allows efficient insertion and search can be used for this. To check consistency, construct the two domains—again, using an appropriate data structure, and check that the instructions at common line numbers match.)
Operations uses two binary operations to build merge maps for the resolvent based on those of the antecedents. We define the operations and give some intuition on their role in . Concrete examples follow the definition of the system in the next subsection.
The select operation identifies equivalent merge maps by means of the isomorphism relation. It also allows a trivial merge map to be discarded; we call a merge map trivial iff it is isomorphic to . (The operation is undefined if the merge maps are neither isomorphic nor do they contain a trivial map.)
Definition 13
(select) Let and be merge maps for which or one of is trivial. Then if is trivial, and otherwise.
The merge operation allows two consistent merge maps to be combined as the children of a fresh query node. Antecedent maps are only ever merged for universal variables right of the pivot x. The inclusion of a natural number n allows the new query node to be identified with the resolvent, via its index in the proof sequence. In this way, query nodes are shared between later merge maps, rather than being duplicated; the result is a DAG-like structure which faithfully follows that of the derivation.
Definition 14
(merge) Let and be consistent merge maps for u over X with domains and , let be a natural number, and let . Then is the function from defined by
Example 15
Definition of
We are now ready to put down the rules of Merge Resolution. Given a non-tautological clause C and a Boolean variable u, the falsifying u-literal for C is if there is a literal with , and otherwise.
Definition 16
(merge resolution) Let be a QBF with existential variables X and universal variables U. A merge resolution () derivation of from is a sequence of lines in which at least one of the following holds for each :
Axiom. There exists a clause in such that is the existential subclause of C, and, for each , is the merge map for u over with domain mapping i to the falsifying u-literal for C;
- Resolution. There exist integers and an existential pivot such that and, for each , either
-
(i), or
-
(ii)and .
-
(i)
The final line is the conclusion of , and is a refutation of iff . The size of is .
Note that the order of the indexes a and b in matches that of . This is why we interpret the triple (x, a, b) as ‘if then goto a else goto b’. Using the conventional ‘if ’ entails swapping the order of the arguments and .
We illustrate the rules of with two examples. The first demonstrates that labelling branching nodes with proof-line indexes sidesteps the exponential blow-up in the computational model of [15].
Example 17
The reductionless proof fragment in Example 6 can be viewed as a proof in if we attach appropriate merge maps at each line.
| Line | Rule | Query | ||
|---|---|---|---|---|
| axiom | ||||
| axiom | ||||
| axiom | ||||
| axiom | ||||
| axiom | ||||
| axiom | ||||
In lines , and , the use of is allowed, since in each case one of the antecedent merge maps is trivial (i.e. isomorphic to ). Notice that at line , we could also have chosen to be ; this would result in a larger merge map.
Now, consider the final merge map . The corresponding branching program has isolated nodes numbered 6, 8, and 10; these can be removed, giving the pruned merge map shown in Fig. 4. Notice how the size blow-up from Example 6 is avoided here; since and are consistent, node 12 simply points to both of them, and the shared part (that is, the branching program containing nodes 1, 2, and 3) is represented just once.
Fig. 4.
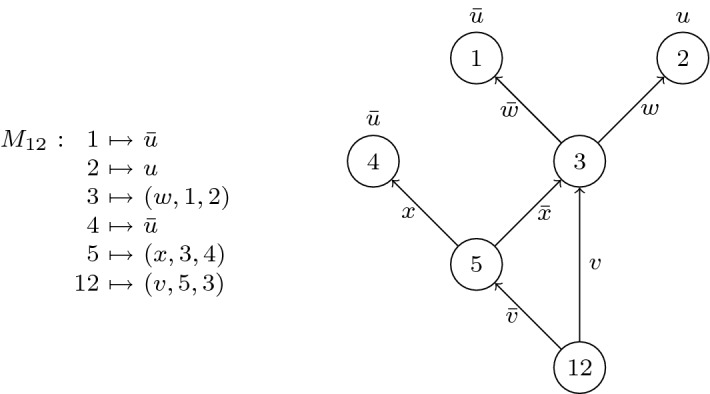
Function and branching program representations of from Example 17
Our second example illustrates how the explicit representation of strategies, in tandem with the isomorphism relation, gives access to resolution steps that are disallowed in reductionless .
Example 18
Consider the following refutation of the QBF with prefix and clauses , , and .
| Line | Rule | Query | ||
|---|---|---|---|---|
| axiom | ||||
| axiom | ||||
| axiom | ||||
| axiom | ||||
As shown in Fig. 5, and are isomorphic, so is defined and equal to . For this reason, the resolution of antecedents and into is allowed, and the final merge map is simply a copy of . The analogous resolution would be disallowed in reductionless because the pivot t is right of u, and the non-constant merge maps and would appear as merged literals in the antecedent clauses.
Fig. 5.

Functions and branching programs for merge maps and from Example 18
We conclude this subsection by showing that the number of lines really is the correct size measure for Merge Resolution. The justification lies in the fact that the domain of the merge map at line i is a subset of [i].
Proposition 19
Let be an refutation of . For each , are pairwise consistent merge maps for u over with for each .
Proof
The claim follows straightforwardly from three observations: (1) each introduces at most one node, which is labelled i; (2) if is an axiom, then each is a merge map over ; (3) the merge operation is only applied when .
Soundness and completeness of
The soundness of comes down to the fact that the merge maps at a given line form a partial strategy for the input QBF, in the technical sense of [54]. This means that any total existential assignment that falsifies the clause will falsify the matrix when extended by the output of the merge maps . Our proof of soundness is an induction on the proof structure with exactly this invariant. At the conclusion, all existential assignments falsify the empty clause , and hence the compute a countermodel. A trivial corollary, then, is that has linear strategy extraction in merge maps. Our formal proof of soundness is preceded by a preliminary proposition.
Proposition 20
Let and be consistent merge maps for u over X with domains and , let be a natural number, let and let . Further, let and h be the functions computed by , and . Then if , and if .
Proof
Let , and suppose that . By Definition 14, and for each . Hence, the computation of from the second iteration of the while loop is identical to the computation of from the first iteration, and it follows that . Suppose instead that . By Definition 14, for each ; by Definition 11, for each . Then for each , and the proposition follows as in first case.
Lemma 21
Let be the conclusion of an refutation of a QBF . Then the functions computed by form a countermodel for .
Proof
Let be an refutation of a QBF , where each . Further, for each ,
let be the smallest assignment falsifying ,
let be all assignments to X consistent with ,
for each , let be the function computed by ,
for each , let and .
(Note that Proposition 19 guarantees that each is defined.) By induction on , we show, for each , that the restriction of by contains the empty clause. Since is the empty assignment, we have . We therefore prove the lemma at the final step , as we show that is a countermodel for .
For the base case , let . As is introduced as an axiom, there exists a clause such that is the existential subclause of C, and each is the merge map from mapping i to the falsifying u-literal for C. Hence, for each , is the falsifying u-literal for C, so .
For the inductive step, let and let . The case where is introduced as an axiom is identical to the base case, so we assume that was derived by resolution. Then there exist integers and an existential pivot such that , and each satisfies either (i) , or (ii) , and . Now, suppose on the one hand that , and let . If u satisfies (i) and is non-trivial, then , and if u satisfies (ii) then by Proposition 20. It follows that only if , and hence . Since , we have , so the restriction of by contains the empty clause by the inductive hypothesis. Supposing, on the other hand, that , a similar argument shows that . Note that, in this case, if u satisfies (i) and is non-trivial, then and by Proposition 10.
We show the completeness of via the p-simulation of reductionless . The simulation copies precisely the structure of the reductionless refutation, while replacing merged literals by merge maps in the natural way.
Theorem 22
p-simulates reductionless .
Proof
Let be a QBF with existential variables X and universal variables Y, and let be a reductionless refutation of . We define a sequence , in which each , and prove that it is an refutation of .
For each , we define to be the existential subclause of . For each , the merge maps are defined recursively as follows: If is an axiom, is defined as the merge map over with domain mapping i to the falsifying u-literal for (note that this covers the definition of ). If is derived by resolution, say with , then
Now, by induction on , we prove that, for each ,
if , then is isomorphic to , where l is the falsifying u-literal for ,
can be derived from previous lines in using an rule.
Both are established trivially when is an axiom; hence it remains to show the inductive step in the case where was derived by resolution. In this case for some and some .
Suppose that , and let be the falsifying u-literals for . By definition of resolution, either (1) , or (2) exactly one of is trivial (, say), the other is equal to . In the former case, and are both isomorphic to , by the inductive hypothesis; in the latter case, is isomorphic to and is trivial. Either way we get , and the inductive step follows.
By Proposition 19, for each , and are consistent merge maps for u over , so is defined for any case. Hence, if we can show that is defined whenever , then it is clear that can be derived by resolution from and . To that end, let u be left of x. If , then is defined by (a). Otherwise, we must have , so the falsifying u-literal for one of and is By the inductive hypothesis, one of and is trivial, and is defined.
This completes the induction. Since contains only universal variables, is the empty clause, and is a refutation.
With soundness and completeness established by Lemma 21 and Theorem 22, it remains to show that refutations can be checked in polynomial time. This is easy to see, since the isomorphism and consistency relations are computable efficiently.
Theorem 23
is a QBF proof system.
Proof complexity: merge resolution versus reductionless
In this section we exponentially separate from reductionless . The separating formulas are a kind of ‘squaring’ of the equality formulas from Definition 2.
Definition 24
(squared equality formulas) The squared equality family is the QBF family whose instance  has the prefix
has the prefix
and the matrix  consisting of the clauses
consisting of the clauses
The only winning strategy for the universal player is to set and for each . At the final block, the existential player is faced with the full set of unit clauses, and to satisfy all of them is to falsify the square clause . No other strategy can be winning, as it would fail to produce all unit clauses.
 lower bound for reductionless
lower bound for reductionless
We first give a formal definition of a refutation path; that is, a sequence of consecutive resolvents beginning with an axiom and ending at the conclusion.
Definition 25
(path) Let be a reductionless refutation. A path from a clause C in is a subsequence of in which:
is an axiom of ;
is the conclusion of ;
for each , there exists a literal and a clause occurring before in such that .
The lower-bound proof is based upon two facts: (1) every total existential assignment corresponds to a path, all of whose clauses are consistent with the assignment (Lemma 26); (2) every path from the square clause contains a ‘wide’ clause containing either all the or all the variables (Lemma 27). It is then possible to deduce the existence of exponentially many wide clauses, i.e. by considering the set of assignments for which each and each , all of whose corresponding paths begin at the square clause (proof of Theorem 28).
Lemma 26
Let be a reductionless refutation of a QBF , and let A be a clause with . Then there exists a path in in which no existential literal outside of A occurs.
Proof
We describe a procedure that constructs a sequence of clauses in reverse order as follows: To begin with, let the ‘current clause’ be the conclusion of . As soon as the current clause is in an axiom, the procedure terminates. Whenever necessary, obtain as follows: find clauses and occurring before in and a literal such that is , and set as the current clause. P is clearly a path in by construction. By induction one shows that the existential subclause of is a subset of A, for each : The base case holds trivially since there are no existential literals in the conclusion of . For the inductive step, observe that , for some subset and literal .
The second lemma is more technical, and its proof more involved. The proof works directly on the definition of path, the rules of reductionless , and the syntax of the squared equality formulas, to show the existence of the wide clause.
Lemma 27
Let , and let be a reductionless refutation of  . On each path from in , there occurs a clause C for which either or .
. On each path from in , there occurs a clause C for which either or .
Proof
Put and . Call a clause R in a p-resolvent if there exist earlier clauses and such that .
Let be a path from in . With each we associate an matrix in which if and otherwise. Let l be the least integer such that has either a 0 in each row or a 0 in each column. Note that since has no zeros.
We prove the lemma by showing that either or must hold.
Suppose that has a 0 in each row. We make use of the following claims, which hold for all :
for each clause C on P, if then ;
each -resolvent in contains as a subset;
for each -resolvent R in , if then .
We proceed to show that every row in also has at least one 1. To see this, suppose on the contrary that contains a full 0 row r (this implies that , and hence that exists). Note that by definition of resolution there can be at most one element that changes from 1 in to 0 in . Since does not have a 0 in every column, it does not contain a full zero row. Hence it must be the case that the unique element that went from 1 in to 0 in is in row r. Since , we deduce that has a 0 in each row, contradicting the minimality of l.
Let . Since the row in contains a 1, there is some for which . From claim (1) it follows that . Moreover, as universal literals accumulate along the path, this means that for each . Since the row in contains a 0, there exists such that . As , there must be a -resolvent on P with . Then we have by claim (3). Also, for each , is not an -resolvent by claim (2). It follows that . Since was chosen arbitrarily, we have .
Suppose on the other hand that does not contain a 0 in each row. Then contains a 0 in each column. A symmetrical argument, with analogous claims involving the variables, then shows that .
It remains to prove the three claims.
Observe that each clause in containing the positive literal also contains the variable (this holds for every axiom and universal literals are never removed). Let C be a clause on the path P for which , and, for the sake of contradiction, suppose that . Since , there cannot be -resolvent on P following C, as such a resolution step is explicitly forbidden in the rules of reductionless . This means that occurs in , the final clause of P. This is a contradiction, since is the conclusion of , which contains no existential literals. Therefore .
Observe that each clause in containing (resp. ) also contains (resp. ) (again, this holds for every axiom and universal literals are never removed). Let R be an -resolvent of and in . Since and , we must have and . It follows immediately that .
Observe that each axiom in containing the positive literal contains variable . Hence, any clause in that contains literal but not variable must appear after an -resolvent on some path, and therefore contains by Claim (2). Now, let R be a -resolvent of and in . Suppose that , which implies that . Since , we have , and it follows that .
It remains to prove the lower bound formally from the preceding lemmata.
Theorem 28
The squared equality family requires exponential-size reductionless refutations.
Proof
Let , and let be a reductionless refutation of  . We show that . The size bound is trivially true for , so we assume . Put and , and let be the long clause from
. We show that . The size bound is trivially true for , so we assume . Put and , and let be the long clause from  . We call a non-tautological clause S
symmetrical iff and for each . (A symmetrical clause represents a total assignment to ). Note that there are distinct symmetrical clauses.
. We call a non-tautological clause S
symmetrical iff and for each . (A symmetrical clause represents a total assignment to ). Note that there are distinct symmetrical clauses.
By Lemma 26, for each symmetrical clause S, there exists a path in in which all existential literals are contained in . Moreover, each begins at clause L, since every other clause in contains some positive literal that does not occur in . By Lemma 27, on each path P from L in there exists a clause C for which either or . It follows that we can define a function f that maps each symmetrical assignment S to a clause f(S) in for which either or . Moreover, since distinct symmetrical clauses and satisfy and , each f(S) is the image of at most two distinct symmetrical clauses. Hence, contains at least clauses.
Close inspection of the lower-bound proof reveals that particular resolution steps are blocked due to the appearance of merged literals in the antecedents (see the proof of claim (1) of Lemma 27). As we noted in Example 18, such steps remain blocked even if both merged literals implicitly represent the same (non-constant) function, in which case the resolution step is actually perfectly sound. As we will see, the upper-bound construction makes crucial use of the isomorphism of non-constant merge maps.
Short refutations of 
Here we construct short refutations of the squared equality formulas. The approach is as follows. First, for each , obtain a line by resolving the axioms for the four clauses in that contain . By the natural application of the and operations, one obtains merge maps in which the merge map for outputs with a single query, the merge map for outputs with a single query, and all other maps are trivial. Notice that all the non-trivial merge maps for a given universal variable are isomorphic, so these unit clauses can all be resolved against the square clause, utilising the select operation. It is precisely this final step which is unavailable in reductionless .
Theorem 29
The squared equality family has -size refutations.
Proof
Let . We construct a refutation in two stages. In the first stage we explicitly construct an derivation from  , where . In the second stage, we show that can be extended to a refutation with a further lines.
, where . In the second stage, we show that can be extended to a refutation with a further lines.
Stage one. For each we let and use L(h, i, j) as an alias for . Similarly, we let C(h, i, j) be the clause, U(h, i, j) be the merge map for , and V(h, i, j) be the merge map for appearing on line L(h, i, j). These U(h, i, j) and V(h, i, j) are the only merge maps in we define explicitly; we consider all others to be defined implicitly as the appropriate trivial merge map.
Letting , we define the first lines with
 |
and observe that each of these lines can be introduced as an axiom.
The next lines are the result of the natural resolutions over . For each we define
Each line L(4, i, j) can be derived by resolution from L(0, i, j) and L(2, i, j); to see this, note that U(0, i, j) is clearly isomorphic to U(2, i, j) and V(0, i, j) is trivially consistent with V(2, i, j) (their domains are disjoint), therefore and
A similar argument shows each that L(5, i, j) can be derived by resolution from L(1, i, j) and L(3, i, j).
The final lines are the result of the natural resolutions over . For each we define
It is easy to see that each L(6, i, j) can be derived by resolution from L(4, i, j) and L(5, i, j), since V(4, i, j) is clearly isomorphic to V(5, i, j) (an isomorphism is ) and U(0, i, j) is trivially consistent with U(1, i, j) (disjoint domains).
Stage two. We now show how can be extended to a refutation. Let denote the final lines of , in each of which appears some unit clause . We observe that, for each , U(6, i, a) is isomorphic to U(6, i, b) (an isomorphism is ); that is, amongst the lines , the non-trivial merge maps for are pairwise isomorphic. Similarly, for each , the non-trivial merge maps for appearing in are pairwise isomorphic.
Now, a line T, consisting of the clause and a full set of trivial merge maps, can be introduced as an axiom in a derivation from  . From T and , in a further steps we obtain a refutation by successively resolving each line in against T, removing a literal each time. All such resolution steps are valid, since the merge map for () in any line can be defined as , where and are the merge maps for appearing in the antecedent lines. The isomorphism of non-trivial merge maps for () is preserved, and ensures that is defined.
. From T and , in a further steps we obtain a refutation by successively resolving each line in against T, removing a literal each time. All such resolution steps are valid, since the merge map for () in any line can be defined as , where and are the merge maps for appearing in the antecedent lines. The isomorphism of non-trivial merge maps for () is preserved, and ensures that is defined.
Theorem 30
does not p-simulate on QBF.
Overview of DQBF
In this section, we provide an overview of DQBF, which will help to explain how Merge Resolution is best extended to a DQBF proof system (in Sect. 7).
S-form versus H-form
A DQBF can be written in one of two forms: Skolem-form (S-form) and Herbrand-form (H-form) [2]. To date, most of the DQBF literature has focused on S-form (whether in computational complexity [1, 16], proof complexity [8, 50], and solving [27, 29, 55, 57, 58]), whereas relatively little has been written about H-form [2]. The DQBF solver presented in [25] uses H-form DQBF to facilitate a reduction to QBF. Otherwise, as far as we are aware, existing DQBF solvers use S-form exclusively [52].
We will recall S-form and H-form DQBFs, their semantics, and the transformation operation that relates them.
An S-form dependency quantified Boolean formula (DQBF) is a formula of the form
| 1 |
in which is a CNF, and each is a subset of the universally quantified variables . S-form DQBF generalises QBF, since the quantifier prefix has a more general specification that allows variable dependencies for the existentials to be written explicitly in the sets . QBF is the fragment of S-form DQBF for which the dependency sets are nested subsets, i.e. .
An S-form DQBF is true if and only if it has a Skolem-function model. A Skolem-function model g for is a set of functions
such that, for each ,
An H-form DQBF is the obvious dual to S-form, namely a formula of the form
in which is a CNF, and each is a subset of the existentially quantified variables . Here the express the variable dependencies for the universals, as opposed to the existentials in S-form.
An H-form DQBF is false if and only if it has an Herbrand-function countermodel, which is dual to a Skolem-function model. An Herbrand-function countermodel h for is a set of functions
such that, for each ,
The dual definitions of S-form and H-form DQBF seem perfectly natural, and both sets of formulas generalise QBF in an obvious way. Nonetheless, it was shown in [2] that the situation in terms of semantics is already quite complex. To see this, consider the transformation operation T defined below. (It is a combination of the negation and complement operators defined in [2]. We find it more convenient here to have a single operation.) This operator is a natural map from S-form onto H-form DQBF and from H-form onto S-form DQBF. The T-transform of the S-form DQBF in (1) is the H-form DQBF
where . Intuitively, in the transformed H-form, a universal variable u depends on the existentials which did not depend on u in the original S-form. The T-transform of the H-form DQBF is defined analogously. (In the notation of [2], for any DQBF , .)
It is easy to see that for any DQBF , .
To see why the T-transform is a natural operation, consider what happens to a QBF. Recall that in an S-form QBF, the dependency sets are nested (), therefore the dependency sets in the T-transform are also nested (). In fact, it is not too hard to see that both collections of dependency sets represent the same (linear) QBF prefix. Therefore, the transform of an S-form QBF is just an H-form representation of the same QBF, and this is verified semantically: an S-form QBF has a Skolem-function model (is true) if and only if its transformed H-form does not have an Herbrand-function countermodel (is not false); and it does not have a Skolem-function model if and only if its transform does have an Herbrand-function countermodel. Thus, every QBF is logically equivalent to ; the only change made by the transformation is from S-form to H-form and vice versa.
But this is not the case in general for DQBF. The authors of [2] partitioned S-form DQBF into four distinct classes:
-
(A)
those which have a Skolem-function model, but whose transform has no Herbrand-function countermodel.
-
(B)
those which have no Skolem-function model, but whose transform does have an Herbrand-function countermodel.
-
(C)
those which have a Skolem-function model, and whose transform also has an Herbrand-function countermodel.
-
(D)
those which have no Skolem-function model, nor does their transform have an Herbrand-function countermodel.
All QBFs are either type A or B. Type C and D are classes of DQBFs whose semantic properties are markedly different from QBF.
Expansion versus QCDCL
Given what we know about the semantics of DQBF, we pose the following question: What is the impact of the existence of type C and D DQBFs on the transfer of solving techniques from QBF? We argue that the impact is indeed visible in theoretical models of solving. Moreover, it forms a decent explanation for the results that we have seen there.
Figure 6 (reproduced from [13]) depicts what happens when one attempts to lift various QBF calculi to DQBF. All of these systems are refutational calculi for S-form DQBFs; that is, they prove that an S-form DQBF does not have a Skolem-function model.
Fig. 6.

The simulation order of QBF resolution systems and soundness/completeness of their versions lifted to S-form DQBF
The main message of Fig. 6 (and the conclusion of [13]) is that expansion-based systems lift to S-form DQBF whereas CDCL-based systems do not. Q-Resolution, for example, is too weak (it is not complete for S-form DQBF), whereas long-distance Q-Resolution is too strong (it is not sound).
A reasonable explanation for this goes as follows:
Expansion-based (D)QBF calculi prove the non-existence of Skolem functions, whereas CDCL-based (D)QBF calculi prove the existence of Herbrand functions.
Such an explanation could scarcely be sought in the QBF realm, where the non-existence of a Skolem-function model and the existence of an Herbrand-function countermodel are equivalent. One really needs to consider the behaviour of type C and D formulas to understand that these two things are not equivalent for DQBF.
Whereas our statement is not the kind that can be proved as a theorem, there appears good reason to promote it as a credible hypothesis, since it explains the situation depicted in Fig 6.
Expansion-based systems prove that the universal expansion of a (D)QBF (i.e. a propositional formula) is unsatisfiable. Satisfying assignments for the expansion are in one-one correspondence with Skolem-function models, so a proof of unsatisfiability is a proof of the non-existence of Skolem functions. Thus, the expansion systems and should lift quite naturally to refutational systems for S-form DQBFs, whose falsity is witnessed by the non-existence of Skolem functions. And indeed, they lift easily to DQBF, as shown in Fig 6 [13].
Moreover, if CDCL-based systems prove the existence of Herbrand functions, we should expect to see difficulties lifting them to S-form DQBF, because the rules of these systems implicitly work on the T-transformed formulas, which is an H-form DQBF. We know that there exist type C S-form DQBFs that are true, but whose transform also has Herbrand functions, and type D S-form DQBFs that are false, but whose transform does not have Herbrand functions. In the former case we could expect to refute a true formula (unsoundness), in the latter case we find false formulas that we cannot refute (incompleteness). This is precisely what we see in Fig. 6: is unsound for S-form DQBF [13], whereas is incomplete [2].
Note that , which is considered an expansion-based system, is also unsound for S-form DQBFs. This is because the system is designed to simulate , and unfortunately also simulates unsound refutations of true S-form DQBFs.
Switching from S-form to H-form
We suggest, then, that it is worthwhile to investigate further the use of H-form DQBF as an input encoding for CDCL-based DQBF solving. At least for theoretical models, this is yet to be investigated. Here we undertake the first such investigation, and we get some positive results: Merge Resolution lifts naturally to a sound and complete CDCL-based refutational proof system on H-form DQBF.
It should be noted that a resolution system for DQBF called Fork Resolution [50] was shown to be sound and complete for S-form DQBF. The system is based on so-called ‘information forks’, and allows the introduction of fresh variables that delegate the responsibility for fork satisfaction between the original variables. Whereas Fork Resolution is clearly a variant of Q-Resolution, it is not clear whether one should call it a CDCL-based system. Certainly, the associated solver DCAQE [55] belongs to the paradigm of clausal abstraction, rather than conflict-driven clause learning. However, we wish to make it clear that switching to H-form is not the only solution to the issues associated with Fig. 6.
Extending merge resolution to H-form DQBF
In this section, we show that extends naturally to a proof system for H-form DQBF with the addition of a single weakening rule.
For consistency with the QBF definition, we introduce an equivalent notation for H-form DQBF. We write the quantifier prefix of the H-form DQBF
as a triple , where:
is the set of existential variables;
is the set of universal variables;
is the support set function, which maps each to its dependency set .
To lift to H-form DQBF, we take to be a DQBF in Definition 16 and add an extra case:
-
(c)
Weakening. There exists an integer such that is an existential superclause of and, for each , either (i) , or (ii) is trivial and for some literal .
By ‘existential superclause’ it is meant that and .
Weakening is, in a clear sense, the simplest rule with which one extends to H-form DQBF. Its function is merely to represent exactly the paths of the countermodel on which the canonical completeness construction is based. In general, the countermodel needs to be represented in full since merge maps must be isomorphic in order to apply the select operation. Note that the DQBF analogue of Proposition 19 is proved easily with an additional case for the weakening rule.
Soundness and completeness
Soundness of for H-form DQBF is proved in the same way as for QBF, i.e. by showing that the concluding merge maps compute a countermodel.
Lemma 31
Let be the conclusion of an refutation of an H-form DQBF . Then the functions computed by form a countermodel for .
Proof
We add an additional case to the inductive step in the proof of Lemma 21. Suppose that was derived by weakening. Then there exists an integer such that and, for each , either (i) , or (ii) is trivial and for some literal . Here , so . For each , if u satisfies (i) then , and if u satisfies (ii) then . Hence we have . It follows that the restriction of by contains the empty clause by the inductive hypothesis.
Completeness, on the other hand, cannot be established with an analogue of Theorem 22; DQBF is strictly larger than QBF, and hence simulation of reductionless does not guarantee completeness. Our proof rather extends the method by which completeness of reductionless was proved in Lemma 5; namely, the construction of a ‘full binary tree’ of resolution steps based on the countermodel, following the prefix order of existential variables.
We give an overview of the construction. Let be a false DQBF with a countermodel h. For each , the assignment falsifies some clause by definition of countermodel. Now, consider the line whose clause is the largest existential clause falsified by and whose merge maps are constant functions computing . Each such line can be derived in two steps, by weakening the axiom corresponding to . Moreover, the clauses form the leaves of a full binary tree resolution refutation which can be completed using an arbitrary order of the existential pivots X. The merge maps are constructed by merging over the pivot x iff ; otherwise the operation takes the merge map from either antecedent, since the full binary tree structure guarantees that they are isomorphic.
As merge maps essentially represent the structure of resolution steps in the subderivation, it is no surprise that the merge maps in our construction also have a full binary tree structure. This structure is captured by the following definition.
Definition 32
(binary tree merge map) A binary tree merge map for a variable u over a sequence of variables is a function M with domain and rule
where each .
At the technical level, we must define existential restrictions for DQBFs and DQBF countermodels. Let be a DQBF with a countermodel h and let l be a literal with . The restriction of by l is , where maps each to . The restriction of h by l is , where the functions are defined by .
The construction itself is defined recursively in the completeness proof, combining full binary tree refutations for and for some with a single resolution step. We use the fact that restrictions preserve countermodels in the following sense.
Proposition 33
Let h be a countermodel for a DQBF and let l be a literal with . Then h[l] is a countermodel for .
As the final precursor to the completeness proof, we show that a derivation of the negated literal and the restricted countermodel h[l] can be obtained easily from a refutation of the restricted DQBF
Proposition 34
Let be a false DQBF, let l be a literal with , and let be the conclusion of be an refutation of . Then there exists an derivation of from .
Proof
Let be the refutation with the given conclusion. The desired derivation may be obtained from simply by adding the literal to each clause, applying weakening where necessary, and adjusting the indexing of the merge maps to account for the extra weakening steps.
Lemma 35
Every false H-form DQBF has an refutation.
Proof
Let be a false DQBF, and let where the are pairwise distinct. For any refutation with conclusion , let be the concluding countermodel for , where the are the functions computed by the concluding merge maps . A merge map for over is said to be complete if it is isomorphic to a binary tree merge map for u over the sequence
which enumerates in increasing index order; that is, is the unique function satisfying and for each . By induction on the number n of existential variables, we show that, for each countermodel h for , there exists an refutation whose concluding countermodel is h and whose concluding merge maps are complete. To that end, let be an arbitrary countermodel for .
For the base case , observe that each is a constant function with some singleton codomain . By definition of countermodel, there exists a clause such that . Applying the axiom rule to C, one obtains a derivation of the line in which computes the constant function if , and is trivial otherwise. With a single weakening step, each trivial can be swapped for a merge map isomorphic to . Then each is trivially complete and computes the constant function .
For the inductive step, let . Combining Propositions 33 and 34 with the inductive hypothesis, we deduce that there exist derivations and of the lines and from in which the and are complete merge maps computing and . Assume that the lines of are indexed from 1 to and that those of are indexed from to . For each , the domains of and are disjoint, so . If , then , and we must have since complete merge maps computing the same function must be isomorphic. It follows that the line can be derived from , where
It is easy to see that the are complete merge maps computing the .
The weakening rule is clearly polynomial-time checkable. Thus the following is immediate from Lemmata 31 and 35.
Theorem 36
is a proof system for H-form DQBF.
It is natural to consider whether the weakening rule is necessary for completeness. This is indeed the case; there exist false H-form DQBFs that cannot be refuted by without weakening.
For example, consider the DQBF in which , , the support set function is given by
and the matrix consists of the clauses
It is easy to see that the only countermodel for sets and . Note that the functions computing this unique countermodel have ranges and
Now, let be a weakening-free derivation from . We will show that each line in is of one of three types:
-
AThe merge maps compute functions with ranges and , where
-
BThe merge maps compute functions with ranges and , where
-
C
The merge maps compute functions with ranges .
From this it follows that is not a refutation, because its concluding merge maps do not compute a countermodel.
The axiom line for the clause is type A, the axiom line for the clause is type B, and the remaining two clauses, which contain no universal literals, are type C. It is easy to see that resolution of a type A line with a type A or C line always yields type A. Similarly, resolution of a type B line with a type B or C line always yields type B. Resolving two type C clauses yields a type C clause. Moreover, type A lines can never be resolved with type B lines; in this case, the merge maps for are non-trivial and non-isomorphic, and similarly for , so neither nor is eligible as the pivot variable.
Conclusions and future work
What is new in ?
To the best of our knowledge, is the first ‘long-distance’ proof system for DQBF. Recent work [13] showed that the DQBF version of is not sound, so it is natural to ask how fares in comparison. We identify three major differences.
Firstly, works with Herbrand-form DQBFs, whereas the system in [13] was defined for Skolem-form DQBFs (which use support sets for existential variables). Merge maps detail precisely how the Herbrand functions are encoded in the resolution structure of long-distance proofs. One could say that such refutations are ‘proving the existence of Herbrand functions’. For QBF, this is of course equivalent to proving the non-existence of Skolem functions, but that does not carry over to DQBF (in a precise technical sense [2]). From this standpoint, it is natural to refute H-form DQBFs by finding the Herbrand functions that certify the falsity of the formula, and this is exactly what achieves. On the other hand, [13] takes the approach of refuting S-form DQBFs—which amounts to proving the non-existence of Skolem functions—by looking for Herbrand functions that may exist even if the formula is true.
The second difference is the absence of universal reduction. The difficulty of dealing with universal reduction in the context of DQBF resolution is to some extent addressed in [7], where it is considered in the (closely related [8]) context of dependency schemes. There it is shown that the interplay between universal reduction and merging is problematic, and additional constraints must be placed on universal reduction to prevent unsound inferences. Given that universal reduction is not necessary for completeness, it seems natural to dispense with it entirely.
The third and final difference is the explicit representation of functions in , versus the function placeholders known as ‘merged literals’ from classical long-distance Q-resolution. Here we argue that the ‘full binary tree’ construction that features in the proofs of Lemmata 5 and 35 is the canonical completeness proof for CDCL-based systems. The explicit representation of functions is key to this construction, since it allows the comparison of non-trivial merge maps. Thus we argue that building strategies into proofs is the natural way to overcome incompleteness.
Relevance to solving
Merge maps may be relevant for QBF and DQBF solving.
In dependency learning for QBF [45], variable dependencies are ignored until clause learning is blocked by an illegal merge. Our work demonstrates that many ‘illegal’ merges are perfectly sound inferences; moreover, provides a mechanism for identifying such cases based on isomorphism. Thus, it is plausible that incorporating merge maps could increase the scope of dependency learning.
In DQBF, practitioners are still looking for a natural ‘CDCL-based’ (as apposed to ‘expansion-based’) solving paradigm. Our discussion in Sect. 6 suggests one possible reason: namely, the use of Skolem form encodings is not conducive to CDCL-based search. An interesting direction for future work, therefore, would be to experiment with Herbrand-form DQBFs as the standard input format for CDCL-based DQBF solving.
It seems natural, then, to suggest Merge Resolution as the underlying resolution engine in a CDCL-based solver for Herbrand-form DQBF. Conceiving such an implementation would require some work; for example, one would need to store partial strategies with learned clauses, and carry out an efficient isomorphism test. Isomorphism is an easy way to determine the equivalence of two Boolean functions, but in general it seems unlikely that two equivalent functions will have identical representations. This points towards efficient (approximate) equivalence testing as the key to a successful implementation of .
Complexity of H-form DQBF
Whereas the decision problem for S-form DQBF is known to be complete [1], the complexity of the decision problem for H-form DQBFs, as far as we are aware, has not been studied. Moreover, the methodology of [1] does not seem appropriate for H-form DQBFs. Since every QBF can be written as an H-form DQBF, the decision problem is certainly -hard, and the NEXP upper bound applies for all DQBFs, but its exact complexity remains an interesting open problem.
Acknowledgements
Open Access funding provided by Projekt DEAL. Research was supported by grants from the John Templeton Foundation (Grant No. 60842) and the Carl Zeiss Foundation.
Footnotes
There exists associated proof systems for true QBFs [30].
Reductionless p-simulates level-ordered by means of a simple construction, and is exponentially separated by the equality formulas [9]. It is also known that reductionless and are incomparable [47].
O. Beyersdorff: An extended abstract of this article appeared at the proceedings of STACS’19 [10].
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Azhar S, Peterson G, Reif J. Lower bounds for multiplayer non-cooperative games of incomplete information. J. Comput. Math. Appl. 2001;41:957–992. doi: 10.1016/S0898-1221(00)00333-3. [DOI] [Google Scholar]
- 2.Balabanov V, Chiang H-JK, Jiang J-HR. Henkin quantifiers and Boolean formulae: a certification perspective of DQBF. Theoret. Comput. Sci. 2014;523:86–100. doi: 10.1016/j.tcs.2013.12.020. [DOI] [Google Scholar]
- 3.Balabanov V, Jiang J-HR. Unified QBF certification and its applications. Form. Methods Syst. Des. 2012;41(1):45–65. doi: 10.1007/s10703-012-0152-6. [DOI] [Google Scholar]
- 4.Balabanov, V., Jiang, J.-H.R., Janota, M., Widl, M.: Efficient extraction of QBF (counter)models from long-distance resolution proofs. In: Bonet, B., Koenig, S. (eds.) National Conference on Artificial Intelligence (AAAI), pp. 3694–3701. AAAI Press (2015)
- 5.Benedetti, M.: sKizzo: a suite to evaluate and certify QBFs. In: Nieuwenhuis, R. (ed.) International Conference on Automated Deduction (CADE), Volume 3632 of Lecture Notes in Computer Science, pp. 369–376. Springer (2005)
- 6.Benedetti M, Mangassarian H. QBF-based formal verification: experience and perspectives. J. Satisf. Boolean Model. Comput. 2008;5(1–4):133–191. [Google Scholar]
- 7.Beyersdorff, O., Blinkhorn, J. (2016) Dependency schemes in QBF calculi: semantics and soundness. In: Rueher, M. (ed.) International Conference on Principles and Practice of Constraint Programming (CP), Volume 9892 of Lecture Notes in Computer Science, pp. 96–112. Springer
- 8.Beyersdorff O, Blinkhorn J, Chew L, Schmidt RA, Suda M. Reinterpreting dependency schemes: soundness meets incompleteness in DQBF. J. Autom. Reason. 2019;63(3):597–623. doi: 10.1007/s10817-018-9482-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Beyersdorff, O., Blinkhorn, J., Hinde, L.: Size, cost, and capacity: a semantic technique for hard random QBFs. Log. Methods Comput. Sci. 15(1), 13:1–13:39 (2019)
- 10.Beyersdorff, O., Blinkhorn, J., Mahajan, M.: Building strategies into QBF proofs. In: Niedermeier, R., Paul, C. (ed.) International Symposium on Theoretical Aspects of Computer Science (STACS), Volume 126 of Leibniz International Proceedings in Informatics (LIPIcs), pp. 14:1–14:18. Schloss Dagstuhl - Leibniz-Zentrum für Informatik (2019)
- 11.Beyersdorff, O., Bonacina, I., Chew, L.: Lower bounds: from circuits to QBF proof systems. In: Sudan, M. (ed.) ACM Conference on Innovations in Theoretical Computer Science (ITCS), pp. 249–260. ACM (2016)
- 12.Beyersdorff O, Chew L, Janota M. New resolution-based QBF calculi and their proof complexity. ACM Trans. Comput. Theory. 2019;11(4):26:1–26:42. doi: 10.1145/3352155. [DOI] [Google Scholar]
- 13.Beyersdorff, O., Chew, L., Schmidt, R.A., Suda, M.: Lifting QBF resolution calculi to DQBF. In: Creignou and Berre [21], pp. 490–499
- 14.Beyersdorff O, Wintersteiger CM, editors. International Conference on Theory and Practice of Satisfiability Testing (SAT), Volume 10929 of Lecture Notes in Computer Science. Berlin: Springer; 2018. [Google Scholar]
- 15.Bjørner, N., Janota, M., Klieber, W.: On conflicts and strategies in QBF. In: Fehnker, A., McIver, A., Sutcliffe, G., Voronkov, A. (eds.) International Conference on Logic for Programming, Artificial Intelligence and Reasoning—Short Presentations (LPAR), Volume 35 of EPiC Series in Computing, pp. 28–41. EasyChair (2015)
- 16.Bubeck, U., Büning, H.K.: Dependency quantified Horn formulas: models and complexity. In: Biere, A., Gomes, C.P. (eds.) International Conference on Theory and Practice of Satisfiability Testing (SAT), Volume 4121 of Lecture Notes in Computer Science, pp. 198–211. Springer (2006)
- 17.Buss SR. Towards NP-P via proof complexity and search. Ann. Pure Appl. Log. 2012;163(7):906–917. doi: 10.1016/j.apal.2011.09.009. [DOI] [Google Scholar]
- 18.Cashmore, M., Fox, M., Giunchiglia, E.: Partially grounded planning as quantified Boolean formula. In: Borrajo, D., Kambhampati, S., Oddi, A., Fratini, S. (eds.) International Conference on Automated Planning and Scheduling (ICAPS). AAAI (2013)
- 19.Cook SA, Nguyen P. Logical Foundations of Proof Complexity. Cambridge: Cambridge University Press; 2010. [Google Scholar]
- 20.Cook SA, Reckhow RA. The relative efficiency of propositional proof systems. J. Symb. Log. 1979;44(1):36–50. doi: 10.2307/2273702. [DOI] [Google Scholar]
- 21.Creignou N, Le Berre D, editors. International Conference on Theory and Practice of Satisfiability Testing (SAT). Lecture Notes in Computer Science. Berlin: Springer; 2016. [Google Scholar]
- 22.Egly U, Kronegger M, Lonsing F, Pfandler A. Conformant planning as a case study of incremental QBF solving. Ann. Math. Artif. Intell. 2017;80(1):21–45. doi: 10.1007/s10472-016-9501-2. [DOI] [Google Scholar]
- 23.Egly, U., Lonsing, F., Widl, M.: Long-distance resolution: proof generation and strategy extraction in search-based QBF solving. In: McMillan, K.L., Middeldorp, K.L., Voronkov, A. (eds.) International Conference on Logic for Programming, Artificial Intelligence and Reasoning (LPAR), Volume 8312 of Lecture Notes in Computer Science, pp. 291–308. Springer (2013)
- 24.Faymonville, P., Finkbeiner, B., Rabe, M.N., Tentrup, L.: Encodings of bounded synthesis. In: Legay and Margaria [39], pp. 354–370
- 25.Finkbeiner, B., Tentrup, L.: Fast DQBF refutation. In: Sinz, C., Egly, U. (eds.) International Conference on Theory and Practice of Satisfiability Testing (SAT), Volume 8561 of Lecture Notes in Computer Science, pp. 243–251. Springer (2014)
- 26.Fröhlich, A., Kovásznai, G., Biere, A.: A DPLL algorithm for solving DQBF. https://arise.or.at/pubpdf/Algorithm_for_Solving__DQBF_.pdf, presented at Workshop on Pragmatics of SAT (POS) (2012)
- 27.Fröhlich, A., Kovásznai, G., Biere, A., Veith, H.: iDQ: instantiation-based DQBF solving. In: Le Berre, D. (ed.) Workshop on Pragmatics of SAT (POS), Volume 27 of EPiC Series in Computing, pp. 103–116. EasyChair (2014)
- 28.Gaspers S, Walsh T, editors. International Conference on Theory and Practice of Satisfiability Testing (SAT). Lecture Notes in Computer Science. Berlin: Springer; 2017. [Google Scholar]
- 29.Gitina, K., Wimmer, R., Reimer, S., Sauer, M., Scholl, C., Becker, B.: Solving DQBF through quantifier elimination. In: Nebel, W., Atienza, D. (eds.) Design, Automation & Test in Europe Conference (DATE), pp. 1617–1622. ACM (2015)
- 30.Giunchiglia E, Narizzano M, Tacchella A. Clause/term resolution and learning in the evaluation of quantified Boolean formulas. J. Artif. Intell. Res. 2006;26:371–416. doi: 10.1613/jair.1959. [DOI] [Google Scholar]
- 31.Heule, M., Seidl, M., Biere, A.: Efficient extraction of Skolem functions from QRAT proofs. In: Conference on Formal Methods in Computer-Aided Design (FMCAD), pp. 107–114. IEEE (2014)
- 32.Heule MJH, Kullmann O. The science of brute force. Commun. ACM. 2017;60(8):70–79. doi: 10.1145/3107239. [DOI] [Google Scholar]
- 33.Janota M, Lynce I, editors. International Conference on Theory and Practice of Satisfiability Testing (SAT). Lecture Notes in Computer Science. Berlin: Springer; 2019. [Google Scholar]
- 34.Janota M, Marques-Silva J. Expansion-based QBF solving versus Q-resolution. Theor. Comput. Sci. 2015;577:25–42. doi: 10.1016/j.tcs.2015.01.048. [DOI] [Google Scholar]
- 35.Büning HK, Karpinski M, Flögel A. Resolution for quantified Boolean formulas. Inf. Comput. 1995;117(1):12–18. doi: 10.1006/inco.1995.1025. [DOI] [Google Scholar]
- 36.Klieber, W., Sapra, S., Gao, S., Clarke, E.M.: A non-prenex, non-clausal QBF solver with game-state learning. In: Strichman, O., Szeider, S. (eds.) International Conference on Theory and Practice of Satisfiability Testing (SAT), Volume 6175 of Lecture Notes in Computer Science, pp. 128–142. Springer (2010)
- 37.Kontchakov, R., Pulina, L., Sattler, U., Schneider, T., Selmer, P., Wolter, F., Zakharyaschev, M.: Minimal module extraction from DL-lite ontologies using QBF solvers. In: Boutilier, C. (ed.) International Joint Conference on Artificial Intelligence (IJCAI), pp. 836–841. AAAI Press (2009)
- 38.Krajíček J. Bounded Arithmetic, Propositional Logic, and Complexity Theory. Encyclopedia of Mathematics and Its Applications. Cambridge: Cambridge University Press; 1995. [Google Scholar]
- 39.Legay, Axel, Margaria, Tiziana (eds.): International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS). Lecture Notes in Computer Science, vol. 10205. Springer, (2017)
- 40.Ling, A.C., Singh, D.P., Brown, S.D.: FPGA logic synthesis using quantified Boolean satisfiability. In: Bacchus, F., Walsh, T. (eds.), International Conference on Theory and Practice of Satisfiability Testing (SAT), Volume 3569 of Lecture Notes in Computer Science, pp. 444–450. Springer (2005)
- 41.Mangassarian H, Veneris AG, Benedetti M. Robust QBF encodings for sequential circuits with applications to verification, debug, and test. IEEE Trans. Comput. 2010;59(7):981–994. doi: 10.1109/TC.2010.74. [DOI] [Google Scholar]
- 42.Marques-Silva, J., Malik, S.: Propositional SAT solving. In: Clarke, E.M., Henzinger, T.A., Veith, H., Bloem, R. (eds.) Handbook of Model Checking, pp. 247–275. Springer (2018)
- 43.Nordström J. On the interplay between proof complexity and SAT solving. SIGLOG News. 2015;2(3):19–44. doi: 10.1145/2815493.2815497. [DOI] [Google Scholar]
- 44.Peitl, T., Slivovsky, F., Szeider, S.: Long distance Q-resolution with dependency schemes. In: Creignou and Berre [21], pp. 500–518 [DOI] [PMC free article] [PubMed]
- 45.Peitl, T., Slivovsky, F., Szeider, S.: Dependency learning for QBF. In: Gaspers and Walsh [28], pp. 298–313
- 46.Peitl, T., Slivovsky, F., Szeider, S.: Polynomial-time validation of QCDCL certificates. In: Beyersdorff and Wintersteiger [14], pp. 253–269
- 47.Peitl, T., Slivovsky, F., Szeider, S.: Proof complexity of fragments of long-distance Q-resolution. In: Janota and Lynce [33], pp. 319–335
- 48.QBFEVAL homepage: http://www.qbflib.org/index_eval.php. Accessed 26 Oct 2018
- 49.Rabe, M.N., Tentrup, L.: CAQE: a certifying QBF solver. In: Kaivola, R., Wahl, T. (eds.) Conference on Formal Methods in Computer-Aided Design (FMCAD), pp. 136–143. IEEE (2015)
- 50.Rabe, M.N.: A resolution-style proof system for DQBF. In: Gaspers and Walsh [28], pp. 314–325
- 51.Samulowitz, H., Davies, J., Bacchus, F.: Preprocessing QBF. In: Benhamou, F. (ed.) International Conference on Principles and Practice of Constraint Programming (CP), Volume 4204 of Lecture Notes in Computer Science, pp. 514–529. Springer (2006)
- 52.Scholl, C., Wimmer, R.: Dependency quantified Boolean formulas: an overview of solution methods and applications—extended abstract. In: Beyersdorff and Wintersteiger [14], pp. 3–16
- 53.Silva, J.P.M., Lynce, I., Malik, S.: Conflict-driven clause learning SAT solvers. In: Biere, A., Heule, M., van Maaren, H., Walsh, T. (eds.) Handbook of Satisfiability, Volume 185 of Frontiers in Artificial Intelligence and Applications, pp. 131–153. IOS Press (2009)
- 54.Suda, M., Gleiss, B.: Local soundness for QBF calculi. In: Beyersdorff and Wintersteiger [14], pp. 217–234
- 55.Tentrup, L., Rabe, M.N.: Clausal abstraction for DQBF. In: Janota and Lynce [33], pp. 388–405
- 56.Vardi MY. Boolean satisfiability: theory and engineering. Commun. ACM. 2014;57(3):5. doi: 10.1145/2578043. [DOI] [Google Scholar]
- 57.Wimmer, R., Gitina, K., Nist, J., Scholl, C., Becker, B.: Preprocessing for DQBF. In: Heule, M., Weaver, S. (eds.) International Conference on Theory and Practice of Satisfiability Testing (SAT), Volume 9340 of Lecture Notes in Computer Science, pp. 173–190. Springer (2015)
- 58.Wimmer, R., Reimer, S., Marin, P., Becker, B.: HQSpre—an effective preprocessor for QBF and DQBF. In: Legay and Margaria [39], pp. 373–390
- 59.Zhang, L., Malik, S.: Conflict driven learning in a quantified Boolean satisfiability solver. In: International Conference on Computer-Aided Design (ICCAD), pp. 442–449 (2002)